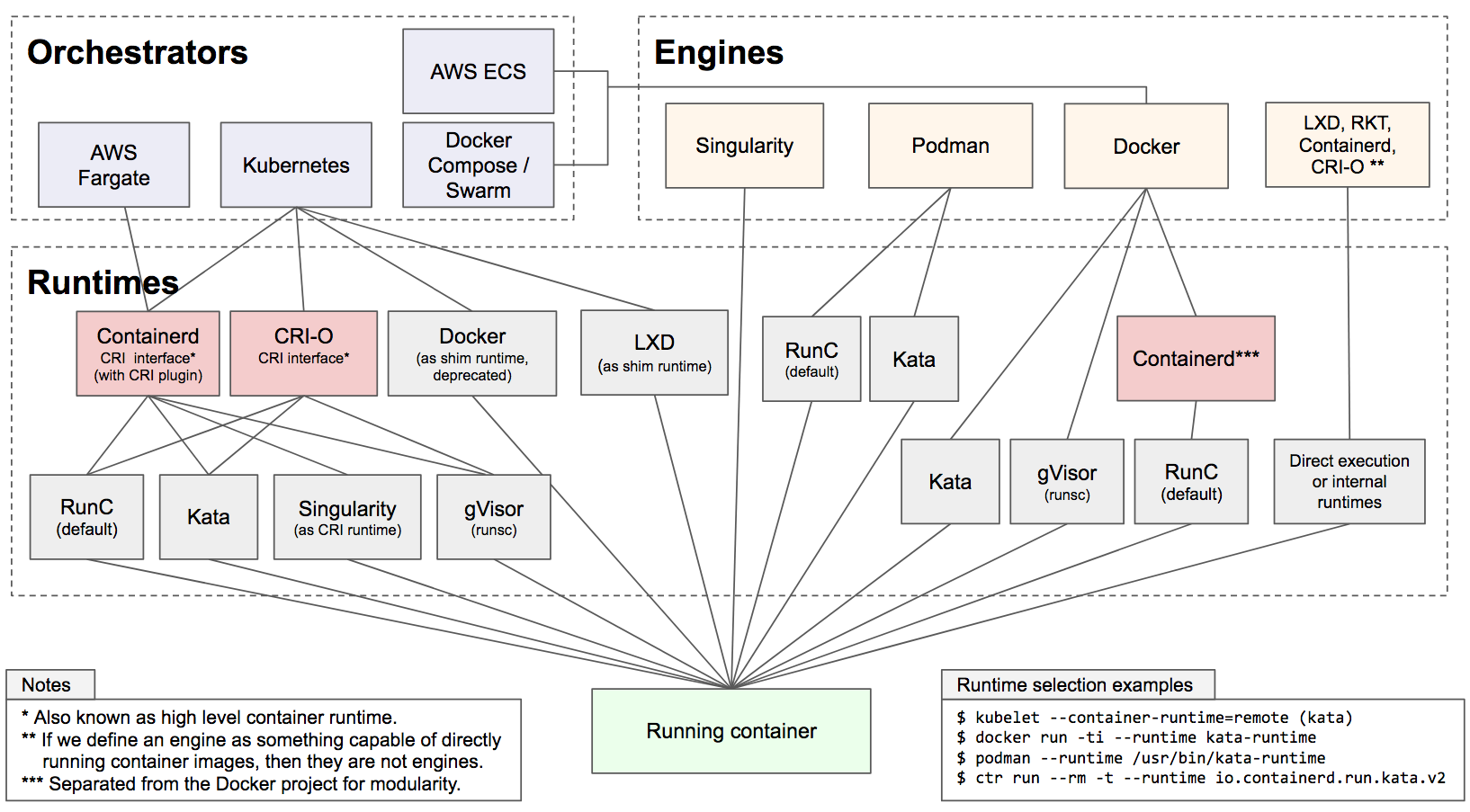
Running local models is good now
- Evolving Quality: Local Large Language Models (LLMs) have achieved major milestones in accuracy, utility, and speed over the past six months, transitioning from simple "personalized Google" documentation lookups to handling localized agentic software development workflows.
- Hardware Requirements: Running larger models effectively requires high-spec hardware (e.g., Apple M-Series with 64 GB+ unified RAM) to maintain an expansive Key-Value (K-V) cache and avoid critical performance degradation.
- Top Performing Architecture: Recent open-weights families, such as Gemma 4 (specifically the
gemma-4-26b-a4band the fastergemma-4-12b-qat), have successfully reached roughly 75% of the accuracy and speed found in cloud-hosted frontier API models. - Agentic Workflows: Local models can now successfully loop and interact with local environments to orchestrate non-trivial tasks like refactoring code, writing unit tests, and bootstrapping full application repositories.
- Secure Execution: Running developer-facing local agents poses local file system security risks, making a decoupled architecture—such as isolating the agent harness inside a containerized Docker Sandbox with restricted shell permissions—an essential security best practice.
- Persistent Ecosystem Bottlenecks: Despite massive progress, challenges remain around slow initial token pre-fill, limited context windows bounded by local hardware constraints, prompt template mismatches on release, and the heavy compute strain that maximizes GPU and RAM workloads.
Hacker News Discussion
- Operational Friction: Many users argue that local models remain painful to run effectively. They note a stark divide between smart but slow dense models (e.g., Qwen 27B, Gemma 31B) and fast but error-prone Mixture of Experts (MoE) models.
- The Quantization Trap: Commenters point out that many users run low-bit quantizations (like 4-bit) to save RAM, which effectively lobotomizes the model's capacity for complex tool calling. Industry recommendations favor a minimum of 5-bit for dense models and 6-bit for MoEs.
- Hardware & Comfort Trademarks: Running these workloads locally often transforms high-end laptops or desktops into loud, hot, and energy-churning machines, making the physical development environment uncomfortable.
- Privacy and Data Sovereignty: A heated debate emerged regarding hosted vs. local options. While some demand local setups due to data-collection practices and copyright concerns of major tech providers, others prefer private API gateways or hosted "open model clouds" (like OpenRouter or specialized European hosters like OVH) that guarantee Zero Data Retention (ZDR).