历史日志没法保留
1,778 Matching Annotations
- Aug 2022
-
funnylog.gitee.io funnylog.gitee.io
Tags
Annotators
URL
-
-
time.geekbang.org time.geekbang.org
-
调用 remove 方法删除元素,往往会遇到 ConcurrentModificationException 异常,原因是什么,修复方式又是什么呢
遍历时,iterable会检测modCount
-
先通过循环获取到那个节点的 Node,然后再执行插入操作
add末尾就没什么问题
-
HttpServletRequestWrapper
-
异常操作是一个非常耗费性能的操作
-
使用 addSuppressed 方法把 finally 中的异常附加到主异常上
-
把原始异常作为转换后新异常的 cause,原始异常信息同样不会丢
-
我不建议在框架层面进行异常的自动、统一处理,尤其不要随意捕获异常。但,框架可以做兜底工作
-
可能需要在异常后转入分支业务流程
-
不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常
-
Controller 层往往会给予用户友好提示,或是根据每一个 API 的异常表返回指定的异常类型,同样无法对所有异常一视同仁
-
MyBatis @Column注解的updateIfNull属性,可以控制,当对应的列value为null时,updateIfNull的true和false可以控制
mybatis-plus有fieldStrategy
-
使用 =NULL 并没有查询到 id=1 的记录,查询条件失效
-
ConcurrentModificationException
-
List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响
-
如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
-
-
zh.wikipedia.org zh.wikipedia.org
-
拜拉克塔尔
-
-
zh.wikipedia.org zh.wikipedia.org
-
阿卜杜拉·居尔[编辑源代码]
-
-
www.yisu.com www.yisu.com
-
在确定了precision后就会要求结合Rounding Mode做一些舍入方面的操作
Tags
Annotators
URL
-
-
zh.wikipedia.org zh.wikipedia.org
-
兼任广东省委办公厅主任,同年8月兼任广东省委改革办主任
-
-
zh.wikipedia.org zh.wikipedia.org
-
现任声称拥有俄罗斯沙皇皇位的皇位请求者
Tags
Annotators
URL
-
-
baomidou.com baomidou.com
-
whereStrategy
即在querywrapper不需要事先判空
Tags
Annotators
URL
-
-
time.geekbang.org time.geekbang.org
-
HashSet 基于 HashMap,数据结构是哈希表。所以,HashSet 的 contains 方法,其实就是根据 hashcode 和 equals 去判断相等的
现在也有红黑树
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
使用 UpdateWrapper (3.x)
-
-
blog.csdn.net blog.csdn.net
-
忽略null值的判断
-
-
juejin.cn juejin.cn
-
比较更新要使用的实体类中的字段值与从数据库中查询出来的字段值,判断其是否有修改
-
使用@DynamicUpdate性能会好一些。因为不使用@DynamicUpdate时,即使没有改变的字段也会被更新
Tags
Annotators
URL
-
-
-
删除元素实际上调用的就是list.remove()方法,但是它多了一个操作
-
-
-
time.geekbang.org time.geekbang.org
-
如果我们希望只比较 BigDecimal 的 value,可以使用 compareTo 方法
-
BigDecimal 有 scale 和 precision 的概念,scale 表示小数点右边的位数,而 precision 表示精度,也就是有效数字的长度
-
使用 BigDecimal 表示和计算浮点数,且务必使用字符串的构造方法来初始化 BigDecimal
或者用valueOf
Tags
Annotators
URL
-
-
time.geekbang.org time.geekbang.org
-
对于自定义的类型,如果要实现 Comparable,请记得 equals、hashCode、compareTo 三者逻辑一致。
-
XX:AutoBoxCacheMax=1000
-
进行判等,需要使用 equals 进行内容判等。因为引用类型的直接值是指针,使用 == 的话,比较的是指针,也就是两个对象在内存中的地址,即比较它们是不是同一个对象,而不是比较对象的内容。
默认情况
-
getClass获得类型信息采用==来进行检查是否相等的操作是严格的判断。不会存在继承方面的考虑
-
那么查询索引本身已经“覆盖”了需要的数据,不再需要回表查询。因此,这种情况也叫作索引覆盖
extra中显示:use index,不是user index condition,也不是null
-
Controller 里出现了一个 UnexpectedRollbackException,异常描述提示最终这个事务回滚了,而且是静默回滚的异常描述提示最终这个事务回滚了,而且是静默回滚的
-
Transactional
是spring的tranactional,而不是javax的
-
也是坑点二,如果要配置 Feign 的读取超时,就必须同时配置连接超时,才能生效
有可能已经修复
-
否则由定时任务调用外部查询接口查询交易结果,然后根据查到的结果补偿本地状态
外部接口一般可以回调
-
发送数据到服务端,因此写入操作可以任务是自己本地的操作,本地操作是不需要什么超时时间的,如果真的有什么异常,那也是连接(TCP)不上,或者超时的问题,连接超时和读取超时就能覆盖这种场景
-
等到count个任务全部执行完毕
-
也就是同一个主机 / 域名的最大并发请求数为 2。我们的爬虫需要 10 个并发,显然是默认值太小限制了爬虫的效率
-
是服务端处理业务逻辑的时间
-
只要服务端收到了请求,网络层面的超时和断开便不会影响服务端的执行
-
-
www.jianshu.com www.jianshu.com
-
沈寅就把街道取名为“易赖街”,即容易耍赖皮
-
-
time.geekbang.org time.geekbang.org
-
校验又是如何触发的
通过拦截器触发,使用max和min校验器

-
Body 对象已经是一个解析过的对象,而不再是一个流了
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
认识中国新富豪:谁在习近平的经济中获益?
-
-
time.geekbang.org time.geekbang.org
-
equest.getParameterValues(name)",返回的是一个 String 数组,最终给上层调用者返回的是单个 String(如果只有一个元素时)或者 String 数组
Tags
Annotators
URL
-
-
www.cnblogs.com www.cnblogs.com
-
Undertow 的优势是高并发下的吞吐量
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
不会还是没解决我们说的一致性问题。如果在3、4之间插入了 Session B的逻辑呢
-
C会同时查询表t的总行数
C没有事务
-
可见的行才能够用于计算“基于这个查询”的表的总行数。
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
这就最大程度地减少了事务之间的锁等待,提升了并发度
-
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议
select ... for update是在读的时候加悲观锁
-
最可能造成锁冲突、最可能影响并发度的锁的申请时机尽量往后放
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
解决了快照读,当前读应该还是没解决
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
知道幻读都是发生在insert之后的, 我们回到假设1当中, 可以看到事务3插入了一条新的数据
-
-
funnylog.gitee.io funnylog.gitee.io
-
LSN
Log sequence number
-
这时候系统会停止所有更新操作,把checkpoint往前推进
-
把innodb_flush_neighbors的值设置成0。因为这时候IOPS往往不是瓶颈,而“只刷自己”,就能更快地执行完必要的刷脏页操作,减少SQL语句响应时间
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
普通索引和change buffer的配合使用,对于数据量大的表的更新优化还是很明显的
-
对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的就是账单类、日志类的系统
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
select还是旧值
-
如果A、B同时喜欢对方,会出现不会成为好友的问题。因为上面第1步,双方都没喜欢对方。第1步即使使用了排他锁也不行,因为记录不存在,行锁无法生效。请问这种情况,在mysql锁层面有没有办法处理
分两步走: 1. 如果是A喜欢B,应该是先执行插入,然后提交, 1. 然后再去查询B是否喜欢A,如果喜欢,则往friend表里插一条数据。
-
version被其他事务抢先更新
version拿到最新的当前值
-
事务B是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务C’释放这个锁,才能继续它的当前读。
-
版本已提交,而且是在视图创建前提交的
-
-
www.cnblogs.com www.cnblogs.com
-
为了防止子线程伪唤醒(spurious wakeup),只要子线程没有TERMINATED的,父线程就需要继续等下去
当前线程对象死亡时,其相关的锁也会被唤醒
-
-
juejin.cn juejin.cn
-
消息恢复系统
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
嵌套事务出错回滚不会影响到主事务
-
-
www.cnblogs.com www.cnblogs.com
-
事务自动开启、提交或回滚,比如insert、update、delete语句,事务的开启、提交或回滚由mysql内部自动控制的
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
数据库引擎不支持事务
-
-
-
SELECT * FROM information_schema.INNODB_TRX
Tags
Annotators
URL
-
-
www.runoob.com www.runoob.com
-
taskkill /T /F /PID 9088
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
事务传播行为是指声明式事务中,在一个事务方法中调用另一个事务方法,另一个事务方法的事务行为,加入现有事务、使用新的事务还是其他的行为
事务传播行为
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
-
ddl-auto
自动建表
-
-
github.com github.com
-
Whether all operations can be retried for this client
false则只有get会重试
Tags
Annotators
URL
-
-
www.elietio.xyz www.elietio.xyz
-
keepAlive解决druid空闲连接socket timeout 15分钟
-
-
time.geekbang.org time.geekbang.org
-
connection-timeout
获取连接超时
-
虽然使用 newFixedThreadPool 可以把工作线程控制在固定的数量上,但任务队列是无界的。如果任务较多并且执行较慢的话,队列可能会快速积压,撑爆内存导致 OOM
默认策略是先塞满队列
-
由于线程池在工作队列满了无法入队的情况下会扩容线程池,那么我们是否可以重写队列的 offer 方法,造成这个队列已满的假象呢?
默认情况下,先塞满队列,再扩容线程池。
线程池不满时,queue直接拒绝,这样就可以让线程池扩容

-
对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。
-
换句话说线程在跑
线程是gc root,然后线程又是引用了外部的线程池,只要线程不被回收(核心线程在allowCoreThreadTimeOut为false的情况下不会被回收),那么线程池也不会被回收。
-
可以想想tomcat为什么觉得这样激进的线程更适合
-
扩容线程池
当队列满的时候才会去扩容线程池
-
由于线程池在工作队列满了无法入队的情况下会扩容线程池,那么我们是否可以重写队列的 offer 方法,造成这个队列已满的假象呢?
- 默认情况下,先塞满队列,再扩容线程池。
- 线程池不满时,queue直接拒绝,这样就可以让线程池扩容
-
firstTask
firstTask默认不入队列
-
由于我们 Hack 了队列,在达到了最大线程后势必会触发拒绝策略,那么能否实现一个自定义的拒绝策略处理程序,这个时候再把任务真正插入队列呢
自定义拒绝策略,然后把runnable重新塞到队列里
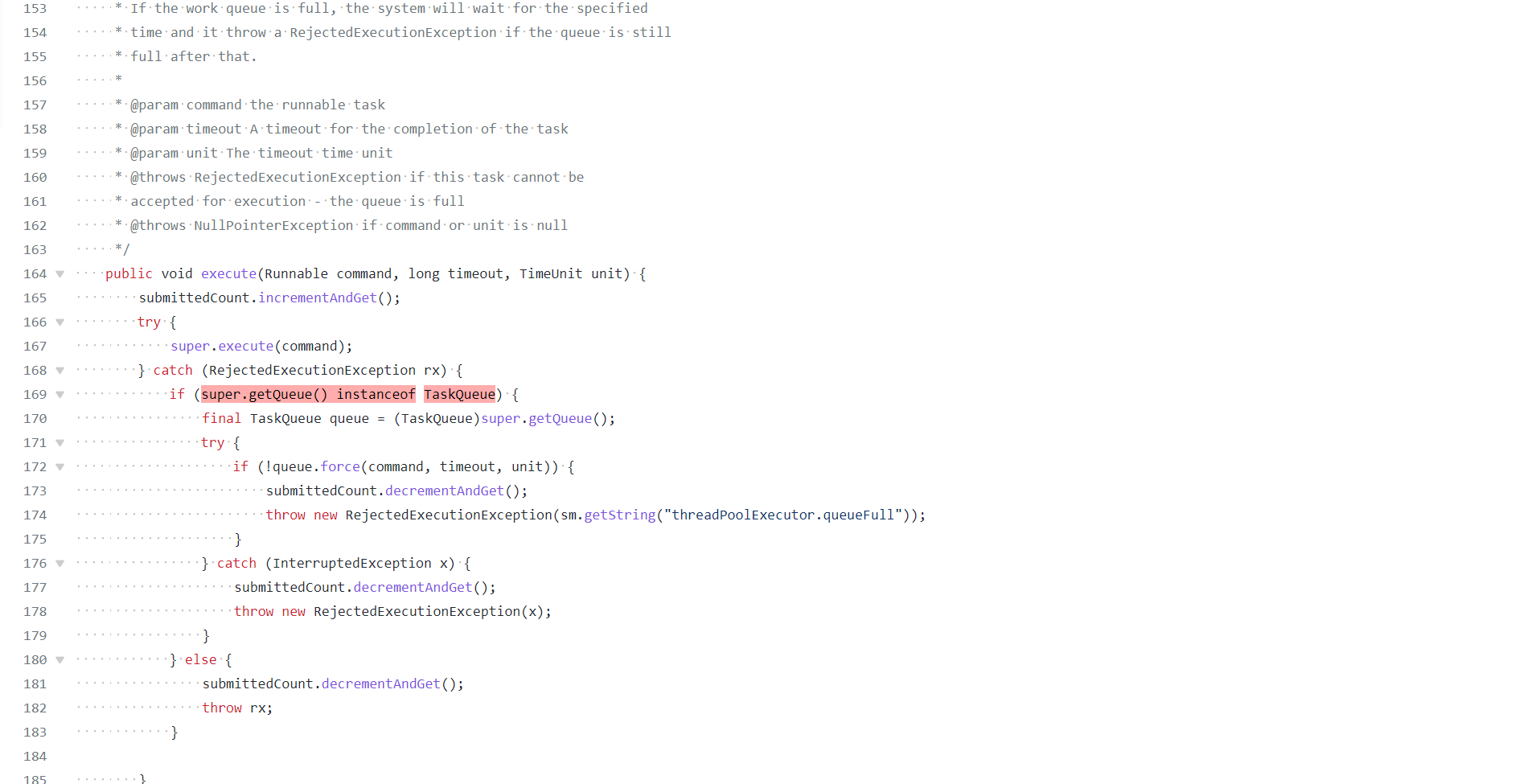
-
线程在跑
线程是gc root,然后线程又是引用了外部的线程池,只要线程不被回收(核心线程在allowCoreThreadTimeOut为false的情况下不会被回收),那么线程池也不会被回收。
-
队列来做缓冲。
类似消息队列
-
对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。
-
每秒输出一次线程池的基本内部信息
可以用在caffeine的缓存监控中

-
任何时候,都应该为自定义线程池指定有意义的名称,以方便排查问题
-
禁止使用这些方法来创建线程池,而应该手动 new ThreadPoolExecutor 来创建线程池
-
然后遍历购物车中的商品依次尝试获得商品的锁,最长等待 10 秒
本地测试最小可以到毫秒
-
Comparator.comparing(Item::getName)
.reversed()
-
如果这个变量不是 volatile 修饰的,子线程可以退出吗?你能否解释其中的原因呢?
不会,可能无限循环下去,因为编译器可能会优化这个循环
-
tem.lock.tryLock(10, TimeUnit.SECONDS)
这里避免了长时间死锁
-
查看抓取出的线程栈,在页面中部可以看到如下日志:

-
Object 类型的静态字段,在操作 counter 之前对这个字段加锁
锁必然是唯一的
-
只能确保多个线程无法执行同一个实例的 wrong 方法,却不能保证不会执行不同实例的 wrong 方法
-
-
time.geekbang.org time.geekbang.org
-
我们的监听器监听的体系是另外一套
这个事件监听器的初始化早于一般的bean
-
,修正起来也就简单了。假设不允许我们去拆分类,我们可以按照下面的思路来修改:
还可以使用order机制
-
它的核心就是通过一个 ThreadLocal 来将 Proxy 和线程绑定起来,这样就可以随时拿出当前线程绑定的 Proxy
当前proxy必然是所调用方法所对应的对象实例(代理)
-
@Autowired
需要lazy注解
-
Disposable 方法的注册
用于缓存spring的解构者
-
doCreateBean 管理了 Bean 的整个生命周期中几乎所有的关键节点
-
@Component(Service 也是一种 Component)将当前类自动注入到 Spring 容器时,shutdown 方法则不会被自动执行
-
当使用收集装配方式来装配时,能找到任何一个对应的 Bean,则返回,如果一个都没有找到,才会采用直接装配的方式
-
@Value 没有注入预期的值
-
寻找不到对应的 Bean,一定会如案例 2 那样直接报错
集合、数组不会

-
CglibSubclassingInstantiationStrategy.LookupOverrideMethodInterceptor
-
根据参数来寻找对应的 Bean
寻找的优化: 1. 事先扫描构建bean的索引(并不实际构建bean) 1. 当需要找个bean的时候,再去构建bean
-
-
docs.oracle.com docs.oracle.com
-
a negative integer, zero, or a positive integer as the first argument is less than, equal to, or greater than the second.
-1,前者小于后者 0,等于 1,前者大于后者
-
-
zhuanlan.zhihu.com zhuanlan.zhihu.com
-
因为无需默认构造函数就可以反射生成对象,这个属性在很多的序列框架可以使用,比如 xml 转换成 bean
-
-
stackoverflow.com stackoverflow.com
-
I came across the same error when trying to deploy a Spring Boot 2 application to Wildfly 13. This is the only Stack Overflow question that came up when I was searching for answers, so I thought I'd leave my findings here in case anyone else has the same issue, because my solution was very different from the only other answer here right now.
-
-
blog.csdn.net blog.csdn.net
-
相当于在application.propertices中的配置
逗号隔开
-
-
time.geekbang.org time.geekbang.org
-
然后提交
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
update t set a = a + 1;
当前事务变更后,可重复读拿到的就是更新的数据
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
事务中的MDL锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
mdl只有在事务之后才会释放
-
比较理想的机制是,在alter table语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃
等待
-
使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。
-
-
stackoverflow.com stackoverflow.com
-
SET collation_connection = 'utf8_general_ci';
编码
-
-
github.com github.com
-
queue.force(command, timeout, unit)
在queue中塞不进去,就直接抛错
-
super.getQueue() instanceof TaskQueue
满了重新塞进去
-
-
-
workerCountOf(recheck) == 0
如果有线程在工作,就直接结束
Tags
Annotators
URL
-
-
github.com github.com
-
if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false
当线程不满时,就让线程池增加线程
-
-
juejin.cn juejin.cn
-
线程池中线程的回收依赖JVM自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被JVM回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可
-
-
-
只有在真正的多核CPU上才可能得到加速(通过多线程)
CPU
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
API网关、防火墙、路由器等流量入口的服务器,要对流量做密集计算、校验、转发,CPU不强那肯定是不行的
-
绝大部分场景,内存才是限制系统性能的主要因素,而cpu一般都是性能过剩
Tags
Annotators
URL
-
-
www.liaoxuefeng.com www.liaoxuefeng.com
-
没有写入时,多个线程允许同时读(提高性能)
写入时,还是不允许读的
-
-
time.geekbang.org time.geekbang.org
-
实例设置到静态变量中,在多线程情况下重用呢?
不能,这样除了主线程,其他线程的seed都是同一个值
-
会根据用每个线程的 thread 的一个实例字段 threadLocalRandomProbe 是否为 0 来判断是否当前线程实例是否为第一次调用随机数生成方法,从而决定是否要给当前线程初始化一个随机的 threadLocalRandomSeed 种子值
current()会初始化一个随机的种子,而跳过了,就只能用一个固定的值
-
而 PIA 是插入 KV 对后,返回 null 值

-
都会用 Arrays.copyOf 创建一个新数组,频繁 add 时内存的申请释放消耗会很大
-
max-threads=1
现在是: server: tomcat: threads: max: 1
-
-
funnylog.gitee.io funnylog.gitee.io
-
alter table T engine=InnoDB
-
第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的
Tags
Annotators
URL
-
-
juejin.cn juejin.cn
-
16 个元素中找到目标元素
一次就要除以2
-
-
funnylog.gitee.io funnylog.gitee.io
-
等值查询
等于
-
-
www.zhihu.com www.zhihu.com
-
高并发
-
-
www.zhihu.com www.zhihu.com
-
-
www.zhihu.com www.zhihu.com
-
乐观锁
-
-
cloud.tencent.com cloud.tencent.com
-
乐观锁为理论基础的MVCC(多版本并发控制)
错误,乐观锁是写写控制,MVCC是写读控制
-
使用行级锁,锁定该行,事务A多次读取操作完成后才释放该锁,这个时候才允许其他事务更改刚才的数据
亦可使用乐观锁
-
幻读是读取了其他事务新增的数据,针对insert和delete操作
可重复读
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
恢复目标时间
-
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
-
就是当系统里没有比这个回滚日志更早的read-view的时候
疑惑点
-
MySQL的隔离级别设置为“读提交
mysql默认是可重复读
-
创建一个视图
-
一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的
非所有数据,而是所读取行
-
幻读(phantom read)
又是可重复读
Tags
Annotators
URL
-
-
funnylog.gitee.io funnylog.gitee.io
-
感觉oracle的DG就诞生了,物理的速度也将远超逻辑的,毕竟只记录了改动向量
-
redo log和binlog都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致
如果中间出现事故,mysql会做相应处理两阶段提交
-
-
blog.csdn.net blog.csdn.net
-
会去比较redolog中的内容和binlog中的内容。如果发现像上面这种情况,也会认为是成功的,因为binlog已经记录,只是差redolog中的一个commit状态没有修改成功
-
-
funnylog.gitee.io funnylog.gitee.io
-
数据表和数据列是否存在, 别名是否有歧义等。如果通过则生成新的解析树,再提交给优化器
-
mysql_reset_connection来重新初始化连接资源
-
参数wait_timeout
连接超时时间
-
-
blog.csdn.net blog.csdn.net
-
Binlog日志保留时长
Tags
Annotators
URL
-
-
-
mysqld
开启binlog
Tags
Annotators
URL
-
-
www.myfreax.com www.myfreax.com
-
:wq
Tags
Annotators
URL
-
-
blog.csdn.net blog.csdn.net
-
ubuntu中的日志文件位置,用于错误查找
Tags
Annotators
URL
-
-
www.jianshu.com www.jianshu.com
-
*.*
mysql
-
-
www.letianbiji.com www.letianbiji.com
-
单例模式中的懒加载和即时加载
Tags
Annotators
URL
-
-
www.cnblogs.com www.cnblogs.com
-
www.baeldung.com www.baeldung.com
-
Person personPrototypeA = (Person) applicationContext.getBean("personPrototype");
Tags
Annotators
URL
-
-
help.aliyun.com help.aliyun.com
-
RabbitMQ版可用于单体应用被拆解为微服务后不同微服务间的通信
- 接受券核销、购买信息(异步解耦、削峰填谷)
- 用户注册信息(异步解耦)
- 推送数据给ES(缓存同步)
- 分销活动,用户购买订单号+券id的最终一致性
- 延时队列,异步(取消订单)
-
BasicRecover
重放unack的消息
-
消息重试
服务器端重试机制
Tags
Annotators
URL
-
-
mp.weixin.qq.com mp.weixin.qq.com
-
无平台维护消息发送方、消费方的关联信息,多个版本迭代后无法确定对接方;
APM
-
镜像队列的方式保证消息在集群的可靠
集群
Tags
Annotators
URL
-
-
mp.weixin.qq.com mp.weixin.qq.com消息队列设计精要5
-
顺序消息
-
顺序消息
顺序消息
-
长事务死锁等各种风险
-
只需要发布一个产品ID变更的通知,由下游系统来处理,可能更为合理
下游系统再去重新拉取上游数据。类似折上折活动数据更新解耦问题
-
最终一致性
最终一致性
-
-
zhuanlan.zhihu.com zhuanlan.zhihu.com
-
在表和字段上强制执行的数据检验规则,为了防止不规范的数据进入数据库
有可能有重复数据进入
Tags
Annotators
URL
-
-
mp.weixin.qq.com mp.weixin.qq.com
-
把请求键值快速传输给缓存更新方,它们之间不关心对方的业务
系统解耦
-
信息采集处理
生产快于消费,类似于日志收集
Tags
Annotators
URL
-
-
zhuanlan.zhihu.com zhuanlan.zhihu.com
-
Interface ApplicationContextAware 和 InitializingBean来获取我们在Configuration class中声明的exchange, queue, binding beans并调用channel的相应方法来声明
源码分析
Tags
Annotators
URL
-
-
-
表示当前Exchange是RabbitMQ内部使用,用户所创建的Queue不会消费该类型交换机下的消息,既然是为了RabbitMQ系统所用,作为用户,我们就没有必要创建该类型的Exchange,当然默认也是选择No
系统使用
-
-
www.cloudamqp.com www.cloudamqp.com
-
for the fastest possible throughput, manual acks should be disabled.
-
-
www.jianshu.com www.jianshu.com
-
retry只能在自动ack模式下使用。如果一定要在手动ack模式下使用retry功能,需保证消息能在有限次重试过程中可以重试成功,否则超过重试次数,又没办法执行ack或者nack,消息就会一直处于unack,并不会转发到死信队列
manul模式下重试可能还有bug:
recover与manual模式也有关系(是否是bug、按理manul不能被自动ack/reject)
重试机制下: 1. 默认情况,manual模式的消息会最终处于unack状态; 1. ImmediateRequeueMessageRecoverer,manual消息会被重新requeue; 1. RejectAndDontRequeueRecoverer,manual模式的消息会最终处于unack状态;
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
-
#onMessage() from ChannelAwareMessageListener class. Then you can do it this way
新的扩展点,manual也可以不用手工确认
-
-
cloud.tencent.com cloud.tencent.com
-
BindingKey 完全匹配的 Queue
bindingKey和queue之间是多多关系
-
零个、一个或多个英文单词
尤其是零个
-
单播路由
Tags
Annotators
URL
-
-
docs.api.xiaomi.com docs.api.xiaomi.com
-
模型图如下:
rabbitmq的简单模式
-
-
docs.api.xiaomi.com docs.api.xiaomi.com
-
Wait Time设为大于0的值,即Long Polling
长轮询
-
Queue中的一条Message被Receiver接收后,将在一段时间内变为不可见
rabbitmq的unack状态 即不被其他消费者看见的时间段
Tags
Annotators
URL
-
-
cloud.tencent.com cloud.tencent.com
-
跟rabbitmq比的优势:
- 消息回溯
- 有push/pull模型
- 简化了direct、topic模式(可以只有topic,没有queue)
- raft优化,可用性提高
- 性能优化
- 有可见性概念、简化了消费者确认模型
- 可以批量处理
-
可从队列删除 Message A,以避免一旦取出消息隐藏时长过期后该消息被再次接受并处理
需要主动删除消息
Tags
Annotators
URL
-