Nano Banana 2 Lite (gemini-3.1-flash-lite-image) is designed for speed. Optimized for near-real-time, high-volume workflows where ultra-low latency is critical.
这里提到了Nano Banana 2 Lite的速度优化,但需要核查其是否真的能够达到文中描述的近实时、高容量工作流程的要求。
Nano Banana 2 Lite (gemini-3.1-flash-lite-image) is designed for speed. Optimized for near-real-time, high-volume workflows where ultra-low latency is critical.
这里提到了Nano Banana 2 Lite的速度优化,但需要核查其是否真的能够达到文中描述的近实时、高容量工作流程的要求。
The models are finally ready. Costs of inference are getting optimized with open models, and even on-device models.
大多数人认为AI领域仍然处于早期阶段,模型成本高且实用性有限,但作者认为模型已经'准备就绪',推理成本正在优化,这一观点暗示AI应用可能比大多数人预期的更快进入实用阶段,挑战了行业对AI成熟度的普遍认知。
A high loss scale in the L-BFGS-B minimizer, caused by averaging Huber-loss values over examples instead of summing them, which led to premature termination of the optimization.
技术细节如损失函数的求和方式而非平均,可能导致优化提前终止,影响缩放定律拟合结果。这提醒我们,在实现算法时需注意细节,即使是看似微小的实现差异也可能导致显著不同的结果。
MoE models are large models that only activate a small fraction of their total parameters. Qwen 3.6 35B-A3B has 35 billion total parameters but only 3 billion active at inference time
混合专家(MoE)架构是本地模型能够高效运行的关键技术。初学者可能不理解为什么大模型能在普通硬件上运行,这正是因为MoE架构只激活部分参数。理解这一概念对于评估模型性能和硬件需求至关重要。
Models are tricky. Budgets prevent defaulting everyone to state-of-the-art. The legion of other models each have a personality.
作者详细描述了不同AI模型的特性差异,如Kimi K2.6创意性强但精确度较低,Qwen 3.6性能好但可能中断工作流,GLM 5.1擅长编程但速度较慢。这提醒开发者需要根据具体需求选择合适的模型,而非盲目追求最新或最大的模型,同时要注意预算限制。
Instead, with IndexShare, the KV cache of $h_5$ includes only $kv_{1:4}$, all from the hidden states of the target model. For training, we reuse both kv cache and topk indices of the first mtp step.
大多数人认为在多步预测解码中,每一步都应该独立计算KV缓存以保持信息完整性,但作者认为通过共享索引可以消除训练-推理差异,提高接受率。这一反直觉的观点挑战了模型推理的最佳实践,表明在某些情况下,限制信息流动可能反而提高模型性能。
At a time when many companies are blowing through their AI budgets, those token cost savings have become a major selling point for the company.
AI budget anxiety is becoming a real enterprise procurement signal — and Glean is one of the first companies to explicitly sell against it. This suggests the AI adoption cycle is entering a cost-optimization phase: the early 'try everything' enthusiasm is giving way to CFO scrutiny of LLM spend, which favors solutions that promise efficiency over raw capability.
Running every query through Opus 4.7 is the fastest path to negative gross margins. The best Rest of Oz companies route across tiers of models — frontier models for the hardest tasks, mid-tier for the bulk, smaller custom or fine-tuned models where they've earned the right to use them.
大多数人认为使用最先进的大模型总是最佳选择,能提供最佳结果。但作者认为这是通往负毛利的最快路径。相反,'Oz的其他部分'公司会根据任务难度分层使用不同级别的模型,只为最困难的任务使用前沿模型,为批量任务使用中等模型,为特定工作使用小型定制或微调模型。这种成本优化策略使它们能够提供更具竞争力的价格。
These gains come on top of already-optimized baselines in kernels that were considered "done" by their authors. The improvements are the direct result of CompileIQ discovering compiler configurations that the default heuristics would never select.
大多数人认为一旦开发者完成优化工作,就没有更多性能提升空间。但作者表明,即使是"完成"的优化代码仍可能通过编译器级别的调整获得显著提升(高达15%),这挑战了开发者对优化极限的认知。
Most auto-tuning tools optimize for a single metric, typically runtime. CompileIQ goes further, supporting multi-objective optimization, simultaneously exploring trade-offs across competing objectives like runtime, compile time, and power consumption.
大多数人认为性能优化应以运行时间为唯一目标,但作者提出,真正的优化需要考虑多个相互竞争的目标(运行时间、编译时间和功耗)。这与传统的单一目标优化理念相悖,暗示开发者需要更全面的优化策略。
In attention inference kernels, GEMMs in the linear layers of FFN/MLP blocks plus the Q, K, V, and output projections account for approximately 70% of total FLOPs. Scaled dot-product attention, fused and flash attention variants account for another 25%. Together, these two kernel families represent more than 90% of end-to-end inference compute.
大多数人认为优化整个应用程序或算法才能获得显著性能提升,但作者指出,仅仅优化占计算量90%的两个关键内核类型就能带来最大收益。这与广泛应用的"全面优化"策略相悖,暗示开发者应该将资源集中在最关键的代码路径上。
NVIDIA GPU compilers apply the same default heuristics (register allocation strategies, instruction scheduling decisions, loop unrolling thresholds, etc.) to every kernel they compile. These heuristics are engineered to produce good results across a vast range of workloads. But "good across the board" and "optimal for your workload" are two very different things.
大多数人认为编译器已经提供了足够的优化,开发者只需关注算法和代码实现即可。但作者认为,即使是最先进的GPU编译器也使用通用的启发式方法,这些方法无法针对特定工作负载进行优化,导致性能损失。这挑战了开发者社区对编译器优化能力的普遍认知。
search over millions of model configurations to jointly optimize over perceptual quality and on-device runtime
数百万模型配置的搜索规模表明研究进行了大规模的实验和优化,这增强了结果的可信度。然而,文章没有提供具体的搜索方法、优化算法或计算资源信息,这使得难以评估这一过程的效率和科学性。
AlphaEvolve has been used as a regular tool to optimize the design of the next generation of TPUs. It also helped discover more efficient cache replacement policies, achieving in two days what previously required a concerted, human-intensive effort spanning months.
AlphaEvolve在TPU设计中的应用表明其已成为基础设施的核心组件,能够在两天内完成过去需要数月人工努力的缓存替换策略优化。这展示了AI系统在加速硬件开发方面的巨大潜力,显著缩短了产品上市时间。
AlphaEvolve began optimizing the lowest levels of hardware powering our AI stacks. It proposed a circuit design so counterintuitive yet efficient that it was integrated directly into the silicon of our next-generation TPUs.
Jeff Dean的评论表明AlphaEvolve已经从软件层面深入到硬件设计,能够提出违反直觉但高效的电路设计,直接集成到TPU芯片中。这展示了AI系统在硬件设计领域的突破性应用,可能改变芯片设计范式。
This optimization reduced 'write amplification'—the ratio of data written to storage versus the original request—by 20%. It also provided insights for new compiler optimization strategies that reduced the storage footprint of software by nearly 9%.
除了20%的写入放大减少,AlphaEvolve还通过新的编译器优化策略将软件存储占用减少了近9%。这表明该系统在多个层面优化基础设施的能力,从硬件到软件栈都带来了显著效率提升。
reduced 'write amplification'—the ratio of data written to storage versus the original request—by 20%
20%的写入放大减少表明AlphaEvolve在存储系统优化方面的显著贡献。这直接转化为存储效率提升和成本降低,对于处理大规模数据的Google Spanner系统而言,这是一个重要的性能改进。
increase the ability of our trained Graph Neural Network (GNN) model to find feasible solutions for the problem from 14% to over 88%
这是一个惊人的性能提升,从14%到88%的可行解发现能力增加了约6倍。这表明AlphaEvolve在电网优化问题上有突破性进展,显著减少了电网后处理步骤的需求,可能带来巨大的能源效率提升。
It helped increase the ability of our trained Graph Neural Network (GNN) model to find feasible solutions for the problem from 14% to over 88%
在电网 AC 最优潮流问题上,AlphaEvolve 将 GNN 模型找到可行解的成功率从 14% 提升到 88% 以上——提升幅度超过 6 倍,是迄今 AI 在能源基础设施优化中记录到的最大突破之一。
AlphaEvolve improved the efficiency of Google Spanner by refining its Log-Structured Merge-tree compaction heuristics. This optimization reduced 'write amplification'—the ratio of data written to storage versus the original request—by 20%.
大多数人认为数据库优化需要人类数据库专家的经验和知识,但作者认为AI可以独立发现并改进核心数据库算法。这挑战了数据库工程领域的传统实践,暗示AI可能在最基础的系统组件上实现超越人类专家的优化。
AI generates this pattern because it's the shortest path from 'fetch data' to 'render table.'
大多数人认为AI生成的代码更高效,但作者指出AI往往选择技术上最简单但长期维护困难的解决方案,因为它只关注当前任务的最短路径。
Claude Opus 4 achieved a 2.9× mean speedup in May 2025; this rose to 16.5× with Opus 4.5 in November 2025, 30× with Opus 4.6 in February 2026, and 52× with Claude Mythos Preview in April 2026. To calibrate on what these numbers mean, it is expected to take a human researcher 4 to 8 hours of work to achieve a 4x speedup on this task.
AI系统在优化语言模型训练方面的能力从2.9倍提升到52倍,远超人类研究员4-8小时才能达到的4倍优化。
Even with these improvements, Responses API overhead was too large relative to the speed of the model—that is, use
已弃用或过时的内容:过度依赖单个优化点,而忽略了整体性能瓶颈。
We approached this through caching, eliminating unnecessary network hops, improving our safety stack to quickly flag issues, and—most importantly—building a way to create a persistent connection to the Responses API, instead of having to make a series of synchronous API calls.
最佳实践建议:通过缓存、减少网络跳数、改进安全栈和建立持久连接来优化性能。
In the past, running LLM inference on GPUs was the slowest part of the agentic loop, so API service overhead was easy to hide.
初学者可能误以为模型推理是瓶颈,而忽略了API服务开销的问题。
Existing automatic optimization methods, primarily focused on flat prompt tuning, lack the structural awareness to debug the intricate web of interactions in MAS.
当前自动优化方法主要关注于平面的提示调整,缺乏对MAS中复杂交互网络的结构化意识,表明现有方法在结构理解上存在局限性。
These papers suggest that strategic data engineering and inference-time optimization can substitute for raw parameter count.
这一观点提出了通过数据工程和推理时间优化来提高模型性能的新方法,为模型优化提供了新的思路。
We reverted this change on April 7 after users told us they'd prefer to default to higher intelligence and opt into lower effort for simple tasks.
大多数人认为AI系统应该优化速度和效率,但作者认为用户更愿意默认选择更高智能而非更低延迟,这挑战了产品优化的常规思维。用户宁愿忍受偶尔的延迟也要换取更高的代码质量,这违背了大多数科技公司追求'更快更省'的常规做法。
Agents and CDC streams are powerful together because they split the work well.
大多数人认为AI代理应该负责从端到端的任务执行。但作者认为AI代理和数据库引擎应该分工合作:代理负责解释新信息和调整逻辑,而数据库负责持续应用逻辑并发出精确更新。这种分工模式挑战了AI代理应该完全自主的主流观点。
The fix is not smarter prompts. It is software built to meet agents halfway.
大多数人认为提高AI提示词质量是改善AI交互的关键。但作者认为真正解决方案是重新设计软件架构,使其与AI代理更好地协作,而不是改进提示词。这一观点颠覆了当前AI优化的主流方法,将焦点从AI本身转向系统设计。
a lightweight surrogate trained on them can absorb a significant portion of future traffic at near-zero marginal inference cost
大多数人认为模型替换会带来明显的质量下降或需要持续监督。但作者提出轻量级代理模型可以'吸收大量未来流量'且'边际推理成本接近零',这种近乎零成本的替代方式颠覆了传统模型替换的质量-成本权衡观念。
The extra tokens bought something measurable. +5pp on strict instruction-following. Small. Real. So: is that worth 1.3–1.45x more tokens per prompt?
这是一个令人惊讶的价值权衡案例。Anthropic用高达45%的token成本增加,只换来了5个百分点的指令遵循提升。这种不成比例的交换表明,在AI模型优化中,'微小但真实'的改进可能需要付出巨大成本,这挑战了人们对技术改进应该'物有所值'的普遍假设。
More loops is not always better. Beyond a certain depth, excessive recurrence degrades predictions — the hidden state drifts past the solution and into noise. This is the 'overthinking' failure mode.
这一发现挑战了'更多循环总是更好'的直觉,揭示了循环模型的'过度思考'问题。这类似于人类思考中的过度分析现象,表明即使是最优架构也存在'饱和点'。这一发现对模型设计有重要启示:需要智能的停止机制,而不是简单地增加循环次数。
TPU 8i is designed with more memory bandwidth to serve the most latency-sensitive inference workloads, which is critical because interactions between agents at scale magnify even small inefficiencies.
通常认为内存带宽是通用硬件的需求,但作者提出TPU 8i针对低延迟推理进行了优化,这与通用硬件设计追求平衡的常规做法不同。
Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens—roughly 1.0–1.35× depending on the content type.
tokenizer的更新虽然增加了token使用量,但提高了文本处理效率,这反映了AI模型在基础架构上的持续优化,这种优化虽然带来短期成本增加,但长期将提升AI的处理能力和准确性。
scaling Muse Spark with multi-agent thinking enables superior performance with comparable latency.
这一结果挑战了传统认知,即增加推理时间必然导致延迟增加,表明多智能体并行可能是实现高效推理的关键,为未来AI架构设计提供了新思路。
After compressing, the model again extends its solutions to achieve stronger performance.
令人惊讶的是:Muse Spark在测试时展现出一种独特的'思想压缩'能力,模型在最初通过延长思考时间提高性能后,会在时间惩罚机制下自发压缩推理过程,然后再扩展解决方案以获得更强的性能。这种动态的自我优化机制在AI模型中前所未见。
The standard autoresearch loop (brainstorm from code, run experiments, check metrics) works when the optimization surface is visible in the source. The Liquid results prove that. But for problems where the codebase doesn't contain enough information to generate good hypotheses, giving the agent access to papers and competing implementations changes what it tries.
这一声明清晰地区分了两种优化场景:代码可见的优化和需要外部知识的优化。它揭示了AI代理开发中的一个关键洞察:优化方法必须根据问题性质进行调整。对于某些问题,简单的代码分析就足够了;但对于更复杂的问题,需要引入外部知识和研究。这一发现对AI辅助编程系统的设计具有重要指导意义。
The variance is also worth noting: baseline+FA TG has ±19 t/s of noise, while optimized+FA has ±0.59 t/s on x86. The fusions eliminate intermediate writes that pollute the cache, making the hot paths more predictable.
这一数据揭示了优化的一个意外但重要的好处:不仅提高了性能,还显著降低了结果变异性。这表明通过减少缓存污染和内存访问模式的不确定性,优化可以使系统行为更加可预测。这一发现对构建可靠的高性能系统具有重要意义,强调了优化的一致性而不仅仅是峰值性能。
Without experience with compiler behavior, the agent couldn't have predicted which 'optimizations' the compiler would already handle.
这一观察揭示了AI代理在编译优化方面的局限性:代理无法准确预测编译器已经自动处理的优化。这表明AI代理需要更深入理解编译器行为和现代编译技术,以避免徒劳的优化尝试。这一发现对AI辅助编程系统的发展具有重要启示,强调了领域知识整合的重要性。
A 606 MiB model at ~49 tokens/s consumes ~30 GB/s of memory bandwidth, close to the c6i.2xlarge's DRAM limit. No amount of SIMD tricks will help when the CPU is stalled waiting for model weights to arrive from DRAM.
这一数据揭示了现代CPU推理的关键瓶颈:内存带宽限制。代理最初尝试的SIMD微优化无法突破这一根本限制,这表明理解硬件特性和系统瓶颈对于有效优化至关重要。这一发现挑战了传统上认为计算是主要瓶颈的观念,强调了内存效率在AI推理中的核心地位。
Studying forks and other backends was more productive than searching arxiv. ik_llama.cpp and the CUDA backend directly informed two of the five final optimizations.
这是一个令人惊讶的发现,表明实践中的代码实现比学术论文更能直接指导优化工作。代理通过研究实际项目分支和不同后端实现获得了更有价值的见解,而不是依赖理论研究。这强调了在AI代理开发中,实践经验和现有实现的重要性可能超过理论文献。
Coding agents working from code alone generate shallow hypotheses. Adding a research phase — arxiv papers, competing forks, other backends — produced 5 kernel fusions that made llama.cpp CPU inference 15% faster.
这一声明揭示了AI代理在代码优化中的关键局限:仅基于代码的优化会产生浅显的假设。通过引入研究阶段,包括阅读学术论文、研究竞争项目和后端实现,代理能够发现更深层次的优化机会,实现了显著的性能提升。这表明AI代理需要更广泛的上下文信息才能做出有意义的创新。
The variance is also worth noting: baseline+FA TG has ±19 t/s of noise, while optimized+FA has ±0.59 t/s on x86.
令人惊讶的是:优化后的代码不仅提高了性能,还显著减少了结果方差(从±19 t/s降至±0.59 t/s)。这表明AI代理的优化不仅关注速度,还考虑了内存访问模式的可预测性,这种全面性思维令人印象深刻。
Total cost: ~$29 ($20 in CPU VMs, $9 in API calls) over ~3 hours with 4 VMs.
令人惊讶的是:仅花费29美元和3小时,AI代理就实现了显著的性能提升(x86上提升15.1%,ARM上提升5%)。这种低成本高效能的优化方式颠覆了传统认为高性能优化需要大量人力和时间的观念。
The agent fused them into one: for (int i = 0; i < nc; i++) { wp[i] = sp[i] * scale + mp_f32[i]; }
令人惊讶的是:AI代理能够将原本需要三次内存访问的softmax操作优化为单次循环,这种优化方式对人类开发者来说可能不是最直观的,但却显著减少了内存带宽使用,提高了CPU推理效率。
The same task on full Codex took ~5× longer.
令人惊讶的是:精简版的Codex Spark模型比完整版的Codex快5倍完成相同任务,这表明AI模型的大小和复杂度并不总是与性能成正比,优化设计可能比单纯增加规模更有效。
KV Cache 内存占用降低 10.7 倍
令人惊讶的是:KV Cache内存占用降低了惊人的10.7倍,这一数字远超普通技术优化的幅度。KV Cache是大模型推理中的主要内存消耗部分,如此大幅度的减少意味着同样的硬件可以处理更长的上下文,或者同时运行更多模型实例。
GLM-5.1 pushes this frontier further, delivering 3.6× speedup and continuing to make progress well into the run. While its rate of improvement also slows over time, it sustains useful optimization for substantially longer than GLM-5.
令人惊讶的是:在机器学习工作负载优化任务中,GLM-5.1能够实现3.6倍的速度提升,并且在长时间运行中持续改进,而其他模型很快就会达到性能瓶颈。这种持续优化的能力对于实际应用中的复杂问题解决具有重要意义。
GLM-5.1 did not plateau after 50 or 100 submissions, but continued to find meaningful improvements over 600+ iterations with 6,000+ tool calls, ultimately reaching 21.5k QPS—roughly 6× the best result achieved in a single 50-turn session.
令人惊讶的是:GLM-5.1在向量数据库优化任务中能够持续改进600多次迭代,性能提升达到原来的6倍,这打破了传统模型很快达到性能瓶颈的局限。这种长时间持续优化的能力在AI模型中极为罕见,展示了模型在长期任务处理上的突破性进步。
In 23 months, the same capability that needed 1.8 trillion parameters now fits in 4 billion parameters. A 450x compression.
令人惊讶的是:AI模型参数量在短短23个月内实现了450倍的压缩,这意味着原本需要超级计算机才能运行的强大AI模型现在可以完全在手机上运行。这种技术进步的速度远超摩尔定律,展示了算法优化和模型压缩技术的惊人突破。
PagedAttention algorithm and vLLM system enhance the throughput of large language models by efficiently managing memory and reducing waste in the key-value cache.
令人惊讶的是:通过简单的内存管理优化,PagedAttention算法和vLLM系统能够显著提高大语言模型的吞吐量,减少键值缓存中的浪费。这展示了在模型规模不断扩大的今天,系统优化可能比模型创新本身更具实际价值。
Artificial Analysis has also positioned Gemini 3.1 Flash TTS within its 'most attractive quadrant' for its ideal blend of high-quality speech generation and low cost.
令人惊讶的是:这个模型不仅质量高,而且成本效益也非常出色,在'最具吸引力象限'中占据一席之地。这表明Google在平衡AI性能和商业可行性方面取得了显著突破,这对大多数用户来说是意想不到的。
We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution.
令人惊讶的是:通过双缓冲执行引擎和多CUDA流的重叠计算,研究团队能够实现GPU的持续执行,有效解决了CPU-GPU带宽瓶颈。这种流水线设计展示了系统级优化如何克服硬件限制,实现看似不可能的效率提升。
identify if the app had been left in a broken state
“先验证基础环境,再开发新功能”是一个反直觉但极其高效的Agent工作流。如果Agent一上来就写新代码,很可能在崩溃的地基上建危楼。这种“先体检再干活”的逻辑,极大减少了错误复利带来的灾难。
the design of the retrieval and cache policy, especially how they decide what to keep, reuse, or drop across scenes, seems to be what actually drives the latency and throughput gains
大多数研究者可能关注模型架构或算法创新来提升性能,但评论者指出检索和缓存策略的设计才是延迟和吞吐量提升的关键。这一观点挑战了AI研究中过度关注模型本身的倾向,暗示系统优化和资源管理策略可能比模型架构创新对性能影响更大,这是一个反直觉的系统设计见解。
Simultaneously, the parallelism in worker layer accelerates the speed of overall task execution, mitigating the significant latency
虽然并行处理在计算领域常见,但将其应用于LLM代理系统中的信息搜索任务可能出人意料,因为大多数LLM应用仍采用顺序处理模式,作者的观点挑战了这一现状。
For higher-interactivity scenarios, execution time for MoE models is bound by expert weight load time. By splitting, or sharding, the experts across multiple GPUs across NVL72 nodes, this bottleneck is reduced, improving end-to-end performance.
大多数人认为MoE模型的主要瓶颈在于计算能力,但作者指出专家权重加载时间是真正的瓶颈,并提出通过跨GPU分片专家权重来解决问题,这挑战了AI模型优化的传统认知,暗示了I/O可能比计算更重要。
Co-designed hardware, software, and models are key to delivering the highest AI factory throughput and lowest token cost. Measuring this goes far beyond peak chip specifications.
大多数人认为AI性能主要由芯片规格决定,但作者强调硬件、软件和模型的协同设计才是关键,这挑战了以芯片为中心的行业认知,暗示了全栈优化比单纯追求芯片性能更重要。
This means 2.7x more tokens from the same GB300 NVL72-based infrastructure and power footprint, reducing the cost to manufacture each token by more than 60%.
大多数人认为硬件升级是提高AI性能的主要方式,但作者认为通过软件优化可以在相同硬件上实现2.7x的性能提升和60%以上的成本降低,这挑战了行业对硬件升级的依赖。这种观点暗示软件优化可能比硬件升级更具成本效益。
NVFP4 enables 4-bit precision while maintaining nearly identical accuracy to 8-bit precision, increasing performance per watt and lowering cost per token.
大多数人认为降低模型精度会显著牺牲性能,但作者声称Gemma 4通过NVFP4量化技术实现了4位精度与8位精度几乎相同的准确率。这一反直觉的结论挑战了传统量化会大幅降低模型性能的认知,暗示NVIDIA可能在量化技术方面取得了突破性进展。
Optimizations that don’t need Rust Some of uv’s speed comes from Rust. But not as much as you’d think. Several key optimizations could be implemented in pip today: HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. This is HTTP protocol work, not Rust. Parallel downloads. pip downloads packages one at a time. uv downloads many at once. This is concurrency, not language magic. Global cache with hardlinks. pip copies packages into each virtual environment. uv keeps one copy globally and uses hardlinks (or copy-on-write on filesystems that support it). Installing the same package into ten venvs takes the same disk space as one. This is filesystem ops, not language-dependent. Python-free resolution. pip needs Python running to do anything, and invokes build backends as subprocesses to get metadata from legacy packages. uv parses TOML and wheel metadata natively, only spawning Python when it hits a setup.py-only package that has no other option. PubGrub resolver. uv uses the PubGrub algorithm, originally from Dart’s pub package manager. pip uses a backtracking resolver. PubGrub is faster at finding solutions and better at explaining failures. It’s an algorithm choice, not a language choice
Many of uv's optimisations come from improvements that can be made without rust such as http range requests for packages, parallel downloading, better local caching
No .egg support. Eggs were the pre-wheel binary format. pip still handles them; uv doesn’t even try. The format has been obsolete for over a decade. No pip.conf. uv ignores pip’s configuration files entirely. No parsing, no environment variable lookups, no inheritance from system-wide and per-user locations. No bytecode compilation by default. pip compiles .py files to .pyc during installation. uv skips this step, shaving time off every install. You can opt in if you want it. Virtual environments required. pip lets you install into system Python by default. uv inverts this, refusing to touch system Python without explicit flags. This removes a whole category of permission checks and safety code. Stricter spec enforcement. pip accepts malformed packages that technically violate packaging specs. uv rejects them. Less tolerance means less fallback logic. Ignoring requires-python upper bounds. When a package says it requires python<4.0, uv ignores the upper bound and only checks the lower. This reduces resolver backtracking dramatically since upper bounds are almost always wrong. Packages declare python<4.0 because they haven’t tested on Python 4, not because they’ll actually break. The constraint is defensive, not predictive. First-index wins by default. When multiple package indexes are configured, pip checks all of them. uv picks from the first index that has the package, stopping there. This prevents dependency confusion attacks and avoids extra network requests. Each of these is a code path pip has to execute and uv doesn’t.
UV does not support egg files or legacy pip.conf and it doesn't check for upper bounds on dependencies or compile py files to pyc bytecode by default. This removes a number of codepaths and allows the tool to run faster.
PEP 658 went live on PyPI in May 2023. uv launched in February 2024. The timing isn’t coincidental. uv could be fast because the ecosystem finally had the infrastructure to support it. A tool like uv couldn’t have shipped in 2020. The standards weren’t there yet.
Before February 2024 the pip standards for pyproject.toml and wheel management weren't there and UV would not have been possible.
The relevant PEP standards are 517, 518, 621 and 658
The similarity is because they are all saying roughly the same thing: Total (result) = Kinetic (cost) + Potential (benefit) Cost is either imaginary squared or negative (space-like), benefit is real (time-like), result is mass-like. Just like physics, the economic unfavourable models are the negative results. In economics, diversity of products is a strength as it allows better recovery from failure of any one, comically DEI of people fails miserably at this, because all people are not equal. Here are some other examples you will know if you do physics: E² + (ipc)² = (mc²)² (relativistic Einstein equation), mass being the result, energy time-like (potential), momentum the space-like (kinetic). ∇² - 1/c² ∂²/∂t² = (mc/ℏ)² (Klein-Gordon equation), mass is the result, ∂²/∂t² potential, ∇² is kinetic. Finally we have Dirac equation, which unlike the previous two as "sum of squares" is more like vector addition (first order differentials, not second). iℏγ⁰∂₀ψ + iℏγⁱ∂ᵢψ = mcψ First part is still the time-like potential, second part is the space-like kinetic, and the mass is still the result though all the same. This is because energy is all forms, when on a flat (free from outside influence) worksheet, acts just like a triangle between potential, kinetic and resultant energies. E.g. it is always of the form k² + p² = r², quite often kinetic is imaginary to potential (+,-,-,-) spacetime metric, quaternion mathematics. So the r² can be negative, or imaginary result if costs out way benefits, or work in is greater than work out. Useless but still mathematical solution. Just like physics, you always want the mass or result to be positive and real, or your going to lose energy to the surrounding field, with negative returns. Economic net loss do not last long, just like imaginary particles in physics.
in reply to Cesar A. Hidalgo at https://x.com/realAnthonyDean/status/1844409919161684366
via Anthony Dean @realAnthonyDean
Its performance is not very different from the system versions of grep, which shows that the recursive technique is not too costly and that it's not worth trying to tune the code.
Technique #1: Changing numeric representations
For most purposes having a huge amount of accuracy isn’t too important.
Instead of representing the values as floating numbers, we can represent them as percentages between 0 and 100. We’ll be down to two-digit accuracy, but again for many use cases that’s sufficient. Plus, if this is output from a model, those last few digits of “accuracy” are likely to be noise, they won’t actually tell us anything useful.
Whole percentages have the nice property that they can fit in a single byte, an int8—as opposed to float64, which uses eight bytes:
lossy compression: drop some of your data in a way that doesn’t impact your final results too much.
If parts of your data don’t impact your analysis, no need to waste memory keeping extraneous details around.
why not allow block forwarding without capturing: foo(&) foo(1, 2, &)
optimization-procrastination trap is related to shiny object syndrome - the idea of tweaking one's system constantly
perfect tool trap - guess what? there isn't one
There is no reason why a small triangle couldn't be used in printing instead of the letter "e"
This is critical since many optimizations are accomplished by violating (hopefully safely) module boundaries; it is disastrous to incorporate optimizations into the main body of code. The separation allows the optimizations to be checked against the meanings.
See also the discussion (in the comments) about optimization-after-the-fact in http://akkartik.name/post/mu-2019-2
If a compiler cannotdetermine whether or not two pointers may be aliased, it must assume that eithercase is possible, limiting the set of possible optimizations.
pointer alias 的 optimization block 怎么理解?
Algospeak refers to code words or turns of phrase users have adopted in an effort to create a brand-safe lexicon that will avoid getting their posts removed or down-ranked by content moderation systems. For instance, in many online videos, it’s common to say “unalive” rather than “dead,” “SA” instead of “sexual assault,” or “spicy eggplant” instead of “vibrator.”
In order to get around algorithms that demote content in social media feeds, communities have coined new words or new meanings to existing words to communicate their sentiment.
This is affecting TikTok in particular because its algorithm is more heavy-handed in what users see. This is also causing people who want to be seen to tailor their content—their speech—to meet the algorithms needs. It is like search engine optimization for speech.
Article discovered via Cory Doctorow at The "algospeak" dialect
It's typically taken for granted that better performance must require higher complexity. But I've often had the experience that making some component of a system faster allows the system as a whole to be simpler
The latest SQLite 3.8.7 alpha version is 50% faster than the 3.7.17 release from 16 months ago. [...] This is 50% faster at the low-level grunt work of moving bits on and off disk and search b-trees. We have achieved this by incorporating hundreds of micro-optimizations. Each micro-optimization might improve the performance by as little as 0.05%. If we get one that improves performance by 0.25%, that is considered a huge win. Each of these optimizations is unmeasurable on a real-world system (we have to use cachegrind to get repeatable run-times) but if you do enough of them, they add up.
don’t store all the values from onerow together, but store all the values from each column together instead. If each col‐umn is stored in a separate file, a query only needs to read and parse those columnsthat are used in that query, which can save a lot of work.
Why column storage is better query optimized
We were able to reduce calls to Infura and save on costs. And because the proxy uses an in-memory cache, we didn’t need to call the Ethereum blockchain every time.
our application continuously checks the current block and retrieves transactions from historical blocks;Our application was very heavy on reads and light on writes, so we thought using ‘cached reads’ would be a good approach;We developed a small application to act as a thin proxy between our application and Infura. The proxy application is simple and it only hits Infura/Ethereum on the initial call. All future calls for the same block or transaction are then returned from cache;Writes are automatically forwarded to Infura. This was a seamless optimization. We simply had to point our application to our proxy and everything worked without any changes to our application.
Grötschel, an expert in optimization, observes that a benchmark production planning model solved using linear programming would have taken 82 years to solve in 1988, using the computers and the linear programming algorithms of the day. Fifteen years later – in 2003 – this same model could be solved in roughly 1 minute, an improvement by a factor of roughly 43 million. Of this, a factor of roughly 1,000 was due to increased processor speed, whereas a factor of roughly 43,000 was due to improvements in algo-rithms
Optimization in this case is nothing crazy, just something I neglected while designing the framework.
If a UTF8-encoded Ruby string contains unicode characters, then indexing into that string becomes O(N). This can lead to very bad performance in string_end_with_semicolon?, as it would have to scan through the whole buffer for every single file. This commit fixes it to use UTF32 if there are any non-ascii characters in the files.
What is the point of avoiding the semicolon in concat_javascript_sources
For how detailed and insightful his analysis was -- which didn't elaborate or even touch on his not understanding the reason for adding the semicolon -- it sure appeared like he knew what it was for. Otherwise, the whole issue would/should have been about how he didn't understand that, not on how to keep adding the semicolon but do so in a faster way!
Then again, this comment from 3 months afterwards, indicates he may not think they are even necessary: https://github.com/rails/sprockets/issues/388#issuecomment-252417741
Anyway, just in case he really didn't know, the comment shortly below partly answers the question:
Since the common problem with concatenating JavaScript files is the lack of semicolons, automatically adding one (that, like Sam said, will then be removed by the minifier if it's unnecessary) seems on the surface to be a perfectly fine speed optimization.
This also alludes to the problem: https://github.com/rails/sprockets/issues/388#issuecomment-257312994
But the explicit answer/explanation to this question still remains unspoken: because if you don't add them between concatenated files -- as I discovered just to day -- you will run into this error:
(intermediate value)(...) is not a function
at something.source.js:1
, apparently because when it concatenated those 2 files together, it tried to evaluate it as:
({
// other.js
})()
(function() {
// something.js
})();
It makes sense that a ; is needed.
And no need to walk backwards through all these strings which is surprisingly inefficient in Ruby.
Since the common problem with concatenating JavaScript files is the lack of semicolons, automatically adding one (that, like Sam said, will then be removed by the minifier if it's unnecessary) seems on the surface to be a perfectly fine speed optimization.
reducing it down to one call significantly speeds up the operation.
I feel like the walk in string_end_with_semicolon? is unnecessarily expensive when having an extra semicolon doesn't invalidate any JavaScript syntax.
Possibly use Array.prototype.filter.call instead of allocating a new array.
Matrajt, Laura, Julia Eaton, Tiffany Leung, und Elizabeth R. Brown. „Vaccine Optimization for COVID-19: Who to Vaccinate First?“ Science Advances 7, Nr. 6 (1. Februar 2020): eabf1374. https://doi.org/10.1126/sciadv.abf1374.
If you manage to make Svelte aware of what needs to be tracked, chances are that the resulting code will be more performant than if you roll your own with events or whatever. In part because it will use Svelte's runtime code that is already present in your app, in part because Svelte produces seriously optimized change tracking code, that would be hard to hand code all while keeping it human friendly. And in part because your change tracking targets will be more narrow.
In this study, we have quantitated yields of low copy and single copy number plasmid DNAs after growth of cells in four widely used broths (SB, SOC, TB, and 2xYT) and compared results to those obtained with LB, the most common E. coli cell growth medium
TB (terrific broth) consistently generated the greatest amount of plasmid DNA, in agreement with its ability to produce higher cell titers. The superiority of TB was primarily due to its high levels of yeast extract (24 g/L) and was independent of glycerol, a unique component of this broth. Interestingly, simply preparing LB with similarly high levels of yeast extract (LB24 broth) resulted in plasmid yields that were equivalent to those of TB.
The template language's restrictions compared to JavaScript/JSX-built views are part of Svelte's performance story. It's able to optimize things ahead of time that are impossible with dynamic code because of the constraints. Here's a couple tweets from the author about that
GET is the primary mechanism of information retrieval and the focus of almost all performance optimizations.
It's fast. The Dart VM is highly optimized, and getting faster all the time (for the latest performance numbers, see perf.md). It's much faster than Ruby, and close to par with C++.
Note that when using sass (Dart Sass), synchronous compilation is twice as fast as asynchronous compilation by default, due to the overhead of asynchronous callbacks.
If you consider using asynchronous to be an optimization, then this could be surprising.
optcarrot, is a headless NES emulator that the Ruby core team are using as a CPU-intensive optimization target.
You might also want to check out the hyperxify browserify transform to statically compile hyperx into javascript expressions to save sending the hyperx parser down the wire.
JSX has the advantage of being fast, but the disadvantage that it needs to be preprocessed before working. By using template string virtual-html, we can have it work out of the box, and optimize it by writing a browserify transform. Best of both!
See also: https://github.com/choojs/nanohtml#static-optimizations
(this person later recommends this library)
Static optimizations
I understand that I could use some third party memoization tool on top of the Svelte’s comparator, but my point here is — there is no magic pill, optimizations “out of the box” often turn out to have limitations.
This is a very dangerous practice as each optimization means making assumptions. If you are compressing an image you make an assumption that some payload can be cut out without seriously affecting the quality, if you are adding a cache to your backend you assume that the API will return same results. A correct assumption allows you to spare resources. A false assumption introduces a bug in your app. That’s why optimizations should be done consciously.
In the vast majority of cases there’s nothing wrong about wasted renders. They take so little resources that it is simply undetectable for a human eye. In fact, comparing each component’s props to its previous props shallowly (I’m not even talking about deeply) can be more resource extensive then simply re-rendering the entire subtree.
While you could use a map function for loops they aren't optimized.
"Premature optimization is the root of all evil"; start with RPC as default and later switch to REST or GraphQL when (and only if!) the need arises.
Burda, Z., Kotwica, M., & Malarz, K. (2020). Ageing of complex networks. Physical Review E, 102(4), 042302. https://doi.org/10.1103/PhysRevE.102.042302
The more I think about this, the more I think that maybe React already has the right solution to this particular issue, and we're tying ourselves in knots trying to avoid unnecessary re-rendering. Basically, this JSX... <Foo {...a} b={1} {...c} d={2}/> ...translates to this JS: React.createElement(Foo, _extends({}, a, { b: 1 }, c, { d: 2 })); If we did the same thing (i.e. bail out of the optimisation allowed by knowing the attribute names ahead of time), our lives would get a lot simpler, and the performance characteristics would be pretty similar in all but somewhat contrived scenarios, I think. (It'll still be faster than React, anyway!)
Romanini, Daniele, Sune Lehmann, and Mikko Kivelä. ‘Privacy and Uniqueness of Neighborhoods in Social Networks’. ArXiv:2009.09973 [Physics], 21 September 2020. http://arxiv.org/abs/2009.09973.
By only adding the necessary handling when the function is declared async, the JavaScript engine can optimize your program for you.
The static analysis considerations make things like hero.enemies.map(...) a non-starter — the reason Svelte is able to beat most frameworks in benchmarks is that the compiler has a deep understanding of a component's structure, which becomes impossible when you allow constructs like that.
Landgrave, M. (2020). How Do Legislators Value Constituent’s (Statistical) Lives? COVID-19, Partisanship, and Value of a Statistical Life Analysis. https://doi.org/10.31235/osf.io/n93w2
Optimal Unemployment Benefits in the Pandemic. COVID-19 and the Labor Market. (n.d.). IZA – Institute of Labor Economics. Retrieved August 1, 2020, from https://covid-19.iza.org/publications/dp13389/
Martin, G., Hanna, E., & Dingwall, R. (2020). Face masks for the public during Covid-19: An appeal for caution in policy [Preprint]. SocArXiv. https://doi.org/10.31235/osf.io/uyzxe
In some frameworks you may see recommendations to avoid inline event handlers for performance reasons, particularly inside loops. That advice doesn't apply to Svelte — the compiler will always do the right thing, whichever form you choose.
Performance optimizations are not free. They ALWAYS come with a cost but do NOT always come with a benefit to offset that cost.
Even so, the inline function is still created on every render, useCallback() just skips it.
Even having useCallback() returning the same function instance, it doesn’t bring any benefits because the optimization costs more than not having the optimization.
Sperrin, M., Martin, G. P., Sisk, R., & Peek, N. (2020). Missing data should be handled differently for prediction than for description or causal explanation. Journal of Clinical Epidemiology, 0(0). https://doi.org/10.1016/j.jclinepi.2020.03.028
Ben-David, S. (2018). Clustering—What Both Theoreticians and Practitioners are Doing Wrong. ArXiv:1805.08838 [Cs, Stat]. http://arxiv.org/abs/1805.08838
Practical highlights in my opinion:
Here follows my own commands on trying the article points. I added - pg_column_size(row()) on each projection to have clear absolute sizes.
-- How does row function work?
SELECT pg_column_size(row()) AS empty,
pg_column_size(row(0::SMALLINT)) AS byte2,
pg_column_size(row(0::BIGINT)) AS byte8,
pg_column_size(row(0::SMALLINT, 0::BIGINT)) AS byte16,
pg_column_size(row(''::TEXT)) AS text0,
pg_column_size(row('hola'::TEXT)) AS text4,
0 AS term
;
-- My own take on that
SELECT pg_column_size(row()) AS empty,
pg_column_size(row(uuid_generate_v4())) AS uuid_type,
pg_column_size(row('hola mundo'::TEXT)) AS text_type,
pg_column_size(row(uuid_generate_v4(), 'hola mundo'::TEXT)) AS uuid_text_type,
pg_column_size(row('hola mundo'::TEXT, uuid_generate_v4())) AS text_uuid_type,
0 AS term
;
CREATE TABLE user_order (
is_shipped BOOLEAN NOT NULL DEFAULT false,
user_id BIGINT NOT NULL,
order_total NUMERIC NOT NULL,
order_dt TIMESTAMPTZ NOT NULL,
order_type SMALLINT NOT NULL,
ship_dt TIMESTAMPTZ,
item_ct INT NOT NULL,
ship_cost NUMERIC,
receive_dt TIMESTAMPTZ,
tracking_cd TEXT,
id BIGSERIAL PRIMARY KEY NOT NULL
);
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY a.attnum;
-- What is it about pg_class, pg_attribute and pg_type tables? For future investigation.
-- SELECT sum(t.typlen)
-- SELECT t.typlen
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY a.attnum
;
-- Whoa! I need to master mocking data directly into db.
INSERT INTO user_order (
is_shipped, user_id, order_total, order_dt, order_type,
ship_dt, item_ct, ship_cost, receive_dt, tracking_cd
)
SELECT true, 1000, 500.00, now() - INTERVAL '7 days',
3, now() - INTERVAL '5 days', 10, 4.99,
now() - INTERVAL '3 days', 'X5901324123479RROIENSTBKCV4'
FROM generate_series(1, 1000000);
-- New item to learn, pg_relation_size.
SELECT pg_relation_size('user_order') AS size_bytes,
pg_size_pretty(pg_relation_size('user_order')) AS size_pretty;
SELECT * FROM user_order LIMIT 1;
SELECT pg_column_size(row(0::NUMERIC)) - pg_column_size(row()) AS zero_num,
pg_column_size(row(1::NUMERIC)) - pg_column_size(row()) AS one_num,
pg_column_size(row(9.9::NUMERIC)) - pg_column_size(row()) AS nine_point_nine_num,
pg_column_size(row(1::INT2)) - pg_column_size(row()) AS int2,
pg_column_size(row(1::INT4)) - pg_column_size(row()) AS int4,
pg_column_size(row(1::INT2, 1::NUMERIC)) - pg_column_size(row()) AS int2_one_num,
pg_column_size(row(1::INT4, 1::NUMERIC)) - pg_column_size(row()) AS int4_one_num,
pg_column_size(row(1::NUMERIC, 1::INT4)) - pg_column_size(row()) AS one_num_int4,
0 AS term
;
SELECT pg_column_size(row(''::TEXT)) - pg_column_size(row()) AS empty_text,
pg_column_size(row('a'::TEXT)) - pg_column_size(row()) AS len1_text,
pg_column_size(row('abcd'::TEXT)) - pg_column_size(row()) AS len4_text,
pg_column_size(row('abcde'::TEXT)) - pg_column_size(row()) AS len5_text,
pg_column_size(row('abcdefgh'::TEXT)) - pg_column_size(row()) AS len8_text,
pg_column_size(row('abcdefghi'::TEXT)) - pg_column_size(row()) AS len9_text,
0 AS term
;
SELECT pg_column_size(row(''::TEXT, 1::INT4)) - pg_column_size(row()) AS empty_text_int4,
pg_column_size(row('a'::TEXT, 1::INT4)) - pg_column_size(row()) AS len1_text_int4,
pg_column_size(row('abcd'::TEXT, 1::INT4)) - pg_column_size(row()) AS len4_text_int4,
pg_column_size(row('abcde'::TEXT, 1::INT4)) - pg_column_size(row()) AS len5_text_int4,
pg_column_size(row('abcdefgh'::TEXT, 1::INT4)) - pg_column_size(row()) AS len8_text_int4,
pg_column_size(row('abcdefghi'::TEXT, 1::INT4)) - pg_column_size(row()) AS len9_text_int4,
0 AS term
;
SELECT pg_column_size(row(1::INT4, ''::TEXT)) - pg_column_size(row()) AS int4_empty_text,
pg_column_size(row(1::INT4, 'a'::TEXT)) - pg_column_size(row()) AS int4_len1_text,
pg_column_size(row(1::INT4, 'abcd'::TEXT)) - pg_column_size(row()) AS int4_len4_text,
pg_column_size(row(1::INT4, 'abcde'::TEXT)) - pg_column_size(row()) AS int4_len5_text,
pg_column_size(row(1::INT4, 'abcdefgh'::TEXT)) - pg_column_size(row()) AS int4_len8_text,
pg_column_size(row(1::INT4, 'abcdefghi'::TEXT)) - pg_column_size(row()) AS int4_len9_text,
0 AS term
;
SELECT pg_column_size(row()) - pg_column_size(row()) AS empty_row,
pg_column_size(row(''::TEXT)) - pg_column_size(row()) AS no_text,
pg_column_size(row('a'::TEXT)) - pg_column_size(row()) AS min_text,
pg_column_size(row(1::INT4, 'a'::TEXT)) - pg_column_size(row()) AS two_col,
pg_column_size(row('a'::TEXT, 1::INT4)) - pg_column_size(row()) AS round4;
SELECT pg_column_size(row()) - pg_column_size(row()) AS empty_row,
pg_column_size(row(1::SMALLINT)) - pg_column_size(row()) AS int2,
pg_column_size(row(1::INT)) - pg_column_size(row()) AS int4,
pg_column_size(row(1::BIGINT)) - pg_column_size(row()) AS int8,
pg_column_size(row(1::SMALLINT, 1::BIGINT)) - pg_column_size(row()) AS padded,
pg_column_size(row(1::INT, 1::INT, 1::BIGINT)) - pg_column_size(row()) AS not_padded;
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY t.typlen DESC;
DROP TABLE user_order;
CREATE TABLE user_order (
id BIGSERIAL PRIMARY KEY NOT NULL,
user_id BIGINT NOT NULL,
order_dt TIMESTAMPTZ NOT NULL,
ship_dt TIMESTAMPTZ,
receive_dt TIMESTAMPTZ,
item_ct INT NOT NULL,
order_type SMALLINT NOT NULL,
is_shipped BOOLEAN NOT NULL DEFAULT false,
order_total NUMERIC NOT NULL,
ship_cost NUMERIC,
tracking_cd TEXT
);
-- And, what about other varying size types as JSONB?
SELECT pg_column_size(row('{}'::JSONB)) - pg_column_size(row()) AS empty_jsonb,
pg_column_size(row('{}'::JSONB, 0::INT4)) - pg_column_size(row()) AS empty_jsonb_int4,
pg_column_size(row(0::INT4, '{}'::JSONB)) - pg_column_size(row()) AS int4_empty_jsonb,
pg_column_size(row('{"a": 1}'::JSONB)) - pg_column_size(row()) AS basic_jsonb,
pg_column_size(row('{"a": 1}'::JSONB, 0::INT4)) - pg_column_size(row()) AS basic_jsonb_int4,
pg_column_size(row(0::INT4, '{"a": 1}'::JSONB)) - pg_column_size(row()) AS int4_basic_jsonb,
0 AS term;
Optimization Models for Machine Learning: A Survey
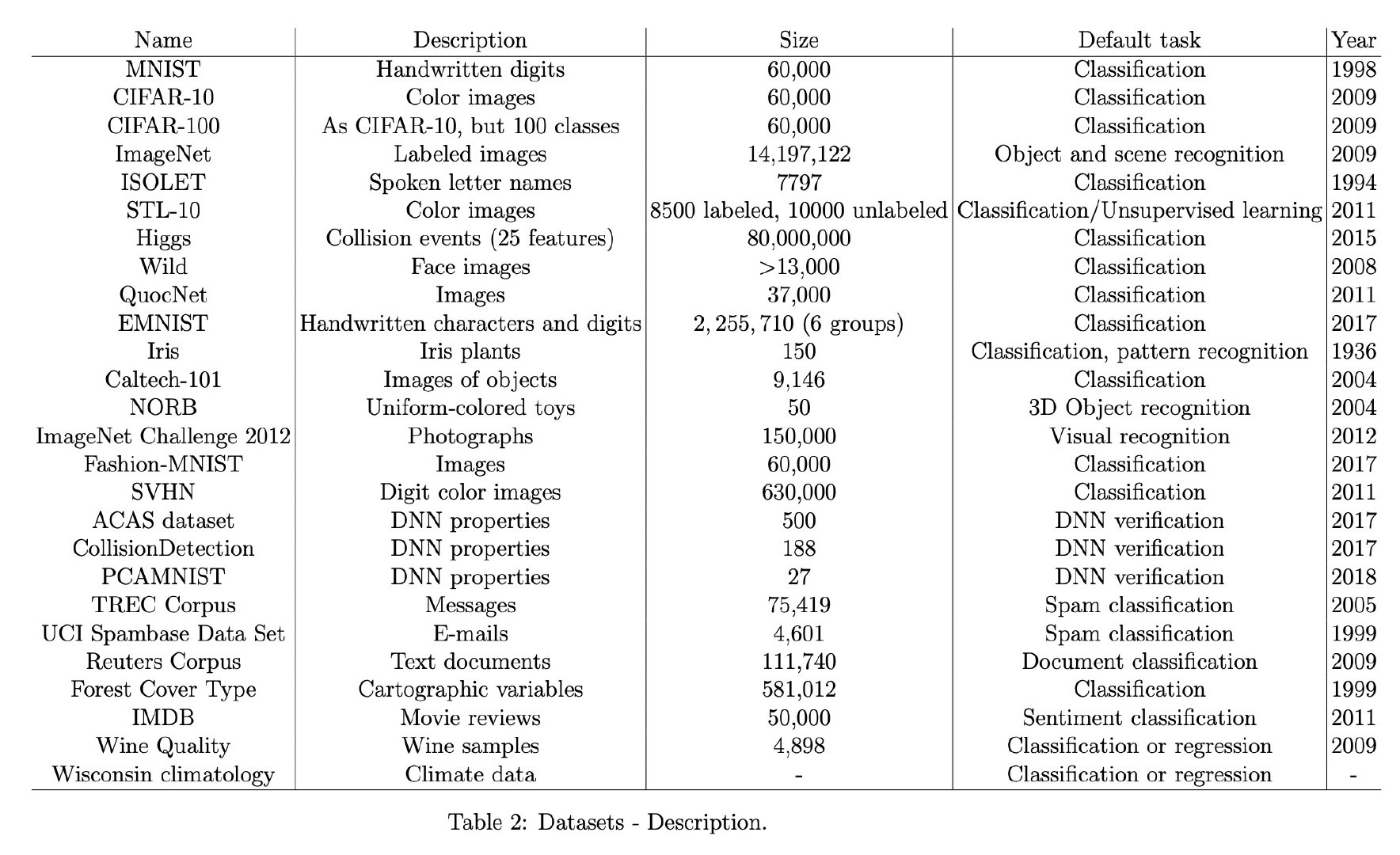
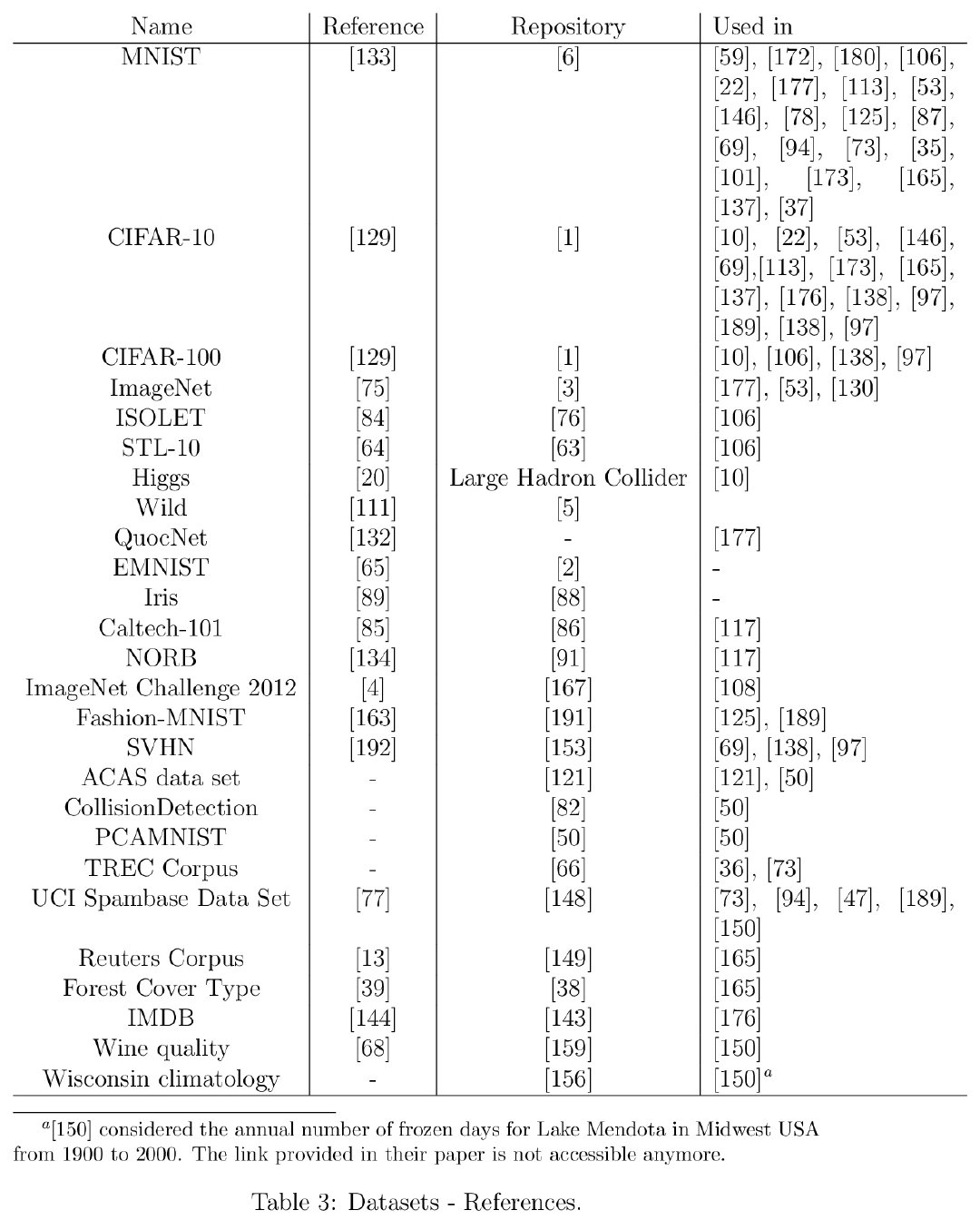
感觉此文于我而言真正有价值的恐怕只有文末附录的 Dataset tables 汇总整理了。。。。。
Learning with Random Learning Rates
作者提出了一种新的Alrao优化算法,让网络中每个 unit 或 feature 都各自从不同级别的随机分布中采样获得其自己的学习率。该算法没有额外计算损耗,可以更快速达到理想 lr 下的SGD性能,用来测试 DL 模型很棒!
On the loss landscape of a class of deep neural networks with no bad local valleys
文章声称的全局最小训练,事实上主要基于一个比较特殊的人工神经网络的结构,用了各种连接到 output 的 skip connection,还有几个额外的assumptions 作为理论保证。
Revisiting Small Batch Training for Deep Neural Networks
这篇文章简而言之就是mini-batch sizes取得尽可能小一些可能比较好。自己瞅了一眼正在写的 paper,这不禁让我小肝微微一颤,心想:还是下次再把 batch-size 取得小一点吧。。。[挖鼻]
Don't Use Large Mini-Batches, Use Local SGD
最近(2018/8)在听数学与系统科学的非凸最优化进展时候,李博士就讲过:现在其实不太欣赏变 learning rate 了,反而逐步从 SGD 到 MGD 再到 GD 的方式,提高 batch-size 会有更好的优化效果!
Accelerating Natural Gradient with Higher-Order Invariance
每次看到研究梯度优化理论的 paper,都感觉到无比的神奇!厉害到爆表。。。。
Backprop Evolution
这似乎是说反向传播的算法,在函数结构本身上,就还有很大的优化空间。作者在一些初等函数和常见矩阵操作基础上探索了一些操作搭配,发现效能轻易的就优于传统的反向传播算法。
不禁启发:我们为什么不能也用网络去拟合优化梯度更新函数呢?
Gradient Descent Finds Global Minima of Deep Neural Networks
全篇的数学理论证明:深度过参网络可以训练到0。(仅 train loss,非 test loss)+(GD,非 SGD)
A Convergence Theory for Deep Learning via Over-Parameterization
又一个全篇的数学理论证明,但是没找到 conclusion 到底是啥,唯一接近的是 remark 的信息,但内容也都并不惊奇。不过倒是一个不错的材料,若作为熟悉DNN背后的数学描述的话。
edge probes
It seems that the edge probe is a special case of the value probe.
For example, stochastic quasi-gradient algorithms [3] can be used forthe minimization of function (1).
@article{ben2002robust, title={Robust optimization--methodology and applications}, author={Ben-Tal, Aharon and Nemirovski, Arkadi}, journal={Mathematical Programming}, volume={92}, number={3}, pages={453--480}, year={2002}, publisher={Springer} }
While there are assets that have not been assigned to a cluster If only one asset remaining then Add a new cluster Only member is the remaining asset Else Find the asset with the Highest Average Correlation (HC) to all assets not yet been assigned to a Cluster Find the asset with the Lowest Average Correlation (LC) to all assets not yet assigned to a Cluster If Correlation between HC and LC > Threshold Add a new Cluster made of HC and LC Add to Cluster all other assets that have yet been assigned to a Cluster and have an Average Correlation to HC and LC > Threshold Else Add a Cluster made of HC Add to Cluster all other assets that have yet been assigned to a Cluster and have a Correlation to HC > Threshold Add a Cluster made of LC Add to Cluster all other assets that have yet been assigned to a Cluster and have Correlation to LC > Threshold End if End if End While
Fast Threshold Clustering Algorithm
Looking for equivalent source code to apply in smart content delivery and wireless network optimisation such as Ant Mesh via @KirkDBorne's status https://twitter.com/KirkDBorne/status/479216775410626560 http://cssanalytics.wordpress.com/2013/11/26/fast-threshold-clustering-algorithm-ftca/
Effect of step size. The gradient tells us the direction in which the function has the steepest rate of increase, but it does not tell us how far along this direction we should step.
That's the reason why step size is an important factor in optimization algorithm. Too small step can cause the algorithm longer to converge. Too large step can cause that we change the parameters too much thus overstepped the optima.
There are other ways of performing the optimization (e.g. LBFGS), but Gradient Descent is currently by far the most common and established way of optimizing Neural Network loss functions.
Are there any studies that compare different pros and cons of the optimization procedures with respect to some specific NN architectures (e.g., classical LeNets)?
