Which is why you need to agree, as a group, on a collaborative tool everyone is comfortable with (TL:DR; it doesn’t exist for groups larger than 4), and then co-create on one platform while chatting on the other.
199 Matching Annotations
- Nov 2024
-
experiments.myhub.ai experiments.myhub.ai
-
- Oct 2023
-
www.thenewatlantis.com www.thenewatlantis.com
-
Jacobs, Alan. “The Garden and the Stream.” Digital magazine. The New Atlantis (blog), May 4, 2018. https://www.thenewatlantis.com/text-patterns/the-garden-and-stream.
-
the Stream replaces topology with serialization.
How do we experience the zettelkasten with respect to the garden and the stream metaphor?
-
- Sep 2023
-
chromestatus.com chromestatus.com
-
gist.github.com gist.github.com
-
-
permit streams to be transferred between workers, frames and anywhere else that postMessage() can be used. Chunks can be anything which is cloneable by postMessage(). Initially chunks enqueued in such a stream will always be cloned, ie. all data will be copied. Future work will extend the Streams APIs to support transferring objects (ie. zero copy).
js const rs = new ReadableStream({ start(controller) { controller.enqueue('hello'); } }); const w = new Worker('worker.js'); w.postMessage(rs, [rs]);js onmessage = async (evt) => { const rs = evt.data; const reader = rs.getReader(); const {value, done} = await reader.read(); console.log(value); // logs 'hello'. };
-
-
stackoverflow.com stackoverflow.com
-
``js // SSE only supports GET request export async function GET({ url }) { const stream = new ReadableStream({ start(controller) { // You can enqueue multiple data asynchronously here. const myData = ["abc", "def"] myData.forEach(data => { controller.enqueue(data: ${data}\n\n`) }) controller.close() }, cancel() { // cancel your resources here } });return new Response(stream, { headers: { // Denotes the response as SSE 'Content-Type': 'text/event-stream', // Optional. Request the GET request not to be cached. 'Cache-Control': 'no-cache', } })} ```
-
-
geoffrich.net geoffrich.net
-
On subsequent page loads using client-side navigation, we can allow the slow data to be streamed in. Client-side navigation will only occur if JavaScript is available, so there are no downsides to using promise streaming. If the user doesn’t have JavaScript, each navigation will trigger a full page load, and we will again wait for all data to resolve.We can switch between these two behaviors using the isDataRequest property on the RequestEvent passed to the load function. When this property is false, the request is for the HTML for the initial page load, and we should wait for all data to resolve. If the property is true, then the request is from SvelteKit’s client-side router and we can stream the data in.
js export async function load({isDataRequest}) { const slowData = getSlowData(); return { nested: { slow: isDataRequest ? slowData : await slowData } }; } -
We can use Promise.race to give our promise a few hundred milliseconds to resolve. Promise.race takes an array of promises, and resolves when any one of those promises resolve. We can pass our delay call and our data fetching call, and conditionally await the result depending on which one resolves first.
In this example, we race two promises: a 200ms delay and the actual data call we want to make. If the delay resolves first, then the data call is taking longer than 200ms and we should go ahead and render the page with partial data. If the data call resolves first, then we got the data under the time limit and we can render the page with complete data.
```js const TIME_TO_RESOLVE_MS = 200; export async function load() { const slowData = getSlowData();
const result = await Promise.race([delay(TIME_TO_RESOLVE_MS), slowData]);
return { nested: { slow: result ? result : slowData } }; }
async function getSlowData() { // randomly delay either 50ms or 1s // this simulates variable API response times await delay(Math.random() < 0.5 ? 50 : 1000); return '😴'; }
function delay(ms) { return new Promise(res => setTimeout(res, ms)); } ```
Tags
Annotators
URL
-
-
twitter.com twitter.com
-
Did you know you can now use streaming promises in SvelteKit? No need to import anything - it just works out of the box
Every property of an object returned by the
loadfunction can be a promise which itself can return an object that can have a promise as property, and so on.Can build a tree of promises based on data delivery priority.
-
- Aug 2023
-
twitter.com twitter.com
-
telefunc.com telefunc.comTelefunc1
-
-
-
SvelteKit will automatically await the fetchPost call before it starts rendering the page, since it’s at the top level. However, it won’t wait for the nested fetchComments call to complete – the page will render and data.streamed.comments will be a promise that will resolve as the request completes. We can show a loading state in the corresponding +page.svelte using Svelte’s await block:
<script lang="ts"> import type { PageData } from './$types'; export let data: PageData; </script> <article> {data.post} </article>js export const load: PageServerLoad = () => { return { post: fetchPost(), streamed: { comments: fetchComments() } }; };```svelte{#await data.streamed.comments} Loading... {:then value} <br />
-
{#each value as comment}
- {comment} {/each}
{/await} ```
Tags
Annotators
URL
-
-
svelte.dev svelte.dev
- Jul 2023
-
stackoverflow.com stackoverflow.com
-
```js async function main() { const blob = new Blob([new Uint8Array(10 * 1024 * 1024)]); // any Blob, including a File const uploadProgress = document.getElementById("upload-progress"); const downloadProgress = document.getElementById("download-progress");
const totalBytes = blob.size; let bytesUploaded = 0;
// Use a custom TransformStream to track upload progress const progressTrackingStream = new TransformStream({ transform(chunk, controller) { controller.enqueue(chunk); bytesUploaded += chunk.byteLength; console.log("upload progress:", bytesUploaded / totalBytes); uploadProgress.value = bytesUploaded / totalBytes; }, flush(controller) { console.log("completed stream"); }, }); const response = await fetch("https://httpbin.org/put", { method: "PUT", headers: { "Content-Type": "application/octet-stream" }, body: blob.stream().pipeThrough(progressTrackingStream), duplex: "half", });
// After the initial response headers have been received, display download progress for the response body let success = true; const totalDownloadBytes = response.headers.get("content-length"); let bytesDownloaded = 0; const reader = response.body.getReader(); while (true) { try { const { value, done } = await reader.read(); if (done) { break; } bytesDownloaded += value.length; if (totalDownloadBytes != undefined) { console.log("download progress:", bytesDownloaded / totalDownloadBytes); downloadProgress.value = bytesDownloaded / totalDownloadBytes; } else { console.log("download progress:", bytesDownloaded, ", unknown total"); } } catch (error) { console.error("error:", error); success = false; break; } }
console.log("success:", success); } main().catch(console.error); ```
-
-
-
On any Web page run the following code
js await startLocalServer(); let abortable = new AbortController; let {signal} = abortable; (await fetch('https://localhost:8443', { method: 'post', body: 'cat local_server_export.js', // Code executed in server, piped to browser duplex: 'half', headers: { 'Access-Control-Request-Private-Network': true }, signal })).body.pipeThrough(new TextDecoderStream()).pipeTo(new WritableStream({ write(v) { console.log(v); }, close() { console.log('close'); }, abort(reason) { console.log(reason); } })).catch(console.warn); await resetLocalServer();
-
- Jun 2023
-
-
```js /* * Response from cache / self.addEventListener('fetch', event => { const response = self.caches.open('example') .then(caches => caches.match(event.request)) .then(response => response || fetch(event.request));
event.respondWith(response); });
/* * Response to SSE by text / self.addEventListener('fetch', event => { const { headers } = event.request; const isSSERequest = headers.get('Accept') === 'text/event-stream';
if (!isSSERequest) { return; }
event.respondWith(new Response('Hello!')); });
/* * Response to SSE by stream / self.addEventListener('fetch', event => { const { headers } = event.request; const isSSERequest = headers.get('Accept') === 'text/event-stream';
if (!isSSERequest) { return; }
const responseText = 'Hello!'; const responseData = Uint8Array.from(responseText, x => x.charCodeAt(0)); const stream = new ReadableStream({ start: controller => controller.enqueue(responseData) }); const response = new Response(stream);
event.respondWith(response); });
/* * SSE chunk data / const sseChunkData = (data, event, retry, id) => Object.entries({ event, id, data, retry }) .filter(([, value]) => ![undefined, null].includes(value)) .map(([key, value]) =>
${key}: ${value}) .join('\n') + '\n\n';/* * Success response to SSE from SW / self.addEventListener('fetch', event => { const { headers } = event.request; const isSSERequest = headers.get('Accept') === 'text/event-stream';
if (!isSSERequest) { return; }
const sseChunkData = (data, event, retry, id) => Object.entries({ event, id, data, retry }) .filter(([, value]) => ![undefined, null].includes(value)) .map(([key, value]) =>
${key}: ${value}) .join('\n') + '\n\n';const sseHeaders = { 'content-type': 'text/event-stream', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', };
const responseText = sseChunkData('Hello!'); const responseData = Uint8Array.from(responseText, x => x.charCodeAt(0)); const stream = new ReadableStream({ start: controller => controller.enqueue(responseData) }); const response = new Response(stream, { headers: sseHeaders });
event.respondWith(response); });
/* * Result / self.addEventListener('fetch', event => { const { headers, url } = event.request; const isSSERequest = headers.get('Accept') === 'text/event-stream';
// Process only SSE connections if (!isSSERequest) { return; }
// Headers for SSE response const sseHeaders = { 'content-type': 'text/event-stream', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', }; // Function for formatting message to SSE response const sseChunkData = (data, event, retry, id) => Object.entries({ event, id, data, retry }) .filter(([, value]) => ![undefined, null].includes(value)) .map(([key, value]) =>
${key}: ${value}) .join('\n') + '\n\n';// Map with server connections, where key - url, value - EventSource const serverConnections = {}; // For each request opens only one server connection and use it for next requests with the same url const getServerConnection = url => { if (!serverConnections[url]) { serverConnections[url] = new EventSource(url); }
return serverConnections[url];}; // On message from server forward it to browser const onServerMessage = (controller, { data, type, retry, lastEventId }) => { const responseText = sseChunkData(data, type, retry, lastEventId); const responseData = Uint8Array.from(responseText, x => x.charCodeAt(0)); controller.enqueue(responseData); }; const stream = new ReadableStream({ start: controller => getServerConnection(url).onmessage = onServerMessage.bind(null, controller) }); const response = new Response(stream, { headers: sseHeaders });
event.respondWith(response); }); ```
-
-
Tags
Annotators
URL
-
-
-
```js self.addEventListener('fetch', event => { const { headers, url } = event.request; const isSSERequest = headers.get('Accept') === 'text/event-stream';
// We process only SSE connections if (!isSSERequest) { return; }
// Response Headers for SSE const sseHeaders = { 'content-type': 'text/event-stream', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', }; // Function formatting data for SSE const sseChunkData = (data, event, retry, id) => Object.entries({ event, id, data, retry }) .filter(([, value]) => ![undefined, null].includes(value)) .map(([key, value]) =>
${key}: ${value}) .join('\n') + '\n\n'; // Table with server connections, where key is url, value is EventSource const serverConnections = {}; // For each url, we open only one connection to the server and use it for subsequent requests const getServerConnection = url => { if (!serverConnections[url]) serverConnections[url] = new EventSource(url);return serverConnections[url];}; // When we receive a message from the server, we forward it to the browser const onServerMessage = (controller, { data, type, retry, lastEventId }) => { const responseText = sseChunkData(data, type, retry, lastEventId); const responseData = Uint8Array.from(responseText, x => x.charCodeAt(0)); controller.enqueue(responseData); }; const stream = new ReadableStream({ start: controller => getServerConnection(url).onmessage = onServerMessage.bind(null, controller) }); const response = new Response(stream, { headers: sseHeaders });
event.respondWith(response); }); ```
-
-
docs.astro.build docs.astro.build
Tags
Annotators
URL
-
-
cloudflare.tv cloudflare.tv
-
jeffy.info jeffy.info
-
astro-sw-demo.netlify.app astro-sw-demo.netlify.appAstro1
Tags
Annotators
URL
-
- May 2023
- Mar 2023
-
reactrouter.com reactrouter.com
-
-
```js // Set up some pub/sub on the server
import { EventEmitter } from "events"; export let emitter = new EventEmitter();
// Set up an event stream with cleanup and queues // and stuff that subscribes to it and streams the // events when new stuff comes through:
import { emitter } from "../some-emitter.server";
type InitFunction = (send: SendFunction) => CleanupFunction; type SendFunction = (event: string, data: string) => void; type CleanupFunction = () => void;
export function eventStream(request: Request, init: InitFunction) { let stream = new ReadableStream({ start(controller) { let encoder = new TextEncoder(); let send = (event: string, data: string) => { controller.enqueue(encoder.encode(
event: ${event}\n)); controller.enqueue(encoder.encode(data: ${data}\n\n)); }; let cleanup = init(send);let closed = false; let close = () => { if (closed) return; cleanup(); closed = true; request.signal.removeEventListener("abort", close); controller.close(); }; request.signal.addEventListener("abort", close); if (request.signal.aborted) { close(); return; } },});
return new Response(stream, { headers: { "Content-Type": "text/event-stream" }, }); }
// Return the event stream from a loader in // a resource route:
import { eventStream } from "./event-stream";
export let loader: LoaderFunction = ({ request }) => { return eventStream(request, send => { emitter.addListener("messageReceived", handleChatMessage);
function handleChatMessage(chatMessage: string) { send("message", chatMessage); } return () => { emitter.removeListener("messageReceived", handleChatMessage); };}); };
// Push into the event emitter in actions:
import { emitter } from "./some-emitter.server";
export let action: ActionFunction = async ({ request }) => { let formData = await request.formData(); emitter.emit("messageReceived", formData.get("something"); return { ok: true }; };
// And finally, set up an EventSource in the browser
function useEventSource(href: string) { let [data, setData] = useState("");
useEffect(() => { let eventSource = new EventSource(href); eventSource.addEventListener("message", handler);
function handler(event: MessageEvent) { setData(event.data || "unknown"); } return () => { eventSource.removeEventListener("message", handler); };}, []);
return data; } ```
Tags
Annotators
URL
-
-
googlechrome.github.io googlechrome.github.io
-
```js // Adds an entry to the event log on the page, optionally applying a specified // CSS class.
let currentTransport, streamNumber, currentTransportDatagramWriter;
// "Connect" button handler. async function connect() { const url = document.getElementById('url').value; try { var transport = new WebTransport(url); addToEventLog('Initiating connection...'); } catch (e) { addToEventLog('Failed to create connection object. ' + e, 'error'); return; }
try { await transport.ready; addToEventLog('Connection ready.'); } catch (e) { addToEventLog('Connection failed. ' + e, 'error'); return; }
transport.closed .then(() => { addToEventLog('Connection closed normally.'); }) .catch(() => { addToEventLog('Connection closed abruptly.', 'error'); });
currentTransport = transport; streamNumber = 1; try { currentTransportDatagramWriter = transport.datagrams.writable.getWriter(); addToEventLog('Datagram writer ready.'); } catch (e) { addToEventLog('Sending datagrams not supported: ' + e, 'error'); return; } readDatagrams(transport); acceptUnidirectionalStreams(transport); document.forms.sending.elements.send.disabled = false; document.getElementById('connect').disabled = true; }
// "Send data" button handler. async function sendData() { let form = document.forms.sending.elements; let encoder = new TextEncoder('utf-8'); let rawData = sending.data.value; let data = encoder.encode(rawData); let transport = currentTransport; try { switch (form.sendtype.value) { case 'datagram': await currentTransportDatagramWriter.write(data); addToEventLog('Sent datagram: ' + rawData); break; case 'unidi': { let stream = await transport.createUnidirectionalStream(); let writer = stream.getWriter(); await writer.write(data); await writer.close(); addToEventLog('Sent a unidirectional stream with data: ' + rawData); break; } case 'bidi': { let stream = await transport.createBidirectionalStream(); let number = streamNumber++; readFromIncomingStream(stream, number);
let writer = stream.writable.getWriter(); await writer.write(data); await writer.close(); addToEventLog( 'Opened bidirectional stream #' + number + ' with data: ' + rawData); break; } }} catch (e) { addToEventLog('Error while sending data: ' + e, 'error'); } }
// Reads datagrams from |transport| into the event log until EOF is reached. async function readDatagrams(transport) { try { var reader = transport.datagrams.readable.getReader(); addToEventLog('Datagram reader ready.'); } catch (e) { addToEventLog('Receiving datagrams not supported: ' + e, 'error'); return; } let decoder = new TextDecoder('utf-8'); try { while (true) { const { value, done } = await reader.read(); if (done) { addToEventLog('Done reading datagrams!'); return; } let data = decoder.decode(value); addToEventLog('Datagram received: ' + data); } } catch (e) { addToEventLog('Error while reading datagrams: ' + e, 'error'); } }
async function acceptUnidirectionalStreams(transport) { let reader = transport.incomingUnidirectionalStreams.getReader(); try { while (true) { const { value, done } = await reader.read(); if (done) { addToEventLog('Done accepting unidirectional streams!'); return; } let stream = value; let number = streamNumber++; addToEventLog('New incoming unidirectional stream #' + number); readFromIncomingStream(stream, number); } } catch (e) { addToEventLog('Error while accepting streams: ' + e, 'error'); } }
async function readFromIncomingStream(stream, number) { let decoder = new TextDecoderStream('utf-8'); let reader = stream.pipeThrough(decoder).getReader(); try { while (true) { const { value, done } = await reader.read(); if (done) { addToEventLog('Stream #' + number + ' closed'); return; } let data = value; addToEventLog('Received data on stream #' + number + ': ' + data); } } catch (e) { addToEventLog( 'Error while reading from stream #' + number + ': ' + e, 'error'); addToEventLog(' ' + e.message); } }
function addToEventLog(text, severity = 'info') { let log = document.getElementById('event-log'); let mostRecentEntry = log.lastElementChild; let entry = document.createElement('li'); entry.innerText = text; entry.className = 'log-' + severity; log.appendChild(entry);
// If the most recent entry in the log was visible, scroll the log to the // newly added element. if (mostRecentEntry != null && mostRecentEntry.getBoundingClientRect().top < log.getBoundingClientRect().bottom) { entry.scrollIntoView(); } } ```
-
-
developer.mozilla.org developer.mozilla.org
-
rolandjitsu.github.io rolandjitsu.github.io
-
beta.nextjs.org beta.nextjs.org
-
Streaming allows you to break down the page's HTML into smaller chunks and progressively send those chunks from the server to the client.
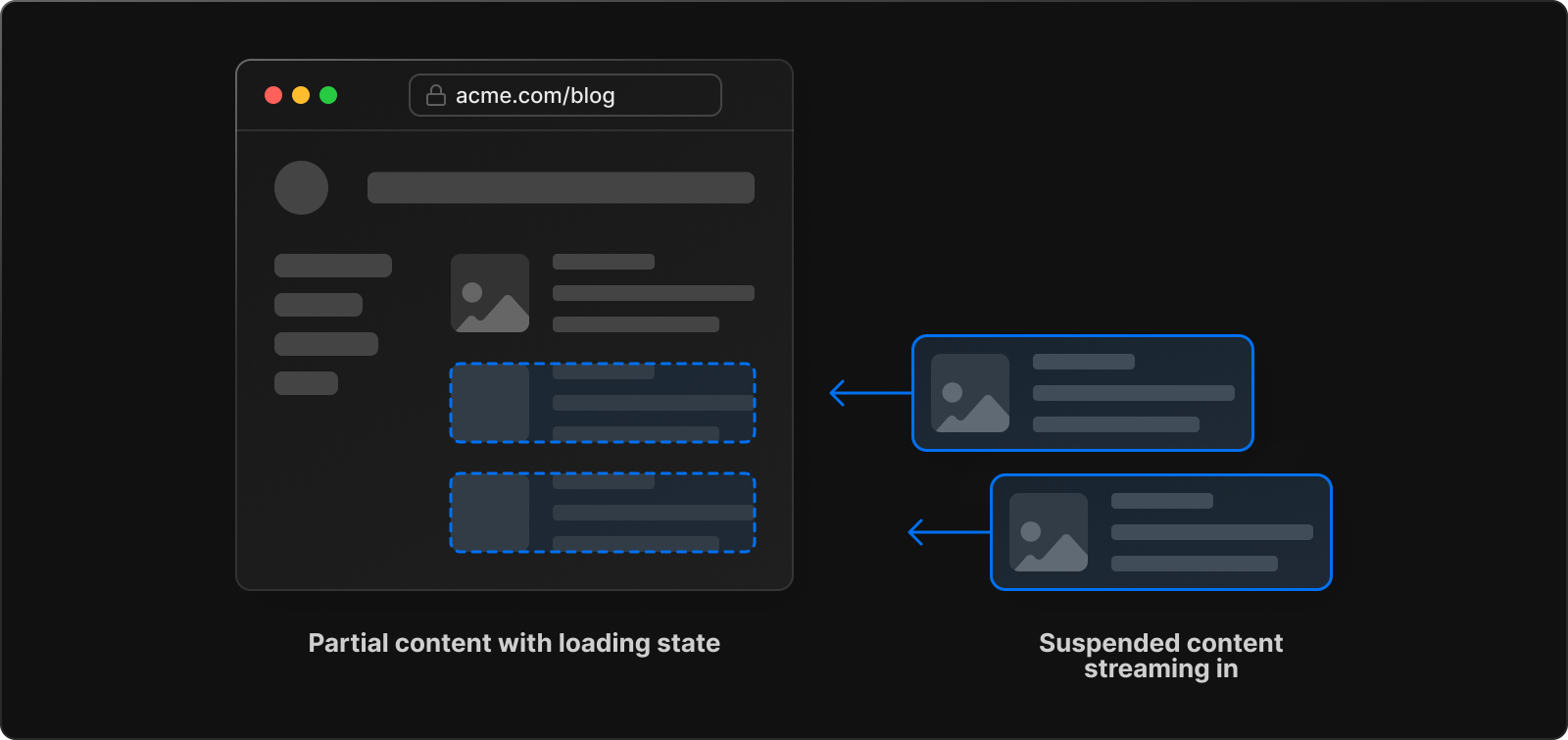
-
-
www.telerik.com www.telerik.com
Tags
Annotators
URL
-
-
www.telerik.com www.telerik.com
-
github.com github.com
-
workers.tools workers.tools
-
HTML templating and streaming response library for Worker Runtimes such as Cloudflare Workers.
js function handleRequest(event: FetchEvent) { return new HTMLResponse(pageLayout('Hello World!', html` <h1>Hello World!</h1> ${async () => { const timeStamp = new Date( await fetch('https://time.api/now').then(r => r.text()) ); return html`<p>The current time is ${timeEl(timeStamp)}.</p>` }} `)); }
Tags
Annotators
URL
-
-
github.com github.com
-
gist.github.com gist.github.com
-
pirxpilot.me pirxpilot.me
Tags
Annotators
URL
-
-
dev.to dev.to
Tags
Annotators
URL
-
-
blog.dwac.dev blog.dwac.dev
-
document.implementation.createHTMLDocument() which can stream dynamic HTML content directly into the page DOM
-
-
-
Fortunately with webpackChunkName in an inline comment, we can instruct webpack to name the file something much friendlier.
js const HeavyComponent = lazy(() => import(/* webpackChunkName: "HeavyComponent" */ './HeavyComponent');
-
-
plainenglish.io plainenglish.io
-
Similar to prefetching, you can specify the chunk name with an inline comment using the webpackChunkName key
js const LazyLoad = lazy(() => import(/* webpackChunkName: 'lazyload' */ './LazyLoad') ); -
For example, if the user is on the login page, you can load the post-login home page. An inline comment with the webpackPrefetch key within the dynamic import function will instruct Webpack to do just this.
```js const PrefetchLoad = lazy(() => import( / webpackPrefetch: true / './PrefetchLoad' ) );
const App = () => { return ( <Suspense fallback="Loading"> {condition && <PrefetchLoad />} </Suspense> ); }; ```
-
Now when App is rendered and a request is initiated to get the LazyLoad code, the fallback Loading is rendered. When this request completes, React will then render LazyLoad.
js const App = () => { return ( <Suspense fallback="Loading"> <LazyLoad /> </Suspense> ); }; -
Now, App and LazyLoad are in separate code chunks. A request is sent to fetch the LazyLoad code chunk only when App is rendered. When the request completes, React will then renderLazyLoad. You can verify this by looking at the Javascript requests in the network inspector.
```js import React, { lazy } from 'react';
const LazyLoad = lazy(() => import('./LazyLoad'));
const App = () => { return <LazyLoad />; }; ```
-
-
linguinecode.com linguinecode.com
-
You can have multiple nested React.lazy components inside React.Suspense.
```js
const CatAvatar = React.lazy(() => import('./path/to/cat/avatar')); const ThorAvatar = React.lazy(() => import('./path/to/cat/thor-avatar'));
const AppContainer = () => ( <React.Suspense fallback="loading..."> <CatAvatar /> <ThorAvatar /> </React.Suspense> ); ```
-
-
www.wireshark.org www.wireshark.org
-
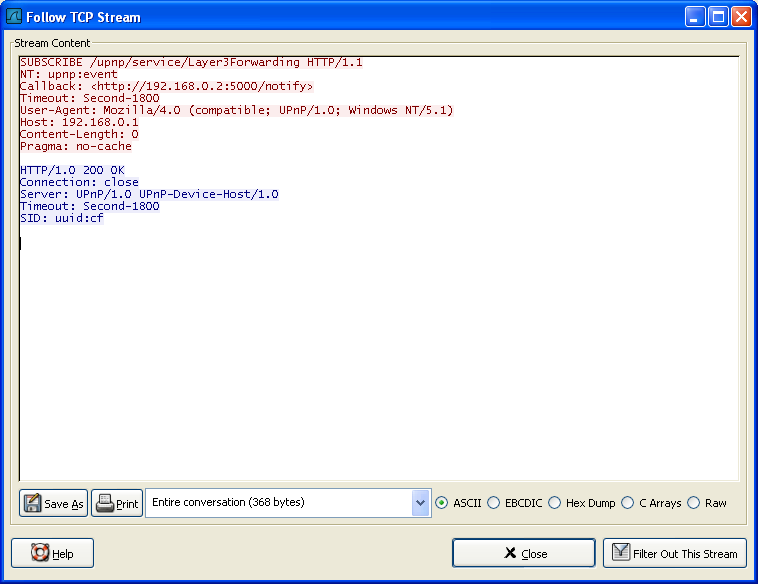
Use Follow TCP Stream to display HTTP response chunks
-
-
developer.mozilla.org developer.mozilla.org
-
Chunked encoding is useful when larger amounts of data are sent to the client and the total size of the response may not be known until the request has been fully processed. For example, when generating a large HTML table resulting from a database query or when transmitting large images.A chunked response looks like this:
```http HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked
7\r\n Mozilla\r\n 11\r\n Developer Network\r\n 0\r\n \r\n ```
-
chunked Data is sent in a series of chunks. The Content-Length header is omitted in this case and at the beginning of each chunk you need to add the length of the current chunk in hexadecimal format, followed by '\r\n' and then the chunk itself, followed by another '\r\n'. The terminating chunk is a regular chunk, with the exception that its length is zero. It is followed by the trailer, which consists of a (possibly empty) sequence of header fields.
-
```abnf Transfer-Encoding: chunked Transfer-Encoding: compress Transfer-Encoding: deflate Transfer-Encoding: gzip
// Several values can be listed, separated by a comma Transfer-Encoding: gzip, chunked ```
-
-
Tags
Annotators
URL
-
-
blog.cloudflare.com blog.cloudflare.com
-
www.cloudflare.com www.cloudflare.com
-
alistapart.com alistapart.com
-
jakearchibald.com jakearchibald.com
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
blog.bitsrc.io blog.bitsrc.io
-
```js // FromStream component
import { PureComponent } from 'react';
export default class FromStream extends PureComponent { constructor(props) { super(props); this.state = { value: false }; }
componentDidMount() { this.initStream(); }
componentDidUpdate(prevProps) { if (prevProps.stream !== this.props.stream) { this.initStream(); } }
componentWillUnmount() { if (this.unSubscribe) { this.unSubscribe(); } }
initStream() { if (this.unSubscribe) { this.unSubscribe(); this.unSubscribe = null; }
if (this.props.stream) { const onValue = (value) => { this.setState(() => ({ value: map(value) })); }; this.props.stream.onValue(onValue); this.unSubscribe = () => stream.offValue(onValue); }}
render() { return this.props.children(this.state && this.state.value); } } ```
```js // Date/Time import React from 'react'; import Kefir from 'kefir'; import FromStream from './FromStream';
const dateStream = Kefir.interval(1000).map(() => new Date().toString());
export default () => ( <FromStream stream={dateStream}> {(dateString) => dateString} </FromStream> ); ```
```js // Scroll import React from 'react'; import Kefir from 'kefir'; import FromStream from './FromStream';
const scrolledPercentStream = Kefir.fromEvents(document, 'scroll').map((e) => { const scrollY = window.document.pageYOffset; const scrollHeight = e.target.body.scrollHeight; return scrollY / (scrollHeight - windiw.innerHeight) * 100; });
export default () => ( <FromStream stream={scrolledPercentStream}> {(percent) => ( <div className="bar" style={{ top: <code>${percent}% }}></div> )} </FromStream> ); ```
-
-
marconijr.com marconijr.com
-
```js import { useState, useEffect } from 'react';
interface StreamState { data: Uint8Array | null; error: Error | null; controller: AbortController; }
const useAbortableStreamFetch = (url: string, options?: RequestInit): { data: Uint8Array | null, error: Error | null, abort: () => void, } => {
const [state, setState] = useState<StreamState>({ data: null, error: null, controller: new AbortController(), });
useEffect(() => { (async () => { try { const resp = await fetch(url, { ...options, signal: state.controller.signal, }); if (!resp.ok || !resp.body) { throw resp.statusText; }
const reader = resp.body.getReader(); while (true) { const { value, done } = await reader.read(); if (done) { break; } setState(prevState => ({ ...prevState, ...{ data: value } })); } } catch (err) { if (err.name !== 'AbortError') { setState(prevState => ({ ...prevState, ...{ error: err } })); } } })(); return () => state.controller.abort();}, [url, options]);
return { data: state.data, error: state.error, abort: () => state.controller && state.controller.abort(), }; };
export default useAbortableStreamFetch; ```
-
-
nodesource.com nodesource.com
-
stackoverflow.com stackoverflow.com
-
ci.mines-stetienne.fr ci.mines-stetienne.fr
Tags
Annotators
URL
-
-
github.com github.com
-
```js import { renderToReadableStream } from 'react-dom/server'; import type { EntryContext } from '@remix-run/cloudflare'; import { RemixServer } from '@remix-run/react'; import { renderHeadToString } from 'remix-island'; import { Head } from './root';
const readableString = (value: string) => { const te = new TextEncoder(); return new ReadableStream({ start(controller) { controller.enqueue(te.encode(value)); controller.close(); }, }); };
export default async function handleRequest( request: Request, responseStatusCode: number, responseHeaders: Headers, remixContext: EntryContext, ) { const { readable, writable } = new TransformStream(); const head = readableString(
<!DOCTYPE html><html><head>${renderHeadToString({ request, remixContext, Head, })}</head><body><div id="root">, ); const end = readableString(</div></body></html>);const body = await renderToReadableStream( <RemixServer context={remixContext} url={request.url} />, );
Promise.resolve() .then(() => head.pipeTo(writable, { preventClose: true })) .then(() => body.pipeTo(writable, { preventClose: true })) .then(() => end.pipeTo(writable));
responseHeaders.set('Content-Type', 'text/html');
return new Response(readable, { status: responseStatusCode, headers: responseHeaders, }); } ```
Tags
Annotators
URL
-
-
-
```js import React, { Component } from 'react'; import './style.css'; import ndjsonStream from 'can-ndjson-stream';
class App extends Component { constructor(props) { super(props);
this.state = { todos: [] };}
componentDidMount(){ fetch('http://localhost:5000/api/10', { method: 'get' }).then(data => { return ndjsonStream(data.body); }).then((todoStream) => { const streamReader = todoStream.getReader(); const read = result => { if (result.done) return;
this.setState({ todos: this.state.todos.concat([result.value.user]) }); streamReader.read().then(read); }; streamReader.read().then(read); }).catch(err => { console.error(err) });}
render() { return ( <div className="App">
React + NDJSON Stream Demo
-
{this.state.todos.map((todo, i) =>
- {todo} )}
export default App; ```
-
-
dbconvert.com dbconvert.com
Tags
Annotators
URL
-
-
exploringjs.com exploringjs.com
-
-
Streaming across worker threads
```js import { ReadableStream } from 'node:stream/web'; import { Worker } from 'node:worker_threads';
const readable = new ReadableStream(getSomeSource());
const worker = new Worker('/path/to/worker.js', { workerData: readable, transferList: [readable], }); ```
```js const { workerData: stream } = require('worker_threads');
const reader = stream.getReader(); reader.read().then(console.log); ```
-
Consuming web streams
```js import { arrayBuffer, blob, buffer, json, text, } from 'node:stream/consumers';
const data1 = await arrayBuffer(getReadableStreamSomehow());
const data2 = await blob(getReadableStreamSomehow());
const data3 = await buffer(getReadableStreamSomehow());
const data4 = await json(getReadableStreamSomehow());
const data5 = await text(getReadableStreamSomehow()); ```
-
Adapting to the Node.js Streams API
```js /* * For instance, given a ReadableStream object, the stream.Readable.fromWeb() method * will create an return a Node.js stream.Readable object that can be used to consume * the ReadableStream's data: / import { Readable } from 'node:stream';
const readable = new ReadableStream(getSomeSource());
const nodeReadable = Readable.fromWeb(readable);
nodeReadable.on('data', console.log); ```
```js /* * The adaptation can also work the other way -- starting with a Node.js * stream.Readable and acquiring a web streams ReadableStream: / import { Readable } from 'node:stream';
const readable = new Readable({ read(size) { reader.push(Buffer.from('hello')); } });
const readableStream = Readable.toWeb(readable);
await readableStream.read();
```
Tags
Annotators
URL
-
-
Tags
Annotators
URL
-
-
2ality.com 2ality.com
-
-
blog.mmyoji.com blog.mmyoji.com
-
deno.com deno.com
Tags
Annotators
URL
-
-
blog.k-nut.eu blog.k-nut.eu
Tags
Annotators
URL
-
-
codepen.io codepen.io
Tags
Annotators
URL
-
-
twitter.com twitter.com
Tags
Annotators
URL
-
-
developer.mozilla.org developer.mozilla.org
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
glitch.com glitch.com
Tags
Annotators
URL
-
-
developer.mozilla.org developer.mozilla.org
-
Async iteration of a stream using for await...ofThis example shows how you can process the fetch() response using a for await...of loop to iterate through the arriving chunks.
```js const response = await fetch("https://www.example.org"); let total = 0;
// Iterate response.body (a ReadableStream) asynchronously for await (const chunk of response.body) { // Do something with each chunk // Here we just accumulate the size of the response. total += chunk.length; }
// Do something with the total console.log(total); ```
Tags
Annotators
URL
-
-
developer.mozilla.org developer.mozilla.org
-
The body read-only property of the Response interface is a ReadableStream of the body contents.
Tags
Annotators
URL
-
- Feb 2023
-
patterns.dev patterns.dev
Tags
Annotators
URL
-
-
github.com github.com
-
```js import type { EntryContext } from "@remix-run/cloudflare"; import { RemixServer } from "@remix-run/react"; import isbot from "isbot"; import { renderToReadableStream } from "react-dom/server";
const ABORT_DELAY = 5000;
const handleRequest = async ( request: Request, responseStatusCode: number, responseHeaders: Headers, remixContext: EntryContext ) => { let didError = false;
const stream = await renderToReadableStream( <RemixServer context={remixContext} url={request.url} abortDelay={ABORT_DELAY} />, { onError: (error: unknown) => { didError = true; console.error(error);
// You can also log crash/error report }, signal: AbortSignal.timeout(ABORT_DELAY), });
if (isbot(request.headers.get("user-agent"))) { await stream.allReady; }
responseHeaders.set("Content-Type", "text/html"); return new Response(stream, { headers: responseHeaders, status: didError ? 500 : responseStatusCode, }); };
export default handleRequest; ```
-
-
github.com github.com
-
js const wss = new WebSocketStream(url); const { readable } = await wss.connection; const reader = readable.getReader(); while (true) { const { value, done } = await reader.read(); if (done) break; await process(value); } done();
js const wss = new WebSocketStream(url); const { writable } = await wss.connection; const writer = writable.getWriter(); for await (const message of messages) { await writer.write(message); }
js const controller = new AbortController(); const wss = new WebSocketStream(url, { signal: controller.signal }); setTimeout(() => controller.abort(), 1000);
-
-
docs.google.com docs.google.com
-
Tags
Annotators
URL
-
-
developer.chrome.com developer.chrome.com
-
```js const supportsRequestStreams = (() => { let duplexAccessed = false;
const hasContentType = new Request('', { body: new ReadableStream(), method: 'POST', get duplex() { duplexAccessed = true; return 'half'; }, }).headers.has('Content-Type');
return duplexAccessed && !hasContentType; })();
if (supportsRequestStreams) { // … } else { // … } ```
Tags
Annotators
URL
-
-
ndjson.org ndjson.orgndjson1
Tags
Annotators
URL
-
-
deanhume.com deanhume.com
-
```js /* * Fetch and process the stream / async function process() { // Retrieve NDJSON from the server const response = await fetch('http://localhost:3000/request');
const results = response.body // From bytes to text: .pipeThrough(new TextDecoderStream()) // Buffer until newlines: .pipeThrough(splitStream('\n')) // Parse chunks as JSON: .pipeThrough(parseJSON());
// Loop through the results and write to the DOM writeToDOM(results.getReader()); }
/* * Read through the results and write to the DOM * @param {object} reader / function writeToDOM(reader) { reader.read().then(({ value, done }) => { if (done) { console.log("The stream was already closed!");
} else { // Build up the values let result = document.createElement('div'); result.innerHTML = `<div>ID: ${value.id} - Phone: ${value.phone} - Result: $ {value.result}</div><br>`; // Prepend to the target targetDiv.insertBefore(result, targetDiv.firstChild); // Recursively call writeToDOM(reader); }}, e => console.error("The stream became errored and cannot be read from!", e) ); } ```
Tags
Annotators
URL
-
-
mxstbr.com mxstbr.com
Tags
Annotators
URL
-
-
marcoghiani.com marcoghiani.com
-
-
Node.js
js import { renderToPipeableStream } from "react-dom/server.node"; import React from "react"; import http from "http"; const App = () => ( <html> <body> <h1>Hello World</h1> <p>This is an example.</p> </body> </html> ); var didError = false; http .createServer(function (req, res) { const stream = renderToPipeableStream(<App />, { onShellReady() { res.statusCode = didError ? 500 : 200; res.setHeader("Content-type", "text/html"); res.setHeader("Cache-Control", "no-transform"); stream.pipe(res); }, onShellError(error) { res.statusCode = 500; res.send( '<!doctype html><p>Loading...</p><script src="clientrender.js"></script>', ); }, onAllReady() { }, onError(err) { didError = true; console.error(err); }, }); }) .listen(3000);Deno
```js import { renderToReadableStream } from "https://esm.run/react-dom/server"; import * as React from "https://esm.run/react";
const App = () => ( <html> <body>
Hello World
This is an example.
</body> </html> );const headers = { headers: { "Content-Type": "text/html", "Cache-Control": "no-transform", }, };
Deno.serve( async (req) => { return new Response(await renderToReadableStream(<App />), headers); }, { port: 3000 }, ); ```
Bun
```js import { renderToReadableStream } from "react-dom/server"; const headers = { headers: { "Content-Type": "text/html", }, };
const App = () => ( <html> <body>
Hello World
This is an example.
</body> </html> );Bun.serve({ port: 3000, async fetch(req) { return new Response(await renderToReadableStream(<App />), headers); }, }); ```
-
-
beta.reactjs.org beta.reactjs.org
-
beta.reactjs.org beta.reactjs.org
-
nodejs.org nodejs.org
-
-
www.youtube.com www.youtube.com
-
-
blog.logrocket.com blog.logrocket.com
-
prateeksurana.me prateeksurana.me
-
suspense.vercel.app suspense.vercel.app
Tags
Annotators
URL
-
-
suspense-npm.vercel.app suspense-npm.vercel.app
-
suspense-npm.vercel.app suspense-npm.vercel.app
Tags
Annotators
URL
-
-
developers.cloudflare.com developers.cloudflare.com
-
developers.cloudflare.com developers.cloudflare.com
-
remix.run remix.run
Tags
Annotators
URL
-
-
www.thesing-online.de www.thesing-online.de
-
This framing makes me think you'd appreciate: <br /> https://hapgood.us/2015/10/17/the-garden-and-the-stream-a-technopastoral/
syndication link: https://mastodon.social/@chrisaldrich/109833797235024284
-
- Nov 2022
-
github.com github.com
Tags
Annotators
URL
-
-
rdf.js.org rdf.js.org
-
- Oct 2022
-
workers.tools workers.tools
Tags
Annotators
URL
-
- Aug 2022
-
nodejs.org nodejs.org
Tags
Annotators
URL
-
- Jul 2022
-
web.dev web.dev
Tags
Annotators
URL
-
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
- Jun 2022
-
www.zylstra.org www.zylstra.org
-
Local file Local file
-
Third, sharing our ideas with others introduces a major element ofserendipity
There is lots of serendipity here, particularly when people are willing to either share their knowledge or feel compelled to share it as part of an imagined life "competition" or even low forms of mansplaining, though this last tends to be called this when the ultimate idea isn't serendipitous but potentially so commonly known that there is no insight in the information.
This sort of "public serendipity" or "group serendipity" is nice because it means that much of the work of discovery and connecting ideas is done by others against your own work rather that you sorting/searching through your own more limited realm of work to potentially create it.
Group focused combinatorial creativity can be dramatically more powerful than that done on one's own. This can be part of the major value behind public digital gardens, zettelkasten, etc.
-
Third, sharing our ideas with others introduces a major element ofserendipity. When you present an idea to another person, theirreaction is inherently unpredictable. They will often be completelyuninterested in an aspect you think is utterly fascinating; they aren’tnecessarily right or wrong, but you can use that information eitherway. The reverse can also happen. You might think something isobvious, while they find it mind-blowing. That is also usefulinformation. Others might point out aspects of an idea you neverconsidered, suggest looking at sources you never knew existed, orcontribute their own ideas to make it better. All these forms offeedback are ways of drawing on not only your first and SecondBrains, but the brains of others as well.
I like that he touches on one of the important parts of the gardens and streams portion of online digital gardens here, though he doesn't tacitly frame it this way.
-
Favorites or bookmarks saved from the web or social media
The majority of content one produces in social media is considered "throw away" material. One puts it in the stream of flotsam and jetsam and sets it free down the river never to be seen or used again. We treat too much of our material and knowledge this way.
-
-
www.youtube.com www.youtube.com
-
https://www.youtube.com/watch?v=bWkwOefBPZY
Some of the basic outline of this looks like OER (Open Educational Resources) and its "five Rs": Retain, Reuse, Revise, Remix and/or Redistribute content. (To which I've already suggested the sixth: Request update (or revision control).
Some of this is similar to:
The Read Write Web is no longer sufficient. I want the Read Fork Write Merge Web. #osb11 lunch table. #diso #indieweb [Tantek Çelik](http://tantek.com/2011/174/t1/read-fork-write-merge-web-osb110
Idea of collections of learning as collections or "playlists" or "readlists". Similar to the old tool Readlist which bundled articles into books relatively easily. See also: https://boffosocko.com/2022/03/26/indieweb-readlists-tools-and-brainstorming/
Use of Wiki version histories
Some of this has the form of a Wiki but with smaller nuggets of information (sort of like Tiddlywiki perhaps, which also allows for creating custom orderings of things which had specific URLs for displaying and sharing them.) The Zettelkasten idea has some of this embedded into it. Shared zettelkasten could be an interesting thing.
Data is the new soil. A way to reframe "data is the new oil" but as a part of the commons. This fits well into the gardens and streams metaphor.
Jerry, have you seen Matt Ridley's work on Ideas Have Sex? https://www.ted.com/talks/matt_ridley_when_ideas_have_sex Of course you have: https://app.thebrain.com/brains/3d80058c-14d8-5361-0b61-a061f89baf87/thoughts/3e2c5c75-fc49-0688-f455-6de58e4487f1/attachments/8aab91d4-5fc8-93fe-7850-d6fa828c10a9
I've heard Jerry mention the idea of "crystallization of knowledge" before. How can we concretely link this version with Cesar Hidalgo's work, esp. Why Information Grows.
Cross reference Jerry's Brain: https://app.thebrain.com/brains/3d80058c-14d8-5361-0b61-a061f89baf87/thoughts/4bfe6526-9884-4b6d-9548-23659da7811e/notes
-
- Apr 2022
-
intothebook.net intothebook.net
-
To read through my life, even as an incomplete picture, fits the permanence I’m envisioning for the site.
If one thinks of a personal website as a performance, what is really being performed by the author?
Links and cross links, well done, within a website can provide a garden of forking paths by which a particular reader might explore a blog despite the fact that there is often a chronological time order imposed upon it.
Link this to the idea of using a zettelkasten as a biography of a writer, but one with thousands of crisscrossing links.
-
-
winnielim.org winnielim.org
-
Also related to this idea of content display is the sentiment in https://anildash.com/2012/08/14/stop_publishing_web_pages/
-
- Jan 2022
- Dec 2021
-
github.com github.com
-
// main.js const { RemoteReadableStream, RemoteWritableStream } = RemoteWebStreams; (async () => { const worker = new Worker('./worker.js'); // create a stream to send the input to the worker const { writable, readablePort } = new RemoteWritableStream(); // create a stream to receive the output from the worker const { readable, writablePort } = new RemoteReadableStream(); // transfer the other ends to the worker worker.postMessage({ readablePort, writablePort }, [readablePort, writablePort]); const response = await fetch('./some-data.txt'); await response.body // send the downloaded data to the worker // and receive the results back .pipeThrough({ readable, writable }) // show the results as they come in .pipeTo(new WritableStream({ write(chunk) { const results = document.getElementById('results'); results.appendChild(document.createTextNode(chunk)); // tadaa! } })); })();// worker.js const { fromReadablePort, fromWritablePort } = RemoteWebStreams; self.onmessage = async (event) => { // create the input and output streams from the transferred ports const { readablePort, writablePort } = event.data; const readable = fromReadablePort(readablePort); const writable = fromWritablePort(writablePort); // process data await readable .pipeThrough(new TransformStream({ transform(chunk, controller) { controller.enqueue(process(chunk)); // do the actual work } })) .pipeTo(writable); // send the results back to main thread };
-
-
spectrum.chat spectrum.chat
-
Currently starting to read https://github.com/substack/stream-handbook, maybe I just need a deeper understanding of streams
According to @xander76 on Twitter the code would have to use a Transform stream, which looks something like this:
let cacheEntry = ""; renderToNodeStream(<Frontend/>) .pipe(new Transform({ transform(chunk, enc, callback) { cacheEntry += chunk; callback(chunk); }, flush(callback) { redis.set(req.path, cacheEntry); } }) .pipe(res);
-
-
github.com github.com
Tags
Annotators
URL
-
-
web.dev web.dev
Tags
Annotators
URL
-
-
wicg.github.io wicg.github.io
Tags
Annotators
URL
-
-
web.dev web.dev
-
-
css-tricks.com css-tricks.com
- Sep 2021
-
oldschool.scripting.com oldschool.scripting.com
- Jul 2021
-
snarkmarket.com snarkmarket.com
-
Revisiting this essay to review it in the framing of digital gardens.
In a "gardens and streams" version of this metaphor, the stream is flow and the garden is stock.
This also fits into a knowledge capture, growth, and innovation framing. The stream are small atomic ideas flowing by which may create new atomic ideas. These then need to be collected (in a garden) where they can be nurtured and grow into new things.
Clippings of these new growth can be placed back into the stream to move on to other gardeners. Clever gardeners will also occasionally browse through the gardens of others to see bigger picture versions of how their gardens might become.
Proper commonplacing is about both stock and flow. The unwritten rule is that one needs to link together ideas and expand them in places either within the commonplace or external to it: essays, papers, articles, books, or other larger structures which then become stock for others.
While some creators appear to be about all stock in the modern era, it's just not true. They're consuming streams (flow) from other (perhaps richer) sources (like articles, books, television rather than social media) and building up their own stock in more private (or at least not public) places. Then they release that article, book, film, television show which becomes content stream for others.
While we can choose to create public streams, but spending our time in other less information dense steams is less useful. Better is to keep a reasonably curated stream to see which other gardens to go visit.
Currently is the online media space we have structures like microblogs and blogs (and most social media in general) which are reasonably good at creating streams (flow) and blogs, static sites, and wikis which are good for creating gardens (stock).
What we're missing is a structure with the appropriate and attendant UI that can help us create both a garden and a stream simultaneously. It would be nice to have a wiki with a steam-like feed out for the smaller attendant ideas, but still allow the evolutionary building of bigger structures, which could also be placed into the stream at occasional times.
I can imagine something like a MediaWiki with UI for placing small note-like ideas into other streams like Twitter, but which supports Webmention so that ideas that come back from Twitter or other consumers of one's stream can be placed into one's garden. Perhaps in a Zettelkasten like way, one could collect atomic notes into their wiki and then transclude those ideas into larger paragraphs and essays within the same wiki on other pages which might then become articles, books, videos, audio, etc.
Obsidian, Roam Research do a somewhat reasonable job on the private side and have some facility for collecting data, but have no UI for sharing out into streams.
-
-
blog.ayjay.org blog.ayjay.org
-
Alan Jacobs seems to be delving into the area of thought spaces provided by blogs and blogging.
In my view, they come out of a cultural tradition of commonplace books becoming digital and more social in the the modern era. Jacobs is obviously aware of the idea of Zettelkasten, but possibly hasn't come across the Sonke Ahrens' book on smart notes or the conceptualization of the "digital garden" stemming from Mike Caulfield's work.
He's also acquainted with Robin Sloane, though it's unclear if he's aware of the idea of Stock and Flow.
-
- Jun 2021
-
www.nytimes.com www.nytimes.com
-
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>Mike Caulfield</span> in Mike Caulfield on Twitter: "Ok, pressing play again." / Twitter (<time class='dt-published'>06/09/2021 15:47:36</time>)</cite></small>
-
- May 2021
-
maggieappleton.com maggieappleton.com
-
The conversational feed design of email inboxes, group chats, and InstaTwitBook is fleeting – they're only concerned with self-assertive immediate thoughts that rush by us in a few moments.
The streamification of the web had already taken hold enough by this point. Anil Dash had an essay in 2012 entitled Stop Publishing Web Pages which underlined this point.
-
- Apr 2021
-
stackoverflow.com stackoverflow.com
-
-
$ ./my_script Will end up in STDOUT(terminal) and /var/log/messages $ tail -n1 /var/log/messages Sep 23 15:54:03 wks056 my_script_tag[11644]: Will end up in STDOUT(terminal) and /var/log/messages
-
-
unix.stackexchange.com unix.stackexchange.com
-
exec &> >(tee -a "$log_file")
-
exec &> >(tee -a "$log_file") echo "This will be logged to the file and to the screen" $log_file will contain the output of the script and any subprocesses, and the output will also be printed to the screen.
-
-
unix.stackexchange.com unix.stackexchange.com
-
-
Write stderr and stdout to a file, display stderr on screen (on stdout) exec 2> >(tee -a -i "$HOME/somefile.log") exec >> "$HOME/somefile.log" Useful for crons, so you can receive errors (and only errors) by mail
-
-
stackoverflow.com stackoverflow.com
-
What you want is not to detect if stdin is a pipe, but if stdin/stdout is a terminal.
The OP wasn't wrong in exactly the way this comment implies: he didn't just ask how to detect whether stdin is a pipe. The OP actaully asked how to detect whether it is a terminal or a pipe. The only mistake he made, then, was in assuming those were the only two possible alternatives, when in fact there is (apparently) a 3rd one: that stdin is redirected from a file (not sure why the OS would need to treat that any differently from a pipe/stream but apparently it does).
This omission is answered/corrected more clearly here:
stdin can be a pipe or redirected from a file. Better to check if it is interactive than to check if it is not.
-
-
unix.stackexchange.com unix.stackexchange.com
-
This question does not show any research effort; it is unclear or not useful Bookmark this question. Show activity on this post. I'm trying to filter the output of the mpv media player, removing a particular line, but when I do so I am unable to control mpv with the keyboard. Here is the command: mpv FILE | grep -v 'Error while decoding frame' When I run the command, everything displays correctly, but I am unable to use the LEFT and RIGHT keys to scan through the file, or do anything else with the keyboard. How do I filter the output of the program while retaining control of it?
-
Quite a lot of programs actually detect if their output goes to a file (e.g. try man | grep -F a and you will not be able to scroll back and forth).
-
-
samba.2283325.n4.nabble.com samba.2283325.n4.nabble.com
-
i found that for the osx host "gonzo" , the vanished files (not the warning message itself) appear in stdout - for linux hosts they _both_ appear in stderr , but nothing in stdout (rsync.err.#num is stderr, rsync.log is stdout)
-
- Feb 2021
-
hapgood.us hapgood.us
-
Stream presents us with a single, time ordered path with our experience (and only our experience) at the center.
And even if we are physically next to another person, our experience will be individualized. We don't know what other people see, nor we can be sure we are looking at each other.
-
In the stream metaphor you don’t experience the Stream by walking around it and looking at it, or following it to its end. You jump in and let it flow past. You feel the force of it hit you as things float by. It’s not that you are passive in the Stream. You can be active. But your actions in there — your blog posts, @ mentions, forum comments — exist in a context that is collapsed down to a simple timeline of events that together form a narrative.
This describes exactly what frustrates me the most about online discussions. Especially on Twitter, it is so hard to build coherence on previous (and future) insight.
-
- Nov 2020
-
github.com github.com
-
logInfoToStdOut (boolean) (default=false) This is important if you read from stdout or stderr and for proper error handling. The default value ensures that you can read from stdout e.g. via pipes or you use webpack -j to generate json output.
-
- Oct 2020
-
stream.jeremycherfas.net stream.jeremycherfas.net
-
Maintaining a website that you regard as your own does require maintenance. Like a garden, you may choose to let a few weeds flourish, for the wildlife, and you may also seek to encourage volunteers, for the aesthetics. A garden without wildlife is dull, a garden without aesthetics is pointless.
-
-
bonkerfield.org bonkerfield.org
-
I love the general idea of where he's going here and definitively want something exactly like this.
The closest thing I've been able to find in near-finished form is having a public TiddlyWiki with some IndieWeb features. Naturally there's a lot I would change, but for the near term a mixture of a blog and a wiki is what more of us need.
I love the recontextualization of the swale that he proposes here to fit into the extended metaphor of the garden and the stream.
-
-
kafka.apache.org kafka.apache.org
-
User topics must be created and manually managed ahead of time
Javadoc says: "should be created".
The reason is: Auto-creation of topics may be disabled in your Kafka cluster. Auto-creation automatically applies the default topic settings such as the replicaton factor. These default settings might not be what you want for certain output topics (e.g., auto.create.topics.enable=true in the Kafka broker configuration).
-
- Sep 2020
-
icla2020b.jonreeve.com icla2020b.jonreeve.com
-
the gentlemen who make a business and a living out of writing books
When the narrator switches into first-person in this new sentence, I wonder if it’s really Collins speaking - especially when he mentions “the gentlemen who make a business and a living out of writing books”; Is this a stream of consciousness (similar to Woolf?)? Can it be measured quantifiably? To me, streams of consciousness, while sometimes inarguably clear, always have something to do with the readers and how they view themselves, a factor that seems so subjective and wildly varying from person to person.
-
- Jun 2020
- May 2020
-
github.com github.com
-
Once running, kaniko will then get the data from STDIN and create the build context as a compressed tar. It will then unpack the compressed tar of the build context before starting the image build.
-
-
thoughtbot.com thoughtbot.com
-
Pipes are great for taking output of one command and transforming it using other commands like jq. They’re a key part of the Unix philosophy of “small sharp tools”: since commands can be chained together with pipes, each command only needs to do one thing and then hand it off to another command.
-
-
en.wikipedia.org en.wikipedia.org
-
www.catb.org www.catb.org
-
Write programs to handle text streams, because that is a universal interface.
-
- Feb 2020
-
charemza.name charemza.name
- Jan 2020
-
developer.mozilla.org developer.mozilla.org
- Jun 2019
-
jscomplete.com jscomplete.com
Tags
Annotators
URL
-
-
jakearchibald.com jakearchibald.com
Tags
Annotators
URL
-
- Apr 2019
-
developer.mozilla.org developer.mozilla.org
Tags
Annotators
URL
-
- Jan 2019
-
docs.oracle.com docs.oracle.com
-
after the terminal operation of the stream pipeline commences.
Above is because of the nature of
Streams in general: they are lazily executed (or put another way, execution is delayed until the latest convenient method call).
-
- Oct 2018
-
-
-
github.com github.com
Tags
Annotators
URL
-
-
developer.mozilla.org developer.mozilla.org
-
developer.mozilla.org developer.mozilla.org
-
The ReadableStream interface of the Streams API represents a readable stream of byte data. The Fetch API offers a concrete instance of a ReadableStream through the body property of a Response object.
-
-
streams.spec.whatwg.org streams.spec.whatwg.org
-
- Sep 2018
-
data-artisans.com data-artisans.com
-
This blog is very interesting and is related to stream processing and micro services
Tags
Annotators
URL
-
- Jul 2018
-
wendynorris.com wendynorris.com
-
Research in HCI has illustrated how this notion of immedi-acy is upheld through the social conventions associated with technologies, as well as through their design. For ex-ample, Harper et al. [16] have described the lived experi-ence (or durée, following Bergson [6]) of Facebook as be-ing located firmly in the now, and have noted that this ne-cessitates a particular approach to the performance of iden-tity on the site by its users. They observe that interactions privilege the present and underpin an impression of events unfolding as they happen (even if this is not the case in terms of spatial time, or Bergson’s temps). Because of this, the performance of identity is one of the moment: users reported feeling it inappropriate to post old content, and were similarly aggrieved when others uploaded photos that surfaced ‘out of time’.
Look up Harper paper.
Friction point of out-of-order, non-chronological streams of events on social media.
-
Research by narrative theorist Ruth Page [35] (a co-author on the above paper) considers fur-ther how Facebook users learn to interpret social media posts when reading the newsfeed. While the series of snip-pets of ‘breaking news’ posted by a variety of members of one’s social network do not offer a typical narrative, readers nevertheless draw their own story-like experience, using their knowledge of those posting content to build a backsto-ry, whilst imagining what may happen next.
Look up Page paper.
Could help to bolster argument about crowdsourcing process friction caused by non-chronological social media.
-
- Nov 2015
-
mfeldstein.com mfeldstein.com
-
most blogs have a feature called “pingbacks,”
Annotations should have “pingbacks”, too. But the most important thing is how to process those later on. We do get into the Activity Streams behind much Learning Analytics.
-