67 Matching Annotations
- Jan 2025
-
en.wikipedia.org en.wikipedia.org
Tags
Annotators
URL
-
- Jul 2024
-
graphmetrix.com graphmetrix.com
-
very organized
-
- May 2024
-
media.dltj.org media.dltj.org
-
Linked Data in Production: Moving Beyond Ontologies
Spring 2024 Member Meeting: CNI website • YouTube
David Newbury Assistant Director, Software and UX Getty
Over the past six years, Getty has been engaged in a project to transform and unify its complex digital infrastructure for cultural heritage information. One of the project’s core goals was to provide validation of the impact and value of the use of linked data throughout this process. With museum, archival, media, and vocabularies in production and others underway, this sessions shares some of the practical implications (and pitfalls) of this work—particularly as it relates to interoperability, discovery, staffing, stakeholder engagement, and complexity management. The session will also share examples of how other organizations can streamline their own, similar work going forward.
http://getty.edu/art/collection/ http://getty.edu/research/collections/ http://vocab.getty.edu https://www.getty.edu/projects/remodeling-getty-provenance-index/
-
- Oct 2023
-
dtinit.org dtinit.org
-
The important part, as is so often the case with technology, isn’t coming up with a solution to the post portability problem, but coming up with a solution together so that there is mutual buy-in and sustainability in the approach.
The solution is to not create keep creating these fucking problems in the first place.
-
- Sep 2023
-
www.w3.org www.w3.org
-
The Hyperdocument "Library System" where hyperdocuments can be submitted to a library-like service that catalogs them and guarantees access when referenced by its catalog number, or "jumped to" with an appropriate link. Links within newly submitted hyperdocuments can cite any passages within any of the prior documents, and the back-link service lets the online reader of a document detect and "go examine" any passage of a subsequent document that has a link citing that passage.
That this isn't possible with open systems like the Web is well-understood (I think*). But is it feasible to do it with as-yet-untested closed (and moderated) systems? Wikis do something like this, but I'm interested in a service/community that behaves more closely in the concrete details to what is described here.
* I think that this is understood, that is. That it's impossible is not what I'm uncertain about.
Tags
Annotators
URL
-
- Aug 2022
-
www.w3.org www.w3.org
-
In practice, a system in which different parts of the web have different capabilities cannot insist on bidirectional links. Imagine, for example the publisher of a large and famous book to which many people refer but who has no interest in maintaining his end of their links or indeed in knowing who has refered to the book.
Why it's pointless to insist that links should have been bidirectional: it's unenforceable.
-
- Jul 2022
-
docs.italia.it docs.italia.it
-
Documentazione
Il problema di questa sezione è derubricare i modelli dati come documentazione. Le ontologie di ontopia (parlo di modelli non tanto di dati come i vocabolari controllati) sono machine-readable. Quindi non è solo una questione di documentare la sintassi o il contenuto del dato. È rendere il modello actionable, ossia leggibile e interpretabile dalle macchine stesse. Io potrei benissimo documentare dei dataset con una bella tabellina in Github o con tante tabelline in un bellissimo PDF (documentazione), ma non è la stessa cosa di rendere disponibile un'ontologia per dei dati. Rendere i modelli parte attiva della gestione del dato (come per le ontologie) significa abilitare l'inferenza che avete richiamato sopra in maniera impropria per me, ma anche utilizzarli per explainable AI e tanti altri usi. Questo è un concetto fondamentale che non può essere trattato così in linee guida nazionali. Dovrebbe anzi avere un capitolo suo dedicato, vista l'importanza anche in ottica data quality "compliance" caratteristica di qualità dello standard ISO/IEC 25012.
-
Nel caso a), il soggetto ha tutti gli elementi per rappresentare il proprio modello dati; viceversa, nei casi b) e c), la stessa amministrazione, in accordo con AgID, valuta l’opportunità di estendere il modello dati a livello nazionale.
Tutta la parte di modellazione dati, anche attraverso il catalogo nazionale delle ontologie e vocabolari controllati, sembra ora in mano a ISTAT, titolare, insieme al Dipartimento di Trasformazione Digitale di schema.gov.it. Qui però sembra AGID abbia il ruolo di definire i vari modelli. Secondo me questo crea confusione. bisognerebbe coordinarsi anche con le altre amministrazioni per capire bene chi fa cosa. AGID al momento di OntoPiA gestisce solo un'infrastruttura fisica.
-
Utilizzando il framework RDF, si può costruire un grafo semantico, noto anche come grafo della conoscenza, che può essere percorso dalle macchine risolvendo, cioè dereferenziando, gli URI HTTP. Ciò significa che è possibile estrarre automaticamente informazione e derivare, quindi, contenuto informativo aggiuntivo (inferenza).
Non è che fate inferenza perché dereferenziate gli URI. Vi suggerisco di leggere bene le linee guida per l'interoperablità semantica attraverso i linked open data che spiega cosìè l'inferenza (e questa sì fa parte di un processo di arricchimento nel mondo linked open data). L'inferenza è una cosa più complessa che si può fare con ragionatori automatici e query sparql. Si possono dedurre nuove informazioni dati dati esistenti e soprattutto dalle ontologie che sono oggetti machine readable!
-
- Jun 2022
-
docs.italia.it docs.italia.it
-
È importante notare che nella pratica si ritiene a volte necessario passare da modelli di rappresentazione tradizionali come quello relazionale per la modellazione dei dati operando opportune trasformazioni per poi renderli disponibili secondo i principi dei Linked Open Data. Tuttavia, tale pratica non è necessariamente quella più appropriata: esistono situazioni per cui può essere più conveniente partire da un’ontologia del dominio e che si intende modellare e dall’uso di standard del web semantico per poter governare i processi di gestione dei dati.
Non trovo utilità in quanto qui scritto onestamente. Molti più sistemi sono ormai linked open data nativi, quindi oltre al fatto che parlare di linked open data in arricchimento è sbagliato, direi di lasciar perdere questo periodo.
-
utilizzano diversi standard e tecniche, tra cui il framework RDF
rifraserei in "si basano su diversi standard, tra cui RDF, e spesso usano vocabolari controllati RDF per rappresentare terminologia controllata del dominio applicativo di riferimento"
-
a formati di dati a quattro stelle come le serializzazioni RDF o il JSON-LD
JSON-LD è una serializzazione RDF nel mondo JSON. Occhio che qui la traduzione in italiano del documento del publications office non è venuta fuori bene (loro dicono data format such as RDF or JSON-LD che sarebbe anche impreciso. RDF è un modello di rappresentazione del dato nel Web. Le serializzazioni RDF sono tipo Ntriple, RDF/Turtle, RDF/XML, JSON-LD). Tra l'altro nell'allegato tecnico sui formati per i dati aperti, testo preso dalla precedente linee guida, JSON-LD è indicato come serializzazione RDF.
-
linked data
Sono open o no?
-
il linking è una funzionalità molto importante e di fatto può essere considerata una forma particolare di arricchimento. La particolarità consiste nel fatto che l’arricchimento avviene grazie all’interlinking fra dataset di origine diversa, tipicamente fra amministrazioni o istituzioni diverse, ma anche, al limite, all’interno di una stessa amministrazione”
Qui c'è un problema di fondo proprio concettuale. Il problema è che il paradigma dei Linked Open Data è stato derubricato come arricchimento, che nelle linee guida che si cita qui era solo una fase di un processo generale per la gestione dei dati linked open data. Fare linked open data non vuol solo dire arricchire i dati, ma è possibile gestire un dato fin dalla sua nascita in linked open data nativamente. Questo era lo spirito delle linee guida qui citate. Estrapolando solo una parte avete snaturato un po' tutto. Consiglio di trattare l'argomento com'era trattato nelle precedenti linee guida. Peccato anche che sia sparita la figura della metropolitana che aiutava molto.
-
Come detto, il collegamento (linking) dei dati può aumentarne il valore creando nuove relazioni e consentendo così nuovi tipi di analisi.
Comunque, farei uno sforzo in più, con tutto quello che l'italia ha scritto sui linked open data, per scrivere frasi che non siano proprio paro paro la traduzione in italiano del documento in inglese.
-
- Apr 2022
-
www.southampton.ac.uk www.southampton.ac.uk
- Mar 2022
-
dorian.substack.com dorian.substack.com
-
Linked data makes it possible to completely decouple computable information from the system that ordinarily houses it.
-
- Feb 2022
-
blog.bib.uni-mannheim.de blog.bib.uni-mannheim.de
-
Linked Data bezieht sich dabei auf die technische Aufbereitung der Daten, so dass eine Verknüpfung (Linking) der Daten möglich ist. Das dabei zum Einsatz kommende Datenmodell ist RDF, das ursprünglich für das Semantic Web entwickelt wurde.
-
-
news.ycombinator.com news.ycombinator.com
-
Wordle's spread on social media was enabled in part by its low-tech approach for e.g. sharing scores.
One low-tech approach that could've been used here for data persistence would be to generate and prompt the user to save their latest scorecard in PDF or Word format—only it's not a PDF or Word format, but instead "wordlescore.html" file, albeit one that they are able to save to disk and double click to open all the same. When they need to update their scorecard with today's data, you use window.open to show a page that prompts the user to open their most recent scorecard (using either Ctrl+/Cmd+O, or by navigating to the place where they saved it on disk via bookmark). What's not apparent on sight alone is that their wordlescore.html also contains a JS payload as an inline script. When wordlescore.html is opened, it's able to communicate with the Wordle tab via postMessage to window.opener, request the newest data from the app, and then update wordlescore.html itself as appropriate.
-
-
-
Sie helfen beispielsweise, die heterogenen Datensilos eines Unternehmens zu erschließen, sie intelligent zu verknüpfen, neu zu interpretieren und im Firmen-Intranet gezielt bereitzustellen.
Potential von semantischen Technologien: Auflösung von heterogenen Daten-Silos Technologie: Linked Data
-
-
www.trendreport.de www.trendreport.de
-
Darüber hinaus ist ein wichtiger Trend Linked Data im Unternehmensumfeld zu etablieren, um eine neue Generation semantischer, vernetzter Daten-Anwendungen auf Basis des Linked Data Paradigmas zu entwickeln, zu etablieren und erfolgreich zu vermarkten. Im BMBF Wachstumskernprojekt „Linked Enterprise Data Services“ entsteht hierfür beispielsweise eine Technologieplattform, die es Unternehmen ermöglichen soll, neue Dienstleistungen im Web 3.0 zu etablieren.
BMBF Wachstumskernprojekt „Linked Enterprise Data Services
-
-
Local file Local file
-
Eine wesentliche Idee von Linked Data ist es, dass Daten und Informationen un-terschiedlichster Herkunft und Struktur auf Basis von Standards interpretiert, (weiter-)verarbeitet, verknüpft und schließlich dem User in einer Form präsentiert werden können,sodass dieser seine Aufwände zur Informationsgewinnung und -aufbereitung verringernkann
Leitidee von Linked Data
-
bbil-dung 2.8 zeigt einen Überblick über die sogenannte „Linking Open Data Cloud“
Abbildung
-
- Dec 2021
-
beachfront.digital beachfront.digital
-
I buy domains on a regular basis and often from more than one registrar because of a better deal or TLD availability. As a result, I tend to forget I have some domains! True story, I once ran a WHOIS search on a domain I own.
The subtext here is, "that's why i created BeachfrontDigital". But this shows how "apps" (and systems) have poisoned how we conceptualize problems and their solutions.
The simplest solution to the problem described is a document, not a never-finished/never-production-ready app. Bespoke apps have lots of cost overhead. Documents, on the other hand—even documents with rich structure—are cheap.
Tags
Annotators
URL
-
- Aug 2021
-
www.legalanthology.ch www.legalanthology.ch
-
One thing I'd like forward-looking hypertext toolmakers to keep in mind is the ability for the tools to help people answer questions like "What led to legalanthology.ch hosting a copy of this document? Given a URL from one organization, is it possible to look at the graph of internal backlinks (let me focus narrowly on incoming edges originating from the same host)?"
-
- Jun 2021
-
iannotate.org iannotate.org
-
some projects to add to the world of linked data
I'm so excited to hear an update on this project!
Tags
Annotators
URL
-
-
jonudell.net jonudell.net
-
But here's the twist. That edit window is wired to your personal cloud. That's where your words land. Then you syndicate your words back to the site you're posting to.
This is more or less how linked data notifications work. (And Solid, of course, goes beyond that.)
Tags
Annotators
URL
-
- May 2021
-
www.skyhunter.com www.skyhunter.com
-
a hypermedia server might use sensors to alert users to the arrival of new material: if a sensor were attached to a document, running a new link to the document would set off the sensor
Linked data notifications?
(I like the "sensor" imagery.)
Tags
Annotators
URL
-
-
graph.global graph.global
-
Surely RDF already has something like this...? I tried looking around briefly but couldn't find it.
-
-
www.dougengelbart.org www.dougengelbart.org
-
Draft notes, E-mail, plans, source code, to-do lists, what have you
The personal nature of this information means that users need control of their information. Tim Berners-Lee's Solid (Social Linked Data) project) looks like it could do some of this stuff.
-
- Jan 2021
-
www.w3.org www.w3.org
-
Why is CORS important? Currently, client-side scripts (e.g., JavaScript) are prevented from accessing much of the Web of Linked Data due to "same origin" restrictions implemented in all major Web browsers. While enabling such access is important for all data, it is especially important for Linked Open Data and related services; without this, our data simply is not open to all clients. If you have public data which doesn't use require cookie or session based authentication to see, then please consider opening it up for universal JavaScript/browser access. For CORS access to anything other than simple, non auth protected resources
Tags
Annotators
URL
-
- Sep 2020
-
s3.us-west-2.amazonaws.com s3.us-west-2.amazonaws.com
-
The RDF model encodes data in the form ofsubject,predicate,objecttriples. The subjectand object of a triple are both URIs that each identify a resource, or a URI and a stringliteral respectively. The predicate specifies how the subject and object are related, and isalso represented by a URI.
Basic description of Resource Description Framework
-
- Jul 2020
-
github.com github.com
Tags
Annotators
URL
-
-
-
Ruby has some really nice libraries for working with linked data. These libraries allow you to work with the data in both a graph and resource-oriented fashion, allowing a developer to use the techniques that best suit his or her use cases and skills.
-
-
json-ld.org json-ld.org
-
- May 2020
-
github.com github.com
-
"Content Relations"
-
-
developer.enonic.com developer.enonic.com
-
References to other content are specified by this input type.
-
-
en.wikipedia.org en.wikipedia.org
-
The goal of the W3C Semantic Web Education and Outreach group's Linking Open Data community project is to extend the Web with a data commons by publishing various open datasets as RDF on the Web and by setting RDF links between data items from different data sources.
-
The above diagram shows which Linking Open Data datasets are connected, as of August 2014.
-
-
agilitycms.com agilitycms.com
-
Easily create one-to-one and one-to-many relationships between content items.
Tags
Annotators
URL
-
- Jan 2020
-
www.w3.org www.w3.org
-
-
en.wikipedia.org en.wikipedia.org
Tags
Annotators
URL
-
-
www.infoworld.com www.infoworld.com
-
Annotation extends that power to a web made not only of linked resources, but also of linked segments within them. If the web is a loom on which applications are woven, then annotation increases the thread count of the fabric. Annotation-powered applications exploit the denser weave by defining segments and attaching data or behavior to them.
I remember the first time I truly understood what Jon meant when he said this. One web page can have an unlimited number of specific addresses pointing into its parts--and through annotation these parts can be connected to an unlimited number of parts of other things. Jon called it: Exploding the web! How far we've come from Vannevar Bush's musings...
-
- Nov 2019
-
www.culturecreates.com www.culturecreates.com
Tags
Annotators
URL
-
- Sep 2019
-
batumi.estate batumi.estate
Tags
Annotators
URL
-
-
www.semantic-web-journal.net www.semantic-web-journal.net
- Apr 2019
-
www.arl.org www.arl.org
-
-
pretty great intro to knowledge graphs
-
- Mar 2019
-
www.archivogeneral.gov.co www.archivogeneral.gov.co
-
Normalización de las entradas descriptivas: Personas, Lugares, Instituciones (utilización de Linked Open Data (LOD) cuando sea posible.
¿Qué sistema de organización de conocimiento se los posibilita? ¿Qué están usando para enlazar datos y en qué formato?
-
- Nov 2017
-
www.imsglobal.org www.imsglobal.org
-
An institution has implemented a learning management system (LMS). The LMS contains a learning object repository (LOR) that in some aspects is populated by all users across the world who use the same LMS. Each user is able to align his/her learning objects to the academic standards appropriate to that jurisdiction. Using CASE 1.0, the LMS is able to present the same learning objects to users in other jurisdictions while displaying the academic standards alignment for the other jurisdictions (associations).
Sounds like part of the problem Vitrine technologie-éducation has been tackling with Ceres, a Learning Object Repository with a Semantic core.
-
-
events.educause.edu events.educause.edu
-
Moving to a Web of Linked Data for Credential Ecosystems
Oh? Credentials going Semantic? CBE going TBL?
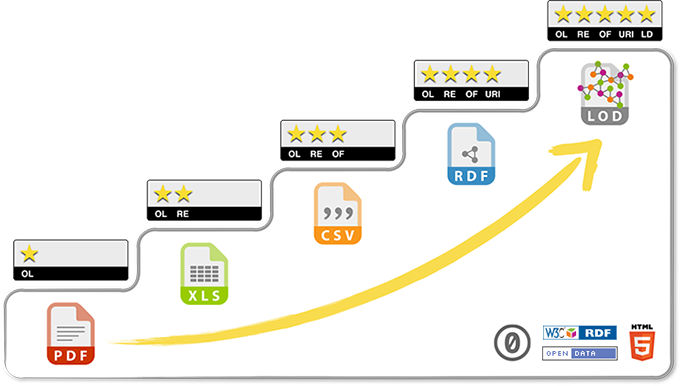
Might be worth a deeper discussion with @jeffgrann, at some point.
-
- Sep 2017
-
signposting.org signposting.org
-
Signposting is an approach to make the scholarly web more friendly to machines. It uses Typed Links as a means to clarify patterns that occur repeatedly in scholarly portals. For resources of any media type, these typed links are provided in HTTP Link headers. For HTML resources, they are additionally provided in HTML link elements. Throughout this site, examples use the former approach.
A kind of light-weight linked data approach to connecting web pages?
Tags
Annotators
URL
-
- Feb 2017
-
en.lodlive.it en.lodlive.it
Tags
Annotators
URL
-
- Jun 2016
-
blog.jonudell.net blog.jonudell.net
-
Annotation can help us weave that web of linked data.
This pithy statement brings together all sorts of previous annotations. Would be neat to map them.
-
- Apr 2016
-
dauwhe.github.io dauwhe.github.io
-
Is it possible to add information to a resource without touching it?
That’s something we’ve been doing, yes.
-
- Mar 2016
-
opentextbc.ca opentextbc.ca
-
Open data
Sadly, there may not be much work on opening up data in Higher Education. For instance, there was only one panel at last year’s international Open Data Conference. https://www.youtube.com/watch?v=NUtQBC4SqTU
Looking at the interoperability of competency profiles, been wondering if it could be enhanced through use of Linked Open Data.
-
- Dec 2015
-
-
add tags for categorization and search
Well-structured annotations can pave the way towards Linked Open Data.
-
-
iso-sc36.auf.org iso-sc36.auf.org
-
tout enregistrement MLR conforme au profil Normetic 2.0 est automatiquement conforme au profil d’application MLR de base.
L’interopérabilité est essentielle à l’avènement du Web des données liées (en éducation comme ailleurs).
-
-
www.meanboyfriend.com www.meanboyfriend.com
-
Among the most useful summaries I have found for Linked Data, generally, and in relationship to libraries, specifically. After first reading it, got to hear of the acronym LODLAM: “Linked Open Data for Libraries, Archives, and Museums”. Been finding uses for this tag, in no small part because it gets people to think about the connections between diverse knowledge-focused institutions, places where knowledge is constructed. Somewhat surprised academia, universities, colleges, institutes, or educational organisations like schools aren’t explicitly tied to those others. In fact, it’s quite remarkable that education tends to drive much development in #OpenData, as opposed to municipal or federal governments, for instance. But it’s still very interesting to think about Libraries and Museums as moving from a focus on (a Web of) documents to a focus on (a Web of) data.
-
- Nov 2015
-
europa.eu europa.eu
-
That's why I say that data is the new oil for the digital age
-
- Oct 2015
-
web.hypothes.is web.hypothes.is
-
why not annotate, say, the Eiffel Tower itself
As long as it has some URI, it can be annotated. Any object in the world can be described through the Semantic Web. Especially with Linked Open Data.
-
- Sep 2015
-
docs.google.com docs.google.com
-
In a nutshell, an ontology answers the question, “What things can we say exist in a domain, and how do we describe those things that relate to each other?”
-
According to inventor of the World Wide Web, Tim Berners-Lee, there are four key principles of Linked Data (Berners-Lee, 2006): Use URIs to denote things. Use HTTP URIs so that these things can be referred to and looked up (dereferenced) by people and user agents. Provide useful information about the thing when its URI is dereferenced, leveraging standards such as RDF, SPARQL. Include links to other related things (using their URIs) when publishing data on the web.
-
In section 4.1.3.2 of the xAPI specification, it states “Activity Providers SHOULD use a corresponding existing Verb whenever possible.”
-
- Aug 2015
-
hypothes.is hypothes.is
-
publisher or museum
Potential for LODLAM!
-
-
www.w3.org www.w3.org
-
I feel that there is a great benefit to fixing this question at the spec level. Otherwise, what happens? I read a web page, I like it and I am going to annotate it as being a great one -- but first I have to find out whether the URI my browser is used, conceptually by the author of the page, to represent some abstract idea?
-
- May 2015
-
-
periods have proven to work poorly with Linked Data principles, which require well-defined entities for linking.
-