это уже давно есть
recursion :)
это уже давно есть
recursion :)

Currently applying backpressure to received messages is not possible with the WebSocket API. When messages arrive faster than the page can handle them, the render process will either fill up memory buffering those messages, become unresponsive due to 100% CPU usage, or bot
Ignoring non-warranted sub-resource validation/requests, the case where immutable would help is when the asset has become stale. I believe that this should be rare because these assets should use max-age: 1 year (maximum value). But I could be missing something.
immutable might well provide a reasonable chunk of benefit over and above the Chrome heuristics
Well it's not just for reloading a page, it also affects opening a new tab. Since the assets are immutable chrome would never have to (try-)fetch the assets again. This would result in not only a refresh being faster but also a load without refresh
А, то есть весь список никогда не показывать, а показывать всегда, допустим, MAX 500 элементов и выводить общее количество, чтоб пользователь понимал, что это не все и искал нужные ему элементы списка поиском? P.S. так то почему нет, достойный способ, но не подойдет для краулеров, котороым нужно проиндексировать все данные.
Автор забыл (а может и специально умолчал) про важное ограничение для этого способа. А именно то, что поле (или поля), используемое для паджинации по ключу, должно быть «уникальным» и обязательно указываться на первом месте с списке полей используемых для сортировки. Такие ограничения очень сильно уменьшает возможности использования этого метода.
Я так считаю, потому что пока вы шли от 1 страницы до 10 появились новые записи, и если вы пойдете обратно и дойдете до как бы первой страницы, то нужен вменяемый интерфейс, что бы сказать пользователю, что там еще записей навалило.
Курсоры не явы драйвер их создает и "держит" на БД. Кроме то-го что это дорого в плане ресурсов само БД это еще головная боль с закрытием этих курсоров в вашем коде- это то что вы не хотите на самом деле иметь в вашем сервисе
Указание номера страницы для щелчка — в любом случае плохое решение при разработке UI
seek method или keyset pagination. Он решает проблему с плавающим результатом
селектом можно выбирать только те строки, что мы еще не видели
время обработки запроса не увеличивается пропорционально номеру запрашиваемой таблицы
Проблема — в определении пагинации по стандарту SQL. Мы говорим СУБД, какую страницу нужно достать или как много записей пропустить. База просто не в состоянии оптимизировать такой запрос
Когда используется offset для пропуска записей с предыдущих страниц, в ситуации добавления новой записи между операциями чтения разных страниц, вероятнее всего, вы получите дубликаты
база все еще должна прочитать эти первые n записей с диска, причем в заданном порядке (прим.: применить сортировку, если она задана), и только после этого будет возможно вернуть записи начиная с n+1
Полгода это такой срок после которого уже можно будет ставить точку.
Нам один из инвесторов рассказал про гугл как Пэдж и Брин очень долго сначала ездтли по долине и им никто денег не давал, а потом вдруг один чел дал своих личных, англет то есть.
Это касается сервисов для бизнеса и средств совместной работы. По развлекаловкам разговоры начинаются, когда кол-во активных пользователей приближается к 100 тысячам.
структурированность даёт возможность реализации других фич совместной работы: привязка к фрагменту чата, обсуждений, ACL. на линейной структуре это всё можно сделать развечто теми же «аннотациями», причом парными, со всеми вытекающими граблями. да и вообще, линейный текст для документов, ИМХО, прошлый век, эдак 78год.
Я недавно общался с руководителем проета walkaround. Он сказал что мы очень верно сделали что не пошли по пути допиливания wiab.
про inention preservation я имел ввиду упомянутый выше случай совмещения операций редактирования и перетаскивания фрагмента. в случае cut-n-paste реализации, фрагмент удаляется из позиции src, а потом добавляется в новом месте dst. если это совмещать с операцией вставки в позиции src+x получится лажа, если эта операция попадёт МЕЖДУ удалением и вставкой другого клиента. даже не представляю, как вы собираетесь выкручиваться в этой ситуации. совсем другое дело, если операцию «перетаскивания» сделать базовой. тогда совмещение операций снова сводится к поправке позиций.
Судя по сорцам и README, у вас модель абсолютно такаяже: документ состоит из линейной последовательности букв. Развечто у вас они разбиты на фрагменты с тарибутами. Тоесть — документ не структурирован. и нет даже принципиальной возможносит, например, редактировать параграф и одновременно перенести его в другое место. Или я что-то упустил?
Изначально мы хотели брать исходники волны (WIAB) и их допиливать. Но разработчики очень сильно фыркали на ихнию технологию и уговорили нас рискнуть и полностью переделать архитектуру. В результате получилось то что получилось. Есть конечно и минусы, но в целом все гораздо стройнее. Например с тем же rich text в GW эту были дополнительный список аннотаций к каждому сообщению. А у нас гладко и ровно в дереве объектов. Ну и кроме этого уже сейчас работают всякие клевые штуки типо востановления удаленного сообщения по ctrl+z.
А у вас редактор и OT по-прежнему ограничены линейным текстом или предполагается поддержка структурных элементов и операций над ними? Ларс говорил, что тут есть всякие сложности, и они так и не придумали как их решить. А в чём именно эти сложности? (помимо необходимости замены корректировки скалярной позиции курсора — корректировкой цепочечного пути к элементу)
преймущество oneNote перед известными мне веб-системами: offline работа: можно редактировать и просматривать документы в офлайн, синхронизация сработает как только появится доступ screen clipper: изображение вставляется с экрана вставляется в документ практически одним кликом. Это сильно выигрывает перед веб системами где нужно сначала сохрянять в файл, а потом аплоадить на страничке. Вообще работа с изображениями в режиме copy/paste вроде в вебе еще не работает. Несколько удобных вещей в редакторе, вроде тегов. производительность и надежность native приложения. практически никогда данные не бывают потеренными, бэкап можно делать по файлам.
О непонимании как можно использовать волну практически всё уже перетёрто по 9000 раз. Не ворошите труп.
отправил письмо с обычной почты на свой адрес %username%@googlewave.com. Оказалось, эта функция не поддерживается. Тогда и подумал впервые, что скорее всего этот проект ждет фейл.
Вообще говоря 150 это нижнаяя граница, только начало жизни это длинной волны:) Часто было и 1000 блипов.
Тут нужно начать с того что Wav использовало для одновременного редактирования технологию operational transformation. Технология в целом очень крутая. Но та реализация которая получилась у Google имела очень много требований к ресурсам как на стороне клиента так и на строне сервера. — Кроме того были утечки в клиете. И поэтому открытая волна постоянно жрала оперативу. —Еще была проблема с не самой эффективной версткой: для волны в 160 блипом имеем 13000 DOM элементов — реализация ОТ требовала отдельно модели данных на JavaScript и рендеринга в HTML (DOM) + много обработчиков самых разных событий нав в этом смысле сильно повезло. Часть команды Wave на так давно разработала альтернативную реализацтю OT проект называетс: sharejs. Проект этот опенсорсный и им можно опльзоваться. то мы и сделали. Вот недавно выложили наш rich editor на базе sharejs. Сылка на код есть выше
Большой волной можно было считать волну из 400 кусочков
огромную простыню

понятнее стало то, что Волна гораздо интереснее бизнесу, нежели «праздным» юзерам
инструмент приглашения в сервис новых пользователей работал очень плохо, а через месяц после открытия вообще сломался и больше не работал инструментов публикации контента из Волны в публичные места не было. Точнее были, но не для простого пользователя. интеграции с Facebook никакой не было. Интересно, как Гугл предполагал переманивать аудиторию, если нет возможности залогиниться под аккаунтом Facebook? А уж про лайкнуть и поделиться — вообще молчим.
На самом своем старте проект встретил много технических сложностей: Ребятам пришлось ради волны специально переписать Chrome. Проблемы другими браузерами так и не были решены. Задумывался серьезный модуль интеграции с Gmail, но многие технические моменты так и не удалось преодолеть, и проект был свернут. Оказалось, что волна жрет очень много ресурсов и очень требовательна к качеству интернет-соединения. Эту информацию мы получили от разработчиков Google Wave. А вот что говорили пользователи


Лучшие фичи GW с точки зрения пользователей
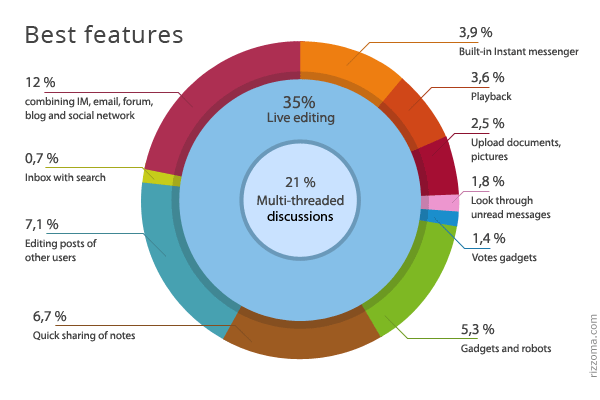
Что, по-вашему, было лучшим в GW

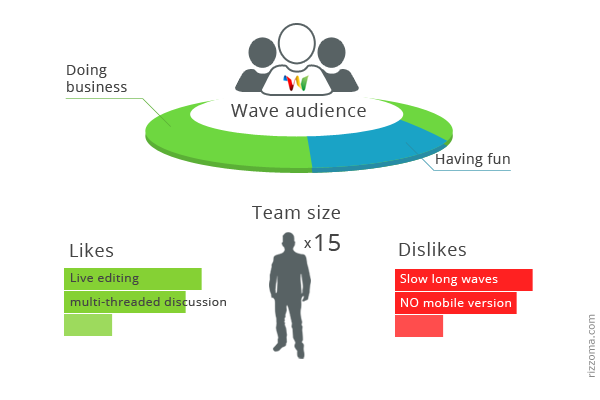
Кто пользуется Google Wave? Зачем

Поэтому мы провели опрос среди пользователей GW из 500 команд. Вот его результаты.
Почти всегда чтобы понять задачу, необходимо осознать и какую-то долю контекста, к которому она относится.
Мы верим в то что контекстное общение и zoom-интерфейсы перевернут устройство информационных потоков внутри компании.
не достаточно удобно чтобы захотеть начать пользоваться?
Очень много времени тратиться при постановке задач на то, чтобы ввести человека в контекст. И из-за этого много непонимания
Посмотрел, не зацепило. Слишком много шума. Чем хороша wiki, так это своей структурой. У вас контекстная структура: где-то куски диалога, где-то вставленное пояснения разрывающее нить повествования, да еще и задачи разбросанные по всему тексту. Task manager хорош когда у него компактное представление, есть иерархичность задач, адресность, приоритет и контекст задачи. Messenger хорош тем что это быстро, можно забить и не видеть то что писали вчера, а можно и покопаться в истории при желании — вы убили оба бонуса. + шум еще и визуальный: фото участников, границы сообщений, время ответа. Wave крут своей новизной, но его нужно полировать и полировать. Идеальный wave — легкий удобный и не замороченный
Очень давно регистрировался в Wave, мне тогда он показался мегакосмической непонятной штукой. Интересно, что вы нашли такое хорошее применение тому что наделал Google
вопрос или задачу можно задать именно в том месте, где она пришла в голову
Вики очень не живая среда. В вики надо заставлять людей писать. Там не удобно общаться, и люди общаются через скайп или джаббер
генерирует идеи до тех пор, пока у него не будет списка по крайней мере из десяти штук. Затем тщательно оценивает этот список, выбирая идею с наибольшими шансами на успех
любая идея, которую я пытаюсь реализовать, определяет бóльшую часть моей жизни в течение как минимум нескольких месяцев. Поэтому ее стоит тщательно выбирать
Создание «быстрого» прототипа в начале проекта казалось дешевым и простым, но всегда занимало недели кодирования, а потом месяцы работы по поиску клиентов.
Интересно, что у самых крупных клиентов даже не было таких пожеланий, и эти сделки закрывались в течение нескольких дней.
Отлично! Можете предварительно оплатить три месяца обслуживания, и ваш платежный цикл не начнется, пока эта функция не станет доступна.
conceived over IRC, sent out via mass e-mail, and collaboratively composed, edited, and compiled in a locally hosted Etherpad
Nobody was interested. Wave's reputation had apparently been set
what is this for?
Performance was better, but still pretty bad
it bring my browser to a screaming, fan-twirling, beachball-spinning halt
I was happy with what I used for similar purposes (Google Docs), Wave was overly complex, and no one else I knew used it for any reason—work, pleasure, or otherwise. What's the point if it's going to be just me?
tried to do too much from the get-go
Google Wave seemed like it could do many of these things decently, but nothing incredibly well.
It wasn't very intuitive, and I didn't feel like it had anything to offer over the collaborative online tools I was already using, like Google Docs
If the developers had found practical ways to make it interoperate with Gmail and Google Talk, it would have been much more useful right away
early users had practically nobody to talk to.
Wave users can really only use Wave to communicate with other Wave users—it can't serve as a bridge to conventional e-mail and instant messaging.
no choice but to use Google's own (and in many cases, less than ideal) Web-based app
a few examples of software from SAP, Novell, and Salesforce.com that have added Wave support, no widespread consumer apps have emerged
When Twitter first launched, it used a Web interface or SMS. But by using a straightforward and simple API, apps such as Twitterrific, Spaz, and Tweetdeck quickly sprang up on the desktop.
Wave just didn't offer a better experience than the tools we already use
In the final accounting, I'm still on board with the general idea of Wave, if not the actual implementation. E-mail does indeed need to be reinvented, but not quite so radically. Wave was just way too complex and ambitious a departure from normal e-mail, IM, and chat, and its terrible interface only served to exacerbate the complexity, instead of hiding it.
So there was never going to be any way to turn it off and enable a kind of "draft preview" that would let you send complete, IM-style messages. This was a major buzzkill; few people are comfortable in an informal chat where others can watch them type.
WTF WTF WTF
a huge issue and a common complaint—was that everyone could watch you type.
a lot of very painful scrolling
obvious how to spot the newest messages, because they could be nested somewhere deep in the middle
Wave's primary interface sin was that it crammed a multiple-window-based desktop metaphor into a single browser window. In other words, Wave was a return to the bad old days of Windows 3.11-style MDI, and that made it ugly and initially confusing for even the savviest of users
After procuring an invite, I dove right in and was immediately hit by how slow and wonky the interface was.
К сожалению, в 2020 году, когда машины распознают дорожную разметку и пешеходов, IDE всё ещё не способны распознать тип переменной в программе.
Гераклита. Платонисты верят в идеальные формы, любят, когда компьютер делает именно то, что ему говорят, и готовы пойти ради этого на любые средства. Всякая неопределённость в поведении должна быть устранена, все побочные эффекты учтены, все входы и выходы записаны — иначе для чего нужны компьютеры, как не для того, чтобы железной логикой быть источником порядка среди непредсказуемых людей? Платонисты придумали статическую типизацию, конечные автоматы, таблицы переходов, Агду, формальную верификацию и соответствие Карри-Ховарда. Когда они подходят к задаче, их мечта — найти именно такую структуру, в которую эта задача идеально влезает. Идеально! Платонистов чаще всего можно встретить в embedded, разработке компиляторов, проектировании сверхнадёжных систем (авионики, например), hard real-time, микроядрах — в общем, чем хардкорнее, тем лучше. Не таковы гераклитяне. Они-то знают, что совершенства не существует, что миром правит хаос, и нет никакого способа привнести порядок туда, где его не было и не может быть никогда. Неожиданности всегда появляются, системы всегда ломаются, учесть всё невозможно, и единственный способ выживать в таком мире — быть достаточно гибким и изворотливым, чтобы восстанавливать всё утраченное. Гераклитяне придумали позднее связывание, аннотации, юнит-тесты, прототипы, горячую замену кода, нулевые указатели, message passing, акторы и супервайзеры. Ну и Perl, само собой. Их мечта — чтобы всё хоть как-то работало, какой бы хаос ни происходил вокруг и какими бы безумными ни были начальные условия и входные данные — а следовательно, гераклитян часто можно встретить в big data, финансах, вебе, телекоммуникациях, devops и других местах, где правит бал Его Величество Случай.»
эта проблема — очень частный случай того, зачем нужны тайпклассы
Соответственно чтобы использовать любые структурно похожие типы клиенту достаточно написать instance Convertible SomeThirdPartyType MyType.
IHasFoo + IHasBar + IHasBaz — это очень хорошо. Это явное минимальное описание интерфейса. То есть автор подумал об интеграции и даже задокументировал своё решение в код. Проблема PDFDocument в том что автор не подумал об интеграции
Методы Qt принимают QString, QList, QHashTable, хотя по хорошему, они должны принимать не эти типы, а все похожие на… В результате, при интеграции Qt с прочими библиотеками в точках сопряжения появляется довольно много лишних операций преобразования типов.
При динамической/структурной типизации требуется реализовать только то, что реально используется.
Например, пользователь написал x.foo(). Значит ли это, что в библиотечном интерфейсе появился метод foo? Нет. Этот метод там может быть (возможно в виде недокументированного кода или бэкдора), и уже является частью интерфейся, либо его там может не быть вообще. В обоих случаях интерфейс сформирован автором библиотеки.
если есть 2 library consumer и 3 объекта, из которых каждому нужно по 2 - номинативная типизация заставит писать каждого консьюмера писать по своему типу и конвертеру
В целом способность библиотек к кооперации между собой в динамических языках выше именно из-за того, что нет привязки к заранее сконструированным интерфейсам. Интерфейсы задаются неявно в момент использования в пользовательском коде, а не в момент конструирования класса автором библиотеки. То есть если в номинальном варианте интерфейс должен явно и жестко прописываться автором библиотеки, то при использовании структурной типизации интерфейс — штука довольно зыбкая
!!!
К тому же, это только "на бумаге", мы можем быть в чем-то уверены, т.к. мы взяли и проверили все типы заранее, а вот машина без этой информации тут же нагенерирует if-ов и косвенных обращений, потому что как только стёрли типы — компилятор их тут же забыл. А если не забыл, то значит вы не убрали типизацию :)
RUNTIME!
Представьте себе, что вы взяли программу на идрисе, прогнали её через тайпчекер, убедились, что она работает, а потом стёрли все аннотации типов. У вас получилась программа без единого типа, но если вы её теперь скомпилируете и запустите, то проверять ничего лишнего вам не придётся.
Дай мне программу на го, удали часть когда, я его восстановлю и починю только глядя на ошибки компайлера. Интересное наблюдение. Я на go никогда не писал, но это утверждение по сути означает, что типичный код на нём очень сильно избыточный, раз его часть можно без особых потерь восстановить?
Главный посыл — в шорт-терм, динамические языки рулят. Лонг-терм, поддержка и добавление изменений это сущий ад, и дальнейшее развитие продукта будет замедленно.
То есть, вместо того, чтобы просто использовать уже готовую систему типов, которая индуктивно гарантирует корректность всей программы, вы будете выписывать частный сулчай этого индуктивного доказательства через тесты.
Напишите шаблонный конструктор (и заодно преобразование обратно), для всех типов соответствующих трейту std::is_integral?) Вы явно недооцениваете современные статически-типизированные языки в их возможности обобщать :)
Проблем будет. 1. Даже если есть тривиальный конструктор, его кто-то должен формально вызвать. Линковщик о нём ничего не знает, так что минимум перекомпиляция. 2. Может не сработать, если этот конструктор explicit, или если нарушается правило «не более одного неявного преобразования». Например, изначальный тип — short, в int он будет преобразован, а вот в NonZero<int> уже нет.
В С++, например, если у NonZero есть конструктор, который принимает int, то никаких проблем не будет. Мне кажется, что эти «ограничения на юзеров» есть фича строгой типизации.
Теперь вы обязаны передавать ноль. По закону. Иначе тюрьма. В статической типизации я изменю сигнатуру кода и все сразу получат ошибку компиляции и не сядут в тюрьму. А вот чуваки с динамической типизацией должны будут исследовать сотни тысяч строк кода в надежде, что теперь никто не передаёт "0". И молиться что ничего не забыли. Иначе всё, тюрьма)
если у нас объявлен тип аргумента int и мы туда передали 0, а потом внутри библиотечной функции на него делим, статическая типизация не особо поможет.
Распарсить мегабайтный json или xml, поменять там пару строк и запарсить обратно. Сейчас у нас везде микросервисы в облаках, которые не должны знать друг о друге. А с точки зрения юзера это всё ещё один документ (файл). В котором вы знаете свой селектор (не путь).
Когда вы работаете в парах, обмен фидбеком происходит во время написания кода
лол, при чем тут trunk-based. ну pairing, какая разница какая ветка
такой способ работы может быть успешным
Empirical Software Engineering х2
а вообще флаги иногда на пустом месте повышают complexity и количество if-ов, особенно когда начинают влиять друг на друга и комбинироваться.
по мне feature флаги это только что-то реально большое. что действительно парит долго держать в ветке и ребейсить
достаточно автоматизированных тестов, чтобы вы были уверены, что кодовая база находится в состоянии, удовлетворительном для релиза
все это должно быть независимо от trunk-based / branch-based development. но для первого требования к test suite (в частности по времени) намного выше
улучшается сконцентрированность команды;люди меньше отвлекаются;работа делается быстрее и качественнее;
я не говорю наоборот, но посмотри Empirical Software Engineering https://www.youtube.com/watch?v=WELBnE33dpY
обмен знаниями
к сожалению на review комменты хотя бы можно сослаться и пошарить их, т.е. шаринг знаний при pairing хуже скейлится
исключает дальнейшую необходимость в PR
нет. pair programming != code review. не факт что нужны оба всегда, но это разное. review больше моделирует "взгляд со стороны", потому что при pairing очень много контекста, который потом сразу теряется
А вот у меня была детская фантазия, что людям необходимо спать в целях, схожих с гигиеническими: засыпая, они снимают с себя свои костюмы командиров и подчиненных, нежных обожателей и злобных истеричек, заботливых мамочек, инфантильных переростков - остаются голыми и идут в общее для всех, неразделенное никакими границами, столбами и стенами внутреннее пространство. Очень большое просто - такое же большое, как и пространство снаружи. Как Вселенная. Поэтому шансов встретить там знакомого или просто другое разумное существо - практически никаких. И там с людьми происходит что-то, смывающее с них шелуху, мусор и ненужные обрывки мыслей и чувств - все это уносит в этот огромный эмоментальный океан. Поэтому все сны - общие, и мысли внутри снов - тоже. И эмоции.
!
You might not break the current internet but its future
There is already centralization in browser WebTorrent during peer discovery where a few wss trackers are used.
Effectively we are re-creating something like the mainline DHT except with websocket tracker servers
!!!
Having a solid library for writing server-side WebRTC applications would have other benefits. For example, most multiplayer browser games I'm aware of use Websockets because there isn't an easy way to write game network servers for WebRTC. This isn't ideal because WebRTC is capable of significantly lower latency and gives you more UDP-like control which is beneficial for game and other latency-sensitive apps
One complication is that the browser blocks connections to insecure origins (ws://) from secure origins (https://). So ws:// can't be used all of the time. Ideally, we could use wss:// instead. However that requires the WebSocket server to have a domain name and a certificate signed by a CA. 😢 3c. Here's a workaround. Say a user on a secure web origin wants to connect to a desktop peer at 12.34.56.78. They would connect to wss://12-34-56-78.force-tls.com. The force-tls.com domain would have DNS set up to return whatever IP is passed in the subdomain. So the DNS for 12-34-56-78.force-tls.com would resolve to 12.34.56.78. The force-tls.com domain would use wildcard certificate to ensure that all of these domains are signed. The secret key for this certificate would be public and any torrent app could use it in their WebSocket server. 3d. So, in this system, TLS isn't actually being used for security. This is just a hack to help secure origins (https://) connect to WebSocket servers running in desktop peers without requiring those desktop peers to buy a domain name and get a TLS certificate that is trusted by the browser peers' browsers.
host means the candidates is generated within the firewall
If you don’t have someone willing to introduce you, perhaps you’re not meant to talk
Async action creators such as redux-thunk have access to the entire state through getState(). An action creator can retrieve additional data from the state and put it in an action, so that each reducer has enough information to update its own state slice.
One way or another you'll be implementing a state machine