Supervisord
sonic 用的就是 supervisord 来管理进程 go daemon 是否可以用 docker 和 docker-compose 来管理
Supervisord
sonic 用的就是 supervisord 来管理进程 go daemon 是否可以用 docker 和 docker-compose 来管理
编译器在执行完语法分析之后会输出一个抽象语法树,这个抽象语法树会辅助编译器进行语义分析
所有编译器理论原理基本一致
实例
协程(Coroutine)编译器级的,进程(Process)和线程(Thread)操作系统级的
概念级理解
编排之争
docker 和 kubernetes 的编排之争,前提是 docker 不安于现状,不想仅仅做提供应用程序打包发布的 “幕后英雄”,而是想要进军完整的 “PaaS”,而完整的 "PaaS" 不仅仅需要应用程序,还需要提供一种
编排,集群管理,负载均衡的能力,所以,docker compose和swarm的出现也是必然,为了应对docker Paas化的冲击,kubernetes应运而生
Rook turns distributed storage systems into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
Rook将分布式存储系统转变为自我管理,自我扩展,自我修复的存储服务。<br> 它可以自动执行存储管理员的任务:
ReplicationController(简称RC)是确保用户定义的Pod副本数保持不变
Replication Controller -- RC<br> 确保用户定义的Pod副本数保持不变,也就是说<br> 如果pod增多,则ReplicationController会终止额外的pod,如果减少,RC会创建新的pod
The representors are created by the host PCI driver whenset in SRIOV and the e-switch is configured to switchdevmode. Currently, in mlx5 the e-switch management is donethrough the PF e-switch vport and hence the VFrepresentors along with the existing PF net-device whichrepresents the uplink share the PCI PF device instance
当在SRIOV中设置并且e-switch配置为switchdev模式时,表示符由主机PCI驱动程序创建。 目前,在mlx5中,e-switch管理是通过PF e-switch vport完成的,因此VF表示器与现有PF网络设备一起完成,后者表示上行链路共享PCI PF设备实例
Traditional hypervisors expose emulated or para-virtual(PV) devices to guest virtual machines and multiplex theI/O requests of the guests onto the real hardware throughthe software switch residing in the host OS
传统的虚拟机管理程序将仿真或半虚拟(PV)设备暴露给guest 虚拟机,并通过驻留在主机操作系统中的软件交换机将guest 的I / O请求多路复用到真实硬件上
This way the OVS code does not “change”... we plug ournew dpif HW acceleration module that exposes the sameAPIs that a dpif provider should expose and use thestandard dpif netlink.
这样OVS代码就不会“改变”...... 我们插入了新的dpif硬件加速模块,它暴露了dpif提供者应该公开的相同API并使用标准的dpif netlink。
Open-vSwitch nic HW acceleration ==> ASAP
We have implemented and upstreamed a design that allowsto enjoy the performance advantages of SRIOV whilekeeping the flow based approach to guest traffic used inOpen-vSwitch
我们已经实现并升级了一种设计,允许享受SRIOV的性能优势,同时保持基于流的方法,以便在Open-vSwitch中使用访客流量。
In order to sup-port HW policy in OVS and to use TC it is required to havea new dpif provider which we named dpif-HW-acc whichaccording to policy either uses TC or dpif netlink.
为了支持OVS中的HW策略并使用TC 需要有一个新的dpif提供程序,我们将其命名为dpif-HW-acc,根据策略使用TC或dpif netlink
取image的大概过程如下
If this is a production situation, and security and stability are important, then just "convenience" is likely not the best deciding factor (any more than leaving your house unlocked all the time might be "convenient").
如果这是生产情况,安全性和稳定性很重要,那么“便利”可能不是最好的决定因素(不仅仅是让你的房子一直解锁可能是“方便的”)
push to master都考虑准备投入生产?显式版本 -- image tag<br> 隐式版本 -- 不可变标记 :image digest
This is now a problem, because different instances of the same service now run different versions of the application; this can lead to hard-to-find issues, such as:
现在这是一个问题,因为同一服务的不同实例现在运行不同版本的应用程序;这可能导致难以发现的问题,例如:
Doing so would revert to the old behavior, where images are just pulled on each node. This used to cause quite some issues and was intended as a stopgap solution at the time (until pinning by digest was implemented). This section illustrates some of the problems with this approach.
docker stack deploy中不推荐使用--resolve-image=never<br>
这样做会恢复到原来的行为,即只在每个节点上拉动图像。这曾经引起相当多的问题,并且当时是作为权宜之计的解决方案(直到通过摘要实现固定)。本节说明了此方法的一些问题。
However, there is not a 1:1 relation of digests to tags, so when pulling an image by digest, only the digest is known. If you happen to have an image pulled (manually) with a tag that matches that digest, the tag is shown, but not otherwise
但是,摘要与标签之间没有1:1的关系,因此在通过摘要pull image时,只知道摘要。如果您碰巧使用与该摘要匹配的标记(手动)拉出图像,则会显示标记,否则不会显示
首先第一个,服务网格是抽象的,实际上是抽象出了一个基础设施层,在应用之外
服务间通讯被完全剥离出来了,通过一个抽象层进行转发,这个抽象层就是服务间通讯专用基础设施层,也就是service mesh
上面的服务不再负责传递请求的具体逻辑,只负责完成业务处理。服务间通讯的环节就从应用里面剥离出来,呈现出一个抽象层。
所有的服务通过“服务间通讯专用基础设施层”来和客户端交互<br> 服务不再负责传递请求的具体逻辑<br> 服务只需要完成业务处理<br> 服务间通讯环节从应用里剥离出来
首先服务网格是一个基础设施层,功能在于处理服务间通信,职责是负责实现请求的可靠传递。在实践中,服务网格通常实现为轻量级网络代理,通常与应用程序部署在一起,但是对应用程序透明
service mesh 是一个基础设施层
To see if the DHCP request was received by ISC DHCP, look in /var/log/syslog of the RackHD host.
检查是否收到dhcp request<br> grep DHCP /var/log/syslog
Discovery: RackHD can automatically discover a node that attempts to do PXE boot on the network that RackHD is monitoring.
RackHD可以自动发现尝试在RackHD正在监控的网络上进行PXE引导的节点
几个关键点:
NodeId is the unique Identity of a node in RackHD. List all the compute type nodes being discovered on the rackhd-server SSH console by typing the following command. Append “?type=compute” as a query string.
NodeId是RackHD中节点的唯一标识。通过键入以下命令,列出在rackhd-server SSH控制台上发现的所有计算类型节点。将“?type = compute”附加为查询字符串。
The Docker Compose setup also enables port forwarding that allows your localhost to access the RackHD instance
Docker Compose设置还启用端口转发,允许您的localhost访问RackHD实例
The rackhd_admin network will be used to connect the services together and to access the RackHD APIs. The rackhd_southbound network will be used by RackHD to connect to the virtual nodes.
Maven世界拥有大量构建,我们需要找一个用来唯一标识一个构建的统一规范
每一个骨架都会建相应的目录结构和一些通用文件,最常用的是maven-archetype-quickstart和maven-archetype-webapp骨架。maven-archetype-quickstart骨架是用来创建一个Java Project,而maven-archetype-webapp骨架则是用来创建一个JavaWeb Project。
archetype是mvn内置的一个插件,create任务可以创建一个java项目骨架,DgroupId是软件包的名称,DartifactId是项目名,DarchetypeArtifactId是可用的mvn项目骨架
-DarchetypeArtifactId 指定ArchetypeId,maven-archetype-quickstart,创建一个Java Project;maven-archetype-webapp,创建一个Web Project
使用mvn archetype:generate命令
### 构建java项目
# mvn archetype:generate -DgroupId=com.mycompany.app -DartifactId=myapp -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
### 构建javaweb项目
# mvn archetype:generate -DgroupId=com.mycompany.app -DartifactId=my-WebApp -DarchetypeArtifactId=maven-archetype-webapp -DinteractiveMode=false
执行命令:java -cp target\myapp-1.0-SNAPSHOT.jar com.mycompany.app.App
运行jjava程序,是通过java命令加上jar包来完成
# java -cp xxxxx.jar xxxxx
在项目的根目录下都会存在一个pom.xml文件,进入myapp目录,可以看到有一个pom.xml文件,这个文件是Maven的核心
使用"mvn archetype:generate"命令和"mvn archetype:create"都可以创建项目,目前没有发现这两者的区别,唯一区别的地方就是发现使用"mvn archetype:generate"命令创建项目时要特别长的时间才能够将项目创建好,而使用"mvn archetype:create"命令则可以很快将项目创建出来。
所以使用"mvn install"命令,就把maven构建项目的【清理】→【编译】→【测试】→【打包】的这几个过程都做了,同时将打包好的jar包发布到本地的Maven仓库中,所以maven最常用的命令还是"mvn install",这个命令能够做的事情最多。
由于Maven命令实际上是执行了Java命令,所以可以通过JAVA命令参数的方式来设置MAVEN运行参数。MAVEN_OPTS环境变量正是用于此用途 MAVEN_OPTS -Xms128m -Xmx512m,分别设置JVM的最小和最大内存
由于Maven命令实际上是执行了Java命令,所以可以通过JAVA命令参数的方式来设置MAVEN运行参数。MAVEN_OPTS环境变量正是用于此用途
MAVEN_OPTS -Xms128m -Xmx512m,分别设置JVM的最小和最大内存
为了能够自动化的解析任何一个java构件,maven必须将他们唯一的标识,这就是依赖管理的底层基础,坐标————maven的坐标为java引入了秩序,任何一个构件都必须为自己定义一个坐标
Cobra既是一个用来创建强大的现代CLI命令行的golang库,也是一个生成程序应用和命令行文件的程序。下面是Cobra使用的一个演示:
在计算机科学领域,反射是指一类应用,它们能够自描述和自控制。也就是说,这类应用通过采用某种机制来实现对自己行为的描述(self-representation)和监测(examination),并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义
大概就是Machine这个类里面维护比较重要的三个元素,States={},Events={}, models= []
Channels by default are blocking on sending and receiving values, so they will be waited on
默认情况下,通道在发送和接收值时会阻塞,因此它们将被等待。
Finally, we add the `xml:"sitemap"` syntax at the end for the parser to understand where it's looking when we go to unpack this with the encoding/xml package.
最后,我们在末尾添加`xml:“sitemap”`语法,以便解析器在我们使用encoding / xml包解压缩它时的位置。
type Sitemapindex struct {
Locations []Location `xml:"sitemap"`
}
Personally, I would test both. If the gains are insignificant by using value receivers where possible and you are using pointer receivers, sure, use all pointer receivers. If you can make sizeable gains by using value receivers where possible, however, I would personally use them.
就个人而言,我会测试两者。
如果在可能的情况下使用值接收器并且您正在使用指针接收器,则增益无关紧要,请确保使用所有指针接收器。
如果使用值接收器获取的收益微不足道,那么在可能的情况下,使用指针接收器,当然,所有地方都使用指针接收器
但是,如果使用值接收器可以获得可观的收益,那么在可能的情况下,会亲自使用它们
Now, we're modifying the struct itself via pointer. Now in the code we could do something like a_car.new_top_speed(500), and this would actually modify the object itself.
现在,我们通过指针修改结构本身。现在在代码中我们可以做类似a_car.new_top_speed(500)的事情,这实际上会修改对象本身
between the func keyword and the name of the function, we pass the variable and type. We use c, short for car, and then car, which is in association with the car struct. In this case, the method gets a copy of the object, so you cannot actually modify it here, you can only take actions or do something like coming up with a calculation
在func关键字和方法名之间,我们传递了变量和类型,
我们使用c,汽车的简称,然后汽车,这是与汽车结构相关联。这样就把struct和method关联了起来
在这种情况下,该方法获取对象的副本,因此您无法在此实际修改它,您只能执行操作或执行类似计算的操作 通过把struct和method关联了起来,使得方法获取到了对象的副本
func (c car) kmh() float64 {
return float64(c.gas_pedal) * (c.top_speed_kmh/usixteenbitmax)
}
In order to do this, we don't need to actually modify the a_car variable, so we can use a method on a value, called a value receiver:
我们想把gas_pedal的值转化成某种实际的速度,为了做到这一点,我们不需要实际修改a_car变量,所以我们可以在值上使用一个方法,称为值 接收器
func (c car) kmh() float64 {
return float64(c.gas_pedal) * (c.top_speed_kmh/usixteenbitmax)
}
Methods that just access values are called value receivers and methods that can modify information are pointer receivers.
只访问值的方法称为值接收器,只有获取值的需求时,用值接收器
可以修改信息的方法是指针接收器,需要修改struct信息时,用指针接收器
可以使用内建函数 make 也可以使用 map 关键字来定义 Map:
// 声明变量,默认 map 是 nil
var map_variable map[key_data_type]value_data_type
// 使用make 函数
map_variable := make(map[key_data_type]value_data_type)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */ number2 := numbers[:2] printSlice(number2) /* 打印子切片从索引 2(包含) 到索引 5(不包含) */ number3 := numbers[2:5] printSlice(number3)
numbers := []int{0,1,2,3,4,5,6,7,8}
len=2 cap=9 slice=[0 1]
len=3 cap=7 slice=[2 3 4]
通过内置函数make()初始化切片s,[]int 标识为其元素类型为int的切片
s := make([]int, len, cap)
初始化切片s,是数组arr的引用
s := arr[:]
/* 未定义长度的数组只能传给不限制数组长度的函数 */ setArray(array) /* 定义了长度的数组只能传给限制了相同数组长度的函数 */ var array2 = [5]int{1, 2, 3, 4, 5}
func setArray(params []int) {
fmt.Println("params array length of setArray is : ", len(params))
}
func setArray2(params [5]int) {
fmt.Println("params array length of setArray2 is : ", len(params))
}
注意:以上代码中倒数第二行的 } 必须要有逗号,因为最后一行的 } 不能单独一行,也可以写成这样:
a = [3][4]int {
{0, 1, 2, 3} ,
{4, 5, 6, 7} ,
{8, 9, 10, 11} , // 此处的逗号是必须要有的
}
上面代码也可以等价于
a = [3][4]int {
{0, 1, 2, 3} ,
{4, 5, 6, 7} ,
{8, 9, 10, 11}}
func getSequence() func() int { i:=0 return func() int { i+=1 return i } }
闭包,A函数 返回一个函数,假设返回的函数为B,那么函数B,可以使用A函数中的变量
nextNumber := getSequence()
nextNumber 是 返回函数B类型,func() int,i是函数A中的变量,初始值 i=0
执行nextNumber(),i+=1, reuturn i ==> 1
再执行nextNumber(),i+=1,return i ==> 2
再执行nextNumber(),i+=1,return i ==> 3
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。
for key, value := range oldMap {
newMap[key] = value
}
以下描述了 select 语句的语法
否则:
1. 如果有default子句,则执行该语句。
2. 如果没有default字句,**select将阻塞,直到某个通信可以运行**;Go不会重新对channel或值进行求值。
iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<< 表示左移的意思),即:i=1, j=6,这没问题,关键在 k 和 l,从输出结果看 k=3<<2,l=3<<3。
package main
import "fmt"
const (
i=1<<iota
j=3<<iota
k
l
)
func main() {
fmt.Println("i=", i)
fmt.Println("j=", j)
fmt.Println("k=", k)
fmt.Println("l=", l)
}
以上实例运行结果为:
i=1
j=6
k=12
l=24
这种因式分解关键字的写法一般用于声明全局变量
var (
vname1 v_type1
vname2 v_type2
)
以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public)
main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)
gRPC 的 service 接口是基于 protobuf 定义的,我们可以非常方便的将 service 与 HTTP/2 关联起来。
/Service-Name/{method name}?( {proto package name} "." ) {service name}{fully qualified proto message name}使用 protobuf 协议定义好 service RPC
基于 HTTP/2 进行通信
一条连接可以包含多个 streams,多个 streams 发送的数据互相不影响。 Stream 可以被 client 和 server 单方面或者共享使用。 Stream 可以被任意一段关闭。 Stream 会确定好发送 frame 的顺序,另一端会按照接受到的顺序来处理。 Stream 用一个唯一 ID 来标识。
Stream: 一个双向流,一条连接可以有多个 streams。 Message: 也就是逻辑上面的 request,response。 Frame::数据传输的最小单位。每个 Frame 都属于一个特定的 stream 或者整个连接。一个 message 可能有多个 frame 组成。
上例中涉及了两个Deferred对象,使用inlineCallbacks装饰器和yield语法,可以用类同步的语法来进行异步编程。
voltha里面有部分代码使用了Twisted架构
The CORD platform brings the economies of a datacenter and the agility of the cloud to the edge of the TELCO network. Built on commodity servers and white box switches, the CORD infrastructure leverages SDN to interconnect the virtual and physical elements and to enable innovative services.
CORD平台将数据中心的经济性和云的灵活性带到了TELCO网络的边缘。
CORD基础架构基于商用服务器和白盒交换机,利用SDN互连虚拟和物理元素,并实现创新服务
R-CORD is an open source solution based on the CORD platform for delivering ultra-broadband residential services. R-CORD transforms the edge of the operator’s network into an agile service delivery platform enabling the operator to deliver the best end-user experience along with innovative next-generation services. Various access technologies can be used including: GPON, G.Fast, 10GPON, and DOCSIS.
R-CORD
R-CORD是一种基于CORD平台的开源解决方案,
用于提供超宽带住宅服务。
R-CORD将运营商网络的优势转变为灵活的服务交付平台, 使运营商能够提供最佳的最终用户体验以及创新的下一代服务。 可以使用各种接入技术,包括:GPON,G.Fast,10GPON和DOCSIS。
Supporting residential subscribers over wireline access technologies like GPON, G.Fast, 10GPON, and DOCSIS
R-CORD
通过有线接入技术支持住宅用户,如GPON,G.Fast,10GPON和DOCSIS
CORD provides a complete integrated platform, integrating everything needed to create a complete operational edge datacenter with built-in service capabilities, all built on commodity hardware using the latest in cloud-native design principles.
CORD提供了一个完整的集成平台,
集成了创建具有内置服务功能的完整运营边缘数据中心所需的一切,
所有这些都使用最新的云原生设计原则构建在商用硬件上。
The CORD (Central Office Re-architected as a Datacenter) platform leverages SDN, NFV and Cloud technologies to build agile datacenters for the network edge. Integrating multiple open source projects, CORD delivers a cloud-native, open, programmable, agile platform for network operators to create innovative services.
CORD(中央办公室重新构建为数据中心)平台
利用SDN,NFV和云技术为网络边缘构建灵活的数据中心。
CORD集成了多个开源项目,为网络运营商提供了一个云原生(cloud-native),开放(open),可编程(programmable),灵活的平台(agile platform),以创建创新服务。
The edge of the operator network (such as the central office for telcos and the head-end for cable operators) is where operators connect to their customers. CORD™ is a project intent on transforming this edge into an agile service delivery platform enabling the operator to deliver the best end-user experience along with innovative next-generation services.
CORD central office re-architected as d datacenter
运营商边缘网络(例如电信公司的中心局和有线电视运营商的前端)是运营商连接到客户的地方。
CORD™旨在将这一优势转变为(agile service delivery platform)灵活的服务交付平台,使运营商能够提供最佳的最终用户体验以及创新的下一代服务 的一个工程
理论上 Calibre-web 会自动新建一个数据库。如果不能新建或者报错,你需要在桌面版的 Calibre 里,在电脑上新建一个空白书库,然后把该目录下的 metadata.db 数据库文件,复制一份到 /books/calibre 目录下,这样应该不会出现问题
自己部署的时候确实会出现新建空白metadata.db出错的问题,不能成功新建DB,所以要利用桌面版新建一个空白db,拷贝到目录下
gt.wait() # 真正开始执行
import eventlet
def func(*args, **kwargs):
... ...
return 0
gt = eventlet.spawn(func, *args, **kwargs)
gt.wait()
当要切换到的目标对象还未激活(从未运行过)时,在切换过程中会执行初始化动作并运行。
主进程执行到gt.wait()时,会切换协程,真正开始执行代码
RoutesMiddleware将HTTP的URL请求应声到相应WSGI函数,并且将路由匹配结果存到environ环境变量中去
RoutesMiddleware 主要作用:
指定了create方法的XML序列化对象为 FullServersTemplate对象,xml反序列化对象为CreateDeserializer,默认的 HTTP Code为202。当HTTP请求处理成功时,Nova API服务器会向客户端返回202 的HTTP Code
@wsgi.response(202)
@wsgi.serializers(xml=FullServerTemlate)
@wsgi.deserializers(xml=CreateDeserializer)
def create(self, req, body):
OpenStack的插件机制,是通过stevedore这个库实现的
NOTE 1: 在使用 Openstack Cammands 的时候一般会发送两次请求:
第一次请求(http://82.0.0.5/v3/tokens)发送给keystone获取授权token,并填充到X-Auth-Token字段中
基于第一次请求获取token,发送第二次请求(http://82.0.0.5/v2.1/servers/detail)给 Nova service 获取虚拟机列表
一开始数据源的上传用的是 -d @/home/centos.tar 这个选项,但是经过反复试验,这个选项TM上传文件不完整,800M的文件只能上传230M,反复查找问题也找不到,最终换成--upload-file选项,上传成功,且根据此镜像可正常启动实例
curl -i -X PUT -H "X-Auth-Token: $token" -H "Content-Type: application/octet-stream" -d @/home/glance/ubuntu-12.10.qcow2 $image_url/v2/images/{image_id}/file
curl -i -X PUT -H "X-Auth-Token: $token" -H "Content-Type: application/octet-stream" --upload-file @/home/glance/ubuntu-12.10.qcow2 $image_url/v2/images/{image_id}/file
curl -H "Content-Type:application/json" -X POST -d 'json data' URL
curl -H "Content-Type:application/json" -X POST -d '{"user": "admin", "passwd":"12345678"}' http://127.0.0.1:8000/login
前面提到OpenStack项目的目录结构是按照功能划分的,而不是服务组件,因此并不是所有的目录都能有对应的组件
*cmd:这是服务的启动脚本,即所有服务的main函数。看服务怎么初始化,就从这里开始。
db: 封装数据库访问,目前支持的driver为sqlalchemy。conf:Nova的配置项声明都在这里。locale: 本地化处理。image: 封装Glance调用接口。network: 封装网络服务接口,根据配置不同,可能调用nova-network或者neutron。volume: 封装数据卷访问接口,通常是Cinder的client封装。virt: 这是所有支持的hypervisor驱动,主流的如libvirt、xen等。objects: 对象模型,封装了所有实体对象的CURD操作,相对以前直接调用db的model更安全,并且支持版本控制。policies: policy校验实现。tests: 单元测试和功能测试代码。在阅读源码之前,首先得了解Openstack代码的架构,至少得知道所有服务的入口
如果不在同一个package中,例如我们希望在module_21.py中调用module_11.py中的FuncA
from module_11包名.module_11 import funcA
Openstack的核心服务为: API、Compute、Scheduler和Network
这两个函数都接收一个分割字符串作为参数,将目标字符串分割为两个部分,返回一个三元元组(head,sep,tail),包含分割符。细微区别在于前者从目标字符串的末尾也就是右边开始搜索分割符。
>>> "django.core.app".partition('.')
('django', '.', 'core.app')
>>> "django.core.app".rpartition('.')
('django.core', '.', 'app')
argarse.ArgumentParser.parse_known_args()解析
有时脚本可能只解析一些命令行参数,将剩下的参数传递给另一个脚本或程序。 在这种情况下,parse_known_args() 方法可能很有用。 它的工作方式与parse_args() 非常相似,只是在出现额外参数时不会产生错误。 相反,它会重新生成包含已填充名称空间和剩余参数字符串列表的两个项目元组。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
'--flag_int',
type=float,
default=0.01,
help='flag_int.'
)
FLAGS, unparsed = parser.parse_known_args()
print(FLAGS)
print(unparsed)
# python test.py --flag_int 1 --flag_bool True --flag_string 'haha, I get it' --flag_float 0.2
Namespace(flag_int=1.0)
['--flag_bool', 'True', '--flag_string', 'haha, I get it', '--flag_float', '0.2']
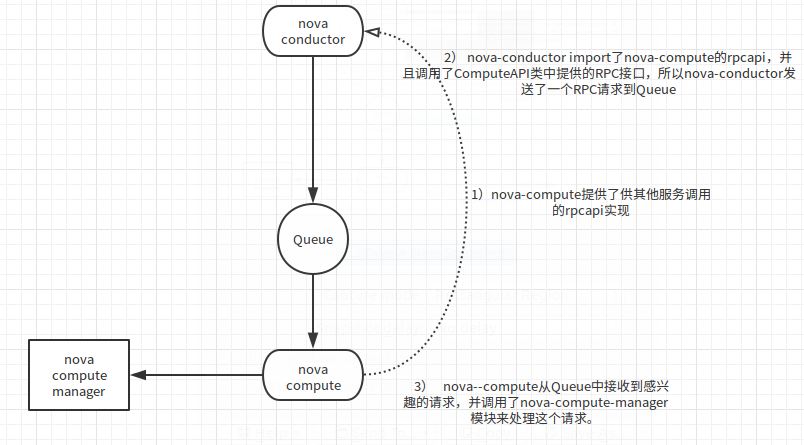
EXAMPLE:当nova-conductor通知nova-compute创建虚拟机实例时,过程如下:
Nova 使用的同步方式是互斥锁,它支持两种类型的锁
Fanout: 相当于广播,producer 可把消息发送给多个 consumer,属于异步调用范畴,如下图
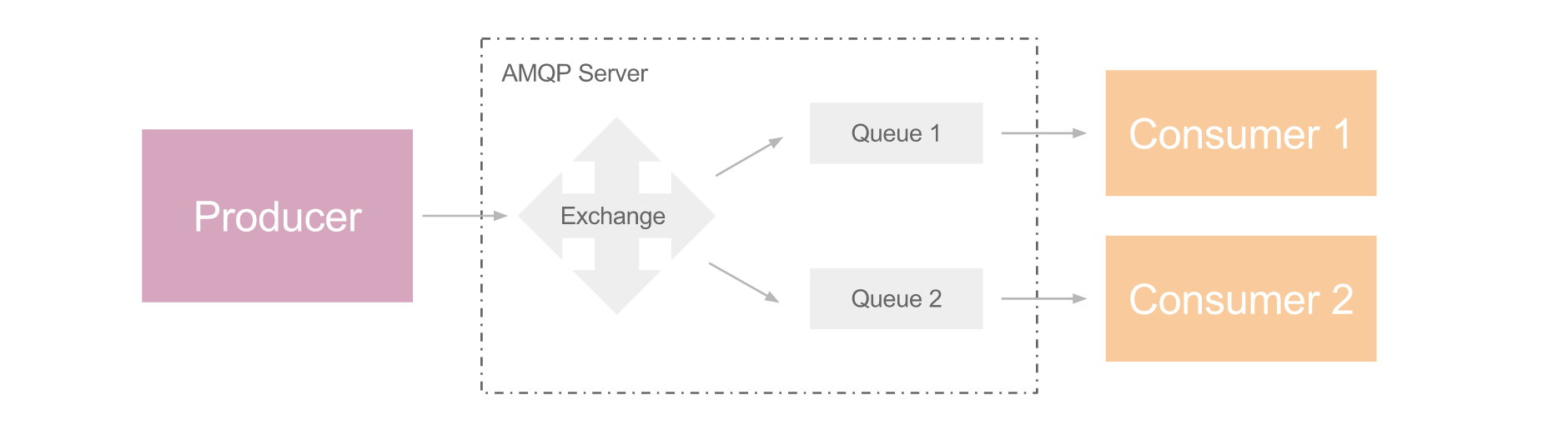
Cast: 异步调用,producer 发送消息后继续执行后续步骤,consumer 接收处理消息,如下图。
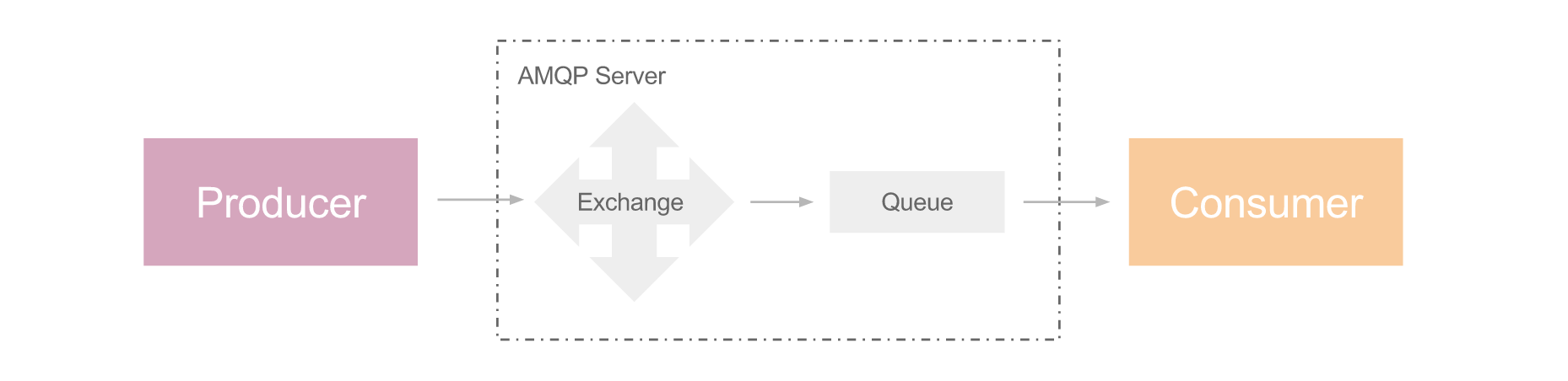
Call: 同步调用,但过程稍微复杂,producer 发送消息后立刻创建一个 direct consumer, 该 direct consumer 阻塞于接收返回值。对端的 consumer 接收并处理 producer 的消息后,创建一个 direct producer,它负责把处理结果发送给 direct consumer
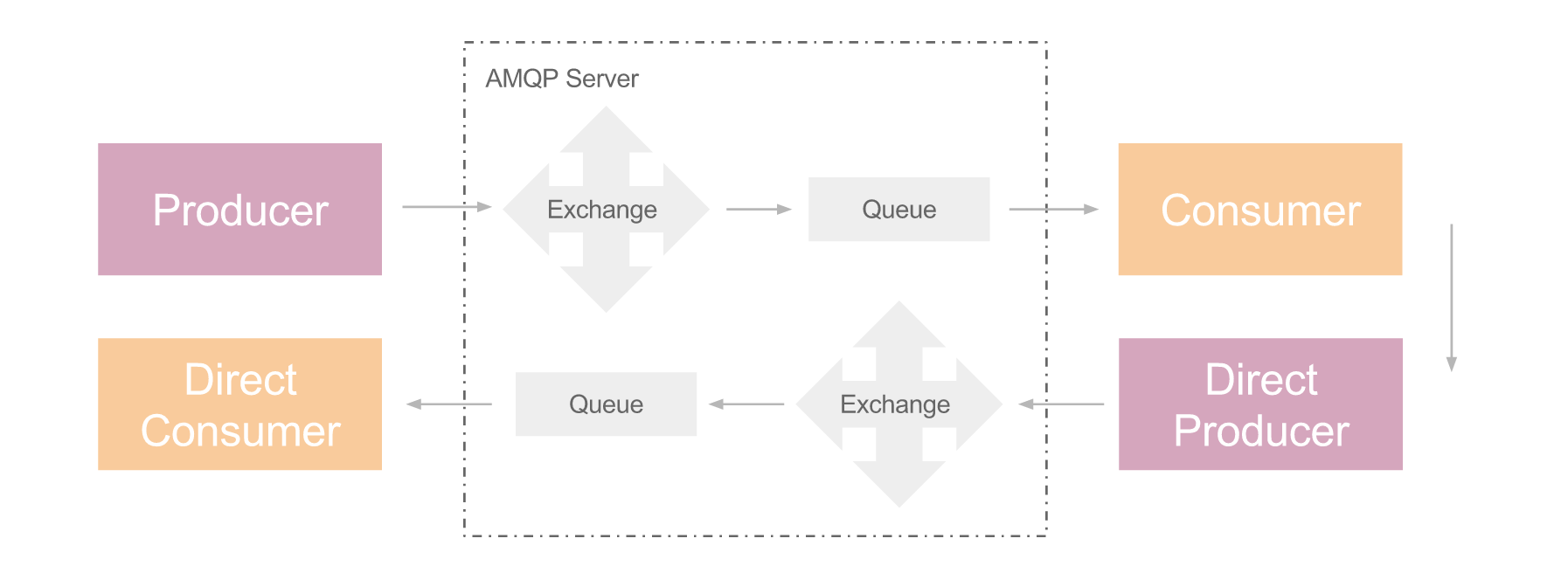
AMQP 是应用层协议,它在 client 和 server 端引入了消息中间件,解耦了 client 和 server 端,支持大规模下的消息通信
AMQP 引入了消息中间件

从RPC角度来看,Client端要远程调用Server端的函数
从AMQP角度来看,Client要发起请求,产生请求消息,所以是Producer,Server端需要获取消息消费,才能进行相应的处理,所以是Consumer
你可以使用传入type=的方式来使用Opt类,或者直接使用其对应类型的子类例如StrOpt类,如果配置项值无法解析成对应类型,将会抛出一个ValueError错误
common_opts = [
cfg.Opt( 'bind_port',
type=PortType,
default=9292,
help='Port number to listen')
]
### 等价于
common_opts = [
cfg.PortOpt( 'bind_port',
default=9292,
help='Port number to listen')
]
最后一种使用插件的方式,相当于Drivers加载和Extensions加载的结合。它允许在给定的entry points组名下有同名的entry point,这样,在给定entry points组名和entry point名的情况下,hook式加载会加载所有找到的插件。
Hook式加载
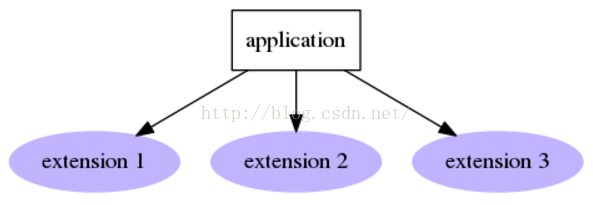
ExtensionManager和DriverManager略有不同,它不需要提前知道要加载哪个插件,它会加载所有找到的插件。 要想调用插件,需要使用map方法,需要传给map一个函数,这里就是format_data函数,针对每个扩展都会调用该函数。format_data函数有两个参数,分别是Extension实例和map的第二个参数da
不需要知道插件的具体名字,指定namespace='xxxx',则会加载xxxx entry point group下的所有插件(扩展)
要调用插件 ==> manager.map(func, args) ==> namespace中的每个插件都会调用该函数func ==> manager.map(func, args) return 一个序列,序列中的每个元素就是每个插件调用回调函数的返回值
定义并注册插件
注册插件是通过 setup.py 来注册插件的
from setuptools import setup, find_packages
setup(
name='test',
version='1.0',
packages=find_packages(),
entry_points={
'namespace': [
'name = module:importable'
],
},
)
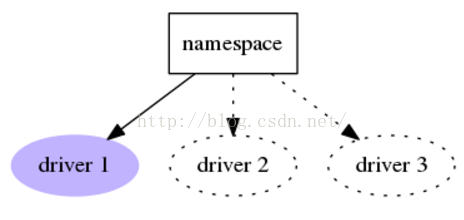
在stevedore中,有三种使用插件的方式:Drivers、Hooks、Extensions
Drivers:一个名字对应一个entry point
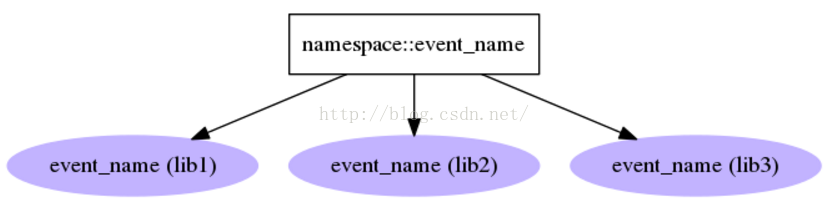
Hooks:一个名字对应多个entry point
Extensions:多个名字对应多个entry point
根据每个插件在entry point中名字和具体实现的数量之间的对应关系不同,stevedore提供了多种不同的类来帮助开发者发现和载入插件,如下图所示:

示例中显示了两个不同的entry points的命名空间,“ceilometer.compute.virt"和"ceilometer.hardware.inspectors",分别注册有3个和1个插件.每个插件都符合"名字=模块:可导入对象”的格式,在“ceilometer.compute.virt"命名空间里的libvirt插件,它的具体可载入的实现是ceilometer.compute.virt.libvirt.inspector模块中的LibvirtInspector类.
ceilometer.compute.virt =
libvirt = ceilometer.compute.virt.libvirt.inspector:LibvirtInspector
hyperv = ceilometer.compute.virt.hyperv.inspector:HyperVInspector
vsphere = ceilometer.compute.virt.vmware.inspector:VsphereInspector
ceilometer.hardware.inspectors =
snmp = ceilometer.hardware.inspectors.snmp:SNMPInspector
Note Due to how Routes matches a list of URL’s, it has no inherent knowledge of a route being a resource. As such, if a route fails to match due to the method requirements not being met, a 404 will return just like any other failure to match a route.
注意:由于路由与URL的列表相匹配,它不具有作为资源的路由的固有知识,因此,如果由于未满足方法要求而导致路由不匹配,则404将像任何其他路由失败一样返回以匹配路由。
A static route is used only for generation – not matching – and it must be named. To define a static route, use the argument _static=True.
静态路由仅用于URL生成,不会用于匹配,并且必须命名。使用参数 _static=True 来定义静态路由
However, if the route defines an extra variable with the same name as a path variable, the extra variable is used as the default if that keyword is not specified.
但是,如果路由定义了一个额外变量和 url() 的路径变量名称相同,如果未指定该关键字,那么额外变量将用 作默认值
### id 作为额外参数
m.connect("archives", "/archives/{id}",
controller="archives", action="view", id=1)
### id作为路径参数
url("archives", id=123) => "/archives/123"
url("archives") => "/archives/1"
url("blog", year=2008, month=10, day=2)
如果路由包含path variables(路径变量),则必须使用关键字参数设置这些变量值:
url("home") => "/"
要生成一个带名字的路由,指定路由名作为位置参数
If the “path_info” variable is used at the end of the URL, Routes moves everything preceding it into the “SCRIPT_NAME” environment variable. This is useful when delegating to another WSGI application that does its own routing: the subapplication will route on the remainder of the URL rather than the entire URL. You still need the ”:.*” requirement to capture the following URL components into the variable.
如果在URL的末尾使用“path_info”变量,则Routes会将其前面的所有内容移动到“SCRIPT_NAME”环境变量中。
当委派另一个WSGI应用程序执行自己的路由时,这非常有用:子应用程序将路由剩余的URL而不是整个URL。
您仍需要“:.*” requirement 才能将以下URL组件捕获到变量中。
map.connect(None, "/cards/{path_info:.*}",
controller="main", action="cards")
# Incoming URL "/cards/diamonds/4.png"
=> {"controller": "main", action: "cards", "path_info": "/diamonds/4.png"}
# Second WSGI application sees:
# SCRIPT_NAME="/cards"
# PATH_INFO="/diamonds/4.png"
map.connect(None, "/error/{action}/{id}", controller="error")
Mapper在Web应用程序中处理URL生成和URL识别。
Mapper是建立处理字典的。 假定Web应用程序将处理返回由URL识别并正确分派的字典。
通过将关键字参数传递到生成函数来完成URL生成,然后返回一个URL。
class Mapper(SubMapperParent):
def __init__(self,
controller_scan=controller_scan,
directory=None,
always_scan=False,
register=True,
explicit=True):
### Create and connect a new
### Route to the Mapper
def connect(self,
routename,
path=None,
**kwargs):
........
app_iter = myfunc(environ, start_response) resp = myfunc(req)
With that myfunc will be a WSGI application, callable like
app_iter = myfunc(environ, start_response).
You can also call it like normal
resp = myfunc(req)
You can also wrap methods
def myfunc(self, req).)
@wsgify def myfunc(req): return webob.Response('hey there')
不添加装饰器,打印type(myfunc)
<type 'function'>
添加装饰器之后,打印type(myfunc)
<class 'webob.dec.wsgify'>
>>> from webob import Request >>> environ = {'wsgi.url_scheme': 'http', ...} >>> req = Request(environ)
### environ 是 WSGI环境变量
req = Request(environ)
把 environ 字典 转换成 <class 'webob.request.Request'> Request对象
所以 webob.Request是对WSGI环境变量的一个封装
@classmethod def factory(cls, global_conf, **kwargs): return cls()
class AnimalApplication(object):
@classmethod
def factory(cls, global_conf, **kwargs):
print cls
return cls()
<class '__main__.AnimalApplication'>
==> cls 指的是类本身
eventlet: python 的高并发网络库 paste.deploy: 用于发现和配置 WSGI application 和 server 的库 routes: 处理 http url mapping 的库
WSGI框架下一些常用的 python module
Middleware 处于 server/gateway 和 application/framework 之间,对 server/gateway 来说,它相当于 application/framework;对 application/framework 来说,它相当于 server/gateway。每个 middleware 实现不同的功能,我们通常根据需求选择相应的 middleware 并组合起来,实现所需的功能
比如,可在 middleware 中实现以下功能:
Callable object 必须满足以下两个条件:
PEP 0333 – Python Web Server Gateway Interface 是一种 web server or gateway 和 python web application or framework 之间简单通用的接口,符合这种接口的 application 可运行在所有符合该接口的 server 上
WSGI -- web server gateway interface
是一种 web server/gateway 和 python web application/framework 之间的通用接口
符合这种接口的application,都可以运行在符合该接口的server上
application <==> web server gateway interface <==> server
a proposed standard interface between web servers and Python web applications or frameworks
WSGI -- a interface of python web applications or frameworks
When the read system call is invoked, the application blocks and the context switches to the kernel. The read is then initiated, and when the response returns (from the device from which you're reading), the data is moved to the user-space buffer
由此可见,系统调用 --- system call 的一些特性:
user-space 只能调用 system call(就像调用普通函数一样) user-space 不能执行 system call,system call 的执行在 kernel-space。 kernel-space 负责执行函数,函数的 body 部分就是与 IO 进行交互,read/write 等。 整个过程,user-space thread 不会 sleep,也就是不释放 CPU,且程序不再前进,所以是 blocking and sync 到底什么是 sync 和 async 注意:
sync 的意思是 不释放CPU async 的意思是 释放CPU 如何理解呢:
释放 CPU 的话,在 CPU 眼里就没有这个线程了,不会给其分配 time slicing, like this:
. | | | |
. | | | |
. | | | |
第一个线程是 async 的,那么他在 CPU 眼里是不存在的, CPU 也不会再给他分配 time slicing.
| | | | |
| | | | |
| | | | |
第一个线程是 sync 的,那么他在 CPU 眼里依旧存在, CPU 照常给他分配 time slicing.
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇 这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
user-space vs. kernel space 系统函数只能在 kernel-space 中执行;但可以在 user-space 中调用。 系统函数在 kernel-space 中执行完毕后需要把结果拷贝给 user-space 中发起调用的线程,作为函数的返回结果。 所以系统调用这个东西吧,像是隔了一层,和普通的 API 函数还不一样。> When the read system call is invoked, the application blocks and the context switches to the kernel. The read is then initiated, and when the response returns (from the device from which you're reading), the data is moved to the user-space buffer.
由此可见,系统调用 --- system call 的一些特性:
注意:
如何理解呢:
释放 CPU 的话,在 CPU 眼里就没有这个线程了,不会给其分配 time slicing, like this:
. | | | |
. | | | |
. | | | |
第一个线程是 async 的,那么他在 CPU 眼里是不存在的, CPU 也不会再给他分配 time slicing.
| | | | |
| | | | |
| | | | |
第一个线程是 sync 的,那么他在 CPU 眼里依旧存在, CPU 照常给他分配 time slicing.
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
这就是 async 和 sync 的区别,他是关于 CPU是否给其分配 time slicing 的词汇
第三种选择,你站在讲台上等,谁解答完谁举手
IO复用模型,Linux下的select, poll, epoll就是干这个的
操作系统为你提供了一个功能,当你的某个socket可读或者可写的时候,它可以给你一个通知
操作系统的这个通知机制,是I/O多路复用技术的基础
Iterator Protocol
The protocol specifies methods to be implemented to make our objects iterable.
该协议指定了要实现我们的对象迭代的方法。
"Iterable" simply means able to be looped over or otherwise treated as a sequence or collection.
“可迭代”仅仅意味着能够循环或像对待序列或集合一样的方式处理。
Classes allow us to create a custom type of object -- that is, an object with its own behaviors and its own ways of storing data.
Introduction of Classes 类允许我们创建一个自定义类型的对象 - 也就是说,一个对象具有自己的行为和自己的存储数据的方式。
Packages provide for accessing variables within multiple files.
从package多文件访问变量的注意事项
A package is a directory of files that work together as a Python application or library module.
Introduction python packages
packages是一个文件目录,可以作为Python应用程序或库模块一起工作
Recursion features three elements
递归调用三要素:
*args and **kwargs to capture all arguments
*args 和 **kwargs 可以代表所有参数
为了允许装饰函数接受参数,我们必须接受它们并将它们传递给装饰函数。
object: a data value of a particular type variable: a name bound to an object
什么是object -- 是一个具有类型的数据 什么是变量 -- 是一个绑定对象的名字
All programs named test_something.py that have functions named test_something()
pytest Basics
unit test: testing individual units (function/method) integration test: testing multiple units together regression test: testing to see if changes have introduced errors end-to-end test: testing the entire program
sqlite> .mode column sqlite> .headers on
At the start of your session,these will format your sqlite3 output so it is clearer, and add columns headers.
pandas is a Python module used for manipulation and analysis of tabular data.
Introduction to Pandas
Pandas is used to manipulation and analysis of tabular data
pandas official documentation
pandas reference and tutorials include:full docs, 10minutes to pandas, blog tutorials
When the entire cluster is brought down, the last node to go down must be the first node to be brought online. If this doesn't happen, the nodes will wait 30 seconds for the last disc node to come back online, and fail afterwards.
当整个群集关闭时, 最后一个要关闭的节点必须是第一个要联机的节点。 如果没有发生这种情况,则节点将等待30秒钟,以使最后一个光盘节点重新联机,然后再失败
All data/state required for the operation of a RabbitMQ broker is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes
运行RabbitMQ代理所需的所有数据/状态都将在所有节点上进行复制。
一个例外是消息队列,默认情况下驻留在一个节点上,尽管它们可以从所有节点看到并且可以访问
rabbitmq是AMQP的一种基于Erlang的实现
rabbit_amqqueue_process是队列进程,rabbit_msg_store是负责进行消息持久化的进程
rabbitmq_amqqueue_process队列进程和rabbit_msg_store消息持久化进程,都是RabbitMQ启动或者创建队列时创建的
Erlang是一门动态类型的函数式编程语言,它也是一门解释型语言,由Erlang虚拟机解释执行。从语言模型上说,Erlang是基于Actor模型的实现。在Actor模型里面,万物皆Actor,每个Actor都封装着内部状态,Actor相互之间只能通过消息传递这一种方式来进行通信。对应到Erlang里,每个Actor对应着一个Erlang进程,进程之间通过消息传递进行通信。
Erlanng是一门动态类型的函数式编程语言,也是一门解释型语言,由Erlang虚拟机解释执行
Tempest的测试结果有四种:测试错误(Error)、测试失败(Failure)、跳过(Skip)、成功(Success)。其含义分别如下
Tempest 测试的4种结果
Running Tests
ostestr 部分命令 ostestr openstack文档部分介绍
Nose identified them as tests since they had the word "tests" as part of their name, and that is one of the things nose uses to identify what is a test and what is not
nosetests 会根据是否带有‘tests’一词作为其名称的一部分,来作为识别什么是测试,什么不是测试
实际情况是,有些带有tests的函数并不是测试,所以nostests和testrs测试的数量不一样
社区推荐使用ostestr
Overview of the current Scenario tests
tempest scenario tests,tempest场景测试用例,相关简要概述,以及需要用到的openstack services
$ testr run --parallel tempest.
### 使用testr测试工具
# testr run --parallel xxxx
### 使用nosetests测试工具
# nosetests -vx xxxxx
如何执行 tempest