The blog post by Cliff Malmborg from Loft Labs discusses optimizing Kubernetes costs using multi-tenancy and virtual clusters. With Kubernetes expenses rising rapidly at scale, traditional cost-saving methods like autoscaling, resource quotas, and monitoring tools help but are not enough for complex environments where underutilized clusters are common. Multi-tenancy enables resource sharing, reducing the number of clusters and, in turn, management and operational costs.
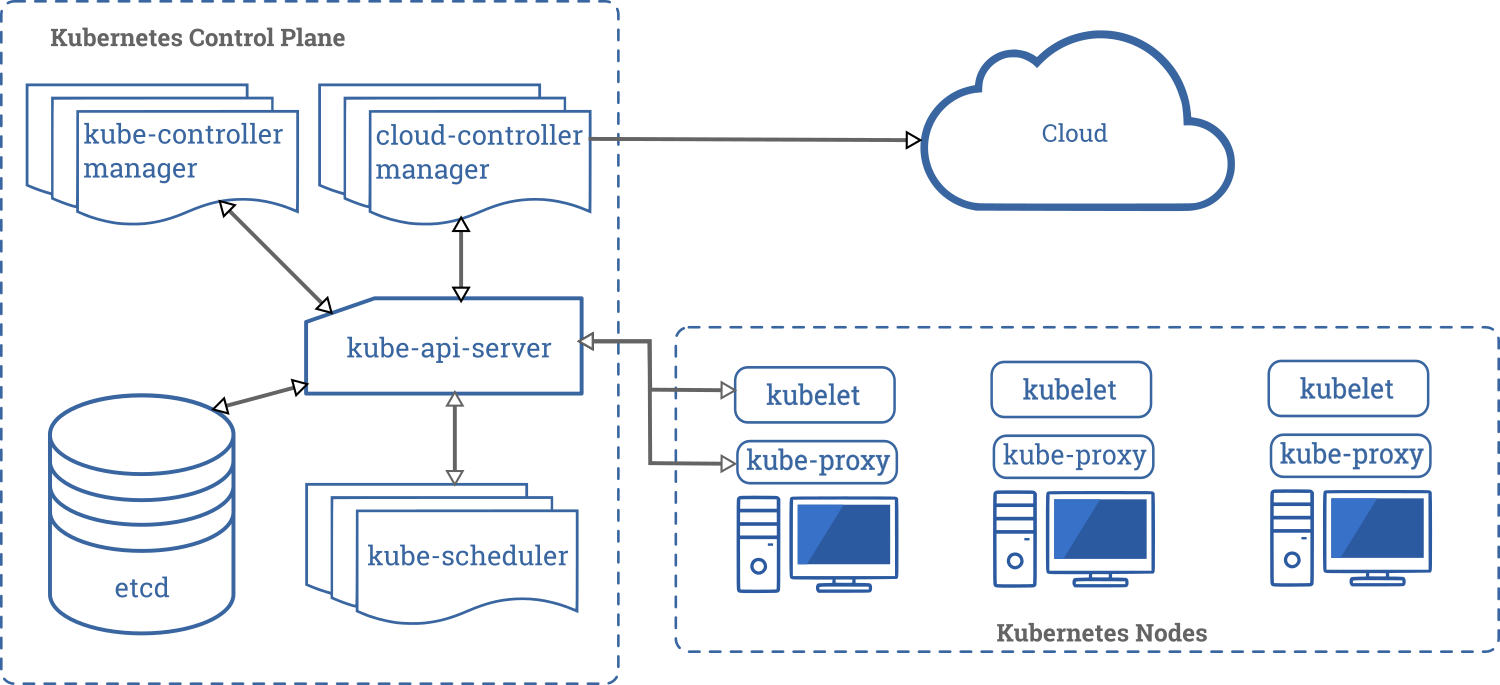
A virtual cluster is a fully functional Kubernetes cluster running within a larger host cluster, providing better isolation and flexibility than namespaces. Unlike namespaces, each virtual cluster has its own Kubernetes control plane, so resources like statefulsets and webhooks are isolated within it, while only core resources (like pods and services) are shared with the host cluster. This setup addresses the "noisy neighbor" problem, where workloads in a shared environment interfere with each other due to resource contention.
Virtual clusters offer the isolation benefits of individual physical clusters but are cheaper and easier to manage than deploying separate physical clusters for each tenant or application. They also support "sleep mode," automatically scaling down unused resources to save costs, and allow shared use of central tools (like ingress controllers) installed in the host cluster. By transitioning to virtual clusters, companies can balance security, isolation, and cost-effectiveness, reducing the need for multiple physical clusters and making Kubernetes infrastructure scalable for modern, resource-demanding applications.