most front-end developers have normalised doing daily trust falls with their codebases
25 Matching Annotations
- Feb 2026
-
adactio.com adactio.com
-
- Nov 2025
-
www.aviarampatzis.com www.aviarampatzis.com
-
for - language - linguistic normalization - different phrases with the same meaning - different syntax, similar semantics - adjacency - language - syntax permutation explosion
-
- Jan 2022
-
www.nytimes.com www.nytimes.com
-
https://www.nytimes.com/2022/01/28/nyregion/steven-strogatz-sundays.html
Nice to see the normalization of math and a mathematician without any math shaming in sight.
I'm more curious to hear about his Mondays or Tuesdays...
-
-
drive.google.com drive.google.comview1
-
Standarisasi
mohon dijelaskan kembali teknik standardisasi (bukan standarisasi), karena ada standardisasi dan ada normalisasi.
-
- Dec 2021
-
learn-us-east-1-prod-fleet01-xythos.content.blackboardcdn.com learn-us-east-1-prod-fleet01-xythos.content.blackboardcdn.com
-
What we’re going to suggest is that American intellectuals – we areusing the term ‘American’ as it was used at the time, to refer toindigenous inhabitants of the Western Hemisphere; and ‘intellectual’to refer to anyone in the habit of arguing about abstract ideas –actually played a role in this conceptual revolution.
I appreciate the way that they're normalizing the idea of "American intellectuals" and what that really means.
-
- Sep 2021
-
-
Because the policies are standardized, we can now use the policy_std columns to evaluate and analyze our IAM policies without having to convert case or account for optional use of scalar values vs array values!
-
AWS IAM policies can have multiple representations that mean the same thing. Converting to a standard, machine-readable format makes them easier to search, analyze, join with other data and to calculate differences.
-
-
steampipe.io steampipe.io
-
Steampipe's standardized schemas allow you to approach tagging queries with common patterns across resources and clouds.
-
- Jul 2021
-
trisquel.info trisquel.info
-
which is the right thing to do btw
No, it isn't.
-
- Jun 2020
-
proandroiddev.com proandroiddev.com
-
Normalize the database for this case if your data is going to be modified multiple times
-
Duplicated data is a common practice when working with non-relational databases as Firebase. It saves us from performing extra queries to get data making data retrieval faster and easier
-
normalizing our dabatase will help us. What means normalize? Well, it simply means to separate our information as much as we can
directly contradicts firebase's official advice: denormalize the structure by duplicating some of the data: https://youtu.be/lW7DWV2jST0?t=378
-
-
www.geeksforgeeks.org www.geeksforgeeks.org
-
Denormalization is a database optimization technique in which we add redundant data to one or more tables
-
- Jul 2019
-
sebastianraschka.com sebastianraschka.com
-
in clustering analyses, standardization may be especially crucial in order to compare similarities between features based on certain distance measures. Another prominent example is the Principal Component Analysis, where we usually prefer standardization over Min-Max scaling, since we are interested in the components that maximize the variance
Use standardization, not min-max scaling, for clustering and PCA.
-
As a rule of thumb I’d say: When in doubt, just standardize the data, it shouldn’t hurt.
-
-
scikit-learn.org scikit-learn.org
-
many elements used in the objective function of a learning algorithm (such as the RBF kernel of Support Vector Machines or the l1 and l2 regularizers of linear models) assume that all features are centered around zero and have variance in the same order. If a feature has a variance that is orders of magnitude larger than others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
-
- Jun 2019
-
sebastianraschka.com sebastianraschka.com
-
However, this doesn’t mean that Min-Max scaling is not useful at all! A popular application is image processing, where pixel intensities have to be normalized to fit within a certain range (i.e., 0 to 255 for the RGB color range). Also, typical neural network algorithm require data that on a 0-1 scale.
Use min-max scaling for image processing & neural networks.
-
The result of standardization (or Z-score normalization) is that the features will be rescaled so that they’ll have the properties of a standard normal distribution with μ=0μ=0\mu = 0 and σ=1σ=1\sigma = 1 where μμ\mu is the mean (average) and σσ\sigma is the standard deviation from the mean
-
- Mar 2019
-
iphysresearch.github.io iphysresearch.github.io
-
Mean-field Analysis of Batch Normalization
BN 的平均场理论
-
-
arxiv.org arxiv.org
-
One of the challenges of deep learning is that the gradients with respect to the weights in one layerare highly dependent on the outputs of the neurons in the previous layer especially if these outputschange in a highly correlated way. Batch normalization [Ioffe and Szegedy, 2015] was proposedto reduce such undesirable “covariate shift”. The method normalizes the summed inputs to eachhidden unit over the training cases. Specifically, for theithsummed input in thelthlayer, the batchnormalization method rescales the summed inputs according to their variances under the distributionof the data
batch normalization的出现是为了解决神经元的输入和当前计算值交互的高度依赖的问题。因为要计算期望值,所以需要拿到所有样本然后进行计算,显然不太现实。因此将取样范围和训练时的mini-batch保持一致。但是这就把局限转移到mini-batch的大小上了,很难应用到RNN。因此需要LayerNormalization.
Tags
Annotators
URL
-
- Feb 2019
-
iphysresearch.github.io iphysresearch.github.io
-
LocalNorm: Robust Image Classification through Dynamically Regularized Normalization
提出了新的 LocalNorm。既然Norm都玩得这么嗨了,看来接下来就可以研究小 GeneralizedNorm 或者 AnyRandomNorm 啥的了。。。[doge]
-
Fixup Initialization: Residual Learning Without Normalization
关于拟合的表现,Regularization 和 BN 的设计总是很微妙,尤其是 learning rate 再掺和进来以后。此 paper 的作者也就相关问题结合自己的文章在 Reddit 上有所讨论。
-
- Dec 2018
-
iphysresearch.github.io iphysresearch.github.io
-
Generalized Batch Normalization: Towards Accelerating Deep Neural Networks
核心是这么一句话: Generalized Batch Normalization (GBN) to be identical to conventional BN but with
standard deviation replaced by a more general deviation measure D(x)
and the mean replaced by a corresponding statistic S(x).
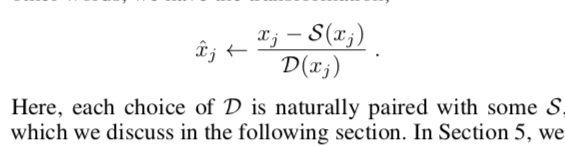
-
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)
BatchNorm有效性原理探索——使优化目标函数更平滑
-
- Sep 2018
-
192.168.199.102:5000 192.168.199.102:5000
-
Normalization
一列数字,如果每个数字都减去平均值,则新形成的数列均值为0.
一列数字,如果每个数字都除以标准差,则新形成的数列标准差为1.
如果我要构造一个均值为0,标准差为 0.1 的数列怎么做?
\(x_i \leftarrow x_i - \mu\)
\(x_i \leftarrow x_i / \sigma\)
\(x_i \leftarrow x_i * 0.1\)
经过这三步归一化的动作,既能保持原来分布的特点,又能做到归一化为均值为0,标准差为 0.1 的分布。
Tags
Annotators
URL
-