- Apr 2020
-
www.figma.com www.figma.com
-
Some of our main takeaways:CRDT literature can be relevant even if you're not creating a decentralized systemMultiplayer for a visual editor like ours wasn't as intimidating as we thoughtTaking time to research and prototype in the beginning really paid off
Key takeaways of developing a live editing tool
-
traditional approaches that informed ours — OTs and CRDTs
Traditional approaches of the multiplayer technology
-
CRDTs refer to a collection of different data structures commonly used in distributed systems. All CRDTs satisfy certain mathematical properties which guarantee eventual consistency. If no more updates are made, eventually everyone accessing the data structure will see the same thing. This constraint is required for correctness; we cannot allow two clients editing the same Figma document to diverge and never converge again
CRDTs (Conflict-free Replicated Data Types)
-
They’re a great way of editing long text documents with low memory and performance overhead, but they are very complicated and hard to implement correctly
Characteristics of OTs
-
Even if you have a client-server setup, CRDTs are still worth researching because they provide a well-studied, solid foundation to start with
CRDTs are worth studying for a good foundation
-
Figma’s multiplayer servers keep track of the latest value that any client has sent for a given property on a given object
✅ No conflict:
- two clients changing unrelated properties on the same object
- two clients changing the same property on unrelated objects.
❎ Conflict:
- two clients changing the same property on the same object (document will end up with the last value sent)
-
Figma doesn’t store any properties of deleted objects on the server. That data is instead stored in the undo buffer of the client that performed the delete. If that client wants to undo the delete, then it’s also responsible for restoring all properties of the deleted objects. This helps keep long-lived documents from continuing to grow in size as they are edited
Undo option
-
it's important to be able to iterate quickly and experiment before committing to an approach. That's why we first created a prototype environment to test our ideas instead of working in the real codebase
First work with a prototype, then the real codebase
-
Designers worried that live collaborative editing would result in “hovering art directors” and “design by committee” catastrophes.
Worries of using a live collaborative editing
-
We had a lot of trouble until we settled on a principle to help guide us: if you undo a lot, copy something, and redo back to the present (a common operation), the document should not change. This may seem obvious but the single-player implementation of redo means “put back what I did” which may end up overwriting what other people did next if you’re not careful. This is why in Figma an undo operation modifies redo history at the time of the undo, and likewise a redo operation modifies undo history at the time of the redo
Undo/Redo working
-
operational transforms (a.k.a. OTs), the standard multiplayer algorithm popularized by apps like Google Docs. As a startup we value the ability to ship features quickly, and OTs were unnecessarily complex for our problem space
Operational Transforms (OT) are unnecessarily complex for problems unlike Google Docs
-
Every Figma document is a tree of objects, similar to the HTML DOM. There is a single root object that represents the entire document. Underneath the root object are page objects, and underneath each page object is a hierarchy of objects representing the contents of the page. This tree is is presented in the layers panel on the left-hand side of the Figma editor.
Structure of Figma documents
-
When a document is opened, the client starts by downloading a copy of the file. From that point on, updates to that document in both directions are synced over the WebSocket connection. Figma lets you go offline for an arbitrary amount of time and continue editing. When you come back online, the client downloads a fresh copy of the document, reapplies any offline edits on top of this latest state, and then continues syncing updates over a new WebSocket connection
Offline editing isn't a problem, unlike the online one
-
An important consequence of this is that changes are atomic at the property value boundary. The eventually consistent value for a given property is always a value sent by one of the clients. This is why simultaneous editing of the same text value doesn’t work in Figma. If the text value is B and someone changes it to AB at the same time as someone else changes it to BC, the end result will be either AB or BC but never ABC
Consequence of approaches like last-writer-wins
-
We use a client/server architecture where Figma clients are web pages that talk with a cluster of servers over WebSockets. Our servers currently spin up a separate process for each multiplayer document which everyone editing that document connects to
Way Figma approaches client/server architecture
-
CRDTs are designed for decentralized systems where there is no single central authority to decide what the final state should be. There is some unavoidable performance and memory overhead with doing this. Since Figma is centralized (our server is the central authority), we can simplify our system by removing this extra overhead and benefit from a faster and leaner implementation
CRDTs are designed for decentralized systems
-
-
dev.to dev.to
-
The ideal is not to mix the abstraction levels in only one function.
Try not mixing abstraction levels inside a single function
-
There is another maxim also that says: you must write the same code a maximum of 3 times. The third time you should consider refactoring and reducing duplication
Avoid repeating the same code over and over
-
Should be nouns, and not verbs, because classes represent concrete objects
Class names = nouns
-
Uncle Bob, in clean code, defends that the best order to write code is: Write unit tests. Create code that works. Refactor to clean the code.
Best order to write code (according to Uncle Bob):
- Write unit tests.
- Create code that works.
- Refactor to clean the code.
-
int d could be int days
When naming things, focus on giving meaningful names, that you can pronounce and are searchable. Also, avoid prefixes
-
naming things, write better functions and a little about comments. Next, I intend to talk about formatting, objects and data structures, how to handle with errors, about boundaries (how to deal with another's one code), unit testing and how to organize your class better. I know that it'll be missing an important topic about code smells
Ideas to consider while developing clean code:
- naming things
- better functions
- comments
- formatting
- objects and data structures
- handling error
- boundaries (handling another's one code)
- unit testing
- organising classes
- code smells
-
Should be verbs, and not nouns, because methods represent actions that objects must do
Methods names = verbs
-
decrease the switch/if/else is to use polymorphism
It's better to avoid excessive switch/if/else statements

-
In the ideal world, they should be 1 or 2 levels of indentation
Functions in the ideal world shouldn't be long
-
-
-
"The Big Picture" is one of those things that people say a whole lot but can mean so many different things. Going through all of these articles, they tend to mean any (or all) of these things
Thinking about The Big Picture:
- The Business Stuff - how to meet KPIs or the current big deadline or whatever.
- The User Stuff - how to actually provide value to the people who use what you make.
- The Technology Stuff - how to build something that will last a long time.
-
Considering that there are still a ton of COBOL jobs out there, there is no particular technology that you need to know
RIght, there is no specific need to learn that one technology
-
read Knuth, or Pragmatic Programming, or Clean Code, or some other popular book
Classic programming related books
-
Senior developers are more cautious, thoughtful, pragmatic, practical and simple in their approaches to solving problems.
Interesting definition of senior devs
-
-
www.fast.ai www.fast.ai
-
In recent years we’ve also begun to see increasing interest in exploratory testing as an important part of the agile toolbox
Waterfall software development ---> agile ---> exploratory testing
-
When I began coding, around 30 years ago, waterfall software development was used nearly exclusively.
-
Mathematica didn’t really help me build anything useful, because I couldn’t distribute my code or applications to colleagues (unless they spent thousands of dollars for a Mathematica license to use it), and I couldn’t easily create web applications for people to access from the browser. In addition, I found my Mathematica code would often end up much slower and more memory hungry than code I wrote in other languages.
Disadvantages of Mathematica:
- memory hungry, slow code
- expensive code
- non-distributable license
-
In the 1990s, however, things started to change. Agile development became popular. People started to understand the reality that most software development is an iterative process
-
a methodology that combines a programming language with a documentation language, thereby making programs more robust, more portable, more easily maintained, and arguably more fun to write than programs that are written only in a high-level language. The main idea is to treat a program as a piece of literature, addressed to human beings rather than to a computer.
Exploratory testing described by Donald Knuth
-
Development Pros Cons
Table comparing pros and cons of:
- IDE/Editor
- REPL/shell
- Traditional notebooks (like Jupyter)
-
This kind of “exploring” is easiest when you develop on the prompt (or REPL), or using a notebook-oriented development system like Jupyter Notebooks
It's easier to explore the code:
- when you develop on the prompt (or REPL)
- in notebook-oriented system like Jupyter
but, it's not efficient to develop in them
-
notebook contains an actual running Python interpreter instance that you’re fully in control of. So Jupyter can provide auto-completions, parameter lists, and context-sensitive documentation based on the actual state of your code
Notebook makes it easier to handle dynamic Python features
-
They switch to get features like good doc lookup, good syntax highlighting, integration with unit tests, and (critically!) the ability to produce final, distributable source code files, as opposed to notebooks or REPL histories
Things missed in Jupyter Notebooks:
- good doc lookup
- good syntax highlighting
- integration with unit tests
- ability to produce final, distributable source code files
-
Exploratory programming is based on the observation that most of us spend most of our time as coders exploring and experimenting
In exploratory programming, we:
- experiment with a new API to understand how it works
- explore the behavior of an algorithm that we're developing
- debug our code through combination of inputs
Tags
Annotators
URL
-
-
-
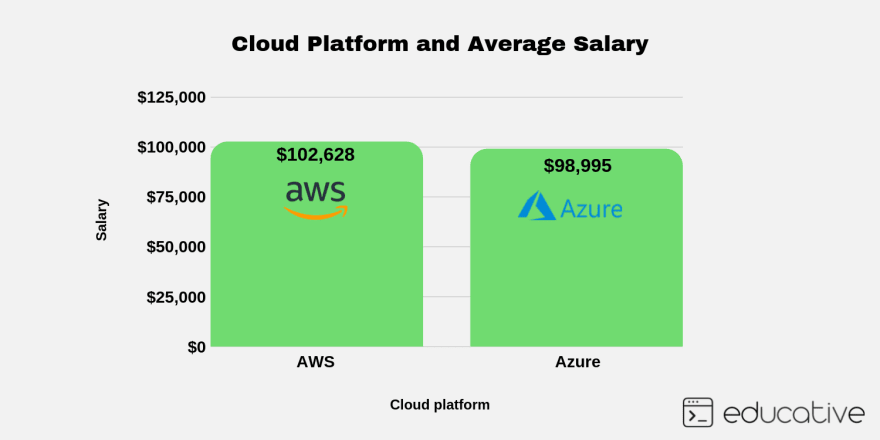
Developing in the cloud
Well paid cloud platforms:
-
Finding a database management system that works for you
Well paid database technologies:
-
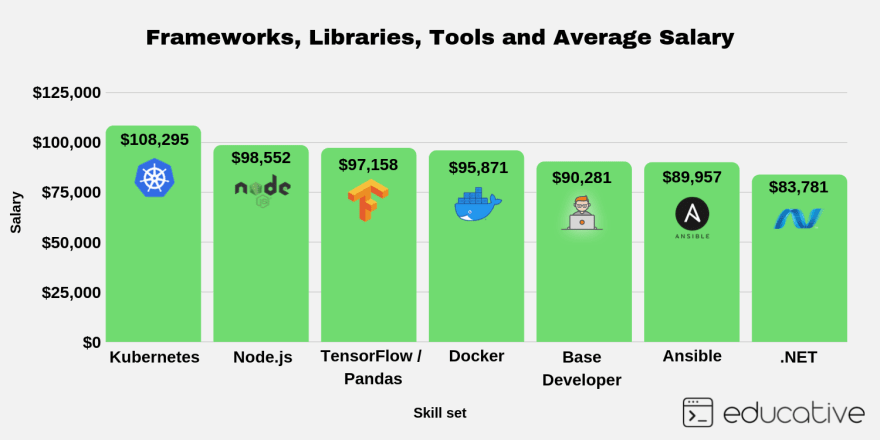
Here are a few very prominent technologies that you can look into and what impact each one might have on your salary
Other well paid frameworks, libraries and tools:
-
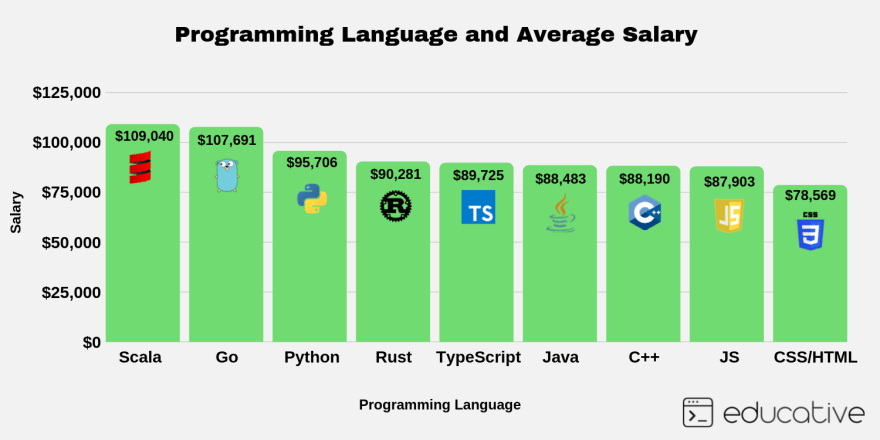
What programming language should I learn next?
Most paid programming languages:
-
Android and iOS
Payment for mobile OS:
-
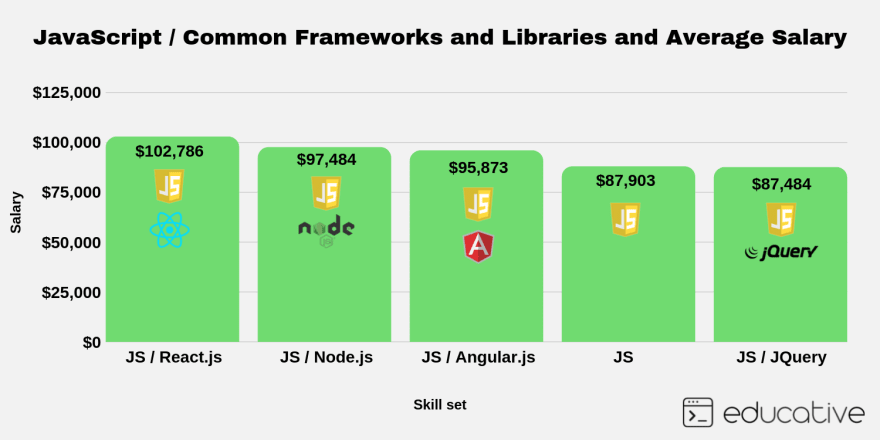
Frontend Devs: What should I learn after JavaScript? Explore these frameworks and libraries
Most paid JS frameworks and libraries:
-
-
www.alexhudson.com www.alexhudson.com
-
First, you’ve spread the logic across a variety of different systems, so it becomes more difficult to reason about the application as a whole. Second, more importantly, the logic has been implemented as configuration as opposed to code. The logic is constrained by the ability of the applications which have been wired together, but it’s still there.
Why "no code" trend is dangerous in some way (on the example of Zapier):
- You spread the logic across multiple systems.
- Logic is maintained in configuration rather than code.
-
the developer doesn’t need to worry about allocating memory, or the character set encoding of the string, or a host of other things.
Comparison of C (1972) and TypeScript (2012) code.
(check the code above)
-
“No Code” systems are extremely good for putting together proofs-of-concept which can demonstrate the value of moving forward with development.
Great point of "no code" trend
-
With someone else’s platform, you often end up needing to construct elaborate work-arounds for missing functionality, or indeed cannot implement a required feature at all.
You can quickly implement 80% of the solution in Salesforce using a mix of visual programming (basic rule setting and configuration), but later it's not so straightforward to add the missing 20%
Tags
Annotators
URL
-
-
google.github.io google.github.io
-
Summary
In doing a code review, you should make sure that:
- The code is well-designed.
- The functionality is good for the users of the code.
- Any UI changes are sensible and look good.
- Any parallel programming is done safely.
- The code isn’t more complex than it needs to be.
- The developer isn’t implementing things they might need in the future but don’t know they need now.
- Code has appropriate unit tests.
- Tests are well-designed.
- The developer used clear names for everything.
- Comments are clear and useful, and mostly explain why instead of what.
- Code is appropriately documented (generally in g3doc).
- The code conforms to our style guides.
-
-
martinfowler.com martinfowler.com
-
"Continuous Delivery is the ability to get changes of all types — including new features, configuration changes, bug fixes, and experiments — into production, or into the hands of users, safely and quickly in a sustainable way". -- Jez Humble and Dave Farley
Continuous Delivery
-
Another approach is to use a tool like H2O to export the model as a POJO in a JAR Java library, which you can then add as a dependency in your application. The benefit of this approach is that you can train the models in a language familiar to Data Scientists, such as Python or R, and export the model as a compiled binary that runs in a different target environment (JVM), which can be faster at inference time
H2O - export models trained in Python/R as a POJO in JAR
-
Continuous Delivery for Machine Learning (CD4ML) is a software engineering approach in which a cross-functional team produces machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.
Continuous Delivery for Machine Learning (CD4ML) (long definition)
Basic principles:
- software engineering approach
- cross-functional team
- producing software based on code, data, and ml models
- small and safe increments
- reproducible and reliable software release
- short adaptation cycles
-
In order to formalise the model training process in code, we used an open source tool called DVC (Data Science Version Control). It provides similar semantics to Git, but also solves a few ML-specific problems:
DVC - transform model training process into code.
Advantages:
- it has multiple backend plugins to fetch and store large files on an external storage outside of the source control repository;
- it can keep track of those files' versions, allowing us to retrain our models when the data changes;
- it keeps track of the dependency graph and commands used to execute the ML pipeline, allowing the process to be reproduced in other environments;
- it can integrate with Git branches to allow multiple experiments to co-exist
-
Machine Learning pipeline for our Sales Forecasting problem, and the 3 steps to automate it with DVC
Sales Forecasting process
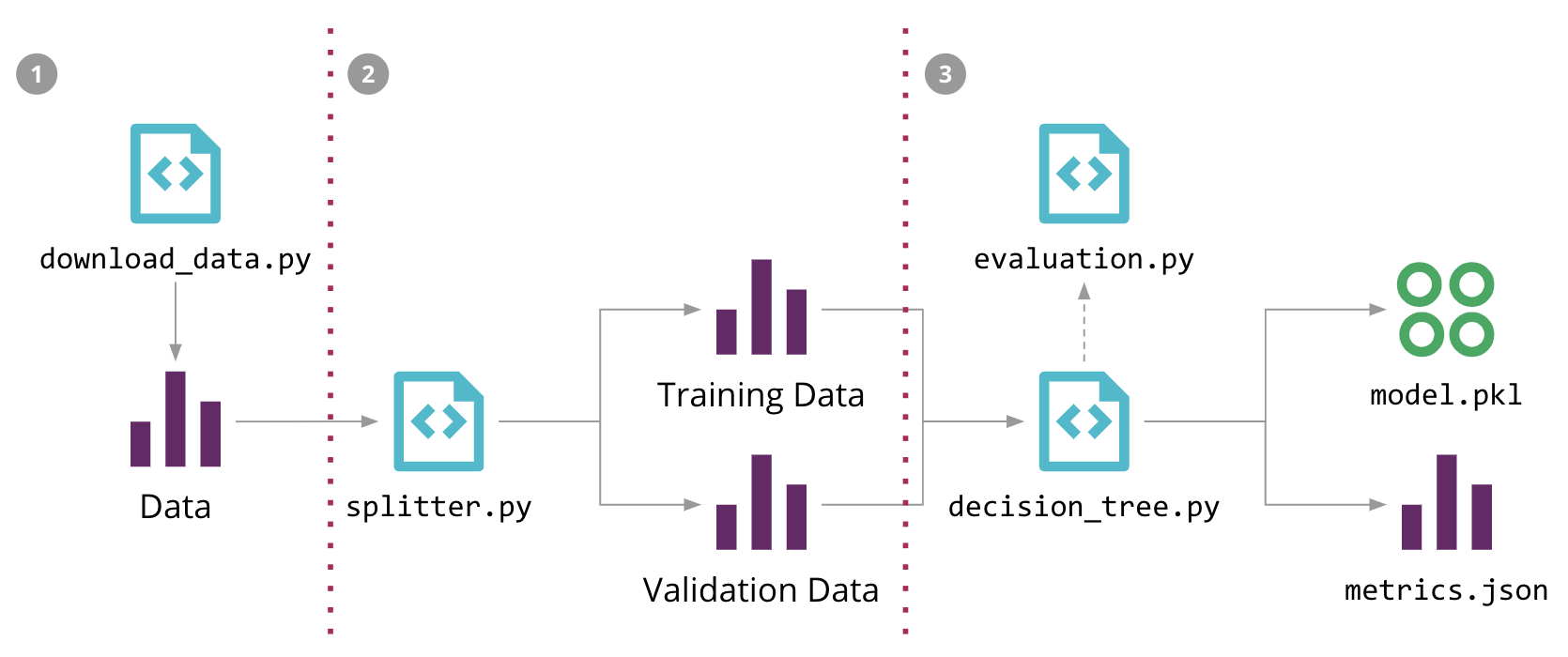
-
Continuous Delivery for Machine Learning end-to-end process
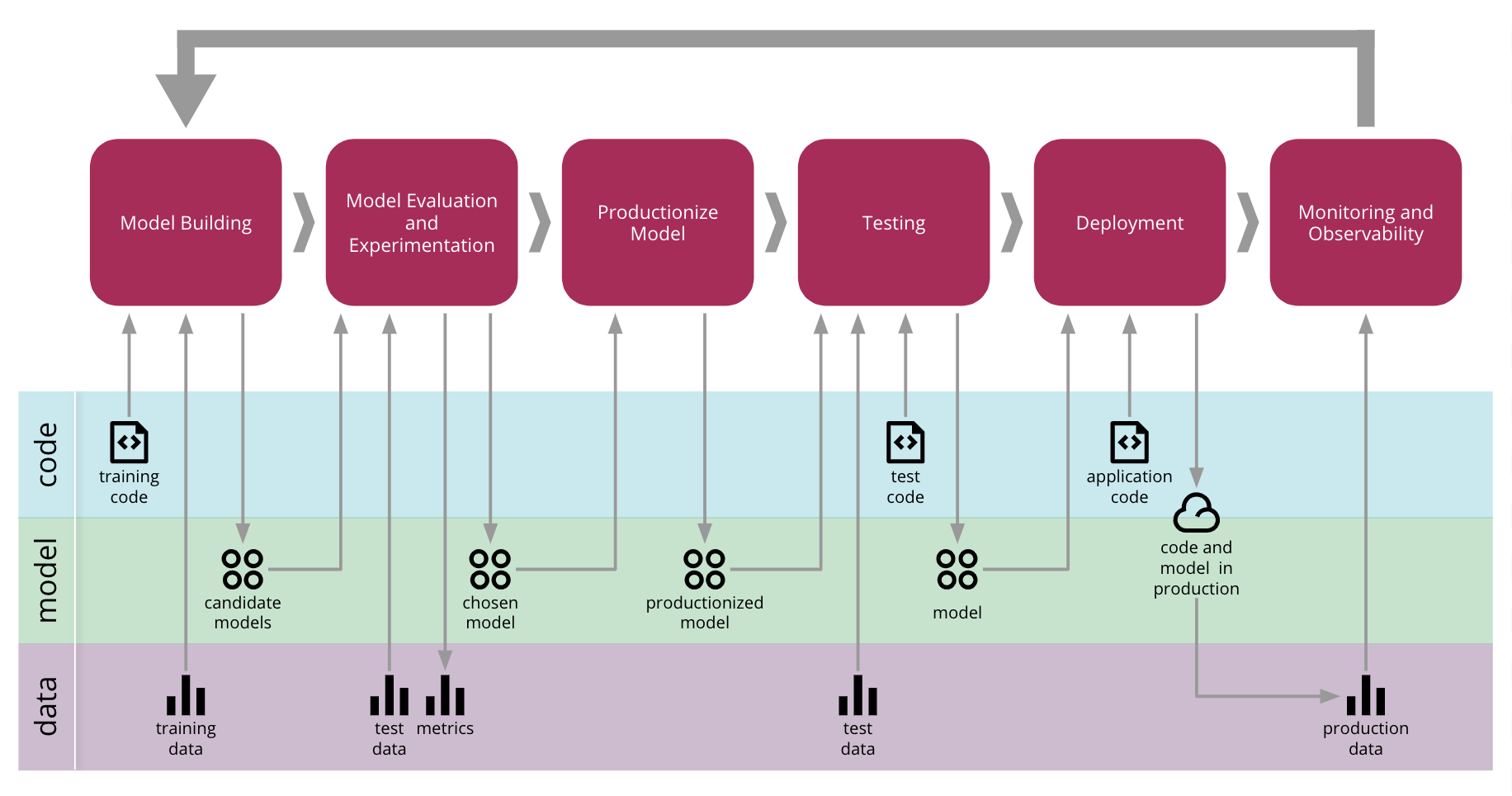
-
common functional silos in large organizations can create barriers, stifling the ability to automate the end-to-end process of deploying ML applications to production
Common ML process (leading to delays and frictions)
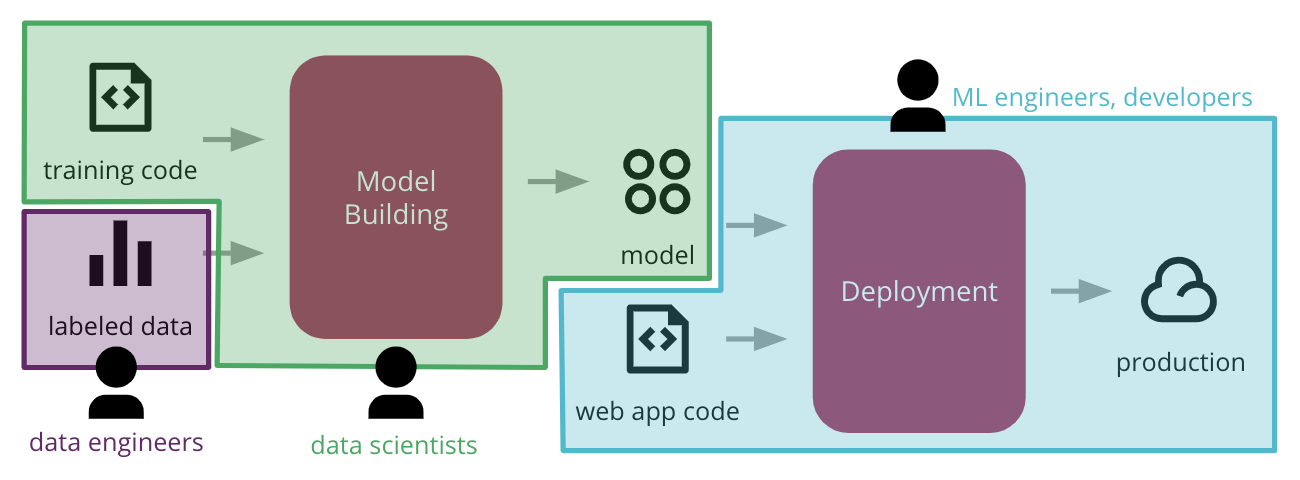
-
There are different types of testing that can be introduced in the ML workflow.
Automated tests for ML system:
- validating data
- validating component integration
- validating the model quality
- validating model bias and fairness
-
example of how to combine different test pyramids for data, model, and code in CD4ML
Combining tests for data (purple), model (green) and code (blue)
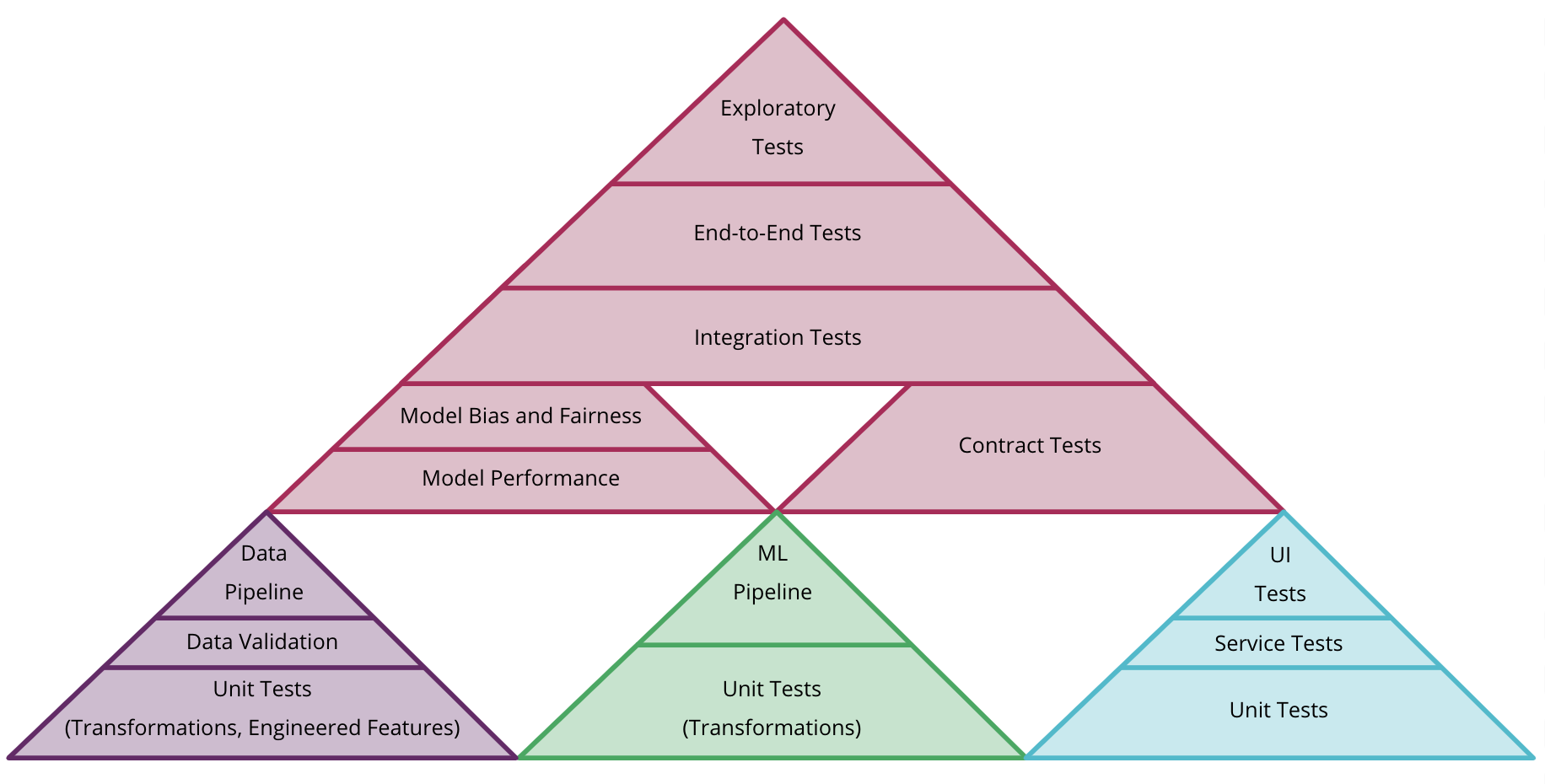
-
A deployment pipeline automates the process for getting software from version control into production, including all the stages, approvals, testing, and deployment to different environments
Deployment pipeline
-
We chose to use GoCD as our Continuous Delivery tool, as it was built with the concept of pipelines as a first-class concern
GoCD - open source Continuous Delivery tool
-
Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications.
Continuous Delivery for Machine Learning (CD4ML)
Tags
Annotators
URL
-
-
realpython.com realpython.com
-
Sometimes, the best way to learn is to mimic others. Here are some great examples of projects that use documentation well:
Examples of projects that use documentation well
(chech the list below)
-
“Code is more often read than written.” — Guido van Rossum
-
Documenting code is describing its use and functionality to your users. While it may be helpful in the development process, the main intended audience is the users.
Documenting code:
- describing use to your users (main audience)
-
Class method docstrings should contain the following: A brief description of what the method is and what it’s used for Any arguments (both required and optional) that are passed including keyword arguments Label any arguments that are considered optional or have a default value Any side effects that occur when executing the method Any exceptions that are raised Any restrictions on when the method can be called
Class method should contain:
- brief description
- arguments
- label on default/optional arguments
- side effects description
- raised exceptions
- restrictions on when the method can be called
(check example below)
-
Comments to your code should be kept brief and focused. Avoid using long comments when possible. Additionally, you should use the following four essential rules as suggested by Jeff Atwood:
Comments should be as concise as possible. Moreover, you should follow 4 rules of Jeff Atwood:
- Keep comments close to the code being described.
- Don't use complex formatting (such as tables).
- Don't comment obvious things.
- Design code in a way it comments itself.
-
From examining the type hinting, you can immediately tell that the function expects the input name to be of a type str, or string. You can also tell that the expected output of the function will be of a type str, or string, as well.
Type hinting introduced in Python 3.5 extends 4 rules of Jeff Atwood and comments the code itself, such as this example:
def hello_name(name: str) -> str: return(f"Hello {name}")- user knows that the code expects input of type
str - the same about output
- user knows that the code expects input of type
-
Docstrings can be further broken up into three major categories: Class Docstrings: Class and class methods Package and Module Docstrings: Package, modules, and functions Script Docstrings: Script and functions
3 main categories of docstrings
-
According to PEP 8, comments should have a maximum length of 72 characters.
If
comment_size> 72 characters:use `multiple line comment` -
Docstring conventions are described within PEP 257. Their purpose is to provide your users with a brief overview of the object.
Docstring conventions
-
All multi-lined docstrings have the following parts: A one-line summary line A blank line proceeding the summary Any further elaboration for the docstring Another blank line
Multi-line docstring example:
"""This is the summary line This is the further elaboration of the docstring. Within this section, you can elaborate further on details as appropriate for the situation. Notice that the summary and the elaboration is separated by a blank new line. # Notice the blank line above. Code should continue on this line. -
say_hello.__doc__ = "A simple function that says hello... Richie style"
Example of using
__doc:Code (version 1):
def say_hello(name): print(f"Hello {name}, is it me you're looking for?") say_hello.__doc__ = "A simple function that says hello... Richie style"Code (alternative version):
def say_hello(name): """A simple function that says hello... Richie style""" print(f"Hello {name}, is it me you're looking for?")Input:
>>> help(say_hello)Returns:
Help on function say_hello in module __main__: say_hello(name) A simple function that says hello... Richie style -
class constructor parameters should be documented within the __init__ class method docstring
init
-
Scripts are considered to be single file executables run from the console. Docstrings for scripts are placed at the top of the file and should be documented well enough for users to be able to have a sufficient understanding of how to use the script.
Docstrings in scripts
-
Documenting your code, especially large projects, can be daunting. Thankfully there are some tools out and references to get you started
You can always facilitate documentation with tools.
(check the table below)
-
Commenting your code serves multiple purposes
Multiple purposes of commenting:
- planning and reviewing code - setting up a code template
- code description
- algorithmic description - for example, explaining the work of an algorithm or the reason of its choice
- tagging -
BUG,FIXME,TODO
-
In general, commenting is describing your code to/for developers. The intended main audience is the maintainers and developers of the Python code. In conjunction with well-written code, comments help to guide the reader to better understand your code and its purpose and design
Commenting code:
- describing code to/for developers
- help to guide the reader to better understand your code, its purpose/design
-
Along with these tools, there are some additional tutorials, videos, and articles that can be useful when you are documenting your project
Recommended videos to start documenting
(check the list below)
-
If you use argparse, then you can omit parameter-specific documentation, assuming it’s correctly been documented within the help parameter of the argparser.parser.add_argument function. It is recommended to use the __doc__ for the description parameter within argparse.ArgumentParser’s constructor.
argparse -
There are specific docstrings formats that can be used to help docstring parsers and users have a familiar and known format.
Different docstring formats:
- Google docstrings (not a formal specification)
- reStructured Text
- NumPy/SciPy docstrings
- Epytext
-
Daniele Procida gave a wonderful PyCon 2017 talk and subsequent blog post about documenting Python projects. He mentions that all projects should have the following four major sections to help you focus your work:
Public and Open Source Python projects should have the
docsfolder, and inside of it:- Tutorials
- How-To Guides
- References
- Explanations
(check the table below for a summary)
-
Since everything in Python is an object, you can examine the directory of the object using the dir() command
dir() function examines directory of Python objects. For example
dir(str).Inside
dir(str)you can find interesting property__doc__ -
Documenting your Python code is all centered on docstrings. These are built-in strings that, when configured correctly, can help your users and yourself with your project’s documentation.
Docstrings - built-in strings that help with documentation
-
Along with docstrings, Python also has the built-in function help() that prints out the objects docstring to the console.
help() function.
After typing
help(str)it will return all the info about str object -
The general layout of the project and its documentation should be as follows:
project_root/ │ ├── project/ # Project source code ├── docs/ ├── README ├── HOW_TO_CONTRIBUTE ├── CODE_OF_CONDUCT ├── examples.py(private, shared or open sourced)
-
In all cases, the docstrings should use the triple-double quote (""") string format.
Think only about """ when using docstrings
-
-
engineering.instawork.com engineering.instawork.com
-
Each format makes tradeoffs in encoding, flexibility, and expressiveness to best suit a specific use case.
Each data format brings different tradeoffs:
- A format optimized for size will use a binary encoding that won’t be human-readable.
- A format optimized for extensibility will take longer to decode than a format designed for a narrow use case.
- A format designed for flat data (like CSV) will struggle to represent nested data.
-
-
-
I would use ESLint in full strength, tests for some (especially end-to-end, to make sure a commit does not make project crash), and add continuous integration.
Advantage of tests
-
It is fine to start adding tests gradually, by adding a few tests to things that are the most difficult (ones you need to keep fingers crossed so they work) or most critical (simple but with many other dependent components).
Start small by adding tests to the most crucial parts
-
I found that the overhead to use types in TypeScript is minimal (if any).
In TypeScript, unlike in JS we need to specify the types:

-
I need to specify types of input and output. But then I get speedup due to autocompletion, hints, and linting if for any reason I make a mistake.
In TypeScript, you spend a bit more time in the variable definition, but then autocompletion, hints, and linting will reward you. It also boosts code readability
-
TSDoc is a way of writing TypeScript comments where they’re linked to a particular function, class or method (like Python docstrings).
-
ESLint does automatic code linting
ESLint <--- pluggable JS linter:
- mark things that are incorrect,
- mark things that are unnecessary or risky (e.g.
if (x = 5) { ... }) - set a standard way of writing code
-
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.
According to the Kernighan's Law, writing code is not as hard as debugging
-
interactive notebooks fall short when you want to write bigger, maintainable code
Survey regarding programming notebooks:

-
Write a new test and the result. If you want to make it REPL-like, instead of writing console.log(x.toString()) use expect(x.toString()).toBe('') and you will directly get the result.
jest <--- interactive JavaScript (TypeScript and others too) testing framework. You can use it as a VS Code extension.
Basically, instead of
console.log(x.toString()), you can useexcept(x.toString()).toBe(''). Check this gif to understand it further -
I recommend Airbnb style JavaScript style guide and Airbnb TypeScript)
Recommended style guides from Airbnb for:
-
Creating meticulous tests before exploring the data is a big mistake, and will result in a well-crafted garbage-in, garbage-out pipeline. We need an environment flexible enough to encourage experiments, especially in the initial place.
Overzealous nature of TDD may discourage from explorable data science
-
-
0.30000000000000004.com 0.30000000000000004.com
-
Computers can only natively store integers, so they need some way of representing decimal numbers. This representation comes with some degree of inaccuracy. That's why, more often than not, .1 + .2 != .3
Computers make up their way to store decimal numbers
-
-
-
Cross-platform development is now a standard because of wide variety of architectures like mobile devices, cloud servers, embedded IoT systems. It was almost exclusively PCs 20 years ago.
-
A package management ecosystem is essential for programming languages now. People simply don’t want to go through the hassle of finding, downloading and installing libraries anymore. 20 years ago we used to visit web sites, downloaded zip files, copied them to correct locations, added them to the paths in the build configuration and prayed that they worked.
How library management changed in 20 years
-
IDEs and the programming languages are getting more and more distant from each other. 20 years ago an IDE was specifically developed for a single language, like Eclipse for Java, Visual Basic, Delphi for Pascal etc. Now, we have text editors like VS Code that can support any programming language with IDE like features.
How IDEs "unified" in comparison to the last 20 years
-
Your project has no business value today unless it includes blockchain and AI, although a centralized and rule-based version would be much faster and more efficient.
Comparing current project needs to those 20 years ago
-
Being a software development team now involves all team members performing a mysterious ritual of standing up together for 15 minutes in the morning and drawing occult symbols with post-its.
In comparison to 20 years ago ;)
-
Language tooling is richer today. A programming language was usually a compiler and perhaps a debugger. Today, they usually come with the linter, source code formatter, template creators, self-update ability and a list of arguments that you can use in a debate against the competing language.
How coding became much more supported in comparison to the last 20 years
-
There is StackOverflow which simply didn’t exist back then. Asking a programming question involved talking to your colleagues.
20 years ago StackOverflow wouldn't give you a hand
-
Since we have much faster CPUs now, numerical calculations are done in Python which is much slower than Fortran. So numerical calculations basically take the same amount of time as they did 20 years ago.
Python vs Fortran ;)
-
-
roadmap.sh roadmap.sh
-
I am not sure how but one kind soul somehow found the project, forked it, refactored it, "modernized" it, added linting, code sniffing, added CI and opened the pull request.
It's worth sharing your code, since someone can always find it and improve it, so that you can learn from it
-
It is solved when you understand why it occurred and why it no longer does.
What does it mean for a problem to be solved?
Tags
Annotators
URL
-
-
-
Let's reason through our memoizer before we write any code.
Operations performed by a memoizer:
- Takes a reference to a function as an input
- Returns a function (so it can be used as it normally would be)
- Creates a cache of some sort to hold the results of previous function calls
- Any future time calling the function, returns a cached result if it exists
- If the cached value doesn't exist, calls the function and store that result in the cache
Which is written as:
// Takes a reference to a function const memoize = func => { // Creates a cache of results const results = {}; // Returns a function return (...args) => { // Create a key for results cache const argsKey = JSON.stringify(args); // Only execute func if no cached value if (!results[argsKey]) { // Store function call result in cache results[argsKey] = func(...args); } // Return cached value return results[argsKey]; }; }; -
Let's replicate our inefficientSquare example, but this time we'll use our memoizer to cache results.
Replication of a function with the use of memoizer (check the code below this annotation)
-
The biggest problem with JSON.stringify is that it doesn't serialize certain inputs, like functions and Symbols (and anything you wouldn't find in JSON).
Problem with
JSON.stringify.This is why the previous code shouldn't be used in production
-
Memoization is an optimization technique used in many programming languages to reduce the number of redundant, expensive function calls. This is done by caching the return value of a function based on its inputs.
Memoization (simple definition)
Tags
Annotators
URL
-
-
code.visualstudio.com code.visualstudio.com
-
The best way to explain the difference between launch and attach is to think of a launch configuration as a recipe for how to start your app in debug mode before VS Code attaches to it, while an attach configuration is a recipe for how to connect VS Code's debugger to an app or process that's already running.
Simple difference between two core debugging modes: Launch and Attach available in VS Code.
Depending on the request (
attachorlaunch), different attributes are required, and VS Code'slaunch.jsonvalidation and suggestions should help with that. -
Logpoint is a variant of a breakpoint that does not "break" into the debugger but instead logs a message to the console. Logpoints are especially useful for injecting logging while debugging production servers that cannot be paused or stopped. A Logpoint is represented by a "diamond" shaped icon. Log messages are plain text but can include expressions to be evaluated within curly braces ('{}').
Logpoints - log messages to the console when breakpoint is hit.
Can include expressions to be evaluated with
{}, e.g.:fib({num}): {result} -
Here are some optional attributes available to all launch configurations
Optional arguments for
launch.json:presentation("order", "group" or "hidden")preLaunchTaskpostDebugTaskinternalConsoleOptionsdebugServerserverReadyAction
-
The following attributes are mandatory for every launch configuration
In the
launch.jsonfile you've to define at least those 3 variables:type(e.g. "node", "php", "go")request("launch" or "attach")name(name to appear in the Debug launch configuration drop-down)
-
Many debuggers support some of the following attributes
Some of the possibly supported attributes in
launch.json:programargsenvcwdportstopOnEntryconsole(e.g. "internalConsole", "integratedTerminal", "externalTerminal")
Tags
Annotators
URL
-
-
towardsdatascience.com towardsdatascience.com
-
Version control is at the heart of any modern engineering org. The ability for multiple engineers to asynchronously contribute to a codebase is crucial—and with notebooks, it’s very hard.
Version control in notebooks?
-
The priorities in building a production machine learning pipeline—the series of steps that take you from raw data to product—are not fundamentally different from those of general software engineering.
- Your pipeline should be reproducible
- Collaborating on your pipeline should be easy
- All code in your pipeline should be testable
-
Reproducibility is an issue with notebooks. Because of the hidden state and the potential for arbitrary execution order, generating a result in a notebook isn’t always as simple as clicking “Run All.”
Problem of reproducibility in notebooks
-
A notebook, at a very basic level, is just a bunch of JSON that references blocks of code and the order in which they should be executed.But notebooks prioritize presentation and interactivity at the expense of reproducibility. YAML is the other side of that coin, ignoring presentation in favor of simplicity and reproducibility—making it much better for production.
Summary of the article:
Notebook = presentation + interactivity
YAML = simplicity + reproducibility
-
Notebook files, however, are essentially giant JSON documents that contain the base-64 encoding of images and binary data. For a complex notebook, it would be extremely hard for anyone to read through a plaintext diff and draw meaningful conclusions—a lot of it would just be rearranged JSON and unintelligible blocks of base-64.
Git traces plaintext differences and with notebooks it's a problem
-
There is no hidden state or arbitrary execution order in a YAML file, and any changes you make to it can easily be tracked by Git
In comparison to notebooks, YAML is more compatible for Git and in the end might be a better solution for ML
-
Python unit testing libraries, like unittest, can be used within a notebook, but standard CI/CD tooling has trouble dealing with notebooks for the same reasons that notebook diffs are hard to read.
unittest Python library doesn't work well in a notebook
-
-
-
Use camelCase when naming objects, functions, and instances.
camelCase for objects, functions and instances
const thisIsMyFuction() {} -
Use PascalCase only when naming constructors or classes.
PascalCase for constructors and classes
// good class User { constructor(options) { this.name = options.name; } } const good = new User({ name: 'yup', }); -
Use uppercase only in constants.
Uppercase for constants
export const API_KEY = 'SOMEKEY';
-
-
code.visualstudio.com code.visualstudio.com
-
If you'd just like to see refactorings without Quick Fixes, you can use the Refactor command (Ctrl+Shift+R).
To easily see all the refactoring options, use the "Refactor" command
-
-
skutecznyprogramista.pl skutecznyprogramista.pl
-
Stary, dobry Uncle Bob mówi, że poza etatem trzeba na programowanie poświęcić 20h tygodniowo.Gdy podzielimy to na 7 dni w tygodniu, to wychodzi prawie 3 godziny dziennie.Dla jednych mało, dla innych dużo.
Uncle Bob's advice: ~ 3h/day for programming
-
-
sciencebusiness.net sciencebusiness.net
-
University of Amsterdam scientists launch website that seeks ideal COVID-19 exit strategy. (2020 April 21) Science|Business. https://sciencebusiness.net/network-updates/university-amsterdam-scientists-launch-website-seeks-ideal-covid-19-exit-strategy
-
-
twitter.com twitter.com
-
Guido Salvaneschi on Twitter referencing thread by Neil Ferguson
-
-
en.wikipedia.org en.wikipedia.org
-
This type relation is sometimes written S <: T
-
subtyping allows a function to be written to take an object of a certain type T, but also work correctly, if passed an object that belongs to a type S that is a subtype of T (according to the Liskov substitution principle)
-
chose the term ad hoc polymorphism to refer to polymorphic functions that can be applied to arguments of different types, but that behave differently depending on the type of the argument to which they are applied (also known as function overloading or operator overloading)
-
-
-
I strongly suggest to anyone who wants to become a developer that they do it as well. I mean, it's really easy to see all the work that's out there, and all the things that are left to learn, and think that it's just way beyond you. But when you write it down, you have a place that you can go back to, and not only have I been able to help other people with my blog posts, but I help myself. I'm constantly Googling something and getting my own website in response, and like, oh yeah, I remember I did that before.
-
-
github.com github.com
-
tony-lang.github.io tony-lang.github.io
-
stackoverflow.com stackoverflow.com
-
it pollutes the MultiDelegator class with every new delegate. If you use MultiDelegator several times, it will keep adding methods to the class, which is undesirable
-
-
guides.rubyonrails.org guides.rubyonrails.org
-
The handler can be a method or a Proc object passed to the :with option. You can also use a block directly instead of an explicit Proc object.
Example of: letting you either pass a proc (as a keyword arg in this case) or as a block.
-
- Mar 2020
-
www.iubenda.com www.iubenda.com
-
Our Cookie Solution plugins for WordPress, Magento, Joomla! and PrestaShop allow you to automate the blocking of scripts drastically reducing the necessity for direct interventions in the site’s code.
-
-
rubyworks.github.io rubyworks.github.io
-
A NackClass is the same as NilClass except for any method it does not recognize, it return the instance of itself. nack.nack.nack.nack #=> nack Note I used to call this NullClass, but "nack" seems a little more fitting a term.
-
-
-
stackoverflow.com stackoverflow.com
-
To be just a bit polemic, your first instinct was not to do that. And you probably wouldn't think of that in your unit tests either (the holy grail of dynamic langs). So someday it would blow up at runtime, and THEN you'd add that safeguard.
-
-
bugs.ruby-lang.org bugs.ruby-lang.org
-
yogthos.net yogthos.net
Tags
Annotators
URL
-
-
gist.github.com gist.github.com
-
You can just leave your website at that address (it'll give you some serious street cred in the developer world), but if you have a custom domain you would like to use, it is very simple to make GitHub redirect your page. Log in to your domain registrar and find where to change your host records. If you don't know, you can usually Google "(domain registrar) change host records", and your registrar will have an explainer telling you how to do it. Change your domain's A Record to 204.232.175.78. This is GitHub's IP address, which allows GitHub to resolve your URL and serve the correct files. In your website's directory folder on your computer, create a file called "CNAME". On the first line, type your domain name. Save the file. In your GitHub application, you should see the file in the left column. Make sure it is checked and enter your commit message. Have it say something like "Adding CNAME file." Click "Sync branches." It can take as long as 48 hours for your domain to resolve to your GitHub page. However, it is usually pretty quick, so check back in an hour or so.
very useful.
Tags
Annotators
URL
-
-
coffeescript.org coffeescript.org
-
Underneath that awkward Java-esque patina, JavaScript has always had a gorgeous heart.
aww
-
- Feb 2020
-
-
Nix is a purely functional package manager. This means that it treats packages like values in purely functional programming languages such as Haskell — they are built by functions that don’t have side-effects, and they never change after they have been built.
-
-
www.solipsys.co.uk www.solipsys.co.uk
Tags
Annotators
URL
-
- Jan 2020
-
en.wikipedia.org en.wikipedia.org
-
en.wikipedia.org en.wikipedia.org
-
drewdevault.com drewdevault.com
-
www.jetbrains.com www.jetbrains.com
-
Optimize imports
Optimize imports on the fly in Webstorm with TypeScript
-
-
www.techrepublic.com www.techrepublic.com
-
Larry Wall famously said he was driven to create Perl by how difficult it was to solve a problem while coding, as well as by an abundance of 'laziness, impatience and hubris'
-
the impetus may have been more the challenge of creating a language of his own.
-
To an outsider, creating your own programming language might seem akin to saying 'I'll build my own airplane
-
-
bugs.ruby-lang.org bugs.ruby-lang.org
-
I've often wished for some standard variable to use for blocks and such. Like some people here, I had considered
it. Usually I use_but I know that means "unused" to many/most programmers. I like the%option that Clojure has.
-
- Dec 2019
-
gist.github.com gist.github.com
-
Environment variables are 'exported by default', making it easy to do silly things like sending database passwords to Airbrake.
airbrake -- monitoring service
Tags
Annotators
URL
-
- Nov 2019
-
gist.github.com gist.github.com
-
This naming convention helps developers understand the component’s contract
-
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
reasonml.github.io reasonml.github.io
-
Reason is not a new language; it's a new syntax and toolchain powered by the battle-tested language, OCaml.
-
-
ocaml.org ocaml.org
-
-
github.com github.com
-
We might have some dirty mutable objects for performance - but our high-level API should be purely functional. You should be able to follow the React model of modelling your UI as a pure function of application state -> UI.
-
-
github.com github.com
-
the abstraction I wished to have was a sort of a pure functional Vim, completely decoupled from terminal UI - where 'vim' is a function of (editor state, input) => (new editor state)
Tags
Annotators
URL
-
-
dplyr.tidyverse.org dplyr.tidyverse.org
-
enquo() uses some dark magic to look at the argument, see what the user typed, and return that value as a quosure
-
-
rubykaigi.org rubykaigi.org
-
www.wildnoodle.com www.wildnoodle.com
-
Online Coding Challenges for Better Programming Skills
-
-
www.wildnoodle.com www.wildnoodle.com
-
Evaluate Talent with Employee Assessment Tools
-
- Oct 2019
-
stackoverflow.blog stackoverflow.blog
-
stackoverflow.blog stackoverflow.blog
-
github.com github.com
-
www.hanselman.com www.hanselman.com
-
If you love Ruby, you'll enjoy CoffeeScript as it makes the JavaScript more like the Ruby.
-
-
itrevolution.com itrevolution.com
-
In 2017, I rewrote it again as a ClojureScript application, and it was only 500 lines of code! Holy cow!!!
going from 3k obj-c to 1,5k js to 0.5k in cljs!
-
-
www.quora.com www.quora.com
-
github.com github.com
-
For example the following pattern: (let [x true y true z true] (match [x y z] [_ false true] 1 [false true _ ] 2 [_ _ false] 3 [_ _ true] 4)) ;=> 4 expands into something similar to the following: (cond (= y false) (cond (= z false) (let [] 3) (= z true) (let [] 1) :else (throw (java.lang.Exception. "No match found."))) (= y true) (cond (= x false) (let [] 2) :else (cond (= z false) 3 (= z true) 4 :else (throw (java.lang.Exception. "No match found.")))) :else (cond (= z false) (let [] 3) (= z true) (let [] 4) :else (throw (java.lang.Exception. "No match found.")))) Note that y gets tested first. Lazy pattern matching consistently gives compact decision trees. This means faster pattern matching. You can find out more in the top paper cited below.
Tags
Annotators
URL
-
- Sep 2019
-
mobx.js.org mobx.js.org
-
reactions bridge reactive and imperative programming
Tags
Annotators
URL
-
-
en.wikipedia.org en.wikipedia.org
-
web.archive.org web.archive.org
-
The problem with the annotation notion is that it's the first time that we consider a piece of data which is not merely a projection of data already present in the message store: it is out-of-band data that needs to be stored somewhere.
could be same, schemaless datastore?
-
many of the searches we want to do could be accomplished with a database that was nothing but a glorified set of hash tables
Hello sql and cloure.set ns! ;P
-
There are objects, sets of objects, and presentation tools. There is a presentation tool for each kind of object; and one for each kind of object set.
very clojure-y mood, makes me think of clojure REBL (browser) which in turn is inspired by the smalltalk browser and was taken out of datomic (which is inspired by RDF, mentioned above!)
-
-
clojure.org clojure.org
-
That said, most Clojure programs begin life as text files, and it is the task of the reader to parse the text and produce the data structure the compiler will see
clojure compiler sees (real) clojure i.e. programs as clojure data structures (we) humans see clojure in their (semi-incidental) representation in text readers bridges the gap
Now, why semi- incidental? It's not necessary for clojure to be text but it is necesserry for it to be represented as some kind of symbolic representations for humans. It's pretty much always text
Tags
Annotators
URL
-
- Aug 2019
-
www.math3ma.com www.math3ma.com
-
Good general theory does not search for the maximum generality, but for the right generality.
Especially true in practical programming
-
-
medium.com medium.com
-
I was so fed up of the mega amounts of boilerplate with Redux and the recommendation of keeping your data loading at view level. It seems to me that things like this, with components being responsible for their own data, is the way to go in the future.
-
-
github.com github.com
-
github.com github.com
-
Null Coalescing Operator
-
- Jun 2019
-
www.kitten-technologies.co.uk www.kitten-technologies.co.uk
-
Entities are the applications, services, and files in the ARGON worldview
smalltalk objects
-