in MLflow 2.0, the mlflow.evaluate() API for model evaluation is now stable and production-ready. With just a single line of code, mlflow.evaluate() creates a comprehensive performance report for any ML model.
2,778 Matching Annotations
- Nov 2022
-
www.linuxfoundation.org www.linuxfoundation.org
-
-
MLflow 2.0 also adds AutoML to MLflow Recipes, dramatically reducing the amount of time required to produce a high-quality model.
AutoML in MLflow 2.0
-
In MLflow 2.0, MLflow Recipes is now a core platform component with several new features, including support for classification models, improved data profiling and hyperparameter tuning capabilities.
MLflow Recipes in MLflow 2.0
-
-
-
As I think today microservice can do much more than just gives predictions using a single model, like:
List of differences between a microservice and inference service.
(see bullet points below annotation)
-
-
mathspp.com mathspp.com
-
notice that defaultdict not only returns the default value, but also assigns it to the key that wasn't there before:
See example below about
defaultdict -
we might need a dictionary subclass, and then we need to access a key that does not exist in that dictionary
Example of applying
__missing__dunder method:```python class DictSubclass(dict): def missing(self, key): print("Hello, world!")
my_dict = DictSubclass() my_dict["this key isn't available"]
Hello, world!
```
-
The table also includes links to the documentation of the dunder method under the emoji 🔗. When available, relevant Pydon'ts are linked under the emoji 🗒️.
Table below lists Python dunder methods
-
>>> 3 in my_list False >>> my_list.__contains__(3) False
python 3 in my_listis the same as:python my_list.__contains__(3) -
“dunder” comes from “double underscore”
dunder = double underscores (__)
-
dunder methods are methods that allow instances of a class to interact with the built-in functions and operators
Python's dunder methods
Tags
Annotators
URL
-
-
thingrex.com thingrex.com
-
take a step back and ask a basic question: “What kind of business value are we trying to provide?"
Recommended approach over saying "it depends" to your stakeholders
-
- Oct 2022
-
medium.com medium.com
-
As of today, a lot of the things in ML are not automated. They are manual or semi-manual.
-
If we say that MLOps is just DevOps + “some things”, then CI/CD is a core principle of that.
-
Not everything can be tested/evaluated with a metric like AUC or R2. Sometimes, people just have to check if things improved and not just metrics got better.
-
I believe that packaging/building/deploying the vanilla, run-of-the-mill ML model will become common knowledge for backend devs.
-
MLOps engineer today is either an ML engineer (building ML-specific software) or a DevOps engineer. Nothing special here.Should we call a DevOps engineer who primarily operates ML-fueled software delivery an MLOps engineer?I mean, if you really want, we can, but I don’t think we need a new role here. It is just a DevOps eng.
Who really is MLOps Engineer ;)
-
The MLOps team should consist of a DevOps engineer, a backend software engineer, a data scientist, + regular software folks.
Recommended MLOps team structure
-
-
stephanango.com stephanango.com
-
By becoming a hybrid you can choose how you want to be unique. Countless unique combinations are available to you.
-
Being U-shaped requires bravery, because it’s so unusual. U-shaped people tend to be subjected to greater skepticism, because no one else really understands what they alone can see.
Advantage of U-shaped hybrid
-
T-shaped. They tend to be natural leaders because they understand how different responsibilities overlap, and how to construct effective teams and processes.
Advantage of T-shaped hybrid
-
The U-shaped path means developing skills that are not often found together. Like engineering and dancing, or singing and design.
U-shaped hybrid type of specialization
-
The T-shaped hybrid path is one that many curious people follow. You grow your skillset and experience in areas that are adjacent to your dominant expertise. For example engineering and design, or singing and dancing.
T-shaped hybrid type of specialization
-
I’m excited to see community efforts like Obsidian Ava
-
The sentence in italics above was not written by me. It was autocompleted as I wrote in Obsidian, using the Text Generator plugin.
-
In some ways it is surprising that filtering text is so technically challenging. Text seems like it would be easier to manipulate than images.
Tags
Annotators
URL
-
-
blog.jim-nielsen.com blog.jim-nielsen.com
-
After decades of experience, he knew and understood that the most meaningful conceptual progress he made on problems was always away from his computer: on a run, in the shower, laying in bed at night. That’s where the insight came. And yet, even after all these years, he still felt a strange obligation to be at his computer because that’s too often our the mental image of “working”.
-
Work at MIT found that brainstorming—where a bunch of people put their heads together to try to come up with innovative solutions—generally “reduced creativity due to the tendency to incrementally modify known successful designs rather than explore radically different and potentially superior ones.”
The "bad" side of brainstorming
-
-
world.hey.com world.hey.com
-
It's like paying a quarter of your house's value for earthquake insurance when you don't live anywhere near a fault line.
What paying for cloud in some scenarios really is
-
The second is when your load is highly irregular. When you have wild swings or towering peaks in usage.
2nd great use of cloud services
-
The cloud excels at two ends of the spectrum, where only one end was ever relevant for us. The first end is when your application is so simple and low traffic that you really do save on complexity by starting with fully managed services.
1st great use of cloud services
-
-
karimjedda.com karimjedda.com
-
The first interaction with a programming language should be what it can do for you, rather than an exhaustive glossary of what it is.
Tags
Annotators
URL
-
-
postgresml.org postgresml.org
-
Python is known for using more memory than more optimized languages and, in this case, it uses 7 times more than PostgresML.
-
PostgresML outperforms traditional Python microservices by a factor of 8 in local tests and by a factor of 40 on AWS EC2.
-
-
www.citizenwatch-global.com www.citizenwatch-global.com
-
Lay the watch horizontally and align the hour hand of the watch with the direction of the sun. The middle point between the alignment of the sun with the hour hand, and the 12 o’clock position on the dial, approximately indicates south.
Using watch as a compass
-
-
blog.thc.org blog.thc.org
-
Use SSH and connect:
Disposable root server:
bash ssh root@segfault.net # Password is 'segfault'
Tags
Annotators
URL
-
-
-
What makes a good error message
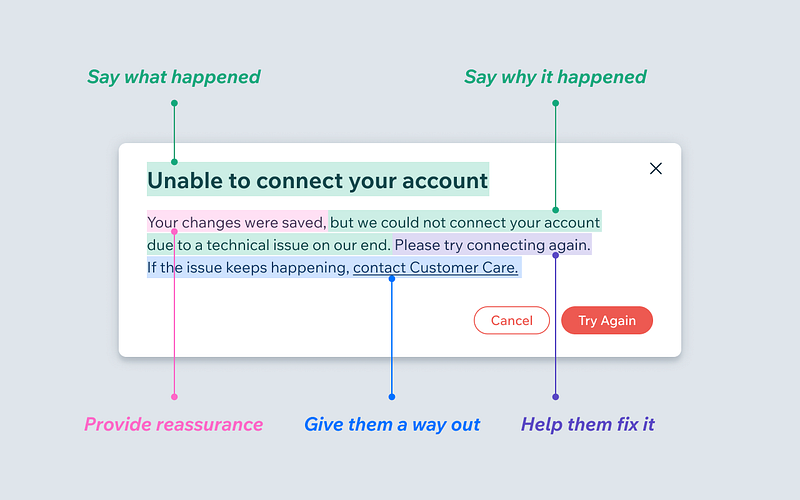
-
What makes a bad error message
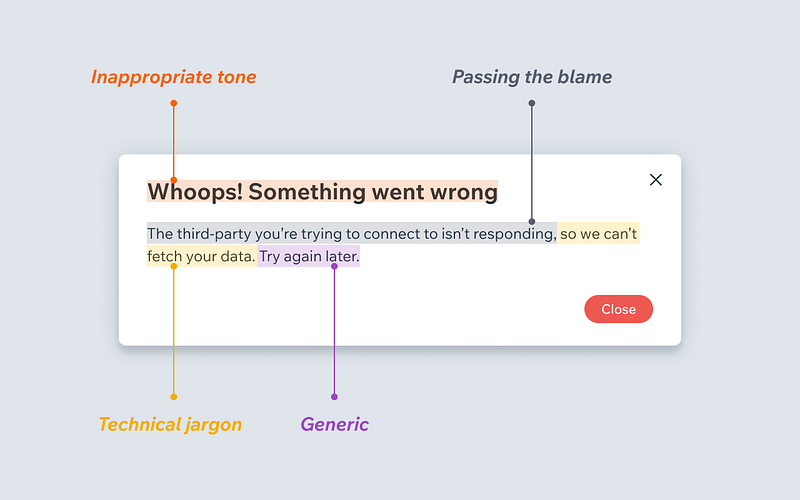
-
-
wifine.gitlab.io wifine.gitlab.ioWi-Fine2
-
By using a VPN, you are only changing who can see your network layer traffic. It does not increase any security.
-
any retailer doing credit card transaction processing is forced to use TLS
-
-
gist.github.com gist.github.com
-
Because it's easy money. You just set up OpenVPN on a few servers, and essentially start reselling bandwidth with a markup.
How to start a VPN business
Tags
Annotators
URL
-
-
www.justworktogether.com www.justworktogether.com
-
Sometimes bullying comes with prejudice, but often it's a more instinctive behavior. There may be no belief, conscious or unconscious, behind it. It can be a plan or just an animal instinct to dominate, to coerce
Bullying
-
-
github.com github.com
-
git show | cat -A
Command to find a zero width no-break space
Tags
Annotators
URL
-
-
lucasfcosta.com lucasfcosta.com
-
For that, you must create a culture of fear in which it’s more important to show others you’ve been productive than to help the team achieve its goals.
-
Once you have convinced your team to estimate tasks, you can pressure people to work longer hours to prove they’re not bad at estimations.
Tags
Annotators
URL
-
-
tylercipriani.com tylercipriani.com
-
But for all of its features, GitHub implements only a subset of git. For instance, GitHub lacks the default merge strategy of git—the fast-forward merge.
-
-
developerpitstop.com developerpitstop.com
-
Be aware that staying at a company too long means you are likely to earn less over your career. But moving too soon means you won’t get the necessary experience that may benefit you later on.
-
Learning and adaptation – 3 – 6 months – getting to grips with the new company, team, and their processes. Creating value for the organization – 6 – 12 months – adding value to the business by becoming a functioning member of the team.Becoming a role expert – 6 – 18 months – owning the role completely and helping to shape the direction of the team.
Job stages
-
Software engineers typically stay at one job for an average of two years before moving somewhere different. They spend less than half the amount of time at one company compared to the national average tenure of 4.2 years.
-
The average performance pay rise for most employees is 3% a year. That is minuscule compared to the 14.8% pay raise the average person gets when they switch jobs.
-
-
abinoda.substack.com abinoda.substack.com
-
On “good” days, developers spend more time developing and less time collaborating
Tags
Annotators
URL
-
-
russ-hyde.rbind.io russ-hyde.rbind.io
-
Speaking from my (R-biased) viewpoint, conda has posed some problems as well:
List of problems while using
condaforr.
Tags
Annotators
URL
-
-
innerjoin.bit.io innerjoin.bit.io
-
You can unknowingly be sending your critical database traffic in the clear because your client uses a default of allow or disable while the server you’re connecting to does, in fact, support SSL.
-
You can unknowingly be sending your critical database traffic in the clear because your client uses a default of prefer, allow or disable and the server you’re connecting to does not support SSL.
-
What Should I Do?
Advices to set
verify-fullencryption for: - developers - PostgreSQL server maintainers - users - PostgreSQL tool makers - PostgreSQL creators -
Many popular SQL clients do not use SSL by default. If you aren’t deliberate about choosing encryption, the connection will be unencrypted.
Table with SQL clients and their default SSL mode:
-
SSL is disabled by default in jdbc, npgsql, node-postgres, and pgx.
Table with programming libraires and their default SSL mode:
-
There are a lot of PostgreSQL servers connected to the Internet: we searched shodan.io and obtained a sample of more than 820,000 PostgreSQL servers connected to the Internet between September 1 and September 29. Only 36% of the servers examined had SSL certificates. More than 523,000 PostgreSQL servers listening on the Internet did not use SSL (64%)
-
At most 15% of the approximately 820,000 PostgreSQL servers listening on the Internet require encryption. In fact, only 36% even support encryption. This puts PostgreSQL servers well behind the rest of the Internet in terms of security. In comparison, according to Google, over 96% of page loads in Chrome on a Mac are encrypted. The top 100 websites support encryption, and 97 of those default to encryption.
-
-
saveall.al saveall.alSave All6
-
new technologies leveraging techniques like spaced repetition mean it's much easier to remember what you learn
Such as Anki
-
In 2019 the UK school inspection body Ofsted went further than this and changed their definition of ”learning” itself to “an alteration in long-term memory”.
learning = alteration in long-term memory
-
to get faster at learning you must get more efficient at moving things into your long-term memory, i.e. stop forgetting things you learn. The less you forget the more you'll understand and the faster you'll learn.
-
To learn more than 4 new concepts we must move some of them into our long-term memory before learning the rest.
-
You can only understand something new if understanding it requires combining less than 4 new pieces of information.
-
our working memory has a maximum capacity of roughly 4. When reading about quantum mechanics we encounter new Concept 1 and store it in our working memory. Then when learning about Concept 1 we encounter Concepts 2, 3, and 4 and our working memory becomes full. We then cannot understand Concept 5.
Our memory is unable to hold 5 new concepts
-
-
-
transferring data across Availability zones within the same region is also a good way to save money
1) data transferring tip on AWS
-
When you use a private IP address, you are charged less when compared to a public IP address or Elastic IP address.
2) data transferring tip on AWS
-
But when you transfer data from one Amazon region to another, AWS charges you for that. It depends on the AWS region you are and this is the real deciding factor. For example, if you are in the US West(Oregon) region, you have to shell out $0.080/GB whereas in Asia Pacific (Seoul) region it bumps up to $0.135/GB.
Transferring data in AWS within separate regions is quite costly
-
When you transfer data between Amazon EC2, Amazon Redshift, Amazon RDS, Amazon Network Interfaces, and Amazon Elasticache, you have to pay zero charges if they are within the same Availability Zone.
Transferring data in AWS within the same AZ is free
-
When you transfer data from the internet to AWS, it is free of charge. AWS services like EC2 instances, S3 storage, or RDS instances, when you transfer data from the Internet into these you don’t have to pay any charge for it. However, if you transfer data using Elastic IPv4 address or peered VPC using an IPv6 address you will be charged $0.01/gb whenever you transfer data into an EC2 instance. The real catch is when you transfer data out of any of the AWS services. This is where AWS charges you money depending on the area you have chosen and the amount of data you are transferring. Some regions have higher charges than others.
Data transfer costs on AWS
-
-
levelup.gitconnected.com levelup.gitconnected.com
-
Building machines and running downscaled tests is my late-night hobby.
Interesting hobby :)
-
We use Javascript everywhere, since we solve the “issues” caused by Javascript rendering we want to build as much expertise as possible in this field. But for the other parts, we are taking advantage of CloudFlare’s distributed system for fast response and global scalability. While our uptime guarantees are supported by Digital Ocean’s cloud platform. We also use a myriad of other SaaS providers to maximize our effectiveness.
Stack of Prerender: - Javascript - CloudFlare - Digital Ocean - SaaS providers
-
we made sure to implement fail safes at each stage of the migration to make sure we could fall back if something were to go wrong. It’s also why we tested on a small scale before proceeding with the rest of the migration.
While planning a big migration, make sure to have a fall back plan
-
We mirrored PostgreSQL shards storing cached_urls tables in CassandraWe switched service.prerender.io to Cloudflare load balancer to allow dynamic traffic distributionWe set up new EU private-recache serversWe keep performing stress tests to solve any performance issues
Steps of phase 3 migration
-
“The true hidden price for AWS is coming from the traffic cost, they sell a reasonably priced storage, and it’s even free to upload it. But when you get it out, you pay an enormous cost.
AWS may be reasonably price, but moving data out will cost a lot (e.g. $0.080/GB in the US West, or $0.135/GB in the Asia Pacific)!
-
In the last four weeks, we moved most of the cache workload from AWS S3 to our own Cassandra cluster.
Moving from AWS s3 to an own Cassandra cluster
-
After testing whether Prerender pages could be cached in both S3 and minio, we slowly diverted traffic away from AWS S3 and towards minio.
Moving from AWS S3 towards minio
-
Phase 1 mostly involved setting up the bare metal servers and testing the migration on a small and more manageable setting before scaling. This phase required minimal software adaptation, which we decided to run on KVM virtualization on Linux.
Migration from AWS to on-prem started by: - setting bare metal servers - testing - adapting software to run on KVM virtualization on Linux
-
The solution? Migrate the cached pages and traffic onto Prerender’s own internal servers and cut our reliance on AWS as quickly as possible.
When the Prerender team moved from AWS to on-prem, they have cut the cost from $1,000,000 to $200,000, for the data storage and traffic cost
-
-
world.hey.com world.hey.com
-
After almost 10 years of remote work, it would be close to impossible for me to go back to an office.
`
Tags
Annotators
URL
-
- Sep 2022
-
-
On the internet today, it seems like it’s more common to use “absolute” domain names (like example.com).
Relative domain names are not as common these days.
-
The technical term for “THIS IS THE WHOLE THING” is “fully qualified domain name” or “FQDN”. So google.com. is a fully qualified domain name, and google.com isn’t.
Example of FQDN
-
So because domain names can actually be translated to something else in some cases, people like to put a "." at the end to communicate “THIS IS THE DOMAIN NAME, NOTHING GETS ADDED AT THE END, THIS IS THE WHOLE THING”.
Reason why one may put a
.at the end of an address -
zone files require a trailing dot at the end of a domain name (because otherwise they’re interpreted as being relative to the zone).
-
a fully qualified domain name is a domain with a “.” at the end!
-
-
staysaasy.com staysaasy.com
-
If you work at a software company, there are some pretty common categories of work that people often avoid, including
(see a list of activities below this annotation)
-
Whenever people ask me for advice on career growth, I share what has worked reasonably well for me: find a growth company, one that really needs you to get work done, and then tackle the unpleasant work that everyone avoids.
Tags
Annotators
URL
-
-
-
That’s why it was such a life-changing event for me when I found Dash in 2012.
Offline docs: - macOS: Dash ($30) - Windows/Linux: Zeal (free) - Windows: [Velocity] (https://velocity.silverlakesoftware.com/) ($20) - Web: DevDocs
-
-
-
This is not "noise"
2 advantages of communicating on group channels instead of using DMs
-
-
www.zerobanana.com www.zerobanana.com
-
Imagine for a moment that, by some quirk of the universe, you are sharing your workspace with a time traveller. Specifically, yourself from 1 year in the future. How will you react to your new co-worker?
That imagination makes one to ponder for a pretty good time :)
Tags
Annotators
URL
-
-
pythonspeed.com pythonspeed.com
-
Mamba installs these packages in only a third of the time that Conda does. Much of that is due to less CPU usage, but even network downloads seem to be little faster; Mamba uses parallel downloads to speed them up.
Mamba is a lot faster than Conda
-
-
pythonspeed.com pythonspeed.com
-
So which should you use, pip or Conda? For general Python computing, pip and PyPI are usually fine, and the surrounding tooling tends to be better. For data science or scientific computing, however, Conda’s ability to package third-party libraries, and the centralized infrastructure provided by Conda-Forge, means setup of complex packages will often be easier.
From my experience, I would use Mambaforge or pyenv and Poetry.
Tags
Annotators
URL
-
-
www.driverlesscrocodile.com www.driverlesscrocodile.com
-
My first recommendation would be fiction. Reading fiction is important to understand the cross-sectional variation in humanity, to understand how difficult generalisations can be, to just get a sense of how different social pieces fit together, and to get a sense of different historical eras – and plus, reading fiction is often just plain flat-out fun.
Why reading fiction is important
-
-
quick-answers.kronis.dev quick-answers.kronis.dev
-
Quicker And More Useful Communication
Great example of asking precise questions
-
-
scanbot.io scanbot.io
-
The different barcode types can be categorized as one-dimensional (1D) and two-dimensional (2D). While one-dimensional barcodes consist only of lines and are usually scanned horizontally with laser scanners, two-dimensional codes make use of vertical space as well and can only be scanned with devices that contain a camera, such as imager scanners or smartphones.
Aparently, there a lot of barcode types
Tags
Annotators
URL
-
-
martinheinz.dev martinheinz.dev
-
# "func" called 3 times result = [func(x), func(x)**2, func(x)**3] # Reuse result of "func" without splitting the code into multiple lines result = [y := func(x), y**2, y**3]
Smart example of using the walrus operator
:=
-
- Aug 2022
-
axbom.com axbom.com
-
First of all, the map does a much better job at preserving the relative size and area of land and water masses, while reducing shape distortion. It is also designed to avoid dead ends, allowing the spherical nature of the world to be visualised by simply expanding the map in any direction.
Authagraph map - granted, this map is still not perfect (it's still not a globe) but remains one of the best attempts yet at representing the world in flat, two dimensions.
-
-
endtimes.dev endtimes.dev
-
Most web servers TCP slow start algorithm starts by sending 10 TCP packets. The maximum size of a TCP packet is 1500 bytes.
10 * 1460 bytes = 14 kb.
If your website is under 14 kb, it can load around 612 ms faster than 15 kb.
-
-
-
Second-order thinking is more deliberate. It is thinking in terms of interactions and time, understanding that despite our intentions our interventions often cause harm. Second order thinkers ask themselves the question “And then what?” This means thinking about the consequences of repeatedly eating a chocolate bar when you are hungry and using that to inform your decision. If you do this you’re more likely to eat something healthy.
Second-order thinking
Tags
Annotators
URL
-
-
medium.com medium.com
-
Mob requires good communication skills. There is no space for passive-aggressiveness; or arrogance. If You want to show You are better than Your colleagues, You aren’t a candidate for Mob.
Main requirement of effective mob programming
-
-
fractionalciso.com fractionalciso.com
-
Even though Chrome, Firefox, and Edge browsers all store passwords in encrypted databases, by default all three products intentionally leave the associated encryption keys completely unprotected in predictable locations.
That's why one should use an external app to store passwords, instead of leaving them in a browser
-
-
deephaven.io deephaven.io
-
Blog posts with images get 2.3x more engagement.
-
Preview: quick before and after
Check out the
Previewsection to see how much better the blog post images are when generated by DALL·E 2 for $45
-
-
jakobgreenfeld.com jakobgreenfeld.com
-
If I’m not able to write down any specific experiments, I know the book, video, podcast, article, or thread is just fluff and I should stop reading, listening, watching as soon as possible. This is an incredibly useful tool. Many authors and speakers are extremely skilled at creating the illusion of powerful insights through engaging stories, fortune cookie wisdom, and the use of sophisticated language.
Major tip for consuming non-fiction
-
-
kevin.burke.dev kevin.burke.dev
-
Instead, they keep a Thing Table and a Data Table. Everything in Reddit is a Thing: users, links, comments, subreddits, awards, etc. Things keep common attribute like up/down votes, a type, and creation date. The Data table has three columns: thing id, key, value. There’s a row for every attribute. There’s a row for title, url, author, spam votes, etc. When they add new features they didn’t have to worry about the database anymore. They didn’t have to add new tables for new things or worry about upgrades. Easier for development, deployment, maintenance.
Reddit uses only 2 tables, with the cost of not being able to use cool relational features
-
Schema updates are very slow when you get bigger. Adding a column to 10 million rows takes locks and doesn’t work. They used replication for backup and for scaling. Schema updates and maintaining replication is a pain.
Schema updates and replications are not easy to handle
-
-
metaphysic.ai metaphysic.ai
-
To Uncover a Deepfake Video Call, Ask the Caller to Turn Sideways
-
-
misc.l3m.in misc.l3m.in
-
When I find a "get X free" button on a website that then asks for my email address, I like to search for the email of the company behind the website (sometimes it's on the legal page, or the privacy policy page) and I submit their email. I also make sure to check the "sign me up for the newsletter" box, to make sure the spammers get at least one of their messages. I don't really know why I do this, it seemed funny a few months ago when I started and now I do it out of habit. I now keep a list of emails from these spam sites, and subscribe them all to the various newsletters I find if I have 5 minutes.
A little trick to spam the spammers :D
-
-
ergo.human.cornell.edu ergo.human.cornell.edu
-
Sit to do computer work. Sit using a height-adjustable, downward titling keyboard tray for the best work posture, then every 20 minutes stand for 8 minutes AND MOVE for 2 minutes. The absolute time isn’t critical but about every 20-30 minutes take a posture break and stand and move for a couple of minutes. Simply standing is insufficient. Movement is important to get blood circulation through the muscles. And movement is FREE! Research shows that you don’t need to do vigorous exercise (e.g. jumping jacks) to get the benefits, just walking around is sufficient. So build in a pattern of creating greater movement variety in the workplace (e.g. walk to a printer, water fountain, stand for a meeting, take the stairs, walk around the floor, park a bit further away from the building each day).
Bottom line: don't just sit or stand at work, but simply change your position often
Tags
Annotators
URL
-
- Jul 2022
-
www.ncbi.nlm.nih.gov www.ncbi.nlm.nih.gov
-
9 evidence-based common denominators among the world’s centenarians that are believed to slow this aging process.
List of 9 habits that will make you live longer (see text below)
Tags
Annotators
URL
-
-
snarky.ca snarky.ca
-
when you use python -m pip with python being the specific interpreter you want to use, all of the above ambiguity is gone. If I say python3.8 -m pip then I know pip will be using and installing for my Python 3.8 interpreter (same goes for if I had said python3.7).
It's better to use python -m pip over pip / pip3 to be sure for which Python version we're installing the dependencies.
However, it's not necessary when using environments.
-
And if you're on Windows there is an added benefit to using python -m pip as it lets pip update itself. Basically because pip.exe is considered running when you do pip install --upgrade pip, Windows won't let you overwrite pip.exe. But if you do python -m pip install --upgrade pip you avoid that issue as it's python.exe that's running, not pip.exe.
If you would like to update pip on Windows, use python -m pip install --upgrade pip
Tags
Annotators
URL
-
-
commoncog.com commoncog.com
-
The only thing that works is to remove yourself from the environment that is causing burnout, and then taking the time off to recover.
The only way to prevent burnout
-
-
-
When you see a job post mentioning REST or a company discussing REST Guidelines they will rarely mention either hypertext or hypermedia: they will instead mention JSON, GraphQL(!) and the like.
-
-
martinheinz.dev martinheinz.dev
-
It’s time to say goodbye to distutils package and switch to setuptools.
Use setuptools over distutils
-
as soon as you switch to Python 3.11, you should get into habit of using import tomllib instead of import tomli
tomlib
-
It's fine to use print if you're debugging an issue locally, but for any production-ready program that will run without user intervention, proper logging is a must.
In production, use logging instead of print
-
Finally, if you don’t use either namedtuple nor dataclasses you might want to consider going straight to Pydantic.
Pydantic: https://pydantic-docs.helpmanual.io/
-
You might be wondering why would you need to replace namedtuple? So, these are some reasons why you should consider switching to dataclasses
There are a number of reasons why to prefer dataclasses over namedtuple
-
Using zoneinfo however has one caveat - it assumes that there's time zone data available on the system, which is the case on UNIX systems. If your system doesn't have timezone data though, then you should use tzdata package which is a first-party library maintained by the CPython core developers, which contains IANA time zone database.
One caveat of zoneinfo
-
Until Python 3.9, there wasn’t builtin library for timezone manipulation, so everyone was using pytz, but now we have zoneinfo in standard library, so it's time to switch!
Prefer zoneinfo over pytz from Python 3.9
-
As per docs, random module should not be used for security purposes. You should use either secrets or os.urandom, but the secrets module is definitely preferable, considering that it's newer and includes some utility/convenience methods for hexadecimal tokens as well as URL safe tokens.
Prefer secrets module over os.urandom
-
pathlib has however many advantages over old os.path - while os module represents paths in raw string format, pathlib uses object-oriented style, which makes it more readable and natural to write
pathlib is the newer os.path with an inclusion of glob.glob
Mappings: https://docs.python.org/3/library/pathlib.html#correspondence-to-tools-in-the-os-module
More about pathlib: https://treyhunner.com/2018/12/why-you-should-be-using-pathlib/
-
-
jerrynsh.com jerrynsh.com
-
If you need to store duplicates, go for List or Tuple.For List vs. Tuple, if you do not intend to mutate, go for Tuple.If you do not need to store duplicates, always go for Set or Dictionary. Hash maps are significantly faster when it comes to determining if an object is present in the Set (e.g. x in set_or_dict).
Python list vs tuple vs set
Tags
Annotators
URL
-
-
www.cybertec-postgresql.com www.cybertec-postgresql.com
-
How does PostgreSQL access a column? It will fetch the row and then dissect this tuple to calculate the position of the desired column inside the row. So if we want to access column #1000 it means that we have to figure out how long those first 999 columns before our chosen one really are. This can be quite complex. For integer we simply have to add 4, but in case of varchar, the operation turns into something really expensive.
Column order matters in PostgreSQL. The time to read 1000th column can be pretty large, especially if there are varchar columns before that.
-
-
blog.jgc.org blog.jgc.org
-
WiFi QR code is simply a text QR code with a special format as follows:WIFI:S:<SSID>;T:<WEP|WPA|blank>;P:<PASSWORD>;H:<true|false|blank>;;The S sets the SSID of the network, T defines the security in use, P is the password and H whether the network is hidden or not.
WiFi QR code format
-
-
scribe.rip scribe.rip
-
If your laptop is extremely old then I would recommend Puppy Linux.If your laptop isn’t very old but doesn’t perform very well I would recommend AntiX.If your laptop is a little old but still can’t handle Windows 7/10 very well I would recommend Lubuntu.
3 OS recommendations for old laptops: 1. Puppy Linux 2. AntiX 3. Lubuntu
Tags
Annotators
URL
-
-
www.phpied.com www.phpied.com
-
In the functions.php of your WordPress theme add:
Same solution but in PHP
php function hints() { header("link: </wp-content/themes/phpied2/style.css>; rel=preload, </wp-includes/css/dist/block-library/style.min.css?ver=5.4.1>; rel=preload"); } add_action('send_headers', 'hints'); -
We can. I cannot because the shared Dreamhost hosting doesn't let me edit Apache config beyond .htaccess. But if you have access to the server or virtual host config, see here. Basically all you need to do in addition to what we did in .htaccess is to add: H2EarlyHints on
Even better solution with:
H2EarlyHints on -
What I describe here is a one-off thing for demonstration. As you can probably guess by the "5.4.1", when you upgrade WordPress or change themes, you might need to change the URLs of the preloaded CSS in the .htaccess.
Currently there may be no plugin to do it automatically
-
And immediately after it, the 2 CSS downloads begin. What we want to do is move the CSS downloads to the left, so all rendering starts (and finishes!) sooner. So all you do it take the URLs of these two files and add them to .htaccess with H2PushResource in front. For me that means the URL to my custom theme's CSS /wp-content/themes/phpied2/style.css as well as some WordPress CSS stuff. While I was there I also added a JavaScript file which is loaded later. Why now start early? So the end result is:
WordPress tip to start loading some CSS and JS files earlier.
Sample code to add to
.htaccess:H2PushResource /wp-content/themes/phpied2/style.css H2PushResource /wp-includes/css/dist/block-library/style.min.css?ver=5.4.1 H2PushResource /wp-includes/js/wp-emoji-release.min.js?ver=5.4.1
-
-
www.quantamagazine.org www.quantamagazine.org
-
If you’ve ever felt that you can’t focus on a task when you’re hungry — or that all you can think about is food — the neural evidence backs you up. Work from a few years ago confirmed that short-term hunger can change neural processing and bias our attention in ways that may help us find food faster.
-
-
slite.com slite.com
-
They are:doers: self-motivated or intrinsically driven to achieve and learndrivers: proactive and decisive; don't wait for orderspromoters: passionate and excited to share what they create for their own benefit and the benefit of others
3 abilities of great async workers
Tags
Annotators
URL
-
-
news.ycombinator.com news.ycombinator.com
-
Review: a formal assessment or examination of something with the possibility or intention of instituting change if necessary.
(comment with good examples of code review comments)
Tags
Annotators
URL
-
-
dkb.show dkb.show
-
On top of that, there’s one thing you can do to extend your life. By studying the philosophies of those who came before you, you absorb their experiences. Every philosophy book you read, you’re adding the author’s lifespan to yours. There’s no better way to spend your time than studying philosophy.13
-
What I was trying to say before was just because someone’s always busy, and lives to an old age, doesn’t mean they’ve lived long. They’ve just existed long.
-
I’m not saying you should lay down on the beach all day. I’m saying you should find something that’s enjoyable to you, and valuable for the world.10 You should live your life intentionally, instead of having your time stolen from you little by little.
-
Even with all that, he was looking forward to the day that he could step down and retire from it all. The man with all the power in the world was happiest when he thought about the day he could let go of all the power.8 How foolish is it to spend your life chasing fame, riches, and power, while being unhappy the entire time, even after you achieve it?
-
The most surprising thing is that you wouldn’t let anyone steal your property, but you consistently let people steal your time, which is infinitely more valuable.2
Tags
Annotators
URL
-
-
apple.stackexchange.com apple.stackexchange.com
-
sudo killall coreaudiod
Disable flashing screen on specific sounds, even while pressing
backspacein a Python terminal and hitting the left end.
-
- Jun 2022
-
blog.driftingruby.com blog.driftingruby.com
-
This is a neat Docker trick for those who have an ARM development machine (Apple M1), but sometimes need to build x86/amd64 images locally to push up to a registry.
Since Apple M1 is based on the ARM architecture, it is still possible to build images based on Linux x86/amd64 architecture using docker buildx:
docker buildx build -f Dockerfile --platform linux/amd64 .However, building such images can be really slow, so we can create a builder profile (see the paragraphs below / my other annotation to this article).
-
So, we can create this builder on our local machine. The nice part about this creation is that it is idempotent, so you can run this command many times without changing the result. All we have to do is to create a builder profile and in this case I have named it amd64_builder.
Example of creating a Docker buildx builder profile on the Apple M1 machine. This will allow for around 10x faster builds on the amd64 architecture pushed to a registry, than on the amd64 emulation on the M1 chip.
Tags
Annotators
URL
-
-
www.facet.net www.facet.net
-
sum(1 to n) = n(n + 1) / 2
Tags
Annotators
URL
-
-
docs.python.org docs.python.org
-
Python 3.11 is up to 10-60% faster than Python 3.10. On average, we measured a 1.25x speedup on the standard benchmark suite. See Faster CPython for details.
On the speed of Python 3.11
-
-
dx.tips dx.tips
-
But to my knowledge, this is the first time anyone has collected public info about Bigco dev environments in one place
Examples of big companies moving to development in the cloud
-
-
-
Git also has a built-in command (maintenance) to optimize a repository’s data, speeding up commands and reducing disk space. This isn’t enabled by default, so we register it with a schedule for daily and hourly routines.
git maintenance
-
On a new clone of the Canva monorepo, git status takes 10 seconds on average while git fetch can take anywhere from 15 seconds to minutes due to the number of changes merged by engineers.
-
Over the last 10 years, the code base has grown from a few thousand lines to just under 60 million lines of code in 2022. Every week, hundreds of engineers work across half a million files generating close to a million lines of change (including generated files), tens of thousands of commits, and merging thousands of pull requests.
-
-
devblogs.microsoft.com devblogs.microsoft.com
-
The perpetrator in question was completing an internship and committed code into the Windows 3.1 code base that was a little prank for the test team: Under a very specific error condition, it changed the index finger pointer to a middle finger.
Funny/rude prank in Windows 3.1
Tags
Annotators
URL
-
-
-
23.0G com.txt # 23 gigs uncompressed
23 GB txt file <--- list of all the existing .com domains
-
-
-
What makes you unique is not your specific attributes. It’s your specific ties to the network around you.
-
Becoming disentangled from your web of mutual commitments, shared history, and collective responsibility is to be rendered into a transaction, a slave.
-
Real friendships don’t form via shared interests. They form via shared context.
Tags
Annotators
URL
-
-
refactoring.fm refactoring.fm
-
In a Staging workflow, releases are slower because of more steps, and bigger because of batching.
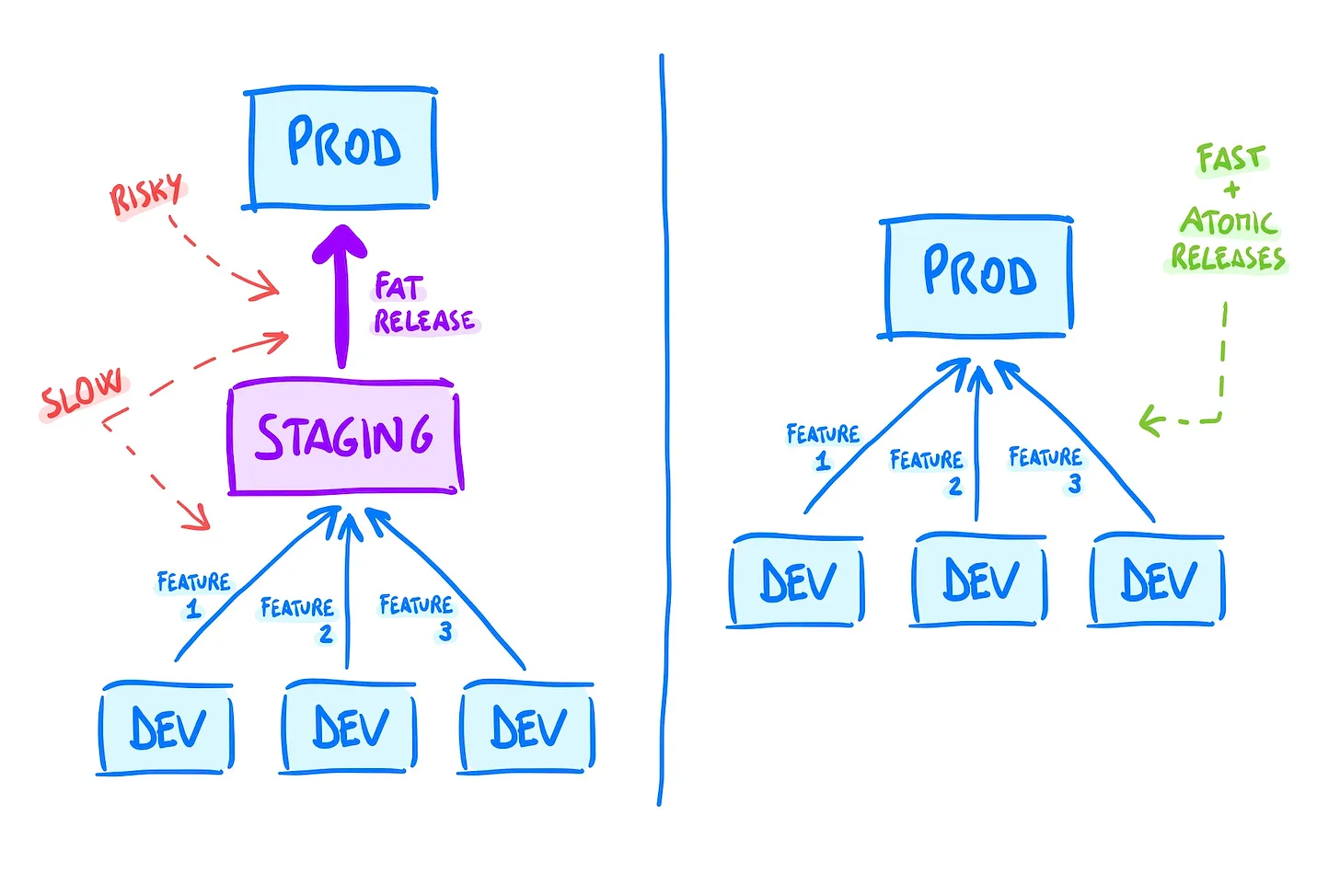
-
For Staging to be useful, it has to catch a special kind of issues that 1) would happen in production, but 2) wouldn’t happen on a developer's laptop.What are these? They might be problems with data migrations, database load and queries, and other infra-related problems.
How "Staging" environment can be useful
Tags
Annotators
URL
-
-
blog.zenml.io blog.zenml.io
-
Another disadvantage of managed platforms is that they are inflexible and slow to change. They might provide 80% of the functionality we require, but it is often the case that the missing 20% provides functionality that is mission critical for machine learning projects. The closed design and architecture of managed platforms makes it difficult to make even the most trivial changes. To compensate for this lack of flexibility, we often have to design custom, inefficient and hard-to-maintain mechanisms that add technical debt to the project.
Main disadvantage of managed MLOps platforms
-
- May 2022
-
about.gitlab.com about.gitlab.com
-
As you've probably already guessed, we've decided to replace the current Web IDE with one built on top of VS Code. In the coming milestones, we will build out custom support for the features not already available in the VS Code core, and validate that the workflows you already depend on in the Web IDE are handled in the new experience. We're working with the team that builds our amazing GitLab Workflow extension for VS Code to make it available in the browser so we can bundle it in the Web IDE, and bring all those great features along for the ride. That includes bringing merge request comments into the Web IDE for the first time ever!
GitLab is planning to onboard VS Code web IDE
-
-
blog.container-solutions.com blog.container-solutions.com
-
A normal Makefile for building projects with Docker would look more or less like this:
Sample of a Makefile for building and tagging Docker images
-
One of the main benefits from tagging your container images with the corresponding commit hash is that it's easy to trace back who a specific point in time, know how the application looked and behaved like for that specifc point in history and most importantly, blame the people that broke the application ;)
Why tagging Docker images with SHA is useful
-
-
www.docker.com www.docker.com
-
Software Bill Of Materials (SBOM) is analogous to a packing list for a shipment; it’s all the components that make up the software, or were used to build it. For container images, this includes the operating system packages that are installed (e.g.: ca-certificates) along with language specific packages that the software depends on (e.g.: log4j). The SBOM could include only some of this information or even more details, like the versions of components and where they came from.
Software Bill Of Materials (SBOM)
-
Included in Docker Desktop 4.7.0 is a new, experimental docker sbom CLI command that displays the SBOM (Software Bill Of Materials) of any Docker image.
New docker sbom CLI command
-
-
towardsdatascience.com towardsdatascience.com
-
With every generation of computing comes a dominant new software or hardware stack that sweeps away the competition and catapults a fledgling technology into the mainstream.I call it the Canonical Stack (CS).Think the WinTel dynasty in the 80s and 90s, with Microsoft on 95% of all PCs with “Intel inside.” Think LAMP and MEAN stack. Think Amazon’s S3 becoming a near universal API for storage. Think of Kubernetes and Docker for cloud orchestration.
Explanation of Canonical Stack (CS)
-
-
blog.shimin.io blog.shimin.io
-
By offering to have a real-time technical discussion, you are reframing the code review process away from an 'instructor correcting student' dynamic and into a 'colleagues working together' mindset.
-
-
blog.shimin.io blog.shimin.io
-
if you are on the job market looking for a team that cares more about being agile than going through the motions to look agile, ask these questions
- "Tell me about the last time you refactored a module or class."
- "Tell me about the last piece of user feedback that became a feature."
- "Tell me about the last feature of yours that got dropped."
-
-
-
Level 5: Stop the line. The highest level of code review comments. Borrowing the term from Toyota's manufacturing process this is when the code reviewer noticed something in the PR that signals a major defect.
Stop the line - 5th type of MR comments
-
Level 4: Infringement. This is where things get more serious, note that infringement means rules were broken. In this context, rules can mean a number of things, from the more obvious feature spec and framework rules to things like style guides and coding principles.
Infringement - 4th type of MR comments
-
Level 3: Suggestions. These can also be thought of as recommendations and alternatives.
Suggestions - 3rd type of MR comments
-
Level 2: Nitpicks. Usually, comments about grammar errors and minor stylistic issues/typos go there. The solution to the nitpicks is usually very obvious and if the solution is opinionated, the opinion is not strongly held. Naming a method foobarGenerator vs foobarFactory goes in here, and nitpick comments often start with Nitpick:.
Nitpicks - 2nd type of MR comments
-
Level 1: Clarifications. I also think of these as sanity checks, I may even start the comment with something like I may be completely off the base here... or Just to sanity check...
Clarifications - 1st type of MR comments
-
-
blog.shimin.io blog.shimin.io
-
Each developer on average wastes 30 minutes before and after the meeting to context switch and the time is otherwise non-value adding. (See this study for the cost of context switching).
-
-
earthly.dev earthly.dev
-
Overall, if speed is your primary concern and you’re on a budget, then Circle CI is the clear choice. If you’re not looking to run a ton of builds each month and your code is already in Github, then Github Actions can offer similar performance with the added convenience of having everything under one service. Even though we liked Travis better, our main criteria was value, and since you can’t use Travis for free after the first month, GitLab was able to grab the third slot, despite it being weaker in almost every other category.
4 CI free tier comparison: * Quality of Documentation * Compute Power * Available Disk Space * Free Build Minutes * Speed and Performance
Tags
Annotators
URL
-
-
www.scottkennedy.us www.scottkennedy.us
-
Somebody once described balance to me as three buckets filled with water. One for career, a second for physical health, and a third for social and family life. At any point, one bucket might be running low. But as long as the overall water level is high enough, things should be fine.
Balance represented by 3 buckets
-
-
dev.to dev.to
-
html[theme='dark-mode'] { filter: invert(1) hue-rotate(180deg); }
Ultimate CSS to turn on dark mode
Tags
Annotators
URL
-
-
thepythoncorner.com thepythoncorner.com
-
Pyenv works by adding a special directory called shims in front of your PATH environment variable
How pyenv works
-
If you are on Linux, you can simply download it from GitHub but the most convenient way is to use the pyenv-installer that is a simple script that will install it automatically on your distro, whatever it is, in the easiest possible way.
Installing pyenv on Linux
-
-
sarusso.github.io sarusso.github.io
-
As of today, the Docker Engine is to be intended as an open source software for Linux, while Docker Desktop is to be intended as the freemium product of the Docker, Inc. company for Mac and Windows platforms. From Docker's product page: "Docker Desktop includes Docker Engine, Docker CLI client, Docker Build/BuildKit, Docker Compose, Docker Content Trust, Kubernetes, Docker Scan, and Credential Helper".
About Docker Engine and Docker Desktop
-
The diagram below tries to summarise the situation as of today, and most importantly to clarify the relationships between the various moving parts.
Containers (the backend):
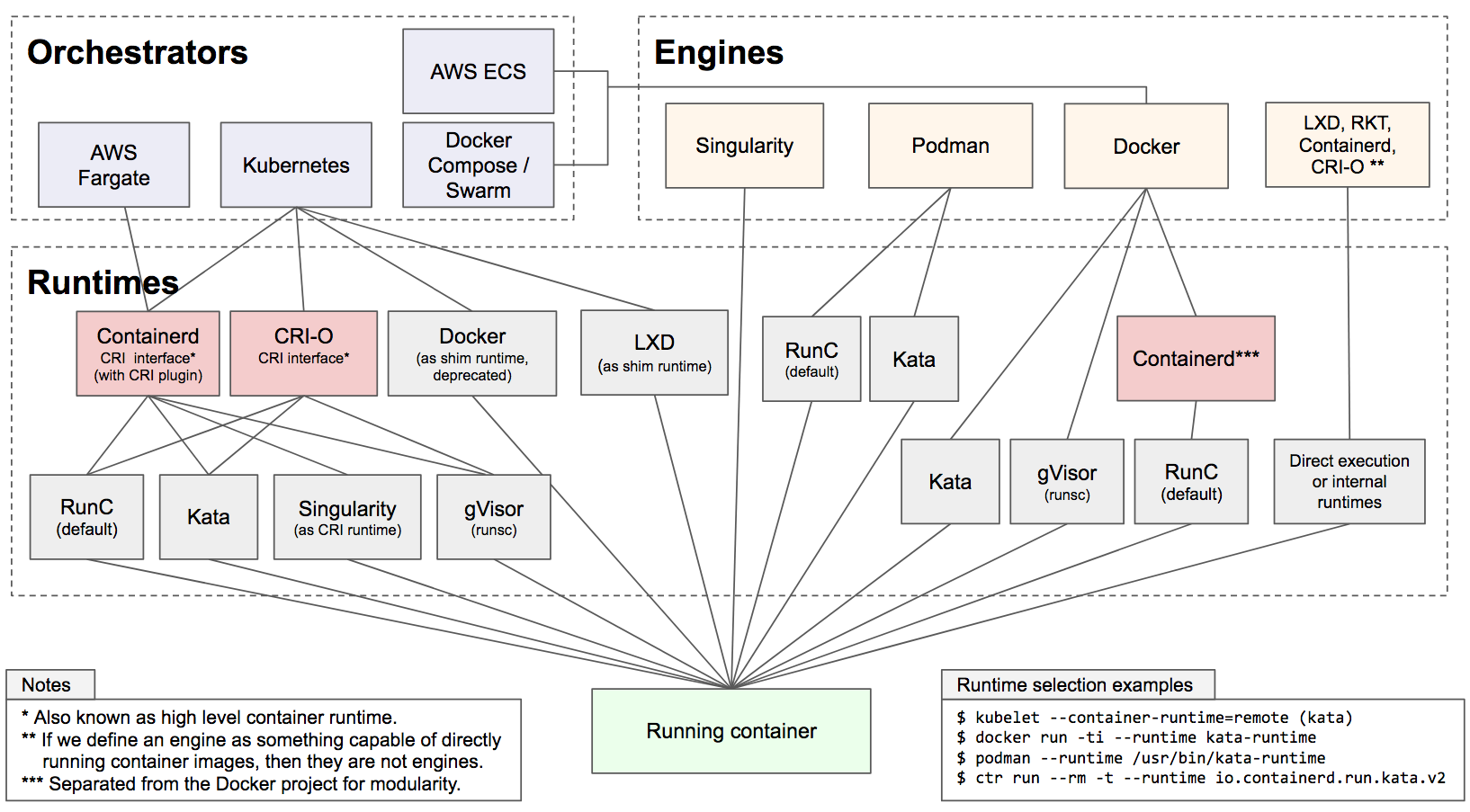
-
-
www.heinrichhartmann.com www.heinrichhartmann.com
-
If you want your voice to be heard (and also improve the usability of your text) you have to design your document for “skim-ability”. You do this by providing anchor points that allow the user to gauge the content without actually reading it. You want the outline and key arguments to keep standing out in the final version of the document.
This is why I like using bullet points
-
When writing an article, I generally visualize a concrete person as representative of the audience, that I am directing this text towards.
I also tend to write to my old self
-
Writing is generally a great way to learn, but one has to realize that you are doing it. Learning is a slow process and requires patience. It is not helped much by agonizing in front of a screen, trying to squeeze out another sentence. Doing more research on the topic by reading a book, blog or paper and taking notes may be a better time investment.
Writing is a great learning method
-
The realization that you don’t have the complete message in your head, will often only become apparent while writing. This surfaces as inability to find a good punch-line or to express yourself clearly. In fact, writing is a great test to see if you have a good understanding of a topic, and have a firm grasp on the vocabulary of the domain.
-
-
johnpublic.mataroa.blog johnpublic.mataroa.blog
-
an asshole test. You see who turns into an asshole under pressure and they don't make it to the next round".
Asshole test: 60 minutes, 8 people, no right answer, but checking who turns into an asshole under pressure
Tags
Annotators
URL
-
-
www.nngroup.com www.nngroup.com
-
A 20-year age difference (for example, from 20 to 40, or from 30 to 50 years old) will, on average, correspond to reading 30 WPM slower, meaning that a 50-year old user will need about 11% more time than a 30-year old user to read the same text.
-
Users’ age had a strong impact on their reading speed, which dropped by 1.5 WPM for each year of age.
Tags
Annotators
URL
-
-
-
Stop using TODO for everything in your comments that requires you to do something later.
Possible alternatives of TODO: * FIXME - something is broken * HACK/OPTIMIZE - the code is suboptimal and should be refactored * BUG - there is a bug in the code * CHECKME/REVIEW - the code needs to be reviewed * DOCME - the code needs to be documented (either in codebase or external documentation) * TESTME - the specified code needs to be tested or that tests need to be written for that selection of code
-
-
-
Create the new empty table Write to both old and new table Copy data (in chunks) from old to new Validate consistency Switch reads to new table Stop writes to the old table Cleanup old table
7 steps required while migrating to a new table
-
-
-
Without accounting for what we install or add inside, the base python:3.8.6-buster weighs 882MB vs 113MB for the slim version. Of course it's at the expense of many tools such as build toolchains3 but you probably don't need them in your production image.4 Your ops teams should be happier with these lighter images: less attack surface, less code that can break, less transfer time, less disk space used, ... And our Dockerfile is still readable so it should be easy to maintain.
See sample Dockerfile above this annotation (below there is a version tweaked even further)
-
scratch is a special empty image with no operating system.
FROM scratch
-
-
news.ycombinator.com news.ycombinator.com
-
Overall, having spent a significant amount of time building this project, scaling it up to the size it’s at now, as well as analysing the data, the main conclusion is that it is not worth building your own solution, and investing this much time. When I first started building this project 3 years ago, I expected to learn way more surprising and interesting facts. There were some, and it’s super interesting to look through those graphs, however retrospectively, it did not justify the hundreds of hours I invested in this project.I’ll likely continue tracking my mood, as well as a few other key metrics, however will significantly reduce the amount of time I invest in it.
Words of the author of https://krausefx.com//blog/how-i-put-my-whole-life-into-a-single-database
It seems as if excessive personal data tracking is not worth it
-
-
howisfelix.today howisfelix.today
-
45% less time spent in video & audio calls that day
I can relate with the author. Spending time in a high number of video/audio calls can drastically decrease my mood
-
-
cbea.ms cbea.ms
-
A properly formed Git commit subject line should always be able to complete the following sentence:If applied, this commit will your subject line hereFor example:If applied, this commit will refactor subsystem X for readability
An example how to always aim for imperative commits
-
Git itself uses the imperative whenever it creates a commit on your behalf.For example, the default message created when using git merge reads:Merge branch 'myfeature'
Using imperative mood in subject line of git commits
-
Commit messages with bodies are not so easy to write with the -m option. You’re better off writing the message in a proper text editor.
I've tested it on Windows, and in PowerShell or Git Bash it is as simple as:
```console git commit -m "Subject line<ENTER>
body line 1 body line 2"<ENTER> ```
However, it does not work in CMD.exe (pressing [ENTER] will not move to the next line)
-
Firstly, not every commit requires both a subject and a body. Sometimes a single line is fine, especially when the change is so simple that no further context is necessary.
Not every commit requires a body part
-
Summarize changes in around 50 characters or less More detailed explanatory text, if necessary. Wrap it to about 72 characters or so. In some contexts, the first line is treated as the subject of the commit and the rest of the text as the body. The blank line separating the summary from the body is critical (unless you omit the body entirely); various tools like `log`, `shortlog` and `rebase` can get confused if you run the two together. Explain the problem that this commit is solving. Focus on why you are making this change as opposed to how (the code explains that). Are there side effects or other unintuitive consequences of this change? Here's the place to explain them. Further paragraphs come after blank lines. - Bullet points are okay, too - Typically a hyphen or asterisk is used for the bullet, preceded by a single space, with blank lines in between, but conventions vary here If you use an issue tracker, put references to them at the bottom, like this: Resolves: #123 See also: #456, #789
Example of a great commit message
-
Separate subject from body with a blank lineLimit the subject line to 50 charactersCapitalize the subject lineDo not end the subject line with a periodUse the imperative mood in the subject lineWrap the body at 72 charactersUse the body to explain what and why vs. how
7 rules of great commit messages
-
What may be a hassle at first soon becomes habit, and eventually a source of pride and productivity for all involved.
-
Commit messages can do exactly that and as a result, a commit message shows whether a developer is a good collaborator.
-
A diff will tell you what changed, but only the commit message can properly tell you why.
Commit messages are important
-
Look at Spring Boot, or any repository managed by Tim Pope.
2 great examples of clean commits: * https://github.com/spring-projects/spring-boot/commits/master * https://github.com/tpope/vim-pathogen/commits/master
Tags
Annotators
URL
-
- Apr 2022
-
ling123labs.com ling123labs.com
-
To access your Linux files in Windows, open the Ubuntu terminal and type explorer.exe . (include the punctuation mark). This will open the linux directory in Windows Explorer, with the WSL prefix “\wsl$\Ubuntu-18.04\home\your-username”.Now, you’ll notice that Windows treats your Linux environment as a second network.
- Accessing WSL files from Windows in the WSL terminal: explorer.exe .
- Accessing Windows files from WSL terminal: cd /mnt
-