建议消费者在 visibilityTimeout 时间内消费成功后需要调用(batch)DeleteMessage 接口删除该消息,否则该消息将会重新变成为 active 状态,此消息又可被消费者重新消费,保证消息至少消费一次,但是不能保证幂等性, 业务侧需要有去重逻辑。
消费者需要delete,不然可能会出现重新消费
建议消费者在 visibilityTimeout 时间内消费成功后需要调用(batch)DeleteMessage 接口删除该消息,否则该消息将会重新变成为 active 状态,此消息又可被消费者重新消费,保证消息至少消费一次,但是不能保证幂等性, 业务侧需要有去重逻辑。
消费者需要delete,不然可能会出现重新消费
当其被取走后在 VisibilityTimeout 的时间内状态为 Inactive,若超过 VisibilityTimeout 时间后消息还未被删除,消息会重新变成 Active 状态
相当于可以从unack自动变成ready状态
避免失败回滚和频繁轮询数据库等传统方式的弊端。
最终一致性
跟rabbitmq比的优势:
您可以将消费过的去重 key 缓存(如 KV 等),然后每次消费时检查去重 key 是否已消费过。去重 key 缓存可以根据消息最大有效时间来淘汰。CMQ 提供了队列当前最小未消费消息的时间(min_msg_time),您可以使用该时间和业务生产消息最大重试时间来确定缓存淘汰时间。存在多个消费者时,去重 key 缓存就需要是分布式的
分布式缓存的最佳实践
去重 key
correlatedata
长轮询
阻塞
采取 Pull 的方式问题就简单了许多,由于 Consumer 是主动到服务端拉取数据,此时只需要降低自己访问频率即可。举例:如前端是 flume 等日志收集业务,不断向 CMQ 生产消息,CMQ 向后端投递,后端业务如数据分析等业务,效率可能低于生产者。
pull适用于日志分析等实时性不高的、吞吐量大的场景
多次复用
也是一种解耦
auto默认的重试机制中,messageReCoverer为设置消息ack状态(即正常确认状态)
MessageReCoverer
recover与manul模式也有关系(是否是bug、按理manul不能被自动ack/reject)
重试机制下: 1. 默认情况,manul模式的消息会最终处于unack状态; 1. ImmediateRequeueMessageRecoverer,manul消息会被重新requeue; 1. RejectAndDontRequeueRecoverer,manul模式的消息会最终处于unack状态;
五次重试后,消费处于一个未被确认的状态。因为需要你手动 ack!下次服务重启的时候,会继续消费这条消息。
仅仅是消费者内部进行了重试,换句话说就是重试跟mq没有任何关系。上述消费者代码不能添加try{}catch(){},一旦捕获了异常,在自动 ack 模式下,就相当于消息正确处理了,消息直接被确认掉了,不会触发重试的。
如果没有异常,消费者也不会进行重试。只有抛出异常,消费者才会进行重试
它会根据方法的执行情况来决定是否确认还是拒绝
重试机制会有单独的recoverer,优先级高于默认的确认机制
AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且 requeue = false(不重新入队列)
auto模式下,可以用这个异常来控制消息进入死信队列
则消息会被拒绝,且 requeue = true(如果此时只有一个消费者监听该队列,则有发生死循环的风险,多消费端也会造成资源的极大浪费,这个在开发过程中一定要避免的)。可以通过 setDefaultRequeueRejected(默认是true)去设置
在开启重试的情况下,默认变成ack。(即不会重新入列),设置不同的recoverer,会有不同的表现:比如 1. RejectAndDontRequeueRecoverer即nack,且requue为false。 1. ImmediateRequeueMessageRecoverer即nack,且requue为true。
channel.basicNack 与 channel.basicReject 的区别在于basicNack可以批量拒绝多条消息,而basicReject一次只能拒绝一条消息。
比当前消息的delivertag数更小的消息都会被拒绝
有可能出现投递丢失的情况,不同于手动确认模式,如果消费者的TCP连接或通道在消息成功交互之前关闭,则此消息会丢失
由spring-rabbit依据消息处理逻辑是否抛出异常自动发送ack(无异常)或nack(异常)到broker。 这些都是消费端的机制
如果某个服务忘记确认 ACK 了,则 RabbitMQ 不会再发送此消息数据给它,只要程序还在运行,没确认的消息就一直是 Unacked 状态,无法被 RabbitMQ 重新投递。
即unack的消息是blocked状态 如果connect断开,unack消息会被释放,则消息会被服务器重新投递
自动确认会在消息发送给消费者后立即确认,但存在丢失消息的可能,如果消费端消费逻辑抛出异常,也就是消费端没有处理成功这条消息,那么就相当于丢失了消息
NONE模式是自动模式,非auto是自动
抛出异常
如果抛出异常,且设置了重试机制,消费者会在客户端自动进行重试(即不通过rabbitmq服务器)
默认情况下消息消费者是NONE模式,默认所有消息消费成功,会不断的向消费者推送消息。 因为rabbitMq认为所有消息都被消费成功,所以队列中不在存有消息,消息存在丢失的危险
这里是真正的auto模式
requeue:被拒绝的是否重新入队列
默认不会重新进入队列, 但basicNack不会造成message在web界面被呈现unacked状态。只有发生异常的消息会在web界面变为unacked状态
会导致生产者和RabbitMq之间产生同步(等待确认),这也违背了我们使用RabbitMq的初衷。所以一般很少采用
很少采用
broker回传给生产者的确认消息中deliver-tag域包含了确认消息的序列号,此外broker也可以设置basic.ack的multiple域,表示到这个序列号之前的所有消息都已经得到了处理。
事务消息中有用
对象内部只有一个 id 属性,用来表示当前消息的唯一性
数据是自定义的
:队列名称
应该是路由key(只是路由key和queue的名称一致),背后隐含有个默认的exchange来路由发送数据
清除给定队列的消息。
不能清空unack的消息
交换器 source 根据路由键找到与其匹配的另一个交换机 destination,并把消息转发到 destination 中,进而存储在 destination 绑定的队列 queue中
备份交换机
audit.# 匹配audit.irs.corporate 或者 audit.irs 等
包括audit
消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
直连模式,routingkey名等于queue名,系统会找到默认的交换机
基于信用证
Prefetch Count
设置message为persistent并不能完全保证消息不丢失,在RabbitMQ将消息保存到disk之前仍可能丢失。
标记message安全存储于exchange中
队列头
队列头的消息会被先消费
但一定要记得basicAck
或nack
会触发: channel.basicNack(tag, false, true);, 这样会告诉rabbitmq该消息消费失败, 需要重新入队
重试次数跟max-attempts的配置有关,并且因为网络等原因,会导致重试次数高于设定次数,
例子:图中设置为2次,实际执行4次

可以看到, 虽然消息确实被消费了, 但是由于是手动确认模式, 而最后又没手动确认, 所以, 消息仍被rabbitmq保存
并且不会被重新requeue
`msg_id` varchar(255) NOT NULL DEFAULT '' COMMENT '消息唯一标识',
唯一性校验
将rabbitmq的队列、交换机、路由key放在一个enum中统一管理
当消息代理(broker)将消息发送给应用后立即删除。(使用AMQP方法:basic.deliver或basic.get-ok)
这是AcknowledgeMode.NONE
此方法会要求服务器重新投递特定信道内所有未确认的消息
重新投递unack的消息
如果channel.basicNack(8, false, false);表示deliveryTag=8的消息处理失败且将该消息直接丢弃。
basicNack的requeue为false情况下,数据会被直接丢弃
Idea设置代理用Fiddler抓包https
抓包
当consumer对消息进行ack以后就会将此消息移除,从而放入新的消息
如果是nack,且可重试,则重试完也会被移除
RabbitMQ Simulator
RabbitMQ Simulator
这个需要利用Spring事务的一个特性TransactionSynchronization,注册一个同步钩子,自动把相关代码放到事务完成之后执行,我们使用拦截器拦截rabbitTemplate.convertAndSend方法,实现不用修改现有代码自动把发送MQ消息逻辑移到事务之外
spring事务拦截机制
Jackson2JsonMessageConverter
如果传递的是string,需要加引号:(实际上是json解析的事情,jackson只认带引号的基本类型)
 如果是template中发送,则不用:
如果是template中发送,则不用:

如果你同时使用了两种方式,即(mandatory为true+Listener监听)和(备份交换机AlternateExchange),消息将只会路由到备份交换机,不会Return回生产者。
备份交换机
当消费端处理异常时,则服务器发送的消息将得不到正确的处理。因此,自动消息确认应该被认为是不安全的
消费者端异常,auto也会自动确认
springboot + redis + 注解 + 拦截器 实现接口幂等性校验
Check out GistBox. It supports searching, editing and labels. Here's a screenshot:
现在叫cacher
CorrelationData correlationData = new CorrelationData(correlationDataId.toString());
不设置,是个空的
在需要使用消息的return机制时候,mandatory参数必须设置为true
// publisher-confirm-type: correlated
// #保证交换机能把消息推送到队列中
// publisher-returns: true
// template:
// #以下是rabbitmqTemplate配置
// mandatory: true) * // 3---设置重试
最新反舰导弹
Routing key does not match but still message gets sent to queue
如果是延时队列,x-delayed-type: direct的模式下,也会出现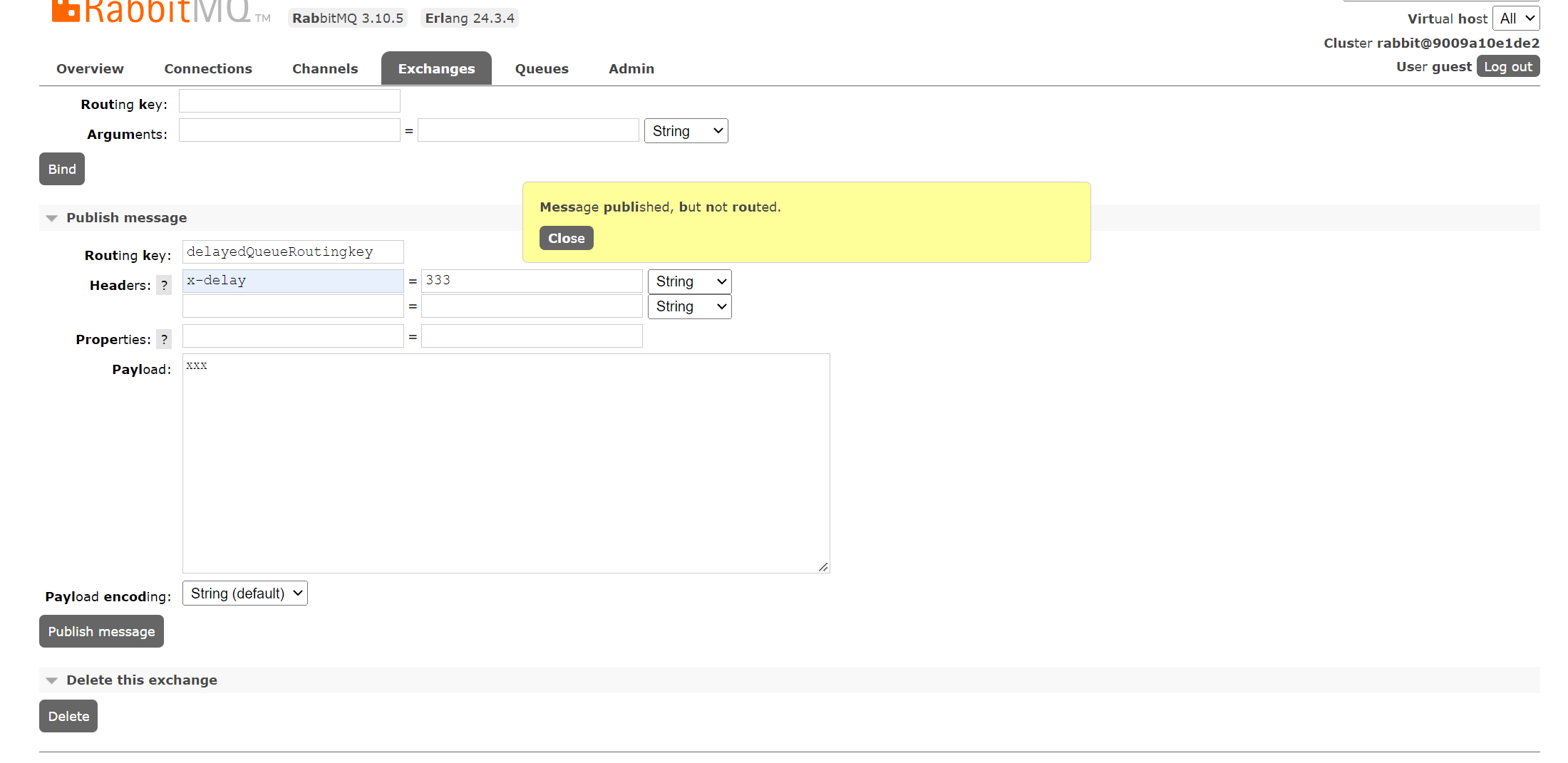
java.net.SocketException: Connection reset
设置vitual host
see that the utilisation increases with the prefetch limit until we reach a limit of about 30. After that the network bandwidth limitation starts to dominate and increasing the limit has no further benefit
Consumer utilisation
而 fanout 的广播模式不利于增加多个 Queue
采用的是轮训机制
the proportion of time that a queue's consumers could take new messages.
相当于单位时间内消费者能消费多少消息
增加fetch值(这个根据我们的实际经验,lan内影响很有限)
提高吞吐量
消息消费速度变慢
prefetch将队列适当堆叠在消费者中
2、查看所用maven的setting.xml文件中的本地仓库路径及镜像是否写错。
maven
使用@Input和@output都是用MessageChannel,这是不对的。@Output对MessageChannel,@Input对应SubscribableChannel
使用@Input和@output都是用MessageChannel,这是不对的。@Output对MessageChannel,@Input对应SubscribableChannel
最好不要自定义输入输出在同一个类里面。这样,如果我们只调用生产者发送消息。会导致提示Dispatcher has no subscribers for channel
会导致提示Dispatcher has no subscribers for channel。并且会让我们发送消息的次数莫名减少几次
Dispatcher has no subscribers for channel
maven 配置指南
maven
第四个参数是autoDelete:true表示服务器不在使用这个队列是会自动删除它
自动删除
第三个参数是exclusive:true表示一个队列只能被一个消费者占有并消费
a.getMessageProperties().setExpiration(String.valueOf(delayTime));
消息中设置过期时间
队列的存活时间是6秒。时间过期后,消息则会被丢失
延时队列的延时时间和存活时间,两者是独立的
通过消费组的设置,虽然能保证同一消息只被一个消费者进行接收和处理,但是对于特殊业务情况,除了要保证单一实例消费之外,还希望那些具备相同特征的消息都能被同一个实例消费,这个就可以使用 Spring Cloud Stream 提供的消息分区功能。修改配置。
todo
MQ中间件与最终用户提供的应用程序代码(生产者/消费者)之间的桥梁
代码和配置中自定义设置的output或input binding
负责与MQ集成的组件
spring-cloud-starter-stream-rabbit这样类似的东西
默会知识、弯道超车
definition: source1;source2
多个用分号隔开
The index is the index of the input or output binding. It is always 0 for typical single input/output function, so it’s only relevant for Functions with multiple input and output arguments.
序号的作用在哪里
StreamBridge模式
主动发送
函数式消息队列的步骤: * 声明supplier或者consumer(function name) * 配置中声明:且将destination设置为同一个,input亦可声明group: 1. * input - functionName+ -in- + index 1. * output - functionName + -out- + index * 配置声明function的definition:名字为function的name
output - <functionName> + -out- + <index>
output以-out-相连
函数式编程模型
functional binding is disabled due to the presence of @enablebinding 函数式和命令式有兼容性问题:https://github.com/spring-cloud/spring-cloud-stream-binder-kafka/issues/882
主要是因为这种一统江湖的趋势让不同的消息中间件厂商都开发了自己的绑定器 Binder 提供给 SpringCloud Stream
可以指明或者直接引入相应的binder器
@EnableBinding:将定义通道的接口绑定到某个 Bean 以便于我们可以通过该 Bean 操作通道进行发送和接收消息。
注解的参数是class,class实例化成一个bean,通过bean来操作消息
统一编程模型
SpringCloud Stream 出生这么久还不广泛流行的原因之一就是,这一套技术体系涉及的东西太多了,万一生产环境出现什么疑难杂症,需要去阅读源码解决的话,这样的技术工作量是很超出预期的。
缺点
发送延迟消息非常简单,首先我们需要在生产者、消费者的配置文件中指定交换机的类型是延迟交换机
rabbitmq特有的机制
'''demoRoutingKey'''
用的是双引号:'"demoRoutingKey"'
不得不说集成 SpringCloud Function 之后,消息的发送和接收又迈进了一个崭新的阶段,但 <functionName> + -in- + <index> 这样的配置规约我觉得让我有些难受......甚至目前我认为 3.1 之前被废弃的注解方式也许更适合我们开发使用
新趋势
spring.cloud.stream.rocketmq.bindings..producer.sync=true
delay
Since it's an expression, you'll need quotes: 'cities' or if the same producer sends to both, something like headers['whereToSendHeader'].
疑惑点
安装插件后会生成新的Exchange类型x-delayed-message,该类型消息支持延迟投递机制,接收到消息后并未立即将消息投递至目标队列中,而是存储在mnesia(一个分布式数据系统)表中,检测消息延迟时间,如达到可投递时间时并将其通过x-delayed-type类型标记的交换机类型投递至目标队列。
可以通过在类上监听队列,然后在类中写带有不同参数类型的方法,来接收不同的操作推送的信息
这种方式不行,找不到相应的messageconverter,会报错。具体原因:https://stackoverflow.com/questions/64029154/spring-amqp-rabbitmq-object-sent-as-one-type-gets-converted-to-map-in-listener
It will work if the @RabbitListener is defined at the method level instead of the class level because we can infer the generic type from the listener method parameter.
@rabbitlistener在方法级别时,类型推导有用
因为Kong Community版本没有Web控制台,为了方便管理,选择安装Konga作为Kong Admin Web控制台。
kong
发布-订阅、消费组、分区
应该叫消费分区,(实际上就是queue)
实现延时队列的核心, 1. 安装插件 2,指明交换机为x-delayed-message。(指明x-delayed-type类型) 3,消息的header指明x-delay时间
rabbiimq延时插件
实现延时队列的核心, 1. 安装插件 2,指明交换机为x-delayed-message。(指明x-delayed-type类型) 3,消息的header指明x-delay时间
args.put("x-delayed-type", "direct");
路由type
编写配置类
连接问题导致无法创建队列
两者中较小的值,即队列无消费者连接的消息过期时间,或者消息在队列中一直未被消费的过期时间
队列或者消息的较小值被作为消息的真正的存活时间
底层通信协议支持选择 KCP 协议
kcp优化
避免了等待与后端服务建立连接以及 frpc 和 frps 之间传递控制信息的时间。
连接池优化
use_compression = true
报文压缩优化
有一个已知的导致资源管理器卡顿的原因,之前用过一款windows软件,clover
卡顿
再来一个新软件——ExTab官网|多标签文件管理器——应该是一个轻便的工具,官网没讲明系统支持情况。时至今日(2021-05-23)这软件还是有一些bug的,如果想要反馈,可以去它的百度贴吧或QQ群发言。
windows
我们看到两个消费者都收到了消息
每个消费者实例都产生一个匿名的queue
创建一个消费者组
实际上是将两个消费者实例绑定同一个queue
我们需要监听之前创建的通道greetingChannel。让我们为它创建一个绑定
如果消费者和生产者在同一个实例中,会优先走本地调用,不会产生队列消息。消费者能正常接收mq消息

使用SubscribableChannel和@Input注解连接到greetingChannel,消息数据将被推送这里
这里怎么让rabbitmq创建匿名的queue的
THREAD(线程隔离):使用该方式,HystrixCommand将会在单独的线程上执行,并发请求受线程池中线程数量的限制。SEMAPHORE(信号量隔离):使用该方式,HystrixCommand将会在调用线程上执行,开销相对较小,并发请求受信号量的个数的限制。
急救锦囊
docker-compose搭建kong和konga,开箱即用
kong
The following command connects an already-running my-nginx container to an already-existing my-net network
将一台运行中的container连接到已有的network
/opt/rabbitmq_delayed_message_exchange-3.10.2.ez复制到容器里去:
docker
docker cp c:\path\to\local\file container_name:/path/to/target/dir/
docker
Repair-WindowsImage -Online –RestoreHealth
Settings > Maven > Importing > Use Maven3 to import project
不能下载source问题
application.yml根据spring.profiles.active配置启用指定配置文件生效
application.yml根据spring.profiles.active配置启用指定配置文件生效
生效规则
发现是给用户授予了角色,只能登录控制台,但是没有给读写以及管理队列的权限,通过控制台admin按钮查看
rabbitmq的virtual host有权限配置
真正地消费/处理消息
UnicastingDispatcher,必然也会存在广播的消息分发器,那就是 BroadcastingDispatcher,它被 PublishSubscribeChannel 这个消息通道所使用。广播消息分发器会把消息分发给所有的 MessageHandler
黄色部分涉及到各消息中间件的 Binder 实现以及 MQ 基本的订阅发布功能
重点
RabbitMQ的基因中没有延时队列这回事,它不能直接指定一个队列类型为延时队列,然后去延时处理,但是经过上面两节的铺垫,我们可以将TTL+DLX相结合,这就能组成一个延时队列。
现在rabbitmq有延时队列插件可以实现延时队列功能 https://juejin.cn/post/6844904163168485383
The management plugin is included in the RabbitMQ distribution. Like any other plugin, it must be enabled before it can be used. That's done using rabbitmq-plugins:
rabbitmq的web界面需要先enable
创建一个消费者,绑定消费队列及死信交换机,交换机默认为direct模型,死信交换机也是,arguments绑定死信交换机和key。(注解支持的具体参数文末会附上)
同一个queue也可以绑定不同的routingKey
如果配置了死信队列,它将被重新publish到死信交换机,死信交换机将死信投递到一个队列上,这个队列就是死信队列
在队列上配置死信队列
key = {"info","error","warning"}
同一个queue也可以绑定不同的routingKey
集群消费
rabbitmq的topic模式、或者使用direct 同一个key加不同队列
广播消费
fanout
它采用pull机制,而 不是一般MQ的push模型
rabbitmq是push模型,kafka是pull模型
消息队列既可以做管子,也可以当做池子
消息短暂存储
RabbitMQ很优秀,但RabbitMQ对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降
消息堆积会对性能有不小影响
搜索团队从kafka直接消费消息
目前主流的操作方式
但第二个问题却让我束手无措
spring event也可以
都是可以根据 RoutingKey 把消息路由到不同的队列
direct模式下,同一个routingkey可以绑定不同的queue,这样路由器可以分别发送同样的消息到相应的两个queue中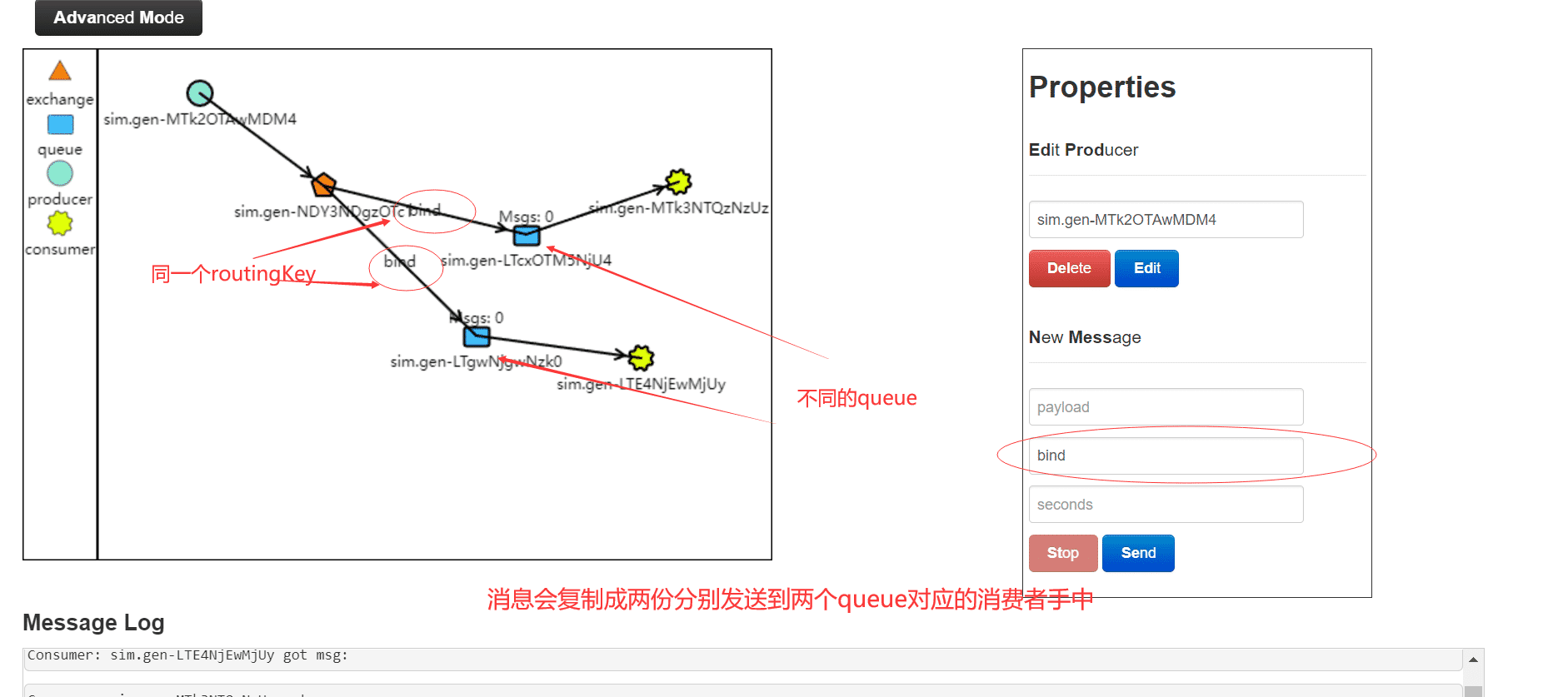
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割
消息队列
UI很漂亮,使用也很便利,一键开关。不用跳转到文章,能在Web端的管理页面直接打开文章进行标注。免费版本笔记数量没有限制
比如不需要交互的离线大规模计算,又比如多数 Web 资讯类网站、小程序、公共 API 服务、移动应用服务端等,都跟无服务架构擅长的短链接、无状态、适合事件驱动的交互形式很契合。
无服务适用范围
没有服务,一大堆的端到端的小应用。
难道没有控制层嘛?
分散治理(Decentralized Governance)
有时候也需要有个控制层来撮合业务
架构的实施是需要对应开发模式支撑的
基础设施自动化,如 CI/CD 的长足发展,大大降低了构建、发布、运维工作的复杂性。
为了职责,而做了职责分离,所以只是半自动化的
一个良好设计的服务,应该是能够报废的,而不是期望得到长久的发展。如果一个系统中出现不可更改、无可替代的服务,这并不能说明这个服务有多么重要,反而是系统设计上脆弱的表现。微服务带来的独立、自治,也是在反对这种脆弱性。
可迁移性
另外,尽管在分布式中,我们要想处理好一致性的问题也很困难,很多时候都没法使用传统的事务处理来保证不出现一致性问题。但是两害相权取其轻,一致性问题这些必要的代价是值得付出的。
分布式事务没有
在单体服务中,通常一个系统的各个功能模块会使用同一个数据库,虽然这种中心化的存储确实天生就更容易避免一致性的问题,但是,同一个数据实体在不同服务的视角里,它的抽象形态往往也是不同的。
营销甚至想访问券库
避免把软件研发看作是要去完成某种功能,而要把它当做是一种持续改进、提升的过程
营销服务就没有当成产品来搞,为业务而业务
这一点在真正实践的时候,其实多少都会留点儿宽松的处理余地。因为大多数的公司都不会在某一个服务用 Java,另一个用 Python,下一个用 Golang,而是通常都会统一主流语言,甚至会有统一的技术栈或专有的技术平台。
大数据那边可能有
如果本应该归属同一个产品内的功能,被划分在了不同的团队当中,那就必然会产生大量的跨团队沟通协作,而跨越团队边界,无论是在管理、沟通,还是在工作安排上,都会产生更高的成本。高效的团队,自然会针对这个情况进行改进,而当团队和产品磨合调节稳定了之后,就会拥有一致的结构
我们的问题应该是相反的:折上折前期电商、券微服务区分度不够。
反对 ESB、BPM 和 SOAP 等复杂的通讯机制
比较关键
通过服务来实现独立自治的组件
那么就需要远程调用方式提供功能
soa和微服务的区别: https://www.cnblogs.com/xuwc/p/13989081.html
潜在的观念是希望系统的每一个部件,甚至每一处代码都尽量可靠,不出、少出错误,致力于构筑一个 7×24 小时不间断的可靠系统
性能打折扣倒是其次
有任何一部分的代码出现了缺陷,过度消耗进程空间内的公共资源,那所造成的影响就是全局性的、难以隔离的
容灾、高可用
可以基于意图去使用各种协调分布式系统的工具,而不用深入具体工具的实现细节去研究怎么解决的分布式难题
sicp作者也提过,现代开发是探针式的开发方式,不需要了解那么多细节,只需要知道点api即可
远程的服务在哪里(服务发现)、有多少个(负载均衡)、网络出现分区、超时或者服务出错了怎么办(熔断、隔离、降级)、方法的参数与返回结果如何表示(序列化协议)、如何传输(传输协议)、服务权限如何管理(认证、授权)、如何保证通信安全(网络安全层)、如何令调用不同机器的服务能返回相同的结果(分布式数据一致性)等一系列问题,就需要设计者耗费大量的心思
分布式设计的核心概念
Function<*, String> means Function<in Nothing, String>.Function<Int, *> means Function<Int, out Any?>.Function<*, *> means Function<in Nothing, out Any?>.
星投影
编译器进行代码流程的推断。比如说,当一个表达式的返回值是 Nothing 的时候,就往往意味着它后面的语句不再有机会被执行
关键点
很灵活的代码
因为kotlin的Unit是单例对象
任何类型,当它被“?”修饰,变成可空类型以后,它就变成原本类型的父类了。所以,从某种程度上讲,我们可以认为“Any?”是所有 Kotlin 类型的根类型
还有助于我们实现函数类型
类型系统与函数式编程在静态类型语言中相辅相成
副词
修饰或限制动词、形容词,表示范围、程度、情态、语气等的词,一般不能修饰或限制名词。如「都」「很」「竟然」「再三」等。
val annotations = method.annotations for (annotation in annotations) { // ④ if (annotation is GET) { // ⑤ val url = baseUrl + annotation.value // ⑥ return@newProxyInstance invoke(url, method, args!!) } }
方法注解是一个列表
val parameterAnnotations = method.parameterAnnotations for (i in parameterAnnotations.indices) { for (parameterAnnotation in parameterAnnotations[i]) { // ② if (parameterAnnotation is Field) { val key = parameterAnnotation.value val value = args[i].toString() if (!url.contains("?")) { // ③ url += "?$key=$value" } else { // ④ url += "&$key=$value" } } }
为什么是这样的一个结构
这是因为它是 private 的,如果你把 private 关键字删掉的话,上面的代码就会报错了。
private 没有getter
改为var后,编译器就会立马报错
fun main() { // 找到一家肯德基 // ↓ val kfc = Restaurant<KFC>() // 需要普通饭店,传入了肯德基,编译器报错 orderFood(kfc) val success:Result.Success<Cat> = Result.Success<Cat>(Cat()) println(success.data) var s:Result.Success<Animal> = success s.data = Dog() println(success.data as Cat) }
sealed class Result<out R> { // 协变 ① // ↓ ↓ data class Success<out T:Animal>(var data: @UnsafeVariance T, val message: String = "") : Result<T>()
data class Error(val exception: Exception) : Result<Nothing>()
data class Loading(val time: Long = System.currentTimeMillis()) : Result<Nothing>()
}
型变(Variance)
表明泛型类型对象在初始化之后还可以型变成其他相关对象
不变性
fun <T:Animal> foo(list: MutableList<T>) {
list.add(Animal("1",1) as T)//为何这里需要as转换,因为T在运行时才知道具体的类型
val animal: Animal = list[0] // 取出的Cat对象
}
对于 contains、indexOf 这样的方法,它们虽然以 E 作为参数类型,但本质上并没有产生写入的行为。所以,我们用 out 修饰 E 并不会带来实际的问题
委托,或者说代理,开发中比较常见的还有 mock 数据,主界面版本的迭代,开源框架的功能包裹。感觉这些概念还是一样,只是 Kotlin 让这些东西写起来更加简单,或者更加方便。
https://blog.csdn.net/c10WTiybQ1Ye3/article/details/122227189
SP读写的委托封装,经常用
https://blog.csdn.net/zhuangchaoxian/article/details/108326249
public operator fun setValue(thisRef: T, property: KProperty<*>, value: V)
软件版本之间的兼容
委托模式
它常常用于实现类的“委托模式”
设计模式
无副作用的函数,它具有引用透明的特性
引用透明,结果可以替代函数调用
(::onClick
函数引用
不同项目可复用某些微服务
好多