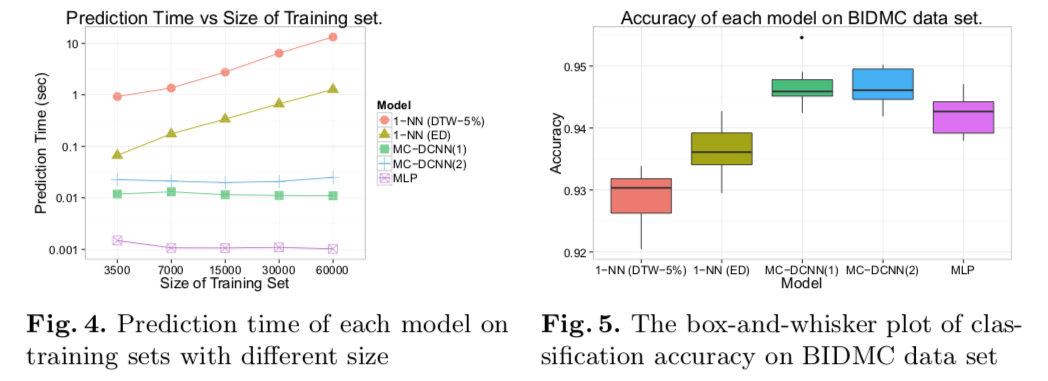
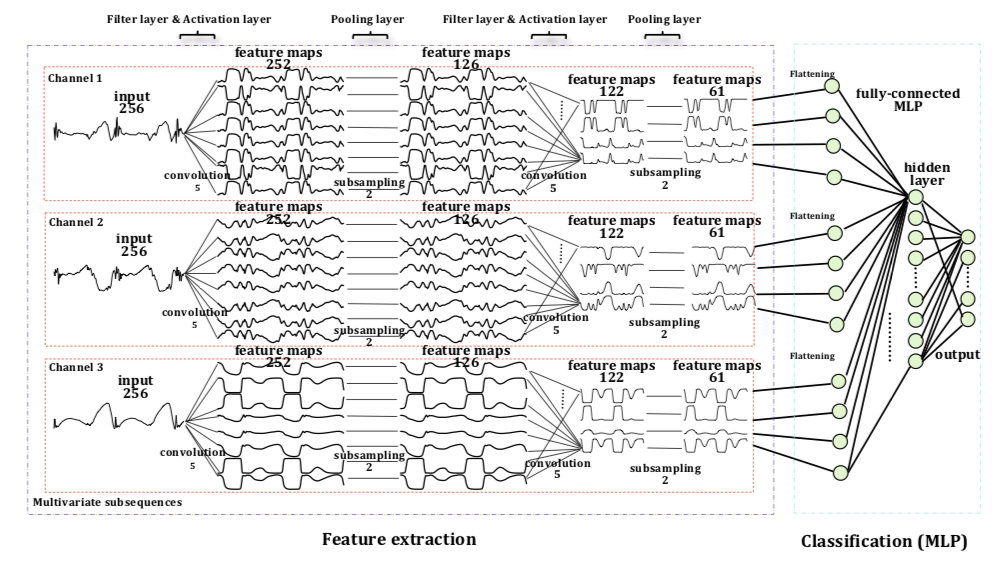
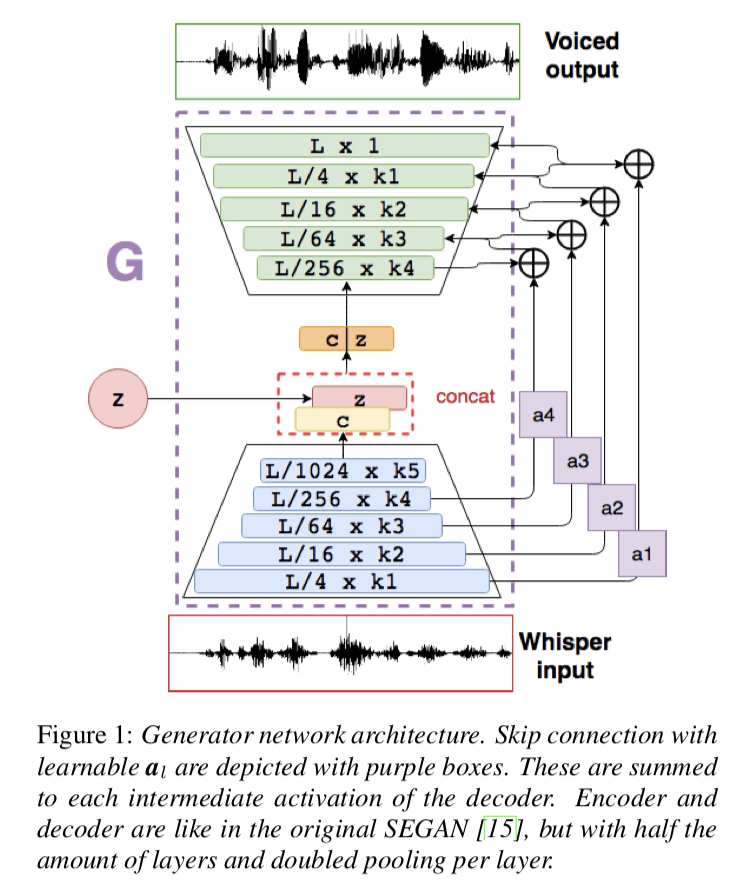
Xu, ICCV, 2019 "Temporal Recurrent Networks for Online Action Detection"
arxiv: https://arxiv.org/abs/1811.07391 hypothesis: https://hyp.is/go?url=https%3A%2F%2Fopenaccess.thecvf.com%2Fcontent_ICCV_2019%2Fpapers%2FXu_Temporal_Recurrent_Networks_for_Online_Action_Detection_ICCV_2019_paper.pdf&group=world