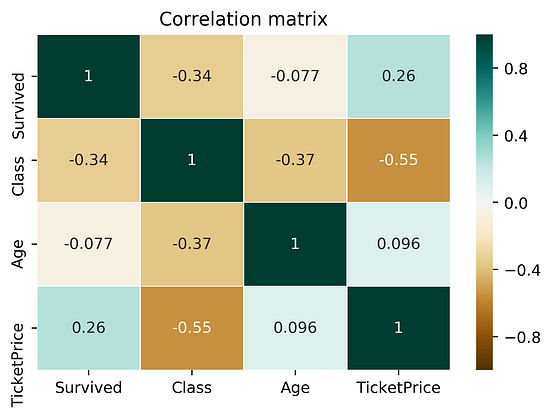
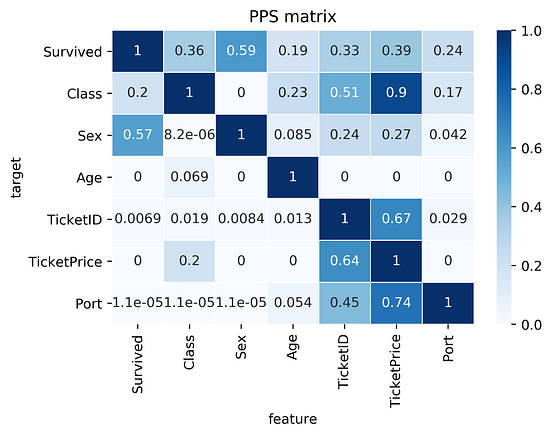
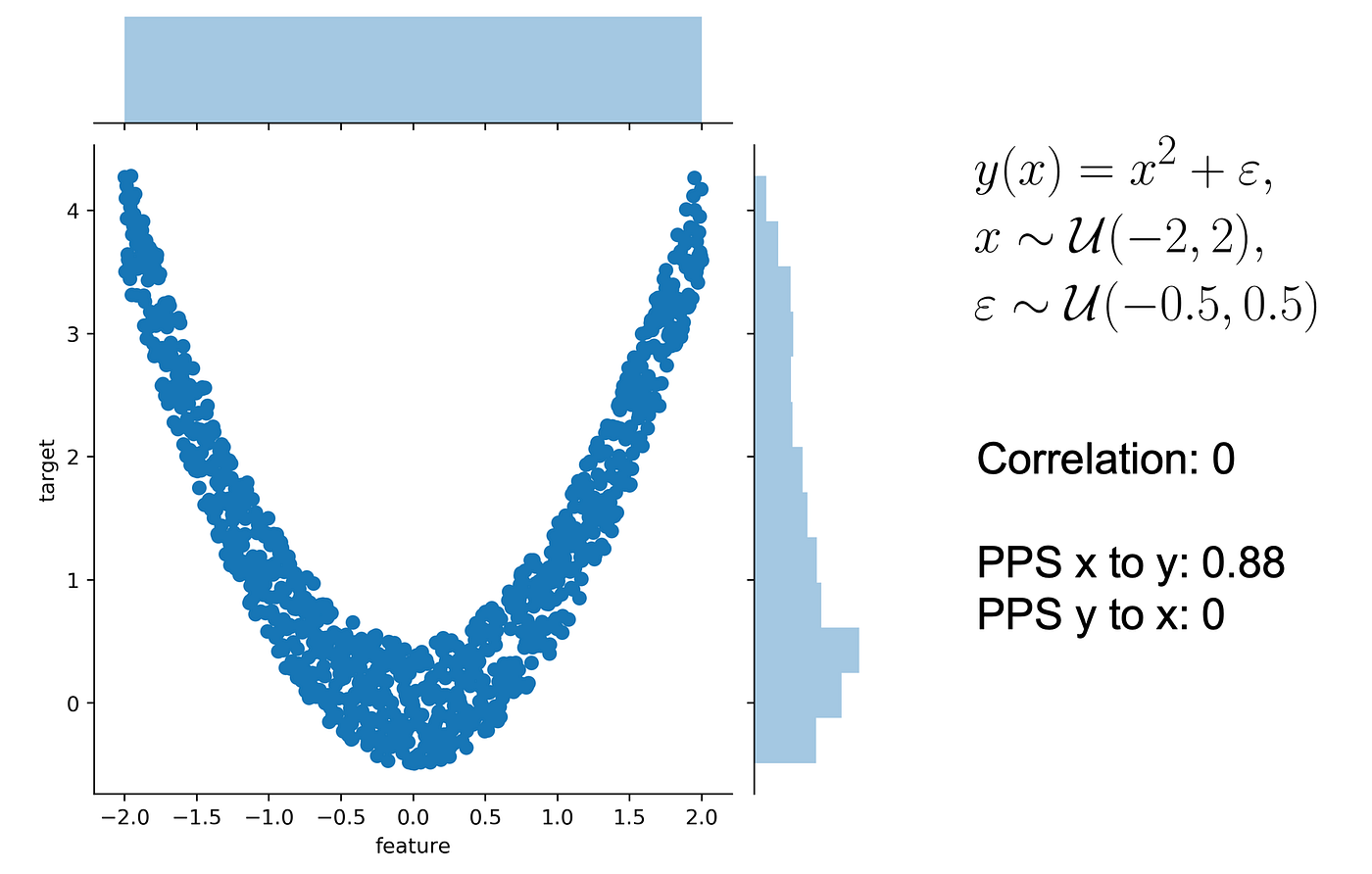
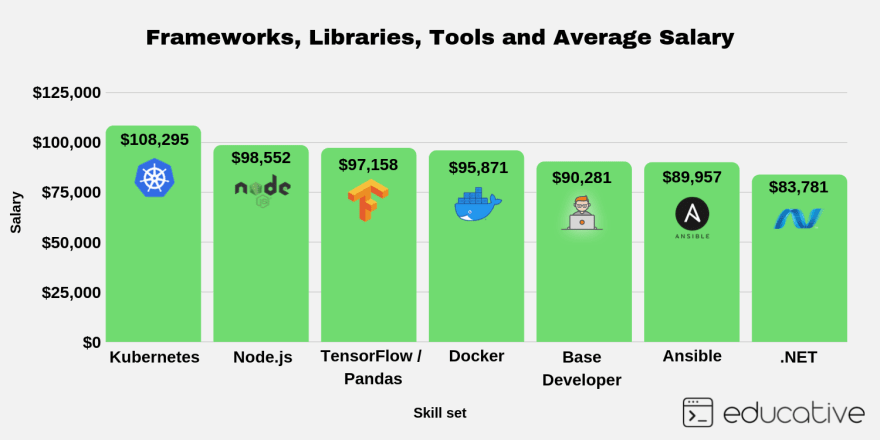
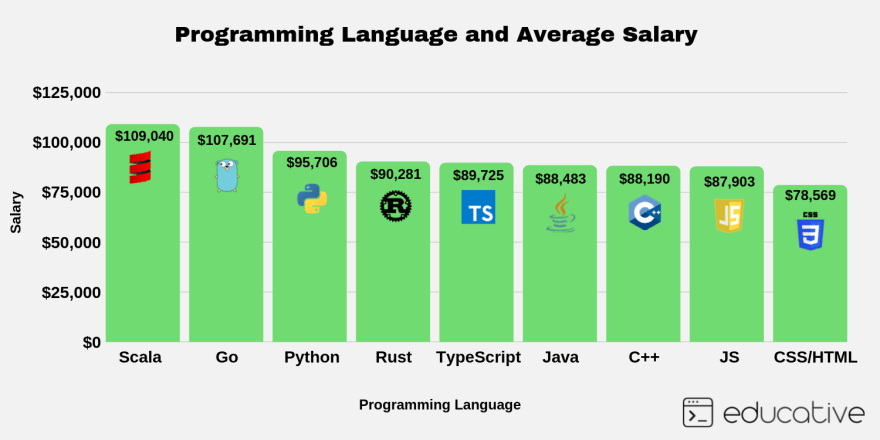
With Intention I:know how much of my time is spent on distractions,decide how much time I need,I see the countdown (so I know if I need to wrap-up a reply, or if it makes sense to start writing a new one),it automatically blocks these sites,yet, it distinguishes between “normal use” of YouTube and e.g. using it for creating a workshop on deep learning (looking for video abstract of recent papers).
Intention is well recommended by Piotr Migdał for your productivity. More than toggl or RescueTime.








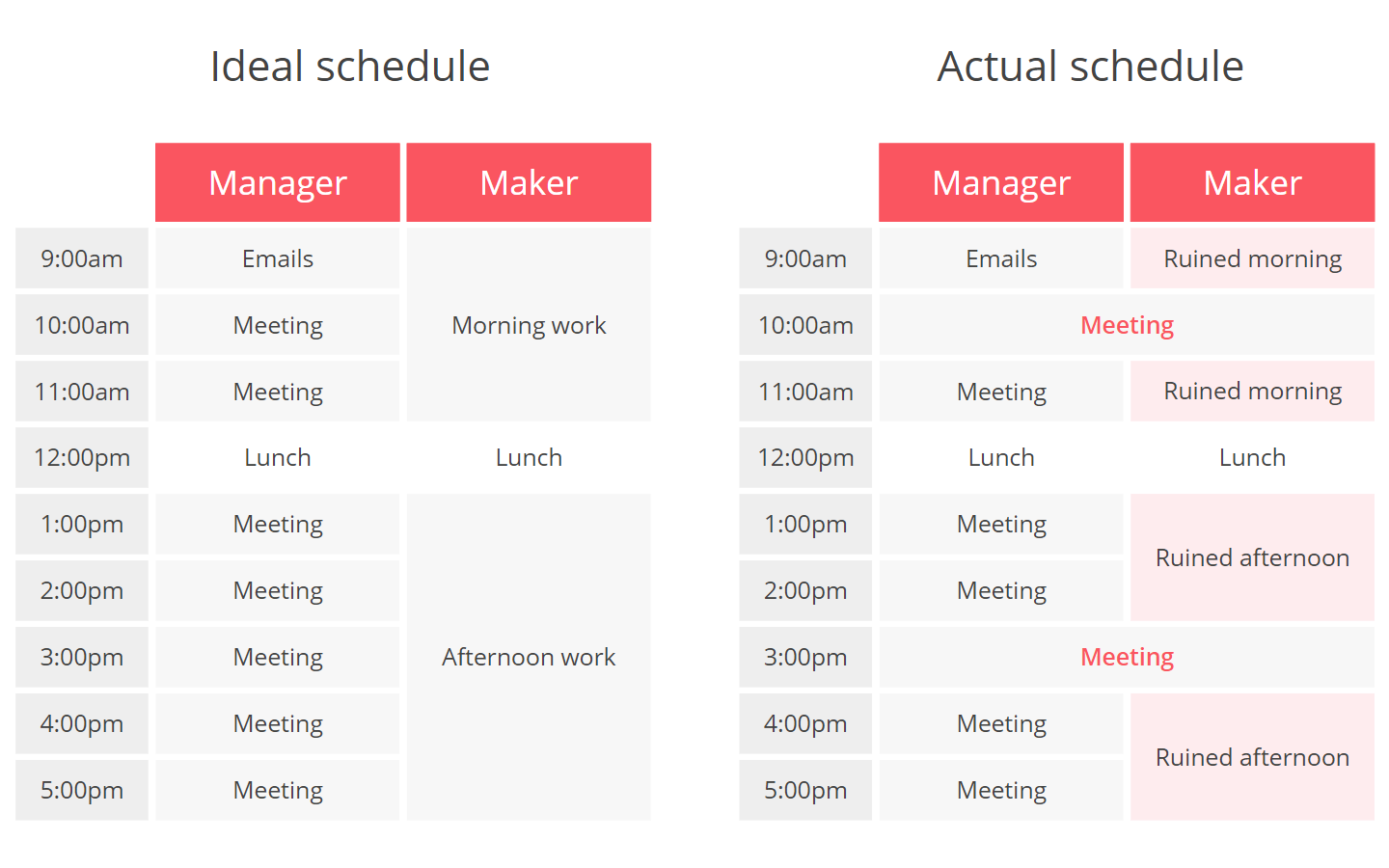
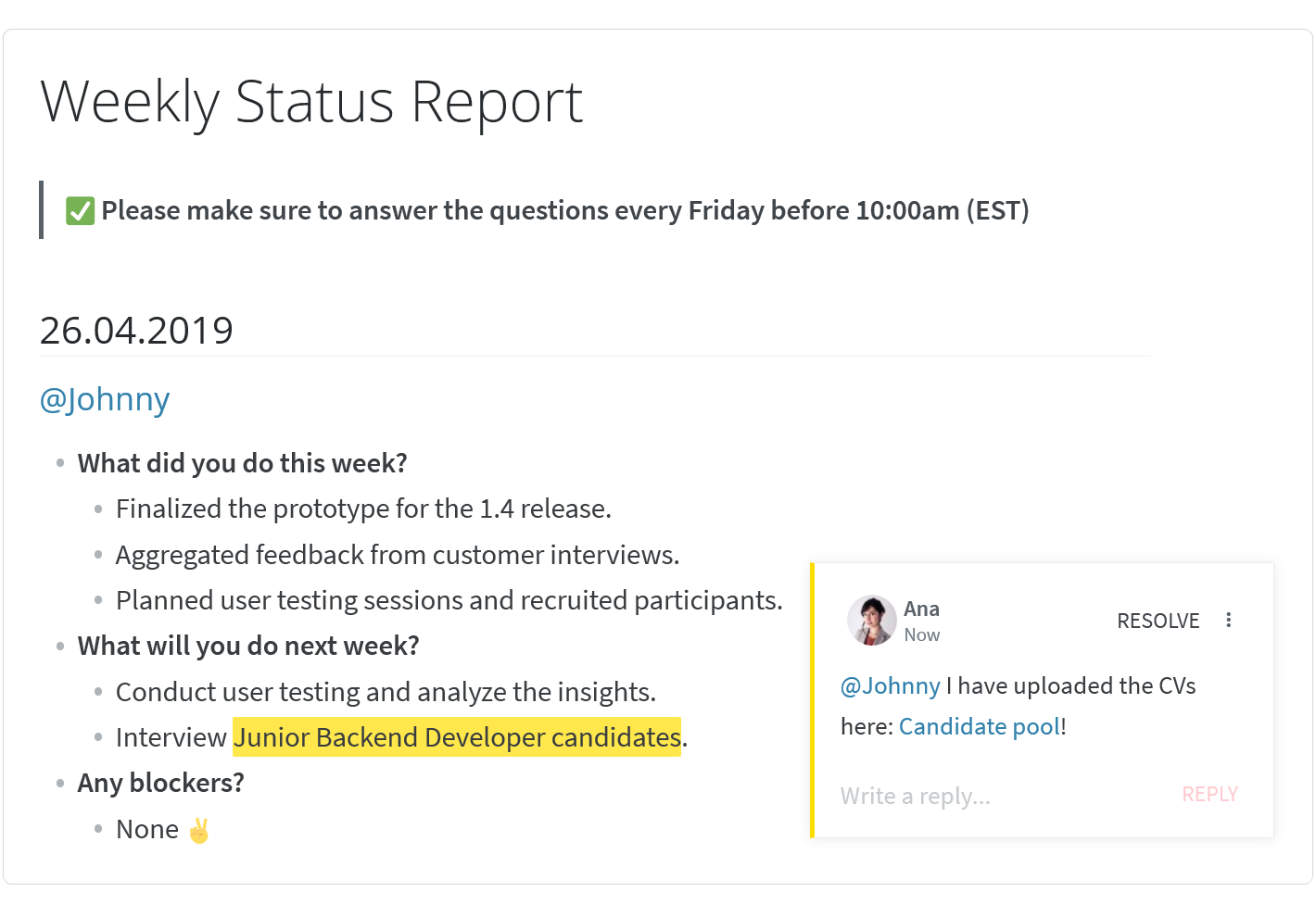


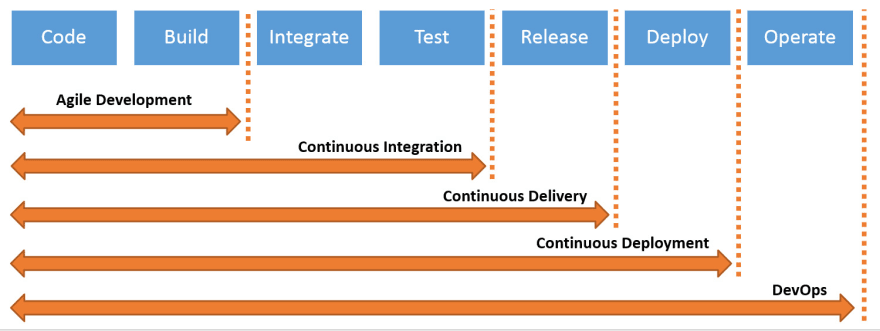
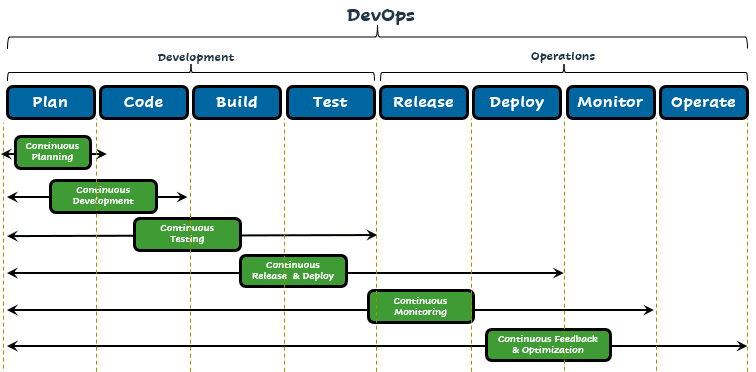 and one more:
and one more: