Author response:
eLife Assessment
This valuable study investigates how the neural representation of individual finger movements changes during the early period of sequence learning. By combining a new method for extracting features from human magnetoencephalography data and decoding analyses, the authors provide incomplete evidence of an early, swift change in the brain regions correlated with sequence learning, including a set of previously unreported frontal cortical regions. The addition of more control analyses to rule out that head movement artefacts influence the findings, and to further explain the proposal of offline contextualization during short rest periods as the basis for improvement performance would strengthen the manuscript.
We appreciate the Editorial assessment on our paper’s strengths and novelty. We have implemented additional control analyses to show that neither task-related eye movements nor increasing overlap of finger movements during learning account for our findings, which are that contextualized neural representations in a network of bilateral frontoparietal brain regions actively contribute to skill learning. Importantly, we carried out additional analyses showing that contextualization develops predominantly during rest intervals.
Public Reviews:
We thank the Reviewers for their comments and suggestions, prompting new analyses and additions that strengthened our report.
Reviewer #1 (Public review):
Summary:
This study addresses the issue of rapid skill learning and whether individual sequence elements (here: finger presses) are differentially represented in human MEG data. The authors use a decoding approach to classify individual finger elements and accomplish an accuracy of around 94%. A relevant finding is that the neural representations of individual finger elements dynamically change over the course of learning. This would be highly relevant for any attempts to develop better brain machine interfaces - one now can decode individual elements within a sequence with high precision, but these representations are not static but develop over the course of learning.
Strengths: The work follows a large body of work from the same group on the behavioural and neural foundations of sequence learning. The behavioural task is well established and neatly designed to allow for tracking learning and how individual sequence elements contribute. The inclusion of short offline rest periods between learning epochs has been influential because it has revealed that a lot, if not most of the gains in behaviour (ie speed of finger movements) occur in these so-called micro-offline rest periods. The authors use a range of new decoding techniques, and exhaustively interrogate their data in different ways, using different decoding approaches. Regardless of the approach, impressively high decoding accuracies are observed, but when using a hybrid approach that combines the MEG data in different ways, the authors observe decoding accuracies of individual sequence elements from the MEG data of up to 94%.
We have previously showed that neural replay of MEG activity representing the practiced skill correlated with micro-offline gains during rest intervals of early learning, 1 consistent with the recent report that hippocampal ripples during these offline periods predict human motor sequence learning2. However, decoding accuracy in our earlier work1 needed improvement. Here, we reported a strategy to improve decoding accuracy that could benefit future studies of neural replay or BCI using MEG.
Weaknesses:
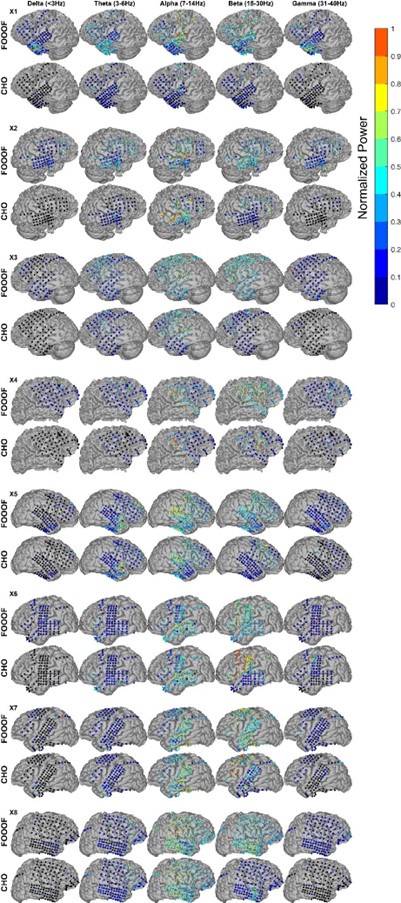
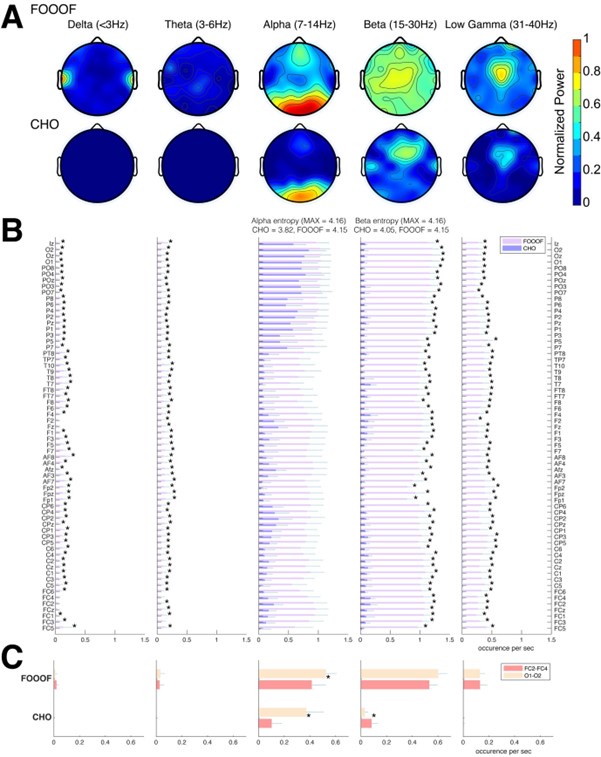
There are a few concerns which the authors may well be able to resolve. These are not weaknesses as such, but factors that would be helpful to address as these concern potential contributions to the results that one would like to rule out. Regarding the decoding results shown in Figure 2 etc, a concern is that within individual frequency bands, the highest accuracy seems to be within frequencies that match the rate of keypresses. This is a general concern when relating movement to brain activity, so is not specific to decoding as done here. As far as reported, there was no specific restraint to the arm or shoulder, and even then it is conceivable that small head movements would correlate highly with the vigor of individual finger movements. This concern is supported by the highest contribution in decoding accuracy being in middle frontal regions - midline structures that would be specifically sensitive to movement artefacts and don't seem to come to mind as key structures for very simple sequential keypress tasks such as this - and the overall pattern is remarkably symmetrical (despite being a unimanual finger task) and spatially broad. This issue may well be matching the time course of learning, as the vigor and speed of finger presses will also influence the degree to which the arm/shoulder and head move. This is not to say that useful information is contained within either of the frequencies or broadband data. But it raises the question of whether a lot is dominated by movement "artefacts" and one may get a more specific answer if removing any such contributions.
Reviewer #1 expresses concern that the combination of the low-frequency narrow-band decoder results, and the bilateral middle frontal regions displaying the highest average intra-parcel decoding performance across subjects is suggestive that the decoding results could be driven by head movement or other artefacts.
Head movement artefacts are highly unlikely to contribute meaningfully to our results for the following reasons. First, in addition to ICA denoising, all “recordings were visually inspected and marked to denoise segments containing other large amplitude artifacts due to movements” (see Methods). Second, the response pad was positioned in a manner that minimized wrist, arm or more proximal body movements during the task. Third, while head position was not monitored online for this study, the head was restrained using an inflatable air bladder, and head position was assessed at the beginning and at the end of each recording. Head movement did not exceed 5mm between the beginning and end of each scan for all participants included in the study. Fourth, we agree that despite the steps taken above, it is possible that minor head movements could still contribute to some remaining variance in the MEG data in our study. The Reviewer states a concern that “it is conceivable that small head movements would correlate highly with the vigor of individual finger movements”. However, in order for any such correlations to meaningfully impact decoding performance, such head movements would need to: (A) be consistent and pervasive throughout the recording (which might not be the case if the head movements were related to movement vigor and vigor changed over time); and (B) systematically vary between different finger movements, and also between the same finger movement performed at different sequence locations (see 5-class decoding performance in Figure 4B). The possibility of any head movement artefacts meeting all these conditions is extremely unlikely.
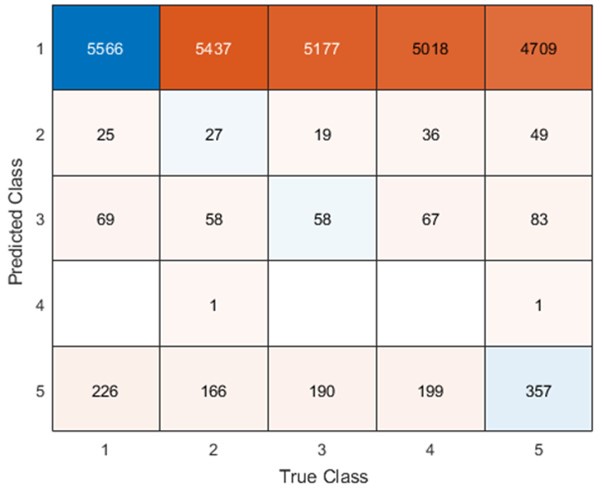
Given the task design, a much more likely confound in our estimation would be the contribution of eye movement artefacts to the decoder performance (an issue appropriately raised by Reviewer #3 in the comments below). Remember from Figure 1A in the manuscript that an asterisk marks the current position in the sequence and is updated at each keypress. Since participants make very few performance errors, the position of the asterisk on the display is highly correlated with the keypress being made in the sequence. Thus, it is possible that if participants are attending to the visual feedback provided on the display, they may move their eyes in a way that is systematically related to the task. Since we did record eye movements simultaneously with the MEG recordings (EyeLink 1000 Plus; Fs = 600 Hz), we were able to perform a control analysis to address this question. For each keypress event during trials in which no errors occurred (which is the same time-point that the asterisk position is updated), we extracted three features related to eye movements: 1) the gaze position at the time of asterisk position update (or keyDown event), 2) the gaze position 150ms later, and 3) the peak velocity of the eye movement between the two positions. We then constructed a classifier from these features with the aim of predicting the location of the asterisk (ordinal positions 1-5) on the display. As shown in the confusion matrix below (Author response image 1), the classifier failed to perform above chance levels (Overall cross-validated accuracy = 0.21817):
Author response image 1.
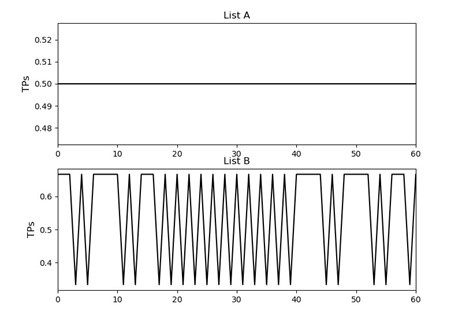
Confusion matrix showing that three eye movement features fail to predict asterisk position on the task display above chance levels (Fold 1 test accuracy = 0.21718; Fold 2 test accuracy = 0.22023; Fold 3 test accuracy = 0.21859; Fold 4 test accuracy = 0.22113; Fold 5 test accuracy = 0.21373; Overall cross-validated accuracy = 0.2181). Since the ordinal position of the asterisk on the display is highly correlated with the ordinal position of individual keypresses in the sequence, this analysis provides strong evidence that keypress decoding performance from MEG features is not explained by systematic relationships between finger movement behavior and eye movements (i.e. – behavioral artefacts).
In fact, inspection of the eye position data revealed that a majority of participants on most trials displayed random walk gaze patterns around a center fixation point, indicating that participants did not attend to the asterisk position on the display. This is consistent with intrinsic generation of the action sequence, and congruent with the fact that the display does not provide explicit feedback related to performance. A similar real-world example would be manually inputting a long password into a secure online application. In this case, one intrinsically generates the sequence from memory and receives similar feedback about the password sequence position (also provided as asterisks), which is typically ignored by the user. The minimal participant engagement with the visual task display observed in this study highlights another important point – that the behavior in explicit sequence learning motor tasks is highly generative in nature rather than reactive to stimulus cues as in the serial reaction time task (SRTT). This is a crucial difference that must be carefully considered when designing investigations and comparing findings across studies.
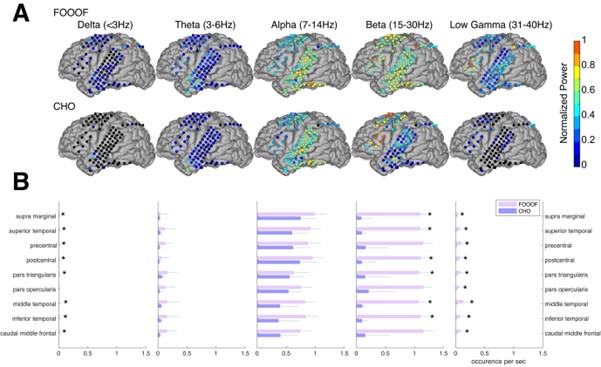
We observed that initial keypress decoding accuracy was predominantly driven by contralateral primary sensorimotor cortex in the initial practice trials before transitioning to bilateral frontoparietal regions by trials 11 or 12 as performance gains plateaued. The contribution of contralateral primary sensorimotor areas to early skill learning has been extensively reported in humans and non-human animals. 1,3-5 Similarly, the increased involvement of bilateral frontal and parietal regions to decoding during early skill learning in the non-dominant hand is well known. Enhanced bilateral activation in both frontal and parietal cortex during skill learning has been extensively reported6-11, and appears to be even more prominent during early fine motor skill learning in the non-dominant hand12,13. The frontal regions identified in these studies are known to play crucial roles in executive control14, motor planning15, and working memory6,8,16-18 processes, while the same parietal regions are known to integrate multimodal sensory feedback and support visuomotor transformations6,8,16-18, in addition to working memory19. Thus, it is not surprising that these regions increasingly contribute to decoding as subjects internalize the sequential task. We now include a statement reflecting these considerations in the revised Discussion.
A somewhat related point is this: when combining voxel and parcel space, a concern is whether a degree of circularity may have contributed to the improved accuracy of the combined data, because it seems to use the same MEG signals twice - the voxels most contributing are also those contributing most to a parcel being identified as relevant, as parcels reflect the average of voxels within a boundary. In this context, I struggled to understand the explanation given, ie that the improved accuracy of the hybrid model may be due to "lower spatially resolved whole-brain and higher spatially resolved regional activity patterns".
We strongly disagree with the Reviewer’s assertion that the construction of the hybrid-space decoder is circular. To clarify, the base feature set for the hybrid-space decoder constructed for all participants includes whole-brain spatial patterns of MEG source activity averaged within parcels. As stated in the manuscript, these 148 inter-parcel features reflect “lower spatially resolved whole-brain activity patterns” or global brain dynamics. We then independently test how well spatial patterns of MEG source activity for all voxels distributed within individual parcels can decode keypress actions. Again, the testing of these intra-parcel spatial patterns, intended to capture “higher spatially resolved regional brain activity patterns”, is completely independent from one another and independent from the weighting of individual inter-parcel features. These intra-parcel features could, for example, provide additional information about muscle activation patterns or the task environment. These approximately 1150 intra-parcel voxels (on average, within the total number varying between subjects) are then combined with the 148 inter-parcel features to construct the final hybrid-space decoder. In fact, this varied spatial filter approach shares some similarities to the construction of convolutional neural networks (CNNs) used to perform object recognition in image classification applications. One could also view this hybrid-space decoding approach as a spatial analogue to common time-frequency based analyses such as theta-gamma phase amplitude coupling (PAC), which combine information from two or more narrow-band spectral features derived from the same time-series data.
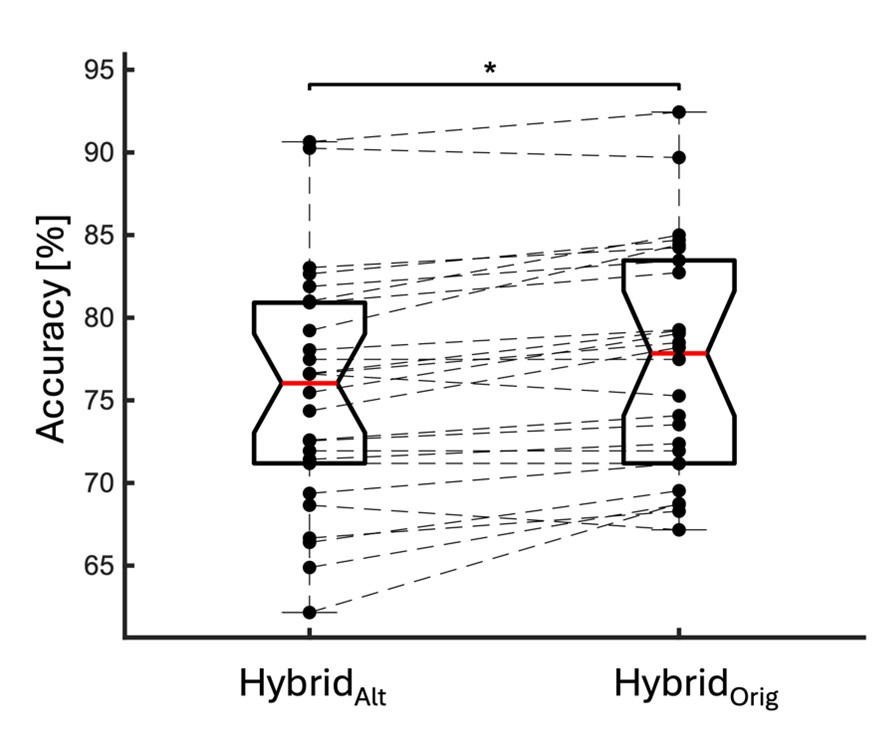
We directly tested this hypothesis – that spatially overlapping intra- and inter-parcel features portray different information – by constructing an alternative hybrid-space decoder (HybridAlt) that excluded average inter-parcel features which spatially overlapped with intra-parcel voxel features, and comparing the performance to the decoder used in the manuscript (HybridOrig). The prediction was that if the overlapping parcel contained similar information to the more spatially resolved voxel patterns, then removing the parcel features (n=8) from the decoding analysis should not impact performance. In fact, despite making up less than 1% of the overall input feature space, removing those parcels resulted in a significant drop in overall performance greater than 2% (78.15% ± SD 7.03% for HybridOrig vs. 75.49% ± SD 7.17% for HybridAlt; Wilcoxon signed rank test, z = 3.7410, p = 1.8326e-04) (Author response image 2).
Author response image 2.
Comparison of decoding performances with two different hybrid approaches. HybridAlt: Intra-parcel voxel-space features of top ranked parcels and inter-parcel features of remaining parcels. HybridOrig: Voxel-space features of top ranked parcels and whole-brain parcel-space features (i.e. – the version used in the manuscript). Dots represent decoding accuracy for individual subjects. Dashed lines indicate the trend in performance change across participants. Note, that HybridOrig (the approach used in our manuscript) significantly outperforms the HybridAlt approach, indicating that the excluded parcel features provide unique information compared to the spatially overlapping intra-parcel voxel patterns.
Firstly, there will be a relatively high degree of spatial contiguity among voxels because of the nature of the signal measured, i.e. nearby individual voxels are unlikely to be independent. Secondly, the voxel data gives a somewhat misleading sense of precision; the inversion can be set up to give an estimate for each voxel, but there will not just be dependence among adjacent voxels, but also substantial variation in the sensitivity and confidence with which activity can be projected to different parts of the brain. Midline and deeper structures come to mind, where the inversion will be more problematic than for regions along the dorsal convexity of the brain, and a concern is that in those midline structures, the highest decoding accuracy is seen.
We definitely agree with the Reviewer that some inter-parcel features representing neighboring (or spatially contiguous) voxels are likely to be correlated. This has been well documented in the MEG literature20,21 and is a particularly important confound to address in functional or effective connectivity analyses (not performed in the present study). In the present analysis, any correlation between adjacent voxels presents a multi-collinearity problem, which effectively reduces the dimensionality of the input feature space. However, as long as there are multiple groups of correlated voxels within each parcel (i.e. - the effective dimensionality is still greater than 1), the intra-parcel spatial patterns could still meaningfully contribute to the decoder performance. Two specific results support this assertion.
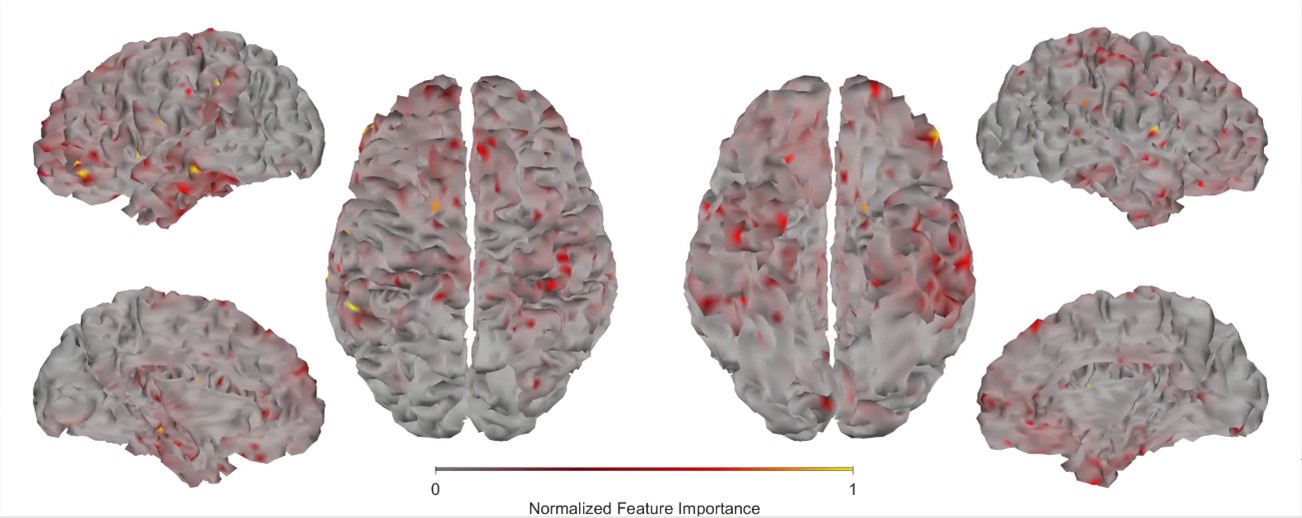
First, we obtained higher decoding accuracy with voxel-space features [74.51% (± SD 7.34%)] compared to parcel space features [68.77% (± SD 7.6%)] (Figure 3B), indicating individual voxels carry more information in decoding the keypresses than the averaged voxel-space features or parcel-space features. Second, Individual voxels within a parcel showed varying feature importance scores in decoding keypresses (Author response image 3). This finding supports the Reviewer’s assertion that neighboring voxels express similar information, but also shows that the correlated voxels form mini subclusters that are much smaller spatially than the parcel they reside in.
Author response image 3.
Feature importance score of individual voxels in decoding keypresses: MRMR was used to rank the individual voxel space features in decoding keypresses and the min-max normalized MRMR score was mapped to a structural brain surface. Note that individual voxels within a parcel showed different contribution to decoding.
Some of these concerns could be addressed by recording head movement (with enough precision) to regress out these contributions. The authors state that head movement was monitored with 3 fiducials, and their time courses ought to provide a way to deal with this issue. The ICA procedure may not have sufficiently dealt with removing movement-related problems, but one could eg relate individual components that were identified to the keypresses as another means for checking. An alternative could be to focus on frequency ranges above the movement frequencies. The accuracy for those still seems impressive and may provide a slightly more biologically plausible assessment.
We have already addressed the issue of movement related artefacts in the first response above. With respect to a focus on frequency ranges above movement frequencies, the Reviewer states the “accuracy for those still seems impressive and may provide a slightly more biologically plausible assessment”. First, it is important to note that cortical delta-band oscillations measured with local field potentials (LFPs) in macaques is known to contain important information related to end-effector kinematics22,23 muscle activation patterns24 and temporal sequencing25 during skilled reaching and grasping actions. Thus, there is a substantial body of evidence that low-frequency neural oscillatory activity in this range contains important information about the skill learning behavior investigated in the present study. Second, our own data shows (which the Reviewer also points out) that significant information related to the skill learning behavior is also present in higher frequency bands (see Figure 2A and Figure 3—figure supplement 1). As we pointed out in our earlier response to questions about the hybrid space decoder architecture (see above), it is likely that different, yet complimentary, information is encoded across different temporal frequencies (just as it is encoded across different spatial frequencies). Again, this interpretation is supported by our data as the highest performing classifiers in all cases (when holding all parameters constant) were always constructed from broadband input MEG data (Figure 2A and Figure 3—figure supplement 1).
One question concerns the interpretation of the results shown in Figure 4. They imply that during the course of learning, entirely different brain networks underpin the behaviour. Not only that, but they also include regions that would seem rather unexpected to be key nodes for learning and expressing relatively simple finger sequences, such as here. What then is the biological plausibility of these results? The authors seem to circumnavigate this issue by moving into a distance metric that captures the (neural network) changes over the course of learning, but the discussion seems detached from which regions are actually involved; or they offer a rather broad discussion of the anatomical regions identified here, eg in the context of LFOs, where they merely refer to "frontoparietal regions".
The Reviewer notes the shift in brain networks driving keypress decoding performance between trials 1, 11 and 36 as shown in Figure 4A. The Reviewer questions whether these substantial shifts in brain network states underpinning the skill are biologically plausible, as well as the likelihood that bilateral superior and middle frontal and parietal cortex are important nodes within these networks.
First, previous fMRI work in humans performing a similar sequence learning task showed that flexibility in brain network composition (i.e. – changes in brain region members displaying coordinated activity) is up-regulated in novel learning environments and explains differences in learning rates across individuals26. This work supports our interpretation of the present study data, that brain networks engaged in sequential motor skills rapidly reconfigure during early learning.
Second, frontoparietal network activity is known to support motor memory encoding during early learning27,28. For example, reactivation events in the posterior parietal29 and medial prefrontal30,31 cortex (MPFC) have been temporally linked to hippocampal replay, and are posited to support memory consolidation across several memory domains32, including motor sequence learning1,33,34. Further, synchronized interactions between MPFC and hippocampus are more prominent during early learning as opposed to later stages27,35,36, perhaps reflecting “redistribution of hippocampal memories to MPFC” 27. MPFC contributes to very early memory formation by learning association between contexts, locations, events and adaptive responses during rapid learning37. Consistently, coupling between hippocampus and MPFC has been shown during, and importantly immediately following (rest) initial memory encoding38,39. Importantly, MPFC activity during initial memory encoding predicts subsequent recall40. Thus, the spatial map required to encode a motor sequence memory may be “built under the supervision of the prefrontal cortex” 28, also engaged in the development of an abstract representation of the sequence41. In more abstract terms, the prefrontal, premotor and parietal cortices support novice performance “by deploying attentional and control processes” 42-44 required during early learning42-44. The dorsolateral prefrontal cortex DLPFC specifically is thought to engage in goal selection and sequence monitoring during early skill practice45, all consistent with the schema model of declarative memory in which prefrontal cortices play an important role in encoding46,47. Thus, several prefrontal and frontoparietal regions contributing to long term learning 48 are also engaged in early stages of encoding. Altogether, there is strong biological support for the involvement of bilateral prefrontal and frontoparietal regions to decoding during early skill learning. We now address this issue in the revised manuscript.
If I understand correctly, the offline neural representation analysis is in essence the comparison of the last keypress vs the first keypress of the next sequence. In that sense, the activity during offline rest periods is actually not considered. This makes the nomenclature somewhat confusing. While it matches the behavioural analysis, having only key presses one can't do it in any other way, but here the authors actually do have recordings of brain activity during offline rest. So at the very least calling it offline neural representation is misleading to this reviewer because what is compared is activity during the last and during the next keypress, not activity during offline periods. But it also seems a missed opportunity - the authors argue that most of the relevant learning occurs during offline rest periods, yet there is no attempt to actually test whether activity during this period can be useful for the questions at hand here.
We agree with the Reviewer that our previous “offline neural representation” nomenclature could be misinterpreted. In the revised manuscript we refer to this difference as the “offline neural representational change”. Please, note that our previous work did link offline neural activity (i.e. – 16-22 Hz beta power and neural replay density during inter-practice rest periods) to observed micro-offline gains49.
Reviewer #2 (Public review):
Summary
Dash et al. asked whether and how the neural representation of individual finger movements is "contextualized" within a trained sequence during the very early period of sequential skill learning by using decoding of MEG signal. Specifically, they assessed whether/how the same finger presses (pressing index finger) embedded in the different ordinal positions of a practiced sequence (4-1-3-2-4; here, the numbers 1 through 4 correspond to the little through the index fingers of the non-dominant left hand) change their representation (MEG feature). They did this by computing either the decoding accuracy of the index finger at the ordinal positions 1 vs. 5 (index_OP1 vs index_OP5) or pattern distance between index_OP1 vs. index_OP5 at each training trial and found that both the decoding accuracy and the pattern distance progressively increase over the course of learning trials. More interestingly, they also computed the pattern distance for index_OP5 for the last execution of a practice trial vs. index_OP1 for the first execution in the next practice trial (i.e., across the rest period). This "off-line" distance was significantly larger than the "on-line" distance, which was computed within practice trials and predicted micro-offline skill gain. Based on these results, the authors conclude that the differentiation of representation for the identical movement embedded in different positions of a sequential skill ("contextualization") primarily occurs during early skill learning, especially during rest, consistent with the recent theory of the "micro-offline learning" proposed by the authors' group. I think this is an important and timely topic for the field of motor learning and beyond. <br />
Strengths
The specific strengths of the current work are as follows. First, the use of temporally rich neural information (MEG signal) has a large advantage over previous studies testing sequential representations using fMRI. This allowed the authors to examine the earliest period (= the first few minutes of training) of skill learning with finer temporal resolution. Second, through the optimization of MEG feature extraction, the current study achieved extremely high decoding accuracy (approx. 94%) compared to previous works. As claimed by the authors, this is one of the strengths of the paper (but see my comments). Third, although some potential refinement might be needed, comparing "online" and "offline" pattern distance is a neat idea.
Weaknesses
Along with the strengths I raised above, the paper has some weaknesses. First, the pursuit of high decoding accuracy, especially the choice of time points and window length (i.e., 200 msec window starting from 0 msec from key press onset), casts a shadow on the interpretation of the main result. Currently, it is unclear whether the decoding results simply reflect behavioral change or true underlying neural change. As shown in the behavioral data, the key press speed reached 3~4 presses per second already at around the end of the early learning period (11th trial), which means inter-press intervals become as short as 250-330 msec. Thus, in almost more than 60% of training period data, the time window for MEG feature extraction (200 msec) spans around 60% of the inter-press intervals. Considering that the preparation/cueing of subsequent presses starts ahead of the actual press (e.g., Kornysheva et al., 2019) and/or potential online planning (e.g., Ariani and Diedrichsen, 2019), the decoder likely has captured these future press information as well as the signal related to the current key press, independent of the formation of genuine sequential representation (e.g., "contextualization" of individual press). This may also explain the gradual increase in decoding accuracy or pattern distance between index_OP1 vs. index_OP5 (Figure 4C and 5A), which co-occurred with performance improvement, as shorter inter-press intervals are more favorable for the dissociating the two index finger presses followed by different finger presses. The compromised decoding accuracies for the control sequences can be explained in similar logic. Therefore, more careful consideration and elaborated discussion seem necessary when trying to both achieve high-performance decoding and assess early skill learning, as it can impact all the subsequent analyses.
The Reviewer raises the possibility that (given the windowing parameters used in the present study) an increase in “contextualization” with learning could simply reflect faster typing speeds as opposed to an actual change in the underlying neural representation. The issue can essentially be framed as a mixing problem. As correct sequences are generated at higher and higher speeds over training, MEG activity patterns related to the planning, execution, evaluation and memory of individual keypresses overlap more in time. Thus, increased overlap between the “4” and “1” keypresses (at the start of the sequence) and “2” and “4” keypresses (at the end of the sequence) could artefactually increase contextualization distances even if the underlying neural representations for the individual keypresses remain unchanged (assuming this mixing of representations is used by the classifier to differentially tag each index finger press). If this were the case, it follows that such mixing effects reflecting the ordinal sequence structure would also be observable in the distribution of decoder misclassifications. For example, “4” keypresses would be more likely to be misclassified as “1” or “2” keypresses (or vice versa) than as “3” keypresses. The confusion matrices presented in Figures 3C and 4B and Figure 3—figure supplement 3A in the previously submitted manuscript do not show this trend in the distribution of misclassifications across the four fingers.
Moreover, if the representation distance is largely driven by this mixing effect, it’s also possible that the increased overlap between consecutive index finger keypresses during the 4-4 transition marking the end of one sequence and the beginning of the next one could actually mask contextualization-related changes to the underlying neural representations and make them harder to detect. In this case, a decoder tasked with separating individual index finger keypresses into two distinct classes based upon sequence position might show decreased performance with learning as adjacent keypresses overlapped in time with each other to an increasing extent. However, Figure 4C in our previously submitted manuscript does not support this possibility, as the 2-class hybrid classifier displays improved classification performance over early practice trials despite greater temporal overlap.
We also conducted a new multivariate regression analysis to directly assess whether the neural representation distance score could be predicted by the 4-1, 2-4 and 4-4 keypress transition times observed for each complete correct sequence (both predictor and response variables were z-score normalized within-subject). The results of this analysis affirmed that the possible alternative explanation put forward by the Reviewer is not supported by our data (Adjusted R2 = 0.00431; F = 5.62). We now include this new negative control analysis result in the revised manuscript.
Overall, we do strongly agree with the Reviewer that the naturalistic, self-paced, generative task employed in the present study results in overlapping brain processes related to planning, execution, evaluation and memory of the action sequence. We also agree that there are several tradeoffs to consider in the construction of the classifiers depending on the study aim. Given our aim of optimizing keypress decoder accuracy in the present study, the set of trade-offs resulted in representations reflecting more the latter three processes, and less so the planning component. Whether separate decoders can be constructed to tease apart the representations or networks supporting these overlapping processes is an important future direction of research in this area. For example, work presently underway in our lab constrains the selection of windowing parameters in a manner that allows individual classifiers to be temporally linked to specific planning, execution, evaluation or memory-related processes to discern which brain networks are involved and how they adaptively reorganize with learning. Results from the present study (Figure 4—figure supplement 2) showing hybrid-space decoder prediction accuracies exceeding 74% for temporal windows spanning as little as 25ms and located up to 100ms prior to the keyDown event strongly support the feasibility of such an approach.
Related to the above point, testing only one particular sequence (4-1-3-2-4), aside from the control ones, limits the generalizability of the finding. This also may have contributed to the extremely high decoding accuracy reported in the current study.
The Reviewer raises a question about the generalizability of the decoder accuracy reported in our study. Fortunately, a comparison between decoder performances on Day 1 and Day 2 datasets does provide some insight into this issue. As the Reviewer points out, the classifiers in this study were trained and tested on keypresses performed while practicing a specific sequence (4-1-3-2-4). The study was designed this way as to avoid the impact of interference effects on learning dynamics. The cross-validated performance of classifiers on MEG data collected within the same session was 90.47% overall accuracy (4-class; Figure 3C). We then tested classifier performance on data collected during a separate MEG session conducted approximately 24 hours later (Day 2; see Figure 3—supplement 3). We observed a reduction in overall accuracy rate to 87.11% when tested on MEG data recorded while participants performed the same learned sequence, and 79.44% when they performed several previously unpracticed sequences. Both changes in accuracy are important with regards to the generalizability of our findings. First, 87.11% performance accuracy for the trained sequence data on Day 2 (a reduction of only 3.36%) indicates that the hybrid-space decoder performance is robust over multiple MEG sessions, and thus, robust to variations in SNR across the MEG sensor array caused by small differences in head position between scans. This indicates a substantial advantage over sensor-space decoding approaches. Furthermore, when tested on data from unpracticed sequences, overall performance dropped an additional 7.67%. This difference reflects the performance bias of the classifier for the trained sequence, possibly caused by high-order sequence structure being incorporated into the feature weights. In the future, it will be important to understand in more detail how random or repeated keypress sequence training data impacts overall decoder performance and generalization. We strongly agree with the Reviewer that the issue of generalizability is extremely important and have added a new paragraph to the Discussion in the revised manuscript highlighting the strengths and weaknesses of our study with respect to this issue.
In terms of clinical BCI, one of the potential relevance of the study, as claimed by the authors, it is not clear that the specific time window chosen in the current study (up to 200 msec since key press onset) is really useful. In most cases, clinical BCI would target neural signals with no overt movement execution due to patients' inability to move (e.g., Hochberg et al., 2012). Given the time window, the surprisingly high performance of the current decoder may result from sensory feedback and/or planning of subsequent movement, which may not always be available in the clinical BCI context. Of course, the decoding accuracy is still much higher than chance even when using signal before the key press (as shown in Figure 4 Supplement 2), but it is not immediately clear to me that the authors relate their high decoding accuracy based on post-movement signal to clinical BCI settings.
The Reviewer questions the relevance of the specific window parameters used in the present study for clinical BCI applications, particularly for paretic patients who are unable to produce finger movements or for whom afferent sensory feedback is no longer intact. We strongly agree with the Reviewer that any intended clinical application must carefully consider these specific input feature constraints dictated by the clinical cohort, and in turn impose appropriate and complimentary constraints on classifier parameters that may differ from the ones used in the present study. We now highlight this issue in the Discussion of the revised manuscript and relate our present findings to published clinical BCI work within this context.
One of the important and fascinating claims of the current study is that the "contextualization" of individual finger movements in a trained sequence specifically occurs during short rest periods in very early skill learning, echoing the recent theory of micro-offline learning proposed by the authors' group. Here, I think two points need to be clarified. First, the concept of "contextualization" is kept somewhat blurry throughout the text. It is only at the later part of the Discussion (around line #330 on page 13) that some potential mechanism for the "contextualization" is provided as "what-and-where" binding. Still, it is unclear what "contextualization" actually is in the current data, as the MEG signal analyzed is extracted from 0-200 msec after the keypress. If one thinks something is contextualizing an action, that contextualization should come earlier than the action itself.
The Reviewer requests that we: 1) more clearly define our use of the term “contextualization” and 2) provide the rationale for assessing it over a 200ms window aligned to the keyDown event. This choice of window parameters means that the MEG activity used in our analysis was coincident with, rather than preceding, the actual keypresses. We define contextualization as the differentiation of representation for the identical movement embedded in different positions of a sequential skill. That is, representations of individual action elements progressively incorporate information about their relationship to the overall sequence structure as the skill is learned. We agree with the Reviewer that this can be appropriately interpreted as “what-and-where” binding. We now incorporate this definition in the Introduction of the revised manuscript as requested.
The window parameters for optimizing accurate decoding individual finger movements were determined using a grid search of the parameter space (a sliding window of variable width between 25-350 ms with 25 ms increments variably aligned from 0 to +100ms with 10ms increments relative to the keyDown event). This approach generated 140 different temporal windows for each keypress for each participant, with the final parameter selection determined through comparison of the resulting performance between each decoder. Importantly, the decision to optimize for decoding accuracy placed an emphasis on keypress representations characterized by the most consistent and robust features shared across subjects, which in turn maximize statistical power in detecting common learning-related changes. In this case, the optimal window encompassed a 200ms epoch aligned to the keyDown event (t0 = 0 ms). We then asked if the representations (i.e. – spatial patterns of combined parcel- and voxel-space activity) of the same digit at two different sequence positions changed with practice within this optimal decoding window. Of course, our findings do not rule out the possibility that contextualization can also be found before or even after this time window, as we did not directly address this issue in the present study. Ongoing work in our lab, as pointed out above, is investigating contextualization within different time windows tailored specifically for assessing sequence skill action planning, execution, evaluation and memory processes.
The second point is that the result provided by the authors is not yet convincing enough to support the claim that "contextualization" occurs during rest. In the original analysis, the authors presented the statistical significance regarding the correlation between the "offline" pattern differentiation and micro-offline skill gain (Figure 5. Supplement 1), as well as the larger "offline" distance than "online" distance (Figure 5B). However, this analysis looks like regressing two variables (monotonically) increasing as a function of the trial. Although some information in this analysis, such as what the independent/dependent variables were or how individual subjects were treated, was missing in the Methods, getting a statistically significant slope seems unsurprising in such a situation. Also, curiously, the same quantitative evidence was not provided for its "online" counterpart, and the authors only briefly mentioned in the text that there was no significant correlation between them. It may be true looking at the data in Figure 5A as the online representation distance looks less monotonically changing, but the classification accuracy presented in Figure 4C, which should reflect similar representational distance, shows a more monotonic increase up to the 11th trial. Further, the ways the "online" and "offline" representation distance was estimated seem to make them not directly comparable. While the "online" distance was computed using all the correct press data within each 10 sec of execution, the "offline" distance is basically computed by only two presses (i.e., the last index_OP5 vs. the first index_OP1 separated by 10 sec of rest). Theoretically, the distance between the neural activity patterns for temporally closer events tends to be closer than that between the patterns for temporally far-apart events. It would be fairer to use the distance between the first index_OP1 vs. the last index_OP5 within an execution period for "online" distance, as well.
The Reviewer suggests that the current data is not convincing enough to show that contextualization occurs during rest and raises two important concerns: 1) the relationship between online contextualization and micro-online gains is not shown, and 2) the online distance was calculated differently from its offline counterpart (i.e. - instead of calculating the distance between last IndexOP5 and first IndexOP1 from a single trial, the distance was calculated for each sequence within a trial and then averaged).
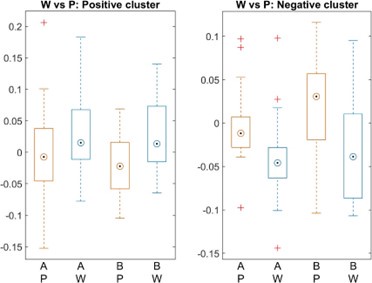
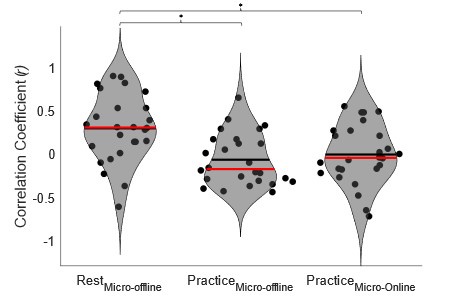
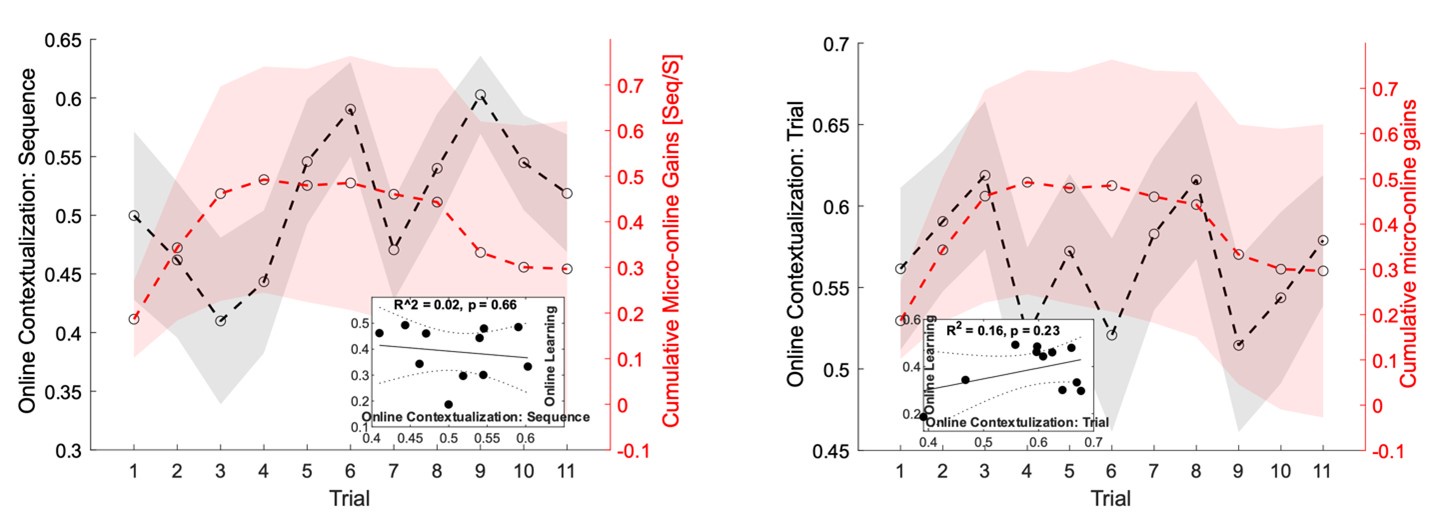
We addressed the first concern by performing individual subject correlations between 1) contextualization changes during rest intervals and micro-offline gains; 2) contextualization changes during practice trials and micro-online gains, and 3) contextualization changes during practice trials and micro-offline gains (Author response image 4). We then statistically compared the resulting correlation coefficient distributions and found that within-subject correlations for contextualization changes during rest intervals and micro-offline gains were significantly higher than online contextualization and micro-online gains (t = 3.2827, p = 0.0015) and online contextualization and micro-offline gains (t = 3.7021, p = 5.3013e-04). These results are consistent with our interpretation that micro-offline gains are supported by contextualization changes during the inter-practice rest period.
Author response image 4.
Distribution of individual subject correlation coefficients between contextualization changes occurring during practice or rest with micro-online and micro-offline performance gains. Note that, the correlation distributions were significantly higher for the relationship between contextualization changes during rest and micro-offline gains than for contextualization changes during practice and either micro-online or offline gain.
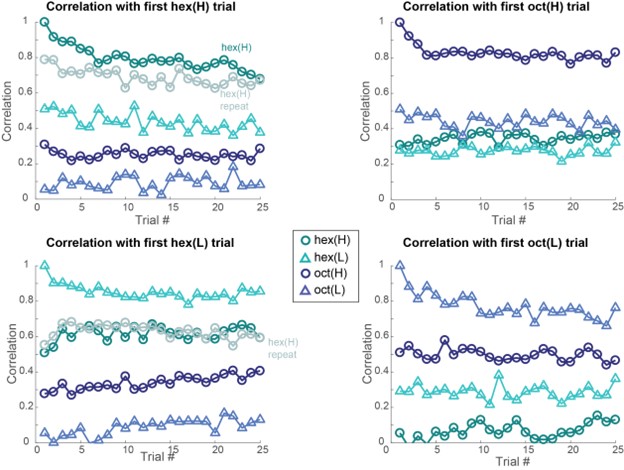
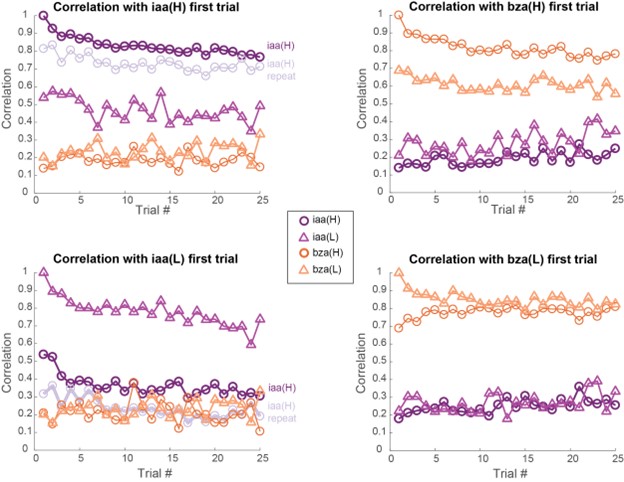
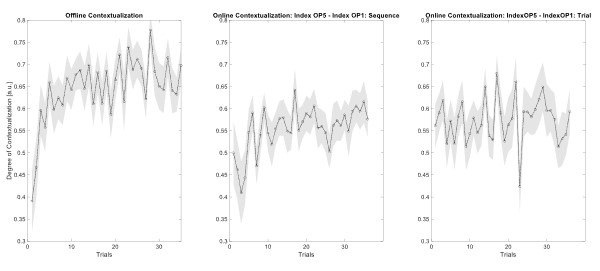
With respect to the second concern highlighted above, we agree with the Reviewer that one limitation of the analysis comparing online versus offline changes in contextualization as presented in the reviewed manuscript, is that it does not eliminate the possibility that any differences could simply be explained by the passage of time (which is smaller for the online analysis compared to the offline analysis). The Reviewer suggests an approach that addresses this issue, which we have now carried out. When quantifying online changes in contextualization from the first IndexOP1 the last IndexOP5 keypress in the same trial we observed no learning-related trend (Author response image 5, right panel). Importantly, offline distances were significantly larger than online distances regardless of the measurement approach and neither predicted online learning (Author response image 6).
Author response image 5.
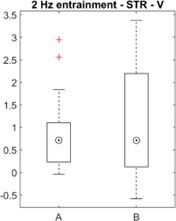
Trial by trial trend of offline (left panel) and online (middle and right panels) changes in contextualization. Offline changes in contextualization were assessed by calculating the distance between neural representations for the last IndexOP5 keypress in the previous trial and the first IndexOP1 keypress in the present trial. Two different approaches were used to characterize online contextualization changes. The analysis included in the reviewed manuscript (middle panel) calculated the distance between IndexOP1 and IndexOP5 for each correct sequence, which was then averaged across the trial. This approach is limited by the lack of control for the passage of time when making online versus offline comparisons. Thus, the second approach controlled for the passage of time by calculating distance between the representations associated with the first IndexOP1 keypress and the last IndexOP5 keypress within the same trial. Note that while the first approach showed an increase online contextualization trend with practice, the second approach did not.
Author response image 6.
Relationship between online contextualization and online learning is shown for both within-sequence (left; note that this is the online contextualization measure used in the reviewd manuscript) and across-sequence (right) distance calculation. There was no significant relationship between online learning and online contextualization regardless of the measurement approach.
A related concern regarding the control analysis, where individual values for max speed and the degree of online contextualization were compared (Figure 5 Supplement 3), is whether the individual difference is meaningful. If I understood correctly, the optimization of the decoding process (temporal window, feature inclusion/reduction, decoder, etc.) was performed for individual participants, and the same feature extraction was also employed for the analysis of representation distance (i.e., contextualization). If this is the case, the distances are individually differently calculated and they may need to be normalized relative to some stable reference (e.g., 1 vs. 4 or average distance within the control sequence presses) before comparison across the individuals.
The Reviewer makes a good point here. We have now implemented the suggested normalization procedure in the analysis provided in the revised manuscript.
Reviewer #3 (Public review):
Summary:
One goal of this paper is to introduce a new approach for highly accurate decoding of finger movements from human magnetoencephalography data via dimension reduction of a "multi-scale, hybrid" feature space. Following this decoding approach, the authors aim to show that early skill learning involves "contextualization" of the neural coding of individual movements, relative to their position in a sequence of consecutive movements. Furthermore, they aim to show that this "contextualization" develops primarily during short rest periods interspersed with skill training and correlates with a performance metric which the authors interpret as an indicator of offline learning. <br />
Strengths:
A clear strength of the paper is the innovative decoding approach, which achieves impressive decoding accuracies via dimension reduction of a "multi-scale, hybrid space". This hybrid-space approach follows the neurobiologically plausible idea of the concurrent distribution of neural coding across local circuits as well as large-scale networks. A further strength of the study is the large number of tested dimension reduction techniques and classifiers (though the manuscript reveals little about the comparison of the latter).
We appreciate the Reviewer’s comments regarding the paper’s strengths.
A simple control analysis based on shuffled class labels could lend further support to this complex decoding approach. As a control analysis that completely rules out any source of overfitting, the authors could test the decoder after shuffling class labels. Following such shuffling, decoding accuracies should drop to chance level for all decoding approaches, including the optimized decoder. This would also provide an estimate of actual chance-level performance (which is informative over and beyond the theoretical chance level). Furthermore, currently, the manuscript does not explain the huge drop in decoding accuracies for the voxel-space decoding (Figure 3B). Finally, the authors' approach to cortical parcellation raises questions regarding the information carried by varying dipole orientations within a parcel (which currently seems to be ignored?) and the implementation of the mean-flipping method (given that there are two dimensions - space and time - what do the authors refer to when they talk about the sign of the "average source", line 477?).
The Reviewer recommends that we: 1) conduct an additional control analysis on classifier performance using shuffled class labels, 2) provide a more detailed explanation regarding the drop in decoding accuracies for the voxel-space decoding following LDA dimensionality reduction (see Fig 3B), and 3) provide additional details on how problems related to dipole solution orientations were addressed in the present study.
In relation to the first point, we have now implemented a random shuffling approach as a control for the classification analyses. The results of this analysis indicated that the chance level accuracy was 22.12% (± SD 9.1%) for individual keypress decoding (4-class classification), and 18.41% (± SD 7.4%) for individual sequence item decoding (5-class classification), irrespective of the input feature set or the type of decoder used. Thus, the decoding accuracy observed with the final model was substantially higher than these chance levels.
Second, please note that the dimensionality of the voxel-space feature set is very high (i.e. – 15684). LDA attempts to map the input features onto a much smaller dimensional space (number of classes-1; e.g. – 3 dimensions, for 4-class keypress decoding). Given the very high dimension of the voxel-space input features in this case, the resulting mapping exhibits reduced accuracy. Despite this general consideration, please refer to Figure 3—figure supplement 3, where we observe improvement in voxel-space decoder performance when utilizing alternative dimensionality reduction techniques.
The decoders constructed in the present study assess the average spatial patterns across time (as defined by the windowing procedure) in the input feature space. We now provide additional details in the Methods of the revised manuscript pertaining to the parcellation procedure and how the sign ambiguity problem was addressed in our analysis.
Weaknesses:
A clear weakness of the paper lies in the authors' conclusions regarding "contextualization". Several potential confounds, described below, question the neurobiological implications proposed by the authors and provide a simpler explanation of the results. Furthermore, the paper follows the assumption that short breaks result in offline skill learning, while recent evidence, described below, casts doubt on this assumption.
We thank the Reviewer for giving us the opportunity to address these issues in detail (see below).
The authors interpret the ordinal position information captured by their decoding approach as a reflection of neural coding dedicated to the local context of a movement (Figure 4). One way to dissociate ordinal position information from information about the moving effectors is to train a classifier on one sequence and test the classifier on other sequences that require the same movements, but in different positions50. In the present study, however, participants trained to repeat a single sequence (4-1-3-2-4). As a result, ordinal position information is potentially confounded by the fixed finger transitions around each of the two critical positions (first and fifth press). Across consecutive correct sequences, the first keypress in a given sequence was always preceded by a movement of the index finger (=last movement of the preceding sequence), and followed by a little finger movement. The last keypress, on the other hand, was always preceded by a ring finger movement, and followed by an index finger movement (=first movement of the next sequence). Figure 4 - Supplement 2 shows that finger identity can be decoded with high accuracy (>70%) across a large time window around the time of the key press, up to at least +/-100 ms (and likely beyond, given that decoding accuracy is still high at the boundaries of the window depicted in that figure). This time window approaches the keypress transition times in this study. Given that distinct finger transitions characterized the first and fifth keypress, the classifier could thus rely on persistent (or "lingering") information from the preceding finger movement, and/or "preparatory" information about the subsequent finger movement, in order to dissociate the first and fifth keypress. Currently, the manuscript provides no evidence that the context information captured by the decoding approach is more than a by-product of temporally extended, and therefore overlapping, but independent neural representations of consecutive keypresses that are executed in close temporal proximity - rather than a neural representation dedicated to context.
Such temporal overlap of consecutive, independent finger representations may also account for the dynamics of "ordinal coding"/"contextualization", i.e., the increase in 2-class decoding accuracy, across Day 1 (Figure 4C). As learning progresses, both tapping speed and the consistency of keypress transition times increase (Figure 1), i.e., consecutive keypresses are closer in time, and more consistently so. As a result, information related to a given keypress is increasingly overlapping in time with information related to the preceding and subsequent keypresses. The authors seem to argue that their regression analysis in Figure 5 - Figure Supplement 3 speaks against any influence of tapping speed on "ordinal coding" (even though that argument is not made explicitly in the manuscript). However, Figure 5 - Figure Supplement 3 shows inter-individual differences in a between-subject analysis (across trials, as in panel A, or separately for each trial, as in panel B), and, therefore, says little about the within-subject dynamics of "ordinal coding" across the experiment. A regression of trial-by-trial "ordinal coding" on trial-by-trial tapping speed (either within-subject or at a group-level, after averaging across subjects) could address this issue. Given the highly similar dynamics of "ordinal coding" on the one hand (Figure 4C), and tapping speed on the other hand (Figure 1B), I would expect a strong relationship between the two in the suggested within-subject (or group-level) regression. Furthermore, learning should increase the number of (consecutively) correct sequences, and, thus, the consistency of finger transitions. Therefore, the increase in 2-class decoding accuracy may simply reflect an increasing overlap in time of increasingly consistent information from consecutive keypresses, which allows the classifier to dissociate the first and fifth keypress more reliably as learning progresses, simply based on the characteristic finger transitions associated with each. In other words, given that the physical context of a given keypress changes as learning progresses - keypresses move closer together in time and are more consistently correct - it seems problematic to conclude that the mental representation of that context changes. To draw that conclusion, the physical context should remain stable (or any changes to the physical context should be controlled for).
The issues raised by Reviewer #3 here are similar to two issues raised by Reviewer #2 above and agree they must both be carefully considered in any evaluation of our findings.
As both Reviewers pointed out, the classifiers in this study were trained and tested on keypresses performed while practicing a specific sequence (4-1-3-2-4). The study was designed this way as to avoid the impact of interference effects on learning dynamics. The cross-validated performance of classifiers on MEG data collected within the same session was 90.47% overall accuracy (4-class; Figure 3C). We then tested classifier performance on data collected during a separate MEG session conducted approximately 24 hours later (Day 2; see Figure 3—supplement 3). We observed a reduction in overall accuracy rate to 87.11% when tested on MEG data recorded while participants performed the same learned sequence, and 79.44% when they performed several previously unpracticed sequences. This classification performance difference of 7.67% when tested on the Day 2 data could reflect the performance bias of the classifier for the trained sequence, possibly caused by mixed information from temporally close keypresses being incorporated into the feature weights.
Along these same lines, both Reviewers also raise the possibility that an increase in “ordinal coding/contextualization” with learning could simply reflect an increase in this mixing effect caused by faster typing speeds as opposed to an actual change in the underlying neural representation. The basic idea is that as correct sequences are generated at higher and higher speeds over training, MEG activity patterns related to the planning, execution, evaluation and memory of individual keypresses overlap more in time. Thus, increased overlap between the “4” and “1” keypresses (at the start of the sequence) and “2” and “4” keypresses (at the end of the sequence) could artefactually increase contextualization distances even if the underlying neural representations for the individual keypresses remain unchanged (assuming this mixing of representations is used by the classifier to differentially tag each index finger press). If this were the case, it follows that such mixing effects reflecting the ordinal sequence structure would also be observable in the distribution of decoder misclassifications. For example, “4” keypresses would be more likely to be misclassified as “1” or “2” keypresses (or vice versa) than as “3” keypresses. The confusion matrices presented in Figures 3C and 4B and Figure 3—figure supplement 3A in the previously submitted manuscript do not show this trend in the distribution of misclassifications across the four fingers.
Following this logic, it’s also possible that if the ordinal coding is largely driven by this mixing effect, the increased overlap between consecutive index finger keypresses during the 4-4 transition marking the end of one sequence and the beginning of the next one could actually mask contextualization-related changes to the underlying neural representations and make them harder to detect. In this case, a decoder tasked with separating individual index finger keypresses into two distinct classes based upon sequence position might show decreased performance with learning as adjacent keypresses overlapped in time with each other to an increasing extent. However, Figure 4C in our previously submitted manuscript does not support this possibility, as the 2-class hybrid classifier displays improved classification performance over early practice trials despite greater temporal overlap.
As noted in the above replay to Reviewer #2, we also conducted a new multivariate regression analysis to directly assess whether the neural representation distance score could be predicted by the 4-1, 2-4 and 4-4 keypress transition times observed for each complete correct sequence (both predictor and response variables were z-score normalized within-subject). The results of this analysis affirmed that the possible alternative explanation put forward by the Reviewer is not supported by our data (Adjusted R2 = 0.00431; F = 5.62). We now include this new negative control analysis result in the revised manuscript.
Finally, the Reviewer hints that one way to address this issue would be to compare MEG responses before and after learning for sequences typed at a fixed speed. However, given that the speed-accuracy trade-off should improve with learning, a comparison between unlearned and learned skill states would dictate that the skill be evaluated at a very low fixed speed. Essentially, such a design presents the problem that the post-training test is evaluating the representation in the unlearned behavioral state that is not representative of the acquired skill. Thus, this approach would not address our experimental question: “do neural representations of the same action performed at different locations within a skill sequence contextually differentiate or remain stable as learning evolves”.
A similar difference in physical context may explain why neural representation distances ("differentiation") differ between rest and practice (Figure 5). The authors define "offline differentiation" by comparing the hybrid space features of the last index finger movement of a trial (ordinal position 5) and the first index finger movement of the next trial (ordinal position 1). However, the latter is not only the first movement in the sequence but also the very first movement in that trial (at least in trials that started with a correct sequence), i.e., not preceded by any recent movement. In contrast, the last index finger of the last correct sequence in the preceding trial includes the characteristic finger transition from the fourth to the fifth movement. Thus, there is more overlapping information arising from the consistent, neighbouring keypresses for the last index finger movement, compared to the first index finger movement of the next trial. A strong difference (larger neural representation distance) between these two movements is, therefore, not surprising, given the task design, and this difference is also expected to increase with learning, given the increase in tapping speed, and the consequent stronger overlap in representations for consecutive keypresses. Furthermore, initiating a new sequence involves pre-planning, while ongoing practice relies on online planning (Ariani et al., eNeuro 2021), i.e., two mental operations that are dissociable at the level of neural representation (Ariani et al., bioRxiv 2023).
The Reviewer argues that the comparison of last finger movement of a trial and the first in the next trial are performed in different circumstances and contexts. This is an important point and one we tend to agree with. For this task, the first sequence in a practice trial (which is pre-planned offline) is performed in a somewhat different context from the sequence iterations that follow, which involve temporally overlapping planning, execution and evaluation processes. The Reviewer is particularly concerned about a difference in the temporal mixing effect issue raised above between the first and last keypresses performed in a trial. However, in contrast to the Reviewers stated argument above, findings from Korneysheva et. al (2019) showed that neural representations of individual actions are competitively queued during the pre-planning period in a manner that reflects the ordinal structure of the learned sequence. Thus, mixing effects are likely still present for the first keypress in a trial. Also note that we now present new control analyses in multiple responses above confirming that hypothetical mixing effects between adjacent keypresses do not explain our reported contextualization finding. A statement addressing these possibilities raised by the Reviewer has been added to the Discussion in the revised manuscript.
In relation to pre-planning, ongoing MEG work in our lab is investigating contextualization within different time windows tailored specifically for assessing how sequence skill action planning evolves with learning.
Given these differences in the physical context and associated mental processes, it is not surprising that "offline differentiation", as defined here, is more pronounced than "online differentiation". For the latter, the authors compared movements that were better matched regarding the presence of consistent preceding and subsequent keypresses (online differentiation was defined as the mean difference between all first vs. last index finger movements during practice). It is unclear why the authors did not follow a similar definition for "online differentiation" as for "micro-online gains" (and, indeed, a definition that is more consistent with their definition of "offline differentiation"), i.e., the difference between the first index finger movement of the first correct sequence during practice, and the last index finger of the last correct sequence. While these two movements are, again, not matched for the presence of neighbouring keypresses (see the argument above), this mismatch would at least be the same across "offline differentiation" and "online differentiation", so they would be more comparable.
This is the same point made earlier by Reviewer #2, and we agree with this assessment. As stated in the response to Reviewer #2 above, we have now carried out quantification of online contextualization using this approach and included it in the revised manuscript. We thank the Reviewer for this suggestion.
A further complication in interpreting the results regarding "contextualization" stems from the visual feedback that participants received during the task. Each keypress generated an asterisk shown above the string on the screen, irrespective of whether the keypress was correct or incorrect. As a result, incorrect (e.g., additional, or missing) keypresses could shift the phase of the visual feedback string (of asterisks) relative to the ordinal position of the current movement in the sequence (e.g., the fifth movement in the sequence could coincide with the presentation of any asterisk in the string, from the first to the fifth). Given that more incorrect keypresses are expected at the start of the experiment, compared to later stages, the consistency in visual feedback position, relative to the ordinal position of the movement in the sequence, increased across the experiment. A better differentiation between the first and the fifth movement with learning could, therefore, simply reflect better decoding of the more consistent visual feedback, based either on the feedback-induced brain response, or feedback-induced eye movements (the study did not include eye tracking). It is not clear why the authors introduced this complicated visual feedback in their task, besides consistency with their previous studies.
We strongly agree with the Reviewer that eye movements related to task engagement are important to rule out as a potential driver of the decoding accuracy or contextualization effect. We address this issue above in response to a question raised by Reviewer #1 about the impact of movement related artefacts in general on our findings.
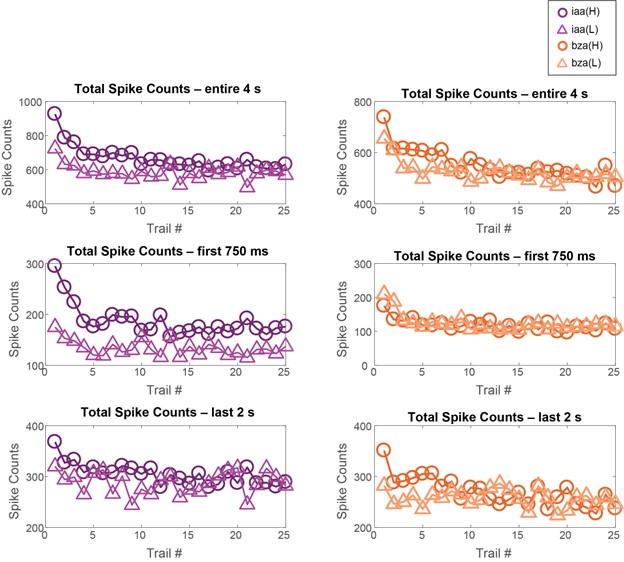
First, the assumption the Reviewer makes here about the distribution of errors in this task is incorrect. On average across subjects, 2.32% ± 1.48% (mean ± SD) of all keypresses performed were errors, which were evenly distributed across the four possible keypress responses. While errors increased progressively over practice trials, they did so in proportion to the increase in correct keypresses, so that the overall ratio of correct-to-incorrect keypresses remained stable over the training session. Thus, the Reviewer’s assumptions that there is a higher relative frequency of errors in early trials, and a resulting systematic trend phase shift differences between the visual display updates (i.e. – a change in asterisk position above the displayed sequence) and the keypress performed is not substantiated by the data. To the contrary, the asterisk position on the display and the keypress being executed remained highly correlated over the entire training session. We now include a statement about the frequency and distribution of errors in the revised manuscript.
Given this high correlation, we firmly agree with the Reviewer that the issue of eye movement-related artefacts is still an important one to address. Fortunately, we did collect eye movement data during the MEG recordings so were able to investigate this. As detailed in the response to Reviewer #1 above, we found that gaze positions and eye-movement velocity time-locked to visual display updates (i.e. – a change in asterisk position above the displayed sequence) did not reflect the asterisk location above chance levels (Overall cross-validated accuracy = 0.21817; see Author response image 1). Furthermore, an inspection of the eye position data revealed that a majority of participants on most trials displayed random walk gaze patterns around a center fixation point, indicating that participants did not attend to the asterisk position on the display. This is consistent with intrinsic generation of the action sequence, and congruent with the fact that the display does not provide explicit feedback related to performance. As pointed out above, a similar real-world example would be manually inputting a long password into a secure online application. In this case, one intrinsically generates the sequence from memory and receives similar feedback about the password sequence position (also provided as asterisks), which is typically ignored by the user. Notably, the minimal participant engagement with the visual task display observed in this study highlights an important difference between behavior observed during explicit sequence learning motor tasks (which is highly generative in nature) with reactive responses to stimulus cues in a serial reaction time task (SRTT). This is a crucial difference that must be carefully considered when comparing findings across studies. All elements pertaining to this new control analysis are now included in the revised manuscript.
The authors report a significant correlation between "offline differentiation" and cumulative micro-offline gains. However, it would be more informative to correlate trial-by-trial changes in each of the two variables. This would address the question of whether there is a trial-by-trial relation between the degree of "contextualization" and the amount of micro-offline gains - are performance changes (micro-offline gains) less pronounced across rest periods for which the change in "contextualization" is relatively low? Furthermore, is the relationship between micro-offline gains and "offline differentiation" significantly stronger than the relationship between micro-offline gains and "online differentiation"?
In response to a similar issue raised above by Reviewer #2, we now include new analyses comparing correlation magnitudes between (1) “online differention” vs micro-online gains, (2) “online differention” vs micro-offline gains and (3) “offline differentiation” and micro-offline gains (see Author response images 4, 5 and 6 above). These new analyses and results have been added to the revised manuscript. Once again, we thank both Reviewers for this suggestion.
The authors follow the assumption that micro-offline gains reflect offline learning.
This statement is incorrect. The original Bonstrup et al (2019) 49 paper clearly states that micro-offline gains must be carefully interpreted based upon the behavioral context within which they are observed, and lays out the conditions under which one can have confidence that micro-offline gains reflect offline learning. In fact, the excellent meta-analysis of Pan & Rickard (2015) 51, which re-interprets the benefits of sleep in overnight skill consolidation from a “reactive inhibition” perspective, was a crucial resource in the experimental design of our initial study49, as well as in all our subsequent work. Pan & Rickard stated:
“Empirically, reactive inhibition refers to performance worsening that can accumulate during a period of continuous training (Hull, 1943). It tends to dissipate, at least in part, when brief breaks are inserted between blocks of training. If there are multiple performance-break cycles over a training session, as in the motor sequence literature, performance can exhibit a scalloped effect, worsening during each uninterrupted performance block but improving across blocks52,53. Rickard, Cai, Rieth, Jones, and Ard (2008) and Brawn, Fenn, Nusbaum, and Margoliash (2010) 52,53 demonstrated highly robust scalloped reactive inhibition effects using the commonly employed 30 s–30 s performance break cycle, as shown for Rickard et al.’s (2008) massed practice sleep group in Figure 2. The scalloped effect is evident for that group after the first few 30 s blocks of each session. The absence of the scalloped effect during the first few blocks of training in the massed group suggests that rapid learning during that period masks any reactive inhibition effect.”
Crucially, Pan & Rickard51 made several concrete recommendations for reducing the impact of the reactive inhibition confound on offline learning studies. One of these recommendations was to reduce practice times to 10s (most prior sequence learning studies up until that point had employed 30s long practice trials). They stated:
“The traditional design involving 30 s-30 s performance break cycles should be abandoned given the evidence that it results in a reactive inhibition confound, and alternative designs with reduced performance duration per block used instead 51. One promising possibility is to switch to 10 s performance durations for each performance-break cycle Instead 51. That design appears sufficient to eliminate at least the majority of the reactive inhibition effect 52,53.”
We mindfully incorporated recommendations from Pan and Rickard51 into our own study designs including 1) utilizing 10s practice trials and 2) constraining our analysis of micro-offline gains to early learning trials (where performance monotonically increases and 95% of overall performance gains occur), which are prior to the emergence of the “scalloped” performance dynamics that are strongly linked to reactive inhibition effects.
However, there is no direct evidence in the literature that micro-offline gains really result from offline learning, i.e., an improvement in skill level.
We strongly disagree with the Reviewer’s assertion that “there is no direct evidence in the literature that micro-offline gains really result from offline learning, i.e., an improvement in skill level.” The initial Bönstrup et al. (2019) 49 report was followed up by a large online crowd-sourcing study (Bönstrup et al., 2020) 54. This second (and much larger) study provided several additional important findings supporting our interpretation of micro-offline gains in cases where the important behavioral conditions clarified above were met (see Author response image 7 below for further details on these conditions).
Author response image 7.
Micro-offline gains observed in learning and non-learning contexts are attributed to different underlying causes. (A) Micro-offline and online changes relative to overall trial-by-trial learning. This figure is based on data from Bönstrup et al. (2019) 49. During early learning, micro-offline gains (red bars) closely track trial-by-trial performance gains (green line with open circle markers), with minimal contribution from micro-online gains (blue bars). The stated conclusion in Bönstrup et al. (2019) is that micro-offline gains only during this Early Learning stage reflect rapid memory consolidation (see also 54). After early learning, about practice trial 11, skill plateaus. This plateau skill period is characterized by a striking emergence of coupled (and relatively stable) micro-online drops and micro-offline increases. Bönstrup et al. (2019) as well as others in the literature 55-57, argue that micro-offline gains during the plateau period likely reflect recovery from inhibitory performance factors such as reactive inhibition or fatigue, and thus must be excluded from analyses relating micro-offline gains to skill learning. The Non-repeating groups in Experiments 3 and 4 from Das et al. (2024) suffer from a lack of consideration of these known confounds.
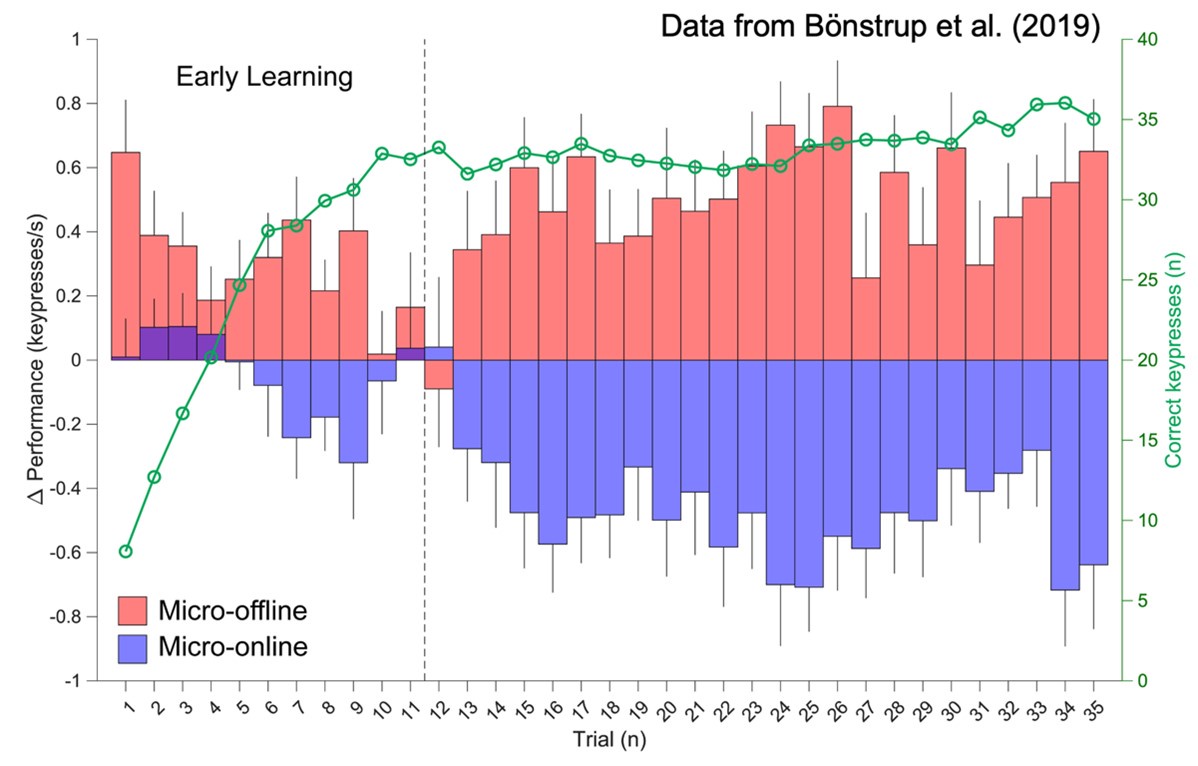
Evidence documented in that paper54 showed that micro-offline gains during early skill learning were: 1) replicable and generalized to subjects learning the task in their daily living environment (n=389); 2) equivalent when significantly shortening practice period duration, thus confirming that they are not a result of recovery from performance fatigue (n=118); 3) reduced (along with learning rates) by retroactive interference applied immediately after each practice period relative to interference applied after passage of time (n=373), indicating stabilization of the motor memory at a microscale of several seconds consistent with rapid consolidation; and 4) not modified by random termination of the practice periods, ruling out a contribution of predictive motor slowing (N = 71) 54. Altogether, our findings were strongly consistent with the interpretation that micro-offline gains reflect memory consolidation supporting early skill learning. This is precisely the portion of the learning curve Pan and Rickard51 refer to when they state “…rapid learning during that period masks any reactive inhibition effect”.
This interpretation is further supported by brain imaging evidence linking known memory-related networks and consolidation mechanisms to micro-offline gains. First, we reported that the density of fast hippocampo-neocortical skill memory replay events increases approximately three-fold during early learning inter-practice rest periods with the density explaining differences in the magnitude of micro-offline gains across subjects1. Second, Jacobacci et al. (2020) independently reproduced our original behavioral findings and reported BOLD fMRI changes in the hippocampus and precuneus (regions also identified in our MEG study1) linked to micro-offline gains during early skill learning. 33 These functional changes were coupled with rapid alterations in brain microstructure in the order of minutes, suggesting that the same network that operates during rest periods of early learning undergoes structural plasticity over several minutes following practice58. Third, even more recently, Chen et al. (2024) provided direct evidence from intracranial EEG in humans linking sharp-wave ripple events (which are known markers for neural replay59) in the hippocampus (80-120 Hz in humans) with micro-offline gains during early skill learning. The authors report that the strong increase in ripple rates tracked learning behavior, both across blocks and across participants. The authors conclude that hippocampal ripples during resting offline periods contribute to motor sequence learning. 2
Thus, there is actually now substantial evidence in the literature directly supporting the assertion “that micro-offline gains really result from offline learning”. On the contrary, according to Gupta & Rickard (2024) “…the mechanism underlying RI [reactive inhibition] is not well established” after over 80 years of investigation60, possibly due to the fact that “reactive inhibition” is a categorical description of behavioral effects that likely result from several heterogenous processes with very different underlying mechanisms.
On the contrary, recent evidence questions this interpretation (Gupta & Rickard, npj Sci Learn 2022; Gupta & Rickard, Sci Rep 2024; Das et al., bioRxiv 2024). Instead, there is evidence that micro-offline gains are transient performance benefits that emerge when participants train with breaks, compared to participants who train without breaks, however, these benefits vanish within seconds after training if both groups of participants perform under comparable conditions (Das et al., bioRxiv 2024).
It is important to point out that the recent work of Gupta & Rickard (2022,2024) 55 does not present any data that directly opposes our finding that early skill learning49 is expressed as micro-offline gains during rest breaks. These studies are essentially an extension of the Rickard et al (2008) paper that employed a massed (30s practice followed by 30s breaks) vs spaced (10s practice followed by 10s breaks) to assess if recovery from reactive inhibition effects could account for performance gains measured after several minutes or hours. Gupta & Rickard (2022) added two additional groups (30s practice/10s break and 10s practice/10s break as used in the work from our group). The primary aim of the study was to assess whether it was more likely that changes in performance when retested 5 minutes after skill training (consisting of 12 practice trials for the massed groups and 36 practice trials for the spaced groups) had ended reflected memory consolidation effects or recovery from reactive inhibition effects. The Gupta & Rickard (2024) follow-up paper employed a similar design with the primary difference being that participants performed a fixed number of sequences on each trial as opposed to trials lasting a fixed duration. This was done to facilitate the fitting of a quantitative statistical model to the data. To reiterate, neither study included any analysis of micro-online or micro-offline gains and did not include any comparison focused on skill gains during early learning. Instead, Gupta & Rickard (2022), reported evidence for reactive inhibition effects for all groups over much longer training periods. Again, we reported the same finding for trials following the early learning period in our original Bönstrup et al. (2019) paper49 (Author response image 7). Also, please note that we reported in this paper that cumulative micro-offline gains over early learning did not correlate with overnight offline consolidation measured 24 hours later49 (see the Results section and further elaboration in the Discussion). Thus, while the composition of our data is supportive of a short-term memory consolidation process operating over several seconds during early learning, it likely differs from those involved over longer training times and offline periods, as assessed by Gupta & Rickard (2022).
In the recent preprint from Das et al (2024) 61, the authors make the strong claim that “micro-offline gains during early learning do not reflect offline learning” which is not supported by their own data. The authors hypothesize that if “micro-offline gains represent offline learning, participants should reach higher skill levels when training with breaks, compared to training without breaks”. The study utilizes a spaced vs. massed practice group between-subjects design inspired by the reactive inhibition work from Rickard and others to test this hypothesis. Crucially, the design incorporates only a small fraction of the training used in other investigations to evaluate early skill learning1,33,49,54,57,58,62. A direct comparison between the practice schedule designs for the spaced and massed groups in Das et al., and the training schedule all participants experienced in the original Bönstrup et al. (2019) paper highlights this issue as well as several others (Author response image 8):
Author response image 8.
(A) Comparison of Das et al. Spaced & Massed group training session designs, and the training session design from the original Bönstrup et al. (2019) 49 paper. Similar to the approach taken by Das et al., all practice is visualized as 10-second practice trials with a variable number (either 0, 1 or 30) of 10-second-long inter-practice rest intervals to allow for direct comparisons between designs. The two key takeaways from this comparison are that (1) the intervention differences (i.e. – practice schedules) between the Massed and Spaced groups from the Das et al. report are extremely small (less than 12% of the overall session schedule) and (2) the overall amount of practice is much less than compared to the design from the original Bönstrup report 49 (which has been utilized in several subsequent studies). (B) Group-level learning curve data from Bönstrup et al. (2019) 49 is used to estimate the performance range accounted for by the equivalent periods covering Test 1, Training 1 and Test 2 from Das et al (2024). Note that the intervention in the Das et al. study is limited to a period covering less than 50% of the overall learning range.
First, participants in the original Bönstrup et al. study 49 experienced 157.14% more practice time and 46.97% less inter-practice rest time than the Spaced group in the Das et al. study (Author response image 8). Thus, the overall amount of practice and rest differ substantially between studies, with much more limited training occurring for participants in Das et al.
Second, and perhaps most importantly, the actual intervention (i.e. – the difference in practice schedule between the Spaced and Massed groups) employed by Das et al. covers a very small fraction of the overall training session. Identical practice schedule segments for both the Spaced & Massed groups are indicated by the red shaded area in Author response image 8. Please note that these identical segments cover 94.84% of the Massed group training schedule and 88.01% of the Spaced group training schedule (since it has 60 seconds of additional rest). This means that the actual interventions cover less than 5% (for Massed) and 12% (for Spaced) of the total training session, which minimizes any chance of observing a difference between groups.
Also note that the very beginning of the practice schedule (during which Figure R9 shows substantial learning is known to occur) is labeled in the Das et al. study as Test 1. Test 1 encompasses the first 20 seconds of practice (alternatively viewed as the first two 10-second-long practice trials with no inter-practice rest). This is immediately followed by the Training 1 intervention, which is composed of only three 10-second-long practice trials (with 10-second inter-practice rest for the Spaced group and no inter-practice rest for the Massed group). Author response image 8 also shows that since there is no inter-practice rest after the third Training practice trial for the Spaced group, this third trial (for both Training 1 and 2) is actually a part of an identical practice schedule segment shared by both groups (Massed and Spaced), reducing the magnitude of the intervention even further.
Moreover, we know from the original Bönstrup et al. (2019) paper49 that 46.57% of all overall group-level performance gains occurred between trials 2 and 5 for that study. Thus, Das et al. are limiting their designed intervention to a period covering less than half of the early learning range discussed in the literature, which again, minimizes any chance of observing an effect.
This issue is amplified even further at Training 2 since skill learning prior to the long 5-minute break is retained, further constraining the performance range over these three trials. A related issue pertains to the trials labeled as Test 1 (trials 1-2) and Test 2 (trials 6-7) by Das et al. Again, we know from the original Bönstrup et al. paper 49 that 18.06% and 14.43% (32.49% total) of all overall group-level performance gains occurred during trials corresponding to Das et al Test 1 and Test 2, respectively. In other words, Das et al averaged skill performance over 20 seconds of practice at two time-points where dramatic skill improvements occur. Pan & Rickard (1995) previously showed that such averaging is known to inject artefacts into analyses of performance gains.
Furthermore, the structure of the Test in Das et. al study appears to have an interference effect on the Spaced group performance after the training intervention. This makes sense if you consider that the Spaced group is required to now perform the task in a Massed practice environment (i.e., two 10-second-long practice trials merged into one long trial), further blurring the true intervention effects. This effect is observable in Figure 1C,E of their pre-print. Specifically, while the Massed group continues to show an increase in performance during test relative to the last 10 seconds of practice during training, the Spaced group displays a marked decrease. This decrease is in stark contrast to the monotonic increases observed for both groups at all other time-points.
Interestingly, when statistical comparisons between the groups are made at the time-points when the intervention is present (as opposed to after it has been removed) then the stated hypothesis, “If micro-offline gains represent offline learning, participants should reach higher skill levels when training with breaks, compared to training without breaks”, is confirmed.
The data presented by Gupta and Rickard (2022, 2024) and Das et al. (2024) is in many ways more confirmatory of the constraints employed by our group and others with respect to experimental design, analysis and interpretation of study findings, rather than contradictory. Still, it does highlight a limitation of the current micro-online/offline framework, which was originally only intended to be applied to early skill learning over spaced practice schedules when reactive inhibition effects are minimized49. Extrapolation of this current framework to post-plateau performance periods, longer timespans, or non-learning situations (e.g. – the Non-repeating groups from Experiments 3 & 4 in Das et al. (2024)), when reactive inhibition plays a more substantive role, is not warranted. Ultimately, it will be important to develop new paradigms allowing one to independently estimate the different coincident or antagonistic features (e.g. - memory consolidation, planning, working memory and reactive inhibition) contributing to micro-online and micro-offline gains during and after early skill learning within a unifying framework.
References
(1) Buch, E. R., Claudino, L., Quentin, R., Bonstrup, M. & Cohen, L. G. Consolidation of human skill linked to waking hippocampo-neocortical replay. Cell Rep 35, 109193 (2021). https://doi.org:10.1016/j.celrep.2021.109193
(2) Chen, P.-C., Stritzelberger, J., Walther, K., Hamer, H. & Staresina, B. P. Hippocampal ripples during offline periods predict human motor sequence learning. bioRxiv, 2024.2010.2006.614680 (2024). https://doi.org:10.1101/2024.10.06.614680
(3) Classen, J., Liepert, J., Wise, S. P., Hallett, M. & Cohen, L. G. Rapid plasticity of human cortical movement representation induced by practice. J Neurophysiol 79, 1117-1123 (1998).
(4) Karni, A. et al. Functional MRI evidence for adult motor cortex plasticity during motor skill learning. Nature 377, 155-158 (1995). https://doi.org:10.1038/377155a0
(5) Kleim, J. A., Barbay, S. & Nudo, R. J. Functional reorganization of the rat motor cortex following motor skill learning. J Neurophysiol 80, 3321-3325 (1998).
(6) Shadmehr, R. & Holcomb, H. H. Neural correlates of motor memory consolidation. Science 277, 821-824 (1997).
(7) Doyon, J. et al. Experience-dependent changes in cerebellar contributions to motor sequence learning. Proc Natl Acad Sci U S A 99, 1017-1022 (2002).
(8) Toni, I., Ramnani, N., Josephs, O., Ashburner, J. & Passingham, R. E. Learning arbitrary visuomotor associations: temporal dynamic of brain activity. Neuroimage 14, 1048-1057 (2001).
(9) Grafton, S. T. et al. Functional anatomy of human procedural learning determined with regional cerebral blood flow and PET. J Neurosci 12, 2542-2548 (1992).
(10) Kennerley, S. W., Sakai, K. & Rushworth, M. F. Organization of action sequences and the role of the pre-SMA. J Neurophysiol 91, 978-993 (2004). https://doi.org:10.1152/jn.00651.2003 00651.2003 [pii]
(11) Hardwick, R. M., Rottschy, C., Miall, R. C. & Eickhoff, S. B. A quantitative meta-analysis and review of motor learning in the human brain. Neuroimage 67, 283-297 (2013). https://doi.org:10.1016/j.neuroimage.2012.11.020
(12) Sawamura, D. et al. Acquisition of chopstick-operation skills with the non-dominant hand and concomitant changes in brain activity. Sci Rep 9, 20397 (2019). https://doi.org:10.1038/s41598-019-56956-0
(13) Lee, S. H., Jin, S. H. & An, J. The difference in cortical activation pattern for complex motor skills: A functional near- infrared spectroscopy study. Sci Rep 9, 14066 (2019). https://doi.org:10.1038/s41598-019-50644-9
(14) Battaglia-Mayer, A. & Caminiti, R. Corticocortical Systems Underlying High-Order Motor Control. J Neurosci 39, 4404-4421 (2019). https://doi.org:10.1523/JNEUROSCI.2094-18.2019
(15) Toni, I., Thoenissen, D. & Zilles, K. Movement preparation and motor intention. Neuroimage 14, S110-117 (2001). https://doi.org:10.1006/nimg.2001.0841
(16) Wolpert, D. M., Goodbody, S. J. & Husain, M. Maintaining internal representations: the role of the human superior parietal lobe. Nat Neurosci 1, 529-533 (1998). https://doi.org:10.1038/2245
(17) Andersen, R. A. & Buneo, C. A. Intentional maps in posterior parietal cortex. Annu Rev Neurosci 25, 189-220 (2002). https://doi.org:10.1146/annurev.neuro.25.112701.142922 112701.142922 [pii]
(18) Buneo, C. A. & Andersen, R. A. The posterior parietal cortex: sensorimotor interface for the planning and online control of visually guided movements. Neuropsychologia 44, 2594-2606 (2006). https://doi.org:S0028-3932(05)00333-7 [pii] 10.1016/j.neuropsychologia.2005.10.011
(19) Grover, S., Wen, W., Viswanathan, V., Gill, C. T. & Reinhart, R. M. G. Long-lasting, dissociable improvements in working memory and long-term memory in older adults with repetitive neuromodulation. Nat Neurosci 25, 1237-1246 (2022). https://doi.org:10.1038/s41593-022-01132-3
(20) Colclough, G. L. et al. How reliable are MEG resting-state connectivity metrics? Neuroimage 138, 284-293 (2016). https://doi.org:10.1016/j.neuroimage.2016.05.070
(21) Colclough, G. L., Brookes, M. J., Smith, S. M. & Woolrich, M. W. A symmetric multivariate leakage correction for MEG connectomes. NeuroImage 117, 439-448 (2015). https://doi.org:10.1016/j.neuroimage.2015.03.071
(22) Mollazadeh, M. et al. Spatiotemporal variation of multiple neurophysiological signals in the primary motor cortex during dexterous reach-to-grasp movements. J Neurosci 31, 15531-15543 (2011). https://doi.org:10.1523/JNEUROSCI.2999-11.2011
(23) Bansal, A. K., Vargas-Irwin, C. E., Truccolo, W. & Donoghue, J. P. Relationships among low-frequency local field potentials, spiking activity, and three-dimensional reach and grasp kinematics in primary motor and ventral premotor cortices. J Neurophysiol 105, 1603-1619 (2011). https://doi.org:10.1152/jn.00532.2010
(24) Flint, R. D., Ethier, C., Oby, E. R., Miller, L. E. & Slutzky, M. W. Local field potentials allow accurate decoding of muscle activity. J Neurophysiol 108, 18-24 (2012). https://doi.org:10.1152/jn.00832.2011
(25) Churchland, M. M. et al. Neural population dynamics during reaching. Nature 487, 51-56 (2012). https://doi.org:10.1038/nature11129
(26) Bassett, D. S. et al. Dynamic reconfiguration of human brain networks during learning. Proc Natl Acad Sci U S A 108, 7641-7646 (2011). https://doi.org:10.1073/pnas.1018985108
(27) Albouy, G., King, B. R., Maquet, P. & Doyon, J. Hippocampus and striatum: dynamics and interaction during acquisition and sleep-related motor sequence memory consolidation. Hippocampus 23, 985-1004 (2013). https://doi.org:10.1002/hipo.22183
(28) Albouy, G. et al. Neural correlates of performance variability during motor sequence acquisition. Neuroimage 60, 324-331 (2012). https://doi.org:10.1016/j.neuroimage.2011.12.049
(29) Qin, Y. L., McNaughton, B. L., Skaggs, W. E. & Barnes, C. A. Memory reprocessing in corticocortical and hippocampocortical neuronal ensembles. Philos Trans R Soc Lond B Biol Sci 352, 1525-1533 (1997). https://doi.org:10.1098/rstb.1997.0139
(30) Euston, D. R., Tatsuno, M. & McNaughton, B. L. Fast-forward playback of recent memory sequences in prefrontal cortex during sleep. Science 318, 1147-1150 (2007). https://doi.org:10.1126/science.1148979
(31) Molle, M. & Born, J. Hippocampus whispering in deep sleep to prefrontal cortex--for good memories? Neuron 61, 496-498 (2009). https://doi.org:S0896-6273(09)00122-6 [pii] 10.1016/j.neuron.2009.02.002
(32) Frankland, P. W. & Bontempi, B. The organization of recent and remote memories. Nat Rev Neurosci 6, 119-130 (2005). https://doi.org:10.1038/nrn1607
(33) Jacobacci, F. et al. Rapid hippocampal plasticity supports motor sequence learning. Proc Natl Acad Sci U S A 117, 23898-23903 (2020). https://doi.org:10.1073/pnas.2009576117
(34) Albouy, G. et al. Maintaining vs. enhancing motor sequence memories: respective roles of striatal and hippocampal systems. Neuroimage 108, 423-434 (2015). https://doi.org:10.1016/j.neuroimage.2014.12.049
(35) Gais, S. et al. Sleep transforms the cerebral trace of declarative memories. Proc Natl Acad Sci U S A 104, 18778-18783 (2007). https://doi.org:0705454104 [pii] 10.1073/pnas.0705454104
(36) Sterpenich, V. et al. Sleep promotes the neural reorganization of remote emotional memory. J Neurosci 29, 5143-5152 (2009). https://doi.org:10.1523/JNEUROSCI.0561-09.2009
(37) Euston, D. R., Gruber, A. J. & McNaughton, B. L. The role of medial prefrontal cortex in memory and decision making. Neuron 76, 1057-1070 (2012). https://doi.org:10.1016/j.neuron.2012.12.002
(38) van Kesteren, M. T., Fernandez, G., Norris, D. G. & Hermans, E. J. Persistent schema-dependent hippocampal-neocortical connectivity during memory encoding and postencoding rest in humans. Proc Natl Acad Sci U S A 107, 7550-7555 (2010). https://doi.org:10.1073/pnas.0914892107
(39) van Kesteren, M. T., Ruiter, D. J., Fernandez, G. & Henson, R. N. How schema and novelty augment memory formation. Trends Neurosci 35, 211-219 (2012). https://doi.org:10.1016/j.tins.2012.02.001
(40) Wagner, A. D. et al. Building memories: remembering and forgetting of verbal experiences as predicted by brain activity. Science (New York, N.Y.) 281, 1188-1191 (1998).
(41) Ashe, J., Lungu, O. V., Basford, A. T. & Lu, X. Cortical control of motor sequences. Curr Opin Neurobiol 16, 213-221 (2006).
(42) Hikosaka, O., Nakamura, K., Sakai, K. & Nakahara, H. Central mechanisms of motor skill learning. Curr Opin Neurobiol 12, 217-222 (2002).
(43) Penhune, V. B. & Steele, C. J. Parallel contributions of cerebellar, striatal and M1 mechanisms to motor sequence learning. Behav. Brain Res. 226, 579-591 (2012). https://doi.org:10.1016/j.bbr.2011.09.044
(44) Doyon, J. et al. Contributions of the basal ganglia and functionally related brain structures to motor learning. Behavioural brain research 199, 61-75 (2009). https://doi.org:10.1016/j.bbr.2008.11.012
(45) Schendan, H. E., Searl, M. M., Melrose, R. J. & Stern, C. E. An FMRI study of the role of the medial temporal lobe in implicit and explicit sequence learning. Neuron 37, 1013-1025 (2003). https://doi.org:10.1016/s0896-6273(03)00123-5
(46) Morris, R. G. M. Elements of a neurobiological theory of hippocampal function: the role of synaptic plasticity, synaptic tagging and schemas. The European journal of neuroscience 23, 2829-2846 (2006). https://doi.org:10.1111/j.1460-9568.2006.04888.x
(47) Tse, D. et al. Schemas and memory consolidation. Science 316, 76-82 (2007). https://doi.org:10.1126/science.1135935
(48) Berlot, E., Popp, N. J. & Diedrichsen, J. A critical re-evaluation of fMRI signatures of motor sequence learning. Elife 9 (2020). https://doi.org:10.7554/eLife.55241
(49) Bonstrup, M. et al. A Rapid Form of Offline Consolidation in Skill Learning. Curr Biol 29, 1346-1351 e1344 (2019). https://doi.org:10.1016/j.cub.2019.02.049
(50) Kornysheva, K. et al. Neural Competitive Queuing of Ordinal Structure Underlies Skilled Sequential Action. Neuron 101, 1166-1180 e1163 (2019). https://doi.org:10.1016/j.neuron.2019.01.018
(51) Pan, S. C. & Rickard, T. C. Sleep and motor learning: Is there room for consolidation? Psychol Bull 141, 812-834 (2015). https://doi.org:10.1037/bul0000009
(52) Rickard, T. C., Cai, D. J., Rieth, C. A., Jones, J. & Ard, M. C. Sleep does not enhance motor sequence learning. J Exp Psychol Learn Mem Cogn 34, 834-842 (2008). https://doi.org:10.1037/0278-7393.34.4.834
53) Brawn, T. P., Fenn, K. M., Nusbaum, H. C. & Margoliash, D. Consolidating the effects of waking and sleep on motor-sequence learning. J Neurosci 30, 13977-13982 (2010). https://doi.org:10.1523/JNEUROSCI.3295-10.2010
(54) Bonstrup, M., Iturrate, I., Hebart, M. N., Censor, N. & Cohen, L. G. Mechanisms of offline motor learning at a microscale of seconds in large-scale crowdsourced data. NPJ Sci Learn 5, 7 (2020). https://doi.org:10.1038/s41539-020-0066-9
(55) Gupta, M. W. & Rickard, T. C. Dissipation of reactive inhibition is sufficient to explain post-rest improvements in motor sequence learning. NPJ Sci Learn 7, 25 (2022). https://doi.org:10.1038/s41539-022-00140-z
(56) Jacobacci, F. et al. Rapid hippocampal plasticity supports motor sequence learning. Proceedings of the National Academy of Sciences 117, 23898-23903 (2020).
(57) Brooks, E., Wallis, S., Hendrikse, J. & Coxon, J. Micro-consolidation occurs when learning an implicit motor sequence, but is not influenced by HIIT exercise. NPJ Sci Learn 9, 23 (2024). https://doi.org:10.1038/s41539-024-00238-6
(58) Deleglise, A. et al. Human motor sequence learning drives transient changes in network topology and hippocampal connectivity early during memory consolidation. Cereb Cortex 33, 6120-6131 (2023). https://doi.org:10.1093/cercor/bhac489
(59) Buzsaki, G. Hippocampal sharp wave-ripple: A cognitive biomarker for episodic memory and planning. Hippocampus 25, 1073-1188 (2015). https://doi.org:10.1002/hipo.22488
(60) Gupta, M. W. & Rickard, T. C. Comparison of online, offline, and hybrid hypotheses of motor sequence learning using a quantitative model that incorporate reactive inhibition. Sci Rep 14, 4661 (2024). https://doi.org:10.1038/s41598-024-52726-9
(61) Das, A., Karagiorgis, A., Diedrichsen, J., Stenner, M.-P. & Azanon, E. “Micro-offline gains” convey no benefit for motor skill learning. bioRxiv, 2024.2007.2011.602795 (2024). https://doi.org:10.1101/2024.07.11.602795
(62) Mylonas, D. et al. Maintenance of Procedural Motor Memory across Brief Rest Periods Requires the Hippocampus. J Neurosci 44 (2024). https://doi.org:10.1523/JNEUROSCI.1839-23.2024