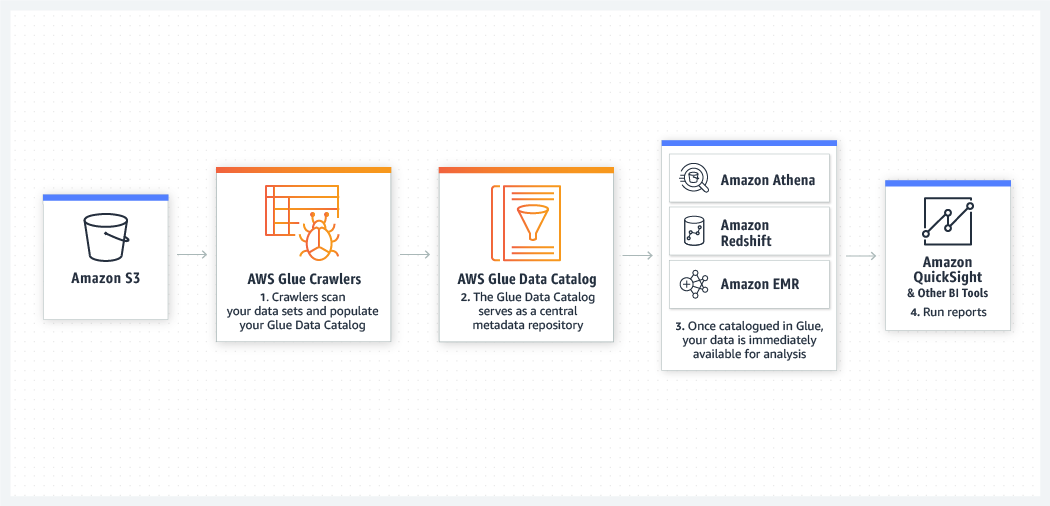
Scale-out analytics frameworks such as Spark, Databricks, and Snowflake rely on clusters composed of many servers to handle memory-intensive ETL workloads, which leads to high infrastructure cost and inefficiencies from data movement and memory pressure.
Targeting Spark/Databricks/Snowflake ETL is a strategic move beyond pure LLM inference: these are massive, established workloads with well-understood cost structures. If MX1 can consolidate multi-server ETL jobs, the ROI argument to CFOs becomes straightforward — fewer servers, same throughput, predictable savings.