open sourcing all of this as part of TensorFlow so that anyone can use these tools to explore their data.
for - tensorflow - data visualization of words - question - tensorflow - for SRG tool?
open sourcing all of this as part of TensorFlow so that anyone can use these tools to explore their data.
for - tensorflow - data visualization of words - question - tensorflow - for SRG tool?
for - data visualization - words in high dimensional space - Google tensorflow - open source data visualization - of words
The models are developed in Python [46], using the Keras [47] and Tensorflow [48] libraries. Detailson the code and dependencies to run the experiments are listed in a Readme file available togetherwith the code in the Supplemental Material.
I have not found the code or Readme file
Here is an example run of the QnA model:
This example doesn't work. The await gets an error. Since it's not inside the promise?
"dividing n-dimensional space with a hyperplane."
This dataset can not be classified by a single neuron, as the two groups of data points can't be divided by a single line.
TensorFlow.js provides theLayers API,which mirrors the Keras API as closely as possible, in-cluding the serialization format.
Surfing TensorFlow I was orbiting this conclusion. It's good to see it it stated clearly.
The key libraries of TFX are as follows
TensorFlow Extend (TFX) = TFDV + TFT + TF Estmators and Keras + TFMA + TFServing
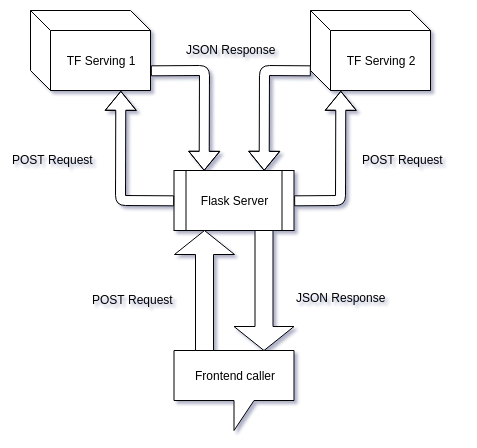
When we are providing our API endpoint to frontend team we need to ensure that we don’t overwhelm them with preprocessing technicalities.We might not always have a Python backend server (eg. Node.js server) so using numpy and keras libraries, for preprocessing, might be a pain.If we are planning to serve multiple models then we will have to create multiple TensorFlow Serving servers and will have to add new URLs to our frontend code. But our Flask server would keep the domain URL same and we only need to add a new route (a function).Providing subscription-based access, exception handling and other tasks can be carried out in the Flask app.
4 reasons why we might need Flask apart from TensorFlow serving
TFX and Tensorflow run anywhere Python runs, and that’s a lot of places
You can run your Tensorflow models on:
since TFX and Tensorflow were built by Google, it has first-class support in the Google Cloud Platform.
TFX and Tensorflow work well with GCP
After consideration, you decide to use Python as your programming language, Tensorflow for model building because you will be working with a large dataset that includes images, and Tensorflow Extended (TFX), an open-source tool released and used internally at Google, for building your pipelines.
Sample tech stack of a ML project:
These components has built-in support for ML modeling, training, serving, and even managing deployments to different targets.
Components of TFX:
Most data scientists feel that model deployment is a software engineering task and should be handled by software engineers because the required skills are more closely aligned with their day-to-day work. While this is somewhat true, data scientists who learn these skills will have an advantage, especially in lean organizations. Tools like TFX, Mlflow, Kubeflow can simplify the whole process of model deployment, and data scientists can (and should) quickly learn and use them.
As a Data Scientist, you shall think of practicing TFX, Mlflow or Kubeflow
TFX Component called TensorFlow Model Analysis (TFMA) allows you to easily evaluate new models against current ones before deployment.
TFMA component of TFX seems to be its core functionality
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research. Use Keras if you need a deep learning library that: Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility). Supports both convolutional networks and recurrent networks, as well as combinations of the two. Runs seamlessly on CPU and GPU. Read the documentation at Keras.io. Keras is compatible with: Python 2.7-3.6.
NVIDIA's CUDA libraries
cuda has moved to homebrew-drivers [1]
its name has alos changed to nvidia-cuda
To install:
brew tap homebrew/cask-drivers
brew cask install nvidia-cuda
https://i.imgur.com/rmnoe6d.png
[1] https://github.com/Homebrew/homebrew-cask/issues/38325#issuecomment-327605803
CS 20: Tensorflow for Deep Learning Research
课程时间: 1月-3月, 2018
TensorFlow provides optimizers that slowly change each variable in order to minimize the loss function. The simplest optimizer is gradient descent. It modifies each variable according to the magnitude of the derivative of loss with respect to that variable
Using Optimizer to auto estimate the parameters
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
sess.run(init) # reset values to incorrect defaults.
for i in range(1000):
sess.run(
train, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]})
print("...", sess.run([W, b]))
这张图给出了谷歌在2015年提出的Inception-v3模型。这个模型在ImageNet数据集上可以达到95%的正确率。然而,这个模型中有2500万个参数,分类一张图片需要50亿次加法或者乘法运算。
95%成功率,需要 25,000,000个参数!
J(t)NEG=logQθ(D=1|the, quick)+log(Qθ(D=0|sheep, quick))
Expression to learn theta and maximize cost and minimize the loss due to noisy words. Expression means -> probability of predicting quick(source of context) from the(target word) + non probability of sheep(noise) from word
If we write that out as equations, we get:
It would be easier to understand what are x and y and W here if the actual numbers were used, like 784, 10, 55000, etc. In this simple example there are 3 x and 3 y, which is misleading. In reality there are 784 x elements (for each pixel) and 55,000 such x arrays and only 10 y elements (for each digit) and then 55,000 of them.
If you would like TensorFlow to automatically choose an existing and supported device to run the operations in case the specified one doesn't exist, you can set allow_soft_placement to True in the configuration option when creating the session.
为了保证op按照自己的要求分配,必须设置为False
Google is merely interested sharing the code. As Dean says, this will help the company improve this code. But at the same time, says Monga, it will also help improve machine learning as a whole, breeding all sorts of new ideas. And, well, these too will find their way back into Google. “Any advances in machine learning,” he says, “will be advances for us as well.”
