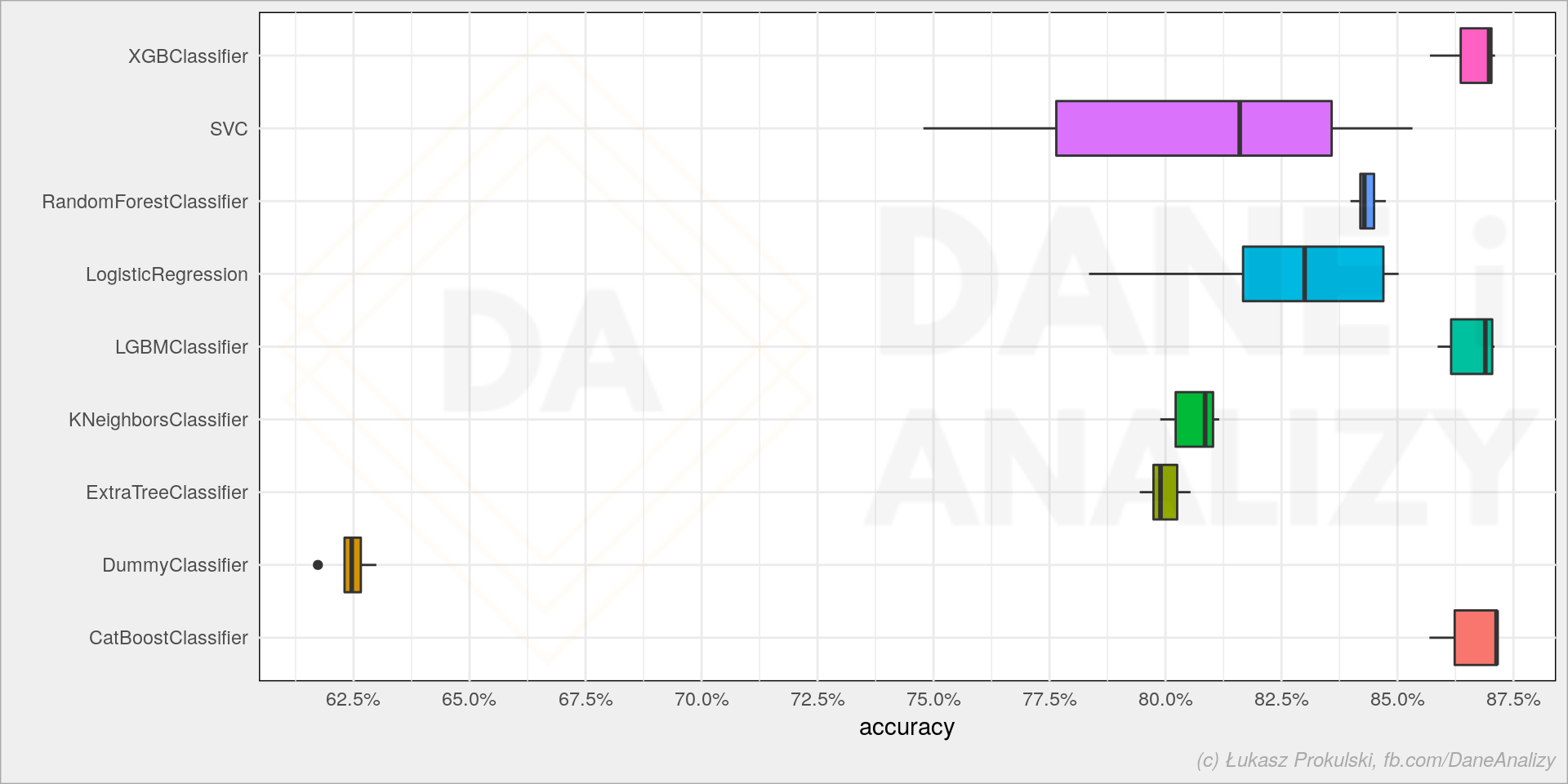
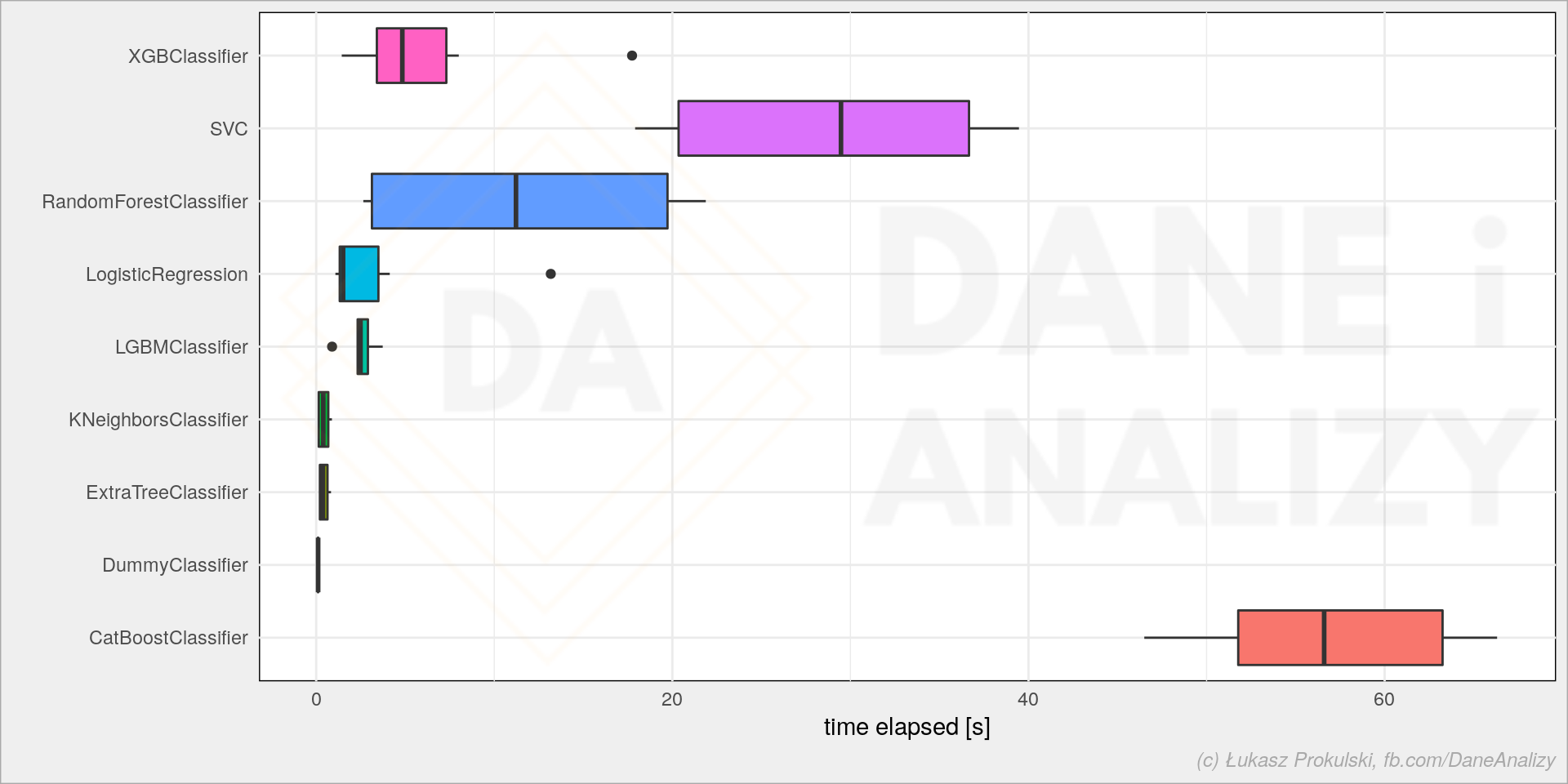
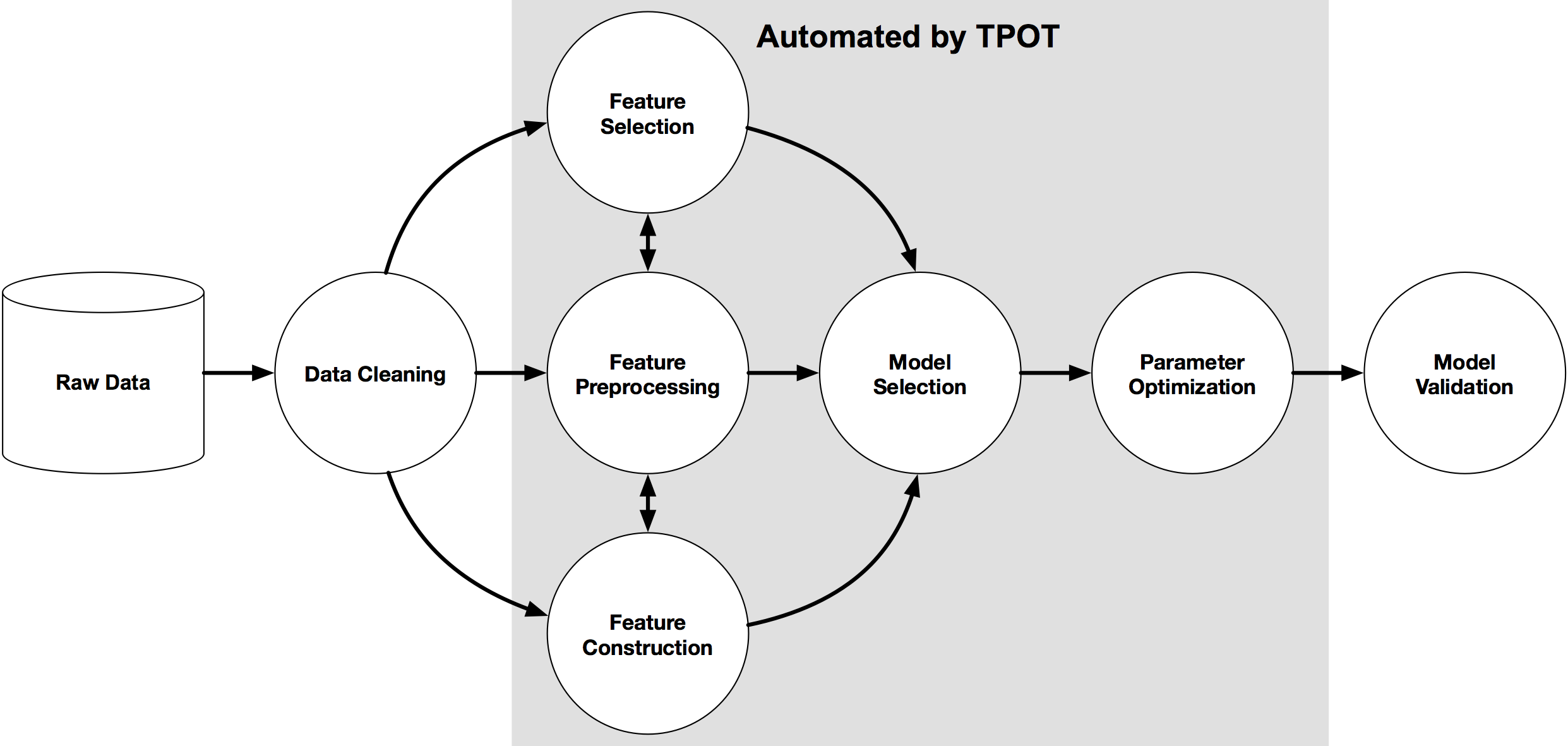
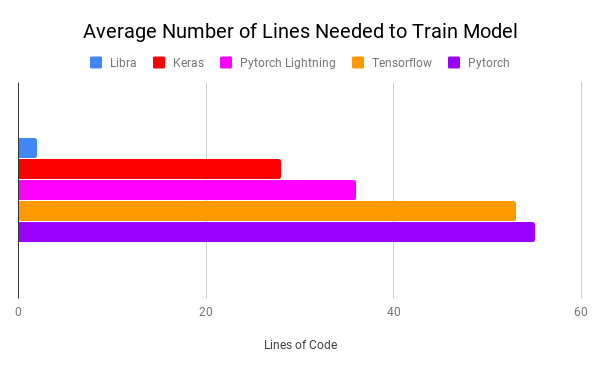
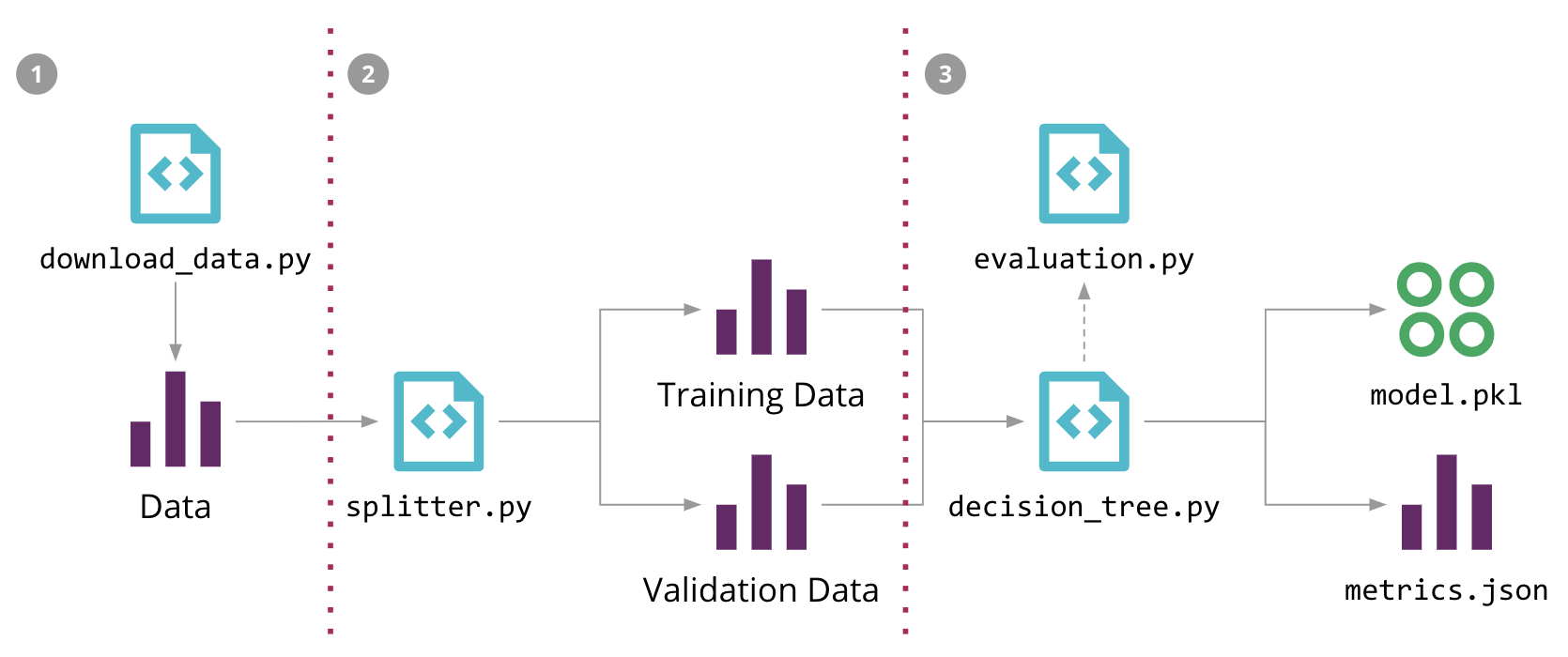
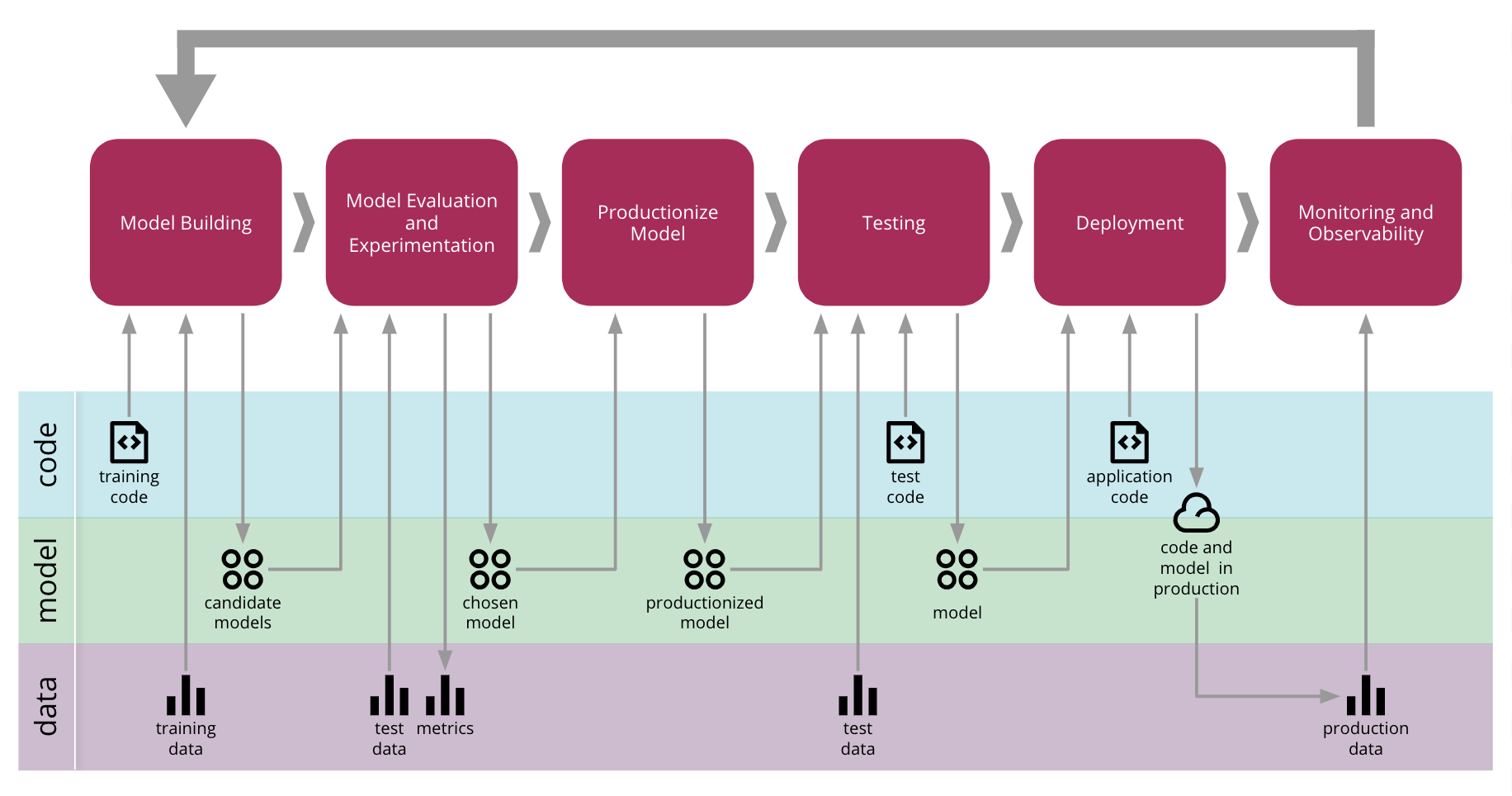
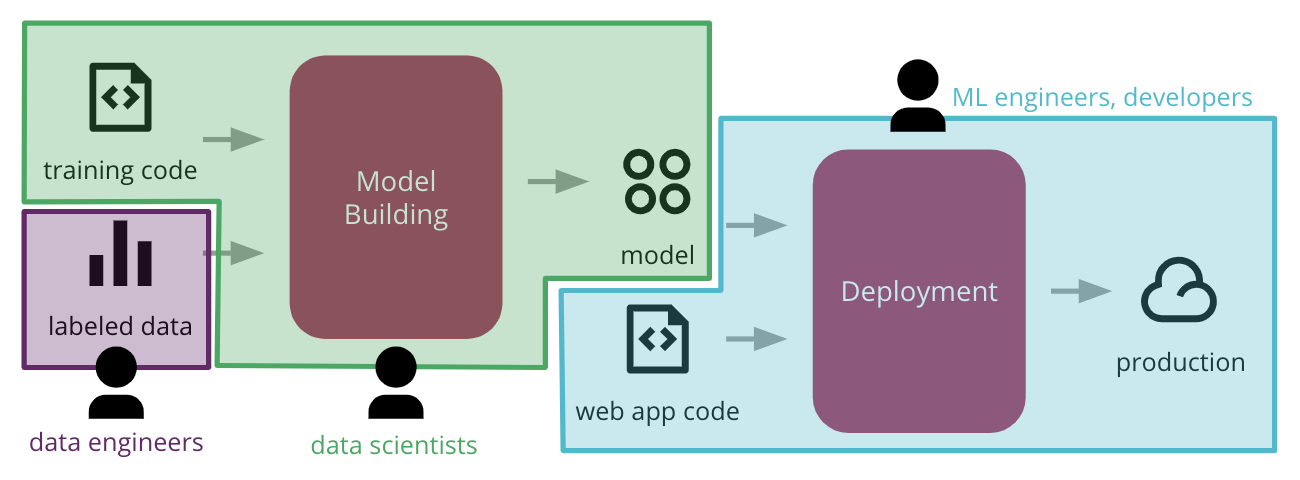
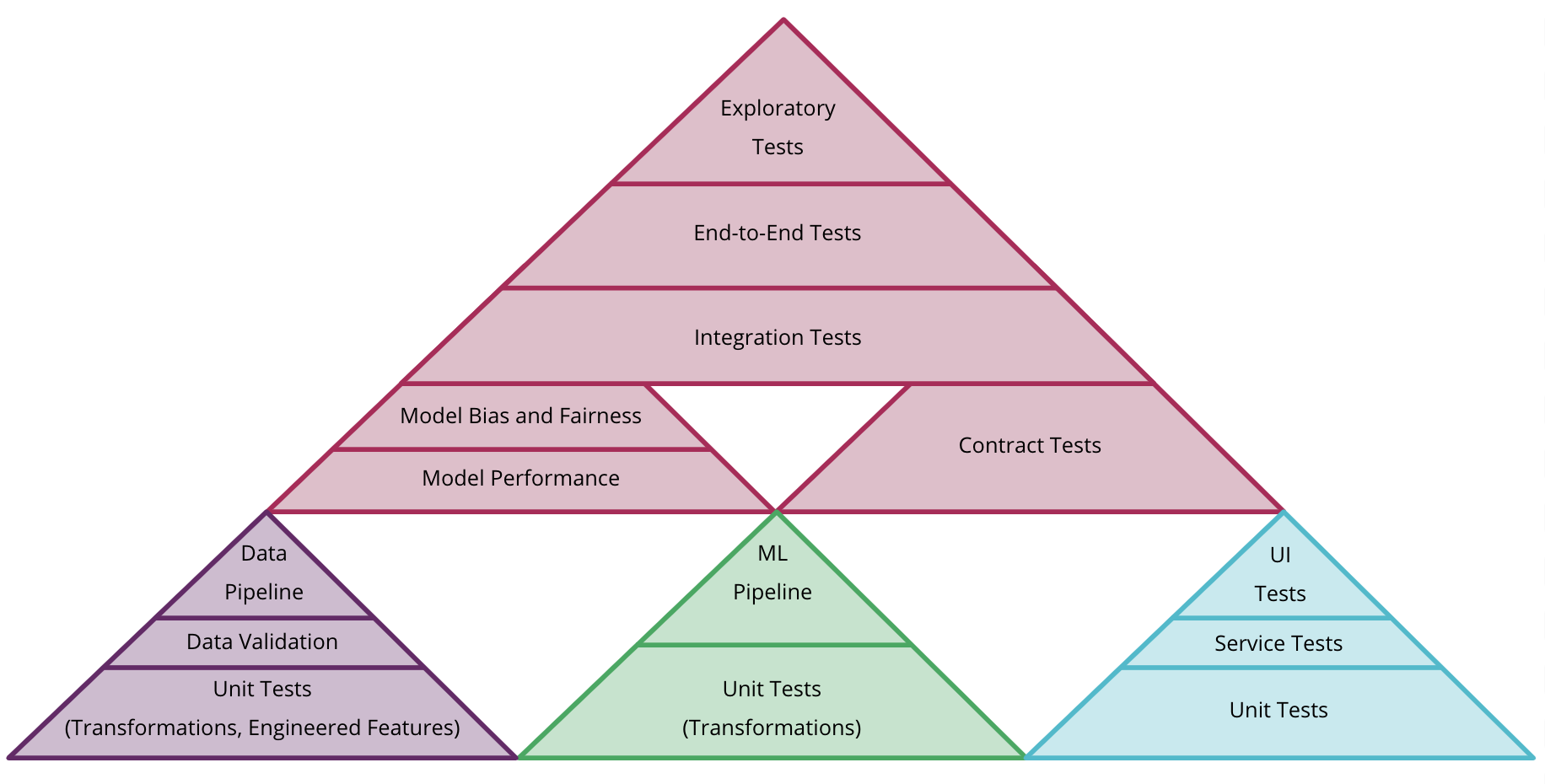
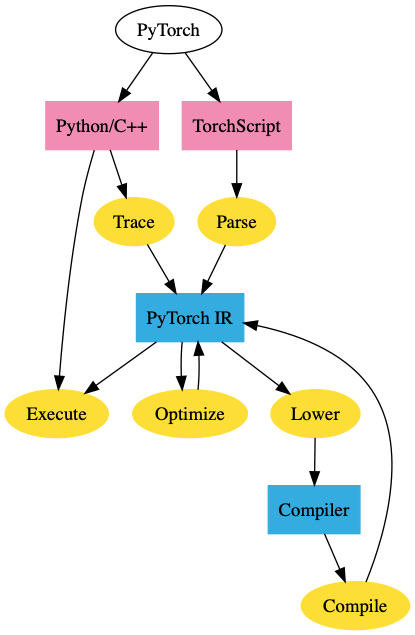
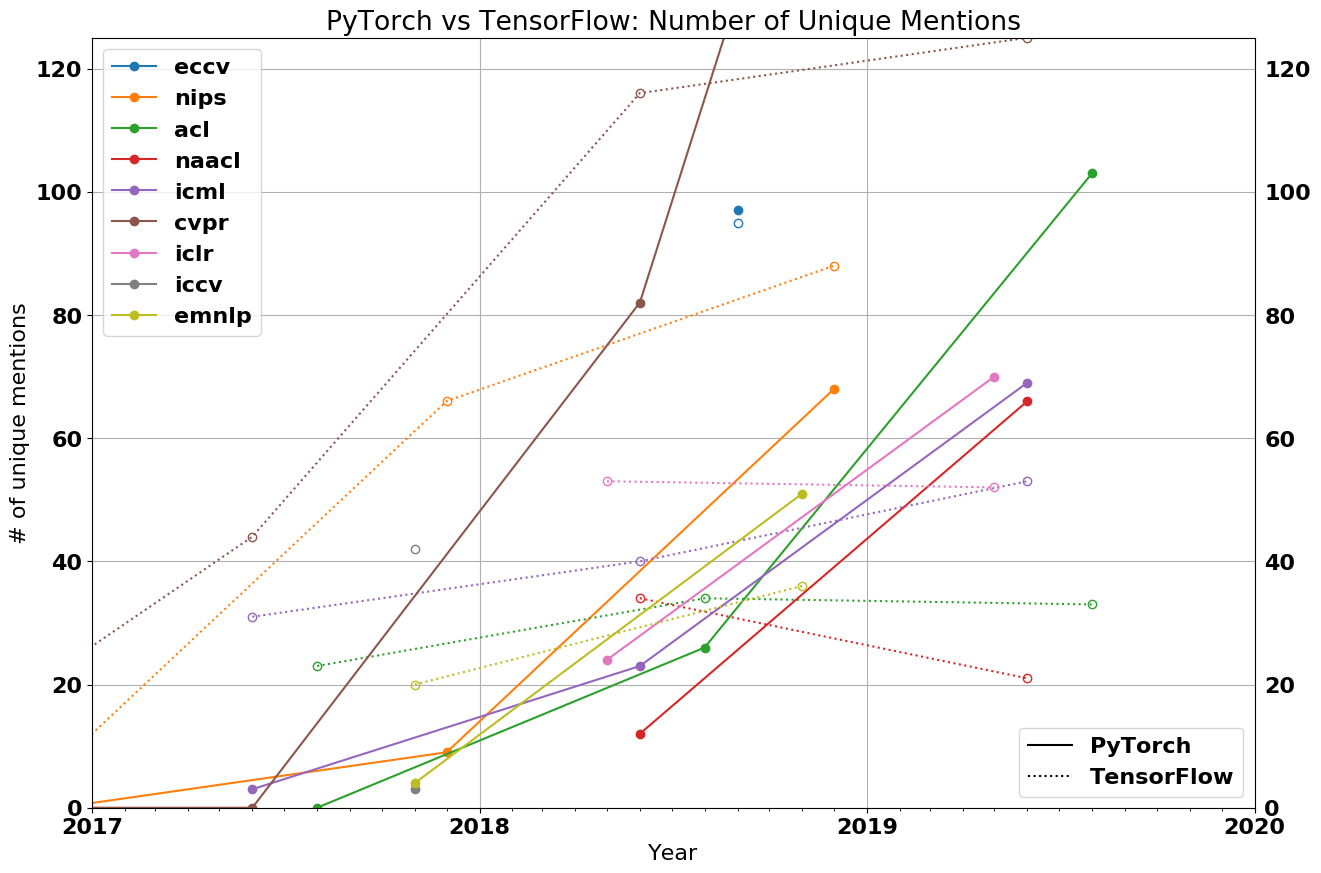
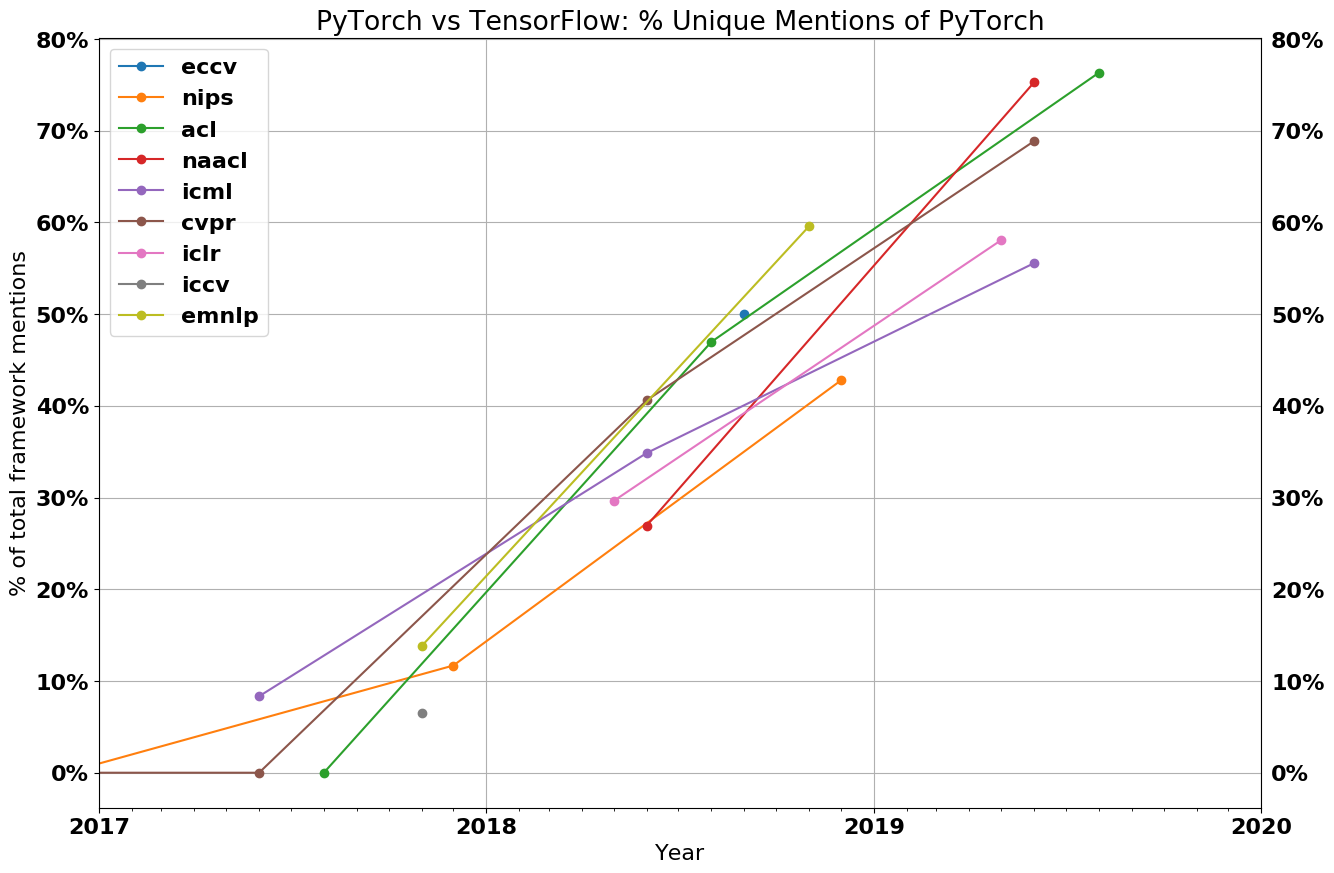
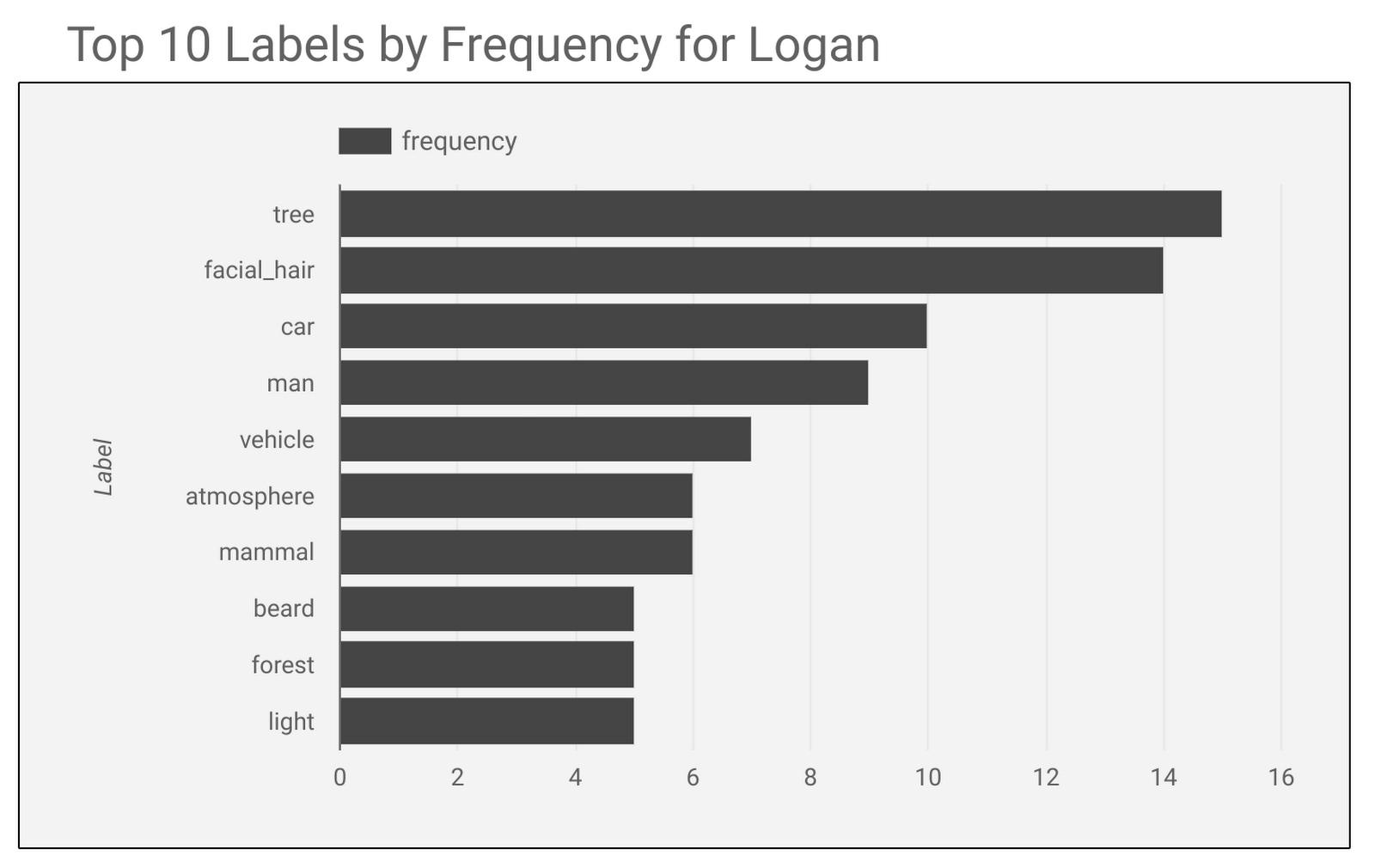
“MLX” is more than just a technical solution; it is an innovative and user-friendly framework inspired by popular frameworks like PyTorch, Jax, and ArrayFire. It facilitates the training and deployment of AI models on Apple devices without sacrificing performance or compatibility.
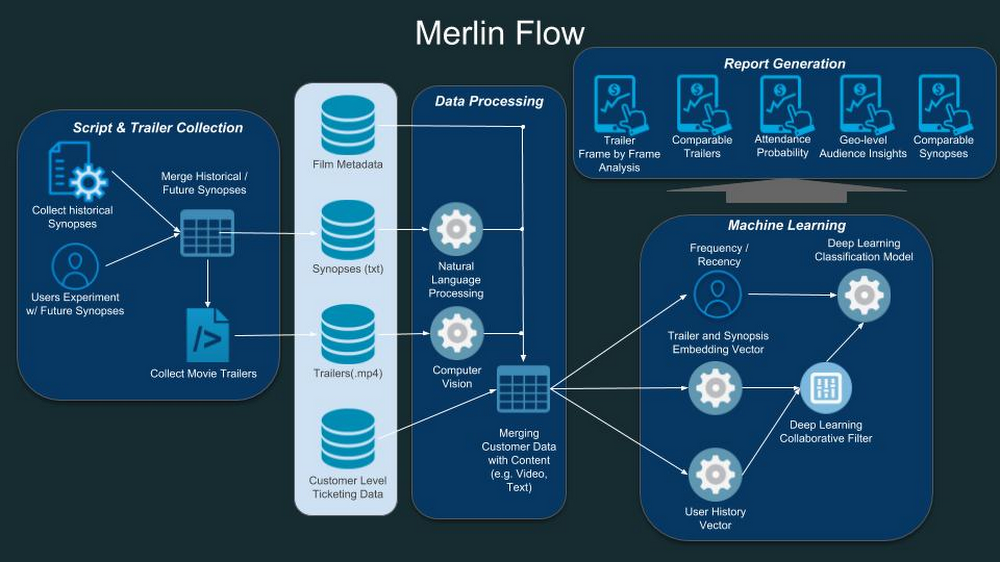
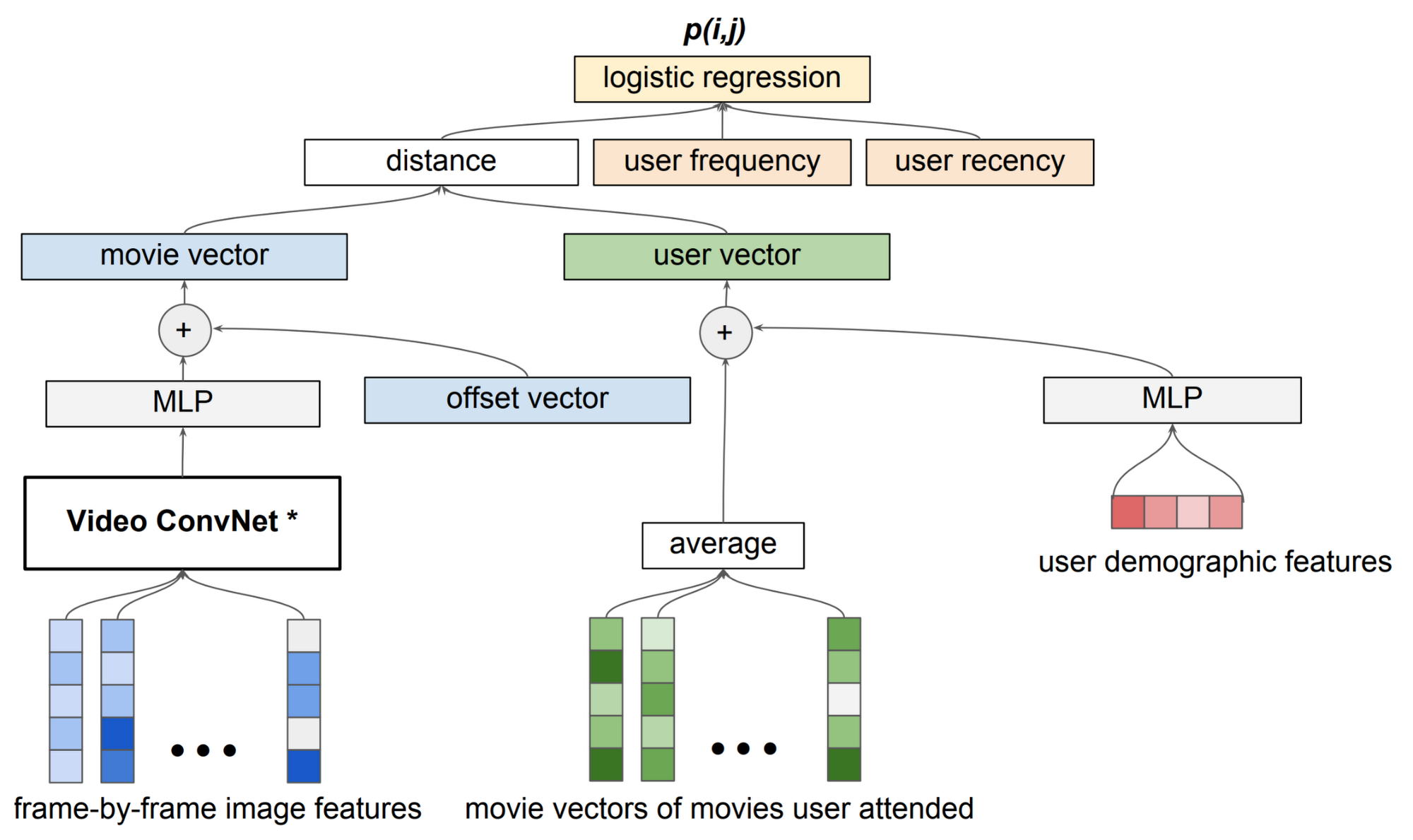
MLX (high overview)