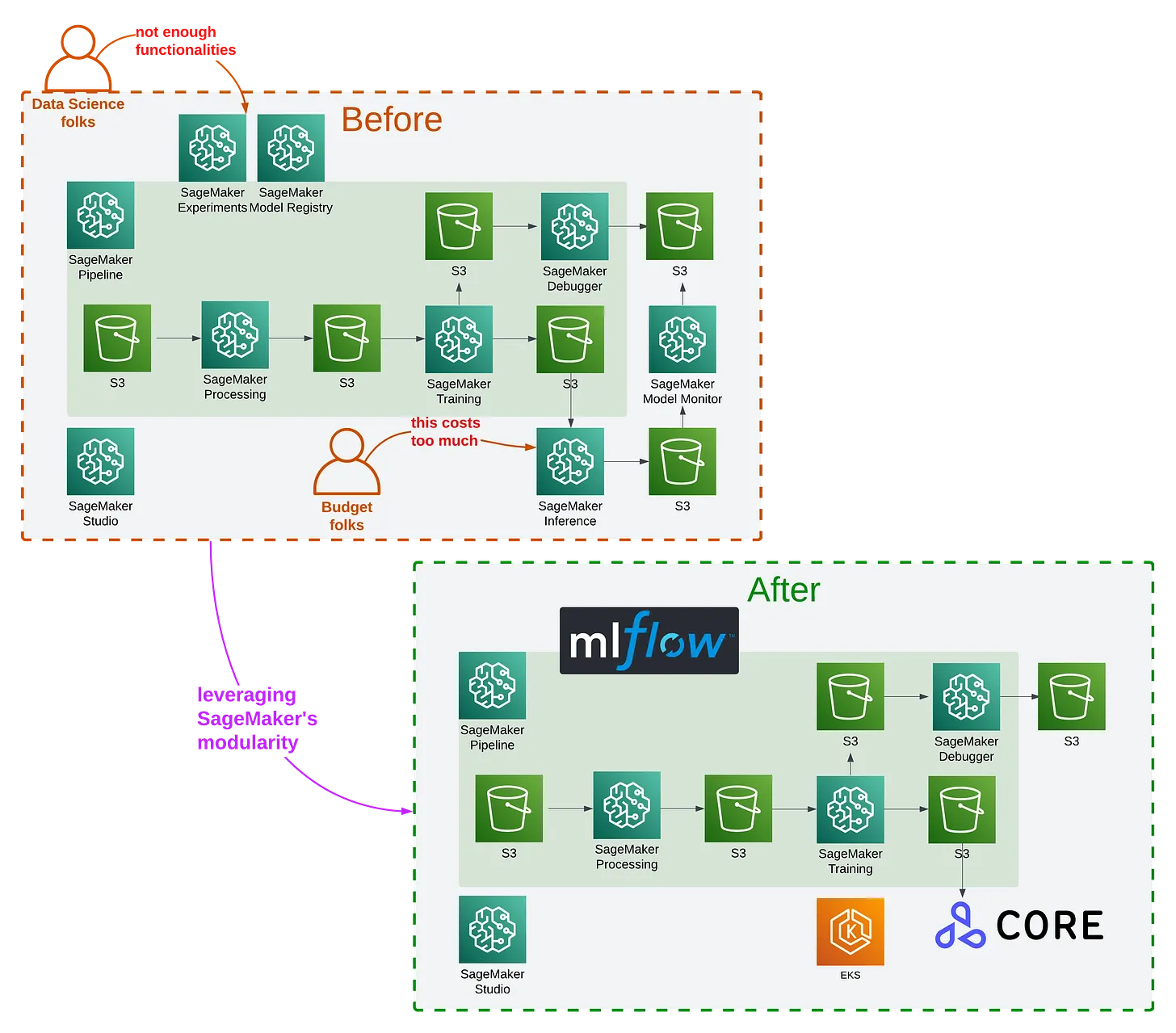
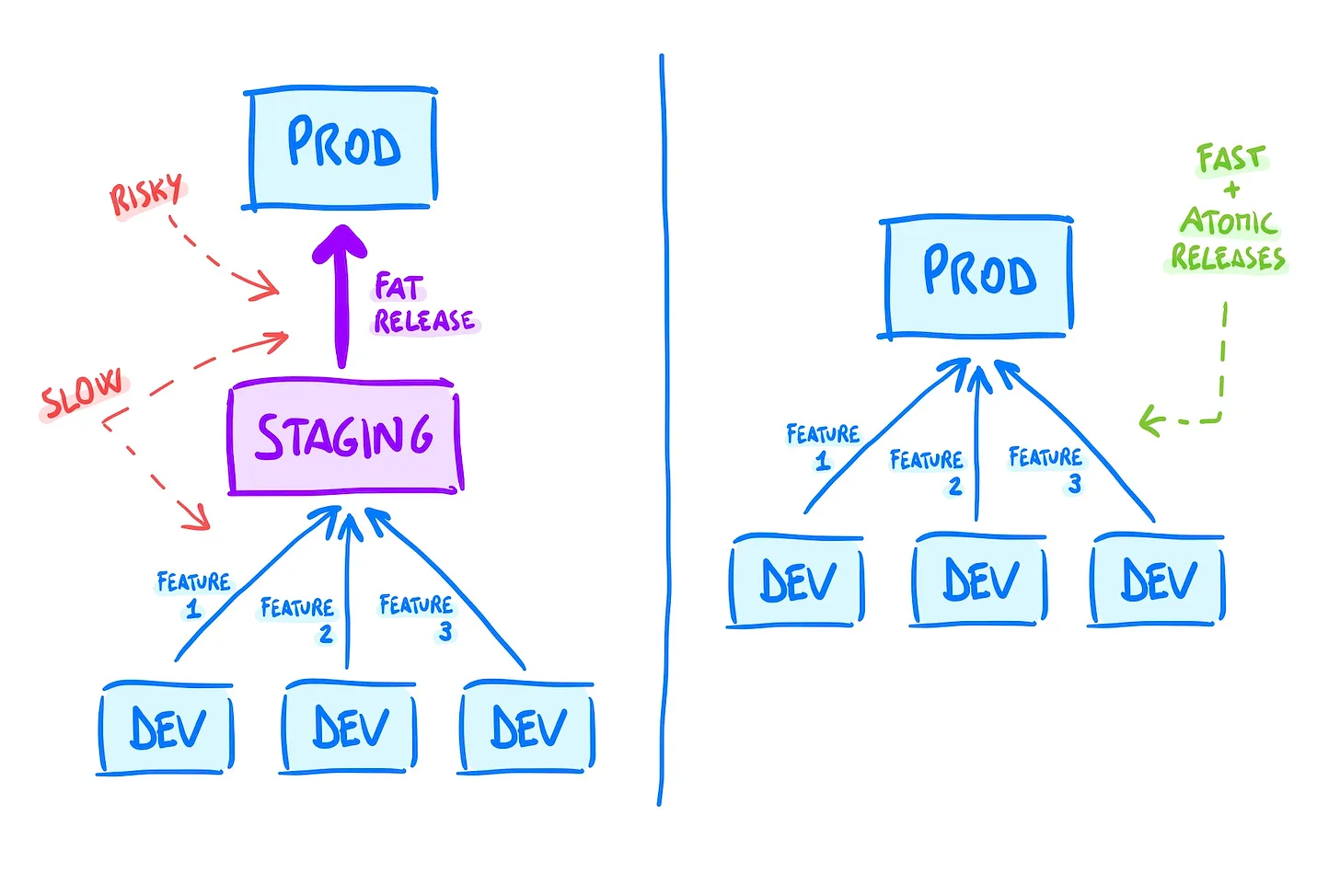
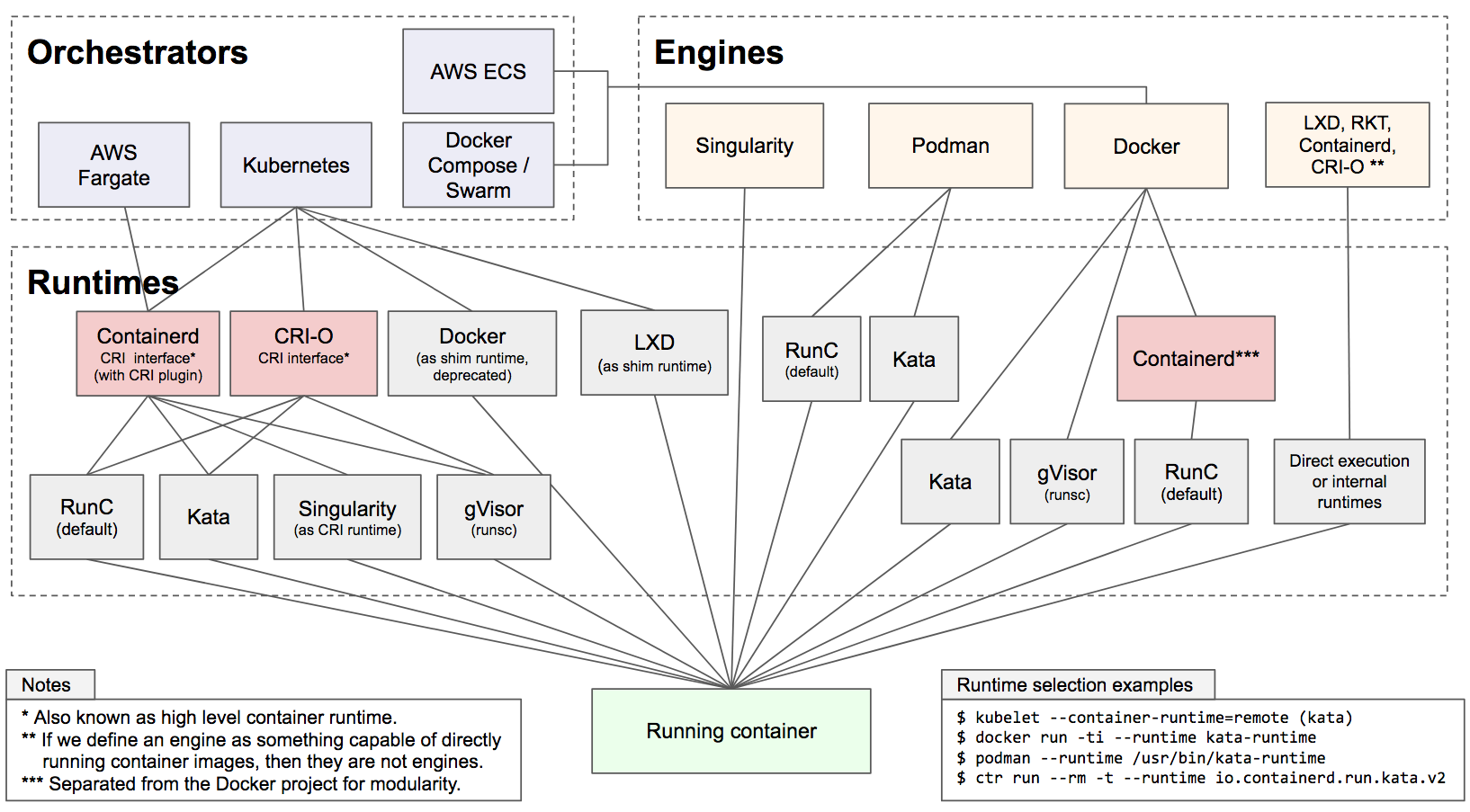
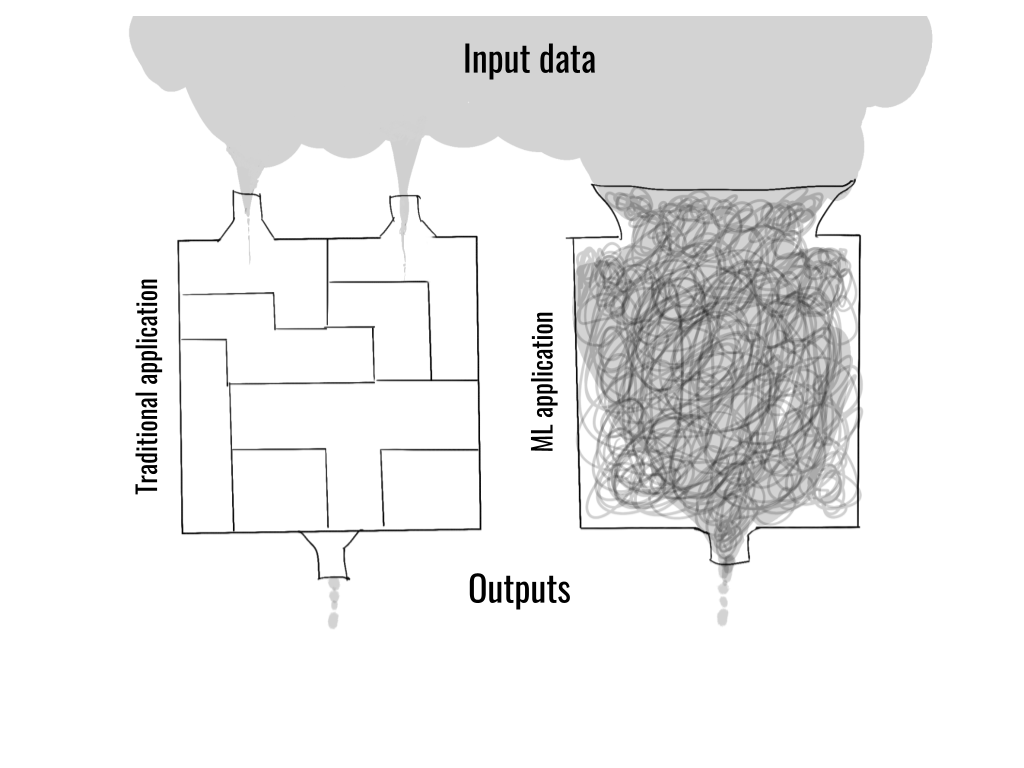
In essence, this article is about:
1) Training a sample model and uploading it to an S3 bucket:
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import joblib
Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train the logistic regression model
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
Save the trained model to a file
joblib.dump(model, 'model.pkl')
```
- Creating a sample Zappa config, because AWS Lambda doesn’t natively support Flask, we need to use Zappa, a tool that helps deploy WSGI applications (like Flask) to AWS Lambda:
```json
{
"dev": {
"app_function": "app.app",
"exclude": [
"boto3",
"dateutil",
"botocore",
"s3transfer",
"concurrent"
],
"profile_name": null,
"project_name": "flask-test-app",
"runtime": "python3.10",
"s3_bucket": "zappa-31096o41b"
},
"production": {
"app_function": "app.app",
"exclude": [
"boto3",
"dateutil",
"botocore",
"s3transfer",
"concurrent"
],
"profile_name": null,
"project_name": "flask-test-app",
"runtime": "python3.10",
"s3_bucket": "zappa-31096o41b"
}
}
```
- Writing a sample Flask app:
```python
import boto3
import joblib
import os
Initialize the Flask app
app = Flask(name)
S3 client to download the model
s3 = boto3.client('s3')
Download the model from S3 when the app starts
s3.download_file('your-s3-bucket-name', 'model.pkl', '/tmp/model.pkl')
model = joblib.load('/tmp/model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
# Get the data from the POST request
data = request.get_json(force=True)
# Convert the data into a numpy array
input_data = np.array(data['input']).reshape(1, -1)
# Make a prediction using the model
prediction = model.predict(input_data)
# Return the prediction as a JSON response
return jsonify({'prediction': int(prediction[0])})
if name == 'main':
app.run(debug=True)
```
- Deploying this app to production (to AWS):
bash
zappa deploy production
and later eventually updating it:
bash
zappa update production
- We should get a URL like this:
https://xyz123.execute-api.us-east-1.amazonaws.com/production
which we can query:
curl -X POST -H "Content-Type: application/json" -d '{"input": [5.1, 3.5, 1.4, 0.2]}' https://xyz123.execute-api.us-east-1.amazonaws.com/production/predict