jdk9为何要将String的底层实现由char[]改成了byte[]?
9 Matching Annotations
- Dec 2022
-
www.zhihu.com www.zhihu.com
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
Java 中字节流与字符流的区别?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
想学摩尔斯码,如何入门?
-
-
www.zhihu.com www.zhihu.com
-
java中GBK编码格式转成UTF8,用一段方法实现怎么做?
-
-
www.zhihu.com www.zhihu.com
-
如何评价阿里近期发布的Java编码规范?
-
-
www.zhihu.com www.zhihu.com
-
Unicode 和 UTF-8 有什么区别?
Tags
Annotators
URL
-
- Aug 2022
-
stackoverflow.com stackoverflow.com
-
SET collation_connection = 'utf8_general_ci';
编码
-
- Apr 2022
-
blog.csdn.net blog.csdn.net
-
以为集合(Set)类型里面的元素总是无序排列的,其实不是的,在特定情况下,它也可以做到有序排列。 在redis里,集合的编码有两种,intset(整数集合)或者hashtable(哈希表)。intset编码的集合里面的元素是有序的(按照整数从小到大排列),hashtable编码的集合是无序的。 当集合同时满足下面两个条件时,会使用intset编码: 保存的所有元素都是整数元素数量不超过512个(这个值可以通过配置文件里的set-max-intset-entries进行调整) 要注意的是,一个使用intset编码的集合,当上述两个条件不能同时满足时,redis就会将集合的编码由intset改为hashtable。
redis 集合(Set)的排序问题
集合的编码有 inset(整数集合)、hashtable(哈希表)。
intset 编码的集合内元素是有序的,按整数从小到大排列。
hashtable 编码的集合是无序的。
集合满足 2 个条件,会使用 intset 编码: 1> 所有元素是整数; 2> 元素数量 <= 512 个; (数量,可在配置文件 set-max-intset-entries 设置)
不满足以上两个条件,redis 会将集合的编码由 intset 改为 hashtable。
-
- Jan 2017
-
exacity.github.io exacity.github.io自动编码器1
-
这些模型能自然地学习大容量、对输入过完备的有用编码,而不需要正则化。 这些编码显然是有用的,因为这些模型被训练为近似训练数据的最大概率而不是将输入复制到输出。
These models naturally learn high-capacity, overcomplete encodings of the input and do not require regularization for these encodings to be useful.Their encodings are naturally useful because the models were trained to approximately maximize the probability of the training data rather than to copy the input to the output.
调整后:
“这些变种(或衍生)自编码器能够学习出高容量且过完备的模型,进而发现输入数据中有用的结构信息,并且也无需对数据做正则化。 相对于只学习简单恒等函数的自编码器而言,变种(衍生自编码器)产生的编码数据更有效,因为得到的模型是在训练数据集上学习的数据概率分布。”
理由:
这段原文指代感觉比较不清晰, 1:我觉得 capacity、overcomplete 是用来修饰模型的,在前文也是这样使用的,在这句突然用来修饰输入数据的编码 不是太合理。 2:the models were trained to approximately maximize the probability of the training data 说说对这句的理解,感觉隐藏了很多信息。 译文中“这些模型被训练为近似训练数据的最大概率......” 这句我的理解是 为求解问题构造的目标损失函数是一种概率函数,以最大化概率值为目标。 而不是产生编码数据的方式是按照近似最大概率的原则产生,因为一旦学习结束,分布就已然得到(通过下文提到的概率分布代入求解),可以直接产生新编码样本点了。因为产生z_mean和z_log_sigma(见相关背景资料)这两个值都是统计量纲,不会有最大化概率这种动作。 相关背景: VAE是个生成模型,三步: 首先,建立编码网络,将输入映射为隐分布的参数 然后从这些参数确定的分布中采样,这个样本相当于之前的隐层值 最后,将采样得到的点映射回去重构原输入。 由此可知变分编码器的工作原理: 首先,编码器网络将输入样本x转换为隐空间的两个参数,记作z_mean和z_log_sigma。然后,我们随机从隐藏的正态分布中采样得到数据点z, 这个隐藏分布我们假设就是产生输入数据的那个分布。z = z_mean + exp(z_log_sigma)*epsilon,epsilon是一个服从正态分布的张量。最后, 使用解码器网络将隐空间映射到显空间,即将z转换回原来的输入数据空间。 即:变分编码器不再学习一个恒等的函数,而是学习数据概率分布的一组参数。通过在这个概率分布中采样。 隐空间参数由两个损失函数来训练,一个是重构损失函数,该函数要求解码出来的样本与输入的样本相似(与之前的自编码器相同),第二项损失函数 是学习到的隐分布与先验分布的KL距离,作为一个正则。实际上把后面这项损失函数去掉也可以,它对学习符合要求的隐空间和防止过拟合有帮助。拓扑结构图:
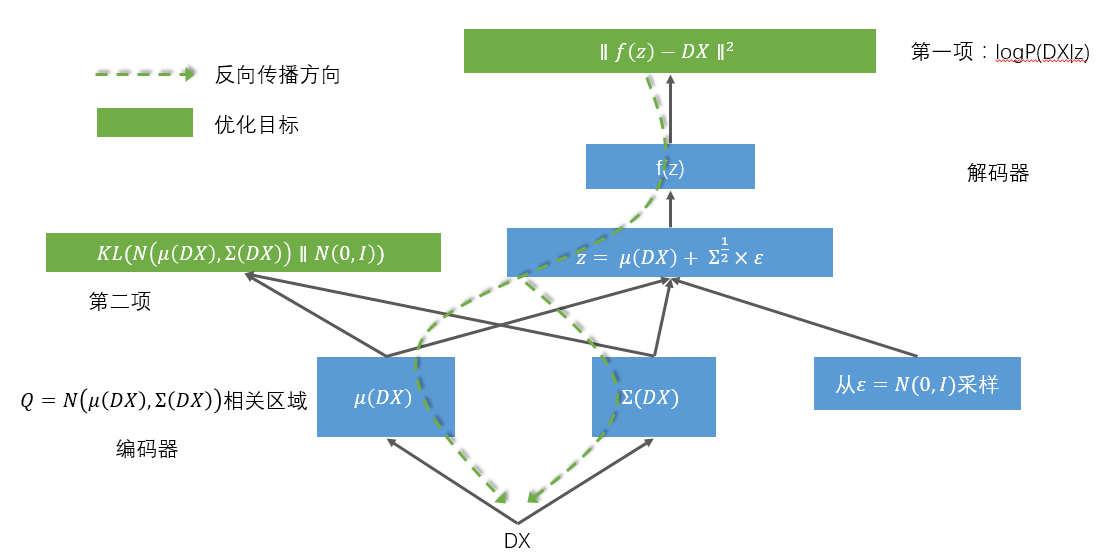
-