93 Matching Annotations
- Sep 2024
-
Tags
Annotators
URL
-
- Jun 2023
- Dec 2022
-
www.zhihu.com www.zhihu.com
-
为什么很多语言的实现里面的 Lexer 都没有使用 DFA?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
Common Lisp 为什么不用卫生宏?
Tags
Annotators
URL
-
-
www.zhihu.com www.zhihu.com
-
读完sicp后应该做些什么?
Tags
Annotators
URL
-
- Nov 2022
-
tomekw.com tomekw.com
Tags
Annotators
URL
-
- Sep 2022
-
blog.griffin.sh blog.griffin.sh
Tags
Annotators
URL
-
- Jun 2022
-
blog.jmibanez.com blog.jmibanez.com
- Mar 2022
- Feb 2022
-
timjaeger.io timjaeger.io
-
Tags
Annotators
URL
-
- Nov 2021
- Oct 2021
-
xtdb.com xtdb.com
Tags
Annotators
URL
-
- Aug 2021
-
stackoverflow.com stackoverflow.com
-
Clojure Vars can have thread-local bindings. binding uses these, while with-redefs actually alters the root binding (which is someting like the default value) of the var. Another difference is that binding only works for :dynamic vars while with-redefs works for all vars.
binding vs. with-redefs
user=> (def ^:dynamic *a* 1) #'user/*a* user=> (binding [*a* 2] *a*) 2 user=> (with-redefs [*a* 2] *a*) 2 user=> (binding [*a* 2] (doto (Thread. (fn [] (println "*a* is " *a*))) (.start) (.join))) *a* is 1 #<Thread Thread[Thread-2,5,]> user=> (with-redefs [*a* 2] (doto (Thread. (fn [] (println "*a* is " *a*))) (.start) (.join))) *a* is 2 #<Thread Thread[Thread-3,5,]>意思是说
- 通过
binding绑定的值是线程间不可见的 - 通过
with-redefs绑定的值是线程间可见的
binding 可以构造 thread-local var; with-redefs 构造的是 thread-shareing var .
- 通过
-
-
clojuredocs.org clojuredocs.org
-
dotoclojure.coreAvailable since 1.0 (source) (doto x & forms)Evaluates x then calls all of the methods and functions with the value of x supplied at the front of the given arguments. The forms are evaluated in order. Returns x. (doto (new java.util.HashMap) (.put "a" 1) (.put "b" 2))
doto不同于do:doto是(doto x & forms)计算第一个表达式 x,一般是构建对象或者线程。之后的所有表达式都是对 x 的调用:x.expr1x.expr2, 并且最后返回的仍然是 x.
doto把 x 对象作为后面方法的所属对象(一般对象调用方法,在 clojure 的写法中都是(.method object &arguments))。进行调用,整体表达式仍然返回 x 对象。因此这种方法通常用来对 x 对象的属性,进行批量修改(如果 x 对象有多个属性),或者是调用 x 的方法,对 x 进行某些改变。
do是(do & forms)只是按顺序执行每一个表达式,并返回最后一个表达式的结果
Tags
Annotators
URL
-
- Jul 2021
-
livebook.manning.com livebook.manning.com
-
Clojure’s four reference types are listed across the top, with their features listed down the left. Atoms are for lone synchronous objects. Agents are for asynchronous actions. Vars are for thread-local storage. Refs are for synchronously coordinating multiple objects.
四种mutable object分别适用不同的并发处理情形:
- vars : 线程隔离
- refs: 多对象协调同步
- atoms: 单对象同步
- agents: 异步
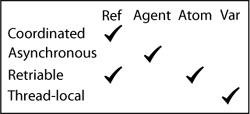
Coordinate :意思是读写多个refs可以保障无冲突
Asynchronous : 意思是更新请求会在另一个线程排队等待稍后执行。
Retriable : 对 reference value 的更新如果遇到异常会重试
Thread-local: 每个线程有单独的数据拷贝,对状态的更改都是独立的
-
Time—The relative moments when events occur State—A snapshot of an entity’s properties at a moment in time Identity—The logical entity identified by a common stream of states occurring over time
clojure 状态管理和更改模型,包含三个核心概念:
- 时间——事件发生的相对时刻
- 状态——某个时刻实体属性的快照
- 身份——逻辑实体, 亦即一段时间内的公共状态流
-
-
clojure.org clojure.org
-
(set! var-symbol expr) Assignment special form. When the first operand is a symbol, it must resolve to a global var. The value of the var’s current thread binding is set to the value of expr. Currently, it is an error to attempt to set the root binding of a var using set!, i.e. var assignments are thread-local. In all cases the value of expr is returned. Note - you cannot assign to function params or local bindings. Only Java fields, Vars, Refs and Agents are mutable in Clojure.
在 clojure 中只有四种 mutable 对象:
- Java fields
- var
- ref
- agent
可以通过
(set! var-symbol expr)对他们进行 thread-loca 更改。
-
- Apr 2021
- Mar 2021
-
stackoverflow.com stackoverflow.com
- Feb 2021
-
kaal-daari.medium.com kaal-daari.medium.com
- Oct 2020
-
robsteranium.github.io robsteranium.github.io
- Sep 2020
-
github.com github.com
Tags
Annotators
URL
-
- Aug 2020
-
www.youtube.com www.youtube.com
-
-
nextjournal.com nextjournal.com
- Jul 2020
-
framed.gitbooks.io framed.gitbooks.io
-
www.slideshare.net www.slideshare.net
-
www.changes.md www.changes.md
Tags
Annotators
URL
-
- May 2020
-
muldoon.cloud muldoon.cloud
-
Programming languages These will probably expose my ignorance pretty nicely.
When to use different programming languages (advice from an Amazon employee):
- Java - enterprise applications
- C# - Microsoft's spin on Java (useful in the Microsoft's ecosystem)
- Ruby - when speed is more important then legibility or debugging
- Python - same as Ruby but also for ML/AI (don't forget to use type hinting to make life a little saner)
- Go/Rust - fresh web service where latency and performance were more important than community/library support
- Haskell/Erlang - for very elegant/mathematical functional approach without a lot of business logic
- Clojure - in situation when you love Lisp (?)
- Kotlin/Scala - languages compiling to JVM bytecode (preferable over Clojure). Kotlin works with Java and has great IntelliJ support
- C - classes of applications (operating systems, language design, low-level programming and hardware)
- C++ - robotics, video games and high frequency trading where the performance gains from no garbage collection make it preferable to Java
- PHP/Hack - testing server changes without rebuilding. PHP is banned at Amazon due to security reasons, but its successor, Hack, runs a lot of Facebook and Slack's backends
-
- Apr 2020
-
clojurequartz.info clojurequartz.info
Tags
Annotators
URL
-
- Mar 2020
-
yogthos.net yogthos.net
Tags
Annotators
URL
-
-
elangocheran.com elangocheran.com
- Feb 2020
-
blog.jeaye.com blog.jeaye.com
Tags
Annotators
URL
-
- Jan 2020
-
github.com github.com
Tags
Annotators
URL
-
-
medium.com medium.com
- Dec 2019
-
clojure.org clojure.org
-
Clojure has a programmatic macro system which allows the compiler to be extended by user code. Macros can be used to define syntactic constructs which would require primitives or built-in support in other languages. Many core constructs of Clojure are not, in fact, primitives, but are normal macros.
Tags
Annotators
URL
-
-
okfnlabs.org okfnlabs.org
-
medium.com medium.com
- Nov 2019
-
stuartsierra.com stuartsierra.com
-
They answer the two chief complaints about Lisp syntax: too many parentheses and “unnatural” ordering
they do that, but I don't think that's their primary rationale and a deeper win more important they neatly express certain structure / shape of computation
Tags
Annotators
URL
-
-
www.innoq.com www.innoq.com
- Oct 2019
-
itrevolution.com itrevolution.com
-
In 2017, I rewrote it again as a ClojureScript application, and it was only 500 lines of code! Holy cow!!!
going from 3k obj-c to 1,5k js to 0.5k in cljs!
-
-
github.com github.com
-
For example the following pattern: (let [x true y true z true] (match [x y z] [_ false true] 1 [false true _ ] 2 [_ _ false] 3 [_ _ true] 4)) ;=> 4 expands into something similar to the following: (cond (= y false) (cond (= z false) (let [] 3) (= z true) (let [] 1) :else (throw (java.lang.Exception. "No match found."))) (= y true) (cond (= x false) (let [] 2) :else (cond (= z false) 3 (= z true) 4 :else (throw (java.lang.Exception. "No match found.")))) :else (cond (= z false) (let [] 3) (= z true) (let [] 4) :else (throw (java.lang.Exception. "No match found.")))) Note that y gets tested first. Lazy pattern matching consistently gives compact decision trees. This means faster pattern matching. You can find out more in the top paper cited below.
http://pauillac.inria.fr/~maranget/papers/ml05e-maranget.pdf
Tags
Annotators
URL
-
- Sep 2019
-
web.archive.org web.archive.org
-
The problem with the annotation notion is that it's the first time that we consider a piece of data which is not merely a projection of data already present in the message store: it is out-of-band data that needs to be stored somewhere.
could be same, schemaless datastore?
-
There are objects, sets of objects, and presentation tools. There is a presentation tool for each kind of object; and one for each kind of object set.
very clojure-y mood, makes me think of clojure REBL (browser) which in turn is inspired by the smalltalk browser and was taken out of datomic (which is inspired by RDF, mentioned above!)
-
-
clojure.org clojure.org
-
That said, most Clojure programs begin life as text files, and it is the task of the reader to parse the text and produce the data structure the compiler will see
clojure compiler sees (real) clojure i.e. programs as clojure data structures (we) humans see clojure in their (semi-incidental) representation in text readers bridges the gap
Now, why semi- incidental? It's not necessary for clojure to be text but it is necesserry for it to be represented as some kind of symbolic representations for humans. It's pretty much always text
Tags
Annotators
URL
-
- May 2019
-
letoverlambda.com letoverlambda.com
-
Although regular macros work on programs in the form of trees, a special type of macro, called a read macro, operates on the raw characters that make up your program.
this make me wonder how is this different from pre-processors? if I'm working on text before compile, is being in the same language giving me any advantage
-
Not only does lisp provide direct access to code that has been parsed into a cons cell structure, but it also provides access to the characters that make up your programs before they even reach that stage.
reader macros user extendible read macros are not present in clojure there is a project to provide that outside vanilla clojure
Tags
Annotators
URL
-
- Apr 2019
-
clojure.org clojure.org
-
deps.edn - install level deps.edn file, with some default deps (Clojure, etc) and provider config
/usr/local/Cellar/clojure/<version> for brew installed
Tags
Annotators
URL
-
-
github.com github.com
-
:deps ; to get access to clojure.tools.deps.alpha.repl/add-lib ;; - now you can add new deps to a running REPL: ;; (require '[clojure.tools.deps.alpha.repl :refer [add-lib]]) ;; (add-lib 'some/library {:mvn/version "RELEASE"}) ;; - and you can git deps too; here's how to get the master version of a lib: ;; (require '[clojure.tools.gitlibs :as gitlibs]) ;; (defn load-master [lib] ;; (let [git (str "https://github.com/" lib ".git")] ;; (add-lib lib {:git/url git :sha (gitlibs/resolve git "master")}))) ;; - e.g., using the GitHub path (not the usual Maven group/artifact): ;; (load-master 'clojure/tools.trace) {:extra-deps {org.clojure/tools.deps.alpha {:git/url "https://github.com/clojure/tools.deps.alpha" :sha "e160f184f051f120014244679831a9bccb37c9de"}}}
add-lib etc
-
;; - see https://github.com/bhauman/rebel-readline ;; - start a Rebel Readline REPL: :rebel {:extra-deps {com.bhauman/rebel-readline {:mvn/version "RELEASE"}} :main-opts ["-m" "rebel-readline.main"]}
run bh's rebel from anywhere
-
-
clubhouse.io clubhouse.io
-
However, we found a few trade-offs when using clojure.spec: clojure.spec requires registering a spec for each key in every path that you care about in a data structure, which can be verbose, especially for deeply-nested data structures. We felt this pain the most when specifying the incoming webhook payloads from the providers. We didn't specify the full payloads, we only specified the values that we actually needed, some of which were nested 7-8 levels deep. To work around this, we used data-spec (part of the spec-tools project) to define the payload specs as a mirror of the shape of the actual data. clojure.spec's error output is concise, and it's not always immediately apparent where the validation failure is within the data, especially when validating a large data structure. To help with this, we used expound to generate friendlier error messages at the REPL and in tests.
spec gotchas
-
This system is the first significant project on which we have used clojure.spec, and it proved useful in a few ways: Specifying the inputs to each layer in one place made it easier to visualize the shape of the data as it flowed through the subsystem, and proved valuable when describing the behavior to other engineers.Instrumenting the inputs and outputs of our layer boundary functions (via Orchestra), during testing, enabled us to quickly catch cases where we deviated from the spec, allowing us to see the issue at that boundary instead of as a random error within the implementation. Validating the layer inputs against our specs in production allows us to quickly diagnose and isolate faults to the layer where it was triggered, and helps us catch when our assumptions about the shape of the webhook event are incorrect. Having specs allowed for more straightforward tests, since we didn't need to assert on the shape of the data.
benefits of spec
-
-
github.com github.com
-
([a b] (if (and (map? a) (map? b)) (merge-with deep-merge a b) b))
deep-merge nice recursive solution piggybacking on merge-with
-
([m k f] (if-let [kv (find m k)] (assoc m k (f (val kv))) m))
update-existing good use of find & combination of if-let and find!
-
([pred coll] (reduce (fn [_ x] (if (pred x) (reduced x))) nil coll))
find-first
-
-
github.com github.com
-
(def current "Get current process PID" (memoize (fn [] (-> (java.lang.management.ManagementFactory/getRuntimeMXBean) (.getName) (string/split #"@") (first)))))
getting current proces id (PID) more importantly:
java.lang.management.ManagementFactory/getRuntimeMXBean
-
-
github.com github.com
-
(defn- file? [f] (instance? java.io.File f)) (defn- find-files-in-dir [dir] (filter #(.isFile ^File %) (file-seq dir)))
finding files nice declarative way
file-seqof this dir
-
-
github.com github.com
-
(s/def :ring.http/field-name (-> (s/and string? not-empty field-name-chars?) (s/with-gen #(gen/not-empty (gen-string field-name-chars)))))
clean way of using with gen!
-
(defn- char-range [a b] (map char (range (int a) (inc (int b))))) (def ^:private lower-case-chars (set (char-range \a \z)))
nice way of defining character range
-
- Mar 2019
-
github.com github.com
-
(PushbackReader. (StringReader. s))
PUshbackReader is the basic impl
-
- Feb 2019
-
github.com github.com
-
(if (instance? Throwable ret)
catching both
Throwables: Errors and Exceptions
-
-
github.com github.com
-
:ok
nice, return value: keyword!
-
(fn [system] (throw (ex-info "initializer not set, did you call `set-init`?" {}))))
interesting pattern, default function throws kind of like abstract base classes methods in python
-
- Dec 2018
-
clojureverse.org clojureverse.org
-
Full disclosure: I’m a co-maintainer of clj-time and I’m pretty vocal about encouraging people not to use clj-time when starting a new project: use Java Time instead. Conversion from an existing, clj-time-heavy project is another matter tho’, unfortunately.
sean cornfield co-mainainter of clj-time use Java.Time
-
- Nov 2018
-
www.reddit.com www.reddit.com
-
One quick trick for making it easier for debugging/understanding your threading macros is to put print statements in between some of the steps. The important thing to remember is that all the print functions in clojure return nil so you need to make a little helper function (I like to call mine ?) that prints and then returns the original input, like this: (defn ? [x] (prn x) x)
debugging trick
-
I don't think passing the entire http client is very idiomatic, but what is quite common is to pass the entire "environment" (aka runtime configuration) that your app needs through every function. In your case if the only variant is the URL then you could just pass the URL as the first parameter to get-data. This might seem cumbersome to someone used to OO programming but in functional programming it's quite standard. You might notice when looking at example code, tutorials, open source libraries etc. that almost all code that reads or writes to databases expects the DB connection information (or an entire db object) as a parameter to every single function. Another thing you often see is an entire "env" map being passed around which has all config in it such as endpoint URLs.
passing state down the call stack configuration, connection, db--pretty common in FP
-
Something that I've found helps greatly with testing is that when you have code with lots of nested function calls you should try to refactor it into a flat, top level pipeline rather than a calling each function from inside its parent function. Luckily in clojure this is really easy to do with macros like -> and friends, and once you start embracing this approach you can enter a whole new world of transducers. What I mean by a top level pipeline is that for example instead of writing code like this: (defn remap-keys [data] ...some logic...) (defn process-data [data] (remap-keys (flatten data))) (defn get-data [] (let [data (http/get *url*)] (process-data data))) you should make each step its own pure function which receives and returns data, and join them all together at the top with a threading macro: (defn fetch-data [url] (http/get url)) (defn process-data [data] (flatten data)) (defn remap-keys [data] ...some logic...) (defn get-data [] (-> *url* fetch-data process-data remap-keys)) You code hasn't really changed, but now each function can be tested completely independently of the others, because each one is a pure data transform with no internal calls to any of your other functions. You can use the repl to run each step one at a time and in doing so also capture some mock data to use for your tests! Additionally you could make an e2e tests pipeline which runs the same code as get-data but just starts with a different URL, however I would not advise doing this in most cases, and prefer to pass it as a parameter (or at least dynamic var) when feasible.
testing flat no deep call stacks, use pipelines
-
One thing Component taught me was to think of the entire system like an Object. Specifically, there is state that needs to be managed. So I suggest you think about -main as initializing your system state. Your system needs an http client, so initialize it before you do anything else
software design state on the outside, before anything else lessions from Component
-
For the sweet spot you're looking for, I suggest being clear about if you're designing or developing. If you're designing and at the REPL, force yourself to step away with pen and paper after you've gotten some fast feedback.
designing vs developing!
-
-
stackoverflow.com stackoverflow.com
-
n
Using the syntax #'a.b/d is a shortcut for (var a.b/d), with returns the "var" which points to the "function" a.b/d. When Clojure sees the var, it automatically substitutes the function before evaluation. I found this (mostly undocumented) behavior quite confusing for several years. – Alan Thompson May 26 '16 at 21:41
-
-
rymndhng.github.io rymndhng.github.io
-
Re-open libraries for exploration I use in-ns to jump into library namespaces and re-define their vars. I insert bits of println statements to help understand how data flows through a library. These monkey-patches only exist in the running REPL. I usually put them inside a comment form. On a REPL restart, the library is back at its pristine state. In this example below, I re-open clj-http.headers to add tracing before the header transformation logic: [source] ;; set us up for re-opening libraries (require 'clj-http.headers) (in-ns 'clj-http.headers) (defn- header-map-request [req] (let [req-headers (:headers req)] (if req-headers (do (println "HEADERS: " req-headers) ;; <-- this is my added print (-> req (assoc :headers (into (header-map) req-headers) :use-header-maps-in-response? true))) req))) ;; Go back to to the user namespace to test the change (in-ns 'user) (require '[clj-http.client :as http]) (http/get "http://www.example.com") ;; This is printed in the REPL: ;; HEADERS: {accept-encoding gzip, deflate} An astute observer will notice this workflow is no different from the regular clojure workflow. Clojure gets out of your way and allows you to shape & experiment in the code in the REPL. You can use this technique to explore clojure.core too!
explore library code in the repl in-ns and the redefinition
-
Unmap namespaces during experimentation I use ns-unmap and ns-unalias to remove definitions from my namespace. These are the complementary functions of require and def. While exploring, you namespace will accrue failed experiments, especially around naming. Instead of using a giant hammer [tools.namespace], you can opt for finer-grained tools like these. Example: (require '[clojure.string :as thing]) (ns-unalias *ns* 'thing) ; *ns* refers to the current namespace
cleaning up the namespace fro repl experimentation
-
-
lispcast.com lispcast.com
-
That is using a specific tool for a specific use case. You don’t actually have a table view of your data. Once it’s in a table, man, you’re good. That is the modeling. A sequel database table, you have this amazing high-level language for doing all sorts of cool operations with it.To turn this into some class hierarchy, it’s almost criminal. There, I said it. It’s like you’re throwing away the power that you have.
about a situation when you sometime want an is-a relationship but in most cases just have it as loosely structured (table-like) data format
-
-
clojurians.slack.com clojurians.slack.com
-
clone the repo, then lein install and use whatever that snapshot version in project.clj is where you want to use it (edited)
how to use specific version of library you can also use checkouts where you just symlink to a local copy from
your-project/checkouts
Tags
Annotators
URL
-
- Oct 2018
-
blog.cognitect.com blog.cognitect.com
-
(def peg? #{:y :g :r :c :w :b})
using set as predicate
-
-
twitter.com twitter.com
-
TIL this is meant to work in Clojure and ClojureScript. Wow… cool! (keys (filter (comp pos? val) {:a 0, :b 1}))
filter returns mapentries so not a map yet keys works on that!
Tags
Annotators
URL
-
-
-
function coll-of allows a :count key to specify the required number of elements:
good to know that there is the keyword directive
:count -
On the flip side, it can go further than mere types, including emulating dependent types and programming-by-contract.
spec though it's used at runtime (not compile time)
- hence: not a replacement for types as such BUT
- enables dependent types
- programming by contract
Tags
Annotators
URL
-
-
en.wikipedia.org en.wikipedia.org
-
Following Christopher Strachey,[2] parametric polymorphism may be contrasted with ad hoc polymorphism, in which a single polymorphic function can have a number of distinct and potentially heterogeneous implementations depending on the type of argument(s) to which it is applied. Thus, ad hoc polymorphism can generally only support a limited number of such distinct types, since a separate implementation has to be provided for each type.
kind of like clojure multimethods but those can dispatch on arbitary function hence arbitrary "property"
-
- Sep 2017
-
slides.klipse.tech slides.klipse.tech
-
Hiccup forms are plain Clojure vectors: you don’t need to learn the Hiccup syntax you don’t need to write a preprocessor you don’t need to write IDE plugins there are no edge cases you can test part of your components as plain clojure functions you can parse your hiccup code
clojure
-
- Aug 2017
-
clojure.org clojure.org
-
Since Clojure uses the Java calling conventions, it cannot, and does not, make the same tail call optimization guarantees. Instead, it provides the recur special operator, which does constant-space recursive looping by rebinding and jumping to the nearest enclosing loop or function frame. While not as general as tail-call-optimization, it allows most of the same elegant constructs, and offers the advantage of checking that calls to recur can only happen in a tail position.
Clojure's answer to the JVM's lack to tail call optimization
-
- Dec 2015
-
mishadoff.com mishadoff.com
-
Clojure Design Patterns
Intro Episode 1. Command Episode 2. Strategy Episode 3. State Episode 4. Visitor Episode 5. Template Method Episode 6. Iterator Episode 7. Memento Episode 8. Prototype Episode 9. Mediator Episode 10. Observer Episode 11. Interpreter Episode 12. Flyweight Episode 13. Builder Episode 14. Facade Episode 15. Singleton Episode 16. Chain of Responsibility Episode 17. Composite Episode 18. Factory Method Episode 19. Abstract Factory Episode 20. Adapter Episode 21. Decorator Episode 22. Proxy Episode 23. Bridge
-
-
www.pitheringabout.com www.pitheringabout.com
-
Clojure at a Real Estate Portal
Clojure stack
-