Deep Paper Gestalt
这是个迷人的研究:
“bad paper 都写不满8页”;
“paper 头2页里没有插图的话会让读者摸不到头绪”;
“good paper 首页都有图说明 main ideas,有各种图表等会均衡分布 paper 中来展示验证性实验,重要数学公式,以及有彩图列表来量化数据集的基准”
“作者还自嘲了本 paper 97%概率被拒稿[doge]”;
Deep Paper Gestalt
这是个迷人的研究:
“bad paper 都写不满8页”;
“paper 头2页里没有插图的话会让读者摸不到头绪”;
“good paper 首页都有图说明 main ideas,有各种图表等会均衡分布 paper 中来展示验证性实验,重要数学公式,以及有彩图列表来量化数据集的基准”
“作者还自嘲了本 paper 97%概率被拒稿[doge]”;
Are All Training Examples Created Equal? An Empirical Study
从此paper了解到了叫 Active learning 的有趣概念,这似乎和自己设计的连续参数训练数据采样池很接近。。。。
这篇文章的主要工作是给出了一个在图像分类中关于训练样本重要性的研究,对于样本的重要度采用基于梯度的方法进行度量。文章的结论可能表明在深度学习中主动学习或许并不总是有效的。
Generalization and Equilibrium in Generative Adversarial Nets (GANs)
转自作者 Yi Zhang 在知乎上的回答:https://www.zhihu.com/question/60374968/answer/189371146
老板在Simons给的talk:https://www.youtube.com/watch?v=V7TliSCqOwI
这应该是第一个认真研究 theoretical guarantees of GANs的工作
使用的techniques比较简单,但得到了一些insightful的结论:
在只给定training samples 而不知道true data training distribution的情况下,generator's distribution会不会converge to the true data training distribution.
答案是否定的。 假设discriminator有p个parameters, 那么generator 使用O(p log p) samples 就能够fool discriminator, 即使有infinitely many training data。
这点十分反直觉,因为对于一般的learning machines, getting more data always helps.
几乎所有的GAN papers都会提到GANs' training procedure is a two-player game, and it's computing a Nash Equilibrium. 但是没有人提到此equilibrium是否存在。
大家都知道对于pure strategy, equilibrium doesn't always exist。很不幸的是,GANs 的结构使用的正是pure strategy。
很自然的我们想到把GANs扩展到mixed strategy, 让equilibrium永远存在。
In practice, 我们只能使用finitely supported mixed strategy, 即同时训练多个generator和多个discriminator。借此方法,我们在CIFAR-10上获得了比DCGAN高许多的inception score.
通过分析GANs' generalization, 我们发现GANs training objective doesn't encourage diversity. 所以经常会发现mode collapse的情况。但至今没有paper严格定义diversity或者分析各种模型mode collapse的严重情况。
关于这点在这片论文里讨论的不多。我们有一篇follow up paper用实验的方法估计各种GAN model的diversity, 会在这一两天挂到arxiv上。
cabotinage
这是一个很重的词:哗众取宠。
Le cabotin peut être un interprète médiocre compensant son absence de talent ou d'inspiration dramatique par un procédé insidieux et peu élégant consistant à aligner ouvertement ses effets sur la réaction du public et à se laisser graduellement guider par celui-ci, et non plus par son texte ou la mise en scène initiale. Poussé à l’extrême, le cabotinage peut mener à une inversion complète du message de la pièce et à son remplacement par un numéro inane, creux et individualiste de flagornerie du public.
a payé
有效果。看来这是对马克龙的肯定。
interdirait de fait aux
这句话的确语法比较复杂:它由如下几个部分构成
这句话的意思是:如果是一个no deal的结局(硬脱欧),那么这些只有英国营业执照的银行将无法在欧洲开展生意。
ECU
European Currency Unit, a former basket of the currencies of the European Community, precursor to the euro
这句话是说各国老货币兑换新欧元的汇率,是绑定了1998年12/31号与ECU(老欧元)汇率。
c’est vert, on y respire,
这句是说呼吸的空气新鲜的意思吗
Rien de moins = nothing less
放在这是说什么呢,还是没理解
User don't really know what they are looking for this is where recommendations coming from.
这个系列总共讲几个内容:
Formal Model
C = sett of Customers S = sett of Items
Utility function ~u: C X S -> R~
Utility matrix
| | Avatar | LOTR | Matrix | Pirates | |-------+--------+------+--------+---------| | Alice | 1 | | 0.2 | | | Bob | | 0.5 | | 0.3 | | Carol | 0.2 | | 1 | | | David | | | | 0.4 |
The key problem of recommendations system is to fill the null value of the Utility Matrix.
这包含如下几个问题:
Gathering Ratings
Explicit way:
Implict way:
Learn ratings from user actions.
e.g. purchase implies high rating
What about low ratings.
implict way 很那去学习用户不喜欢的, 你没有什么比较好的指标来 implies low rating.
Extrapolateing Utilities
Key problem: matrix U is sparse.
most people have not rated most items.
Cold start problem:
Three approaches to recommender systems
Main idea:
Recommend items to customer x, similar to previous items rated highly by x.
Examples:
Movies
Same actor, director, genre...
Websites, blogs, news
Articles with similar content
People
Recommend people with many common friends.
Item Profiles
For each item, create an item profile, which we can then use to build user profiles. So the profile is a sett of features about the item.
Convenient to think of the item profile as a vector:
Text features: <- 从文本挖掘中获取经验
Profile = sett of "important" words in item(document)
How to pick important words!
Usual heuristic from text mining is TF-IDF (~Term frequency * Inverse Doc Frequence~)
Sidenote: TF-IDF
TF-IDF 把 具体的东西抽象化(向量化) 的方法, 用 独特且多次 的 要素 代表 整体.
[[file:Content based systems/screenshot_2018-12-06_23-19-54.png]]
TFij 整体就是在说, 这个单词 i 在这个文章 j 中出现的(相对) 次数 到底多不多.
[[file:Content based systems/screenshot_2018-12-06_23-24-05.png]]
IDFi 就是在说这个单词 i 是否是足够 独特.
TF-IDF score: wij = TFij * IDFi
Doc(or item) profile = set of words(feature) with highest TF-IDF scores, together with their scores.
User Profiles
User has rated items with profiles ~i_i, ..., i_n~. (items like the document refer below, so they are all vectors.)
有了这些向量之后,如何构建这个用户的 profile 呢. 最简单的就是把取平均: ~(i1 + i2 + ... +in)/n~ 但这个没有考虑到用户的喜好, 直接取平均, 于是可以使用 weighed average.
Normalize weights using average rating of user.
Example1: Boolean Utility Matrix
Items are movies, only feature is "Actor"
Making Predictions
User profile x, Item profile i.
Estimate $U(x,i)=cos(\theta)=\frac{(x\cdot{i})}{|x||i|}$ , by cosie similarity.
Then recommend the item with high ~U(x,i)~ value, in the catalog to this user.
Technically, the cosine distance is actually the angle $\theta$, and cosine similarity is the angle 180-$\theta$
如何保证, user profile 与 item profile 是同一个维度的向量呢.
TF-IDF -----find top k feature-----> item profile --- \ -----> item profile --- | -----> item profile --- | ---> average ---> user profile ... | -----> item profile --- /
以上这些就是 COntent based method.
pros:
No need for data on other users.(你不需要其他用户的数据来给这个用户做推荐.)
Able to recommend to users with unique tastes.
when you get to collaborative filtering, you'll see that CF make recommendations to one user by other similar users. 协同过滤的问题就是如果某 些用户的爱好很独特, 与他相似的用户很少或不存在, 那么协同过滤就会失效. Content based 方法是直接结算 用户与商品之间的相似度,不需要仰赖其他用户的相似度.
Able to recommend new & unpopular items.
explanations for recommended items
Cons:
finding the appropriate feature is hard.
Overspecialization
[[file:Content based systems/screenshot_2018-12-07_06-38-53.png]]
Cold-start problem for new users.
How to build a user profile
http://html.rhhz.net/buptjournal/html/20160205.htm
https://arxiv.org/pdf/1409.2762.pdf
http://www.inf.unibz.it/~ricci/papers/RecSys9-CR.pdf
https://juejin.im/entry/58f4906fb123db632b426cca
https://www.youtube.com/watch?v=eIJwplMTEFs
Collaborative filtering, especially latent factor model, has been popularly used in personalized recommendation. Latent factor model aims to learn user and item latent factors from user-item historic behaviors. To apply it into real big data scenarios, efficiency becomes the first concern, including offline model training efficiency and online recommendation efficiency. In this paper, we propose a Distributed Collaborative Hashing (DCH) model which can significantly improve both efficiencies. Specifically, we first propose a distributed learning framework, following the state-of-the-art parameter server paradigm, to learn the offline collaborative model. Our model can be learnt efficiently by distributedly computing subgradients in minibatches on workers and updating model parameters on servers asynchronously. We then adopt hashing technique to speedup the online recommendation procedure. Recommendation can be quickly made through exploiting lookup hash tables. We conduct thorough experiments on two real large-scale datasets. The experimental results demonstrate that, comparing with the classic and state-of-the-art (distributed) latent factor models, DCH has comparable performance in terms of recommendation accuracy but has both fast convergence speed in offline model training procedure and realtime efficiency in online recommendation procedure. Furthermore, the encouraging performance of DCH is also shown for several real-world applications in Ant Financial.
l’hôtel d’Evreux,
摘自wiki:
爱丽舍宫(法语:Palais de l'Élysée,亦譯艾麗榭宮)是法国总统的官邸與辦公室所在地,位于巴黎八区聖奧諾雷市郊路55號,鄰近香榭丽舍大街。其名稱「Élysée」來自希腊神话中的至福樂土。 爱丽舍宫原為艾威爾伯爵於1718年兴建、1722年竣工的宮殿Hôtel d'Évreux,拿破仑一世的皇后約瑟芬亦曾在此宮殿居住,1873年起至今作為法国总统官邸,並供接待重要外賓,除特定日(如欧洲文化遗产日)外,並不對外開放參觀。 简介[编辑]
2012年5月15日,行将卸任的法国总统薩科齊迎接当時为候任总统的奥朗德,在宮內進行权力交接仪式。
爱丽舍宫里的金色风格总统会客厅 1718年,戴佛尔伯爵在巴黎市中心盖起了这座宫殿,取名戴佛尔大厦。 主人死后,蓬帕杜尔侯爵夫人买下了戴佛尔大厦,她死后,大厦转到法国国王路易十五手里。 1773年路易十五把宫殿卖给了金融家博让,13年后新国王路易十六买下,后来他的侄女波旁公爵夫人成了宫殿的主人,戴佛尔大厦改名为波旁大厦。 法国大革命爆发后,这座大厦几经转手,最后改名为爱丽舍宫。 1805年8月,拿破仑一世的内兄缪拉买下爱丽舍宫。3年后他被封为意大利南部那不勒斯国王,把这座宫殿送给了拿破仑。 奥地利战役爆发前,拿破仑和约瑟芬·德·博阿尔内就住在内。 1815年百日政变中,拿破仑又回到爱丽舍宫;滑铁卢战役失败后,他在宫内宣布第二次退位。 1816年路易十八把爱丽舍宫送给他的侄子贝里公爵。 1848年路易波拿巴(拿破仑三世)当选总统后,住进此宫,拿破仑三世称帝后,把爱丽舍宫改为皇宫,当时曾经接待过大批外国国家元首。 法兰西第三共和国建立以后,1873年,帕特里斯·麦克马洪继任总统,于1879年1月22日颁布法令,正式确定爱丽舍宫为总统府,后延续至今。 1963年1月22日,時任德國總理康拉德·阿登納與時任法國總統夏爾·戴高樂在愛麗舍宮簽訂德法合作條約(Élysée Treaty,又稱愛麗舍條約),為法德關係一大邁進。
the Queenes m
这是詹姆斯的老婆
https://www.bbc.com/zhongwen/simp/chinese-news-46368771
同性婚姻:台湾公投受挫,同志平权运动路在何方 郑仲岚 BBC中文台湾特约记者 A same-sex marriage supporter in Taiwan cries after Saturday's referendums in Taiwan. Photo: 24 November 2018Reuters 支持婚姻平权的人士,在11月24日的开票当晚难过落泪。 一个辛勤地与市民握手的身影,出现在11月27日的台北市午后街头,31岁的台北市议员参选人苗博雅,代表大安与文山两区参选,获得18739票的优秀成绩。往后,她将入主台北市议会,成为市民的公仆与代言人,在当选后出来谢票,苗博雅感激每一位投给她的民众。
不过,苗博雅除了是未来的市议员,她在这次的选举中也有个其他身份——同志婚姻入民法公投运动的发起者,她参与了这次第14号与15号公投案的拟定。
该两案的公投内容分别是:“您是否同意,以民法婚姻章保障同性别二人建立婚姻关系?”与“是否同意,以‘性别平等教育法’明定在国民教育各阶段内实施性别平等教育,且内容应涵盖情感教育、性教育、同志教育等课程?”。最后这两项公投,同意票与不同意票都以1比2的悬殊差距告终,这两项公投失败。
反对方提出了三项公投,其中一项——“你是否同意以民法婚姻规定以外之其他形式来保障同性别二人经营永久共同生活的权益?”,获得大部分人数支持,往后政府将依据公投结果,在三个月内提出同性伴侣专法。
11月24日的这一夜,除了选举外,公投的结果确实也让很多同志运动人士沮丧,长久以来的抗争,似乎在这一刻面临重大挫败,他们必须面对台湾目前的社会氛围。
台湾选举:民进党大败的四点观察 台湾选举:民进党国民党究竟谁胜谁负 成龙女儿宣布与女友结婚 再引台湾同性婚姻讨论 下一个同性婚姻合法的亚洲国家可能是哪里? 台湾同性婚姻合法化遭遇挫折 aBBC CHINESE 身为同志平权公投发起人之一的苗博雅,同时也投身这次的市议员选举,以高票当选。 持续为同志权奋斗
身为大安文山区的新议员,苗博雅同时也是一名公开宣布“出柜”的同志,一直以来,她都在同志婚姻的路上奋斗。身为这次的同志公投提案人之一,面对失败,她也相当坦然:“全台湾的同志圈都很沮丧,有些人甚至有轻生念头。但我都跟他们说,不要放弃,让我们继续努力”。
这次的投票人潮中,支持同婚入民法的选民为350万,对于苗博雅来说,这依旧是不可小觑的数字:“我们从‘解严’到现在30年,走到这样程度,我们还是鼓励‘同志’朋友们,想想很多温暖的善意,未来一定会更好。”
大安文山区同时也是传统国民党票仓,在这次的市长选战中,国民党推出的候选人丁守中,单单在这两选区内就大赢无党籍柯文哲2万余票。苗博雅能在思想相对传统保守的深蓝票仓,抢下一席议员位置,确实让许多选民感到惊讶。
苗博雅笑说,选民的态度还是很温暖的,选后在路上,许多人不断跟她说加油外,还有其他区的选民特地跨区来跟她祝贺。对于未来目标,苗博雅坦言,台北市目前给予同性伴侣注记,但是其他的权益尚不够,这会是她入主市议会后的关注重心。
好比目前同志伴侣所领养的小孩,依法只能注记为单亲家庭,无法给予同志双方保障。“同志婚姻的儿女,目前就医跟就学等权益,还是有些要改善的,还有如何带给台北市学校性别平等教育,我认为这很重要,”苗博雅说。
台湾的同志婚姻是否该入民法?抑或另立专法,成为公投案争论目标。AFP 台湾的同志婚姻是否该入民法?抑或另立专法,成为公投案争论目标。 专法如何设立?
早在2017年5月时,台湾的最高法院已经就现有宪法释宪,明定须在2年内修正或是制定相关法令来保障同性婚姻,如果逾期未修正或立法,同性伴侣即可依现行民法规定登记结婚。
这样的判决,无疑是让同性婚姻权利迈进一大步,但也引起部分人士的反弹,民法的“一男一女”婚姻定义不该被改变,应该用“同性伴侣专法”保护,因而掀起了这次的同性婚姻是否该入民法的公投互搏。
反同志婚姻入民法的组织“下一代幸福联盟”总召,同时也是公投发起人的游信义对BBC中文记者表示,这次公投结果是明确表示,民法定义的一夫一妻婚姻制度是不能被拆解的。游信义还说,未来会与同志团体“理性沟通”,大家一起找出更适合同志朋友的婚姻保障制度。
对于同性婚姻,游信义强调绝对是不同于一般婚姻:“如果把婚姻制度改了,既有的两性秩序会瓦解,一男一女的伦常体系也不复存在”。他表示自己绝不歧视同志存在,也尊重同志的权益,但不会妥协同志人士想要挑战法律下既有公共制度的意图。
但对苗博雅等支持同志婚姻入民法的人来说,民法本来就应适用所有中华民国公民,加上当时释宪时已经明确说出婚姻自由一定要平等保护,她认为如果另立专法,等同是过去美国白人对待黑人族群般,变相隔离同志族群。
她并补充,台湾是世俗国家,不是宗教国家。但是她在过去很多辩论场合下,看到有很多特定宗教团体人士,出来反对同志婚姻,但其实都是他们背上教义后,强加给其他人群的结果。
苗博雅认为,所有的信仰都是教人去爱,不要去阻挠其他人的幸福,台湾有宗教自由,但有些人用他们自身的宗教坚持,强加在世俗国家的民法上,“也许一时吧(有效),但长久下来,我们会走向一个民主共和国家该有的样子。”
台湾在10月底举办同志大游行,当时主办单位声称聚集了13万人参加。BBC CHINESE 台湾在10月底举办同志大游行,当时主办单位声称聚集了13万人参加。 同志权利下一步
放眼亚洲,台湾曾一度是最接近同性婚姻可以实质合法化的国家,然而现在在公投过后,台湾政府必须要参考公投结果,并作出适当地回复。同志婚姻虽然依旧会立法保障,但无法入民法,对同志族群的打击,显然不是一时半刻可以恢复的。
对于反同志婚姻入民法的一派,重申要提同志伴侣专法,苗博雅轻松地回应:“他们要提案是他们的自由,但我相信,未来的某一天,台湾会迎接真正的婚姻平权”。
游信义则说,台湾人对于同志一直是很友善的,可以合法登记伴侣跟办结婚仪式,就连他也有同志朋友。但他认为是部分激进派同志人士为了自已利益,想要修改民法规范,这是很不可取的。他说:“婚姻不就是为了孩子吗?那不然是为了什么?”。
他并补充,民法保障的异性婚姻是高于任何一切的,同性婚姻的“价值跟重要性没有那么高”。游信义认为同志人士一直口口声声喊人权,但他们要去探讨,同志人士也是异性结合下出生的,对于同性人士一直抨击他歧视,他觉得很遗憾。
然而,对于苗博雅来说,同志平权本来就不是容易的路。她举例说,过去德国、法国与美国等国家,都是历经数十年的争取才慢慢得到权益。
苗博雅坚定地说:“人无知的时候,就会一直散布恐慌。但社会改革就是这样吧,往前走三步,还是会一时退两步。慢慢地走,目标总是会到的”。
未来他们将先朝着与民法同样规格的目标审慎订立专法,而台湾依旧是亚洲最先承认同志伴侣关系的地区之一。而台湾同志权益的下一一步,苗博雅与她的同志战友们,依旧在真正同志婚姻的崎岖道路上缓缓而行。
水平线 中国大陆与香港的同志权益现况
BBC中文记者林祖伟
同性婚姻或同志公民结合权利,暂时在中国大陆或香港也是遥不可及的梦。
湖南长沙一对男同性恋伴侣,2015年曾向民政局办理登记结婚被拒,其后向法院提告,成为大陆首宗同志争取婚姻权的案例。结果,法院判处他们败诉,理由是《中华人民共和国婚姻法》中规定“只有一男一女才能结婚”。
孙文林(右)与他的男朋友在湖南的法院提告,但他们败诉。CNS 孙文林(右)与他的男朋友在湖南的法院提告,但他们败诉。 在大陆较开放的城市,民众对同志的印象并非完全反感,粉红经济甚为活跃,会有同志酒吧、同志交友软件等等,亦会举办较大型的同志活动,例如上海骄傲节等等,不过这些活动因为政治因素,不会以“同志游行”作宣传字眼。
但由于中国此前的“一孩政策”持续已久,家庭基于传统观念,对下一代有传宗接代的要求,令许多男同志被迫隐瞒自己性向,与异性恋女性结婚,结果造成了“同妻”(同志恋者的妻子)的问题。根据哈尔宾工业大学发表的研究成果,估计中国大陆有1600万“同妻”。
一些男同志亦会寻找女同志结婚以应对家庭压力,此称为“形式婚姻”。
非政府组织人权监察2017年发表报告,深度访问了17名被强迫接受“转化治疗”(又称矫正治疗、扭转治疗)的同性恋者,列出他们如何因为接受治疗而身心受损。
国际医学机构早已不视同性恋为精神病,世界精神病协会把“转化治疗”视为违反道德、没有科学根据和具伤害性。
中国政府在1997年把同性恋去刑事化,由于官方也不再视同性恋为精神病,根据《精神卫生法》规定,“转化治疗”或被视为违法,但官方对坊间的“转化治疗”并没有任何表态。河南一名男同性恋者曾被妻子强迫送入精神病院接受“转化治疗”,结果告上法庭,法院认为他的人身自由被侵犯,获赔5000元人民币。
中国政府没有公开认可同性恋,关注团体一直担心官方随时会施以打压,例如过往有同性恋体裁的影视作品遭下架,中国曾推出《网络视听节目内容审核通则》,称同性恋是“渲染淫秽色情和庸俗低级趣味”,引发社会广泛讨论官方是否为同性恋定性。
而在香港,同志平权运动被观察人士认为“停滞不前”,先不谈同性婚姻,连反对歧视不同性倾向人士的法例也讨论了十多年,也无法达成共识。
根据港大2017年一项研究,香港逾半人支持同性婚姻,但社会的反同宗教保守声音强大。
香港立法会上周以27票反对、24票赞成三票之差,否决了同志缔结伴侣关系的议案,有宗教背景的议员公开表示,同志是异数,“歧视他们并没有问题”。
专访:或改写香港同志历史的公务员与机师 值得留意的是,香港近年同志运动的维权方式,逐渐走向法律层面。
近期,一名女同志MK,认为香港并无让同性伴侣缔结的相关机制,入禀法院提出司法复核,争取民事结合权,将会是香港首宗直接谈及同志配偶关系的案件。
另外,英国女同性恋者QT今年7月获判胜诉,令在外国民事结合的同性伴侣可以申请受养人签证,被视为香港同志运动的里程碑。而公务员梁镇罡则与在新西兰注册的英国籍伴侣,争取政府给予他们平等待遇,希望可以申请异性恋公仆享有的配偶福利,案件已获批上诉至终审法院。
Spurious samples in deep generative models: bug or feature?
此文引言还算引人入胜的。全文似乎就为了阐述一件事情:Spurious samples are not simply errors but a feature of deep generative nets. 但我怎么觉得这是一句废话呢?不然你以为 generate model 是根据什么 generate samples 的呢?
Deep processing of structured data
此文提出“set aggregation network”(SAN)子网络,但说白了是将卷积完的各特征图都做非线性化操作后再求和为一个图,so就有所谓pooling和flatten是其特例了。后文的实验还远算不上效果显著,甚至在我看来还没做完[挖鼻]~此文就随便看看得了~我这还没吐槽: 图像文本等不应该是“非结构化数据”嘛?[哼]
An analytic theory of generalization dynamics and transfer learning in deep linear networks
这是一篇谈论泛化error和Transfer L.的理论 paper. 虽实验细节还没看懂, 但结论很意义:新提出一个解析的理论方法,发现网络最首要先学到并依赖的是tast structure(通过early-stoping)而不是网络size!这也就解释了为啥随机data比real data更容易被学习,似乎存在更好的non-GD优化策略.
关于 SNR 也有迁移实验,说可以从高 SNR 迁移到低 SNR。。。
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
这文帅了~ 信息丰富 超多的图~ 让人眼前一亮~
探讨了18个模型的鲁棒性和准确率。结论很多,如模型构架是影响鲁棒性和准确率的重要因素(似乎是废话);相似模型构架基础上增加“深度”对鲁棒性的提升很微弱;有些模型(Vgg类)的表现出很强的对抗样本迁移性。。。
Towards a universal neural network encoder for time series
数据任务是“时序序列的分类”,这是我感兴趣的问题。Universal 代表不需要额外设置和训练,从某数据集训练后,就可以拿到另一个新训练集类型去搞事情~ 另一个特点是用了 encoder 得到了低维不变的表示。
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
如果不是看到大神 Goodfellow 是作者之一,我就还以为这是一片水文呢~ 结论说DNN的随机初始化下,不管从可视化还是量化的角度上看都和训练好后的很像。猜测可能这些“解释”都是与低层的表示相关联导致,影射了模型本身存在很强的先验。
An Information-Theoretic View for Deep Learning
这是一篇关于DL理论的 paper,很有亮点!其给出了期望泛化误差范围内 CNN 层数的理论上界!“the deeper the better” 的神话终将是要设限的。。
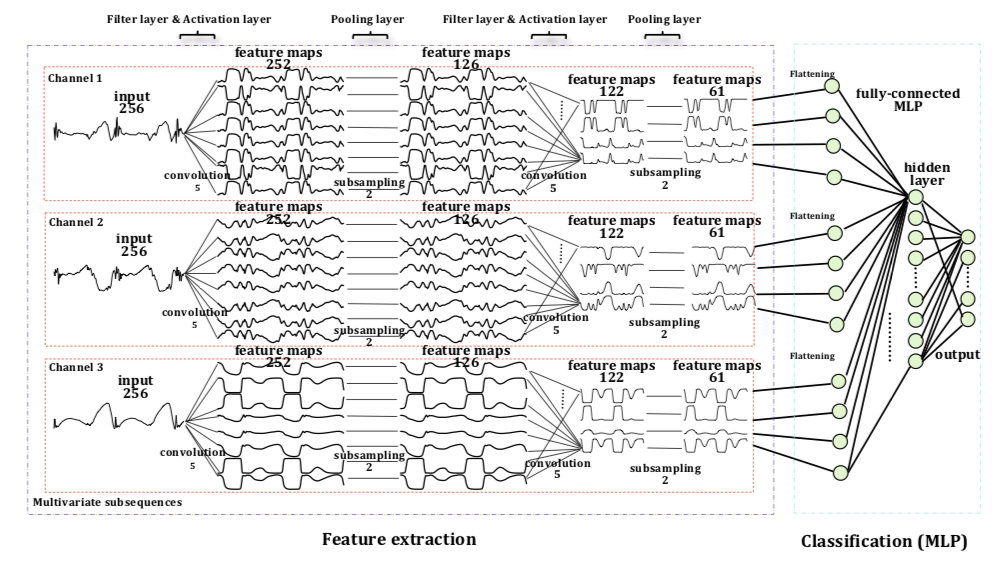
Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks
这是一个三通道并列输入的时序信号模型。效果貌似不错,还针对不同模型算法的预测时间在不同训练规模数据上的模型表现做了对比,
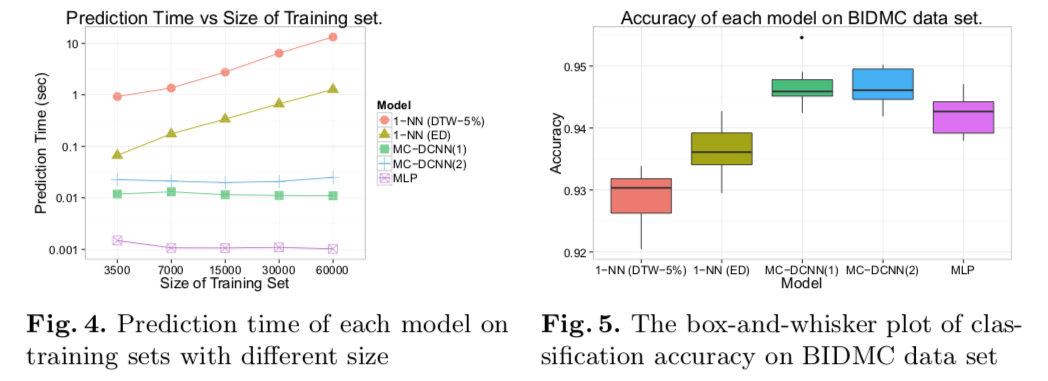
另外文章的模型图示也很有启发性。
Efficient Identification of Approximate Best Configuration of Training in Large Datasets
这篇有微软和阿里参与的 paper,说白了就是提出了一个 ABC (approximate best configuration) 算法,一种自动化调参预判逻辑,实现了成倍的训练加速还基本不失准确率。显然这对玩 AutoML 类的商家是很有用的,而且算法还木有开源出来。。
Deep Learning in Neural Networks: An Overview
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
This paper shows that local explanations for DNNs with random-initialized weights are qualitatively and quantitatively similar to explanations produced by DNNs with learned weights.
The paper is clear, the problem is well stated and the method is sound.
The impact of the findings in this paper is unclear. Perhaps the most important point made in the paper is the importance of the architecture over fine-tuning of the weights for explanation tasks (and more in general).
其实 goodfellow 这文章篇幅很短,可视化图像的效果是很棒的!
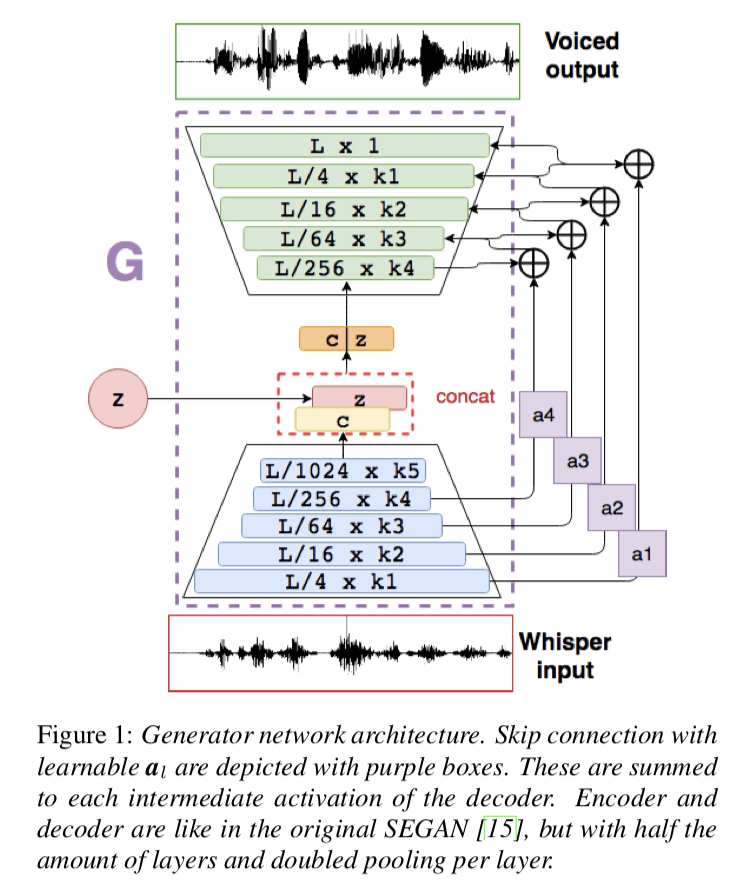
Whispered-to-voiced Alaryngeal Speech Conversion with Generative Adversarial Networks
这是一篇用 GAN 来做 Voiced Speech Restoration 的,并且使用了作者自己提出的 speech enhancement using GANs (SEGAN) 。
于我而言,亮点有二:
Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift
该文做的实验是探索对数据集进行 shifts (某种可控的扰动) 后的模型表现,提出了classifier-based的方法/pipeline 来观察和评价:
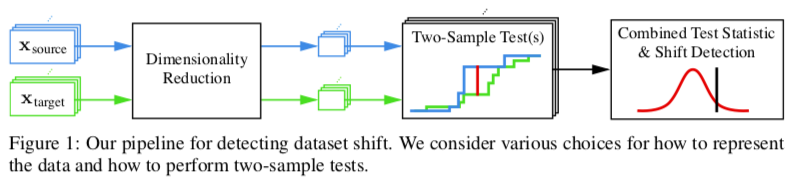
这对于我的引力波数据研究来说,可以借鉴其数据的 shift 方法以及评价机制 (two-sample tests)。
Generative adversarial networks and adversarial methods in biomedical image analysis
这是一篇很有 review 气质的 paper,对GAN 和对抗方法等做了介绍(在生物医药领域中),也谈论了这些技术应用的优势和劣势。
对我来说,这是一篇很适合快速入门GAN应用的 paper。
Toward an AI Physicist for Unsupervised Learning
提出了 AI Physicist 这样的概念(paradigm),这也算是我的某种终极目标吧。
只能说是有趣吧,对理论的归纳和理解也比较有趣。
Training neural audio classifiers with few data
这是一个比较初步的简单实验。
图像结论其实并不意外:数据量越多当然表现越好;迁移学习在极小量数据上表现良好;Prototypical 模型可能因结构的特异性会表现出一定程度上的优势;数据量越小,过拟合问题越严重。。。
My verse your vertues
这两个到底哪个是主动的一方?
report
report = postponement
这句话是说martial law的三个可能后果:断绝与俄罗斯关系,国家进入紧急状态,推迟2019年3月的大选。
devait
devait 是devoir 的indicatif imparfait. 这句话什么意思呢?是说刚过去的会本来应该是一个关于经济的会么?
un droit de regard
这是个什么权利?
我目前还处于很低级的水平.
我很清楚, 从零开始开发一个软件完全是浪费和低效的.
一个软件可以由大到小采用树形去理解. 首先, 第一层由数个模块组成, 下钻, 每个模块又由数个子模块组成, 这样不断下钻, 直至每一行代码. 这之间的每一层都有自己的原理和实现细节, 我们没办法理解所有层的所有细节, 做不到.
但每一层都有一些通用的知识, 越到底层越趋同. 学习这些, 在需要的时候可以迅速理解具体的模块.
上层的原理需要理解, 因为这是集成和评估的基础.
锻炼自己的码力的同时少造轮子, 注意完善自己的工具箱.
solaire
像太阳一样。但是这是什么意思?阳光?是么?
快慢速度调整和分段拍摄是抖音最大的特点。利用好这两个功能就能玩出很酷炫的抖音效果。
快慢调整 分段拍摄
Ceasse now my song, my woe now wasted is. 我的歌结束,我不再难过。 O ioyfull verse. 啊,唱一首欢快的歌。
这一点与别的挽诗不一样? 这一个stanza确实是他自己发明的
但美德长久来卑躬屈膝, And mighty manhode brought a bedde of ease: 猛虎落平阳任凭恶狗欺: The vaunting Poets found nought worth a pease, 自负诗家们找不到点滴, To put in preace emong the learned troupe. 来与学识渊博之军相比。 Tho gan the streames of flowing wittes to cease, 奔涌才思溪流开始停息, And sonnebright honour pend in shamefull coupe. 灿烂荣耀遭受可耻一击。
这一段是说诗的内容无论多么伟大,都不直接影响诗本身的力量??
iPhone unit growth and revenue were obviously highly correlated in the early years of the iPhone, when the only price difference in the line concerned the amount of storage on the flagship device.
注意 纵轴 是增长率,对比的是 销售单元的增长情况 和 营收的增长情况
你好,我买了您的书《函数式攻城指南》,我才读到第二章,但是我对书里面出现的Clojure代码完全搞不懂(一个是持久性数据结构的实现,一个是惰性求指的实现),因为我对Clojure这门语言完全不了解。我在想如果这些贴clojure源码的内容如果转化为js来讲解会不会好一些?
不过这是个实验项目,只是证明idea,如果想要production ready的项目是 -> https://github.com/jcouyang...
企业界流行的IT规划方法论以注重协同性为主,但较为成功的IT规划结果多以注重影响性的方法论作为指导。
两种方法论有何优劣,对于后者来说是怎样实现的。这是不是意味着IT系统改变业务方式的效用越来越显著
准备Rmd文件 一个典型的bookdown文档包含多个章节,每个章节在一个RMarkdown文件里面 (文件的语法可以是pandoc支持的markdown语法,但后缀必须为Rmd); 每一个章节都必须以# 章节标题开头。后面可以跟一段概括性语句,概述本章的内容,方便理解,同时也防止二级标题出现在这一页。默认系统会按照文件名的顺序合并Rmd文件。 另外章节的顺序也可在_bookdown.yml文件中通过rmd_files:[“file1.Rmd”, “file2.Rmd”, ..]指定; 如果有index.Rmd,index.Rmd总是出现在第一个位置。通常index.Rmd里面也需要有一章节,如果不需要对这一章节编号的话,可以写作# 前言 {-}, 关键是{-}。 在第一个出现的Rmd文件中,可以定义Pandoc相关的YAML metadata, 比如标题、作者、日期等(去掉#及其后的内容),如下指令集所示:
不知道在rstudio里怎么编辑rmd文件,这里感觉缺少了步骤
Textbook: chapter 1.6
\(Ax=b\)
能否找到一个 x 使得 \(Ax=b\) 成立.
有没有解这个问题非常重要:假设 Linear system 是一个电路,现在老板告诉你这个电路要输出 b 这么大的电流,你能不能找到合适的电压源or电流源,还是根本就找不到?
consistent
A system of linear equations is called consistent if it has one or more solutions。
只要有解就叫做 consistent.
inconsistent
A system of linear equations is called inconsistent if its solution set is empty(no solution)
没有解就叫做 inconsistent.
Naive 方法:线的交点
把 system of linear equations 的方程都画成直线,如果他们有交点,那么就是有解,否则无解。
General 方法
定义引入:Linear Combination
Given a vector set \(\{u_1,u_2,...,u_k\}\)
The linear combination of the vectors in the set: \(v=c_1u_1+c_2u_2+...+c_ku_k,\ c_1,c_2,...,c_k\ are\ scalars\ coefficients\ of\ linear\ combination\)
linear combination is a vector.
有了 Linear combination 的定义之后,我们再回一下 lec5 篇末讲解的关于 使用 column view of product of matrix and vector 所以我们可以得到的结论是:
\(Ax\) 其本质就是一个 linear combination, 他是
矩阵与向量的乘法就是对矩阵的列做线性组合。
对于 \(Ax=b\) 是否有解(x是变量)这件事,实际就是在问:b 是否是columns of A的所有可能的线性组合中的一种。
从是否有解到是否是线性组合
如果两个向量不是平行的同时不是0向量,那么他们可以组合出二维空间中所有可能的向量(亦即,线性组合的所有可能性覆盖整个2D空间)。
【判断题】:如上所说,如果非零非平行的两个向量的线性组合可以覆盖整个二维空间的话,那么非零非平行的三个向量的线性组合是否可以覆盖整个三维空间呢?
【答案】:否
引入 independent 向量
在三维空间中对参与线性组合的向量不能仅仅给出【非零】【非平行】两个限制,还得加上一个【不在同一个二维平面】。试想,如果三个向量处在同一平面的话,那么不论如何线性组合都不可能与第三维有任何关系。
引入 反之不反
非零非平行 ===> 有解;有解 ==X==> 非零非平行。
引入 span
vector set 的所有可能的 linear combination (另一个vector set)就是这组 vector set 的 span。
\(v = c_1u_1+c_2u_2+...+c_ku_k\)
\(v\) 毫无疑问是一个向量。
如果我们穷举所有可能的\(c_1,c_2,...,c_k\),他们所得到的向量的集合(vector set \(V\))就是\(x_1,x_2,...,x_k\)的span,同时,\(x_1,x_2,...,x_k\) 叫做 vector set \(V\) 的 generating set.
引入 generating set
\(if\ Vector\ set\ V=Span(S),\ then\ V\ is\ Span\ of\ S, also\ S\ is\ a\ generating\ set\ for\ V,\ or\ S\ generates\ V\)
\(S\) 可以作为一种描述 \(V\) 特性的方法。为什么我们需要这种描述方法呢?因为 \(V\) 作为一个 span,他通常都非常非常的大(一般都是无穷多个),如果我们想要描述这种无穷大(“无穷”都意味着抽象)的向量的集合,最好的方法就是找到一个更具体(“有限”意味着具体)的可联想的“指标” --- generating set --- 这个向量集合是由什么样的向量集合生成的。
相同的向量集(span)可能由不同的向量集(generating set)产生:
\(S_1=\begin{vmatrix} 1 \\ -1\end{vmatrix}\)
同
\(S_2=\{\begin{vmatrix}1\\-1\end{vmatrix},\begin{vmatrix}-2\\2\end{vmatrix}\}\)
产生的向量集是相同的。
引入 span of standard vector
standard vector 其实就是 one-hot encoding vector. 可以见下:
\(e_1=\begin{vmatrix}1\\0\\0\end{vmatrix}, e_1=\begin{vmatrix}0\\1\\0\end{vmatrix}, e_1=\begin{vmatrix}0\\0\\1\end{vmatrix}\)
\(span(e_1)=one\ R^1\ in\ R^3\), one axis in 3D-space \(span(e_1,e_2)=one\ R^2\ in\ R^3\), one 2D-space in 3D-space \(span(e_1,e_2,e_3)=R^3\), whole 3D-space.
其实今天学的东西就是“换句话说”,
换句话说
换句话说
第三节课讲过,一个线性系统不仅仅是一条“直线”,直线只是一种特殊到不能再特殊的情况。线性系统的本质是:
'->' 以下表示线性系统
符合加法性:x->y ==> x1+x2->y1+y2
符合乘法(scalar)性:x->y ==> x1k->yk
再结合一个超级牛逼的观点广义向量 --- 函数也是一种向量。我们就把线性系统是一条直线的观点边界向外扩展了一些:
线性系统是以向量(亦即,包含函数和数字和普通向量)作为输入
现实世界中的很多东西都可以表示为向量,就连函数也不例外。
他可以造就这样的奇迹:
加法性:fn->fc ===> fn1 + fn2-> fc1+fc2
乘法性:fn->fc ===> fn1k->fc1k
也就是说,线性系统接收的输入和输出都是一个向量,而数字和函数只是特殊的向量。,满足这一特殊性质的线性系统就是【微分】and【积分】。微分和积分更像是一种【功能】而不是一个【函数】,这也是为什么我们不把系统说成函数的原因,因为他强调功能而不是记号表示性,或者说函数只是功能的一个可记号话的特例
线性代数这门学科研究的主要目标就是线性系统。
于是新的关于线性系统的定义至此形成:
\(vector\ \Rightarrow LinearSystem\ \Rightarrow vector\)
\(domain\ \Rightarrow LinearSystem\ \Rightarrow co-domain\)
可以证明的是(in lec3)任何线性系统都可以表示为联立线性等式,也就是说联立等式与线性系统是等价的
Linear system is equal to System of linear equations.
因为
矩阵=线性系统,
联立方程=线性系统,
所以
矩阵=联立方程。
联立方程式 ---> 按列看待matrix的 product of matrix and vector ---> 联立方程式可以写成 Product of matrix and vector. 因为之前说过任何一个线性系统都可以写成联立方程式,那么矩阵就是一个线性系统。
\(Ax=b\) 中的 \(A\) 就是一个线性系统
方差、平均值这些统计量的计算,都只能算是【叙述统计】。真正统计的核心在于【推理统计】,推理统计有两个学派:frequentist vs. bayesian (频率统计学派 vs. 贝叶斯学派)。
bayes 实际解决的是一个【推论 inference --- 我们想知道大自然是什么样子的,于是 collect 很多 data,根据这些data做推断,这就是 Inference】的问题。
【注意:教授说,预测和推断是有区别的, prediction and inference is different】
【注:这里从参数模型parameters model 来考虑】
a particular mathematical approach to apply probability to statistical problems.
incorporating our prior beliefs and evidence, to produce new posterior beliefs.
这是bayes学派的思路。而频率学派的思路是:对于模型的某个参数,先得到其【点估计】,然后给出这个点估计的【准确度 confidence?】, bayes 不是得到一个点估计,而是得到一个【distribution】
\(P(A|B) = \frac{P(B|A)P(A)}{P(B)}\)
\(P(B|A) = \frac{P(A|B)P(B)}{P(A)}\)
bayes 来自于 bayes' Rule --- 一个条件概率计算式子。
顺序:今天下雨,我带伞的概率; 逆序:今天带伞,外面下雨的概率;
\(P(\Theta|D)=\frac{P(D|\Theta)P(\Theta)}{P(D)}\)
因为 evidence 可以消掉,所以我们经常把 bayesian inference 写作:
\(P(\Theta|D)\propto P(D|\Theta)P(\Theta)\)
posterior propto likelihood * prior
频率学派和贝叶斯学派最大的不同在于,random 来自哪里,前者认为其来自 data,后者认为其来自 parameter
一般大学的统计学教学都是 频率学派,杜克大学是个例外,他是bayes学派。MLE 就是典型的频率学派的研究对象。这个学派的特点是得到的是模型参数的【点估计】,它认为在宇宙表象之后有一个【绝对的公理】在支配宇宙万事的运行,它认为 random 来自于 data,比如 linear model 只有两个参数 w and b,\(y = wx+b\),这个 linear model 的 w 和 b 是有两个绝对正确的量的(标准答案)。那为什么我学习or估测的这两个参数的结果会与标准答案不符合呢,是因为我的 data 来自于 random sample。
亦即:parameter is fixed, data is random.
所以,这也就解释了
why get a value not a distribution --- parameter is fixed.
Bayesian statistics: preserve and refine uncertainty by adjusting individual beliefs in light of new evidence.
bayes 学派得到的是模型参数的【分布】,认为这个参数并不是一个 fix 的值,这体现了统计学中 random 这一概念。与频率学派不同的是,bayes学派认为 data 已经在那了,我不可能去改 data 来 fit parameter,所以它认为: data is fixed, parameter is random. 它认为 parameter 不是固定的,而是符合某种分布的。比如 Linear model 的两个参数 w 和 b, bayesian 认为他们【没有绝对正确】的值,所以我寻找他的先验估计,通过 fitting 不同的 data 对其进行 update (ps:怎么看着有点像是 iterative 优化方法)从而得到 posterior, 而 posterior 就是模型对这个参数的估计。
Linear Regression model: \(y_i = w_0 + \sum_jw_jx_{ij}=w_0+w^Tx_i\)
Maximum Likelihood Estimation(MLE):
between the func keyword and the name of the function, we pass the variable and type. We use c, short for car, and then car, which is in association with the car struct. In this case, the method gets a copy of the object, so you cannot actually modify it here, you can only take actions or do something like coming up with a calculation
在func关键字和方法名之间,我们传递了变量和类型,
我们使用c,汽车的简称,然后汽车,这是与汽车结构相关联。这样就把struct和method关联了起来
在这种情况下,该方法获取对象的副本,因此您无法在此实际修改它,您只能执行操作或执行类似计算的操作 通过把struct和method关联了起来,使得方法获取到了对象的副本
func (c car) kmh() float64 {
return float64(c.gas_pedal) * (c.top_speed_kmh/usixteenbitmax)
}
美国调查研究表明,一个人会更喜欢喜欢自己的人。
求人帮一个忙,是一种交换‘尊敬’的方法。
以此发展出的推销方法:
真理:当一个人帮过你一个忙,这个人就倾向于帮您一个更大的忙。
罗胖分享的第二个故事:
大妈出钱帮助创业公司,从中体会出一个特别重要的道理:
无论你在什么样的局面里,不论谁,会在你多么急迫的时刻,会冲出来帮你一把。所以,成为一个受欢迎的人,这不是你想讨好这个世界,是你想过好自己的一生,把这局无限游戏玩下去的必要条件。
找人帮忙,别人帮你一个忙,就会倾向于帮你一个更大的忙
尊重每一个人,喜欢别人。人的互惠天性导致会喜欢那些喜欢我们的人。
永远不要鄙视别人,这将永远得不到原谅
有实力,有用处,能够提供交换价值,这也是人生的意义所在。你的存在要能够改变一些东西的价值。
尊重要落到实处,要真诚,尽量不假手于他人。
之前介绍的所有方法都存在相同的弊病:
similar data are close, but different data may collapse,亦即,相似(label)的点靠的确实很近,但不相似(label)的点也有可能靠的很近。

\(x \rightarrow z\)
t-SNE 一样是降维,从 x 向量降维到 z. 但 t-SNE 有一步很独特的标准化步骤:
一, t-SNE 第一步:similarity normalization
这一步假设我们已经知道 similarity 的公式,关于 similarity 的公式在【第四步】单独讨论,因为实在神妙。
这一步是对任意两个点之间的相似度进行标准化,目的是尽量让所有的相似度的度量都处在 [0,1] 之间。你可以把他看做是对相似度进行标准化,也可以看做是为求解KL散度做准备 --- 求条件概率分布。
compute similarity between all pairs of x: \(S(x^i, x^j)\)
我们这里使用 Similarity(A,B) 来近似 P(A and B), 使用 \(\sum_{A\neq B}S(A,B)\) 来近似 P(B)
\(P(A|B) = \frac{P(A\cap B)}{P(B)} = \frac{P(A\cap B)}{\sum_{all\ I\ \neq B}P(I\cap B)}\)
\(P(x^j|x^i)=\frac{S(x^i, x^j)}{\sum_{k\neq i}S(x^i, x^k)}\)
假设我们已经找到了一个 low dimension z-space。我们也就可以计算转换后样本的相似度,进一步计算 \(z^i\) \(z^j\) 的条件概率。
compute similarity between all pairs of z: \(S'(z^i, z^j)\)
\(P(z^j|z^i)=\frac{S(z^i, z^j)}{\sum_{k\neq i}S(z^i, z^k)}\)
Find a set of z making the two distributions as close as possible:
\(L = \sum_{i}KL(P(\star | x^i)||Q(\star | z^i))\)
二, t-SNE 第二部:find z
我们要找到一组转换后的“样本”, 使得转换前后的两组样本集(通过KL-divergence测量)的分布越接近越好:
衡量两个分布的相似度:使用 KL 散度(也叫 Infomation Gain)。KL 散度越小,表示两个概率分布越接近。
\(L = \sum_{i}KL(P(\star | x^i) || Q(\star | z^i))\)
find zi to minimize the L.
这个应该是很好做的,因为只要我们能找到 similarity 的计算公式,我们就能把 KL divergence 转换成关于 zi 的相关公式,然后使用梯度下降法---GD最小化这个式子即可。
三,t-SNE 的弊端
因为 t-SNE 要求我们计算数据集的两两点之间的相似度,所以这是一个非常高计算量的算法。同时新数据点的加入会影响整个算法的过程,他会重新计算一遍整个过程,这个是十分不友好的,所以 t-SNE 一般不用于训练过程,仅仅用在可视化中,即便在可视化中也不会仅仅使用 t-SNE,依旧是因为他的超高计算量。
在用 t-SNE 进行可视化的时候,一般先使用 PCA 把几千维度的数据点降维到几十维度,然后再利用 t-SNE 对几十维度的数据进行降维,比如降到2维之后,再plot到平面上。
四,t-SNE 的 similarity 公式
之前说过如果一种 similarity 公式:计算两点(xi, xj)之间的 2-norm distance(欧氏距离):
\(S(x^i, x^j)=exp(-||x^i - x^j||_2)\)
一般用在 graph 模型中计算 similarity。好处是他可以保证非常相近的点才会让这个 similarity 公式有值,因为 exponential 会使得该公式的结果随着两点距离变大呈指数级下降。
在 t-SNE 之前有一个算法叫做 SNE 在 z-space 和 x-space 都使用这个相似度公式。
similarity of x-space: \(S(x^i, x^j)=exp(-||x^i - x^j||_2)\) similarity of z-space: \(S'(z^i, z^j)=exp(-||z^i - z^j||_2)\)
t-SNE 神妙的地方就在于他在 z-space 上采用另一个公式作为 similarity 公式, 这个公式是 t-distribution 的一种(t 分布有参数可以调,可以调出很多不同的分布):
\(S(x^i, x^j)=exp(-||x^i - x^j||_2)\) \(S'(z^i, z^j)=\frac{1}{1+||z^i - z^j||_2}\)
可以通过函数图像来理解为什么需要进行这种修正,以及这种修正为什么能保证x-space原来近的点, 在 z-space 依旧近,原来 x-space 稍远的点,在 z-space 会拉的非常远:
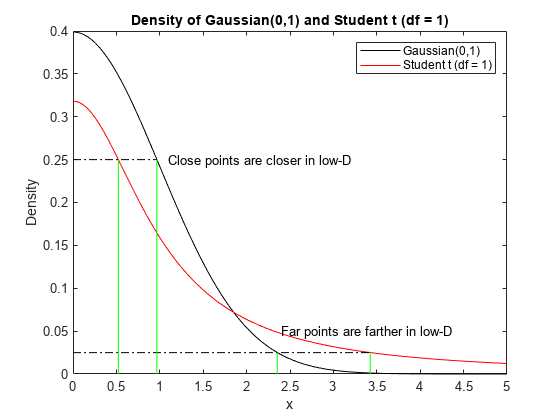
也就是说,原来 x-space 上的点如果存在一些 gap(similarity 较小),这些 gap 就会在映射到 z-space 后被强化,变的更大更大。

本节介绍三个相互依存的概念:单位向量,span,线性无关。
是一种新的看待线性代数的观点,非常重要的三个知识点,至此向量的表示可以变成在各个单位向量做放缩然后取和,或者,单位向量的线性组合:
\((-5)\hat{i} + (2)\hat{j}\)
可以表示为:
$$ \begin{vmatrix} -5 \\ 2 \end{vmatrix} $$
虽然不论使用什么方向的两个单位向量,其线性组合始终可以覆盖全部二维空间,但是我们仍然得到了同一个向量的两个不同的表示:
although \((3.1)\hat{i} + (-2.9)\hat{j} = \(-0.8)\hat{i}+(1.3)\hat{j}\) 但是该向量的实际表示却完全不同:
$$ \begin{vmatrix} -0.8 \\ 1.3 \end{vmatrix} \neq \begin{vmatrix} 3.1 \\ -2.9 \end{vmatrix} $$
所以这里需要给出一种关于线性代数的数字表示法\([3.1, -2.9]\)的一个基本条件:每当使用这种表示法时都必须明确单位向量是什么。
可以想象的是:
引入概念span
The "span" of \(\vec{v}\) and \(\vec{w}\) is the set of all their linear combinations:
\(a\vec{v} + b\vec{w}\)
let \(a\) and \(b\) vary over all linear numbers.
两个向量的 span 与另一个表述是等价的,仅仅通过加法和乘法两种操作可以产生的所有向量
【tips】如果仅仅考虑一个向量,经常将向量想象成带箭头线段;如果考虑一堆向量的集合,经常将向量想象成点。
任何时候如果你有多个向量,但是去掉其中一个或几个,前者和后者的span没有减少(span is essencially a set --- set of all possible linear combination)
\(span(\vec{v},\vec{w},\vec{u})=span(\vec{v},\vec{w})\)
那么就可以说这个向量与其他向量是 Linear dependent (线性相关), 或者说这个(可以去掉的)向量可以表示为其他向量的线性组合, 因为这个可以去掉的向量处在其他向量的span中。
\(redundant\ \vec{u} \in span(\vec{v}, \vec{w})\)
或者说,他对扩大span(set of linear combination of vectors)没有作用。
由此衍生出另一个概念:Linearly independent
\(\vec{u} \neq a\vec{v} + b\vec{w},\ for\ all\ values\ of\ a\ and\ b\)
如果某个单位向量无法通过其他单位向量的任何一种系数的线性组合来得到,那么就说这个向量与其他向量都是线性无关的
有了之前的 span linearly dependent 两个概念,下面才能正式定义第三个概念:何为 basis vector ?
The basis of a vector space is a set of linearly independent vectors that span the full space
著名的 tSNE 算法('NE' --- Neighbor Embedding)
什么是 manifold,manifold 其实就是一个 2D 平面被卷曲起来成为一个3D物体,其最大的特点是3D空间中的两点之间Euclidean distance并不能衡量两者在(卷曲前)2D空间中的'远近',尤其是两者距离较大的时候,欧式几何不再适用 --- 3D远距离情况下欧式几何失效问题,在3D空间中欧式几何只能用在距离较近的时候。
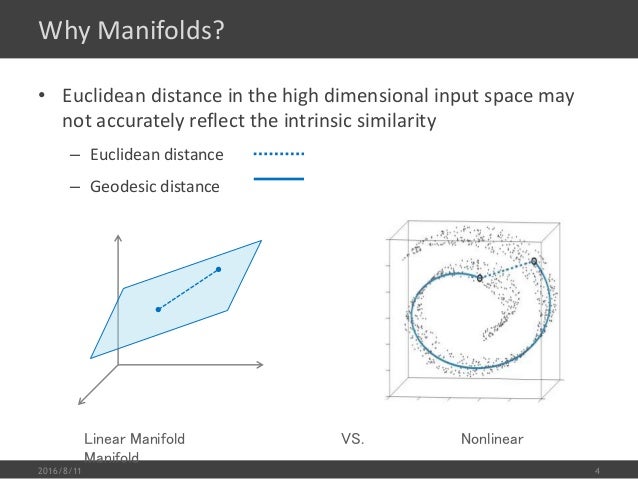
manifold learning 就是针对3D下欧式几何失效问题要做的事情就是把卷曲的平面摊平,这样可以重新使用欧式几何求解问题(毕竟我们的很多算法都是基于 Euclidean distance)。这种摊平的过程也是一种降维过程。
又是一种“你的圈子决定你是谁”的算法
第一步, 计算 w
针对每个数据集中的点,【选取】他的K(超参数,类似KNN中的K)个邻居,定义名词该\(x^i\)点与其邻居\(x^j\)之间的【关系】为:\(w_{ij}\), \(w_{ij}\) represents the relation between \(x^i\) and \(x^j\)
\(w_{ij}\) 就是我们要寻找的目标,我们希望借由 \(w_{ij}\) 使得 \(x^i\) 可以被K个邻居通过\(w_{ij}\)的加权和来近似,使用 Euclidean distance 衡量近似程度:
given \(x_i, x_j\),, find a set of \(w_{ij}\) minimizing
\(w_{ij} = argmin_{w_{ij},i\in [1,N],j\in [1,K]}\sum_i||x^i - \sum_jw_{ij}x^j||_2\)
第二步, 计算 z 做降维,keep \(w_{ij}\) unchanged, 找到 \(z_{i}\) and \(z_{j}\)将 \(x^i, x^j\) 降维成\(z^i, z^j\), 原则是保持 \(w_{ij}\) 不变,因为我们要做的是 dimension reduction, 所以新产生的 \(z_i, z_j\) 应该比 \(x_i, x_j\) 的维度要低:
given \(w_{ij}\), find a set of \(z_i\) minimizing
\(z_{i} = argmin_{z_{i},i\in [1,N],j\in [1,K]}\sum_i||z^i - \sum_jw_{ij}z^j||_2\)
LLE 的特点是:它属于 transductive learning 类似 KNN 是没有一个具体的函数(例如: \(f(x)=z\))用来做降维的.
LLE 的一个好处是:看算法【第二步】,及时我们不知道 \(x_i\) 是什么,但只要知道点和点之间的关系【\(w_{ij}\)】我们依然可以使用 LLE 来找到 \(z_i\) 因为 \(x_i\) 起到的作用仅仅是找到 \(w_{ij}\)
LLE 的累赘:必须对 K(邻居数量)谨慎选择,必须刚刚好才能得到较好的结果。
K 太小,整体 w (模型参数)的个数较少,能力不足,结果不好
K 太大,离 \(x_i\) 较远距离的点(x-space 就是卷曲的 2D 平面)也被考虑到,之前分析过 manifold 的特点就是距离太大的点 Euclidean distance 失效问题。而我们的公式计算 w 的时候使用的就是 Euclidean distance,所以效果也不好。
这也就是为什么 K 在 LLE 中非常关键的原因。
Graph-based approach, to solve manifold
算数据集中点的两两之间的相似度,如果超过某个阈值就连接起来,如此构造一个 graph。得到 graph 之后,【两点之间的距离】就可以被【连线的长度】替代,换言之 laplacian eigenmaps 并不是计算两点之间的直线距离(euclidean distance)而是计算两点之间的曲线距离:
回忆我们之前学习的 semi-supervised learning 中关于 graph-based 方法的描述:如果 x1 和 x2 在一个 high-density region 中相近,那么两者的标签(分类)相同,我们使用的公式是:
\(L=\sum_{x^r}C(y^r, \hat{y}^r)\) + \lambda S
\(S=\frac{1}{2}\sum_{i,j}w_{i,j}(y^i - y^j)^2=y^TLy\)
\(L = D - W\)
\(w_{i,j} = similarity between i and j if connected, else 0\)
同样的方法可以用在 unsupervised learning 中, 如果 xi 与 xj 的 similarity(\(w_{i,j}\)) 值很大,降维之后(曲面摊平之后)zi 和 zj 的距离(euclidean distance)就很近:
\(S=\frac{1}{2}\sum_{i,j}w_{i,j}(z^i - z^j)^2\)
但是仅仅最小化这个 S 会导致他的最小值就是 0,所以要给 z 一些限制 --- 虽然我们是把高维的扭曲平面进行摊平,但我们不希望摊平(降维)之后他仍然可以继续'摊'(曲面 ->摊平,依然是曲面 -> 继续摊), 也就是说我们这次摊平的结果应该是【最平的】,也就是说:
if the dim of z is M, \(Span{z^1, z^2, ..., z^N} = R^M\)
【给出结论】可以证明的是,这个 z 是 Laplacian (\(L\)) 的比较小的 eigenvalues 的 eigenvectors。所以整个算法才叫做 Laplacian eigenmaps, 因为他找到的 z 就是 laplacian matrix 的最小 eigenvalue 的 eigenvector.
结合刚才的 laplacian eigenmaps, 如果对 laplacian eigenmaps 找出的 z 做 clustering(eg, K-means) 这个算法就是 spectral clustering.
spectral clustering = laplacian eigenmaps reduction + clustering
Word Embedding 是 Diemension Reduction 一个非常好,非常广为人知的应用。
1-of-N Encoding 及其弊端
apple = [1 0 0 0 0]
bag = [0 1 0 0 0]
cat = [0 0 1 0 0]
dog = [0 0 0 1 0]
elephant = [0 0 0 0 1]
这个 N 就是这个世界上所有的单词的数量,或者你可以自己创建 vocabulary, 那么这个 N 就是 vocabulary 的 size.但是这样向量化的方式,太众生平等了,原本有一定关系的单词,比如 cat 和 dog 都是动物,这根本无法从 [0 0 1 0 0] 和 [0 0 0 1 0] 中看出任何端倪。
解决这件事情的一个方法是 Word Class
Word Class 及其弊端
先把所有的单词 cluster 成簇,然后用簇代替 1-of-N encoding 来表示单词。
虽然 Word Class 保留了单词的词性信息使得同类单词聚在一起,但是不同词性之间的关系依旧无法表达:名词 + 动词 + 名词/代词, 这种主谓宾的关系就没法用 Word Class 表示。
这个问题可以通过 Word Embedding 来解决
Word Embedding 把每个单词的 1-of-N encoding 向量都 project 到一个低维度空间中(Dimension Reduction),这个低维度空间就叫做 Embedding. 这样每个单词都是低维度空间中的一个点,我们希望:
相同语义的单词,在该维度空间中也相互接近
不但如此,当 Embedding 是二维空间(能够可视化)时,所有的点及其原本单词画在坐标图上之后,很容易就可以看到这个低维度的空间的每个维度(x,y轴)都带有具体的某种含义. 比如,dim-x 可能表示生物,dim-y 可能表示动作。
Word Embedding 本质上是【非监督降维】,我们之前学习的方法最直接的就是使用 autoencoder, 但用在这里很显然是无效的。因为你的输入是 1-of-N encoding 向量,在这种向量表示下每个输入样本都是 independent 的,也就是单个样本之间没有任何关系 --- 毫无内在规律的样本,你怎么可能学出他们之间的关系呢?(ps, 本来无一物,何处惹尘埃。)
我们的目的是让计算机理解单词的意思,这个完全不可能通过常规语言交流达此目的,所以需要曲径通幽,你只能通过其他方法来让计算机间接理解。最常用的间接的方法就是:understand word by its context.
及其肯定不知道马英九和蔡英文到底是什么,但是只要他读了【含有‘马英九’和‘蔡英文’的】大量的文章,知道马英九和蔡英文的前后经常出现类似的文字(similar context),机器就可以推断出“马英九”和“蔡英文”是某种相关的东西。
这种方法最经典的做法叫做 Glove Vector https://nlp.stanford.edu/projects/glove/
代价函数与 MF 和 LSA 的一模一样,使用 GD 就可以解,目标是找到越是经常共同出现在一篇文章的两个单词(num. of occur),越是具有相似的word vector(inner-product)。
这种【越是。。。越是。。。】的表达方式,就可以使用前一个“越是”的量作为后一个“越是”的目标去优化。
越是 A,越是 B ===> \(L = \sum(A-B)^2\)
if two words \(w_i\) and \(w_j\) frequently co-occur(occur in the same document), \(V(w_i)\) and \(V(w_j)\) would be close to each other.
核心思想类似 MF 和 LSA:
\(V(w_i) \cdot V(w_j) \Longleftrightarrow N_{i,j}\)
\(L = \sum_{i,j}(V(w_i)\cdot V(w_j) - N_{i,j})^2\)
find the word vector \(V(wi)\) and \(V(w)\), which can minimize the distance between inner product of thses two word vector and the number of times \(w_i\) and \(w_j\) occur in the same document.
prediction based 获取 word vector 是通过训练一个 单层NN 用 \(w_{i-1}\) 预测 \(w_i\) 单词的出现作为样本的数据和标签(\(x=w_{i-1}, y=w_i\)),选取第一层 Hiden layer 的输入作为 word vector.
【注意】:上面不是刚说过 autoencoder 学不到任何东西么,那是因为 autoencoder 的input 和 output 都是单词 \(w_i\),亦即(\(x=w_i, y=w_i\)),但是这里 prediction-based NN 用的是下一个单词的 1-of-encoding 作为label.
本质是用 cross-entropy 作为loss-fn训练一个 NN,这个 NN 的输入是某个单词的 1-of-encoding, 输出是 volcabulary-size 维度的(概率)向量--- 表示 volcabulary 中每个单词会被当做下一个单词的概率。
$$ Num.\ of\ volcabulary\ = 10w $$
$$ \begin{vmatrix} 0 \\ 1 \\ 0 \\ 0 \\ 0 \\.\\.\\. \end{vmatrix}^{R^{10w}} \rightarrow NN \rightarrow \begin{vmatrix} 0.01 \\ 0.73 \\ 0.02 \\ 0.04 \\ 0.11 \\.\\.\\. \end{vmatrix}^{R^{10w}} $$
训练好这个 prediction-based NN 之后,一个新的词汇进来就可以直接用这个词汇的 1-of-N encoding 乘以第一层隐含层的权重,就可以得到这个单词的 word vector.
$$ x_i = 1-of-N\ encoding\ of\ word\ i $$
$$ W = weight\ matrix\ of\ NN\ between\ input-layer\ and\ 1st-hidden-layer $$
$$ WordVector_{x_i} = W^Tx_i $$
【注意】虽然这里的例子不是单词,但意会一下即可。
因为 “马英九” 和 “蔡英文” 后面跟的都是 “520宣誓就职”,所以用在 prediction-based NN 中
也就是说给 prediction-based NN 输入 马英九 or 蔡英文的时候 NN 会“努力”把两个不同的输入 project 到同一个输出上。那么之后的每一层都会做这件事情,所以我们可以使用第一层的输入来做为 word vector.
一般情况下我们不会只用前一个单词去预测下一个单词(\(w_{i-1} \Rightarrow w_i\)),并抽取 1st layer's input 作为 word vector, 我们会使用前面至少10个词汇来预测下一个词汇(\([w_{i-10}, w_{i-9}, ..., w_{i-1}] \Rightarrow w_i\))
如果使用不同的权重,(以前两个预测下一个为例)
[w1:马英九] + [w2:宣誓就职时] => [w3:说xxxx]
[w1:宣誓就职时] + [w2:马英九] => [w3:说xxxx]
如果使用不同的权重,那么 [w1:马英九] + [w2:宣誓就职时] 和 [w1:宣誓就职时] + [w2:马英九] 就会产生不同的 word vector.
具体过程描述如下:
|z| : word vector size, the dimension of embedding space
the length of \(x_{i-1}\) and \(x_{i-2}\) are both |V|.
How to make wi equal to wj?
Given wi and wj the same initialization, and the same update per step.
\(w_0 = w_0\)
\(w_i \leftarrow w_i - \eta \frac{\partial C}{\partial w_i} - \eta \frac{\partial C}{\partial w_i}\)
\(w_i \leftarrow w_i - \eta \frac{\partial C}{\partial w_i} - \eta \frac{\partial C}{\partial w_i}\)
\([w_{i-1}, w_{i+1}] \Rightarrow w_i\)
\(w_i \Rightarrow [w_{i-1}, w_{i+1}]\)
有了 word vector, 很多关系都可以数字化(向量化)
两类词汇的 word vector 的差值之间存在某种平行和相似(相似三角形or多边形)性,可以据此产生很多应用。
\(WordVector_{China} - WordVector_{Beijing} // WordVector_{Spain} - WordVector_{Madrid}\)
for \(WordVector_{country} - WordVector_{capital}\), if a word A \(\in\) country, and word B \(\in\) capital of this country, then \(A_0 - B_0 // A_1 - B_1 // A_2 - B_2 // . ..\)
问题回答也是这个思路---利用word vector差值是相互平行的。
\(V(Germany) - V(Berlin) // V(Italy) - V(Rome)\)
\(vector = V(Berlin) + V(Italy) - V(Rome)\)
\(find\ a\ word\ from\ corpus\ whose\ word\ vector\ closest\ with\ 'vector'\)
学习 word embedding prediction-based NN 的网络原理(单层; 前后单词为一个样本;取第一层输入)可以实现更进一步的应用。
先获取中文的 word vector, 然后获取英文的 word vector, (这之后开始使用 prediction-based NN 的原理)然后 learn 一个 NN 使得他能把相同意思的中英文 word vector 投影到某个 space 上的同一点,这之后提取这个网络的第一层 hidden layer 的输入权重,就可以用来转换其他的英文和中文单词到该 space 上,通过就近取意的方法获取该单词的意思。
这里也是学习 word embedding prediciton-based NN 的网络原理,他可以实现扩展型图像识别,一般的图像识别是只能识别数据集中已经存在的类别,而通过 word embedding 的这种模式,可以实现对图像数据集中不存在(但是在 word 数据集中存在)的类别也正确识别(而不是指鹿为马,如果image dataset 中原本没有 ‘鹿’ 的话,普通的图像识别会就近的选择最'像'的类别,也就是他只能在指定的类别中选最优的)。
先通过大量阅读做 word vector, 然后训练一个 NN 输入为图片,输出为(与之前的 word vector)相同维度的 vector, 并且使得 NN 把与 word(eg, 'dog') 相同类型的image(eg, dog img) project 到该word 的 word vector 附近甚至同一点上。
如此面对新来的图片比如 '鹿.img', 输入给这个 NN 他就会 project 到 word vector space 上的 “鹿” 周围的某一点上。
如何把 document 变成一个 vector 呢?
首先把 document 用 bag of word(a vector) 来表示,然后将其输入给一个 auto encoder , autoencoder 的 bottle-neck layer 就是这篇文章的 embedding vector。
这里与使用 autoencoder 无法用来做 word embedding 的道理是一样的,只不过对于 word embedding 来说 autoencoder 面对的是完全相互 independent 的 1-of-N encoding, 其本身就无规律可言,所以 autoencoder 不可能学到任何东西,所以没有直接规律,就寻找间接规律 通过学习 context 来判断单词的语义。
这里 autoencoder 面对的是 document(bag-of-word), bag of word 中包含的信息仅仅是单词的数量 (大概是这样的向量\([22, 1, 879, 53, 109, ....]\))不论 bag-of-word(for document) 还是 1-of-N encoding(for word) 都是语义缺乏的编码方式。所以想通过这种编码方式让NN萃取有价值的信息是不可能的。
还是那个原则没有直接规律,就寻找间接规律:
1-of-N encoding, lack of words relationship, what we lack, what we use NN to predict, we discover(construct) some form of data-pair (x -> y) who can represent the "relationship" to train a NN , and the BY-PRODUCT is the weight of hiden layer --- a function(or call it matrix) who can project the word to word vector(a meaningful encoding)
bag-of-word encoding, lack of words ordering(another relationship), using (李宏毅老师没有明说,只列了 reference)
white blood cells destroying an infection
an infection destroying white blood cells
they have same bag-of-words, but vary differentmeaning.
其中,后五者其实都可以看做迁移学习的子类。
转导学习的典型算法是 KNN:
由上述过程可见:
我们使用了 unlabeled data 作为测试集数据,并使用之决定新的中心点(新的分类簇)
这就是课件中所说的:
Transfuctive learning: unlabeled data is the testing data.
归纳学习的典型算法是 Bayes:
\(P(y|x) = \frac{P(x|y)P(y)}{P(x)=\sum^K_{i=1}{P(x|y_i)P(y_i)}}\)
通过 count-based method 和 Naive Bayes 或者 Maximum Likelihood(详见 lec5 笔记)(
\(P([1,3,9,0] | y_1)=P(1|y_1)P(3|y_1)P(9|y_1)P(0|y_1)\) ) 先计算出:
\(P(x|y_1)P(y_1)\)
\(P(x|y_2)P(y_2)\)
\(P(x|y_3)P(y_3)\)
...
然后就可以带入 Bayes 公式,就可以得到一个模型公式。
\(P(y|x) = \frac{P(x|y)P(y)}{P(x)=\sum^K_{i=1}{P(x|y_i)P(y_i)}}\)
由此可见,inductive 和 transductive 最大的不同就是,前者会得到一个通用的模型公式,而后者是没有模型公式可用的。新来的数据点对于 inductive learning 可以直接带入模型公式计算即可,而 transductive learning 每次有新点进来都需要重新跑一次整个计算过程。
对于通用模型公式这件事,李宏毅老师 lec5-LogisticRegression and Generative Model 中提到:
Bayes model 会脑补出数据集中没有的数据。
这种脑补的能力会使得他具有一些推理能力,但同时也会犯一些显而易见的错误。
而 transudctive learning 则是针对特定问题域的算法。
在 inductive learning 中,学习器试图自行利用未标记示例,即整个学习过程不需人工干预,仅基于学习器自身对未标记示例进行利用。
transductive learning 与 inductive learning 不同的是
transfuctive learning 假定未标记示例就是测试例,
即
学习的目的就是在这些未标记示例上取得最佳泛化能力。
换句话说:我处理且只处理这些点。
inductive learning 考虑的是一个“开放世界”,即在进行学习时并不知道要预测的示例是什么,而直推学习考虑的则是一个“封闭世界”,在学习时已经知道了需要预测哪些示例。
实际上,直推学习这一思路直接来源于统计学习理论[Vapnik],并被一些学者认为是统计学习理论对机器学习思想的最重要的贡献1。其出发点是不要通过解一个困难的问题来解决一个相对简单的问题。V. Vapnik认为,经典的归纳学习假设期望学得一个在整个示例分布上具有低错误率的决策函数,这实际上把问题复杂化了,因为在很多情况下,人们并不关心决策函数在整个示例分布上性能怎么样,而只是期望在给定的要预测的示例上达到最好的性能。后者比前者简单,因此,在学习过程中可以显式地考虑测试例从而更容易地达到目的。这一思想在机器学习界目前仍有争议
有时候你会有两种 object, 他们之间由某种共通的 latent factor 去操控。
比如我们都会喜欢动漫人物,但我们不是随随便便就喜欢的,而是说在我们自己的性格和动漫人物的性格背后隐含着某个相同的“属性列表”
每个人根据自己的【特点】都可以看成是【属性列表】中的一个向量或是高维空间中的一个点(向量),每个动漫人物也可以根据其【特点】看成是【属性列表】中的一个向量或高维空间中的一个点(向量)。
如果这两个向量很相似的话,那么两者 match,就会产生【喜欢】
假设:
现在:
【注意】这个 latent vector 的数目是试出来的,一开始我们并不知道。
比如 latent attribute = ['傲娇', '天然呆']
person A : \(r^A = [0.7, 0.3]\)
character 1: \(r^1 = [0.7, 0.3]\)
\(r^A \cdot r^1 = 0.58\)
$$ X \in R^{M*N} \approx \begin{vmatrix} r^A \\ r^B \\r^C\\.\\.\\. \end{vmatrix}^{M*K} * \begin{vmatrix} r^1 & r^2 & r^3 &.&.&. \end{vmatrix}^{K*N} $$
这个问题可以直接使用 SVD 来解决,虽然SVD分解得到的是三个矩阵,你可以视情况将中间矩阵合并给前面的或后面的
上面的是理想情况:table X 中所有的值都完备;
现实情况是:tabel X 通常是缺值的,有很多 Missing value. 那该如何是好呢?
使用 GD,来做,目标函数是:
\(L = \sum_{(i,j)}(r^i \cdot r^j - n_{ij})^2\)
通过对这个目标函数最小化,就可以求出 r.
然后就可以用这些 r 来求出 table 中的每一个值。
MF 的求值函数(table X 的计算函数,我们之前一直假设他是两个 latent vector 的匹配程度)可以考虑更多的因素。他不仅仅可以表示匹配程度。
从: \(r^A \cdot r^1 \approx 5\) 到更精确的: \(r^A \cdot r^1 + b_A + b_1\approx 5\)
如此新的 GD 优化目标就变成:
\(L = \sum_{(i,j)}(r^i \cdot r^j + b_i + b_j - n_{ij})^2\)
也可以加 L1 - Regularization, 比如 \(r^i, r^j\) 是 sparse 的---喜好很明确,要么天然呆,要么就是傲娇的,不会有模糊的喜好。
MF 技术用在语义分析就叫做 LSA(latent semantic analysis):
注意:通常我们在做 LSA 的时候还会加一步操作,term frequency always weighted by inverse document frequency, 这步操作叫做 TF-IDF.
也就是说,你用作 \(L = \sum_{(i,j)}(r^i \cdot r^j + b_i + b_j - n_{ij})^2\) 中的 \(n_{ij}\) 不是原始的某篇文章中的某个单词的出现次数,而是出现次数乘以包含这个单词的文章数的倒数亦即,
(n_{ij} = \frac{TF}{IDF})\
如此当我们通过 GD 找到 latent vector 时,这个向量的每一个位表示的是 topics(财经,政治,娱乐,游戏等)
根据之前通过 SVD 矩阵分解得到的结论: u = w
和公式:\(\hat{x} = \sum_{k=1}^Kc_kw^k \approx x-\bar{x}\)
再结合线性代数的知识,我们可以得到,能让 reconstruction error 最小的 c 就是:
\(c^k = (x-\bar{x})\cdot w^k\)
结合这两个公式,我们就可以找到一个 Autoencoder 结构:
$$ \begin{vmatrix} x_1 - \bar{x} \\ x_2 - \bar{x} \\ .\\.\\. \end{vmatrix} \Rightarrow \begin{vmatrix} c^1 \\ c^2 \end{vmatrix} \Rightarrow \begin{vmatrix} \bar{x_1} \\ \bar{x_2} \\ .\\.\\. \end{vmatrix} $$
autoencoder 的缺点 --- 无法像 PCA 一样得到完美的数学解
这样一个线性的 autoencoder 可以通过 Gradient Descent 来求解,但是 autoencoder 得到的解只能无限接近 PCA 通过 SVD 或者 拉格朗日乘数法的解,但不可能完全一致,因为 PCA 得到的 W 矩阵是一个列和列之间都相互垂直的矩阵,autoencoder 确实可以得到一个解,但无法保证参数矩阵 W 的列之间相互垂直。
autoencoder 的优点 --- 可以 deep,形成非线性函数,面对复杂问题更 power
PCA 只能做压扁不能做拉直
就像下面显示的这样,PCA 处理这类 manifold(卷曲面)的数据是无能为力的。他只能把数据都往某个方向压在一起。

而 deep autoencoder 可以处理这类复杂的降维问题:

你要把数据降到几维度,是你可以自己决定的,但是有没有什么比较好的数学依据来hint这件事情呢?
常用的方法是:
\(eigen\ ratio\ = \frac{\lambda_i}{\lambda_1 + \lambda_2 + \lambda_3 + \lambda_4 + \lambda_5 + \lambda_6}\)
我们求解 PCA 的函数的时候给出的结论是:
W 的列是 \(S=Cov(x)\) 的topmost K 个 eignen values 对应的 eigen vectors.
eigen values 的物理意义是降维后的 z 空间中的数据集在这一维度的 variance。
在决定 z 空间的维度之前,我们引入一个指标: eigen ratio,这个指标有什么用呢?他能帮助我们估算出前多少个 eigen vector 是比较合适的。
假设我们预先希望降维到 6 dimension,那么我们就可以通过之前学到的方法得到 6 个 eigen vector 和 6 个 eigen value, 同时也可以得到 6 个 eigen ratio.
通过这 6 个 eigen ratio 我们就可以看出谁提供的 variance 是非常小的(而我们的目标是找到最大 Variance(z))。eigen ration 太小表示映射之后的那个维度,所有的点都挤在一起了,他没什么区别度,也就是提供不了太多有用的信息。
之前没有提过,component 的维度应该是与原始 x 样本的维度是一致的,因为你可以把 component 看成是原始维度的一种组合(笔画 <- 像素)。
以宝可梦为例,说明: 如果把原本 6 个维度的宝可梦,降维到4维度,可以发现的是这个 4 个 componets 大概的物理意义是:
'component' 不一定是 ‘部分’。
对手写数字图片进行降维
对人脸图片进行降维

上面的图片所展示的似乎异于我们期望看到的啊!
我们一直强调 component 似乎是一种部分与整体的感觉,而这里给出的图片似乎是一种图层的感觉 --- 每一张 'component' 给出的不是笔画和五官,而是完整的数字和脸的不同颜色or阴影。
提出一种可能性:先看之前的公式,
$$ img_9 = c_1w_1 + c_2w_2 + ... $$
由于我们并没有限制,factor 系数的符号(factor 可正可负),所以他极有可能做的一件事情是,
为了生成图片 数字9,我的第一个component可以比较复杂,比如图片数字8,给与其正的factor,第二个component可以是一个0,给与其正的factor,第三个component可以是一个 6,给与其负值的factor
这样 img8 + img0 - img6 看上去就约等于 img9 了。
PCA 我们使用的分解是 SVD 或者 lagrange multiplier. 这种方法无法保证我得到的 component 和 其对应的 factor 都是正的。于是可以使用 NMF(non-negative matrix factorization)
NMF:
李宏毅老师没有具体讲解这个方法,只列出索引:
Algorithms for non-negative matrix factorization
如下图, NMF 使用的 components 更像是 ‘部分’ 而不是 ‘滤镜’

Basic Component can ba analogy to sample after projection
可以从比较形象的角度来理解 PCA,之前的角度是从x -> z , PCA 其本质就是一个线性函数,把 x 空间中一点,转换到 z 空间中一点。
$$ img_{28*28} \rightarrow x = \begin{vmatrix} 204 \\ 102 \\ 0 \\ 1 \\ . \\ . \\ . \end{vmatrix}^{784*1} \rightarrow z = \begin{vmatrix} 1 \\ 0.5 \\ 0 \\ 1 \\ 0.3 \end{vmatrix} $$
如果把 z 的每一位都看成是某种笔画的系数,那么我们就可以用另外一种方式来表示一张图片:
$$ x - \bar{x} \approx c_1u_1 + c_2u_2 + ... + c_ku_k = \hat{x} $$
这就提供了另一种看待问题的视角:
于是优化目标的函数也就改变了:
$$ argmax_{w_i} Var(x) = \sum_x(x-\bar{x})^2, with\ ||w_i||_2 = 1, and\ w_i \cdot \{w_j\}_{j=1}^{i-1} = 0 $$
\(argmin_{u_1, ..., u_K}\sum||(x-\bar{x}) - (\sum_{k=1}^Kc_ku_k)||_2\)
\(\sum_{k=1}^Kc_ku_k = \hat{x}\)
可以证明的是:这个 \(\{u_k\}_{k=1}^K\) 就是我们要找的 \(\{w_k\}_{k=1}^K\)
$$ \begin{vmatrix} z_1 \\ z_2 \\ . \\. \\. \\z_K \end{vmatrix} = \begin{vmatrix} w_1 \\ w_2 \\ . \\. \\. \\w_K \end{vmatrix} x = \begin{vmatrix} u_1 \\ u_2 \\ . \\. \\. \\u_K \end{vmatrix} x $$
$$ x^1 - \bar{x} \approx c_1^1u^1 + c_2^1u^2 + ... $$
$$ x^2 - \bar{x} \approx c_1^2u^1 + c_2^2u^2 + ... $$
$$ x^3 - \bar{x} \approx c_1^3u^1 + c_2^3u^2 + ... $$
【注意】component 对任意样本都是一样的,样本之间不同的是component的系数(权重)
我们可以把上面 3 个式子组合成矩阵的形式:
可以写成 向量 = 矩阵 * 向量
$$ c_1^2u^1 + c_2^2u^2 + ... = \sum_{k=1}^Kc_k^1u^k = [u^1, u^2, ...] \cdot \begin{vmatrix}c_1^1\\c_2^1\\.\\.\\.]\end{vmatrix} $$
可以写成 矩阵 = 矩阵 * 矩阵
$$ \underbrace{[x^1 - \bar{x}, x^2-\bar{x}, x^3-\bar{x}, ...]}_{\text{dataset:X}} \approx \underbrace{[u^1, u^2, ...]}_{\text{components matrix}} \cdot \underbrace{ \begin{vmatrix} c_1^1 & c_1^2 & c_1^3\\ c_1^1 & c_1^2 & c_1^3\\ c_1^1 & c_1^2 & c_1^3\\ .&.&.\\ .&.&.\\ .&.&. \end{vmatrix}}_{\text{factor matrix}} \text{how to find the best u to make two side of approx as near as possible?} $$
我们可以使用 SVD 矩阵分解,对 X 进行分解:
X 可以分解成3个矩阵的乘积:
\(X_{m*n} \approx U_{m*k} \Sigma_{k*k}V_{k*n}\)
这里直接给出答案,具体过程见线性代数课程。
K columns of U: a set of orthonormal eigen vectors corresponding to the k largest eigenvalues of \(XX^T\)
这个 \(XX^T\) 就是 \(Cov(x)\) , 因为这里的 X 是由 \(x - \bar{x}\) 得到的。所以,u = w。
再回忆下我们对于 u w 和 z 的定义:
启示:PCA 找出的那些 w(转换矩阵 W 的 columns) 就是 components
一,例子1 为什么 Dimension Reduction 可能是有用的,如下图示:

如果我们用 3 dimension 的样本维度去描述他其实是非常浪费的,因为很明显他是卷曲在一起的,如果我们有办法把他展平,不同类型(不同颜色代表不同类型)就很容易区隔开,而展平之后我们只需要 2 dimension 的样本维度。所以根本不需要把这个问题放在 3d 中去考虑,2d 就可以了。

二,例子2
在手写数字辨识的任务中,你或许根本用不到 28*28 的维度,比如数字 3 他可能有很多形态,但其实大部分都是旋转一下角度而已,所以对于辨识 3 这件事可能需要的维度仅仅是一个旋转角度而已(1维度)
对数据降维就是找一个function
\(f(x) \rightarrow x', dim(x) >> dim(x')\)
PCA 的本质就是通过一个一次线性函数 \(W^Tx\)把高维度的数据样本转换为低维度的数据样本。就像 \(w^Tx\) 如果\(W^T\)矩阵只有一行,这个函数就是两个向量的内积 --- 结果是一个(一维)数值,如果 \(W^T\) 是一个矩阵,那么 \(W^T\) 有多少行最终内积结果就有多少维:
$$ R_W^{1*N} \cdot R_x^{N*1} = R_{x'}^{1*1} R_W^{2*N} \cdot R_x^{N*1} = R_{x'}^{2*1} ... $$
\(f(x) \rightarrow x', dim(x) >> dim(x')\)
\(z = Wx, to\ find\ 'W'\)
该如何找到 W 呢,从最简单的开始,我们假设 :
如此一来,'z' 就可以看做是 'x' 在 'w' 方向上的投影(内积的几何意义)。
所有的 x: \(x^1, x^2, x^3,...\) 都在 w 方向上做投影就得到了 z: \(z^1, z^2, z^3,...\) , 而我们要做的就是从:
如何找到 W 变成 找到一个 x 的更好的投影方向
we want the variance of \(z_1\) as large as possible.
variance 在图像上的表现就是,投影之后的 z 的取值范围(值域),取值范围越大variance越大。
对于投影到一维空间,找到最佳的 w('w' is a row vector) 使得 x('x' is N dimension) 投影到该方向得到的 z ('z' is a digit)的 variance 是最大的, 用公式表示就是:
\(find\ a\ w\ to\ maximize:\)
\(Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2)\)
\(with\ constaint\ :\ ||w_1||_2=1\)
对于投影到二维(甚至多维)空间,我们要给每个后面的w一个限制就是: 后面的 w(n+1 th row) 要跟前面的所有 w({1~n} rows) 相互垂直, \(w_{n+1} \cdot \{w_{i}\}_{i=1}^n = 0\).
整体来看就是:
the 1st row of W should be:
\(w_1 = argmax(Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2)\)
\(constraint:\ ||w_1||_2=1\)
the 2nd row of W should be:
\(w_2 = argmax(Var(z_2) = \sum_{z_2}(z_2 - \bar{z_2})^2)\)
\(constraint:\ ||w_2||_2=1, w_2 \cdot w_1 = 0\)
the 3rd row of W should be:
\(w_3 = argmax(Var(z_3) = \sum_{z_3}(z_3 - \bar{z_3})^2)\)
\(constraint:\ ||w_3||_2=1, w_3 \cdot w_1 = 0, w_3 \cdot w_2 = 0\)
.......
then the W should be:
$$ W = \begin{vmatrix} (w_1)T \\ (w_2)T \\ . \\ . \\ . \end{vmatrix}\quad $$
这里 W 会是一个 Orthogonal matrix, 因为每一行的 norm 都等于1,并且行行之间相互垂直。
Lagrange multiplier 可以把带限制条件的优化问题转换>为无限制优化问题: target - a(zero_form of >constraint1) - b(zero_form of constraint2)
无限制的优化问题,就可以通过
偏微分=0来找到最优解
如果 W 矩阵只有一行
$$ one\ x\ one\ z_1 \bar{z_1} = \sum{z_1} = \sum{w_1 \cdot x} = w_1 \cdot \sum x = w_1 \cdot \bar{x} Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 $$
对于 \(w \cdot (x - \bar{x})\), 他是两个向量的内积,对于这种内积的平方,要注意如下的惯用转换公式(值得记住)。
$$ (a \cdot b)^2 = (a^Tb)^2 $$
因为 \(a \cdot b\) 是内积,是一个数值,数值的平方无关乎顺序,所以可以写成:
$$ (a^Tb)^2 = a^Tba^Tb $$
因为 \(a \cdot b\) 是内积,是一个数值,数值的转置还是自身,所以可以写成:
$$ (a^Tba^Tb = a^Tb(a^Tb)^T $$
化简之后:
$$ a^Tb(a^Tb)^T = a^Tbb^Ta $$
所以之前 var 的式子可以化简为:
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 $$
因为是对 x 来求和,所以 w 可以提出去:
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 = (w_1)^T(\sum_x(x-\bar{x})(x-\bar{x})^T)w_1 $$
其中 \(\sum_x(x-\bar{x})(x-\bar{x})^T\) 是什么,这个是 x 向量(样本都是向量)的 covariance matrix. covariance 是对称且半正定对的, 也就是说所有的 eigenvalues 都是非负的
$$ Var(z_1) = \sum_{z_1}(z_1 - \bar{z_1})^2 = \sum_x(w_1 \cdot x - w_1 \cdot \bar{x})^2 = \sum_x(w_1 \cdot (x-\bar{x}))^2 = \sum_x(w_1)^T(x-\bar{x})(x-\bar{x})^Tw_1 = (w_1)^T(\sum_x(x-\bar{x})(x-\bar{x})^T)w_1 = (w_1)^TCov(x)w_1 $$
我们设 \(S = Cov(x)\) ,于是我们得到了一个新的优化问题:
find w1 maximizing:
\(w_1^T S w_1, with\ constraint\ ||w_1||_2 = 1, means\ w_1^Tw_1 = 1\)
Lagrange multiplier is target - zero_form of constraints
之前说明过 \(w_1\) 是 W 矩阵的第一个row,再次提醒下。
\(g(w_1) =w_1^TSw_1 - \alpha(w_1^Tw_1 - 1)\)
\(\frac{\partial g(w_1)}{\partial w_{11}} = 0\)
\(\frac{\partial g(w_1)}{\partial w_{12}} = 0\)
....
通过对 Lagrange 式子 \(g(w_1)\) 的微分为0来求最大最优的w,可以得到如下化简后的式子:
\(Sw_1 - \alpha w_1 = 0\)
\(Sw_1 = \alpha w_1\)
这种形式我们就熟悉了,\(w_1\) 是 S 的 eigen vector
但是这样的 w1 有很多,因为 S 的 eigen vector 有很多,所以 w1 的潜在选择也很多,哪一个是最好的选择呢?通过我们的优化目标来判断。
\(w_1^TSw_1 = \alpha w_1^Tw_1 = \alpha\)
而这里的 \(\alpha\) 是 eigen value,
所以,因为我们要最大化的目标最后等于 alpha, 而 alpha 是 eigen value, 所以我们选择最大的 eigen value, 一个 eigen value 对应一个 eigen vector, 所以最优的 w1 就是最大的 eigen value 对应的那个 eigen vector.
之前分析过, Find w2 的情况与 Find w1 略有不同,不同在优化问题的限制条件多出一个与之前所有的w都垂直,那么就是:
\(Find\ w_2\ maximizing: w_2^TSw_2, w_2Tw_2=1, w_2^Tw_1=0\)
按照 目标函数 - 系数*zero_form of 限制条件 的拉格朗日使用方法,可以得到如下无限制条件的优化问题:
如果 W 矩阵有多行
对于 W 矩阵有多行的情况,优化目标函数需要改变, 要增加限制条件,如果不加改变的话你得到的 wn 永远与 w1 一样,增加的这个限制条件是:后面的每个w都要与前面的所有w相互垂直 --- 内积为0。
\(Find\ w_2\ maximizing:\)
$$ g(w_2) = w_2^TSw_2 - \alpha(w_2^Tw_2-1)-\beta(w_2^Tw_1-0) $$
同样的通过微分等于0来求无限制条件的优化问题:
\(\frac{\partial g(w_1)}{\partial w_{11}} = 0\)
\(\frac{\partial g(w_1)}{\partial w_{12}} = 0\)
化简上述结果可以得到:
\(Sw_2 - \alpha w_2 - \beta w_1 = 0\)
上述等式两边同时乘以 w1:
\(w_1^TSw_2 - \alpha w_1^Tw_2 - \beta w_1^Tw_1 = 0\)
\(w_1^TSw_2 - \alpha * 0 - \beta * 1 = 0\)
因为 \(w_1^TSw_2\) 本身是一个 向量矩阵向量 的形式,他是一个数值,数值的转置还是自身:
\(w_1^TSw_2 = (w_1STw_2)^T = w_2^TS^Tw_1\)
因为 S 是 Covariance Matrix of x, 是对称的,所以 \(S^T=S\)
\(w_2^TS^Tw_1= w_2^TSw_1\)
使用 w1 的结论,\(Sw_1 = \lambda_1w_1\), 所以有
\(w_2^TSw_1=\lambda_1w_2^Tw_1=0\)
所以,综合起来看:
\(w_1^TSw_2 - \alpha w_1^Tw_2 - \beta w_1^Tw_1 = 0\)
\(w_1^TSw_2 - \alpha * 0 - \beta * 1 = 0\)
\(0 - \alpha * 0 - \beta * 1 = 0\)
所以:
\(\beta=0\)
所以:
\(Sw_2 - \alpha w_2= 0\)
\(Sw_2 = \alpha w_2\)
由于 w2 也是 eigen vector, 同样有很多选择,与 w1 选择的依据一样,我们只能选择剩下最大的那个 eigenvalue of S 对应的 eigenvector
so,结论是:
$$ z = Wx $$
$$ W = \begin{vmatrix} (w_1)T \\ (w_2)T \\ . \\ . \\ . \end{vmatrix}\quad $$
$$ W = \begin{vmatrix} 1st\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ 2nd\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ 3rd\ largest\ eigenvalues'\ eigenvector\ of\ Cov(x) \\ ...\end{vmatrix} $$
数据点的各个维度互相垂直
用数学语言来表述就是
数据点的协方差矩阵是一个 Diagonal matrix
也就是
数据点的各个维度之间没有 correlation
这样有什么作用呢?
一个很好的作用是,原来的 data 经过 PCA 之后输出的新的 data 可以接其他较为简单的(或是对数据点维度要求无 correlation 的)model ---> eg. Naive Bayes.
$$ Cov(z) = \sum(z - \bar{z})(z-\bar{z})^T $$
这一项,可以可以展开合并后成为下面这种形式:
$$ Cov(z) = \sum(z - \bar{z})(z-\bar{z})^T = WSW^T,\ \ S = Cov(x) $$
$$ W^T=\begin{vmatrix} w_1 \\ .\\.\\.\\ w_k \end{vmatrix}^T= [w_1, ..., w_k] $$
注意转置之前 w1 是 W矩阵的行向量,转置后,w1 是 W^T 的 列向量:
$$ \begin{vmatrix} 1 & 2 & 3 & \rightarrow w_1\\ 4 & 5 & 6 & \rightarrow w_2 \\ 7 & 8 & 9 & \rightarrow w_3 \end{vmatrix}^T \rightarrow \begin{vmatrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \\ \downarrow & \downarrow & \downarrow \\ w_1 & w_2 & w_3 \end{vmatrix} $$
$$ WSW^T = WS[w_1, ..., w_k] = W[Sw_1, ..., Sw_k] $$
利用之前的结论:
\(Sw_1 = \lambda_1 w_1\)
$$ W[Sw_1, ..., Sw_k] = W[\lambda_1 w_1, ..., \lambda_k w_k] = [\lambda_1Ww_1, ..., \lmabda_kWw_k] = [\lambda_1e_1, ..., \lambda_ke_k] $$
其中 \(e_i\) 是指第 \(i\) 位为 1, 其余位都为 0 的列向量。
所以 \(Cov(z)\) 就是一个 Diagonal matrix.
PCA 关键词:
一个重要的结论需要记住: Covariance Matrix is a symmetric, positive-semidefinite matrix, so it has non-negative eigenvalues
一个重要的技术:
带限制条件优化
--- Lagrange multiplier ---> 无限制条件优化
--- partial dirivitive = 0 --->
求解。
一个重要的机器学习常识:
数据点的各个维度互相垂直
用数学语言来表述就是
数据点的协方差矩阵是一个 Diagonal matrix
也就是
数据点的各个维度之间没有 correlation
\(b_i^n = 1\ if\ x^n\ is\ most\ close\ to\ c_i,\ else\ 0\)
\(c_i = \sum_{x^n}b_i^nx^n/\sum_{x^n}b_i^n\)
一, build a tree
把原来的样本都看作叶子节点,merge 后的样本看成父亲节点,这样一直做下去直到产生root,这样就构成了一棵树。
二,pick a threshold
这一刀切在哪里就决定了你有多少个分类。比如下图所示,在第二层节点下切一刀就产生出四个簇。
如果只做 clustering 就像是我们做的非黑即白假设一样,未免过于武断,所以这里引入了Distribution representation .
英雄包含7个种类: [强化系,放出系,变化系,操作系,具现化系,特质系]
Cluster Representation: clustering 方法要求所有样本都属于并且必须只能属于一个簇,
\(Noxus\ of\ LOL \in Strength\)
但有时候这样做未免武断,所以考虑用概率分布的形式来表示一个样本,同时这种表示样本的方法也可以用在 Dimension reduction 中。
Distribution Representation: [0.7, 0.25, 0.05, 0.0, 0.0, 0.0, 0.0]
Distribution Representation 还一个作用,就是用作降维。这个东西与 Dimension reduction 有莫大的关系,对于一个有很高维度的向量样本而言,如果我们用一些特点来描述他,那就可以大幅度的减少样本的维度。
半监督学习的第一个假设是 非黑即白,进阶版是未必非黑即白,也差不多,基于这个假设我们有了算法 self-training(hard-label) 和 entropy-based regularization。
半监督学习的第二个知名假设是 近朱者赤,近墨者黑。
不精确的说法: Assumption: "similar" x has the same y.
精确的说法:
解释下上面这句话的意思:
如果 x 的分布是不平均的,有些地方很集中,某些地方很分散。如果两个 x 样本,x1 x2 在一个高密度区域内很近的话,那么他们的标签应该一样。
一言以蔽之,相近一个必须的前提是:这两个点必须经过一个稠密区间相连。 connected by high density region.
形象一点该如何理解 稠密区间 呢?也就是一个样本和另一个样本之间存在连续的渐进变换的很多样本,那么就说明两者之间存在稠密区间。
举例说明:
1 <====> 11 <-------> 15
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ___, 15
<====> 表示这里有很多渐变的无标数据点<-------> 表示这里几乎没有无标数据点我们如何判断无标数据 11 的标签?
‘1’ 和 ‘11’ 之间存在稠密区间,则两者的label应该是一样的。‘11’ 和 ‘15’ 之间不存在稠密区间。
这招在文档分类中,作用颇大。Classify astronomy vs. Travel articles.我们做文档分类是基于文档的vocabulary是否存在较大重叠,但是由于人类使用的词汇是如此的多,不同的人对同一个意思会使用不同的词汇去表达,所以文档之间的单词重叠的非常少,这时候就可以借助high density region的假设,只要两个文档之间(一个带标一个无标)存在连续的渐变的很多文档,就可以判断两个数据点具有相同的标签。
天文:文档1 = [asteroid, bright]
_ :文档2 = [bright,comet]
_ :文档3 = [comet,year]
_ :文档4 = [year,zodiac]
文档1 与 文档2 标签一致;
文档2 与 文档3 标签一致;
文档3 与 文档4 标签一致;
所以 文档1 与 文档4 标签一致;
一,构建 pseudo 数据集阶段
二,supervised learning 算法阶段
注意:clustering then label, 这个方法未必会有用啊,只有在你可以把同一个类 cluster 在一起的时候才有可能有用,如果是图像分类并且用 pixel 做clustering,就非常苦难,基于像素的距离做 clustering 本身就不太可能把同一类 cluster 在一起(同一个 class 可能在像素级别很不像,比如数字识别中像‘1’的‘4’和像‘9’的‘4’;不同 class 可能像素级别很像‘1’和‘4’,‘9’和‘4’),这第一步误差就这么大(各种分类的数据点混在一起),第二步不论怎么搞都不可能有太好的准确率。
所以,如果要用这个 cluster then label 算法的话,你的 cluster 要非常强,也就是第一步的准确率要足够高。一般使用 deep autoencoder 中间的 code 做 cluster,而不是像素。
cluster, then label 是一种比较直觉的做法,另一种做法是通过引入 graph structure 来做。用 graph structure 来表达 connected by a high density path 这件事。
把数据集映射成一个 graph, 每个数据都是图中的一个点。你要做的就是定义并计算两两之间的 similarity,这个similarity就是 graph 中两点之间的边(连线)。
构建graph之后:
但是 similarity 也就是 “边” 很多时候不是那么明显的可以定义出来。如果是网页分类,那么网页之间的连接可以看做是一种similarity(医疗的网页应该不会连接到游戏网页),这很直觉。论文分类,论文的索引也可以用在“边”。但更多时候,你需要自己去定义。
graph construction: 该如何构造一张图呢?
一, define the similarity \(s(x_i, x_j)\) between xi and xj.
(可以基于像素或者更高阶的方法是用 deep autoencoder 来做相似度),李宏毅教授推荐使用 RBF function 定义相似度:
\(s(x_i, x_j) = exp(-\gamma||x_i - x_j||^2)\)
如果想使用欧几里得距离衡量相似度,最好使用 RBF function 作为 similarity function. 为什么呢?因为RBF是一个衰减很快的函数,只要 xi xj 距离稍微远一点相似度就急剧下降。只有具备这种性质,你才能构造出较好的 cluster,他虽然不能保证同簇的相似度高,但至少可以保证不同簇的相似度一定较低(跨簇的距离更大一些的话)。
二, add edge
方法1: 可以使用 KNN 建立“边”,每个点都与相似度最近的 K 个点相连: \(|V_{x_i->[x_j]_{j=1}^K}| = argmax_{D'\subset{D}, |D'|=K}s(x_i, x_j)\)
方法2: 可以使用 e-Neighborhood 方法建立“边”,所有与 xi 相似度大于 e 的数据点都与 xi 建立连接。
三,edge weightedge
可以带有权重,他可以与相似度成正比。
graph-based approach 方法的核心精神是标签传染: graph 中的带标节点会依据“边”来传递自己的“标”,而且会一直“传染”下去。
graph-based approach 方法的核心缺点是数据量必须够大: 基于图的传染机制,如果数据不够多,没收集到位,那么本来相连的图由于数据量不够就可能断连,一旦断连就没法传染了。
我们基于以下认知和观察,来定义 loss functin 用以衡量 DNN 训练出的模型的好坏:
是否可以直接使用 cross-entropy,不加任何“佐料”?
pseudo labels 是在近朱者赤近墨者黑的假设下产生的,不管产生的算法是什么,他都可以看成是一个函数,这个函数是如此特殊他就像是ground truth function(监督学习下,我们不知道的那个f) 一样产生了我们以为真实的标签,所以,我们需要做的是去逼近这样的函数
我们能做的是,通过 loss function 来“诱导”优化器往这个特殊的函数去优化。
我们像产生 pseudo labels 的算法那样利用数据集 x 的距离模拟 density 来增加限制,但我们可以通过对标签来近似这种限制,我们可以看到同一个类的标签之间差距很小,类和类之间的标签差距很大,但是(构造 pseudo label 时用到的边的weight)同类数据点的边的weight很大,而不同类的数据点的边的weight很小。我们设置两点之间的标签差值乘以两点之间的边的权重作为限制, 希望他不要太大,以此来近似同类标签数据是高密度的这件事,虽然这是一种普杀式的限制 --- 他同样会限制类间标签的差异,但是考虑不同类两点的边权重很小,相乘之后影响较少,这种方法还是可以接受的。
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2\)
这个值越小,说明越平滑。
进一步化简这个公式,用矩阵的形式书写(引入 Graph Laplacian):
把带标和无标的(预测)标签拼在一起,形成一个长向量: \(\vec{y} = [...y_i, ..., y_j...]^T\)
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2 = \vec{y}^TL\vec{y}\)
L: (R+U) * (R+U) matrix
L 可以写成两个矩阵相减: \(L = D - W\)
现在把这个 smoothness 公式与loss-fn 统合起来,形成一个新的代价函数:
\(L(\Theta) = \sum_{x^r}C(y^r, \hat{y}^r) + \lambdaS\)
这个 \(\lambdaS\) 有点像是一个正则项,你不仅仅要调整data 让那些 label data 与真正的 label 越接近越好,同时还要做到你预测的标签(包括代标数据和无标数据)要足够平滑。
在 DNN 中 smoothness 的计算不一定是在 output layer 哪里才计算,而是在任何隐含层都可以(就像 L2 正则项可以加载任何层一样,keras API)可以从某一层输出接触一个 embedding layer 保证这个 embedding layer 是 smooth 的即可, 也可以完全套用 L2 的模式 --- 在每一个隐含层都加入这个正则项,要求每一层的输出都是 smooth 的。
J.Weston, F.Ratle, "Deep learning via semi-supervised embedding," ICML, 2008
上面的算法框架中出现过两次 similarity 公式:
其中产生 pseudo 数据集部分,‘similarity’ 是 “similarity of x” --- 计算两个点之间的距离(eg,RBF function)以此作为是否连线两点的依据,而距离作为边的权重。
而在训练模型的部分,‘similarity’ 是 ‘similarity of y’ 我们用 y 之间的距离不宜过大来近似 'similarity of x'
Semi-supervised 部分我们介绍了两个假设,
两个假设都是为了通过有标数据产生无标数据的标签。这一步仅仅是准备数据集,并没有训练任何模型,他就像是监督学习中,产生数据集的那个我们不知道的函数。
而我们在训练模型时,必须要考虑到这个特殊的“函数”,也就是我们训练模型的时候需要让给与训练过程一些限制,让优化器朝着这两个假设的方向去优化函数:
\(L = \sum_{x^r}C(y^r, \hat{y}^r) + \lambda\sum_{x^u}E(y^u)\)
\(S = \frac{1}{2}\sum_{i,j}w_{i,j}(y_i - y_j)^2 = \vec{y}^TL\vec{y}\)
\(L(\Theta) = \sum_{x^r}C(y^r, \hat{y}^r) + \lambdaS\)
EM 系算法产生标签(边产生边更新) -----
|--- 生成模型: 初始化prior proba, 预测无标,更新 prior proba
|--- 归纳学习,产生model,标签为实数
|--- low density separation: 用带标产生 f,预测无标,更新 f
|--- 归纳学习,产生model,标签为整数
非 EM 系算法产生标签(先构造后产生)----
|--- high density region using **cluster and label**: 先构造簇,整簇分为标签最多者
|--- high density region using **graph-based algo**: 先构造图,相连的分为一类(同标签)
low-density separation 这个假设的意思是说非黑即白, 亦即两个class的数据点之间有一条明显的鸿沟,亦即两个class之间的data量是很少的。
Low-density Separation Assumption 最具代表性的算法就是 self-training
关于这个 self-training 算法的几个注意点
self-training 是从带标数据集得到一个函数 f, 然后用这个函数去求一个值 y = f(x), x是无标数据, 然后再把这个 (x,y) 加入代标数据集中,这个 y 本身就是通过 f(x) 得到的,他怎么可能改变 f 呢。所以 f 根本就不会变。所以 regression 不能使用这个算法来做。为什么呢,因为 regression 得到的是一个实数,而不是离散的分类。
两者看起来相似:
EM-generative model算法(KNN算法,transductive 学习通用框架):
self-training 算法:
两者的不同在于,
举例:
毫无疑问,如果是 self-training 使用 DNN 来训练的化, soft-label 完全没用啊,这点和 regression 问题无法使用 self-training 的道理是一样的。你的标签本身就是你的NN得到的一模一样的值,你重新将其加入数据集,他根本不会更新 NN 的参数。
核心本质:
我们使用 Hard-label 时我们在使用什么?我们在使用假设 Low density separation* --- 非黑即白,中间地带无数据**.
如果觉得非黑即白太武断了,可以使用 Entropy-based Regularization 方法
Entropy-based regularization 的意思是 未必非黑即白但也差不多啦
以刚才的例子来说明:
这样规定x的标签太武断了,我们希望标签还是可以保留一些小数,亦即NN的输出还是一个正常的概率分布,但不能是下面这样:
我们希望可以通过加入某种限制,来实现增加区别度,使概率分布更集中的目标。这个限制叫做 entropy of distribution. 他可以告诉我们这个分布集中与否。
entropy 值越小说明越集中(激光小且集中),最小为0。
\(E(y^u) = - \sum_{m=1}^Uy_m^uln(y_m^u)\)
根据这个假设,我们可以重新设计 loss-function
labeled data:
\(L = \sum_{x^r}C(y^r, \hat{y}^r)\)
unlabeled data(这里是说之前讨论的通用算法框架步骤2中的预测无标数据的标签):
\(\lambda\sum_{x^u}E(y^u)\)
我们希望NN对于无标数据的预测结果(一个概率分布)应该越集中越好。
综合起来看,就是如下公式:
\(L = \sum_{x^r}C(y^r, \hat{y}^r) + \lambda\sum_{x^u}E(y^u)\)
参考论文:transductive inference for text classification using SVM
核心精神就是,
遗留问题:
穷举 怎么做?论文中给出了一个近似的方法,每次该一个无标数据点的标签,看看 SVM 是否会变好,如果可以的话就改。
unlabeled data 虽然只有数据没有标签,但是 unlabeled data 的分布可以告诉我们一些东西。比如可以告诉我们什么样的边界是更好的。
semi-supervised learning 使用 unlabeled data 的情况经常伴随一些假设。semi-supervised learning 有没有效果就取决于你的假设好不好。
semi-supervised learning 未必有用,这取决于你的假设是否足够好。
回忆之前讲过的 Supervised Generative Model, 我们假设每一个 class 的数据点的分布都是一个 gaussian distribution(类的分布共享 \(\Sigma\)):
\(P(x|y_1) \sim G(\mu_1, \Sigma)\) \(P(x|y_2) \sim G(\mu_2, \Sigma)\)
得到 prior proba 然后就可以根据公式得到 posterior proba:
\(P(y_1|x_{new}) = \frac{P(x_{new}|y_1)P(y_1)}{P(x_{new}|y_1)P(y_1) + P(x_{new}|y_2)P(y_2)}\)
对于 semi-supervised Generative Model, 由于我们多了很多 unlabeled data, 这回改变我们对原来(仅仅通过 supervised Generative Model)获取的分布的认知。就像 KNN 每个新来的数据都会改变原来的中心点的位置。
3.1 update prior proba:
\(P(C_1) = \frac{N_1 + \Sigma_{x^{\mu}}P(C_1|x^{\mu})}{N}\)
\(N\): total number of examples
\(N_1\): number of examples belonging to C1
\(x^u\): unlabeled data
这里注意,supervised learning 中计算 \(P(C_1)\)的公式是:
\(P(C_1) = \frac{N_1}{N}\)
现在需要考虑 unlabeled data 对于分类的贡献。
我们可以把 Posterior praba \(P(C_1|x^u)\) 近似的理解成 (xu贡献的)C1的出现次数,毕竟概率也可以看做是(0.7个,0.5个。。。),我们只要加总所有样本对于 C1 的后验概率,就可以将其近似的理解成 unlabeled data 贡献的分类数据。
\(\Sigma_{x^{\mu}}P(C_1|x^{\mu})\)
3.2 update \(\mu_1\)
这里注意,supervised learning 中计算 \(\mu_1\)的公式是:
\(\mu_1 = \frac{1}{N_1}\Sigma_{x^r\in{C_1}}x^r\)
现在需要考虑 unlabeled data 对于分类的贡献。
对于 unlabeled data 我们同样需要借用 posterior probability 来计算 unlabeled data 的 weighted sum 的平均。
\(\frac{1}{\sum_{x^u}P(C_1|x^u)}\sum_{x^u}P(C_1|x^u)x^u\)
理论上这个方法会收敛,但是初始值对结果的影响非常大。同时这个方法也可以理解为 EM 算法。
两者最大的区别是前者只能通过 EM 算法进行 iteratively 解;后者有公式解。
我们是通过【 Maximum likelihood 来找到分类为 Ci 的样本点的最有可能的高斯分布】来求得 Prior proba \(P(x|C_i)\), 我们优化的公式很好解:
\(logL(\Theta)=\sum_{x^r}logP_{\Theta}(x^r, \hat{y}^r)\)
但是对于 unlabeled data 我们怎么估测 \(logL(\Theta)\) 呢?
\(logL(\Theta) = \sigma_{x^r}logP_{\Theta}(x^r) + ?\)
这里的思想与【把\(P_{\Theta}(C_i|x^u)\)看做 \(x^u\) ‘贡献’的‘次数’】思想类似,只不过利用的是 Prior probability因为我们并不知道 \(x^u\)的分类是多少,所以他可能属于任何分类。
所以这里 \(P_{\Theta(x^u)}\) 应该等于 \(x^u\) 与每个分类的联合概率的和:
\(P_{\Theta}(x^u)=P_{\Theta}(x^u|C_1)P(C_1) + P_{\Theta}(x^u|C_2)P(C_2)\)
模组化的意思是不直接解原始问题,而是找到一些中间量作为推论'桥'再过渡到原始问题。
每多一层隐含层,就多了一次 萃取 和 推理
1 hidden layer: 原始数据 -> 解析特征 -> 通过特征推理结果
2 hidden layer: 原始数据 -> 解析特征的特征 -> 通过特征的特征推理特征 -> 通过特征推理结果
...
每多一层隐含层,就多了一次抽取特征 和 通过特征进行推理。
实例说明:
四分类问题,把样本分成四类:
no hidden layer: dataset -> [1|2|3|4]
很显然,由于分类1的样本太少,分类器处理分类1的错误率就会很高。整体错误率也会较高。
1 hidden layer: dataset -> [长发|短发] + [男|女] -> [1|2|3|4]
这样一来,就可以避免某些样本过少会削弱分类器的问题,虽然长发男很少,但是长发vs短发两者几乎相等,男vs.女也几乎相等,也就是 [长|短] 分类器和 [男|女] 分类器都很强。
把这两个子分类器的结果作为新的样本(new dataset)学出[长发男]的分类器也就很强。
模组化(modularize) 在这里就是指可以直接利用子分类器的结果作为新的输入,这就有点像是\(f(g(h(x)))\)一样。
deep learning 可以只给出 input(样本) 和 output(标签) 而我们并不参与中间具体函数的设计,这些具体的函数是自动学出的,这就是 end to end learning。
现实问题中经常会遇到:
哈士奇和狼的图片作为输入,标签一个是狗,一个是狼
正面的火车和侧面的火车作为输入,标签却都是火车
如果你的NN只有一层,你大概只能做简单的转换,没办法形成层次结果和复用。
记忆: 小抠样
记忆:small, regions, subsampling
这个是说 filter 一般采取小于整张图片的形状
这个是说 filter 会逐行逐列移动扫描整张图片
这个是说 pooling 是切割图片为多块,每块只取一格(1 pixel)
这里的意思是说,对于 featuremap 如果池化层 size = 2*2 , maxpooling 会只去最大的一个值(averagePooling 会取平均,但也只是一个值)而忽略其他值。这件事情的物理意义是:featuremap 是由 filter 扫描整张图片得到的,某个pattern(pattern较大,stride较小时)可能被多次扫描到并体现在 featuremap 中类似于 \([0,1,2,5,2,1,0]\),直接丢弃这种长尾效应的尾对判定该某个pattern的位置以及匹配程度是没有任何影响的,他完全可以被最大的那个 5 hold住。
围棋(连续型pattern) vs. 图像识别(离散型pattern)
图像识别就是这种最大值可以完全hold位置以及匹配程度信息的任务。可是对于其他任务比如围棋,他的核心任务虽然也是识别某个模式,但长尾效应的尾部是有作用的。
在图像识别中被识别的模式是独立的或者叫离散的 --- 一个圆的是形状是眼睛,3/4个圆就不是眼睛了。在围棋中 \([0,1,2,5,2,1,0]\) 那些\(0,1,2\)对判断当前棋子所处的状态是有影响的,甚至他可能更重视长尾效应中的尾。
所以,对于是否使用 maxpooling 层要根据你的具体任务来做具体对待:
当任务识别的pattern‘’比较离散”---目标仅仅是寻找和定位pattern,别无其他 适合加上 maxpooling,让模型更专注,也让模型参数更少。
当任务识别的pattern“比较连续”---长尾效应之尾会影响任务目标 最好不加 maxpooling,这样模型可以保存更多现场信息,让结果更精确。
像围棋这种任务,显然就不能使用纯粹的CNN(包含 maxpooling),所以 alpha-go 中没有使用 maxpooling.
google 的 deepdream 的核心思想就是借用最大化某个filter or neuron.不同的是 deepdream 不是单纯“最大化某个filter or neuron的输出”,而是针对某层,让该层神经元原本输出大的更大,原本输出小的更小。,亦即,
CNN of deepdream exaggerates what it sees
assume output of k-th hidden layer is
\(output_k = [3.9, -1.5, 2.3, ...]\)
正的扩大,负的缩小
\([3.9\Uparrow, -1.5\Downarrow, 2.3\Uparrow, ...]\)
成为
\(output_k' = [10, -5, 8, ...]\)
以其为目标,找到 \(x^\star\)
\(x^\star = argmin_x(output_k - output_k')\)
之前都是只考虑了输出这件事,不论是 filter or neuron 还是某一层 hidden layer 我们关注的都是输出。现在如果我们把filter 和 filter 之间的 correlation 纳入考虑范畴。就可以实现风格迁移,这就是 deepstyle 的核心思想。
一个训练好的 CNN,输入某张图片,获取某一层 hidden layer 的输出(取内容);
一个训练好的 CNN,输入某张图片,获取某一层 hidden layer 的correlation(取风格);
目标是:找到一个 \(x\),他经过CNN得到的相同层 hidden layer 的内容像步骤1中的;风格像步骤2中的。
也就是什么样的图片可以让 filter 被激活(度高)
定义: 核的激活度
Degree of the activation of k-th filter, 核激活度表示这个 filter 被激活的程度, 他等于该filter输出的 featuremap 矩阵的所有元素的和(一个 filter 只会生成dim=1的featuremap)。
\(k-th\ filter\ is\ a\ matrix : A^k\)
assum \(A^k\) is a 11 * 11 matrix
\(element\ of\ A^k: a_{ij}^k\)
\(degree\ of\ activation\ of\ k-th\ filter: a^k = \sum_{i=1}^{11}\sum_{j=1}^{11}a_{ij}^k\)
我们的目标是:找一张img,他可以让这个filter被激活度最大
\(img^\star = argmax_{img}a^k\) , 亦即
\(x^\star = argmax_{x}a^k\)
我们使用 Gradient Ascent 去更新 \(x\) 使得某个filter的被激活度 \(a^k\) 最大。
也就是什么样的屠屏可以让 neuron 被激活。
定义:神经元的激活度
某个神经元的激活度,很简单,就是这个神经元的输出。
第 j 个神经元的输出记做 \(a^j\)
我们的目标是: 找一张img, 他可以让这个neuron的输出最大
\(img^\star = argmax_{img}a^j\) , 亦即
\(x^\star = argmax_{x}a^j\)
同上,也使用 Grandient Ascent.
其他同上
\(img^\star = argmax_{img}a^j\) , 亦即
\(x^\star = argmax_{x}y^j\)
由于是输出层神经元,如果我们在做手写数字识别mnist的话,那么输出层神经元应该有10个(对应数字 0~9),我们是否可以据此产生图片了?类似生成模型。
但结果并不如人意料,机器学出的东西与人类理解的东西有非常大的不同。我们确实可以通过这种GradientAscent的方法找到10张图片,他们也确实可以被模型正确分类到10个类别中,但这10张图片却无法被人类识别。
但我们依然可以对这些数字做一些处理(对 \(x^\start\) 做一些限制 --- 加一些 constraints),让他看起来像是数字:
\(x^\star = argmax_{x}y^j\)
change to:
\(x^\star = argmax_{x}(y^i - \sum_{i,j}|x_{ij}|)\)
类比 L1-regularization of GD on w:
\(||\Theta||_1 = |w_1| + |w_2| + ...... + |w_N|\)
\(L^{'}(\Theta) = L(\Theta) + \lambda ||\Theta||_1\)
\(w^\star = argmin_wL'(\Theta))\)
\(w^\star = argmin_{w}(L + \sum_{i=1}^{dim}|w_{i}|)\)
加上这个限制的意思是,人类可以识别的数字图片(灰度图)应该是大部分为0,小部分为正,并且为正的部分应该相连。
我们给原始的 \(argmax\) 公式加入 \(L1\) 正则项,让这个 x 可以尽量的稀疏(这是 L1 的特点),也就是大部分 x 的元素是 0,少量为1.
简单记忆训练 DNN 的技巧:
对于坏习惯, 早弃则自活
前三个针对训练误差小测试误差大的情况;
后两个针对训练误差就很大的情况;
tips for good training but bad testing
tips for bad training
每一次更新参数之前(我们一般一个 mini-batch 更新一次参数,也就是每个 mini-batch 都对神经元做一次随机丢弃),对每一个神经元(包括input layer,这点要注意)做丢弃:
1 mini-batch -> 1 dorpout -> 1 thin-network
每一个神经元都有 p% 几率被丢弃,所有与被丢弃的神经元相连的权重 w 也都会被丢弃,这样整个网络的结构就变了,深度不变宽度变窄。
dropout 毫无疑问会让训练结果变差,因为整体模型复杂度降低了。
需要注意两点:
假设 dropout rate 设为 50%, 在训练的时候我们得到的某个神经元的输出 \(z\) ,是丢弃了输入层一半的神经元及权重得到的:
\(z=f([x1,x2,x3,x4])\) --> \(z=f([x1,x4])\)
在测试的时候这个由于不做任何丢弃:
\(z=f([x1,x2,x3,x4])\))
该神经元的输出大约会是原来的两倍:
\(f(\vec{x}) = w * x + b\)
\(f([x1,x2,x3,x4]) \approx 2 * f([x1,x4])\)
\(w_{new} = 0.5 * w_{old}\) ,这样:
\(f([x1,x2,x3,x4]) \approx f([x1,x4])\)
为了防止 overfitting,防止参数量太多而引起的数据集和模型的优化方向 mis-match 的情况。我们经常人为设定:
\(\Sigma_1 = \Sigma_2\)
需要说明的是:如果做了公用 \(Sigma\) 这种假设的话,最后得到的就是一个直线边界,不做这一假设的话得到的是一个曲线边界。
likelihood 公式就变成:
\(N1 = num(samples of C1)\)
\(N2 = num(samples of C2)\)
\(L(\mu_1, \mu_2, \Sigma) = f_{\mu_1,\Sigma}(x^1)f_{\mu_1,\Sigma}(x^2)f_{\mu_1,\Sigma}(x^3)......f_{\mu_1,\Sigma}(x^{N1}) * f_{\mu_2,\Sigma}(x^1)f_{\mu_2,\Sigma}(x^2)f_{\mu_2,\Sigma}(x^3)......f_{\mu_2,\Sigma}(x^{N2})\)
对上面的式子可以通过微分,或者直接记住下面的公式解(其中 \(\mu_1\) \(\mu_2\) 跟原来一样,都是 样本的均值,\(\Sigma\) 是某类别的样本比例作为权重的 \(\Sigma\) 之和):
\(\mu_1 = avg(sample of C1)\)
\(\mu_1 = avg(sample of C1)\)
\(\Sigma = \frac{N_1}{N_1+N_2}\Sigma^1 + \frac{N_2}{N_1+N_2}\Sigma^2\)
logistic regression 有非常严格的使用限制,线性可分。
logistic regression 虽然可以理解为对分布的近似,但其本质仍然是一个直线分界线,因为他也是要求出 w 和 b,使用的函数集仍然是 wx+b = y , 也就是要求数据集必须是线性可分的。
如果遇到线性不可分的数据集,可以考虑采用特征转换。但如何做特征转换呢?
一个很好的方法是cascading logistic regression models --- 把很多个 logistic regression 接起来,就可以做到这件事情。这个东西有点像是在解释 NN,以及为什么他可以做到自动化 feature transform, 然后做分类。
李老师由此引入 "Neuron" 概念:
每一个逻辑斯模型的输入可以是其他逻辑斯模型的输出。
他们可以串在一起形成一个网络,这个网络就叫做神经网络。
这是另一个也许令人惊讶的运用名称修饰的例子:_MangledGlobal__mangled = 23 class MangledGlobal: def test(self): return __mangled >>> MangledGlobal().test() 23 在这个例子中,我声明了一个名为_MangledGlobal__mangled的全局变量。然后我在名为MangledGlobal的类的上下文中访问变量。由于名称修饰,我能够在类的test()方法内,以__mangled来引用_MangledGlobal__mangled全局变量。Python解释器自动将名称__mangled扩展为_MangledGlobal__mangled,因为它以两个下划线字符开头。这表明名称修饰不是专门与类属性关联的。它适用于在类上下文中使用的两个下划线字符开头的任何名称。
??????
module.exports属性表示当前模块对外输出的接口,其他文件加载该模块,实际上就是读取module.exports变量。
也就是说:
require 获得的是 module.export 对象;export === modue.export 指向同一块内存;export 是一个快捷方式,覆盖就没有意义; module.export 可以覆盖,这取决与需要暴露什么对象或方法;覆盖后 export 无效,因为 第 1 条;沿这种思路产生的设计将是非常笨拙的,会大大增加程序的复杂程度。相反,新建类的时候,首先应考虑“组织”对象;这样做显得更加简单和灵活。利用对象的组织,我们的设计可保持清爽。一旦需要用到继承,就会明显意识到这一点。
先设计好,不要盲目地继承
The edge of the operator network (such as the central office for telcos and the head-end for cable operators) is where operators connect to their customers. CORD™ is a project intent on transforming this edge into an agile service delivery platform enabling the operator to deliver the best end-user experience along with innovative next-generation services.
CORD central office re-architected as d datacenter
运营商边缘网络(例如电信公司的中心局和有线电视运营商的前端)是运营商连接到客户的地方。
CORD™旨在将这一优势转变为(agile service delivery platform)灵活的服务交付平台,使运营商能够提供最佳的最终用户体验以及创新的下一代服务 的一个工程
有时候,上面四个 Accept 字段并不够用,例如要针对特定浏览器如 IE6 输出不一样的内容,就需要用到请求头中的 User-Agent 字段。类似的,请求头中的 Cookie 也可能被服务端用做输出差异化内容的依据。 由于客户端和服务端之间可能存在一个或多个中间实体(如缓存服务器),而缓存服务最基本的要求是给用户返回正确的文档。如果服务端根据不同 User-Agent 返回不同内容,而缓存服务器把 IE6 用户的响应缓存下来,并返回给使用其他浏览器的用户,肯定会出问题 。 所以 HTTP 协议规定,如果服务端提供的内容取决于 User-Agent 这样「常规 Accept 协商字段之外」的请求头字段,那么响应头中必须包含 Vary 字段,且 Vary 的内容必须包含 User-Agent。同理,如果服务端同时使用请求头中 User-Agent 和 Cookie 这两个字段来生成内容,那么响应中的 Vary 字段看上去应该是这样的: Vary: User-Agent, Cookie 也就是说 Vary 字段用于列出一个响应字段列表,告诉缓存服务器遇到同一个 URL 对应着不同版本文档的情况时,如何缓存和筛选合适的版本。
也就是说,Vary 字段是给缓存服务器用的。
比如说,如果没有 Vary 字段中的 User-Agent,
缓存服务器就会不加区分地转发服务器的数据给客户端,
这可能导致不同 User-Agent 的客户端收到不与之相对应的数据。
我们用表示用来评估和改进的策略,用 表示产生样本数据的策略
评估和改进是一个策略,而采样是另一个策略 因为采样和评估不是一个,所以评估时一定要做修正 二者计算积分时有不同的分布,所以是在不同的分布上求期望或积分,这是后面推导和证明的关键
正如其他人所指出的——所以本条回答本应作为他们回答的回复,但这样的话对小小的回复框而言又显得太长了——这个目录用于存放一些初始化脚本,通常是在系统启动的过程中执行,此时,你系统中的其他文件系统可能是只读的,或者根本都还没挂载上。
文件系统会在系统启动完毕后挂载,正如初始化脚本也有可能在系统运行中的任何时候被运行(比如手动启动一项服务,或者开关一项运行等级等)。已经挂载了的 /lib/init 即使在变成只读的情况下,你也不应该将它卸载。如果不是处于实际的存储数据的过程,它不会占用太多的系统资源,所以它不是一个性能考虑的点。
我是没看到你将自己的脚本放到里面会对系统产生什么损害啦,当然你的脚本必须经过良好的测试,并且还要确保你的脚本不要完全占用它,以免其他脚本要使用时使用不了,不过,实现同样的目的更安全的方式是创建你自己的 tmpfs 挂载点(理论上而言,这样的挂载点你想要多少有多少,而且它们只在存储数据的过程中才占用系统内存空间),或者也可以使用 /tmp,它同样也被挂载成 tmpfs 文件系统,而不占用实际的硬盘空间(译注:它占用的是内存)。
当你在使用 tmpfs 文件系统作为临时数据的目录时,必须注意它也会占用系统内存空间,当内存不够用时,则会转移到交换空间(译注:交换空间可以理解为硬盘上的虚拟内存)。这就是为什么我通常使用的都是一块独立的硬盘空间,而不是 /tmp 目录(该目录什么进程放的东西都有,占用的空间可比我单独一个脚本占用的要多得多)。如果你大部分时间都拥有大量的“空闲”内存的话,就当我没说。需要注意的是,在诸如 free 和 top 一类的管理工具的输出信息中,tmpfs 文件系统存储的数据所占用的内存通常会被记录在 “cached” 一栏中——这点可以详见 In Linux, what is the difference between "buffers" and "cache" reported by the free command?
补充:差点忘了……创建你自己的 tmpfs 文件系统挂载点,而不是使用 Debian 创建的用来存放标准脚本的目录的另一个原因是,这样你对发行版的依赖就少了,这意味着当你的脚本要迁移到其他配置环境下时,你所需要做的改动要相对小得多。
Introduction
这是我加的批注
早点遇到的话,高考肯定能+20分!!
这是一个测试
1)第一种情况:如果两台主机不在同一个子网络,那么事实上没有办法得到对方的MAC地址,只能把数据包传送到两个子网络连接处的"网关"(gateway),让网关去处理;2)第二种情况:如果两台主机在同一个子网络,那么我们可以用ARP协议,得到对方的MAC地址。ARP协议也是发出一个数据包(包含在以太网数据包中),其中包含它所要查询主机的IP地址,在对方的MAC地址这一栏,填的是FF:FF:FF:FF:FF:FF,表示这是一个"广播"地址。它所在子网络的每一台主机,都会收到这个数据包,从中取出IP地址,与自身的IP地址进行比较。如果两者相同,都做出回复,向对方报告自己的MAC地址,否则就丢弃这个包。
ARP协议的主要作用是通过IP地址得到MAC地址。
Desirable aspects
这三种灵活性分别是模型、解释,以及表示,可以解释各种模型,也可以用各种形式去解释,也可以解释模型并没直接用到但涉及到的表示。
crt*.o files are used when linking against libc
这是干啥的
前面提到OpenStack项目的目录结构是按照功能划分的,而不是服务组件,因此并不是所有的目录都能有对应的组件
*cmd:这是服务的启动脚本,即所有服务的main函数。看服务怎么初始化,就从这里开始。
db: 封装数据库访问,目前支持的driver为sqlalchemy。conf:Nova的配置项声明都在这里。locale: 本地化处理。image: 封装Glance调用接口。network: 封装网络服务接口,根据配置不同,可能调用nova-network或者neutron。volume: 封装数据卷访问接口,通常是Cinder的client封装。virt: 这是所有支持的hypervisor驱动,主流的如libvirt、xen等。objects: 对象模型,封装了所有实体对象的CURD操作,相对以前直接调用db的model更安全,并且支持版本控制。policies: policy校验实现。tests: 单元测试和功能测试代码。这是一个标题
我注意到有关报道。美方试图把邀请不邀请参加军演和美方提出来的所谓中国在南海的行动挂钩。我在这儿必须严肃指出,中国对南海诸岛及其附近海域拥有无可争辩的主权。中方在自身的领土上开展正常建设活动,进行正常军事训练,这是主权国家固有的权利,也是中方捍卫自身主权安全、维护地区和平稳定的必要举措,与美方一直无端指责中国的所谓“军事化”毫无关系。美方没有资格在这个问题上对中国说三道四。
厉害我的国
这是test
Middleware 处于 server/gateway 和 application/framework 之间,对 server/gateway 来说,它相当于 application/framework;对 application/framework 来说,它相当于 server/gateway。每个 middleware 实现不同的功能,我们通常根据需求选择相应的 middleware 并组合起来,实现所需的功能
比如,可在 middleware 中实现以下功能:
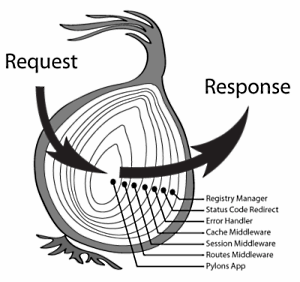
When the read system call is invoked, the application blocks and the context switches to the kernel. The read is then initiated, and when the response returns (from the device from which you're reading), the data is moved to the user-space buffer
由此可见,系统调用 --- system call 的一些特性:
user-space 只能调用 system call(就像调用普通函数一样) user-space 不能执行 system call,system call 的执行在 kernel-space。 kernel-space 负责执行函数,函数的 body 部分就是与 IO 进行交互,read/write 等。 整个过程,user-space thread 不会 sleep,也就是不释放 CPU,且程序不再前进,所以是 blocking and sync 到底什么是 sync 和 async 注意:
sync 的意思是 不释放CPU async 的意思是 释放CPU 如何理解呢:
释放 CPU 的话,在 CPU 眼里就没有这个线程了,不会给其分配 time slicing, like this:
. | | | |
. | | | |
. | | | |
第一个线程是 async 的,那么他在 CPU 眼里是不存在的, CPU 也不会再给他分配 time slicing.
| | | | |
| | | | |
| | | | |
第一个线程是 sync 的,那么他在 CPU 眼里依旧存在, CPU 照常给他分配 time slicing.
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇 这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
user-space vs. kernel space 系统函数只能在 kernel-space 中执行;但可以在 user-space 中调用。 系统函数在 kernel-space 中执行完毕后需要把结果拷贝给 user-space 中发起调用的线程,作为函数的返回结果。 所以系统调用这个东西吧,像是隔了一层,和普通的 API 函数还不一样。> When the read system call is invoked, the application blocks and the context switches to the kernel. The read is then initiated, and when the response returns (from the device from which you're reading), the data is moved to the user-space buffer.
由此可见,系统调用 --- system call 的一些特性:
注意:
如何理解呢:
释放 CPU 的话,在 CPU 眼里就没有这个线程了,不会给其分配 time slicing, like this:
. | | | |
. | | | |
. | | | |
第一个线程是 async 的,那么他在 CPU 眼里是不存在的, CPU 也不会再给他分配 time slicing.
| | | | |
| | | | |
| | | | |
第一个线程是 sync 的,那么他在 CPU 眼里依旧存在, CPU 照常给他分配 time slicing.
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
Erlang是一门动态类型的函数式编程语言,它也是一门解释型语言,由Erlang虚拟机解释执行。从语言模型上说,Erlang是基于Actor模型的实现。在Actor模型里面,万物皆Actor,每个Actor都封装着内部状态,Actor相互之间只能通过消息传递这一种方式来进行通信。对应到Erlang里,每个Actor对应着一个Erlang进程,进程之间通过消息传递进行通信。
Erlanng是一门动态类型的函数式编程语言,也是一门解释型语言,由Erlang虚拟机解释执行
Determining Whether to Gather More Data
如何确定是否要更多的数据?
其实很多人最直接的方法是一下尝试很多的模型。这也ok。
那加多少数据够呢?可以画下数据量和泛化误差之间的关系图。一般来说连续两次的数据量double下会比较好。
Recursion features three elements
递归调用三要素:
先说说原理。本地过程调用RPC就是要像调用本地的函数一样去调远程函数。在研究RPC前,我们先看看本地调用是怎么调的。假设我们要调用函数Multiply来计算lvalue * rvalue的结果:1 int Multiply(int l, int r) { 2 int y = l * r; 3 return y; 4 } 5 6 int lvalue = 10; 7 int rvalue = 20; 8 int l_times_r = Multiply(lvalue, rvalue); 那么在第8行时,我们实际上执行了以下操作:将 lvalue 和 rvalue 的值压栈进入Multiply函数,取出栈中的值10 和 20,将其赋予 l 和 r执行第2行代码,计算 l * r ,并将结果存在 y将 y 的值压栈,然后从Multiply返回第8行,从栈中取出返回值 200 ,并赋值给 l_times_r以上5步就是执行本地调用的过程。远程过程调用带来的新问题在远程调用时,我们需要执行的函数体是在远程的机器上的,也就是说,Multiply是在另一个进程中执行的。这就带来了几个新问题:Call ID映射。我们怎么告诉远程机器我们要调用Multiply,而不是Add或者FooBar呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用Multiply,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <--> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。序列化和反序列化。客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。网络传输。远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty也属于这层的东西。所以,要实现一个RPC框架,其实只需要把以上三点实现了就基本完成了。Call ID映射可以直接使用函数字符串,也可以使用整数ID。映射表一般就是一个哈希表。序列化反序列化可以自己写,也可以使用Protobuf或者FlatBuffers之类的。网络传输库可以自己写socket,或者用asio,ZeroMQ,Netty之类。
事例举得不错
If you want to be successful as a developer (or anything else in life), you need to be consistent.
2个月时间学习设计模式,然后再看自定义控件。 我的学习的连续性受影响,往往跟自己大脑活跃有关。总是在找更适合自己的方向。实质并不存在所谓更好的方向。长期扑在一个目标上非常重要。这是一种非常重要的能力。之前我已经算是学习过很多东西的人了,但却一无所成。原因就是急于求成,总是转换方向。关于这点,我还没有很好地分析总结。目前的《算法设计与分析》执行得就很好。这才是非常正确的学习方法。斯科特·杨的方法从本质上就是错误的。那种策略学习方法适合短期突破。并不适合成为一个行业的专家。成为一个行业的专家,需要耐心的投入。在这点上,李笑来可以说是极端强大。他意识到耐心的重要性。我自己总结为在开放的世界中保持自律和专注,对我来说更加贴切。
"Perfect" is a subjective term, but as a rule of thumb, try to achieve the best possible version of the product that you are required to deliver, all the time.
在当前的工作里,我逐步开始这样做,这使我收获非常大。但要明确一点。首要的是严格要求自己,而不是别人。只有对自己的要求提高了,别人才会信服。我们的基本要求是把事情做好。要想做好,就要力求完美。但完美,并不是一次可达的。真正的完美是需要多次修改的。咖啡98%是水。
Make it a habit to discover new and better ways of making your tools work for you, thereby improving your workflow and productivity.
这点非常重要。快捷键的本质是缩短时间,提高效率。
If you have developed a library, plugin, or other useful piece of code and you're using it in your own app, consider open-sourcing it. There's much to learn in the process of contributing to open-source projects or maintaining your own. It's an excellent crash course in open-source development that will exponentially increase your value as a developer.
关于这点,非常感谢林周玉的提醒。但是要学会克制。目前对我来说,算法的学习是重点,开源项目放到下半年。把对屈老师例题写成的代码共享出去或许是个不错的思路。
need
这条建议非常重要。东西是学不完的。但是如果专注于自己工作中所用的知识,提升工作效率,再逐步扩展,则是非常行之有效的方法。对我而言,能把心神视讯做好,已经很不错了。理解网易云信就是一个很大的工作量。学习自定义控件和设计模式,这个项目足矣。
pipelining
HTTP Pipelining是这样一种技术:在等待上一个请求响应的同时,发送下一个请求。(译者注:作者这个解释并不完全正确,HTTP Pipelining其实是把多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应;只不过,客户端还是要按照发送请求的顺序来接收响应。)但就像在超市收银台或者银行柜台排队时一样,你并不知道前面的顾客是干脆利索的还是会跟收银员/柜员磨蹭到世界末日(译者注:不管怎么说,服务器(即收银员/柜员)是要按照顺序处理请求的,如果前一个请求非常耗时(顾客磨蹭),那么后续请求都会受到影响),这就是所谓的线头阻塞(Head of line blocking)。 http://blog.csdn.net/qq_28885149/article/details/52922107
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量
解释了什么是汉明距离,即两个相同长度的字对于位不同的数量
例: 0000000 1111111 这两个的汉明距离就是 1 + 1 + 1 + 1 + 1 + 1 + 1 = 7
Simple SNP File Format:
这貌似是个简单的snp格式
如果我想多级排序呢,先用score排序,再用name排序:
这是针对列表中字典排序的更高升华
大五毛。
荒木飞吕彦 荒木飞吕彦 霍格沃茨学校六年级肄业生-----------大佑哥来了,改名,不然多不好啊 202 人赞同了该回答 因为你和老大一模一样,只能跟在老大后边,最好也就是当老二的命 毕竟你什么都学的他,那你肯定比他慢啊 想当老大,就必须走不一样的道路 所以老大就要天天宣传老二家的,摸着石头过河不好,应该走我一样的路 老二:呵呵 和你一模一样,宪法都照抄的墨西哥和菲律宾还在后山的歪脖子树上看着我呢 自古除了英国之外,剩下的后发国家都是富强了民主的,没富强就先民主的,都在歪脖子树下边等摇号呢 看到后边这四个字没? 都给我看半个时辰 只见一个牌匾升了起来,上边写着:要当第一 至于所谓的美国不担心中国民主的超过自己的问题 题主啊! 美帝的F22航母航天飞机卖不卖??不卖! 民主自由呢?卧槽倒贴钱给你送你不要还不行啊! 然后雇一堆公知喊,美国不怕你的歼二十你的航母,怕你民主 你说美帝是傻逼呢?还是公知是傻逼呢,还是被公知这些装傻的骗的那些人是真傻呢?
作者:NealDie 链接:https://www.zhihu.com/question/25416895/answer/31555889 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
9月29日,广电总局正式下发“封杀劣迹艺人”的通知,所有有“劣迹艺人”参与的作品,被要求暂停播出。之前所有以广电只是口头通知而非正式封杀为由来为广电洗地的答案全部站不住脚(这得多猪队友啊...)。怎么说呢,当初看这题的答案,很多人纠结于“口头通知”这个概念不放。实际上在这样一个国家的这样一个部门,发出“口头通知”就已然是一个很危险的信号了,单纯的去相信“口头通知”真的仅仅就是“口头”上的,是不是多少有点天真。这次下发正式通知倒也说不上打脸,只不过越发坐实了我一直以来的想法:以最大的恶意去揣测广电总是不会错的。对劣迹艺人进行封杀这种行为,我个人认为最大的利就在于收拢人心。从微博投票和各种评论来看,大部分人对于广电的封杀行为是叫好的,这是广电千载难逢在民众里提升形象的机会。当你去反对广电这种扰乱市场的行为时,不少高冷人士呵呵一笑,说你逢共必反,支持封杀这些劣迹艺人,似乎是站在了道德制高点上一般。从弊端来讲,这种行为严重侵扰市场,并体现出广电对于整个国内从业环境的把控之严。这是一件很悲哀的事情,我国的文艺作品处于必将长期出于这种管控之下。如果是制作单位考虑到市场需求,而拒绝使用这些艺人,这才是正常的模式。在广电阉割(或拒绝进口)自己喜欢的电影时,人们就是唾骂它的,在广电封杀自己不喜欢的劣迹艺人时,人们对它就是高度赞扬的。所以说,大部分人其实要的根本不是自由,而是一个符合自己的心意的主子罢了。恩,大概这才是最大的弊端吧。=====================================2014.10.10更新:我认为 @Sven提到的政企不分和垄断问题是有比较有道理的(详见他的专栏),但很多人似乎把他的观点看成是支持广电封杀“劣迹”艺人一样。ma大和Sven答案最大的分歧是广电错在哪,而不是广电到底错了没。我在微博上看了下关于这个新闻的评论,很大一部分支持者同时这么评论:能不能把王菲和谢霆锋也封杀了?能不能把姚晨也封杀了?我再也不想见到他们了。而我相信万一哪天广电封杀了这群评论者喜欢的明星,想必他们一定是要跳脚的。支持广电的行为在我看来没有过错,那是个人的权利,但在为广电的行为辩护时,请同时证明政企不分是好的,(政府管控下的)行业垄断是好的,广电阉割电影是好的,禁止任何影片上映也是好的,这样才能构成一套完整的逻辑。同时反对广电阉割电影又支持封杀劣迹艺人的,只能是精分。至于我说的“大部分人其实要的根本不是自由,而是一个符合自己的心意的主子罢了”,很多人在评论下非议不少。很多人觉得这是抖机灵,但是喜欢大政府的人,实际上政府本来就担当着主子的角色,这是个事实罢了。何况这又不是什么错,我追求自由或许只是我年轻气盛罢了,若干年后身心俱疲,乞求的不也是个好主子吗,谁说得准呢。============================2014.11.27更新:人人和射手被关闭,综合这一年多以来广电的做法,还在为广电说话的,不是脑残就是斯德哥尔摩综合症。
magasa
可敬之人,他有这样的回答:
如何评价广电局叫停「劣迹」艺人? 18,858 人赞同了该回答 有何利弊?百弊而无一利。
但你看微博上、知乎上,大把的人为此举叫好,说「广电总局终于做了一件好事」。
这真是应了一句老话,有什么样的人民就有什么样的政府呢。
又想到成龙说的,「中国人需要管」。
是这样吗?中国人真的这么热爱集权的大政府?中国人不相信社会和市场的自我调控能力?你有道德洁癖,你不爱看他们演戏,你不看就是了。出品商和广告商自会慎重考虑。
政府有什么资格充当全社会的道德判官?何况是这么XXXXX一个政府。
今天它管你看什么人演戏,明天它就要管你上什么网站。好吧,事实上早就管了。
支持封杀,或对封杀幸灾乐祸,不仅是在放纵政府那只无所不在的讨厌的手,也是助长社会道德风气的败坏。以道德的高尚借口,因为自己不喜欢某人,就可以让公权力来打压,这是败德。
不说道德说法律。
《禁毒法》第五十二条及《戒毒条例》第七条均规定: 戒毒人员在入学、就业、享受社会保障等方面不受歧视。 直接封杀工作机会,这不叫歧视,那就没什么是歧视了。
再重复一遍,封杀之举,违法违德,百弊而无一利。
参考: 中国电影比世界落后六十年:再说对「劣迹艺人」的封杀 编辑于 2014-10-15 18K
比特币:我是未来的时间旅行者,在此我请求你停下来
这是五毛任务
红黄蓝
「红黄蓝」已经成为知乎敏感词,但有趣的是这个问题居然被保留下来了。是什么力量或人让它得在保留呢?也许可以利用这股力量打破中国的信息封锁。
make会在当前目录下找名字叫“Makefile”或“makefile”的文件。 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“edit”这个文件,并把这个文件作为最终的目标文件。 如果edit文件不存在,或是edit所依赖的后面的 .o 文件的文件修改时间要比edit这个文件新,那么,他就会执行后面所定义的命令来生成edit这个文件。 如果edit所依赖的.o文件也存在,那么make会在当前文件中找目标为.o文件的依赖性,如果找到则再根据那一个规则生成.o文件。(这有点像一个堆栈的过程) 当然,你的C文件和H文件是存在的啦,于是make会生成 .o 文件,然后再用 .o 文件声明make的终极任务,也就是执行文件edit了。
具体规则的执行过程示例
交易输出包含两部分: ▷ 一定量的比特币,被命名为“聪”,是最小的比特币单位; 一个锁定脚本,也被当作是“障碍”,提出支付输出所必须被满足的条件以“锁住”这笔总额。
交易输出 -> 锁定脚本
血会像瀑布一样涌出来(原话是滝のように,这句不是我夸张
邻居看到了吗
说,不了解河南就不了解中国;中国人说,不了解开封就不了解河南。可见开封这座城市在人们心目中的地位。开封文化是中原文化乃至华夏文化的一个代表和缩影。在这座城市中,随便捡起一块陈砖旧瓦,随便捧起一把黄土沉沙,说不定就有一段动人的历史故事。在这座城市,厚土
000
Ad hoc polymorphism: when a function denotes different and potentially heterogeneous implementations depending on a limited range of individually specified types and combinations. Ad hoc polymorphism is supported in many languages using function overloading. Parametric polymorphism: when code is written without mention of any specific type and thus can be used transparently with any number of new types. In the object-oriented programming community, this is often known as generics or generic programming. In the functional programming community, this is often shortened to polymorphism. Subtyping (also called subtype polymorphism or inclusion polymorphism): when a name denotes instances of many different classes related by some common superclass.[3] In the object-oriented programming community, this is often referred to as simply Inheritance.
个人认为 这里其实 ad hoc 和 subtype 是有相近之处的 都是一样东西 比如 function 或者 object, 我们使用不同的角度去看 比如 不同 parameter 和 type 可以得到(部分)不同(也可能相同)的实现. (其实对于 object 应该是相同?) 这里倾向于去利用一个东西 as a user
而 parametric polymorphism (generic/template) 这是在接受一个对象 (as an implementer) 时候 对于该对象的类型不限定, 而是使用固定的手段去操作
as a user: 限定名字 不限定操作方法 as an implementer: 限定操作方法 不限定名字
虽然是strict模式,但语句var x = 'Hello, ' + y;并不报错,原因是变量y在稍后申明了。但是alert显示Hello, undefined,说明变量y的值为undefined。这正是因为JavaScript引擎自动提升了变量y的声明,但不会提升变量y的赋值。
这个确实不错。
对于那些被迫不可爱的工作,这是一个不同的故事。
parents always say love their kids, but they do not care what they want to do. For example, they think reading is very good thing, so they compel kids to read a lot of books.
着这个问题不能被指定,即使是通过与ImageNet一样大的数据集
这是什么意思?
在古典哲学中,“主体”与“客体”,一个在另一个之外,一个在另一个之前。在绝对这个漩涡中,在原始的或者终极的同一性中,它们又将重新结合在一起。今天,精神的与社会的都存在于实践中:存在于想象和真实的空间中。
请问 这句话的出处是?
仿射函数
作者:Cascade 链接:https://www.zhihu.com/question/20666664/answer/15790507 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以下内容仅涉及图形变换,未考虑更为抽象的概念。为了方便起见,以下叙述均采用平面直角坐标系。一个矢量(1,2)可以表示为从原点指向该点的箭头。你可以对这个矢量进行缩放,比如放大两倍就变成了(2,4)这个操作可以表示为2 x(1,2)。也就是说放大k倍就是k(x,y)上面的例子写成矩阵的话就是,这里用到了矩阵乘法。<img src="https://pic2.zhimg.com/b7962fe4cfb1a49a4fda71d2b93657e9_b.jpg" data-rawwidth="98" data-rawheight="51" class="content_image" width="98">这个很简单。你也可以把矩阵中的两个值弄成不一样的。那么如果你对一张图片操作的话,横竖两个方向上的缩放倍数不同图像就变形了。方的变成长方的。这个很简单。你也可以把矩阵中的两个值弄成不一样的。那么如果你对一张图片操作的话,横竖两个方向上的缩放倍数不同图像就变形了。方的变成长方的。你也可以对矢量进行旋转。比如想把向量(1,0)逆时针旋转45度。旋转以后的向量和这个向量会构成一个三角形。旋转以后的是斜边,长度和原来向量长度一样。用勾股定理计算一下。三角形的顶点会变成(√2/2, √2/2)。这个看起来比较麻烦。但是如果你明白矩阵乘法是怎么算的,那很容易理解为什么一个旋转矩阵会是这样的:<img src="https://pic4.zhimg.com/9c70a69a8f0b3dcebc73b3aeccb2a677_b.jpg" data-rawwidth="159" data-rawheight="56" class="content_image" width="159">有些变换,比如反射。相当于你在第一种情况里面对角线上的两个值有一个是负的。那么对应的就会把这个轴翻转过去。别的都很好理解。这些变换被称为线性变换。它提供了把一个图像扭成任意形状的方法。但在二维坐标系内,用2x2的矩阵所不能表示的变换就是平移操作。你在上面所有的操作无非都是给向量的两个分量乘一个系数。没办法再加一个数。想要表达这种计算就得给你的矩阵变成这样:<img src="https://pic4.zhimg.com/6f0b8ce45cb1d2f89083f9e39d8311d7_b.jpg" data-rawwidth="95" data-rawheight="64" class="content_image" width="95">这样的话你的(x,y)向量就没法乘进去了。你可以在后面添个1,编程(x,y,1)这样的。那么变换以后的结果就是(xa1+yb1+c1,xa2+yb2+c2,1),去掉最后面的1,前面的就是线性变换加上一个平移变换的结果。这就是仿射变换。简单的说就是一个线性变换加上平移。写公式和矩阵真坑爹啊。。。
坐标下降法坐标轴下降法顾名思义,是沿着坐标轴的方向去下降,这和梯度下降不同。梯度下降是沿着梯度的负方向下降。不过梯度下降和坐标轴下降的共性就都是迭代法,通过启发式的方式一步步迭代求解函数的最小值。坐标轴下降法的数学依据主要是这个结论(此处不做证明):一个可微的凸函数J(θ), 其中θ是nx1的向量,即有n个维度。如果在某一点θ¯,使得J(θ)在每一个坐标轴θ¯i(i = 1,2,...n)上都是最小值,那么J(θ¯i)就是一个全局的最小值
coordinate descent definition
什么是SVM?Support Vector Machine, 一个普通的SVM就是一条直线罢了,用来完美划分linearly separable的两类。但这又不是一条普通的直线,这是无数条可以分类的直线当中最完美的,因为它恰好在两个类的中间,距离两个类的点都一样远。而所谓的Support vector就是这些离分界线最近的『点』。
这个SVM定义直观
信息通过眼睛输入,经过大脑识别、理解、处理之后又运用口腔的种种器官形成正确的声音,而后又通过耳朵反馈回大脑;而与此同时,大脑在一刻不停闲进行各种处理过程:句子成分都有哪些、哪几个字词构成什么样的成分、这些成分各自是什么意思、成分之间的关系究竟是什么、这些成分组合起来又构成怎样的含义,等等。 反过来也一样,如果阅读者面对一个语法正确、逻辑严谨的句子竟然不能够把它流利地朗读出来,就说明阅读者“拆解”有误或者“重组”有误。重新把句子结构与成分意义以及它们之间的关系都搞清楚之后,句意也就自然明朗了,读起来自然就“顺”了;而后再把句子多读几遍——其实就是“通过重复练习理解过程、巩固理解能力”了。
这是通过朗读提高阅读理解能力的过程(绝对不是单纯地读)
之所以朗读是提高“理解能力”的最基本方法,是因为当一个人可以流利地朗读一个句子的时候,即意味着说他正在完成对这个句子的“拆解”与“重组”的过程——这是个复杂的系统工程:
所谓朗读,应该是基于理解这个句子的前提下。
但与希腊的当代废墟相比,纳什维尔帕台农神庙拥有一个重要的历史细节:多色。随着建筑物外部和内部的部分,大量的金色雅典娜雕像以明亮的色彩绘制。这是令人震惊的,甚至有点愚蠢的今天的标准,因为我们习惯了错误的想法,古代被一个简单的,未装饰的白色大理石审美主导。实际上,古希腊人画了他们所有的雕像:看到他们以绿色,红色,蓝色和其他颜色印有更为历史的准确性。它也使古代过去的长期和历史错误的观点受到白色主导的影响。就像原来的那样,纳什维尔帕台农神庙已经成为一个旅游陷阱,但这并不意味着有趣。所以写这个感觉很奇怪,这是真的:在你去田纳西州纳什维尔之前,你还没有真正看到帕台农神庙。
The culture is a international. People can study different culture. But it will changed undoubtedly burring different culture background and different style of people's life. Which is a new culture.
南非分公司与前往中国朝鲜皇室收藏品的台北故宫不同,南非分公司是前瞻性的,为亚洲人的身份叙述奠定了基础。推动这一转变是台湾地缘政治的根本策略,减轻对中国大陆的依赖,增加与亚洲其他地区的联系。
The relationship between countries is more international, which is especially the culture that is an important part of the people,and also a part of the country, more people understand their own culture to carry forward Chinese culture. The other county know about China culture which is a opportunity to make China culture more international.
文化管理一直是台湾政府的首要担忧。台北故宫博物院在全球被公认为中国艺术的领先研究机构,其中所存在的文化物品已经使台北政府声称这是中国文化的真正管家者的合法性。
China is a really old country, it has a thousands of years history. There has a lot of things are antiquity. It is very important and meaningful for the country. People should to thinking about which is best way to protect our culture.
16岁以下定期吸烟的少年数量减少到2007年的一半,即3%,这是最低记录。
但并没有给出16岁以上的成年人的吸烟率变化
我们最终全部切换到了G1,16年双十一线上MetaQ集群采用的也是这一组参数,基本上GC时间能控制在20ms以内(一些超大的共享集群除外)。
阿里在消息中间件中全部启用G1GC,从16年双十一就开始。这对G1GC是个不错的案例
他的数据分析的思路是将一段时间内所有完成了三个引导页的用户都筛选出来,然后再计算他们在这之后持续回访产品的比例,同时也将这段时间里未完成三个引导页的用户筛选出来,将这些用户的留存率与完成的引导页的用户留存率做对比。
首先用时间作为一个分类,然后将是否完成引导页作为一个用户行为的抽象,最后使用这个抽象在时间分类上做对比,以确定该行为对用户留存率是否有意义
Firefox 使用的是 Gecko,这是 Mozilla 公司“自制”的呈现引擎。而 Safari 和 Chrome 浏览器使用的都是 WebKit。
webkit -> 开源
在CNN火起来之前,对象检测这一问题基本是遵循着“设计手工特征(Hand-crafted feature)+分类器”的思路
这是CNN之前的思路,需要手工地把特征标注出来。话说Annotations不也是手工标注吗?
当你说「整倍数」的时候他们无法想到用余数,当你先提到 3 和 5 的整倍数时,他们无法想到 15 应该放在他们两个之前判断。
这是训练的结果
总结 用Quizlet打造你自己的单词体系并不断学习巩固,至于学习的频率,就交给reminDO。具体操作方法如下: 1.将你要背的单词分为几个小块,比如一天想背100个单词,列为一个List,如“List 1”。 2.将这个“List 1”的单词输入进Quizlet里,定义最好是英文+例句,这样在输入的时候便是一次记忆过程。vital、important、significant在中文里都可以是“重要的”,但是不同语境下使用情况不同,这是有例句或者英文释义,你的理解便会深入得多。在此,顺道推荐一个网站http://vocabulary.com,最贴切的用法、来自权威期刊的例句,这里通通都有;完全可以用这个网站取代其他词典,网站也有背单词功能,下次会找个机会评测。 3.将“List 1”添加至reminDO中。 4.根据reminDO划定的时间表,在Quizlet里用四个学习工具背。
教你如何用remindo和quizlet进行学习
Getting Started With TensorFlow
首先你需要安装TensorFlow,参考地址 ,开始本向导要求读者具备如下知识:
TensorFlow有两层API,一层是TensorFlow-core ,这层是比较底层的,提供给机器学习研究者和其他对于模型控制要求较高的人员使用。 另一层是Higher level API,这一层提供非常方便的机器学习调用api,任何人都可以快速的使用它构建机器学习应用。<br> 这个向导从TensorFlow Core API开始。因为了解了Core API后,有利于你对整个流程建立较好的理解。
从扩展程序向内容脚本发送请求与上面类似,唯一的区别是您需要指定发送至哪一个标签页。这一例子演示如何向选定标签页中的内容脚本发送消
reterter
而事实上,我们说的话之中,几乎99.9%是在重复我们曾经听到的、看到的句子。所以,即便是文盲,也不可能每一句话都是病句。不过,显而易见的另外一个事实是文盲通常说的话都是表达简单思想的,用得都是简单词汇、简单句型,这也从另外一个方面降低了他们犯错的可能性。
没学过语法也能沟通的原因是,我们一般都是在重复曾经听到或者看到的句子。而且基本上表达都比较简单。
We will be using the classical active-passive cluster architecture which is the recommended solution for OpenNebula.
我们将使用经典的主备群集架构,这是OpenNebula的推荐解决方案。
注:由于信工所发展迅速,人员流动频繁,且以下内容不能保证实时更新,故本文的一些内容可能过时甚至有所误导,请大家自己注意辨别,有问题请向信工所在读学生了解。 导师列表:http://www.iie.cas.cn/yjsjy_101173/dsyd/ 中国科学院大学导师主页:http://www.ucas.ac.cn/site/77 信工所有三个园区,香山园区(北京市海淀区闵庄路丙87号、甲89号、91号)、益园园区(北京市海淀区四季青镇杏石口路中部80号益园文创基地C1)和肖家河园区(毗邻圆明园,面积是软件所软件园区的4倍,未启用),香山园区是最早的园区,香山园区和益园园区都是租住的。信工所的学生研一住在中国科学院大学雁栖湖校区,研二住在玉泉路校区,也有部分学生住在中关村校区。 信工所硕士招生名额为210(增加中),博士招生名额为150(增加中)。 中国科学院信息工程研究所,简称信工所,英文全称Institute of Information Engineering,Chinese Academy of Sciences,英文缩写IIECAS,是2011年批准成立的中国科学院直属科研机构。信工所受到国家大力支持,包括信工所前任所长田静研究员调任国家保密局局长,中国工程院院士方滨兴为信工所兼职博导、二室首席科学家等,因此信工所得到了国家保密局和工信部的支持,另外北京邮电大学、北京交通大学、上海交通大学等很多高校的信息安全领域重要学者都成为了信工所的客座博导,因此信工所的六个研究室都出身不凡。2014年中科院提出”率先行动“计划,成立以信息工程研究所为主体的信息工程创新研究院,根据新的改革发展需要,调整内部结构,凝练科研目标,优化科研布局,进一步整合相关优势科研力量,充实和加强科研队伍,涉及声学研究所、计算机网络信息中心、计算技术研究所、高能物理研究所、半导体研究所等5个研究所近100名科研骨干。 信工所承担了中国科学院大学网络空间安全学院的建设。中国科学院大学网络空间安全学院主办了全国高校网安联赛(http://xnuca.erangelab.com)。 信工所2012年第一年招硕士研究生,博士招生名额也十分充裕。因为信工所的实验室还在扩建和完善,所以这几年的招生比预期多,等到信工所的实验室建制稳定后,就不会再接受考研调剂学生了。信工所建立不久,各个实验室都在引进人才,有些研究室如五室、六室也很年轻。客座导师中有部分是亲自指导学生的,也有一部分客座老师不带学生,他们的招生名额主要是为其他没有招生资格的老师提供名额。另外,由于信工所仍处于创业阶段并且短期内不会脱离这一阶段,信工所在很多方面管理都没有形成规范,另外各组组里助研的水平参差不齐,这都是起步阶段的正常现象,主要看考生在意与否。 所里工程压力和强度最大的研究室是二室和四室,一室、三室工程组、五室和六室的工作压力根据课题组的不同而不同,最自由的、可以有时间做自己的项目和事情的研究室是三室理论组。信息安全国家重点实验室中的一室和三室在密码学与安全协议领域实力强劲,适合数学类专业考生;二室和六室是纯计算机学科研究室;除二室和六室外,其他研究室都有适合电子通信类专业考生报考的研究团队;考生无论本科是什么专业,如果具有较强的动手能力,会受到所有研究室的欢迎。 信工所的学生待遇由三部分组成,分别是RA+所补贴+国家补贴,其中RA(助研津贴)分等级,根据表现确定,不过有些实验室和课题组是所有学生都一个标准;所补贴是由课题组发放;国家补贴是固定的,标准是硕士生每月600元,博士生每月900元。本科实习生初入组是1000元起,外加餐补400元。学生待遇根据不同课题组和导师而不同,不过不管是哪个研究室的理论组,待遇肯定是研究室里最低的,因为不做工程项目。四室的情况有所不同,虽然四室整个研究室都是做工程的,但是其整体待遇类似其他研究室的理论组。一般来说,参与到工程部建设的科研团队拥有充足的科研经费和更好的待遇,是直接受益者。信工所实行研究室主任负责制,所有研究团队,无论是做理论还是工程研究,都是有业务需求的。 下面介绍一下各个研究室: 第一研究室: 第一研究室科研队伍主要来自于信息安全国家重点实验室(http://sklois.iie.ac.cn),位于香山园区,地址是北京市海淀区闵庄路甲89号B2栋。该实验室筹建于1989年,1991年通过国家验收并正式对外开放,是我国信息安全领域创建最早的研究机构之一。实验室原由中国科学院主管,原依托于中国科学院研究生院、软件研究所,2012年起依托于中国科学院信息工程研究所。 第一研究室的强项是密码算法与数学理论(代数密码、非对称密码、安全协议、视觉密码、密码数学理论等)、信息对抗(信息隐藏、密码工程学、侧信道与能量分析攻击)、安卓安全和恶意代码分析、图像与视频理解(图像与视频检索、加密、敏感信息检测、深度学习)。来自软件所的信息安全国家重点实验室,在国内相关领域的排名,一直都是第一,是很多学生报考软件所之后的选择方向。第一研究室的理论水平是所里最高,博士毕业要求普遍较高。一室对考勤管理比较严格,另外部分组研一学生需要每周从怀柔雁栖湖校区回到信工所参加组会。 一室包含如下团队: 林东岱研究员(http://sklois.iie.cas.cn/rcdw/yjy/201501/t20150107_275226.html)是信息安全国家重点实验室主任、一室主任,很有亲和力,没有架子,主动与学生交流,并且尊重学生的个人选择,不会过度限制学生。研究方向主要包括格密码、计算复杂性、密码分析、算法数论、序列密码、零知识证明、信息安全战略研究、视觉密码等,老师普遍不错,并且都是学术大牛。 刘峰研究员(http://www.fengliu.net.cn)的研究方向是网络空间安全战略研究(主要是写政策、报告等)、视觉安全与隐私保护、虚拟现实及网络空间安全理论,网络空间安全战略研究是此团队以后的重点发展方向。邓燚研究员和陈宇副研究员在一组,研究方向是理论密码学、零知识证明、概率证明系统,特别是协议的轮、通信、计算复杂性问题,团队在这一领域很有造诣。邓燚老师提出了一系列新的实例依赖的密码学工具,构造性的证明了零知识证明及论证系统中一个由B. Barak、O. Goldreich、S. Goldwasser和Y. Lindell提出的有关随机数重复使用的猜测,于2009年在理论计算机科学最顶级会议之一FOCS上发表了这一成果,并收到了领域内顶级期刊SIAM Journal on Computing邀请投稿,此外还在EUROCRYPT 2007和ASIACRYPT 2011上发表了2篇论文,并获得过中国密码学会首届优秀青年奖和首届密码创新奖一等奖。张文涛副研究员(http://sklois.iie.cas.cn/yjdw/fyjy/201406/t20140624_242295.html)的研究方向是密码分析与算法设计,与华为公司有很多合作项目,人品非常好,经常组织学生出去参加团建活动。孙瑶副研究员和黄震宇副研究员是林东岱研究员课题组的成员,主要研究方向是密码分析和代数攻击,具体研究内容分别是Groebner基算法和特征列算法,这两个算法是代数攻击的最主要两个算法,两位老师的研究成果都达到了国际先进水平。两位老师都毕业于中国科学院数学与系统科学研究院,其中黄震宇老师毕业于中国科学技术大学大学少年班,都具有扎实的理论功底。两位老师博士阶段的研究方向都是符号计算,在符号计算顶级会议ISSAC和期刊JSC上发表过多篇论文,工作后重点从事代数攻击方面的研究,和多个涉密部门有深入的项目合作。刘美成副研究员是林东岱研究员课题组的成员,硕士师从广州大学裴定一教授,博士师从林东岱研究员。博士期间重点研究布尔函数代数免疫度,博士毕业前已发表多篇高水平论文(包括IEEE Transactions on Information Theory、ASIACRYPT),并获得中科院优秀博士毕业生的称号。刘美成老师2016年在新加坡国立大学访问时,与国防科技大学孙兵老师合作在密码学领域顶级会议EUROCRYPT上发表了一篇论文。罗晓广研究员来自国防科学技术大学、61786部队。 薛锐研究员是一室副主任,研究方向是安全协议、形式化方法、计算复杂性、数理逻辑,对学生的专业背景和其他方面都没有特别的限制,只要有很强的求知欲就可以,他的学生可以根据自己的兴趣选择做理论或者是做工程方向,并且在经济上给予学生实质性的帮助。 陈驰正研级高级工程师团队的研究内容是数据安全、云计算安全、密文检索、生物密码,主持参与了大量国家级重大工程项目,2016年在IEEE TPDS顶级期刊上发表了论文。陈恺研究员(http://www.kaichen.org)团队是一室工程组中学术方面最强的,是学术大牛,研究方向是软件安全(包括恶意代码分析、漏洞检测)、智能终端安全(包括安卓、iOS安全等)、安全测评、隐私保护、CTF竞赛与对抗。陈老师学术实力很强,2015年与国外团队合作发表了中国大陆第2篇、中科院内第一篇USENIX Security顶会,还合作发表了ACM CCS和IEEE S&P顶会(中国大陆第7篇)文章,在信息安全领域公认的“四大”国际顶级安全会议(IEEE S&P、USENIX Security、ACM CCS、NDSS)中发表论文数在国内名列前茅,部分成果还发表在BlackHat等工业界的顶级会议中,另外还在ICSE、ASE等顶级会议上合作发表了论文。陈恺老师与学生关系非常融洽,几乎每天都会到工位上与学生讨论,在指导学生方面很有一套,而且他是80后研究员,与学生有很多共同语言。他对学生要求较高,对待学术的态度非常的严谨,提供的待遇也能使学生没有经济压力,组里的压力也较为适中。此外,团队与国内外多所高校都有合作,包括伊利诺伊大学香槟分校(UIUC)、宾州州立大学(PSU)、印第安纳大学(IUB)、南洋理工大学、新加坡管理大学、香港中文大学等,国内包括清华大学、 北京大学等。团队在工业界与Google、微软、苹果、亚马逊、Palo Alto Networks、FireEye、百度、阿里巴巴、腾讯、360、安天等均有紧密联系。陈老师的学生除了由他亲自指导外,也有去国外联合培养的机会,学生就业也非常好,多数都拿到公司的Special Offer,指导的学生所在的CTF战队已在国际大赛中获得世界第4、国内第1的成绩。吴槟高级工程师(http://sklois.iie.cas.cn/rcdw/fg/201501/t20150107_275238.html)团队的研究内容是网络攻防与安全事件检测分析,包括网络异常行为检测、隐蔽通信及其检测、实用网络安全通信协议及密码算法设计与分析、网络与通信系统安全性测评,主持或参与了多个重要科研项目。 密码工程组: 张锐研究员的研究方向是密码工程学(密码算法的软硬件快速实现、侧信道密码分析学)、应用密码学与安全协议、数据安全与隐私保护技术,要求较高,压力较大,但是亲自指导学生,实力很强,在IEEE TDSC、IEEE TIFS、IEEE TPDS等CCF-A类和B类期刊和会议上发表了很多篇论文。张锐老师本科毕业于清华大学,硕士和博士毕业于日本东京大学,是百人计划研究员。张锐老师和周永彬老师共同指导组内学生。王明生研究员的研究方向是计算代数、轻量密码学、大数据密码、密码相关的困难问题,组内还有李永强副研究员。王明生老师的理论功底很强,成果包括解决在多维系统论中关于多变量矩阵分解方面,20世纪80年代以来全球未解决的公开问题。周永彬研究员是第二工程部主任,团队的研究内容是密码工程学(侧信道分析和能量分析攻击、安全密码芯片设计与分析)、应用密码学、云计算安全与智能终端系统安全性分析测评,曾在DPA国际学术大赛夺得全球第一(http://www.iie.ac.cn/xwdt_101144/kydt/201403/t20140312_4050399.html)。周老师本人非常勤奋,另外他看起来严肃,实际上和蔼。 赵险峰研究员团队的研究内容是信息隐藏与隐蔽通信及其检测、安全异常行为与内容取证、大数据安全分析以及相关技术在信息内容保护和网络空间安全等中的应用,具体包括多媒体隐写术与隐写分析、编码和模式识别、基于数字水印的多媒体安全防护、多媒体篡改盲取证,以及相关的图像、音视频处理、GPU并行加速、隐写分析技术在网络流处理中的应用,团队在信息隐藏领域最好的会议ACM IH & MMSec上发表了多篇论文。组内老师包括曹纭高级工程师、关晴骁、易小伟。曹纭老师在ACM IH & MMSec、ICME等领域相关的高水平国际期刊和会议上发表了多篇论文,研发了视频隐写对抗平台、轻量级多媒体内容加密算法等成果;关晴骁老师主要做图像视频编解码、加密、隐写术,是组内的顶梁柱。赵老师组里的气氛非常融洽,因为赵老师崇尚君子之交,而且他经常主动到学生工位与学生们讨论具体的科研问题,看到学生有经济压力还会给予实质性的帮助。在学生就业方面,组内硕士毕业生的就业去向主要是创业公司。 刘偲副研究员(http://liusi-group.com)领衔S-LAB团队,研究方向是深度学习在图像视频处理中的应用、人工智能理论与应用系统、模式识别,曾经获得ACM MM最佳论文奖和最佳技术展示奖,截止到2016年已在CCF-A类和B类顶级期刊和会议上发表论文50余篇。刘老师曾在新加坡国立大学(NUS)跟随颜水成老师(现360首席科学家)团队学习、工作长达5年时间,与美国伊利诺伊大学香槟分校 (UIUC)、新加坡国立大学(NUS)、微软亚洲研究院(MSRA)、Adobe研究院(San Jose, California)、360研究院以及多家创业公司等都有合作,团队还经常邀请国际国内一线学者和企业技术大神来组里作报告。刘老师为人非常和蔼,认真负责,时刻关心学生的学习科研情况并进行详细指导,会与学生一起调试代码,并且对学生的编程能力(C、C++、MATLAB、Python等)要求较高。刘老师组论文阅读量很大,紧跟学术步伐。在学生培养方面,学生入组后第一年就能在CCF-A类期刊和会议上发表论文,出成果很快。2016年,3名大四实习生(2013级本科生)在进入课题组学习2个月之后,参加了中国计算机学会主办的CCF大数据与计算智能大赛,击败了来自国内知名高校和企业的全部团队,最终夺得大赛终极奖项CCF综合特等奖,赛事成果同时获得新华网、光明日报、凤凰网等多家主流媒体的报道。刘老师注重团建,定期组织大家吃饭,爬山,桌游,K歌等,团队内部氛围非常融洽。在学生就业方面,刘老师会帮助组内学生推荐工作,组内毕业生实力也很强,能获得包括“BAT”在内等多家企业的offers。郭晓杰副研究员(http://cs.tju.edu.cn/orgs/vision/~xguo/homepage.htm)的研究方向是稀疏表示在计算机视觉、模式识别、多媒体内容理解与安全中的应用,具体包括可视数据恢复、视频监控智能处理、机器学习算法设计和数学基础,每年都在领域内CCF-A类和B类顶级会议和期刊上发表论文10余篇,科研实力很强,研究成果具有很强的实用性,外表也非常英俊,人品也很好。 于海波正研级高级工程师是第一工程部主任,主持或作为骨干参与了大量国家级重大工程项目,研究方向是网络空间信息对抗技术,具体是利用入侵检测、访问控制、密码学等工程技术手段应对各类安全威胁,以实现信息保障。第一工程部导师还包括刘长军高级工程师,主要从事信息安全工程技术研究和产品开发。第一工程部的部分学生在赵险峰老师组培养。操晓春研究员团队包括王蕊副研究员、许倩倩副研究员等老师。侯锐研究员是处理器安全体系结构团队的负责人。侯锐在2016年以前是中科院计算所先进计算机系统研究中心CPU实验室的负责人,2017年加入信息工程研究所,曾工作于IBM中国研究院。侯锐老师在HPCA等国际顶级会议上发表文章多篇,领导团队做出过ARMv8、Power等系列高性能处理器芯片,他是国际自然科学基金优秀青年获得者。该团队致力于研究和解决处理器芯片相关的安全问题,着重关注安全体系结构、CPU设计与实现、侧信道攻击与预防、云计算和大数据的安全计算与隐私保护,以及CPU安全性评价等方面。团队以“做一流工作,育一流人才”为目标,面向国家战略需求,积极开展前瞻性探索,注重工程落地和成果转化。 研究方向 密码理论与技术、安全协议与体系、网络与系统安全、信息对抗和物联网安全等。 第二研究室: 第二研究室科研队伍主要来自于信息内容安全技术国家工程实验室(http://nelist.iie.cas.cn),该实验室成立于2008年底,是国家发展和改革委员会首批批准建设的100个工程实验室之一,原依托于中国科学院计算技术研究所,2012年起依托单位更改为中国科学院信息工程研究所。硕士研二起每月的待遇在3000-3600之间,与三室工程组硕士待遇不相上下,甚至有个别组的学生因为参与一些重要项目而每月超过10000元,博士生待遇比硕士生每月至少高600。这个实验室的工程研发能力在信工所排第一,实验室以工程为导向(如实验室名称所示),所以基本上以工程为主,做研究的时间和精力比较少,硕士从事研究工作的参与度和比例都较低,但博士生的论文都较为不错,经常发表A类论文,另外研究室的工程压力普遍比较大,是所里压力最大的研究室之一,不过仅有个别组需要考勤打卡,另外研一学生不需要每周回所,部分团队可能会布置一些研一学生可以做的工作,让他们在怀柔完成。一般来说,老师给学生布置任务,就会给学生发RA,学生不参与任务就只能领取基本的补助。二室的主要研究方向是大规模信息内容处理、并行与分布式计算,本质上是数据分析、机器学习、分布式系统之类的研究,也就是大数据。 二室分布在香山园区(地址是北京市海淀区闵庄路91号A3楼)、国家互联网应急中心(CNCERT/CC)、益园园区以及华严北里。 二室硕博连读的学生不多,因为二室的研究方向与工业界结合很紧密,硕士就业非常好,另外研究室的工程压力较大,所以大部分学生读完硕士就选择直接就业,而每年的博士招生计划主要通过招收直博生和普博生(即统考博士)来完成。 这个实验室考分要求很高,以前在计算所的时候,分数要求基本370+,搬到信工所以后也是复试竞争最激烈的实验室,很喜欢把一志愿和调剂生混在一起复试,而且只喜欢能力强的学生,刷人也是最厉害的,拟录取结果也是最晚公布。二室在考研复试中有机试,机试成绩低于30分(百分制)会被慎重考虑是否录取。 郭莉老师的学生在二室培养;谭建龙老师是二室主任,研究方向是云内容安全、密码破解超级计算机、海量正则表达式匹配,老师本人也非常勤奋。孟丹老师的很多学生也分配到了二室。 二室包含如下团队: 刘燕兵老师是内容计算组(http://www.escience.cn/people/liuyanbing/index.html)组长,研究内容涉及了软硬件多个层次,导师还包括马伟、曹亚男(http://nelist.iie.cas.cn/yjspy/sssds/201607/t20160705_341584.html)。王斌老师(http://nelist.iie.cas.cn/yjdw/zgry/201407/t20140721_246792.html)是信息检索研究组组长,研究方向是信息检索及数据挖掘。作为信息检索领域的知名学者,他独立或合作翻译了多本信息检索、数据挖掘、自然语言处理、机器学习相关的学术型和实战型书籍,这些书籍在学术界和业界具有较高知名度。他曾经在国科大计算机与控制学院开设现代信息检索课程,2016年度起在国科大网络空间安全学院开设信息检索导论课程,讲课很受学生欢迎,亲自指导自己的研究生。他的学生出路也都不错,他培养出来的学生都活跃于“BAT”等国内外互联网企业(还有很多毕业生之后跳槽到了Google、Facebook等互联网公司)和创业市场,还会帮助学生推荐工作,并且为申请出国的学生推荐导师。王老师不要求学生必须发表顶会文章,但要求所做的科研工作一定要有价值,在这种情况下,团队也已经在信息检索领域最顶级会议SIGIR以及其他顶级会议(包括CIKM、IJCAI、ACL、EMNLP等)上发表了多篇长文。他更看重学生的综合素质和人品,希望学生性格开朗易沟通,对计算机有浓厚的兴趣,并且具有很强的计算机算法基础、动手能力以及中英文文字表达能力。信息检索研究组下设三个课题组: 社会计算课题组:由沙灜副研究员(http://nelist.iie.cas.cn/yjdw/fgry/201405/t20140513_232647.html)和李锐博士负责,主要研究社交网络的获取及人物、社区和事件的建模;Web挖掘课题组:由李鹏博士负责,主要研究Web挖掘和搜索中的表示、匹配和性能优化等问题;知识挖掘课题组:由王泉副研究员(http://nelist.iie.cas.cn/yjdw/fgry/201606/t20160621_339338.html)负责,研究知识的自动获取、表示和推理等关键技术及其在文本处理领域中的应用。 研究组还包括毛震东、齐保元、邱泳钦、周美林、梁棋、余姚霖、郝炜等工作人员,整个研究组气氛很和谐,师生互相尊重理解,教学相长,很多人毕业多年后还会想起在组里既开心和谐又共同奋斗的生活。王斌老师爱好广泛,尤其喜欢体育,曾经获得全科学院京区乒乓球男单第五名。胡玥老师负责整个第二研究室的学生工作以及前瞻研究组的管理工作,非常和蔼,对学生很好。前瞻研究组包括:戴琼、谢洪涛、周晓飞(http://nelist.iie.cas.cn/yjdw/fgry/201405/t20140513_232673.html)、周川(http://nelist.iie.cas.cn/yjspy/sssds/201607/t20160705_341585.html)、张闯等老师的小团队,各团队之间都是完全独立的。戴琼老师的团队是前瞻组中最大的团队,成员还包括谢洪涛。韩毅老师是科技处副处长,学生在周川老师组里培养,研究方向是社交网络分析。熊刚老师(http://nelist.iie.cas.cn/yjdw/zgry/201507/t20150709_299374.html)是信息对抗组(网络信息对抗课题组)组长,第三工程部副主任,研究方向是网络测量和行为分析、信息对抗、网络取证、海量数据分析等,包括隐蔽式网络攻击检测、网络痕迹留存和取证,具体实践内容例如SQL注入如何在网络层面检测出来等。团队工程实力很强,与国家多个部门及国家电网有合作,同时也在不断加强科研方面,建立更多定期学术交流渠道,论文在质量和数量上更佳。组内学生参加竞赛和培训的机会较多。组内还有李真真、苟高鹏、徐菲、曹自刚、康翠翠等老师,徐菲是数字取证领域专家,跨信息安全和法律两界,承担了360公司的流量异常检测的课题,与国内外此领域的强校也有合作。团队周末一般不加班,每周按工作日工作,只有每周一晚上的讨论班学生一定要参加。熊刚老师对团队有绝对的控制力。牛温佳老师的学生在信息对抗组培养。陈小军老师是保密防护组组长,研究方向是数据隐私保护、网络空间安全。时金桥老师是第一工程部副主任,研究团队挂靠在保密防护组,研究方向是数据泄露检测防护与隐私保护领域的工程研究,他的思维能力和写作能力都很强,团队的工程实力很强,导师还包括柳厅文。郝志宇老师是网络安全组组长,研究方向是网络虚拟化技术。王树鹏老师团队的研究方向是大数据管理与处理,导师还包括吴广君、张晓宇等。李波老师是数据管理组负责人,研究方向是大数据存储和管理、数据库检索。数据管理组主要位于益园园区。刘庆云老师是处理架构组(http://www.mesalab.cn)组长,研究方向是网络内容分析与检测、高性能处理架构,导师还包括孙永、杨嵘、周舟、张鹏,工程实力很强。团队位于华严北里。张永铮老师是第三工程部主任,方向是网络安全态势感知,导师还包括肖军、臧天宁、李书豪等,团队位于CNCERT/CC。张永铮老师的研究团队挂靠在网络安全组。韩冀中老师是第五工程部(网络空间技术实验室)负责人,主要做的是分布式计算与系统,工程实力很强,压力比较适中,老师也很好,在信工所的多个园区都有工位,大部分位于香山园区。导师还包括周宇、刘万涛。韩冀中老师的研究团队挂靠在数据管理组。岳银亮老师是二部成员,负责科技处王伟平处长的团队,研究方向是大数据存储和管理、数据库检索,团队位于益园园区。导师还包括马灿。团队工程任务量很大,项目开发中采用的技术也是非常新颖的,而且对学生编程开发的效率和速度要求都很高,开组会的频率也很高。岳银亮老师的研究团队挂靠在数据管理组。 研究方向 信息内容识别理解,数据挖掘深度学习,信息检索舆情计算,网络安全信息对抗,融合安全检测防护,网络安全态势感知,数据存储管理,信息处理架构。 第三研究室: 第三研究室科研队伍主要来自于中国科学院数据与通信保护研究教育中心(以下简称DCS中心,http://dacas.iie.cas.cn、http://dacas.cn),强项是密码与安全协议、电子认证技术、信息对抗(密码分析、密码工程学)、安卓安全、可穿戴设备安全,项目主要是手机加密、FPGA、GPU开发、智能家居、虚拟桌面等方面的内容,位于香山园区,地址是北京市海淀区闵庄路丙87号信工所4号楼。DCS中心是信息安全国家重点实验室的创建者和重要组成部分,前身是1980年以曾肯成教授为学术带头人的电子密钥研制小组(EKOS)。1985年,中国科学技术大学正式批准成立数据与通信保护研究教育中心,2012年起依托单位更改为中国科学院信息工程研究所。第四工程部的工作由三室负责。DCS中心已经主导或参与研发了包括ZUC(祖冲之算法集)、SM2、SM3、SM4、SM9在内的多种国家商用密码算法。荆继武老师是DCS中心主任,同时也是信工所副所长、工程组总负责人。 这个实验室的工程组的工程研发能力在信工所内仅次于第二研究室,而理论组做的理论都很高深,无论是工程组还是理论组,科研实力都很强。三室理论组在密码学领域的顶级期刊和会议上多年来都可以不断发表论文,而工程组厚积薄发,也持续不断发表顶级论文。三室工程组的老师们在各自的领域都造诣很深,实力也都非常强劲,各个团队的学术水平也在不断提高。表面上看理论组的老师比工程组多,但实际上工程组的规模远远大于理论组。 三室不需要考勤打卡,但即使这样,学风也很好,另外研一学生不需要回所,而是可以通过远程会议参加组会。三室待遇很好,能让学生安心全力投入科研而全无经济压力,而且学生也能参与中心的项目利润分红,待遇在所内排在前列,另外出国访问交流机会也非常多。工程组博士生博一开始的待遇至少有3500,硕士生研二起待遇跟二室差不多,博士生待遇比硕士生更高些,理论组会根据不同组而不同,大部分组比工程组低。 三室工程组所有学生基本可以说是不分导师,因为大家都在一起干活,相当于是有一个领导层。三室博士生比例较高,大部分人都会读博,如果不读博,一般只能拿到专硕名额,而且这个事情要事先与老师谈好,否则硕士会读四年才能毕业。三室的研究方向比较高深,只读硕士很难做出好的成果,需要读博才能做出比较好的成果。工程组博导除了荆继武老师,还包括朱文涛、高能、向继、林璟锵。叶顶锋老师的学生可能分配到理论组或工程组。三室的微信公众号是DACAS_Camp。 三室工程组包含: 安全测评研究部:研究方向是网络协议与密码应用系统安全、移动终端应用运行监测与保护。高能老师的研究方向是网络安全、密码工程、云计算安全、身份认证授权技术、社交网络分析等,工程能力很强;王跃武老师的研究方向是安卓安全,团队发表过ACM CCS顶会文章;刘丽敏、雷灵光等老师在这一团队中。安全芯片研究部:研究方向是嵌入式硬件系统安全、硬件高速加解密系统、可穿戴智能设备安全。刘宗斌老师的研究方向是安全密码运算芯片、硬件密钥保护技术、不可克隆函数技术,工程能力很强;马存庆等老师在这一团队中。服务安全研究部:研究方向是高速签名验签、跨多公共云的安全分布存储、非受控环境移动终端保护、支付安全、Web安全。朱文涛老师(http://if.ustc.edu.cn/~wtzhu/)的研究方向是物联网安全,学术水平很高;王平建老师是全栈工程师,工程能力很强;潘无穷老师主要做密码机,水平很高;王琼霄等老师在这一团队中。服务安全部与终端安全部在研究方向和业务上有很多交叉,合作很密切。终端安全研究部:研究方向是云计算、云存储、系统安全、随机数、嵌入式(IC卡)、恶意代码防护、安全隔离。林璟锵老师(http://www.escience.cn/people/linjingqiang/index.html)的研究方向是网络安全、密码工程、容错技术、分布式系统安全,2015年团队在IEEE Symposium on Security and Privacy(简称S&P或Oakland)上发表了一篇正式论文,是中国大陆第5篇IEEE S&P,主要介绍了一种基于cache的密钥保护技术,团队还在信息安全领域的其他顶级期刊和会议中发表了很多论文。团队中还有夏鲁宁、马原等老师。马原老师在随机数研究领域很有造诣,发表过很多论文。 三室理论组包含: 安全协议研究部:李红达、杨理、姚刚、姬东耀、徐海霞、周展飞、黄桂芳、顾小卓。研究方向是零知识证明协议、外包计算(云计算)、格上的复杂性、SSL协议的安全性分析、理性秘密分享、量子密码和量子计算。理论密码学研究部:李宝、王鲲鹏、王丽萍、吕克伟、路献辉。研究方向包括可证明安全公钥密码学、椭圆曲线密码学、格密码。其他老师还包括刘亚敏、景文盼、贾仃仃等。密码算法研究部:胡磊、王鹏、孙思维。研究方向是密码算法设计与分析、密码攻防技术。胡磊老师每年都不断产出顶级论文,组内学生待遇与工程组差不多,是学生在信工所做理论研究的首选之一。 第四工程部:向继老师是第四工程部主任,工程技术能力非常强,是全栈工程师,四部导师还包括查达仁、王雷老师。 研究方向 网络与系统安全、数据安全与密码工程、密码学、安全协议等。 第四研究室: 第四研究室科研队伍主要来自中共中央办公厅国家保密技术研究所保密技术攻防重点实验室,位于益园园区,地址是北京市海淀区四季青桥西杏石口路益园文创基地C1栋中段。保密技术攻防重点实验室是一个专门为中央保密工作提供技术支持的机构,与国家保密局、国家保密技术测评中心等机构保持持续稳定业务合作关系。四室也是物联网信息安全技术北京市重点实验室的依托部门。 这个实验室的实力也就不再过多介绍。现在四室的工作压力已经超越二室了,整个研究室的工作时间基本上都是996(朝九晚九,一周六天),压力较大,而且对考勤管理很严格,不过研一学生不需要每周回所。 研究室共分五个组: 电磁安全组,学科带头人是黄伟庆老师,是四室第一大组,研究方向是声光泄漏、电磁泄漏、涉密物品管控、嵌入式设备、云计算安全、虚拟机逃逸等来自863、核高基、保密局等方面的国家级项目。无线攻防组,学科带头人是朱大立老师,研究组主要承担国家先导项目、安卓安全等项目,具体项目是海云手机、海云平板电脑等。朱大立老师的学生完全由自己负责,对学生也不错。网络攻防组,学科带头人是黄伟庆老师,主要承担网络工程相关项目,比如涉密网建设、木马检测、电子取证等。王竹老师团队挂靠在此组,王竹老师对学生很负责,团队的科研能力也较强。专用通信技术组,学科带头人是汪永明老师,汪永明老师是百人计划研究员,曾为西门子公司副总裁,主要做4G信号干扰器、运动感知等项目。汪老师偏好努力的学生,对学生也很认真负责,会为学生实现理想提供实质性的全面帮助而不顾自己的难处。物联网组,学科带头人是孙利民老师,研究方向是物联网安全、图像与视频理解、车联网,博导包括孙利民、石志强两位老师,硕导包括葛仕明、朱红松、芦翔,正在争取成为独立的研究室,实力很强,物联网这个研究方向本身难度也很大。孙老师拉到什么项目,团队就做什么项目,做的工程项目很杂,不局限于物联网相关的项目。葛仕明老师组比较独立。 研究方向 网络安全保密防护技术、移动通信无线网络安全保密技术、TEMPEST电磁安全保密技术、安全保密风险评估与测试技术专网通信安全技术、场所声光信息泄漏检测评估与电磁综合防护技术、网络渗透测试与检查取证技术等。 第五研究室: 第五研究室成立于2013年,是信息安全国家重点实验室的重要组成部分,是互联网智能设备安全北京市工程实验室的依托部门。在2014年10月进行了重组(现与第一研究室、第三研究室共同组成信息安全国家重点实验室),重组后的队伍主要来自信息安全国家重点实验室(网络与系统安全大组、中国科技网研发一部、声学所高性能网络实验室等)和计算所相关团队。五室主要研究方向是网络与系统安全(计算机体系结构安全、可信计算、工业控制安全、认证授权、智能信息设备安全、移动互联网安全、隐私保护等)、互联网架构与应用、网络数据与云计算等,位于益园园区和香山园区,益园园区的地址是北京市海淀区四季青桥西杏石口路益园文创基地C1栋东段,香山园区的地址是北京市海淀区闵庄路91号A3楼。五室整体的工程压力都普遍较大,部分组的工程压力可以比肩二室,不过也要具体问题具体分析,因为五室有信工所压力最大的组,也有全所最轻松的组之一。 五室包含如下团队: 徐震老师负责的网络与系统安全大组的项目非常多,主要是智能电视、智能电网、智能手机等方面的项目,老师也都很不错。王雅哲老师主要研究移动互联网安全、智能设备安全、身份认证授权技术,王利明老师主要研究可信网络、云计算安全、下一代互联网、入侵检测,于爱民老师主要研究可信计算、安卓安全、智能电网终端安全,张妍老师主要研究安卓安全、访问控制,马多贺老师主要研究Web应用安全。葛敬国老师负责的中国科技网网络中心研发一部来自中科院计算机网络信息中心,研究内容是计算机网络体系结构与安全防护、网络测量与行为分析,承接华为公司的项目,项目和经费都非常充足。导师还包括韩春静、鄂跃鹏、李佟、吕红蕾、弭伟、游军玲、张潇丹等。团队与虎嵩林老师团队有密切合作,经常参与到第五工程部的项目中。高性能网络实验室来自声学所,原由慈松老师领导,研究方向是移动网络体系结构与安全防护,适合通信专业学生,导师包括谭红艳、唐鼎、林涛、刘延伟、张棪、张宇、胡亚辉、李宏佳、李杨等。团队的研究方向包含移动内容分发网络、移动互联网、无线宽带移动通信、传感网与物联网、多媒体传输与编解码技术、分布式与P2P网络技术等。虎嵩林老师(网络数据科学组)的研究方向是分布式系统、数据库、中间件与服务计算、智能电网大数据处理,是第五工程部(网络空间技术实验室)的主要科研人员,亲自带学生,他是一个很有学术追求的人,可以说是厚积薄发,团队从2014年开始不断产出顶级会议和期刊论文,而且研究方向适合就业,学生就业都很不错,因为团队以工程为主,工程能力很强。组内导师还包括刘万涛老师(二室)。团队位于香山园区。李凤华老师是可信计算与系统安全方面的大牛,信工所副总工、中国科学院特聘研究员、百人计划终期考核优秀、国务院学位委员会网络空间安全学科评议组成员。研究方向主要是网络与信息安全、访问控制、信息保护、密码学等,项目主要是国家重点研发计划、国家重大专项、863计划主题项目、核高基等,是多项国家重要项目的负责人或首席专家。同时注重科研与理论基础。组里实行超996工作制,工程任务量大,工作强度高,需要学生有较强的实力和抗压能力。殷丽华老师团队于2016年从二室转入李凤华老师团队,研究方向是访问控制、网络安全态势感知、可信计算,导师还包括郭云川,从2014年开始产出多篇CCF-A、B类论文。组内的学生主要由殷丽华老师等成员进行实际指导,所以相比团队初期,师生沟通会更有效。安全计算机体系结构方面的研究团队主要来自计算所,涂碧波老师的研究方向是硬件协助下的操作系统安全,导师还包括文雨;史岗老师的研究方向是嵌入式系统、处理器安全,导师还包括朱子元。史岗老师的学生经常需要去计算所无线通信技术研究中心帮忙。信工所所长孟丹老师也是五室的博导,他的部分学生分配到安全计算机体系结构相关团队中,是团队的总负责人。 研究方向 计算机系统与安全(安全计算机体系结构、系统芯片SOC与嵌入式系统、操作系统安全、可信计算等)、云计算与网络安全、智能设备与移动互联网安全、网络安全防护与管控、网络体系结构、互联网架构与应用、网络空间数据科学等。 第六研究室: 第六研究室成立于2014年,是中国科学院网络测评技术重点实验室的依托部门,重点围绕网络空间安全评测(Cyberspace Risk Assessment)领域开展工作,位于益园园区,具体地址是北京市海淀区四季青桥西杏石口路益园文创基地C1栋中段。六室重点研究方向是漏洞挖掘、逆向工程、Web安全、恶意代码分析、虚拟机安全、高级威胁检测、溯源取证、态势感知等网络安全技术,实力不错,要求较高。六室在考研复试中有机试和笔试。六室需要考勤打卡,另外部分组研一学生需要每周从怀柔雁栖湖校区回到信工所参加组会。 邹维研究员主要研究网络与软件安全、攻防对抗理论与技术(包括整数溢出漏洞挖掘、模糊测试中穿透校验和检查、后门消减等),重点研究基于云计算、大数据技术的安全脆弱性分析与检测、Web与移动互联网、嵌入式软件的安全评估技术等,原北京大学计算机科学技术研究所副所长,现任信工所副所长,负责实验室的整体发展规划,具体工作由实验室成员共同完成。他团队中的学生在IEEE Symposium on Security and Privacy(简称S&P或Oakland)上发表了多篇论文,这个会议是计算机安全领域顶会中最好之一,另外他的团队曾经成功发现10多个零日漏洞。他的学生在学术界和工业界认可度都不低。 刘宝旭研究员是六室主任、网络安全防护技术北京市重点实验室主任。研究方向是网络攻防技术、网络安全评测技术、软件与系统安全、安全态势感知等,来自高能所计算中心。作为课题负责人承担并完成国家科技支撑计划、863、国家信息安全专项、部委重点专项等四十多个网络安全课题项目的研究,获省部级科技进步一等奖、二等奖各两项。已培养硕士/博士研究生30余人,大都在从事网络安全相关工作并成为技术骨干。 六室包含如下团队: 霍玮副研究员的研究方向是软件安全分析及支撑系统,主要关注软件漏洞挖掘、基于大数据的软件安全分析、智能终端系统及应用安全分析等,来自计算所计算机体系结构国家重点实验室。团队包含4个小组,工程与科研有比较好的结合。组里的刘剑副研究员的研究方向是程序分析与验证,来自中科院软件所。团队与计算所武成岗老师组有合作。龚晓锐高级工程师的研究方向是网络安全对抗、逆向工程、样本分析等,来自北大。他带领的NeSE(Never Stop Exploiting)积极参加XCTF联赛和各类国际CTF比赛,是一支国内一流的CTF战队,2016年队员获信息安全与对抗技术竞赛个人挑战赛全国赛区冠军。杨泽明副研究员的研究方向是是高级威胁检测与溯源,承担中科院先导、国家863计划、部委重点项目的研究开发与实施,研究组开发建设了恶意代码自动化分析技术研究实验平台,并基于该平台从事高级威胁检测发现、攻击追踪溯源、威胁情报共享利用等方面的技术研究。卢志刚高级工程师的研究方向是态势感知,包括安全数据融合挖掘、可视化分析、数据统一存储、威胁情报等关键技术,负责建设威胁情报库,为安全事件的挖掘、追踪溯源和主动防御等工作提供情报支援,成果已在多个国家部委的重大工程/项目中有落地应用。崔翔研究员是六室副主任,研究方向是Web安全、网络攻防与漏洞挖掘、僵尸网络、蜜罐技术等,侧重Web主机和应用,对软件或恶意应用的行为进行分析,来自中科院计算所,团队中还有刘奇旭副研究员,研究方向是Web安全、网络空间安全评测,来自国科大计算机与控制学院,团队实力很强劲,组内老师均在ACM CCS上发表了多篇poster。团队还研究渗透测试技术、APT。另外,组内的氛围好,大家也都很努力,培养出来的学生也都实力很强,这些学生不是只会纸上谈兵的信息技术从业者,并且能够获得一些较难获得的奖项。中国科学院大学网络空间安全学院主办的全国高校网安联赛(http://xnuca.erangelab.com)由此团队负责,有利于提高学生的网络空间安全技术水平。贾晓启研究员的主要研究方向是虚拟化安全、云计算安全、操作系统安全、攻防技术,来自于信息安全国家重点实验室。他是80后研究员,科研组非常年轻有活力,科研氛围浓厚,工程实力强,承担了多项国家重点部门的工程项目,在这个组里不仅能学到前沿知识,而且有充足的动手实践机会。组里毕业生就业情况普遍不错,今年的两个毕业生分别去了阿里和因特尔。贾晓启老师还是中央国家机关青联委员,中国科学院青联委员。 研究方向 软件脆弱性分析、移动及Web安全检测、pentest(渗透测试)技术。 第一工程部 第二工程部 第三工程部 第四工程部 第五工程部(网络空间技术实验室) 各个工程部中的导师均在各自所属的研究室中招生。工程一、四、五部位于香山园区,二部位于益园园区,三部位于华严北里,在CNCERT也有部分办公点。一部对口国家保密局,二部对口公安部,三部对口工信部,四部对口国家安全部,五部对口中共中央网络安全和信息化领导小组办公室(中央网信办,国家互联网信息办公室)。 信息安全共性技术国家工程研究中心: 中科信息安全共性技术国家工程研究中心有限公司位于益园园区,是信息工程研究所的系统集成部门,对口重点行业部门,面向国家重大科技需求和重点任务开展工作,代表研究所承担和配合重点行业部门的工作和任务,根据所内各个研究室的研究方向和特点,进行任务分解和分派,参与和督促相关科研工作,负责整体任务的集成和交付,并根据所内研究室的研发成果与应用功能特点,进行集成或包装,形成适合行业应用的产品、工具、系统和平台,指导和参与企业的推广应用工作。中心主要由四室负责。益园园区也是公安部中国科学院网络空间安全应用研究中心的依托基地。
这种特定的性质并不仅仅适用于\,EM\,算法
这点并不是EM算法独有的
如果我们选择条件概率分布来引入相对于图结构描述的额外的独立性这种情况也是可能出现的。
如果我们选择条件概率分布来引入图结构描述的之外的独立性就可能出现这种情况。【这句话是接着上一句话说的】
值得指出的是,这些方法往往利用
或许可以说(It can be argued that...),这是因为利用了
这一点不同于纯优化最小化JJJ本身
这一点不同于纯优化,纯优化的目标是最小化J本身
网络能够包含任意多的卷积层,只要硬件可以支持,这是因为卷积运算并没有改变相关的结构
只要有硬件支持,网络能包含任意多的卷积层,这是因为卷积运算不改变下一层网络的结构。
他们在监督目标的情况下最小化重构误差 ,并在监督MLP的隐藏层注入噪声,通过引入重构误差和注入噪声提升泛化能力
他们的方法除了最小化重构误差这一监督目标项之外,还在隐藏层加入了噪音,目地是通过引入重构误差和注入噪音来改善泛化能力
这
这是
这是一个普适于日常生活,普适于计算机科学的基本原则,也普适于机器学习。
这里用“普适于” 好像不太准确。
为了防止这一点的一种方法是显式地对标签上的噪声进行建模。
中文语法有误。考虑: 显示地对标签噪声进行建模是防止这一点的一种方法。
这通常是指通过迭代地更新解来解决数学问题的算法,而不是解析地提供正确解的符号表达。
改成“这里通常是指迭代法,而不是直接给出解析解的直接法。”如何?
无论这是否是正确的类别都只能获得反馈
然后只能获得该类别正确与否的反馈
在这之前的长达十年左右的时间基于GMM-HMM的系统的传统技术已经停滞不前了,尽管数据集的规模是随时间增长的
在这之前的长达十年左右的时间内,尽管数据集的规模随时间增长,然而基于GMM-HMM的系统的传统技术已经停滞不前了
这是使用
使用的则是
线性代数
此处集中写一个不归属于翻译问题的错误。是式子(如定义、定理)等的索引。在v4.0-alpha中,有一些索引出了问题,比如图2,2被建立了索引,这是不应该的,再比如式子2.80的上一行提到了式2.55,但是这个索引是不对的,应该是2.52。并且现在的索引和原书中也不完全一致。因为这个问题比较大,而且涉及比较多,所以于此统一指出,而不在后面细究每一个索引是否有问题。
It is composed of relations on the columns that are part of the PRIMARY KEY and/or have a secondary index defined on them.
WHERE 所允许的关系只能是定义在PRIMARY KEY 或者 建立了secondary index的columns上。这或许是出于对query效率的考虑,和SQL存在本质的差异。
:tt !WilE'll~ilfPJWt;-~~iB,
反映了劳动人民的朴素与节俭,同时也反映了物质条件的匮乏和生活的贫瘠。人们辛勤劳动了一个月,人都瘦了,岂是一条黄鱼所能补回来的,但他们只要一条鱼就已经心满意足了。这是一个靠双手努力创造的时代,也是一个离我们越来越远的时代。
•r·~~-~8~•7.@::k~~~/f~:lt!l•*••·~ ~-··_t_~-~~&~-{lj>_t_*·zii:i:~iliM~~T*~ ••4•*·••••a~fr-~&lltr.~@;f!!~•~~m£ *ff~.~~:i:~~~~Z·D~E*~.Xffi**~ffi'ta W.-~llJig4~o£T~.~m&ililf-MT.CM_t_*·~· •:lt!l•~.@~~~••T~*·m·~i't~;f!!-~•~•l3: :Jt~_t_. l'UU "~!%" I. :'/Sllli.:E~~fl'ff, ~@~HH~W ~jff~Jt JL;f!!~JZ:$:W*· @::k*** "1!J~". Wtb\~II!l¥I ~u••~-Jt~~~•*~•l3:"1!J~"_t_,x•l:t:'/5lffi:E ¥I~fl'ff*.~"1!J~"a~fl'ff_t_,'f'A.~;Jt~_t_~M ~l3:"1il~"_t_@&JLa,ff1tJt.~~•*~.§~·_g, ~". Ua~JJ~ "~:lit" !l.T. -H. il'Hlt. ...... llllauT• :/li Ji"i-\'IEA~# •• a®:~~-1'-·~··£.*7· II!l::k~X .T.R~_t_Jl~~ "~i't", N!!M~-~-~ ·~·" ~~JLL
这是一个复杂的传统程序,无论迷信与否,都是现代人或任何机器或科技所不能取代的。他是先人们的智慧的结晶。我也被这种有组织的各司其职般的团结劳动所深深触动,在这样一种氛围下工作收获的一定是欢乐!
:h ll':1 1t 1: iii: * ~ _1;1!, JJ~ illiTJ!J ll':1 %!; tr " rr 1ilJ l"f * r , il':1 '¥ w .A.1n1'ill Jif T l"f S r ;& Hit. ~~·*J! fk '¥ 11-.A -J'E Off. Jm l'!f; * 'f , 1;p i\lt :fU lllia§>r.A.. FP*ol!H'~M/f%1; "JT1ilJM'*r" T,
这里说明了当时的知识分子是矛盾的。他们一方面知道外国人对中国带来的弊端。但是,同时他们也知道外国的美好。所以,潜意识里他们都是从洋的一份子。只是祖国所教育的爱国情怀不允许他们这样做。但是毋庸置疑的,当时的中国已经与外界脱离了很多,为了生存,中国必须学习外国的知识,尤其是科技这一块。自给自足的中国已经不复存在,为了不被时代淘汰,她只能与时并进,学习外国人的智慧,并与中国的文化和知识贯通,这样就会达到事半功倍的效果,同时也保留了中国长达五千年的文化。
Ai$:~~iJI. "1-':'§.l\!." ~IDJfOJ{§T -tt, llU!W.:E.i!i!~ "1$~4";!<:" ~~ll;'litli\:!Jlt, Jilfll.<Ji&J?.)JX .Z.t:lto ~1'-, ~li'li&~A:fr;f§{ti; ~A.l\!.~tlfl£, %~~~ 1NS'J< ~4" ;&; .Z. 4'<=1!U T .l'% ~ il!l? OJ -~li'li'7E&~~Il]j 8J;J1t.Z. "1*~4"*" iW "Ji&" 4'< *~~~i$:o~-~~-~Bi!t#&3~1-':'5iWtli\:MoA~~ '7ETil9~:ll<-rtJI., :!!fjg(JJ~•m5i::l:!lltli1-':'511i'ii~ati~, ~J511 ·T-1-:iili~~/],1-':'5, ~BtiJtl!, .R:!!fffiT{l!!,
这是那个时代典型的迷信思想,只要是人们想不通或不能理解的东西,总会找出一些离奇的由头,作为无知人民的答案。这些不为普通老百姓所理解的“神鬼之力”就变成了他们心中的不可逾越的界限,久而久之的成为任何问题的答案。
好一部命名为“祝福”的小说,名字却含有些许反讽意味,让笔者读完的心情既沉重又复杂。祥林嫂一生的不幸,让她沦为那个时代迷信封建旧社会的牺牲品。从祥林嫂的出生背景,到一路的历程遭遇,以及最后几年过着被世俗抛弃了的日子,从她身上,仿佛不见“祝福”踪影。究竟是谁害死了祥林嫂?是冷血的社会,无聊的舆论;还是在这体系存活,却有自主能力的大众?祥林嫂的死,或是个谜,或是个解脱,谁也说不清。她的离世,就这样被新一年的爆竹声以及弥漫空气的祝福声给掩盖和遗忘了,就好如她的存在,永远那么卑微,让人省略。文本中所指的“祝福”,或许是献给祥林嫂的,愿她一路走好,祝福她来世过得幸福。
当计算图变得非常之深时,神经网络优化算法必须克服的另一个难题出现了。 多层前馈网络会有这么深的计算图。 \chap?会介绍的循环网络会在很长的时间序列的每个时间点上重复应用相同的操作,因此也会有很深的计算图。 反复使用相同的参数产生了尤为突出的困难。
当计算图变的极深时,神经网络优化算法会面临的另外一个难题就是长期依赖问题——由于变深的结构使模型丧失了学习到先前信息的能力,让优化变得极其困难。 深层的计算图不仅前馈网络中存在,在循环神经网络(在第十章中描述)结构中也是一样的,因为要在很长时间序列的各时刻重复操作相同的网络模块,并且模型参数共享,这使问题更加凸显。
说明:
这段感觉原文表述就有些问题,读起来感觉意思不连贯,在此小节并没有详说“长期依赖”是个什么东西,我调整了一下, 增加已经对长期依赖的简单说明来呼应标题,在破折号后面的一句行文解释来说明长期依赖对优化的困难,后接作者描述就显得意思上连贯了。
这一般是对的
这样做一般没问题
这通过使得核的规模远小于输入的规模来实现
这是使核的规模远小于输入的规模来达到的。
然后我们会介绍一种几乎所有的卷积神经网络都会用到的操作池化。
然后我们会介绍池化,这是一种几乎所有卷积网络都会用到的操作。
我们可以认为整个稀疏自动编码器框架是对带有隐变量的生成模型的近似最大似然训练
we can think of the entire sparse autoencoder framework as approximating maximum likelihood training of a generative model that has latent variables.
这句话是否可以帮助理解
Their encodings are naturally useful because the models were trained to approximately maximize the probability of the training data rather than to copy the input to the output.呢? 近似最大化概率(似然)是指的对隐变量训练,这个解析比较明确了。
这些模型能自然地学习大容量、对输入过完备的有用编码,而不需要正则化。 这些编码显然是有用的,因为这些模型被训练为近似训练数据的最大概率而不是将输入复制到输出。
These models naturally learn high-capacity, overcomplete encodings of the input and do not require regularization for these encodings to be useful.Their encodings are naturally useful because the models were trained to approximately maximize the probability of the training data rather than to copy the input to the output.
调整后:
“这些变种(或衍生)自编码器能够学习出高容量且过完备的模型,进而发现输入数据中有用的结构信息,并且也无需对数据做正则化。 相对于只学习简单恒等函数的自编码器而言,变种(衍生自编码器)产生的编码数据更有效,因为得到的模型是在训练数据集上学习的数据概率分布。”
理由:
这段原文指代感觉比较不清晰,
1:我觉得 capacity、overcomplete 是用来修饰模型的,在前文也是这样使用的,在这句突然用来修饰输入数据的编码 不是太合理。
2:the models were trained to approximately maximize the probability of the training data 说说对这句的理解,感觉隐藏了很多信息。
译文中“这些模型被训练为近似训练数据的最大概率......” 这句我的理解是 为求解问题构造的目标损失函数是一种概率函数,以最大化概率值为目标。
而不是产生编码数据的方式是按照近似最大概率的原则产生,因为一旦学习结束,分布就已然得到(通过下文提到的概率分布代入求解),可以直接产生新编码样本点了。因为产生z_mean和z_log_sigma(见相关背景资料)这两个值都是统计量纲,不会有最大化概率这种动作。
相关背景:
VAE是个生成模型,三步:
首先,建立编码网络,将输入映射为隐分布的参数
然后从这些参数确定的分布中采样,这个样本相当于之前的隐层值
最后,将采样得到的点映射回去重构原输入。
由此可知变分编码器的工作原理:
首先,编码器网络将输入样本x转换为隐空间的两个参数,记作z_mean和z_log_sigma。然后,我们随机从隐藏的正态分布中采样得到数据点z,
这个隐藏分布我们假设就是产生输入数据的那个分布。z = z_mean + exp(z_log_sigma)*epsilon,epsilon是一个服从正态分布的张量。最后,
使用解码器网络将隐空间映射到显空间,即将z转换回原来的输入数据空间。
即:变分编码器不再学习一个恒等的函数,而是学习数据概率分布的一组参数。通过在这个概率分布中采样。
隐空间参数由两个损失函数来训练,一个是重构损失函数,该函数要求解码出来的样本与输入的样本相似(与之前的自编码器相同),第二项损失函数
是学习到的隐分布与先验分布的KL距离,作为一个正则。实际上把后面这项损失函数去掉也可以,它对学习符合要求的隐空间和防止过拟合有帮助。
拓扑结构图:
这是神经网络热潮的第一次大幅下降
这导致了神经网络热潮的第一次大消退
知识分享属于共享经济;
虽然没有实体,但是知识本身是有价值的; 且知识分享的接受者,没有限制,不像易到、airbnb 固定的实体,注定了享受者数量上、地域上的限制;
但是知识这个商品的优点也是其缺点,那就是易被复制性; 知识产权问题是解决分享动力的基础;
但是悠然一指反其道而行,鼓励其分享,没关系,导入更多流量;但是若脱离了悠然一指平台,则没有了好处,没有了收益,就会降低分享欲望,这是重点要解决的------知识保护;
什么是统计量的size和power? size是指size of the test,就是置信水平(1 - 阿尔法)里面的那个“阿尔法”,又称“检验水平”。 power是指power of test statistic,是统计量的“统计检验力”。 在有限样本时,即使当N和T分别小于50和2时,该检验统计量仍然拥有合理的size, 特别当T大于等于10时,该检验拥有良好的power.——这句话怎样理解? "合理的size就是能够满足合理的置信水平条件,也就是犯I类错误的概率很低。良好的power是指犯II类错误的概率很低,也就是H0为假时拒绝H0的概率很高。"
在试验样本确定的情况下,\(\alpha\)越小,\(\beta\)就越大。
梁启超的古籍辨伪方法 梁启超先生不仅是近代史界革命的倡导者,也是古籍辨伪的宣传者与实践者,同时还是传统辨伪方法的总结者。1922年,梁启超先生正式发表了《中国历史研究法》,1927年发表《古书真伪及其年代》,对古籍辨伪的重要性与方法进行了论述。 什麽是伪书?伪书有哪几种情况?梁启超先生在《古书真伪及其年代》中「伪书的种类及作伪的来历」一章中归纳了十种情况: 一、为全部伪; 二、一部伪; 三、本无其书而伪; 四、曾有其书,因佚而伪; 五、内容不尽伪,而书名伪; 六、内容不尽伪,而书名人名皆伪; 七、内容及书名不伪而人名伪; 八、盗袭割裂旧书而伪; 九、伪后出伪; 十、伪中益伪。 换言之,凡有以上十类问题的图书皆可入「伪书」之列。按照这个标准,在传世先秦两汉文献中,不是「伪书」的大概就没有几种了,就连《论语》、《史记》等等都包括在内,因此梁先生也不禁感慨道:「中国的伪书,真是多极了!」[7] 显然,梁启超先生提出的上述伪书的标准,有些是有问题的。 在辨伪方法上,梁启超先生在总结前人特别是胡应麟辨伪方法的基础上,将古籍辨伪的方法归纳为两方面,即:从传授统绪上和文义内容上辨别。如何从传授统绪上辨别?梁启超先生提出了八种办法: 一、从旧志不着录,而定其伪或可疑; 二、从前志着录,后志已佚,而定其伪或可疑; 三、从今本和旧志说的卷数篇数不同,而定其伪或可疑; 四、从旧志无着者姓名,而定后人随便附上去的姓名是伪; 五、从旧志或注家已明言是伪书而信其说; 六、后人说某书出现于某时,而那时人并未看见那书,从这上可断定那书是伪; 七、书初出现,已发生许多问题,或有人证明是伪造,我们当然不能相信; 八、从书的来历暧昧不明而定其伪。 如何从文义内容上来辨别?梁启超先生提出了「五大法门」: 一、从字句缺漏处辨别(如从人的称谓上辨别、从用后代的人名地名朝代名来辨别、从后代的事实或法制来辨别等等); 二、从抄袭旧文处辨别; 三、从佚文上辨别; 四、从文章上辨别(如从名词、文体、文法、音韵等等); 五、从思想上辨别(如从思想系统和传授家法辨别、从思想和时代的关係辨别、从专门术语和思想的关係辨别、从袭用后代学说辨别。[8] 胡适先生在《中国哲学史大纲》中也对古籍的辨伪工作给予了高度的重视,尤其对梁启超先生从文义内容上辨别伪书的「五大法门」极为推崇。除在《古书真伪及其年代》中对辨伪之法进行了专门论述,梁启超先生在《中国历史研究法》中还提出了辨伪书的十二条「公例」。 较之胡应麟的辨伪八法,梁启超先生的辨伪方法无疑要全面得多,因此备受学术界的重视,并且在古籍的考辨中被广泛应用。
辨伪学
~reams allow us on<' ot o few privileged glimpses of it at work. Dreams for Freud are essentia symbolic fulfilments of unconscious wishes; and they are cast in form because if this material were expressed directly then it shocking and disturbing enough to wake us u,V
梦境是人类窥见脑中潜意识/无意识的管道。对于Freud而言,人类潜意识/无意识欲望将在梦中实现。在梦境里,这些欲望将以符号的形式呈现。这是由于过于直接,而毫不遮掩的画面会使人类感到过度震惊和不安,从而使他们从梦中惊醒。
Wh . ~t> IS that in this period such . ory. at zs perhaps expenences becom · . way as a systematic field of knowled e e constituted m a as psychoanalysis developed b s· g
在这时期值得关注的一点是这种经验(焦虑,被迫害的恐惧,和社会脱离)被构成系统性的知识。这种知识就是精神分析
在这时期值得关注的一点是这种经验(焦虑,被迫害的恐惧,和社会脱离)被构成系统性的知识。这种知识就是精神分析。
The Three Roles of Functions in JavaScript
感觉这三个role的主要区别是this的值
this指向Global Object
this指向新建的Object
this指向method所属的Object
但254弗里尔自己的 中国,日本,韩国和中东的陶器和石器陶瓷,这是他留给博物馆。
As far as I know, China is all popular in eastern countries .
赵丽颖圆圆的包子脸萌到
我靠,这是什么鬼
其中最复杂的恢复和重新规划项目中的历史中的 大都会博物馆艺术 相撞W¯¯ 第i 一个9英尺3英寸高的门口。 在门口赢了。这是因为英雄和多产的流行的1851年 “ 华盛顿穿越特拉华州, ”熟悉的小学生代,是在一个博物馆最大的油画,尺寸为21英尺,宽12英尺高。
characteristic of the museum
关于基因编辑技术的7件小事
这是个啥啊
矛盾
矛盾 máodùn ①名 矛和盾。《韩非子难一》中说:楚国有一个卖矛和盾的人夸口说,我的盾是最坚硬的,什么东西也戳不破;又说,我的矛是最锐利的,什么东西都能刺进去。有人问,用你的矛刺你的盾怎么样?那个人不能回答。后用“矛盾”比喻言论或行为自相冲突或两种事物彼此抵触,互不相容的现象。 这篇文章前后有很多矛盾。 ②名 指隔阂或嫌隙。 他们之间的矛盾由来已久。 ③名 哲学上指客观事物和人类思维中普遍存在着的对立的两方面之间互相排斥又互相依存的关系。 ④名 形式逻辑中指两个概念互相排斥或两个判断不能同真也不能同假的相互关系。 ⑤形 形容人或事物互相抵触或排斥。 这两项规则之间很矛盾 | 自相矛盾
针对
针对 zhēnduì ①动 对准(某个对象)。 他这番话是针对我的。 ②介 引进有明确目的的行为对象。 针对大家提出的问题,他一一作了回答。
近期动态很重要,因为它表明,中国当局尚未找到解决这三个难题的办法。更糟糕的是,他们在过去7年里所尝试的权宜之计甚至已使困境变得更麻烦。或许,市场先生已预感到,中国的处境将是多么的艰难,而中国可能会采取的一些选项实际上会造成多么大的动荡。中国的选项包括货币贬值、超低利率,甚至还有量化宽松。如果真是如此,当前市场动荡或许并不显得愚蠢。全球储蓄过剩可能变得更严重。那会让所有人都受到影响。
中国当局尚未找到解决三个难题的办法,在当前可行的选项面前,市场动荡不一定是坏事。
现在,这给中国当局留下了三个巨大的经济难题。第一个是清理过去金融过度行为的遗产,同时避免发生金融危机。第二个是重塑经济,使增长更依赖私人与公共部门的消费,减轻对超高水平投资的依赖。第三个是在实现以上所有目标的同时维持总需求的强劲增长。
中国目前的投资繁荣给当局留下了三个经济难题:要一边减少金融过度,一边避免金融危机;要实现经济从依赖投资到依赖消费的转变;要继续维持总需求的强劲增长。
这种对总需求不足的担忧由来已久。自从西方的金融危机以来,这就成了一个非常令人担心的问题,因为危机摧毁了对于中国出口的需求。正因如此,中国自己推动了一次信贷助长的投资繁荣。潜在产出增长率下降的同时,投资占GDP的比例却在显著地(并令人担忧地)升高。长期来看,这两种状况的组合是不可持续的。
中国当前的投资繁荣是自己通过信贷推动的,是不可持续的。
假设这是真的。根据官方数据,2014年固定资产投资占国内生产总值(GDP)的44%。投资数字有可能比GDP数字更准确。但是,一个经济体的投资占到GDP的44%,增长率却仅为5%,这在经济上合理吗?不合理。这些数据反映了超低的(如果不是负值的话)边际回报率。如果这样,投资可能大幅下降。如果首先砍掉浪费性投资的话,这或许不会降低潜在增长率,但将造成需求大减。中国当局在做的每一件事都表明,他们担心的正是这一点。
中国当局实际担心的是,在边际回报率超低的情况下减少投资,将造成需求大减。
以上并非中国当局的行为让人有理由担心的唯一方面。其他方面还有8月11日的人民币贬值。就本身而言,这不算重大事件,迄今人民币兑美元汇率累计跌幅仅为2.8%。但人民币贬值有重要的含义。中国当局想要大幅降息的空间,如同本周二降息那样。这再次突出显示了他们对经济健康状况的担心。另一个可能的含义是,北京方面或许在寻求重振出口驱动的增长。我发现这一点难以置信,因为它的全球后果将是毁灭性的。但至少,对其破坏稳定的可能性感到担忧是合理的。最后一个可能的含义是,中国当局开始准备容忍资本外流。如果是这样,美国将会自食其果。华盛顿方面一直敦促中国放开资本项目管制。那么,美国或许不得不忍受破坏稳定的短期后果:人民币贬值。
人民币贬值有三层可能的重要含义:一是中国当局担心经济状况,二是中国寻求重振出口,三是开始准备容忍资本外流。
然而,由于两个相互关联的原因,中国股市行情有了更重要的含义。第一个原因是,中国当局决定押上巨大的资源、甚至他们的政治权威,试图阻止股市泡沫破裂(这一努力没有成功并非意外)。第二个是,他们一定是出于担心经济才这么做的。如果他们担心到对这样渺茫的希望下注的地步,我们其他人也应当感到担忧。
中国股市行情因为当局的介入,而具有重要的含义。
我没有聪明到理解“市场先生”(Mr Market)行为的程度,也没有愚蠢到认为自己能理解他的地步。“市场先生”是投资大师本杰明•格雷厄姆(Benjamin Graham)虚构出的患有燥狂抑郁症的人物。但是,市场先生的确处于抑郁之中。背后的原因似乎是对中国的担忧。市场先生的焦躁是合理的吗?简单说,是的。
开篇这一段,作者认为:市场先生对中国的担忧是合理的。
我没有聪明到理解“市场先生”(Mr Market)行为的程度,也没有愚蠢到认为自己能理解他的地步。“市场先生”是投资大师本杰明•格雷厄姆(Benjamin Graham)虚构出的患有燥狂抑郁症的人物。但是,市场先生的确处于抑郁之中。背后的原因似乎是对中国的担忧。市场先生的焦躁是合理的吗?简单说,是的。
开篇这一段,作者认为:市场先生对中国的担忧是合理的。
我没有聪明到理解“市场先生”(Mr Market)行为的程度,也没有愚蠢到认为自己能理解他的地步。“市场先生”是投资大师本杰明•格雷厄姆(Benjamin Graham)虚构出的患有燥狂抑郁症的人物。但是,市场先生的确处于抑郁之中。背后的原因似乎是对中国的担忧。市场先生的焦躁是合理的吗?简单说,是的。
开篇这一段,作者认为:市场先生对中国的担忧是合理的。
前面已经说了,试图去理解比我们高两层台阶的机器就已经是徒劳的,所以让我们很肯定的说,我们是没有办法知道超人工智能会做什么,也没有办法知道这些事情的后果。任何假装知道的人都没搞明白超级智能是怎么回事。
”前面已经说了,试图去理解比我们高两层台阶的机器就已经是徒劳的,所以让我们很肯定的说,我们是没有办法知道超人工智能会做什么,也没有办法知道这些事情的后果。任何假装知道的人都没搞明白超级智能是怎么回事。“
虽然经过与原来的生物进行对比,似乎我们不可能理解比自己高两个层次的智能体,但是我们要想到另一个变量, 就是这些智能体不同于以往的生物,它们是由我们这种人类制造出来的。因此,他的一切活动都是基于逻辑推理(至少现在想从计算机技术的角度去演进这种高智能体是基于此的)的,而逻辑推理是人可以理解的,只不过可能会有时间的限制。另外一个不同的地方在于,人类与其他的生物是无法进行交流的(当然指狭隘的以人的语言和一般人能够理解的方式来交流),而更高一级的智能体却是可以与人类进行交流,这也是因为人类是其造物主引起的。我想,这几点已经足以说明,人类与其高等智能体可能会发生一种渐进共生。