np = __import__('numpy') # Same as doing 'import numpy as np'
2,778 Matching Annotations
- Oct 2021
-
-
-
This refers to the module spec. It contains metadata such as the module name, what kind of module it is, as well as how it was created and loaded.
__spec__ -
let’s say you only want to support integer addition with this class, and not floats. This is where you’d use NotImplemented
Example use case of NotImplemented:
class MyNumber: def __add__(self, other): if isinstance(other, float): return NotImplemented return other + 42 -
__radd__ operator, which adds support for right-addition
class MyNumber: def __add__(self, other): return other + 42 def __radd__(self, other): return other + 42 -
Now I should mention that all objects in Python can add support for all Python operators, such as +, -, +=, etc., by defining special methods inside their class, such as __add__ for +, __iadd__ for +=, and so on.
For example:
class MyNumber: def __add__(self, other): return other + 42and then:
>>> num = MyNumber() >>> num + 3 45 -
NotImplemented is used inside a class’ operator definitions, when you want to tell Python that a certain operator isn’t defined for this class.
NotImplemented constant in Python
-
Doing that would even catch KeyboardInterrupt, which would make you unable to close your program by pressing Ctrl+C.
except BaseException: ... -
every exception is a subclass of BaseException, and nearly all of them are subclasses of Exception, other than a few that aren’t supposed to be normally caught.
on Python's exceptions
-
print(dir(__builtins__))
command to get all the builtins
-
builtin scope in Python:It’s the scope where essentially all of Python’s top level functions are defined, such as len, range and print.When a variable is not found in the local, enclosing or global scope, Python looks for it in the builtins.
builtin scope (part of LEGB rule)
-
Global scope (or module scope) simply refers to the scope where all the module’s top-level variables, functions and classes are defined.
Global scope (part of LEGB rule)
-
you can use the nonlocal keyword in Python to tell the interpreter that you don’t mean to define a new variable in the local scope, but you want to modify the one in the enclosing scope.
nonlocal
-
The enclosing scope (or nonlocal scope) refers to the scope of the classes or functions inside which the current function/class lives.
Enclosing scope (part of LEGB rule)
-
The local scope refers to the scope that comes with the current function or class you are in.
Local scope (part of LEGB rule)
-
A builtin in Python is everything that lives in the builtins module.
Python's builtin
-
-
sadh.life sadh.life
-
in Python 3.0 (alongside 2.6), A new method was added to the str data type: str.format. Not only was it more obvious in what it was doing, it added a bunch of new features, like dynamic data types, center alignment, index-based formatting, and specifying padding characters.
History of str.format in Python
-
-
cloudcasts.io cloudcasts.io
-
So, while DELETE operations are free, LIST operations (to get a list of objects) are not free (~$.005 per 1000 requests, varying a bit by region).
Deleting buckets on S3 is not free. If you use either Web Console or AWS CLI, it will execute the LIST call per 1000 objects
Tags
Annotators
URL
-
-
sadh.life sadh.life
-
TypedDict is a dictionary whose keys are always string, and values are of the specified type. At runtime, it behaves exactly like a normal dictionary.
TypedDict
-
you should only use reveal_type to debug your code, and remove it when you’re done debugging.
Because it's only used by mypy
-
What this says is “function double takes an argument n which is an int, and the function returns an int.
def double(n: int) -> int: -
This tells mypy that nums should be a list of integers (List[int]), and that average returns a float.
from typing import List def average(nums: List[int]) -> float: -
for starters, use mypy --strict filename.py
If you're starting your journey with mypy, use the --strict flag
-
-
www.oreilly.com www.oreilly.com
-
few battle-hardened options, for instance: Airflow, a popular open-source workflow orchestrator; Argo, a newer orchestrator that runs natively on Kubernetes, and managed solutions such as Google Cloud Composer and AWS Step Functions.
Current top orchestrators:
- Airflow
- Argo
- Google Cloud Composer
- AWS Step Functions
-
To make ML applications production-ready from the beginning, developers must adhere to the same set of standards as all other production-grade software. This introduces further requirements:
Requirements specific to MLOps systems:
- Large scale of operations
- Orchestration
- Robust versioning (data, models, code)
- Apps integrated to surrounding busness systems
-
In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand.
One of the best ways to picture a difference between DevOps and MLOps
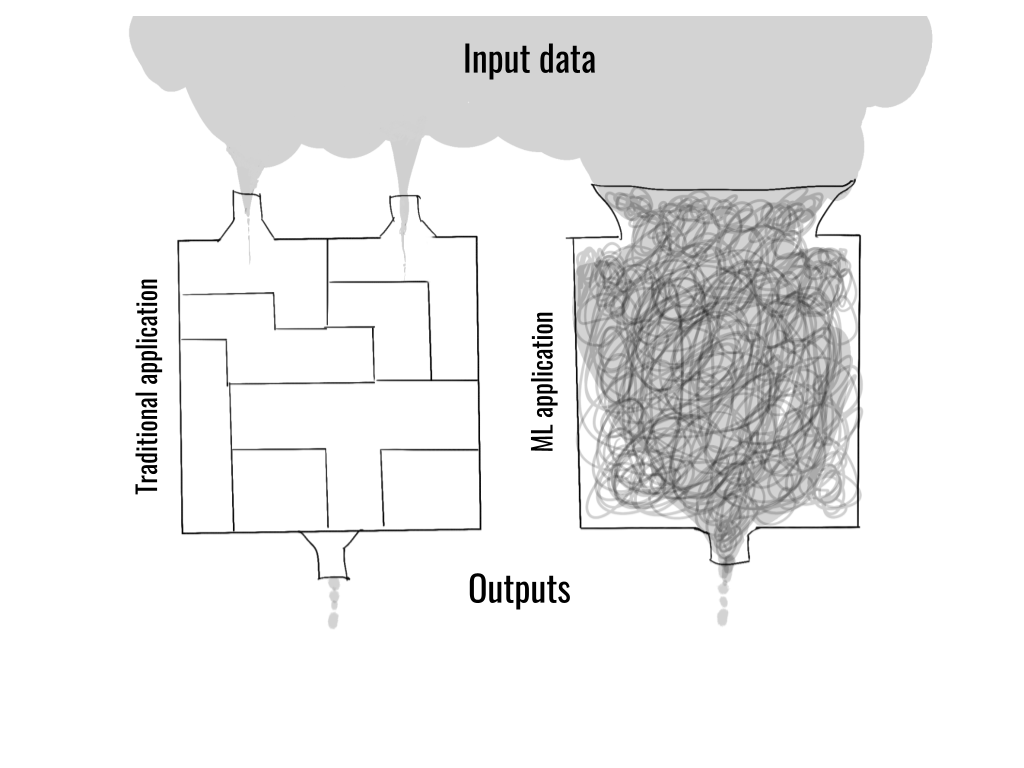
-
-
www.linkedin.com www.linkedin.com
-
As a character, I believe that I am quite a responsible and hardworking person. The combination of the two becomes dangerous when you lose the measure of how much you should work to get a job done right.
That sounds like me, and I completely agree with the author that it can be truly dangerous at times
-
-
-
UPDATE--SHA-1, the 25-year-old hash function designed by the NSA and considered unsafe for most uses for the last 15 years, has now been “fully and practically broken” by a team that has developed a chosen-prefix collision for it.
SHA-1 has been broken; therefore, make sure not to use it in a production based environment
-
-
blog.jooq.org blog.jooq.org
-
So, what’s a better way to illustrate JOIN operations? JOIN diagrams!
Apparently, SQL should be taught using JOIN diagrams not Venn diagrams?
-
-
www.kaggle.com www.kaggle.com
-
State of Data Science and Machine Learning 2021
Tags
Annotators
URL
-
-
naehrdine.blogspot.com naehrdine.blogspot.com
-
iOS 15.0 introduces a new feature: an iPhone can be located with Find My even while the iPhone is turned "off"
-
-
-
Argo Workflow is part of the Argo project, which offers a range of, as they like to call it, Kubernetes-native get-stuff-done tools (Workflow, CD, Events, Rollouts).
High level definition of Argo Workflow
-
Argo is designed to run on top of k8s. Not a VM, not AWS ECS, not Container Instances on Azure, not Google Cloud Run or App Engine. This means you get all the good of k8s, but also the bad.
Pros of Argo Workflow:
- Resilience
- Autoscaling
- Configurability
- Support for RBAC
Cons of Argo Workflow:
- A lot of YAML files required
- k8s knowledge required
-
If you are already heavily invested in Kubernetes, then yes look into Argo Workflow (and its brothers and sisters from the parent project).The broader and harder question you should ask yourself is: to go full k8s-native or not? Look at your team’s cloud and k8s experience, size, growth targets. Most probably you will land somewhere in the middle first, as there is no free lunch.
Should you go into Argo, or not?
-
In order to reduce the number of lines of text in Workflow YAML files, use WorkflowTemplate . This allow for re-use of common components.
kind: WorkflowTemplate
-
-
blog.royalsloth.eu blog.royalsloth.eu
-
Wet behind the ears: the ones that have just started working as a professional programmers and need lots of guidance. Sort of knows what they are doing: professional programmers, who have sort of figured what is going on and can mostly finish their tasks on their own. Experienced: the ones who have been around the block for a while and are most likely the brains behind all the major design decisions of a large software project. Coworkers usually turn to them when they need advice for a hard technical problem. Some programmers will never reach this level, despite their official title stating otherwise (but more on that later).
3 levels of programming experience:
- wet behind the ears
- sort of knows what they are doing
- experienced
-
-
lucasfcosta.com lucasfcosta.com
-
The problem with the first approach is that it considers software development to be a deterministic process when, in fact, it’s stochastic. In other words, you can’t accurately determine how long it will take to write a particular piece of code unless you have already written it.
Estimation around software development is a stochastic process
-
-
durmonski.com durmonski.com
-
Reading books, being aware of the curiosity gap, and asking a lot of questions:
Ways to boost creativity
-
The difference between smart and curious people and only smart people is that curiosity helps you move forward in life. If you shut the door to curiosity. You shut the door to learning. And when you don’t learn. You don’t move forward. You must be curious to learn. Otherwise, you won’t even consider learning.
Curiosity is the core drive of learning
-
Smart people become even smarter because they are smart enough to understand that they don’t have all the answers.
Smartness is driven by curiosity
-
-
github.com github.com
-
You probably shouldn't use Alpine for Python projects, instead use the slim Docker image versions.
(have a look below this highlight for a full reasoning)
-
-
medium.com medium.com
-
Cost — it’s by far the most affordable headset in its class, and while I have a tendency to be lavish with my gadgetry I’m still a cheapskate: I love a good deal and a favorably skewed cost/benefit ratio even more.
Oculus seems to be offering a good quality/cost ratio
-
Adapting to the new environment is immediate, like moving between rooms, and since the focal length in the headset matches regular human vision there’s no acclimating or adjustment.
Adaptation to VR work should be seamless
-
I do highly contextual work, with multiple work orders and their histories open, supporting reference documentation, API specifications, several areas of code (and calls in the stack), tests, logs, databases, and GUIs — plus Slack, Spotify, clock, calendar, and camera feeds. I tend to only look at 25% of that at once, but everything is within a comfortable glance without tabbing between windows. Protecting that context and augmenting my working memory maintains my flow.
Application types to look at during work:
- work orders and their histories
- supporting reference documentation
- API specs
- areas of code (and calls in the stack)
- tests
- logs
- databases
- GUIs
- Slack
- Spotify
- clock
- calendar
- camera feeds
With all that, we may look at around 25% of the stuff at once
-
Realism will increase (perhaps to hyperrealism) and our ability to perceive and interact with simulated objects and settings will be indistinguishable to our senses. Acting in simulated contexts will have physical consequences as systems interpret and project actions into the world — telepresence will take a quantum leap, removing limitations of time and distance. Transcending today’s drone piloting, remote surgery, etc., we will see through remote eyes and work through remote hands anywhere.
On the increase of realism in the future
-
It has a ton of promise, but… I don’t really care for the promise it’s making. 100% of what you can do in Workrooms is feasible in a physical setting, although it would be really expensive (lots of smart hardware all over the place). But that’s the thing: it’s imitating life within a tool that doesn’t share the same limitations, so as a VR veteran I find it bland and claustrophobic. That’s going to be really good for newcomers or casual users because the skeuomorphism is familiar, making it easy to immediately orient oneself and begin working together — and that illustrates a challenge in design vocabulary. While the familiar can provide a safe and comfortable starting point, the real power of VR requires training users for potentially unfamiliar use cases. Also, if you can be anywhere, why would you want to be in a meeting room, virtual-Lake Tahoe notwithstanding?
Author's feedback on why Workrooms do not fully use their potential
-
For meeting with those not in VR, or if I have a video call that needs input rather than passive attendance, I’ll frequently use a virtual webcam to attend by avatar. It’s sufficiently demonstrative for most team meetings, and the crew has gotten used to me showing up as a digital facsimile. I’ll surface from VR and use a physical webcam for anything sensitive or personal, however.
On VR meetings with other people while they are using normal webcams
-
Meetings are best in person, in VR, in MURAL, and in Zoom — in that order. As a remote worker of several years, “in person” is a rarity for me — so I use VR to preserve the feeling of shared presence, of inhabiting a place with other people, especially when good spatial audio is used. Hand tracking enables meaningful gestures and animated expression, despite the avatars cartoonish appearance — somehow it all “just works”, your brain accepts that these people you know are embodied through these virtual puppets, and you get on with communicating instead of quibbling about missing realism (which will be a welcome improvement as it becomes available but doesn’t stop this from working right now).
Author's shared feeling over working remotely
-
What’s it like to actually use? In a word: comfortable. Given a few more words, I’d choose productive and effective. I can resize, reposition, add, or remove as much screen space as I need. I never have to squint or lean forward, crane my neck, hunt for an application window I just had open, or struggle to find a place for something. Many trade-offs and compromises from the past no longer apply — I put my apps in convenient locations I can see at a glance, and without getting in my way. I move myself and my gaze enough throughout the day that I’m not stiff at the end of it and experience less eye strain than I ever did with a bunch of desk-bound LCDs.
Author's reflections on working in VR. It seems like he highly values the comfortability and space for multiple windows
-
Since all I need is a keyboard, mouse, and a place to park myself, I’ve completely ditched the traditional desk. I can use a floor setup for part of the day and mix it up with a standing arrangement for the rest.
Working in VR, you don't need the screens in front of your eyes
-
-
www.duckware.com www.duckware.com
-
Supporting 4×4 MIMO takes a lot more power, and for battery powered devices, runtime is FAR more important.
Reason why client devices still use 2x2 MIMO, not 4x4 MIMO
-
How did your router even get a 'rating' of 5300 Mbps in the first place? Router manufacturers combine/add the maximum physical network speeds for ALL wifi bands (usually 2 or 3 bands) in the router to produce a single aggregate (grossly inflated) Mbps number. But your client device only connects to ONE band (not all bands) on the router at once. So, '5300 Mbps' is all marketing hype.
Why routers get such a high rating
-
The only thing that really matters to you is the maximum speed of a single 5 GHz band (using all MIMO antennas).
What to focus on when choosing a router
-
You have 1 Gbps Internet, and just bought a very expensive AX11000 class router with advertised speeds of up to 11 Gbps, but when you run a speed test from your iPhone XS Max (at a distance of around 32 feet), you only get around 450 Mbps (±45 Mbps). Same for iPad Pro. Same for Samsung Galaxy S8. Same for a laptop computer. Same for most wireless clients. Why? Because that is the speed expected from these (2×2 MIMO) devices!
Reason why you may be getting slow internet speed on your client device (2x2 MIMO one)
Tags
Annotators
URL
-
-
www.python-engineer.com www.python-engineer.com
-
Before we dive into the details, here's a brief summary of the most important changes:
List of the most important upcoming Python 3.10 features (see below)
-
- Sep 2021
-
-
It’s been a hot, hot year in the world of data, machine learning and AI.
Summary of data tools in October 2021: http://46eybw2v1nh52oe80d3bi91u-wpengine.netdna-ssl.com/wp-content/uploads/2021/09/ML-AI-Data-Landscape-2021.pdf
Tags
Annotators
URL
-
-
blog.kubeflow.org blog.kubeflow.org
-
we will be releasing KServe 0.7 outside of the Kubeflow Project and will provide more details on how to migrate from KFServing to KServe with minimal disruptions
KFServing is now KServe
-
-
betterdatascience.com betterdatascience.com
-
You can attach Visual Studio Code to this container by right-clicking on it and choosing the Attach Visual Studio Code option. It will open a new window and ask you which folder to open.
It seems like VS Code offers a better way to manage Docker containers
-
You don’t have to download them manually, as a docker-compose.yml will do that for you. Here’s the code, so you can copy it to your machine:
Sample
docker-compose.ymlfile to download both: Kafka and Zookeeper containers -
Kafka version 2.8.0 introduced early access to a Kafka version without Zookeeper, but it’s not ready yet for production environments.
In the future, Zookeeper might be no longer needed to operate Kafka
-
Kafka consumer — A program you write to get data out of Kafka. Sometimes a consumer is also a producer, as it puts data elsewhere in Kafka.
Simple Kafka consumer terminology
-
Kafka producer — An application (a piece of code) you write to get data to Kafka.
Simple producer terminology
-
Kafka topic — A category to which records are published. Imagine you had a large news site — each news category could be a single Kafka topic.
Simple Kafka topic terminology
-
Kafka broker — A single Kafka Cluster is made of Brokers. They handle producers and consumers and keeps data replicated in the cluster.
Simple Kafka broker terminology
-
Kafka — Basically an event streaming platform. It enables users to collect, store, and process data to build real-time event-driven applications. It’s written in Java and Scala, but you don’t have to know these to work with Kafka. There’s also a Python API.
Simple Kafka terminology
-
-
github.com github.com
-
Then I noticed in the extension details that the "Source" was listed as the location of the "bypass-paywalls-chrome-master" file. I reasoned that the extension would load from there, and I think it does at every browser start-up. So before I re-installed it, I moved the source folder to a permanent location and then dragged it over the extensions page to install it. It has never disappeared since. You need to leave the source folder in place after installation.
Solution to "Chrome automatically deleting unwanted extensions" :)
-
-
benhoyt.com benhoyt.com
-
Some problems with the feature
Chapter with list of problems pattern matching brings to Python 3.10
-
One thing to note is that match and case are not real keywords but “soft keywords”, meaning they only operate as keywords in a match ... case block.
match and case are soft keywords
-
Use variable names that are set if a case matches Match sequences using list or tuple syntax (like Python’s existing iterable unpacking feature) Match mappings using dict syntax Use * to match the rest of a list Use ** to match other keys in a dict Match objects and their attributes using class syntax Include “or” patterns with | Capture sub-patterns with as Include an if “guard” clause
pattern matching in Python 3.10 is like a switch statement + all these features
-
It’s tempting to think of pattern matching as a switch statement on steroids. However, as the rationale PEP points out, it’s better thought of as a “generalized concept of iterable unpacking”.
High-level description of pattern matching coming in Python 3.10
Tags
Annotators
URL
-
-
tomgamon.com tomgamon.com
-
We have decided to spend some extra time refactoring the Goose Protocol. The impact of this is that we will have to push the release out a week, but it will save us time when we implement the Duck and Chicken protocols next quarter.
Good example of communicating impact
-
Often, when you ask someone to perform a task, you have an expectation of what the output of that task will look like. Making sure that you communicate that expectation clearly means that they are set up for success and that you get the outcome you anticipated.
As a team leader make sure to be clear in your communication
-
I am finding that it is often more important to bring wider context (“Ah, that would align with the work that Team Scooby are working on.") and ask the right questions (“How are we going to roll back if this fails?"), allowing the engineers (more experienced than you or not) to do their best work.
How to think as a team lead
-
-
mlopsroundup.substack.com mlopsroundup.substack.com
-
Machine Unlearning is a new area of research that aims to make models selectively “forget” specific data points it was trained on, along with the “learning” derived from it i.e. the influence of these training instances on model parameters. The goal is to remove all traces of a particular data point from a machine learning system, without affecting the aggregate model performance.Why is it important? Work is motivated in this area, in part by growing concerns around privacy and regulations like GDPR and the “Right to be Forgotten”. While multiple companies today allow users to request their private data be deleted, there is no way to request that all context learned by algorithms from this data be deleted as well. Furthermore, as we have covered previously, ML models suffer from information leakage and machine unlearning can be an important lever to combat this. In our view, there is another important reason why machine unlearning is important: it can help make recurring model training more efficient by making models forget those training examples that are outdated, or no longer matter.
What is Machine UNlearning and why is it important
-
-
-
The difference appears to be what the primary causes of that burnout are. The top complaint was “being asked to take on more work” after layoffs, consolidations or changing priorities. Other top beefs included toxic workplaces, being asked to work faster and being micromanaged.
The real reason behind burnouts
Tags
Annotators
URL
-
-
-
What’s left are two options, but only one for the WWW. To capture the most internet users, the best option is to use a .is TLD; however, for true anonimity and control, a .onion is superior.
The 2 most liberal domains: .is (Iceland) and .onion (world)
-
-
medium.dave-bailey.com medium.dave-bailey.com
-
When you notice someone feeling anxious at work, try grabbing a notebook and helping them to get their concerns and questions onto paper. Often this takes the form of a list of to-dos or scenarios.
Fight anxiety by organizing your mind
-
Anxiety comes from not seeing the full picture.
Where anxiety comes from
-
Overreaction is often a sign that something else might be going on that you aren’t aware of. Perhaps they didn’t get enough sleep or recently had a fight with a friend. Maybe something about the situation is triggering an unresolved trauma from their childhood — a phenomenon called transference.
Possible reason for emotion overreactiveness
-
-
matt-rickard.com matt-rickard.com
-
In 2020, 35% of respondents said they used Docker. In 2021, 48.85% said they used Docker. If you look at estimates for the total number of developers, they range from 10 to 25 million. That's 1.4 to 3 million new users this year.
Rapidly growing popularity of Docker (2020 - 2021)
Tags
Annotators
URL
-
-
matt-rickard.com matt-rickard.com
-
kind, microk8s, or k3s are replacements for Docker Desktop. False. Minikube is the only drop-in replacement. The other tools require a Linux distribution, which makes them a non-starter on macOS or Windows. Running any of these in a VM misses the point – you don't want to be managing the Kubernetes lifecycle and a virtual machine lifecycle. Minikube abstracts all of this.
At the current moment the best approach is to use minikube with a preferred backend (Docker Engine and Podman are already there), and you can simply run one command to configure Docker CLI to use the engine from the cluster.
-
-
askubuntu.com askubuntu.com
-
The best practice is this: #!/usr/bin/env bash #!/usr/bin/env sh #!/usr/bin/env python
The best shebang convention:
#!/usr/bin/env bash.However, at the same time it might a security risk if the $PATH to bash points to some malware. Maybe then it's better to point directly to it with
#!/bin/bash
-
-
-
As python supports virtual environments, using /usr/bin/env python will make sure that your scripts runs inside the virtual environment, if you are inside one. Whereas, /usr/bin/python will run outside the virtual environment.
Important difference between
/usr/bin/env pythonand/usr/bin/python
-
-
stackoverflow.com stackoverflow.com
-
Here's my bash boilerplate with some sane options explained in the comments
Clearly explained use of the typical bash script commands:
set -euxo pipefail
-
-
viralinstruction.com viralinstruction.com
-
This post is about all the major disadvantages of Julia. Some of it will just be rants about things I particularly don't like - hopefully they will be informative, too.
It seems like Julia is not just about pros:
- Compile time latency
- Large memory consumption
- Julia can't easily integrate into other languages
- Weak static analysis
- The core language is unstable
- The ecosystem is immature
- The type system works poorly
- You can't extend existing types with data
- Abstract interfaces are unenforced and undiscoverable
- Subtyping is an all-or-nothing thing
- The iterator protocol is weird and too hard to use
- Functional programming primitives are not well designed
- Misc gripes (no Path type and no Option type)
Tags
Annotators
URL
-
- Aug 2021
-
blog.placemark.io blog.placemark.io
-
And back in the day, everything was GitHub issues. The company internal blog was an issue-only repository. Blog posts were issues, you’d comment on them with comments on issues. Sales deals were tracked with issue threads. Recruiting was in issues - an issue per candidate. All internal project planning was tracked in issues.
Interesting how versatile GitHub Issues can be
-
-
bash-prompt.net bash-prompt.net
-
set -euo pipefail
One simple line to improve security of bash scripts:
-e- Exit immediately if any command fails.-u- Exit if an unset variable is invoked.-o pipefail- Exit if a command in a piped series of commands fails.
Tags
Annotators
URL
-
-
www.benkuhn.net www.benkuhn.net
-
The real world is the polar opposite. You’ll have some ultra-vague end goal, like “help people in sub-Saharan Africa solve their money problems,” based on which you’ll need to prioritize many different sub-problems. A solution’s performance has many different dimensions (speed, reliability, usability, repeatability, cost, …)—you probably don’t even know what all the dimensions are, let alone which are the most important.
How real world problems differ from the school ones
-
-
yankee.dev yankee.dev
-
k3d is basically running k3s inside of Docker. It provides an instant benefit over using k3s on a local machine, that is, multi-node clusters. Running inside Docker, we can easily spawn multiple instances of our k3s Nodes.
k3d <--- k3s that allows to run mult-node clusters on a local machine
-
Kubernetes in Docker (KinD) is similar to minikube but it does not spawn VM's to run clusters and works only with Docker. KinD for the most part has the least bells and whistles and offers an intuitive developer experience in getting started with Kubernetes in no time.
KinD (Kubernetes in Docker) <--- sounds like the most recommended solution to learn k8s locally
-
Contrary to the name, it comes in a larger binary of 150 MB+. It can be run as a binary or in DinD mode. k0s takes security seriously and out of the box, it meets the FIPS compliance.
k0s <--- similar to k3s, but not as lightweight
-
k3s is a lightweight Kubernetes distribution from Rancher Labs. It is specifically targeted for running on IoT and Edge devices, meaning it is a perfect candidate for your Raspberry Pi or a virtual machine.
k3s <--- lightweight solution
-
All of the tools listed here more or less offer the same feature, including but not limited to
7 tools for learning k8s locally:
- k3s
- k0s
- Microk8s
- DinD
- minikube
- KinD
- k3d
-
There are multiple tools for running Kubernetes on your local machine, but it basically boils down to two approaches on how it is done
We can run Kubernetes locally as a:
- binary package
- container using dind
-
Before we move on to talk about all the tools, it will be beneficial if you installed arkade on your machine.
With arkade, we can quickly set up different k8s tools, while using a single command:
e.g.
arkade get k9s
Tags
Annotators
URL
-
-
www.goethena.com www.goethena.com
-
The hard truth that many companies struggle to wrap their heads around is that they should be paying their long-tenured engineers above market rate. This is because an engineer that’s been working at a company for a long time will be more impactful specifically at that company than at any other company.
Engineer's market value over time:
-
-
www.banterly.net www.banterly.net
-
This one implements the behavior of git checkout when running it only against a branch name. So you can use it to switch between branches or commits.
git switch <branch_name> -
When you provide just a branch or commit as an argument for git checkout, then it will change all your files to their state in the corresponding revision, but if you also specify a filename, it will only change the state of that file to match the specified revision.
git checkout has a 2nd option that most of us skipped
-
if you are in the develop branch and want to change the test.txt file to be the version from the main branch, you can do it like this
git chekout main -- test.txt
Tags
Annotators
URL
-
-
-
CBL-Mariner is an internal Linux distribution for Microsoft’s cloud infrastructure and edge products and services.
CBL-Mariner <--- Microsoft's Linux distribution
-
-
blog.kowalczyk.info blog.kowalczyk.info
-
Open source is not a good business model.If you want to make money do literally anything else: try to sell software, do consulting, build a SAAS and charge monthly for it, rob a bank.
Open-source software is not money friendly
-
The only way for one person to even attempt cross-platform app is to use a UI abstraction layer like Qt, WxWidgets or Gtk.The problem is that Gtk is ugly, Qt is extremely bloated and WxWidgets barely works.
Why releasing cross-platform apps can make them ugly
-
- Jul 2021
-
-
However, human babies are also able to immediately detect objects and identify motion, such as a finger moving across their field of vision, suggesting that their visual system was also primed before birth.
-
A new Yale study suggests that, in a sense, mammals dream about the world they are about to experience before they are even born.
-
-
realdougwilson.com realdougwilson.com
-
The visual and spacing differences between proportional and monospaced fonts
Proportional vs Monospaced fonts:

-
-
-
you don’t want to miss out on a great engineer just because they spent all of their energy making great products for prior employers rather than blogging, speaking and coding in public.
valuable HR tip
Tags
Annotators
URL
-
-
mtszkw.medium.com mtszkw.medium.com
-
Why do 87% of data science projects never make it into production?
It turns out that this phrase doesn't lead to an existing research. If one goes down the rabbit hole, it all ends up with dead links
-
-
pets.stackexchange.com pets.stackexchange.com
-
Cats don't understand smiles, but they have an equivalent: Slow blinking. Slow blinking means: We are cool, we are friends. Beyond that you can just physically pet them, use gentle voice.
Equivalent of smiling in cats language = slow blinking
-
-
-
PyPA still advertises pipenv all over the place and only mentions poetry a couple of times, although poetry seems to be the more mature product.
Sounds like PyPA does not like poetry as much for political/business reasons
-
The main selling point for Anaconda back then was that it provided pre-compiled binaries. This was especially useful for data-science related packages which depend on libatlas, -lapack, -openblas, etc. and need to be compiled for the target system.
Reason why Anaconda got so popular
-
Many of Python’s standard tools allow already for configuration in pyproject.toml so it seems this file will slowly replace the setup.cfg and probably setup.py and requirements.txt as well. But we’re not there yet.
Potential future of pyproject.toml
-
-
www.joshwcomeau.com www.joshwcomeau.com
-
When I'm at the very beginning of a learning journey, I tend to focus primarily on guided learning. It's difficult to build anything in an unguided way when I'm still grappling with the syntax and the fundamentals!As I become more comfortable, though, the balance shifts.
Finding the right balance while learning. For example, start with guided and eventually move to unguided learning:

-
I try and act like a scientist. If I have a hypothesis about how this code is supposed to work, I test that hypothesis by changing the code, and seeing if it breaks in the way I expect. When I discover that my hypothesis is flawed, I might detour from the tutorial and do some research on Google. Or I might add it to a list of "things to explore later", if the rabbit hole seems to go too deep.
Soudns like shotgun debugging is not the worst method to learn programming
-
Things never go smoothly when it comes to software development. Inevitably, we'll hit a rough patch where the code doesn't do what we expect.This can either lead to a downward spiral—one full of frustration and self-doubt and impostor syndrome—or it can be seen as a fantastic learning opportunity. Nothing helps you learn faster than an inscrutable error message, if you have the right mindset.Honestly, we learn so much more from struggling and failing than we do from effortless success. With a growth mindset, the struggle might not be fun exactly, but it feels productive, like a good workout.
Cultivating a growth mindset while learning programming
-
I had a concrete goal, something I really wanted, I was able to push through the frustration and continue making progress. If I had been learning this stuff just for fun, or because I thought it would look good on my résumé, I would have probably given up pretty quickly.
To truly learn something, it is good to have the concrete GOAL, otherwise you might not push yourself as hard
-
-
tenthousandmeters.com tenthousandmeters.com
-
Any import statement compiles to a series of bytecode instructions, one of which, called IMPORT_NAME, imports the module by calling the built-in __import__() function.
All the Python import statements come down to the
__import__()function
-
-
devops.com devops.com
-
Furthermore, in order to build a comprehensive pipeline, the code quality, unit test, automated test, infrastructure provisioning, artifact building, dependency management and deployment tools involved have to connect using APIs and extend the required capabilities using IaC.
Vital components of a pipeline
-
59% of organizations are following agile principles, but only 4% of these organizations are getting the full benefit.
-
-
-
databases is an async SQL query builder that works on top of the SQLAlchemy Core expression language.
databases Python package
-
The fact that FastAPI does not come with a development server is both a positive and a negative in my opinion. On the one hand, it does take a bit more to serve up the app in development mode. On the other, this helps to conceptually separate the web framework from the web server, which is often a source of confusion for beginners when one moves from development to production with a web framework that does have a built-in development server (like Django or Flask).
FastAPI does not include a web server like Flask. Therefore, it requires Uvicorn.
Not having a web server has pros and cons listed here
-
FastAPI makes it easy to deliver routes asynchronously. As long as you don't have any blocking I/O calls in the handler, you can simply declare the handler as asynchronous by adding the async keyword like so:
FastAPI makes it effortless to convert synchronous handlers to asynchronous ones
Tags
Annotators
URL
-
-
docs.pytest.org docs.pytest.org
-
Fixtures are created when first requested by a test, and are destroyed based on their scope: function: the default scope, the fixture is destroyed at the end of the test.
Fixtures can be executed in 5 different scopes, where function is the default one:
- function
- class
- module
- package
- session
-
When pytest goes to run a test, it looks at the parameters in that test function’s signature, and then searches for fixtures that have the same names as those parameters. Once pytest finds them, it runs those fixtures, captures what they returned (if anything), and passes those objects into the test function as arguments.
What happens when we include fixtures in our testing code
-
“Fixtures”, in the literal sense, are each of the arrange steps and data. They’re everything that test needs to do its thing.
To remind, the tests consist of 4 steps:
- Arrange
- Act
- Assert
- Cleanup
(pytest) fixtures are generally the arrange (set up) operations that need to be performed before the act (running the tests. However, fixtures can also perform the act step.
Tags
Annotators
URL
-
-
speedtestdemon.com speedtestdemon.com
-
Get the `curl-format.txt` from github and then run this curl command in order to get the output $ curl -L -w "@curl-format.txt" -o tmp -s $YOUR_URL
Testing server latency with curl:
1) Get this file from GitHub
2) Run the curl:
curl -L -w "@curl-format.txt" -o tmp -s $YOUR_URL
-
-
medium.com medium.com
-
there is a drawback, docker-compose runs on a single node which makes scaling hard, manual and very limited. To be able to scale services across multiple hosts/nodes, orchestrators like docker-swarm or kubernetes comes into play.
- docker-compose runs on a single node (hard to scale)
- docker-swarm or kubernetes run on multiple nodes
-
We had to build the image for our python API every-time we changed the code, we had to run each container separately and manually insuring that out database container is running first. Moreover, We had to create a network before hand so that we connect the containers and we had to add these containers to that network and we called it mynet back then. With docker-compose we can forget about all of that.
Things being resolved by a docker-compose
-
-
paulgraham.com paulgraham.com
-
A deep interest in a topic makes people work harder than any amount of discipline can.
deep interest = working harder
-
Whereas what drives me now, writing essays, is the flaws in them. Between essays I fuss for a few days, like a dog circling while it decides exactly where to lie down. But once I get started on one, I don't have to push myself to work, because there's always some error or omission already pushing me.
Potential drive to write essays
-
And if you think there's something admirable about working too hard, get that idea out of your head. You're not merely getting worse results, but getting them because you're showing off — if not to other people, then to yourself.
It is not right to work hard
-
That limit varies depending on the type of work and the person. I've done several different kinds of work, and the limits were different for each. My limit for the harder types of writing or programming is about five hours a day. Whereas when I was running a startup, I could work all the time. At least for the three years I did it; if I'd kept going much longer, I'd probably have needed to take occasional vacations.
The limits of work vary by the type of work you're doing
-
There are three ingredients in great work: natural ability, practice, and effort. You can do pretty well with just two, but to do the best work you need all three: you need great natural ability and to have practiced a lot and to be trying very hard.
3 ingredients of great work:
- natural ability
- practice
- effort
-
One thing I know is that if you want to do great things, you'll have to work very hard.
Obvious, yet good to remember
-
-
fossil-scm.org fossil-scm.org
-
rebase is really nothing more than a merge (or a series of merges) that deliberately forgets one of the parents of each merge step.
What rebase really is
Tags
Annotators
URL
-
-
mitelman.engineering mitelman.engineering
-
Here is how you can create a fully configured new project in a just a couple of minutes (assuming you have pyenv and poetry installed already).
Fast track setup of a new Python project
-
After reading through PEP8, you may wonder if there is a way to automatically check and enforce these guidelines? Flake8 does exactly this, and a bit more. It works out of the box, and can be configured in case you want to change some specific settings.
Flake8 does PEP8 and a bit more
-
Pylint is a very strict and nit-picky linter. Google uses it for their Python projects internally according to their guidelines. Because of it’s nature, you’ll probably spend a lot of time fighting or configuring it. Which is maybe not bad, by the way. Outcome of such strictness can be a safer code, however, as a consequence - longer development time.
Pylint is a very strict linter embraced by Google
-
The goal of this tutorial is to describe Python development ecosystem.
tl;dr:
INSTALLATION:
- Install Python through pyenv (don't use python.org)
- Install dependencies with Poetry (miniconda3 is also fine for some cases)
TESTING:
- Write tests with pytest (default testing framework for Poetry)
- Check test coverage with pytest-cov plugin
- Use pre-commit for automatic checks before git commiting (for example, for automatic code refactoring)
REFACTORING:
- Lint your code with flake8 to easily find bugs (it is not as strict as pylint)
- Format your code with Black so that it looks the same in every project (is consistent)
- Sort imports with isort (so that they are nicely organised: standard library, third party, local)
-
For Windows, there is pyenv for Windows - https://github.com/pyenv-win/pyenv-win. But you’d probably better off with Windows Subsystem for Linux (WSL), then installing it the Linux way.
You can install pyenv for Windows, but maybe it's better to go the WSL way
-
-
stackoverflow.com stackoverflow.com
-
There are often multiple versions of python interpreters and pip versions present. Using python -m pip install <library-name> instead of pip install <library-name> will ensure that the library gets installed into the default python interpreter.
Potential solution for the Python's ImportError after a successful pip installation
-
-
www.encode.io www.encode.io
-
In addition to SQLAlchemy core queries, you can also perform raw SQL queries
Instead of SQLAlchemy core query:
query = notes.insert() values = [ {"text": "example2", "completed": False}, {"text": "example3", "completed": True}, ] await database.execute_many(query=query, values=values)One can write a raw SQL query:
query = "INSERT INTO notes(text, completed) VALUES (:text, :completed)" values = [ {"text": "example2", "completed": False}, {"text": "example3", "completed": True}, ] await database.execute_many(query=query, values=values)=================================
The same goes with fetching in SQLAlchemy:
query = notes.select() rows = await database.fetch_all(query=query)And doing the same with raw SQL:
query = "SELECT * FROM notes WHERE completed = :completed" rows = await database.fetch_all(query=query, values={"completed": True})
Tags
Annotators
URL
-
-
www.reactivemanifesto.org www.reactivemanifesto.org
-
This means that an event-driven system focuses on addressable event sources while a message-driven system concentrates on addressable recipients. A message can contain an encoded event as its payload.
Event-Driven vs Message-Driven
-
-
www.reactivemanifesto.org www.reactivemanifesto.org
-
we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
Reactive Systems:
- responsive - responds in a timely manner
- resilient - stays responsive in the face of failure
- elastic - system stays responsive under varying workload
- message driven - asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency
as a result, they are:
- flexible
- loosely-coupled
- scalable
- easy to develop and change
- more tolerant of failure
- highly responsive with interactive feedback

-
Resilience is achieved by replication, containment, isolation and delegation.
Components of resilience
-
Today applications are deployed on everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users expect millisecond response times and 100% uptime. Data is measured in Petabytes.
Today's demands from users
-
-
www.openshift.com www.openshift.com
-
Even though Kubernetes is moving away from Docker, it will always support the OCI and Docker image formats. Kubernetes doesn’t pull and run images itself, instead the Kubelet relies on container engines like CRI-O and containerd to pull and run the images. These are the two main container engines used with CRI-O and they both support the Docker and OCI image formats, so no worries on this one.
Reason why one should not be worried about k8s depreciating Docker
-
-
pythonspeed.com pythonspeed.com
-
We comment out the failed line, and the Dockerfile now looks like this:
To test a failing Dockerfile step, it is best to comment it out, successfully build an image, and then run this command from inside of the Dockerfile
-
-
github.com github.com
-
Some options (you will have to use your own judgment, based on your use case)
4 different options to install Poetry through a Dockerfile
-
-
stackoverflow.com stackoverflow.com
-
When you have one layer that downloads a large temporary file and you delete it in another layer, that has the result of leaving the file in the first layer, where it gets sent over the network and stored on disk, even when it's not visible inside your container. Changing permissions on a file also results in the file being copied to the current layer with the new permissions, doubling the disk space and network bandwidth for that file.
Things to watch out for in Dockerfile operations
-
making sure the longest RUN command come first and in their own layer (again to be cached), instead of being chained with other RUN commands: if one of those fail, the long command will have to be re-executed. If that long command is isolated in its own (Dockerfile line)/layer, it will be cached.
Optimising Dockerfile is not always as simple as MIN(layers). Sometimes, it is worth keeping more than a single RUN layer
-
-
stackoverflow.com stackoverflow.com
-
Docker has a default entrypoint which is /bin/sh -c but does not have a default command.
This StackOverflow answer is a good explanation of the purpose behind the
ENTRYPOINTandCMDcommand
-
-
towardsdatascience.com towardsdatascience.com
-
To prevent this skew, companies like DoorDash and Etsy log a variety of data at online prediction time, like model input features, model outputs, and data points from relevant production systems.
Log inputs and outputs of your online models to prevent training-serving skew
-
idempotent jobs — you should be able to run the same job multiple times and get the same result.
Encourage idempotency
-
Uber and Booking.com’s ecosystem was originally JVM-based but they expanded to support Python models/scripts. Spotify made heavy use of Scala in the first iteration of their platform until they received feedback like:some ML engineers would never consider adding Scala to their Python-based workflow.
Python might be even more popular due to MLOps
-
Spotify has a CLI that helps users build Docker images for Kubeflow Pipelines components. Users rarely need to write Docker files.
Spotify approach towards writing Dockerfiles for Kubeflow Pipelines
-
Most serving systems are built in-house, I assume for similar reasons as a feature store — there weren’t many serving tools until recently and these companies have stringent production requirements.
The reason of many feature stores and model serving tools built in house, might be, because there were not many open-source tools before
-
Models require a dedicated system because their behavior is determined not only by code, but also by the training data, and hyper-parameters. These three aspects should be linked to the artifact, along with metrics about performance on hold-out data.
Why model registry is a must in MLOps
-
five ML platform components stand out which are indicated by the green boxes in the diagram below
- Feature store
- Workflow orchestration
- Model registry
- Model serving
- Model quality monitoring
-
-
eng.uber.com eng.uber.com
-
we employed a three-stage strategy for validating and deploying the latest binary of the Real-time Prediction Service: staging integration test, canary integration test, and production rollout. The staging integration test and canary integration tests are run against non-production environments. Staging integration tests are used to verify the basic functionalities. Once the staging integration tests have been passed, we run canary integration tests to ensure the serving performance across all production models. After ensuring that the behavior for production models will be unchanged, the release is deployed onto all Real-time Prediction Service production instances, in a rolling deployment fashion.
3-stage strategy for validating and deploying the latest binary of the Real-time Prediction Service:
- Staging integration test <--- verify the basic functionalities
- Canary integration tests <--- ensure the serving performance across all production models
- Production rollout <--- deploy release onto all Real-time Prediction Service production instances, in a rolling deployment fashion
-
We add auto-shadow configuration as part of the model deployment configurations. Real-time Prediction Service can check on the auto-shadow configurations, and distribute traffic accordingly. Users only need to configure shadow relations and shadow criteria (what to shadow and how long to shadow) through API endpoints, and make sure to add features that are needed for the shadow model but not for the primary model.
auto-shadow configuration
-
In a gradual rollout, clients fork traffic and gradually shift the traffic distribution among a group of models. In shadowing, clients duplicate traffic on an initial (primary) model to apply on another (shadow) model).
gradual rollout (model A,B,C) vs shadowing (model D,B):

-
we built a model auto-retirement process, wherein owners can set an expiration period for the models. If a model has not been used beyond the expiration period, the Auto-Retirement workflow, in Figure 1 above, will trigger a warning notification to the relevant users and retire the model.
Model Auto-Retirement - without it, we may observe unnecessary storage costs and an increased memory footprint
-
For helping machine learning engineers manage their production models, we provide tracking for deployed models, as shown above in Figure 2. It involves two parts:
Things to track in model deployment (listed below)
-
Model deployment does not simply push the trained model into Model Artifact & Config store; it goes through the steps to create a self-contained and validated model package
3 steps (listed below) are executed to validate the packaged model
-
we implemented dynamic model loading. The Model Artifact & Config store holds the target state of which models should be served in production. Realtime Prediction Service periodically checks that store, compares it with the local state, and triggers loading of new models and removal of retired models accordingly. Dynamic model loading decouples the model and server development cycles, enabling faster production model iteration.
Dynamic Model Loading technique
-
The first challenge was to support a large volume of model deployments on a daily basis, while keeping the Real-time Prediction Service highly available.
A typical MLOps use case
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
-
pip install 'poetry==$POETRY_VERSION'
Install Poetry with pip to control its version
-
- Jun 2021
-
blog.waleedkhan.name blog.waleedkhan.name
-
To address this problem, I offer git undo, part of the git-branchless suite of tools. To my knowledge, this is the most capable undo tool currently available for Git. For example, it can undo bad merges and rebases with ease, and there are even some rare operations that git undo can undo which can’t be undone with git reflog.
You can use
git undothrough git-brancheless. There's also GitUp, but only for macOS
-
-
databasearchitects.blogspot.com databasearchitects.blogspot.com
-
the logical and physical page addresses are decoupled. A mapping table, which is stored on the SSD, translates logical (software) addresses to physical (flash) locations. This component is also called Flash Translation Layer (FTL).
Flash Translation Layer (FTL)
-
NAND flash pages cannot be overwritten. Page writes can only be performed sequentially within blocks that have been erased beforehand.
Overwriting data on SSDs
-
For example, if one looks at write latency, one may measure results as low as 10us – 10 times faster than a read. However, latency only appears so low because SSDs are caching writes on volatile RAM. The actual write latency of NAND flash is about 1ms – 10 times slower than a read.
SSDs writes aren't as fast as they seem to be
-
Another important difference between disks and SSDs is that disks have one disk head and perform well only for sequential accesses. SSDs, in contrast, consist of dozens or even hundreds of flash chips ("parallel units"), which can be accessed concurrently.
2nd difference between SSDs and HDDs
-
SSDs are often referred to as disks, but this is misleading as they store data on semiconductors instead of a mechanical disk.
1st difference between SSDs and HDDs
-
-
stackoverflow.com stackoverflow.com
-
It basically takes any command line arguments passed to entrypoint.sh and execs them as a command. The intention is basically "Do everything in this .sh script, then in the same shell run the command the user passes in on the command line".
What is the use of this part in a Docker entry point:
#!/bin/bash set -e ... code ... exec "$@"
-
-
smallstep.com smallstep.com
-
The alternative for curl is a credential file: A .netrc file can be used to store credentials for servers you need to connect to.And for mysql, you can create option files: a .my.cnf or an obfuscated .mylogin.cnf will be read on startup and can contain your passwords.
- .netrc <--- alternative for curl to store secrets
- .my.cnf or .mylogin.cnf <--- option files for mysql to store secrets
-
Linux keyring offers several scopes for storing keys safely in memory that will never be swapped to disk. A process or even a single thread can have its own keyring, or you can have a keyring that is inherited across all processes in a user’s session. To manage the keyrings and keys, use the keyctl command or keyctl system calls.
Linux keyring is a considerable lightweight secrets manager in the Linux kernel
-
Docker container can call out to a secrets manager for its secrets. But, a secrets manager is an extra dependency. Often you need to run a secrets manager server and hit an API. And even with a secrets manager, you may still need Bash to shuttle the secret into your target application.
Secrets manager in Docker is not a bad option but adds more dependencies
-
Using environment variables for secrets is very convenient. And we don’t recommend it because it’s so easy to leak things
If possible, avoid using environment variables for passing secrets
-
As the sanitized example shows, a pipeline is generally an excellent way to pass secrets around, if the program you’re using will accept a secret via STDIN.
Piped secrets are generally an excellent way to pass secrets
-
A few notes about storing and retrieving file secrets
Credentials files are also a good way to pass secrets
Tags
Annotators
URL
-
-
www.renehersecycles.com www.renehersecycles.com
-
vibrating bike (and rider) is absorbing energy that reduces the bike’s speed.
The narrower tires, the more vibrations
-
And since we now have very similar tires in widths from 26 to 54 mm, we could do controlled testing of all these sizes. We found that they all perform the same. Even on very smooth asphalt, you don’t lose anything by going to wider tires (at least up to 54 mm). And on rough roads, wider tires are definitely faster.
Wider tires performe as well as the narrower ones, but they definitely perform better on rough roads
-
Tire width influences the feel of the bike, but not its speed. If you like the buzzy, connected-to-the-road feel of a racing bike, choose narrower tires. If you want superior cornering grip and the ability to go fast even when the roads get rough, choose wider tires.
Conclusion of a debunked mth: Wide tires are NOT slower than the narrower ones
-
-
drewdevault.com drewdevault.com
-
This is where off-site backups come into play. For this purpose, I recommend Borg backup. It has sophisticated features for compression and encryption, and allows you to mount any version of your backups as a filesystem to recover the data from. Set this up on a cronjob as well for as frequently as you feel the need to make backups, and send them off-site to another location, which itself should have storage facilities following the rest of the recommendations from this article. Set up another cronjob to run borg check and send you the results on a schedule, so that their conspicuous absence may indicate that something fishy is going on. I also use Prometheus with Pushgateway to make a note every time that a backup is run, and set up an alarm which goes off if the backup age exceeds 48 hours. I also have periodic test alarms, so that the alert manager’s own failures are noticed.
Solution for human failures and existential threads:
- Borg backup on a cronjob
- Prometheus with Pushgateway
-
RAID is complicated, and getting it right is difficult. You don’t want to wait until your drives are failing to learn about a gap in your understanding of RAID. For this reason, I recommend ZFS to most. It automatically makes good decisions for you with respect to mirroring and parity, and gracefully handles rebuilds, sudden power loss, and other failures. It also has features which are helpful for other failure modes, like snapshots. Set up Zed to email you reports from ZFS. Zed has a debug mode, which will send you emails even for working disks — I recommend leaving this on, so that their conspicuous absence might alert you to a problem with the monitoring mechanism. Set up a cronjob to do monthly scrubs and review the Zed reports when they arrive. ZFS snapshots are cheap - set up a cronjob to take one every 5 minutes, perhaps with zfs-auto-snapshot.
ZFS is recommended (not only for the beginners) over the complicated RAID
-
these days hardware RAID is almost always a mistake. Most operating systems have software RAID implementations which can achieve the same results without a dedicated RAID card.
According to the author software RAID is preferable over hardware RAID
-
Failing disks can show signs of it in advance — degraded performance, or via S.M.A.R.T reports. Learn the tools for monitoring your storage medium, such as smartmontools, and set it up to report failures to you (and test the mechanisms by which the failures are reported to you).
Preventive maintenance of disk failures
-
RAID gets more creative with three or more hard drives, utilizing parity, which allows it to reconstruct the contents of failed hard drives from still-online drives.
If you are using RAID and one of the 3 drives fail, you can still recover its content thanks to XOR operation
-
A more reliable solution is to store the data on a hard drive1. However, hard drives are rated for a limited number of read/write cycles, and can be expected to fail eventually.
Hard drives are a better lifetime option than microSD cards but still not ideal
-
The worst way I can think of is to store it on a microSD card. These fail a lot. I couldn’t find any hard data, but anecdotally, 4 out of 5 microSD cards I’ve used have experienced failures resulting in permanent data loss.
microSD cards aren't recommended for storing lifetime data
-
-
www.maketecheasier.com www.maketecheasier.com
-
As it stands, sudo -i is the most practical, clean way to gain a root environment. On the other hand, those using sudo -s will find they can gain a root shell without the ability to touch the root environment, something that has added security benefits.
Which
sudocommand to use:sudo -i<--- most practical, clean way to gain a root environmentsudo -s<--- secure way that doesn't let touching the root environment
-
Much like sudo su, the -i flag allows a user to get a root environment without having to know the root account password. sudo -i is also very similar to using sudo su in that it’ll read all of the environmental files (.profile, etc.) and set the environment inside the shell with it.
sudo -ivssudo su. Simply,sudo -iis a much cleaner way of gaining root and a root environment without directly interacting with the root user -
This means that unlike a command like sudo -i or sudo su, the system will not read any environmental files. This means that when a user tells the shell to run sudo -s, it gains root but will not change the user or the user environment. Your home will not be the root home, etc. This command is best used when the user doesn’t want to touch root at all and just wants a root shell for easy command execution.
sudo -svssudo -iandsudo su. Simply,sudo -sis good for security reasons -
Though there isn’t very much difference from “su,” sudo su is still a very useful command for one important reason: When a user is running “su” to gain root access on a system, they must know the root password. The way root is given with sudo su is by requesting the current user’s password. This makes it possible to gain root without the root password which increases security.
Crucial difference between
sudo suandsu: the way password is provided -
“su” is best used when a user wants direct access to the root account on the system. It doesn’t go through sudo or anything like that. Instead, the root user’s password has to be known and used to log in with.
The
sucommand is used to get a direct access to the root account
-
-
jmmv.dev jmmv.dev
-
A good philosophy to live by at work is to “always be quitting”. No, don’t be constantly thinking of leaving your job 😱. But act as if you might leave on short notice 😎.
"always be quitting" = making yourself "replaceable"
Tags
Annotators
URL
-
-
skamille.medium.com skamille.medium.com
-
An incomplete list of skills senior engineers need, beyond coding
23 social skills to look for in great engineers
-
-
stackoverflow.com stackoverflow.com
-
if a module's name has no dots, it is not considered to be part of a package. It doesn't matter where the file actually is on disk.
what if Python module's name has no dots
-
if you imported moduleX (note: imported, not directly executed), its name would be package.subpackage1.moduleX. If you imported moduleA, its name would be package.moduleA. However, if you directly run moduleX from the command line, its name will instead be __main__, and if you directly run moduleA from the command line, its name will be __main__. When a module is run as the top-level script, it loses its normal name and its name is instead __main__.
When Python's module name is
__main__vs when it's a full name (preceded by the names of any packages/subpackages of which it is a part, separated by dots) -
A file is loaded as the top-level script if you execute it directly, for instance by typing python myfile.py on the command line. It is loaded as a module if you do python -m myfile, or if it is loaded when an import statement is encountered inside some other file.
3 cases when a Python file is called as a top-level script vs module
-
-
scatter.wordpress.com scatter.wordpress.com
-
After working on the problem for a while, we boiled it down to a 4-turn (2 per player), 9 roll (including doubles) game. Detail on each move given below. If executed quickly enough, this theoretical game can be played in 21 seconds (see video below).
The shortest possible 2-player Monopoly game in 4 turns (2 per player). See the details below this annotation
-