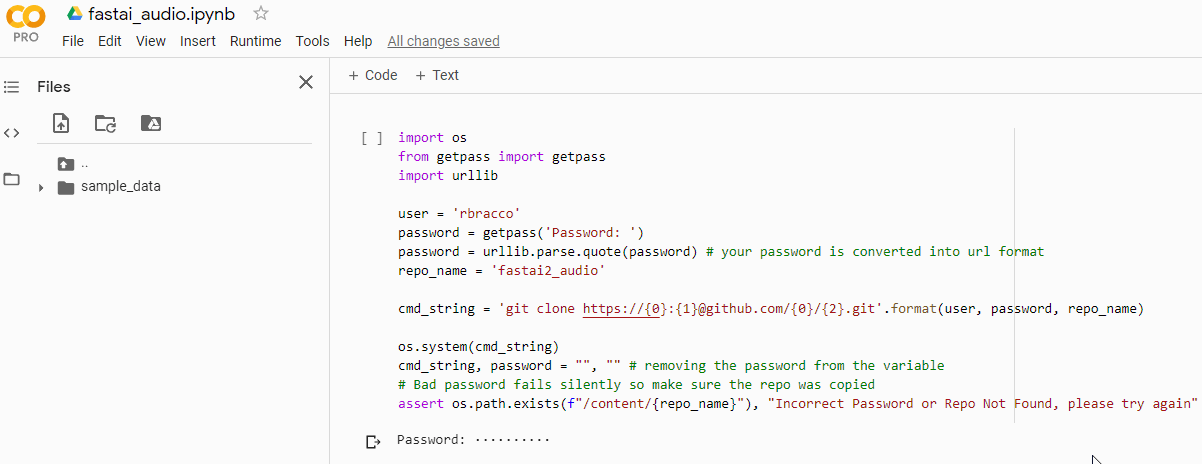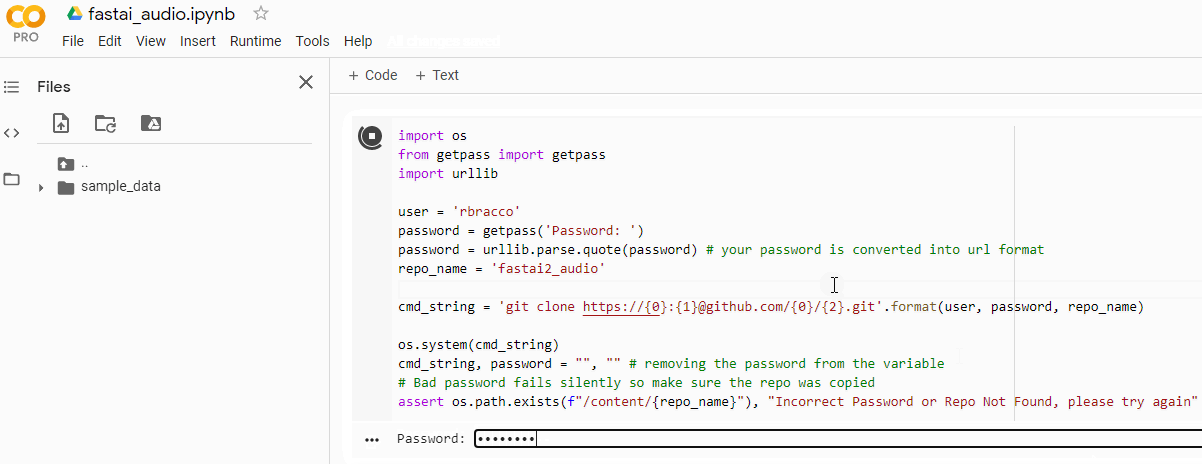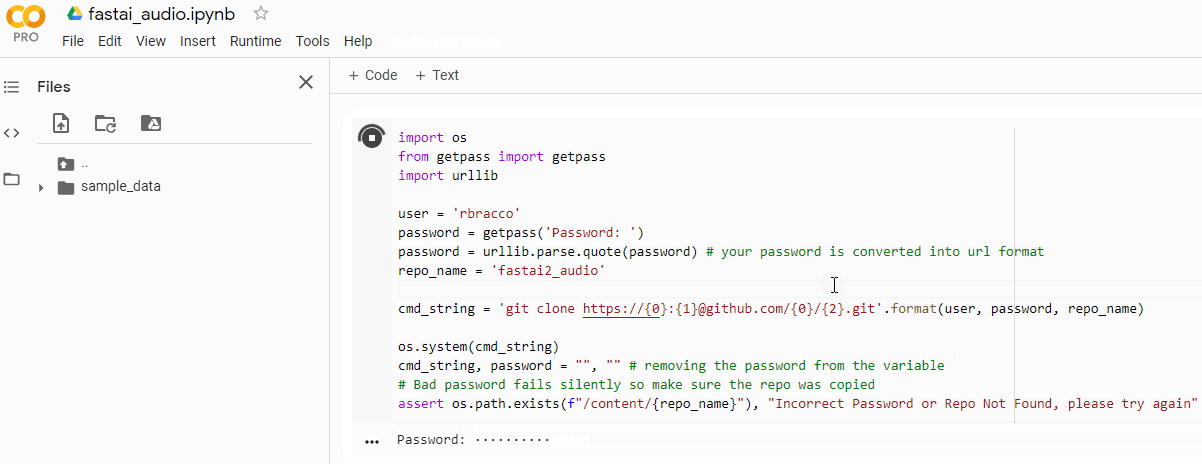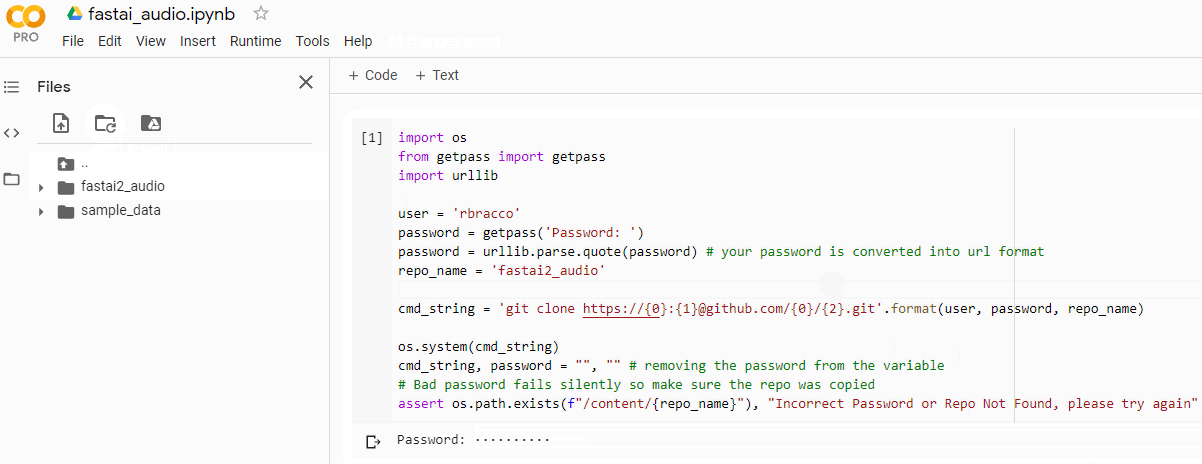
Devenir (to become) past participle: devenu
Revenir (to come back) past participle: revenu
Monter (to climb) past participle: monté
Rester (to stay) past participle: resté
Sortir (to leave) past participle: sorti
Passer (to pass) past participle: passé
.
Venir (to come) past participle: venu
Aller (to go) past participle: allé
Naître (to be born) past participle: né
Descendre (to descend) past participle: descendu
Entrer (to enter) past participle: entré
Rentrer (to re-enter) past participle: rentré
Tomber (to fall) past participle: tombé
Retourner (to turn around) past participle: retourné
Arriver (to arrive / to come) past participle: arrivé
Mourir (to die) past participle: mort
Partir (to leave) past participle: parti