You can think of it a little like GraphQL's feature of only fetching the data your component needs to render, and nothing else.
116 Matching Annotations
- Jun 2025
-
final-form.org final-form.org
-
- Feb 2025
- Jan 2024
- Sep 2023
-
www.graphile.org www.graphile.org
Tags
Annotators
URL
-
- Aug 2023
-
evilmartians.com evilmartians.com
-
TL;DR For classic Rails apps we have a built-in scope for preloading attachments (e.g. User.with_attached_avatar) or can generate the scope ourselves knowing the way Active Storage names internal associations.GraphQL makes preloading data a little bit trickier—we don’t know beforehand which data is needed by the client and cannot just add with_attached_<smth> to every Active Record collection (‘cause that would add an additional overhead when we don’t need this data).That’s why classic preloading approaches (includes, eager_load, etc.) are not very helpful for building GraphQL APIs. Instead, most of the applications use the batch loading technique.
-
-
evilmartians.com evilmartians.com
- Jul 2023
-
github.com github.com
-
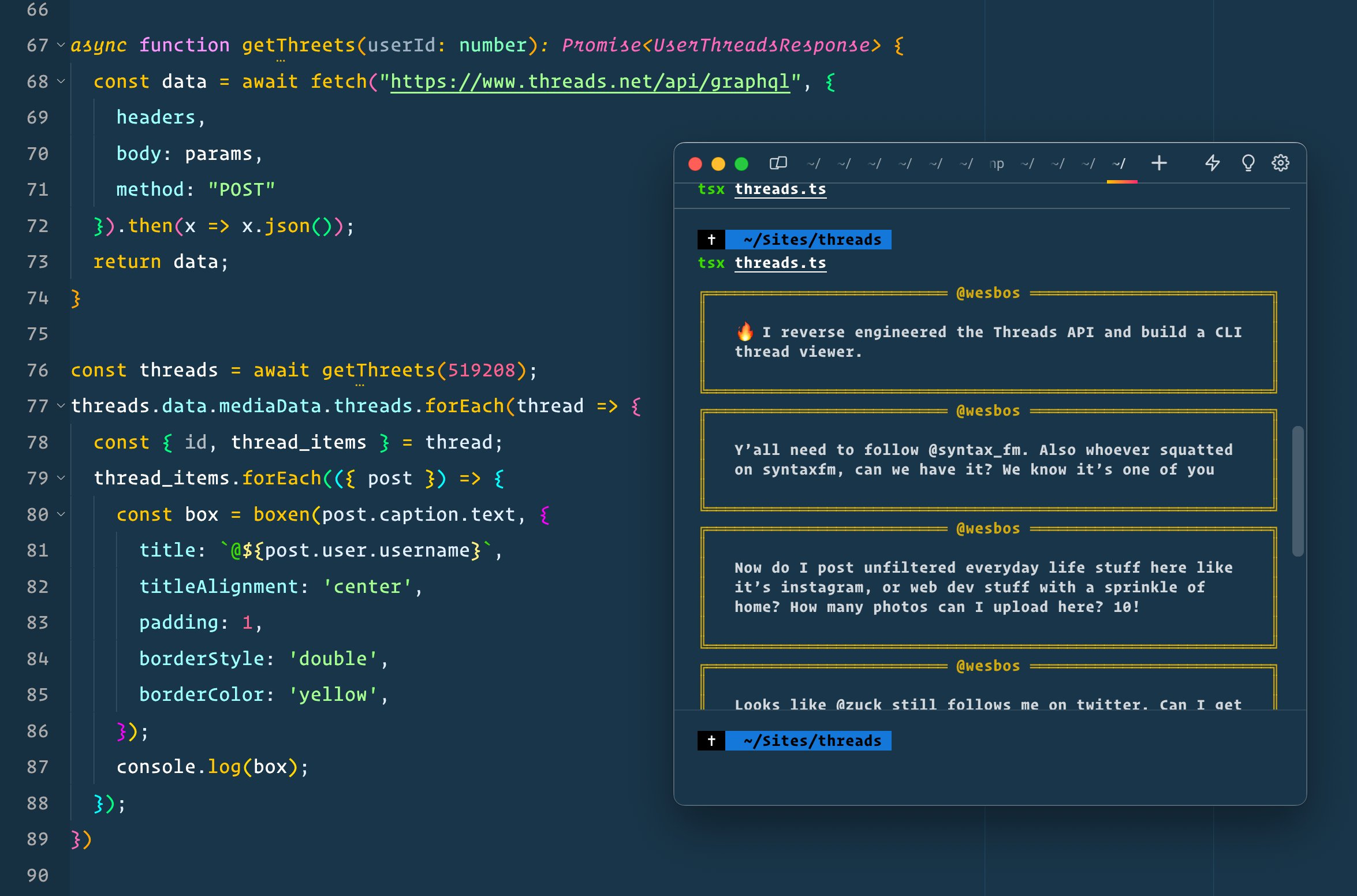
```js // Getting details on a Threads user and outputting it to the console
const getUserDetails = async (username) => { let userInfo = await threads.getUserData(username); console.log( "",
Name: ${userInfo.full_name}\n,Bio: ${userInfo.biography}\n,ID: ${userInfo.user_id}\n,Followers: ${userInfo.follower_count}\n,Website: ${userInfo.bio_links[0].url}); } getUserDetails("Gisgar3"); ```
Tags
Annotators
URL
-
-
github.com github.com
-
```js import { ThreadsAPI } from 'threads-api';
// or in Deno 🦖: // import { ThreadsAPI } from "npm:threads-api";
const main = async () => { const threadsAPI = new ThreadsAPI();
const username = '_junhoyeo'; const id = await threadsAPI.getUserIDfromUsername(username); console.log(id);
if (!id) { return; }
const user = await threadsAPI.getUserProfile(username, id); console.log(JSON.stringify(user));
const posts = await threadsAPI.getUserProfileThreads(username, id); console.log(JSON.stringify(posts));
const replies await threadsAPI.getUserProfileReplies(username, id); console.log(JSON.stringify(replies)); }; main(); ```
Tags
Annotators
URL
-
-
twitter.com twitter.com
Tags
Annotators
URL
-
-
graphbrainz.fly.dev graphbrainz.fly.devGraphiQL1
Tags
Annotators
URL
-
- May 2023
-
spec.graphql.org spec.graphql.orgGraphQL1
Tags
Annotators
URL
-
-
spec.graphql.org spec.graphql.org
Tags
Annotators
URL
-
-
docs.nestjs.com docs.nestjs.com
-
Sharing models
This looks worth trying as an alternative to generating types from inspecting the schema from a running API instance.
Tags
Annotators
URL
-
- Mar 2023
-
hydrogen.shopify.dev hydrogen.shopify.devRoadmap1
-
```js import {defer} from "@shopify/remix-oxygen";
export async function loader({ params: {handle}, context: {storefront} }) { const {product} = storefront.query({ query:
#graphql query Product( $country: CountryCode, $language: LanguageCode, $handle: String! ) @inContext(country: $country, language: $language) product(handle: $handle) { id title }, variables: {handle}, cache: storefront.CacheLong() }); const {productRecommendations} = storefront.query({ query:#graphql query ProductRecommendations( $country: CountryCode, $language: LanguageCode, $handle: String! ) @inContext(country: $country, language: $language) productRecommendations(handle: $handle) { id title } }, variables: {handle} }); if (!product) { throw new Response('Not Found', { status: 404, }); } return defer({ product: await product, productRecommendations, }); } ```
Tags
Annotators
URL
-
- Feb 2023
-
graphql.org graphql.org
-
[Episode!]! represents an array of Episode objects. Since it is also non-nullable, you can always expect an array (with zero or more items) when you query the appearsIn field. And since Episode! is also non-nullable, you can always expect every item of the array to be an Episode object.
Note that this still allows an empty array,
[]. It only disallows:nulland[null].
-
- Nov 2022
-
sebneumaier.wordpress.com sebneumaier.wordpress.com
-
comunica.dev comunica.dev
Tags
Annotators
URL
-
- Oct 2022
-
www.moesif.com www.moesif.com
-
GraphQL APIs should prefer evolution over versioning, but overall, nobody has an absolute opinion about either approach
-
-
codesandbox.io codesandbox.io
Tags
Annotators
URL
-
- Aug 2022
-
gql.reddit.com gql.reddit.com
-
- Jun 2022
-
chelseatroy.com chelseatroy.com
-
The creator of GraphQL admits this. During his presentation on the library at a Facebook internal conference, an audience member asked him about the difference between GraphQL and SOAP. His response: SOAP requires XML. GraphQL defaults to JSON—though you can use XML.
-
Conclusion There are decades of history and a broad cast of characters behind the web requests you know and love—as well as the ones that you might have never heard of. Information first traveled across the internet in 1969, followed by a lot of research in the ’70s, then private networks in the ’80s, then public networks in the ’90s. We got CORBA in 1991, followed by SOAP in 1999, followed by REST around 2003. GraphQL reimagined SOAP, but with JSON, around 2015. This all sounds like a history class fact sheet, but it’s valuable context for building our own web apps.
-
- May 2022
-
hasura.io hasura.io
-
But in GraphQL, all types are nullable by default, and you opt into non-nullability
-
-
www.parismuseescollections.paris.fr www.parismuseescollections.paris.fr
- Feb 2022
-
-
-
learning.atheros.ai learning.atheros.ai
-
Rejecting based on query complexity (cost analysis)Amount limitingDepth limiting
limit the load on the network
-
We can reduce the load on the database significantly by batching and caching with Data Loader
-
The issue is that potential attackers can easily call complex queries, which may be extremely expensive for your server and network.
-
If you are in a development environment, it is definitely useful to allow introspection for various purposes. In production, however, it can leak important information for potential attackers, or it can also just reveal information about a new feature which has not yet been implemented on the frontend.
-
-
learning.atheros.ai learning.atheros.ai
-
When testing and trying out your mutations, I suggest you only use variables, and use inline arguments as little as possible. This will force you to make GraphQL documents that can be copy-pasted right from the GraphiQL into your integration test suits and to your frontend. If you only use inline arguments, you will need to rewrite the GraphQL document in the client.
-
In most cases, it is much better to use the object type and input object type. If you want to add some field as the return, you should not use simple scalars as return values, as this will cause your GraphQL document to break.
-
GraphQL does not support versioning out of the box, but is designed in a way that minimises the need for it
-
-
www.graphql.com www.graphql.com
-
The risk is that when you build a new thing for the second time, you'll feel less cautious and more experienced, and end up over designing the whole thing.
-
Avoid implementing things that you might need in the future in favor of things that you definitely need today.
-
When building queries, focus on the underlying data, rather than how it's represented in your application.
-
Describe the data, not the view. Make sure that your API isn't linked too closely with the demands of your initial interface.
-
Your objective with GraphQL should be to create a unified, cohesive graph that allows users of your API to create subsets of that graph in order to build new product experiences.
-
-
www.howtographql.com www.howtographql.com
-
GraphQL minimizes the amount of data that needs to be transferred over the network
Tags
Annotators
URL
-
-
-
If you are building a more complex app, just do not use GraphQL schema generators blindly.
-
-
learning.atheros.ai learning.atheros.ai
-
it is much better to nest the output types. This way we can call everything with one single request, and also perform caching and batching with the data loader.
-
Whenever you fetch lists, I suggest you use paginated if it makes sense. You will avoid breaking changes of the schema in the future, and it is almost always a much more scalable solution.
-
Returning affected objects as a result of mutations
-
Using the input object type for mutations
-
Use consistent naming in your schema
camelCase for fields, PascalCase for type names
-
- Jan 2022
-
developers.radiofrance.fr developers.radiofrance.fr
Tags
Annotators
URL
-
-
www.hypergraphql.org www.hypergraphql.org
-
HyperGraphQL is a GraphQL interface for querying and serving linked data on the Web. It is designed to support federated querying and exposing data from multiple linked data services using GraphQL query language and schemas. The basic response format is JSON-LD, which extends the standard JSON with the JSON-LD context enabling semantic disambiguation of the contained data.
Tags
Annotators
URL
-
-
ods-qa.openlinksw.com ods-qa.openlinksw.comGrappa1
-
Grappa : A GraphQL-SPARQL-Bridge test tool
Tags
Annotators
URL
-
-
comunica.github.io comunica.github.io
-
-
I just got caught out by realising I wasn't wrapping my component in a <Provider> that provides our own GraphQL client because the default context value is a urql client. I get why this is a good default out the box for getting started, but I'd love to disable that so that we can ensure all our components are wrapped with a provider that exposes our custom client.
defaults
disable defaults/safeguard to make sure you always provide a value
Tags
Annotators
URL
-
-
-
Exchanges are bi-directional. So suppose you have the default order: [dedupExchange, cacheExchange, fetchExchange], then an operation describing the GraphQL request, which is only the intent to send a request, goes from outer to inner, or left to right. It'll reach dedup first, then cache, then fetch. This is the operation stream. The operation result stream goes the other way. fetch might emit a result, which is seen by cache, and then seen by dedup. This is a little abstract and we will need some visuals to make this an accessible concept to everyone. This is how it works because every exchange receives a stream of operations. It can then transform this stream and call forward with an altered stream (so every exchange has full control over filtering, mapping, reducing, timing of operations). Furthermore, every return value of an exchange is a stream of results. This means that the simplest exchange just forwards all operations and returns an unaltered stream of results: ({ forward }) => ops$ => forward(ops$). For your "error exchange" (which we should probably provide by default?) this means that it must come before the fetch exchange: [dedupExchange, cacheExchange, errorExchange, fetchExchange] Specifically, it won't need to alter the operations probably, but it will need to look at the results from the fetchExchange which means it must be outside fetch or come before it. Here's an example of a simple implementation of such an exchange: import { filter, pipe, tap } from 'wonka'; import { Exchange } from 'urql'; export const errorExchange: Exchange = ({ forward }) => ops$ => { return pipe( forward(ops$), tap(({ error }) => { // If the OperationResult has an error send a request to sentry if (error) { // the error is a CombinedError with networkError and graphqlErrors properties sentryFireAndForgetHere() // Whatever error reporting you have } }) ); };
exchange
Tags
Annotators
URL
-
- Dec 2021
-
stackoverflow.com stackoverflow.com
-
declaration accepts: | null | [] | [null] | [{foo: 'BAR'}] ------------------------------------------------------------------------ [Vote!]! | no | yes | no | yes [Vote]! | no | yes | yes | yes [Vote!] | yes | yes | no | yes [Vote] | yes | yes | yes | yes
-
[Vote!]! means that the field (in this case votes) cannot return null and that it must resolve to an array and that none of the individuals items inside that array can be null. So [] and [{}] and [{foo: 'BAR'}] would all be valid (assuming foo is non-null). However, the following would throw: [{foo: 'BAR'}, null] [Vote]! means that the field cannot return null, but any individual item in the returned list can be null. [Vote!] means that the entire field can be null, but if it does return a value, it needs to an array and each item in that array cannot be null. [Vote] means that the entire field can be null, but if it does return a value, it needs to an array. However, any member of the array may also be null.
-
- Nov 2021
-
www.taniarascia.com www.taniarascia.com
-
Feature GraphQL REST
GraphQL vs *REST (table)
-
There are advantages and disadvantages to both systems, and both have their use in modern API development. However, GraphQL was developed to combat some perceived weaknesses with the REST system, and to create a more efficient, client-driven API.
List of differences between REST and GraphQL (below this annotation)
Tags
Annotators
URL
-
- Jul 2021
-
blog.logrocket.com blog.logrocket.com
-
Because GraphQL is an opinionated API spec where both the server and client buy into a schema format and querying format. Based on this, they can provide multiple advanced features, such as utilities for caching data, auto-generation of React Hooks based on operations, and optimistic mutations.
-
-
stackoverflow.com stackoverflow.com
- Jun 2021
-
graphql-ruby.org graphql-ruby.org
-
This kind of error handling does express error state (either via HTTP 500 or by the top-level "errors" key), but it doesn’t take advantage of GraphQL’s type system and can only express one error at a time.
-
It works, but a stronger solution is to treat errors as data.
-
In mutations, when errors happen, the other fields may return nil. So, if those other fields have null: false, but they return nil, the GraphQL will panic and remove the whole mutation from the response, including the errors!
-
Tags
- works for many (array) in addition to one (no arbitrary limitation)
- limitation: works for one but not many (array)
- disadvantages/drawbacks/cons
- GraphQL: top-level errors
- unintended consequence
- GraphQL: mutation errors
- errors as data
- recoverable vs. non-recoverable errors
- unfortunate limitations
- typing
- irony
- limitations
- unintentionally breaking something
Annotators
URL
-
-
graphql-ruby.org graphql-ruby.org
-
In general, top-level errors should only be used for exceptional circumstances when a developer should be made aware that the system had some kind of problem. For example, the GraphQL specification says that when a non-null field returns nil, an error should be added to the "errors" key. This kind of error is not recoverable by the client. Instead, something on the server should be fixed to handle this case. When you want to notify a client some kind of recoverable issue, consider making error messages part of the schema, for example, as in mutation errors.
-
-
graphql-ruby.org graphql-ruby.org
-
With GraphQL-Ruby, it’s possible to hide parts of your schema from some users. This isn’t exactly part of the GraphQL spec, but it’s roughly within the bounds of the spec.
-
-
www.apollographql.com www.apollographql.com
-
docs.gitlab.com docs.gitlab.com
-
-
We want the GraphQL API to be the primary means of interacting programmatically with GitLab. To achieve this, it needs full coverage - anything possible in the REST API should also be possible in the GraphQL API.
-
-
-
github.com github.com
-
IDE
-
- Mar 2021
-
www.moesif.com www.moesif.com
-
GraphQL is missing:
- Caching (and other REST)
- Monitoring (errors are still 200OK)
-
- Feb 2021
-
ithelp.ithome.com.tw ithelp.ithome.com.tw
Tags
Annotators
URL
-
- Oct 2020
-
github.com github.com
-
For an API used by many third parties with many diverse uses cases, GraphQL is the right tool.
-
- Sep 2020
-
-
-
github.com github.com
-
urql/packages/svelte-urql/ Go to file Add file Go to file Create new file Upload files urql/packages/svelte-urql/
-
-
github.com github.com
-
you may specify only the form state that you care about for rendering your gorgeous UI. You can think of it a little like GraphQL's feature of only fetching the data your component needs to render, and nothing else.
-
-
nystudio107.com nystudio107.com
-
Intro to using GraphQL with Craft CMS, using a practical example. Rather technical (many things I don't understand). But it gives a good idea of what is happening.
-
- Jun 2020
-
github.com github.com
-
const httpLink = new HttpLink({ uri: 'https://instagram-clone-3.herokuapp.com/v1/graphql' }); const authLink = setContext((_, { headers }) => { const token = accessToken; if (token) { return { headers: { ...headers, authorization: `Bearer ${token}` } }; } else { return { headers: { ...headers } }; } }); const client = new ApolloClient({ link: authLink.concat(httpLink), cache: new InMemoryCache() });
concat two link
-
- May 2020
-
docs.gitlab.com docs.gitlab.com
-
-
Although there were some patenting and licensing concerns with GraphQL, these have been resolved to our satisfaction by the relicensing of the reference implementations under MIT, and the use of the OWF license for the GraphQL specification.
-
-
github.com github.com
-
Using the GraphQL API
Tags
Annotators
URL
-
-
blog.logrocket.com blog.logrocket.com
-
Apollo client, help with handling errors, but not as easily as in a REST API
Error handling conventions
-
not recommended because it adds more complexity because of things such as: Types Queries Mutators Resolvers High-order components
Using GraphQL in a simple application (for example, one that uses a few fields in the same way, every time)
-
- Apr 2020
-
-
GraphQL gels especially well with modern JavaScript driven front ends, with excellent tools like Apollo and Apollo-Server that help optimise these calls by batching requests.
GraphQL + Apollo or Apollo-Server
-
BFF is an API that serves one, and specifically only one application
BFF (backend for frontend):
- translates an internal domain into the terminal language of the app it serves
- takes care of authentication, rate limiting, and other stuff you don't want to do more than once
- reduces needless roundtrips to the server
- translates data to be more suitable for its target app
- is pretty front-end-dev friendly. Queries and schema strongly resemble JSON & it keeps your stack "JS all the way down" without being beholden to some distant backend team
-
GraphQL really is just a smart and effective way to schema your APIs, and provide a BFF – that’s backend for frontend
-
What sets GraphQL apart a little from previous approaches (notably Microsofts’ OData) is the idea that Types and Queries are implemented with Resolver code on the server side, rather than just mapping directly to some SQL storage.
What makes GraphQL favorable over other implementations.
In result:
- GraphQL can be a single API over a bunch of disparate APIs in your domain
- it solves the "over fetching" problem that's quite common in REST APIs (by allowing the client to specify a subset of data to return)
- acts as an anti-corruption layer of sorts, preventing unbounded access to underlying storage
- GraphQL is designed to be the single point of connection that your web or mobile app talks to (it highly optimises performance)
-
GraphQL is confusingly, a Query Language, a standard for HTTP APIs and a Schema tool all at once.
GraphQL
-
- Mar 2020
-
larsgw.blogspot.com larsgw.blogspot.com
-
-
The combination of WordPress, React, Gatsby and GraphQL is just that - fun
Intriguing combination of technologies.
Keep an eye on the post author, who is going to discuss the technologies in the next writings
-
- Feb 2020
-
blog.loadimpact.com blog.loadimpact.com
Tags
Annotators
URL
-
- Jan 2020
-
relay.dev relay.dev
- Dec 2019
-
blog.logrocket.com blog.logrocket.com
-
The foundation of GraphQL is its type system. There are basic types like String and Integer and there are complex types that have named attributes.
Type system is the foundation of GraphQL
-
- Nov 2019
-
github.com github.com
-
REST and GraphQL are wonderful tools to create an API that is meant to be consumed by third parties. Facebook's API, for example, is consumed by ~200k third parties. It is no surprise that Facebook is using (and invented) GraphQL; a GraphQL API enables third parties to extensively access Facebook's social graph enabling them to build all kinds of applications. For an API with that many consumers, GraphQL is the fitting tool. But, to create an internal API (an API developed and consumed by code written by the same organization), RPC offers a simpler and more powerful alternative. Large companies, such as Netflix, Google and Facebook, are starting to replace REST/GraphQL with RPC for their internal APIs. Most notably with gRPC which is getting popular in the industry.
-
RPC is increasingly used to create backend APIs as most are internal: most of the time, a backend API is consumed only by frontends developed within the same organization. In general, REST and GraphQL are the right tools if you want to create an API consumed by code written by third parties and RPC is the right tool if you want to create an API consumed by code written by yourself / your organization.
-
-
www.ag-grid.com www.ag-grid.comag-Grid1
-
Server-side operations with GraphQL
Tags
Annotators
URL
-
-
blog.codeship.com blog.codeship.com
-
graphql-ruby.org graphql-ruby.org
Tags
Annotators
URL
-
-
vitobotta.com vitobotta.com
- Jun 2019
-
www.howtographql.com www.howtographql.com
- Nov 2018
-
www.linuxfoundation.org www.linuxfoundation.org
-
GraphQL is being used in production by a variety of high scale companies such as Airbnb, Atlassian, Audi, CNBC, GitHub, Major League Soccer, Netflix, Shopify, The New York Times, Twitter, Pinterest and Yelp. GraphQL also powers hundreds of billions of API calls a day at Facebook.
Usage of graphql by companies
-
- Oct 2018
-
-