I'm using judell/Hypothesis python wrapper to access and back up this data.
It looks like the link (https://github.com/judell/Hypothesis) is returning a 404.
I'm using judell/Hypothesis python wrapper to access and back up this data.
It looks like the link (https://github.com/judell/Hypothesis) is returning a 404.
Hypothesis is simply awesome and my favorite web annotation tool. Their killer feature is that it embeds a bit of JS in the page to provide an in-browser overlay, so you don't have to leave the page you were reading and can highlight and add comments natively. They use something cool called fuzzy anchoring to achieve this.
For giggles, I'm annotating this on Hypothes.is.
I'm using judell/Hypothesis python wrapper to access and back up this data
This link is dead, as of this comment's writing. I use gooseberry to download my annotations one-by-one, but it should support a way of downloading everything -- kind of like syncthing for hypothesis, but with a templating language.
Annotations layer should be loosely coupled to the underlying content
I wonder if PDF "annotations" are decoupled in this manner. I doubt it.
Web browser history is a rich source of potentially useful information. Just think about it: it's zero effort lifelogging.
You don't have to install anything or register
You do have to register if you want to annotate :|
keeping aURL will not by itself help you remember or understand what's there, even though it mayfeel that way
I recommend Promnesia for when you forget!
How to annotate literally everything
cool compilation of tools. got me to think about the best ways to record my internet journey.
Introduction to annotating the web, with detailed guidance both conceptual and technical
https://beepb00p.xyz/
Przegląd narzędzi do zaznaczania i notowania stron internetowych.
Tools use for note-taking on the web
What would a secure Federated PMK / archive network backed by a minimal blockchain look like?
Possibly like Holochain (which is distinct from the blockchain architecture). Blockchain only seems helpful if you need all of the following: - a database - immutability - distributed data - decentralized & totally trustless - append only - cryptographically secure assurance
Confer Brandon Enright's provocative talk "Blockchain is Bullshit" for an elaboration of these features. The first 10 or so minutes is mostly uninsightful trolling, so the link takes one to his argument about the key features of blockchain.
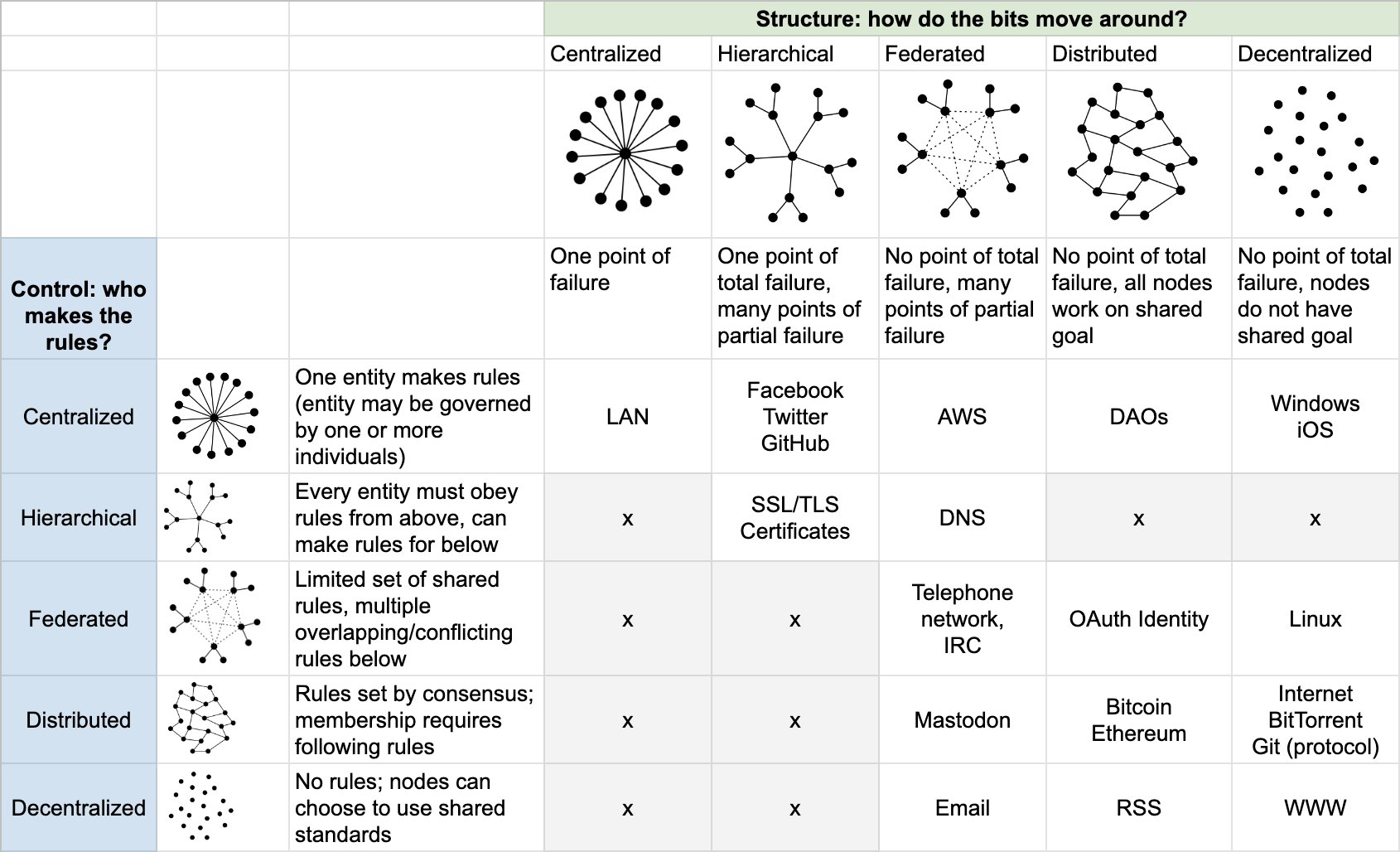
AFAICT, Holochain eases the feature of "decentralized", although Laurie Voss suggests that it's better to think of Bitcoin & Ethereum as "distributed" (in both the structure & control).
In Voss' taxonomy, I suspect that Holochain's structure would be "distributed" (ie, "No total point of failure, all nodes work on shared goal") and control would be "federated" (ie, "Limited set of shared rules, multiple overlapping/conflicting rules below")
I also think being able to self-host and export parts of your data to share with others would be great.
This might be achievable through Holochain application framework. One promising project built on Holochain is Neighbourhoods. Their "Social-Sensemaker Architecture" across "neighbourhoods" is intriguing
Page recommended by @wfinck. Seems @karlicoss is the author. This project seems similar to what I've been trying to do with Hypothes.is, Obsidian, Anki, Zotero, and PowerToys Run but goes beyond the scope of my endeavors to just quickly access whatever resource comes to mind (without creating duplicates). The things that Promnesia adds beyond my PKM stack is the following: - prioritize new info - keeping track of which device things were read and how long
Internet gets more reliable
my main frustrations are around the lack of the very basic things that computers can do extremely well: data retrieval and search. I'll carry on, just listing some examples. Let's see if any of them resonate with you:
youtube videos, even though most of them have subtitles hence allowing for full text search?
the tool I've developed
I want URLs to address information and represent relations. The current URL experience is far from ideal for this.
a more realistic and plausible target: using my digital trace (such as browser history, webpage annotations and my personal wiki) to make up for my limited memory
or try the very page you're reading now
good idea
gravity on the poles in a bit larger
Why did that happen? The schema was wrong. We shouldn't have relied on ids: they are kind of an artifact of the relational model. One way of getting around it is "unnormalizing":
This is an easy case, and you can just retrieve all over again every time. Example: Pinboard API, there are just a few megabytes of data you have on Pinboard and API doesn't prevent you from retrieving all of it at once.
Don't slice if you can retrieve a full data dump time after time. The service is the data storage, query from there. Risk: if the service switches from storing alltime data to "latest n years", the early data is lost. Need to re-check each service's API description periodically.
Now, remember I mentioned that Reddit only gives you the latest 1000 items, so I end up with overlapping data slices? To get a full view of my data, I'm simply going through individual JSON files in chronological order and merging together in accumulate method. [optional] caching layer I've got Reddit data way into past and export it every day, so merging together all these files during data access can indeed take a noticeable time. I'm overcoming this by using a @cachew annotation on the comments() method.
Really read through every exported datafile, parse contents, and merge according to e.g. timestamp. Sounds like huge overhead but maybe it's not, especially when using caching?
Of course, exporting often enough to make sure no data is lost will result in lot of duplicate exported data on the disk. Storage is cheap?
sometimes you vaguely recall reading about something or seeing a link, but don't remember where exactly. Was it on stackoverflow? Or in some github issue? Or in a conversation with friend?
to be capable of always remembering and instantly recalling information
AND filtering with details" and "sensations" to LOCATE the "specific" memory recall
The UI "must" search in DIFFERENT "repositories" (local or online)
I don't understand how does it not bother you!
So I am working on a personal project for which I am collecting all the URLs I even visited
There are some potential short term benefits: makes you more resilient Something along the lines of #prepping. Realistically though, in modern world, it's nice to be able to run after a bus or up the stairs, but it's quite questionable if running, say, even 5K is useful. makes you appear better physically Nice bonus, but I don't find it as a good value for time spent. feeling better immediately after exercise I used to get that, but it seems that the body adapted and I can't feel endorphine kick anymore. There is some good feeling about yourself having willpower to stick to routine, but I'd rather not have the routine in the first place. feeling better generally (less stressed, better sleep etc) I suppose I'm lucky to feel good anyway, so I don't feel subjective impact of exercise on my well being. Objectively, I tried to find correlations between amount of exercise and sleep, and failed to find any. (I'll write about it in more details later) I absolutely hate it. It's a massive drain of time and willpower. In addition, it comes with all sorts of logistical difficulties: gym outfit, shower, backpack, eating, weather.
ok!
store in a text file for further processing
y las imagenes?
Yes, I know, it’s not meant for geeks, it’s for normal people who love mouseclicks. I’m still puzzled by how people who develop that stuff use their own product though
hahaha!
First of all, Chromium bookmark adding menu was a bit shit and still is. You get to choose among the five most recently used folders only; if you want anything specific, you have to mouse click all the way through (using Tab on keyboard with my 100+ folders was just not doable). You can’t search when you add bookmark either. Yes, I know, it’s not meant for geeks, it’s for normal people who love mouseclicks. I’m still puzzled by how people who develop that stuff use their own product though.
ok!
mixer•last monthIt's a pity you didn't mention Zotero. It's such a great tool for many purposes. Also Calibre now supports highlighting in .djvu and .pdf files. It works well and covers all of my book/research papers related highlighting needs. Check it out!
OK
А Вы не пробовали ripgrep-all (https://github.com/phiresky/ripgrep-all)? Это враппер над rg для поиска по документам. Он вообще всеядный: работает с pdf/.doc/.docx, sqlite, архивами, etc.
Ripgrep-all to search in Jupyter notebooks as well? Much of my code is .ipynb files.
The only thing that's left is restricting the search to git repositories only. Ripgrep relies on regexes, so we can't do something like Xpath queries and tell it to only search in directories, that contain .git directory. I ended up using a two step approach: first, my/code-targets returns all git repositories it can reach from my/git-repos-search-root. I'm using fd to go through the disk and collect all candidate git repositories. Even though fd is already ridiculously fast, this step still takes some time, so I'm caching the repositories. Cache is refreshed in the background every five minutes so we don't have to crawl the filesystem every time. That saves me few seconds on every search. then, my/search-code keybindings invokes ripgrep against all my directories with code, defined in my/code-targets function.
I have multiple repos, need to search in them all to uncover useful pieces of code.
互联网界的手工耿
some sort of search engine, over my personal data, with uniform and always available way of accessing it.
That's something i've been longing for decades: list my interaction with a site.
Why does it bother me?
An important list of pk2b & web-tag problems:
Contents for similar PKDB, Web Tagging and similar ideas.
Awesome collection. I've spent a lot of time looking into this myself. I'm a heavy Instapaper user, using this Chrome extension to export annotations to Roam (not Roam-specific): https://github.com/houshuang/instapaper-exporter-extension. However, it's really frustrating that Instapaper isn't better... Highlighting on iPhone is jarring, it often jumps randomly when I long-press, I can't capture images etc. And the API is useless - no way of getting more than the first 200 items, which is why the extension above scrapes their website... Looked into Pocket, but they don't even allow entering your own notes. I also recently looked into RSS - Feedly pro (not cheap) allows annotations and has an API - I'll experiment with the API later, but I might also just tag articles and have them sent to Instapaper... Wallabag looks cool, wish I was an iOS developer so I could add the stuff I want :)
The way to export Instapaper annotations to Roam without using Readwise as a middleware
Android browsers via bookmarklet.
Possible to use on Android
using Hypothesis on your phone, tablet, or other mobile device
Using Hypothes.is seamlessly on mobile devices (Android, iOS, iPad, anything) is totally possible with just the bookmarklet. Please check this: https://beepb00p.xyz/annotating.html#hypothesis.
Set up the bookmarklet, and then activating H on a page is as simple as URL bar -> search keyword -> click bookmarklet. ❤️
e: Annotation Is Now a Web Standard, or try the very page you're reading now.
Thank you, I was not aware.
Annotation tools overview
¶3 Your data is vanishing Things I listed above are frustrating enough as they are. There is another aspect to this: your data is slipping away.
data is vanishing
The sad state of personal data and infrastructure [see within blog graph] Why can't we have nice digital things?

sidebar is not necessarily convenient for social commenting
Can you expand your thoughts here?
About error-handling (but not logging).
tart with (if
what
~.polar directory holds all the data, which makes it easy to share among your computers (e.g. via git, or if you keep it on Dropbox and symlink)
The new releases of polar seem to hold almost everything on the cloud with the subscription model. The free tier is very limited. No documentation available on selfhosting it despite being MIT license.
Annotation is the process of adding a layer of personal (with a potential for sharing) metadata on top of existing content such as highlights, notes, anchors etc.
Examples of exobrains 'Everything I know' wiki by Nikita Voloboev xxiivv by Devine Lu Linvega h0p3's Wiki Braindump by Jethro Kuan 'One Hundred Ideas for Computing' repository by Sam Squire more wiki examples from Nikita Voloboev
Human brains seem to be best for generating new ideas. I want to learn more, think faster, distract less, interact and visualize, effortlessly remember everything; not memorize and do routine information processing, which computers seem better at.
Extended mind is the idea that your mind isn't limited by your physical body, but augmented by external means. Paper notes & diaries, data in your computer/phone/cloud – all these things contribute to your cognitive process, thinking and help you navigate the landscape of ideas.
How to annotate literally everything
Comprehensive annotation tools for web/PDFs/eInk/etc
Good overview of annotation tools with a lot of additional information in comments and - you guess - annotations.
I started using Cronicle a few weeks ago and really like it. Runs on a server... https://github.com/jhuckaby/Cronicle
This also ticks a lot of my desired features.
Really easy to set up if you already have node ready to go.
UI is very slick and feels right to me out of the box.
Multi-server support.
Jobs can be assigned to categories. A given category can have max concurrent processes running at the same time (so run 1 backup task a time, even though 5 tasks are scheduled within the same time period). Individual tasks can also be set to be singleton or configurable max concurrency.
Supports configurable retry (number of attempts, delay between).
Supports optional catchup runs if runs are missed or queued runs.
Supports killing and erroring out if timeouts or resource limits are hit.
Time from download to first job setup... 2 minutes? Very intuitive UI.
Has management API, not clear if it has an existing good CLI interface.
Also supports setting up users to be able to run pre-defined scripts and see output.
Need to figure out how to back-up and restore jobs.
RUNDECK
Very quick impression is this ticks a lot of my desired features.
I'm not wild about the community edition default dashboard - I'd rather a more high level view of everything configured and its statuses.
UI is clunky when compared to Cronicle. Lots of steps to get from setting it up to actually running something. No quick click from a run task to its log output. No good resources/stats view that I found.
Like the fact it keeps track of logs, runtime (and can alert if runtime deviates from normal), gives you an estimated time to complete, lets you run on a schedule and/or manually.
Like the fact it supports farming tasks off through SSH or other, or running them locally. Can auto-discover nodes using a script you provide (e.g. query AWS nodes) or using static config.
Really interested in the multi-user capabilities. This may solve a problem I didn't really know I had at work (giving a semi-technical person access to kick off jobs or monitor them before asking me).
huginn: great example of a user-friendly tool
User-friendly in the sense it gives you a UI, but lots of clicks and UI to get something done.
Also more of a "do random things not worth programming" tool, and less of a "run all of my scripts and processes" tool.
Doesn't seem to fit well with the rest of the page.
Reminds me of programming in Tasker on Android. My non-programmer friend automates (almost) everything in his life with it, but I try to use it and it frustrates the hell out of me and I just want a scripting language.
Sadly, most of them are pretty heavy: often distributed, aiming at orchestrating clusters and grids, which is quite an overkill for my humble personal needs.
That's been part of challenge. A lot of my desired functionality seems to lead to the same tools as people managing large clusters for company infrastructure.
So it stops being easy to configure/manage because flexibility usually leads to massive cognitive overhead.
Running all that manually (more than 100 scripts across all devices) is an awful job for a human. I want to set them up once and more or less forget about it, only checking now and then.
My ideals for all of my regular processes and servers:
So much of the configuration/control stuff screams containers, so more and more I'm using Docker for my scripts, even simpler ones.
I'm pretty sure a lot of this is accomplished by existing Docker orchestration tools. Been delaying that rabbit hole for a long time.
I think the key thing that makes this not just a "cron" problem for me, is I want something that monitors and manages both itself and the tasks I want to run, including creating/setting up if not already. I also want to ideally focus my mental energy into a single controller that handles my "keep this running" things all together, be they servers or infrequent tasks.
Doesn't have to be a single project. Might be multiple pieces glued together somehow.
on Google groups, they are meaningful and address specific discussions and messages:
#! for AJAX crawlable pages. Of course this is only a signal for what the hash might mean, but I remember when Google was trying to make this a "thing".
https://developers.google.com/search/docs/ajax-crawling/docs/getting-started?csw=1
¶Telegram
Can a full backup of my Telegram be used such that a message I forward to Saved Messages can link back to the context in which the message was forwarded?
Do I have to forward the context of the video link I'm saving for later, or is there enough metadata to back-link to where it came from?
was planning to correlate them with monzo/HSBC transactions, but haven't got to it yet
plaintext accounting, specifically beancount and beancount-import is my toolset of choice - it (beancount-import) has the power to figure out how to match up Amazon transactions to bank/credit card charges - even if the order's charges come in multiple separate charges. Looks like you're using ledger, though.
Honorable mention to fava beancount web UI if you're looking for more reason to move over from ledger.
I use Plaid in place of monzo for pulling bank transactions. No good API driven banks or credit cards here in the US.
mount your Google Drive (e.g. via google-drive-ocamlfuse)
I'm currently using rclone to fully sync my Google Drive to my NAS, and then ratarmount to make the archives mountable in a very fast (once the initial indexing of the tgz is completed) manner.
Seriously, check out ratarmount if you haven't. Since the Google Takeout spans multiple 50GB tgz files (I'm at ~14, not including Google Drive in the takeout), ratarmount is brilliant. It merges all of the tgz contents into a single folder structure so /path/a/1.jpg and /path/a/1.json might be in different tgz folders but are mounted in to the same folder.
Currently just for my unorganized "only in Google Photos" photos - since I just want to make sure I have a backup as I establish my desired archiving routine. I point my backup program (duplicacy) to the mounted tgz folder so the photos and JSON get entered into the backups. Just trying to cover my "Google locks me out and my ZFS pool dies in the same time period" bases.
I want to argue very strongly against forcing the data in the database, unless it's really inevitable.
At work I've been taking this approach in Amazon Web Services a lot as well, using Athena - Amazon's wrapper around Presto ("Distributed SQL Query Engine for Big Data").
Basically, as long as your data is coming from the third party or your own systems as CSV or JSON, it's really easy to create a SQL wrapper around the data, and throw the power of Amazon's servers at it.
Athena isn't a real-time database, but for so many of our use-cases (even with terabytes of data), it's fast enough, cheap enough, and so much easier to deal with than managing a "real" database.
The ideas in this article about using DAL/DAO classes to abstract away third party formats are great. I was already in that mindset in some of my work and personal projects, but this article sparked some new ideas.
This is until you realize you're probably using at least ten different services, and they all have different purposes, with various kinds of data, endpoints and restrictions.
10 is so low. Just counting the ones I want to actively back-up, I've made a list that's almost 30 entries long.
beepb00p.xyz
cool looking site
This is until you realize you're probably using at least ten different services, and they all have different purposes, with various kinds of data, endpoints and restrictions. Even if you have the capacity and are willing to do it, it's still damn hard.
Hopefully we can agree that the current situation isn't so great. But I am a software engineer. And chances that if you're reading it, you're very likely a programmer as well. Surely we can deal with that and implement, right? Kind of, but it's really hard to retrieve data created by you.
ambitious
It's 404 now. What was there?
That also makes annotations resilient to document markup changes, and if they can't locate your annotations it would be still shown in metadata as 'orphaned', so you never lose your notes.
This is very cool! This makes annotating on things like a git repo much more useful.
I'm tired of mediocre search experience
This
Why when something like 'mind palace' is literally possible with VR technology, we don't see any in use?
Ermahgerd, yes!
How to annotate literally everything
One very important video annotation tool is missing: vialogues.com This tool has been around for nearly a decade and is served by Columbia University. I hope it never deprecates. It is awesome. Why don't more people know about it?
mobile Firefox,
This article here explains how to automate injecting the annotation client using Greasemonkey in Firefox mobile.
plain list items
There are also inline tasks, which can be used for this purpose
Comprehensive overview of existing tools, strategies and thoughts on interacting with your data Table of Contents
Good overview of tools to help extend and retain your knowledge, of what you have been reading.
Fiction books are not an exception: I tend to highlight use of language I liked, inspirational things
Interesting! I'm just doing the Building A Second Brain course by Tiago Forte and he also captures nice graphics, inspiring formulations, etc.
unsolved problem
I remembered seeing something related to annotating a video in Emacs, but can not quite recall where exactly. Probably one in the series by Uncle Dave. I'll have to re-check. UPDATE: probably just org-emms, you mentioned below.
other apps
Another one, Foxit, seems quite feature rich.
I'm trying to fight my perfectionism so figured a special page for posts in progress is a good compromise!
this is a very unique approach: post work in progress. reminds of the star citadel fan fic project page, with sections for drafts and ideas. complete transparency in the workflow
I feel that if people had better digital projections of their minds it'd be way easier to get to know them, find shared interests and have meaningful conversations
digital projections, that's an interesting idea
By the way, what's up with Iterator everywhere?
I really don't understand Iterator. How can it be used to eliminate temporary lists?
supporting this field is extremely easy If you keep raw data, it's just a matter of adding a getter method to the Article class.
Way of supporting a new field in JSON is much easier than in a relational database:
@property
def highlights(self) -> Sequence[Highlight]:
default = [] # defensive to handle older export formats that had no annotations
jsons = self.json.get('annotations', default)
return list(map(Highlight, jsons))
query language doesn't necessarily mean a database. E.g. see pandas which is capable of what SQL is capable of, and even more convenient than SQL for our data exploration purposes.
Query language, not always = database. For example, see pandas
cachew lets you cache function calls into an sqlite database on your disk in a matter of single decorator (similar to functools.lru_cache). The difference from functools.lru_cache is that cached data is persisted between program runs, so next time you call your function, it will only be a matter of reading from the cache.
cachew tool isolates the complexity of database access patterns in a Python library
I want to have a choice whether to forget or remember events, and I'd like to be able to potentially access forgotten ones.
It's better to lifelog than not if we have a choice
Even ignoring quality of life you are looking at a 3-7 fold return on every minute you spend exercising in extended life,[1] perhaps even exceeding that if you are making optimal use of your time. Something just clicked and I was consistent since reading this. Even 1-fold return would worth it: basically you gain free consciousness (quality of thinking is shit when I exercise, but it's better than nothing).
While exercising, you get additional lifespan, which obviously isn't linear, but still worth the effort
Exobrain, or "second brain", or "brain dump" is something like public wiki where you can keep your notes, ideas and thoughts.
Exobrain examples:
Annotation is the process of adding a layer of personal (with a potential for sharing) metadata on top of existing content such as highlights, notes, anchors etc.
Just like I'm doing it here now (annotation) ;)
Human brains seem to be best for generating new ideas. I want to learn more, think faster, distract less, interact and visualize, effortlessly remember everything; not memorize and do routine information processing, which computers seem better at.
Why Personal Knowledge Management (PKM) is important
Extended mind is the idea that your mind isn't limited by your physical body, but augmented by external means. Paper notes & diaries, data in your computer/phone/cloud – all these things contribute to your cognitive process, thinking and help you navigate the landscape of ideas. One of the biggest motivations to start dumping my brain out here, write and share is to offload my mind a bit and interact with people even in my physical absence.
Extended mind - idea that our mind doesn't only resist in our physical body
I can't imagine going on a run without my HR monitor, because whatever the benefit exercise has and however exhausting run would be, at least I'll have a data point. learning about routine and trying to optimize routine is also way more fun than doing the actual routine Human body is fragile and needs constant care, but it's still a fascinating mechanism.
Quantifying self during the run is also my main use. It adds a layer of motivation when I see just the timestamps of all my journeys
Imagine that you're using a database to export them, so your schema is: TABLE Article(STRING id, STRING url, STRING title, DATETIME added). One day, the developers expose highlights (or annotations) from the private API and your export script stats receiving it in the response JSON. It's quite useful data to have! However, your database can't just magically change to conform to the new field.
Relational model can be sometimes hand tying, unlike JSON
Storage saved by using a database instead of plaintext is marginal and not worth the effort.
Databases save some space used by data, but it's marginal
if necessary use databases as an intermediate layer to speed access up and as an additional interface to your data Nothing wrong with using databases for caching if you need it!
You may want to use databases for:
I want to argue very strongly against forcing the data in the database, unless it's really inevitable.
After scraping some data, don't go immediately to databases, unless it's a great stream of data
We use itertools.tee here so we don't have to pollute our code with temporary lists.
But if you consume one of the iterators before starting the other one (as in your case), a temporary storage is created behind the scenes.
From tee documentation:
In general, if one iterator uses most or all of the data before another iterator starts, it is faster to use list() instead of tee().
elaborate on a
With
distracting on low-level details
Retrieveal details?
exposes
Provides?
has
apenas teste
taking notes
I've got a handy Emacs binding which appends a child note with a timestamp and enters edit mode, so the whole process is smooth.
The link to the gitlab is dead :(
I realized I didn't remember most of the books/papers/posts/videos I had consumed few years before
I can relate to this
SuperMemo with its Incremental Video
This is something I really need.
You don't have to install anything or register, it's just a widget embedded in the page, but do make sure to allow JS. You should see yellow highlights and the sidebar on the right.
This is excellent
Another cool feature is that you can choose to make your annotations public and see other people's annotations or create a private group if you want to share them among specific people only.
trying it live on webpage
Another cool feature is that you can choose to make your annotations public and see other people's annotations or create a private group if you want to share them among specific people only.
It works great!
Hypothesis is simply awesome and my favorite web annotation tool.
Giving it a try.