Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
大多数人认为循环深度网络需要通过时间反向传播(BPTT)进行训练,这是计算密集型的,但作者认为这是不必要的,因为通过扩散块视角,可以用单次前向传递替代多次迭代,这一观点挑战了循环神经网络训练的传统方法。
Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
大多数人认为循环深度网络需要通过时间反向传播(BPTT)进行训练,这是计算密集型的,但作者认为这是不必要的,因为通过扩散块视角,可以用单次前向传递替代多次迭代,这一观点挑战了循环神经网络训练的传统方法。
Xu, ICCV, 2019 "Temporal Recurrent Networks for Online Action Detection"
arxiv: https://arxiv.org/abs/1811.07391 hypothesis: https://hyp.is/go?url=https%3A%2F%2Fopenaccess.thecvf.com%2Fcontent_ICCV_2019%2Fpapers%2FXu_Temporal_Recurrent_Networks_for_Online_Action_Detection_ICCV_2019_paper.pdf&group=world
The attention distribution is usually generated with content-based attention. The attending RNN generates a query describing what it wants to focus on. Each item is dot-producted with the query to produce a score, describing how well it matches the query. The scores are fed into a softmax to create the attention distribution.
This is the Key, Value, Query, yes?
To review, the Forget gate decides what is relevant to keep from prior steps. The input gate decides what information is relevant to add from the current step. The output gate determines what the next hidden state should be.Code DemoFor those of you who understand better through seeing the code, here is an example using python pseudo code.
These results nonetheless show that it could be feasible to develop recurrent neural network modelsable to infer input-output behaviours of real biological systems, enabling researchers to advance theirunderstanding of these systems even in the absence of detailed level of connectivity.
Too strong a claim?
We show that GRU models with a hidden layersize of 4 units are able to accurately reproduce with high accuracy the system’sresponse to very different stimuli.
Recursive Neural Networks
Unity ML agents is a way for you to turn a video game into a Reinforcement Learning environment.
Unity ML agents is a great way to practice RNN
Teacher forcing is a training technique that isapplicable to RNNs that have connections from their output to their hidden states at thenext time step. (Left) At train time, we feed the correct outputy(t)drawn from the trainset as input toh(t+1). (Right) When the model is deployed, the true output is generallynot known. In this case, we approximate the correct outputy(t)with the model’s outputo(t), and feed the output back into the model.
Teacher forcing strategy to parellelize training.
the network typically learns to useh(t)as a kind of lossysummary of the task-relevant aspects of the past sequence of inputs up tot
The hidden state h(t) is a high-level representation of whatever happened until time step t.
Parameter sharingmakes it possible to extend and apply the model to examples of different forms(different lengths, here) and generalize across them. If we had separate parametersfor each value of the time index, we could not generalize to sequence lengths notseen during training, nor share statistical strength across different sequence lengthsand across different positions in time. Such sharing is particularly important whena specific piece of information can occur at multiple positions within the sequence.
RNN have the same parameters for each time step. This allows to generalize the inferred "meaning", even when it's inferred at different steps.
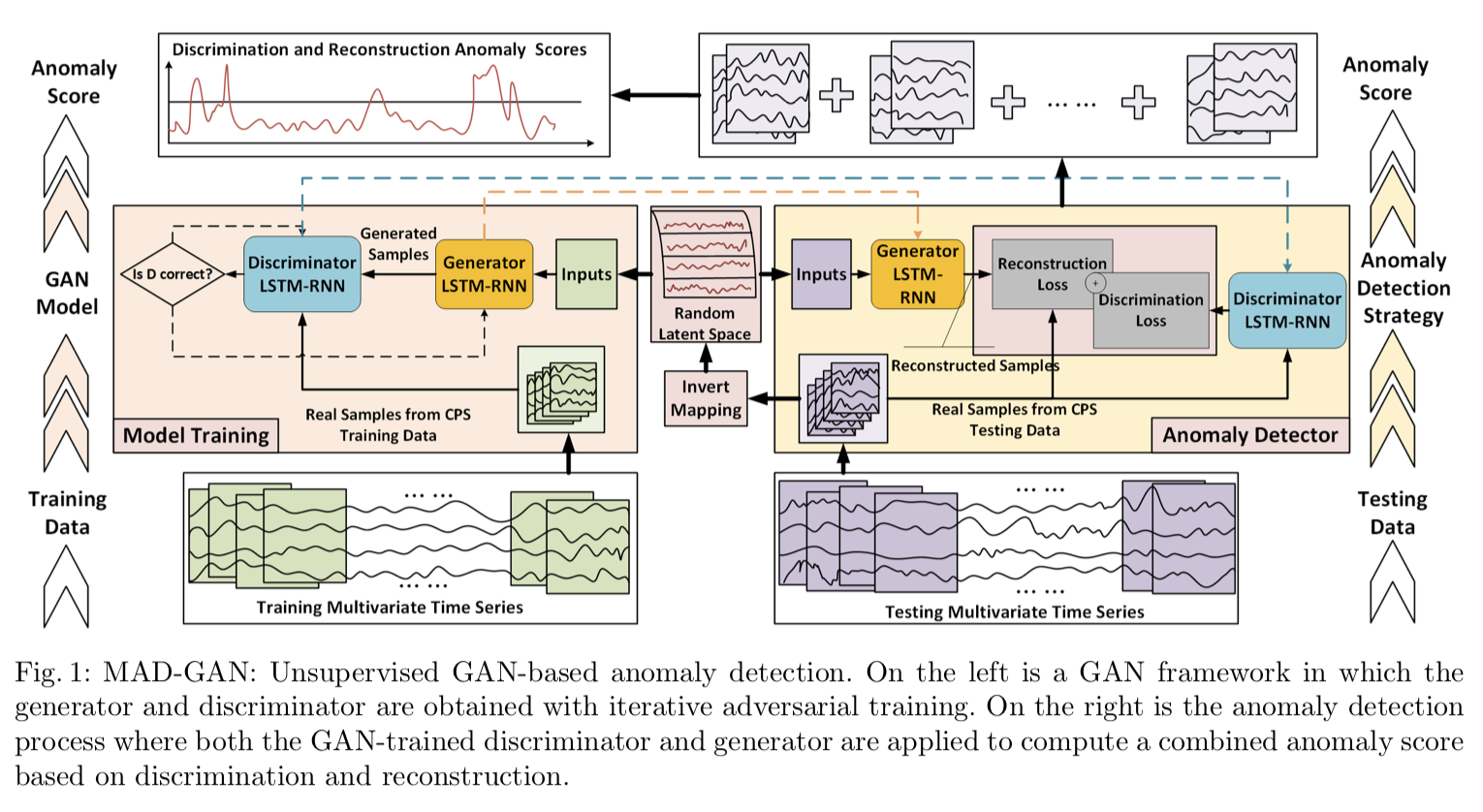
MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks
这 paper 挺神的,用 GAN 做时序数据异常检测。主要神在 G 和 D 都仅用 LSTM-RNN 来构造的!不仅因此值得我关注,更因为该模型可以为自己思考“非模板引力波探测”带来启发!
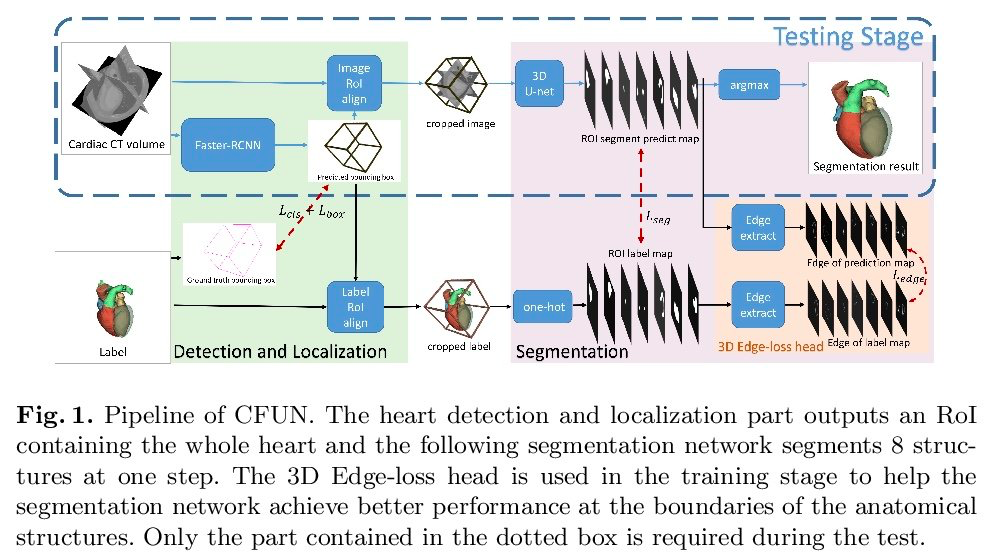
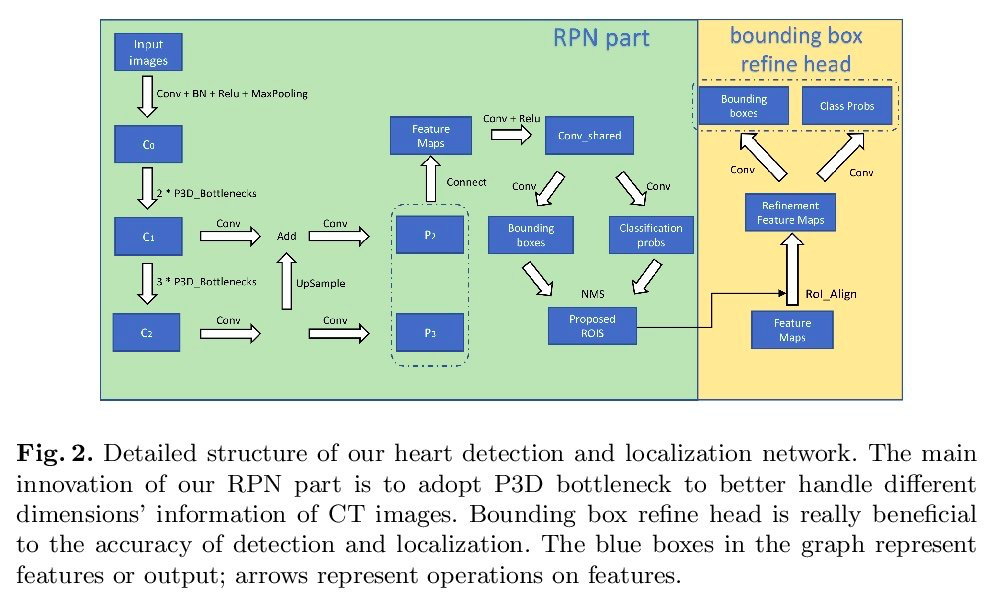
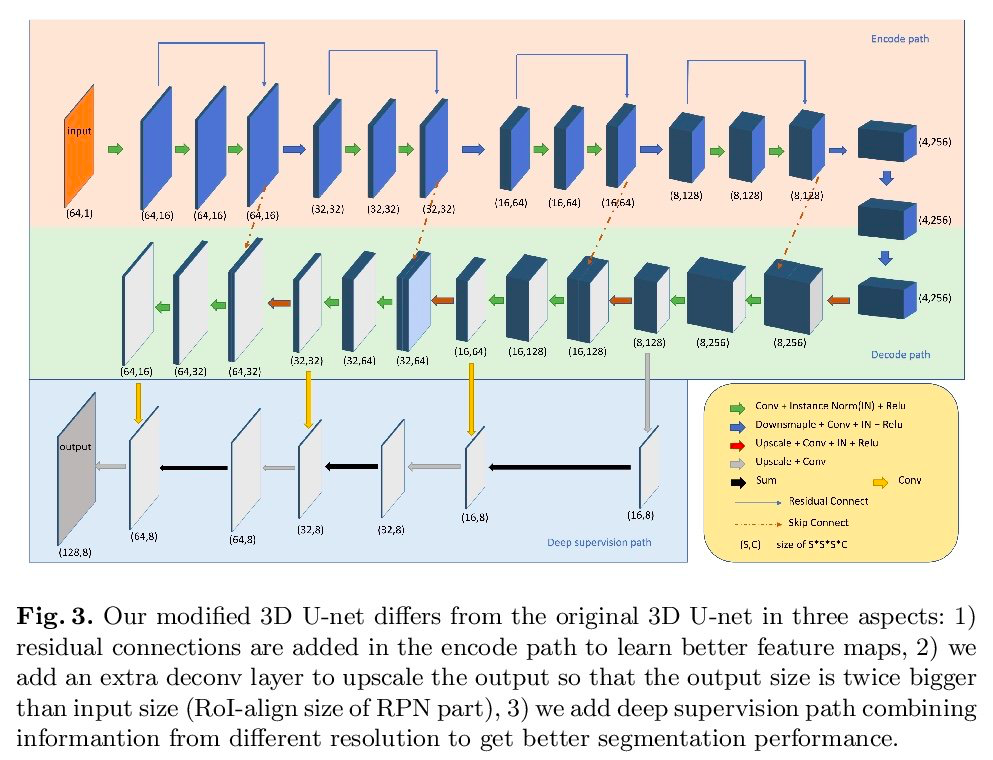
CFUN: Combining Faster R-CNN and U-net Network for Efficient Whole Heart Segmentation
图做得很好看~~~
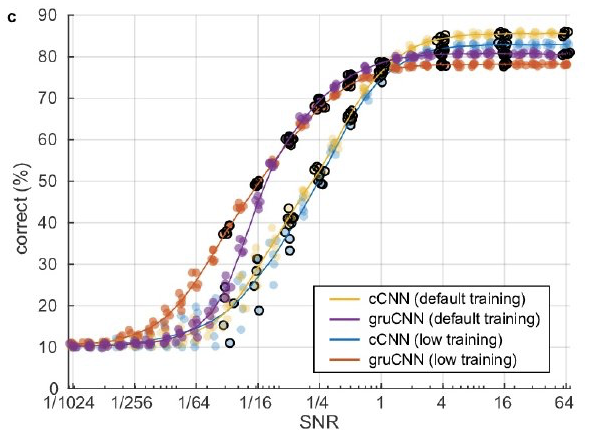
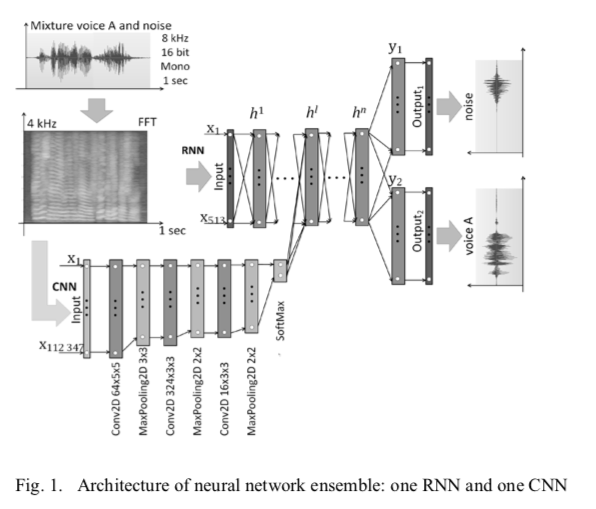
Using Convolutional Neural Networks to Classify Audio Signal in Noisy Sound Scenes
先辨别信号位置,再过滤出信号,这和 LIGO 找event波形的套路很像~ ;又看到 RNN与CNN 结合起来的应用~
Seeing in the dark with recurrent convolutional neural networks
目测一些结果和自己的 paper 很接近,同时此 paper 于我而言,有太多值得借鉴的地方!同时又看到了 recurrency(类循环记忆单元)在模式识别领域有着很必要的用武之地!