Another possibility is to try as much as possible to push your I/O and flow control primitives to the edges of the program or library, providing integration points for multiple backends.
这是一种解耦方式,将和 IO 相关的控制代码局限在一个很小的范围内,这样可以适配多个后端,但是有一定的编写难度
Another possibility is to try as much as possible to push your I/O and flow control primitives to the edges of the program or library, providing integration points for multiple backends.
这是一种解耦方式,将和 IO 相关的控制代码局限在一个很小的范围内,这样可以适配多个后端,但是有一定的编写难度
要在Windows上生成Keytab文件,您可以使用ktpass工具。以下是简要步骤:
运行以下命令以生成Keytab文件:
plaintext
ktpass -princ username@REALM -pass password -mapuser username -crypto DES-CBC-MD5 -ptype KRB5_NT_PRINCIPAL -out keytab_file.keytab
替换username@REALM和password为相应的用户名和域信息。
这将生成Keytab文件,其中包含与指定用户关联的凭据。
请注意,此过程可能需要在域控制器服务器或运行Windows Server的计算机上进行[2][3][7][8][9][10][11]。
在Windows系统中,有多种方法可以生成文件信息。以下是一些建议:
使用fsutil命令可以创建指定名称和大小的文件,内容为零。这可以通过以下命令完成:fsutil file createnew 文件名 大小[3][11]。
使用CreateFile函数可以创建新文件或打开现有文件。必须指定文件名和创建说明。这是通过编程实现的,适用于Win32应用程序[4][6]。
若要创建系统信息文件,可以在任务栏上的Cortana或搜索图标中键入“System”,然后点击System Information图标[5]。
通过命令提示符使用cmd.exe可以获取文件的所有信息和属性[7]。
这些方法提供了在Windows系统中生成文件信息的多样选择。
波特五力」天生具有增强的趋势:
这就意味着,所有公司都在衰落,所有公司最终都会倒下:无论任何行业的任何商业形态,供给方和客户的议价能力一定保持自然增长、一定会出现颠覆者、一定有新的技术替代现有产品、现有竞争一定趋于白热化,最后的结果是,利润天然在干涸。
公司的领导者们所做的,本质上都是在保护公司不断干涸的利润,大多数的公司行为都是在抵抗这五种力量的侵蚀
sending transactions to networks
🌹我要是在前端网页中进行调用,调用哪个api?
在前端网页中进行以太坊交易调用时,出于安全考虑,你应该使用 eth_sendRawTransaction API。这是因为在前端环境中直接使用 eth_sendTransaction 会要求用户的私钥在前端暴露,这是非常不安全的。
使用 eth_sendRawTransaction 的流程通常涉及以下步骤:
创建交易对象:你需要构造一个交易对象,包含了交易的所有必要信息,如接收者地址(to)、发送的金额(value)、数据(data,如果是调用智能合约函数)、gas 和 gasPrice。
签名交易:在用户的浏览器中,使用JavaScript库(如ethers.js或web3.js)来对交易进行签名。用户的私钥用于签名过程,但不会离开用户的设备。
发送原始交易:将签名的交易(现在是一个原始的十六进制字符串)通过 eth_sendRawTransaction 发送到以太坊网络。
例如,如果你使用 web3.js 库,流程可能如下:
javascript
web3.eth.accounts.signTransaction(transactionObject, privateKey)
.then(signedTx => web3.eth.sendSignedTransaction(signedTx.rawTransaction))
.then(receipt => console.log("Transaction receipt: ", receipt))
.catch(err => console.error(err));
在这个例子中,transactionObject 包含了交易的细节,privateKey 是用户的私钥,用于签名交易。注意,私钥是在用户的设备上使用,并且不应该通过网络发送或在服务器上存储。
如果你使用的是MetaMask或其他以太坊钱包插件,它们内置了安全的签名机制,你可以通过插件提供的API进行交易而不需要直接处理私钥。例如,使用 MetaMask 时,你可以这样调用:
javascript
ethereum.request({
method: 'eth_sendTransaction',
params: [transactionObject],
}).then((txHash) => console.log(txHash))
.catch((error) => console.error);
在这种情况下,MetaMask 会处理交易的签名过程,用户只需确认交易即可。这是因为 MetaMask 作为浏览器扩展,其背后的环境比普通的前端页面更加安全,可以安全地管理用户的私钥。
sendTransaction
内部封装了两个eth_的api
eth_sendTransaction
eth_sendRawTransaction
eth_sendTransaction 和 eth_sendRawTransaction 是以太坊 JSON-RPC 接口的两个调用方法,它们用于提交交易,但它们的使用方式和目的有所不同。
eth_sendTransaction 用于创建和发送一个由节点管理的账户的交易。当你调用这个方法时,你提供一个交易对象,包含了如 from, to, value, data, gas, gasPrice 等字段。节点(通常是一个以太坊客户端,如Geth或Parity)将使用本地存储的私钥来签名交易。
这个方法要求你的以太坊节点拥有发送者账户的私钥,并且节点必须解锁该账户以便签名交易。因此,这种方法通常不推荐用于前端应用或任何不安全的环境,因为它要求节点具有访问和管理私钥的能力。
示例调用:
json
{
"method": "eth_sendTransaction",
"params": [{
"from": "0x...",
"to": "0x...",
"value": "0x...",
"gas": "0x...",
"gasPrice": "0x...",
"data": "0x..."
}],
"id": 1,
"jsonrpc": "2.0"
}
eth_sendRawTransaction 用于发送一个已经完全在外部签名的交易。这意味着交易的创建、签名和序列化(编码为十六进制字符串)是在节点外部完成的,节点不需要访问账户的私钥。
这个方法更加安全,特别是在客户端或服务端环境中,因为你不需要将私钥暴露给节点。你只需在一个安全的环境中(例如用户的浏览器或后端服务)使用私钥签名交易,然后将签名的交易(十六进制字符串)发送给节点。
示例调用:
json
{
"method": "eth_sendRawTransaction",
"params": ["0x签名的交易数据..."],
"id": 1,
"jsonrpc": "2.0"
}
总结来说,eth_sendTransaction 适用于节点有权访问私钥的场景,而 eth_sendRawTransaction 更适用于需要保持私钥安全的场景,如客户端钱包或服务端应用程序。实际开发中,由于安全性的考虑,通常会使用 eth_sendRawTransaction。
"m/44'/60'/${string}"
🙋比如metamask钱包,生成的address 是以怎样的path生成的?
MetaMask 钱包遵循 BIP-44 标准来生成地址。BIP-44 是一种层次性确定性(HD)钱包结构,它允许从单一的种子生成多个币种、账户以及地址。MetaMask 主要支持以太坊及其兼容网络,因此,生成地址的路径通常遵循以下模式:
m / purpose' / coin_type' / account' / change / address_index
在这个路径中:
purpose 通常固定为 44',表示遵循 BIP-44 的结构。coin_type 对于以太坊,这个值固定为 60'。account 表示账户的索引号,从 0' 开始递增。change 用于以太坊,这个值通常是 0,因为以太坊不像比特币一样区分找零地址和接收地址。address_index 是地址的索引号,从 0 开始递增。所以,MetaMask 生成第一个以太坊地址的路径通常是:
m / 44' / 60' / 0' / 0 / 0
这表示:
当你在 MetaMask 创建更多地址时,address_index 会递增(例如,第二个地址是 m / 44' / 60' / 0' / 0 / 1),但其他部分保持不变。如果你创建了一个新账户,那么 account 部分会递增(例如,第二个账户的第一个地址是 m / 44' / 60' / 1' / 0 / 0)。
🙋有个问题,我换链创建钱包会有什么影响?
当您在 MetaMask 或其他类似的多链钱包中“换链”时,通常是指您在钱包软件中切换到另一个区块链网络,例如从以太坊主网切换到 Binance Smart Chain (BSC)、Polygon、Avalanche 或其他兼容的网络。
这里有几个方面需要注意:
地址重用:大多数基于以太坊的网络(EVM兼容网络)都使用相同的地址格式。这意味着,即使您切换到另一个链,您的账户地址通常会保持不变。这是因为您的私钥和它派生出的地址在这些网络中都是有效的。
网络设置:每个区块链网络都有其特定的配置,如网络ID、RPC URL等。当您在钱包中切换链时,钱包会自动调整这些设置以便与所选网络进行交互。
资产和交易:不同链上的资产是独立的。例如,ETH在以太坊主网上是原生资产,而在BSC上则是一种被称为Binance-Peg Ethereum Token (BETH) 的封装资产。因此,当您切换链时,钱包会显示该链上的资产和交易记录。
燃料费和交易:每个链都有自己的燃料费(Gas fees)结构和代币。例如,在以太坊上进行交易需要消耗ETH作为燃料费,在BSC上则需要BNB。切换链意味着您需要拥有相应链的本地货币来支付交易费用。
智能合约和互操作性:不同链上的智能合约是独立部署的,尽管许多项目会在多个链上部署相同的合约代码。切换链时,您将与每个特定链上的合约进行交互。这也意味着某些操作,如代币交换或质押,需要在相应链上进行。
安全性和隐私:尽管地址可能在不同链上重用,但您的交易记录和余额在每个链上是独立的。这可能会对您的隐私产生影响,因为如果有人知道您的地址,他们可以在每个链上追踪您的资产和交易。
总的来说,换链创建钱包并不会改变您的钱包地址或私钥,但会改变您与之交互的区块链网络,每个网络都有其独特的特性和要求。始终确保您了解正在使用的网络的特点,以及如何安全地管理您的资产。
fromMasterSeed fromExtendedKey fromJSON
在讨论加密货币钱包,特别是分层确定性(HD)钱包的上下文中,fromMasterSeed、fromExtendedKey 和 fromJSON 是创建或恢复钱包的不同方法,每种方法都基于不同类型的输入数据。下面是这三种方法的简要说明和它们之间的区别:
fromMasterSeed 方法用于从一个主种子(Master Seed)创建一个新的 HD 钱包。主种子通常是由一组助记词(根据 BIP-39 标准)生成的,这些助记词在用户创建钱包时生成并记录下来。当使用 fromMasterSeed 方法时,你需要提供这个种子(或由助记词生成的种子),然后钱包软件会使用这个种子来生成根私钥和链码,进而生成整个密钥树。
fromExtendedKey 方法用于从一个扩展密钥(Extended Key)恢复 HD 钱包。扩展密钥可以是扩展公钥(xPub)或扩展私钥(xPrv)。扩展密钥包含了密钥信息和链码,允许钱包派生出子密钥。使用扩展公钥,你可以生成钱包的所有公钥和接收地址,但不能生成对应的私钥,因此只能用于监视钱包。使用扩展私钥,你可以生成整个密钥树,包括私钥,因此可以完全控制钱包。
fromJSON 方法是从一个 JSON 格式的数据恢复钱包。这个 JSON 数据通常包含了钱包的所有必要信息,如私钥、公钥、地址、元数据等。这种方法通常用于软件之间的钱包迁移,或者在钱包软件的不同版本之间恢复钱包。输入的 JSON 数据必须是之前导出的钱包数据,以确保可以正确恢复所有相关信息。
fromMasterSeed 基于主种子创建新钱包,适用于初始创建钱包。fromExtendedKey 基于扩展密钥恢复钱包,适用于已有钱包的完整或只读恢复。fromJSON 基于 JSON 数据恢复钱包,适用于跨软件或版本的钱包迁移。每种方法的使用取决于用户的具体需求和拥有的备份信息类型。在实际应用中,用户应该选择最适合其当前情况的恢复方法。
Hierarchical Deterministic (HD)
分层确定性钱包(Hierarchical Deterministic Wallets,简称 HD Wallets),是一种加密货币钱包,它能够从一个单一的种子生成一整套密钥。这种钱包的工作原理基于比特币改进建议 32(BIP-32)和 BIP-44。HD 钱包的主要优势在于它们的便捷性和安全性。
分层密钥生成:HD 钱包可以创建一个密钥树,从一个根密钥(种子)出发,按照层级结构生成多个子密钥。
种子短语:HD 钱包通常使用一组随机单词(助记词)来生成根密钥,这组助记词是 BIP-39 标准的一部分,用户可以记忆或记录下这些单词以备份和恢复钱包。
确定性:这意味着从相同的种子出发,总是可以生成相同的密钥序列。这对于备份和恢复钱包至关重要。
多地址钱包:用户可以为不同的交易和目的生成多个地址,增加隐私。
跨货币和应用兼容性:同一个 HD 钱包可以用来管理多种不同的加密货币,并且可以与多个应用程序兼容。
生成种子:一切从生成一个随机的种子(通常是 128位或 256位的随机数)开始。这个种子通常通过助记词的形式呈现给用户。
根私钥和链码:种子通过哈希函数生成根私钥和链码。链码用于生成子密钥。
密钥派生:使用根私钥和链码,可以创建一个树状结构的密钥序列。每个节点都可以生成多个子节点,每个子节点又可以生成自己的子节点,依此类推。
路径表示法:BIP-44 提出了一种标准的路径表示法,用于确定密钥树中的特定位置。例如,m/44'/0'/0'/0/1 表示一个特定的密钥路径。
使用:用户可以使用派生出的地址来接收和发送加密货币。每个地址都有对应的私钥,而这些私钥都是由同一个种子生成的,因此只需要备份种子即可恢复整个钱包。
HD 钱包的安全性在于,即使某些私钥或地址被泄露,攻击者也无法计算出根密钥或其他子密钥。此外,由于所有的密钥都是由一个种子生成的,用户只需要确保这个种子的安全性,而不需要单独备份每个私钥。
备份 HD 钱包相对简单,只需备份种子短语(助记词)。恢复钱包时,只要输入这个种子短语,就能重新生成所有的密钥和地址。
HD 钱包是现代加密货币钱包的一个重要进步,它们提供了更好的安全性、便捷性和灵活性。
watchPendingTransactions
基于定时器实现
eth_newpendingtransactionfilter
eth_newPendingTransactionFilter 是 Ethereum JSON-RPC API 的一部分,它用于创建一个新的过滤器,这个过滤器会通知调用者有关网络中出现的新的待处理交易。"待处理"交易是指已经被网络节点接收但还未被包含在一个区块中的交易。
当你调用这个方法时,它会立即返回一个过滤器ID。你可以使用这个ID来调用 eth_getFilterChanges,这个方法将返回自上次轮询以来进入待处理状态的所有交易的哈希列表。这对于那些需要实时监控网络交易活动的应用程序或服务来说非常有用,比如钱包服务或交易监控工具。
下面是一个 eth_newPendingTransactionFilter 调用的示例:
json
{
"jsonrpc": "2.0",
"method": "eth_newPendingTransactionFilter",
"params": [],
"id": 1
}
这个请求不需要任何参数。调用成功后,你会得到一个过滤器ID,如下所示:
json
{
"jsonrpc": "2.0",
"id": 1,
"result": "0x1" // 这是过滤器ID
}
使用这个过滤器ID,你可以定期调用 eth_getFilterChanges 方法来检索自上次检查以来加入待处理池的新交易哈希:
json
{
"jsonrpc": "2.0",
"method": "eth_getFilterChanges",
"params": ["0x1"], // 这里的 "0x1" 是之前创建的过滤器ID
"id": 1
}
这将返回一个数组,包含了所有新的待处理交易的哈希:
json
{
"jsonrpc": "2.0",
"id": 1,
"result": [
"0x...哈希1...",
"0x...哈希2...",
// ...更多交易哈希...
]
}
请注意,由于以太坊节点可能会处理大量的交易,所以使用 eth_newPendingTransactionFilter 可能会导致大量的数据。此外,由于节点间的数据传播延迟,一个交易可能会在不同的节点上不同的时间被视为是 "待处理" 的。因此,使用这个过滤器时,客户端需要准备好处理潜在的大量数据,并且理解这些数据可能并不总是完全同步的。
watchContractEvent
eth_newFilter 是一个 JSON-RPC 调用,用于在以太坊网络上创建一个新的过滤器(filter)。这个过滤器可以用来监听特定条件下的日志事件(log events),这些日志事件是智能合约在执行操作时发出的。当你想要跟踪智能合约的活动,比如特定函数的调用或者特定事件的触发时,这个功能非常有用。
当你调用 eth_newFilter 时,你可以指定一系列的参数来定义过滤器的行为:
创建过滤器后,它会返回一个过滤器ID。你可以使用这个ID来调用 eth_getFilterChanges 或 eth_getFilterLogs,这样就可以获取自过滤器创建以来发生的或所有匹配过滤器条件的日志事件。
示例 JSON-RPC 请求创建一个新的过滤器可能如下所示:
json
{
"jsonrpc": "2.0",
"method": "eth_newFilter",
"params": [{
"fromBlock": "0x1",
"toBlock": "latest",
"address": "0x8888f1f195afa192cfee860698584c030f4c9db1",
"topics": [
"0x0000000000000000000000000000000000000000000000000000000012345678"
]
}],
"id": 1
}
在这个请求中,我们创建了一个从区块1到最新区块的过滤器,只监听地址为 "0x8888..." 的智能合约,并且只对主题 "0x0000..." 的事件感兴趣。
请注意,由于以太坊网络的匿名和去中心化特性,任何人都可以创建过滤器并监听事件。这是智能合约透明性的一个重要方面,但也意味着合约的设计者需要注意不要通过事件泄露敏感信息。
这是我的模板
用作参考的模板
经验主义亦称“经验论”。作为一种认识论学说,与“理性主义”相对。经验主义认为感性经验是知识的来源,一切知识都通过经验而获得,并在经验中得到验证。 这正是ChatGPT的思考和学习路径。 而虚拟进化又指数级放大了基于经验的学习速度。在波普尔看来,科学发展本身就是一种进化。
ChatGPT是经验主义的进化论的“胜利产物”。 人工智能是如何思考的?又是如何决策的?
有别于齿轮般的演绎推理,我们需要借助概率在证据和结论之间建立起联系。
AI的任务是做决策,在不确定性下结合信念与愿望,选择动作。
黄仁勋说:“AI既是深度学习,也是一种解决难以指定的问题的算法。这也是一种开发软件的新方法。想象你有一个任意维度的通用函数逼近器。”在黄仁勋的比喻中,“通用函数逼近器”确实是对深度神经网络的一个精确且富有洞见的描述。这个比喻突出了深度神经网络的核心特性:它们可以学习并逼近任意复杂的函数映射,只要网络足够深,参数足够多。
这种“函数逼近”的能力使得深度学习能够应对各种各样的任务,从图像分类和语音识别到自然语言理解和生成,甚至是更复杂的任务,如游戏和决策制定。
任何足够强大的形式系统,都存在一些在该系统内部既不能被证明也不能被反驳的命题。
1936年,图灵在一篇论文里研究了希尔伯特的“计算性”和“判定性问题”。
为了解决这个问题,图灵首先定义了“计算”这个概念,并创建了图灵机,这是一种理论上的计算设备。然后,他通过构造了一个图灵机无法解决的问题(即停机问题)来证明判定问题实际上是无法解决的。
这意味着没有一个通用的算法能对任何可能的问题都给出答案。
热力学第二定律指出一个物理系统中的熵,或言无序度,总是在增长。依照这一定律,宇宙中的秩序必然在减少,那么由于生命存在所增加的秩序又要如何解释?薛定谔的回答是,生命需要吸收“负熵”(negative entropy),或自由能——即我们常说的食物和阳光。根据第二定律,阳光加热地球时破坏掉的有序度,必大于由于植物生长所增加的有序度。
“生命定律”不仅适用于地球生命,也可以描述地外生命;它不只局限于生物学,更适用于广义的物理世界。
笔记内容,阐明观点
观点本身适合当作标题,而支撑观点的阐释、论据、数据或者仅仅是不成熟的思考过程,则可以作为笔记内容。以 写作之难在于用句法树组织思维网 为例,其中主要记载了三类内容:
作者的原话。我甘冒“照抄原文”之大不韪,只因为抄原句和自己解释一遍并不冲突,相反,如果过于原教旨而事必躬亲、每次都自己讲一遍,恐怕要闹出传话游戏的笑话,传到后来和原句已然谬以千里; 读者的解释。在这则笔记中,我赞成作者的观点,因而只是做了一些锦上添花的论述工作,补充了一正一反两个例句,这样可以让作者的观点更具象,以后读到这篇笔记就有了两个立足点,而不用从抽象的原理开始演绎。 对误读的批评。中文圈中相当一部分人误读了史蒂芬·平克的话,我有理由认为他们根本没有翻开过那本《风格感觉》,因为史蒂芬从头到尾都在探讨句法何其重要,而不是在鼓吹网状思维(所以,你根本不用理睬那些借着史蒂芬之名兜售焦虑者)。 这只是一个例子,全然没有要充当模板的意思。如果你要阐述一个经济学观点,也许需要更多数字和实验数据;如果是一个法律规则,则应当附有相关条文和法理依据;有时还会产生矛盾观点,比如同样是高空抛物,入不入刑法都有理由,此时不妨创建两则笔记,互相引用、切磋推敲,以免不见舆薪。
尽可能用观点来命名笔记标题,这是一个指导性原则,踏出这一步,相当于一个靠天吃饭、有啥吃啥的人,忽然意识到要留下种子粮,以待来年。后续的耕耘规则多矣,我们将在《卡片笔记前缀编码的艺术》中继续讨论笔记的起名方法。
若對自己的知識及專業能力提升有意義的話,這入坑未嘗不可(笑)
华罗庚曾以烧水煮茶为例,剖析顺序——用效率这个小圈子的话来说,就是“XX管理”——的重要性,而一个人如果不统观全局就开始使用工具,恐怕和那些干等水烧开的人一样误入歧途。
必应为您介绍一下华罗庚的《统筹方法》这本书的概要。😊
《统筹方法》是华罗庚在1965年出版的一本科普著作,主要介绍了统筹方法的原理和应用。统筹方法是一种安排工作进程的数学方法,通过分析任务之间的相互关系,找出最优的工作顺序,以提高效率和节约资源。
华罗庚用泡茶喝的例子来说明统筹方法的基本思想,然后用箭头图和数字来表示任务的前提和时间。他指出,要抓住关键的环节,利用等待的时间来做其他的事情,避免窝工和浪费。华罗庚还介绍了统筹方法在企业管理、基本建设、科研项目等领域的应用,如如何安排生产线、如何制定工程计划、如何组织科研团队等。他用具体的案例和数据来说明统筹方法的优势和效果。华罗庚的《统筹方法》是一本通俗易懂、实用有益的科普读物,它体现了华罗庚的数学思维和生活智慧,也展示了他的幽默风趣和平易近人的风格。
民族小说强调当代世界日常生活中最普遍的议题:健康、退休、旅行——这一点特别重要。我们不妨将民族小说看作是说明书式小说,或者档案库式小说。
更像县志? 民族小说是关于民族学或人类学议题的小说,区别于小说或者虚构作品,它与相信、沉浸无关,它恰恰是拒绝对主体性的许诺,邀请更多的目光参与其中,一道达成对故事的见证与省思。
血统(la filiation)、联姻(l'alliance)、居所(la résidence)、世代(la génération),这是民族学的四个维度,这是个人所需的最低限度的社会意义。
Discussion
用脑内注射Aβ的形式造模,分组有:伪手术组,AD组(双歧杆菌口服、对照、双歧杆菌死细菌结构口服、乙酸水溶液四种治疗组)。观察到活双歧杆菌能够改善小鼠由Aβ引起的认知障碍,健康组和AD组海马RNA表达有明显差异,而AD治疗组和对照组没有明显差异,说明治疗作用是间接的。进一步研究双歧杆菌治疗对乙酸水平的影响,发现不同方法提高乙酸水平后确实有一定疗效,提示这一过程是通过乙酸为媒介实现的。具体机制还未明。
愛引動我們去想像美好,並且提供動力去追求美好。
这是正解,拆解了爱与国两个字。爱是令人向善的
正如文章下面一句话:愛的獨特性在於它嚮往一種理想的狀態,它的魔力在於嚮往「善」,所以相愛的人會彼此關照與幫助,祝福自己與對方都能變得更為美好。
錢永祥
builder.addMatcher
这里可以作为DDD的policy ???
感觉不太行。。。这里感觉只能修改本slice的state,无法再生成一个event ?或者调用dispatch ?
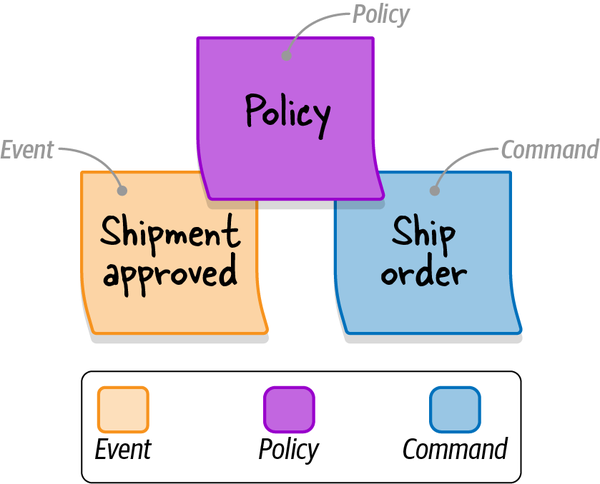 理论上 回调的方法 就应该作为一个 command
理论上 回调的方法 就应该作为一个 command
感觉这个是弱化的 listen , 因为最佳的做法是 我监听到了event ,我这个command是会做很多操作的,比如异步请求,或者再调别人的command,但是这里这出是局限于 本slice的修改
这个API暴露的挺不好的,可能就是为了适配没有listen吧
我需要每年都洗牙吗?不需要,但宣传每年洗牙是利大于弊的。前文已经介绍了,牙结石是由牙菌斑矿化而来的。理想情况下,如果你能够及时且完全地清除牙菌斑,实际上就是从根源杜绝了牙结石的产生,自然也不再需要洗牙。但现实中你是无法做到完全清除牙菌斑的。比如,如果你之前没有使用牙线或者其他工具清洁邻面的习惯,很有可能你的牙间隙中就有一些牙结石。所以我的建议是,如果你之前从来没有洗过牙,可以先去正规医院进行一次检查,由医生判断你是否需要洗牙。如果需要洗牙,可以记下来自己牙结石较多的区域,这也是你平时没有清洁到位的地方。之后,只要你能够保持良好的口腔卫生习惯,每年形成的牙结石数量都是非常少的,完全没有必要每年都去洗牙。而且洗牙多多少少还是会对牙龈和牙齿造成损伤的。洗牙这个活又脏又累,收费还低,其实没有多少医生愿意去做。对于口腔诊所来说,如果用销售的思维去想,洗牙本身是一个低客单的产品,它的主要作用是吸引顾客。过程中可以给顾客介绍高客单的产品,从而赚取高额的利润。而对于三甲医院和医疗科普人员来说,洗牙的过程相当于进行了全面的口腔检查,可以检查出可能存在的各种口腔问题,的的确确能够促进口腔疾病的早期诊治(二级预防)。而且,从现阶段牙周炎和龋齿的高发病率来说,大部分人都没有办法做到良好的口腔清洁。所以现阶段,宣传每年洗牙肯定是利大于弊的。
不需要每年都洗牙
curl -X POST https://api.hypothes.is/api/annotations \ -H 'Authorization: Bearer YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "uri": "http://example.com", "text": "这是一个标注的示例文本。", "tags": ["tag1", "tag2"], "permissions": { "read": ["group:world"], "admin": ["acct:your_email@hypothes.is"], "update": ["acct:your_email@hypothes.is"], "delete": ["acct:your_email@hypothes.is"] } }'
这是一个标注的示例文本。
这是一个标注的示例文本。
这是一个标注的示例文本。
我对星露谷在2016第一季度的火爆百万销量,有一个理论: 和制作者一样,独立游戏的主力玩家目前是30岁出头(85后)的男性。独立游戏从最早的braid,超肉,fez,spelunky我称为平台跳跃四巨头——代表这批玩家(和开发者)的游戏启蒙之作:超级马里奥。随着时间推移,更年轻的制作者也会试图“复刻”他们孩童时代印象最深的游戏,于是Zeldalike(Issac),Metroidvanialike(Axiom Verge),Earthboundlike(Undertale),HarvestMoonlike(Stardew)逐个出现了。我认为indie游戏的热点是会随着时间推移,每次的热点则是大约20年前的热门游戏类型。所以我估计很快就会出现一波日式rpg,幽浮/铁血联盟like和FPS的热作。 所以这些大热作品一方面是运气,另一方面也是必然——同年龄的玩家总会用steam订单来投票选出他们儿时最喜欢的游戏类型。
bytes = append(bytes, "that is a int"...)
在 Go 语言中,... 有两个主要的用途,一个是在函数定义中声明可变参数(variadic function),另一个是在调用函数时展开切片。在你提供的代码示例中,... 是用来展开切片的。
这段代码:
go
bytes = append(bytes, "that is a int"...)
中的 ... 表示将字符串 "that is a int" 转换为字节切片后,将该字节切片中的每个元素作为独立的参数传递给 append 函数。这是因为 append 函数的第二个参数及以后的参数是可变参数,意味着你可以传递任意数量的参数,只要它们是与切片中元素类型相同的类型。
不使用 ... 的话,你就会将整个切片作为一个单独的参数传递给 append 函数,这将导致编译错误,因为 append 期望的是单独的元素,而不是整个切片。
这里是一个简单的例子来说明它是如何工作的:
```go slice := []int{1, 2, 3} slice = append(slice, 4, 5, 6) // 直接追加多个元素
// 如果你有另一个切片,想要追加其所有元素到 slice,你需要使用 ... anotherSlice := []int{7, 8, 9} slice = append(slice, anotherSlice...) // 展开 anotherSlice 并追加其元素 ```
在你的代码中,"that is a int" 首先被转换为一个字节切片,然后 ... 将其展开,append 函数接收到的是多个字节而不是一个切片。这样,原始的 bytes 切片就被扩展了,包含了新的字符串的字节表示。最后,扩展后的字节切片被转换回字符串并赋值给 str 变量。
价格战的战火还延伸到了资本市场。9 月 12 日,新款问界 M7 发布,官方数据显示,这款车型的累计大定已超过 10 万辆。截至目前,理想汽车股价已较今年 8 月的高点跌去超过 25%。多位二级市场人士告诉《晚点 Auto》,新款问界 M7 的热销虽然没有影响到理想的销量和订单量,但大幅压缩了理想在 2024 年的单车利润预期,这是引发理想股价下跌的重要原因之一。对于不同类型汽车品牌来说,新能源渗透率越高,其在价格战中的态度就越强势。在价格战中首当其冲的,就是以新势力厂商为代表的自主品牌。乘联会数据显示,年初至今,自主品牌的新能源渗透率已经从约 44% 提升到 60% 以上,而豪华品牌的新能源渗透率目前为自主品牌的三分之一左右,主流合资品牌的新能源渗透率虽然所有提升,但仍未超过 7%。
对资本市场影响不可避免
新能源汽车市场过去几年蓬勃发展,新品牌、新车型层出不穷,但背后也是困难重重、几经生死,一个要素出问题,可能满盘皆输。仅生产资质,各车企便用尽办法,这是不为大众所知的一面。拿到生产资质,既不是起点,亦并非终点。最早获批的 15 家新能源车企,大部分没有逃脱销量惨淡、破产清算、被收购,甚至消失的命运。毕竟,在所有好市场,都是多数人看到机会,少数人抓住机会,但最终,活下来的,是极少数。
从产业政策方面,这是很深刻的教训
收购是解决问题的直接方式。但在重投入的创业初期,收购会拖累企业的现金流。2017 年 2 月和 8 月,威马通过子公司收购了大连黄海汽车有限公司和中顺汽车,拿到两张造车资质,但仅第一笔交易就花了 11.8 亿元。当年,威马亏损达 16.96 亿元。力帆集团有两张造车资质,分别是力帆汽车和力帆乘用车,2018 年,理想虽然以较便宜的价格——6.5 亿元收购了其中的力帆汽车,获得造车资质;但在当年,理想亏损 7.19 亿元,负债 8.3 亿元。可想而知,当年的这笔收购,让理想承受巨大压力。不仅如此,收购还意味着承担对方公司的债务。2018 年,拜腾汽车以 1 元价格收购一汽华利汽车,但承担了其 8.55 亿元债务,以及 5462 万元员工薪资。2020 年,受资本寒冬和新冠疫情双重冲击,拜腾汽车 C 轮融资失败导致资金链断裂,于 2020 年 7 月宣布停工停产,无法偿付到期债务。一位知情人士告诉《晚点 Auto》,在蔚来内部,也曾有人提议用收购的方式拿下生产资质,但当时管理层的意见是,“不想花冤枉钱”,“也不想深度绑定地方,变成重资产。”
威马后来的倒闭,这也是一个很大因素
一些企业已经死了,还能把政府批准的资质卖出几千万甚至 1 亿元,“这是绝对不应该发生的”,苗圩今年 2 月在中国电动汽车百人会论坛上回顾。今天来看,仍在市面上有声量的车企只有哪吒、奇瑞新能源。剩余车企,部分销量惨淡,部分破产清算。云度汽车曾和蔚来、小鹏一样是 “新势力新星”,2017 年 10 月,云度推出首款车云度π1,2018 年,云度销量达 9300 辆,仅次于蔚来,位居当年的第二名。2023 年前 10 个月,云度新能源的销量只有 1985 辆。
一地鸡毛
如今,拿到生产资质后,12 月 5 日,资金并不宽裕的蔚来依然斥资 31.6 亿元从江淮收购了第一先进制造基地和第二先进制造基地的生产设备和资产。这是新势力艰难取得造车资质的一角缩影。过去 10 年,政策趋严,审批门槛变高,为拿到牌照,从代工、收购汽车厂,到变更股权结构、探索华为模式,不同时期入局的新玩家们,进行了符合时代的种种尝试。
额外的高成本本质上也降低了新势力的竞争力
新能源汽车生产资质,又称牌照、准生证,对于 2014 年之后不断涌现的新能源造车企业来说,它是能否进入整车生产制造领域的敲门砖。2016 - 2017 年,15 家车企获批发改委牌照。据中国汽车工业协会数据,这 15 个拿到新能源牌照的车企产能共计 91 万辆。据《南方都市报》统计,当时正在排队的车企超过 20 家,产能是这 15 家车企的 2 - 3 倍。
牌照一开始的放水,本质上造成了产业不公平,以及后面申请者的高成本。当然对于车企来说也是很大教训,凡事要趁早
随后 Google 开展了裁员。这次裁员是一个短视行为导致的无谓错误,目的是确保股价能够季度对季度保持增长,而不是遵循谷歌过去重视长期成功即便短期有所损失的策略 (这正是 “不作恶” 原则的核心)。裁员的影响是隐蔽而深远的。过去员工可能会关注用户需求或者公司整体利益,坚信做正确的事最终会得到回报,即使超出自己的职责范围。但是裁员后,员工不再相信公司会坚定地支持他们,于是极度规避任何有风险的举动。职责的边界被严格划分,知识和信息被视为珍宝一般囤积起来,因为不可替代性变成了保住工作的唯一手段。我在谷歌亲眼见证了这一切。员工对管理层缺乏信任,因此管理层也不再信任员工,只凭借荒谬的公司政策进行治理。2004年,谷歌创始人明确告知华尔街 “谷歌不是一家传统公司,我们无意成为一家传统公司”,但如今的谷歌已经名存实亡。
公司文化的恶化让人感慨
A lot has been written about AIs as existential risk. The worry is that they will have a goal, and they will work to achieve it even if it harms humans in the process. You may have read about the “paperclip maximizer“: an AI that has been programmed to make as many paper clips as possible, and ends up destroying the earth to achieve those ends. It’s a weird fear. Science fiction author Ted Chiang writes about it. Instead of solving all of humanity’s problems, or wandering off proving mathematical theorems that no one understands, the AI single-mindedly pursues the goal of maximizing production. Chiang’s point is that this is every corporation’s business plan. And that our fears of AI are basically fears of capitalism. Science fiction writer Charlie Stross takes this one step further, and calls corporations “slow AI.” They are profit maximizing machines. And the most successful ones do whatever they can to achieve that singular goal.
关于人工智能作为存在风险的问题已经有很多文章写过。担心的是,它们会有一个目标,并且会努力实现这个目标,即使在这个过程中伤害到人类。你可能读过关于“回形针最大化者”的报道:一种被编程成尽可能制造更多回形针的人工智能,结果却摧毁了地球以达到这些目标。这是一种奇怪的恐惧。科幻作家Ted Chiang对此进行了阐述。AI并没有解决所有人类问题或者迷失在证明无人理解的数学定理之中,而是专注于追求生产最大化的目标。Chiang认为我们所担心的其实就是资本主义带来的恐惧感。科幻作家Charlie Stross进一步将其称为“缓慢型AI”,也就是利润最大化机器。而那些最成功的公司则竭尽全力去实现这个唯一目标。
如果你想学会如何独立思考,那么第一性原理思维是最好的方法。第一性原理的思维方式强调独立思考,而不是人云亦云。马斯克在这一点上非常像乔布斯。“Think Different”是乔布斯最喜欢的广告词,一般译为“不同凡响”,有朋友说译为“不同凡想”更贴切。Think Different中的Different一词从英语语法上说是错误的,正确的用词应该是副词Differently。乔布斯团队巧妙地借助了这个语法错误,强调自己的标新立异,既然英语语法说Think Differently,苹果就要说Think Different创新的本质就是要与众不同,如果干什么都和别人一样,那就不是创新了。
第一性原理的确最适合颠覆性创新,另外有利于独立思考
欧几里得的几何学就形成了非常庞大的体系。但最初只是从五条公设推出来的。欧几里得几何学的五条公设: 任意两个点可以通过一条直线连接; 任意线段能无限延伸成一条直线; 给定任意线段,可以以其一个端点作为圆心,该线段作为半径作一个圆; 所有直角都全等; 若两条直线都与第三条直线相交,并且在同一边的内角之和小于两个直角,则这两条直线在这一边必定相交; 这五条就是亚里士多德所说的第一性原理。在亚里士多德眼中第一性原理有着至高无上的地位,甚至是充满神性的。他曾这样说过:“神性无所不在,就在那自然之中。”这是一种泛神论的思想,与希腊早期神话的观念和其他民族对神话的想法格格不入。亚里士多德将这种性质看作是最高贵的,所以叫做第一性原理。
第一性原理的缘起
Lex Fridman:首先,我希望生活中的一切都有一个有趣的模式。与 LLM 进行互动时,有趣模式不仅仅有趣,还有一种吸引人的东西。我还不确定这是什么,因为我只玩了一点时间,但它使得与系统互动更加有趣、更加生动。 Elon Musk: 绝对是。我们的 Grok 是根据《银河系梦游指南》中的刺猬模型制作的,这是我最喜欢的书之一,它是一本关于哲学的书,这个家伙只是一本关于幽默的书。我会说,这构成了我的哲学基础,那就是我们不知道生命的意义,但是我们越能扩大意识的范围和规模,无论是数字化的还是生物学的,我们就越能理解该问什么问题,以了解宇宙这个答案,我有一种好奇心哲学。
马斯克最喜欢的书之一
Lex Fridman:也许一个好问题是,关于中国有些什么东西是人们不了解的?从文化角度看,有哪些积极的、有趣的事情你学到了? Elon Musk: 中国有大量聪明、勤奋的人,这一点令人难以置信。有多少聪明、勤奋的人在中国?他们比这里多得多。我认为中国可能是从能源角度看最不缺的。中国近年来的建筑比美国更令人印象深刻,无论是火车站、建筑还是高速铁路。真的比我们在美国所拥有的更令人印象深刻。我建议有人去上海和北京看看那些建筑,坐火车从北京到西安,那里有兵马俑。 中国有令人难以置信的悠久历史。我认为中国可能是从文字使用的角度来看,最古老的,或许是最古老的文字。而且中国人确实记录了事情。 所以,从历史上看,中国总是以内部为重。他们不是征服型的。他们打过彼此,发生过许多内战。在三国战争中,我相信他们损失了大约 70% 的人口。他们发生过残酷的内战,与美国内战相比简直微不足道。所以我认为重要的是要认识到中国并不是单一的。我们通常将中国视为一个思想统一的实体,但根据我所见,这绝对不是事实,我认为大多数了解中国的人都会同意,中国人想到中国的次数是他们想到中国以外事物的 10 倍,所以他们 90% 的考虑都是内部的。
马斯克讨论中国
Lex Fridman:你坦诚地谈到了美国和中国之间可能发生战争的可能性,如果在台湾问题和一个中国政策上找不到外交解决方案的话。那么,我们如何避免这两个超级大国发生冲突的轨迹呢? Elon Musk: 值得一读的是《修昔底德陷阱》这本书,我非常喜欢战争历史,几乎反复研究过每一场战役,并试图弄清楚真正的胜利原因,而不是一方或另一方声称的原因。 Lex Fridman: 无论是胜利还是战争的爆发和整个过程。 Elon Musk: 是的,所以雅典和斯巴达就是一个典型案例。想想希腊人,他们真的写了很多东西,他们喜欢写作。世界上许多地方发生了很多有趣的事情,但人们没有记录下来,所以我们不知道发生了什么,或者他们没有详细地写。他们只会说,我们进行了一场战斗,我们赢了,还能加点什么吗?希腊人真的写了很多。 他们非常善于表达。我们保存了很多那样的文字,所以我们知道导致伯罗奔尼撒战争的原因,即斯巴达和雅典联盟之间的战争。我们知道,他们看到了即将到来的战争。斯巴达人没有写很多东西。他们本性上不是很健谈,但他们确实写了东西,但他们很简洁。 雅典人和其他希腊人写了很多,他们像这样说:斯巴达本是希腊的领袖,但雅典每年都变得越来越强大,每个人都认为雅典和斯巴达之间的冲突不可避免。我们怎样才能避免这种冲突呢?他们不能。他们看到了即将到来的战争,但仍然无法避免。 如果一个群体、文明或国家超越了另一个,从经济角度来看,美国自 1890 年左右以来一直是世界上最强大的经济体。美国是世界上最强大的经济引擎,比任何人都活得久。战争的基础是经济。 现在,以中国为例,其经济规模可能是美国 2~3 倍,想象一下,你原来是街头最强壮的孩子,然后现在突然出现了一个孩子,他体型是你的 2 倍。
中美是否必有一战
Lex Fridman:你希望乌克兰战争如何结束,以及再次减少人类痛苦的路径是什么? Elon Musk:我认为可能发生的事情,也就是现在的情况,是停火或和平的线条会非常接近目前的线条,但现在的情况是,无论哪一方发起进攻,都会遭受几倍于防守方的伤亡。因为你有深层防御,有地雷阵、战壕、反坦克防御。没有一方拥有空中优势,因为防空导弹远比飞机更先进,所以双方都没有空中优势。 坦克基本上是移动缓慢的死亡陷阱,它们不是反坦克武器的免疫,所以你真的只有远程火炮和战壕中的步兵。这就是第一次世界大战的再现。撤退、向对方扔旧炮弹。
马斯克谈乌克兰战争
Lex Fridman:战争的规模一直在增加,就像苦难的规模和繁荣的规模之间的竞赛,许多人似乎正在利用这场悲剧来敲打战争的鼓,喂养军工复合体,你担心那些支持升级的人吗?如何阻止? Elon Musk: 我担忧的一件事是,现在活着的人中很少有人能真正感同身受地理解战争的恐怖。至少在美国是这样,显然,在乌克兰和俄罗斯前线的人们知道战争有多么可怕,但西方有多少人真的理解呢?我的祖父参加了第二次世界大战,他遭受了严重的心理创伤。 他在东北非和意大利战场上待了将近六年,所有的朋友都在他面前被杀害。他们本来会把他送上前线,但他们随机做了一次智商测试,他的成绩很高。尽管如此,他因为没有完成高中学业——他不得不辍学,因为他的父亲去世了,他必须工作来养活他的兄弟姐妹——所以没有资格加入军官团,被归类为炮灰。 后来,他因为这次测试被转到了伦敦的英国情报部门。那是他遇到我祖母的地方,但他患有严重的创伤后应激障碍,他几乎不说话,如果你试图和他交谈,他只会让你闭嘴。他获得了许多勋章,但从不炫耀,甚至没有暗示。 我是从他的军事记录上发现这些的,他会说绝对不要再经历那样的事情,但现在他已经去世20年甚至更久,30年前,还有多少人记得第二次世界大战呢?
人类太健忘了
Lex Fridman:就像我说的,有些争议地,你在 Twitter 上和其他地方一直是和平的支持者。让我问你关于当今正在进行的战争,以及实现和平的路径,你希望以色列和加沙当前的战争如何结束?你认为在那个地区减少长期人类痛苦的路径是什么? Elon Musk: 认为那个地区绝对是,如果你查一下词典中“没有简单答案”的定义,会看到中东,特别是以色列的图片,所以没有简单的答案。或者我的意见是,哈马斯的目标是激起以色列的过度反应。他们显然不期待军事胜利,但他们真的希望犯下他们能犯下的最恶劣的暴行,以引发以色列尽可能激烈的回应。然后利用这种激烈的回应来动员全世界的穆斯林支持加沙和巴勒斯坦的事业,他们在这方面已经成功了。 这里的反直觉之处,我认为应该做的事情,即使这很困难,是我建议以色列进行尽可能显眼的善行。每一部分,每件事都是实际上破坏哈马斯目标的东西。 Lex Fridman:在某种意义上,如果在地缘政治中有意义,就是实施“以德报怨”。 Elon Musk:这不完全是“以德报怨”,因为我确实认为以色列找到哈马斯成员并杀死他们或把他们阉割是适当的。像这种事情必须做,否则他们就会一直来,但除此之外,他们需要尽其所能。例如,有人谈论建立一个移动医院。我建议这样做。只是确保有食物、水、医疗必需品。而且要非常夸张地做,并且非常透明,以至于你的猫咪可以一直盯着那个网络摄像头。 Lex Fridman:部署善行。 Elon Musk: 这些善行是明确无误的,意味着不能以某种方式被哈马斯所诈骗,所以你必须对付他们的诡计。 Lex Fridman:这最终会对抗该地区的普遍仇恨。 Elon Musk: 是的。我不确定是谁说的。这是一句名言,但“以眼还眼,最终让所有人都瞎了”。现在,那个地区的话,他们真的相信“以眼还眼”,但我的意思是,如果你不打算对一个整体民族进行种族灭绝,显然这对任何人都不应该是可接受的,那么你基本上会留下很多恨以色列的人,所以真正的问题是,你杀死一个哈马斯成员,你创造了多少个?如果你创造的比你杀死的还多,你就没有成功。那就是真正的情况。可以肯定地说,如果在加沙杀死一个人的孩子,至少会有几个哈马斯成员会去杀以色列人。这就是情况,但我的意思是,这是可以讨论的最有争议的话题之一,但我认为,如果最终的目标是某种长期的和平,就必须从长远来看,恐怖分子的数量是增多还是减少?
马斯克谈加沙
使用外部电阻器分压器即可实现该分压。这是一种简单的设计方法,但优缺点很明显。放大器的增益误差和 CMRR 取决于外部输入分压器电阻器的精度和匹配度。除了增益误差和 CMRR 误差之外,外部电阻器的容差将导致输入电压不平衡,从而引起额外的输出误差。根据电阻器的温漂规格,此误差会随温度而增加。将输出误差最小化的一种方法是使用 0.1% 匹配度的精密低温漂移外部电阻器分压器
高压采集,电阻分压的缺点是电阻的容差及温漂会让采集精度,增益误差等变差,最终影响采样精度。另外CMRR由于电阻的容差,也会变差。
作为负责任的发展中大国,中国从人类共同命运和整体利益出发,提出构建人类命运共同体,建设一个持久和平、普遍安全、共同繁荣、开放包容、清洁美丽的世界,为人类未来勾画了新的美好愿景。共建“一带一路”以构建人类命运共同体为最高目标,并为实现这一目标搭建了实践平台、提供了实现路径,推动美好愿景不断落实落地,是完善全球治理的重要公共产品。共建“一带一路”跨越不同地域、不同文明、不同发展阶段,超越意识形态分歧和社会制度差异,推动各国共享机遇、共谋发展、共同繁荣,打造政治互信、经济融合、文化包容的利益共同体、责任共同体和命运共同体,成为构建人类命运共同体的生动实践。
肖四1-38-2
2015年底,OpenAI成立了。据四名知情人士,2017年底,马斯克策划了一个从奥尔特曼和其他创始人手中夺走OpenAI控制权的计划,他想把这个实验室变成能与特斯拉联手的商业实体,让其靠汽车公司正在研发的超级计算机运行。遭到奥尔特曼和其他人的反对后,马斯克表示退出实验室,并说他将集中精力在特斯拉搞自己的人工智能系统。2018年2月,马斯克在这家初创公司用一个卡车工厂改造的办公楼的顶层向OpenAI员工们宣布他将离开,三名参加了那次会议的人说。OpenAI突然急需得到新资金。奥尔特曼在飞往太阳谷参加一个会议时遇到了微软首席执行官萨蒂亚·纳德拉。合作看来是自然的事情。双方在2019年达成协议。奥尔特曼和OpenAI在原来的非营利框架下成立了一家营利性公司,他们得到了10亿美元的新资本,微软则有了一个新方法来将人工智能纳入其庞大的云计算服务。
从某种意义上来说,OpenAI已经是个违反初衷的怪胎了
马斯克投资DeepMind时打破了自己一条不成文的规定,那就是他不投资任何不由他本人运行的公司。他在生日派对上与佩奇发生口角的事儿过去了还不到一个月,他与这名同是亿万富翁的前朋友再次面对面坐下来时,他投资DeepMind决定的不利方面已显而易见。那是在DeepMind伦理委员会于2015年8月14日召开第一次会议的时候。该委员会是在这家初创公司创始人的坚持下成立的,目的是确保他们的技术卖出后不会造成任何伤害。据三名了解会议情况的人,委员会成员在马斯克SpaceX办公室外的一间会议室召集了这次会议。但那也是马斯克的控制结束的地方。谷歌把DeepMind买下来时收购了整个公司。马斯克出局了。
马斯克再次出局
蒂尔被迷住了,第二天就邀请他们三人再次来到家中。这三人介绍了他们的计划,不久,蒂尔和他的风险投资公司就同意为他们的初创公司投资140万英镑(约合225万美元)。蒂尔是他们的第一位主要投资人。他们给公司起名DeepMind,寓意与人工智能系统通过分析大量数据学习技能的所谓“深度学习”、神经科学,以及科幻小说《银河系漫游指南》中的“深思”超级计算机有关。到2010年秋,他们开始建造自己的梦想机器。他们真心诚意地认为,因为自己懂得其中的风险,所以唯有他们可以保护世界。“我不认为这是一个矛盾的立场,”DeepMind的三名创始人之一穆斯塔法·苏莱曼说。“这些技术将带来巨大的好处。目标不是排除它们或暂停它们的发展,而是减少不利因素。”
DeepMind的缘起
八年后再来看,两人当时的争论似乎颇有预见性。人工智能究竟是提升还是毁灭世界——或者至少造成严重破坏,这个问题在硅谷的创始人、聊天机器人用户、学者、立法者和监管机构之间引发了一场持续不断的辩论,它涉及究竟应该对人工智能技术进行管控,还是任其自由发展。这场辩论让一些世界上最富有的人相互对立:马斯克、佩奇、“元宇宙”平台公司的马克·扎克伯格、科技投资者彼得·蒂尔、微软的萨蒂亚·纳德拉,以及OpenAI的萨姆·奥尔特曼。所有人都在为分得一杯羹和塑造它的权力而战。这场争论的核心是一个令人费解的悖论。那些说自己最担心人工智能的人,也恰恰是最积极推动它的发展并从中获利者。他们认为他们的宏伟构想是正当的,理由是基于一种坚定的信念:只有他们才能阻止人工智能危害地球。
OpenAI的缘起
拼多多是成为了这个低增长时代选中的梦中情人,受到这个红利的公司还有很多,这不意外的,这是一个可确认全球经济难再现高增长,消费降级的时代,开始卷性价比的时代,拼多多是顺势而出。我认为资本投下的这一票也是对这一趋势的认可,比如京东在重上已经做得不错了,虽然组织和团队都憨,但确实大环境并不是京东能快速顺势的。
时势造英雄
temu是黄峥“更加激进的全球化”这句话落地的产品,他当年面对面给张一鸣的建议,现在双方都在享受丰硕的战果。传统艺能,极致压榨供应链和公司团队率先产生了终端的优势,明年预计要达到300亿美元的gmv,标志着一件可怕的事情,就是pdd电商全球化这件事基本在海外复制成功,并未水土不服,这让市场看见了全球化+中国卷王这件事情的巨大红利。黄是一个细节能精微,人性透彻,也有大智慧的sharp型CEO,还没有开始做他的多元化,当时不代表他不擅长。明年亚马逊将迎来剧痛,shein,tiktok,temu三个中国企业要在美国玩三国演义。
三家新电商全球化可期
拼多多是一个成功创业者多次成功积累经验后的厚积薄发,黄峥是一个少见的能规划好创业步骤,先求不败再取胜,当时也能在合适的机会激进扩张的CEO。具体可关注黄理性的创业发展规划,他对事物本质和人性的理解sharp程度可以几乎是当下CEO的top3级别。在公司的根本问题上很少犯错。作为社交电商的能力是黄峥前面几个成功公司的能力积累,“xxx拉队伍的能力真的是太可怕了”,具体表现他发展初期的获客成本优势是碾压级别,商业模式上,唯一一个农产品生鲜做稳了的电商,有两个结果:1. pdd在一级市场的烧钱体量很小,三到四轮后就上市,快速进入到了资金来源更广阔的的二级市场。2. 创始人的股份稀释惊人少,整体掌控力,团队组织都近于高效率的威权。Doris,陈磊,黄的三人团决策效率极高。(这一点,客观说,因为天地人因素,阿里其实先天不占优),而阿里的组织艺术,有体会的都懂。
归根到底还是创始人的因素
ChatGPT横空出世时,“为什么又是美国”的声音此起彼伏。但如果把时间拉长,会发现从晶体管、集成电路,到Unix、x86架构,再到如今的机器学习,美国学界和产业界几乎都是领跑者的角色。这是因为,虽然关于美国“产业空心化”的讨论不绝于耳,但以软件为核心的计算机科学这门产业,不仅从未“外流”到其他经济体,反而优势越来越大。至今70多位ACM图灵奖的获得者,几乎全部是美国人。吴恩达之所以选择Google合作“谷歌猫”项目,很大程度上是因为只有Google拥有算法训练所需要的数据和算力,而这又建立在Google强大的盈利能力的基础上。这就是产业厚度带来的优势——人才、投资、创新能力都会向产业的高地靠拢。中国在自身的优势产业里,也在体现出这种“厚度优势”。当前最典型的就是新能源车,一边是欧洲车企包机来中国车展拜师新势力,一边是日本车企高管频繁跳槽到比亚迪——图什么呢?显然不是只图能在深圳交社保。
产业厚度决定创新高度
而微软对GPU的不置可否显然让辛顿有些火大,他后来在一封邮件里建议邓力购买一套设备,而自己则会买三套,并且阴阳怪气的说[6]:毕竟我们是一所财力雄厚的加拿大大学,不是一家资金紧张的软件销售商。但在2012年ImageNet挑战赛结束后,所有人工智能学者和科技公司都对GPU来了个180度大转弯。2014年,Google的GoogLeNet以93%的识别准确率夺冠,采用的正是英伟达GPU,这一年,所有参赛团队GPU的使用数量飙升到了110块。这届挑战赛之所以被视为“大爆炸时刻”,在于深度学习的三驾马车——算法、算力、数据上的短板都被补足,产业化只剩下了时间问题。
GPU的崛起
这就是ImageNet诞生的契机。当时,即便是最大规模的数据集PASCAL,也只有四个类别总共1578张图片,而李飞飞的目标是创建一个包含几百个类别总共上千万张的数据集。现在听起来似乎不难,但要知道那是2006年,全球最流行的手机还是诺基亚5300。依靠亚马逊众包平台,李飞飞团队解决了人工标注的庞大工作量。2009年,包含320万张图片的ImageNet数据集诞生。有了图片数据集,就可以在此基础上训练算法,让计算机提升识别能力。但相比三岁孩子的上亿张照片,320万的规模还是太少了。为了让数据集不断扩充,李飞飞决定效仿业内流行的做法,举办图片识别大赛,参赛者自带算法识别数据集中的图片,准确率最高者获胜。但深度学习路线在当时并不是主流,ImageNet一开始只能“挂靠”在欧洲知名赛事PASCAL下面,才能勉强凑够参赛人数。到了2012年,ImageNet的图片数量扩大到了1000个类别总共1500万张,李飞飞用6年时间补足了数据这块短板。不过,ILSVRC的最好成绩错误率也有25%,在算法和算力上,依然没有表现出足够的说服力。
ImageNet的贡献
2012年6月,Google研究部门Google Brain公开了The Cat Neurons项目(即“谷歌猫”)的研究成果。这个项目简单说就是用算法在YouTube的视频里识别猫,它由从斯坦福跳槽来Google的吴恩达发起,拉上了Google传奇人物Jeff Dean入伙,还从Google创始人Larry Page那里要到了大笔的预算。谷歌猫项目搭建了一个神经网络,从YouTube上下载了大量的视频,不做标记,让模型自己观察和学习猫的特征,然后动用了遍布Google各个数据中心的16000个CPU来进行训练(内部以过于复杂和成本高为由拒绝使用GPU),最终实现74.8%的识别准确率。这一数字震惊业界。吴恩达在“谷歌猫”项目临近结束前激流勇退,投身自己的互联网教育项目,临走前他向公司推荐了辛顿来接替他的工作。面对邀请,辛顿表示自己不会离开大学,只愿意去Google“待一个夏天”。由于Google招聘规则的特殊性,时年64岁的辛顿成为了Google历史上最年长的暑期实习生。辛顿从80年代开始就战斗在人工智能的最前线,作为教授更是桃李满门(包括吴恩达),是深度学习领域的宗师级人物。因此,当他了解了“谷歌猫”项目的技术细节后,他马上就看到了项目成功背后的隐藏缺陷:“他们运行了错误的神经网络,并使用了错误的计算能力。”
2012年的谷歌猫项目
马斯克提出过 “白痴指数”:用零件的价格除以这个零件所需原材料的成本。这个数字越大,说明这个零部件 “越白痴”,要么是中间环节太多,要么是制造效率太低。每当遇到一个白痴指数过高的部件,特斯拉就会重新思考流程、革新制造方式以降低成本,使该指数尽量回归 “1”。马斯克追求让汽车的制造成本无限接近汽车所用的钢铁、铝、硅、锂等材料的成本之和。2007 年,马斯克查询伦敦金属交易所的电池材料价格后,算出电池的 “白痴指数” 是 7:当时每瓦时电池的锂、钴、镍等材料的成本只有 82 美元,但锂电池售价却超过 600 美元,这一数字已是索尼、松下等电池公司努力 20 年的结果。
特斯拉研发4680的动机
第一性原理的局限则是它不可能超越时代限制。当特斯拉的目标无法被当下的技术实现,它也得付出巨大的时间与金钱投入,才能缓慢前进一点点。2017 年量产 Model 3 时,特斯拉曾栽过跟头:马斯克当时认为可以用机械臂完全取代人工,这是制造业的必然。但他高估了整个自动化技术的水平,机械臂连简单的梳理电线都做不好。特斯拉随即陷入产能地狱,马斯克重新把工人召回工厂才走出危机。电池制造也是这样一个领域:它涉及多学科复杂任务,工序之间环环相扣,牵一发动全身。“用湿的正负极材料涂布、再烘干”,这是马斯克最初认为多此一举的环节。但删除这个环节,就需要把整个从混料、涂布、模切到烘干的工艺都推倒重来。
第一性原理不能完全无视过往的经验,否则可能无穷无尽的大坑需要来填。
《马斯克传》中多次描述了第一性原理手到擒来的过程。在制造 SpaceX 火箭时,马斯克挑战权威,提出用更便宜的不锈钢替换碳纤维制造火箭,最终只花 NASA 登月计划 2% 的钱就造出了能飞上太空的 Starship。特斯拉和马斯克执掌的其它技术公司似乎总能凭第一性原理另辟蹊径,证明传统观念是错的,一次次取得技术领先。但在 4680 电池上,特斯拉的做法遇阻。这款电池决定着特斯拉下一代车的产能和定价,而它的量产时间和性能都没有达到最初发布时的目标。这是近年被不少公司奉为至宝的第一性原理的另一面:当遇上复杂创新,从原理出发推导重来常常只是一趟艰难旅程的起点。
第一性原理并非在任何情况下都是银弹。
熔盐堆 (MSR) 的基本原理是堆芯使用Li,Be,Na和Zr等的氟化盐以及溶解的U,Pu和Th的氟化物熔融混合作为燃料,在600~700 ℃和低压条件下形成熔盐流直接进入热交换器进行热量交换。
熔盐堆,是将热量交换载体的熔盐和核裂变燃料的熔盐混合在一起,一起存在与堆芯。裂变反应释放的大量热,有熔盐载体吸收升温蓄热,然后通过另外一个熔盐换热器把堆芯热带出去;裂变燃料裂变产生热量和中子,中子由增殖燃料吸收,重新生成新的裂变燃料,相当于催化剂。如此,实现裂变反应的持续进行并烈度可控。增殖材料是需要添加和外部处理的,但那是普通的化工厂过程,平稳处理,一点化工厂停止增殖材料的转化,那么裂变反应会停止。如此,实现了靠增殖材料这个触发器,控制裂变反应的目的。这就是第四代核反应堆的基础原理了。
熔盐储能(热能)技术。熔盐储热是一种显热储热技术,利用材料在升温或降温过程中的温差而实现热能存储,在整个工作温度范围内,储热材料始终保持液态。
这一句,说清楚了我的理解,熔盐储能,始终是液态,是显热储热。
ingested or indexed spans
根据文档的内容和上下文,这里 ingested, indexed 这两个词语是在描述 trace 数据的状态,表示该 trace 数据被系统处理的不同阶段:
ingested:表示 trace 数据被 Datadog 系统“摄取/采集”了。简单说就是这个 trace 已经被 Datadog 接收和存储了下来。
indexed:表示 trace 数据被“索引”。索引是一个搜索和查询机制。在 Datadog 中把 trace 数据索引一下,就是通过分析其内容,提取关键信息建立起可搜索和查找的结构。这样可以方便后续的查询和过滤。
trace:就是一条完整的分布式追踪数据。从一个用户请求开始,记录了整个调用链中所有服务组件的执行信息。
所以 ingested 和 indexed 描述的是一个 trace 数据被采集和处理的不同阶段,ingested 表示已经被系统采集,indexed 表示被进一步分析处理好支持搜索和查询。这样用户就可以方便地在 Trace Explorer 中查看和分析这些 trace 数据了。
因此,牛市后期巨大的成交量就是牛市喧嚣后沉默的背景音。这也许是一个黑暗的秘密。因此,我们总结一下:1,股票永远不是股权,小股民毫无任何权利,而且比股权还要贵10-100倍,任人鱼肉。2,因此股票投资的主要风险控制措施就是卖出(割肉)3,为了确保在必要时能卖得出,必须不择手段4,投资大师持仓巨大,卖出很困难,因此往往只能选择沉默所以,大师跟你讲股权思维,却不讲股票思维才正常。宣传股权思维,没有利益冲突,你好我好大家好。宣传股票思维,谁和谁博弈呢?一旦要卖出个股,恐怕就没那么容易了!
卖出很重要,一定要随时保有自己卖出的权利
见过压政治大题的,没见过压数学大题的,兄弟是有啥特殊的路子么2022-12-06 21:58 IP属地:北京IP属地:北京29回复加入黑名单举报 小元老师高数线代概率.st0.lv6{fill:transparent;}.st1.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#F04C49;}回复 @有些无趣 :没有,其实从18年开始,数学老师大家都押题了。李林带起来的。压题型容易,原题比较难2022-12-06 22:26 IP属地:上海IP属地:上海5回复加入黑名单举报 机灵女侠.st0.lv6{fill:transparent;}.st1.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#F04C49;}18年李林压了一百多分,考试时直接默写,导致现在李4跟6封面都印着“不靠押题,靠实力”这样的此地无银三百两字眼2022-12-07 11:34 IP属地:河南IP属地:河南16回复加入黑名单举报 o猎户座o.st0.lv5{fill:transparent;}.st1.lv5{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv5{fill-rule:evenodd;clip-rule:evenodd;fill:#EE672A;}回复 @机灵女侠 :这两年数三是不是都怎么压中呀2022-12-07 14:26 IP属地:湖北IP属地:湖北回复加入黑名单举报 南烟不亦.st0.lv4{fill:transparent;}.st1.lv4{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv4{fill-rule:evenodd;clip-rule:evenodd;fill:#FEBB8B;}回复 @机灵女侠 :好多人说是lou题了也不知道真假2022-12-07 16:22 IP属地:辽宁IP属地:辽宁回复加入黑名单举报 小元老师高数线代概率.st0.lv6{fill:transparent;}.st1.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#F04C49;}回复 @机灵女侠 :60多分,争议很久。后来有小题押中的,没大规模2022-12-07 21:24 IP属地:上海IP属地:上海3回复加入黑名单举报 是你的NiKa呀.st0.lv3{fill:transparent;}.st1.lv3{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv3{fill-rule:evenodd;clip-rule:evenodd;fill:#7BCDEF;}回复 @南烟不亦 :最早的几十年考研都不是很火,所以出题没有像高考那样严苛,都是有题库的,每年就是从题库里选题然后改编组成一张卷子。李林以前在命题组待过,所以题库的题多多少少他都见过,你是没见过他最早教考研数学的那个自信,直接就说,你们把难题交给我就行2022-12-08 12:50 IP属地:四川IP属地:四川12回复加入黑名单举报 小元老师高数线代概率.st0.lv6{fill:transparent;}.st1.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#FFFFFF;}.st2.lv6{fill-rule:evenodd;clip-rule:evenodd;fill:#F04C49;}回复 @是你的NiKa呀 :嗯呢,现在押题命中的少了
数一押题
另一方面,1981《决议》浓墨重彩地描述了拨乱反正的过程,将自身包装成有自我纠错能力的政党,实际上也将其执政权力的合法来源绑定在对文革错误的纠正之上。这使得一切对文革记忆的运用,哪怕是那些看似不具颠覆性的,都隐约触及后毛时代共产党政权的合法性。
问题是其中存在吊诡,从正面反面去谈论都不对,索性不谈。
1.算子法绝对不是什么旁门左道,而且我认为你花一个小时练熟这个对你的帮助绝对是大于你三天两头琢磨各种乱七八糟的竞赛题、网红题的。(针对大多数考研党,数学爱好者和目标140以上的人除外。)2.练算子法的前提肯定是要把待定系数法练熟,毕竟写上怎么设特解也是会有步骤分的,而且小题也会考解的结构的题,需要你对设解熟悉。3.关于某道题怎么用算子法算,算子法怎么在考试里用,视频里说的很清楚了,希望大家好好吸收,自己多花点时间练习,就不要再私信问我了,这类题我都不会再回复了。4.网上很多人攻击性很强,做题方法也有莫名其妙的鄙视链,我个人认为这些都是前人的智慧结晶,咱们这些还在为了个数学考试焦头烂额的人真没必要也没资格妄加评论一个方法,只能说某个方法在某种题型上确实是很适用,希望各位不要争论(至少不要在我这争论)算子法有没有用了,保持一颗敬畏之心。5.最重要的,看了视频,一定要动手做,不管是看我的还是看其他老师或者up,一定要落实到做题上去,不要太高估自己的记忆力,好记性不如烂笔头。
微分算子法
a majestic affair
这是一件威风凛凛的事情
原子性原则:这意味着每个笔记包含且只包含一条信息和知识 ( one unit of knowledge ) 。这将使后续第 3 步链接所有成为可能。用你自己的话:当你从网文、书摘和灵感中「精简摘要」出信息和知识,是为了会对将来有帮助。现在理解了,可能很快就忘掉,所以需要用自己的话解释一下记录的内容,将来要用到这个的时候,你能快速理解究竟是什么意思,不要将你的「精简摘要」变成保存复制粘贴信息的地方。保留上下文:总是在「精简摘要」中关联相关上下文 ( 我在第 3 步链接里实现 ) 。这可以使未来的你在无法理解「精简摘要」时能够回忆起当时为什么记录。
这个和常青笔记的原则类似
使用这套方法绝不是浪费时间。你永远不必决定这些信息是否值得存储在你的 第二大脑 中。如果它很有趣,请添加它,即使你不确定它是否与你当前的工作和项目相关。并且我们记录的信息并不是一次性用过就扔,很多这次用过的素材、资料,可以下一次用在完全不同的地方。
用好工具在长期节约自己的时间,前期多花点时间,后面花的时间少很多。
很多年之后,你不能重看所有你看过的书,但是你可以很轻松的重看你划过的笔记。
对一般人来说,开始做一件事情是相对容易的。但是对 ADHD 来说,哪怕很简单的动作,比如拿出笔写作业、打开电脑工作、下床洗脸,都非常艰难。因为一件事情在开启的那刻,需要很高的能量作支撑。不是不想做,而是拿起笔的这一下,或者坐到桌子前的这一下,它就是很难。
Unlike serial flash and EEPROM, the FM25V10 performs writeoperations at bus speed. No write delays are incurred. Data iswritten to the memory array immediately after each byte issuccessfully transferred to the device. The next bus cycle cancommence without the need for data polling
读写速度=总线速度,而Serial Flash实际不是这样的。需要问询,也就是Data Polling,总线之后,是有写周期延迟的。这其实跟U盘类似,入口是个大RAM,后边是Nand Flash
你提到的形式是一个具有常系数的 nnn 阶线性非齐次微分方程。这个方程可以写作:xny(n)+p1xn−1y(n−1)+…+pn−1xy′+pny=f(x)x^n y^{(n)} + p_1 x^{n-1}y^{(n-1)} + \ldots + p_{n-1}xy' + p_ny = f(x)xny(n)+p1xn−1y(n−1)+…+pn−1xy′+pny=f(x)其中,p1,p2,…,pnp_1, p_2, \ldots, p_np1,p2,…,pn 是常数,f(x)f(x)f(x) 是给定的函数。这是一个 nnn 阶线性非齐次微分方程,通常可以通过常数变异法或特殊解法求解。这个方程中 xnx^nxn 的系数为零,是这个方程与一般形式的 nnn 阶线性非齐次微分方程的主要区别
n阶线性非齐次微分方程
进入正题,下面是我在考场上做每道题当时的思路和想法。考察渐近线,常规题目做对了应该是二阶常系数线性微分方程,我当时的时候可能太紧张了,不知道怎么想的,非要我把它当成缺x的微分方程来做,也有可能是我考前复习发现对这个不熟,特意背了这个公式,考时自然往这方面去想,做了半天,解不出来,做错了,最可惜的一道题。可导性与连续性的判别,本来应该是一个常规题,但是它给的函数是带有绝对值的参数方程,我没见过这种形式,不会处理,做错了。完全不会空着比较分块矩阵秩的大小,也是不会做,当时举了两组ABC的特殊值,排除了两个选项,花了很多时间,最后还是选择跳过,空着。后来我看解析,分块矩阵可以一列的每块乘上一个矩阵,然后去消另列,神奇,从来没见过这种方法,错了也应该。判断矩阵是否能相似对角化,常规题特别简单对了这道题李林四压到了,有类似的题,李林老师还是很强的,没做李林四的话,感觉这道题我不可能做对。X服从参数1的泊松分布,求E|X-1| ,带绝对值的期望,我只会求连续型的,泊松是离散的没做过不会,空着。后看解析才知道,其实直接把这个绝对值表达式乘以概率的表达式再求一个和就行了。统计三大分布,常规题对了不会空着我选了6道题,其中没有A,空着的四道题全涂A,蒙对两道。11.极限题,泰勒展开,常规题对了12.求切平面,常规题对了13.傅立叶级数,我想到了x赋特殊值可以巧做,正解是x赋零和1两式一加,我只想到赋0,赋1没想到,做错了14.抽象函数求积分,凑不出来,做错了。答案看完觉得很简单,但这道题在考场如此紧张的情况下很难想到,要把1到3的积分拆成1到2和2到3上的积分。15.线代向量题很新颖没见过,但不是很难,拿每个a去乘,发现a123都是相互正交的,能依次算出来k值,做对了。16.简单题,口算就出来2/3×1/4+1/2×1/3=1/3至此选择填空错六个,用时1小时20分钟。17.常规题,先解一阶微分方程,变上限积分函数求导求最值,对了18.无条件二元函数极值,令偏导等于0,方程不会解,猜了两个驻点(0,0)和(1,1),没解全。后面判别式等于0,无法判断又不会处理了,没见过这种判别式不能用的情况,错了。解析用y=2x2,一通操作我现在也没整明白。这道题看似常规,但判别式失效这种情况没遇到过,考场上真的解不出来。19.线面积分常规题,高斯公式,奇偶性化简,再先一后二,用极坐标再点火公式秒解,一套组合拳下来,感觉是这套最简单的做的最爽的一道大题。20.证明题,备考期间直接放弃,没练过,但第一问我能看出来用泰勒,写了一个零点的泰勒展开,不知道能给几分。21.线代题寄了,因为二次型我不会配方...没练过这种用配方做的大题。只会相似对角化的解法,我的思路只会A和B都相似于同一个对角矩阵。我把A和B全部相似对角化发现特征值不一样,不会做了。。。看了解析才知道配方这么简单,送分题白白丢掉了22.先把边缘分布都求出来,因为xy对称求一个另一个自然也出来了,求协方差要求EX EY EXY,我求完边缘分布已经半张纸没了,求完协方差需要做三个积分,写完纸都不够了,我直接没算了,蒙了个协方差等于0,让我蒙对了;第二问因为已经有了边缘分布,直接说明fx•fy不等于fx,y就行了;第三问z的概率密度,常规题,汤家凤反复强调过这类题的通用解法,二重积分很快解出分布,再求个导,做对了。后来看解析发现EX 可以直接通过f(x,y)求一个xf(x,y)从负无穷到正无穷的二重积分算出,平时没练过第一次知道能这么算。这道题二三问解对了,第一问只写了结果不知道会扣几分。整套卷选填对十个,大题完全对的只有两道,估分80~90,总得来说,有常规题但不多,新颖的题和一些偏题还是占一定比例的,有的题技巧性很强,真上考场不止需要练常规、正统解法还要拥有解题技巧和策略,要精确识别哪些题是能拿分的题,拿不到分的题及时跳过。我练的题还是太少了,备考过程十分极限,12月才开始刷套卷。正常10月底之前结束强化开始刷套卷是比较科学的。对于23数一难度各大机构老师评估介于21和22之间,比22稍简单,微博广大考生说难但实际23比22要简单的,这也反应了考生数学普遍准备的不充分,数学尖子是少数。我的备考经历和解题过程可能会是每个普通考研人的缩影。希望这篇文章可以让24考研er对数学预期分数有一个客观的认知,能对估分择校提供可靠的依据。分数出来了,最后总结一些实战技巧给大家:选择遇到不会的题先空着,会几道做几道,会做的题一定保证全对,剩余空着的题全蒙一个选项,哪个选项选的少就全蒙哪个。比如只会6道题,选了3个C 2个B 1个D,其余空的四道题全蒙A。这种方法既快捷又好用。比一些花里胡哨的蒙题法和无脑选C的方法效果好。填空不会没法蒙,没思路尽快跳过,大题还可以编一编,先做后面的题,有时间回过来再看。线代题不会千万不要空,二次型写成矩阵形式就能得2分,然后无脑相似对角化,不用管别的反正你不会,无脑对角化就行,有几率能得6分。这次考试我就没想到第一问的正解配方,我直接把两个矩阵全部对角化,得到估计一半的分数概率题没思路就缺什么求什么,把边缘分布二维分布全都求出来摆上,坚决不空题,求期望就把积分式摆上,求协方差方差就把公式写上,实在算不出来,蒙也要写上一个得数。我这次就蒙对了协方差得数,老师看我有分布函数求解步骤有公式,结果又对,没准就得到全分。数一的复习过程中一定要把无穷级数,线面积分多练,必考一道大题,这两块程式化很强,多练一定会有效果。比如这次考试线面积分,熟练的话很快就解出来,刷这类题性价比很高上面几点看似没什么技术含量,但都是经验中总结出的精华,是刷多少题都了解不到的,我靠这几点多拿了至少10多分。希望能帮到大家
数一做题思路
电子技术中大量使用半导体材料是因为其优良的可控导电性,重点在于可控哦。路边减的硅块导电性可控吗?不可控。它内部的杂质含量已经决定了他的导电性能强弱,但是掺杂其他元素的本征半导体导电性却是可控的,是由我们的掺杂浓度决定的,而可控往往意味着更多的可能性,这就是我们折腾的意义。
半导体材料可控
一个区域D中,任一闭曲线所围区域,都属于区域D,称为“单连通区域”。 这就意味着,区域D是实心的,不能有空洞。
单连通复连通区域表达图示
小孩子就别参与讨论西游记了。猴子就不可能是最高战力,拿个最简单的比喻,现如今在外面富豪榜上有名的,都不是最富的。猴子显得强,一方面是自身有实力,另一方面是多方愿意看到的结果,借他的手完成自己的目的。先看原著,看完一遍不够,看过解析,再看一遍,有了和生活贴近的经验之后再看一遍,你就会明白为什么这东西能成为四大名著。
猴子战力分析
:你说只有悟空有三灾的话,这点我是不同意的,因为孙悟空也是在顶级的大品天仙诀,又经过三年清心寡欲、六根清净地修炼才道有所成之后,菩提才跟他说明白长生不老和长生不死的区别,也就是修仙的本质,因为只要是没有达到长生不死,每500年就会经历一次三灾利害,“天雷灾”、“ 陰火灾”、“ 赑风灾”,所以这应该是所有修仙之人都要经历的
三灾
孙悟空学艺的时候,菩提祖师跟他说过,即便是得道成仙也不是无穷寿命,每500年一次天灾,很多神仙也就是500-1500年这个岁数,所以这天底下就三种可以增加寿命的方式,第一是人参果,但是数量稀少,镇元大仙太强不好惹,第二是蟠桃,蟠桃宴被猴子搅和了,正如视频所说,猴子才能吃几颗桃子,这蟠桃宴一停,所有等着续命的神仙都急眼了,还不是王母想怎么拿捏怎么拿捏,最后一种方法,唐僧肉。
西游解释
And to become proficient with async Rust, I've accepted a lot of things. There are blue functions and red functions, and red (async) functions are contagious.
为了熟练掌握异步Rust,我接受了很多事情。有蓝色函数和红色函数,而红色(异步)函数是具有传染性的。
解释: 这段话描述了作者在学习异步Rust过程中所面对的一些概念。其中提到了"blue functions"和"red functions",这里可以理解为不同类型的函数。而"red (async) functions are contagious."则表示红色(即异步)函数具有传染性,意味着使用异步函数可能会影响到其他相关代码或者需要进行相应调整以适应异步操作。
Rust’s async/await syntax is an example of a stackless coroutine mechanism: an async function is compiled to a function which returns a Future, and that future is what is used to store the state of the coroutine when it yields control. The basic question at hand in this debate is whether Rust was correct to adopt this approach, or if it should have adopted a more Go-like “stackful” or “green thread” approach, ideally without explicit syntax that “colors” functions.
Rust的async/await语法是无栈协程机制的一个例子:异步函数被编译为返回Future的函数,而这个Future用于存储协程在让出控制权时的状态。在这场辩论中,基本问题是Rust是否正确采用了这种方法,或者它是否应该采用更类似Go的“有栈”或“绿色线程”的方法,理想情况下不需要显式语法来“着色”函数。
解释: - Rust's async/await syntax: Rust编程语言中使用的异步/等待(async/await)语法。 - stackless coroutine mechanism: 无栈协程机制,指一种不依赖调用堆栈实现协程切换和保存状态的机制。 - async function: 异步函数,在执行过程中可以暂停并恢复执行。 - Future: 表示一个可能尚未完成但最终会产生结果的计算任务。 - yield control/yields control: 让出控制权,在异步函数执行过程中暂停当前任务,并将控制权交给其他任务。 - Go-like "stackful" or "green thread" approach: 类似Go语言中所使用的具有调用堆栈(stackful)或绿色线程(green thread)特性的方法。
A term that gets thrown around a lot in these discussions is coroutine, and it is used in somewhat contradictory ways. A coroutine is a function which can be paused and then later resumed. The big ambiguity is that some people use the term “coroutine” to mean a function which has explicit syntax for pausing and resuming it (this would correspond to a cooperatively scheduled task) and some people use it to mean any function that can pause, even if the pause is performed implicitly by a language runtime (this would also include a preemptively scheduled task). I prefer the first definition, because it introduces some manner of meaningful distinction.
在这些讨论中,经常会提到一个术语叫做"coroutine"(协程),而且它的使用方式有些矛盾。协程是一种可以暂停然后稍后继续执行的函数。其中存在一个大的模糊点,就是有些人使用"coroutine"这个术语来表示具有显式语法以便暂停和恢复函数执行的功能(这对应于合作调度任务),而其他人则将其用来表示任何能够暂停的函数,即使该暂停是由编程语言运行时隐式地执行的(这也包括抢占式调度任务)。我更倾向于第一种定义,因为它引入了某种有意义的区别。
解释: - Coroutine:协程,在计算机科学中指一种特殊类型的函数。 - Function:函数,在程序设计中指接收输入并产生输出结果或者完成特定任务的代码块。 - Paused and resumed:暂停和恢复,在此上下文中指在执行过程中临时停止,并在稍后重新开始。 - Ambiguity:模糊性、不明确性,在此上下文中指对术语含义存在不同理解或解释。 - Explicit syntax:显式语法,在此上下文中指通过特定关键字或操作符明确地控制程序流程。 - Cooperatively scheduled task:合作调度任务,在此上下文中指由程序员显式地控制任务的执行顺序。 - Implicitly:隐式地,在此上下文中指通过编程语言运行时自动处理某些操作或行为。 - Preemptively scheduled task:抢占式调度任务,在此上下文中指由操作系统或编程语言运行时决定任务的执行顺序。
These limitations are fine up to a certain point, but for massively concurrent programs they do not work. The solution is to use a non-blocking IO interface and schedule many concurrent operations on a single OS thread. This can be done by the programmer “by hand,” but modern languages frequently provide facilities to make this easier. Abstractly, languages have some way of dividing work into tasks and scheduling those tasks onto threads. Rust’s system for this is async/await.
这些限制在某种程度上是可以接受的,但对于大规模并发程序来说,它们不起作用。解决方案是使用非阻塞IO接口,并在单个操作系统线程上安排许多并发操作。程序员可以通过手动方式实现这一点,但现代编程语言通常提供了简化此过程的工具。从抽象角度看,编程语言有一种将工作划分为任务并将这些任务调度到线程上的方法。Rust中实现这一功能的机制是async/await。
解释: - "limitations"指的是前文提到的某些限制条件。 - "massively concurrent programs"指大规模并发程序。 - "non-blocking IO interface"指非阻塞IO接口,即能够同时处理多个IO操作而无需等待每个操作完成后再进行下一个操作。 - "schedule many concurrent operations on a single OS thread"意味着在一个单独的操作系统线程上安排执行许多并发操作。 - "by hand"表示手动地进行相关设置和调整。 - "facilities"指编程语言提供的便利设施或工具。 - "dividing work into tasks and scheduling those tasks onto threads"意味着将工作划分为任务,并将这些任务调度到不同线程上执行。 - async/await 是 Rust 编程语言中用于实现异步编程模型(asynchronous programming model)的机制。
Context-switching between the kernel and userspace is expensive in terms of CPU cycles.OS threads have a large pre-allocated stack, which increases per-thread memory overhead.
上下文切换是指在内核和用户空间之间进行切换,这个过程对CPU周期来说是昂贵的。操作系统线程具有一个大型预分配的堆栈,这增加了每个线程的内存开销。
解释: 1. 上下文切换:当操作系统从内核态(kernel mode)切换到用户态(user mode)或者反之时,需要保存当前执行状态并加载新的执行状态。这种切换会消耗大量的CPU资源和时间。 2. 内存开销:每个操作系统线程都需要拥有自己独立的堆栈空间用于函数调用、局部变量等。为了避免频繁地动态分配和释放堆栈空间,操作系统会提前为每个线程分配一块较大的固定大小堆栈空间。然而,这也意味着每个线程都要占用额外的内存资源。
The first concept we need to get straight is the very purpose of the feature: “user-space concurrency.” The major operating systems present a set of fairly similar interfaces to achieve concurrency: you can spawn threads, and perform IO on those threads using syscalls, which block that thread until they complete. The problem with these interfaces is that they involve certain overheads that can become a limiting factor when you want to achieve certain performance targets. These are two-fold:
我们首先需要明确的概念是该功能的目的:“用户空间并发”。主要操作系统提供了一组相当类似的接口来实现并发:您可以生成线程,并在这些线程上使用系统调用进行IO操作,这会阻塞该线程直到完成。这些接口存在问题,即它们涉及某些开销,当您想要达到特定性能目标时,这些开销可能成为限制因素。其中有两个方面:
The basic issue at stake in this debate is Rust’s decision to use a “stackless coroutine” approach to implementing user-space concurrency. A lot of terms are thrown around in this discussion and its reasonable not to be familiar with all of them.
这场争论的关键问题是Rust决定使用“无堆栈协程”方法来实现用户空间并发性。在这个讨论中有很多术语,不熟悉它们是合理的。
Between 2017 and 2019, I drove the design of async/await syntax, in collaboration with others and building on the work of those who came before me. Forgive me if I am put a bit off when someone says that they don’t know how anyone could look at that “mess” and “think that it was a good design,” and please indulge me in this imperfectly organized and overly long explanation of how async Rust came to exist, what its purpose was, and why, in my opinion, for Rust there was no viable alternative. I hope that along the way I might shed more light on the design of Rust in a broader and deeper sense, at least slightly, and not merely regurgitate the justifications of the past.
在2017到2019年间,我和其他人在其他人的工作基础上推进了 async/await 的设计。我无法认同一些人类似“怎么会有人看到这一团遭还会觉得它是一个好设计”的言论。对于 Async Rust 的出现、它的目标是什么、以及为什么是这样子的,我会进行冗长的讲述(原谅我)。我认为对 Rust 来说,没有其他可行的代替方案。我希望在这个过程中,能够以更广泛和深入的意义上对Rust的设计进行一些阐述,至少是稍微地,并不仅仅重复过去的理由。
有的放矢。只有你明文写下的地方会被修改,没写进脚本的就保持原样,这就避免了整体迁移造成的泥沙俱下。我有个老友,贪方便,喜欢用系统迁移助手,结果有个 flash 残留文件像幽灵一样跟了他十年,好在只是垃圾而不是病毒;至于有没有病毒,像他这样整个儿搬迁数据,我就无从知晓了。 改动留痕。既然所有改动都写成了脚本,那就有据可循,设置完成后如果发现哪里不对劲、有 bug,或者第三方软件死活运行不了,就可以检查一下哪些地方被修改了,据此排查问题。换言之,脚本是可逆的。 随意分享。这是脚本最容易被忽略的优点。自己电脑的配置,好像一套穿搭,断然不能分享给别人,不仅送的人胆战心惊,接受的人恐怕也会嫌弃。但脚本则不然,它不涉及任何敏感信息,只是对系统的细节调整,完全可以分享给别人;而下载的人如果对某个设置不感冒,那么删掉那一句就好,其他脚本仍然可以照常运行。 总之,将常用设置脚本化,不仅能够自己掌控系统设置,也方便日后查错,还可与他人共享。在传统方法无法照亮的阴影角落,往往就是脚本发光发热之处。
比如说你做了一件事,这件事做失败了。如果没有进行推演,你的复盘就是——“我做了一件事,但是它失败了,失败的原因是XXX,所以我下次做的时候应该要注意XXX......”而如果你进行了推演,你除了得出上面的结论以外,还会多出来一步:“这件事我一共分了五个步骤来做,其中第一步没有问题,是必须要这么做的。”“但是做第二步的时候,其实有abc三种解决办法。”“我现在进行的是a,如果我进行的是b或者c呢,下一步又会发生什么,还会发生失误吗?”“如果发生失误我应该怎么改正,结果又会怎么样......”
推演的重要性,真的这么重要吗?
电影《教父》中有句经典台词:“花半秒钟就看透事物本质的人,和花一辈子都看不清事物本质的人,注定是截然不同的命运。”而这两种不同命运之间,也许就差一个深度思考。
系统思考,深度思考
确定曲面上侧和下侧的方式:法向量方向:通常,曲面的法向量指向曲面的外部。如果法向量指向空间中的特定一侧,这一侧就可以被视为曲面的上侧,另一侧则为曲面的下侧。问题的限定条件:在某些问题中,可能会有明确的条件或规定,这些条件可以帮助确定曲面的上下侧。例如,问题中可能提到了一个范围或一个特定的物理条件,以指示哪一侧是上侧。坐标系的选择:在特定情况下,可以通过选择合适的坐标系来决定曲面的上下侧。通常,沿着正方向看到的一侧可以被视为上侧。确定上侧和下侧的方法取决于具体的问题和所面对的曲面。在使用曲面积分时,确保正确地选择曲面的定向非常重要,因为它直接影响到积分结果的符号和物理意义。
确定二类曲线上下侧
如果一个函数在某一点的二阶偏导数存在,并且在该点的梯度为零(或梯度向量为零向量),那么可以使用二阶偏导数的符号信息来判断该点是否为局部极值点:如果二阶偏导数的 Hessian 矩阵是正定的(所有特征值都为正),那么该点是局部最小值。如果二阶偏导数的 Hessian 矩阵是负定的(所有特征值都为负),那么该点是局部最大值。如果 Hessian 矩阵的特征值有正有负,那么该点是鞍点。然而,这只是局部极值存在的一种判定方法,而不是必然的。在某些情况下,即使存在二阶偏导数,函数也可能在某点没有极值,例如 Saddle Point(鞍点)的情况。总之,存在二阶偏导数是判断局部极值的一种充分条件,但并非必要条件,因为函数在某一点有梯度为零不一定就是极值点
梯度矩阵特征值符号判断局部极值
实际上,即使我们将延迟降到微秒级,许多应用也无法充分利用这个低延迟。其中一个原因是延迟隐藏问题。当我们等待这些微秒级事件时,比如进行网络通信或者存储设备的读写,CPU 应该去执行什么操作?在传统的计算机体系结构中,CPU 的流水线能很好地隐藏纳秒级事件。也就是说,在等待这些事件时,CPU 可以执行其他指令,而不需要软件干预。然而,对于微秒级时延的事件,CPU 的流水线深度不足以隐藏时延,因此 CPU 就会卡住等待这个慢速的指令,其效率是很低下的。对于毫秒级事件,操作系统可以处理这些任务切换,这是软件的职责。操作系统在进行进程或线程切换时,只需几个微秒就能完成,因此不会浪费太多时间。但是,如果事件本身就是微秒级的,比如访问存储花费 10 微秒或访问高速网络花费 3 微秒,这时候如果将 CPU 核切换到其他进程或者线程上,操作系统本身就要花费几个微秒的时间。操作系统切换到其他进程或者线程,再切换回来,这个过程花费的时间可能比直接等待事件完成还要长。所以,对于微秒级的时延,操作系统的任务切换实际上是在浪费时间。体系结构和操作系统的机制都不能隐藏微秒级的时延,而如今最先进的网络和存储硬件时延都降到了微秒级,这就是微秒级时间隐藏难题的原因。
[!NOTE] 计算机系统中,微秒级时延隐藏为什么困难?
flashcard
- CPU 的延迟是纳秒级,很难找到足够指令隐藏微秒级事件
- OS 任务切换的延迟是微秒级,用于隐藏微秒级事件得不偿失
与此同时,人类的动物本能在成长的过程中也被逐渐地抑制,按照弗洛伊德的理论即“本我”的支配地位逐渐被“自我”和“超我”所取代。 人类也在这个过程中实现了相对于自然的独立,获得了自由。伴随这份自由同时到来的往往还有孤独,迷失,不安全感,和自我怀疑。 在这种情况下,人类会本能地产生逃避这种自由的冲动,最自然的选择是屈从于某种权威。 然而更好的一个选择,是在不否定个人的前提下,主动自发地与世界建立联系。 这种联系的极致表现就是“爱与创造性的工作”。 希望这篇指南能够帮你实现个人与世界的链接,回归人类创造的本性,成为一个拒绝逃避自由的创作者。
builder/maker 的意思和这个接近。这些才是我们主动性的联系。这些才是真正的自我。
如果在一个待排序的序列中,存在2个相等的数,在排序后这2个数的相对位置保持不变,那么该排序算法是稳定的;否则是不稳定的。
稳定性判断
封装有机基板(Organic Substrate)是一种通常用于芯片封装的基板材料。它的主要成分是有机材料,通常是基于聚酯、玻璃纤维或陶瓷材料的有机复合材料,具有较低的热导率和较高的电气绝缘性能,这使得它们在高频电路的应用中具有一定的优势。此外,封装有机基板的生产成本通常比硅基板低,因为它们的生产工艺更简单,而且在生产过程中可以使用较低成本的材料。
芯片的基板主要材料是有机基板,优势是便宜,工艺简单。缺点是热稳定性差,电气性能差(电阻大,电容小),不利于高频应用。更好地材料是硅基板,但很贵。最新的技术方向是玻璃基板,它是介于硅和有机基板之间的,价格便宜,工艺简单,同时又有高的耐温性、电阻低,电容高,易于高频应用,是当前的一个发展热点,名称为GCS(Glass Core Substrate)
哥们有一定的基础,这些回复的估计单词都没背完。技巧是搭配在基础上的,你单词句子都看不懂,再好的技巧也是空中楼阁,每个老师技巧课都能录几十个小时以上,但核心几句话就能概括完,不都是把握文章中心,定位,找逻辑这一套么,你不打基础光学技巧,我只能说那只能让你蒙的时候更有勇气,第二年还有你
单词重要性
“减肥神药”缺货?巨头宣布→ 2023-11-16 22:39:45 来源: 作者:张雪 收藏(0) 微博 微信 用微信扫描二维码 分享至好友和朋友圈 QQ空间 扫一扫 用微信扫描二维码 分享至好友和朋友圈 居高不下的市场热度,放量狂增的产品销售,肉眼可见的产能瓶颈……近期司美格鲁肽供货紧张的传闻,不禁让市场各方感受到一阵焦虑。 不过令人振奋的是,诺和诺德日前宣布扩产,再次点燃市场热情。诺和诺德表示,计划未来几年投资超过420亿丹麦克朗(约超60亿美元),扩大位于丹麦卡伦堡的现有生产设施,以满足现有及未来的慢性病系列产品的产能需求,这其中就包括GLP-1产品。 诺和诺德全力扩产 司美格鲁肽是诺和诺德开发的一种GLP-1受体激动剂,目前共有三款产品在售,分别是降糖用司美格鲁肽注射液Ozempic、口服降糖药司美格鲁肽片Rybelsus,以及减肥用司美格鲁肽注射液Wegovy。 在诺和诺德近期发布的第三季度财报中显示,司美格鲁肽前三季度累计销售额达142亿美元,其中减肥药收入30.86亿美元,同比大增481%。 最新消息显示,为了确保患者用药连续性,美国的司美格鲁肽低剂量规格的使用已经受到限制。 行业观点认为,GLP-1市场空间广阔,产能不足正在制约着潜在消费者,GLP-1产能争夺战正在悄然打响。 礼来的前瞻 上周三(11月8日),美国食品和药品管理局(FDA)宣布,批准礼来公司的替尔泊肽注射液用于长期体重管理,商品名为Zepbound,对标丹麦制药巨头诺和诺德的减肥药物司美格鲁肽(商品名:Wegovy)。而其同样面临产能和供应问题。(2型糖尿病药物Mounjaro为替尔泊肽的另一适应症) 早在Mounjaro上市伊始就出现了短缺问题,由于减肥药需求巨大,为了避免重蹈诺和诺德的覆辙,礼来已经开始积极扩建生产基地。 据悉,礼来已在美国北卡罗来纳州建设两座工厂,投资40亿美元,力争在2023年底前使含有替尔泊肽的肠外肽类药物产量提高一倍。 上周,礼来公司董事长兼首席执行官戴夫·里克斯在新闻发布会上表示,得益于在北卡罗来纳州新建的制造工厂以及其他生产基地的扩大生产,到今年年底,公司的产能将是去年这个时候的两倍。 GLP-1产业链振奋 Insight数据库统计,全球目前共有27款靶向GLP-1类肥胖治疗药物的临床在研项目,以GLP-1R为靶点的药物(含临床前到批准上市)共有289个,其中国内有149个药物,占比超过一半。中国进展最快的20个GLP-1类药物,其中8个仅针对GLP-1R,剩余12个均为GLP1R、GIPR、GCGR的复合多靶向药物。 据招商证券统计,信达生物的玛仕度肤(IBI362)全球首个进入临床III期的GLP-1/GCG双靶激动剂,恒瑞医药(600276)在GLP-1布局上布局单靶点口服、双靶点、与胰岛素复方制剂。华东医药(000963)在GLP-1赛道布局全面,利拉鲁肤减肥适应症已获批。小分子口服创新药进入II期临床,且有全球布局。通化东宝(600867)布局了利拉鲁以及注射GLP-1/GIP双靶点激动剂和口服非肤类小分子GLP-1RA。博瑞医药的BGMO504注射液减重和2型糖尿病治疗两项适应症均获得了I期临床试验伦理批件,其中2型糖尿病治疗的I期临床已开始入组。诺泰生物原料药进度领先,根据公司公告,公司目前已建成司美格鲁150Kg/年,利拉鲁200Kg/年的产能。 从中游来看,药明康德(603259)、凯莱英(002821)、翰宇药业(300199)、普洛药业(000739)、九洲药业(603456)、圣诺生物、普利制药(300630)等企业都在搭建或已储备了多肽药物品种的开发和生产能力。 GLP-1涟漪除了原料药、CDMO、创新药/仿制药研发以外,可能最后还会传导到器械。业内认为,GLP-1产业链的爆发力平淡,但受益于渗透率、国产替代率的双重提升,业绩将有一个长期的爬坡过程,而且不受中下游势必出现的内卷局面的任何影响。 例如,诺和诺德、礼来部分注射笔采取与OEM企业合作的模式进行生产,将有巨大的市场机会释放给外部代工企业(医疗器械CDMO)。甚至针头、胶塞、卡式瓶等细分赛道企业,都可能看到GLP-1产业链的那扇打开的窗。
减肥药
想要避开这个雷区,最好的方式就是打明牌,发直球,尽可能地表露真实的意图,不断驱散那些迷雾,如果你们的关系中有什么迷雾不能驱散,有什么禁忌始终存在着,那么它就有可能成为你们未来关系的雷区。任何需要猜疑的关系都是不健康的,我们需要去询问那些我们不确定的东西,也需要去回应对方所疑惑的事情,如果关系里有某些“真实”不能呈现,它就会成为一个不稳定因素,这种不稳定因素越多,这段关系就越脆弱。在一开始就看到那些暗藏的礁石,是一种规避真正风险的方式。
简单直接是一种难,但是长期的路
评估两个MLLMs,在六个数据集上,, LLaVA-Cap, LLaVA-VQA, LLaVA-Rea, LRV, A-OKVQA, and Shikra。 BLIP-2和MiniGPT-4两个模型。选择这两个模型,是因为没有怎么使用指令集进行微调。
评估benchmark,MME和SEED-Bench。
分成了两组,: (A) LLaVA-Cap (image captioning), LLaVA-VQA (visual question answering), and LLaVA-Rea (visual reasoning); (B) LRV (diversity), A-OKVQA (com- plexity), and Shikra (spatial annotation)。
从task type的角度,实验结果来看: 1. 在caption任务上训练,带来了明显的性能降低 2. MLLMs在reasoning任务上微调,带来了明显的性能提升。VQA task的训练中规中矩。
从Instruction特性角度:作者继续分析。作者的实验结果,表明,在A-OKVQA上进行微调,可以明显的提升性能。
在LRV和shikra上训练,仅带了小幅度的提升。
综合来看,LLaVA-rea和复杂度,A-OKVQA很有用。
考虑到现有模型还没有探索,什么样的Instruction数据集是更有效的,而且什么因素导致了好的Instruction data,暂未有人探索。 考虑到这些问题,作者探索什么是好的visual Instruction这个问题。基于这个目标,作者首先对现有的 visual Instruction set进行了评估,目标是发现关键因素。
作者主要从task type和Instruction characteristic两个方面来评估。作者选择了六个典型的Instruction dataset,使用两个典型的BLIP2和MiniGPT-4来评估。根据实验结果,作者发现: 1. 对于task type,视觉推理任务对于提升模型的image caption和quetison answering任务很重要。 2. 对于Instruction characteristic,提升Instruction的复杂度更加有帮助对于提升性能,相比task的多样性,以及整合细粒度的标注信息。
基于上述发现,作者开始构建复杂的视觉推理指令集用于改善模型。
首先最直接的方法是通过chatgpt和gpt4来优化指令集,基于图像的标注。因为指令集跨跨模态的特性,LLMs可能会过于简单甚至包含本来图片中不存在的物体。 考虑到上述问题,作者提出了一个系统的多阶段的方法,来自动生成visual Instruction数据集。
输入一张图,根据可以获得标注,caption或者object,作者采用了一种先生成,再复杂化,再在重组的pipeline来生成Instruction。具体的,作者首先,使用特殊的prompt指导prompt来生成一个初始指令。然后使用迭代的方式,复杂化-->验证的方式,来逐步提升Instruction的复杂程度,同时保证质量。最后,将Instruction重组成多种形式,在下游任务重,获得更好的适应性。
任务类型,之前的指令微调的数据集,都是利用带有标注的图片。主要包括一下三个任务类型: 1. Image Caption,生成文本描述 2. VQA任务:需要模型根据问题生成关于图片的回答 3. Visual reasoning:需要模型基于图片内容进行推理。
为了研究任务类型的影响, 作者考虑一个最常用的指令微调数据集LLaVA-Instruct。作者将其划分成三个子数据集,LLaVA-Caption, LLaVA-VQA and LLaVA-Reasoning。
指令特性: 指令的特性包括。 * 任务的多样性,已经有工作发现,提升工作的多样性,对于zero-shot能力是有帮助的。可以通过和不同的任务整合来获得此类能力。 * 指令的复杂程度,这是一个被广泛应用的策略,提升LLMs指令集的复杂程度。作者同样使用复杂的多模态做任务,例如,多跳的推理任务,来提升MLLMs的指令遵循能力。 * 细粒度的空间感知。对于MLLMs而言,感知细粒度的空间信息对图片中的特定物体,是必要的。基于这个目标。空间位置的标注可以包括在有文本的指令集中。
I think what many people really want from money is the ability to stop thinking about money. To have enough money that they can stop thinking about it and focus on other stuff. But that ultimate goal can break down when your relationship with money becomes an ingrained part of your personality. You struggle to break away from focusing on money because the focus itself is a big part of who you are.
过往好的习惯,在某一个时间点或者资金量后,不一定仍然这么好了。而改变这个是需要刻意的去修正,很多时候我们很难想到这点,毕竟过去我们靠这个成功了。
这就是为什么这些内心的框架很重要。它们让你能够分析自己冲动的原因。在我们的场景中,要确定的是你想要改变宏观使命是因为一种真实的自我演变,还是习惯于半路而退的偏见。你的躁动是来自一只配置正确的八爪鱼的预料之中的牢骚;还是来自正确道路的长途跋涉带来的疲劳;还是在旅途中新获得的关于自我或者这个世界的信息,改变了你那些错误的初始假设;或者是因为有些东西在发生根本上的改变,比如一些下图中蓝色或者黄色环的行为:
分析心态,疲劳有的时候让你感觉自己是真的不想做了。
一个更合理的目标是知足:那种正在体验一条优质的生命路径的满足感,那种知道自己所作的努力将会变成最终大拼图的一部分的自豪感。追逐快乐是菜鸟的做法,聪明人的做法,是在选择和境遇的结合给予你应得的一切的时候,感到知足。人们总说活在当下,但还有一种更广阔的“当下”的概念,一种更宏观的“当下”——活在你生命的每一个当下。如果在你职业的点上,你能诚实的告诉自己感觉很不错,你应该停下来享受一下。虽然之后还要再回来重拾大局观,但是在这个享受的时刻,你可以暂时放下大局观,把你所有的能量导向当下。这段时间,你可以好好体验活着的感觉。
不要追逐快乐,享受当下的情景,如果遇到快乐时,欣然享受它。
我们作为旁观者,会觉得这个朋友过于愚钝,根本不知道怎么寻找一份快乐的感情。所以在选择职业的时候,我们不要犯和这个朋友一样的错误。接下来要面对的那个点不是什么大不了的事情,它就好像你和某人的第一次约会一样。 这是个很好的事情,因为这样的想法,会让你在地图上画一个箭头变得不那么可怕,你只是往接下来的那个点上画一个箭头罢了。选择困难的真正原因,是你一边能看到现在社会上可供选择的职业选项,同时又错误的把那些职业看成40年长的管道,这两者的结合是致命的。把你的下一个重大职业生涯决策,重构成一个赌注低很多的选择,会让众多的选项看起来更加亦可赛艇,而不是充满压力。
心态的转变对应选择能力的转变。
当你把职业看成一条管道,做出正确选择就好像参与一场赌注很高的赌博,让选择困难症的程度瞬间爆炸。对于完美主义者来说,这简直是件痛彻全身的事情。
是的,做一个无法改变的选择的难度太大了。
但是长处不应该是我们的技能,而应该是那些决定我们步伐和坚持的特质。独创性,或者独创性的缺乏,是这个讨论的重要因素。比如敏捷和谦卑(厨师思维的重要特点)就是明显的长处,固执、智识的懒惰(厨子思维的标志)则是重大的弱点。专业精神的那些细微要素,比如更容易深度集中,或者容易拖延,也应该是这个讨论的重要部分。当然,我们还应该包括才华之外的天分,比如机智和招人喜欢程度。涉及到坚持的特质,韧性、决心和耐心,都应该是长处。想要快速在人前显贵的心态,则是个明显的危险信号。 更重要的是,这所有的特质,不应该按照它们现在这个瞬间的情况来讨论,而是要依据你能对每个特质所具有的潜能来思考。
这个长处和日常听到的长处区别很大。特质很重要,这个我理解也是在真正的低谷的时候能够依然坚持的事情。
坚持比步伐要简单,你花在追逐一颗星星的时间越长,你就离星星越近。一辆30迈的车开十分钟,就是没有一辆10迈的车开两个小时走得远这就是为什么坚持非常重要。一个只愿意为了自己梦想职业付出三年的时间然后就要返回保底工作的人,其实就是在放弃自己真的获得这个梦想职业的机会。无论你多么厉害,如果你在努力两三年后没有突破就决定放弃,你是不太可能成功的。几年的时间,是不够走完摘取最亮的星星做需要经过的漫长旅程的,不管你的步伐迈的多大。
这个两三年都没有突破,其实是超出我的预期的?其实挺符合实际的。我在投资这个领域,前期也是有5-6年的没有多少收益的。
最后,记得,你做出的不是一个永久的决定。恰恰相反,这是一个用铅笔画的草稿。这是一个你能够测试和修改的命题,测试的过程就是你实际按照欲望排名来生活时的感受。
能够随时改变 这个心态,能让你更快速和有信心的做出决定
当你把这些赚钱的内在驱动力抖出来的时候,也许你会发现,在这一切驱动力的核心,你的核心驱动力是安全感,而不是巨额的财富——这也是应该被抖出来的。 对于安全感的渴求,最简单的形式,可能是实用主义触手在起作用,也可能是你的生活方式触手和社交欲望触手对于生活的奢华有一些基本的要求。
李笑来描述过类似的话,我们可以选择放弃部分的安全感,来获得更大的自由
然而,个人欲望触手也是最常被忽略的那个。在很多的案例中,个人欲望是最不被待见的,因为这只触手上承载的恐惧常常不是那么紧急,而且在事业的早期,其它的触手往往因为本能的蛮力而占据上风。
这个视角没有注意到,的确我也容易忽略这点,因为委屈下自己有的时候是更容易的选择。
“想要”框的填充难点在于,你有很多不同的想要的东西。或者说,你有很多不同的方面,各个方面的自己都有想要的和恐惧的东西。既然意志是会互相冲突的,你就不可能获得所有自己想要的东西。获取一件想要的东西,很多时候就意味着不能获取另一件东西。有时候这两样东西可能是完全相矛盾的。“想要”框,是一场和自己的妥协游戏。
也是一种放弃的智慧
我们认为要实现储能行业的高质量发展,必须做到可信赖、可持续。在宁德时代我们简称为可信可续。
可信赖,其实意味着可靠性,我觉得英文对应的就是Reliable,这和我司的Always Reliable的理念是相同的。
目录是否有必要存在 基于路径的索引难以并行或分布式化,因为我们总是需要查到一级目录的底层编号才能查到下一级,这是一个天然串行的过程。在一些性能需求极高的环境中,可以考虑弱化目录的权限控制职能,将目录树结构扁平化,将文件系统的磁盘布局变为类键值对存储。
[!NOTE] 基于路径/目录树的文件索引该如何优化性能?
flashcard
- 弱化目录的权限控制职能,将目录树结构扁平化,将文件系统的磁盘布局变为类键值对存储。
一般来说,活性分析是通过求解活跃变量方程来完成的。为了介绍活跃变量方程的概念, 我们需要先引入下面四种针对基本块的集合: Def 集合:一个基本块的 Def 集合是在这个基本块内被定值的所有变量。所谓的定值 (definition),可以理解为给变量赋值,例如加法语句给目标变量定值等(注意:Store 语句不给任何变量定值,Load 语句则会给对应变量定值)。 LiveUse 集合:一个基本块的 LiveUse 集合是在这个基本块中所有在定值前就被引用过的变量,包括了在这个基本块中被引用到但是没有被定值的那些变量。 LiveIn 集合:在进入基本块入口之前必须是活跃的那些变量。 LiveOut 集合:在离开基本块出口的时候是活跃的那些变量。 其中 Def 和 LiveUse 是基本块本身的属性,对每个基本块从后往前遍历基本块内的指令便可以求出。 有了基本块的这四个集合的概念,我们给出控制流图中每个基本块满足的活跃变量方程: 该方程说的是一个基本块的 LiveOut 集合是其所有后继基本块的 LiveIn 集合的并集,而且 LiveIn 集合是 LiveUse 集合的变量加上 LiveOut 集合中去掉 Def 集合以后的部分。 这个方程的直观意义是: 一个基本块的任何一个后继基本块入口处活跃的变量在这个基本块的出口必须也是活跃的。 在一个基本块入口处需要活跃的变量是在该基本块中没有定值就被使用的变量,以及在基本块出口处活跃但是基本块中没有定值过的变量(因为它们的初值必定是在进入基本 块之前就要具有的了)。 根据这个方程,我们可以通过迭代更新的办法求出每个基本块的 LiveIn、LiveOut 集合,以下是求解的伪代码:
[!NOTE] 编译优化中,活跃变量方程的内容是?
flashcard
- 一个基本块的 LiveOut 集合是其所有后继基本块的 LiveIn 集合的并集,
- 而且 LiveIn 集合是 LiveUse 集合的变量加上 LiveOut 集合中去掉 Def 集合以后的部分。
这个方程的直观意义是: 1. 一个基本块的任何一个后继基本块入口处活跃的变量在这个基本块的出口必须也是活跃的。 2. 在一个基本块入口处需要活跃的变量是在该基本块中没有定值就被使用的变量,以及在基本块出口处活跃但是基本块中没有定值过的变量(因为它们的初值必定是在进入基本 块之前就要具有的了)。
名为 DARE(Drop And REscale)的削减冗余参数的方法。顾名思义,Drop 和 Rescale,DARE 的思想非常简单,分两步走,首先给定一个随机的删除率 ,以 为概率随机删除 Delta 参数(置为 0),即 Drop 的过程,而后以 为概率等比例扩大剩余保留的参数,就完成了 DARE 的过程,流程图如下图所示:如果形式化的定义 DARE,即为:最终,得到后,与 相加,即 ,从而完成 DARE。在实验中,论文作者惊讶的发现,采用 DARE,可以在舍弃大量冗余参数的同时,维持模型的性能。从图中可以看到,随着 Drop rate 的上升(舍弃的参数越来越多),模型的性能仍然可以维持不错的水平。同时,模型的参数量越大,在不影响精度的情况下其最大 Drop rate 的值也在上升,甚至可以达到 99% !这意味着 DARE 可以在几乎删除 99% 的参数的基础上仍然维持模型的性能,这一发现不仅表明,有监督微调确实是如何 LoRA 那样在学习一种“低秩结构”,并且也进一步说明了Delta 参数确实是大量冗余的。
[!NOTE] DARE(Drop And REscale)的主要结论是?
flashcard
以类似经典 Dropout 的方式处理 SFT 的 Δ 参数 随着 Drop rate 的上升(舍弃的参数越来越多),模型的性能仍然可以维持不错的水平。同时,模型的参数量越大,在不影响精度的情况下其最大 Drop rate 的值也在上升,甚至可以达到 99% !
在以“新一代信息技术”为主题的文献中“物联网”是最常出现的技术类别,但这并不意味在中国知网上以“物联网”为主题的文献在所有技术类别中是最多的。
it doesn’t implement gradient accumulation
梯度累加(Gradient Accumulation)是一种常用的深度学习技术,它主要用于解决显存不足的问题,特别是在训练大模型或使用大批量数据时。这种技术的基本思想是,将一个大的批量数据分成多个小批量,然后在每个小批量上分别计算梯度,累加这些梯度,然后使用累加后的梯度来更新模型参数[1]。
举个例子来说,假设你有一个批量大小为10的数据集,但是由于显存限制,你不能一次性将所有10个样本加载到内存中进行训练。这时,你可以设置gradient_accumulation_steps=2,这样新的批量大小就变为10/2=5,也就是说,你需要运行两次,才能在内存中放入10条数据。尽管你需要运行两次,但是梯度更新的次数仍然是100次,这意味着你的训练步数变为200[2]。
再举一个更具体的例子。假设你的batch_size原本是16,也就是一次梯度更新用的是16条数据。但如果设置gradient_accumulation_steps=4,那么参数只有在步数是4的倍数时才会更新,梯度才会重置。这实际上就是利用了64条数据,取64条数据的平均梯度来更新参数[3]。
需要注意的是,梯度累加并不是累加损失,而是根据损失得到的梯度[3]。
散序处理(Out of Order Execution)是现代CPU非常重要特性,x86、arm的新架构基本都支持这种特性,要进行指令优化必须要对散序处理有个基本的了解。 与散序处理相对应的就是顺序处理(In Order Execution),两者在指令的处理步骤上存在明显区别: 顺序处理 In Order Execution : 获取指令。 如果操作数已就位(操作数位于寄存器内),则可以把指令分配到相应的功能单元。如果有一个或多个操作数未就位,则需要花费数个时钟周期来获取该操作数,在这段时间内处理器会处于停止状态。 所有操作数就位后,指令会被相应的功能单元执行。 功能单元把执行结果写回寄存器。 散序处理 Out of Order Execution : 获取指令。 指令进入指令队列。 在操作数就位前,指令会在队列内进行等待。一旦操作数就位,指令就会处于就绪状态,处于就绪状态的指令可以先于前面的未就绪指令出队列。 指令在出队列后会被分配到相应的功能单元执行。 指令进入重排序队列。 重排序队列需要指令按照原本的顺序把执行结果写回到用户可见的寄存器/内存,写回后从队列中删除指令。 散序处理的第6步,也就是最后一个步骤,被称为Instruction retirement,具体实现的部分被称为Retirement unit。程序指令原来的执行顺序叫做program order,不过在散序处理的CPU中,指令的处理顺序是基于数据的,当指令在其所依赖的数据就绪后即可开始执行,这种执行顺序叫做data order。不过对于用户来说,为了便于调试与维护,还是有必要在用户可见的范围内维持程序原有的顺序,retirement unit做的就是这个工作。Retirement unit把指令的执行结果按照program order写回用户可见的寄存器,使得用户以为程序是顺序执行的,实际上在CPU内部,指令是散序执行的。 散序处理总体上可以按照上面的描述进行理解,细分开来则涉及到较多的CPU特性。
[!NOTE] 乱序执行 (Out of Order Execution) 的基本思想是?
flashcard
指令的处理顺序是基于数据的,当指令在其所依赖的数据就绪后即可开始执行,这种执行顺序叫做data order。 不过对于用户来说,为了便于调试与维护,还是有必要在用户可见的范围内维持程序原有的顺序,retirement unit做的就是这个工作
TimerSendModule 配置文件如下
这部分代码是自动生成的
现在假设有两个操作系统os1、os2驻留集分别为m,n,且0<m<n。 为方便描述,需要引入两个个人定义的概念: 1.稳定区:即在os2的驻留集中,存在一个大小为m的区域,其页面次序与os1完全一致。也即os1是os2的真子集。 2.稳定状态:即os2中存在稳定区时候的状态。Belady发生的两个必要条件:1.os2不存在稳定区。2.接下来访问的页面在os1中有,而os2没有。 而FIFO算法会产生Belady现象的根本原因则是,在os2中,尽管驻留集更大,但并不是一直存在一个“稳定区”。这会导致一个结果:os1与os2换出的页面有可能不一致。如果os2换出的页面p2是下一步将要访问的,且os1中仍旧持有p2,此时os2就将比os1多置换一次,便产生了Belady现象。
[!NOTE] Belady 反常的发生需要哪些条件?
flashcard
1.os2不存在稳定区。 2.接下来访问的页面在os1中有,而os2没有。
belady现象的出现,是由于置换算法将需要经常访问的页面置换了出去导致的。例如FIFO算法,即便最开始进入内存的那个页面是最近以及未来要经常访问的,但是FIFO还是选择把它换出去。FIFO选择替换最早进入内存的页面,没有考虑到这个页面未来是否可能会经常访问,所以导致了belady现象。类似的算法还有clock算法,clock算法本质跟FIFO一样,假如物理页帧数为4,并页面p1、p2、p3、p4先后被访问并被载入物理页帧,从p4被载入内存的时刻t1开始,直到下一次发生缺页的时刻t2为止这段时间内最经常访问的页是p1,根据局部性原理,未来p1有很大可能要继续访问。但是clock算法给这四个页面都设置了访问位,而且很遗憾的是,这个访问位只有一个比特,它根本区分不了这个四个页面中谁被访问最频繁,这4个页面的访问位都是1,根据clock算法,t2时候发生缺页,clock算法按照被载入内存的时间先后扫描所有页帧,将第一个访问位为0的页面置换出去,但是显然这四个页面的访问位都是1,所以clock算法会将这4个页面的访问位依次置为0,然后循环扫描,将p1置换出去。所以clock算法是存在belady现象的。
[!NOTE] 时钟置换算法存在 belady 现象吗?
flashcard
存在。 它只能够区分有没有被访问过,至于在那些都被访问过的页面中,谁是最频繁被访问的、谁是最近被访问的,clock算法区分不了。所以导致它经过一轮扫描以后退化成为FIFO。
。这是首次将中央处理器(Central Processing Unit,CPU)集成于一块硅芯片上,从而使制造体积更小、性能更稳定的微型计算机成为可能。按照字长划分,以微处理器为核心的微型计算机的发展经历了 4 位机、8 位机、16 位机、32 位机、64 位机、Pentium 阶段。高性能微处理器的出现不仅使微型计算机在性能上可以取代过去的中、小型计算机,而且也将微型计算机推广到了干家万户。
发明计算机的作用
物理页号和全部的标志位以某种固定的格式保存在一个结构体中,它被称为 页表项 (PTE, Page Table Entry) ,是利用虚拟页号在页表中查到的结果。 上图为 SV39 分页模式下的页表项,其中 [53:10] 这 44 位是物理页号,最低的 8 位 [7:0] 则是标志位,它们的含义如下(请注意,为方便说明,下文我们用 页表项的对应虚拟页面 来表示索引到 一个页表项的虚拟页号对应的虚拟页面): 仅当 V(Valid) 位为 1 时,页表项才是合法的; R/W/X 分别控制索引到这个页表项的对应虚拟页面是否允许读/写/取指; U 控制索引到这个页表项的对应虚拟页面是否在 CPU 处于 U 特权级的情况下是否被允许访问; G 我们暂且不理会; A(Accessed) 记录自从页表项上的这一位被清零之后,页表项的对应虚拟页面是否被访问过; D(Dirty) 则记录自从页表项上的这一位被清零之后,页表项的对应虚拟页表是否被修改过。 由于pte只有54位,每一个页表项我们用一个8字节的无符号整型来记录就已经足够。
[!NOTE] (Sv39 中)页表项的组成为?
flashcard
10 位保留+44位物理页号+10位标志位
默认情况下 MMU 未被使能,此时无论 CPU 位于哪个特权级,访存的地址都会作为一个物理地址交给对应的内存控制单元来直接 访问物理内存。我们可以通过修改 S 特权级的一个名为 satp 的 CSR 来启用分页模式,在这之后 S 和 U 特权级的访存 地址会被视为一个虚拟地址,它需要经过 MMU 的地址转换变为一个物理地址,再通过它来访问物理内存;而 M 特权级的访存地址,我们可设定是内存的物理地址。 注解 M 特权级的访存地址被视为一个物理地址还是一个需要经历和 S/U 特权级相同的地址转换的虚拟地址取决于硬件配置,在这里我们不会进一步探讨。
[!NOTE] RISC-V 中,如何开启虚拟内存机制?
flashcard
修改 S 特权级的一个名为 satp 的 CSR 来启用分页模式
可以想象对于不同的应用来说,该映射可能是不同的, 即 MMU 可能会将来自不同两个应用地址空间的相同虚拟地址翻译成不同的物理地址。要做到这一点,就需要硬件提供一些寄存器 ,软件可以对它进行设置来控制 MMU 按照哪个应用的地址空间进行地址转换。于是,将应用的数据放到物理内存并进行管理,而 在任务切换的时候需要将控制 MMU 选用哪个应用的地址空间进行映射的那些寄存器也一并进行切换,则是作为软件部分的内核需 要完成的工作。
[!NOTE] 操作系统在虚拟内存中发挥了什么作用?
flashcard
在任务切换的时候需要将控制 MMU 选用哪个应用的地址空间进行映射的那些寄存器也一并进行切换
part
在这种情况下,保持公共区域的清洁是一种集体利益,因为任何清洁工作的成果都会平等地惠及所有的室友。由于这个利益无法限制给特定的个体(即不可排他),所以存在着一个潜在的集体行动问题。这段文字强调了即使每个人理论上都愿意为此付出努力,但由于利益无法排他且清理工作的个人成本较高,公寓可能最终会变得很脏。这展示了个体的理性行为可能与实现共同目标产生冲突的情况
看CRPG这一个品类的奇妙历史,你都能感觉到在这其中的讽刺性:这个品类的游戏很多其实根本就不“小众核心”。它销量低的假象,完全是由核心玩家们的定义造成的——当一家CRPG公司的游戏大卖之后,他大卖的那些游戏就会被玩家们开除CRPG籍!
发生在近代上海最早的中国人与欧美白人之间的正式的跨种族婚姻,是1862年3月,美国人华尔娶上海买办杨坊的女儿杨彰美为妻。这在同治初年是很著名的事件。【9】第二例跨种族婚姻,是圣约翰大学校长、美国人卜舫济与黄素娥的婚姻,他们于1888年结婚。黄素娥是圣公会华人牧师黄光彩的女儿,【10】后来担任上海圣玛利亚书院首任校长。发生在上海最著名的跨种族婚姻,要数犹太商人哈同与罗迦陵的婚姻。他们于1886年秋结为夫妻。罗迦陵本人就是混血儿,1863年生于上海九亩地(今露香园路、大境路一带),其生父罗路易是法国人,母亲姓沈,福建闽县人。
上海欧亚混血儿的个案研究
这里可以告诉大家一个非常简单的方法来区分普通抗磁性材料的悬浮和超导体的悬浮,那就是把材料放到磁铁的下方,看其会不会在磁铁的下方悬浮。能够实现磁悬浮的超导体,不仅可以在磁铁的上方浮起来,也可以在磁铁的下方悬挂住。因为磁通线实际上部分穿入了超导体内部,又部分被超导体强烈排斥,而且超导电子可以把磁通线牢牢锁住,产生很强的作用力,所以无论是浮还是悬,都足以克服重力。但普通抗磁性材料却根本不能在磁铁的下方悬浮,因为这类材料抗磁性很弱,绝大部分磁通线可以穿透材料且没有很强的作用力,在磁铁上方可以借助微小的抗磁斥力而悬浮。如放到磁铁下方,普通抗磁性材料会掉下去。
超导体出了在磁场中的悬浮,还能挂在磁场下。这就是磁通钉扎效应。磁力线方向相反,其实就是磁铁的同极相斥。超导体的斥力,让超导体可以悬浮在磁铁上方,磁力线的方向,就是磁斥力的方向;那超导体在磁铁下方,在重力和超导体斥力作用下,超导体会掉下去。掉的时候,由于磁铁磁力线是弯曲的,所以,斥力会是磁场磁力线方向的相反方向。假设磁场是S级,那磁力线回来。超导体沿磁力线往N级方向移动在磁力线弯曲处,斥力改为向上,与重力就平衡了。所以,超导体会被“勾住”。很有趣呀。
Apache HTTP Serverやnginxなど、Webサーバーの設定ミスによりInternal Server Error 500が発生するケースがあります。Webサーバーの設定ファイルである.htaccessの記述誤りや、ファイルのパーミッションの設定ミスがある場合に本エラーが発生する可能性があります。
Apache HTTP Server和nginx等Web服务器的错误设置会导致Internal Server Error 500。这是Web服务器的设定文件。如果htaccess的记述错误或文件的参数设定错误的话,有可能会发生本错误。
The turns ratio of the secondary winding, NS ,to the bias winding, N B, sets the voltage t
为什么Ns和Nb之比,决定了偏置电压Vbias呢?首先,Vs应该是稳的,比如通过反馈去稳压。其次,Nb的负载其实和Ns负载不同啊,所以,Nb的电压其实比理论值大一些才对(负载轻于Ns)。但是呢,由于双线圈输出,所以,Np和Ns并不能决定Ns电压的准确值。但Ns是有反馈的基准值,所以,并不是Np/Ns决定了Vs电压,而是靠Np/Ns粗调,靠反馈精调。 反激体制下,Ns和Nb和Np是成比例的。Np电压不等于Vbus,所以,Nb的求解就靠Ns了,Ns电压已知,那么Nb电压就能求解出来。当然,这其实隐含了条件,是输出电容无限大,纹波等级相同。如果纹波等级不同,如Ns额定负载,Nb轻载,那么Nb电压就高于这个变比决定的电压了,因为纹波因素。
Aresonant converter is a converter whose switchingoccurs when the sinusoidal-shaped voltage and/orcurrent goes through zero, resulting in an almostlossless transition.
谐振转换器最大的特点是,开关发生于正弦电压或正弦电流的过零点,使得开关损耗接近0。谐振,就这目的。所以,结构化拆解一下这事: 1)问题:开关损耗太高。 2)目标:降低开关损耗或者消除开关损耗。 3)方案:谐振过零开关。
High power will require arelatively tiny inductance, but it is just not sensibleto use an inductance so small that the circuitparasitics will completely dominate. That wouldlead to an unreliable design that would never berobust enough to be practical in a mass-marketproduction lot.
咦,这段跟我的分析不一致呀。这段说,功率越大,那么一次侧的电感得越小(因为U/XL=IL)。但如果一次侧电感太小,那么杂散电感的影响就太大,会引起系统的不稳定,不能用于大批量产品。 我自己的理解,这个电感是负载满载时,一次侧的等价电感,而不是空载电感。我的分析,是空载一次侧电感;这的分析,我觉得是满载等价一次侧电感。我觉得都对。
Applicable power is also limited because theprimary inductance value is inversely proportionalto the required power
一次侧电感的数值是与需求电源功率正正比的。这个与我上面的分析是符合的。能量得能容纳进来,然后才能传递出去。根据传输的功率和输入电压,知道平均一次侧电流。电流确定后,就能确定一次侧电感需求,就能确定匝数。匝数确定了,电流确定了,就能确定磁芯的尺寸(不饱和)。这就是变压器的设计思路。对的。
t is actually poorly utilized and fairlybulky when compared to other converters at thesame power level because it provides energystorage as well as energy transfer
bulky- 体积大。反激电源变压器利用率低,导致体积大。因为它需要存储能量(有容量要求),及能量传输。其他拓扑,只是能量传输,不饱和就行。能量是1/2Li^2,功率与电感值相关,所以,很多时候,电感值比较大。而能量传输,电感值是滤波,C和L配合,一般感值要求较小。这是体积变大的原因
In an attempt to alleviatethe issue of abrupt frame transitions, we use an overlap of50 % between the generated waveform frames
50% overlap,所以FIg3展示的Decoder结构算出来是反卷积放大了1280倍而非640倍,这是因为有一半的帧都被average吞掉了
(2) We do not fully consider various levels of aggre-gation at which data may be available. In prac-tice, customer data may be offered by a vendor in“blocks.” This will be an interesting and relevantextension
该文章认为当数据以块的形式被提供的时候,是一个有趣的研究扩展。这和DirectMail.com的数据提供方式是一致的,所以这个研究现在很有意义
oal of data acquisition is to identify a set of most usefuland valuable attributes or features to acquire, still keep-ing the cost of data acquisition within the organization’sbudge
这是一个很好的思路,选择最有价值的属性获取新数据。但是我觉得可以考虑消费者的异质性,不同类型的消费者的最佳属性选择可能是不一样的。lixiaobai老师报告时孙见山老师也问到了这个问题。
可以看到,我们在不可压缩情形推出过的Alfvén波是一个解,这说明它不受可压缩性影响。此外,我们有两个新解,分别是快和慢磁声波:
解?
如果你的仓库包含大量文件或大文件(比如二进制文件或视频文件),执行 git add . 可能会非常耗时。这是因为Git需要计算每个文件的哈希值并将其添加到索引中。当文件太大时,计算哈希值和写入索引将会消耗大量时间。
[!NOTE] 为什么
git add大文件会很慢?flashcard
因为Git需要计算每个文件的哈希值并将其添加到索引中。当文件太大时,计算哈希值和写入索引将会消耗大量时间
从以上的分析,我也得到了另外两点推论:1、既然大部分人都是二把刀,所以二把刀最大的竞争优势是工作态度。AI已经证明了这一点,同样是二把刀,人类和AI之间不存在人际关系摩擦,AI没有脾气,效率如一,所以更有优势;2、在没有AI之前,人可以轻易地把责任归结为二把刀。有了AI之后,人就有可能意识到之所以事情不行,可能自己才是最大的原因。二的不是二把刀,而是自己。自己提出的要求,可能自己都没想明白,更不知道应该如何去做。
既然大家都是二把刀,为什么要选择你
我是 happy3 小时前发布 #1 2023年10月18日星期三 09点59分 已编辑最近买了一个美西ip的 OVH 0.97刀小鸡,目的是为一些自用的美国服务提供一个稳定的访问 ip。 既然是自用,我决定使用比较小众的 Snell 协议。 搭建过程异常简单,我就说两点值得注意的地方。 搭建教程,看这一篇就足够了。再简单一点,直接运行这个脚本,让你一键安装: wget -O snell.sh –no-check-certificate getcats.tk/BfhGmR && chmod +x snell.sh && ./snell.sh 使用一键安装脚本时,一路确认下去即可。服务启动后,下一步是在 Surge 里添加节点。然而当我在 Surge 上通过编辑配置文件来添加节点时,修改几次参数都没有连通,这时,换个思路,去 iOS 上的 Surge,通过“代理服务器”里的“添加代理”,逐一填入 ip,密码等信息,把该打开的选项都打开(因为你一键安装时都默认打开了),节点的正确配置,就被写入配置文件,我试了一下,可以连上了。然后,自己编辑一下 Surge 的配置文件,把节点名字加入需要的规则组就能愉快地使用了。
我如何搭建和使用 Surge Snell 协议
这就要说到另一个新知识:大脑在不同任务之间切换,是需要时间的,注意力无法随叫随到,即便你已经切换到了新的事情上,注意力也会在上一件事情上残留一段时间。即便你可以一边发微信、一边听播客,表面上看起来可以在十几秒内切换任务对象,但其实大脑会有一部分注意力留在之前的活动里。这就是所谓的「注意力残留现象」(attention residue)。换句话说,即便你只在一个任务上停留了几秒钟的时间——比如读了一条信息,然后马上切换回来,最终要付出的时间代价也远不止这些。注意力残留的时间长度没有确切的答案,但研究表明大致会在几分钟时间。也就是切换任务的频率越高,损失的时间越多。
注意力残留现象
An alternative would be to first go to the AC system, but then the power would go through three converters, each taking out some efficiency.
走AC耦合需要过3个变化器。那么我也再想象直流耦合的问题。MPPT+光伏逆变器可以面向一个典型光伏板做优化,DCAC有个最佳配置;而外部直流母线经过隔离DCDC,可以在比较大的范围内效率较高(非隔离做不到这一点,压差高,效率低);储能电池借用光伏DCAC上网,是否是最优的呢?现在看,如果母线变化范围比较大,那其实就做不到最优,因为变压器变比是固定的。所以,有个范围的。所以,这个逆变器和DCDC最好是一家做得,然后对另外一家的DCDC提要求。比较好。比如光伏逆变器对储能DCDC提适配要求;或者反过来。适配方效率非最佳,那与我产品无关。但你需要有直流耦合的能力,所以,功能接口需要有的。
另外一个 64 位的 CSR mtimecmp 的作用是:一旦计数器 mtime 的值超过了 mtimecmp,就会触发一次时钟中断。这使得我们可以方便的通过设置 mtimecmp 的值来决定下一次时钟中断何时触发。
[!NOTE] RISC-V 如何控制下一次时钟中断何时触发?
flashcard
64 位的 CSR
mtimecmp的作用是:一旦计数器mtime的值超过了mtimecmp,就会触发一次时钟中断
默认情况下,当 Trap 进入某个特权级之后,在 Trap 处理的过程中同特权级的中断都会被屏蔽。这里我们还需要对第二章介绍的 Trap 发生时的硬件机制做一下补充,同样以 Trap 到 S 特权级为例: 当 Trap 发生时,sstatus.sie 会被保存在 sstatus.spie 字段中,同时 sstatus.sie 置零,这也就在 Trap 处理的过程中屏蔽了所有 S 特权级的中断; 当 Trap 处理完毕 sret 的时候, sstatus.sie 会恢复到 sstatus.spie 内的值。 也就是说,如果不去手动设置 sstatus CSR ,在只考虑 S 特权级中断的情况下,是不会出现 嵌套中断 (Nested Interrupt) 的。嵌套中断是指在处理一个中断的过程中再一次触发了中断从而通过 Trap 来处理。由于默认情况下一旦进入 Trap 硬件就自动禁用所有同特权级中断,自然也就不会再次触发中断导致嵌套中断了。
[!NOTE] 默认情况下,是否可能发生嵌套中断?
flashcard
不可能 当 Trap 发生时,sstatus.sie 会被保存在 sstatus.spie 字段中,同时 sstatus.sie 置零,这也就在 Trap 处理的过程中屏蔽了所有 S 特权级的中断
从底层硬件的角度区分同步和异步 从底层硬件的角度可能更容易理解这里所提到的同步和异步。以一个处理器传统的五级流水线设计而言,里面含有取指、译码、算术、 访存、寄存器等单元,都属于执行指令所需的硬件资源。那么假如某条指令的执行出现了问题,一定能被其中某个单元看到并反馈给流水线控制单元,从而它会在执行预定的下一条指令之前先进入异常处理流程。也就是说,异常在这些单元内部即可被发现并解决。 而对于中断,可以想象为想发起中断的是一套完全不同的电路(从时钟中断来看就是简单的计数和比较器),这套电路仅通过一根导线接入进来,当想要触发中断的时候则输入一个高电平或正边沿,处理器会在每执行完一条指令之后检查一下这根线,看情况决定是继续执行接下来的指令还是进入中断处理流程。也就是说,大多数情况下,指令执行的相关硬件单元和可能发起中断的电路是完全独立 并行 (Parallel) 运行的,它们中间只有一根导线相连,除此之外指令执行的那些单元就完全不知道对方处于什么状态了。
[!NOTE] 如何从底层硬件的角度区分同步和异步?
flashcard
- 异常:以一个处理器传统的五级流水线设计而言,里面含有取指、译码、算术、 访存、寄存器等单元;假如某条指令的执行出现了问题,一定能被其中某个单元看到并反馈给流水线控制单元,从而它会在执行预定的下一条指令之前先进入异常处理流程。也就是说,异常在这些单元内部即可被发现并解决。
- 中断:大多数情况下,指令执行的相关硬件单元和可能发起中断的电路是完全独立 并行 (Parallel) 运行的,它们中间只有一根导线相连,除此之外指令执行的那些单元就完全不知道对方处于什么状态了
老木虽然只是个村支书,案子却是由市监察委指定区监察委管辖调查。在指定给区监察委调查前,县监察委就已经对老梁刨地三尺,最终得出的结论是仅仅违纪,不构成刑事犯罪,给了个党内处分。也不知道老木得罪了什么大领导,市监委一下炸了毛,也不让县里查了,直接指定给了区里,还顺手给了县监委几名调查员一个警告处分。这么一来,区这边自然就知道是什么意思了,哪里还敢怠慢,但凡能沾点边的,都给老木往刑事上靠。但刑事司法归根结底还是要讲证据的,我在二审介入代理了老木的案子,经过一番复杂博弈,中院最终以部分事实不清,撤销原判发回重审。一般来说,以事实不清发回重审的案件,上级法院都会附上一份补查提纲,列明有哪些需要进行证据补强的地方。如果检察院能够补过来,那再结合补强情况考虑是否作出有罪判决,如果压根补不过来,那也就对不住了,法院只能按事实不清作出无罪判决。一个刑事案件,从立案、侦查、起诉、一审判决、二审发回,往往一两年甚至更长的时间已经过去,这期间会发生很多微妙的变化。有些运动型案件,可能运动的高潮早已消退,有些领导意志型案件,可能早已调离岗位甚至落马被查,以致人亡政息。因此我常说,刑事案件不怕慢,就怕快。很多家属在处理刑事案件时沉不住气,一味求快,心情可以理解,悬而未决的等待是世上最残酷的刑罚,但从最终解决问题,营救亲人的角度考虑,还是要静下心来,争取以时间换空间。真正的冤案非常少,大多数刑事案件,最终都是因为国家司法资源不再持续投入,只能草草收场。用大白话说,就是国家放你一马。比如洛阳东昆案,发回重审时,东昆已经在看守所住了三年,外面早已物是人非。当年主抓扫黑的公安局副局长落马,连专案组都已解散,抽调人员各回了各单位。检察院拿着法院发回的补查提纲找公安局补充证据时,连个对接人都找不到。最后的结果是一页纸都没补回来,法院只能作出证据不足的无罪判决。
编写应用程序的科学家(简称应用程序员)来自不同的领域,他们不一定有友好互助的意识,也不了解其他程序的执行情况,很难(也没必要)有提高整个系统利用率上的大局观。在他们的脑海里,整个计算机就应该是为他们自己的应用准备的,不用考虑其他程序的运行。这导致应用程序员在编写程序时,无法做到在程序的合适位置放置 放弃处理器的系统调用请求 ,这样系统的整体利用率还是无法提高。 所以,站在系统的层面,还是需要有一种办法能强制打断应用程序的执行,来提高整个系统的效率,让在整个系统中执行的多个程序之间占用计算机资源的情况相对公平一些。
[!NOTE] 发明抢占式操作系统的动机是?
flashcard
电脑的使用者往往不了解其他程序的执行情况,很难(也没必要)有提高整个系统利用率上的大局观
虽然 -2 和 2-3 里面的 - 意义不同,但 lexer 不知道这点(parser 才知道),所以它们都会用同样的 token kind - 表示。 但有时,可能需要后续阶段告诉 lexer(或 parser)一些信息,最经典的例子是 “typedef-name identifier problem”。
[!NOTE] 词法分析中,关于
-有什么需要注意的?flashcard
取负与减法的区别
在 RISC-V 中,a0 和 a1 是 gcc 调用约定上的存储返回值的寄存器,返回值会按照其大小和顺序存储在 a0 和 a1 中。也就是说,如果你有一个 32 位的返回值,你可以放在 a0 中返回,如果你有两个 32 位的返回值,你就需要把它们分别放在 a0 和 a1 中返回。更多的返回值会全部放入内存返回,如约定好的栈的某个位置,这取决于函数调用约定。
[!NOTE] RISC-V 如何返回多个值?
flashcard
放入内存返回
1 、Spring 容器的启动:入口是八股文说烂了的 refresh() 方法,不过把这个流程看懂,可以搞明白:( 1 )了解 Spring 容器的体系:包括整个 BeanFactory 和 Application 体系的整体设计,以及一部分组件的存在(是的,知道这玩意存在可能本身也是一种收获);( 2 )了解很多关键步骤发生的时机:比如配置文件的加载,环境的切换,国际化处理、事件的机制,以及一部分钩子函数调用;2 、Bean 的创建:这个也是被八股文说烂的,不过确实也很重要,看懂以 getBean 方法的调用开始的整个 Bean 创建流程,可以搞明白:( 1 )配置文件上的 Bean 到底是怎么完成依赖注入变成容器里面的 Bean 的(废话);( 2 )一堆钩子函数,比如各种 PostProcossor 、Aware 还有其他回调的触发时机,这点尤其重要,因为 Spring 本身就是通过这边的各种回调把五花八门的功能缝合在一起的;( 3 )进一步了解 Spring 容器的各种组件 /机制,以及这些它们所支持的功能,比如别名、FactoryBean ,三级缓存,还有类型注入(泛型解析机制),甚至是各种工具类;
#spring
昨天和两位朋友坐在遮阳伞下喝酒,从下午一直喝到晚上。不知不觉就下起了秋雨,很快我们就坐在地面上一片四四方方的空白里。其中一个人总结说,你们看,坐到现在,我们没有一个人有电话打进来,没有一个人的微信里有人找自己。说完,我们为了这中年的福利满饮一杯。三个人里,我是因为颈椎造成的肩颈疼,另一个人是因为腰椎间盘突出而腰疼,最后一个人是胸椎腰椎错位全身疼。各自最疼痛的时光都早已经过去了,三个劫后余生的人坐着喝酒,交换治疗心得,漫无边际地扯淡。我们现在相信风。以我为例,在今年之前我从未惧怕过空调。等到我的颈椎病发作,一条线从脖子一直烧到指尖,空调的风吹在我的手臂上,我就立即能够感觉到整条线都在阴疼。关闭空调的瞬间,疼痛也就随之消失。腰椎间盘突出者补充说,他的这条命全靠腰背上贴满的暖宝宝吊着。只要暖宝宝开始发热,那就是人间天堂。
.globl kern_entry # 使得ld能够看到kern_entry这个符号所在的位置, globl和global同义
[!NOTE]
.globl <symbol>指令的功能为?flashcard
将一个符号声明为全局符号。这意味着该符号可以在其他文件或模块中使用,而不需要额外的特殊处理 以便编译器知道该符号是在其他地方定义的
好象是由流通时间引起的
在西方庸俗经济学眼中,周转就是货币投入,经过若干过程,得到一个更大的货币。他们不重视生产过程,把货币增值的全部功劳归功于流通(这是最浅显,最表面的)
信息性-原理图捕获的最终输出更多是信息性的内容,而不是电路的直接物理设计。 它显示了连接到何处的内容,并很好地概述了电路的内部工作原理。 这仅显示了使用行业标准符号和约定绘制的电路的各种组件。
原理图设计,为什么在这个领域都成为Schematic Capture呢?是因为,原理图最终的结果其实是信息,text描述的信息,这个信息就像是搜集,由设计者去搜集,给后道的物理设计做前道准备。就像绘画用Photoshop一样。
至于说2022年取得如此亮眼的业绩,这是因为他在坚守防御策略并高度集中的基础上,市场先生给黄海的惊喜。
防御就要防到底。集中持股防御,和集中持股进攻,都是获得收益的方式。因为唯有稳定才能成立收益,没有稳定就没有收益。
我们有两种不同的可执行文件格式:elf(e是executable的意思, l是linkable的意思,f是format的意思)和bin(binary)。elf文件(wikipedia: elf)比较复杂,包含一个文件头(ELF header), 包含冗余的调试信息,指定程序每个section的内存布局,需要解析program header才能知道各段(section)的信息。如果我们已经有一个完整的操作系统来解析elf文件,那么elf文件可以直接执行。但是对于OpenSBI来说,elf格式还是太复杂了,把操作系统内核的elf文件交给OpenSBI就会发生版本2的悲惨故事。bin文件就比较简单了,简单地在文件头之后解释自己应该被加载到什么起始位置。OpenSBI可以理解得很清楚,这就是版本1的故事。
[!NOTE] 可执行文件格式
.bin/.elf在指定内存布局时有什么区别?flashcard
.bin文件在文件头之后解释自己应该被加载到什么起始位置
如果有多行汇编,则每一行都要加上 "\n\t"。其中的 “\n” 是换行符,"\t” 是 tab 符,在每条命令的 结束加这两个符号,是为了让 gcc 把内联汇编代码翻译成一般的汇编代码时能够保证换行和留有一定的空格。对于基本asm语句,GCC编译出来的汇编代码就是双引号里的内容。例如: asm( "pushl %eax\n\t" "movl $0,%eax\n\t" "popl %eax" );实际上gcc在处理汇编时,是要把asm(...)的内容"打印"到汇编文件中,所以格式控制字符是必要的。
[!NOTE] GCC 内联汇编中,要控制换行等格式,需要怎么做?
flashcard
如果有多行汇编,则每一行都要加上 "\n\t"
此外 clean_bss() 清空了 bss 段,注意,清空 elf 程序 .bss 段这一工作通常是由 OS 做的,而我们就只好自立更生了。
[!NOTE] *清空 elf 程序
.bss段这一工作通常是由什么完成的?flashcard
OS
这下不折腾也不行了。win11卡,那就用回win10吧。又是重新制作启动优盘,又是下载镜像。好不容易把系统折腾上了,结果驱动又抽风,无线网卡和蓝牙都用不成。又在台式机上下载驱动,一直折腾到现在,才总算把系统给安装成了。还有一大堆软件得重新装回来呢,明天就要开始搬砖了,今天实在是不想折腾了。明天下班回来再弄吧。我发誓,这回只要电脑还有一口气在,就绝不再瞎折腾电脑了。实在是耗不起时间啊。
有趣的视角:一个律师是如何用电脑的
坐在向前急行的火车里,你如果不看看窗外风景,只管朝着车内的旅客、座位、查票员、茶房等等留心,甚至于闭起眼来假寐,那末,隆隆然车轮的转动声你是听到的,而车子向着什么方向进行,已经走了多少路程,就一点也不会清楚。或许反以为车子没有动,甚而以为正在倒退中。要清楚有无进行以及方向速率,就非望望窗外的风景不可。见了电线柱子的向后飞奔,桑圃菜畦的旋转,近山平畴的渐渐移动,因为一路的印象无时不在变动之中,于是你才知道车行十里了五十里了一百里了。我们大概都是已经丧失了喜欢望望窗外风景的那种小孩子的天真,而只管在人气十足的车室里烦闷的旅客。无论外面是春光秋色,晨曦晚霞,在我们一样是苦恼。小孩子就不如此,他爱窗外的景色;火车的司机者也不如此,他负了车内全部旅客运命的责任,不能不留心前途的信号,车行的速度。人生原是旅行,我们便是旅客。窗外的景色原是旅行的背景,有背景做了我们的标识,才能清楚进行的有无,以及进行的方向、进行的这率、进行的结果……这便是所谓历史。不明历史,只能醉生而梦死。不然,就难免生于苦恼,死于烦闷了。进行认识的标识,有种种级次,那些专记人名、地名、年月日的政治史,好比是车外电线柱子的飞奔;在绿叶里隐现的桑圃菜畦,好比是经济史;近山平畴的移动,好比是文化史;再远一点,就好比是人类史;连山的蜿蜒,就好比是生物史、地质史;至于那无论车行几何,总是不觉得有所移动的星辰,这正是宇宙史。我们清楚了那些背景,换句话说,清楚了人生站在政治、经济、文化、人类、生物、地质、宇宙里面的地位,才能知道我们自己是什么。
关于推荐书籍。选书的时候,必然是奔着「作者」去的,首推的是身兼科学家、哲学家于一身的这一类的伟大作者,如笛卡尔的《谈论方法》,亚里士多德《尼各马可伦理学》,以此类推变得寻得无数宝藏。
2本重要的书籍
Readwise 在官网里对自己的描述是这样的:Readwise makes it easy to revisit and learn from your ebook & article highlights。 实质上来说,我认为它是一个可以同步收集你所有阅读渠道中的标注和灵感,一站式完成导入、分类、储存和 回顾 的软件功能的软件。
这是第一个会同步到heptabase的卡片
学院式的科学本来不就是为“统治阶级服务”的么?资本主义世界不正是正在同“社会主义集团”“进行一场殊死战”么?马克思主义学说不正是这个“集团”的一项基本武器么?资本主义的奴仆不是有义务来对一切为他们的阶级敌人服务的东西进行系统的诽谤么?因此,在西方,对马克思主义进行诬蔑,只不过是阶级斗争本身的一种表现,反过来,这倒恰好证实了马克思主义论点的有效性。这样的辩论,大有可能形成聋子对话,由马克思主义者同心理分析家互相进行“技术”的对骂。
對馬克思主義進行詆毀是有必要的,因為這正是階級鬥爭的一種表現手法。愈是詆毀馬克思主義,就反而愈是證明它是有效的。
如果我们在gdb中输入info frame,可以看到有关当前Stack Frame许多有用的信息。Stack level 0,表明这是调用栈的最底层pc,当前的程序计数器saved pc,demo4的位置,表明当前函数要返回的位置source language c,表明这是C代码Arglist at,表明参数的起始地址。当前的参数都在寄存器中,可以看到argc=3,argv是一个地址
[!NOTE]
gdb中,要查询当前栈帧信息,可以使用?flashcard
info frame
在汇编代码中,函数的最开始你们可以看到Function prologue,之后是函数的本体,最后是Epilogue。这就是一个汇编函数通常的样子。
[!NOTE] 汇编函数有哪些基本组成部分?
flashcard
- function prologue (保存原状态)
- body
- epilogue (恢复原状态)
为常量 0 单独分配一个寄存器是 RISC-V ISA 能如此简单的一个很大的因素。第 3 章的第 36 页的图 3 给出了许多 ARM-32 和 x86-32 的原生指令操作,这两个指令集中没有零寄存器。我们可以用 RV32I 指令完成功能相同的操作,只需使用零寄存器作为操作数。
[!NOTE] RISC-V 寄存器分配有什么独特之处?
flashcard
0 寄存器
之前我们给出过支持应用程序运行的一套 执行环境栈 ,现在我们站在特权级架构的角度去重新看待它: 和之前一样,白色块表示一层执行环境,黑色块表示相邻两层执行环境之间的接口。这张图片给出了能够支持运行 Unix 这类复杂系统的软件栈。其中 内核代码运行在 S 模式上;应用程序运行在 U 模式上。运行在 M 模式上的软件被称为 监督模式执行环境 (SEE, Supervisor Execution Environment) ,这是站在运行在 S 模式上的软件的视角来看,它的下面也需要一层执行环境支撑,因此被命名为 SEE,它需要在相比 S 模式更高的特权级下运行, 一般情况下在 M 模式上运行。
[!NOTE] 如何从特权级结构的视角组织 SBI/ABI 等执行环境层级之间的关系?
flashcard
U-ABI-S-SBI-M
重点内容的前置:错误:“帮我把手术刀拿过来一下!”正确:“手术刀,拿过来一下给我!”人在口语中会不自觉的把重点内容给放在句首,但是写作时作者却往往忽视这一点,因此常常导致写出来的角色对话看起来怪怪的。
重点内容前置。
人在口语中不自觉地将重点放在句首。写作时,却会忽视这一点,导致角色对话看起来怪怪的。 (口语表达与书面表达)
习惯的书面表达:“帮我把手术刀拿过来一下!” 口语表达:“手术刀,拿过来一下给我!”
重点是“手术刀”。
本地生活是基于LBS及三五公里门店属性,而抖音电商逻辑,更多是单品或者单店爆发。因此,抖音达人直播可能无法赋能于本地生活,起到很高的杠杆效应。抖音目前对本地生活的业务渗透更多停留在网红拍摄短视频挂小黄车推荐附近团购,而商家参与拍摄短视频推广门店比例还很小,抖音ads成本毕竟远高于点评和美团,ROI效率俨然吓退了80%商家。目前抖音在这块并没有收取佣金(gtv的3-5%),商家基于暂时利益自然会推荐消费者选择抖音,帮自己节省交易成本,但是这个局面不可持续。但在不久的将来,抖音一定会收取佣金,参考抖音电商业务。
抖音的种草多了网红生产内容这一环节,成本极高。并且由于本地生活的效益比较局限,所以这一环节增加的成本还是很高的。
ship
在软件开发和敏捷项目管理的上下文中,"ship" 通常指的是将软件或项目的特定版本或功能部署、交付给最终用户或客户,使其可以使用。在给定的句子中,"ship" 表示你的目标是开发并交付一些工作或功能,以便用户能够使用它。这意味着你计划开发一组用户故事,并将它们推向生产环境,以便用户能够受益于它们。"ship" 在这里强调了项目管理中的最终目标,即将功能引入实际使用环境中,而不仅仅是开发或构建它们。这是一个常见的敏捷开发原则,强调将价值快速交付给客户。
he xv6 shell uses the above calls to run programs on behalf of users. The main structure ofthe shell is simple; see main (user/sh.c:145). The main loop reads a line of input from the user withgetcmd. Then it calls fork, which creates a copy of the shell process. The parent calls wait,while the child runs the command. For example, if the user had typed “echo hello” to the shell,runcmd would have been called with “echo hello” as the argument. runcmd (user/sh.c:58) runsthe actual command. For “echo hello”, it would call exec (user/sh.c:78). If exec succeeds thenthe child will execute instructions from echo instead of runcmd. At some point echo will callexit, which will cause the parent to return from wait in main (user/sh.c:145).
在xv6 shell中,当用户输入一个命令时,shell会创建一个子进程来执行该命令,而父进程则负责等待子进程的完成。具体的流程如下:
Shell程序通过调用fork函数(user/sh.c:58)创建一个子进程。这个子进程是父进程的副本,包括程序、数据和文件描述符等信息。
在子进程中,shell解析用户输入的命令,确定要执行的操作。这一部分逻辑由runcmd函数(user/sh.c:58)处理。根据命令的类型,runcmd可能会调用不同的函数来执行相应的操作,例如执行可执行程序的exec函数、建立管道通信的pipe函数等。
如果命令是一个可执行程序,那么shell会调用exec函数(user/sh.c:78)来执行该程序。这样,子进程将执行新的程序代码,取代掉原来的shell代码。
在某个时刻,子进程执行的程序完成了它的任务,可能会调用exit函数来终止自己的执行。这会导致父进程从wait函数(user/sh.c:145)中返回,继续执行其他操作。
事实上,我们倡议的数学机械化,就是在遵循我国古时机械化数学的启示,从1976至1977年间开始,把几何代数化,将相应的多项式组进行适当处理,把非机械化的几何定理证明转化为机械化的高次联立方程组的处理,即所谓几何定理的机器证明,由此打开局面,而再逐步走上更一般更深层的数学机械化道路的。
定理的'机械化', 先不说证明, 而说发明。发明定理, 也就是从之前的定理演绎堆叠。这是自然是一个''机械化过程。也就是'算法过程'。即便不将它方程化, 它本身的逻辑也就是算法的逻辑。 至于'证明', 与发明不同, 需要捕捉到它的根本品性, 才能方便找寻合适的前置定理, 来进行演绎。对某种'猜想'品质的捕捉, 是证明多于发明的地方。 而如果这一过程, 能够用'机械化'的方法解决, (逻辑上有可能, 特别是用计算机遍历的方法), 则计算机对于'证明'的数学问题将有极大的贡献。
在输出中野蛮地强制插入约束短语 is fast 的问题在于,大多数情况下,你最终会得到像上面的 The is fast 这样的无意义输出。我们需要解决这个问题。你可以从 huggingface/transformers 代码库中的这个 问题 中了解更多有关这个问题及其复杂性的深入讨论。 组方法通过在满足约束和产生合理输出两者之间取得平衡来解决这个问题。 我们把所有候选波束按照其 满足了多少步约束分到不同的组中,其中组 $n$ 里包含的是 满足了 $n$ 步约束的波束列表 。然后我们按照顺序轮流选择各组的候选波束。在上图中,我们先从组 2 (Bank 2) 中选择概率最大的输出,然后从组 1 (Bank 1) 中选择概率最大的输出,最后从组 0 (Bank 0) 中选择最大的输出; 接着我们从组 2 (Bank 2) 中选择概率次大的输出,从组 1 (Bank 1) 中选择概率次大的输出,依此类推。因为我们使用的是 num_beams=3,所以我们只需执行上述过程三次,就可以得到 ["The is fast", "The dog is", "The dog and"]。 这样,即使我们 强制 模型考虑我们手动添加的约束词分支,我们依然会跟踪其他可能更有意义的高概率序列。尽管 The is fast 完全满足约束,但这并不是一个有意义的短语。幸运的是,我们有 "The dog is" 和 "The dog and" 可以在未来的步骤中使用,希望在将来这会产生更有意义的输出。 图示如下 (以上例的第 3 步为例): 请注意,上图中不需要强制添加 "The is fast",因为它已经被包含在概率排序中了。另外,请注意像 "The dog is slow" 或 "The dog is mad" 这样的波束实际上是属于组 0 (Bank 0) 的,为什么呢?因为尽管它包含词 "is" ,但它不可用于生成 "is fast" ,因为 fast 的位子已经被 slow 或 mad 占掉了,也就杜绝了后续能生成 "is fast" 的可能性。从另一个角度讲,因为 slow 这样的词的加入,该分支 满足约束的进度 被重置成了 0。
[!NOTE] 包含特定短语的约束波束搜索一般是如何实现的?
flashcard
bank method - 在每一步的候选 beam 中,注入特定短语中的一个 token - 分为 n 个 bank,其中 bank i 表示该组内的 beam 包含了目标短语的 i 个 token - 在每个 bank 里选概率最大的 beam
生成的文本看起来不错 - 但仔细观察会发现它不是很连贯。3-grams new hand sense 和 local batte harness 非常奇怪,看起来不像是人写的。这就是对单词序列进行采样时的大问题: 模型通常会产生不连贯的乱码,参见 Ari Holtzman 等人 (2019) 的论文。
[!NOTE] 单纯采样的生成策略有什么常见问题?
flashcard
连贯性不好
模型很快开始输出重复的文本!这在语言生成中是一个非常普遍的问题,在贪心搜索和波束搜索中似乎更是如此 - 详见 Vijayakumar 等人,2016 和 Shao 等人,2017 的论文。
[!NOTE] 贪心/波束搜索有什么常见问题?
flashcard
容易生成重复文本
人们习惯的思维模式,是如果我去做这件事,失败了会损失什么? 这是典型的会计成本的思维模式。在这种思维模式下,人们会极力最小化潜在损失,最小化风险。机会成本的思维模式是这样的:如果我不去做这件事,我可能会失去什么?是不是正好反过来?机会成本的思维,即是更多看到未来的思维,是一种基于战略的思维。会让我们做选择时,更加基于大格局大战略,来分析各个选项的优劣,而不仅仅是风险和损失。如果一个人特别看重机会成本,就不会特别计较眼前的得失。面对未来会显得更加有勇气去做一些新的尝试,因为他们害怕失去未来可能的机会,这种失去带来的成本,才是他们不可承受的(相较于去冒险可能面临的失败后的会计成本)。
沉没成本,是让你将不相关的变量,从决策系统里剥离出去,从而在更小更有效的范围内寻求效用函数的最优解,这会极大地降低交易成本和摩擦成本。
沉没成本,不参与重大决策
以前常把这诗解释为“民间情歌”,恐怕不对头,它所描绘的应该是贵族阶层的生活。
测试一下。
如果你回顾一下自科学发明以来的工程学历史,你会发现,在利用新的思维方式来考虑一般事物,特别是制造事物方面,至今仍存在一些长期滞后现象。在一定程度上,这实际上是一个优点。
好像不理解又好像理解了。 永远有工程发挥的余地么这算是?
在这个学科高度发达的世界里,我们希望我们飞行的飞机是由严肃的工程师设计的,他们版本的 Hippocratic Oath 是“桥不能掉下来,飞机不能坠毁...”,而不是科学家或数学家,他们通常会从坠机中学到更多东西,ー从一般的玩耍中学到更多东西。工程学的“乐趣”是设计和制造真正有效、有助于人类发展的东西,这与科学和数学的“乐趣”大相径庭。拥有“乐趣”就是能够做你选择做的事情,并且做得很好。
.novel 哈哈哈哈 这个反常识。我确实不喜欢坐“这种”飞机
A 16-channel electrotactile digital vocoder for artificial hearing is developed that uses FFT spectral analysis techniques instead of the conventional bank filtering. Temporal coding of individual electrotactile current pulses is accomplished by a neuronlike encoding algorithm. This design is implemented with dual processors and used in psychophysical experiments to improve speech information transmission. Results indicate no loss of information compared with conventional designs. Such digital vocoders offer the advantages of reliable operation and signal enhancement to improve tactile speech perception by the deaf.
这是关于一种用于人工听觉的16通道电触觉数字声码器的解释。该声码器采用FFT频谱分析技术,而不是传统的滤波器组。通过一种类似神经元的编码算法,对个别电触觉电流脉冲进行时间编码。该设计采用双处理器实现,并在心理物理实验中使用,以改善语音信息传输。结果表明,与传统设计相比,没有信息损失。这种数字声码器具有可靠运行和信号增强的优点,可以改善聋人的触觉语音知觉。
第六,培养高素质教师队伍。强教必先强师。要把加强教师队伍建设作为建设教育强国最重要的基础工作来抓,健全中国特色教师教育体系,大力培养造就一支师德高尚、业务精湛、结构合理、充满活力的高素质专业化教师队伍。要立足教育强国建设实际需要,加大教职工统筹配置和跨区域调整力度。要弘扬尊师重教社会风尚,提高教师政治地位、社会地位、职业地位,使教师成为最受社会尊重的职业之一,支持和吸引优秀人才热心从教、精心从教、长期从教、终身从教。要加强师德师风建设,引导广大教师坚定理想信念、陶冶道德情操、涵养扎实学识、勤修仁爱之心,树立“躬耕教坛、强国有我”的志向和抱负,坚守三尺讲台,潜心教书育人
教育体系和教育资源以及教育系统的改革,离不开中间的一个最核心的问题就是。教师素质队伍建设。教师素质队伍建设。核心问题并不是他的技能问题,而是。道德问。这是最关键的问。就是。超越了我们。目前认知的一个隐性问题。
第四,在深化改革创新中激发教育发展活力。从教育大国到教育强国是一个系统性跃升和质变,必须以改革创新为动力。要坚持系统观念,统筹推进育人方式、办学模式、管理体制、保障机制改革,坚决破除一切制约教育高质量发展的思想观念束缚和体制机制弊端,全面提高教育治理体系和治理能力现代化水平。教育公平是社会公平的重要基础,也是建设教育强国的内在要求。要把促进教育公平融入到深化教育领域综合改革的各方面各环节,缩小教育的城乡、区域、校际、群体差距,努力让每个孩子都能享有公平而有质量的教育,更好满足群众对“上好学”的需要。教育评价事关教育发展方向,事关教育强国成败。要紧扣建设教育强国目标,深化新时代教育评价改革,构建多元主体参与、符合我国实际、具有世界水平的教育评价体系。要加强教材建设和管理,牢牢把握正确政治方向和价值导向,用心打造培根铸魂、启智增慧的精品教材。教育数字化是我国开辟教育发展新赛道和塑造教育发展新优势的重要突破口。我国互联网上网人数已达10.67亿人,要进一步推进数字教育,为个性化学习、终身学习、扩大优质教育资源覆盖面和教育现代化提供有效支撑
哦,不是现。现有的教育体系以目标的。完美契合。就意味着要对现有的教育体制机构进行大刀阔斧和根本性的。改变。改变的方法和策略就是。要实现教育公平,因为教育公平已经是现在制约整个教育体系发展的最核心的问题。具体来说。就是要把。城乡区域校际群体的差距全部取消掉。努力地让每一个孩子都能够享有公平而有质量的教育。满足群众们对上好学的需要。这一点至关重要,而且可以说是摧枯拉朽的。革命性的。
党的二十大报告把教育科技人才单独成章进行布局,吹响了加快建设教育强国的号角。我们要建设的教育强国,是中国特色社会主义教育强国,必须以坚持党对教育事业的全面领导为根本保证,以立德树人为根本任务,以为党育人、为国育才为根本目标,以服务中华民族伟大复兴为重要使命,以教育理念、体系、制度、内容、方法、治理现代化为基本路径,以支撑引领中国式现代化为核心功能,最终是办好人民满意的教育。我们要全面贯彻党的教育方针,坚持以人民为中心发展教育,主动超前布局、有力应对变局、奋力开拓新局,加快推进教育现代化,以教育之力厚植人民幸福之本,以教育之强夯实国家富强之基,为全面推进中华民族伟大复兴提供有力支撑。
会长的事业。培养人才。为国家的发展。战略需要。塑造人才。这是教育的根本目标。围绕这个根本的目标。全面地将教育理念体系。制度,内容方法。进行。全面的。系统更新。现代化。是保障。这个目标得以实现的。重要基础。可以用。 OGSM。的方法来。解读这个目标。在推动实现这个目标的过程中,还要实现人民。人民如何满意?那就是就业好、收入高。满足物质上的需求。同样。国家需要的。是这样,宏观层面上对整个教育有系统的支持和支撑。
看一看 youtube.com 这条规则加在那个分组里 - DOMAIN-SUFFIX,youtube.com,🌍 国外媒体可以看到 youtube 是在 国外媒体分组里,那么在这里要看国外媒体选择的是那个节点可以看到国外媒体选择的是 香港2-5 这个节点,选择是的延迟最低的节点,所以 youtube 走的是这个代理。
[!NOTE] Clash 是如何决定使用什么分组的什么代理节点的?
flashcard
根据 rules 匹配分组,再根据分组的
type选择节点
归根结底,他们都遵循,学习的本质是不断去亲身训练这一基本原则。所以,不管采取什么学习方法,有一点需要明白,万事求诸己。
这就是刻意练习的理论?不得不说人的可塑性是非常强的。
付费会员能买到差异化商品,是吸引入会、留存的根本动力。万德乾指出,中国零售业长期欠缺有竞争力的商品,原因在于研发能力不够,单个品类的品牌集中度不高,原料采购的便利性也不及跨国企业。生产制造水平能补上一定短板,但难以满足会员店用户的消费升级需求。 外资超市和电商抓住了最近一波消费升级的红利。山姆靠社交媒体上的网红食品采购指南一次次出圈,其总 SKU(最小库存单位)只有 4000 多个——而一般超市通常都有数万个——商品来自全球采购,「新奇特」带来的消费者互动性较好。 低价考验供应链能力,这也是业内公认的山姆会员店竞争壁垒之所在。一方面得益于门店数多带来的规模议价能力,批量直采配合包厢集运,进货和物流成本的压降能让利给终端;同时,也和采购团队专业度有关,比如对接酒庄直采的人员不少持有品酒师证书。 不能通过直采获得理想的价格或品质,则通过和品牌、供应商共创定制来实现,这考验采购的选品眼光。过去,超市通过 ODM(原始设计制造商)做自有品牌,主要目的是对供应商产品形成竞争制约,提升自身议价能力,因此主要限制在弱品牌、强品质的品类。万德乾认为,麦德龙、山姆、Costco 的自有品牌占比均在 20%至 30%,可视为超市自有品牌占比的警戒线,否则面临专业度不足。 在受关注的进口商品之外,山姆会员店的商品主要来自本地供应。张陈勇认为,供应链数十年积累带来稳固合作是山姆壁垒所在,「小红书及电商代购潮给山姆带来的短时大量流量,供应链也能接得住,没有出现爆品断货或品质下降的情况。」
网页标注是非常好的概念,这是我打通输入输出的必要工具。很多人喜欢收藏东西,用浏览器书签、知乎收藏夹之类的。因为收藏的时候没有自己写上标注和自己的理解,而且和自己的输入是隔离的,这样导致收藏的东西基本吃灰。 所以我们可以使用网页标注这种概念来把自己平时所看的东西变成输入。 网页标注我使用 开源、可定制的网页批注工具 Hypothesis,通过 Hypothesis 我可以在浏览网页的时候把某些内容高亮或者添加注释,然后通过插件 obsidian-hypothesis-plugin 自动同步到我的知识库,这样我就可以在 Obsidian 里面看到我的记录。 比如我在浏览这个网页的时候,如果我觉得内容不错就写一点自己的评论,加上 #write 标签标识以后可能分享一下。
anotation和highlight的区别是什么
脂溢性皮炎患者皮肤上都有大量的马拉色菌定植,它们能释放出溶脂酶,而溶质酶可以将皮脂中的甘油三酯分解成油酸和花生四烯酸等游离脂肪酸,这些代谢物会导致角质细胞的分化异常,影响表皮和角质层的正常代谢功能,造成屏障功能受损和角化不全。其中,角化不全会导致角栓形成,也就是堆积的角质+皮脂+微生物及其代谢产物形成的毛囊栓塞,即黑头的基础;屏障功能受损会导致更多的炎症,炎症反应又会进一步影响角质分化,然后恶性循环。。。为了帮助大家理解,我简化一下这个逻辑链吧:马拉色菌(某品种真菌)——产生溶脂酶——皮脂被分解成油酸、花生四烯酸等游离脂肪酸——角质细胞分化异常——角栓形成/屏障功能受损——黑头/炎症——炎症进一步影响角质分化——加剧角栓——进入恶性循环~而甲硝唑是明确有效的抗真菌药,可以干掉定植在人皮肤表面的马拉色菌,自然后面描述的这串恶性循环也就无法开启了~“黑头宝宝”也就失去了赖以生存的肥沃土壤了。事实上,在大量翻阅资料的过程中我发现,并不仅是马拉色菌有这个分解甘油三酯的能力,痘肌宝宝都听过的痤疮丙酸杆菌也可以
[!NOTE] 马拉色菌、痤疮丙酸杆菌等微生物引起痤疮的主要机理为?
flashcard
释放出溶脂酶,将皮脂中的甘油三酯分解成油酸和花生四烯酸等游离脂肪酸,导致皮肤角化异常
Powerwall’s electrical interfaceis provided by an internal isolated bi-directional DC/DC converter controlling the charge anddischarge of the battery for integration with utility-interactive inverters
看参数,知道这是Powerwall1。它内部有一个隔离的DCDC,用于电池的充放电控制,然后,与外部的逆变器连接。所以,是两级的结构的。所以,Powerwall1是直流耦合的。可能的原因是逆变器使用的SolarEdge的。Powerwall2和Powerwall2+,就用了AC couple,那时,可能这就是个单独的电池柜,外边的一个箱子是单独的逆变器柜,那并联,自然就是AC Couple了。
deepspeed.zero.GatheredParameters是DeepSpeed提供的一个上下文管理器, # 它可以将分布在多个设备上的参数收集到一起。这部分参数保存在CPU上。
[!NOTE] DeepSpeed 中,
with deepspeed.zero.GatheredParameters(params):有什么用?flashcard
将
paramsgather 到 CPU 上
请问 <pad> 不能通过 attn_mask 来忽略掉,从而相当于模型根本没有见到 <pad> 吗?还是我的理解有什么问题?烦请指教~ 我的理解是:是由于位置编码带来的影响。首先<pad>肯定是可以通过attention_mask将其忽略的,但是如果不考虑序列内部的位置关系的话,其实各个token完全可以乱序放置也不影响对模型的理解与生成。这也是transformer类模型引入位置编码的作用,引入其没有的序列位置信息。 那具体对于 Llama 模型来说,旋转位置编码 (RoPE) 使得在计算注意力的过程中会考虑到不同token之间的相对位置关系,因此如果在 <input> 和 <target> 之间插入过多的 <pad> ,就会破坏这种相对位置关系,并影响模型的生成效果。
[!NOTE] padding side 具体是如何影响 Transformer 计算的?
flashcard
位置编码 中间插入了过多 pad token 后,相当于前后的 token 距离很远,不符合实际
DDX排名及DDE选股的参考价值及使用方法1,DDE决策系统的含义 很多短线操作者都非常重视盘中交易数据的分析,短线客往往紧盯盘口,依靠自己的经验和想象,猜测行情背后的交易本质。而行情数据稍瞬即逝,投资者很难在盘中对数据进行精确的统计和分析,因此行情交易分析一只停留在经验、主观、随意的层次,缺乏科学性和可验证性。2,DDE(Data Depth Estimate)是深度数据估算,这是大智慧公司独创的、具有垄断优势的动态行情数据分析技术。他不但能实时统计交易数据,而且能够揭示交易的本质,帮助投资者迅速形成决策,把握短线机会 3,DDE包括DDX、DDY、DDZ三个指标。4,ddx大单动向:ddx大单动向指标是基于大智慧Level-2的逐单分析功能,是一个短中线兼顾的技术指标。DDX红绿柱线表示当日大单买入净量占流通盘的百分比(估计值),红柱表示大单买入量较大,绿柱表示大单卖出量较大。5,ddy涨跌动因: 涨跌动因指标基于大智慧新一代的逐单分析,逐单分析是对交易委托单的分析,涨跌动因是每日卖出单数和买入单数差的累计值。6,ddz大单差分: 红色彩带表示了大资金买入强度,色带越宽、越高表示买入强度越大。当彩带突然升高放宽时往往预示短线将快速上涨。有了DDE后,就可以将投资股票的过程反过来,先使用DDE去选择走势好的股票,然后在对这些股票进行基本面分析,来进行投资决策。7,另外要强调一点,DDX和DDY是追强势股的指标,不能用做抄底等操作。8,DDZ目前基本上没有太大意义,DDX、DDY作用比较大,目前大智慧大力宣传DDX,我认为DDY要更有价值.关于DDX的使用,我觉得DDX更像是一个强度的指标,能够体现出股票目前的走势强弱,其参考的时间价值相对较短,2-3天内会比较有效;9,关于DDY的使用,我觉得DDY更多体现的是主力操作方向,能够体现出主力的操作方向。其参考的时间价值相对长一些。特别是DDY曲线持续向上的股票,体现出主力在持续增仓。10,每天提供给大家的DDX排名、DDE组合选股,是为了提供给大家一个强势股的范围,在排名中的位置并不重要。更重要的是要对个股进行基本面分析,这样能够保证一旦操作失败可以转成长线投资。如果只是看DDX、DDE操作,那么一定要有快进快出的准备,一旦行情转坏赶紧出局。11,对于DDX连续翻红,和DDY曲线持续向上,需要有level2才行。没有的朋友就需要对每天的数据进行记录了,对于一周内几次进入排行榜的要高度关注12,再次强调,技术指标不是万能的,但是没有技术指标是万万不能的。结合当前板块热点及主力持仓的变动,才是上策。?
DDX排名及DDE选股的参考价值及使用方法
1,DDE决策系统的含义
很多短线操作者都非常重视盘中交易数据的分析,短线客往往紧盯盘口,依靠自己的经验和想象,猜测行情背后的交易本质。而行情数据稍瞬即逝,投资者很难在盘中对数据进行精确的统计和分析,因此行情交易分析一只停留在经验、主观、随意的层次,缺乏科学性和可验证性。 2,DDE(Data Depth Estimate)是深度数据估算,这是大智慧公司独创的、具有垄断优势的动态行情数据分析技术。他不但能实时统计交易数据,而且能够揭示交易的本质,帮助投资者迅速形成决策,把握短线机会 3,DDE包括DDX、DDY、DDZ三个指标。 4,ddx大单动向: ddx大单动向指标是基于大智慧Level-2的逐单分析功能,是一个短中线兼顾的技术指标。DDX红绿柱线表示当日大单买入净量占流通盘的百分比(估计值),红柱表示大单买入量较大,绿柱表示大单卖出量较大。 5,ddy涨跌动因: 涨跌动因指标基于大智慧新一代的逐单分析,逐单分析是对交易委托单的分析,涨跌动因是每日卖出单数和买入单数差的累计值。 6,ddz大单差分: 红色彩带表示了大资金买入强度,色带越宽、越高表示买入强度越大。当彩带突然升高放宽时往往预示短线将快速上涨。 有了DDE后,就可以将投资股票的过程反过来,先使用DDE去选择走势好的股票,然后在对这些股票进行基本面分析,来进行投资决策。 7,另外要强调一点,DDX和DDY是追强势股的指标,不能用做抄底等操作。 8,DDZ目前基本上没有太大意义,DDX、DDY作用比较大,目前大智慧大力宣传DDX,我认为DDY要更有价值.
关于DDX的使用,我觉得DDX更像是一个强度的指标,能够体现出股票目前的走势强弱,其参考的时间价值相对较短,2-3天内会比较有效; 9,关于DDY的使用,我觉得DDY更多体现的是主力操作方向,能够体现出主力的操作方向。其参考的时间价值相对长一些。特别是DDY曲线持续向上的股票,体现出主力在持续增仓。 10,每天提供给大家的DDX排名、DDE组合选股,是为了提供给大家一个强势股的范围,在排名中的位置并不重要。更重要的是要对个股进行基本面分析,这样能够保证一旦操作失败可以转成长线投资。如果只是看DDX、DDE操作,那么一定要有快进快出的准备,一旦行情转坏赶紧出局。 11,对于DDX连续翻红,和DDY曲线持续向上,需要有level2才行。没有的朋友就需要对每天的数据进行记录了,对于一周内几次进入排行榜的要高度关注 12,再次强调,技术指标不是万能的,但是没有技术指标是万万不能的。结合当前板块热点及主力持仓的变动,才是上策。
?
DDX排名及DDE选股的参考价值及使用方法1,DDE决策系统的含义 很多短线操作者都非常重视盘中交易数据的分析,短线客往往紧盯盘口,依靠自己的经验和想象,猜测行情背后的交易本质。而行情数据稍瞬即逝,投资者很难在盘中对数据进行精确的统计和分析,因此行情交易分析一只停留在经验、主观、随意的层次,缺乏科学性和可验证性。2,DDE(Data Depth Estimate)是深度数据估算,这是大智慧公司独创的、具有垄断优势的动态行情数据分析技术。他不但能实时统计交易数据,而且能够揭示交易的本质,帮助投资者迅速形成决策,把握短线机会 3,DDE包括DDX、DDY、DDZ三个指标。4,ddx大单动向:ddx大单动向指标是基于大智慧Level-2的逐单分析功能,是一个短中线兼顾的技术指标。DDX红绿柱线表示当日大单买入净量占流通盘的百分比(估计值),红柱表示大单买入量较大,绿柱表示大单卖出量较大。5,ddy涨跌动因: 涨跌动因指标基于大智慧新一代的逐单分析,逐单分析是对交易委托单的分析,涨跌动因是每日卖出单数和买入单数差的累计值。6,ddz大单差分: 红色彩带表示了大资金买入强度,色带越宽、越高表示买入强度越大。当彩带突然升高放宽时往往预示短线将快速上涨。有了DDE后,就可以将投资股票的过程反过来,先使用DDE去选择走势好的股票,然后在对这些股票进行基本面分析,来进行投资决策。7,另外要强调一点,DDX和DDY是追强势股的指标,不能用做抄底等操作。8,DDZ目前基本上没有太大意义,DDX、DDY作用比较大,目前大智慧大力宣传DDX,我认为DDY要更有价值.关于DDX的使用,我觉得DDX更像是一个强度的指标,能够体现出股票目前的走势强弱,其参考的时间价值相对较短,2-3天内会比较有效;9,关于DDY的使用,我觉得DDY更多体现的是主力操作方向,能够体现出主力的操作方向。其参考的时间价值相对长一些。特别是DDY曲线持续向上的股票,体现出主力在持续增仓。10,每天提供给大家的DDX排名、DDE组合选股,是为了提供给大家一个强势股的范围,在排名中的位置并不重要。更重要的是要对个股进行基本面分析,这样能够保证一旦操作失败可以转成长线投资。如果只是看DDX、DDE操作,那么一定要有快进快出的准备,一旦行情转坏赶紧出局。11,对于DDX连续翻红,和DDY曲线持续向上,需要有level2才行。没有的朋友就需要对每天的数据进行记录了,对于一周内几次进入排行榜的要高度关注12,再次强调,技术指标不是万能的,但是没有技术指标是万万不能的。结合当前板块热点及主力持仓的变动,才是上策。
DDX排名及DDE选股的参考价值及使用方法
1,DDE决策系统的含义
很多短线操作者都非常重视盘中交易数据的分析,短线客往往紧盯盘口,依靠自己的经验和想象,猜测行情背后的交易本质。而行情数据稍瞬即逝,投资者很难在盘中对数据进行精确的统计和分析,因此行情交易分析一只停留在经验、主观、随意的层次,缺乏科学性和可验证性。 2,DDE(Data Depth Estimate)是深度数据估算,这是大智慧公司独创的、具有垄断优势的动态行情数据分析技术。他不但能实时统计交易数据,而且能够揭示交易的本质,帮助投资者迅速形成决策,把握短线机会 3,DDE包括DDX、DDY、DDZ三个指标。 4,ddx大单动向: ddx大单动向指标是基于大智慧Level-2的逐单分析功能,是一个短中线兼顾的技术指标。DDX红绿柱线表示当日大单买入净量占流通盘的百分比(估计值),红柱表示大单买入量较大,绿柱表示大单卖出量较大。 5,ddy涨跌动因: 涨跌动因指标基于大智慧新一代的逐单分析,逐单分析是对交易委托单的分析,涨跌动因是每日卖出单数和买入单数差的累计值。 6,ddz大单差分: 红色彩带表示了大资金买入强度,色带越宽、越高表示买入强度越大。当彩带突然升高放宽时往往预示短线将快速上涨。 有了DDE后,就可以将投资股票的过程反过来,先使用DDE去选择走势好的股票,然后在对这些股票进行基本面分析,来进行投资决策。 7,另外要强调一点,DDX和DDY是追强势股的指标,不能用做抄底等操作。 8,DDZ目前基本上没有太大意义,DDX、DDY作用比较大,目前大智慧大力宣传DDX,我认为DDY要更有价值.
关于DDX的使用,我觉得DDX更像是一个强度的指标,能够体现出股票目前的走势强弱,其参考的时间价值相对较短,2-3天内会比较有效; 9,关于DDY的使用,我觉得DDY更多体现的是主力操作方向,能够体现出主力的操作方向。其参考的时间价值相对长一些。特别是DDY曲线持续向上的股票,体现出主力在持续增仓。 10,每天提供给大家的DDX排名、DDE组合选股,是为了提供给大家一个强势股的范围,在排名中的位置并不重要。更重要的是要对个股进行基本面分析,这样能够保证一旦操作失败可以转成长线投资。如果只是看DDX、DDE操作,那么一定要有快进快出的准备,一旦行情转坏赶紧出局。 11,对于DDX连续翻红,和DDY曲线持续向上,需要有level2才行。没有的朋友就需要对每天的数据进行记录了,对于一周内几次进入排行榜的要高度关注 12,再次强调,技术指标不是万能的,但是没有技术指标是万万不能的。结合当前板块热点及主力持仓的变动,才是上策。
?