82 Matching Annotations
- Jan 2024
-
en.wikipedia.org en.wikipedia.org
- May 2023
-
infomesh.net infomesh.net
-
almost all beginners to RDF go through a sort of "identity crisis" phase, where they confuse people with their names, and documents with their titles. For example, it is common to see statements such as:- <http://example.org/> dc:creator "Bob" . However, Bob is just a literal string, so how can a literal string write a document?
This could be trivially solved by extending the syntax to include some notation that has the semantics of a well-defined reference but the ergonomics of a quoted string. So if the notation used the sigil
~(for example), then~"Bob"could denote an implicitly defined entity that is, through some type-/class-specific mechanism associated with the string "Bob".
-
- Apr 2023
-
Local file Local file
-
These systems provide quite powerful tools for automaticreasoning, but encoding many kinds of knowledge using their rigid formal representations requiressignificant- -and often completely infeasible-amounts of effort.
-
-
philip.greenspun.com philip.greenspun.com
-
There are a few obvious objections to this mechanism. The most serious objection is that duplicate information must be maintained consistently in two places. For example, if the conference organizers decide to change the abstracts deadline from 10 August to 15 August, they'll have to make that change both in the META element in the HEAD and in some human-readable area of the BODY.
Microdata addresses this.
-
- Aug 2022
-
www.ischool.berkeley.edu www.ischool.berkeley.edu
-
Historical Hypermedia: An Alternative History of the Semantic Web and Web 2.0 and Implications for e-Research. .mp3. Berkeley School of Information Regents’ Lecture. UC Berkeley School of Information, 2010. https://archive.org/details/podcast_uc-berkeley-school-informat_historical-hypermedia-an-alte_1000088371512. archive.org.
https://www.ischool.berkeley.edu/sites/default/files/audio/2010-10-20-vandenheuvel_0.mp3

Interface as Thing - book on Paul Otlet (not released, though he said he was working on it)
- W. Boyd Rayward 1994 expert on Otlet
- Otlet on annotation, visualization, of text
- TBL married internet and hypertext (ideas have sex)
- V. Bush As We May Think - crosslinks between microfilms, not in a computer context
- Ted Nelson 1965, hypermedia
t=540
- Michael Buckland book about machine developed by Emanuel Goldberg antecedent to memex
- Emanuel Goldberg and His Knowledge Machine: Information, Invention, and Political Forces (New Directions in Information Management) by Michael Buckland (Libraries Unlimited, (March 31, 2006)
- Otlet and Goldsmith were precursors as well
four figures in his research: - Patrick Gattis - biologist, architect, diagrams of knowledge, metaphorical use of architecture; classification - Paul Otlet, Brussels born - Wilhelm Ostwalt - nobel prize in chemistry - Otto Neurath, philosophher, designer of isotype
Paul Otlet
- wrote bibliography on law
- book: Something on Bibliography #wanttoread
- universal decimal classification system
- mundaneum
- Le Corbusier - architect worked with Otlet for building for Mundaneum; See: https://socks-studio.com/2019/05/05/the-shape-of-knowledge-the-mundaneum-by-paul-otlet-and-henri-la-fontaine/
Otlet was interested in both the physical as well as the intangible aspects of the Mundaneum including as an idea, an institution, method, body of work, building, and as a network.<br /> (#t=1020)
Early iPhone diagram?!?

(roughly) armchair to do the things in the web of life (Nelson quote) (get full quote and source for use) (circa 19:30)
compares Otlet to TBL
Michael Buckland 1991 <s>internet of things</s> coinage - did I hear this correctly? https://en.wikipedia.org/wiki/Internet_of_things lists different coinages
Turns out it was "information as thing"<br /> See: https://hypothes.is/a/kXIjaBaOEe2MEi8Fav6QsA
sugane brierre and otlet<br /> "everything can be in a document"<br /> importance of evidence
The idea of evidence implies a passiveness. For evidence to be useful then, one has to actively do something with it, use it for comparison or analysis with other facts, knowledge, or evidence for it to become useful.
transformation of sound into writing<br /> movement of pieces at will to create a new combination of facts - combinatorial creativity idea here. (circa 27:30 and again at 29:00)<br /> not just efficiency but improvement and purification of humanity
put things on system cards and put them into new orders<br /> breaking things down into smaller pieces, whether books or index cards....
Otlet doesn't use the word interfaces, but makes these with language and annotations that existed at the time. (32:00)
Otlet created diagrams and images to expand his ideas
Otlet used octagonal index cards to create extra edges to connect them together by topic. This created more complex trees of knowledge beyond the four sides of standard index cards. (diagram referenced, but not contained in the lecture)
Otlet is interested in the "materialization of knowledge": how to transfer idea into an object. (How does this related to mnemonic devices for daily use? How does it relate to broader material culture?)
Otlet inspired by work of Herbert Spencer
space an time are forms of thought, I hold myself that they are forms of things. (get full quote and source) from spencer influence of Plato's forms here?
Otlet visualization of information (38:20)
S. R. Ranganathan may have had these ideas about visualization too
atomization of knowledge; atomist approach 19th century examples:S. R. Ranganathan, Wilson, Otlet, Richardson, (atomic notes are NOT new either...) (39:40)
Otlet creates interfaces to the world - time with cyclic representation - space - moving cube along time and space axes as well as levels of detail - comparison to Ted Nelson and zoomable screens even though Ted Nelson didn't have screens, but simulated them in paper - globes
Katie Berner - semantic web; claims that reporting a scholarly result won't be a paper, but a nugget of information that links to other portions of the network of knowledge.<br /> (so not just one's own system, but the global commons system)
Mention of Open Annotation (Consortium) Collaboration:<br /> - Jane Hunter, University of Australia Brisbane & Queensland<br /> - Tim Cole, University of Urbana Champaign<br /> - Herbert Van de Sompel, Los Alamos National Laboratory annotations of various media<br /> see:<br /> - https://www.researchgate.net/publication/311366469_The_Open_Annotation_Collaboration_A_Data_Model_to_Support_Sharing_and_Interoperability_of_Scholarly_Annotations - http://www.openannotation.org/spec/core/20130205/index.html - http://www.openannotation.org/PhaseIII_Team.html
trust must be put into the system for it to work
coloration of the provenance of links goes back to Otlet (~52:00)
Creativity is the friction of the attention space at the moments when the structural blocks are grinding against one another the hardest. —Randall Collins (1998) The sociology of philosophers. Cambridge, MA: Harvard University Press (p.76)
Tags
- octagonal index cards
- atomic ideas
- Emanuel Goldberg
- memex
- atomic notes
- W. Boyd Rayward
- Tim Cole
- references
- Wilhelm Ostwalt
- mnemonic devices
- Herbert Van de Sompel
- Mundaneum
- Herbert Spencer
- semantic web
- Web 2.0
- evidence
- Paul Otlet
- atomist philosophy
- Jane Hunter
- Hypothes.is
- Ted Nelson
- listen
- Charles van den Heuvel
- material culture
- S. R. Ranganathan
- Universal Decimal Classification
- Tim Berners-Lee
- Michael Buckland
- Le Corbusier
- Vannevar Bush
- index cards
- Otto Neurath
- Open Annotation Collaboration
- hypermedia
- materialization of knowledge
- idea links
- Randall Collins
Annotators
URL
-
- Jun 2022
-
www.researchgate.net www.researchgate.net
-
MemoNote, an annotation-based personal knowledge management tool for teachers
-
- Feb 2022
-
web2-unterricht.ch web2-unterricht.ch
-
Hypothes.is
Semantic Web Tool: Hypothes.is
-
-
www.oreilly.com www.oreilly.com
-
Table 8-2. Various manifestations/eras of the Web and their defining characteristics
Internet bis Web 3.0 (semantic web)
-
-
-
Um dem entgegenzuwirken, werden im Forschungsbereich Corporate Semantic Web innovative Konzepte und Lösungen für die Gewinnung, Verwaltung und Nutzung von Wissen auf Basis von semantischen Technologien mit speziellem Fokus auf den Unternehmenskontext entwickelt.
Forschungsbereich: Corporate Semantic Web Ziel: Innovative Konzepte und Lösung für die Gewinnung, Verwaltung und Nutzung von Wissen auf Basis von semantischen Technologien im Unternehmenskontext
-
-
Local file Local file
-
Während das Semantic Web im Kern auf Standards zur Beschreibung von Prozessen, Dokumenten und Inhalten sowie entsprechenden Metadaten – vorwiegend vom W3C27 vorge-schlagen – aufsetzt, und damit einen Entwurf für das Internet der nächsten Generation darstellt, adressieren semantische Technologien Herausforde-rungen zur Bewältigung komplexer Arbeitsprozesse, Informationsmengen bzw. RetrievalProzessen und Vernetzungs- oder Integrationsaktivitäten, die nicht nur im Internet, sondern auch innerhalb von Organisationsgrenzen in Angriff genommen werden.
Unterschied zwischen Semantic Web und semantische Technologien
-
-
-
Innerhalb eines Jahres wurde ein neuer Begriff geprägt: Web 3.0, der die Entwicklung des Webs über die 1.0-Ära der HTML-Webseiten und den frühen E-Commerce hinaus in die grelle 2.0-Periode markiert, in der soziale Medien und „benutzergenerierte Inhalte“ geboren wurden. .
Web 3.0
-
-
Local file Local file
-
Eine wesentliche Idee von Linked Data ist es, dass Daten und Informationen un-terschiedlichster Herkunft und Struktur auf Basis von Standards interpretiert, (weiter-)verarbeitet, verknüpft und schließlich dem User in einer Form präsentiert werden können,sodass dieser seine Aufwände zur Informationsgewinnung und -aufbereitung verringernkann
Leitidee von Linked Data
-
Zusätzlich bietet die Abfragesprache SPARQL die Möglichkeit,RDF-kodierte semantische Daten strukturiert abzufragen, wobei bereits (beschränkter)Gebrauch der Möglichkeit logischer Schlussfolgerungen gemacht werden kann.
SPARQL = Abfragesprache von RDF
-
OWL basiert auf einer speziellen mathematischen Beschreibungslogik (SHROIQ(D)) undstellt ein ausdrucksmächtiges Instrument zur Modellierung von Wissensrepräsentationen(Ontologien) dar [34].
OWL = Instrument zur Modellierung der Wissensrepräsentationen
-
Abbildung 2.3 zeigt den vorgeschlagenen SemanticWeb Technologie-Stapel, der das traditionelle World Wide Web ergänzt, und gibt den ak-tuellen Stand der Standardisierung an.
-
Diese Form von Wissens-repräsentation wird in der Informatik als Ontologie bezeichnet.
Ontologie = Zieldefiniton von Semantic Web
-
Die Idee hinter dem Semantic Web liegt darin, die Bedeutung von sprachlichen Be-griffen und anderen bedeutungstragenden Entitäten explizit in einer maschinenlesbarenund vom Computer korrekt interpretierbaren Form anzugeben
-
Die mit Linked Data beschrittene Lösung macht sich existierende Technologien zu Nut-ze, die vom W3C2 als Semantic Web Technologien standardisiert wurden.
Tags
- Semantic Web Technologien
- ziel
- rdf
- ontologie
- linked data
- stack
- SPARQL
- W3C
- Abfragesprache
- semantic web
- owl
Annotators
-
-
www.mkbergman.com www.mkbergman.com
-
Practical guidance on KR, knowledge graphs, semantic technologies, and KBpedia
Titel: A knowledge representation practionary Autor: Michael K. Bergman
-
-
halfanhour.blogspot.com halfanhour.blogspot.com
-
it depends on businesses working together, on them cooperating.
semantic web will fail because businesses are not working together
-
- Jan 2022
-
-
my main frustrations are around the lack of the very basic things that computers can do extremely well: data retrieval and search. I'll carry on, just listing some examples. Let's see if any of them resonate with you:
- 20 years waiting from Semantic Web promises!!!
- Conclusions:
- competition vs cooperation (reinventing the wheel again and again)
- minority interested in knowledge vs majority targeted to consume
-
youtube videos, even though most of them have subtitles hence allowing for full text search?
- GREAT IDEA: VIDEOS (VISUAL+AUDIO) ++ TRANSCRIPTION (FULL TEXT), permits searches!!!
-
-
beepb00p.xyz beepb00p.xyz
-
the tool I've developed
- REINVENT THE WHEEL!
- SADLY, DO IT YOURSELF IS OFTEN THE ONLY ALTERNATIVE!
-
a more realistic and plausible target: using my digital trace (such as browser history, webpage annotations and my personal wiki) to make up for my limited memory
- OK: tools for register, but NEED "THE TOOL" for searching and RECOVER these data!
Tags
Annotators
URL
-
- Dec 2021
-
blog.jonudell.net blog.jonudell.net
-
Advocates of Deep/Machine Learning often dismiss the Semantic Web, claiming that algorithms are much better at constructing knowledge from large amounts of data than are these painstaking efforts to encode knowledge
- SEE [citation needed]
- EXPLORE
- ok! "these painstaking efforts to encode knowledge"
-
Web documents are databases full of facts and assertions that we are ill-equipped to find
- not designed for Semantic Web!!!
-
How will we retrofit the web we already have?
- "parallel" web???
- bots??? explore and pass
-
The semantic web is, of course, another idea that’s been kicking around forever. In that imagined version of the web, documents encode data structures governed by shared schemas. And those islands of data are linked to form archipelagos that can be traversed not only by people but also by machines. That mostly hasn’t happened because we don’t yet know what those schemas need to be, nor how to create writing tools that enable people to easily express schematized information
- Semantic Web: an utopia???
- I have been waiting for it for 20 years, and counting...
- Instead "plain text": "triplets"; properties and wikidata-Qs
-
-
twitter.com twitter.comTwitter1
-
there was line of thought among those making native GUIs (see also Sherlock) that future of the web was having more things from web pulled into native GUIs
The dream is still alive among semweb people (incl. Tim Berners-Lee himself).
The sad state of current norms re webapps created by professional devs leads to what probably seems like a paradox but isn't, which is that the alternate future outlined in this tweet is closer to the ideal of the Web than the "Modern Web".
-
- Sep 2021
-
semanticbible.com semanticbible.com
-
Bibleref is a simple approach to automatically identifying Bible references that are embedded in blog posts and other web pages. This enables search engines, content aggregators, and other automated tools to correctly label the references so they're more easily searchable. Bibleref is part of a general movement toward markup that expresses more semantic, rather than presentational, element.
-
- Aug 2021
-
www.benmyers.dev www.benmyers.dev
-
https://benmyers.dev/blog/on-the-dl/
Curious double entendre title here.
Note to self: I should use these patterns more.
-
- Mar 2021
-
stackoverflow.com stackoverflow.com
-
Screen readers for the blind can help them fill out a form more easily if the logical sections are broken into fieldsets with one legend for each one. A blind user can hear the legend text and decide, "oh, I can skip this section," just as a sighted user might do by reading it.
-
Fits the ideal behind HTML HTML stands for "HyperText Markup Language"; its purpose is to mark up, or label, your content. The more accurately you mark it up, the better. New elements are being introduced in HTML5 to more accurately label common web page parts, such as headers and footers.
-
- Sep 2020
-
react-spectrum.adobe.com react-spectrum.adobe.com
-
The fully styleable primitives that the web offers (e.g. <div>) are quite powerful, but they lack semantic meaning. This means that accessibility is often missing because assistive technology cannot make sense of the div soup that we use to implement our components.
-
- Apr 2020
-
www.w3.org www.w3.org
-
This graph view is the easiest possible mental model for RDF and is often used in easy-to-understand visual explanations
Tags
Annotators
URL
-
- Feb 2020
-
www.vice.com www.vice.com
- Jan 2020
-
twobithistory.org twobithistory.org
-
www.semantic-mediawiki.org www.semantic-mediawiki.org
Tags
Annotators
URL
-
- Sep 2019
-
batumi.estate batumi.estate
Tags
Annotators
URL
-
-
www.semantic-web-journal.net www.semantic-web-journal.net
- Oct 2018
-
www.slideshare.net www.slideshare.net
-
Do neural networks dream of semantics?
Neural networks in visual analysis, linguistics Knowledge graph applications
- Data integration,
- Visualization
- Exploratory search
- Question answering
Future goals: neuro-symbolic integration (symbolic reasoning and machine learning)
-
-
www.slideshare.net www.slideshare.net
-
Intelligent agents the vision revisited
Memex, 1945 (for storing individual memories) License + societal norms + interoperability
-
-
dkm-static.fbk.eu dkm-static.fbk.eu
-
Learning Expressive Ontological Concept Descriptions via Neural NetworksMARCO ROSPOCHERTheRoadLessTraveledTransforming a sentence into an axiom
Building ontology from text: transforming a sentence into an axiom.
-
- Nov 2017
-
www.imsglobal.org www.imsglobal.org
-
An institution has implemented a learning management system (LMS). The LMS contains a learning object repository (LOR) that in some aspects is populated by all users across the world who use the same LMS. Each user is able to align his/her learning objects to the academic standards appropriate to that jurisdiction. Using CASE 1.0, the LMS is able to present the same learning objects to users in other jurisdictions while displaying the academic standards alignment for the other jurisdictions (associations).
Sounds like part of the problem Vitrine technologie-éducation has been tackling with Ceres, a Learning Object Repository with a Semantic core.
-
-
events.educause.edu events.educause.edu
-
Moving to a Web of Linked Data for Credential Ecosystems
Oh? Credentials going Semantic? CBE going TBL?
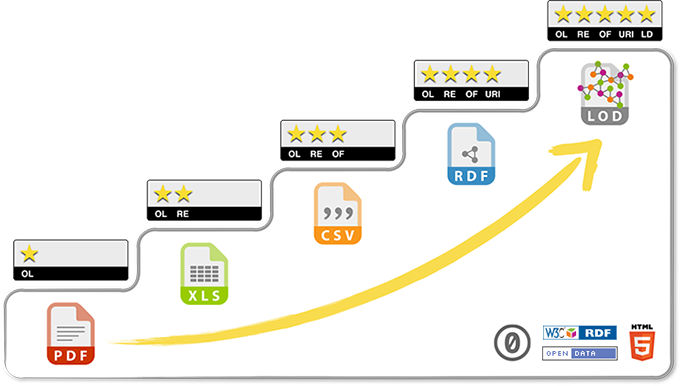
Might be worth a deeper discussion with @jeffgrann, at some point.
-
- Apr 2017
-
www.budapestopenaccessinitiative.org www.budapestopenaccessinitiative.org
-
hat Velterop essentially does is to generalize the Wikipedia implementation of distributed contributions by linking it to the semantic web
Fascinating. Mark this for followup.
-
- Mar 2017
-
Tags
Annotators
URL
-
- Feb 2017
-
wiki.dbpedia.org wiki.dbpedia.orgDBpedia1
Tags
Annotators
URL
-
-
www.cyc.com www.cyc.com
-
demo.dbpedia-spotlight.org demo.dbpedia-spotlight.org
-
lod-cloud.net lod-cloud.net
Tags
Annotators
URL
-
-
www.sensebot.net www.sensebot.net
Tags
Annotators
URL
-
-
labs.sparna.fr labs.sparna.fr
-
en.wikipedia.org en.wikipedia.org
Tags
Annotators
URL
-
-
sandbox.semantic-mediawiki.org sandbox.semantic-mediawiki.org
-
www.wikidata.org www.wikidata.orgWikidata1
-
query.wikidata.org query.wikidata.org
Tags
Annotators
URL
-
-
cognonto.com cognonto.com
Tags
Annotators
URL
-
-
cognonto.com cognonto.com
- Aug 2016
-
web.hypothes.is web.hypothes.is
-
I Annotate 2016 shows that it’s ready for prime time.
Will 2017 be “the year of annotations”?
-
- Jun 2016
-
blog.jonudell.net blog.jonudell.net
-
produce schema-aware writing tools that everyone can use to add new documents to a nascent semantic web
That dream does live on. Since Vannevar’s 1945 article on the Memex, we’ve been dreaming of such tools. Our current tools are quite far from that dream.
-
Annotation can help us weave that web of linked data.
This pithy statement brings together all sorts of previous annotations. Would be neat to map them.
-
- Apr 2016
-
dauwhe.github.io dauwhe.github.io
-
Is it possible to add information to a resource without touching it?
That’s something we’ve been doing, yes.
-
- Mar 2016
-
opentextbc.ca opentextbc.ca
-
Open data
Sadly, there may not be much work on opening up data in Higher Education. For instance, there was only one panel at last year’s international Open Data Conference. https://www.youtube.com/watch?v=NUtQBC4SqTU
Looking at the interoperability of competency profiles, been wondering if it could be enhanced through use of Linked Open Data.
-
- Jan 2016
-
manual.calibre-ebook.com manual.calibre-ebook.com
-
Set Semantics¶ This tool is used to set semantics in EPUB files. Semantics are simply, links in the OPF file that identify certain locations in the book as having special meaning. You can use them to identify the foreword, dedication, cover, table of contents, etc. Simply choose the type of semantic information you want to specify and then select the location in the book the link should point to. This tool can be accessed via Tools->Set semantics.
Though it’s described in such a simple way, there might be hidden power in adding these tags, especially when we bring eBooks to the Semantic Web. Though books are the prime example of a “Web of Documents”, they can also contribute to the “Web of Data”, if we enable them. It might take long, but it could happen.
-
- Dec 2015
-
hypothes.is hypothes.is
-
personal note taking, peer review, copy editing, post publication discussion, journal clubs, classroom uses, automated classification, deep linking
Useful list, almost a roadmap or set of scenarios. The last two might be especially intriguing, in view of the Semantic Web.
-
deep linking
Ah, yes! It may sound technical to some, but there’s something very useful about deep linking which can help fulfill Berners-Lee’s Semantic Web idea much more appropriately than what is currently available. Despite so many advances in Web publishing (and the growing interest in Linked Open Data), it’s often difficult to link directly to an online item of interest. In a way, Hypothesis almost allows readers to add anchor tags to an element so it can be used in a direct link.
-
-
-
add tags for categorization and search
Well-structured annotations can pave the way towards Linked Open Data.
-
-
iso-sc36.auf.org iso-sc36.auf.org
-
tout enregistrement MLR conforme au profil Normetic 2.0 est automatiquement conforme au profil d’application MLR de base.
L’interopérabilité est essentielle à l’avènement du Web des données liées (en éducation comme ailleurs).
-
-
www.meanboyfriend.com www.meanboyfriend.com
-
Anyone can say Anything
The “Open World Assumption” is central to this post and to the actual shift in paradigm when it comes to moving from documents to data. People/institutions have an alleged interest in protecting the way their assets are described. Even libraries. The Open World Assumption makes it sound quite chaotic, to some ears. And claims that machine learning will solve everything tend not to help the unconvinced too much. Something to note is that this ability to say something about a third party’s resource connects really well with Web annotations (which do more than “add metadata” to those resources) and with the fact that no-cost access to some item of content isn’t the end of the openness.
-
- Nov 2015
-
bbf.enssib.fr bbf.enssib.fr
-
Les représentants de la Bibliothèque nationale de France (BnF) annoncèrent leur objectif de ramener le délai de traitement des documents à six semaines en moyenne
C’était long, en 2002! Où en est la BnF, aujourd’hui? D’une certaine façon, ce résumé semble prédire la venue des données, la fédération des catalogues, etc. Pourtant, il semble demeurer de nombreux obstacles, malgré tout ce temps. Et si on pouvait annoter le Web directement?
-
-
mfeldstein.com mfeldstein.com
-
entity called “comment,”
Post, comment, annotation… All different, but can all have the same predicate.
-
-
-
www.nrc-cnrc.gc.ca www.nrc-cnrc.gc.ca
-
e-learning technologies and standards: SCORM, LOM, IMS-LD, IMS-CC, IMS-QTI, IMS-CP, LDL, SLD
Standards matter.
-
-
www.educationdive.com www.educationdive.com
-
some kind of curated library
Which is where OER catalogues (tied to the Semantic Web) may shine. Sure, they can require a lot of work. But this is precisely why they matter.
-
- Oct 2015
-
web.hypothes.is web.hypothes.is
-
why not annotate, say, the Eiffel Tower itself
As long as it has some URI, it can be annotated. Any object in the world can be described through the Semantic Web. Especially with Linked Open Data.
-
machine-readable, ‘semantic’ annotations.
Waiting for those to be promoted, through Hypothesis and other Open Annotations platforms.
-
- Aug 2015
-
www.w3.org www.w3.org
-
I feel that there is a great benefit to fixing this question at the spec level. Otherwise, what happens? I read a web page, I like it and I am going to annotate it as being a great one -- but first I have to find out whether the URI my browser is used, conceptually by the author of the page, to represent some abstract idea?
-
- Oct 2014
-
news.ycombinator.com news.ycombinator.com
-
Maybe the driver for semantic web data is humans trying to programmatically consume human-readable information, rather than the other way around?
-
-
www.well.com www.well.comMetacrap1
-
observational metadata is far more reliable than the stuff that human beings create for the purposes of having their documents found. It cuts through the marketing bullshit, the self-delusion, and the vocabulary collisions
Read the whole essay it is worth the while...
Tags
Annotators
URL
-