8,037 Matching Annotations
- Oct 2023
-
ns.inria.fr ns.inria.frLDScript1
Tags
Annotators
URL
-
-
www.dailymotion.com www.dailymotion.com
-
-
www.ahp-numerique.fr www.ahp-numerique.fr
-
www.ahp-numerique.fr www.ahp-numerique.fr
Tags
Annotators
URL
-
-
api.bnf.fr api.bnf.fr
Tags
Annotators
URL
-
-
www.biblibre.com www.biblibre.com
-
graphdb.ontotext.com graphdb.ontotext.com
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
-
w3c.github.io w3c.github.io
Tags
Annotators
URL
-
-
www.slideshare.net www.slideshare.net
Tags
Annotators
URL
-
-
cambridgesemantics.com cambridgesemantics.com
-
cambridgesemantics.com cambridgesemantics.com
-
buildkite.com buildkite.com
-
UUID Version 7 (UUIDv7) is a time-ordered UUID which encodes a Unix timestamp with millisecond precision in the most significant 48 bits. As with all UUID formats, 6 bits are used to indicate the UUID version and variant. The remaining 74 bits are randomly generated. As UUIDv7 is time-ordered, values generated are practically sequential and therefore eliminates the index locality problem.
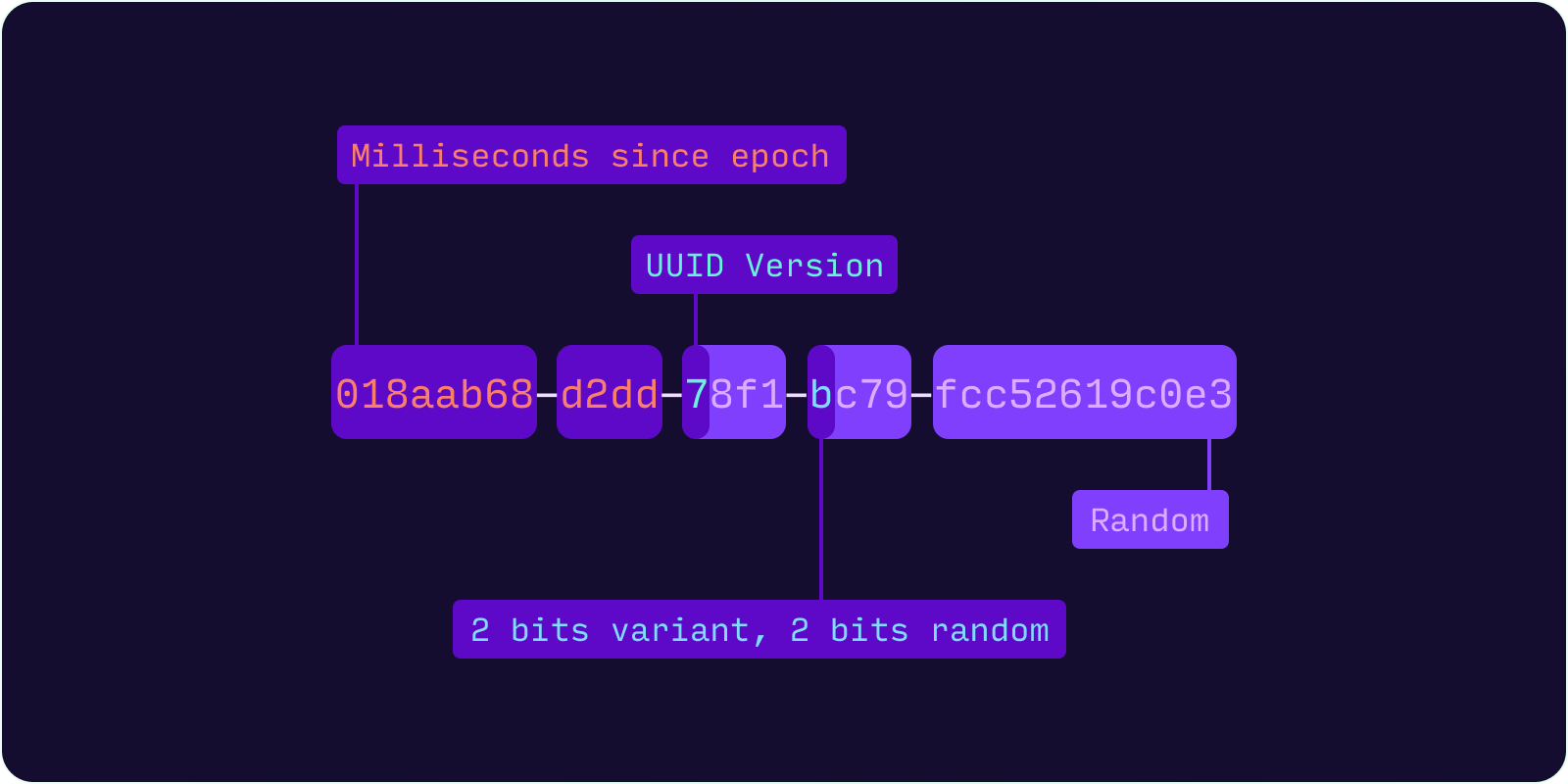
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | unix_ts_ms | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | unix_ts_ms | ver | rand_a | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |var| rand_b | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | rand_b | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-
-
datatracker.ietf.org datatracker.ietf.org
-
www.wikiart.org www.wikiart.org
Tags
Annotators
URL
-
-
www.nortonsimon.org www.nortonsimon.org
Tags
Annotators
URL
-
-
johnsamuel.info johnsamuel.info
Tags
Annotators
URL
-
-
gist.github.com gist.github.com
-
console curl -G https://wdqs-beta.wmflabs.org/bigdata/namespace/wdq/sparql --data-urlencode query=' select distinct ?type where { ?thing a ?type } limit
Tags
Annotators
URL
-
-
-
Federated SPARQL Query, incorporating data from both DBpedia & Wikidata
```sparql PREFIX wd: http://www.wikidata.org/entity/ PREFIX wdt: http://www.wikidata.org/prop/direct/ PREFIX wikibase: http://wikiba.se/ontology# PREFIX p: http://www.wikidata.org/prop/ PREFIX ps: http://www.wikidata.org/prop/statement/ PREFIX pq: http://www.wikidata.org/prop/qualifier/ PREFIX bd: http://www.bigdata.com/rdf# PREFIX owl: http://www.w3.org/2002/07/owl# PREFIX rdfs: http://www.w3.org/2000/01/rdf-schema# PREFIX foaf: http://xmlns.com/foaf/0.1/ PREFIX dct: http://purl.org/dc/terms/SELECT DISTINCT ?dbpediaID AS ?href xsd:string(?label) AS ?name ?description ?subjectText ?item AS ?wikidataID ?dbpediaID ?image ?picture WHERE { SERVICE http://query.wikidata.org/sparql { SELECT DISTINCT ?item ?itemLabel ?numero ( SAMPLE(?pic) AS ?picture ) WHERE { ?item p:P528 ?catalogStatement . ?catalogStatement ps:P528 ?numero . ?catalogStatement pq:P972 wd:Q14530 . OPTIONAL { ?item wdt:P18 ?pic } . SERVICE wikibase:label { bd:serviceParam wikibase:language "en" } } GROUP BY ?item ?itemLabel ?numero ORDER BY ?numero }
SERVICE <http://dbpedia.org/sparql> { SELECT ?item ?dbpediaID ?label ?image ?description ?subjectText FROM <http://dbpedia.org> WHERE { ?dbpediaID owl:sameAs ?item ; rdfs:label ?label ; foaf:depiction ?image ; rdfs:comment ?description ; dct:subject [ rdfs:label ?subjectText ] . FILTER ( LANG(?label) = "en" ) FILTER ( LANG(?description) = "en" ) } }} ```
-
-
stackoverflow.com stackoverflow.com
-
meta.wikimedia.org meta.wikimedia.org
-
hypothes.is hypothes.is
Tags
Annotators
URL
-
-
dj-smoke.bandcamp.com dj-smoke.bandcamp.com
-
stackoverflow.com stackoverflow.com
- Sep 2023
-
sveltejs.github.io sveltejs.github.io
-
sveltejs.github.io sveltejs.github.io
-
sveltejs.github.io sveltejs.github.io
-
github.com github.com
-
Undocumented Hypothes.is Badge API (used by Chrome extension):
```python """ Return the number of public annotations on a given page.
This is for the number that's displayed on the Chrome extension's badge.
Certain pages are blocklisted so that the badge never shows a number on those pages. The Chrome extension is oblivious to this, we just tell it that there are 0 annotations. """ ```
https://hypothes.is/api/badge?uri=*same ashttps://hypothes.is/api/search?limit=0&uri=*.
-
-
chromestatus.com chromestatus.com
-
gist.github.com gist.github.com
-
-
permit streams to be transferred between workers, frames and anywhere else that postMessage() can be used. Chunks can be anything which is cloneable by postMessage(). Initially chunks enqueued in such a stream will always be cloned, ie. all data will be copied. Future work will extend the Streams APIs to support transferring objects (ie. zero copy).
js const rs = new ReadableStream({ start(controller) { controller.enqueue('hello'); } }); const w = new Worker('worker.js'); w.postMessage(rs, [rs]);js onmessage = async (evt) => { const rs = evt.data; const reader = rs.getReader(); const {value, done} = await reader.read(); console.log(value); // logs 'hello'. };
-
-
developer.chrome.com developer.chrome.com
Tags
Annotators
URL
-
-
web.archive.org web.archive.org
-
```svelte
<script> $: getFirstValue = () => { // here be calculations // that does not fit on one line return result } $: getSecondValue = () => { // here be calculations // that does not fit on one line return result } // will rerun everytime getFirstValue or getSecondValue is updated because of reactivity $: value = getFirstValue() || getSecondValue() </script> <div id="app"> {value} </div>```
-
if the function declaration is reactive, then Svelte will redeclare the function everytime something within it changes, which makes the function rerun in the markup
```svelte
<script> $: giveMeSomething = () => { //... some code return something } </script> <div id="app"> {giveMeSomething()} </div>```
-
-
developer.mozilla.org developer.mozilla.org
-
sveltesociety.dev sveltesociety.dev
-
archive.org archive.org
-
archive.org archive.org
Tags
Annotators
URL
-
-
blog.cloudflare.com blog.cloudflare.com
-
datatracker.ietf.org datatracker.ietf.org
-
www.youtube.com www.youtube.com
-
-
swoose.bandcamp.com swoose.bandcamp.com
-
soundcloud.com soundcloud.com
-
overmono.bandcamp.com overmono.bandcamp.com
-
soundcloud.com soundcloud.com
-
stackoverflow.com stackoverflow.com
-
``js // SSE only supports GET request export async function GET({ url }) { const stream = new ReadableStream({ start(controller) { // You can enqueue multiple data asynchronously here. const myData = ["abc", "def"] myData.forEach(data => { controller.enqueue(data: ${data}\n\n`) }) controller.close() }, cancel() { // cancel your resources here } });return new Response(stream, { headers: { // Denotes the response as SSE 'Content-Type': 'text/event-stream', // Optional. Request the GET request not to be cached. 'Cache-Control': 'no-cache', } })} ```
-
-
Tags
Annotators
URL
-
-
codapi.org codapi.org
-
-
hypothes.is hypothes.is
-
-
wordpress.com wordpress.com
-
wordpress.org wordpress.org
-
hachyderm.io hachyderm.io
Tags
Annotators
URL
-
-
geoffrich.net geoffrich.net
-
On subsequent page loads using client-side navigation, we can allow the slow data to be streamed in. Client-side navigation will only occur if JavaScript is available, so there are no downsides to using promise streaming. If the user doesn’t have JavaScript, each navigation will trigger a full page load, and we will again wait for all data to resolve.We can switch between these two behaviors using the isDataRequest property on the RequestEvent passed to the load function. When this property is false, the request is for the HTML for the initial page load, and we should wait for all data to resolve. If the property is true, then the request is from SvelteKit’s client-side router and we can stream the data in.
js export async function load({isDataRequest}) { const slowData = getSlowData(); return { nested: { slow: isDataRequest ? slowData : await slowData } }; } -
We can use Promise.race to give our promise a few hundred milliseconds to resolve. Promise.race takes an array of promises, and resolves when any one of those promises resolve. We can pass our delay call and our data fetching call, and conditionally await the result depending on which one resolves first.
In this example, we race two promises: a 200ms delay and the actual data call we want to make. If the delay resolves first, then the data call is taking longer than 200ms and we should go ahead and render the page with partial data. If the data call resolves first, then we got the data under the time limit and we can render the page with complete data.
```js const TIME_TO_RESOLVE_MS = 200; export async function load() { const slowData = getSlowData();
const result = await Promise.race([delay(TIME_TO_RESOLVE_MS), slowData]);
return { nested: { slow: result ? result : slowData } }; }
async function getSlowData() { // randomly delay either 50ms or 1s // this simulates variable API response times await delay(Math.random() < 0.5 ? 50 : 1000); return '😴'; }
function delay(ms) { return new Promise(res => setTimeout(res, ms)); } ```
Tags
Annotators
URL
-
-
docutils.sourceforge.io docutils.sourceforge.io
-
docutils.sourceforge.io docutils.sourceforge.io
-
docutils.sourceforge.io docutils.sourceforge.io
-
mistlog.medium.com mistlog.medium.com
-
mistlog.github.io mistlog.github.io
-
www.copetti.org www.copetti.org
-
svelte.dev svelte.dev
-
Runes are an additive feature, but they make a whole bunch of existing concepts obsolete: the difference between let at the top level of a component and everywhere else export let $:, with all its attendant quirks different behaviour between <script> and <script context="module"> the store API, parts of which are genuinely quite complicated the $ store prefix $$props and $$restProps lifecycle functions (things like onMount can just be $effect functions)
-
-
johtela.github.io johtela.github.io
-
blog.bitsrc.io blog.bitsrc.io
-
www.digitalocean.com www.digitalocean.com
-
Modules do not add anything to the global (window) scope. Modules always are in strict mode. Loading the same module twice in the same file will have no effect, as modules are only executed once. Modules require a server environment.
-
-
fidoalliance.org fidoalliance.org
-
www.youtube.com www.youtube.comYouTube2
-
-
hypothes.is hypothes.is
-
-
musicbrainz.org musicbrainz.org
-
coverartarchive.org coverartarchive.org
Tags
Annotators
URL
-
-
moderat.bandcamp.com moderat.bandcamp.com
-
moderat.bandcamp.com moderat.bandcamp.com
-
soundcloud.com soundcloud.com
-
brave.com brave.com
-
Google claims this new API addresses FLoC’s serious privacy issues. Unfortunately, it does anything but. The Topics API only touches the smallest, most minor privacy issues in FLoC, while leaving its core intact. At issue is Google’s insistence on sharing information about people’s interests and behaviors with advertisers, trackers, and others on the Web that are hostile to privacy.
-
-
arstechnica.com arstechnica.com
-
Chrome now directly tracks users, generates a "topic" list it shares with advertisers.
-
-
www.graphile.org www.graphile.org
Tags
Annotators
URL
-
-
openbiblio.social openbiblio.social
-
www.100ms.live www.100ms.live
Tags
Annotators
URL
-
-
-
```svelte
<script> let m = { x: 0, y: 0 }; function handleMousemove(event) { m.x = event.clientX; m.y = event.clientY; } </script> <div on:mousemove={handleMousemove}> The mouse position is {m.x} x {m.y} </div> <style> div { width: 100%; height: 100%; } </style>```
```js / React Hook - sample code to capture mouse coordinates/
import React, { useState, useCallback, useEffect, useRef } from 'react';
function useEventListener(eventName, handler, element = window) { // Create a ref that stores handler const savedHandler = useRef();
// Update ref.current value if handler changes. // This allows our effect below to always get latest handler ... // ... without us needing to pass it in effect deps array ... // ... and potentially cause effect to re-run every render. useEffect(() => { savedHandler.current = handler; }, [handler]);
useEffect(() => { // Make sure element supports addEventListener const isSupported = element && element.addEventListener; if (!isSupported) return;
// Create event listener that calls handler function stored in ref const eventListener = event => savedHandler.current(event); // Add event listener element.addEventListener(eventName, eventListener); // Remove event listener on cleanup return () => { element.removeEventListener(eventName, eventListener); }; }, [eventName, element] // Re-run if eventName or element changes); }
export default function App() { // State for storing mouse coordinates const [coords, setCoords] = useState({ x: 0, y: 0 });
// Event handler utilizing useCallback ... // ... so that reference never changes. const handler = useCallback( ({ clientX, clientY }) => { // Update coordinates setCoords({ x: clientX, y: clientY }); }, [setCoords] );
// Add event listener using our hook useEventListener('mousemove', handler);
return (
The mouse position is ({coords.x}, {coords.y})
); } ```
-
-
coderpad.io coderpad.io
-
-
Add a new, undocumented separate_replies=True option to the search API. If separate_replies=True option is _not_ given to the search API, then it reverts to its previous behaviour: _do_ include replies in the "rows" list returned. This is the same behaviour that the search API had befor: it returns both top-level annotations and replies in the one "rows" list, but without any guarantee that if some annotations/replies from a given thread are in the list then all annotations/replies from that thread will be in it. If separate_replies=True _is_ given then the API follows the new behaviour: "rows" contains top-level annotations only, and a separate "replies" list containing all replies to the annotations in rows is also inserted into the result.
-
-
twitter.com twitter.com
-
Did you know you can now use streaming promises in SvelteKit? No need to import anything - it just works out of the box
Every property of an object returned by the
loadfunction can be a promise which itself can return an object that can have a promise as property, and so on.Can build a tree of promises based on data delivery priority.
-
-
xmpp.org xmpp.org
Tags
Annotators
URL
-
-
github.com github.com
-
Otherwise, you can manually call goto instead of history.replaceState is a good way to maintain client-side navigation (no reloads).
-
I highly recommend using GET forms to implement this as SvelteKit will intercept and retain client-side navigation on form submission. https://kit.svelte.dev/docs/form-actions#get-vs-post Submitting the form will update the URL with the search parameters matching the input names and values.
```html
<form action="/baz"> <label> Query <input name="query"> </label> <label> Sort <input name="sort"> </label> <label> Order <input name="order"> </label> <label> Page <input name="page"> </label> </form>```
Tags
Annotators
URL
-
-
www.thinkprogramming.co.uk www.thinkprogramming.co.uk
-
stackoverflow.com stackoverflow.com
-
```js let query = new URLSearchParams($page.url.searchParams.toString());
query.set('word', word);
goto(
?${query.toString()}); ```js $page.url.searchParams.set('word',word); goto(`?${$page.url.searchParams.toString()}`);
-
-
www.dericbourg.net www.dericbourg.net
-
hypothes.is hypothes.is
-
-
www.wikidata.org www.wikidata.org
Tags
Annotators
URL
-
-
medium.com medium.com
-
timdeschryver.dev timdeschryver.dev
-
blog.logrocket.com blog.logrocket.com
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
Tags
Annotators
URL
-
-
type-level-typescript.com type-level-typescript.com
-
-
datatracker.ietf.org datatracker.ietf.org
-
www.bortzmeyer.org www.bortzmeyer.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
chrome.google.com chrome.google.com
-
Disable all settings related to Privacy Sandbox
Disables "adMeasurementEnabled", "fledgeEnabled", "topicsEnabled" and "privacySandboxEnabled" for your browser.
-
-
stackoverflow.com stackoverflow.com
-
kaviisuri.com kaviisuri.com
Tags
Annotators
URL
-
-
webgl-shaders.com webgl-shaders.com
Tags
Annotators
URL
-
-
openarchives.sncf.com openarchives.sncf.com
Tags
Annotators
URL
-
-
hturan.com hturan.com
Tags
Annotators
URL
-
-
shalabh.com shalabh.com
-
hypothes.is hypothes.is
-
-
www.theregister.com www.theregister.com
-
If a site you visit queries the Topics API, it may learn of this interest from Chrome and decide to serve you an advert about bonds or retirement funds. It also means websites can fetch your online interests straight from your browser.
The Topics API is worst than 3rd-parties cookies, anyone can query a user ad profile:
```js // document.browsingTopics() returns an array of BrowsingTopic objects. const topics = await document.browsingTopics();
// Get data for an ad creative. const response = await fetch('https://ads.example/get-creative', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(topics) });
// Get the JSON from the response. const creative = await response.json();
// Display the ad. (or not) ```
-
-
wavacity.com wavacity.com
-
-
Tags
Annotators
URL
-
-
cheatsheetseries.owasp.org cheatsheetseries.owasp.org
-
hypothes.is hypothes.is
-
-
soundcloud.com soundcloud.com
-
podcast.ausha.co podcast.ausha.co
-
soundcloud.com soundcloud.com
-
stackoverflow.com stackoverflow.com
- Aug 2023
-
svelte.dev svelte.dev
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
-
developer.chrome.com developer.chrome.com
-
www.youtube.com www.youtube.comYouTube2
-
-
direct.mit.edu direct.mit.edu
-
cso.kmi.open.ac.uk cso.kmi.open.ac.uk
-
developer.mozilla.org developer.mozilla.org
-
investcoder.com investcoder.com
-
dev.to dev.to
-
dexie.org dexie.org
Tags
Annotators
URL
-
-
soundcloud.com soundcloud.com
-
profiler.firefox.com profiler.firefox.com
-
twitter.com twitter.com
-
joyofcode.xyz joyofcode.xyz
Tags
Annotators
URL
-
-
telefunc.com telefunc.comTelefunc1
-
-
www.unicode.org www.unicode.org
Tags
Annotators
URL
-