happened at a
What is that?
happened at a
What is that?
Eric just made a 220 second case for firing him
???
PromQL Example - http requests total https://youtu.be/STVMGrYIlfg?t=417
To understand Prometheus even better, let's have a look at its core features. The dimensional data model, the metrics transfer format, the query language, integrated alerting, and support for service discovery.
All right, with that out of the way, let's have a look at the system architecture of a basic Prometheus monitoring setup.
Prometheus Architecture
Target
A target is the definition of an object to scrape. For example, what labels to apply, any authentication required to connect, or other information that defines how the scrape will occur.
Time Series
The Prometheus time series are streams of timestamped values belonging to the same metric and the same set of labeled dimensions. Prometheus stores all data as time series.


A sample is a single value at a point in time in a time series.
In Prometheus, each sample consists of a float64 value and a millisecond-precision timestamp.
Prometheus
Prometheus是希腊神话中的一个重要人物,他是泰坦神族的成员之一。在神话故事中,普罗米修斯以其智慧和对人类的善意著称,他从众神那里偷取了火种赠予人类,使人类得以进步和发展,象征着知识和文明的光辉。然而,这一行为激怒了宙斯,导致普罗米修斯受到了惩罚,被绑在高加索山上,每天有一只鹰来啄食他的肝脏,而他的肝脏会在夜间再生,这样的折磨持续了数百年,直到赫拉克勒斯将他解救。
在选择“Prometheus”作为监控系统的名字时,可能寓意着这个系统具有带来光明和知识的能力,就像普罗米修斯将火的力量带给了人类一样,Prometheus监控系统旨在通过提供对系统和应用程序性能的深入了解,帮助人们管理和改善其技术基础设施。这个名字反映了该系统作为技术领域中的一个“启明者”和“赋能者”的角色。
throttles
Throttle原本的意思是节流阀或者油门,用于控制流体(如汽油、空气)流动的速度或量。在汽车中,踩油门就是通过控制油门来增加燃油流向引擎的速度,从而加快车速。在计算机科学(CS)中,"throttle"这个概念被借用来表示限制或控制数据传输或处理的速率。这种概念转移是因为在两个领域中,throttle都涉及到通过调节流量来达到控制系统行为的目的。
在Alertmanager的上下文中,throttle意味着控制警报通知的发送频率,以避免过多的通知造成接收者或者系统的负担。例如,如果有大量相似的警报被触发,而不加以控制地发送所有通知,那么接收方(比如运维团队)可能会被大量重复的信息淹没,从而难以迅速准确地响应真正重要的警报。通过throttling,Alertmanager可以合理地控制通知的发送,确保信息的有效传达而不造成不必要的干扰。
binary
在这个上下文中,"a binary"指的是一个可执行文件,也就是一个编译好的程序,可以直接在计算机上运行。它被称为"binary"是因为它以二进制格式存储,这是计算机能够直接理解和执行的格式。所以,虽然"binary"确实有二进制的意思,但在软件和编程领域,提到"a binary"时,通常是指一个编译后的可执行程序。
要直接抓取on-premise服务的metrics,你需要掌握以下几个关键领域的知识:
具体到操作层面,设置Prometheus直接抓取on-premise服务的metrics大致需要以下步骤:
掌握这些知识和步骤后,你应该能够有效地配置Prometheus直接抓取你的on-premise服务的metrics。
"Federation"(联邦)这个术语在Prometheus的上下文中被用来描述一种特定的数据聚合模式,它允许从多个Prometheus实例中汇总数据到一个中心实例。这个概念源于更广泛的联邦理念,即不同实体(在这种情况下是Prometheus服务器)保持相对的自治,同时共享一些资源或数据以实现更大的目标。
在政治和组织领域,联邦是由几个部分或州组成的一个单一实体,这些部分或州在某些方面保持自主,但在其他方面共享共同的中央政府或组织。这个概念转移到数据管理和监控领域时,有以下含义:
Prometheus联邦的典型使用场景包括:
总之,Prometheus的联邦机制体现了一种旨在结合自治和共享的平衡方式,通过分散和集中的结合来实现更有效、更灵活的监控策略。
要实现这个目标,你可以通过几种方法来配置Kubernetes中的Prometheus,使其能够监控集群外的on-premise services。以下是一些建议的解决方案:
Prometheus支持使用联邦(Federation)功能来从其他Prometheus服务器中汇聚数据。你可以配置Kubernetes集群中的Prometheus实例作为一个联邦父节点,从集群外的on-premise Prometheus实例中抓取metrics。这种方法允许你从多个Prometheus实例中选择性地聚合数据。
/federate端点,并使用match[]参数指定要抓取的metrics集。如果on-premise服务的metrics端点是对外可访问的,并且与Kubernetes集群的Prometheus网络可达,你可以直接在Kubernetes集群的Prometheus配置中添加静态targets来抓取这些服务的metrics。
prometheus.yaml),添加一个新的scrape job。如果直接抓取on-premise服务的metrics存在网络隔离或安全策略的问题,可以考虑使用Prometheus PushGateway。on-premise服务可以定期将metrics推送到PushGateway,而Kubernetes集群中的Prometheus则可以从PushGateway抓取这些metrics。
选择哪种方法取决于多个因素,包括网络配置、安全需求、以及是否愿意维护额外的组件(如PushGateway)。如果可能,使用Federation或直接抓取on-premise服务的metrics通常更简单直接,因为这两种方法不需要维护额外的中间件。但是,如果网络或安全策略限制了这两种方法的使用,那么使用PushGateway可能是一个可行的解决方案。

在Prometheus的上下文中,当配置scrape jobs以收集来自不同服务的metrics时,安全性变得至关重要,尤其是当这些服务部署在不受信任的网络或者需要确保数据传输安全和访问控制时。Prometheus支持几种认证和加密机制来保证数据的安全传输和访问控制,包括基本认证、Bearer Token认证和通过TLS进行传输加密。下面是对这些机制的简要解释:
基本认证是HTTP协议支持的一种简单的认证方式,它允许HTTP用户代理(如Prometheus服务器)通过请求头中的Authorization字段提供用户名和密码。这种方式不需要复杂的请求编码或会话管理,但因为用户名和密码是以明文形式发送的(虽然是Base64编码,但容易被解码),所以只有在HTTPS等加密通道中使用时才安全。
在Prometheus配置中,可以为特定的scrape job配置基本认证,示例如下:
yaml
scrape_configs:
- job_name: 'my-secure-service'
scheme: https # 确保使用https
static_configs:
- targets: ['secure-service.example.com:443']
basic_auth:
username: 'myUsername'
password: 'myPassword'
Bearer Token认证是一种更安全的HTTP认证方法,通常用于OAuth 2.0等认证框架。在这种方法中,客户端发送一个Authorization请求头,包含一个安全令牌,这个令牌代表客户端的认证凭据。
在Prometheus的场景中,Bearer Token可以用于访问需要OAuth2.0或类似机制保护的服务。配置示例如下:
yaml
scrape_configs:
- job_name: 'my-oauth2-service'
scheme: https # 使用https
static_configs:
- targets: ['oauth2-service.example.com:443']
authorization:
type: 'Bearer'
credentials: 'mySecretToken'
传输层安全(TLS)是一种加密协议,旨在提供计算机网络通信的安全和数据完整性保护。Prometheus支持通过TLS连接到目标服务,这样可以确保抓取过程中的数据加密和安全传输。
配置TLS,你需要指定TLS证书和密钥,有时还需要CA证书来验证服务器的证书。这在访问使用自签名证书的服务或在强制加密环境下特别有用。TLS配置示例:
yaml
scrape_configs:
- job_name: 'my-tls-service'
scheme: https # 使用https
static_configs:
- targets: ['tls-service.example.com:443']
tls_config:
ca_file: '/path/to/ca.crt' # CA证书,用于验证服务器证书
cert_file: '/path/to/client.crt' # 客户端证书
key_file: '/path/to/client.key' # 客户端密钥
# 如果服务使用的是自签名证书,则需要设置下面这个选项
insecure_skip_verify: false
使用这些机制,你可以确保Prometheus与你的服务之间的通信既安全又受控,保护敏感的metrics数据不被未授权访问或泄露。
在Prometheus中,"scrape job"是指定定时抓取(或称为"scraping")目标服务metrics的配置单元。每个scrape job定义了一组目标(targets),这些目标是Prometheus需要定期访问并收集metrics数据的服务或实例。scrape job的配置包括抓取频率、目标服务的地址、认证信息(如果需要的话)以及其他抓取行为的配置细节。
job标签的值,用于区分来自不同scrape jobs的数据。scrape_interval: 15s意味着Prometheus每15秒向每个目标发送一次抓取请求。/metrics。下面是一个简单的scrape job配置示例,它定义了一个名为my-service的scrape job,用于抓取运行在localhost:9090上的服务的metrics。
yaml
scrape_configs:
- job_name: 'my-service'
scrape_interval: '15s'
static_configs:
- targets: ['localhost:9090']
Prometheus支持多种服务发现机制来动态发现scrape targets,比如Kubernetes、Consul、AWS EC2等。使用服务发现,Prometheus可以自动更新它的目标列表,以匹配动态变化的环境,例如在Kubernetes集群中自动发现和抓取新部署的服务。
Scrape jobs是Prometheus监控配置的核心。它们确保Prometheus能够定期从配置的服务中收集metrics,从而提供系统和应用性能的实时视图。合理配置scrape jobs对于确保数据的准确性和时效性至关重要。
Prometheus Federation 是一种机制,允许一个Prometheus服务器从另一个Prometheus服务器中抓取选定的数据。这种方法经常用于创建层次化的监控架构,其中高层级的Prometheus实例聚合和监控来自多个源的数据,而这些源可能是其他Prometheus实例。Federation特别适用于大规模环境、多层监控策略,或者当需要跨不同网络区域汇总监控数据时。
在Federation设置中,有两个关键组件:父Prometheus实例(Federator)和子Prometheus实例。父实例负责抓取(scrape)来自一个或多个子实例的数据。这个过程是通过子实例上的/federate端点完成的。
要通过Federation抓取metrics,你需要在父Prometheus实例上配置一个新的scrape job,专门用于抓取来自子Prometheus实例的数据。这个配置可以指定要从子实例抓取哪些metrics,使用match[]参数来过滤。
假设你想从一个on-premise Prometheus实例抓取特定的metrics到Kubernetes集群中的Prometheus实例。你可以在Kubernetes Prometheus的配置文件中添加类似以下的配置:
yaml
scrape_configs:
- job_name: 'federate'
scrape_interval: '15s'
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'on-premise-prometheus.example.com:9090'
在这个示例中:
job_name:这个scrape job的名称。scrape_interval:抓取数据的频率。honor_labels:设置为true,意味着Prometheus将保留从源Prometheus实例获取的metrics的标签,避免标签冲突。metrics_path:指向子实例的/federate端点。params:定义了一个match[]列表,用于指定哪些metrics应该被抓取。在这个例子中,它匹配所有标签为job="prometheus"的metrics,以及所有名称与job:.*正则表达式匹配的metrics。static_configs:定义了子Prometheus实例的地址。优势:
需要考虑的因素:
scrape_interval和选择要抓取的metrics非常重要。Federation提供了一种强大的方式来集中管理和聚合来自多个Prometheus实例的监控数据,但它也需要仔细的规划和配置以确保有效和高效地使用。
Searching the call stack for the exception handler
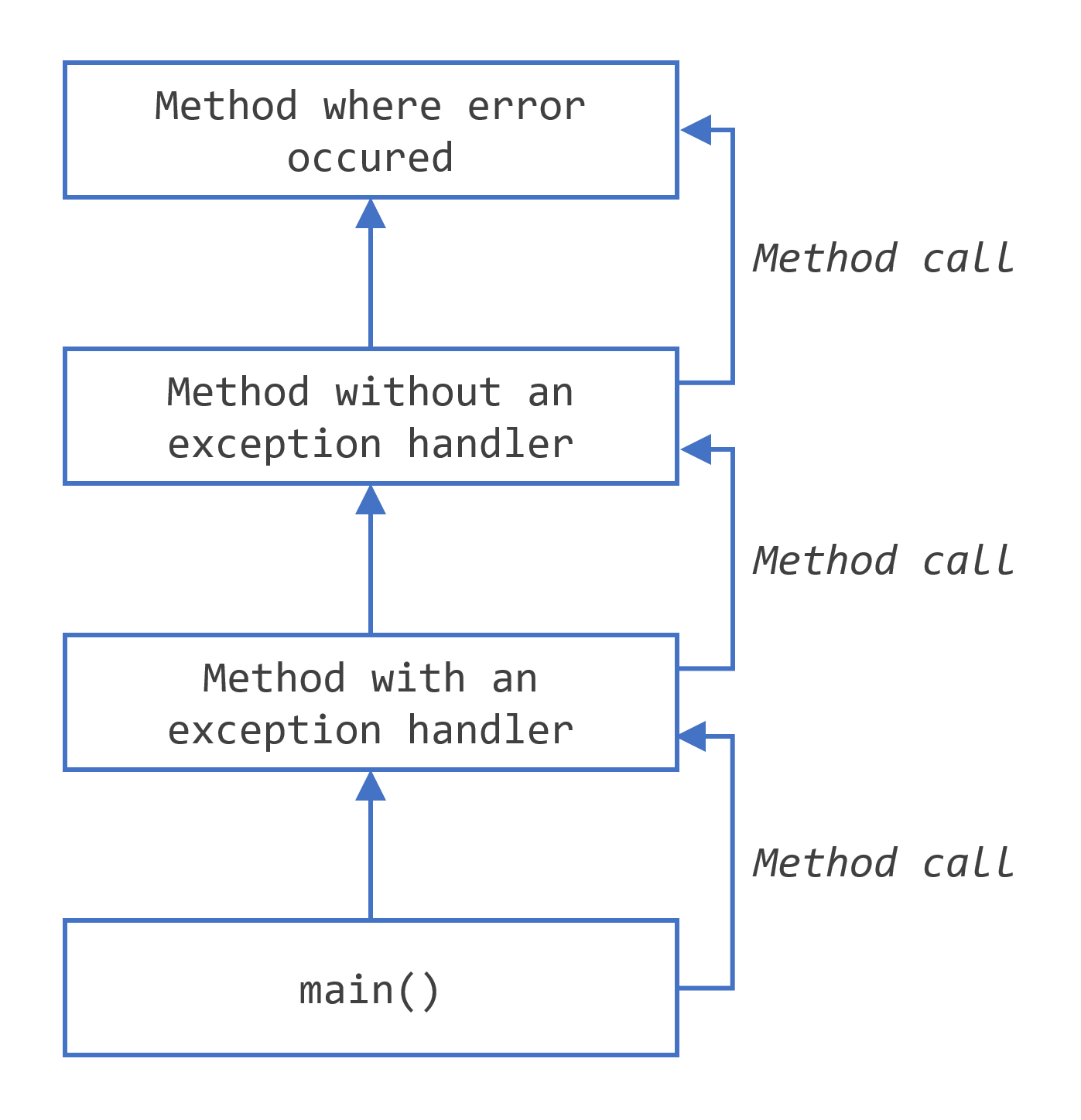
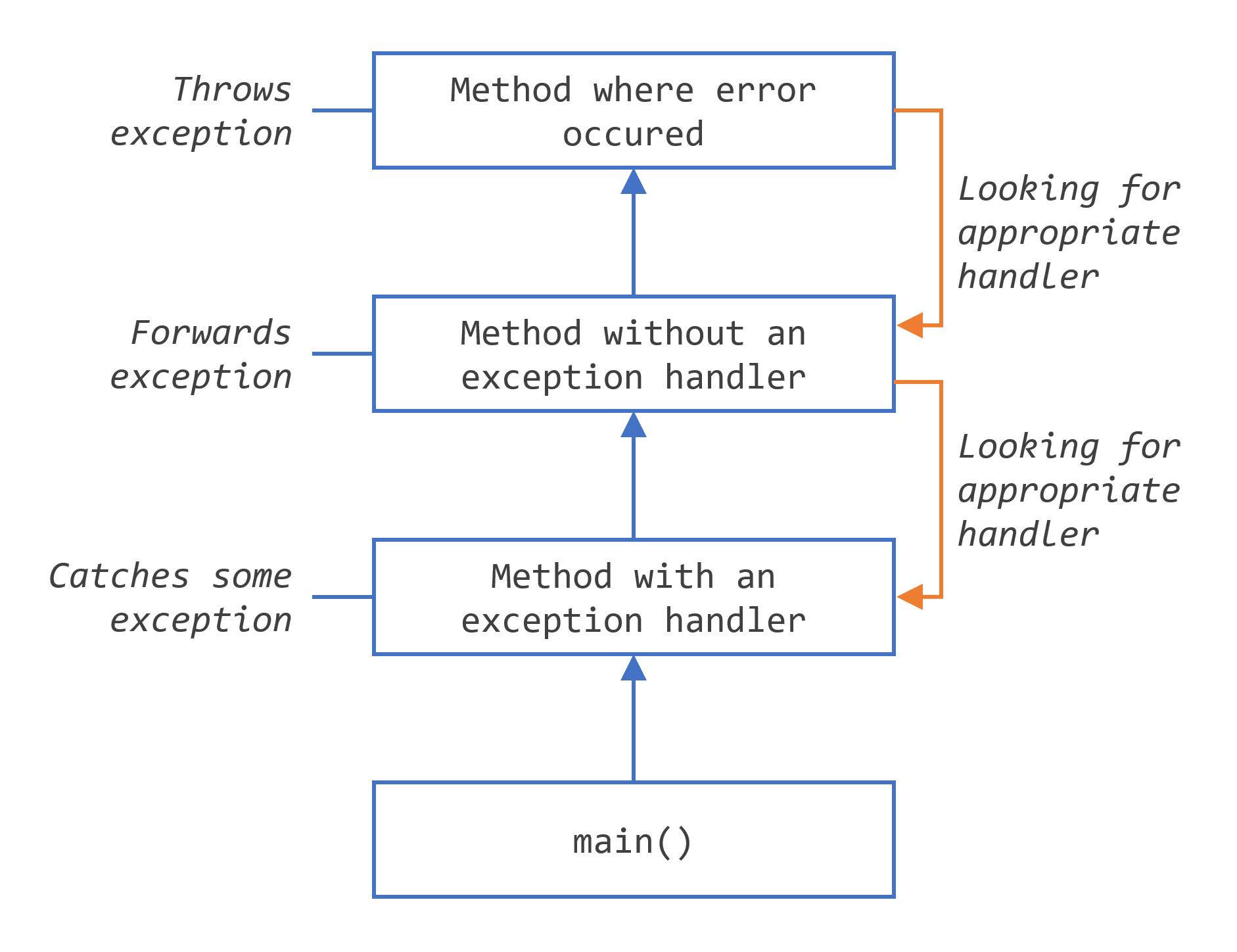
checked exception
在Java中,异常分为两大类:checked exception(受检异常)和unchecked exception(非受检异常)。受检异常是那些在编译时期就必须处理的异常,否则程序无法编译通过。这种机制确保了开发者能够提前考虑到各种异常情况,并强制要求处理这些可能发生的异常,以增强程序的健壮性。
以下是一些常见的checked exception的例子:
```java import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException;
public class Main { public static void main(String[] args) { try { BufferedReader reader = new BufferedReader(new FileReader("somefile.txt")); String line; while ((line = reader.readLine()) != null) { System.out.println(line); } reader.close(); } catch (IOException e) { e.printStackTrace(); } } } ```
```java import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException;
public class DBConnect { public static void main(String[] args) { try { Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "user", "password"); // 使用连接对象进行数据库操作 } catch (SQLException e) { e.printStackTrace(); } } } ```
Class.forName()动态加载类时。java
public class Main {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
这些checked exception必须被显式地捕获(try-catch)或者在方法签名中通过throws子句声明。这样做的目的是提醒开发者,这些操作可能会失败,并且需要有相应的处理逻辑来应对这些失败的情况。
error
在Java中,一个Error代表了一个严重的问题,通常情况下,合理的应用程序不应该尝试去捕获这些错误。Error在Java运行时系统中用于指示运行环境(JVM)中的错误。以下是Java中Error的几个例子:
OutOfMemoryError:当Java虚拟机因为内存耗尽而无法分配对象时,将抛出此错误,此时已经没有更多的内存可以被分配了。
StackOverflowError:这个错误发生在应用程序递归调用自身的过程中堆栈溢出时。例如,一个方法不断地调用自己,而没有适当的终止条件。
NoClassDefFoundError:当Java虚拟机或ClassLoader实例试图加载类定义时,如果找不到对应的类,就会抛出这个错误。
UnsatisfiedLinkError:当Java虚拟机无法找到某个本地(native)方法的声明时,会抛出此错误。这通常发生在尝试使用Java本地接口(JNI)来调用本地代码时,但找不到相应的本地库。
这些错误通常指示着存在一些不能通过应用程序代码来恢复的底层问题。处理这些错误的最佳做法通常是尽量避免它们发生,例如,通过优化内存管理来避免OutOfMemoryError,或者确保所有必须的类都在类路径中以避免NoClassDefFoundError。在极少数情况下,应用程序可能会捕获某些错误,例如,为了在应用程序崩溃前记录一些诊断信息。
runtime exception
运行时异常是指在程序运行期间可能出现的异常情况,这些异常通常是由程序内部的错误引起的,比如逻辑错误或者API的不当使用。运行时异常通常是程序员无法预料或者难以从中恢复的异常条件。这些异常表明了程序中可能存在的编程错误。
例如,如果一个程序错误地传递了一个null给FileReader的构造器,这将引发一个NullPointerException。这种情况下,虽然程序可以捕获这个异常,但更合理的做法是修正导致异常发生的逻辑错误。
运行时异常的一个关键特点是它们不受Java语言强制的“捕获或声明抛出”(Catch or Specify Requirement)规则约束。这意味着编写方法时,你不需要显式地声明方法可能抛出的运行时异常,也不强制要求捕获这些异常。运行时异常及其子类都是通过RuntimeException类来表示的。
这种设计允许程序员处理真正需要关注的异常情况,而不是被迫处理每一个可能的异常,从而使代码更加清晰和易于维护。然而,这也意味着程序员需要更加小心地编写代码,避免因忽视这些运行时异常而导致的程序崩溃。
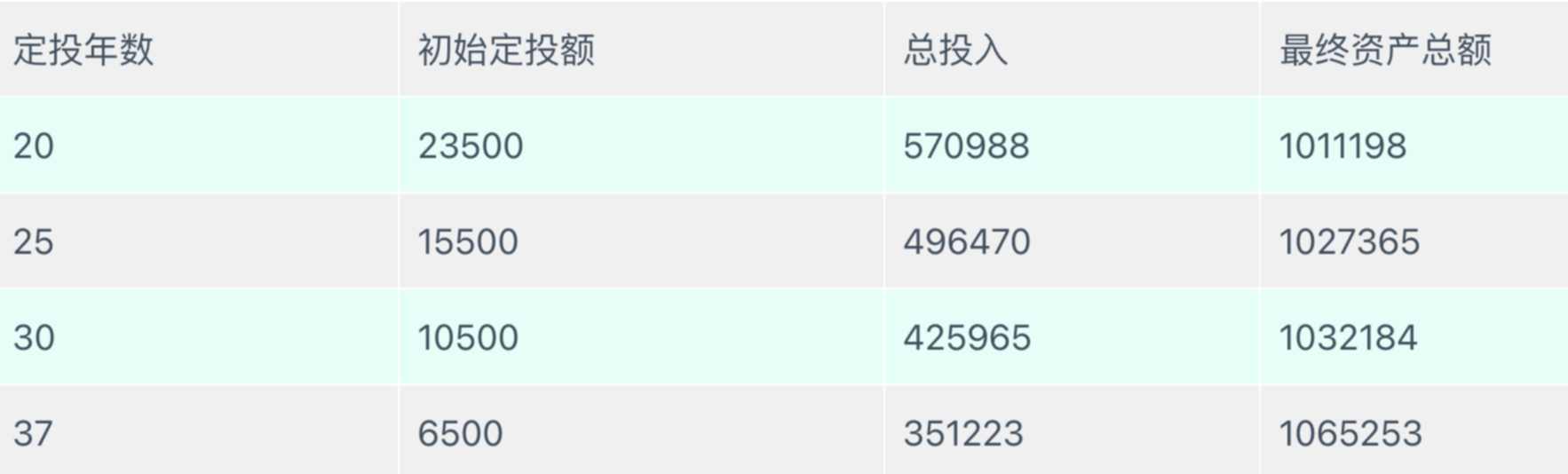
根据自己的年龄,可以依据上表的计算结果估计第一年需要的定投量。比如67岁退休,而现在是30岁,退休前还可以定投37年。那么想要退休时拥有百万欧元的资产,第一年要定投6500欧元,相当于每月投入542欧元。当然股市是有波动的,假如在定投的最后几年赶上了超级熊市,可能资产并不能在退休时达到100万欧元,但是只要再等等,总会等到牛市的。
定投年数和初始定投额
这四步骤旨在指导个人如何有效地管理和增加财富。
MSCI World
MSCI World是一个国际性的股票指数,由摩根士丹利资本国际公司(Morgan Stanley Capital International,简称MSCI)编制。该指数旨在反映全球发达市场中大型和中型股票的表现。MSCI World指数涵盖了23个发达国家,包括美国、日本、英国、加拿大、法国、德国等国家的股票市场,是衡量全球股市表现的重要指标之一。投资者通过投资MSCI World指数相关的金融产品,如指数基金或交易所交易基金(ETF),可以实现对全球发达市场股票的广泛投资。
ETF指数基金和个股比有什么好处呢?ETF是大量股票的集合,买它可以很容易做到分散投资。全世界所有的大公司同时倒闭或者亏损的可能性是微乎其微的,所以持有ETF的风险是比较小的。而投资个股,运气不好就可能碰上大众尾气门这样的事件,对收益打击很大;运气再不好一些公司还可能会倒闭,血本无归。想自己买大量个股进行分散投资,则需要花费大量的时间和精力。
投资指数基金的盈利逻辑也很简单,只要全球经济长期来看是增长的,那么买入MSCI World全球发达国家股票指数基金,我们就能盈利。
ETF指数基金和个股比有什么好处呢?ETF是大量股票的集合,买它可以很容易做到分散投资。全世界所有的大公司同时倒闭或者亏损的可能性是微乎其微的,所以持有ETF的风险是比较小的。而投资个股,运气不好就可能碰上大众尾气门这样的事件,对收益打击很大;运气再不好一些公司还可能会倒闭,血本无归。想自己买大量个股进行分散投资,则需要花费大量的时间和精力。
sudo chsh -s /bin/sh bob
这条命令用于更改用户的默认shell。具体来说,sudo chsh -s /bin/sh bob 将用户bob的默认shell更改为/bin/sh。在这里,chsh是用于更改shell的命令,-s选项表示要更改shell,/bin/sh是要更改为的shell,bob是要更改的用户。通过这条命令,用户bob将使用/bin/sh作为其默认shell。
Bourne Shell(Bourne壳)是Unix操作系统下的一种命令行界面和脚本语言解释器。它由Stephen Bourne在贝尔实验室开发,最初发布于1979年,作为Version 7 Unix的一部分。Bourne Shell是许多后来的Unix Shell的前身,如Bash(Bourne Again SHell)和Ksh(Korn Shell)。它的标识符是sh。Bourne Shell引入了许多编程功能,如变量、控制流语句和函数,极大地增强了Unix系统的脚本编写和任务自动化能力。
User profile scripts,如~/.zshrc,是存储在用户主目录下的配置文件,用于自定义Shell的行为和环境。这些脚本文件在Shell启动时自动执行,允许用户配置环境变量、别名、函数、Shell选项和其他Shell启动时需要的设置。
例如,~/.zshrc是Z Shell(zsh)的用户配置文件,仅在zsh启动时读取和执行。如果你使用Bash Shell,相应的配置文件是~/.bashrc。
这些脚本的作用包括但不限于:
PATH这样的环境变量,定义Shell查找可执行文件的目录。通过定制这些配置文件,用户可以创建一个符合个人工作习惯和偏好的命令行环境。
这条命令的作用是将export MY_VARIABLE="example_value"这个命令追加到~/.profile文件的末尾。这意味着每当你登录或启动一个新的登录Shell时,MY_VARIABLE这个环境变量就会被设置为example_value。
具体来说:
echo命令用于输出其后面的字符串。'export MY_VARIABLE="example_value"'是被输出的字符串,它是一个Shell命令,用于将MY_VARIABLE这个环境变量导出并设置其值为example_value。>>操作符用于将左侧命令的输出追加到右侧指定的文件中。如果文件不存在,Shell会创建这个文件。~/.profile是用户的个人初始化文件,用于登录时设置个人环境和启动程序。它通常在登录时被Shell自动执行。这样做的效果是,每当你登录系统时,MY_VARIABLE这个环境变量就会自动被设置为example_value,你可以在任何运行在这个Shell会话中的程序里访问它。

Linux Kernel, Librarian Analogy
股票期权基础知识 厦门大学 16讲