楽観的
大体いい結果で返ってくるだろう的な
実際にはアクションの完了には時間がかかるにも関わらず、そのアクションの実行結果をユーザに即座に提示するために通常使用されるものだから
例: いいね機能 ショッピングカート機能など
楽観的
大体いい結果で返ってくるだろう的な
実際にはアクションの完了には時間がかかるにも関わらず、そのアクションの実行結果をユーザに即座に提示するために通常使用されるものだから
例: いいね機能 ショッピングカート機能など
その他のAI/MLマネージドサービス
画像や動画を分析
履歴に基づいてレコメンドをする
画像やPDFからテキストを抽出(テキストが入力でないことに注意)
テキストを分析する(感情や固有名詞を検出)
テキストを音声に変換する
意味とコンテキストを理解して検索するサービス(生成AIとRAGで使われることが多い)
言語理解・音声認識を行いチャットボットを作成できる
翻訳サービス
音声をテキストに変換するサービス
S3の個人情報や機密データを検出して分類・保護するサービス(コンプラ対応に向く)
不正行為(詐欺)の検出を自動化するサービス
出力側
入力→モデル内→出力
にすると分かりやすいかも
Augmented AI
推論エンドポイントの予測結果の信頼性が高くない場合人間のレビューができる機能
Feature Store
Athenaを使ってるらしい
SageMakerの機能
SageMakerは推論のタイプをいくつかに分けて考えることができます
リアルタイム推論 - 60秒で終わる処理、データサイズは6MB以下 - サーバーが常時起動のため高価
サーバーレス推論 - 60以内に終わる処理、データサイズは6MB以下 - コールドスタートがあるためレイテンシー要件に当てはまらない可能性あり
非同期推論 - 1時間以内に終わる処理、データサイズは1GB以下
バッチ推論 - 数日間の処理時間、データサイズも1GB以上OK
抽象度合いで階層が分かれているイメージ
SageMaker Canvas
↓
SageMaker JumpStart
↓
SageMaker その他
SageMaker Studio
SageMakerを実行するための環境
SageMaker Studioを使うことでローカルマシンを使わずにすぐにSageMakerを使うことができる
SageMakerのその他機能の組み合わせ
より発展的なカスタマイズをする用
SageMaker JumpStart
データサイエンティストや機械学習エンジニアがスタートダッシュを決めるための目的別ツール・テンプレート
SageMaker Canvas
専門知識がない人でも利用可能
プロビジョンド・スループット
一定量の推論キャパシティを確保すること
エージェントとは
第三者がおすすめのツールを提案している感じ
入力と正解のペアのデータを複数個渡すことで特定のタスクに特化した調整が行えます
モデル自体を改変する(ファインチューニング)これはパラメーターの改変をしている
入力と正解を自分好みにチューニングして学習を繰り返す
これって専用GPT作る方法だ!
教師なし学習というよりは自己教師あり学習
表面上はテキストを送信してるだけだが、内部で教師データを作成しているから
継続的事前学習
検索を裏で回してプロンプトエンジニアリング
意外と単純
リクエスト送ってLambdaか何かがDBに検索かけて、その結果をGenAIが処理して回答してる感じかな
ある程度動作をコントロール
タスク→ 0 か1か複数か
Zero-Shot, One-Shot, Few-Shot
生成AI向けの評価指標
生成されたテキストと正解テキスト巻の単語やフレーズの一致度を測定
機械翻訳の評価指標で、生成された翻訳と正解の翻訳間の一致度を測定
生成されたテキストと正解テキスト間の意味的な類似度を測定
トークン
日本語だと大体文字数らしい
ランダム性を下げることができます
AI Starterでは会話のスタイルで厳密や創造的が選べるからこの値を制御してそう
システムプロンプト
AI Starterでは記述できるけど一般のChatGPTでシステムプロンプトってあったけ?
回答にランダム性がある点
バリエーションを制御するパラメータが複数ある - temprature - top-k - top-p
数値が苦手
1 + 1ができないことで一時期問題になった
(計算機ではないから)
もう一つは様々な論理的な熟考を重ねた結果ではない
プロンプトで見返してやもう一度考えてと言うのは実はあんま効果ない?
「自然な続き」を予測するだけ
勘違いすることをハルシネーションという
Bedrock
岩盤って意味らしい
回帰問題のメトリクス
回帰問題で汎用的に使用されるメトリクス - MAE (Mean Absolute Error) - 予測値と実際の値の平均絶対誤差。値は0から無限大まで、値が小さいほどモデルの精度が高い。 - 回帰分析で使用され、予測誤差の平均を評価する。 - MSE (Mean Squared Error) - 予測値と実際の値の二乗誤差の平均。値は常に正で、値が小さいほどモデルの精度が高い。 - 回帰分析で使用され、モデルの予測精度を評価する。 - R2 (Coefficient of Determination) - 回帰モデルが従属変数の分散をどれだけ説明できるかを定量化する。値は1から-1の間で、1に近いほどモデルが良好であることを示す。0に近いとモデルがほとんど説明できないことを示す。 - 回帰分析で、モデルがどの程度データの変動を説明できるかを評価する。 - RMSE (Root Mean Squared Error) - 予測値と実際の値の二乗誤差の平方根。値は0から無限大まで、値が小さいほどモデルの精度が高い。 - 回帰分析で、特に大きな誤差や外れ値を評価するために使用される。
その他のメトリクス - Inference Latency - モデルのリアルタイム予測リクエストに対する応答時間を秒単位で測定。 - モデルの推論速度を評価し、特にエンドポイントでのリアルタイム推論において使用される。
分類問題のメトリクス
多クラス分類用のメトリクス 1. F1 Macro - 各クラスのF1スコアを平均して計算する。0から1の値を取り、1が最高の性能を示す。 - 多クラス分類に使用され、各クラスに対するモデルの全体的な性能を評価する。 2. Precision Macro - 各クラスのPrecisionを計算し、それを平均して算出する。0から1の値を取り、1が最高の構成を示す。 - 多クラス分類で、モデルの全体的なPrecisionを評価する。 3. Recall Macro - 各クラスのRecallを計算し、それを平均して算出する。0から1の値を取り、1が最高のRecallを示す。 - 多クラス分類で、モデルの全体的なRecallを評価する。 4. LogLoss - 予測確率の品質を評価するメトリクス。値は0から無限大までで、0が完全予測を示す。 - バイナリおよび多クラス分類で、確率出力の精度を評価する。
教師なし学習・画像分析
教示なし学習 - IP Insights - IPv4アドレスの使用パターンを学習し、IPv4アドレスとユーザーIDやアカウント番号などのエンティティ巻の関係をとらる - 不正検出や異常な IPアドレスの使用パターンを特定するために使用 - K-Means - データ内の離散的なグループを見つけ、グループ内のメンバーが互いに似ており他のグループとは異なるようにする - クラスタリングに使用。データポイントをk個のグループ分けに使用 - Principal Component Analysis(PCA) - データセット内の次元を削減、データポイントを主成分に投影してできるだけ多くの情報や変動を保持する - 次元削減でデータの可視化やモデルの計算効率の向上に使用 - Random Cut Forest(RCP) - 規則的またはパターン化されたデータから逸脱する異常なデータポイントを検出する - 異常検知に使用され、特に異常なデータ点や外れ値を検出するタスクに適している
テキスト分析・時系列分析
AWS Certified AI Practitioner(AIF)
AWSの試験のこと
勾配ブースティング決定木のアルゴリズム
難しいから理屈は覚えなくてもいいかも 一応リンクだけ...
XGBoost、LightGBM、CatBoostはライブラリやフレームワークの名前
k-means
クラスタリング(グループ化)
k-近傍法(k-NN)
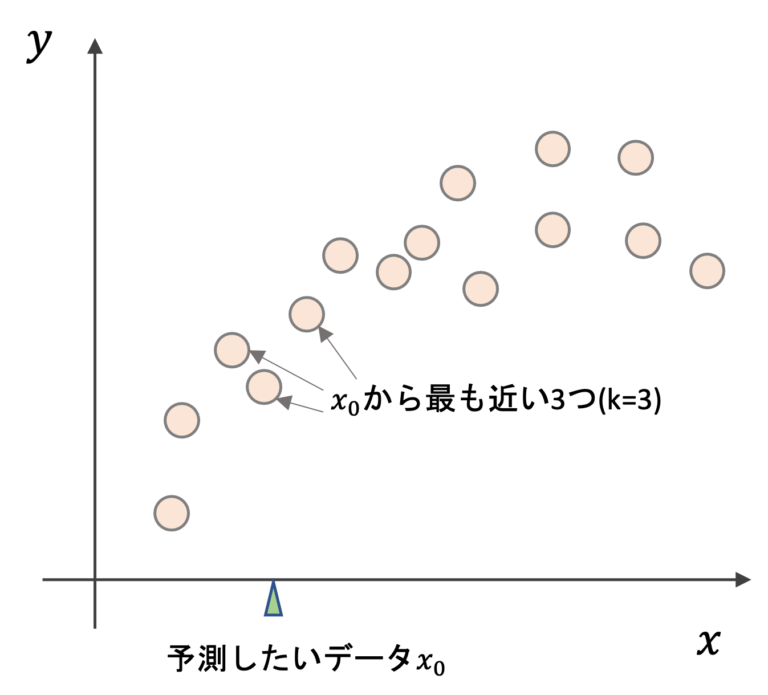
分類・回帰タスク
上記の図で説明
学習データ→ミニバッチ ミニバッチの中で予測されたデータと正解の誤差を計算 各パラメータの微分に負の符合( - )と学習関数をかける この更新方法を確率的勾配降下法という
勾配降下法
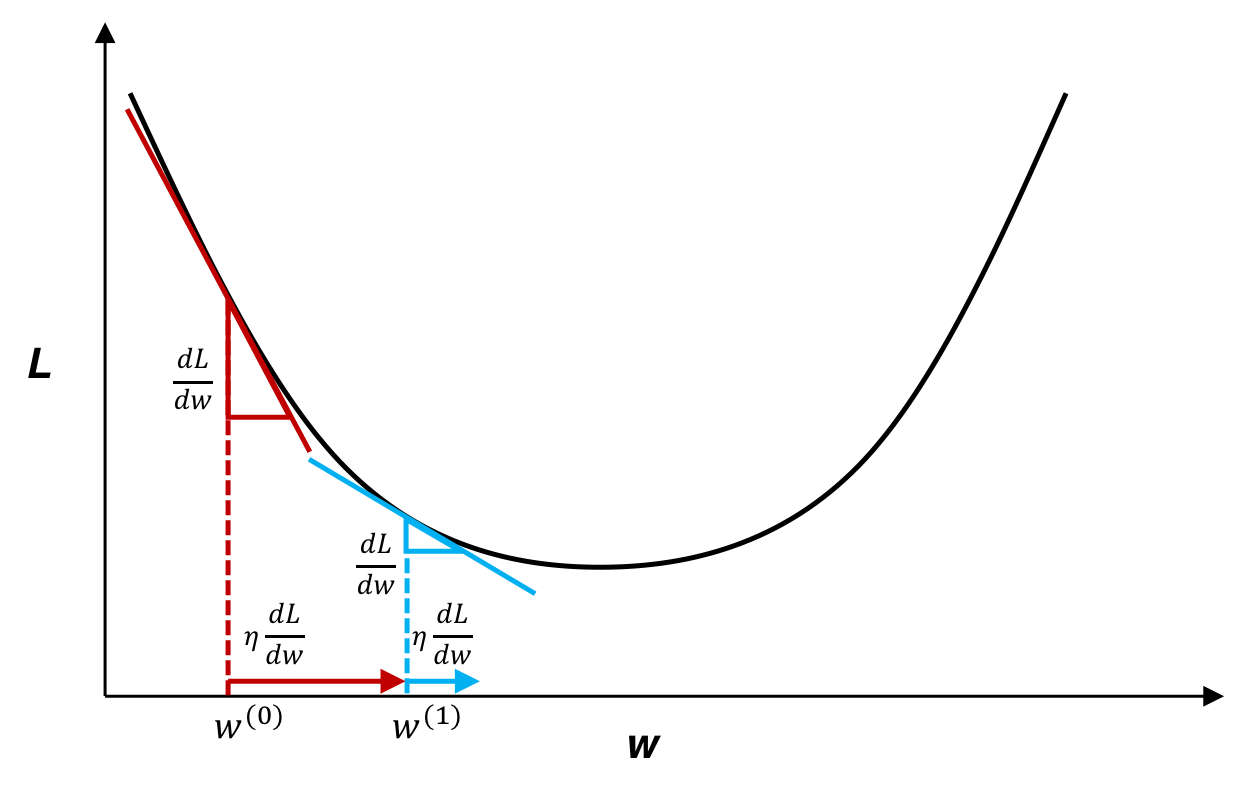
並列処理
並列処理をするからGPUなどのハードウェアに負担がかかるため高性能なマシンが必要
モデル学習を適切に制御する過程で、検証データが必要になるケース
常に監視して検証をすることで過学習や余分な処理をなくす