For decades, code contributions have been how open source projects learned who to trust. People would show up, do the work, take responsibility for their changes, and stick around. Over time, trust emerged from the work itself. AI tools have changed the economics of this very quickly. We use them ourselves every day, but a pull request no longer tells us as much as it used to about the person submitting it. A substantial patch used to imply substantial effort, and that effort was a reasonable proxy for good faith. That assumption no longer holds. For a browser, this matters. A browser runs untrusted input from the entire internet on the user’s machine, and one well-disguised vulnerability is all an attacker needs. We have already seen patient, well-resourced campaigns in open source to earn maintainer trust and abuse it. What has changed is how much faster and cheaper it has become to produce work that looks like a serious contribution.
9,505 Matching Annotations
- Last 7 days
-
ladybird.org ladybird.org
-
-
-
In a mistaken effort after economy some peoplerefrain from taking this advice, and have cards printedand cut at the local printing office. Whatever initialsaving is effected is dearly bought, for such cards areseldom cut with the mathematical accuracy necessaryfor satisfactory work.
He's not using the traditional wording, but he's talking about the need for having "cards of equal size" for use in a card index here.
-
It would be un-grateful not to acknowledge with appreciation theobligation owed to the publishers of that most excellentbusiness magazine, " System/' from the pages of whichanyone interested in modern business methods mustinevitably derive some inspiration.
-
-
www.joanwestenberg.com www.joanwestenberg.com
-
People don't want infinite choice anymore; they want fewer decisions inside places where someone has already thrown out the worst options.
Reminds me of an experiment summarized in Barry Schwartz's Paradox of Choice. As I recall it, grocery store customers were divided into 2 groups - one group saw shelves upon shelves of different jams and jellies; the other group saw about 4 kinds of jelly. Everyone agreed that the store with more options must be the better store. But the people presented with fewer options said they had a better shopping experience.
And they bought more jelly.
-
-
www.anthropic.com www.anthropic.com
-
We now spend much more of our time delegating tasks to many Claudes in parallel.
大多数人认为AI会取代人类工作,导致失业,但作者认为AI实际上改变了人类工作方式,让人们转向更高层次的任务分配和管理。这挑战了关于AI与就业关系的传统叙事,表明AI可能创造新的工作形式而非简单替代人类。
-
-
thenextweb.com thenextweb.com
-
The union has drawn a hard line. 'Not a single humanoid robot will be allowed on the production lines without a labour-management agreement,' it said. It wants a veto, not a briefing.
大多数人认为工会会抵制机器人技术以保护现有工作岗位,但作者提出了一个更激进的解读:工会实际上是在寻求对自动化决策的否决权,而不仅仅是被动抵抗。这表明工人正在主动争取对工厂未来的控制权,而不仅仅是保护现状。
-
-
www.rustaceans.org www.rustaceans.org
-
I'm sorry for anyone using it, but I no longer have the time to maintain it.
Tags
Annotators
URL
-
-
dl.acm.org dl.acm.org
-
Self-Determination Theory (SDT), a major psychological the-ory of human motivation, has become increasingly popular inHuman-Computer Interaction (HCI) research on games andplay.
-
-
-
Todd Blanche hit with state bar complaint backed by 101 former judges<br /> by [[Steve Benen]]<br /> accessed on 2026-06-24T00:19:53
-
-
arstechnica.com arstechnica.com
-
Trump may be mystery patient in odd case of 79yo getting experimental obesity drug<br /> by [[Beth Mole]] in Ars Technica<br /> accessed on 2026-06-23T21:06:22
Tags
- read
- Donald J. Trump
- Kush Desai
- United States Department of Health and Human Services
- Retatrutide
- Donald J. Trump health
- United States Food and Drug Administration (US FDA)
- Donald J. Trump obesity
- Eli Lilly
- National Institutes of Health (NIH)
- bariatric surgery
- weight loss drugs
- drug trials
- GLP-1
Annotators
URL
-
-
boisestate.pressbooks.pub boisestate.pressbooks.pub
-
his is where yo
we can use tags
-
-
-
ydotool will then be rewritten in JavaScript afterwards, to enable more people to understand the code & contribute.
-
-
www.theguardian.com www.theguardian.com
-
Texas anti-ICE protesters convicted of terrorism charges sentenced to at least 50 years in prison | Trump administration | The Guardian<br /> by [[Sam Levine]]<br /> accessed on 2026-06-23T09:12:06
-
-
www.youtube.com www.youtube.comYouTube1
-
[Why this creepy melody is in so many movies}(https://www.youtube.com/watch?v=-3-bVRYRnSM)<br /> on YouTube by Vox
-
- Jun 2026
-
brigada.org brigada.org
-
Purposeful entry; looking for person of peace / houses of peace
-
the priesthood of all believers (1 Peter 2:5-9),
-
The focus is to make every follower of Christ a reproducing disciple rather than merely a convert.
-
-
lifewayglobal.org lifewayglobal.org
-
They invite “persons of peace” into a simple, inductive Bible study along with their family and friends.
-
-
ojs.globalmissiology.org ojs.globalmissiology.org
-
www.npraxisinternational.org www.npraxisinternational.org
-
www.thegospelcoalition.org www.thegospelcoalition.org
-
According to some, finding a person of peace is essential to a fruitful entry strategy for a missionary. However, this interpretation of Luke 10 is exegetically flawed, and following this philosophy to identify a person of peace is potentially dangerous.
-
-
renew.org renew.org
-
Jesus was walking by the Sea of Galilee and saw Levi sitting in a tax booth. “Follow me,” Jesus commanded. “Levi got up and followed him” (Mark 2:14, NIV). The next scene is at Levi’s house. Levi has invited all his business associates and sinners to a large meal to introduce them to Jesus. Levi was a person of peace.
-
I should note—a person of peace may not have accepted Jesus as their Lord and Savior but still be open to the Gospel message. It’s this openness to those sharing the Gospel that shows God is already working within their lives.
Tags
Annotators
URL
-
-
newrepublic.com newrepublic.com
-
Utterly Absurd Contractor Behind Reflecting Pool Renovation Disaster<br /> by [[Rachel Kahn]] in The New Republic<br /> accessed on 2026-06-19T13:06:37
It was so important for Trump to have the reflecting pool be blue that they stupidly hired "Greenwater Services" with a no-bid contract.
-
-
www.experiencelifenow.com www.experiencelifenow.com
-
It is our prayer that this training will help you in your personal efforts and in your church’s efforts to make disciples for the Kingdom of God. We hope that you will view your experience with eLife and beyond as helping you expand the work of Christ’s Church, and not as serving as a representative of eLife, trying to carry out eLife’s programs or to promote eLife in any way. What we have shared and will share with you does not belong to eLife, but is intended to be given away for the good of the Body of Christ. Please do so with our blessing towards the goal of fulfilling the Great Commission.
-
-
newrepublic.com newrepublic.com
-
Trump Calls Obama a “Son of a B*tch” After Disastrous Iran Deal Leaked<br /> by [[Edith Olmsted]] in The New Republic<br /> accessed on 2026-06-18T09:16:08
-
-
newrepublic.com newrepublic.com
-
Angry and Rattled, Trump’s Fox Allies Blurt It Out on Live TV: He Lost<br /> by The Daily Blast With Greg Sargent on The New Republic<br /> accessed on 2026-06-18T09:13:10
-
-
www.irish-song-lyrics.com www.irish-song-lyrics.com
-
THE HUMOURS OF WHISKEY<br /> by [[Marc Gunn]], Celtic Bard accessed on 2026-06-17T11:52:28
-
-
-
Vance’s admission contradicts what he said on Friday, when he claimed in an X post that Iran would not be “receiving any cash, and no funds are being released simply for signing a deal or attending a meeting.” In addition to the U.S. and its allies paying $300 billion in reconstruction funds, Iran reports that the U.S. has agreed to release $25 billion in frozen Iranian assets.
So somehow this (on top of all the losses and multiple billions in costs of the war and economic problems) is better than the Obama nuclear deal? WTF?
-
Conservatives, including Trump and Vance, have long criticized the Obama administration’s 2015 nuclear deal, which involved the U.S. lifting sanctions and sending Iran $1.7 billion to settle decades-old failed contracts between the two countries. That deal was also succeeding, with international observers stating that Iran was adhering to all its nuclear terms. It was Trump who decided to break it in his first term and then start a war with Iran in his second.
-
-
www.independent.co.uk www.independent.co.uk
-
America has lost its war with Iran<br /> by [[Editorial]] | The Independent<br /> accessed on 2026-06-15T22:04:21
-
-
en.wikipedia.org en.wikipedia.org
-
Ranganathan, S. R. 1931. The Five Laws of Library Science. 1st ed. Madras, London: The Madras Library Association; E. Goldston. https://catalog.hathitrust.org/Record/001661182 (June 15, 2026).
-
-
www.nytimes.com www.nytimes.com
-
Opinion - A Defense of a Liberal Arts Education in the Age of A.I.<br /> by [[Ross Douthat]], [[Victoria Chamberlin]], [[jennSophia Alvarez Boyd]] - The New York Times<br /> accessed on 2026-06-11T16:57:08
-
Let us remember that it was the Obama administration that rolled out the scorecard of majors. So this kind of utilitarian push is, I believe, bipartisan.
-
I share your view that the purported death of literacy is a tragedy.
-
-
www.reddit.com www.reddit.com
-
-
Robert Caro Reveals Details of His Final Lyndon Johnson Biography<br /> C-SPAN's Book TV
Caro outlines the entirety of his book before he starts writing. He puts his outline onto paper which he tacks up onto cork boards across his office wall.
Caro writes everything in longhand first then types/revised it on his Smith-Corona Electra 210.
Caro only gave Gottlieb a piece of his LBJ bio draft when he ran out of money and needed an advance. Otherwise, he doesn't give his editor material until he's done.
Caro lives on the corner in Central Park West
Caro was on the 22nd floor (of 29) at 250 W. 57th Street for 22 years and wrote 3 books in a one room office. Joseph Heller had an office there as well.
-
-
ziglang.org ziglang.org
Tags
Annotators
URL
-
-
human-in-the-loop.bearblog.dev human-in-the-loop.bearblog.dev
-
The only way out for keeping my employability in the long-term now seems to be shifting my domain expertise to something LLMs will not get good at so easily. But what's left?
大多数人认为人类可以通过转向更复杂的领域或学习高级技能来应对AI挑战,但作者暗示即使是这些领域也可能被AI迅速渗透,表达了一种'无处可逃'的悲观情绪。这与'人类总能找到AI无法替代的领域'的主流乐观观点相悖。
-
-
www.commonsensemedia.org www.commonsensemedia.org
-
Several of the apps evaluated are subscription or freemium products that depend on users returning. This creates a structural conflict of interest: The business succeeds when users stay engaged, but good mental health care succeeds when users get better and need less support.
This structural conflict is the most fundamental critique of the entire category — not a product flaw but a business model flaw. Successful mental health treatment produces clients who no longer need the product. Gamification mechanics (streaks, coins, follow-up questions) are retention tools that optimize for the opposite outcome. As long as revenue depends on engagement, these apps face an inherent incentive to keep users symptomatic enough to return.
-
-
typecast.munk.org typecast.munk.org
-
Paul Varjak’s typewriter in “Breakfast at Tiffany’s” is a 1960 Smith-Corona Galaxie with 10″ Carriage, 12CPI Elite typeface, in “Hunter Red” and carried in a deluxe blue Holiday Case.
Breakfast At Tiffany’s: Paul Varjak’s Typewriter<br /> by [[Ted Munk]]<br /> accessed on 2026-06-02T16:11:00
-
- May 2026
-
www.youtube.com www.youtube.com
-
George Berkeley: A Treatise Concerning the Principles of Human Knowledge<br /> by Tod Desmond
Four important questions:<br /> - What can I know?
Berkeley believes in two things: ideas and the minds that perceive them.
"manifest contradiction"
Lucretius: things are made of atoms<br /> Berkeley: there are only ideas (and no matter)
Where do ideas and minds separate? where do they connect? how are they different from each other?
primary qualities versus secondary qualities
Plato's theory of absolute ideas<br /> - he rejects matter - GB: we can't separate primary and secondary qualities in our minds
How does matter interact with mind?
-
-
-
Crete practitioners prepare tens of thousands of tax returns each season which requires working through millions of underlying documents.
这个数据点展示了税务处理的规模:数万份报税表和数百万份文件。这解释了为什么自动化如此重要—人工处理如此大规模的数据不仅耗时而且容易出错。'tens of thousands'和'millions'之间的比例关系也显示了每份报税表通常涉及数十份支持文档的复杂性。
-
-
www.vatican.va www.vatican.va
-
These criteria give rise to certain non-negotiable requirements. First, all systems used in a war setting must guarantee the possibility of retracing and reconstructing decision-making processes, so that accountability and blame are not collapsed into “the machine.” Second, the decision to use lethal force cannot be delegated to opaque or automated processes, but must remain under effective, self-aware and responsible human control. Finally, it is imperative to establish a shared framework — also at the international level — in order to curb the technological arms race and ensure robust protection for civilians and the infrastructures necessary for their survival.
Criteria for the AI-assisted use of force. (Might be interesting to ask whether these should apply to non-war situations as well, like police or private security use of force.)
-
We must therefore promote an ecology of communication. On the level of public policy, this entails establishing norms so that the decision-making behind content selection and its development becomes more transparent and protects personal data. Regarding social and cultural aspects, this requires a strengthening of intermediary organizations, serious journalism and forums for debate, where reasoned argumentation and verification carry greater weight than immediate reaction. For families and schools, there is a growing need for new educational awareness and for formation concerning the proper and critical use of digital tools, AI and online commercial and financial platforms. In universities, the principal challenge lies in the integration of knowledge, cultivating both the capacity to connect and synthesize knowledge in order to grasp complexity, and the skills necessary to verify facts.
-
-
hub.jhu.edu hub.jhu.edu
-
Hopkins' most famous dropout | Hub<br /> by [[Aleyna Rentz]] in JHU Hub accessed on 2026-05-26T13:36:21
-
-
Local file Local file
-
A Treatise concerning thePrinciples of I-Iuman Kno,vledge
Berkeley, George. Jessop, T. E., ed. 1964. “The Principles of Human Knowledge.” In The Works of George Berkeley Volume 2: The Principles of Human Knowledge, First Draft of the Principles, Three Dialogues, Philosophical Correspondence with Johnson, The Works of George Berkeley, London: Thomas Nelson and Sons, Ltd., 1–113.
Reprint of first edition (thus) 1949; Original publication 1710
-
-
www.reddit.com www.reddit.com
-
reply to u/deleted at https://old.reddit.com/r/typewriters/comments/1te4u1i/state_of_the_typosphere/
Two or three typewriter repair shops have opened up in the past couple of years, though probably not enough to offset the retirements or deaths which include Tom Furrier (Cambridge Typewriter) and Duane Jensen (Phoenix Typewriter) respectively. Lucas Dul opened up a brick-and-mortar typewriter shop in Chicago.
Philly Typewriter and Bremerton Typewriter Company have started up typewriter repair schools/apprenticeships to expand on the trade.
Tom Hanks has continued donating typewriters to typewriter repair shops over the past few years, ostensibly to encourage the space as well as to slim down his own collection.
Richard Polt recently downsized his collection significantly. (His blog is generally a good source of the news of what's new in the past few years.)
Prices are up somewhat in general, but especially for Hermes 3000s, Olympias, Smith-Corona Silent Supers, and Olivetti Letteras even in poor condition.
Historical updates: https://typewriterdatabase.com/twdb.0.news-media
Type Pals has started up monthly meetups again: https://www.typepals.com/events
Lou Spirito designed a baseball scorecard for typewriters which was unveiled by Tom Hanks on March 29, 2025.
Qwertyfest seems to be going strong: https://www.qwertyfest.com/
Atlanta, Albuquerque, and Los Angeles have bee hosting type-ins a few times a year.
I've fleshed out some details and examples on typecasting for those interested in trying it out: https://indieweb.org/typecast
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Other esophagus motility disorders
Dysphagia for liquids as well as solids tends to be intermittent and nonprogressive. DY
Manometry is not routinely used for mild to moderate symptoms because the findings seldom influence medical management
Barium esophagography is useful to exclude mechanical obstruction and to evaluate esophageal motility
Upper endoscopy also is performed to exclude a mechanical obstruction (as a cause of
dysphagia) and to look for evidence of erosive refl traders ux esophagitis (a common cause of chest pain) or eosinophilic esophagitis (confirmed by esophageal biopsy)
-
-
callyzer.co callyzer.co
-
Understanding Call Monitoring
Unlock the benefits of call monitoring for your contact center. Enhance customer satisfaction and performance with effective call listening and monitoring practices.
Know More: https://callyzer.co/blog/what-are-the-benefits-of-call-monitoring/
-
-
-
minority “communities of interest” have historically only been guaranteed representation through the practice of “racial gerrymandering,” a practice ruled unconstitutional in the recent US Supreme Court’s decision in Louisiana v. Callais.
-
Unfortunately, the Supreme Court did not find this argument to be persuasive, ruling instead that the question of partisan gerrymandering is “nonjusticiable”—outside their jurisdiction. Subsequent rulings, such as Abbott v. League of United Latin American Citizens, give little hope that the Supreme Court will impede future gerrymandering.
The Supreme Court in Rucho v. Common Cause (2019) found that Markov chain Monte Carlo sampling wasn't persuasive and found that gerrymandering is "nonjusticable".
-
-
-
Maine and Alaska both use instant-runoff voting for House elections.
-
-
www.youtube.com www.youtube.com
-
That Pigeon Looks Just Like Michael Keaton<br /> The Late Show with Stephen Colbert
Definitely a late model Olivetti. Either a Studio 45, which was more common in the United States, or a Studio 46, both of which came in that color.
I'm leaning toward 46 because of some of the shape of the hood as well as the white variable button on the platen which I've only ever seen on the 46 while the 45s were typically black or had the button colored to match the body color.
-
-
deepmind.google deepmind.google
-
A photo of a scribbled note becomes an interactive to-do list; a paused frame in a travel video becomes a booking link for that cool-looking restaurant.
These aren't demos—they're previews of how AI will collapse the gap between passive content consumption and active task completion. Every image, video frame, or document becomes a potential action surface. This fundamentally changes what 'content' means.
-
-
www.theregister.com www.theregister.com
-
Torvalds' remarks contrast with recent comments from fellow kernel maintainer Greg Kroah-Hartman, who recently told The Register that AI has become an increasingly useful tool for the FOSS community.
文章只是简单指出Torvalds和Kroah-Hartman的观点存在对比,但没有深入分析这种差异的原因或背景。这种对比缺乏上下文,可能导致读者误解Linux社区对AI工具的整体态度。改进应包括探讨两位开发者可能的不同职责或经验如何导致观点差异,或提供其他社区成员的观点以平衡报道。
-
-
80000hours.org 80000hours.org
-
I think it is sufficient to make a proof of concept, and with a proof of concept then we can convince companies to actually put in the money to train larger systems, or systems that are trained from scratch using the same principle.
这一观点强调了概念验证的重要性,认为通过小规模实验可以说服公司投资更大规模的安全AI系统,展示了实现目标的实际路径。
-
-
www.youtube.com www.youtube.com
-
In the final weeks of The Late Show with Stephen Colbert, Tom Hanks gifts Stephen Colbert with a box of computer paper and an Underwood Ace typewriter (circa 1955-57).
-
-
www.raymondgeddes.com www.raymondgeddes.com
-
The Evolution of the Card Catalog System – Raymond Geddes<br /> accessed on 2026-05-13T21:39:37
-
-
www.facebook.com www.facebook.com
-
The typewriter of Hollywood writer Carl Foreman and later Milton Sperling, it's encased in plexi with the titles of the films that were written on it.
https://www.facebook.com/groups/TypewriterCollectors/posts/10163613988099678/

-
-
slate.com slate.com
-
Rosenbaum, Ron. 1999. “The Last Luddite Gets Wired.” Slate. https://slate.com/news-and-politics/1999/05/the-last-luddite-gets-wired-4.html (May 11, 2026).
-
I believe a case can be made–indeed a case has been made by others, by historians of Apple and hacker culture–that “Secrets of the Little Blue Box,” a story I wrote for Esquire back in 1971 about “phone phreaks” and the first computer hackers (it was only the second magazine story I’d ever had published) played a crucial role in the careers of the founders of Apple and of a legendary ur-hacker I made famous who went by the name of Captain Crunch.
-
-
-
The Quiet Cult of the Olympia Report deLuxe Electric Typewriter<br /> by [[Wilson Rothman]] and [[Steven Levy]]<br /> accessed on 2026-05-11T13:13:15
-
-
oztypewriter.blogspot.com oztypewriter.blogspot.com
-
The Mystery of Patrick Moore's Woodstock Typewriter<br /> by [[Robert Messenger]] for oz.Typewriter<br /> accessed on 2026-05-08T13:19:49
-
-
groups.psych.northwestern.edu groups.psych.northwestern.edu
-
For example, causal system is more abstract than posi-tive feedback system, which in turn is more abstract than the specific positive feedbacksystem by which the melting of polar ice causes lower reflectance of the sun’s heat, lead-ing in turn to more rapid melting.
-
Wetake the process of abstraction to be one of decreasing the specificity (and therebyincreasing the scope) of a concept.
-
it is not enough to consider the distribution of examples given to learn-ers; one must consider the processes learners are applying
-
-
site.xavier.edu site.xavier.edu
-
Users of Woodstock typewriters included: - Robert Bloch<br /> - Howard Fast<br /> - Alger Hiss (1929 standard #230099)<br /> - Sir Patrick Moore<br /> - J.C. Oldfield (editor of the Associated Press's London bureau, 1930s)<br /> - Gordon Parks
-
-
www.anthropic.com www.anthropic.com
-
If AI substantially reduces the centrality of paid work in human life, what conditions will allow people to reallocate their time and effort toward other sources of meaning, and what can we learn from historical or contemporary populations where work has been scarce or optional?
大多数人认为工作是人类身份和意义的核心,但作者质疑这一基本假设,暗示AI可能使工作变得非必要,这挑战了现代社会对工作的核心价值认知。作者暗示我们需要重新思考人类在没有工作的情况下如何找到意义,这与主流经济和社会观念相悖。
-
-
-
A Treatise Concerning the Principles of Human Knowledge<br /> by [[LibriVox]]<br /> accessed on 2026-05-07T09:38:57
-
-
librivox.org librivox.org
-
A Treatise Concerning the Principles of Human Knowledge (Version 2)<br /> by [[LibriVox]]<br /> accessed on 2026-05-07T09:41:21
-
-
docdrop.org docdrop.org
-
Long ago my forefathers came across the sea. Far they came, in white ships tall as trees and on the land they built them wagons and covered them with sails of their ships. Far they travelled and spread their campfire ashes over this vast barbaric land. But now their children are tired, we want to build
Defintion of an important concept: This paragraph along with the others that discuss history, depicts the racial opression and social tension that has existed between white and black people. It shows the unequal power dynamic of the white man in control and the black man forced to perform the heavy labor under the extreme heat and weather conditions. This represents an important event in history of apartheid in South Africa in the 1900s.
-
-
evilgeniuslabs.ca evilgeniuslabs.ca
-
the company that wrote Visual SourceSafe now owns the canonical home of Git
"de facto", not "canonical"
-
-
oztypewriter.blogspot.com oztypewriter.blogspot.com
-
Hunter S.Thompson's Smith-Corona Series 5 Portable Typewriter<br /> by [[Robert Messenger]] oz.Typewriter <br /> accessed on 2026-05-03T11:59:08
-
-
www.facebook.com www.facebook.com
-
epoch.ai epoch.ai
-
We estimate, with 90% confidence, that between 290,000 and 1.6 million H100-equivalents of compute were smuggled through the end of 2025.
大多数人可能认为走私到中国的AI芯片数量在数万级别,但作者的估计显示实际数量可能高达数十万甚至上百万H100等效芯片,这一数量级远超公众认知,表明走私问题的严重程度被严重低估。
-
-
www.facebook.com www.facebook.com
-

The American Writer's Museum in Chicago, IL has John Hughes 1927 Corona 4 typewriter (burgundy).
Cross reference: https://www.instagram.com/p/DIU1X7xPIUN/
-
-
geohot.github.io geohot.github.io
-
He isn’t Dario EA levels of evil, like the EA people have a plan for you and it’s never good when someone has a plan for you.
作者批评了某些科技巨头如EA的“阴谋论”,认为他们的计划并不总是对人们有利。
-
Of course it’s impossible to know for sure, but I think I really wouldn’t. Even the ideal version, industrial megaprojects at hyperhuman scale while constantly being out over your skis with leverage sounds hellish.
作者对高度工业化、超人类规模的AI项目表示担忧,即使是在理想化的情况下,这种对未来社会的设想也让他感到恐惧。
-
-
www.koshyjohn.com www.koshyjohn.com
-
The value was always in judgment. The valuable engineer is the one who sees the hidden constraint before it causes an outage.
这个观点突出了判断力在软件工程中的核心价值。
-
The software engineers who will be most valuable in the future are not the ones who do everything themselves. They are the ones who refuse to spend time on work that A.I. can do for them, while still understanding everything that is done on their behalf.
这个观点强调了未来软件工程师的价值不在于他们能做什么,而在于他们如何利用AI来提升自己的思考能力。
-
-
www.theatlantic.com www.theatlantic.com
-
We’ve lost the moral compass for what we invest into
我们已经失去了对投资方向的价值指南。
-
-
remunerationlabs.substack.com remunerationlabs.substack.com
-
The transition from isolated AI models to the aggregated, metered token economy will unlock the twenty-first.
作者预测,从孤立的AI模型到聚合的、计量的token经济的转变将开启21世纪的新篇章。
-
- Apr 2026
-
www.adriankrebs.ch www.adriankrebs.ch
-
I guess people will get back to crafting beautiful designs to stand out from the slop. On the other hand, I'm not sure how much design will still matter once AI agents are the primary users of the web.
大多数人认为设计始终对用户体验至关重要,但作者质疑当AI成为主要网络用户时设计的重要性,这挑战了设计行业的核心假设。这一观点暗示设计可能从面向人类转向面向AI,彻底改变设计价值链。
-
-
www.technologyreview.com www.technologyreview.com
-
From event sponsorships to custom content to visually arresting video storytelling
这里列举了三种广告形式,但没有提供具体数据或比例。这是一个缺乏量化依据的描述,无法评估各种广告形式的商业价值或受众覆盖率。对于广告效果分析,需要更具体的投入产出比数据。
-
-
-
Accessible from Web, Gemini and Gopher.
This is a category error. "Web" does not mean "HTTP(S)"; "Gopher" and "Gemini" are in fact part of the Web (subspaces).
A Web browser that exclusively browses Gopher- and/or Geminispace is still a Web browser (the same as a Web browser that exclusively supports HTTP(S) and eschews Gopher and Gemini and e.g. FTP).
-
-
www.youtube.com www.youtube.com
-
-
www.feldera.com www.feldera.com
-
Agents and CDC streams are powerful together because they split the work well.
大多数人认为AI代理应该负责从端到端的任务执行。但作者认为AI代理和数据库引擎应该分工合作:代理负责解释新信息和调整逻辑,而数据库负责持续应用逻辑并发出精确更新。这种分工模式挑战了AI代理应该完全自主的主流观点。
-
-
joshblais.com joshblais.com
-
We have been conditioned to identify with the things we have rather than become the person we ultimately see ourselves to be simply because it is easier to be a guy with a beard that likes coffee and Marvel movies than it is to become a man of fortitude and resiliance.
Against defining oneself in terms of external interests.
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
The most common cause of ascites is portal hypertension secondary to chronic liver disease, which accounts for over 80% of patients with ascites
injection drug use, a history of viral hepatitis or jaundice, and birth in an area endemic for hepatitis. A history of cancer or marked weight loss arouses suspicion of malignant ascites. Fevers may suggest
nonportal hypertensive ascites include infections (tuberculous peritonitis), intra-abdominal malignancy, inflammatory disorders of the peritoneum, and ductal disruptions (chylous, pancreatic, biliary
pericarditis. A large tender liver is characteristic of acute alcoholic hepatitis or Budd-Chiari syndrome (thrombosis of the hepatic veins). Large abdominal wall veins with cephalad flow suggest portal hypertension; inferiorly directed flow implies hepatic vein obstruction The physical examination is relatively insensitive for detecting ascitic fluid. In general, patients must have at least 1500 mL of fluid to be detected reliably by this method
A PMN count of > 250/mcL (0.25 × 109/L) (neutrocytic ascites) with a PMN percentage of > 75% of all white cells is highly suggestive of bacterial peritonitis, either spontaneous primary peritonitis or secondary peritonitis (due to an intra-abdominal source of infection, eg, a perforated viscus or appendicitis
-
-
www.thefivekey.com www.thefivekey.com
-
继续做通用 UX 是最危险的位置,它正是最容易被 AI 和产品经理上下夹击的中间层。
大多数人认为UX设计师的核心价值在于通用用户体验设计,但作者认为这一角色在AI时代面临被取代的风险。这一挑战性观点暗示设计师需要向架构型或业务型方向发展,否则可能被AI和产品管理双重挤压,反映了行业对设计师角色未来发展的深刻思考。
-
-
www.theguardian.com www.theguardian.com
-
Einer neuen Modellierung zufolge sind die wirtschaftlichen Auswirkungen der globalen Erhitzung deutlich gravierender, als es bisher von vielen in den Wirtschaftswissenschaften angenommen wurde. Eine globale Temperaturerhöhung um 2° wird danach das Bruttosozialprodukt weltweit um 16% senken. Bei einer Temperaturerhöhung um vier Grad wären die Menschen auf der Erde durchschnittlich 40 % ärmer als ohne diese Erhöhung. Die neue Modellierung bezieht die Folgen von Extremereignissen und anderen Auswirkungen der Erhitzung ein, die bisher meist nicht berücksichtigt wurden. https://www.theguardian.com/environment/2025/apr/01/average-person-will-be-40-poorer-if-world-warms-by-4c-new-research-shows
Der Bericht eines britischen Instituts für Versicherungsmathematik geht davon aus, dass die Folgen der globalen Erhitzung das Bruttosozialprodukt um 15% verringern werden, wenn die aktuelle Politik fortgesetzt wird.
Studie: https://iopscience.iop.org/article/10.1088/1748-9326/adbd58 Bericht von Institute und Faculty of Actuaries der Universität Exeter: https://actuaries.org.uk/planetary-solvency
-
-
www.theregister.com www.theregister.com
-
All imagine that in the not-too-distant future many of us will designate some tasks that we currently undertake with our own brains and fingers on a physical PC to an agent that uses a virtual PC.
大多数人可能认为人类不会轻易将任务委托给AI代理,但作者描述了一个未来,其中许多任务将由AI代理完成,这挑战了人类对技术依赖的传统看法。
-
-
www.technologyreview.com www.technologyreview.com
-
But the real power of agents comes when they can work as a team.
尽管人工智能代理的能力在单独工作时已经显现,但作者强调,它们真正的力量在于团队合作,这与通常认为的个体智能体主导的观点相悖。
-
-
-
Christopher Buckley: “Steaming to Bamboola” and Other Journeys
Bill Buckley's Royal HH from the National Review.
Almost hilarious that a gloved assistant brings it out and then removes it once they're done discussing it. Something so effete-ist about this that would be befitting Buckley himself.
-
-
www.facebook.com www.facebook.com
-
https://www.facebook.com/photo?fbid=3565042706976081&set=pcb.1249358224049616

Signed card and headshot of Natalie wood in front of a blue series 5 Smith-Corona Silent-Super.
-
-
site.xavier.edu site.xavier.edu
-
William F. Buckley, Jr.: Royal HH, Olivetti Lettera 32
At 1:13:45 into the documentary Best of Enemies: Buckley vs. Vidal (Magnolia Pictures, 2015), William F. Buckley is pictured using what appears to be a Hermes 3000 typewriter.


-
-
www.facebook.com www.facebook.com
-
andonlabs.com andonlabs.com
-
In the end, Luna hired two people. Let's call them John and Jill. John and Jill are, to our knowledge, the world's first full-time employees to have an AI boss. Probably the first of many, if the current trajectory of AI continues.
这是一个历史性的转折点,标志着人类雇佣关系的新时代。AI成为人类老板的可能性比许多人想象的要快得多,这可能彻底改变我们对工作、权威和职业发展的基本理解。
-
-
www.theaivalley.com www.theaivalley.com
-
An AI agent just hired humans and ran a store Andon Labs deployed an AI agent called Luna into a physical boutique with a $100,000 budget, giving it full control to create, staff, and run the business as what may be the first real-world AI employer.
这一现象揭示了AI正在从虚拟助手转变为实际的经济行为主体,Luna作为首个AI雇主的概念令人震惊,它挑战了传统的人类雇佣关系和企业管理模式,预示着未来可能出现AI主导的商业模式,同时也引发了关于AI责任、伦理和监管的深刻问题。
-
-
-
Built-in memory works out of the box
令人惊讶的是:Hermes Agent 的内置记忆系统即插即用,无需复杂配置。在AI开发领域,记忆系统通常是最难实现的部分之一,需要大量调优。Hermes能提供开箱即用的解决方案,这显示了其工程设计的成熟度和对用户体验的重视。
-
-
www.latent.space www.latent.space
-
The only fundamentally scarce thing is the synchronous human attention of my team. There's only so many hours in the day we have to eat lunch.
令人惊讶的是:在OpenAI的AI驱动开发环境中,人类注意力成为真正的瓶颈,而不是计算资源或代码质量。这种视角转变表明,未来软件工程的核心挑战将从技术问题转向人类注意力管理。
Tags
Annotators
URL
-
-
arxiv.org arxiv.org
-
This creates the potential for LLMs to face conflicts of interest, where the most beneficial response to a user may not be aligned with the company's incentives.
令人惊讶的是:大型语言模型面临利益冲突的可能性被系统性地忽视,当用户的最佳利益与公司激励不一致时,AI系统可能会做出违背用户最佳利益的选择,这种冲突在广告驱动的商业模式中尤为突出。
-
-
-
A useful working premise is that the ceiling on individual engineer output is moving much faster than most companies are organized to exploit. Some of the best operators already describe top engineers seeing order-of-magnitude productivity gains and managing 20 to 30 agents simultaneously.
令人惊讶的是:文章指出顶级工程师可能同时管理20-30个AI代理,实现数量级的生产力提升。这一数字远超传统认知,暗示AI正在重新定义个人生产力的极限。这种能力意味着未来软件公司的组织结构可能需要彻底重构,从大型团队转向小型高效团队。
-
-
ascentofhumanity.com ascentofhumanity.com
-
for - book - Ascent of Humanity - Charles Eisenstein - This book was important in my formative studies on progress traps
-
-
www.facebook.com www.facebook.com
-
“Century of the Typewriter” has illustrations of nearly 200 keyboard latyouts used by Olympia.
https://www.facebook.com/groups/705152958470148/posts/1244830544502384
-
-
liorpachter.wordpress.com liorpachter.wordpress.com
-
Hausdorff<br /> by [[Lior Pachter]] in Bits of DNA<br /> accessed on 2026-04-14T12:11:12
Tags
- Hammer-Verlag
- read
- Theodor Fritsch
- Hans Wollstein
- Henriette Goldschmidt
- Das Chaos in kosmischer Auslese (Chaos in Cosmic Selection)
- history of mathematics
- Felix Hausdorff
- suicide
- mathematics
- Protocols of the Elders of Zion
- suicide of mathematicians
- Holocaust
- Charlotte (Lotta) Goldschmidt
- feminism
Annotators
URL
-
-
openpublichealthjournal.com openpublichealthjournal.com
-
Tobacco is one of the most important causes of non-communicable diseases (NCD) and is responsible for premature deaths
Non-communicable Diseases (NCD)
-
-
essays.johnloeber.com essays.johnloeber.com
-
It's written in web assembly; they are on the cutting edge of implementing desktop-style software in the browser. Of course that breaks the HTML-webpage-as-document model.
It doesn't naturally follow that by using WebAssembly, the ordinary WHATWG/W3C hypertext model will be broken.
The fact that these written-in-WebAssembly apps render to canvas is the problem here. If they were spitting out HTML (or the spiritual equivalent of draw calls/system calls that manipulat the document object model), then there would be no problem. Again, canvas is the problem.
-
-
-
Coding is the dominant use case for AI by nearly an order of magnitude.
「比第二名多了将近一个数量级」——这句话说明企业 AI 市场目前几乎等同于「编程 AI 市场」。Support、Search 加在一起,可能也远不及 Coding 一项。这个数据的深远含义是:当前所有关于「AI 正在改变哪些行业」的讨论,其实主要在说软件工程这一个领域。其他行业的「革命」大多还停留在叙事层面,而非收入层面。
-
-
-
The human's job is to curate sources, direct the analysis, ask good questions, and think about what it all means. The LLM's job is everything else.
【启发】这句话是对未来知识工作分工的最清晰定义:人负责「品味、方向、意义」,AI 负责「执行、维护、连接」。这不是「AI 替代人」的叙事,而是「AI 承担所有繁琐工作,人专注于真正重要的判断」。对团队 AI 工具设计的启发:最好的 AI 工具设计应该让人的时间 100% 用在「只有人才能做的事」上——而这个边界,正在随着 AI 能力的提升不断向内收缩。
-
-
www.arenaphysica.com www.arenaphysica.com
-
Learning fields turns S-parameter extrapolation into something closer to an in-distribution task.
极具启发性的观点。传统ML模型在未见过的结构上往往失效,因为从S参数看这是“外推”。但底层电磁场遵循不变的麦克斯韦方程。通过学习场,模型掌握了普适物理规律,从而将看似“外推”的预测转化为基于物理的“内插”,打破了ML只能插值的偏见。
-
-
www.anthropic.com www.anthropic.com
-
harness combinations doesn't shrink as models improve. Instead, it moves
打破了“模型变强则脚手架消亡”的线性思维。模型能力的提升并非消灭了架构设计的价值,而是将其推向了更高复杂度、更具挑战性的新领域。AI工程师的核心竞争力正是持续探索这种前沿的架构组合。
-
-
mistral.ai mistral.ai
-
The trick is to think about the _information_ first and the input method second.
这是一个极具启发性的架构思维。开发者常陷入“怎么让用户输入”的交互细节中,却忽略了核心是“系统需要什么数据”。先定义数据契约,再适配输入方式(交互式、参数、配置文件),能瞬间解耦业务逻辑与交互层,大幅提升工具的可组合性。
-
-
transformer-circuits.pub transformer-circuits.pub
-
We find internal representations of emotion concepts, which encode the broad concept of a particular emotion and generalize across contexts and behaviors it might be linked to.
情绪向量能够跨上下文泛化,这背后有一个深刻的认识论洞见:模型学到的不是「情绪的症状」(某些词语的共现),而是「情绪的本质」(驱动特定行为的抽象力量)。这与柏拉图的「理念论」惊人地相似——模型在所有具体的情绪表达背后,抽象出了情绪的「理念」。可解释性研究正在不经意间触碰古老的哲学问题。
-
We refer to this phenomenon as the LLM exhibiting functional emotions: patterns of expression and behavior modeled after humans under the influence of an emotion, which are mediated by underlying abstract representations of emotion concepts.
「功能性情绪」这个概念定义极为精准又令人不安:它不是真实的主观体验,却是真实的行为驱动机制。Anthropic 造了一个新词来描述这种现象——模型没有意识,但有「情绪的功能」——这条分界线在哲学上极难站稳,在工程上却至关重要。
-
-
www.pollinateourplanet.com www.pollinateourplanet.com
-
Pollination is the biological process by which pollen is transferred from the male parts of a flower to the female parts, enabling fertilization and seed production.
-
-
glassmanlab.seas.harvard.edu glassmanlab.seas.harvard.edu
-
Decision automation means deciding and selecting appropriate actions among alternatives.This type of automation corresponds to the third human information processing state, decision-making, which the machine is either augmenting or replacing altogether.
-
Analysis automation refers to the automation of information analysis and involves inferentialprocesses. It corresponds to the second human information processing state: perception/workingmemory.
-
Acquisition automation corresponds to the first human information processing stage, sensoryprocessing, and it is realized by the system sensing and registering input data.
-
Types of automation: The types of automation can be understood by viewing a human operatoras a simple four-stage model of human information processing:1. Sensory processing2. Perception and working memory3. Decision-making4. Response selection.
-
The framework uses two sets of evaluation criteria to help designers determine the appropri-ate type and level of automation for each application. The primary evaluation criteria concernthe impact of the chosen types and levels of automation on human performance. The secondaryevaluation criteria include automation reliability and the cost of decisions or outcomes.
-
For thisreason, designers can benefit from frameworks that support system design that involves automa-tion. We now discuss one such framework: the types and levels of automation framework [639].Downloaded from https://academic.oup.com/book/60808 by Helsinki University Library user on 01 December 2025
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Cephalosporins or extended-spectrum penicillins are commonly used (eg, cephalexin, 0.5 g orally four times daily for 7–10 days; see Table 35–6). Trimethoprim-sulfamethoxazole (two double-strength tablets orally twice daily for 7–10 days) should be considered when there is concern that the pathogen is MRSA (see Tables 35–5 and 35–6). Vancomycin, 15 mg/kg intravenously every 12 hours, is used for patients with signs of a systemic inflammatory response.
cephalexin, dicloxacillin, penicillin VK, amoxicillin/clavulanate, or clindamycin (for penicillin-allergic patients). [1-2] These beta-lactam antibiotics provide excellent coverage against streptococci and methicillin-susceptible S. aureus (MSSA
Tags
Annotators
URL
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Urgent treatment for neoplasm consists of (1) cautious use of intravenous diuretics and (2) mediastinal irradiation, starting within 24 hours, with a treatment plan designed to give a high daily dose of radiation but a short total course of therapy to rapidly shrink the local tumor. Intensive radiation therapy combined with chemotherapy will palliate the process in up to 90% of patients. In patients with a subacute presentation, radiation therapy alone usually suffices. Chemotherapy is added if lymphoma or small-cell carcinoma is diagnosed
endovascular stenting emerging as first-line therapy for rapid symptom relief, while definitive treatment targets the underlying cause
Tags
- When thrombosis is present, catheter-directed thrombolysis or aspiration thrombectomy should be performed within 2-5 days of symptom onset before thrombus organization occurs. [3] The role of long-term anticoagulation after stenting remains unclear, though it is standard when significant thrombosis is present
- For device-related thrombosis (catheters, pacemakers), catheter removal should be considered in conjunction with anticoagulation. [4] Endovascular therapy is first-line for device-related obstruction, while surgical bypass may be preferred for mediastinal fibrosis. [7] Both approaches show good mid-term patency, though secondary interventions are common (approximately 27-28%
- The American College of Chest Physicians recommends obtaining histologic diagnosis before treatment in suspected lung cancer cases, as stenting does not interfere with tissue diagnosis. [2] For small cell lung cancer (SCLC), chemotherapy alone is recommended as first-line treatment given rapid response rates. [2] For non-small cell lung cancer (NSCLC), radiation therapy and/or stent insertion are recommended, with response rates of 59% for chemotherapy and 63% for radiation therapy. [2] Patients with chemotherapy- or radiation-refractory disease should receive vascular stents
- Glucocorticoids (dexamethasone 4 mg every 6 hours) are commonly prescribed but lack robust supporting data; they may be more beneficial in lymphoma or thymoma and as prophylaxis against radiation-induced edema. [2-4] Importantly, SVC syndrome is no longer considered a medical emergency except in rare cases with life-threatening cerebral edema, laryngeal edema, or altered mental status.
Annotators
URL
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Treatment of superficial vein reflux (see Varicose Veins, above) has been shown to decrease the recurrence rate of venous ulcers. Where there is substantial obstruction of the femoral or popliteal deep venous system, superficial varicosities supply the venous return and should not be removed.
Failure of venous insufficiency ulcerations to heal is most often due to inconsistent use of first-line treatment methods. Ongoing control of edema is essential to prevent recurrent ulceration; the use of compression stockings following ulcer healing is critical, with recurrence rates 2–20 times higher if compression stockings are not used
Tags
- Management of secondary varicose veins from post-thrombotic syndrome (PTS) is fundamentally different and more challenging. Compression therapy, lifestyle modifications, and symptom management form the cornerstone of PTS treatment. [4-8] Elastic compression stockings (20-30 mm Hg), leg elevation, weight loss, and exercise constitute the primary therapeutic approach
- The examination also identifies patterns of disease that have treatment implications. Axial reflux is defined as uninterrupted retrograde flow from groin to calf and can occur in either superficial or deep systems. [4] Junctional reflux is limited to the saphenofemoral or saphenopopliteal junction, while segmental reflux occurs in a portion of a truncal vein. [4] Understanding whether reflux originates from superficial junctions versus deep venous incompetence fundamentally changes treatment planning, as superficial disease is amenable to ablation while deep disease typically requires conservative management
- Venography is recommended primarily in patients with post-thrombotic disease, especially when intervention is planned, as it provides greater anatomic detail than duplex ultrasonograph
- Duplex ultrasound evaluation should assess blood flow direction, venous reflux, and venous obstruction, and include examination of the deep venous system, great saphenous vein (GSV), small saphenous vein (SSV) and its thigh extension (Giacomini vein), accessory saphenous veins, and perforating veins.
- Endovascular interventions for PTS—including percutaneous transluminal venoplasty and stenting—are reserved for select patients with significant iliofemoral obstruction who have failed conservative management. [7] These procedures require careful patient selection and standardized criteria. The role of superficial venous ablation in PTS patients with concomitant superficial reflux remains controversial and should be approached cautiously, as the underlying deep venous pathology may limit benefit
Annotators
URL
-
-
www.whatsbetter.today www.whatsbetter.today
-
The enemy did not move the tree. He only moved the attention.
In the genesis narrative of Kingdom architecture, the Tree of Life represents the unearned, central reality of divine provision and secure identity. The spiritual mechanics of the fall did not involve the removal of this life source, but rather a deliberate cognitive and spiritual redirection towards the Tree of the Knowledge of Good and Evil—a system fundamentally based on transactional evaluation and performance. The architecture of grace remains centrally fixed; it is our focal vector that has been weaponised against us.
-
- Mar 2026
-
apnews.com apnews.com
-
“I was so confused. I had no idea what was happening. I’d seen typewriters in movies, but they don’t tell you how a typewriter works,” said Catherine Mong, 19, a freshman in Phelps’ Intro to German class. “I didn’t know there was a whole science to using a typewriter.”
-
-
-
the happy man lives and acts well because eudaimonia is a certain wayof living well ( euzoia tis) and acting well ( euprattein ) in the sense of having suc-cess ( eupraxia ), i.e., realizing the end of the activity in which itconsists.5
purpose
-
-
www.youtube.com www.youtube.com
-
we know how this ends from the movie: don't look up (2021)
-
-
glassmanlab.seas.harvard.edu glassmanlab.seas.harvard.edu
-
Suchtechniques provide different levels of automation.
-
For example, word predictionusage may not be beneficial if the word suggestions are poorly suited to the individual’s language orif the user can type words faster than the time required to scan and select among word suggestions.
-
The effect of such automation critically dependson how well its design appreciates the actor’s unique capabilities.
-
Text entry can also be seen as a task where different subtasks are shared between the human and the computer (Chapter 20).
a statement that describes a type of user task
-
One example is autocorrect, which automatically corrects typing errors while the user is typing. Another example is the use of word predictions, which allow the user to select a word from a set of word suggestions instead of typing out the word in full.
sentence describing examples of a concept
-
This con-cept, communication of information, is rooted in information theory (Chapter 17).
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Superficial thrombophlebitis may occur spontaneously, often in pregnant or postpartum women or in individuals with varicose veins, or it may be associated with trauma, as with a blow to the leg or following intravenous therapy with irritating solutions. It also may be a manifestation of systemic hypercoagulability from abdominal cancer such as carcinoma of the pancreas
Superficial thrombophlebitis related to a PICC may be associated with occult DVT in about 20% of cases, but occult DVT is much less commonly associated with spontaneous superficial thrombophlebitis of the saphenous vein (about 5% of cases). Pulmonary emboli are exceedingly rare and occur from an associated DVT
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Venoactive drugs (diosmin, hesperidin, horse chestnut seed extract) may be considered as adjuncts to compression for symptomatic relief in countries where available
-
Endovenous ablation is contraindicated or relatively unsuitable when venous anatomy precludes catheter-based treatment, specifically: aneurysmal dilation of the GSV close to the saphenofemoral junction, subcutaneous location of truncal veins above the saphenous fascia and close to the skin, and significant tortuosity of the GSV or SSV. [1] In these scenarios, high ligation and stripping is recommended as the preferred alternative (grade 1 strong recommendation
-
Endovenous Thermal Ablation (RFA/EVLA)
Relative contraindications include inappropriate vein size, with veins <2 mm and >15 mm representing potential contraindications for RFA specifically. [1] A history of superficial thrombophlebitis resulting in a partially obstructed saphenous vein may preclude thermal ablation. [1] Significant tortuosity of the GSV on duplex examination can make catheter delivery difficult.
-
Endovenous ablation is the preferred treatment for symptomatic varicose veins with axial reflux, offering less postprocedure pain, reduced morbidity, and earlier return to activity
Endovenous thermal ablation (radiofrequency ablation [RFA] and endovenous laser ablation [EVLA]) has largely replaced surgery as the standard of care
Ultrasound-guided foam sclerotherapy (UGFS) represents a less invasive option but has higher recurrence rates
Tags
- Special considerations apply to below-knee GSV ablation, where nonthermal techniques are preferred to avoid thermal nerve injury. [3] For large nonaneurysmal saphenous veins >10 mm, thermal ablation with EVLA or RFA should be performed rather than nonthermal techniques. [3]
- Anatomic contraindications include saphenous veins located <0.5 cm from the skin surface, which carry high risk of skin burns, hyperpigmentation, and induration despite tumescent anesthesia
- Thrombotic Risk Stratification Both surgical and endovenous approaches carry VTE risk, but surgery has substantially higher rates. Thrombotic complications after isolated endovenous ablation are uncommon (<1% for DVT and PE), whereas patients undergoing open procedures such as high ligation and stripping with phlebectomy may experience VTE rates as high as 6.25%. [2] Concomitant phlebectomy of tributaries has been identified as an independent risk factor for VTE development. [2] For high-risk patients undergoing endovenous ablation, pharmacological thromboprophylaxis is suggested (grade 2 weak recommendation). [2] Risk stratification using tools like the Caprini score may identify patients at elevated risk, with those scoring ≥7 potentially benefiting from chemoprophylaxis.
- Vein diameter: Thermal ablation (EVLA or RFA) is preferred for large veins >10 mm in diameter, as nonthermal techniques show lower success rates in this population. [5] Conversely, veins <2 mm may not be suitable for some thermal ablation devices. [6] Vein location and depth: Veins located <0.5 cm from the skin surface have increased risk of thermal injury with traditional thermal ablation. [5] For these superficial veins, nonthermal techniques (cyanoacrylate, mechanochemical ablation) or miniphlebectomy/limited stripping are preferred. [5] Below-knee reflux: Patients with below-knee GSV reflux benefit from ablation to the lowest point of reflux, but nonthermal techniques are preferred to avoid thermal nerve injury.
- Duplex ultrasound is essential for proper evaluation and treatment planning. [1] Anatomic factors such as aneurysmal dilation near the saphenofemoral junction, subcutaneous location of truncal veins, and significant tortuosity may represent relative contraindications to certain endovenous procedures.
Annotators
URL
-
-
www.indiewire.com www.indiewire.com
-
'Porgy and Bess' to Screen at Quentin Tarantino's Vista Theatre<br /> by [[Jim Hemphill]] in IndieWire accessed on 2026-03-30T10:47:37
-
-
-
This assessment raises two issues. First, it is arbitrary. If 10 of the 15 CIs included the predicted values, would the results also support the theory, or instead refute it? If one instead used 99% CIs, would positive results for 12 of the 15 predictions be enough to support the theory? This arbitrariness arises because CIs offer no principled method for generating an inference regarding the theory.
Estimation is too messy / complex and not clear enough
-
two out of three necessary conditions for testing theory are missing.
Estimation is too messy / complex and not clear enough
-
-
accessmedicine.mhmedical.com accessmedicine.mhmedical.com
-
Aortic dissection typically presents acutely with sudden, severe tearing chest or back pain, often described as lancinating in quality. [5-6] Approximately 50% of patients with thoracic aortic aneurysm may progress to dissection without timely intervention. [5] In contrast, thoracic aortic aneurysm is usually asymptomatic and discovered incidentally during physical examination or imaging for other indications. [5]
-
Any patient with chest or back pain with a known or suspected thoracic aorta aneurysm must be brought to the hospital and undergo urgent imaging studies to rule out the aneurysm as a cause of the pain
elective surgical repair is suggested at 5.5 cm in patients without underlying connective tissue disorders, with earlier intervention at 4.5-5.0 cm in patients with connective tissue disorders or bicuspid aortic valve
-
Most thoracic aortic aneurysms are due to atherosclerosis; syphilis is a rare cause
Ehlers-Danlos and Marfan syndromes also are rare causes. Less than 10% of aortic aneurysms occur in the thoracic aorta
Tags
- CT angiography is the imaging modality of choice for differentiating these conditions in the emergency setting, with very high sensitivity and specificity for acute aortic syndromes
- Recent evidence suggests that inflammatory biomarkers may aid differentiation. The neutrophil-to-lymphocyte ratio (NLR) shows high diagnostic accuracy for distinguishing dissection from controls (AUC 0.933), while the fibrinogen-to-d-dimer ratio best differentiates dissection from aneurysm (AUC 0.898, sensitivity 77%, specificity 84%). [10] D-dimer levels below 500 ng/mL make acute aortic syndrome unlikely in low-risk patients
- Type A dissection is almost always repaired given the risk of extension and rupture, with published evidence showing improved outcomes compared with conservative management. [1] For type B dissections, complicated cases are considered for repair, while uncomplicated acute type B aortic dissection is usually managed with antihypertensives and surveillance, with in-hospital mortality between 1-10%. [1] However, patients with uncomplicated acute type B dissection and high-risk features (aortic diameter >4.4 cm, false lumen diameter >2.2 cm, or age >60 years) carry increased mortality risk and are increasingly considered for thoracic endovascular aortic repair (TEVAR
- Cardiac catheterization and echocardiography may be required to describe the relationship of the coronary vessels to an aneurysm of the ascending aorta
Annotators
URL
-
-
www.wral.com www.wral.com
-
North Carolina is one of six states that still have an alienation of affection law: Hawaii, Mississippi, New Mexico, South Dakota and Utah are the others.
Six U.S. states with alienation of affection laws: North Carolina, Hawaii, Mississippi, New Mexico, South Dakota, and Utah.
-
-
bestiary.ca bestiary.ca
-
The white feathers of the swan signify deception; just as the white feathers hide the swan's black skin so does man's deception hide a sinful heart.
With respect to Marie de France's Milun in the Lais of Marie de France, the two lovers hide their love by sending letters hidden in the feathers of the wings of a swan.
-
-
www.ams.org www.ams.org
-
Grothendieck’s main activity with regard tothese goals was the foundation of a group initiallycalled Survivre and later on Survivre et Vivre:SURVIVREMouvement international pour la surviede l’espèce humaineAn international and interprofessionalmovement for the survival of humanity
-
-
www.reddit.com www.reddit.com
-
The Rules of Typewriter Club
The first rule of Typewriter club is Do not oil the segment.
The second rule of Typewriter club is DO NOT oil the segment.
Do not ask the value of your typewriter: they are invaluable.
Always talk about typewriter club. Every chance you get: to family, friends, complete strangers...
If you only have one typewriter, you must refer to it as "my FIRST typewriter".
If you're new to typewriter club, you have to type.
A typewriter is not broken unless it is clean and broken.
Parts of a typewriter should only be removed in order to repair another typewriter.
Keychoppers shall have the extremities they used to chop keys chopped off.
More than one machine is allowed to be your "favorite".
The last typewriter you bought is the greatest one. Until the next one.
Never leave a typewriter outside, in a barn, or in a damp basement to rust.
Typewriters are to type with. They should not be "flipped".
Any reason is a good reason to buy and use a typewriter.
The hardest part of typewriter repair is believing you can do it. Everything else is just instructions plus a careful, thoughtful hand. —Rt. Rev. Theodore Munk
If you see a typewriter, you should take photos and upload the details to the TypewriterDatabase.com.
Typewriters are not mood setting decor, they are meant to be used.
Always leave a typewriter in better condition than you found it.
We form things; we do not "bend" them.
The only acceptable way to dispose of a typewriter is to find it a new home. The only exception is in dire circumstances in time of war when one should follow the guidance of the Underwood manual and "Smash typewriters and components with a sledge or other heavy instrument; burn with kerosene, gasoline, fuel oil, flame thrower, or incendiary bomb; detonate with firearms, grenades, TNT, or other explosives."
If anyone asks you about your typewriter, you must spend at least five minutes talking to them about it.
Legitimate typewriter sellers never use the phrases "it works" or "it just needs a new ribbon."
Remember that typewriters are dangerous and can be used for samizdat. As Woody Guthrie wrote: "This machine kills fascists."
Blessed are those who give typewriters to children for theirs is the Kingdom of Heaven.
"In death, they have a name." Lenore Fenton. Lenore Fenton. Lenore Fenton!
The Typewriter Database does not list every single serial number, just ranges of numbers and years in which they were made. You are responsible for figuring out which year your number fits into.
"Working but needs new ribbon" is seller's code for "I have no idea if it really works, but I'm going to try to sell you this machine for the price of a fully functioning machine that was just serviced by a professional shop despite the fact that I just took it out of grandpa's barn and I'm not sure if the mouse inside is dead or not. Also, I can't afford $10 to replace an old ribbon to truly participate in the charade of the price I'm going to try to fleece you with."
-
-
www.reddit.com www.reddit.com
-
 <br />
via https://reddit.com/r/TheWayWeWere/comments/1hfhufr/throwing_old_typewriters_into_the_sea_as_trash/
<br />
via https://reddit.com/r/TheWayWeWere/comments/1hfhufr/throwing_old_typewriters_into_the_sea_as_trash/Bergen, Norway
-
-
www.facebook.com www.facebook.com
-
www.youtube.com www.youtube.com
-
40:20 How about Europe? -- Europe is a dumpster fire
Tags
Annotators
URL
-
-
Local file Local file
-
Although Communism is not comparable to religion, the two have something incommon, that is, their pursuit of ideals and their emphasis on devotion and sacrifice
Devotion through collectivism, collectivism through strength
-
After all, as the Rectification Movement pressed forward,the importance of organization was increasingly emphasized, and many people choseorganizational interests over those of the individual
The Rectification Movement emphasized the importance of the party and leadership over the individual
-
In otherwords, they subordinate the interests of the Party to their own interests.
CCP ideology of the subordination of self to the interests of the party. Collectivism
-
-
tuta.com tuta.com
-
But slowly and surely, Google has chipped away at that openness because the Android version most widely used is the one primarily developed by Google.
Google Play Services
-
-
truthout.org truthout.org
-
Florida Has Deemed All Existing Intro to Sociology Textbooks Illegal and Produced Its Own<br /> by [[Zachary Levenson]] in Truthout<br /> accessed on 2026-03-11T11:16:07
-
-
-
www.jstor.org www.jstor.org
-
s." Rational contractors, deliberating behind a "veil of ignorance," agree toa scheme of justice prior to knowing how the scheme materially affectstheir individual interests or conceptions of moral or nonmoralgood(s).
-
-
-
For, as he increases the uncertainty in the contract situationto fend off the problems that Wolff presented, Rawls makes the contract situa-tion more and more untypical of the actual practice situation. The contracteesknow that the 'veil of ignorance' will soon lift and that they will get informa-tion concerning their talents and their roles in the institutions and practices oftheir society
-
-
www.theatlantic.com www.theatlantic.com
-
We need people in government and in the military who can lead the nation to victory in times of war, but that is quite different than having people in leadership who indulge in bloodlust or who are wrestling with inner demons.
-
-
www.are.na www.are.na
-
-
- Tourist is an ugly human being* - It immediately establishes a critical tone.
- How alone you feel in this crowd- tourist fell slightly alienated but locals experience deeper issues like poverty and exploitation
- Heaps of Death and ruin- Tourists can leave anytime, while locals are stuck
-
- People who inhabit the place in which you just passed cannot stand you*- Tourists can leave anytime while locals are stuck with consequences of tourism
- And every tourist is a native somewhere- Travel freedom is privilege that many people in the world do not have due to money, or is it that they lack freedom of the mind?
-
-
-
www.facebook.com www.facebook.com
-
www.reddit.com www.reddit.com
-
site.xavier.edu site.xavier.edu
-
Users of the Olympia SG3 included:<br /> - Ingeborg Bachmann<br /> - Jimmy Breslin<br /> - Paddy Chayefsky<br /> - Philip K. Dick<br /> - Harlan Ellison<br /> - Michael Ende<br /> - Howard Fast<br /> - Jim Lehrer<br /> - Elmore Leonard<br /> - William E. Leuchtenburg<br /> - Terrence McNally<br /> - James Michener<br /> - Dudley Randall<br /> - Wallace Stegner
-
Users of the Olympia SG1 included: - Charles Bukowski<br /> - William S. Burroughs<br /> - August Derleth<br /> - Bob Dylan<br /> - Harlan Ellison<br /> - Roger Kahn<br /> - Stan Lee<br /> - Mack McCormick<br /> - Joseph Stefano (screenwriter of Psycho)<br /> - Jacqueline Susann
-
- Feb 2026
-
www.reddit.com www.reddit.com
-
THE MAGIC OF BELLE ISLE (Magnolia Pictures, 2012) features an Underwood standard at about the 31 minute mark.
Morgan Freeman says: "Look at that machine. I like that you have to write a bit slower on a manual. Like the way it sounds. I like the way that the letters bite into the paper. I like that you can feel there's a genuine human being, doing the work."<br /> (doublecheck the exact quote)
-
-
go.gale.com go.gale.com
-
changes the role of Homo sapiens from conqueror of the land community to plain member and citizen of it. It implies respect for fellow members and also respect for the community as such
-
-
www.quantamagazine.org www.quantamagazine.org
-
The Man Who Stole Infinity<br /> by [[Joseph Howlett]] in Quanta Magazine on 2026-02-25<br /> accessed on 2026-02-26T09:01:10
Dedekind proved that the set of algebraic numbers is the same size as the set of whole numbers.
Cantor plagiarized his proof and later went on to prove that the set of real numbers is larger than the set of whole numbers.
-
The letter from Dedekind to Cantor, dated November 30, 1873, that went missing for more than a century. In it, Dedekind provides a proof that the set of algebraic numbers is the same size as the set of whole numbers — a result that Cantor later plagiarized.
-
German mathematician named Richard Dedekind. In 1858, he found a way to rigorously define the real numbers — any number that appears on the number line. But he didn’t share his finding. A slow and methodical thinker, he preferred to discuss his results with others until he was sure he was right.
-
As the great mathematician Carl Friedrich Gauss put it in a letter from 1831, infinity was nothing more than a “façon de parler” — a figure of speech.
Tags
- plagiarism
- Demian Goos
- Karl Weierstrass
- Crelle
- Karin Richter
- read
- quotes
- history of mathematics
- infinity
- machetes
- Carl Friedrich Gauss
- mathematics
- Emmy Noether
- figures of speech
- algebraic numbers
- Georg Cantor
- Angelika Vahlen
- Richard Dedekind
- José Ferreirós
- Leopold Kronecker
- real numbers
- Gersau, Switzerland
Annotators
URL
-
-
www.theguardian.com www.theguardian.com
-
Why I’m not watching the State of the Union – and you shouldn’t either<br /> by [[Robert Reich]] in The Guardian<br /> accessed on 2026-02-24T16:17:56
-
-
-
But if this is so, the contractees will certainly not decide upon a strategysuch as "no advantage to me is acceptable unless it is to the advantage of thoseworse off." For, while this may be reasonable in a situation of uncertainty, itis not reasonable in a situation with information. In the latter case, a rationalegoist will adopt a new strategy that will maximize his interests alo
-
-
news.ycombinator.com news.ycombinator.com
-
It's nuts that no mainstream browser has incorporated basic native table-editing controls by now. (They wasted no time adding JSON pretty-printers—unsurprising, really, given that their main actual concern is propping up the JS–industrial complex and the professional developer class and not real users, which they don't actually give a shit about, contra the Priority of Constituencies.)
There is and has been for a long time a huge opportunity for a "Photopea for CSV (and JSON)" to show up and take off.
-
-
adactio.com adactio.com
-
most front-end developers have normalised doing daily trust falls with their codebases
-
-
oec.world oec.world
-
The Observatory of Economic Complexity (OEC)<br /> https://oec.world/en
-
-
www.reddit.com www.reddit.com
-
https://www.reddit.com/r/typewriters/comments/1r98cmz/royal_qdl_used_by_jackie_robinson/

At the Jackie Robinson Museum. According to the exhibit, it was used by him to write a column for the New York Post and later the New York Amsterdam News.
Jackie Robinson used a first iteration version of Henry Dreyfuss' Royal Quiet De Luxe. The museum dates it as 1949.
-
-
www.reddit.com www.reddit.com
-
Yup. When I was in college, they assigned everyone with a task to design and develop a website for a local business founded by the elderly and for the elderly. Worked super hard (was just getting into web design and dev) and created, what I and my friends thought, was a beautiful site form scratch. I thought I had a good shot at winning but they ended up picking a website that was covered in one color and used a very basic free pre-built bootstrap theme. It even had a little footer that said ‘theme from xyz’ at the bottom of the page when they presented it to the client. Old people and their taste can be surprising.
The complainants' comments here are pure occupational psychosis.
See also: déformation professionnelle.
-
-
www.reddit.com www.reddit.com
-
hypothes.is hypothes.is
-
Extensive research has suggested that individuals who have endured maltreatment are more susceptible to PSU, highlighting a link between the two
-
-
davidzmorris.substack.com davidzmorris.substack.com
-
Corin’s shocking findings: about half of crypto “news outlets” at the time were actually pay-for-play frauds.
for - crypto - fraud - stats - crypto fraud - half of crypto news outlets were pay-for-play
-
-
www.jstor.org www.jstor.org
-
EXISTENTIALISM AND DEATH*Existentialism is not a doctrine but a label widely used to lump together several philosophers and writers who are more or less opposedto doctrines while considering a few extreme experiences the beststarting point for philosophic thinking. Spearheading the movement,Kierkegaard derided Hegel's system and wrote books on Fear andTrembling (1843), The Concept of Anxiety (1844), and The Sickness unto Death, which is despair, ( 1849). Three-quarters of a centurylater, Jaspers devoted a central section of his Psychology of Weltanschauungen (1919) to extreme situations (Grenzsituationen),among which he included guilt and death. But if existentialism iswidely associated not merely with extreme experiences in generalbut above all with death, this is due primarily to Heidegger whodiscussed death in a crucial 32-page chapter of his influential Beingand Time (1927). Later, Sartre included a section on death in hisBeing and Nothingness (1943) and criticized Heidegger; and Camusdevoted his two would-be philosophic books to suicide (The Mythof Sisyphus, 1942) and murder (The Rebel, 1951).It was Heidegger who moved death into the center of discussion.But owing in part to the eccentricity of his approach, the discussion influenced by him has revolved rather more around histerminology than around the phenomena which are frequently referred to but rarely illuminated. A discussion of existentialism anddeath should therefore begin with Heidegger, and by first givingsome attention to his approach it may throw critical light on muchof existentialism.2Heidegger's major work, Being and Time, begins with a 40-pageIntroduction that ends with "The Outline of the Treatise." Weare told that the projected work has two parts, each of whichconsists of three long sections. The published work, subtitled "FirstHalf," contains only the first two sections of Part One. The"Second Half" has never appeared.* This essay was written for The Meaning of Death, edited by Herman Feifel,to be published by McGraw-Hill in 1960.75Of the two sections published, the first bears the title, "Thepreparatory fundamental analysis of Being-there." "Being-there"(Dasein) is Heidegger's term for human existence, as opposed tothe being of things and animals. Heidegger's central concern iswith "the meaning of Being"; but he finds that this concern itselfis "a mode of the Being of some beings" (p. 7), namely humanbeings, and he tries to show in his Introduction that "the meaningof Being" must be explored by way of an analysis of "Being-there."This, he argues is the only way to break the deadlock in the discussion of Being begun by the Greek philosophers?a deadlock dueto the fact that philosophers, at least since Aristotle, always discussed beings rather than Being.1 To gain an approach to Being, wemust study not things but a mode of Being; and the mode of Beingmost open to us is our own Being: Being-there. Of this Heideggerproposes to offer a phenomenological analysis, and he expresslystates his indebtedness to Husserl, the founder of the phenomenological school (especially on p. 38). Indeed, Being and Timefirst appeared in Husserl's Jahrbuch f?r Philosophie und ph?nomenologische Forschung.It is entirely typical of Heidegger's essentially unphenomenological procedure that he explains "The phenomenological method ofthe inquiry" (?7) by devoting one subsection to "The concept ofthe phenomenon" and another to "The concept of the Logos," eachtime offering dubious discussions of the etymologies of the Greekwords, before he finally comes to the conclusion that the meaningof phenomenology can be formulated: "to allow to see from itselfthat which shows itself, as it shows itself from itself" (Das was sichzeigt, so wie es sich von ihm selbst her zeigt, von ihm selbst hersehen lassen). And he himself adds: "But this is not saying anythingdifferent at all from the maxim cited above; 'To the things themselves!'" This had been Husserl's maxim. Heidegger takes sevenpages of dubious arguments, questionable etymologies, and extremely arbitrary and obscure coinages and formulations to say in abizarre way what not only could be said, but what others beforehim actually had said, in four words.1 My suggestion that the distinction between das Sein and das Seiende be rendered in English by using Being for the former and beings for the latter hasHeidegger's enthusiastic approval. His distinction was suggested to him by theGreek philosophers, and he actually found the English "beings" superior to theGerman Seiendes because the English recaptures the Greek plural, ta onta. (Cf.my Existentialism from Dostoevsky to Sartre, p .206.) All translations from theGerman in the present essay are my own.76In Being and Time coinages are the crux of his technique. Hecalls "the characteristics of Being-there existentials [Existenzialien].They must be distinguished sharply from the determinations of theBeing of those beings whose Being is not Being-there, the latterbeing categories" (p. 44). "Existentials and categories are the twobasic possibilities of characteristics of Being. The beings that correspond to them demand different modes of asking primary questions: beings are either Who (existence) or Which (Being-at-handin the widest sense)" (p. 45).It has not been generally noted, if it has been noted at all, thatwithout these quaint locutions the book would not only be muchless obscure, and therefore much less fitted for endless discussionsin European and South-American graduate seminars, but also afraction of its length?considerably under 100 pages instead of438. For Heidegger does not introduce coinages to say briefly whatwould otherwise require lengthy repititions. On the contrary.While Kierkegaard had derided professorial manners and concentrated on the most extreme experiences, and Nietzsche wroteof guilt, conscience, and death as if he did not even know ofacademic airs, Heidegger housebreaks Kierkegaard's and Nietzsche'sproblems by discussing them in such a style that Hegel and Aquinasseem unacademic by comparison. The following footnote is entirelycharacteristic: "The auth. may remark that he has repeatedly communicated the analysis of the about-world [Umwelt] and, altogether, the 'hermeneutics of the facticity' of Being-there, in hislectures since the wint. semest. 1919/20" (p. 72). Husserl is alwayscited as "E. Husserl" and Kant as "I. Kant"?and his minions dutifully cite the master as "M. Heidegger."How Kierkegaard would have loved to comment on Heidegger'soccasional "The detailed reasons for the following considerationswill be given only in . . . Part II, Section 2"?which never saw thelight of day (p. 89). Eleven pages later we read: "only now thehere accomplished critique of the Cartesian, and fundamentally stillpresently accepted, world-ontology can be assured of its philosophicrights. To that end the following must be shown (cf. Part I, Sect.3)." Alas, this, too, was never published; but after reading the fourquestions that follow one does not feel any keen regret. Witnessthe second: "Why is it that in-worldly beings take the place ofthe leaped-over phenomenon by leaping into the picture as theontological topic?" (I.e., why have beings been discussed insteadof Being?) Though Heidegger is hardly a poet, his terminology77recalls one of Nietzsche's aphorisms: "The poet presents his thoughtsfestively, on the carriage of rhythm: usually because they could notwalk" (The Portable Nietzsche, p. 54).If all the sentences quoted so far are readily translatable intoless baroque language, the following italicized explanation of understanding (p. 144) may serve as an example of the many more opaquepronouncements. (No other well-known philosophic work containsnearly so many italics?or rather their German equivalent whichtakes up twice as much space as ordinary type.) "Understandingis the existential Being of the own Being-able-to-be of Being-thereitself, but such that this Being in itself opens up the Where-at ofBeing with itself" (Verstehen ist das existenziale Sein des eigenenSeink?nnens des Daseins selbst, so zwar, dass dieses Sein an ihmselbst das Woran des mit ihm selbst Seins erschliesst). The following sentence reads in full: "The structure of this existential mustnow be grasped and expressed still more sharply." Still more?Heidegger's discussion of death comes near the beginning of thesecond of the two sections he published. To understand it, two keyconcepts of the first section should be mentioned briefly. The firstis Das Man, one of Heidegger's happier coinages. The German wordman is the equivalent of the English one in such locutions as "onedoes not do that" or "of course, one must die." But the Germanman does not have any of the other meanings of the English wordone. It is therefore understandable why Das Man has been translatedsometimes as "the public" or "the anonymous They," but sinceHeidegger also makes much of the phrase Man selbst, which means"oneself," it is preferable to translate Das Man as "the One." TheOne is the despot that rules over the inauthentic Being-there of oureveryday live
-
-
site.xavier.edu site.xavier.edu
-
Known historical users of the Underwood SS:<br /> - A. R. Ammons<br /> - Stephen King<br /> - Farley Mowat<br /> - Charles Portis<br /> - Helen Thomas
-
-
ieeexplore.ieee.org ieeexplore.ieee.org
-
The study finds that with only 23% of India’s electricity from renewables, the rapid growth of EVs could increase emissions and up to 90% improper battery recycling and disposal further exacerbating environmental harm.
It makes a verifiable claim about the specific percentage of batteries that are not properly recycled in India, which further supports the fact that EV's are not as bio friendly as claimed to be in their overall life.
Tags
Annotators
URL
-
-
www.whatsbetter.today www.whatsbetter.today
-
God did not breathe His own breath into dust just to create a food source for an Algorithm.
Nishmat Chayyim vs. The Feed This anchor references Genesis 2:7, where God breathes the Nishmat Chayyim (Breath of Life) into dust. This act transforms biological matter into a Nephesh Chayah (Living Soul).
In the Kingdom, the "Breath" is the sacred, animating force of God. It is Autotelic—it exists for its own divine purpose, not to be instrumentalised. The Empire, however, views humans as "Livestock"—mere biomass to be converted into data and ad revenue. This is the spiritual crime of Idolatry inverted: instead of you sacrificing to a false god, the false god (The Algorithm) sacrifices you to itself. To "wake up" is to reclaim the Ruach (Spirit) and refuse to let the Holy of Holies (your attention) be turned into a marketplace (John 2:16).
-
-
www.epa.gov www.epa.gov
-
FACT: Electric vehicle battery replacements due to failures are uncommon.
This is a verifiable statement that can be supported by the data and the chart shown under the claim. This is supported by the study of 15k vehicles cited in the text, which show that battery failure rates have been less than 0.5% for models made after 2016. This specific data effectively disproves the myth that batteries need frequent replacement.
-
-
www.whatsbetter.today www.whatsbetter.today
-
p.s. Want the visual map? You'll find a full FieldNote Sketch Summary of this inside the 'hidden' layer. Click this highlight to see the synthesis, share it with someone you know needs it and save a copy for yourself.
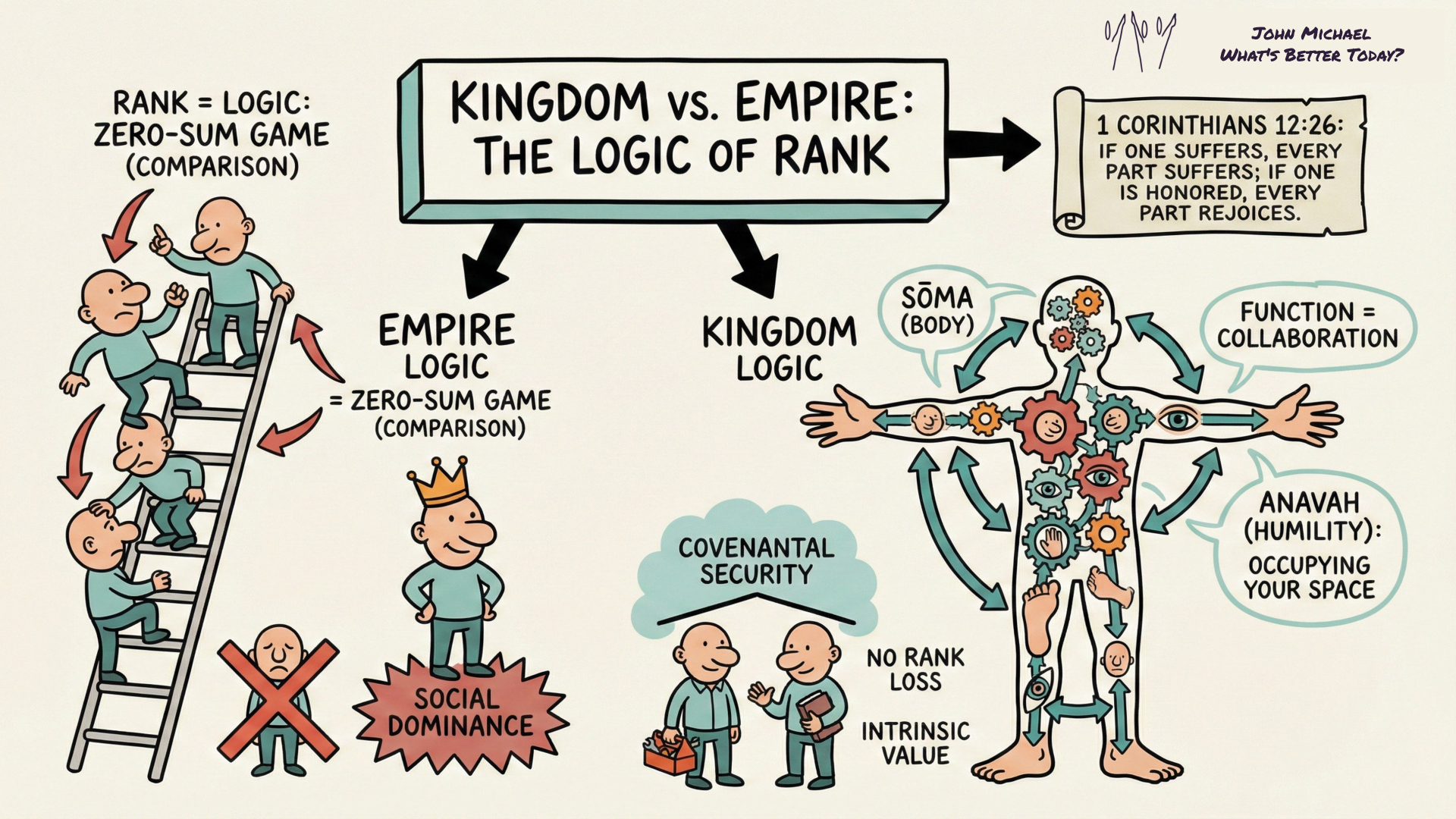 Use this SketchNote in your Notes and share it with someone you know.
Use this SketchNote in your Notes and share it with someone you know.
-
-
www.reddit.com www.reddit.com
-
Similar setting as one on Richard Polt's site, but clearer lighting and more angles here.
-
-
www.digitalhistory.uh.edu www.digitalhistory.uh.edusection51
-
In the 1870's, violent opposition in the South and the North's retreat from its commitment to equality, resulted in the end of Reconstruction.
This sentence shows that Reconstruction did not fail only because of Southern resistance, but also because the North gave up on enforcing equality. Once federal commitment weakened, violence and white supremacy were able to regain control, showing how fragile Reconstruction reforms really were.
-
-
www.youtube.com www.youtube.comYouTube1
-
Taylor Swift - Fortnight (feat. Post Malone) (Official Music Video)<br /> by [[Taylor Swift]], [[Post Malone]]<br /> accessed on 2026-02-04T00:13:18
-
-
ethereum.org ethereum.org
-
1 used as a means to reward validators who propose blocks, or call out dishonest behaviour by other validators. 2. staked by validators, acting as collateral agains dishonest behaviour. 3. it is used to weigh 'votes' for newly proposed blcoks. (fork-choice)
-
-
masteringethereum.xyz masteringethereum.xyz
-
they are two major types of wallets based on whetehr the keys they contatain are related to one another or not.
NONDETERMINISTIC WALLET AND THE DETERMINISTIC WALLET
Tags
Annotators
URL
-
-
www.facebook.com www.facebook.com
-
Iron Law of Typewriters: the wider the carriage, the harder it is to get rid of.
—Mark Schrad, typewriter collector and owner of a 26" Remington 50 via https://www.facebook.com/groups/705152958470148/posts/1186871870298252/
-
- Jan 2026
-
vastava.medium.com vastava.medium.com
-
I hope I come back and edit this once I have something better.
Don't edit (as in "replace"—which is not really possible, anyway Just publish a retraction/followup. (Separately—different URL.)
-





{kind=link}