一次最多生成 12 张风格一致的图片,支持最多 9 张参考图输入。做系列海报、产品多角度图、故事连续画面时不用一张一张调。
令人惊讶的是:该模型能够一次性生成最多12张风格一致的图片,并支持最多9张参考图输入。这项功能对于需要保持一致性的创作场景(如系列海报、产品多角度图、故事连续画面)来说极为实用,大大提高了工作效率,解决了传统AI图像生成中难以保持风格一致的问题。
一次最多生成 12 张风格一致的图片,支持最多 9 张参考图输入。做系列海报、产品多角度图、故事连续画面时不用一张一张调。
令人惊讶的是:该模型能够一次性生成最多12张风格一致的图片,并支持最多9张参考图输入。这项功能对于需要保持一致性的创作场景(如系列海报、产品多角度图、故事连续画面)来说极为实用,大大提高了工作效率,解决了传统AI图像生成中难以保持风格一致的问题。
先在 Evernote 中選擇需要的筆記、記事本,匯出成 enex 檔案。
Confirming Upnote support ENEX import from Evernote. I'm ready to pay $1/month for this!
AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS. AWS Batch dynamically provisions the optimal quantity and type of compute resources (e.g., CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted.
Mean-field Analysis of Batch Normalization
BN 的平均场理论
Interplay Between Optimization and Generalization of Stochastic Gradient Descent with Covariance Noise
一个有趣的事实:batch-size 对训练收敛和模型泛化表现是有影响的,batch-size 越大,收敛越好,泛化变差。。。
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
提出了新的 LocalNorm。既然Norm都玩得这么嗨了,看来接下来就可以研究小 GeneralizedNorm 或者 AnyRandomNorm 啥的了。。。[doge]
Fixup Initialization: Residual Learning Without Normalization
关于拟合的表现,Regularization 和 BN 的设计总是很微妙,尤其是 learning rate 再掺和进来以后。此 paper 的作者也就相关问题结合自己的文章在 Reddit 上有所讨论。
Generalized Batch Normalization: Towards Accelerating Deep Neural Networks
核心是这么一句话: Generalized Batch Normalization (GBN) to be identical to conventional BN but with
standard deviation replaced by a more general deviation measure D(x)
and the mean replaced by a corresponding statistic S(x).
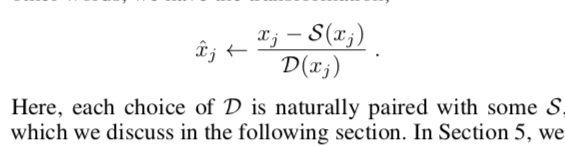
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)
BatchNorm有效性原理探索——使优化目标函数更平滑
Revisiting Small Batch Training for Deep Neural Networks
这篇文章简而言之就是mini-batch sizes取得尽可能小一些可能比较好。自己瞅了一眼正在写的 paper,这不禁让我小肝微微一颤,心想:还是下次再把 batch-size 取得小一点吧。。。[挖鼻]
Don't Use Large Mini-Batches, Use Local SGD
最近(2018/8)在听数学与系统科学的非凸最优化进展时候,李博士就讲过:现在其实不太欣赏变 learning rate 了,反而逐步从 SGD 到 MGD 再到 GD 的方式,提高 batch-size 会有更好的优化效果!
Approximate Fisher Information Matrix to Characterise the Training of Deep Neural Networks
深度神经网络训练(收敛/泛化性能)的近似Fisher信息矩阵表征,可自动优化mini-batch size/learning rate
挺有趣的 paper,提出了从 Fisher 矩阵抽象出新的量用来衡量训练过程中的模型表现,来优化mini-batch sizes and learning rates | 另外 paper 中的figure画的很好看 | 作者认为逐步增加batch sizes的传统理解只是partially true,存在逐步递减该 size 来提高 model 收敛和泛化能力的可能。
Combining data from multiple RNASeq experiments: release the Kruskal! (...Wallis test)
Batch Editing and Updating
Batch Editing - Very interesting feature for ASP.NET data grid!!!