I also did the other analysis regarding the quality of sleep, i'll link the notebook: [(https://www.kaggle.com/code/manuiaccarino/eda-and-predicting-sleep-quality) I was surprised by the predictive ability of a "simple model" without any preprocessing. The data seams to be real (and not syntetic, at least that's what the source of the data say) and nonetheless the data size being small I figure it out that the variables were highly correlated with each other, so either the sleep quality variable was just obtained through a similar algorithms or predicting the quality of sleep can be quite easy with a few relevant variables. Waiting for ur feedback on this one as well. I'm sorry I can't work also on the other dataset but I don't have a lot of time this week and, by a first look, there seams like a lot of work on preprocessing to do there
- Mar 2024
-
www.frontiersin.org www.frontiersin.org
-
-
I just finished to analyze one of the dataset I suggested last week, i'll link the Kaggle notebook: [(https://www.kaggle.com/code/manuiaccarino/interesting-finding-predicting-activity-calories?scriptVersionId=166551904) I made some interesting find while trying to predict the Activity detected by the sportwatch depending by the measured data. I don't want to spoiler anything, I hope you can read the work and provide me a feedback so we can discuss about it . Thank you
-
The amount of tecnical information such as Brand, info about each sportwear device and so on were a little bit confusing, a lot information came but I managed to understand the key points at least. IT would be interesting to analyze some example data provided by this device to have a clear understand of how it works and how we can use it by a statistical point of view. I'll check online some dataset that may come from the mentioned brand where we can perform a classification task regarding the risk or injury, or other metric depending by type and quality of the data. The sport wear mentioned here seams professional, alias expensive, but if u know some cheap wearable such as a sportwatch who provide either raw or processed data it would be interesting to do some self analysis
-
-
link.springer.com link.springer.com
-
Since i already have been reading and searching about Sport Analytics by myself after your seminary I already have a grasp about what it talks about and the problems associate with it. Last year I did an analysis about Napoli winning the championship, trying to understand through data how it happened, I’ll link the github repository here:
While doing the analysis, the main problem was regarding the data, which are actually almost impossible to find. I was looking for raw data to analyze but you need to pay for that, so the only avaible were on Fbref, the problem was that they were processed data so I have to adapt my question to the answer that the data could give me.
Having to deal with a real problem helped me to understand the issue of working with sport data and how important the quality and the source of the data are, I’d say they are worth 90% of problem, the other 10% are the analyst ability.
Talking about that, the paper spent time talking about the possible task an analyst can perform in sport analytics problem. It talk about Machine Learning but we need to be more specific. Expect for an emotion analysis and the injury prediction (which we can be propery labeled so that we can think about it as a proper classification task with Y/N as label or the probability of belonging to a certain class), I can’t imagine a way to use ML techniques into Sport Analytics since, as the paper said, without being able to give a proper label (it tallked about truth) we can’t perform any prevision, and even if we could, there is so much bias (since we should take into consideration a lot variables) that our analysis would be worthless. It’s different regarding the unsupervised learning, where using for instance cluster could give us a lot of information regarding player position and so on but for what I can think and what I understand the role of an analyst would be mostly of a Story teller, trying to explain data in a easy way to coach and manager to take data-based decisions.
Regarding the use of metric to give like an overall score to a player, I agree with the paper with the problems you can find to determine a balanced score, I would say soccer remind me a lot of Poker, where we have incomplete information and taking decisions based on what we have can be extremely hard, the use of the formula provided on the first video presentation of the course regarding the Basketball can’t be use in soccer because a lot more variables come into play.
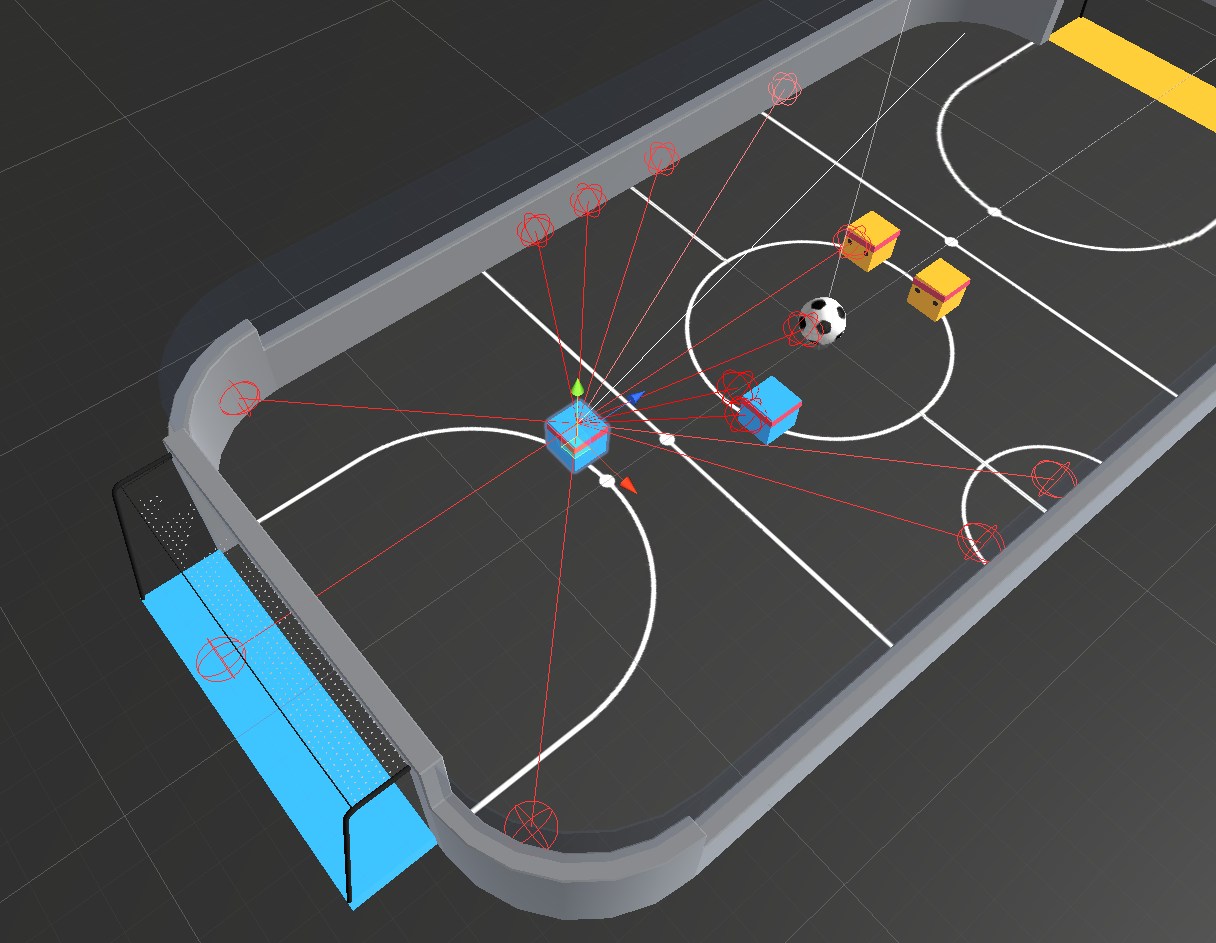
A last consideration I would like to do is about the tracking system, regarding player positioning and so on. All the provided examples have their own weaknesses and strengths but I think the paper didn’t talk about the use of ray-casts. During my exchange year I did a paper regarding the use of Reinforcement Learning to train football players bot (like the one we have on fifa when we play against the computer). I trained the model though Unity, I game developer application and to let the player know about the space and their surroundings it use this ray-casts system. A photo of how it works it’s implemented below
I don’t know if a similar method already exists but would be a lot cheaper and easier by a computational level to gather info from a football match. The object can be detected through similar device as GPS but lighter and easier to program. If not, after match a simple computer vision algorithm can add the information from the ray-casts to the player position to gather all the required information.
-