GitHub
10,000 Matching Annotations
- Jan 2024
-
netflix.github.io netflix.github.ioPolly.JS2
-
-
ipfs.indy0.net ipfs.indy0.net
-
Standalone, framework-agnostic JavaScript library that enables recording, replaying, and stubbing HTTP interactions.
-
Open Source record and playback test automation for the web. electron ... Open-source and privacy-friendly. react open-source mac screenshot app typescript .
record · GitHub Topics to
-
Netflix/pollyjs: Record, Replay, and Stub HTTP Interactions.
-
-
session-replay · GitHub Topics
-
tomgallagher/RecordReplay
Automated functional testing via the Chrome DevTools Protocol. Easy to use and open source. Generates unique CSS and Xpath selectors.
-
-
github.com github.com
-
record Here are 449 public repositories matching this topic..
-
-
openreplay.com openreplay.com
-
-
Prior Art
The "Client Server" API of Polly is heavily influenced by the very popular mock server library pretender.
-
Use Polly's client-side server
client0side server
to modify or intercept requests and responses to simulate different application states (e.g. loading, error, etc.).
-
-
-
ipfs.indy0.net ipfs.indy0.net
-
docdrop.org docdrop.org
-
-
-
www.startpage.com www.startpage.com
-
https://github.com/tomgallagher/RecordReplay tomgallagher/RecordReplay - GitHub Automated functional testing via the Chrome DevTools Protocol. Easy to use and open source ... No coding skills are required to record and to replay tests.
-
https://www.freecodecamp.org/news/use-typescript-with-react/ How to Use TypeScript with React - freeCodeCamp Nov 15, 2023 ... If the file does not contain any JSX-specific code, then you can use the .ts extension instead of the .tsx extension. To create a component in ...
-
-
www.youtube.com www.youtube.com
-
Record/Replay Demonstration Video
-
-
github.com github.com
-
About Automated functional testing via the Chrome DevTools Protocol. Easy to use and open source. Generates unique CSS and Xpath selectors. Outputs code for multiple testing frameworks, including Jest, Puppeteer, Selenium Webdriver and Cypress.
-
-
ecosystem-wg.notion.site ecosystem-wg.notion.site
-
Getting Started With IPFS & Filecoin

-
-
docs.filebase.com docs.filebase.com
-
IPFS DesktopLearn how to configure IPFS Desktop for use with Filebase.

-
-
www.pinata.cloud www.pinata.cloud
-
Kubo vs Helia vs Elastic-IPFS: Comparing the major IPFS implementations

-
-
-
greattransition.org greattransition.org
-
What's Next for the Global Movement?

-
-
www.freecodecamp.org www.freecodecamp.org
-
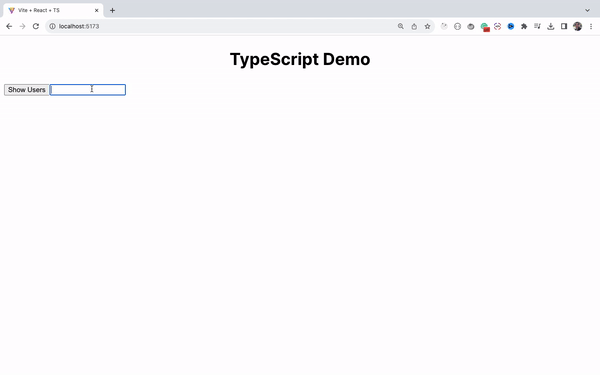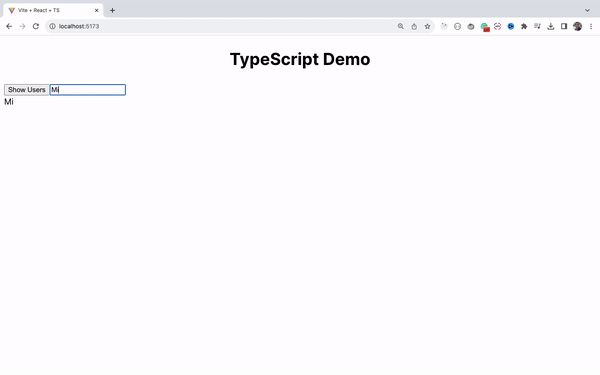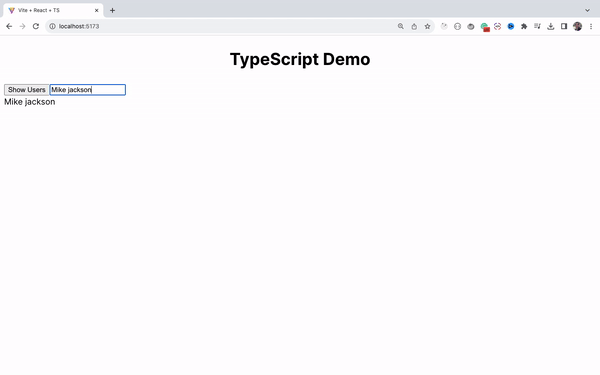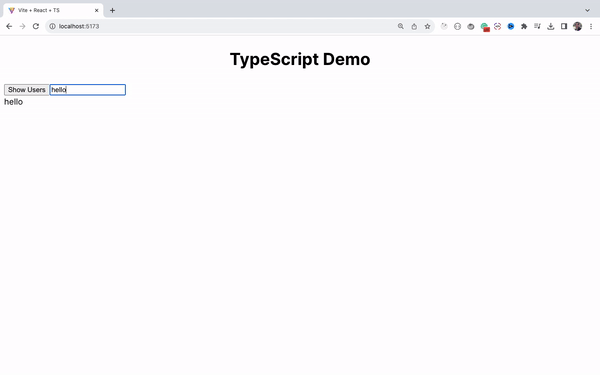
How to Handle the Change Event
-
-
ipfs.indy0.net ipfs.indy0.net
-
Web Intents
-
-
en.wikipedia.org en.wikipedia.org
-
a standalone protocol for describing multicast sessions
=on - multicast.sessions
-
The set of properties and parameters is called a session profile.
= on - session.profile
-
-
github.com github.com
-
self-host your own Chitchatter instance.
self-host
-
Secure peer-to-peer chat that is serverless, decentralized, and ephemeral
-
ecure medium of your choosing (such as Burner Note or Yopass).
-
File transfer functionality is powered by secure-file-transfer.
-
would not be possible without Trystero.
-
The secure networking and streaming magic
would not be possible without Trystero.
File transfer functionality is powered by secure-file-transfer.
-
Chitchatter is a
free ( - as in both - price and - freedom) - communication tool.
Designed to be the
simplest way to - connect with others - privately and
securely,
-
-
-
for - Quarksoft - techwriter

-
-
en.wikipedia.org en.wikipedia.org
-
CAP theorem

n a way IPFS going against the CAP theorem which says you cannot have Consistency Availability and Partition tolerance all three
As we can see availability is indeed very problematic. But as one of the great talks pointed out the more people join the IPFS networks availability will improve exponentially. In terms of ipns as a protocol when combined with dnsink seems to be giving us a pretty good availability which is a half way house
alternatively use this
from : https://hyp.is/k9U7pPxNEe2ZYAf5Jr2Xlg/docs.ipfs.tech/concepts/ipns/
-
-
www.bookstackapp.com www.bookstackapp.com
-
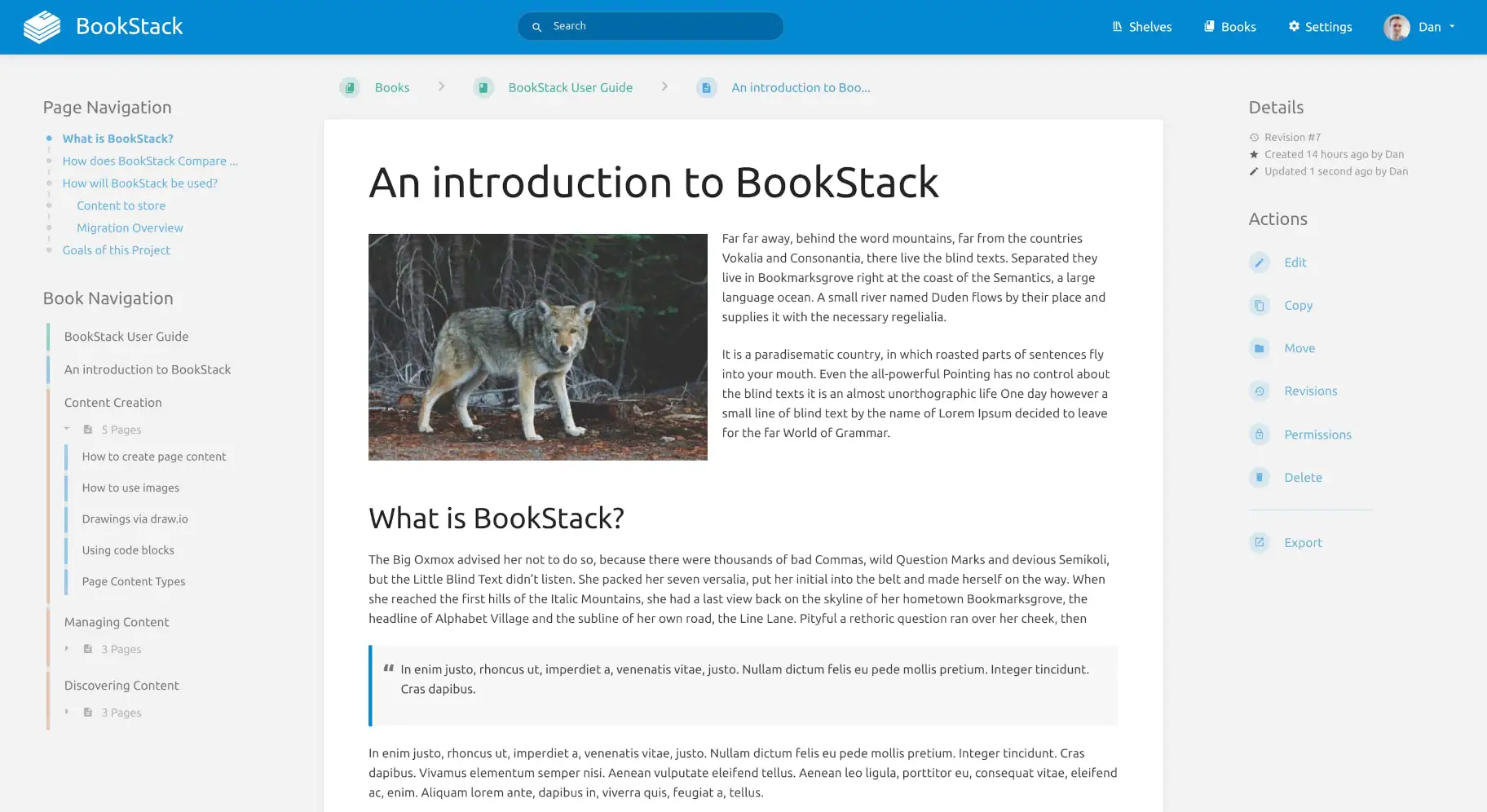
BookStack is a simple, self-hosted, easy-to-use platform for organising and storing information.
-
-
ipfs.indy0.net ipfs.indy0.net
-
from hylo self.link
-
-
-
Conformal Mapping -- from Wolfram MathWorldWolfram MathWorldhttps://mathworld.wolfram.com › ConformalMappingWolfram MathWorldhttps://mathworld.wolfram.com › ConformalMappingby EW Weisstein · 2000 · Cited by 14 — A conformal mapping, also called a conformal map, conformal transformation, angle-preserving transformation, or biholomorphic map, is a
-
-
ipfs.indy0.net ipfs.indy0.net
-
math.stackexchange.com math.stackexchange.com
-
holomorphic functions are conformal: they preserve angles between curves (this is a fifth, partially independent, way to think about complex differentiable functions.)
holomorphigenic plex spaces
preserve the spanning structure of trailmarks
thought vectors in hyperdocument spaces
-
-
github.com github.com
-
for - tech.mix - Indy.Web
-
Simple, robust, BitTorrent peer wire protocol implementation
BitTorrent protocol
-
Extension for Peers to Send Metadata Files (BEP 9)
-
extension api
protocol extension API
-
-
symbl.cc symbl.cc
-
Ideographic Telegraph Symbol for January ㋀
㋀
-
-
-
Clipboard Emoji (List) 📋
📋
-
-
-
Eyes Emoji (Eyeballs) 👀
👀
-
-
web.archive.org web.archive.org
-
Round Trip Website Authoring

-
-
techwriter.me techwriter.me
-
to - https://hypothes.is/a/q8Yy2rgjEe6_pG8CGfrV5w - https://web.archive.org/web/20240121055817/https://techwriter.me/doc/TechWriterUserGuide/UserGuide.htm
-
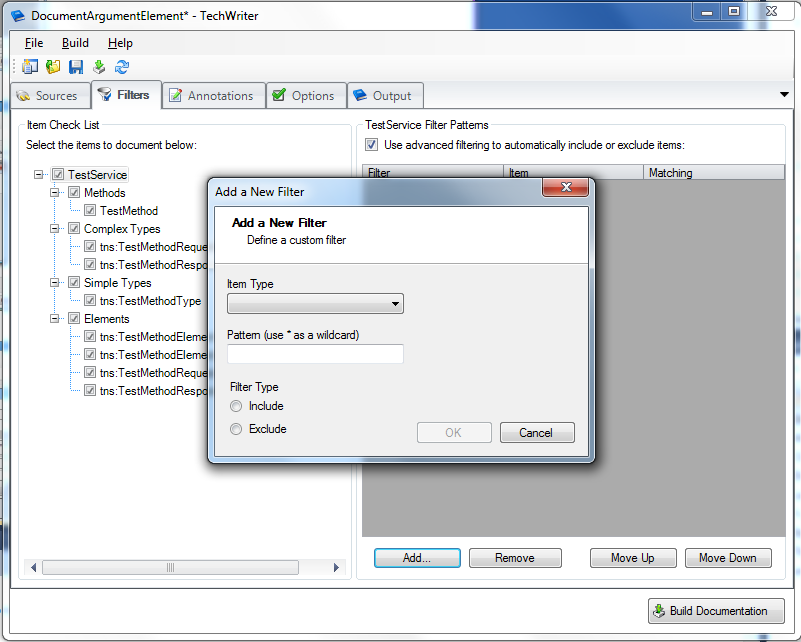
Take Control of Your IT Documentation with TechWriter ®




-
-
web.archive.org web.archive.org
-
TechWriter is a documentation authoring tool that automatically generates documentation for databases, XML schemas, web services and more. With minimal effort, you can use TechWriter to create documentation that captures the information locked inside your IT projects with the accuracy and completeness of an experienced technical writer.
-
TechWriter is a documentation authoring tool that
TechWriter is a documentation authoring tool that automatically generates documentation for - databases, - XML schemas, - web services and more.
With minimal effort, you can use TechWriter to create - documentation
that captures the information locked inside your - IT projects
with the - accuracy and - completeness
of an experienced technical writer.
-
-
techwriter.me techwriter.me
-
-
TechWriter is a documentation authoring tool that automatically generates documentation for databases, XML schemas, web services and more.
Flip that!
-
-
-
-
Visual Tour of TechWriter

-
-
techwriter.me techwriter.me
-
Round Trip Database Authoring

-
-
www.pinata.cloud www.pinata.cloud
-
Collaborate with your entire team, all under one account
One Account
-
Introducing Pinata Workspaces

-
from - pinata-blog - thoughts worth pinning

-
-
www.pinata.cloud www.pinata.cloud
-
Thoughts Worth PinningFor crafty coders, ambitious creators and trailblazing businesses who want to grow (and have fun) with web3.
trailblazing businesses
-
-
fontawesome.com fontawesome.com
-
fontawesome plans

-
x
-
More icons like file-pdf…
<svg xmlns="http://www.w3.org/2000/svg" height="16" width="16" viewBox="0 0 512 512"><path d="M64 464l48 0 0 48-48 0c-35.3 0-64-28.7-64-64L0 64C0 28.7 28.7 0 64 0L229.5 0c17 0 33.3 6.7 45.3 18.7l90.5 90.5c12 12 18.7 28.3 18.7 45.3L384 304l-48 0 0-144-80 0c-17.7 0-32-14.3-32-32l0-80L64 48c-8.8 0-16 7.2-16 16l0 384c0 8.8 7.2 16 16 16zM176 352l32 0c30.9 0 56 25.1 56 56s-25.1 56-56 56l-16 0 0 32c0 8.8-7.2 16-16 16s-16-7.2-16-16l0-48 0-80c0-8.8 7.2-16 16-16zm32 80c13.3 0 24-10.7 24-24s-10.7-24-24-24l-16 0 0 48 16 0zm96-80l32 0c26.5 0 48 21.5 48 48l0 64c0 26.5-21.5 48-48 48l-32 0c-8.8 0-16-7.2-16-16l0-128c0-8.8 7.2-16 16-16zm32 128c8.8 0 16-7.2 16-16l0-64c0-8.8-7.2-16-16-16l-16 0 0 96 16 0zm80-112c0-8.8 7.2-16 16-16l48 0c8.8 0 16 7.2 16 16s-7.2 16-16 16l-32 0 0 32 32 0c8.8 0 16 7.2 16 16s-7.2 16-16 16l-32 0 0 48c0 8.8-7.2 16-16 16s-16-7.2-16-16l0-64 0-64z"/></svg>
-
-
www.youtube.com www.youtube.com
-
Google might be proudly say okay we're doing a lot to help people find things out on that front error and okay but then who's 00:17:43 doing the job of really making better Maps understanding the footcare
Google and other search engine do a great job of auto-associative recall, i.e. giving you all the documents on the web that contain the terms you search for.
But as Engelbart asked back in 2007 at Google:
"Google might be proudly say, we are doing a lot to - help people find things - on the net frontier,
Who is doing the job of maybe - making better maps - understanding the frontier"

**blaze trails @ the net frontier augmenting mutual learning
new profession of trail blazers MEMEX
mutual learning
- Organizing mutul learning right at the edges of the
- "endless frontier" of knowledge
- responsibility to dream
- from inception, through indwelling and growth of understanding
- stemming from our increased capacities for honouring the complexitiesof our situation
- scaling synthesis and reach together
- within in networks of people who care,
- to the point of it being notable and part of
- "The Common Record".
Empower People at the edges - to do it for themselves, - share and have conversations around their - HyperMaps of their own(ed) collaborative mutual learning in the commons - at the edge of knowledge in the long tail of the emergent autonomous indy software internet - empower people with the problem for solve if for themeselves
- turning the Curse of LISP into blissful blessings
federate these conversations in emergent communities.
With the Wiki, Ward Cunningham gave us the ability to "create a new linked" page when you reach the edge of your knowledge"
What we need is for everybody to be able to do that, and at the same time have conversations with other people in an interest based emergent social networked thoughts and thinkers.
https://www.youtube.com/watch?v=xQx-tuW9A4Q&feature=youtu.be&t=1063
-
-
learn.microsoft.com learn.microsoft.com
-
Git settings
for name and email settings in git

-
-
code.visualstudio.com code.visualstudio.com
-
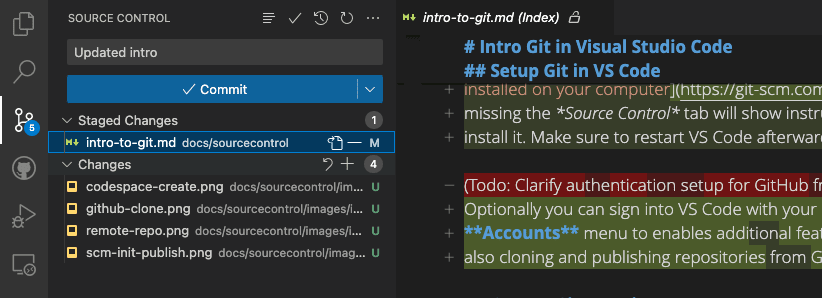
Introduction to Git in VS Code
-
-
-
Tails is a portable operating system that protects against surveillance and censorship.

-
-
www.educative.io www.educative.io
-
Progressive Web Apps (PWAs) are
highly advanced websites that
combine web technologies like - HTML, - CSS, and - JavaScript
with intelligent features such as:
Responsive design:
Adapts to - all devices and - screen sizes
for a consistent user experience.
Offline access:
Uses service workers - to work offline or - in low network conditions.
App-Like feel:
Can be installed on - home screens, - resembling native apps.
Manifest files:
Includes - metadata for app installation and - appearance.
Push notifications: Sends - updates and messages
even when not open.
Fast loading:
Optimized for - quick loading,
especially on slow connections.
-
How to perform a PWA performance auditing
-
-
obsproject.com obsproject.com
-
Display Capture capturing literally everything??

-
-
stackoverflow.com stackoverflow.com
-
VS Code's Source Control icon has gone missing, how do I get it back?

-
-
www.youtube.com www.youtube.com
-
How to create a Git repository with git init, GitHub and Git GUI tools Cameron McKenzie Cameron McKenzie 14.8K subscribers SubscribeSubscribed 15Sha
-
-
www.indiehackers.com www.indiehackers.com
-
Build an app with me: Youtube Bookmark Manager

-
-
ipfs.indy0.net ipfs.indy0.net
-
community.brave.com community.brave.com
-
Cannot use independent IPFS node with Brave nor configure the Brave node to use different port
Brave issue
-
-
github.com github.comHome2
-
from https://hyp.is/AFs6PrUEEe6ay-c4IYPy9w/www.thescottkrause.com/emerging_tech/neodigm55_ux_library/
-
Neodigm 55 Easy JavaScript Popups
-
-
www.thescottkrause.com www.thescottkrause.com
-
It's low-code, performant, responsive, and open source. Because it’s so easy to get started it is the perfect solution for quick landing pages, business accelerators, and event sites.
-
Neodigm 55 Low Code UX micro-library Scott C. Krause | Friday, Nov 25, 2022
from - https://hyp.is/HysQdrUCEe6HgDNGpn7Q4w/gist.github.com/neodigm/ffa4a9e22a5da14e2472274d476eaa55

-
-
gist.github.com gist.github.com
-
Now part of the Neodigm 55 UX micro-library
-
snackbar_toast.js
-
-
github.com github.com
-
self.link: neodigm - github - Scott.C.Krause
-
DataVis 👁️ UX 🍭 PWA 👁️ ThreeJS ✨ Vue..
neodigmToast
-
I code
- performant,
- functional,
- testable,
- future-proof, and
- trusted
what? - JavaScript, TypeScript, Vue, and SolidJS.
I've enchanted the UX for Abbott Laboratories, AbbVie, CDW, Corporate Express, Hyundai, Microsoft, and Sears.
-
Scott C. Krause neodigm
-
-
ipfs.indy0.net ipfs.indy0.net
-
ipfs.indy0.net ipfs.indy0.net
-
-
HTML Over the Wire - Scott C. Krausethescottkrause.comhttps://www.thescottkrause.com › curated-htmx-linksthescottkrause.comhttps://www.thescottkrause.com › curated-htmx-linksAug 5, 2023 — Is HTMX worth the effort to learn as a pragmatic skill? Yes ... browser automation. /* _____ / __ \ | / \/_ _ _ __ _ __ ___ ___ ___ ...
-
-
ipfs.indy0.net ipfs.indy0.net
-
HTML Over The Wire means that HTML, instead of JSON, is transported between the client and the server / API. Considered to be a simpler approach when compared to popular bloated reactive frameworks.
broader reactive frameworks
-
-
-
No accounts. 100% privacy.
Funded by happy users' donations.
No accounts 100% privacy
as a USP

-
No accounts. 100% privacy. Funded by happy users' donations.
**No accounts **
-
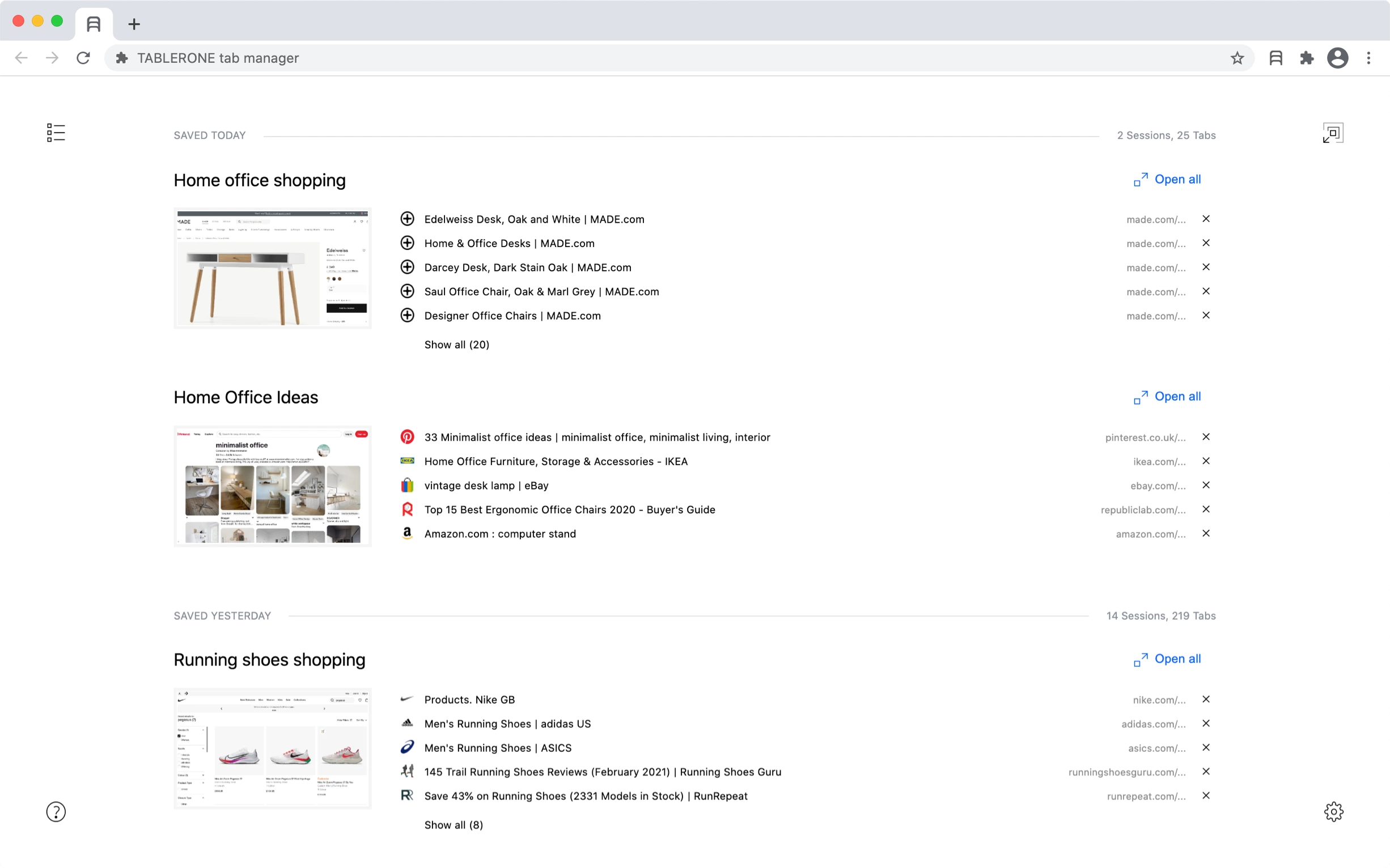
All-in-one tab session manager for Chrome Stay in the flow with saved workspaces and organised bookmarks. Get to tab zero in seconds.
from - HN privacy focused bookmarks manager
-
-
www.youtube.com www.youtube.com
-
Google Chrome - SAVE TAB GROUPS is now available - Keep your tabs organized!
23,794 views 23 Mar 2023 Google Google Chrome came out with the ability to add Tab Groups in April 2021. I know, I made a video on how to use Tab Groups. What was missing was the ability to Save the Tab Groups. You can now save Tab Groups if you turn on Chrome Flags. Chrome Flags are new or experimental features. This tells me soon Saved Tab Groups will be part of the Chrome browser. What are Tab Groups? Tabs in Chrome that are related. For example, Delta Air Lines, Southwest Airlines, Hilton, and Marriott may be grouped together under the Travel Group. Think of Tab Groups as Folders in File Explorer. Groups can be collapsed and expanded. They can be Saved, the new feature. Tab Groups that are saved will appear when Chrome is closed and re-opened. You need to Enable Tab Group Save in Flags.
How to enable Chrome flags? Open Chrome and copy and paste this into the address bar chrome://flags Screenshot https://drive.google.com/file/d/1-3vf...
-
-
news.ycombinator.com news.ycombinator.com
-
natannikolic 7 months ago | prev | next [–] https://tabler.one — Tablerone is a 100% private tabs, sessions, and bookmarks manager browser extension.
privacy focus zero knowledge encryption
-
-
-
ipfs.indy0.net ipfs.indy0.net
-
Ask HN: What's a good, privacy focused bookmark manager?News YCombinatorhttps://news.ycombinator.com › itemNews YCombinatorhttps://news.ycombinator.com › itemhttps://www.partizion.io/ is a great bookmark manager / session manager. Privacy focused, auto-saved sessions, and can add new links with the chrome extension.

-
What's the best way to manage 1000's of bookmarks?Reddit · r/chrome10+ comments · 10 months agoReddit · r/chrome10+ comments · 10 months agoChrome's bookmark manager is abysmal for organizing. A long time ago, Internet Explorer used to store it's bookmarks like files, meaning ...
-
Build an app with me: Youtube Bookmark ManagerIndie Hackershttps://www.indiehackers.com › post › build-an-app-w...Indie Hackershttps://www.indiehackers.com › post › build-an-app-w...Jan 26, 2021 — Why am I building it? · Pretty positive product hunt campaign product hunt campaign · Some traction bookmark it chrome store · No updates for a ..
-
luciancostinailenei/pretty-bookmarksGitHubhttps://github.com › luciancostinailenei › pretty-book...GitHubhttps://github.com › luciancostinailenei › pretty-book...pretty-bookmarks. A pretty Google Chrome bookmark manager created with productivity with mind. Why use it. It's a more clean and usable alternative to chrome
-
search,google - pretty bookmarks manager
do.how - identify the page with a permanent self link - permanence is assured as the search result itself - is saved on the Permanent Web powered by IPFS - and indy0.net provides a way to load hypothesis social annotation to work on the page - the above link names this page using trailmarks - indicating that it is a result of doing a search with google - after the hyphen the keywords are given - use this convention to name a link to the page itself - the purpose being that we can even manually - copy this link the markdown wource in here - from the annotation 0 and use it in the pagers that it links to - when you annotate them to the pages - that we visit and annotate from here - so we can always answer the question - where (and how in details( did you find that site
-
-
-
10Posted byu/dix-hill10 months agoArchivedWhat's the best way to manage 1,000's of bookmarks?
-
-
github.com github.com
-
Install extension for Chrome Web Store
.png)
-
-
-
ipfs.indy0.net ipfs.indy0.net
-
-
Bookmark Miscellaneous Symbols and Pictographs
🔖

-
📑
-
Page with Circled Text Miscellaneous Symbols and Pictographs
🗟
-
Document with Picture Miscellaneous Symbols and Pictographs
🖻
-
Document with Text and Picture Miscellaneous Symbols and Pictographs
(◕‿◕) SYMBL
-
註 Ideograph explain; annotate; make entry CJK
Chinese symbol annotate
-
-
docs.cryptpad.org docs.cryptpad.org
-
Known caveats¶ No unique usernames
neither account names or display names are unique
-
-
docs.cryptpad.org docs.cryptpad.org
-
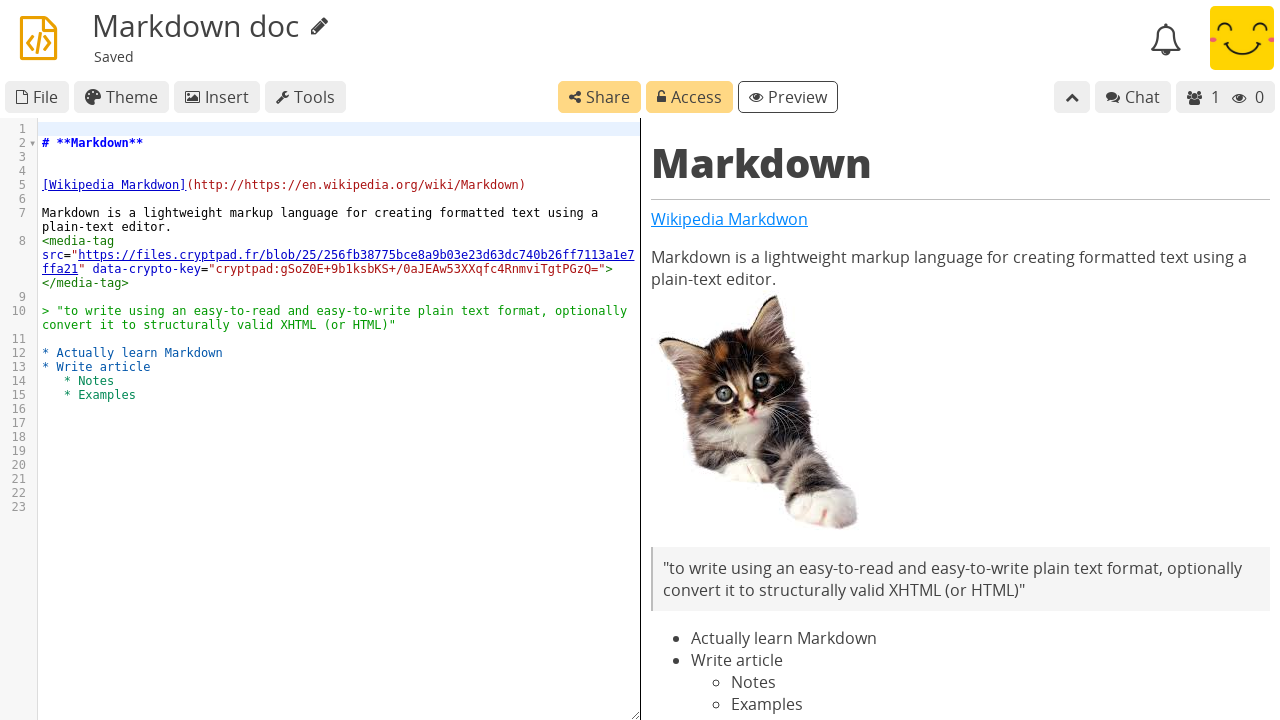
Code / Markdown
-
-
-
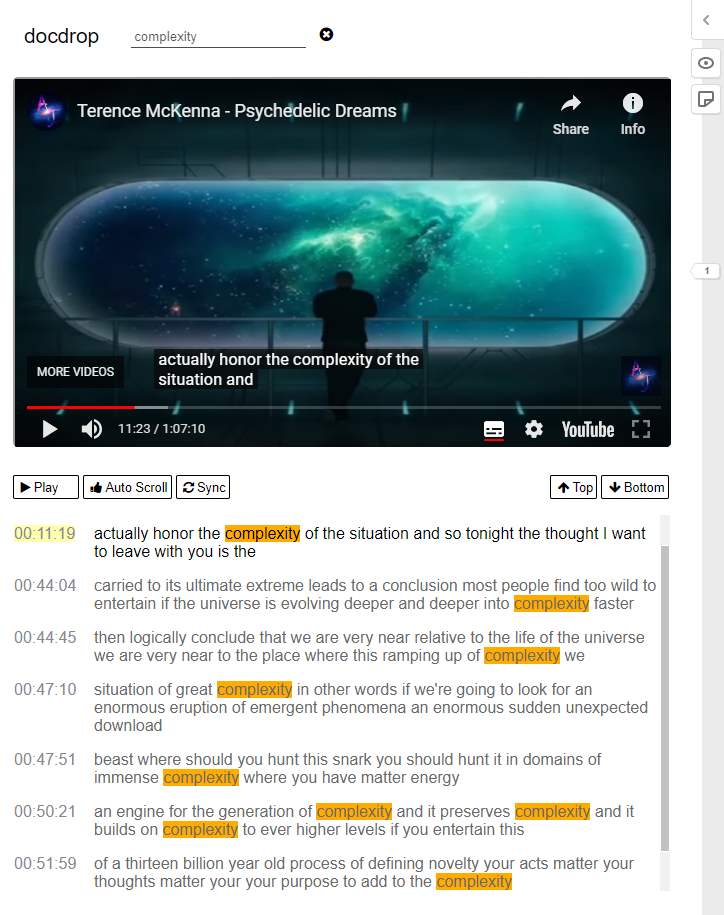
we begin to 00:11:19 actually honor the complexity of the situation
honour complexity situation
-
this awakening must not be disempowering
this awakening must not be disempowering and
the mantle that can be spread over the awakening
to counteract the possibility of disempowerment is this wish to - evoke - realize and - serve the
project of - bringing ever greater amounts of beauty into the world
-
planetary warming complete 00:12:11 collapse of any concern for the destiny of future generations
collapse of any concern for - the destiny of future generations
-
-
www.google.com www.google.com
-
search.google - ethereum name service why
-
What Is Ethereum Name Service? (ENS) - Krakenkraken.com
-
-
www.kraken.com www.kraken.com
-
The Ethereum Name Service (ENS) is a domain name service (DNS) built on the Ethereum blockchain ENS works in a similar way to the Internet's DNS system and helps users to find Ethereum addresses via human-readable names, rather than complex hexadecimal characters
from - search.google - etherium name service why
-
-
github.com github.com
-
Functions for interacting with the Ethereum Name Service
-
Web3.js provider for the HTTP protocol
-
Collection of comprehensive TypeScript libraries for Interaction with the Ethereum JSON RPC API and utility functions. web3js.org/
-
-
docs.web3js.org docs.web3js.org
-
Quickst
web3.js documentation
-
-
web3js.org web3js.org
-
A JavaScript library for building on Ethereumweb3.js is
-
-
sedm.org sedm.org
-
Sovereignty Education and Defense Ministry (SEDM)

-
-
github.com github.com
-
protocol extension api for adding new extension
-
peer discovery via dht, tracker, lsd, and ut_pex
peer discovery
-
Torrent client for node.js & the browser (same npm package!)
-
WebTorrent is a streaming torrent client for node.js and the browser. YEP, THAT'S RIGHT. THE BROWSER. It's written completely in JavaScript – the language of the web – so the same code works in both runtimes.
WebNative
all you need is a browser
-
Streaming torrent client for the web
-
-
www.npmjs.com www.npmjs.com
-
BitTorrent Extension for Peers to Send Metadata Files (BEP 9)
peers send metadata files
-
ut_metadata
ut_metadata
-
-
github.com github.com
-
Chitchatter Community Rooms
-
-
-
ou can use the official Chitchatter SDK
learn
-
-
-
chitchatter.im chitchatter.imAbout3
-
Message size is limited to 10,000 characters.
10 k limit
-
User Guide
for - ChitChatter
-
Chat rooms
xxx
-
-
chitchatter.im chitchatter.im
-
read the docs.
-
-
ipfs.indy0.net ipfs.indy0.net
-
meta.do.how -
-
-
www.linkedin.com www.linkedin.com
-
How we can set meaningful learning intentions?
-
-
ipfs.indy0.net ipfs.indy0.net
-
google.search - journal folder structure
google.search - journal folder structure
meta.do.how use trailmarks for link names that make explicit the intent, intended meaning and the subject of the lin
-
-
yopass.se yopass.se
-
No accounts neededSharing should be quick and easy; No additional information except the encrypted secret is stored in the database.
No accounts needed
Sharing should be quick and easy; No additional information except the encrypted secret is stored in the database.
<svg aria-hidden="true" focusable="false" data-prefix="fas" data-icon="user-large-slash" class="svg-inline--fa fa-user-large-slash fa-4x " role="img" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 640 512" color="black"><path fill="currentColor" d="M38.8 5.1C28.4-3.1 13.3-1.2 5.1 9.2S-1.2 34.7 9.2 42.9l592 464c10.4 8.2 25.5 6.3 33.7-4.1s6.3-25.5-4.1-33.7L381.9 274c48.5-23.2 82.1-72.7 82.1-130C464 64.5 399.5 0 320 0C250.4 0 192.4 49.3 178.9 114.9L38.8 5.1zM545.5 512H528L284.3 320h-59C136.2 320 64 392.2 64 481.3c0 17 13.8 30.7 30.7 30.7H545.3l.3 0z"></path></svg>
-
-
burnernote.com burnernote.com
-
On the back end we utilise Laravel's out of the box encryption protocols
-
more useable and technically transparent
= technically transparent
-

-
We "Encrypt-then-MAC"
encrypt-then-MAC
to - crypto.stackexchange.com - encrypt-then-MAC

-
-
crypto.stackexchange.com crypto.stackexchange.com
-
-
Should we MAC-then-encrypt or encrypt-then-MAC?
[from - burnernote.com - Encrypt-then-MAC])(https://hyp.is/TkRxmLMLEe6etTvzQy5TEQ/burnernote.com/about)
-
-
burnernote.com burnernote.com
-
Send secure and encrypted notes that self destruct once they've been read
-
-
github.com github.com
-
A library to encrypt and transfer files P2P in the browser
from - annote

-
, encrypting data prior to sending it
-
-
github.com github.com
-
🤝 Trystero Serverless WebRTC matchmaking for painless P2P: make any site multiplayer in a few lines
-
-
github.com github.com
-
ipfs.indy0.net ipfs.indy0.net
-
ipfs.indy0.net ipfs.indy0.net
-
www.bittorrent.org www.bittorrent.org
-
magnet URI format
URI format
-
In order to support future extensability, an unrecognized message ID MUST be ignored.
extensibility
unrecognized messages ignored
-
only transfers the info-dictionary part of the .torrent file. This part can be validated by the info-hash.
metadata portiion
info plex is not a hash but a human/machine readabl clue structure with info/content hashes
for the plex page
-
the info hash
the info hash
-
support magnet links
magnet links
a link on a web page only containing enough information to join the swarm (the info hash).
the info hash
-
Extension for Peers to Send Metadata Files
-
-
www.npmjs.com www.npmjs.com
-
support magnet links
gloss magnet links = a link on a web page only containing enough information to join the swarm (the info hash).
-
JavaScript implementation of the
-
ut_metadata
-
-
webtorrent.io webtorrent.io
-
-
Running your own private instance of bittorrent-tracker
own bitttorent tracker 
-
if the hash of the file leaks out somehow -- say via a bug in webtorrent #271 -- the file will be worthless.
hash of a file leaking
the base case for ipfs
-
-
Best solution for private torrents? #386
-
-
sariazout.medium.com sariazout.medium.com
-
from - https://hyp.is/yJbgqndsEe6ks4MoZlHwyQ/sariazout.medium.com/
for - Indy Learning Commons

-
-
-
Related searchesYou will see more English now.Open source peer to peer chat voice no server reddit
-
-
www.reddit.com www.reddit.com
-
from - hyp
-
I built a decentralized, serverless, peer-to-peer private chat app
that's - open source, - ephemeral, and - runs entirely in the browser
chitchatter
-
-
ipfs.indy0.net ipfs.indy0.net
-
for - chitchatter - chitchatter.im
-