Ultimately the data scientists need me more than I need them; I’m the reason their stuff is in production and runs smoothly.
48 Matching Annotations
- Dec 2022
-
ryxcommar.com ryxcommar.com
-
- Jan 2021
-
news.ycombinator.com news.ycombinator.com
-
I can't recommend the Data Engineer career enough for junior developers. It's how I started and what I pursued for 6 years (and I would love doing it again), and I feel like it gave me such an incredible foundation for future roles :- Actually big data (so, not something you could grep...) will trigger your code in every possible way. You quickly learn that with trillions of input, the probabily to reach a bug is either 0% or 100%. In turn, you quickly learn to write good tests.- You will learn distributed processing at a macro level, which in turn enlighten your thinking at a micro level. For example, even though the order of magnitudes are different, hitting data over network versus on disk is very much like hitting data on disk versus in cache. Except that when the difference ends up being in hours or days, you become much more sensible to that, so it's good training for your thoughts.- Data engineering is full of product decisions. What's often called data "cleaning" is in fact one of the import product decisions made in a company, and a data engineer will be consistently exposed to his company product, which I think makes for great personal development- Data engineering is fascinating. In adtech for example, logs of where ads are displayed are an unfiltered window on the rest of humanity, for the better or the worse. But it definitely expands your views on what the "average" person actually does on its computer (spoiler : it's mainly watching porn...), and challenges quite a bit what you might think is "normal"- You'll be plumbing technologies from all over the web, which might or might not be good news for you.So yeah, data engineering is great ! It's not harder than other specialties for developers, but imo, it's one of the fun ones !
Many reasons why Data Engineer is a great starting position for junior developers
Tags
Annotators
URL
-
-
www.mihaileric.com www.mihaileric.com
-
When machine learning become hot 🔥 5-8 years ago, companies decided they need people that can make classifiers on data. But then frameworks like Tensorflow and PyTorch became really good, democratizing the ability to get started with deep learning and machine learning. This commoditized the data modelling skillset. Today, the bottleneck in helping companies get machine learning and modelling insights to production center on data problems.
Why Data Engineering became more important
-
There are 70% more open roles at companies in data engineering as compared to data science. As we train the next generation of data and machine learning practitioners, let’s place more emphasis on engineering skills.
The resulting 70% is based on a real analysis
-
- Dec 2020
-
stackoverflow.blog stackoverflow.blog
-
TFX and Tensorflow run anywhere Python runs, and that’s a lot of places
You can run your Tensorflow models on:
- web pages with Tensorflow.js
- mobile/IoT devices with Tensorflow lite
- in the cloud
- even on-prem
-
since TFX and Tensorflow were built by Google, it has first-class support in the Google Cloud Platform.
TFX and Tensorflow work well with GCP
-
After consideration, you decide to use Python as your programming language, Tensorflow for model building because you will be working with a large dataset that includes images, and Tensorflow Extended (TFX), an open-source tool released and used internally at Google, for building your pipelines.
Sample tech stack of a ML project:
- Python <--- programming
- Tensorflow <--- model building (large with images)
- TFX (Tensorflow Extended) <--- pipeline builder (model analysis, monitoring, serving, ...)
-
These components has built-in support for ML modeling, training, serving, and even managing deployments to different targets.
Components of TFX:
-
Most data scientists feel that model deployment is a software engineering task and should be handled by software engineers because the required skills are more closely aligned with their day-to-day work. While this is somewhat true, data scientists who learn these skills will have an advantage, especially in lean organizations. Tools like TFX, Mlflow, Kubeflow can simplify the whole process of model deployment, and data scientists can (and should) quickly learn and use them.
As a Data Scientist, you shall think of practicing TFX, Mlflow or Kubeflow
-
TFX Component called TensorFlow Model Analysis (TFMA) allows you to easily evaluate new models against current ones before deployment.
TFMA component of TFX seems to be its core functionality
-
In general, for smaller businesses like startups, it is usually cheaper and better to use managed cloud services for your projects.
Advice for startups working with ML in production
-
This has its pros and cons and may depend on your use case as well. Some of the pros to consider when considering using managed cloud services are:
Pros of using cloud services:
- They are cost-efficient
- Quick setup and deployment
- Efficient backup and recovery Cons of using cloud services:
- Security issue, especially for sensitive data
- Internet connectivity may affect work since everything runs online
- Recurring costs
- Limited control over tools
-
The data is already in the cloud, so it may be better to build your ML system in the cloud. You’ll get better latency for I/O, easy scaling as data becomes larger (hundreds of gigabytes), and quick setup and configuration for any additional GPUs and TPUs.
If the data for your project is already in the cloud, try to stick to cloud solutions
-
ML projects are never static. This is part of engineering and design that must be considered from the start. Here you should answer questions like:
We need to prepare for these 2 things in ML projects:
- How do we get feedback from a model in production?
- How do you set up CD?
-
The choice of framework is very important, as it can decide the continuity, maintenance, and use of a model. In this step, you must answer the following questions:
Questions to ask before choosing a particular tool/framework:
- What is the best tool for the task at hand?
- Are the choice of tools open-source or closed?
- How many platforms/targets support the tool?
Try to compare the tools based on:
- Efficiency
- Popularity
- Support
-
These questions are important as they will guide you on what frameworks or tools to use, how to approach your problem, and how to design your ML model.
Critical questions for ML projects:
- How is your training data stored?
- How large is your data?
- How will you retrieve the data for training?
- How will you retrieve data for prediction?
-
- Sep 2020
-
-
DuckDB is an embeddable SQL OLAP database management system
Database not requiring a server like SQLite and offering advantages of PostgreSQL
-
- Jul 2020
-
-
An end-user (resource owner 👤) grants a printing service (app 📦) access to their photo (resource 🖼) hosted in a photo-sharing service (resource server 📚), without sharing their username and password. Instead, they authenticate directly with a server trusted by the photo-sharing service (authorization server 🛡), which issues the printing service delegation-specific credentials (access token 🔑).
Clear OAuth flow example
-
- Mar 2020
-
pythonspeed.com pythonspeed.com
-
from Docker Compose on a single machine, to Heroku and similar systems, to something like Snakemake for computational pipelines.
Other alternatives to Kubernetes:
- Docker Compose on a single machine
- Heroku and similar systems
- Snakemake for computational pipelines
-
if what you care about is downtime, your first thought shouldn’t be “how do I reduce deployment downtime from 1 second to 1ms”, it should be “how can I ensure database schema changes don’t prevent rollback if I screw something up.”
Caring about downtime
-
The features Kubernetes provides for reliability (health checks, rolling deploys), can be implemented much more simply, or already built-in in many cases. For example, nginx can do health checks on worker processes, and you can use docker-autoheal or something similar to automatically restart those processes.
Kubernetes' health checks can be replaced with nginx on worker processes + docker-autoheal to automatically restart those processes
-
Scaling for many web applications is typically bottlenecked by the database, not the web workers.
-
Kubernetes might be useful if you need to scale a lot. But let’s consider some alternatives
Kubernetes alternatives:
- cloud VMs with up to 416 vCPUs and 8 TiB RAM
- scale many web apps with Heroku
-
Distributed applications are really hard to write correctly. Really. The more moving parts, the more these problems come in to play. Distributed applications are hard to debug. You need whole new categories of instrumentation and logging to getting understanding that isn’t quite as good as what you’d get from the logs of a monolithic application.
Microservices stay as a hard nut to crack.
They are fine for an organisational scaling technique: when you have 500 developers working on one live website (so they can work independently). For example, each team of 5 developers can be given one microservice
-
you need to spin up a complete K8s system just to test anything, via a VM or nested Docker containers.
You need a complete K8s to run your code, or you can use Telepresence to code locally against a remote Kubernetes cluster
-
“Kubernetes is a large system with significant operational complexity. The assessment team found configuration and deployment of Kubernetes to be non-trivial, with certain components having confusing default settings, missing operational controls, and implicitly defined security controls.”
Deployment of Kubernetes is non-trivial
-
Before you can run a single application, you need the following highly-simplified architecture
Before running the simplest Kubernetes app, you need at least this architecture:
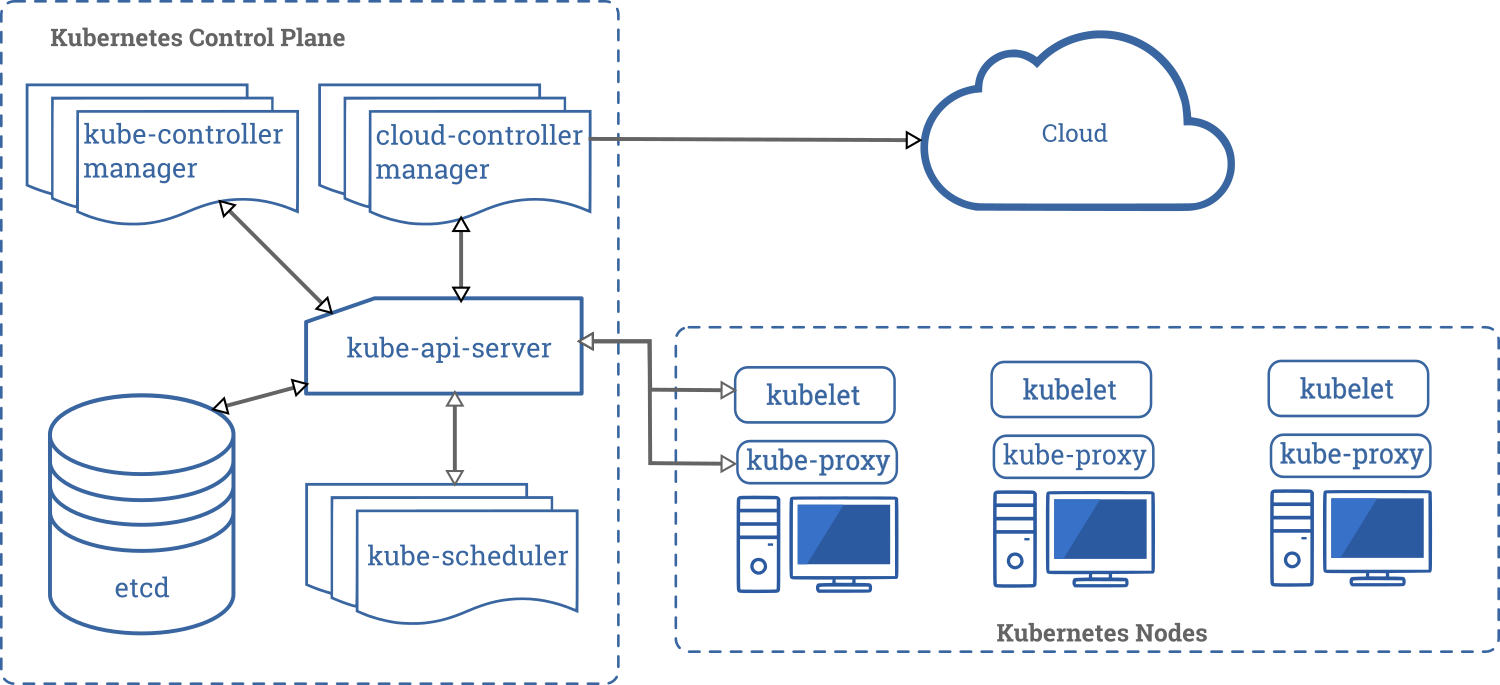
-
the Kubernetes codebase has significant room for improvement. The codebase is large and complex, with large sections of code containing minimal documentation and numerous dependencies, including systems external to Kubernetes.
As of March 2020, the Kubernetes code base has more than 580 000 lines of Go code
-
Kubernetes has plenty of moving parts—concepts, subsystems, processes, machines, code—and that means plenty of problems.
Kubernetes might be not the best solution in a smaller team
-
-
developer.sh developer.sh
-
Here is a high level comparison of the tools we reviewed above:
Comparison of Delta Lake, Apache Iceberg and Apache Hive:

-
To address Hadoop’s complications and scaling challenges, Industry is now moving towards a disaggregated architecture, with Storage and Analytics layers very loosely coupled using REST APIs.
Things used to address Hadoop's lacks
-
Hive is now trying to address consistency and usability. It facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage.
Apache Hive offers:
- Streaming ingest of data - allowing readers to get a consistent view of data and avoiding too many files
- Slow changing dimensions - dimensions of table change slowly over time
- Data restatement - supported via INSERT, UPDATE, and DELETE
- Bulk updates with SQL MERGE
-
Delta Lake is an open-source platform that brings ACID transactions to Apache Spark™. Delta Lake is developed by Spark experts, Databricks. It runs on top of your existing storage platform (S3, HDFS, Azure) and is fully compatible with Apache Spark APIs.
Delta Lake offers:
- ACID transactions on Spark
- Scalable metadata handling
- Streaming and batch unification
- Schema enforcement
- Time travel
- Upserts and deletes
-
Apache Iceberg is an open table format for huge analytic data sets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table. Iceberg is focussed towards avoiding unpleasant surprises, helping evolve schema and avoid inadvertent data deletion.
Apache Iceberg offers:
- Schema evolution (add, drop, update, rename)
- Hidden partitioning
- Partition layout evolution
- Time travel (reproducible queries)
- Version rollback (resetting tables)
-
in this disaggregated model, users can choose to use Spark for batch workloads for analytics, while Presto for SQL heavy workloads, with both Spark and Presto using the same backend storage platform.
Disaggregated model allows more flexible choice of tools
-
rise of Hadoop as the defacto Big Data platform and its subsequent downfall. Initially, HDFS served as the storage layer, and Hive as the analytics layer. When pushed really hard, Hadoop was able to go up to few 100s of TBs, allowed SQL like querying on semi-structured data and was fast enough for its time.
Hadoop's HDFS and Hive became unprepared for even larger sets of data
-
These projects sit between the storage and analytical platforms and offer strong ACID guarantees to the end user while dealing with the object storage platforms in a native manner.
Solutions to the disaggregated models:
- Delta Lake
- Apache Iceberg
- Apache Hive
-
Disaggregated model means the storage system sees data as a collection of objects or files. But end users are not interested in the physical arrangement of data, they instead want to see a more logical view of their data.
File or Tables problem of disaggregated models
-
ACID stands for Atomicity (an operation either succeeds completely or fails, it does not leave partial data), Consistency (once an application performs an operation the results of that operation are visible to it in every subsequent operation), Isolation (an incomplete operation by one user does not cause unexpected side effects for other users), and Durability (once an operation is complete it will be preserved even in the face of machine or system failure).
ACID definition
-
Currently this may be possible using version management of object store, but that as we saw earlier is at a lower layer of physical detail which may not be useful at higher, logical level.
Change management issue of disaggregated models
-
Traditionally Data Warehouse tools were used to drive business intelligence from data. Industry then recognized that Data Warehouses limit the potential of intelligence by enforcing schema on write. It was clear that all the dimensions of data-set being collected could not be thought of at the time of data collection.
Data Warehouses were later being replaced with Data Lakes to face the amount of big data
-
As explained above, users are no longer willing to consider inefficiencies of underlying platforms. For example, data lakes are now also expected to be ACID compliant, so that the end user doesn’t have the additional overhead of ensuring data related guarantees.
SQL Interface issue of disaggregated models
-
Commonly used Storage platforms are object storage platforms like AWS S3, Azure Blob Storage, GCS, Ceph, MinIO among others. While analytics platforms vary from simple Python & R based notebooks to Tensorflow to Spark, Presto to Splunk, Vertica and others.
Commonly used storage platforms:
- AWS S3
- Azure Blob Storage
- GCS
- Ceph
- MinlO
Commonly used analytics platforms:
- Python & R based notebooks
- TensorFlow
- Spark
- Presto
- Splunk
- Vertica
-
Data Lakes that are optimized for unstructured and semi-structured data, can scale to PetaBytes easily and allowed better integration of a wide range of tools to help businesses get the most out of their data.
Data Lake definitions / what do offer us:
- support for unstructured and semi-structured data.
- scalability to PetaBytes and higher
- SQL like interface to interact with the stored data
- ability to connect various analytics tools as seamlessly as possible
- modern data lakes are generally a combination of decoupled storage and analytics tools
-
-
golden.com golden.com
-
'Directed' means that the edges of the graph only move in one direction, where future edges are dependent on previous ones.
Meaning of "directed" in Directed Acyclic Graph
-
Several cryptocurrencies use DAGs rather than blockchain data structures in order to process and validate transactions.
DAG vs Blockchain:
- DAG transactions are linked to each other rather than grouped into blocks
- DAG transactions can be processed simultaneously with others
- DAG results in a lessened bottleneck on transaction throughput. In blockchain it's limited, such as transactions that can fit in a single block
-
graph data structure that uses topological ordering, meaning that the graph flows in only one direction, and it never goes in circles.
Simple definition of Directed Acyclic Graph (DAG)
-
'Acyclic' means that it is impossible to start at one point of the graph and come back to it by following the edges.
Meaning of "acyclic" in Directed Acyclic Graph
Tags
Annotators
URL
-
