if you imported moduleX (note: imported, not directly executed), its name would be package.subpackage1.moduleX. If you imported moduleA, its name would be package.moduleA. However, if you directly run moduleX from the command line, its name will instead be __main__, and if you directly run moduleA from the command line, its name will be __main__. When a module is run as the top-level script, it loses its normal name and its name is instead __main__.
When Python's module name is __main__ vs when it's a full name (preceded by the names of any packages/subpackages of which it is a part, separated by dots)
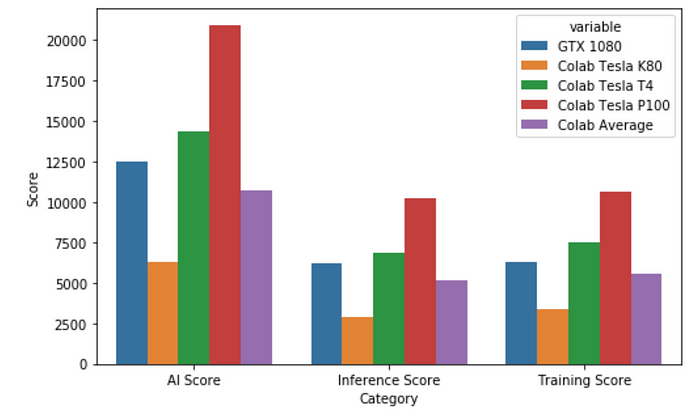

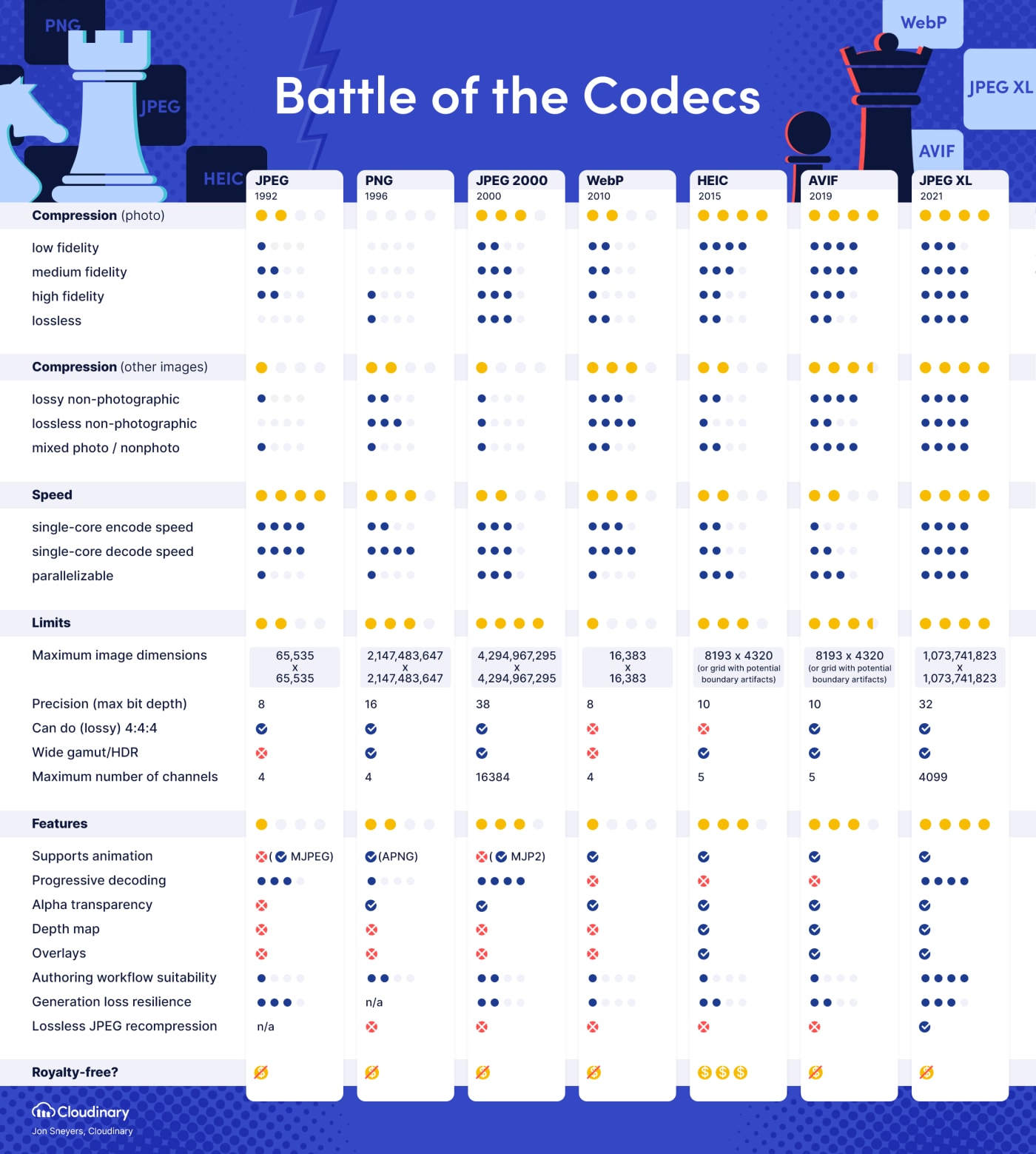
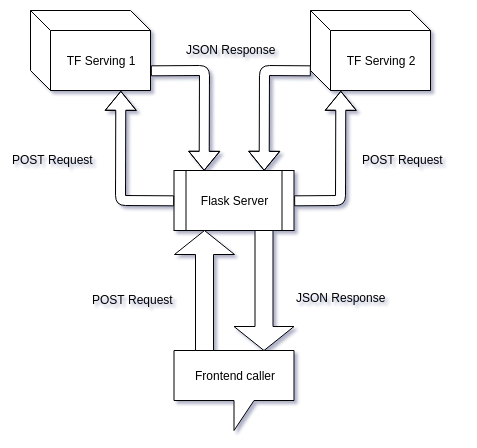





 consolidated:
consolidated:
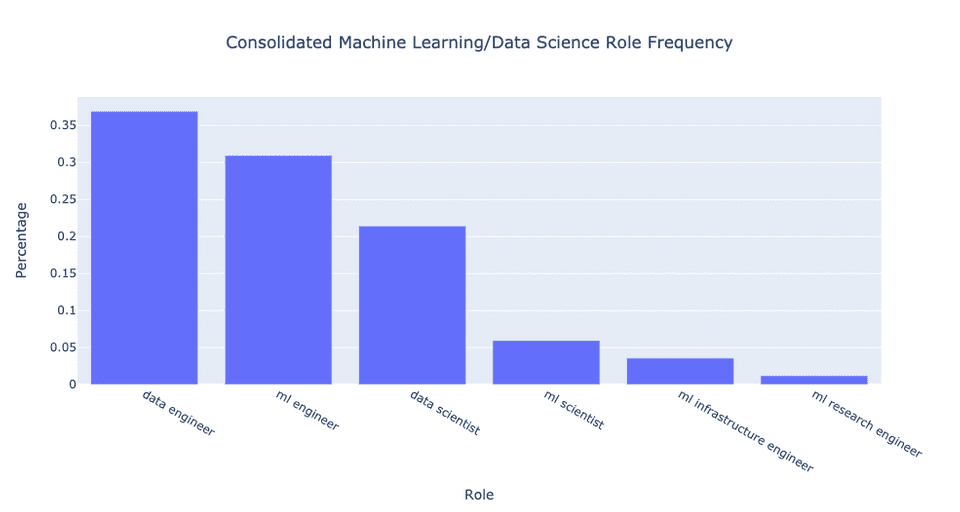

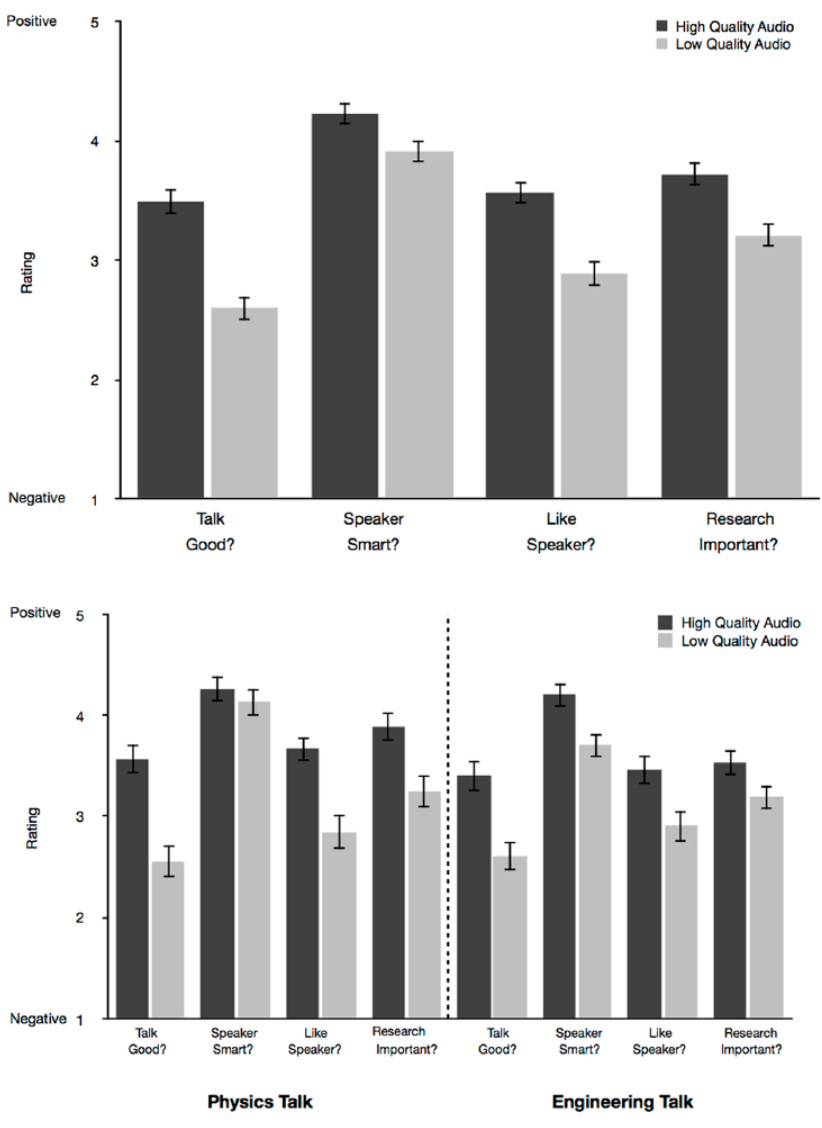
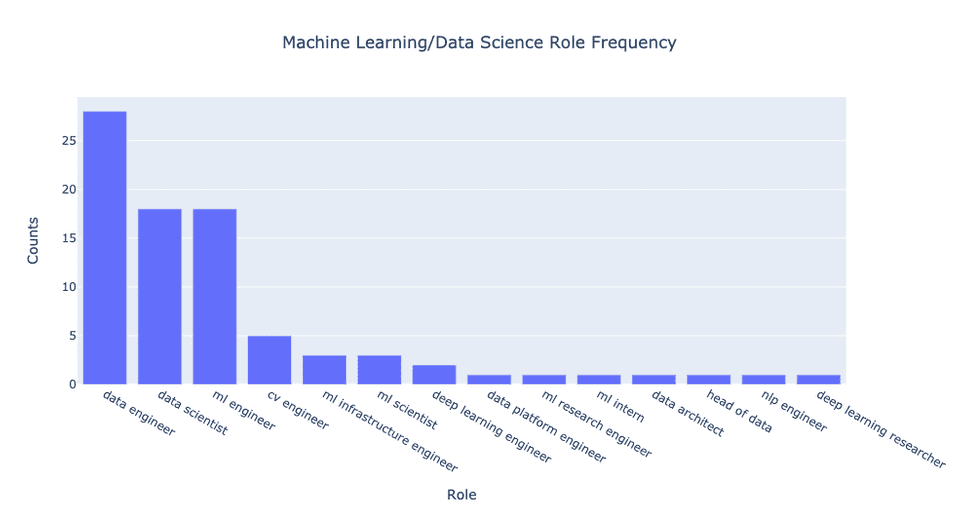
 Another graph:
Another graph: