Online DDL是对于历史DDL的优化,默认对于支持的DDL操作生效。如果使用Copy算法,则会阻塞DML。
17 Matching Annotations
- Apr 2025
-
book.originit.top book.originit.top
Tags
Annotators
URL
-
-
book.originit.top book.originit.top
-
他的主机磁盘用的是SSD,但是innodb_io_capacity的值设置的是300。于是,InnoDB认为这个系统的能力就这么差,所以刷脏页刷得特别慢,甚至比脏页生成的速度还慢,这样就造成了脏页累积,影响了查询和更新性能
错误的io能力设置,导致mysql错估磁盘io,影响脏页的刷新效率
-
-
book.originit.top book.originit.top
-
查询语句中即使存在索引没有的字段信息,也可能选中索引
比如索引是字段的前缀,如email(6)
Tags
Annotators
URL
-
-
book.originit.top book.originit.top
-
如何解决选错索引?
无法从根上解决。 缓解的方法(仍然可能选错索引): - analyze table更新统计信息 - force index(索引可能变更,不灵活) - 删除错误的索引(很多时候,其他业务需要用到该索引) - 通过修改sql引导mysql优化器,让其觉得错的索引成本高(不通用)
-
子查询无法使用limit问题
在in中子查询不能使用limit,但是可以在from后面使用limit,因此可以在in的子查询中套一个子查询,如下:
select *from cidy where id in(select id from(select id from cidy limit 0,10) as cd);
Tags
Annotators
URL
-
-
book.originit.top book.originit.top
-
redo log 主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗。
可是实际上是对随机写攒批呀。如果没有change buffer则会在页缺失的时候加载,当然change buffer延迟了加载的时间,只在需要的时候加载,但是如何保证数据存在呢?比如更新的时候需要返回影响行数的,那是否只能用于没有唯一索引的表插入?
-
-
book.originit.top book.originit.top
-
大量插入数据时,Auto-INC锁会阻塞其他事务的插入,如何解决?
使得innodb_autoinc_lock_mode设置为1或者2,默认0,使得在插入时申请到自增值后立即释放auto-inc锁。在不同值下的行为: - 若是1,则insert ... select from这种仍然会执行完成后释放锁 - 若是2,则获取到了自增值就立即释放,但会引起主从不一致,因此需要将binlog设置为mixed或者row格式。
-
如果更新的时候走的全表扫描,则会锁住扫描的所有数据,如何避免?
- 删除时查询出来通过id删除
- 开启
sql_safe_updates,其要求sql能够击中索引或者通过limit限制了更新的行数
-
事务语句顺序优化
对于一个事务,应该将更容易被多个事务访问的锁放在后面加,比如说店铺,而比如用户的锁则先加,这样能够减少店铺的锁占用的时间
-
死锁检测以及相应开销
由于事务之间可能产生死锁,因此要么设置最大等待超时时间,要么设置死锁检测。
死锁检测
1. 维护等待图(Wait-for Graph)
InnoDB 内部维护一个有向图,图中的节点表示事务(Transaction),边表示锁的等待关系。
例如:事务A持有行X的锁,事务B请求行X的锁并被阻塞,则图中有一条边从B指向A(B→A,表示B在等待A释放锁)。
当某个事务请求锁时,如果锁已被其他事务持有,InnoDB 会更新等待图,添加一条新的边。
2. 检测环(Cycle)
每次有事务请求锁失败(进入等待状态)时,InnoDB 会触发死锁检测。
深度优先搜索(DFS):InnoDB 通过DFS遍历等待图,检查是否存在环。如果发现环,则判定为死锁。
优化:为了减少性能开销,InnoDB 不会每次都全图遍历,而是从新加入的边出发,仅检查可能形成环的路径。
3. 选择牺牲者(Victim)
如果检测到死锁,InnoDB 会选择一个事务作为牺牲者(通常选择回滚成本更低的事务,例如修改数据量较小的事务),强制回滚该事务,并释放其持有的锁。
回滚后,等待图中对应的边被移除,其他被阻塞的事务可以继续执行。
死锁的开销
问题
因此由于事务的不断加入,图会变得越来越大,进行环检测是O(n)的操作,若n很大则cpu大量消耗。
解决
可以通过中间件对操作相同key的事务限流,这样事务虽然也在等待,但是没有增加死锁检测的负担。
-
-
book.originit.top book.originit.top
-
这个跟索引c的数据是一模一样的。
当索引值相同时,按照主键排序,因此索引最后的字段是主键的话,可以去掉该索引
-
-
book.originit.top book.originit.top
-
如果有不合适的,为什么,更好的方法是什么?
重建主键
删除主键相当于重建整个表,mysql内部会使用一个隐式的自增字段存储记录。而创建主键则再次进行更改,将其从隐式转成显示的字段。因此如果需要重建主键索引则可以直接使用alter table T engine=InnoDB。
删除自增主键
如果要删除自增主键,那么主键列必须将自增删除掉,因为隐式的主键也是自增的,一个表只能有一个自增字段
-
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
尽量使用自增主键,能够避免页分裂,同时减少普通索引叶子节点的占用空间
-
-
book.originit.top book.originit.top
-
覆盖索引、前缀索引、索引下推
索引主要优化手段。尽量避免回表从而提高查询性能
-
- Mar 2022
-
www.cnblogs.com www.cnblogs.com
-
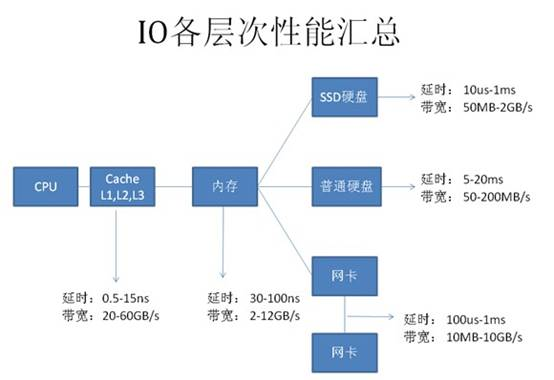
由图中可看到,每种设备都有两个指标: - 延时(响应时间):表示硬件的突发处理能力; - 带宽(吞吐量):代表硬件持续处理的能力。
-
大多数情况,性能最慢的设备会是瓶颈点。
如,下载时网络速度可能会是瓶颈点,本地复制文件时硬盘可能是瓶颈点。
为什么这些一般的工作能快速确认瓶颈点呢?
因为我们队这些慢速设备的性能数据有一些基本的认识,如网络带宽是 2 Mbps,硬盘是每分钟 7200 转等等。
(结论)因此,为了快速找到 SQL 的性能瓶颈点,需要了解计算机系统的硬件基本性能指标,如当前主流计算机性能指标数据。
-
数据库访问优化法则
(目的):要正确的优化 SQL;
(条件):需要快速定位性能的瓶颈点;
(进一步阐释说明):即是快速找到 SQL 主要的开销在哪里?
-