The card systemis a " one-place " system.
How does the "one-place" system work with respect to the idea of "multiple storage"?
What about cross-indexing?
The card systemis a " one-place " system.
How does the "one-place" system work with respect to the idea of "multiple storage"?
What about cross-indexing?
This optimization reduced 'write amplification'—the ratio of data written to storage versus the original request—by 20%. It also provided insights for new compiler optimization strategies that reduced the storage footprint of software by nearly 9%.
除了20%的写入放大减少,AlphaEvolve还通过新的编译器优化策略将软件存储占用减少了近9%。这表明该系统在多个层面优化基础设施的能力,从硬件到软件栈都带来了显著效率提升。
reduced 'write amplification'—the ratio of data written to storage versus the original request—by 20%
20%的写入放大减少表明AlphaEvolve在存储系统优化方面的显著贡献。这直接转化为存储效率提升和成本降低,对于处理大规模数据的Google Spanner系统而言,这是一个重要的性能改进。
Battery storage was the fastest-growing power technology, with around 110 gigawatts (GW) of new capacity added – more than any year of natural gas capacity additions on record.
大多数人认为储能技术仍处于早期发展阶段,但作者认为电池储能已经成为增长最快的电力技术,其新增容量超过了历史上任何一年的天然气装机容量,这表明能源存储正在经历爆发式增长。
The inbox becomes the agent's memory, without needing a separate database or vector store.
大多数人认为AI代理需要专门的数据库或向量存储来维护状态和记忆,但作者提出一个颠覆性观点:电子邮件收件箱本身可以作为代理的内存系统,这挑战了构建AI代理时需要复杂后端存储的行业共识,暗示电子邮件可能是一种未被充分利用的状态管理工具。
An example: for a hydrogen peaking power plant in Germany running 200 hours a year, the capped network capacity charge for withdrawing from the planned Kernnetz pipeline network of 25 EUR/(kWh/h-peak)/a [BNetzA, 2025] works out at 25 EUR/kW/a / 200 h/a = 125 EUR/MWh ~ 4 EUR/kg. Add this to a production cost near Germany of 120 EUR/MWh and a storage charge of 120 EUR/MWh [EWI, 2024], and you are quickly at 360 EUR/MWh for the fuel alone.
Wow, storage and transport is two thirds of the cost of h2 for backup power? I had no idea it was such a big share of costs
"Use Work-Organizers" advertisement, Bookseller & Stationer and Office Equipment Journal, Toronto, October 1920, Vol XXXVI, No. 10, p70.
Photo of a work organizer for indexing/filing on both a desktop as well as within the desk drawer.
Flash storage is prone to failure if power is cut while writing or modifying stored data. Basically because an SD card or SSD is a tiny computer that writes files and updates its map of file locations. If this is interrupted, bad things result. When this happens to storage-only, you can repair the file system and usually come away ok. When it happens to the boot drive, the system can be un-bootable. Also other failures can suddenly cause SD card failure, but the most common is power interruption during file writes. The system drive is frequently updated for normal operating system tasks, making a power loss event more like russian roulette for data loss. Tl;dr you may wish to have a periodic task and a separate flash drive whose only role is to sit idle, then get a copy of any files changed recently. Rsync is a great tool to do so in the Linux/raspberry pi world. This way the really expensive part of your work is preserved, even if your system's SD card fails.
How to display Typewriters properly?
You can certainly keep them out on shelves and rely on occasional dusting.
If they're in a dustier-than-typical room or you have compounding factors, like the presence of cats or dogs (like my German Shedder, I meant German Shepherd), and don't want to go the route of traditional fabric-like dust covers, you might consider doing a thicker plastic/acrylic cover which will give you a clear plastic layer of protection, but still show off your machines.
I live in Los Angeles and there are half a dozen places that do this sort of custom plastic work all the time for very reasonable rates. Searching for "plastic fabricator memorabilia case" along with variations of plastics (acrylic, lucite, plexiglass) should get you what you want locally. (Here's a few examples I've used in Los Angeles before to give you an idea: https://solterplastics.com/, https://www.plasticfactoryinc.com/, https://www.customacrylicproducts.com/, https://plexidisplays.com/). Search for something similar in your area for easier communication and cheaper pick up/shipping.
If you search around for companies that make plastic displays, particularly for memorabilia (baseball bats, baseball cards, etc.), you can have them design and make a custom sized clear plastic box/enclosure that will keep the dust and dirt out, but still allow you to see the machine inside. If done well it may actually make them appear more precious because you've taken the additional precaution.
Enclosed glass shelving is also a potential solution as well, but requires a larger investment and also requires more work to rotate machines out for regular use.
Most of my machines get daily use, so I'm not really using them for display or presentation purposes (except for one machine which sits on our library card catalog, but even then, it is frequently used as a standing desk, for occasional poetry by everyone in the family, or for guests who want to try their hand). I go through lots of index cards, so I'll usually temporarily protect against dust, dirt, and fur by slipping an index card on top of the hood or slightly into it to protect the segment.
But at the end of the day, as long as you haven't used WD-40 or some other lubricant on your segment and typebars (and what typewriter monster would do such barbaric things?), you should easily be able to go long periods between dustings and still have a highly functional machine. After all, who hasn't bought a machine full of dirt, dust, White Out, and eraser shavings/crumbs that still works like a dream?
It may bear brief mention for those who display their machines and forget, that you might also disengage the paper lock/paper release lever which will release the tension on your rubber rollers against the platen so that they don't go "flat" or become misshapen when not in use for long periods.
Expansion of https://hypothes.is/a/NjoVMA1REe-f47d0T4ZOkg
Reply to u/Styr0foam at https://www.reddit.com/r/typewriters/comments/1djgjv2/how_to_display_typewriters_properly/
Eine Studie zeigt, dass das Kraftwerk Drax in North Yorkshire trotz Carbon Capture and Storage (CCS) bis in die 2050er Jahre die CO₂-Emissionen erhöhen wird. Die intensive Waldnutzung zur Gewinnung von Holzpellets in den USA reduziert die Kohlenstoffspeicher in Wäldern für mindestens 25 Jahre. Selbst mit CCS-Technologie bleiben die Emissionen über Jahrzehnte hoch, was die Klimakrise verschärft. Kritiker bezweifeln Drax' Behauptung, "klimaneutral" zu sein, und fordern eine Neubewertung der staatlichen Unterstützung für Biomasse-Energie. [Zusammenfassung generiert mit Mistral] https://www.theguardian.com/business/2024/nov/04/drax-will-keep-raising-carbon-emission-levels-until-2050s-study-says
Die Studie des Potsdam-Instituts für Klimafolgenforschung zeigt, dass Bioenergy with Carbon Capture and Storage (BECCS) theoretisch bis 2050 jährlich 7,5 Milliarden Tonnen CO₂ entfernen könnte. Allerdings würde dies die planetaren Belastungsgrenzen stark überschreiten, insbesondere in Bezug auf Stickstoffeintrag, Süßwasserverbrauch, Entwaldung und Biosphärenintegrität. Unter Berücksichtigung dieser Grenzen reduziert sich das Potenzial auf nur 200 Millionen Tonnen CO₂ jährlich. Die Studie betont die Notwendigkeit, neben der CO₂-Bilanz auch andere ökologische Faktoren zu berücksichtigen und schlägt vor, durch weniger Fleischkonsum Flächen für Klimaplantagen freizumachen. [Zusammenfassung generiert mit Mistral]
https://www.derstandard.at/story/3000000257365/kein-platz-fuer-klimaplantagen
He displayed antique typewriters in his small apartment and tucked the ugly ones in closets.
this is a graph showing the average connection speed uh of the G7 countries and this is from 2007 to 2012 and the average connection speed hasn't increased as much as other things like processing power or or storage
for - stats - internet - average connection speed - hasn't increased as much as storage and processing power
TRSP Desirable Characteristics The repository applies documented processes to ensure data and metadata storage and integrity.
for - progress trap - reducing nitrogen air pollution - reduces soil carbon storage
Relaxo uses the git persistent data structure for storing documents. This data structure exposes a file-system like interface, which stores any kind of data.
Third year in a row that power storage capacity has doubled in Europe. The graph suggests that doubling will not continue, but was more a function of the low level of storage previously. Germany is a leading actor in storage.
Overview of the rapidly reducing prices for power storage. At scale the price wil drop below 100USD/KWh by 2025.
https://web.archive.org/web/20240531083407/https://www.euronews.com/green/2024/02/06/this-disused-mine-in-finland-is-being-turned-into-a-gravity-battery-to-store-renewable-ene publ #2024/02/06 A deep mineshaft to be used in Finland for gravity-storage of green energy. The mine is 1400m deep and a 530m shaft would be used. 2MW means about 1 windmill's capacity in storage. I think the deepest Dutch mine was 1100m (Hendrik mijn, Heerlen), but don't know about shaft length, and if that still exists.
"I made a great study of theology at one time," said Mr Brooke, as if to explain the insight just manifested. "I know something of all schools. I knewWilberforce in his best days.6Do you know Wilberforce?"Mr Casaubon said, "No.""Well, Wilberforce was perhaps not enough of a thinker; but if I went intoParliament, as I have been asked to do, I should sit on the independent bench,as Wilberforce did, and work at philanthropy."Mr Casaubon bowed, and observed that it was a wide field."Yes," said Mr Brooke, with an easy smile, "but I have documents. I began along while ago to collect documents. They want arranging, but when a question has struck me, I have written to somebody and got an answer. I have documents at my back. But now, how do you arrange your documents?""In pigeon-holes partly," said Mr Casaubon, with rather a startled air of effort."Ah, pigeon-holes will not do. I have tried pigeon-holes, but everything getsmixed in pigeon-holes: I never know whether a paper is in A or Z.""I wish you would let me sort your papers for you, uncle," said Dorothea. "Iwould letter them all, and then make a list of subjects under each letter."Mr Casaubon gravely smiled approval, and said to Mr Brooke, "You have anexcellent secretary at hand, you perceive.""No, no," said Mr Brooke, shaking his head; "I cannot let young ladies meddle with my documents. Young ladies are too flighty."Dorothea felt hurt. Mr Casaubon would think that her uncle had some special reason for delivering this opinion, whereas the remark lay in his mind aslightly as the broken wing of an insect among all the other fragments there, anda chance current had sent it alighting on her.When the two girls were in the drawing-room alone, Celia said —"How very ugly Mr Casaubon is!""Celia! He is one of the most distinguished-looking men I ever saw. He is remarkably like the portrait of Locke. He has the same deep eye-sockets."
Fascinating that within a section or prose about indexing within MiddleMarch (set in 1829 to 1832 and published in 1871-1872), George Eliot compares a character's distinguished appearance to that of John Locke!
Mr. Brooke asks for advice about arranging notes as he has tried pigeon holes but has the common issue of multiple storage and can't remember under which letter he's filed his particular note. Mr. Casaubon indicates that he uses pigeon-holes.
Dorothea Brooke mentions that she knows how to properly index papers so that they might be searched for and found later. She is likely aware of John Locke's indexing method from 1685 (or in English in 1706) and in the same scene compares Mr. Casaubon's appearance to Locke.
viable sources of backups had been identified that wereunaffected by the cyber-attack and from which the Library’s digital and digitised collections,collection metadata and other corporate data could be recovered
I suddenly have a new respect for write-once-read-many (WORM) block storage like AWS’ Object Lock: https://aws.amazon.com/blogs/storage/protecting-data-with-amazon-s3-object-lock/
reply to oxytonic on 2023-01-08 at https://hypothes.is/a/8QdgetQOEe2XG6u5i9iAHQ
In my experience, alternating alphanumeric codes give you the "gist" of the original context. Purely with reference to my rough outline, my notecard "3516/b" implies psychology (3XXX), cognition (35XX), and memory (351X). Even the single slash implies a level of abstraction and/or specificity.
But it's not enough because it runs the risk of locking you in. Forward links on the card (or forward links to the card!) offer comparable if not competitive recontextualization, which is most likely what Luhmann means by "multiple storage".
Caution: My note here has some significant missing context which results from significant additional research.
The primary issue with analog slip boxes, particularly in academic research of Luhmann's day, was one of multiple storage. No one else I'm aware of prior to his time used Luhmann's filing scheme (and very few after until about 2013). Instead most filed multiple copies of their notes under category headings like "psychology", "cognition", and "memory" (to use your example) so that those ideas would be readily available when they came to work on their ideas relating to cognition, for example. This involved a tremendous amount of copying work. (For reference, see Heyde, Johannes Erich. Technik des wissenschaftlichen Arbeitens: zeitgemässe Mittel und Verfahrungsweisen. Junker und Dünnhaupt, 1931. which is the handbook which Luhmann used to scaffold his method.) It was this copying and filing under multiple categories which was commonly referred to as multiple storage. Many academics got around it by hiring assistants or secretaries who would do this duplicative work and filing on their behalf; Luhmann didn't have this additional help and it may have been a portion of the pressure for the evolution of his method.
Instead Luhmann used branching and cross-indexing his ideas along with regular use and familiarity of the space within his boxes. While his zettelkasten may seem on the surface to be done by category, the way you suggest, it definitely is not. Some of this appearance is suggested by editorial decisions made by the curators of his digital archive and, in larger part, by Scott Scheper who (sadly in my opinion) recommends using the Academic Outline of Disciplines as top level categories a practice which heavily belies some of what Luhmann was doing. While Luhmann was inspired by the Dewey Decimal System, he wasn't using the parts of it that equated numbers with topics, in part because he didn't need to and it would have been counterproductive to his ultimate method—specifically causing him to deal with multiple storage. Modern (digital) database theory and practice allows some note takers an easier way around this problem.
For more on this see: - https://boffosocko.com/2022/10/27/thoughts-on-zettelkasten-numbering-systems/ - https://boffosocko.com/2023/01/19/on-the-interdisciplinarity-of-zettelkasten-card-numbering-topical-headings-and-indices/
According to the International Hydropower Association, or IHA, a facility with two reservoirs roughly the size of two Olympic swimming pools, and a 500-metre height difference between them, would have an energy capacity of about three and a half megawatt hours. And they last for decades,
The ANU found more than six hundred thousand potential sites around the world where closed loop pumped hydro systems could work, 00:07:29 at least from a geographical and topographical point of view anyway, representing a potential of about twenty-three million gigawatt hours of energy storage, which would be about a hundred times what we’d need for a one hundred percent renewable powered global electricity system. Now, obviously not all of those sites will turn out to be appropriate, so we need to keep our feet well and true planted on the ground here. The ANU itself points out that, apart from discounting any 00:07:56 urban areas and known areas of environmentally protected zones, no other comprehensive geological, hydrological, environmental, or heritage studies were carried out as part of their research project, so it’s highly likely that only a relatively small percentage will prove to be viable. But, even if it’s only one percent, that still gets us over the line, doesn’t it?
As a rough rule of thumb, based on analysis in Australia, to achieve a one hundred percent 00:08:21 renewable electricity grid, you need about one gigawatt of power for every one million people, plus probably twenty hours of energy storage to give yourself plenty of leeway from the five hours minimum number in the recent studies I mentioned earlier. So that’s twenty gigawatt hours of energy storage per million people in a well-connected high-energy-use country like Aus, with good wind and solar resources. That equates to a total Australian requirement of about 00:08:46 five hundred gigawatt hours in a country that has storage potential about three hundred times
the National Renewable Energy Laboratory, or NREL used well established Geographic Information Systems, or GIS, to assess potential new closed-loop pumped storage hydropower, or PSH, systems across ALL the states, including Alaska and Hawaii, as well as Puerto Rico. That analysis turned up no fewer than fourteen-thousand-eight-hundred-and-forty-six 00:04:51 potential sites with a combined storage capacity of three-point five terawatts that could be discharged over a ten-hour period, providing some thirty-five terawatt-HOURS of energy into the various American grid networks.
Physical vs Digital Note Systems
There's a lot of useful detail hiding in this 15 minutes as an overview, but nothing new/interesting for me.
I will say that he completely misses a lot of the subtleties of indexing and multiple storage within the analog space, but it's likely because he's not done it personally or doesn't have enough experience there.
I take a lot of notes during my day job. More like a huge amount of notes. On paper. As an experiment I started using several Dingbats* notebooks during the day job to see how they would work4 for me. After about 9 weeks of trials, I learned that I could fill up a 180 page notebook in about 3 weeks, plus or minus a few days. Unfortunately, when you factor in the cost of these notebooks, that’s like spending $1 - $2 per day on notebooks. Dingbats* are lovely, durable notebooks. But my work notes are not going to be enshrined in a museum for the ages5 and until I finally get that sponsorship from Dingbats* or Leuchtuurm19176, I probably need a different solution.
Mark Dykeman indicates that at regular work, he fills up a 180 page notebook and at the relatively steep cost of notebooks, he's paying $1-2 a day for paper.
This naturally brings up the idea of what it might cost per day in index cards for some zettlers' practices. I've already got some notes on price of storage...
As a rough calculation, despite most of my note taking being done digitally, I'm going through a pack of 500 Oxford cards at $12.87 every 5 months at my current pace. This is $0.02574 per card and 5 months is roughly 150 days. My current card cost per day is: $0.02574/card * 500 cards / (150 days) = $12.78/150 days = $0.0858 per day which is far better than $2/day.
Though if I had an all-physical card habit, I would be using quite a bit more.
On July 3, 2022 I was at 10,099 annotations and today May 11, 2023 I'm at 15,259 annotations. At one annotation per card that's 5,160 cards in the span of 312 days giving me a cost of $0.02574/card * 5,160 cards / 312 days = $0.421 per day or an average of $153.75 per year averaging 6,036 cards per year.
(Note that this doesn't also include the average of three physical cards a day I'm using in addition, so the total would be slightly higher.)
Index cards are thus, quite a bit cheaper a habit than fine stationery notebooks.
For $1,900.00 ?
reply to rogerscrafford at tk
Fine furniture comes at a fine price. 🗃️🤩 I suspect that it won't sell for quite a while and one could potentially make an offer at a fraction of that to take it off their hands. It might bear considering that if one had a practice large enough to fill half or more, then that price probably wouldn't seem too steep for the long term security and value of the contents.
On a price per card of storage for some of the cheaper cardboard or metal boxes you're going to pay about $0.02-0.03 per card, but you'd need about 14 of those to equal this and those aren't always easy to stack and access regularly. With this, even at the full $1,900, you're looking at storage costs of $0.10/card, but you've got a lot more ease of use which will save you a lot of time and headache as more than adequate compensation, particularly if you're regularly using the approximately 20,400 index cards it would hold. Not everyone has the same esthetic, but I suspect that most would find that this will look a lot nicer in your office than 14 cheap cardboard boxes. That many index cards even at discount rates are going to cost you about $825 just in cards much less beautiful, convenient, and highly usable storage.
Even for some of the more prolific zettelkasten users, this sort of storage is about 20 years of use and if you compare it with $96/year for Notion or $130/year for Evernote, you're probably on par for cost either way, but at least with the wooden option, you don't have to worry about your note storage provider going out of business a few years down the line. Even if you go the "free" Obsidian route, with computers/storage/backups over time, you're probably not going to come out ahead in the long run. It's not all apples to apples comparison and there are differences in some of the affordances, but on balance and put into some perspective, it's probably not the steep investment it may seem.
And as an added bonus, while you're slowly filling up drawers, as a writer you might appreciate the slowly decreasing wine/whiskey bottle storage over time? A 5 x 8 drawer ought to fit three bottles of wine or as many fifths of Scotch. It'll definitely accommodate a couple of magnums of Jack Daniels. 🥃🍸🍷My experience also tells me that an old fashioned glass can make a convenient following block in card index boxes.

Auch die Korrektur einer Textstelle ist in der Datenbank sofort global wirksam. Im Zettelarchiv dagegen ist es kaum zu leisten, alle alphabetisch einsortierten Kopien eines bestimmten Zettels zur Korrektur wieder aufzufinden.
Correcting a text within a digital archive or database allows the change to propagate to all portions of the collection compared with a physical card index which has the hurdle of multiple storage and requires manual changes on all of the associated copies.
This sort of affordance can be seen in more modern note taking tools like Obsidian which does this sort of work with global search and replace of double bracketed words which change everywhere in the collection.
Die so angelegten Zettel wurden lithographisch jeweils 40mal kopiert. Sodann wurde für jedes auf dem Zettel verzeichnete ägyptische Wort eine solche Kopie herangezogen, das jeweilige Wort in der Textabschrift rot unterstrichen, und die Lautfolge des Wortes, wie man sie damals zu kennen glaubte, in der gebräuchlichen ägyptologischen Umschrift in der rechten oberen Ecke des Zettels notiert. Die so vorbereiteten Zettel wurden dann alphabetisch und unter Trennung der Homonyme nach Wörtern in eigens für das Wör terbuch angefertigte Zettelkästen einsortiert. Dabei wurden von vornherein bestimmte Sondergruppen, die für das Wörterbuch selbst nur von begrenztem Interesse waren, neben dem lexikalischen Hauptalphabet separat gestellt, so vor allem die Namen von Personen, Königen, Göttern und Orten. Aus diesen Nebenprodukten der Verzettelung entstand z.B. Hermann Rankes maßgebliches Lexikon der ägyptischen Personennamen.
Once made, the initial note excerpts were copied 40 times using a lithography process. Then each word in the original slip was underlined in red on respective copies to be filed away alphabetically. At the top right corner of each slip was written down the phonetic sound of the rubricated word's Egyptian transcription. Within the collection certain special words were also separated for the names of people, kings, gods, and places to allow for additional study.
Talk about a problem of multiple storage!!
9/8b2 "Multiple storage" als Notwendigkeit derSpeicherung von komplexen (komplex auszu-wertenden) Informationen.
Seems like from a historical perspective hierarchical databases were more prevalent in the 1960s and relational databases didn't exist until the 1970s. (check references for this historically)
Of course one must consider that within a card index or zettelkasten the ideas of both could have co-existed in essence even if they weren't named as such. Some of the business use cases as early as 1903 (earlier?) would have shown the idea of multiple storage and relational database usage. Beatrice Webb's usage of her notes in a database-like way may have indicated this as well.
9/8b2 "Multiple storage" als Notwendigkeit derSpeicherung von komplexen (komplex auszu-wertenden) Informationen.
9/8b2 "Multiple storage" as a necessity of<br /> storage of complex (complex<br /> evaluating) information.
Fascinating to see the English phrase "multiple storage" pop up in Luhmann's ZKII section on Zettelkasten.
This note is undated, though being in ZKII likely occurred more than a decade after he'd started his practice. One must wonder where he pulled the source for the English phrase rather than using a German one? Does the idea appear in Heyde? It certainly would have been an emerging question within systems theory and potentially computer science ideas which Luhmann would have had access to.
I started capturing everything directly in Obsidian but it has two major drawbacks. The first is that I will inevitably end up taking a lot of fleeting notes that I don't want to be included in the literature note. By taking the fleeting notes and highlights in Zotero, and then exporting a copy to Obsidian, I have the piece of mind that much raw material (that I might possibly need one day) is in Zotero, but that a more polished and reduced version is in my literature notes. The clutter stays in Zotero, in other words, while Obsidian is the home of the more processed notes.
Keeping one's fleeting notes separate from their permanent notes can be useful for managing the idea of clutter.
Luhmann generally did this by keeping things in different boxes. Modern academics may use different digital applications (Zotero/Obsidian, Hypothes.is/Zettlr, etc.as examples) for each as long as there is some reasonable dovetail between the two for data transfer when necessary.
If you want one final piece of (unsolicited) advice: if you bulk-import those Kindle highlights, please do not try to create literature Zettels out of everything. I did it and I DO NOT RECOMMEND. It was just too much work to rehash stuff that I had already (kind of) assimilated. Reserve that energy to write permanent notes (you probably know much more than you give yourself credit for) and just use the search function (or [^^]) to search for relevant quotes or notes. Only key and new papers/chapters you could (and should, I think) take literature notes on. Keep it fun!
Most veteran note takers will advise against importing old notes into a new digital space for the extra amount of administrative overhead and refactoring it can create.
Often old notes may be: - well assimilated into your memory already - poorly sourced or require lots of work and refactoring to use or reuse them - become a time suck trying to make them "perfect"
Better advice is potentially pull them into your system in a different spot so they're searchable and potentially linkable/usable as you need them. If this seems like excessive work, and it very well may be, then just pull in individual notes as you need or remember them.
With any luck the old notes are easily searchable/findable in whichever old system they happen to be in, so they're still accessible.
I'll note here the conflicting definitions of multiple storage in my tags to mean: - storing a single note under multiple subject headings or index terms - storing notes in various different (uncentralized locations), so having multiple different zettelkasten at home/office, storing some notes in social media locations, in various notebooks, etc. This means you have to search across multiple different interfaces to find the thing you're looking at.
I should create a new term to distinguish these two, but for now they're reasonably different within their own contexts that it's not a big problem unless one or the other scales.
Related here is the horcrux problem of note taking or even social media. The mental friction of where did I put that thing? As a result, it's best to put it all in one place.
How can you build on a single foundation if you're in multiple locations? The primary (only?) benefit of multiple locations is redundancy in case of loss.
Ryan Holiday and Robert Greene are counter examples, though Greene's books are distinct projects generally while Holiday's work has a lot of overlap.
Should You Have One Zettelkasten or Many?<br /> by Christian Tietze
“multiple storage”
Within the history of personal knowledge management, one was often faced with where to store their notes so that it would be easy to find and use them again. Often this was done using slip methods by means of "multiple storage" by making multiple copies and filing them under various headings. This copying process was onerous and breaks the modern database principle "don't repeat yourself" (DRY).
Alternate means of doing this include storing it in one place and then linking that location to multiple subject headings in an index, though this may cause issues of remembering which subject heading when there are many appropriate potential synonyms.
Modern digital methods allow one to store a note in one location and refer to it in multiple ways electronically as well as with aliases.
With a category you can just bypass idea-connection and jump right to storage.
Categorizing ideas (and or indexing them for search) can be useful for quick bulk storage, but the additional work of linking ideas to each other with in a Luhmann-esque zettelkasten can be more useful in the long term in developing ideas.
Storage by category means that ideas aren't immediately developed explicitly, but it means that that work is pushed until some later time at which the connections must be made to turn them into longer works (articles, papers, essays, books, etc.)
Rekentool warmtepotentie waterzuiveringsinstallaties
Aquathermie Rekentool
Energy Storage Cost and Performance Database
Energy Storage Cost and Performance Database. U.S. Department of Energy
Expansion is led by focus. By taking time to edit, carve up, and refactor our notes, we put focus on ideas. This starts the Great Wheel of Positive Feedback. All hail to the Great Wheel of Positive Feedback.
How can we better thing of card indexes as positive feedback mechanisms? Will describes it as the "Great Wheel of Positive Feedback" which reminds me a bit of flywheels for storing energy for later use.
https://www.target.com/p/6qt-clear-storage-box-white-room-essentials-8482/-/A-80162146
6qt Clear Storage Box White - Room Essentials™<br /> Outside Dimensions: 13 1/2" x 8 1/8" x 4 5/8"<br /> Interior Dimensions at bottom: 11 1/2" x 6 3/8" x 4 3/8"<br /> Ideal for a variety of basic and lightweight storage needs, for use throughout the home<br /> Opaque lid snaps firmly onto the base and provides a grip for easy lifting<br /> Clear base allows contents to easily be viewed and located<br /> Indexed lids allow same size storage boxes to neatly stack upon each other<br /> BPA-free and phthalate-free<br /> Proudly made in the USA
Specifications<br /> Closure Type: Snap<br /> Used For: Organizing<br /> Capacity (Volume): 6 Quart<br /> Features: Portable, Lidded, Nesting, Stackable<br /> Assembly Details: No Assembly Required<br /> Primary item stored: Universal Storage<br /> Material: Plastic<br /> Care & Cleaning: Spot or Wipe Clean<br /> TCIN: 80162146<br /> UPC: 073149215284<br /> Item Number (DPCI): 002-02-9534<br /> Origin: Made in the USA<br /> Description<br /> Organize, sort and contain! The Room Essentials 6 Quart Storage Box is ideal for a variety of basic and lightweight household storage needs, helping to keep your living spaces neat. The clear base allows contents to be easily identified at a glance, while the opaque lid snaps firmly onto the base to keep contents contained and secure. Stack same size containers on top of each other for efficient use of vertical storage space. When storing items away, use good judgment and don’t overload them or stack them too high; be mindful of the weight in each box and place the heaviest box on the bottom. This storage box is ideal for sorting and storing shoes, accessories, crafts and other small items around the home and fits conveniently on 16" wire closet shelving, bringing order to closets. The overall assembled dimensions of this item are 13 1/2" L x 8 1/8" W x 4 5/8" H.
Examples of this and similar products in use as a box for zettelkasten: - https://photos.google.com/share/AF1QipN5GmVoIhCwma1czj27bXlVDKIUfbOU3a91dYuPBNZaGsEhcZYllmotxup6OxUHhA?pli=1&key=RlhXMTM0WUpuQ2hlQkdDNzA0S1BmNzVQblo4Ti1n - https://imgur.com/a/rW8TZKt
Generate the keys using WebCrypto and mark them as non exportable Store the key into IndexedDB
Learning is defined to be “storage of automated schema in long-term memory.
How is learning defined by Sweller in 2002? (Metiri Group, Cisco Sytems, 2008) The storage of automated schema in long-term memory
What term does Sweller define as the "storage of automated schema in long-term memory"?
one recognizes in the tactile realitythat so many of the cards are on flimsy copy paper, on the verge of disintegration with eachuse.
Deutsch used flimsy copy paper, much like Niklas Luhmann, and as a result some are on the verge of disintegration through use over time.
The wear of the paper here, however, is indicative of active use over time as well as potential care in use, a useful historical fact.
in south australia we've got the hornsdale power reserve which is a 00:32:43 100 megawatt capacity this is one that elon musk very famously uh put in so this is what the european union is now using as the standard to talk about you know it's 00:32:56 been done in australia we can do it here so in the global system we would need 15 million 635 and 478 such stations across the planet 00:33:08 in the power grid system just for that four week buffer so and that is actually about 30 times capacity uh compared to the entire global
!- for : global capacity renewable energy storage - this is not realistic
https://www.ebay.com/itm/115477031627?hash=item1ae2f7aacb:g:yUIAAOSwQp1ix3zT

Another example of someone using a library card catalog as wine storage
Drawers hold a standard size bottle of wine.

Someone was apparently using an old library card catalog to store wine bottles!
https://en.wikipedia.org/wiki/Punched_card
Link to Beatrice Webb's use of note taking methods as a means of data storage, search, and sort in the early 1900s.
quoting David G. Allen, “Your mind is for having ideas, not holding them.”
```js function formatBytes(bytes, decimals = 2) { if (bytes === 0) return '0 Bytes';
const k = 1024; const dm = decimals < 0 ? 0 : decimals; const sizes = ['Bytes', 'KB', 'MB', 'GB', 'TB', 'PB', 'EB', 'ZB', 'YB']; const i = Math.floor(Math.log(bytes) / Math.log(k)); return parseFloat((bytes / Math.pow(k, i)).toFixed(dm)) + ' ' + sizes[i]; } ```
I also like the simplicity of a box. There’s a purpose here, and it has a lot to dowith efficiency. A writer with a good storage and retrieval system can write faster.He isn’t spending a lot of time looking things up, scouring his papers, and patrollingother rooms at home wondering where he left that perfect quote. It’s in the box.
A card index can be a massive boon to a writer as a well-indexed one, in particular, will save massive amounts of time which might otherwise be spent searching for quotes or ideas that they know they know, but can't easily recreate.
It’s not the only answer, of course. Maurice Sendak has a room that’s theequivalent of my boxes, a working studio that contains a huge unit with flat pulloutdrawers in which he keeps sketches, reference materials, notes, articles. He works onseveral projects at a time, and he likes to keep the overlapping materials out of sightwhen he’s tackling any one of them. Other people rely on carefully arranged indexcards. The more technological among us put it all on a computer. There’s no singlecorrect system. Anything can work, so long as it lets you store and retrieve yourideas—and never lose them.
Regardless of what sort of physical instantiation one's notes may take, a workable storage option for them is necessary whether it is a simple box, a shelving system, a curiosity cabinet, a flat file, or even an entire room itself.
a society-wide hyperconversation. This hyperconversation operationalizes continuous discourse, including its differentiation and emergent framing aspects. It aims to assist people in developing their own ways of framing and conceiving the problem that makes sense given their social, cultural, and environmental contexts. As depicted in table 1, the hyperconversation also reflects a slower, more deliberate approach to discourse; this acknowledges damaged democratic processes and fractured societal social cohesion. Its optimal design would require input from other relevant disciplines and expertise,
The public Indyweb is eminently designed as a public space for holding deep, continuous, asynchronous conversations with provenance. That is, if the partcipant consents to public conversation, ideas can be publicly tracked. Whoever reads your public ideas can be traced.and this paper trail is immutably stored, allowing anyone to see the evolution of ideas in real time.
In theory, this does away with the need for patents and copyrights, as all ideas are traceable to the contributors and each contribution is also known. This allows for the system to embed crowdsourced microfunding, supporting the best (upvoted) ideas to surface.
Participants in the public Indyweb ecosystem are called Indyviduals and each has their own private data hub called an Indyhub. Since Indyweb is interpersonal computing, each person is the center of their indyweb universe. Through the discoverability built into the Indyweb, anything of immediate salience is surfaced to your private hub. No applications can use your data unless you give exact permission on which data to use and how it shall be used. Each user sets the condition for their data usage. Instead of a user's data stored in silos of servers all over the web as is current practice, any data you generate, in conversation, media or data files is immediately accessible on your own Indyhub.
Indyweb supports symmathesy, the exchange of ideas based on an appropriate epistemological model that reflects how human INTERbeings learn as a dynamic interplay between individual and collective learning. Furthermore, all data that participants choose to share is immutably stored on content addressable web3 storage forever. It is not concentrated on any server but the data is stored on the entire IPFS network:
"IPFS works through content adddressibility. It is a peer-to-peer (p2p) storage network. Content is accessible through peers located anywhere in the world, that might relay information, store it, or do both. IPFS knows how to find what you ask for using its content address rather than its location.
There are three fundamental principles to understanding IPFS:
Unique identification via content addressing Content linking via directed acyclic graphs (DAGs) Content discovery via distributed hash tables (DHTs)" (Source: https://docs.ipfs.io/concepts/how-ipfs-works/)
The privacy, scalability, discoverability, public immutability and provenance of the public Indyweb makes it ideal for supporting hyperconversations that emerge tomorrows collectively emergent solutions. It is based on the principles of thought augmentation developed by computer industry pioneers such as Doug Englebart and Ted Nelson who many decades earlier in their prescience foresaw the need for computing tools to augment thought and provide the ability to form Network Improvement Communities (NIC) to solve a new generation of complex human challenges.
In explaining his approach, Luhmann emphasized, with the first stepsof computer technology in mind, the benefits of the principle of “multiple storage”: in the card index itserves to provide different avenues of accessing a topic or concept since the respective notes may be filedin different places and different contexts. Conversely, embedding a topic in various contexts gives rise todifferent lines of information by means of opening up different realms of comparison in each case due tothe fact that a note is an information only in a web of other notes. Furthermore it was Luhmann’s intentionto “avoid premature systematization and closure and maintain openness toward the future.”11 His way oforganizing the collection allows for it to continuously adapt to the evolution of his thinking and his overalltheory which as well is not conceptualized in a hierarchical manner but rather in a cybernetical way inwhich every term or theoretical concept is dependent on the other.
While he's couching it in the computer science milieu of his day, this is not dissimilar to the Llullan combinatorial arts.
Also, keep in mind that you don’t need to find a single app to fulfill all your needs. You might use more than one tool at a time depending on the use case.
It's true that each note taking application may be purpose fit for a particular use, but having a single store for all of your notes is incredibly important for future search and re-discovery. Keeping one's notes across a range of applications is disaster waiting to happen, at least until there is a bigger aggregate search function that can search across multiple platforms.
Open protocol for per-user storage on the Web Webfinger + OAuth + CORS + REST
The steel tower is a giant mechanical energy storage system, designed by American-Swiss startup Energy Vault, that relies on gravity and 35-ton bricks to store and release energy.
Like pumped hydro with rocks
Guarascio, F. (2022, January 14). Poorer nations reject over 100 mln COVID-19 vaccine doses as many near expiry. Reuters. https://www.reuters.com/business/healthcare-pharmaceuticals/more-than-100-million-covid-19-vaccines-rejected-by-poorer-nations-dec-unicef-2022-01-13/
snap list --all and remove with snap remove --revision XXX gnome-3-26-1604
Edge computing is an emerging new trend in cloud data storage that improves how we access and process data online. Businesses dealing with high-frequency transactions like banks, social media companies, and online gaming operators may benefit from edge computing.
Edge Computing: What It Is and Why It Matters0
https://en.itpedia.nl/2021/12/29/edge-computing-what-it-is-and-why-it-matters/
Edge computing is an emerging new trend in cloud data storage that improves how we access and process data online. Businesses dealing with high-frequency transactions like banks, social media companies, and online gaming operators may benefit from edge computing.

Here, I also briefl y digress and examine two coinciding addressing logics: In the same decade and in the same town, the origin of the card index cooccurs with the invention of the house number. This establishes the possibility of abstract representation of (and controlled access to) both texts and inhabitants.
Curiously, and possibly coincidently, the idea of the index card and the invention of the house number co-occur in the same decade and the same town. This creates the potential of abstracting the representation of information and people into numbers for easier access and linking.
wn oral cultures the sorting function canbe performedW for exampleW by integration into a narrative Sstorytelling orbardic poetryTY
The sorting function is also done by mental links from one space to another similar to the method of loci in Western culture. cross reference the idea of songlines
́herange of storage media operative in different historical contexts includesthe marked stone tokenW the clay tabletW the knotted cord or quipuW the paX
pyrus scroll and the sheet of parchment.
Which others is she missing from a mnemonics perspective? I'm impressed that she indicates the khipu, but there are certainly other indigenous methods from oral cultures.
In building this system we simultaneously solved three high-level challenges: supporting exabyte-scale, isolating performance between tenants, and enabling tenant-specific optimizations. Exabyte-scale clusters are important for operational simplicity and resource sharing. Tectonic disaggregates the file system metadata into independently scalable layers, and hash-partitions each metadata layer into a scalable shared key-value store. Combined with a linearly scalable storage node layer, this disaggregated metadata allows the system to meet the storage needs of an entire data center.
So, it seems to add a layer of indirection, so instead of everyone needing to read off the same bits of a disk, the data is stored in places indexed by the KV store, which allows reads and writes to be spread across a linearly scaling storage layer.
Worth reading the paper to check if this guess is close to reality
When salvinorin A isolated from leaves of Salvia divinorum was irradiated with 300 nm UV light in ethyl acetate, it degraded from 100 μg/mL to 2.84 ± 0.05 μg/mL in 30 min. The calculated average rate constant k of this degradation was 0.12/min and the half-life was 5.7 min. When authentic salvinorin A was irradiated by UV light in an organic solution or an aqueous solution, it degraded over 90% within 40 min, whereas when it was irradiated by natural sunlight, it took 8 h to degrade 50% both in an organic and an aqueous solution.
Incredible. I may have destroyed my current batch. I'll have to start over. Good thing I only made a moderate amount.
By making the storage and organization of information everyone’s responsibility and no one’s, the internet and web could grow, unprecedentedly expanding access, while making any and all of it fragile rather than robust in many instances in which we depend on it.
This system was invented by Carl Linnaeus,[1] around 1760.
How is it not so surprising that Carl Linnaeus, the creator of a huge taxonomic system, also came up with the idea for index cards in 1760.
How does this fit into the history of the commonplace book and information management? Relationship to the idea of a zettelkasten?
Preferences DataStore and Proto DataStore DataStore provides two different implementations: Preferences DataStore and Proto DataStore. Preferences DataStore stores and accesses data using keys. This implementation does not require a predefined schema, and it does not provide type safety. Proto DataStore stores data as instances of a custom data type. This implementation requires you to define a schema using protocol buffers, but it provides type safety.
Currently, I am using SharedPreference which is still alright to use. However, there is a better option called DataStore. This allows data to be stored asynchronously.
What about seed banks? There have been efforts to try to ensure that not only the most popular seeds survive. Let’s call these seed banks, where the more rare gems are maintained and passed on as generational wealth.
And Ashampoo Office 8 doesn't save your files in some online cloud service but where they belong: on your PC!
nucleus accumbens
RESEARCH MORE. What is this? What it's role in memory storage?
Now, where the emotional memory is stored in response to these survival-enhancing positive memories is not yet entirely clear.
I have heard this from several of my sources. This one is a bit more dated than some of the others I've used, so I need to look at something more recent and see if this has changed.
class Session extends Map { set(id, value) { if (typeof value === 'object') value = JSON.stringify(value); sessionStorage.setItem(id, value); } get(id) { const value = sessionStorage.getItem(id); try { return JSON.parse(value); } catch (e) { return value; } } }
I think that the webStorage is one of the most exciting improvement of the new web. But save only strings in the value key-map I think is a limitation.
The Web Storage API provides mechanisms by which browsers can store key/value pairs, in a much more intuitive fashion than using cookies.
This is the accepted way to handle problems related to authentication, because user data has a couple of important characteristics: You really don't want to accidentally leak it between two sessions on the same server, and generating the store on a per-request basis makes that very unlikely It's often used in lots of different places in your app, so a global store makes sense.
Small Unit
Size: 1.3m x 2m
The real heart of the matter of selection, however, goes deeper than a lag in the adoption of mechanisms by libraries, or a lack of development of devices for their use. Our ineptitude in getting at the record is largely caused by the artificiality of systems of indexing. When data of any sort are placed in storage, they are filed alphabetically or numerically, and information is found (when it is) by tracing it down from subclass to subclass. It can be in only one place, unless duplicates are used; one has to have rules as to which path will locate it, and the rules are cumbersome. Having found one item, moreover, one has to emerge from the system and re-enter on a new path.
Bush emphasises the importance of retrieval in the storage of information. He talks about technical limitations, but in this paragraph he stresses that retrieval is made more difficult by the "artificiality of systems of indexing", in other words, our default file-cabinet metaphor for storing information.
Information in such a hierarchical architecture is found by descending down into the hierarchy, and back up again. Moreover, the information we're looking for can only be in one place at a time (unless we introduce duplicates).
Having found our item of interest, we need to ascend back up the hierarchy to make our next descent.
So much for the manipulation of ideas and their insertion into the record. Thus far we seem to be worse off than before—for we can enormously extend the record; yet even in its present bulk we can hardly consult it. This is a much larger matter than merely the extraction of data for the purposes of scientific research; it involves the entire process by which man profits by his inheritance of acquired knowledge. The prime action of use is selection, and here we are halting indeed. There may be millions of fine thoughts, and the account of the experience on which they are based, all encased within stone walls of acceptable architectural form; but if the scholar can get at only one a week by diligent search, his syntheses are not likely to keep up with the current scene.
Retrieval is the key activity we're interested in. Storage only matters in as much as we can retrieve effectively. At the time of writing (1945) large amounts of information could be stored (extend the record), but consulting that record was still difficult.
To request tokens for Azure Storage
That is, to request token if the app is not running in the Azure cloud with a managed identity:
Acquire a token from Azure AD for authorizing requests from a client application
Request an access token in Azure Active Directory B2C (and the other chapters in the Authorization protocols section)
This impacts monetization and purchasing at companies. Paying for a new design tool because it has new features for designers may not be a top priority. But if product managers, engineers, or even the CEO herself think it matters for the business as a whole—that has much higher priority and pricing leverage.
If a tool benefits the entire team, vs. just the designer, it becomes an easier purchase decision.
A key strength of OnlyOffice is its cloud-based storage options, which let you connect your Google Drive, Dropbox, Box, OneDrive, and Yandex.Disk accounts.
If there is no other lawful basisjustifying the processing (e.g. further storage) of the data, they should be deleted by the controller.
Supporting Open Science Data Curation, Preservation, and Access by Libraries. (2020, June 25). https://www.youtube.com/watch?v=SbmGWHpzAHs&feature=youtu.be
However, when you use an SD card as internal storage, Android formats the SD card in such a way that no other device can read it. Android also expects the adopted SD card to always be present, and won’t work quite right if you remove it.
Your Amazon Athena query performance improves if you convert your data into open source columnar formats, such as Apache Parquet
s3 perfomance use columnar formats
Available Internet Connection Theoretical Min. Number of Days to Transfer 100TB at 80% Network Utilization When to Consider AWS Snowball? T3 (44.736Mbps) 269 days 2TB or more 100Mbps 120 days 5TB or more 1000Mbps 12 days 60TB or more
when snowball
1000Mbps 12 days 60TB
One of the GDPR's principles of data processing is storage limitation. You must not store personal data for longer than you need it in connection with a specified purpose.
100MB storage
Destul de puțin...
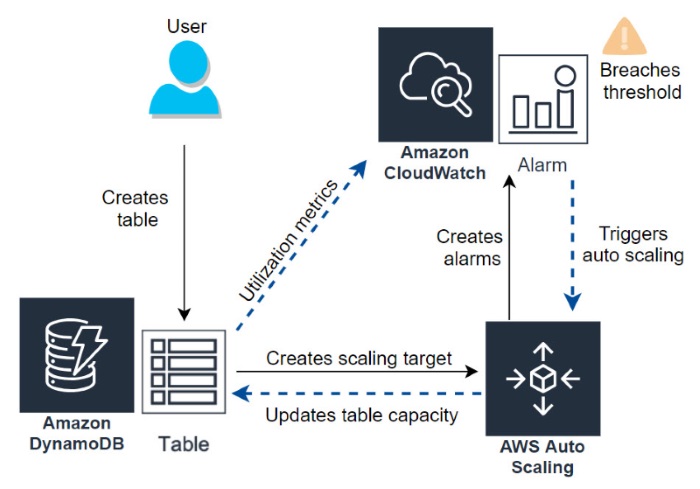
When you create a DynamoDB table, auto scaling is the default capacity setting, but you can also enable auto scaling on any table that does not have it active
Data Erasure and Storage Time The personal data of the data subject will be erased or blocked as soon as the purpose of storage ceases to apply. The data may be stored beyond that if the European or national legislator has provided for this in EU regulations, laws or other provisions to which the controller is subject. The data will also be erased or blocked if a storage period prescribed by the aforementioned standards expires, unless there is a need for further storage of the data for the conclusion or performance of a contract.
I would like to make an appeal to core developers: all design decisions involving involuntary session creation MUST be made with a great caution. In case of a high-load project, avoiding to create a session for non-authenticated users is a vital strategy with a critical influence on application performance. It doesn't really make a big difference, whether you use a database backend, or Redis, or whatever else; eventually, your load would be high enough, and scaling further would not help anymore, so that either network access to the session backend or its “INSERT” performance would become a bottleneck. In my case, it's an application with 20-25 ms response time under a 20000-30000 RPM load. Having to create a session for an each session-less request would be critical enough to decide not to upgrade Django, or to fork and rewrite the corresponding components.
Size of the warehouse management systems (WMS) market worldwide, from 2015 to 2024
Practical highlights in my opinion:
Here follows my own commands on trying the article points. I added - pg_column_size(row()) on each projection to have clear absolute sizes.
-- How does row function work?
SELECT pg_column_size(row()) AS empty,
pg_column_size(row(0::SMALLINT)) AS byte2,
pg_column_size(row(0::BIGINT)) AS byte8,
pg_column_size(row(0::SMALLINT, 0::BIGINT)) AS byte16,
pg_column_size(row(''::TEXT)) AS text0,
pg_column_size(row('hola'::TEXT)) AS text4,
0 AS term
;
-- My own take on that
SELECT pg_column_size(row()) AS empty,
pg_column_size(row(uuid_generate_v4())) AS uuid_type,
pg_column_size(row('hola mundo'::TEXT)) AS text_type,
pg_column_size(row(uuid_generate_v4(), 'hola mundo'::TEXT)) AS uuid_text_type,
pg_column_size(row('hola mundo'::TEXT, uuid_generate_v4())) AS text_uuid_type,
0 AS term
;
CREATE TABLE user_order (
is_shipped BOOLEAN NOT NULL DEFAULT false,
user_id BIGINT NOT NULL,
order_total NUMERIC NOT NULL,
order_dt TIMESTAMPTZ NOT NULL,
order_type SMALLINT NOT NULL,
ship_dt TIMESTAMPTZ,
item_ct INT NOT NULL,
ship_cost NUMERIC,
receive_dt TIMESTAMPTZ,
tracking_cd TEXT,
id BIGSERIAL PRIMARY KEY NOT NULL
);
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY a.attnum;
-- What is it about pg_class, pg_attribute and pg_type tables? For future investigation.
-- SELECT sum(t.typlen)
-- SELECT t.typlen
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY a.attnum
;
-- Whoa! I need to master mocking data directly into db.
INSERT INTO user_order (
is_shipped, user_id, order_total, order_dt, order_type,
ship_dt, item_ct, ship_cost, receive_dt, tracking_cd
)
SELECT true, 1000, 500.00, now() - INTERVAL '7 days',
3, now() - INTERVAL '5 days', 10, 4.99,
now() - INTERVAL '3 days', 'X5901324123479RROIENSTBKCV4'
FROM generate_series(1, 1000000);
-- New item to learn, pg_relation_size.
SELECT pg_relation_size('user_order') AS size_bytes,
pg_size_pretty(pg_relation_size('user_order')) AS size_pretty;
SELECT * FROM user_order LIMIT 1;
SELECT pg_column_size(row(0::NUMERIC)) - pg_column_size(row()) AS zero_num,
pg_column_size(row(1::NUMERIC)) - pg_column_size(row()) AS one_num,
pg_column_size(row(9.9::NUMERIC)) - pg_column_size(row()) AS nine_point_nine_num,
pg_column_size(row(1::INT2)) - pg_column_size(row()) AS int2,
pg_column_size(row(1::INT4)) - pg_column_size(row()) AS int4,
pg_column_size(row(1::INT2, 1::NUMERIC)) - pg_column_size(row()) AS int2_one_num,
pg_column_size(row(1::INT4, 1::NUMERIC)) - pg_column_size(row()) AS int4_one_num,
pg_column_size(row(1::NUMERIC, 1::INT4)) - pg_column_size(row()) AS one_num_int4,
0 AS term
;
SELECT pg_column_size(row(''::TEXT)) - pg_column_size(row()) AS empty_text,
pg_column_size(row('a'::TEXT)) - pg_column_size(row()) AS len1_text,
pg_column_size(row('abcd'::TEXT)) - pg_column_size(row()) AS len4_text,
pg_column_size(row('abcde'::TEXT)) - pg_column_size(row()) AS len5_text,
pg_column_size(row('abcdefgh'::TEXT)) - pg_column_size(row()) AS len8_text,
pg_column_size(row('abcdefghi'::TEXT)) - pg_column_size(row()) AS len9_text,
0 AS term
;
SELECT pg_column_size(row(''::TEXT, 1::INT4)) - pg_column_size(row()) AS empty_text_int4,
pg_column_size(row('a'::TEXT, 1::INT4)) - pg_column_size(row()) AS len1_text_int4,
pg_column_size(row('abcd'::TEXT, 1::INT4)) - pg_column_size(row()) AS len4_text_int4,
pg_column_size(row('abcde'::TEXT, 1::INT4)) - pg_column_size(row()) AS len5_text_int4,
pg_column_size(row('abcdefgh'::TEXT, 1::INT4)) - pg_column_size(row()) AS len8_text_int4,
pg_column_size(row('abcdefghi'::TEXT, 1::INT4)) - pg_column_size(row()) AS len9_text_int4,
0 AS term
;
SELECT pg_column_size(row(1::INT4, ''::TEXT)) - pg_column_size(row()) AS int4_empty_text,
pg_column_size(row(1::INT4, 'a'::TEXT)) - pg_column_size(row()) AS int4_len1_text,
pg_column_size(row(1::INT4, 'abcd'::TEXT)) - pg_column_size(row()) AS int4_len4_text,
pg_column_size(row(1::INT4, 'abcde'::TEXT)) - pg_column_size(row()) AS int4_len5_text,
pg_column_size(row(1::INT4, 'abcdefgh'::TEXT)) - pg_column_size(row()) AS int4_len8_text,
pg_column_size(row(1::INT4, 'abcdefghi'::TEXT)) - pg_column_size(row()) AS int4_len9_text,
0 AS term
;
SELECT pg_column_size(row()) - pg_column_size(row()) AS empty_row,
pg_column_size(row(''::TEXT)) - pg_column_size(row()) AS no_text,
pg_column_size(row('a'::TEXT)) - pg_column_size(row()) AS min_text,
pg_column_size(row(1::INT4, 'a'::TEXT)) - pg_column_size(row()) AS two_col,
pg_column_size(row('a'::TEXT, 1::INT4)) - pg_column_size(row()) AS round4;
SELECT pg_column_size(row()) - pg_column_size(row()) AS empty_row,
pg_column_size(row(1::SMALLINT)) - pg_column_size(row()) AS int2,
pg_column_size(row(1::INT)) - pg_column_size(row()) AS int4,
pg_column_size(row(1::BIGINT)) - pg_column_size(row()) AS int8,
pg_column_size(row(1::SMALLINT, 1::BIGINT)) - pg_column_size(row()) AS padded,
pg_column_size(row(1::INT, 1::INT, 1::BIGINT)) - pg_column_size(row()) AS not_padded;
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'user_order'
AND a.attnum >= 0
ORDER BY t.typlen DESC;
DROP TABLE user_order;
CREATE TABLE user_order (
id BIGSERIAL PRIMARY KEY NOT NULL,
user_id BIGINT NOT NULL,
order_dt TIMESTAMPTZ NOT NULL,
ship_dt TIMESTAMPTZ,
receive_dt TIMESTAMPTZ,
item_ct INT NOT NULL,
order_type SMALLINT NOT NULL,
is_shipped BOOLEAN NOT NULL DEFAULT false,
order_total NUMERIC NOT NULL,
ship_cost NUMERIC,
tracking_cd TEXT
);
-- And, what about other varying size types as JSONB?
SELECT pg_column_size(row('{}'::JSONB)) - pg_column_size(row()) AS empty_jsonb,
pg_column_size(row('{}'::JSONB, 0::INT4)) - pg_column_size(row()) AS empty_jsonb_int4,
pg_column_size(row(0::INT4, '{}'::JSONB)) - pg_column_size(row()) AS int4_empty_jsonb,
pg_column_size(row('{"a": 1}'::JSONB)) - pg_column_size(row()) AS basic_jsonb,
pg_column_size(row('{"a": 1}'::JSONB, 0::INT4)) - pg_column_size(row()) AS basic_jsonb_int4,
pg_column_size(row(0::INT4, '{"a": 1}'::JSONB)) - pg_column_size(row()) AS int4_basic_jsonb,
0 AS term;
Best Overall: SanDisk Extreme PRO 128 GB Drive 3.5 Buy on Amazon The SanDisk PRO gives you blistering speeds, offering 420 MB/s on the reading front and 380 MB/s on the writing end, which is 3–4x faster than what a standard USB 3.0 drive will offer. The sleek, aluminum casing is both super durable and very eye-catching, so you can bring it with you to your business meetings and look professional as well. The onboard AES, 128-bit file encryption gives you top-of-the-line security for your sensitive files.
It is an append-only, totally-ordered sequence of records ordered by time.
When you get started, you get signed up by default for the FREE Gaia storage provided by Blockstack PBC. Yes, that's right, you get FREE encrypted storage.
The NSA must be psyched about this.
In 2005, the figure had raised to 1%. They are now responsible for more carbon-dioxide emissions per year than Argentina or the Netherlands and, if current trends hold, their emissions will have grown four-fold by 2020, reaching 670m tonnes
How is information, for example, a conversation accounted for in this model? As we go forward and find more efficient ways to store and convey information in fewer 1s and 0s, must we constantly reevaluate this relationship? Passive vs Active storage of information seems to be key here as well.
unprecedented accumulation of contemporary data
this is the storage question everyone always goes to 1st when we use the word "data" in libraries. Is there possibly another question we should ask first?
Do I own my content on The Grid? Yes, you own your content. The engine AutoDesigns your site, publishes it, and stores it on Github. Your source content will live in a Github repository that you can access and download anytime.
Is access private/public?
Fast restart. If a server is temporarily taken down, this capability restores the index from a saved copy, eliminating delays due to index rebuilding.
This point seems to be in direct contradiction to the claim above that "Indexes (primary and secondary) are always stored in DRAM for fast access and are never stored on Solid State Drives (SSDs) to ensure low wear."
Unlike other databases that use the linux file system that was built for rotational drives, Aerospike has implemented a log structured file system to access flash – raw blocks on SSDs – directly.
Does this really mean to suggest that Aerospike bypasses the linux block device layer? Is there a kernel driver? Does this mean I can't use any filesystem I want and know how to administrate? Is the claim that the "linux file system" (which I take to mean, I guess, the virtual file system layer) "built for rotation drives" even accurate? We've had ram disks for a long, long time. And before that we've had log structured filesystems, too, and even devices that aren't random access like tape drives. Seems like dubious claims all around.
There are three kinds of storage locations: stack locations, heap locations, and registers.

