SUMMARY (From)
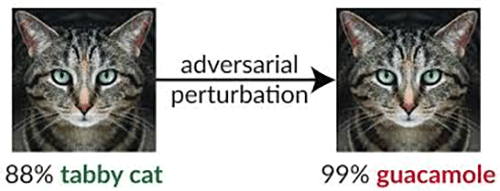
The researchers found that defenses against adversarial examples commonly use obfuscated gradients, which create a false sense of security but, in fact, can be easily circumvented. The study describes three ways in which defenses obfuscate gradients and shows which techniques can circumvent the defenses. The findings can help organizations that use defenses relying on obfuscated gradients to fortify their current methods.
WHAT’S THE CORE IDEA OF THIS PAPER?
WHAT’S THE KEY ACHIEVEMENT?
- Demonstrating that most of the defense techniques used these days are vulnerable to attacks, namely:
- 7 out of 9 defense techniques accepted at ICLR 2018 cause obfuscated gradients;
- new attack techniques developed by researchers were able to successfully circumvent 6 defenses completely and 1 partially.
WHAT DOES THE AI COMMUNITY THINK?
- The paper won the Best Paper Award at ICML 2018, one of the key machine learning conferences.
- The paper highlights the strengths and weaknesses of current technology.
WHAT ARE FUTURE RESEARCH AREAS?
- To construct defenses with careful and thorough evaluation so that they can defend against not only existing attacks but also future attacks that may be developed.
WHAT ARE POSSIBLE BUSINESS APPLICATIONS?
- By using the guidance provided in the research paper, organizations can identify if their defenses rely on obfuscated gradients, and if necessary, switch to more robust methods.