Possibly like Holochain (which is distinct from the blockchain architecture). Blockchain only seems helpful if you need all of the following:
- a database
- immutability
- distributed data
- decentralized & totally trustless
- append only
- cryptographically secure assurance
Confer Brandon Enright's provocative talk "Blockchain is Bullshit" for an elaboration of these features. The first 10 or so minutes is mostly uninsightful trolling, so the link takes one to his argument about the key features of blockchain.
AFAICT, Holochain eases the feature of "decentralized", although Laurie Voss suggests that it's better to think of Bitcoin & Ethereum as "distributed" (in both the structure & control). 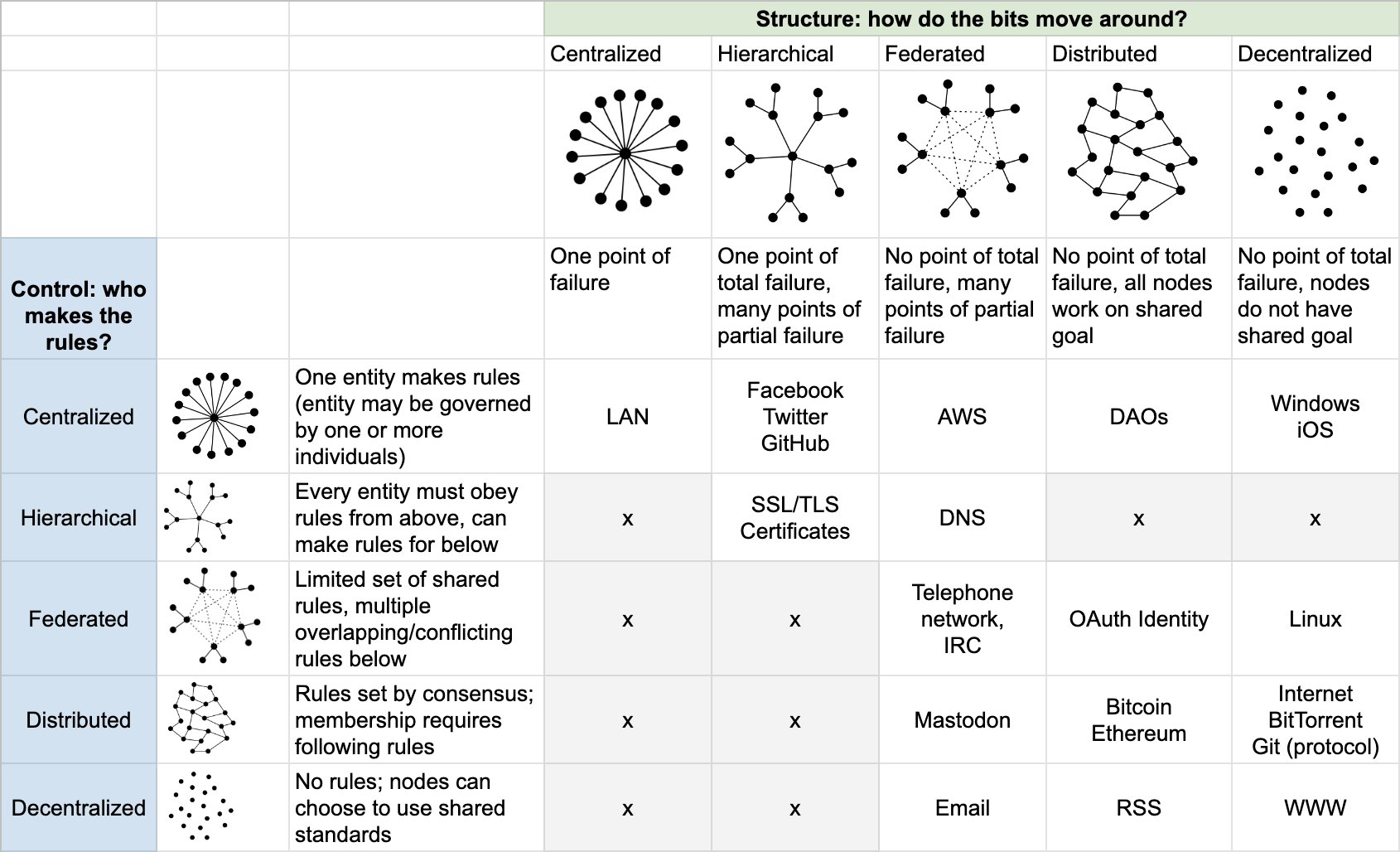
In Voss' taxonomy, I suspect that Holochain's structure would be "distributed" (ie, "No total point of failure, all nodes work on shared goal") and control would be "federated" (ie, "Limited set of shared rules, multiple overlapping/conflicting rules below")

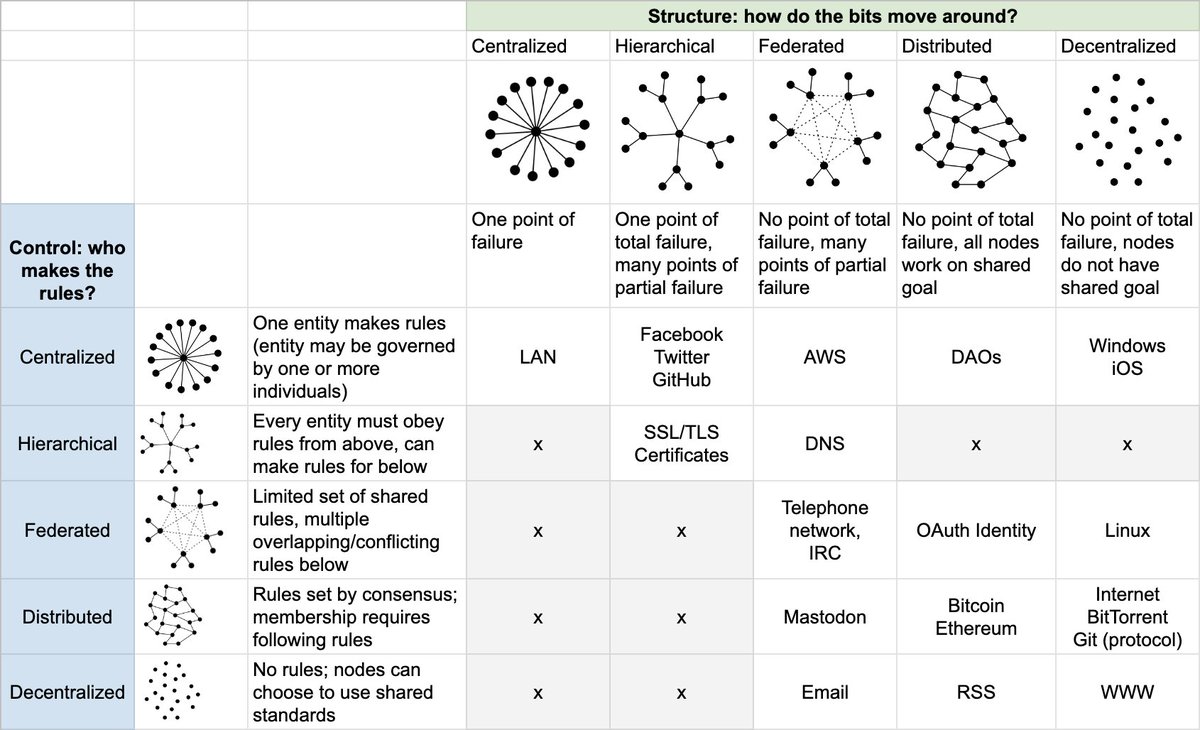 Link to tweet:
Link to tweet: