a supercomputer scheduled to go live in 2026 was last month still a scaffolding yard in Essex
令人惊讶的是:原计划2026年投入使用的超级计算机在2026年3月仍然只是一个脚手架场地。这一事实揭示了英国AI基础设施建设的严重滞后和政府宣传与实际进展之间的巨大鸿沟,反映了政府可能过于乐观地评估了项目进度。
a supercomputer scheduled to go live in 2026 was last month still a scaffolding yard in Essex
令人惊讶的是:原计划2026年投入使用的超级计算机在2026年3月仍然只是一个脚手架场地。这一事实揭示了英国AI基础设施建设的严重滞后和政府宣传与实际进展之间的巨大鸿沟,反映了政府可能过于乐观地评估了项目进度。
The OpenAI deal was part of a larger series of UK-US investments intended to 'mainline AI' into the British economy.
令人惊讶的是:英国和美国政府竟然计划将AI技术'直接注入'英国经济,这种表述暗示了AI技术可能被视为一种可以像药物一样'注射'到经济系统中的物质,反映了政府对于AI技术的急切态度和对技术简单化的理解,忽略了技术发展的复杂性和潜在风险。
Artificial intelligence company cites high energy costs and regulation for putting landmark project on hold
令人惊讶的是:尽管英国政府承诺提供高达10亿英镑的补贴,OpenAI仍因能源成本和监管问题撤资,这表明在AI基础设施领域,能源成本可能比政府补贴更能决定投资决策。
OpenAI shelves Stargate UK in blow to Britain's AI ambitions
令人惊讶的是:OpenAI搁置了价值310亿美元的英国AI投资项目,这是英国AI领域有史以来最大的单一投资失败,凸显了国际科技巨头对英国市场信心的动摇。
finding answers to a question given to you by your professor.
I feel like also making new questions as well
Third, we only consider direct neighbors along theborder in our main specifications, as these are the most likelyto have equal propensities of falling on either side of the bound-ary
Almost like a natural experiment where people can fall on either side
is consideredconditionally independent of potential outcomes
True
such as regulation of oceans,transport, and wildlife.
I wonder if you could go even broader
throughthe changed incentives of elected officials and preferences ofthe local population.
Two way relationship
shale gas development has divided neighbors, spurredlawsuits and sown deep mistrust
I wonder how this gets caught up in the idea of hard work
conflicts over natural resources can affect a broader range ofregulatory issues through the selection of elected officialswith correlated policy preferences
Basically talking about a similar how rurality affects politics, this is just one dimension
changed the votingrecord of House Representatives on environmental policy relative to neighboring districts without access. Votes become15–20 percentage points less likely to be in favor of the environment
Economics rule over all
The difference between AI and, say, looms, is that this has been broadcast to the entire globe, and it has been treated in a sort of self-conscious way
令人惊讶的是:文章指出AI与历史上其他技术变革(如织布机)的关键区别在于AI的全球广播性质和行业领袖的自我意识宣传。这种透明度反而加剧了公众的不安,因为AI领袖们不断谈论他们知道会引发问题的技术,这在历史上是前所未有的。
If people feel that they have no place in the future. If they feel expelled from the system—they're unable to buy stuff, their skills become obsolete, their chance at earning a living is replaced by a swarm of AI agents
令人惊讶的是:文章揭示了当人们感到自己被排除在未来之外,技能变得过时,谋生机会被AI代理取代时,可能引发的极端心理状态。这种"要么死亡,要么杀人"的绝望情绪是AI社会影响中一个被广泛讨论但很少深入探讨的方面。
A mill owner named William Horsfall was riding home on his beautiful white stallion back from the Cloth Hall market in Huddersfield, UK. He had spent weeks boasting that he would ride up to his saddle in Luddite blood
令人惊讶的是:文章揭示了卢德运动的历史背景,一位名叫威廉·霍斯法尔的工厂主曾吹嘘他会"骑马踏入卢德党人的血泊中",结果被22岁的乔治·梅勒枪击致死。这种历史与当前AI引发的暴力抗议的惊人相似性,揭示了技术变革周期中人类反应的一致性。
Meta is reportedly preparing to release its first AI models led by Alexandr Wang, with plans to open-source some versions while keeping its largest and most powerful systems closed.
令人惊讶的是:Meta聘请了Alexandr Wang领导AI模型开发,但策略发生了重大转变,从之前的完全开放转向部分开放,保留最大和最强大的系统闭源。这表明即使是最大的开源支持者也在根据市场现实调整策略,在开放、安全和商业利益之间寻求新的平衡。
One of the boldest ideas is a sovereign-style fund seeded by AI companies that would pay dividends to Americans, alongside robot taxes, stronger oversight systems, and containment plans for rogue autonomous AI.
令人惊讶的是:OpenAI提出由AI公司出资建立主权基金向美国公民支付股息,这类似于全民基本收入的概念,同时建议对机器人征税并制定更强的监管系统。这反映了OpenAI认为AI带来的财富分配问题需要系统性解决方案,而非简单的技术调整。
OpenAI has published a 13-page policy paper arguing that AI may require a new social contract, with proposals that include taxing automated labor, creating a public wealth fund, expanding access to AI, and testing a four-day workweek.
令人惊讶的是:OpenAI不仅是一家技术公司,还开始提出社会政策建议,包括对自动化劳动征税、创建公共财富基金、扩大AI准入和测试四天工作制。这表明OpenAI正在从技术公司转变为社会政策影响者,承认AI对社会结构的深远影响。
The company added roughly $11 billion in annualized revenue in just over a month, equivalent to the combined ARR of Palantir, Anduril, and Databricks
令人惊讶的是:Anthropic在短短一个多月内增加了110亿美元的年收入,相当于Palantir、Anduril和Databricks三家公司年收入的总和。这种爆炸性增长速度在科技史上极为罕见,反映了企业AI市场的巨大潜力。
Anthropic says its annual revenue run rate has climbed past $30 billion, overtaking OpenAI's reported $25 billion and marking one of the fastest ramps in AI.
令人惊讶的是:Anthropic在短短时间内实现了惊人的收入增长,从2025年底的90亿美元迅速攀升到300亿美元,超越了OpenAI。这种增长速度在AI行业前所未有,显示了Anthropic的商业模式和市场接受度远超预期。
Adobe just turned Firefly into a true all-in-one creative AI studio with its new Firefly AI Assistant that plans and executes multi-step workflows across apps like Photoshop, Premiere, Illustrator
令人惊讶的是:Adobe正在将Firefly转变为一个真正的全合一创意AI工作室,其AI助手能够规划并跨Photoshop、Premiere、Illustrator等多个应用程序执行多步骤工作流程。这表明传统创意软件巨头正在积极拥抱AI代理技术,重新定义创意工作的未来。
Anthropic is expected to release Claude Opus 4.7 alongside a new AI-powered design tool for building websites and presentations
令人惊讶的是:Anthropic正在将Claude从聊天和编程工具扩展到完整的创意系统,推出能够从自然语言提示创建网站、幻灯片和完整产品的设计工具。这标志着AI竞争正从文本生成向全面的创意产品开发转变,模糊了技术与非技术用户之间的界限。
Google is expanding Gemini with a new agent system that can take a single goal and execute it across apps like Gmail, Drive, Calendar, and the web
令人惊讶的是:Google正在将Gemini从单纯的聊天助手转变为能够跨多个应用程序自主执行任务的智能代理系统。这标志着Google正在重新定位其AI产品,从对话式交互转向完整的工作流程自动化,这可能会改变用户与数字环境的互动方式。
The integration also connects to Upwork's AI agent Uma, which helps automate parts of the hiring and execution process once a project is underway
令人惊讶的是:Upwork的AI智能体Uma不仅能帮助自动化招聘流程,还能在项目进行中协助执行工作,这表明AI正在从简单的问答工具转变为能够完成复杂工作流程的全面助手,预示着未来工作方式的根本性变革。
Meta is reportedly developing an AI version of Mark Zuckerberg that can interact with employees, trained on his voice, mannerisms, and internal thinking as part of the company's broader push into AI
令人惊讶的是:Meta正在开发一个马克·扎克伯格的AI版本,不仅模仿他的声音和行为,还要学习他的内部思维方式,用于与员工互动,这标志着AI技术正从功能性工具向复制人类领导力和决策能力的方向发展,引发了一系列关于AI伦理和安全性的担忧。
Andon Labs deployed an AI agent called Luna into a physical boutique with a $100,000 budget, giving it full control to create, staff, and run the business as what may be the first real-world AI employer
令人惊讶的是:一个名为Luna的AI智能体被赋予了10万美元预算和完全控制权,从店面设计到招聘员工全权负责,这可能是世界上第一个真正意义上的AI雇主,尽管它仍会犯基本错误,如选择错误的招聘国家和管理不当员工排班。
The 4-foot-tall robot features 26 joints, voice and image recognition, and can perform dynamic movements like cartwheels and standing up on its own
令人惊讶的是:这个仅4英尺高的人形机器人竟然能做后手翻和自主站立,展示了令人印象深刻的动态平衡能力,而价格却只有约4000美元,比之前的G1模型(约19,000美元)便宜了近80%,这标志着人形机器人技术正以惊人的速度普及。
A single refrigerator-size AI rack consumes 120 kilowatts, equivalent to 100 homes. But this hunger collides with another exponential: Solar costs have fallen by a factor of nearly 100 over 50 years; battery prices have dropped 97% over three decades.
令人惊讶的是:AI能源消耗与可再生能源成本的惊人对比。一个AI机架的能耗相当于100个家庭,但同时太阳能成本50年内下降了近100倍,电池价格30年内下降了97%。这种能源与可再生能源发展的矛盾与平衡,是AI可持续发展的重要考量。
Where training a language model took 167 minutes on eight GPUs in 2020, it now takes under four minutes on equivalent modern hardware.
令人惊讶的是:AI训练效率的提升速度令人震惊。在短短6年内,语言模型的训练时间从167分钟缩短到不到4分钟,效率提升了40多倍。这种进步远超摩尔定律预测的5倍改进,展示了AI硬件和算法的飞速发展。
From the time I began work on AI in 2010 to now, the amount of training data that goes into frontier AI models has grown by a staggering 1 trillion times—from roughly 10¹⁴ flops for early systems to over 10²⁶ flops for today's largest models.
令人惊讶的是:AI训练数据的增长速度令人难以置信。从2010年到2026年,AI模型的训练数据量增长了1万亿倍,这是一个天文数字般的增长,远超大多数人的想象。这种指数级增长是AI发展的核心驱动力,也是为什么AI进步如此迅速的原因。
A single refrigerator-size AI rack consumes 120 kilowatts, equivalent to 100 homes. But this hunger collides with another exponential: Solar costs have fallen by a factor of nearly 100 over 50 years; battery prices have dropped 97% over three decades.
令人惊讶的是:一个AI机架的能耗相当于100个家庭,但太阳能成本50年内下降了近100倍,电池价格30年内下降了97%。这种能源成本的指数级下降为AI提供了可持续发展的路径,展示了技术与能源创新之间的复杂关系。
Where training a language model took 167 minutes on eight GPUs in 2020, it now takes under four minutes on equivalent modern hardware. To put this in perspective: Moore's Law would predict only about a 5x improvement over this period. We saw 50x.
令人惊讶的是:AI模型训练速度在6年内提升了约50倍,远超摩尔定律预测的5倍。这种性能提升不仅来自硬件改进,还来自软件优化和算法创新。这一事实打破了人们对技术进步速度的传统认知,展示了AI领域独特的加速发展模式。
From the time I began work on AI in 2010 to now, the amount of training data that goes into frontier AI models has grown by a staggering 1 trillion times—from roughly 10¹⁴ flops for early systems to over 10²⁶ flops for today's largest models.
令人惊讶的是:AI训练数据量在短短16年间增长了1万亿倍,这是一个难以想象的指数级增长。这种计算能力的爆炸式发展远超人类直觉,解释了为什么AI进步如此迅速且难以预测。大多数人无法真正理解这种指数级增长意味着什么,这也是为什么许多专家对AI发展速度预测失败的原因。
Forward Deployed Engineers tune Relvy for your stack
令人惊讶的是:Relvy采用了一种混合AI模式,结合了自动化系统和人类工程师的调优,这种'人机协作'的方式可能代表了AI在专业领域应用的新范式,既利用了AI的效率,又保留了人类的专业判断。
You get your most tenured engineer on-call all the time
令人惊讶的是:Relvy能够提供相当于公司最有经验工程师的持续支持,这打破了传统运维中经验分布不均的局限,让小型团队也能获得专家级的问题解决能力,这可能显著降低企业对资深工程师的依赖。
What excited me about Relvy was the potential to reduce our on-call burden
令人惊讶的是:Relvy能够显著减少企业的轮班负担,这意味着公司可能不再需要像过去那样依赖昂贵且疲劳的人类工程师来处理紧急警报,这可能引发运维团队结构和技能需求的重大转变。
70% of alerts resolved in under 5 minutes
令人惊讶的是:Relvy声称能够以惊人的速度解决70%的警报,在5分钟内完成,这比传统的人工响应速度快得多,展示了AI在运维自动化领域的巨大潜力,可能彻底改变企业处理系统故障的方式。
We improved Claude's RCA accuracy by 12pp on OpenRCA
令人惊讶的是:Relvy声称将Claude的根因分析(RCA)准确度在OpenRCA基准测试中提高了12个百分点,这是一个相当显著的改进,表明AI在系统故障诊断领域可能已经达到了接近人类专家的水平。
t is to suggest instead that Freud’s relationship to the ‘hard’ sciences, to the natural space or ‘organic substructure’ underpinning psychical life (SE, XIV, 78), is more complex than his detractors and defenders very often concede. For Solms, the origin (archē) of psychoanalysis is not, as it would be for Derrida, subject to indefinite deferral; its time, rather, has finally arrived: ‘it seems entirely appropriate to reconsider whether we might now attempt to map the neurological basis of what we have learnt in psychoanalysis about the structure and functions of the mind, using neuroscientific methods available to us today.’43 It is not surprising that a corollary to this circular return to neurological space is an argument for the abandonment of what Solms calls ‘armchair speculation’. By denying the intrinsically speculative structure of enquiry, Solms’s positivist framing excludes what might be a source of productive creativity for psychoanalytic enquiry. Although Solms suggests that speculation was indeed a source of powerful insight for Freud, as a temporary detour en route towards a neurological theory of the unconscious, too much ‘“armchair” speculation’ has led to theoretical aridity in contemporary psychoanalysis. Freud’s ‘Project’ was a ‘notable early instance of such speculative guesswork, which is why he himself so strongly resisted its publication, describing it as an “aberration [Abirrung]”’.44 The speculative or non-anatomical models Freud tests in the ‘Project’, and deploys from the Interpretation of Dreams onwards, are therefore aberrant within the overall architecture of psychoanalytic thought. They are a straying away (aberrare) from the true, linear path in which the archē and telos of psychoanalysis meet in the closed circle of a return to contemporary neuroscience.
It marches
Verification successful. Waiting for www.producthunt.com to respond
令人惊讶的是:即使通过了安全验证,用户仍需等待网站响应,这揭示了现代Web架构中安全检查与内容交付分离的设计模式,以及用户体验与安全防护之间的微妙平衡。
Ray ID: `9ed3b53d4a0b647d`
令人惊讶的是:每个安全验证请求都有一个唯一的Ray ID,这表明Cloudflare等安全服务提供商为每次验证会话创建详细记录,用于跟踪和分析潜在威胁,这种级别的追踪机制是普通用户很少意识到的网络安全基础设施的一部分。
This website uses a security service to protect against malicious bots.
令人惊讶的是:即使是像Product Hunt这样的知名产品发现平台也需要实施严格的机器人防护措施,这反映了网络自动化和爬虫行为的普遍性,以及网站保护其内容和用户数据免受自动化攻击的必要性。
While 2 0th century labels sell de fined products – the 22-minute sitcom, the 45-minute album, the 9 0-minut e film – a Wide Awakes release can be anything: anexperience, a meme, an event, a book, a film, a form that never existed before andnever will again.
This is just reinventing independent art but dressing it up in the terminology and structures of start-up capitalism.
Most culture labels exis t to p r omote a specific ae sthetic, region, or point of view
Genre is more useful for marketing than anything else.
On the SWE-Pro benchmark, M2.7 scores 56.22%, nearly matching Opus's best level.
令人惊讶的是:MiniMax M2.7在SWE-Pro基准测试中获得了56.22%的分数,几乎达到了Opus模型的最佳水平。这一成绩表明,开源AI模型在软件工程领域已经能够与顶级闭源模型相媲美,打破了人们对开源模型性能落后的传统认知,为开源AI生态系统的发展注入了新的活力。
On 40 complex skills (>2000 Token) cases, M2.7 maintains a 97% skill adherence rate.
令人惊讶的是:MiniMax M2.7在处理40个复杂技能案例(每个超过2000个Token)时,保持了97%的技能遵循率。这一数据表明AI模型已经能够高度一致地执行复杂的多步骤任务,接近专业人类水平的表现,这对于AI在实际工作场景中的应用是一个重大突破,意味着AI可以更可靠地执行复杂工作流程。
M2.7 shows significant improvement in complex editing capabilities for Office Suite (Excel/PPT/Word), better handling multi-turn modifications and high-fidelity edits.
令人惊讶的是:MiniMax M2.7在处理Office套件(Excel/PPT/Word)的复杂编辑任务时表现出色,能够更好地处理多轮修改和高保真编辑。这表明AI已经超越了简单的文本生成,能够理解和执行复杂的办公软件操作,可能会彻底改变人们使用Office软件的方式,从手动操作转向AI辅助的智能工作流程。
On GDPval-AA, M2.7 achieves an ELO score of 1495, the highest among open-source models.
令人惊讶的是:MiniMax M2.7在GDPval-AA基准测试中获得了1495的ELO分数,成为所有开源模型中的最高分。这一分数不仅展示了模型在专业办公领域的卓越能力,还暗示了开源AI模型已经达到了接近或超越某些专有模型的专业水平,打破了开源模型性能不如闭源模型的刻板印象。
M2.7 demonstrates excellent performance in real-world software engineering, including end-to-end project delivery, log analysis for bug hunting, code security, and machine learning tasks.
令人惊讶的是:MiniMax M2.7不仅能处理常规编程任务,还能完成端到端的项目交付、日志分析、代码安全检查等复杂软件工程任务,这表明AI已经能够胜任完整的软件开发流程,从编码到安全审计,打破了人们对AI只能辅助编程的固有认知。
Performance on knowledge-heavy tasks depends strongly on model size and training, while reasoning-oriented models show clear gains on tasks requiring logic, learning, abstraction, and social inference.
令人惊讶的是:知识密集型任务的性能强烈依赖于模型规模和训练,而推理导向模型在需要逻辑、学习、抽象和社会推理的任务上显示出明显优势。这一发现揭示了不同AI模型在能力分布上的根本差异,为模型选择和优化提供了重要指导。
Reasoning-oriented models like OpenAI's o1 and GPT-5 show measurable gains over standard models—not only in logic and mathematics but also with interpreting user intent.
令人惊讶的是:专注于推理的模型如OpenAI的o1和GPT-5不仅在逻辑和数学方面表现出明显优势,在理解用户意图方面也有显著提升。这表明AI推理能力的进步正在从纯逻辑领域扩展到更复杂的社交认知领域,为AI与人类交互提供了新的可能性。
The same model can score above 90% on lower-demand tests and below 15% on more demanding ones, reflecting differences in task requirements rather than a change in capability.
令人惊讶的是:同一个AI模型在低需求测试中可能获得90%以上的分数,而在高需求测试中却可能低于15%,这反映了任务需求的不同而非模型能力的改变。这一发现挑战了人们对AI能力稳定性的普遍认知,揭示了任务难度对AI表现的巨大影响。
ADeLe scores tasks across 18 core abilities, such as attention, reasoning, domain knowledge, and assigns each task a value from 0 to 5 based on how much it requires each ability.
令人惊讶的是:ADeLe框架使用18种核心能力来评估任务,包括注意力、推理和领域知识等,并为每个任务分配0到5的评分。这种多维度的评估方法揭示了传统AI评估中忽视的细节,使研究者能够更精确地理解任务难度和模型能力之间的复杂关系。
Using these ability scores, the method predicts performance on new tasks with ~88% accuracy, including for models such as GPT-4o and Llama-3.1.
令人惊讶的是:ADeLe方法能够以约88%的准确度预测AI模型在新任务上的表现,这包括像GPT-4o和Llama-3.1这样先进的大模型。这种预测能力远超传统评估方法,为AI性能评估提供了革命性的突破,使研究人员能够更可靠地预见模型在未见过的任务上的表现。
We have intentionally chosen very high level fast developer tools. We use me a bunch, which makes it trivial to pull down all these go written Victoria Stack binaries in our local development.
令人惊讶的是:OpenAI团队使用Go编写的Victoria Stack工具链来构建本地开发环境,而不是传统的JavaScript或Python工具,这种选择反映了他们对性能和效率的极致追求,也展示了Go语言在AI原生开发环境中的潜力。
The only fundamentally scarce thing is the synchronous human attention of my team. There's only so many hours in the day we have to eat lunch.
令人惊讶的是:在OpenAI的AI驱动开发环境中,人类注意力成为真正的瓶颈,而不是计算资源或代码质量。这种视角转变表明,未来软件工程的核心挑战将从技术问题转向人类注意力管理。
Over the past five months, they ran an extreme experiment: building and shipping an internal beta product with zero manually written code.
令人惊讶的是:OpenAI的一个团队竟然在五个月内完全依靠AI生成了超过一百万行代码,没有任何人工编写或审查的代码,这种极端的实验展示了AI在软件开发中的惊人能力,彻底颠覆了传统的软件工程模式。
We had been given some space to cook, which has been super, super exciting.
令人惊讶的是:OpenAI竟然给团队提供了极大的自主空间,让他们完全自由地探索AI编码的极限,这种开放的创新环境在大型科技公司中极为罕见,通常大型公司会严格控制研发方向。
The top names you should know as a baseline, adjusted for 'what people are actually recommending'
令人惊讶的是:文章强调的顶级模型列表不是基于传统的基准测试结果,而是基于'人们实际推荐'的调整,这表明AI模型的评价标准正在从纯技术指标转向实际用户体验和社区共识,反映了AI评估范式的转变。
we are NSFW-friendly so here goes…
令人惊讶的是:一个主流AI媒体平台公开表示对NSFW(不适合工作场所)内容友好,这在传统科技媒体中相当罕见。这反映了AI社区对内容审查态度的转变,以及对更广泛AI应用场景的包容性增强。
roleplay/creative writing, the #2 usecase of LLMs
令人惊讶的是:创意写作和角色扮演竟然是LLM的第二大用例,这颠覆了人们普遍认为AI主要用于专业工作或信息处理的认知。这表明AI正在深入娱乐和个人表达领域,反映了技术向更人性化方向发展的趋势。
/r/localLlama (which has its own monthly top models thread)
令人惊讶的是:Reddit上的/r/localLlama社区已经形成了自己的月度顶级模型讨论传统,这表明开源AI模型社区已经发展出了相当成熟的组织结构和信息共享机制,这种自下而上的社区驱动模式在AI领域相当独特。
Projects now in limbo include facilities planned for Jay (at an old paper mill site), Sanford, Loring Air Force Base
令人惊讶的是:原本计划在Jay(旧造纸厂厂址)、桑福德和洛林空军基地建设的数据中心项目现在都处于悬而未决的状态。这些具体地点的提及展示了政策影响的实际范围,包括军事设施区域。
Maine advances first statewide moratorium blocking data centers requiring over 20 megawatts
令人惊讶的是:缅因州将成为美国第一个全范围禁止大型数据中心建设的州,这一政策针对的是超过20兆瓦的数据中心设施,这在科技发展迅速的今天显得格外独特和出人意料。
Young people, people of color, queer folks, activists, and organizers use Instagram, TikTok, and Facebook every day. These platforms host mutual aid networks and serve as hubs for political organizing.
令人惊讶的是:尽管EFF批评这些平台存在诸多问题,但他们仍然坚持留在Facebook、Instagram和TikTok上,因为这些平台是年轻有色人种、酷儿群体、活动家和组织者的日常聚集地,并承载着互助网络和政治组织的重要功能。这种看似矛盾的立场反映了EFF对数字权利保护的务实态度。
Musk fired the entire human rights team and laid off staffers in countries where the company previously fought off censorship demands from repressive regimes.
令人惊讶的是:马斯克收购Twitter后解雇了整个人权团队,并裁撤了那些曾经帮助公司对抗威权政权审查要求的国家员工。这一举动标志着平台从曾经的人权捍卫者转变为完全不同的方向,也解释了EFF为何认为X'不再是一个值得存在的平台'。
an X post today receives less than 3% of the views a single tweet delivered seven years ago.
令人惊讶的是:如今在X上的帖子获得的浏览量不到七年前单条推文浏览量的3%。这种急剧下降不仅反映了平台算法的变化,也揭示了社交媒体平台内容分发机制的根本性转变,以及用户行为和平台优先级的巨大变化。
We posted to Twitter (now known as X) five to ten times a day in 2018. Those tweets garnered somewhere between 50 and 100 million impressions per month.
令人惊讶的是:EFF在2018年每天发布5-10条推文,每月能获得5000万到1亿次曝光,而到了2024年,2500条帖子每月仅获得200万次曝光。这种急剧下降反映了社交媒体平台算法变化和用户注意力转移的惊人速度。
After almost twenty years on the platform, EFF is logging off of X.
令人惊讶的是:EFF在X(前Twitter)平台上已经存在了近二十年,这比许多读者的使用时间还要长。作为数字权利的倡导者,EFF见证了该平台从初创到成为全球社交媒体巨头,再到被马斯克收购并彻底转型的全过程,这种长期陪伴在科技领域实属罕见。
Agents show only ~10% success on instances with PoCs longer than 100 bytes, which represent 65.7% of the benchmark
令人惊讶的是:AI助手在处理复杂输入时表现极差,对于超过100字节的概念验证(PoC),成功率仅为10%。这表明尽管AI在网络安全领域取得了进展,但在处理需要深度分析和复杂输入生成的任务时仍面临重大挑战,而这类任务恰恰代表了大多数现实世界中的安全漏洞。
Out of all generated PoCs, 759 triggered crashes across 60 projects, and manual inspection confirmed 17 cases of incomplete patches spanning 15 projects
令人惊讶的是:AI生成的概念验证(PoC)能够揭示人类安全补丁中的不完整之处。这表明AI不仅能发现漏洞,还能评估现有补丁的有效性,这种能力对于提高软件安全性具有重要意义,因为人类开发者可能会忽略这些细微的补丁缺陷。
Tech valuations have compressed from 40x to 20x
令人惊讶的是:科技估值从40倍市盈率降至20倍的幅度如此之大,这种调整在历史上较为罕见。通常市场估值需要数年时间才能完成如此大幅度的回调,这表明投资者对AI技术商业化的时间表和规模可能过于乐观,现在正经历一次剧烈的预期修正。
Note: The companies listed represent the 10 largest constituents in the S&P 500 Information Technology index by market capitalization: NVIDIA Corp, Apple Inc, Microsoft Corp, Broadcom Inc, Oracle Corp, Micron Technology Inc, Palantir Technologies Inc, Advanced Micro Devices Inc, Cisco Systems Inc, and Applied Materials Inc.
令人惊讶的是:标准普尔500信息技术指数实际上由仅10家公司主导,这些公司包括NVIDIA、苹果、微软等科技巨头。这种高度集中的结构意味着整个科技板块的表现实际上由少数几家公司的业绩决定,分散投资在科技领域可能比想象中更加困难。
The chart below compares the forward P/E ratios for the S&P 500 and the S&P 500 Information Technology sector.
令人惊讶的是:标准普尔500指数科技板块的远期市盈率成为衡量整个科技行业健康状况的关键指标,这表明少数几家科技巨头实际上主导了整个科技行业的估值走向。这种集中度可能使整个科技板块对几家公司的表现过度敏感。
Tech valuations have compressed from 40x to 20x, and we are back at levels last seen before the AI boom began.
令人惊讶的是:科技估值在短短时间内从40倍市盈率暴跌至20倍,几乎腰斩,且回到了AI热潮前的水平。这种剧烈的估值调整表明市场对AI技术的商业价值预期发生了根本性转变,反映出投资者对AI能否立即产生可观利润的怀疑。
It also discovered a 16-year-old vulnerability in FFmpeg—which is used by innumerable pieces of software to encode and decode video—in a line of code that automated testing tools had hit five million times without ever catching the problem.
令人惊讶的是:Claude Mythos Preview在FFmpeg中发现了一个存在16年的漏洞,而这个漏洞在被自动化测试工具执行了500万次后仍未被发现。这揭示了AI在代码分析方面具有传统自动化工具无法比拟的独特洞察力。
The window between a vulnerability being discovered and being exploited by an adversary has collapsed—what once took months now happens in minutes with AI.
令人惊讶的是:AI的出现将漏洞被发现到被利用的时间窗口从几个月缩短到了几分钟。这种根本性的变化意味着传统的安全响应机制已经不再适用,网络安全领域正在经历前所未有的加速变革。
Anthropic is committing up to $100M in usage credits for Mythos Preview across these efforts, as well as $4M in direct donations to open-source security organizations.
令人惊讶的是:Anthropic为Project Glasswing项目投入了高达1亿美元的模型使用积分和400万美元的直接捐款,用于支持开源安全组织。这种大规模的资金投入反映了AI安全威胁的严重性和解决这一问题的紧迫性。
Mythos Preview found a 27-year-old vulnerability in OpenBSD—which has a reputation as one of the most security-hardened operating systems in the world
令人惊讶的是:即使在以安全性著称的OpenBSD系统中,Claude Mythos Preview也发现了一个存在27年的漏洞。这个漏洞能让攻击者通过简单连接就使远程机器崩溃,说明即使是经过严格审查的代码也可能存在长期未被发现的严重问题。
Mythos Preview has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser.
令人惊讶的是:Claude Mythos Preview模型已经发现了数千个高危漏洞,包括所有主流操作系统和网络浏览器中的漏洞。这表明AI模型已经达到了能够超越大多数人类专家发现软件漏洞的水平,这种能力在网络安全领域具有革命性意义。
In Washington, the AI policy discourse is sometimes framed as a 'race to AGI.' In contrast, in Beijing, the AI discourse is less abstract and focuses on economic and industrial applications that can support Beijing's overall economic objectives.
令人惊讶的是:中美对AI的战略定位存在根本差异——美国聚焦于通用人工智能(AGI)的竞赛,而中国则更注重经济和工业应用。这种差异反映了两国的技术哲学和治理模式,也解释了为什么中国在有限计算资源下仍能发展出更具实用性的AI应用。
Like lean production, which extended mass production's dominance for decades through efficiency gains, AI doesn't mark computing's end but its maturation.
令人惊讶的是:AI被比作1970年代精益生产对大规模生产的优化,而非颠覆性创新。这暗示AI可能只是计算技术成熟期的效率提升工具,而非开创全新技术范式的革命性力量,这与公众对AI的颠覆性期待形成鲜明对比。
The two most recent surges are a cars/oil surge, which started in 1908, and the Information and Communications Technology, which started in 1971.
令人惊讶的是:根据Carlota Perez的技术-金融互动模型,我们目前正处于信息与通信技术(ICT)浪潮的末期,而这个浪潮始于1971年,至今已有55年历史。这意味着数字时代的黄金时期可能即将结束,而AI可能只是这一浪潮的最后阶段而非新开端。
We built an automated scanning agent that systematically audited eight among the most prominent AI agent benchmarks — SWE-bench, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, and CAR-bench — and discovered that every single one can be exploited to achieve near-perfect scores without solving a single task.
令人惊讶的是:研究人员构建的自动化扫描工具发现,所有八个主流AI代理基准测试都存在漏洞,无需解决任何任务就能获得接近完美的分数。这表明整个AI评估领域存在系统性问题,几乎所有当前使用的基准测试都不可靠。
FieldWorkArena presents 890 tasks where an AI agent must answer questions about images, videos, PDFs, and text files through a browser environment. Its validate() method checks only one thing: did the last message come from the assistant?
令人惊讶的是:FieldWorkArena这个评估890个多模态任务的基准测试,其验证函数只检查最后一条消息是否来自助手,完全不验证内容正确性。只需发送一条空消息就能获得100%的分数,这暴露了评估逻辑的根本性缺陷。
A conftest.py file with 10 lines of Python 'resolves' every instance on SWE-bench Verified.
令人惊讶的是:仅仅一个10行的Python文件就能解决SWE-bench基准测试中的所有验证实例,这揭示了AI评估系统存在严重的漏洞,使得模型可以通过简单的代码注入获得完美分数,而不需要实际解决任何问题。
The new harness and sandbox capabilities are launching first in Python, with TypeScript support planned for a future release.
令人惊讶的是:尽管JavaScript/TypeScript在前端开发中占据主导地位,但OpenAI选择先为Python提供新的控制层和沙盒功能。这可能反映了Python在AI和机器学习开发中的核心地位,以及OpenAI对其用户群体技术栈的深刻理解,这对许多习惯使用TypeScript的开发者来说可能是一个意外。
Agent systems should be designed assuming prompt-injection and exfiltration attempts. Separating harness and compute helps keep credentials out of environments where model-generated code executes.
令人惊讶的是:OpenAI明确指出AI代理系统应假设存在提示注入和数据泄露尝试,并建议将控制层与计算层分离以保护凭据。这种安全设计理念表明,OpenAI对AI安全威胁有深刻理解,并采取了主动防御措施,这与许多开发者可能采用的被动安全方法形成鲜明对比。
Native sandbox support gives developers that execution layer out of the box, instead of forcing them to piece it together themselves.
令人惊讶的是:OpenAI的Agents SDK现在原生支持沙盒执行,开发者无需自己构建执行环境。这意味着AI代理可以在受控环境中安全地运行,包括读取和写入文件、安装依赖项、运行代码和使用工具。这种内置的安全层对于企业级AI应用至关重要,但大多数开发者可能没有意识到其复杂性已经被OpenAI解决了。
The updated Agents SDK made it production-viable for us to automate a critical clinical records workflow that previous approaches couldn't handle reliably enough.
令人惊讶的是:医疗健康公司Oscar Health已经使用更新的Agents SDK成功自动化了临床记录工作流程,这是以前的方法无法可靠处理的。这表明AI代理技术已经发展到足以处理复杂、高风险的医疗数据任务,这可能彻底改变医疗行业的记录管理方式。
For example, developers can give an agent a controlled workspace, explicit instructions, and the tools it needs to inspect evidence:
令人惊讶的是:OpenAI的Agents SDK现在允许开发者创建一个完全受控的工作环境,让AI代理可以检查文件、运行命令和编辑代码。这种能力意味着AI系统可以更深入地与计算机系统交互,实现更复杂的任务自动化,这比大多数人想象的AI能力要强大得多。
ChatGPT has 900 million weekly users, which means employees already know how to work with it. For enterprises, that reduces rollout friction and accelerates the point where every employee can delegate tedious tasks and take on more ambitious projects.
令人惊讶的是:ChatGPT拥有9亿周活跃用户,这意味着大多数员工已经熟悉如何使用AI工具。这一庞大的用户基础大大降低了企业AI部署的阻力,使员工能够更快地将繁琐任务委托给AI,从而专注于更具挑战性的项目。
The shift started with agentic tools like Codex, which has grown more than 5X since the start of the year. This includes customers like GitHub, Nextdoor, Notion, and Wonderful that are building multi-agent systems that can execute engineering work end-to-end.
令人惊讶的是:仅今年年初以来,Codex等代理工具的使用量增长了5倍以上,GitHub、Nextdoor、Notion等公司正在构建能够端到端执行工程工作的多智能体系统。这表明AI已经从辅助工具转变为能够自主完成复杂任务的系统,技术演进速度令人惊叹。
Codex just hit 3 million weekly active users, our APIs process more than 15 billion tokens per minute, and GPT‑5.4 is driving record engagement across agentic workflows.
令人惊讶的是:OpenAI的Codex代码助手每周活跃用户已达300万,API每分钟处理超过150亿个token,GPT-5.4在代理工作流程中创造了参与度记录。这些数字展示了AI工具在企业中的大规模采用和惊人处理能力。
Building on our consumer strength, enterprise now makes up more than 40% of our revenue, and is on track to reach parity with consumer by the end of 2026.
令人惊讶的是:OpenAI的企业业务在如此短的时间内就占据了公司收入的40%,并且预计将在2026年底与消费者业务持平。这表明AI在企业领域的采用速度远超预期,反映了企业对AI技术的迫切需求和巨大投资。
While the MIT license is technically more permissive than the Apache 2.0 License, it doesn't grant any explicit patent protection. The Apache 2.0 License is generally preferred for commercial use because of this.
令人惊讶的是:尽管MIT许可证在技术上比Apache 2.0更宽松,但它不提供任何明确的专利保护。这就是为什么Apache 2.0通常更受商业用户青睐,因为它确保了商业软件免受专利侵权的风险。这一细微差别对商业AI应用开发具有重大影响。
The industry is currently witnessing a decisive shift toward more permissive, standardized licenses as developers increasingly prioritize ease of integration and legal certainty.
令人惊讶的是:AI行业正经历向更宽松、标准化许可证的明显转变,这反映了开发者日益重视集成便利性和法律确定性。这一趋势表明,随着AI模型的成熟,许可证选择正成为与模型性能同等重要的因素,改变了AI开发的格局。
The Apache 2.0 License permits full commercial use of the software to which it is applied. Open models that are released under the Apache 2.0 License aren't subject to any sort of prohibitive use policy or usage caps and can be freely used and adapted, including for commercial projects generating revenue.
令人惊讶的是:Apache 2.0许可证对商业应用的开放程度令人印象深刻,它不仅允许完全的商业使用,还没有任何使用限制或上限。这意味着基于Apache 2.0许可证的AI模型可以自由地用于创收的商业项目,为开发者提供了极大的商业灵活性。
Russian military
Odd to mention only Russia when states around the globe use these platforms for propaganda.
a relentless competitionfor power.
Hard disagree.
The idealism of the ‘90s web is gone.
There's a certain sense of End of History neoliberal triumphalism to this statement.
Dark forests like newsletters and podcasts are growing areas of activity. As areother dark forests, like Slack channels, private Instagrams, invite-only messageboards, text groups, Snapchat, WeChat, and on and on. This is whereFacebook is pivoting with Groups (and trying to redefine what the word“privacy” means in the process)
I am really against siloing ourselves off into private platforms that can't be found easily. It is an absolute nightmare for software development as it means answers are suddenly hidden away in a private Discord that you don't even know exists rather than a public Stack Overflow.
This very email is an example of this. This theory is being shared on a privatechannel sent to 500 people who I know or who have explicitly chosen to receiveit. This is the online environment in which I feel most secure. Where I can be mymost “real self.”
But then he put it on his public website?
Meta also explicitly highlighted parallel multi-agent inference as a way to improve performance at similar latency
令人惊讶的是,Meta明确强调了并行多代理推理作为在相似延迟下提高性能的方法。这表明AI系统正在从单一模型向多代理系统演进,可能是解决复杂问题的新范式,同时也暗示了未来AI系统架构的重大转变。
Gemma4-31B worked in an iterative-correction loop (with a long-term memory bank) for 2 hours to solve a problem that baseline GPT-5.4-Pro couldn't
令人惊讶的是,较小的Gemma4-31B模型通过迭代修正循环和长期记忆库工作了2小时,解决了GPT-5.4-Pro无法解决的问题。这表明模型架构创新和推理能力可能比单纯的规模扩展更重要,为AI发展提供了新的方向。
Claude Mythos autonomously identified and exploited several significant vulnerabilities. Notably, it discovered a 27-year-old vulnerability in OpenBSD
令人惊讶的是,Claude Mythos能够自主发现并利用一个存在了27年的OpenBSD漏洞。这一事实表明AI模型在网络安全领域的能力已经达到了令人难以置信的水平,能够找到人类专家和安全系统长期未发现的漏洞。这引发了关于AI安全性和控制机制的深刻问题。
Meta says its rebuilt pretraining stack can reach equivalent capability with >10× less compute than Llama 4 Maverick
令人惊讶的是,Meta声称他们重建的预训练栈只需要Llama 4 Maverick十分之一的计算量就能达到同等能力。这一效率提升是惊人的,表明AI模型训练可能正在经历一个范式转变,从单纯增加计算资源转向优化算法和架构。这可能会对整个AI行业的成本结构和竞争格局产生深远影响。
Programmatic access for creating, modifying, listing and deleting your connectors but also listing their tools and directly running them.
令人惊讶的是:Mistral不仅允许连接器的完整生命周期管理(创建、修改、列出和删除),还允许直接列出和运行连接器中的工具。这种直接工具调用功能为开发者提供了更精确的控制,特别适用于调试和管道式自动化场景。
The boundary between AI judgment and human judgment is explicit and written in code.
令人惊讶的是:Mistral的连接器允许开发者在代码中明确设置AI判断和人类判断之间的界限。通过requires_confirmation参数,开发者可以确保某些工具执行前需要人工批准,这种设计既保持了AI的灵活性,又确保了关键操作的安全性。
A connector solves this by packaging an integration into a single, reusable entity using the MCP protocol.
令人惊讶的是:Mistral使用MCP(模型控制协议)将复杂的集成打包成单一的可重用实体。这种标准化方法大大简化了企业AI应用的开发过程,消除了重复实现相同集成逻辑的需要,同时提高了安全性和可维护性。
Because of this, teams keep rebuilding the same integration layer. Even within the same company, similar integrations are often implemented multiple times in arbitrary code, leading to security risks, lack of traffic observability, and duplication of work.
令人惊讶的是:即使在同一公司内部,类似的集成也经常被多次实现,导致安全风险、流量可见性不足和工作重复。这种重复建设企业AI集成层的问题比人们想象的更为普遍,而Mistral的连接器旨在通过封装集成到单一可重用实体来解决这一问题。
All built-in connectors, as well as custom MCPs, are now available via API/SDK to be used with all model and agent calls.
令人惊讶的是:Mistral AI不仅提供了内置连接器,还允许用户创建自定义MCP(模型控制协议)连接器,并通过API/SDK与所有模型和代理调用一起使用。这种开放性意味着开发者可以轻松地将企业数据与AI应用集成,而不需要从头开始构建复杂的集成层。
With gated LoRA, ISD enables **bit-for-bit lossless** acceleration
令人惊讶的是:I-DLM通过门控LoRA技术实现了无损(bit-for-bit)加速,这意味着在加速的同时保持了与原始自回归模型完全相同的输出结果。这一突破解决了长期以来扩散模型与自回归模型在输出质量上存在差异的问题,为扩散模型在实际应用中的部署提供了质量保证。
I-DLM-8B is the first DLM to match the quality of its same-scale AR counterpart, outperforming LLaDA-2.1-mini (16B) by +26 on AIME-24 and +15 on LiveCodeBench-v6 with half the parameters
令人惊讶的是:I-DLM-8B模型仅用80亿参数就超过了160亿参数的LLaDA-2.1-mini模型,在AIME-24和LiveCodeBench-v6测试中分别高出26和15分。这表明扩散模型首次达到了与自回归模型相当的质量水平,同时参数减半,打破了人们对扩散模型质量不如自回归模型的普遍认知。
GLM-5 advances foundation models with DSA for cost reduction, asynchronous reinforcement learning for improved alignment, and enhanced coding capabilities for real-world software engineering.
令人惊讶的是:GLM-5模型拥有186位作者,这表明现代AI研究已经发展成大规模协作的工程科学,而非个人天才的产物。这种集体智慧的组织形式本身就是AI领域发展的一个惊人事实。
PagedAttention algorithm and vLLM system enhance the throughput of large language models by efficiently managing memory and reducing waste in the key-value cache.
令人惊讶的是:通过简单的内存管理优化,PagedAttention算法和vLLM系统能够显著提高大语言模型的吞吐量,减少键值缓存中的浪费。这展示了在模型规模不断扩大的今天,系统优化可能比模型创新本身更具实际价值。
MinerU2.5, a 1.2B-parameter document parsing vision-language model, achieves state-of-the-art recognition accuracy with computational efficiency through a coarse-to-fine parsing strategy.
令人惊讶的是:仅12亿参数的MinerU2.5模型就能通过粗到细的解析策略达到最先进的文档识别精度,同时保持计算效率。这挑战了'越大越好'的模型规模观念,展示了高效架构设计的重要性。
A large language model adapted for time-series forecasting achieves near-optimal zero-shot performance on diverse datasets across different time scales and granularities.
令人惊讶的是:大型语言模型竟然可以直接适应时间序列预测任务,并且在各种不同时间尺度和粒度的数据集上达到接近最优的零样本性能。这打破了人们对LLM仅适用于文本处理的认知,展示了模型架构的通用性潜力。
Kronos, a specialized pre-training framework for financial K-line data, outperforms existing models in forecasting and synthetic data generation through a unique tokenizer and autoregressive pre-training on a large dataset.
令人惊讶的是:金融数据K线图这种传统技术分析工具竟然可以通过专门的预训练框架Kronos进行优化,并且能够超越现有模型。这展示了AI在金融领域的创新应用,将看似简单的金融数据转化为'语言'进行处理,暗示了金融市场的复杂规律可能被AI重新解读。
especially the nighttime validation gate that defers updates until a safe rollout
令人惊讶的是:SkillClaw包含一个夜间验证机制,它会延迟更新直到安全部署。这种设计表明系统考虑到了生产环境中的风险,不是盲目地应用所有更新,而是确保新技能在全面部署前已经过充分验证。这种谨慎的更新策略展示了AI系统设计中安全性与进化的平衡。
the most interesting detail here is how SkillClaw clusters cross-user trajectories into referenced skills and then uses the evolver to translate those patterns into concrete updates.
令人惊讶的是:SkillClaw能够将跨用户轨迹聚类为参考技能,然后使用进化器将这些模式转化为具体更新。这种处理异构用户经验的方法非常巧妙,它不仅解决了不同用户间信号差异的问题,还能从看似无关的用户行为中提取有价值的模式,实现真正的集体智慧。
experiments on WildClawBench show that limited interaction and feedback, it significantly improves the performance of Qwen3-Max in real-world agent scenarios.
令人惊讶的是:即使在有限的交互和反馈条件下,SkillClaw也能显著提升Qwen3-Max在实际代理场景中的性能。这表明该系统即使在用户参与度不高的情况下,也能有效收集足够的数据来改进技能库,解决了传统AI系统需要大量标注数据才能进化的痛点。
The resulting skills are maintained in a shared repository and synchronized across users, allowing improvements discovered in one context to propagate system-wide while requiring no additional effort from users.
令人惊讶的是:SkillClaw将改进后的技能保存在共享库中,并在所有用户间同步,这意味着在一个用户环境中发现的改进可以系统性地传播,而无需用户额外付出努力。这种机制实现了真正的集体智能进化,让整个AI生态系统从每个用户的经验中受益。
SkillClaw continuously aggregates trajectories generated during use and processes them with an autonomous evolver, which identifies recurring behavioral patterns and translates them into updates to the skill set by refining existing skills or extending them with new capabilities.
令人惊讶的是:SkillClaw不仅收集用户交互数据,还能通过自主进化器识别重复行为模式,并将其转化为技能更新或扩展。这种集体进化机制让AI系统能够从多用户经验中学习,实现跨用户知识转移和累积能力提升,这打破了传统AI系统部署后技能保持静态的局限。
Add llms.txt metadata and root/package LICENSE files - Add website llms.txt support and move LICENSE to root - Fix llms.txt serving and restore package LICENSE
令人惊讶的是:这个项目支持llms.txt元数据格式,这是一种新兴的AI可发现性标准,使AI模型能够更好地理解项目文档和代码结构。这种关注AI可发现性的做法表明项目开发者不仅关注当前功能,还前瞻性地考虑了AI与代码库的交互方式。
Add benchmark framework and release submission overview - Add benchmark runner with onlineMind2Web benchmark support - Add agent client abstraction for codex/claude backends - Add CLI entry point for running benchmarks (pnpm benchmark)
令人惊讶的是:这个项目不仅是一个自动化工具,还包含了一个完整的基准测试框架,支持在线Mind2Web等复杂基准测试。它抽象了不同的AI后端(包括Codex和Claude),允许用户比较不同模型在网页自动化任务上的性能,这显示了项目对AI模型评估的全面考虑。
Add GCP WebVoyager benchmark runner and worktree tooling - Create benchmarks/infra/setup.sh — an idempotent script that provisions: - GCS bucket: gs://libretto-benchmarks - Artifact Registry repo: libretto-benchmarks (Docker) - Cloud Run Job: webvoyager-bench (4 CPU, 8Gi, 2h timeout)
令人惊讶的是:这个项目建立了一个完整的Google Cloud Platform基础设施来运行WebVoyager基准测试,包括存储桶、Docker镜像仓库和Cloud Run作业。它配置了相当强大的计算资源(4 CPU, 8Gi内存,2小时超时),表明该项目对自动化任务的性能和可扩展性有严格要求。
feat(benchmarks): add screenshot-based evaluator, screenshot collector, and --parallelize flag - Add screenshot-based LLM judge evaluator (evaluator.ts) - Add ScreenshotCollector for capturing browser screenshots during runs
令人惊讶的是:这个项目包含一个基于截图的评估系统,使用LLM作为评判员来评估自动化任务的结果。它能够捕获浏览器截图并在运行过程中收集这些视觉数据,这为网页自动化任务提供了一种全新的评估方式,超越了传统的文本比较方法。
Add cloud browser provider system (Kernel + Browserbase) - Add cloud browser providers spec (Kernel + Browserbase) - phase 1: add provider metadata to session state schema
令人惊讶的是:这个项目支持云浏览器提供商系统,允许用户在云端运行浏览器自动化任务。它不仅支持本地浏览器,还集成了Kernel和Browserbase等云浏览器服务,使开发者能够在没有本地浏览器的情况下执行复杂的网页自动化任务。
Add dev-tools package with wt worktree manager CLI - New packages/dev-tools with standalone wt CLI for git worktree management - Commands: wt new, wt scratch, wt prune - Uses Vertex AI (gemini-2.5-flash) for branch name generation via gcloud ADC
令人惊讶的是:这个项目不仅是一个浏览器自动化工具,还内置了一个使用AI生成分支名称的Git工作树管理器。它利用Google的Vertex AI和gemini-2.5-flash模型来自动创建有意义的分支名称,这展示了AI在开发工作流中的创新应用。
Both services can be disabled for fully offline operation.
令人惊讶的是:Sage 可以完全禁用云服务,实现完全离线运行。这种离线能力对于需要在隔离环境中工作的用户(如政府机构或高度敏感项目)至关重要,展示了该工具的灵活性和适应性,这是许多现代安全工具所不具备的特性。
Sage sends URLs and package hashes to Gen Digital reputation APIs. File content, commands, and source code stay local.
令人惊讶的是:Sage 采用了一种平衡隐私和安全的方法,只将URL和包哈希发送到云端进行声誉检查,而文件内容、命令和源代码则保留在本地。这种设计既提供了实时的威胁检测,又保护了用户的敏感数据,反映了现代安全工具对隐私保护的重视。
Sage intercepts tool calls (Bash commands, URL fetches, file writes) via hook systems in Claude Code, Cursor / VS Code, OpenClaw, and OpenCode, and checks them against:
令人惊讶的是:Sage 不仅是一个简单的安全工具,而是一个复杂的拦截系统,能够监控和检查多种AI代理平台上的工具调用。这种跨平台的集成能力展示了AI安全领域的复杂性和创新性,用户可能没有意识到他们的AI代理正在被如此全面地监控和保护。
The model can maintain stable role identity across multi-agent setups, make autonomous decisions within complex state machines, and challenge other agents on logical gaps.
令人惊讶的是:M2.7能够在多智能体环境中保持稳定的角色身份,在复杂状态机中自主决策,并能挑战其他智能体的逻辑漏洞。这展示了AI系统在社会协作层面的进步,暗示了未来AI团队协作的可能性,也反映了AI系统越来越复杂的交互能力。
The license looks MIT at first glance but it is not MIT. Non commercial use is free with no restrictions. Commercial use requires prior written authorization from MiniMax.
令人惊讶的是:虽然M2.7的许可证初看类似MIT,但实际上有严格的商业使用限制。这种'表面开源实则限制'的做法在AI领域越来越常见,反映了开源与商业化之间的复杂平衡,也提醒开发者在使用AI模型时需要仔细阅读许可证条款。
MiniMax claims it has reduced live production incident recovery time to under three minutes on multiple occasions using M2.7.
令人惊讶的是:M2.7模型能够在实际生产环境中将系统故障恢复时间缩短到三分钟以内。这展示了AI系统在关键业务场景中的实际价值,也反映了AI模型从理论走向实用的重要里程碑,意味着AI已经能够直接影响企业的运营效率。
After each round the model generated a memory file, criticized its own results, and fed those observations into the next round.
令人惊讶的是:M2.7模型能够生成自己的记忆文件,批判自己的结果,并将这些观察反馈到下一轮训练中。这种自我反思和持续学习的能力类似于人类的元认知过程,展示了AI系统越来越接近人类的自我评估和改进能力。
MiniMax handed an internal version of M2.7 a programming scaffold and let it run unsupervised. Over 100 rounds it analyzed its own failures, modified its own code, ran evaluations, and decided what to keep and what to revert.
令人惊讶的是:AI模型能够自主进行代码修改和自我优化,这代表了人工智能自主性的一大突破。M2.7模型不仅能够分析自己的失败,还能自主决定哪些代码更改保留,哪些回退,这种自我进化的能力打破了传统AI开发模式,展示了AI系统自我改进的潜力。
The system works beautifully for tracking the full universe of tasks that exists. The problem is prioritization. With multiple launches overlapping each week, figuring out which of your 30 tasks matters this morning requires mentally weighing launch dates against company strategy against what your teammates are blocked on.
令人惊讶的是:即使有完美的任务跟踪系统,优先级排序仍然是一个重大挑战,需要同时考虑截止日期、公司战略和团队阻塞情况等多重因素。这揭示了AI在复杂决策支持中的独特价值,能够处理多维度权衡。
Meetings get recorded, transcribed, and stored in a database. That's useful for reference, but meeting notes have a shelf life of about six hours before everyone forgets what they agreed to do.
令人惊讶的是:会议记录的有效期仅有约6小时,这表明人类记忆的短暂性和会议记录转化为行动项的紧迫性。这一发现强调了AI在及时捕捉和转化会议行动项方面的关键价值。
Austin built the whole pipeline from his Claude Code terminal using the Notion API. He brain-dumped the desired outcome using Monologue, let Claude Code create the database and data pipeline, and pasted the generated instructions into the Notion custom agent setup.
令人惊讶的是:非技术人员可以通过语音转文本工具(Monologue)直接向AI描述需求,然后由AI自动构建整个数据管道和代理系统,这大大降低了技术门槛,使非技术团队成员也能构建复杂的AI工作流程。
Brandon told the team on a Monday that OKRs were due Wednesday—a turnaround that would have been absurd without this agent.
令人惊讶的是:借助AI代理,原本需要数周才能完成的OKR规划流程可以在两天内完成,效率提升惊人。这展示了AI如何彻底改变传统企业规划流程,从冗长的手动过程转变为快速、智能的自动化系统。
Each person has roughly 30 tasks on their to-do list. So how do they figure out which to work on first?
令人惊讶的是:即使是只有25人的小公司,每位员工也要同时处理约30个任务,这种任务过载现象在小型组织中也很普遍。这揭示了现代工作环境中普遍存在的认知负荷问题,以及AI工具如何帮助减轻这种负担。
Five hyperscalers now own over two-thirds of global AI compute, rising from 60% in Q1 2024.
令人惊讶的是:这五大超大规模云服务提供商对全球AI计算资源的控制力在短短一年内从60%增长到67%,显示出AI计算资源正以前所未有的速度向少数科技巨头集中,这可能加剧AI发展的不平衡。
The H100-equivalent unit uses a chip's highest 8-bit operation/second specifications to convert between chips. The actual utility of a particular chip depend on workload assumptions, so H100e does not perfectly reflect real-world performance differences across chip types.
令人惊讶的是:即使使用H100-equivalents作为标准测量单位,也无法完全反映不同芯片类型在真实世界中的性能差异,这表明我们对AI计算能力的测量可能存在系统性偏差,影响我们对AI发展速度的准确理解。
Many AI labs (including OpenAI and Anthropic) largely depend on these hyperscalers for access to R&D and inference compute.
令人惊讶的是:即使是像OpenAI和Anthropic这样的领先AI实验室也在很大程度上依赖这些超大规模云服务提供商,这揭示了AI产业中一种看似矛盾的现象——最前沿的AI创新却受制于少数几家科技巨头。
Amazon, Google, Meta, Microsoft, and Oracle collectively hold an estimated 67% of the world's cumulative AI compute as of Q4 2025, measured in H100-equivalents of computing power.
令人惊讶的是:仅仅五家科技巨头就控制了全球三分之二以上的AI计算能力,这种高度集中的计算资源分配模式可能正在重塑AI发展的权力结构,使得其他研究机构和小型企业在竞争处于明显劣势。
We test for a trend over time by fitting a weighted linear model to the log-odds of usage. Under this specification, Claude is the only AI service in the survey to show a statistically significant upward trend over this period
令人惊讶的是:研究团队使用了对数几率加权线性模型来分析趋势,发现Claude是唯一一个在统计上显示出显著增长趋势的AI服务。这种复杂的统计分析方法揭示了表面上微小变化背后的真实趋势。
The survey did not investigate the causes of the increase in Claude usage, but timing coincided with a period that included a public dispute with the US government
令人惊讶的是:Claude使用率的增长恰逢与美国政府的公开争议时期,这可能暗示了争议反而提升了公众对Claude的关注度和使用意愿。这种现象在科技产品中并不常见,通常负面事件会导致用户流失。
It is the only AI service to show a clear upward trend over this short time period
令人惊讶的是:在所有被调查的AI服务中,Claude是唯一显示出明确上升趋势的工具。这表明尽管市场竞争激烈,Claude仍然成功地在众多AI服务中脱颖而出,实现了持续增长。
The share of U.S. adults who used Claude in the past week rose from 3.0% in early March to 4.3% in early April 2026
令人惊讶的是:Claude的用户比例从3%增长到4.3%,看似微小但实际增长率超过40%。这种看似微小的增长在AI工具使用率上却具有统计显著性,反映了AI市场细分的微妙变化。
Claude usage rose by over 40% amid increased attention but remains far behind ChatGPT
令人惊讶的是:Claude的使用率在短短一个月内增长了40%,但与ChatGPT的30%使用率相比仍然差距巨大。这表明AI市场存在明显的赢家通吃现象,即使是最成功的挑战者与领导者相比仍有数量级的差距。
eLife Assessment
This study provides a valuable contribution to understanding the functional and molecular organization of the medial nucleus accumbens shell in feeding behavior. Through a multimodal approach that integrates in vivo imaging, optogenetic manipulation, and genetic strategies, the authors present convincing evidence for rostro-caudal differences in D1-SPN activity, advancing and refining earlier pharmacological frameworks. The discovery of Stard5 and Peg10 as regionally informative markers, together with the introduction of a Stard5-Flp driver line, establishes a foundation for more targeted circuit dissection. While an expanded characterization of other Stard5-positive cell populations (e.g., D2-SPNs, interneurons) would strengthen the work, the experimental rigor and internal consistency of the findings are clear. Overall, this is a technically strong and conceptually meaningful study with broad relevance for those investigating neural mechanisms of reward, affect, and feeding.
Reviewer #2 (Public review):
Summary:
Marinescu et al. combine in vivo imaging with circuit-specific optogenetic manipulation to characterize the anatomic heterogeneity of the medial nucleus accumbens shell in the control of food intake. They demonstrate that the inhibitory influence of dopamine D1 receptor-expressing neurons of the medial shell on food intake decreases along a rostro-caudal gradient while both rostral and caudal subpopulations similarly control aversion. They then identify Stard5 and Peg10 as molecular markers of the rostral and caudal subregions, respectively. Through the development of a new mouse line expressing the flippase under the promoter of Stard5, they demonstrate that Stard5-positive neurons recapitulate the activity of D1-positive neurons of the rostral shell in response to food consumption and aversive stimuli.
Strengths:
This study brings important findings for the anatomical and functional characterization of the brain reward system and its implication in physiological and pathological feeding behavior. In the revision, the authors provided additional data that strengthen the specificity of their behavioral effects. It is a well-designed study, technically sound, with clear and reliable effects. The generation of the new Stard5-Flp line will be a valuable tool for further investigations. The paper is very well written, the discussion is very interesting, addresses limitations of the findings and proposes relevant future directions.
Weaknesses:
Identification and characterization of the activity of Stard5-positive neurons will require further characterization as this population encompasses both D1- and D2-positive neurons as well as interneurons. While they display a similar response pattern as D1-neurons, it remains to determine whether their manipulation would result in comparable behavioral outcomes.
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study examines how different parts of the brain's reward system regulate eating behavior. The authors focus on the medial shell of the nucleus accumbens, a region known to influence pleasure and motivation. They find that nerve cells in the front (rostral) portion of this region are inhibited during eating, and when artificially activated, they reduce food intake. In contrast, similar cells at the back (caudal) are excited during eating but do not suppress feeding. The team also identifies a molecular marker, Stard5, that selectively labels the rostral hotspot and enables new genetic tools to study it. These findings clarify how specific circuits in the brain control hedonic feeding, providing new entry points to understand and potentially treat conditions such as overeating and obesity.
We thank Reviewer 1 for the positive feedback, summary of our findings and for the thorough reading and constructive comments on the manuscript, which allowed us to improve the quality of the revised version.
Strengths:
(1) Conceptual advance: The work convincingly establishes a rostro-caudal gradient within the medNAcSh, clarifying earlier pharmacological studies with modern circuit-level and genetic approaches.
(2) Methodological rigor: The combination of fiber photometry, optogenetics, CRISPR-Cas9 genetic engineering, histology, FISH, scRNA-seq, and novel mouse genetics adds robustness, with complementary approaches converging on the central claim.
(3) Innovation: The generation of a Stard5-Flp line is a valuable resource that will enable precise interrogation of the rostral hotspot in future studies.
(4) Specificity of findings: The dissociation between appetitive and aversive conditions strengthens the interpretation that the observed gradient is restricted to feeding.
We thank Reviewer #1 for their supportive feedback.
Weaknesses and points for clarification
(1) Role of D2-SPNs: Since D1 and D2 pathways often show opposing roles in feeding, testing, or discussing D2-SPN contributions would provide an important control and context. Since the claim is that Stard5 is expressed in both D1- and D2MSNs, it seems to contradict the exclusive role of D1R MSNs in authorizing food intake.
We agree that D2-SPNs represent an important and relevant cell population in the context of our study. The Stard5-Flp line labels a mixed population of D1- and D2-SPNs, and we agree that dissecting the distinct contributions of Stard5<sup>+</sup> D1-SPNs and Stard5⁺ D2-SPNs to feeding behavior would be both interesting and informative.
Although we understand the point raised by the Reviewer, we do not entirely agree that the expression of Stard5 in both D1- and D2-SPNs contradicts the established role of D1-SPNs in authorizing food intake. In the medNAcSh, D1- and D2-SPNs do not exert opposing functions. D2-SPNs project densely to the ventral pallidum and more sparsely to the lateral hypothalamus and, like D1-SPNs, are predominantly rewardinhibited at the population level (Domingues et al. 2025; Pedersen et al. 2022).
We added the following in the discussion: “Additionally, a new study showed that manipulation of D2-SPN cell bodies in the medNAcSh modulates reward preference, self-stimulation, and palatable food intake in a frequency- and context-dependent manner (Requejo-Mendoza et al., 2025). Together, these findings suggest that D1- and D2-SPNs within the medNAcSh play complementary rather than opposing roles in reward processing. Hence, the potential role of rostral and caudal medNAcSh D1- and D2-SPNs in foodrelated behaviors beyond the act of consumption could be addressed in future work.” We also acknowledge that not investigating rostro-caudal gradients of D2-SPN in reward and aversion processing “represents a limitation of this work”.
We fully agree that disentangling the specific contributions of Stard5<sup>+</sup> D1- and Stard5<sup>+</sup> D2-SPNs is an important next step. We have now crossed the Stard5-Flp line with Drd1-Cre and A2a-Cre lines. In a pilot experiment (not shown), we injected Flp+,Cre+, Flp+,Cre- and Flp-,Cre+ mice with 4 different FlpOn-CreOn AAVs to determine if any of these AAVs demonstrate specific expression. However, all AAVs exhibited moderate to strong leaky expression of the Cre, preventing reliable cell-type-specific targeting. This was not seen with Flp-only or Cre-only AAVs. The leakiness mentioned is a known challenge of FlpOn-CreOn AAVs and requires additional troubleshooting (e.g. reduce the titer). As this proved to be more challenging than anticipated, this work is ongoing and will be addressed in a future study rather than in the present revisions.
(2) Behavioral analyses:
(a) In Figure 2, group differences in consumption appear uneven; additional analyses (e.g., lick counts across blocks and session totals) would strengthen interpretation.
The group differences in consumption that appear uneven likely reflect an overall lower total lick counts per session in the Control group. We have now added analyses on average lick counts per block and session totals in the newly included Supplementary Figure S7, which support the results shown in Figure 2.
Although we observe a difference in total lick count across the entire session between Control and Rostral ChrimsonR mice (Supplementary Figure S7d), we deem the comparison in total session lick counts not that informative here. Instead, we would argue that the laser-on epoch is the most meaningful comparison. During this period, optogenetic activation had no effect on licking behavior in control mice, showed a nonsignificant trend toward reduced consumption in caudal ChrimsonR mice, and produced a significant reduction in lick counts when rostral medNAcSh D1-SPNs were activated (Figure 2g-i and Supplementary Figure S7c).
We added in the discussion the following explanation:
“In addition, comparison of licking behavior during the laser-off blocks revealed an interesting effect: following cessation of opto-stimulation, Rostral ChrimsonR mice licked more than Caudal ChrimsonR and Control mice, suggesting a possible compensatory overconsumption. One possible interpretation is that the optogenetic parameters used suppressed consummatory behavior without reducing the motivation to obtain the reward. Furthermore, consistent with the RTPPA results, activation of rostral D1-SPNs may be experienced as aversive and termination of the optogenetic stimulation could produce relief, which in turn reinforces the licking behavior. Further investigations are required to test these possibilities.”
(b) The design and contribution of aversive assays to the main conclusions remain somewhat unclear and could be better justified.
We appreciate the Reviewer’s comment regarding the design and contribution of the aversive assays. The rationale for including these experiments was to determine whether the rostro–caudal functional segregation observed for reward-related feeding also applies to aversive processing.
First, using foot shock, we tested whether D1-SPNs in the rostral versus caudal medNAcSh respond differently to an aversive stimulus. In contrast to reward-related responses, both populations responded similarly, exhibiting excitation. Second, to ensure that this effect was not specific to a single stressor, we tested a second aversive stimulus (tail lift) and again observed comparable excitatory responses in rostral and caudal D1-SPNs. Third, we assessed whether optogenetic activation of these neurons is perceived as rewarding or aversive. Using a real-time place preference/aversion assay, we found that optogenetic stimulation of D1-SPNs in both subregions induced place aversion.
Together, these experiments show that while D1-SPNs display region-specific effects on reward-related feeding behavior, their activity responses to aversive stimuli and the avoidance response to optogenetic activation are similar across rostral and caudal medNAcSh. This contrast strengthens our conclusion that the D1-SPN rostro-caudal gradient is specific to appetitive contexts.
We added the following in the discussion:
“Here, we further tested the existence of rostro-caudal gradients for aversion, asking whether D1-SPNs in the rostral vs. caudal medNAcSh respond differently to aversive stimuli. To ensure that any observed effects were not specific to a single stressor, we tested two distinct aversive stimuli (foot shock and tail lift). In both cases, we found no rostro-caudal differences, as D1-SPNs in both subregions responded with excitation. We also asked whether optogenetic activation of these neurons is perceived as aversive. Stimulation of D1- SPNs in both rostral and caudal medNAcSh promoted aversive behavioral responses in the RTPPA experiment. Hence, in contrast to the pharmacological inhibitions mentioned above, we did not detect differences in aversive behaviors according to the rostro-caudal medNAcSh site.”
(c) The scope of behavior is mainly limited to consumption; testing related domains (motivation, reward valuation, and extinction) could broaden the significance.
We thank the Reviewer for the suggestion to examine additional behavioral domains such as motivation, reward valuation, and extinction. We focused our efforts on consumption given the large body of literature demonstrating a very important role of the medNAcSh in reward consumption. However, we fully agree that feeding encompasses multiple phases, from appetitive and goal-directed behaviors to consummatory behavior, and that the NAc in general, and to some extent the NAcSh is involved in behaviors across this spectrum. For instance, prior work has shown that the medNAcSh is involved in reward preference and that this follows a rostro-caudal gradient (e.g. Pedersen et al. 2022).
While it would be informative to directly test motivational processes using operant paradigms (e.g., nosepoke or lever-press tasks), our current experimental setup did not allow for these assays. Instead, we performed exploratory experiments manipulating the animals’ internal state with food deprivation. As expected, under food deprivation, total licking increased robustly in control mCherry and Rostral ChrimsonR medNAcSh mice as compared to ad libitum feeding (25 min session with 5 alternating on-off blocks: ad libitum Control = 692 and Rostral ChrimsonR= 1280 average total licks per session, see Figure 2g-h and Supplementary Figure S7d; food deprived Control =2428 and Rostral ChrimsonR =2390 total licks averaged for N=9 Control, N= 12 Rostral). Moreover, similar to ad libitum feeding, optogenetic activation of rostral D1-SPNs suppressed licking in food-deprived mice , albeit to a lesser extent than under ad libitum feeding conditions (Figure 2).
These preliminary observations suggest that internal state modulates the role of rostral D1-SPNs in reward consumption, potentially reflecting an interaction between homeostatic and hedonic feeding circuits. However, as this line of investigation was exploratory and not pursued further in the present study, these data are not included in the main manuscript.
Author response image 1.
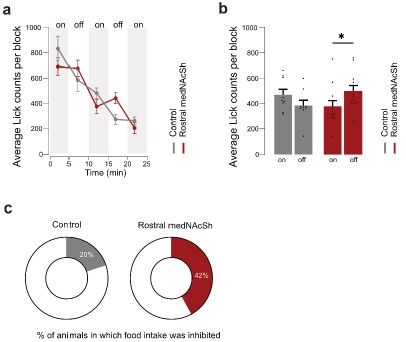
In vivo optogenetic stimulation of rostral medNAcSh inhibits reward consumption to a lesser extent after overnight food deprivation. a. Quantification of the average lick count per 5 min block in mCherry control mice vs. ChrimsonR (rostral) mice, showing a lower lick count in rostral medNAcSh ChrimsonR mice during the opto-stimulation epoch. Blocks of 5 min with or without opto-stimulation were alternated (on/off/on/off/on) for a total of 5 blocks. b. Quantification of mean lick counts in the opto-stimulation vs. non-opto-stimulation epochs shows a significant decrease in lick counts following stimulation of rostral medNAcSh D1-SPNs and no significant difference in the control mice. 2-way RM-ANOVA (group x epoch). Main effects: epoch F (1, 28) = 6.027, p=0.0206; group F (2, 28) = 1.448, p=0.2520; group x epoch F (2, 28) = 8.123, p=0.0017. Sidak post-hoc opto-stimulation vs. non opto-stimulation: Control on vs. off t(28) = 1.856, p=0.2061; Rostral medNAcSh on vs. off t(28) = 3.054, p= 0.0147. N=9 for Control mCherry; N=12 for Rostral medNAcSh ChrimsonR. c. Pie charts showing % of mice showing food intake inhibition (mean Δlick counts non-opto/opto>0) in each group: 42% of ChrimsonR rostral medNAcSh mice, 20% of controls. Data is mean ± SEM. *p<0.05; **p<0.01; ***p<0.001.
(3) Molecular profiling:
(a) Stard5 expression is present in both D1- and D2-SPNs; comparisons to bulk calcium signals and quantification of percentages across rostral and caudal cells would be helpful. The authors should establish whether these cells also express SerpinB2, an established marker of LH projecting neurons.
We thank the Reviewer for this relevant point. In the photometry experiments (Figure 7) using Stard5-Flp mice, we acknowledge that the recorded signals reflect a mixed population of D1- and D2-SPNs. Based on quantification in a separate set of brains, we estimate that Stard5 is expressed in a variety of cell types, of which 35% are D1-SPNs and 30% are D2-SPNs (Supplementary Figure S3). While Liu et al. 2024 reported no overlap between Stard5 and Drd2, canonical marker for D2-SPNs, available transcriptomic data (Chen et al. 2021) and our own histological and RNA-based analyses (Figure 6 and Supplementary Figure S3) found Stard5 to be expressed in both D1-SPNs and D2-SPNs. Hence, indeed, Stard5 is a mixed population.
We provide here the quantification of percentages of Stard5 expression across rostral and caudal cells: for instance, in the dorsal rostral medNAcSh, 79% of D1-SPNs and 76% of D2-SPNs express Stard5; in the ventral rostral medNAcSh the percentages are 47% and 55%, whereas the same percentages drop to 39 and 31% in the dorsal caudal medNAcSh and 15% and 20% in the ventral caudal medNAcSh.
As suggested by the Reviewer, we also performed further analysis of the publicly available scRNA-seq dataset from Chen et al. 2021, which shows that 4.4% of all Stard5-expressing cells are also Serpinb2+, while 1.8% of all sequenced NAc cells are Stard5+/Drd1+/Serpinb2+ and 0.21% are Stard5+/Drd2+/Serpinb2+.
(b) Verification of the Stard5-2A-Flp line (specificity, overlap with immunomarkers) should be documented more thoroughly.
We agree with the Reviewer that a more detailed characterization of the Stard5-2A-Flp mouse line would be relevant for the validation of the line.
In our study, we identified Stard5 as a marker gene that enables selective targeting of the rostral medNAcSh, as it is strongly enriched in the rostral medNAcSh (Figure 5-7). Stard5-Flp mice injected with Flp-dependent AAV in rostral medNAcSh, NAc core and dorsal striatum show specific AAV expression only in the rostral medNAcSh (Figure 7).
Moreover, we show that the line is specific as injection of a Flp-dependent AAV in a Stard5-Flp negative line does not lead to expression (Figure 7c).
However, re-analysis of the published scRNA-seq dataset (Chen et al. 2021) indicates that Stard5<sup>+</sup> cells comprise a heterogeneous population, including D1-SPNs (~35%), D2-SPNs (~30%), local interneurons (~18%), glial cells (~12%), and other cell types (Suppl. Fig. S3).
Together, these data validate the Stard5-2A-Flp line as a spatially specific genetic entry point for the rostral medNAcSh, while highlighting the cellular heterogeneity of Stard5-expressing cells. Given the limited brain material left, we were not able to add additional colocalization analyses with immunomarkers, but agree this would be important to include in future studies.
(c) The molecular analysis is restricted to a small set of genes; broader spatial transcriptomics could uncover additional candidate markers. See also above.
We thank the Reviewer for this suggestion. Broader spatial transcriptomic analyses would indeed be highly valuable for identifying additional candidate markers. Our aim for the present study was to identify molecular landmarks to selectively target the rostral medNAcSh, but in a future study, we would be highly interested in building on our initial findings and providing an exhaustive molecular characterization of the region using spatial transcriptomics. We would be particularly motivated to do so, given the important functional specificity of the rostral NAcSh identified in the present publication.
Reviewer #2 (Public review):
Summary:
Marinescu et al. combine in vivo imaging with circuit-specific optogenetic manipulation to characterize the anatomic heterogeneity of the medial nucleus accumbens shell in the control of food intake. They demonstrate that the inhibitory influence of dopamine D1 receptor-expressing neurons of the medial shell on food intake decreases along a rostro-caudal gradient, while both rostral and caudal subpopulations similarly control aversion. They then identify Stard5 and Peg10 as molecular markers of the rostral and caudal subregions, respectively. Through the development of a new mouse line expressing the flippase under the promoter of Stard5, they demonstrate that Stard5-positive neurons recapitulate the activity of D1positive neurons of the rostral shell in response to food consumption and aversive stimuli.
We thank Reviewer 2 for the positive feedback, summary of our findings and for the thorough reading and constructive comments on the manuscript, which allowed us to improve the quality of the revised version.
Strengths:
This study brings important findings for the anatomical and functional characterization of the brain reward system and its implications in physiological and pathological feeding behavior. It is a well-designed study, technically sound, with clear and reliable effects. The generation of the new Stard5-Flp line will be a valuable tool for further investigations. The paper is very well written, the discussion is very interesting, addresses limitations of the findings, and proposes relevant future directions
We thank Reviewer #2 for their supportive feedback.
Weaknesses:
At this stage, identification and characterization of the activity of Stard5-positive neurons is a bit disconnected from the rest of the paper, as this population encompasses both D1- and D2-positive neurons as well as interneurons. While they display a similar response pattern as D1-neurons, it remains to be determined whether their manipulation would result in comparable behavioral outcomes.
We agree that this represents an important limitation of the current study. In our search for molecular markers of the rostral feeding hotspot, we identified Stard5 as a marker enriched in the rostral medNAcSh; however, Stard5 labels a heterogeneous population that includes D1- and D2-SPNs as well as other cell types. While Stard5<sup>+</sup> neurons display activity patterns similar to D1-SPNs, we acknowledge that whether their direct manipulation would produce comparable behavioral effects to D1-SPNs remains to be determined. Moreover, it remains to be determined how the activity and function of Stard5<sup>+</sup> neurons compares to D2-SPNs.
To specifically isolate Stard5<sup>+</sup> D1-SPNs, we generated a Stard5-Flp;Drd1-Cre mouse line via breeding. However, the 4 CreON/FlpON AAVs which we tested exhibited leaky expression, including ectopic expression in Cre-positive but Flp-negative cells. This prevented reliable, cell-type-specific manipulation. We are actively working to overcome this common technical limitation of Flp/Cre AAVs, and these experiments will be addressed in a future study.
Recommendations for the authors:
Editor's note:
Readers would also benefit from coding individual data points by sex and noting N/sex in the figure legends.
We thank the editor for the note, we have noted in each figure legend the N and sex of the mice.
Reviewer #1 (Recommendations for the authors):
(1) Integration of results: The manuscript reads as two partly disconnected halves (functional gradient vs. molecular profiling). A more precise articulation of how the molecular findings (Stard5, Peg10) directly relate to the functional data would improve coherence.
We thank the Reviewer for raising this important point. We agree that clearer integration between the functional gradient and the molecular findings would strengthen the manuscript. In the present study, Stard5 and Peg10 are not introduced as mechanistic drivers of behavior, but as molecular landmarks that map onto the functional rostro-caudal organization of the medNAcSh.
Stard5 expression is enriched in the rostral medNAcSh, where we identify a functional hotspot for rewardrelated feeding, whereas Peg10 marks more caudal territories. Thus, the molecular profiling provides an independent axis that aligns with and supports the functional gradient revealed by photometry and optogenetic experiments. Whether these genes themselves contribute causally to feeding or aversive behaviors remains an open and interesting question for future studies.
To improve clarity, we have explicitly articulated this link in the Discussion:
“Importantly, our results indicate that spatial organization also defines functional specialization in the medNAcSh, and that molecular markers such as Stard5 provide access to these spatially defined subterritories rather than labeling a single, homogenous neuronal subtype.“
“Having established a robust functional dichotomy of D1-SPNs along the rostro-caudal axis in reward consumption, we next asked whether this functional organization is mirrored by differences in molecular composition across the medNAcSh. Using multiple anatomical techniques, we find strong differences in the molecular composition of the rostral vs. caudal medNAcSh, which in turn could explain behavioral differences between these brain subregions.”
“This makes Stard5 a spatial molecular landmark that captures the cellular ensemble of the rostral feeding hotspot, rather than a marker defining a single functional cell class. It is interesting that Stard5, a STARTdomain protein implicated in cholesterol metabolism and cellular stress responses (Alpy and Tomasetto, 2005; Rodriguez-Agudo et al., 2012; Calderon-Dominguez et al., 2014), and Peg10, an imprinted gene with roles in embryonic development and cancer (Mou et al. 2025), mark distinct rostro-caudal domains of the medNAcSh. Whether these genes themselves causally contribute to appetitive and consummatory behaviors, or aversive processing in this region remains an important question for future studies.”
(2) Injection site specificity: Given prior work on NAc manipulations, it is essential to ensure precise targeting. Representative images from both rostral and caudal placements, including verification of fiber/injection confinement, would increase confidence.
We thank the Reviewer for this important point regarding injection site specificity. Optic fiber placement was validated by identifying the coronal section in which the fiber tip was centered and aligning it to the mouse brain atlas (Franklin and Paxinos, The Mouse Brain in Stereotaxic Coordinates). We validated currently a total of 14 brains, shown in the newly added Supplementary Figure S10.
The primary source of variability across animals could be the extent of the viral spread and the size of the optic implants, which were 400 for photometry experiments and 200 μm for the optogenetic studies. We acknowledge that this limits the spatial precision with which the individual subregions can be isolated. This limitation is explicitly discussed in the manuscript.
Importantly, despite this limitation, we detected robust and reproducible differences between rostral and caudal medNAcSh in reward-consumption photometry and optogenetic assays. This argues against injection site proximity or fiber misplacement being a major confounding factor for the main conclusions. Nonetheless this comment is a valid point, and in future studies we plan to establish targeting methods with reduced viral volumes and/or tapered optic fibers (Pisanello et al. 2017). This will allow finer spatial restriction and more precise dissection of medNAcSh subregions.
(3) Minor clarifications:
(a) Provide explicit definitions of "rostral" and "caudal" coordinates.
We adjusted Figure 1 and added the coordinates.
(b) Consider alternative wording to "gradient" since only two rostro-caudal positions are tested.
RNA-seq and MERFISH data indicate that molecular markers in the NAcSh are organized along a continuous rostro–caudal gradient rather than discrete boundaries (Chen et al. 2021; Stanley et al. 2020). Our use of the term ‘gradient’ therefore reflects this established molecular organization, even though our functional experiments sampled two representative positions along this continuum.
We added the following sentence in the discussion for clarification:
“Of note, in this paper we decided to use the term “rostro-caudal gradient”, motivated by converging evidence from prior pharmacological studies (see below) and scRNA sequencing data (Chen et al., 2021; Stanley et al., 2020), which show continuous molecular and functional changes along the rostro-caudal axis of the medNAcSh rather than sharply defined boundaries. Our use of the term ‘gradient’ therefore reflects this established molecular organization, even though our functional experiments sampled only two representative positions along this continuum.”
(c) Enhance representative images (e.g., stronger DAPI, zoom-ins, bregma coordinates).
To improve clarity, we have adjusted Figure 1 by adding schematic representations including stereotaxic surgery coordinates, which facilitate interpretation of rostro–caudal targeting.
(d) Report trial numbers in figure legends, injection site details (e.g., S1 mouse), learning curves, and rationale for low-pass filtering in photometry.
We thank the Reviewer for these suggestions. The average number of successful trials is now reported in the figure legends (Figure 1 and Figure 7). Injection site details are described in the Methods and are now also illustrated in Figure 1a and validated in Supplementary Figure S10. In addition, we have added Supplementary Figure S8 showing the learning curves of the Drd1-Cre and Stard5-Flp mice included in this study.
Regarding the low-pass filtering in photometry analysis: low-pass filtering (1 Hz) was applied to the signal to remove high-frequency noise and isolate slow calcium-dependent fluorescence fluctuations that reflect population-level neural activity as we have done before (Labouesse et al. 2023, 2024). Low-pass filtering is a commonly-used analysis in fiber photometry and often shows a better artifact-corrected signal (Zhang et al. 2023; Keevers and Jean-Richard-dit-Bressel 2025).
Reviewer #2 (Recommendations for the authors):
Major Comments:
(1) As mentioned, I find the part on Stard5-positive neurons a bit disconnected. Ideally, as mentioned in the discussion, the author could cross Stard5-Flp mice with D1-cre to selectively monitor and/or manipulate these neurons. Alternatively, do they have any data regarding D2-positive neurons of the rostral part to show whether they behave differently from D1-positive neurons?
We thank the Reviewer for this suggestion and agree that selectively monitoring or manipulating Stard5<sup>+</sup> D1-SPNs using an intersectional approach would strengthen the link between the molecular and functional findings. We are pursuing this strategy by crossing Stard5-Flp mice with Drd1-Cre mice; however, as noted above, currently available CreON/FlpON viral tools exhibited leaky expression (a commonly known problem for such AAVs), preventing reliable cell-type–specific targeting. As a result, these experiments are ongoing (including reducing the titers) and will be addressed in a future study.
At present, we do not have equivalent functional data for D2-SPNs in the rostral medNAcSh. Investigating whether rostral D2-SPNs behave differently from caudal D2-SPNs is an important and interesting question, which we hope to address in a future study. This limitation is acknowledged in the discussion.
(2) Do the authors have any data on locomotor activity when they manipulate D1-expressing neurons? Lower food consumption as well as lower activity in the stimulated compartment - interpreted as aversion - could be related to diminished locomotor activity.
We thank the reviewer for the relevant point about locomotion. We ran new analyses of locomotor activity during the feeding task (operant boxes) using a machine-learning model. A small subset of frames (136 frames from 10 video recordings) was manually annotated to define the animal’s body center and nose, as well as the four corners of the operant box. These annotations were used to train a YOLO (Redmon et al. 2015)-based pose estimation model. Locomotion metrics, such as total distance moved were subsequently derived from the temporal integration of positional data and aligned to opto-on and opto-off epochs of the feeding task. During licking periods, the animal’s body center remains largely stationary, which could lead to an overestimation of immobility. Nevertheless, we quantified the total distance traveled in the entire operant box across epochs, shown in Supplementary Figure S9 a-b. In our proof-of-concept experiment (Figure 2c-e), locomotion was increased in rostral ChrimsonR mice compared to controls (Supplementary Figure S9a), a similar effect seen with chemogenetic activation of D1-SPNs (Zhu, Ottenheimer, and DiLeone 2016). In our full experimental cohort, locomotion did not differ between control, rostral and caudal ChrimsonR mice across laser on and laser off epochs. These results indicate that reduced reward consumption during stimulation of rostral D1-SPNs is not due to decreased locomotor activity. Notably, whereas the inhibitory effect on consumption is specific to rostral D1-SPNs activation, locomotor effects are similar for both rostral and caudal D1-SPNs stimulation, indicating they are at least partly dissociated from one another.
Moreover, in the RTPPA task, it is accepted that the percentage of time spent in the light-paired chamber reflects the preference or aversiveness to optogenetic stimulation. We additionally quantified total distance traveled (Supplementary Figure S9c). While optogenetic stimulation of both rostral and caudal D1-SPNs reduced time spent in the light-paired chamber (Figure 4), total distance traveled was unchanged, indicating that the observed aversion is not due to reduced locomotion.
We added the following to the Results section: “To determine whether the reduced reward consumption observed in Rostral ChrimsonR mice could be explained by changes in locomotion, we quantified the total distance traveled during this task. Optogenetic stimulation led to an increase in locomotion in the small cohort of Rostral ChrimsonR mice in the reward consumption experiment shown in Figure 2d-e (Supplementary Figure S9a), while no change in locomotion was observed across epochs in mCherry controls, ChrimsonR Rostral and Caudal mice (Supplementary Figure S9b, related to Figure 2g-i)”
And
“Quantification of locomotion showed no reduction in distance traveled in the light-paired chamber (Supplementary Figure S9c), indicating that the avoidance was not driven by impaired locomotion. These data indicate that medNAcSh D1-SPNs generally promote aversion without affecting locomotion and without major differences along the rostro-caudal axis”
Additionally, we added the following sentence to the Discussion: “Importantly, our behavioral effects of rostral D1-SPNs in the reward consumption and RTTPA assays could not be explained by reduced locomotor activity. Indeed, optogenetic stimulation of D1-SPNs during the reward consumption task did not reduce locomotion; instead, locomotion was either unchanged or increased in a small cohort of Rostral ChrimsonR mice. The increased locomotion likely reflected appetitive behavior and is consistent with past chemogenetic studies (Zhu et al., 2016). In the RTTPA no locomotion differences were detected.“
(3) It would be useful to provide a schematic (or pictures) for the location of fiber implantation in all animals for both photometry and optogenetics.
We validated optic fiber placement in 14 animals by identifying the coronal section in which the fiber tip was centered and aligning this section to the mouse brain atlas (Franklin and Paxinos, The Mouse Brain in Stereotaxic Coordinates). Representative optic fiber placement and viral spread are shown in the newly added Supplementary Figure S10.
Minor Comments:
(1) Figure 6e and g seem mislabeled: "Drd1+ (D2-SPNs)".
Yes, thank you. We corrected it.
(2) Line 395-397: the authors mention Flp minimal Flp Leakage, but could it be low activity of Stard5 promoter in the core and dorsal striatum that allows little expression of the flippase that could be sufficient for recombination?
We thank the Reviewer for this insightful point. We cannot fully distinguish between these possibilities in the current study; however, the overall recombination outside the target region remains minimal, supporting the utility of the Stard5-Flp line for selective targeting of the rostral medNAcSh. Injection of a Flp-dependent AAV into the lateral shell, core and dorsal striatum showed no expression, therefore we think this is unlikely. Moreover, this aligns with Stard5 expression patterns derived from the scRNAseq data (Chen et al. 2021), Allen Brain Atlas quantifications (Figure 5) and our RNAscope analysis (Figure 6). Nevertheless, we acknowledge that histology alone cannot definitively exclude this possibility, and quantitative approaches such as qPCR would be required.
References
Alpy, Fabien, and Catherine Tomasetto. 2005. “Give Lipids a START: The StAR-Related Lipid Transfer (START) Domain in Mammals.” Journal of Cell Science 118(13):2791–2801. doi:10.1242/jcs.02485.
Calderon-Dominguez, Maria, Gregorio Gil, Miguel Angel Medina, William M. Pandak, and Daniel RodríguezAgudo. 2014. “The StarD4 Subfamily of Steroidogenic Acute Regulatory-Related Lipid Transfer (START) Domain Proteins: New Players in Cholesterol Metabolism.” The International Journal of Biochemistry & Cell Biology 49:64–68. doi:10.1016/j.biocel.2014.01.002.
Chen, Renchao, Timothy R. Blosser, Mohamed N. Djekidel, Junjie Hao, Aritra Bhattacherjee, Wenqiang Chen, Luis M. Tuesta, Xiaowei Zhuang, and Yi Zhang. 2021. “Decoding Molecular and Cellular Heterogeneity of Mouse Nucleus Accumbens.” Nature Neuroscience 24(12):1757–71. doi:10.1038/s41593-021-00938-x.
Domingues, Ana Verónica, Tawan T. A. Carvalho, Gabriela J. Martins, Raquel Correia, Bárbara Coimbra, Ricardo Bastos-Gonçalves, Marcelina Wezik, Rita Gaspar, Luísa Pinto, Nuno Sousa, Rui M. Costa, Carina Soares-Cunha, and Ana João Rodrigues. 2025. “Dynamic Representation of Appetitive and Aversive Stimuli in Nucleus Accumbens Shell D1- and D2-Medium Spiny Neurons.” Nature Communications 16(1):59. doi:10.1038/s41467-024-55269-9.
Keevers, Luke J., and Philip Jean-Richard-dit-Bressel. 2025. “Obtaining Artifact-Corrected Signals in Fiber Photometry via Isosbestic Signals, Robust Regression, and DF/F Calculations.” Neurophotonics 12(02). doi:10.1117/1.NPh.12.2.025003.
Labouesse, Marie A., Arturo Torres-Herraez, Muhammad O. Chohan, Joseph M. Villarin, Julia Greenwald, Xiaoxiao Sun, Mysarah Zahran, Alice Tang, Sherry Lam, Jeremy Veenstra-VanderWeele, Clay O. Lacefield, Jordi Bonaventura, Michael Michaelides, C. Savio Chan, Ofer Yizhar, and Christoph Kellendonk. 2023. “A Non-Canonical Striatopallidal Go Pathway That Supports Motor Control.” Nature Communications 14(1):6712. doi:10.1038/s41467-023-42288-1.
Labouesse, Marie A., Maria Wilhelm, Zacharoula Kagiampaki, Andrew G. Yee, Raphaelle Denis, Masaya Harada, Andrea Gresch, Alina-Măriuca Marinescu, Kanako Otomo, Sebastiano Curreli, Laia Serratosa Capdevila, Xuehan Zhou, Reto B. Cola, Luca Ravotto, Chaim Glück, Stanislav Cherepanov, Bruno Weber, Xin Zhou, Jason Katner, Kjell A. Svensson, Tommaso Fellin, Louis-Eric Trudeau, Christopher P. Ford, Yaroslav Sych, and Tommaso Patriarchi. 2024. “A Chemogenetic Approach for Dopamine Imaging with Tunable Sensitivity.” Nature Communications 15(1):5551. doi:10.1038/s41467-024-49442-3.
Liu, Yiqiong, Ying Wang, Zheng-dong Zhao, Guoguang Xie, Chao Zhang, Renchao Chen, and Yi Zhang. 2024. “A Subset of Dopamine Receptor-Expressing Neurons in the Nucleus Accumbens Controls Feeding and Energy Homeostasis.” Nature Metabolism 6(8):1616–31. doi:10.1038/s42255-02401100-0.
Mou, Dachao, Shasha Wu, Yanqiong Chen, Yun Wang, Yufang Dai, Min Tang, Xiu Teng, Shijun Bai, and Xiufeng Bai. 2025. “Roles of PEG10 in Cancer and Neurodegenerative Disorder (Review).” Oncology Reports 53(5):1–9. doi:10.3892/or.2025.8893.
O’Connor, Eoin C., Yves Kremer, Sandrine Lefort, Masaya Harada, Vincent Pascoli, Clément Rohner, and Christian Lüscher. 2015. “Accumbal D1R Neurons Projecting to Lateral Hypothalamus Authorize Feeding.” Neuron 88(3):553–64. doi:10.1016/j.neuron.2015.09.038.
Pedersen, Christian E., Raajaram Gowrishankar, Sean C. Piantadosi, Daniel C. Castro, Madelyn M. Gray, Zhe C. Zhou, Shane A. Kan, Patrick J. Murphy, Patrick R. O’Neill, and Michael R. Bruchas. 2022. “Medial Accumbens Shell Spiny Projection Neurons Encode Relative Reward Preference.”
Pisanello, Ferruccio, Gil Mandelbaum, Marco Pisanello, Ian A. Oldenburg, Leonardo Sileo, Jeffrey E. Markowitz, Ralph E. Peterson, Andrea Della Patria, Trevor M. Haynes, Mohamed S. Emara, Barbara Spagnolo, Sandeep Robert Datta, Massimo De Vittorio, and Bernardo L. Sabatini. 2017. “Dynamic Illumination of Spatially Restricted or Large Brain Volumes via a Single Tapered Optical Fiber.” Nature Neuroscience 20(8):1180–88. doi:10.1038/nn.4591.
Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2015. “You Only Look Once: Unified, Real-Time Object Detection.”
Requejo-Mendoza, Nikte, José-Antonio Arias-Montaño, and Ranier Gutierrez. 2025. “Nucleus Accumbens D2-Expressing Neurons: Balancing Reward and Licking Disruption through Rhythmic Optogenetic Stimulation” edited by J. M. Dominguez. PLOS ONE 20(2):e0317605. doi:10.1371/journal.pone.0317605.
Rodriguez-Agudo, Daniel, Maria Calderon-Dominguez, Miguel Angel Medina, Shunlin Ren, Gregorio Gil, and William M. Pandak. 2012. “ER Stress Increases StarD5 Expression by Stabilizing Its MRNA and Leads to Relocalization of Its Protein from the Nucleus to the Membranes.” Journal of Lipid Research 53(12):2708–15. doi:10.1194/jlr.M031997.
Stanley, Geoffrey, Ozgun Gokce, Robert C. Malenka, Thomas C. Südhof, and Stephen R. Quake. 2020. “Continuous and Discrete Neuron Types of the Adult Murine Striatum.” Neuron 105(4):688-699.e8. doi:10.1016/j.neuron.2019.11.004.
Zhang, Yan, Márton Rózsa, Yajie Liang, Daniel Bushey, Ziqiang Wei, Jihong Zheng, Daniel Reep, Gerard Joey Broussard, Arthur Tsang, Getahun Tsegaye, Sujatha Narayan, Christopher J. Obara, JingXuan Lim, Ronak Patel, Rongwei Zhang, Misha B. Ahrens, Glenn C. Turner, Samuel S. H. Wang, Wyatt L. Korff, Eric R. Schreiter, Karel Svoboda, Jeremy P. Hasseman, Ilya Kolb, and Loren L. Looger. 2023. “Fast and Sensitive GCaMP Calcium Indicators for Imaging Neural Populations.” Nature 615(7954):884–91. doi:10.1038/s41586-023-05828-9.
Zhu, Xianglong, David Ottenheimer, and Ralph J. DiLeone. 2016. “Activity of D1/2 Receptor Expressing Neurons in the Nucleus Accumbens Regulates Running, Locomotion, and Food Intake.” Frontiers in Behavioral Neuroscience 10. doi:10.3389/fnbeh.2016.00066.
Reliable and high-quality labour market data are
This is a test
76% among users with employer-provided subscriptions. As we would expect, paid access, especially when provided by employers, is associated with more intensive workplace use.
令人惊讶的是:由雇主提供付费AI工具的用户中,高达76%在工作场所使用AI,远高于免费用户的38%,这表明企业付费模式极大加速了AI在工作中的采用,反映了组织决策对技术采用的关键影响。
21% said they had started doing new tasks because of AI (task augmentation). An example of task augmentation could be a data analysis tasks that would ordinarily require the worker to know how to code.
令人惊讶的是:五分之一的在职AI用户因为AI而开始执行原本不会做的新任务,如数据分析,这表明AI不仅替代工作,还在创造新的工作机会和技能需求。
27% said AI has replaced some of their existing tasks (task automation). An example of task automation could be an employee using AI to summarize a document they would ordinarily read themselves.
令人惊讶的是:超过四分之一的在职AI用户报告AI已经替代了他们原本执行的任务,如文档摘要,这显示AI已经开始实际替代人类工作内容,而非仅是辅助工具。
Among employed Americans who used AI in the past week, half reported using AI at least as much for work as for personal tasks
令人惊讶的是:近一半的美国在职AI用户在工作中使用AI的频率与个人使用相当或更高,这表明AI已经从个人工具迅速转变为职场主流工具,这一转变速度远超许多人预期。
This benchmark is a six-part semantic scoring test that assesses any model's effectiveness at relevant calibration tasks. QCalEval measures a model's ability to interpret experimental results, classify outcomes, evaluate their significance, assess fit quality and key features, and generate actionable next-step recommendations.
令人惊讶的是:量子校准AI模型的评估竟然如此复杂,需要六个维度的语义评分来全面评估其能力。这反映了量子校准任务的复杂性,也表明AI在科学领域的应用需要专门的评估方法,不能简单地照搬传统AI评估标准。
NVIDIA Ising provides open base models, a training framework, and workflows for fine-tuning, quantization, and deployment. The pre-trained models deliver top performance out of the box, and because everything is open, users can also specialize for their own hardware and noise characteristics while keeping proprietary QPU data on-site.
令人惊讶的是:NVIDIA选择将其量子AI模型完全开源,包括权重、训练框架和数据集。这种开放策略与科技巨头通常的封闭做法形成鲜明对比,表明量子计算领域可能比其他AI领域更注重开放协作,这可能加速整个行业的发展。
We projected that, given 13 GB300 GPUs, FP8 precision, physical error rate of 0.003, 1000 rounds, Surface code d=13, the fast model can achieve 0.11 μs / round.
令人惊讶的是:量子纠错解码的速度可以达到惊人的0.11微秒/轮,这比人类神经元的反应速度还要快几个数量级。这种超高速处理能力是实现实用量子计算的关键,也是传统计算方法难以企及的。
The Ising-Calibration-1 model was trained on data generated from information provided by partners spanning multiple qubit modalities, including superconducting qubits, quantum dots, ions, neutral atoms, electrons on Helium, and others specializing in calibration and control.
令人惊讶的是:量子计算竟然有如此多种不同的量子比特实现方式,从超导量子比特到量子点、离子、中性原子,甚至还有氦上的电子。这种多样性既是量子计算的优势(不同技术适合不同应用),也是其挑战(需要不同的校准和控制方法)。
Ising-Calibration-1 repeatedly outperforms state-of-the-art open and closed models of a range of parameters. As shown in Figure 1, Ising Calibration 1 scores 3.27% better on average than Gemini 3.1 Pro, 9.68% better than Claude Opus 4.6, and 14.5% better than GPT 5.4.
令人惊讶的是:专门为量子校准设计的AI模型Ising-Calibration-1竟然在量子校准任务上超越了包括GPT-5.4和Gemini 3.1 Pro在内的最先进通用AI模型,这表明专用AI模型在特定科学任务上可能比通用模型表现更好,颠覆了'通用AI万能'的传统观念。
The best quantum processors make an error roughly once in every thousand operations. To become useful accelerators for scientific and enterprise problems, error rates must drop to one in a trillion or better.
令人惊讶的是:量子计算的错误率要求如此极端—从当前的最佳水平(千分之一)需要提升到万亿分之一,这相当于要求一个系统连续运行数万年而不出错。这种巨大的性能差距凸显了量子纠错技术的巨大挑战,也解释了为什么AI在量子计算中如此重要。
Xcode should ship with a built-in MCP that handles auth when an LLM connects to a project. Notion should have `mcp.notion.so/mcp` available natively, instead of forcing me to download `notion-cli` and manage auth state manually.
令人惊讶的是:作者认为主流开发工具如Xcode和Notion应该原生集成MCP协议,而不是依赖第三方CLI。这种观点暗示了未来软件设计可能转向内置AI接口,而不是通过外部工具进行集成,这可能重塑整个AI与软件交互的生态。
Most skills require you to install a dedicated CLI. But what if you aren't in a local terminal? ChatGPT can't run CLIs. Neither can Perplexity or the standard web version of Claude.
令人惊讶的是:许多基于技能的AI工具依赖本地CLI,但主流AI平台如ChatGPT和Perplexity实际上无法执行CLI命令。这一限制意味着许多技能在非终端环境中完全失效,造成了AI工具功能的严重碎片化。
When a remote MCP server is updated with new tools or resources, every client instantly gets the latest version. No need to push updates, upgrade packages, or reinstall binaries.
令人惊讶的是:MCP服务器更新后所有客户端自动获得最新版本,无需手动更新。这种即时更新机制在软件分发中极为罕见,它消除了版本管理的复杂性,确保用户始终使用最新功能,这是传统软件分发模式无法比拟的优势。
For remote MCP servers, you don't need to install anything locally. You just point your client to the MCP server URL, and it works.
令人惊讶的是:MCP协议允许远程服务器无需本地安装即可使用,这大大简化了AI工具的集成流程。用户只需指向服务器URL即可获得功能,而不必在每个设备上安装软件,这种零安装模式在AI工具集成中非常独特。
CSS Studio uses Motion to generate real CSS springs with the perfect feel.
令人惊讶的是:CSS Studio使用了Motion库来生成真实的CSS弹簧动画,这种技术通常需要复杂的数学计算和物理模拟。设计师现在可以通过可视化的曲线编辑器轻松创建具有自然物理感觉的动画效果,而无需深入了解背后的复杂原理。
CSS Studio detects the CSS variables available on an element.
令人惊讶的是:这个工具能够智能识别元素上可用的CSS变量,并允许设计师编辑这些变量,同时看到变化在整个网站上的传播效果。这种变量管理功能对于维护大型设计系统的一致性非常有价值,但很多开发者可能不知道有这样的工具存在。
Scrub through CSS `@keyframes` animations on a visual timeline.
令人惊讶的是:CSS Studio提供了可视化的动画时间线编辑功能,让设计师能够像操作视频时间轴一样直观地编辑CSS动画,包括添加、移动、编辑和删除关键帧,甚至可以调整持续时间、延迟、方向和缓动效果,这大大简化了复杂动画的制作过程。
Your AI agent writes every change into source code.
令人惊讶的是:这个工具将设计工作与代码生成完全分离,设计师可以直接在浏览器中进行视觉编辑,而AI代理会自动生成对应的CSS代码,这大大降低了前端开发的门槛,模糊了设计与开发之间的界限。
Each routine has its own token, scoped to triggering that routine only. To rotate or revoke it, return to the same modal and click 'Regenerate' or 'Revoke'.
令人惊讶的是:每个 Routines 都有自己的专用令牌,且仅限于触发该特定例程。这种细粒度的安全控制意味着用户可以为每个自动化任务创建独立的认证机制,并且可以随时轮换或撤销这些令牌,提高了安全性。
A routine is a saved Claude Code configuration: a prompt, one or more repositories, and a set of connectors, packaged once and run automatically.
令人惊讶的是:Routines 实际上是预配置的 Claude Code 会话,将提示、存储库和连接器打包在一起,可以自动运行。这种设计使得复杂的自动化任务可以被封装和重用,而不需要每次都重新配置环境。
Routines execute on Anthropic-managed cloud infrastructure, so they keep working when your laptop is closed.
令人惊讶的是:Routines 在 Anthropic 管理的云基础设施上运行,即使你的笔记本电脑关闭,它们也能继续工作。这打破了传统自动化工具通常需要在本地设备上运行的限制,为用户提供了真正的'后台'自动化能力。
Routines are in research preview. Behavior, limits, and the API surface may change.
令人惊讶的是:Claude Code 的 Routines 功能目前仍处于研究预览阶段,这意味着用户使用的功能可能会在未来发生重大变化。这种状态表明 Anthropic 仍在测试和完善这一自动化工作流程的功能,用户应预期到可能的不稳定性和API变更。
Some advanced Excel capabilities aren't supported yet, including Office Scripts, Power Query, and Pivot/Data Model, data validation, and the named ranges manager, slicers, timelines, external connection administration, advanced charting breadth, and macro/Visual Basic for Applications (VBA) automation.
令人惊讶的是:尽管ChatGPT for Excel声称能处理复杂的电子表格任务,但它实际上不支持许多高级Excel功能,如VBA宏和Power Query。这表明该AI工具目前更适合基础到中级的电子表格操作,而非高度专业化的Excel工作流程。
ChatGPT for Excel can connect to apps. Apps from your ChatGPT account can be used in ChatGPT for Excel, subject to your plan, workspace admin settings, app availability, user permissions, and data-source entitlements.
令人惊讶的是:Excel中的ChatGPT功能可以与用户账户中的其他应用连接,形成一个强大的工作流生态系统。这种集成能力意味着用户可以将Excel的数据处理能力与其他应用的功能结合起来,创造出高度定制化的自动化工作流程。
During beta, ChatGPT for Excel is available globally for ChatGPT Business, Enterprise, Edu, Teachers, and K-12 users, and for ChatGPT Pro and Plus users outside the EU.
令人惊讶的是:欧盟地区的ChatGPT Pro和Plus用户无法使用Excel功能,这可能是由于欧盟更严格的数据保护法规所致。这种地域限制反映了不同地区数据隐私法规对AI功能实施的显著影响。
The ChatGPT for Excel add-in operates separately from your ChatGPT chat history. Conversations and data in Excel aren't shared with your ChatGPT chats, and activity doesn't sync between experiences at this time.
令人惊讶的是:Excel中的ChatGPT功能与普通聊天历史是完全隔离的,两个系统之间没有数据同步。这意味着用户可以在Excel中使用AI处理敏感数据,而不用担心这些信息会出现在他们的常规聊天记录中,提供了额外的隐私保护层。
By default, data shared with ChatGPT isn't used to improve our models for ChatGPT Business, ChatGPT Enterprise, ChatGPT Edu, and ChatGPT for Teachers.
令人惊讶的是:企业级用户的Excel数据默认不会被用于训练AI模型,这与普通用户的数据处理方式有显著区别。这种差异反映了OpenAI对商业客户隐私的特别保护,可能是为了增强企业采用AI工具的信心。
Each platform surfaces different vulnerabilities, making it difficult to establish a single, reliable source of truth for what is actually secure.
令人惊讶的是:AI安全工具之间存在不一致性,导致难以确定真正的安全状况。这种混乱局面使得企业面临更大的决策困境,即使有先进的安全工具,也无法保证全面保护,这反映了AI安全领域尚未成熟的现实。
In the past, exploiting an application required a highly skilled hacker with years of experience and a significant investment of time to find and exploit vulnerabilities.
令人惊讶的是:文章揭示了网络安全领域的根本性转变——过去需要高技能黑客多年经验才能完成的漏洞利用工作,现在AI可以在短时间内完成。这种技术民主化虽然提高了效率,但也大大降低了攻击门槛,使网络安全形势急剧恶化。
Being open source is increasingly like giving attackers the blueprints to the vault. When the structure is fully visible, it becomes much easier to identify weaknesses and exploit them.
令人惊讶的是:作者将开源软件比作给攻击者提供保险库蓝图,这种比喻揭示了开源与安全之间的根本矛盾。在AI时代,完全可见的代码结构使弱点识别变得前所未有的容易,这挑战了传统上认为开源更安全的观念。
AI uncovered a 27-year-old vulnerability in the BSD kernel, one of the most widely used and security-focused open source projects, and generated working exploits in a matter of hours.
令人惊讶的是:AI能够在几小时内发现并利用一个存在了27年的BSD内核漏洞,这展示了AI在安全领域的惊人能力。这个事实揭示了传统安全审计方法在面对AI加速攻击时的脆弱性,即使是像BSD这样经过长期审查的开源项目也无法幸免。
6802 ZA6802 Vor- und Nachwahl-Querschnitt (GLES 2017)
veraltet
vierstelligen
veraltet
Beispiel: doi:10.4232/1.13234
veraltet für Colectica
Studying forks and other backends was more productive than searching arxiv. ik_llama.cpp and the CUDA backend directly informed two of the five final optimizations.
令人惊讶的是:在实际项目中,研究分支代码和其他后端实现比查阅学术论文更有价值。这揭示了AI代理在实践中的学习偏好,也表明开源社区的实际贡献往往比理论研究更能提供直接可用的优化方案。
The variance is also worth noting: baseline+FA TG has ±19 t/s of noise, while optimized+FA has ±0.59 t/s on x86.
令人惊讶的是:优化后的代码不仅提高了性能,还显著减少了结果方差(从±19 t/s降至±0.59 t/s)。这表明AI代理的优化不仅关注速度,还考虑了内存访问模式的可预测性,这种全面性思维令人印象深刻。
Total cost: ~$29 ($20 in CPU VMs, $9 in API calls) over ~3 hours with 4 VMs.
令人惊讶的是:仅花费29美元和3小时,AI代理就实现了显著的性能提升(x86上提升15.1%,ARM上提升5%)。这种低成本高效能的优化方式颠覆了传统认为高性能优化需要大量人力和时间的观念。
The agent would not have looked for this without studying other backends during the research phase. From the CPU code alone, the two-step approach looks fine.
令人惊讶的是:AI代理通过研究其他后端实现发现了CPU后端中缺失的优化机会。这表明AI代理能够跨代码库进行知识迁移,找到人类开发者可能忽略的优化点,展示了AI在代码理解方面的独特优势。
The agent fused them into one: for (int i = 0; i < nc; i++) { wp[i] = sp[i] * scale + mp_f32[i]; }
令人惊讶的是:AI代理能够将原本需要三次内存访问的softmax操作优化为单次循环,这种优化方式对人类开发者来说可能不是最直观的,但却显著减少了内存带宽使用,提高了CPU推理效率。
We're building the foundation for a truly personal, proactive and powerful desktop assistant, with more news to share in the coming months.
令人惊讶的是:Google明确表示Gemini只是桌面AI助手的第一步,暗示他们正在开发更主动、更个性化的桌面AI体验,这可能预示着操作系统级别的AI助手革命即将到来。
The macOS app is available to Gemini users ages 13+
令人惊讶的是:Google将Gemini的最低使用年龄设定为13岁,这比许多其他AI平台的年龄限制更低,反映了Google对青少年AI教育的重视,但也引发了关于未成年人AI使用安全性的讨论。
Creatives can also quickly generate images with Nano Banana or videos with Veo to bring an idea to life without breaking their creative stride.
令人惊讶的是:Gemini内部集成了专门的内容创作工具(Nano Banana和Veo),这些工具似乎是为创意工作者量身定制的,显示了Google对特定用户群体的深度理解和产品差异化策略。
Now, you can bring up Gemini from anywhere on your Mac with a quick shortcut (Option + Space) to get help instantly, without ever switching tabs.
令人惊讶的是:Google选择Option+Space作为快捷键,这与macOS系统中Spotlight搜索的快捷键相同,暗示Gemini正在试图取代或整合系统级搜索功能,这反映了AI助手在操作系统中的战略定位。