RRID:SCR_019600
DOI: 10.1038/s41589-024-01660-y
Resource: BD LSRFortessa cell analyzer (RRID:SCR_018655)
Curator: @scibot
SciCrunch record: RRID:SCR_018655
RRID:SCR_019600
DOI: 10.1038/s41589-024-01660-y
Resource: BD LSRFortessa cell analyzer (RRID:SCR_018655)
Curator: @scibot
SciCrunch record: RRID:SCR_018655
RRID:AB_1280939
DOI: 10.1038/s41589-024-01660-y
Resource: (Abcam Cat# ab9049, RRID:AB_1280939)
Curator: @scibot
SciCrunch record: RRID:AB_1280939
RRID:CVCL_0063
DOI: 10.1038/s41467-025-65730-y
Resource: (RRID:CVCL_0063)
Curator: @scibot
SciCrunch record: RRID:CVCL_0063
RRID:CVCL_0422
DOI: 10.1038/s41467-025-65730-y
Resource: (CLS Cat# 602280/p823_MDCK_(NBL-2), RRID:CVCL_0422)
Curator: @scibot
SciCrunch record: RRID:CVCL_0422
ll correspondence is filed under the correspond-ent's number, unless it relates to branch offices orto a subject relating to some special division ofthe correspondent's business, for which it has beennecessary to assign a separate folder. In this casethey are assigned auxiliary numbers to the mainnumber. This is known as a Duplex Numericsystem of numbering.American Express Co. 52431234 Market St. , Phila., PaNew York City, N. Y.Pittsburgh , Pa.-1-2Rochester , N. Y. -3
Welcome to my Lab Notebook - Reloaded Welcome to my lab notebook, version 3.0. My original open lab notebooks began on the wiki platform OpenWetWare, moved to a personally hosted Wordpress platform, and now run on a Jekyll-powered platform (site-config), but the basic idea remains the same. For completeness, earlier entries from both platforms have been migrated here. Quoting from my original introduction to the Wordpress notebook: Disclaimer: Not a Blog Welcome to my open lab notebook. This is the active, permanent record of my scientific research, standing in place of the traditional paper bound lab notebook. The notebook is primarily a tool for me to do science, not communicate it. I write my entries with the hope that they are intelligible to my future self; and maybe my collaborators and experts in my field. Only the occasional entry will be written for a more general audience. […] In these pages you will find not only thoughts and ideas, but references to the literature I read, the codes or manuscripts I write, derivations I scribble and graphs I create and mistakes I make. Why an open notebook? Is it working? My original introduction to the notebook from November 2010 dodged this question by suggesting the exercise was merely an experiment to see if any of the purported benefits or supposed risks were well-founded. Nearly three years in, can I draw any conclusions from this open notebook experiment? In that time, the notebook has seen six projects go from conception to publication, and a seventh founder on a null result (see #tribolium). Several more projects continue to unfold. I have often worked on several projects simultaneously, and some projects branch off while others merge, making it difficult to capture all the posts associated with a single paper into a single tag or category. Of course not all ideas make it into the paper, but they remain captured in the notebook. I often return to my earlier posts for my own reference, and frequently pass links to particular entries to collaborators or other colleagues. On occasion I have pointed reviewers of my papers to certain entries discussing why we did y instead of x, and so forth. Both close colleagues and researchers I’ve never met have emailed me to follow up on something they had read in my notebook. This evidence suggests that the practice of open notebook science can faciliate both the performance and dissemination of research while remaining compatible and even synergistic with academic publishing. I am both proud and nervous to know of a half dozen other researchers who have credited me for inspiring them to adopt open or partially open lab notebooks online. I am particularly grateful for the examples, interactions, and ideas from established practitioners of open notebook science in other fields. My collaborators have been largely been somewhere between favorable and agnostic towards the idea, with the occasional request for delayed or off-line notes. More often gaps arise from my own lapses in writing (or at least being intelligible), though the automated records from Github in particular, as well as Flickr (image log), Mendeley (reading log), and Twitter and the like help make up for some of the gaps. The Integrated Notebook becomes the Knitted Notebook In creating my wordpress lab notebook, I put forward the idea of an “Integrated Lab Notebook”, a somewhat convoluted scheme in which I would describe my ideas and analyses in Wordpress posts, embed figures from Flickr, and link them to code on Github. Knitr simplified all that. I can now write code, analysis, figures, equations, citations, etc, into a single Rmarkdown format and track it’s evolution through git version control. The knitr markdown format goes smoothly on Github, the lab notebook, and even into generating pdf or word documents for publication, never seperating the code from the results. For details, see “writing reproducibly in the open with knitr.” Navigating the Open Notebook You can page through the notebook chronologically just like any paper notebook using the “Next” and “Previous” buttons on the sidebar. The notebook also leverages all of the standard features of a blog: the ability to search, browse the archives by date, browse by tag or browse by category. follow the RSS feed add and share comments in Disqus I use categories as the electronic equivalent of separate paper notebooks, dividing out my ecological research projects, evolutionary research topics, my teaching notebook, and a few others. As such, each entry is (usually) made into exactly one category. I use tags for more flexible topics, usually refecting particular projects or methods, and entries can have zero or multiple tags. It can be difficult to get the big picture of a project by merely flipping through entries. The chronological flow of a notebook is a poor fit to the very nonlinear nature of research. Reproducing particular results frequently requires additional information (also data and software) that are not part of the daily entries. Github repositories have been the perfect answer to these challenges. (The real notebook is Github) My Github repositories offer a kind of inverted version of the lab notebook, grouped by project (tag) rather than chronology. Each of my research projects is now is given it’s own public Github repository. I work primarily in R because it is widely used by ecologists and statisicians, and has a strong emphasis on reproducible research. The “R package” structure turns out to be brilliantly designed for research projects, which specifies particular files for essential metadata (title, description, authors, software dependencies, etc), data, documentation, and source code (see my workflow for details). Rather than have each analysis described in full in my notebook, they live as seperate knitr markdown files in the inst/examples directory of the R package, where their history can be browsed on Github, complete with their commit logs. Long or frequently used blocks of code are written into functions with proper documentation in the package source-code directory /R, keeping the analysis files cleaner and consistent. The issues tracker connected to each Github repository provides a rich TO DO list for the project. Progress on any issue often takes the form of subsequent commits of a particular analysis file, and that commit log can automatically be appended to the issue. The social lab notebook When scripting analyses or writing papers, pretty much everything can be captured on Github. I have recently added a short script to Jekyll which will pull the relevant commit logs into that day’s post automatically. Other activities fit less neatly into this mold (reading, math, notes from seminars and conferences), so these things get traditional notebook entries. I’m exploring automated integration for other activities, such as pulling my current reading from Mendeley or my recent discussions from Twitter into the notebook as well. For now, feed for each of these appear at the top of my notebook homepage, with links to the associated sites.
This emphasis on reproducibility matters to history too. It suggests I should keep detailed logs: where I got a manuscript image, how I interpreted marginalia, what uncertainties remain. That way future readers or researchers can trace my reasoning or redo steps themselves.
subtract_vector(x, y, z);
配列と関数について
関数に配列を返す時,return文では配列全体を返すことはできないことに注意
for (i = 0; i < DIM; i++) { z[i] = x[i] - y[i];
ヒント
for文で入力される配列の動き
1週目: z[0] = x[0] - y[0] z[0] = 1 - 2
2週目: z[1] = x[1] - y[1] z[1] = (-2) - 0
3週目: z[2]= x[2] - y[2] z[2] = 1 - (-2)
このように,配列z[ ]に引き算の結果が入る.
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Manuscript number: RC-2025-03195R
Point-by-Point Response to Reviewers
We thank the reviewers for their thoughtful and constructive evaluations, which have helped us substantially improve the clarity, rigor, and balance of our manuscript. We are grateful for their recognition that our integrated ATAC-seq and RNA-seq analyses provide a valuable and technically sound contribution to understanding soxB1-2 function and regenerative neurogenesis in planarians.
We have carefully addressed the reviewers' major points as follows:
Reviewer #1 (Evidence, reproducibility and clarity (Required)):
Summary
The authors of this interesting study take the approach of combining RNAi, RNA-seq and ATAC-seq to try to build a regulatory network surrounding the function of a planarian SoxB1 ortholog, broadly required for neural specification during planarian regeneration. They find a number of chromatin regions that differentially accessible (measured by ATAC-seq), associate these with potential genes by proximity to the TSS. They then compare this set of genes with those that are differentially regulated (using RNA-seq), after SoxB1 RNAi mediated knockdown. This allows them the authors some focus on potential directly regulated targets of the planarian SoxB1. Two of these downstream targets, the mecom and castor transcription factors are then studied in greater detail.
Major Comments
I have no suggestions for new experiments that fit sensibly with the scope of the current work. There are other analyses that could be appropriate with the ATAC-seq data, but may not make sense in the content of SoxB1 acting as pioneer factor.
I would like to see motif enrichment analysis under the set of peaks to see if SoxB1 is opening chromatin for a restricted set of other transcription factors to then bind. Much of this could be taken from Neiro et al, eLife 2022 (which also used ATAC-seq) and matched planarians TF families to likely binding motifs. This could add some breadth to the regulatory network. It could be revealing for example if downstream TF also help regulate other targets that SoxB1 makes available, this is pattern often seen for cell specification (as I am sure the authors are aware). Alternatively, it may reveal other candidate regulators.
Thank you for this suggestion. We agree with the reviewers that this analysis should be done. We ran the motif enrichment analysis using the same methods as outlined in Neiro et al. eLife, 2022. We have included a new motif enrichment analysis in the supplement to contextualize possible co-regulators within the SoxB1-2 network.
Overall peak calling consistency with ATAC-sample would be useful to report as well, to give readers an idea of noise in the data. What was the correlation between samples?
__Excellent point. In response to this comment, we ran a Pearson correlation test on replicates within gfp and soxB1-2 RNAi replicates to get an idea of overall correlation between replicates. Additionally, we calculated percent overlap of peaks for biological replicates and between treatment groups. __
While it is logical to focus on downregulated genes, it would also be interesting to look at upregulated genes in some detail. In simple terms would we expect to see the representation of an alternate set of fate decisions being made by neoblast progeny?
This is also an important point that we considered but initially did not pursue it due to the lack of tools to test upregulated gene function. However, the reviewer is correct that this is straightforward to perform computationally. Thus, we have performed Gene Ontology analysis on the upregulated genes in all RNA-seq datasets (soxB1-2 RNAi, mecom RNAi, and castor RNAi). Both mecom and castor datasets did not reveal enrichment within the upregulated portion of the dataset. Genes upregulated after soxB1-2 RNAi were enriched for metabolic, xenobiotic detoxification, potassium homeostasis, and endocytic programs. Rather than indicating a shift toward alternative lineages, including non-ectodermal fates, these signatures are consistent with stress-responsive and homeostatic programs activated following loss of soxB1-2. We did not detect enrichment patterns strongly associated with alternative cell fates. We conclude that this analysis does not formally exclude potential shifts in lineage-specific transcriptional programs, but does support our hypothesis that soxB1-2 functions as a transcriptional activator.
Can the authors be explicit about whether they have evidence for co-expression of SoxB1/castor and SoxB1/mecom? I could find this clearly and it would be important to be clear whether this basic piece of evidence is in place or not at this stage.
We included co-expression plots for soxB1-2 with mecom and castor in the supplemental material. These plots were generated from previously published scRNA-seq data and demonstrate that cells expressing soxB1-2 also express mecom and castor. We have not done experiments showing co-expression via in situ at this time.
Minor comments
Formally loss of castor and mecom expression does mean these cells are absent, strictly the cell absence needs an independent method. It might be useful to clarify this with the evidence of be clear that cells are "very probably" not produced.
We agree that loss of castor and mecom expression does not formally demonstrate the physical absence of these cells, and that independent methods would be required to definitively confirm their loss. In response, we have revised our wording to indicate that castor- and mecom-expressing cells are very likely not being produced, rather than stating that they are absent.
Reviewer #1 (Significance (Required)):
Significance
Strengths and limitations.
The precise exploitation of the planarian system to identify potential targets, and therefore regulatory mechanisms, mediated by SoxB1 is an interesting contribution to the fi eld. We know almost nothing about the regulatory mechanisms that allow regeneration and how these might have evolved, and this work is well-executed step in that direction.
Advance
The paper makes a clear advance in our understanding of an important process in animals (neural specification) and how this happens in the context in the context during an example of animal regeneration. The methods are state-of-the-art with respect to what is possible in the planarian system.
Audience
This will be of wide interest to developmental biologists, particularly those studying regeneration in planarians and other regenerative systems,and those who study comparative neurodevelopment.
Expertise
I have expertise in functional genomics in the context of stem cells and regeneration, particularly in the planarian model system
Reviewer #2 (Evidence, reproducibility and clarity (Required)):
Review - Cathell, et al (RC-2025-03195)
Summary and Significance:
Understanding regenerative neurogenesis has been difficult due to the limited amount of neurogenesis that occurs after injury in most animal species. Planarians, with their adult neurogenesis and robust post-injury response, allow us to get a glimpse into regenerative neurogenesis. The Zayas laboratory previously revealed a key role for SoxB1-2 in maintenance and regeneration of a broad set of sensory and peripheral neurons in the planarian body. SoxB1-2 also has a role in many epidermal fates. Their previous work left open the tempting possibility that SoxB1-2 acts as a very upstream regulator of epidermal and neuronal fates, potentially acting as a pioneer transcription factor within these lineages. In the manuscript currently under review, Cathell and colleagues use ATAC-Seq and RNA-Seq to investigate chromatin changes after SoxB1-2(RNAi). With the experimental limitations in planarians, this is a strong first step toward testing their hypothesis that SoxB1-2acts as a pioneer within a set of planarian lineages. Beyond these cell types, this work is also important because planarian cell fates often rely on a suite of transcription factors, but the nature of transcription factor cooperation has been much less well understood. Indeed, the authors do show that loss of SoxB1-2 by RNAi causes changes in a number of accessible regions of the genome; many of these chromatin changes correspond to changes in gene expression of genes nearby these peaks. The authors also examine in more detail two genes that have genomic and transcriptomic changes after SoxB1-2(RNAi), mecom and castor. The authors completed RNA-Seq on mecom(RNAi) and castor(RNAi) animals, identifying genes downregulated after loss of either factor that are also seen in SoxB1-2(RNAi). The results in this paper are rigorous and very well presented. I will share two major limitations of the study and some suggestions for addressing them, but this work may also be acceptable without those changes at some journals.
Limitation 1:
The paper aims to test the hypothesis that SoxB1-2 is a pioneer transcription factor. Observation that SoxB1-2(RNAi) leads to loss of many accessible regions in the chromatin supports the hypothesis. However, an alternate possibility is that SoxB1-2 leads to transcription of another factor that is a pioneer factor or a chromatin remodeling enzyme; in either of these cases, the accessibility peak changes may not be due to SoxB1-2 directly but due to another protein that SoxB1-2 promotes. The authors describe how they can address this limitation in the future; in the meantime, is it known what the likely binding for SoxB1-2 would be (experimentally or based on homology)? If so, could the authors examine the relative abundance of SoxB1-2 binding sites in peaks that change after SoxB1-2(RNAi)? This could be compared to the abundance of the same binding sequence in non-changing peaks. Enrichment of SoxB1-2 binding sites in ATAC peaks that change after its RNAi would support the argument that chromatin changes are directly due to SoxB1-2.
We appreciate the feedback and agree that distinguishing between direct SoxB1-2 pioneer activity and indirect effects mediated through downstream regulators is an important consideration. While we did not perform a direct abundance analysis of potential chromatin-remodeling cofactors, we conducted a motif enrichment analysis following the approach of Neiro et al. (eLife, 2022), comparing control and soxB1-2(RNAi) peak sets. This analysis revealed that Sox-family motifs, particularly SoxB1-like motifs, were among the most enriched in regions that remain accessible in control animals relative to soxB1-2(RNAi) animals, consistent with a model in which SoxB1-2 directly contributes to establishing or maintaining accessibility at these loci. We have now included this analysis in the supplemental materials to further contextualize potential co-regulators and transcriptional partners within the SoxB1-2 regulatory network. We agree and acknowledge in the report that future studies assessing chromatin remodeling factor expression and abundance will be valuable to definitively separate direct and indirect pioneer activity.
Limitation 2:
The characterization of mecom and castor is somewhat preliminary relative to the deep work in the rest of the paper. I think this could be addressed with a few experiments. The authors could validate RNA-seq findings with ISH to show that cells are lost after reduction of either TF (this would support the model figure). The authors could also try to define whether loss of either TF causes behavioral phenotypes that might be similar to SoxB1-2(RNAi); this would be a second line of evidence that the TFs are downstream of key events in the SoxB1-2
pathway.
Thank you for this suggestion. We agree that additional validation of the mecom and castor RNA-seq results and further phenotypic characterization would strengthen this section. We are currently conducting in situ hybridization experiments to validate transcriptional changes in mecom and castor using the same experimental framework applied to soxB1-2 downstream candidates. We anticipate completing these studies within the next three months and will incorporate the results into future work.
Regarding behavioral phenotypes, we performed preliminary screening for robust behavioral responses, including mechanosensory responses, but did not observe overt defects. However, the lack of established, standardized behavioral assays in planarians presents a current limitation; such assays need to be developed de novo, and predicting specific behavioral phenotypes in advance remains challenging. We fully agree that functional behavioral assays represent an important next step and are actively exploring strategies to systematically develop and implement them going forward.
Other questions or comments for the authors:
Is it known how other Sox factors work as pioneer TFs? Are key binding partners known? I wondered if it would be possible to show that SoxB1-2 is co-expressed with the genes that encode these partners and/or if RNAi of these factors would phenocopy SoxB1-2. This is likely beyond the scope of this paper, but if the authors wanted to further support their argument about SoxB1-2 acting as a pioneer in planarians, this might be an additional way to do it.
In other systems, Sox pioneer factors often act together with POU family transcription factors (for example, Oct4 and Brn2) and PAX family members such as Pax6. In planarians, a POU homolog (pou-p1) is expressed in neoblasts and may represent an interesting candidate co-factor for future investigation in the context of SoxB1-2 pioneer activity. We have also previously examined the relationship between SoxB1-2 and the POU family transcription factors pou4-1 and pou4-2. Although RNAi of these factors does not fully phenocopy soxB1-2 knockdown, pou4-2(RNAi) results in loss of mechanosensation, suggesting that downstream POU factors may contribute to aspects of neural function regulated by SoxB1-2 (McCubbin et al. eLife 2025). We agree that co-expression and functional interaction studies with these candidates would be highly informative, and we view this as an exciting future direction beyond the scope of the current manuscript.
This paper is one of few to use ATAC-Seq in planarians. First, I think the authors should make a bigger deal of their generation of a dataset with this tool! Second, it would be great to know whether the ATAC-Seq data (controls and/or RNAi) will be browsable in any planarian databases or in a new website for other scientists. I believe that in addition to the data being used to test hypotheses about planarians, the data could also be a huge hypothesis generating resource in the planarian community, so I would encourage the authors to both self-promote their contribution and make plans to share it as widely and usably as possible.
Thank you very much for this encouraging feedback. We appreciate the suggestion and have strengthened the text to emphasize the significance of generating this ATAC-seq resource for the planarian field. We agree that these datasets represent a valuable community resource and are committed to making all control and soxB1-2(RNAi) ATAC-seq data publicly accessible.
Reviewer #2 (Significance (Required)):
This paper's strengths are that it addresses an important problem in regenerative biology in a rigorous manner. The writing and presentation of the data are excellent. The paper also provides excellent datasets that will be very useful to other researchers in the fi eld. Finally, the work is one of, if not the first to examine how the action of one transcription factor in planarians leads to changes in the cellular and chromatin environment that could then be acted upon by subsequent factors. This is an important contribution to the planarian fi eld, but also one that will be useful for other developmental neuroscientists and regenerative biologists.
I described a couple of limitations in the review above, but the strengths outweigh the weaknesses.
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
The authors investigated the role of soxB1-2 in planarian neural and epidermal lineage specification. Using ATAC-seq and RNA-seq from head fragments after soxB1-2 RNAi, they identified regions of decreased chromatin accessibility and reduced gene expression, demonstrating that soxB1-2 induces neural and sensory programs. Integration of the datasets yielded 31 overlapping candidate targets correlating ATAC-seq and RNA-seq. Downstream analyses of transcription factors that had either/or differentially accessible regulatory region or showed differential expression (castor and mecom) implicated these transcription factors in mechanosensory and ciliary modules. The authors combined additional techniques, such as in situ hybridization to support the observations based on the ATACseq/RNAseq data. The manuscript is clearly written as well as data presentation in the main and supplementary figures. The major claim of the manuscript is that SoxB1-2 is likely a pioneer transcription factor that alters the accessibility of the chromatin, which if true, would be one of the first demonstrations of direct transcriptional regulation in planarians. As described below, I am not certain that this interpretation of the data is more valid than alternative interpretations.
Major comments
We agree that distinguishing between direct SoxB1-2 pioneer activity and indirect chromatin changes mediated by downstream factors is an important consideration. As suggested, examining the enrichment of SoxB1-2 binding motifs in regions that lose accessibility following soxB1-2(RNAi) can provide supporting evidence for direct regulation.
While we did not conduct a direct abundance analysis of all potential chromatin-remodeling cofactors, we performed a motif enrichment analysis following the methodology of Neiro et al. (eLife, 2022), comparing control-specific and soxB1-2(RNAi)-specific accessible peak sets. Consistent with a direct role for SoxB1-2 in chromatin regulation, Sox-family motifs, particularly SoxB1-like motifs, were among the most significantly enriched in regions that maintain accessibility in control animals relative to soxB1-2(RNAi) animals.
Evidence for pioneer activity. The authors correctly acknowledge that they do not present direct evidence of soxB1-2 binding or chromatin opening. However, the section title in the Discussion could be interpreted as implying otherwise. The claim of pioneer activity should remain explicitly tentative until supported (at least) by motif or binding data.
We have performed suggested motif analysis and changed the language in this section to better fit the data.
Replication and dataset comparability. Both ATAC-seq and soxB1-2 RNA-seq were performed on head fragments, but the number of replicates differ between assays (ATAC-seq n=2 per group, RNA-seq n=4-6). This is of course acceptable, but when interpreting the results, it should be taken into consideration that the statistical power is different when using data collected using different techniques and having a varied number of replicates.
Thank you for raising this important point regarding replication and comparability across datasets. We agree that the differing number of biological replicates between the ATAC-seq and RNA-seq experiments results in different statistical power across assays. We have now clarified this consideration in the manuscript text.
Minor comments
"Thousands of accessible chromatin sites". Please state the number of peaks and the thresholds for calling them. Ensure consistency between text (264 DA peaks) and Figure 1 legend (269 DA peaks).
__We have clarified specific peak numbers and will include the calling parameters in the methods section. Additionally, we will fix the discrepancies between differential peaks. __
Specify the y-axis normalization units in all coverage plots.
We have specified this across plots.
Clarify replicate numbers consistently in the text and figure legends.
We have identified and corrected discrepancies in the figure legends vs text and correct them and ensured they are included consistently across datasets.
Referees cross commenting
The reviews are highly consistent. They recognize the value of the work, and raise similar points. The main shared view is that the current data do not distinguish direct from indirect effects, and claims about pioneer activity should be softened, and further analysis of the differentially accessible peaks could strengthen the link between SoxB1-2 and the chromatin changes.
-I don't think that it's necessary to further characterize experimentally mecom or castor (as suggested), but of course that it could have value.
We thank all three reviewers for their positive assessment of the value of our work aiming to elucidate mechanisms by which SoxB1-2 programs planarian stem cells. In the revision, we have improved the presentation and carefully edited conclusions about the function of SoxB1-2. Performing motif analysis and GO annotation of upregulated genes has strengthened our observation that SoxB1-2 acts as an activator and has revealed putative binding sites.
The preliminary revision does not yet include further characterization of mecom and castor downstream genes. In response to Reviewer #2, we appreciate that additional validation of the mecom and castor RNA-seq results and further phenotypic characterization would strengthen this section. Although we are currently conducting in situ hybridization experiments to validate transcriptional changes in mecom and castor using the same experimental framework applied to soxB1-2 downstream candidates, we also reconsidered, as we did in our first revision, whether this is necessary or better suited for future investigations.
In the revision, we noted that our Discussion points were not balanced and that we emphasized the mecom and castor results in a manner that distracted from the major focus of the work, likely contributing to the impression that additional experimental evidence was required. Therefore, we have revised the section accordingly and streamlined the Discussion to avoid repetitive statements and to focus on the insights gained into the mechanism of SoxB1-2 function in planarian neurogenesis. We remain open to including these additional experiments if the reviewers or handling editors consider them essential; however, we agree that their inclusion is not absolutely necessary.
Reviewer #3 (Significance (Required)):
General assessment. The study offers valuable observations by combining chromatin and transcriptional analysis of planarian neural differentiation. The integration with in situ validation convincingly demonstrates effects on neural tissues and provides a solid resource for future functional work. However, mechanistic interpretation remains limited, partly because of technical limitations of the system. The data support an important role for soxB1-2 in neural and epidermal lineage regulation, but not direct binding or chromatin-opening activity. The authors have previously published analysis of soxB1-2 in planarians, so the addition of ATAC-seq data contributes to solving another piece of the puzzle.
__Advance. __
This is one of the first studies to couple ATAC-seq and RNA-seq in planarian tissue to dissect regulatory logic during regeneration. It identifies new candidate regulators of sensory and epidermal differentiation and identifies soxB1-2 as a likely upstream factor in ectodermal lineage networks. The work extends previous studies on soxB1-2 activity and neural cell production by integrating chromatin and transcriptional layers. In that respect the results are very solid, although the study remains correlative at the mechanistic level.
Audience.
This work will potentially interest researchers interested in regeneration and transcriptional networks. The datasets and gene lists will be valuable references for follow-up studies on planarian ectodermal lineages, and therefore will appeal to this community.
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
The authors investigated the role of soxB1-2 in planarian neural and epidermal lineage specification. Using ATAC-seq and RNA-seq from head fragments after soxB1-2 RNAi, they identified regions of decreased chromatin accessibility and reduced gene expression, demonstrating that soxB1-2 induces neural and sensory programs. Integration of the datasets yielded 31 overlapping candidate targets correlating ATAC-seq and RNA-seq. Downstream analyses of transcription factors that had either/or differentially accessible regulatory region or showed differential expression (castor and mecom) implicated these transcription factors in mechanosensory and ciliary modules. The authors combined additional techniques, such as in situ hybridization to support the observations based on the ATACseq/RNAseq data. The manuscript is clearly written as well as data presentation in the main and supplementary figures. The major claim of the manuscript is that SoxB1-2 is likely a pioneer transcription factor that alters the accessibility of the chromatin, which if true, would be one of the first demonstrations of direct transcriptional regulation in planarians. As described below, I am not certain that this interpretation of the data is more valid than alternative interpretations.
Major comments
Minor comments
"Thousands of accessible chromatin sites". Please state the number of peaks and the thresholds for calling them. Ensure consistency between text (264 DA peaks) and Figure 1 legend (269 DA peaks). Specify the y-axis normalization units in all coverage plots. Clarify replicate numbers consistently in the text and figure legends.
Referees cross commenting
The reviews are highly consistent. They recognize the value of the work, and raise similar points. The main shared view is that the current data do not distinguish direct from indirect effects, and claims about pioneer activity should be softened, and further analysis of the differentially accessible peaks could strengthen the link between SoxB1-2 and the chromatin changes.
General assessment. The study offers valuable observations by combining chromatin and transcriptional analysis of planarian neural differentiation. The integration with in situ validation convincingly demonstrates effects on neural tissues and provides a solid resource for future functional work. However, mechanistic interpretation remains limited, partly because of technical limitations of the system. The data support an important role for soxB1-2 in neural and epidermal lineage regulation, but not direct binding or chromatin-opening activity. The authors have previously published analysis of soxB1-2 in planarians, so the addition of ATAC-seq data contributes to solving another piece of the puzzle.
Advance. This is one of the first studies to couple ATAC-seq and RNA-seq in planarian tissue to dissect regulatory logic during regeneration. It identifies new candidate regulators of sensory and epidermal differentiation and identifies soxB1-2 as a likely upstream factor in ectodermal lineage networks. The work extends previous studies on soxB1-2 activity and neural cell production by integrating chromatin and transcriptional layers. In that respect the results are very solid, although the study remains correlative at the mechanistic level.
Audience. This work will potentially interest researchers interested in regeneration and transcriptional networks. The datasets and gene lists will be valuable references for follow-up studies on planarian ectodermal lineages, and therefore will appeal to this community.
Over the course of eleven years, he served as prior of the community (1988–1992), formation director (1988–1998), and instructor for professed members (1992–1998), and in the Archdiocese of Trujillo as judicial vicar (1989–1998) and professor of Canon Law, Patristics, and Moral Theology at the Major Seminary “San Carlos y San Marcelo.” At the same time, he was also entrusted with the pastoral care of Our Lady Mother of the Church, later established as the parish of Saint Rita (1988–1999), in a poor suburb of the city
Shows Leo's human interest and proximity to marginalized communities. This quote reinforces the narrative surrounding him of being a compassionate individual who's dedicated to service.
Reverse engineering the neocortex to revolutionize AI
With TDD, you develop code by incrementally adding a test for a new feature, which fails. Then you write the “simplest code” that passes the new test. You add new tests, refactoring as needed, until you have fully covered everything that the new feature should fulfil, as specified by the tests. But: Where do tests come from? When you write a test, you actually have to “guess first” to imagine what objects to create, exercise and test. How do we write the simplest code that passes? A test that fails gives you a debugger context, but then you have to go somewhere else to add some new classes and methods. What use is a green test? Green tests can be used to detect regressions, but otherwise they don't help you much to create new tests or explore the running system. With Example-Driven Development we try to answer these questions.
Desde que me lo presentaron, siempre me ha desagradado el Test Driven Design (TDD), pues me parecía absurdamente burocrático y contra flujo. Afortunadamente, gracias al podcast de Book Overflow, encontré un autor reconocido, John Ousterhout, creador de Tcl/Tk y "A Philosophy of software design", que comparte mi opinón respecto a escribir los test antes de escribir el código y dice que en el TDD no se hace diseño, sino que se depura el software hasta su existencia.
Mi enfoque, que podría llamarse Argumentative Driven Design o ADD es uno en el que el código se desarrolla para mostrar un argumento en favor de una hipótesis, y las pruebas de código se van creando en la medida en que uno necesita inspeccionar y manipular los objetos que dicho código produce.
En palabras práctica, esto quiere decir que los test y su configuración deberían hacerse cuando uno necesita hacer un "print" (para probar/inspeccionar/manipular un estado/elemento del sistema) y no antes, lo cual aumenta la utilidad, no interrumpe el flujo y responde preguntas similares a las de este apartado, respecto a de dónde provienen las pruebas y qué hacer con los resultados exitosos.
Existe una relación entre confianza en el Estado y creencia en el interés del gobierno por la opinión pública (H0= no existe relación entre la confianza en el Estado y creencia en el interés del gobierno por la opinión pública) La confianza en el Estado es menor en población joven que en generaciones mayores. (H0 = confianza en el Estado es igual o mayor en población joven que en generaciones mayores) Existe una relación proporcional entre la confianza en el Estado y la confianza en los organismos municipales y locales. (H0= No existe una relación proporcional entre la confianza en el Estado y la confianza en los organismos municipales y locales).
no hay definición de factores asociados
En base a esto, definimos la confianza de acuerdo a la definición conceptual de Irarrázaval y Cruz (2023), que la caracteriza como la expectativa que el otro actuará acorde a las normas sociales, de manera honesta o al menos no perjudicial hacia el prójimo; de la misma forma, la confianza puede tener expectativas en la capacidad o en la integridad, ambas fundamentales para el entendimiento de la confianza.
esto es confianza interpersonal, no confianza en instituciones
fluence and Impact Giving autonomy to persons and groups oo Freeing people to “do their thing Expressing own ideas and feelings as one aspect of the group data Facilitating learning Giving orders Directing subordinates’ behavior Keeping own ideas and feelings “close to the vest” Exercising authority over people and organizations Coercing when necessary Teaching, instructing, advising Evaluating others Stimulating independence in d action Delenuting: siving full responsibility Offering feedback and receiving it Encouraging and relying on self-evaluation Finding rewards in the achievements of others Being rewarded by own achievements > Pp Pp d control. NT . wee Douglas McGregor’s Human Side of eo theory X and theory Y.° They are not oppos ‘ poles views about work—including teaching and obs a ae ement and the assumptions underlying it. Ty nived from research in the social sciences. Three basic assumptions of theory X are ggests two approaches to management, oles on a continuum but two different Theory X applies to traditional s based on assumptions de- isli i id it if Th age human being has an inherent dislike of work and will avoi 4. The aver possible. e of this hu * threatened with punishment to get them to put forth adeq achievement of organizational objectives. i i ibility, e human being prefers to be directed, wishes to avoid responsibility 3. The averag i 1. has relatively little ambition, and wants security above al i e an ick” tivation fits reason- i “ d the stick” theory of mo indicates that the “carrot an oe OE te alan theory X. External rewards and punishments are mu monn ee The oer ‘quent direction and control does not recognize intrinsic ' ms Theory Y is more humanistic and is based on six assumptions: i sh. and mental effort in work is as natural as play or re 1. The expenditure of physical ly means for bringing i the on 2. External controls and the threat of punishment are not i i ise self- iectives. Human beings will exercise sof obi h they are committed. izational o t effort toward organiza s. n ‘ineotion and self-control in the service of objectives to wh Notes 121 3. Commitment to objectives is a function of the rewards associated with their achievement. 4. The average human being learns, under proper conditions, not only to accept but also to seek responsibility, 5. The capacity to exercise a relatively hi creativity in the solution of organizatio tributed in the population. 6. Under the conditions of modern industrial life, th average human being are only partially utilized. gh degree of imagination, ingenuity, and nal problems is widely, not natrowly, dis- e intellectual potentialities of the McGregor saw these assumptions leading to superior—subordinate relationships in which the subordinate would have greater influence over the activities in his or her own work and also have influence on the Superior’s actions. Through participatory manage- Inent, greater creativity and productivity are expected, and also a greater sense of personal accomplishment and satisfaction by the workers. Chris Argyris,”° Warren Bennis,2” and Rensis Likert” cite evidence that a participatory system of management can be more ef- fective than traditional management. Likert’s studies showed that high production can be achieved by people- rather than production-oriented managers. Mor cover, these high-production managers were willing to delegate; to allow subordinates to participate in decisions; to be relatively nonpunitive; and to use open, two-way communication patterns. High morale and effective planning were also characteristic of these “person-centered” managers. The results may be applied to the supervisory relationship in education as well as to industry. There have been at least two theory Z candi broached in Abraham Maslow’s Nature.” The other dealt with when they were applied to pos circles, cooperative learning, influenced by those theories. dates in more recent years. One was posthumous publication, The Farther Reaches of Human the success of ideas from the 1930s in the United States twar Japan following WWII. Innovations such as quality participatory management, and shared decision making were NOTES 1. Shwartz, T. ( 1996). What really matters: Searching for wis- 7. Hersey, P. and Blanchard, K, (1982). Management of organi- dom in America. New York: Bantam Books. zational behavior: Utilizing human resources. Englewood Cliffs, 2. Bales, R. F. (1976). Interaction process analysis: A method NJ: Prentice-Hall. Jor the study of small 8roups. Chicago: Midway Reprint, Univer- 8. Gregorc, A. F. (1986). Gregore style delineator. Gregorc sity of Chicago Press, Associates. 9. Myers-Briggs: Quenk, N. L. (2000). Essentials of Myers- Briges type indicator assessment. New York: John Wiley & Sons. 10. Keirsey, D., & Bates, M. (1978). Please understand me. Del 3, Cattell; See Hall, Lindsey, and Campbell, (1997). Theories of Personality. New York: John Wiley & Sons. 4, Murray, Rorschach: See Buros, O. (1970-1975). Personality tests and reviews (Vol. 1 & 2). Highland Park, NI: Gryphon Mar, CA: Prometheus Nemesis Book Company. Press, : 11. Keirsey, D. (1998). Please understand me TT; Temperament, 5. Amidon, E., & Flanders, N. (1967), Interaction analysis asa character, intelligence. Loughton, UK: Prometheus Books. feedba¢k system. In Interaction Analysis: Theory, Research, and Applica’ ; ‘ 12. Goldberg, L. R. http://www.ori.org/scientists/goldberg. htm! ton (pp. 122-124). Reading, MA: Addison-Wesley. 6.8 . ; 13. Spaulding, R. I. (1967). A coping analysis schedule for edu- o lumberg, A, (1974). Supervisors and teachers: A Private cational settings (CASES). In A. Simon & EG. Boyer (Eds.), ‘var Berkeley, CA: McCutchan, 1974. Mirrors for behavior. Philadelphia: Research for Better Schools.
I agree that most teachers need influence and impact, NOT power and control from their leadership!
114 Chapter6 Styles of Interperson al Communication in Clinical Supervision idea to a different situation 18 but one example; pointing to a logical consequence 1S at other. ¥ araphrasing can be OV erdone if to 0 many responses are similar, or if they are inap ee ing 60 miles an hour,” her says, “The car was going . : ed. For example, if a teac . . m obile was ED atta much to respond, “What you are saying 1S a rat to communi- : vel a mile a minute.” An effective paraphrase must bea.g eer: idea shows cate that we understand what the other person 1s a 7 sane Of course, it can be pur- cee ood is pursuing the thougnt. . er heard, understood, and is pu x’s. Generally, ea ar it ceases to be the teacher's idea and becomes the observe sue wev Vv. y y i is rewarding. however, having a person ou respect use your idea is re zg 3 NS COMMUNICATION TECHNIQUE 3: ASK CLARIFYING QUESTIO ify the observer’s understanding , ften need to be probed to clarify ot The Fea teacher vink carefully about inferences and decisions. “Tell me what you eacher to th s nk. 0 1 nat oF “Can you say a little more about that?” are examples. So is mean by idence that... .” | waist Ae © maunoes if we do not clarify, miscommunication 1s ne result woroceeds z someone will say, “You're absolutely right! Moreover ao oh cv Pet SO eel i ht you said. ; t opposite of what you thoug, aid on Oe anal st teay of a case of not listening at all, but a clarifying question avoids u stra’ . : ; . \ understandings. ; . wees stions took place in a high schoo Anexample of paraphrasing and asking clarifying que o fill out anonymously. here the principal gave the faculty an administrator appraisal stactlty meeting, “What you ‘After analyzing the compiled responses, the principal said 5 & would like.” Several aeeatobe ling me in this survey is that I'm not as accessible as you we id look like?” an id almost in unison, “Could you tell us what "being eS a ome ‘drop-in’ we which the ptincipal replied: “Well, I'd keep my door open me = oan ewer it briefly ae And if you stopped me in the hall and asked a question, I'd try cnats. . tone 3? a way to a meeting. ; ant ane and Clarified his iatentions in public, he was destined to become i nced an a Mi sev eesible” in the next few months. Of course he had some help from wags “ T. ing, “ ible?” t resist asking, “Are you feeling accessi station fe veal veints ca be made with this example: (1) the ee pears oft into lech and-blood behavior; (2) the clarifying question checked the per
this is important with the work I often do with teachers who speak english as a second language. We have to clarify and not make assumptions of understanding.
OMMUNICATION TECHNIQUE 1: LISTEN MORE, TALK LESS Many observers domi and objectives Saualnate oe conversation. The teacher has little chance to identify goal Teachers talk to stile . interpret information, or reach decisions about future acti ns. suspect) observers talk in os avenge) about two-thirds of the time they teach and (we about the same proporti ° € but too many obs proportion to teachers. The i i ervers do most of the talki is di : exact ratio varies . : ng. It is difficult , cerns in a co: A to attend to a t , nference or encourage a teacher’s plans for improvement when the obs ver observer g COMMUNICATION TECHNIQUE 2: ACKN AND USE WHAT THE TEACHER IS ave benABHBASES teacher’s conversation indi y w indicate that they are listeni ° ¢ listening. Accurate paraphrases al at "Using the each, p ‘0 sho that hey understand the teacher. Using the teacher’s ideas can be even more conv ncing than merel y i i y acknowledging (hearing) or par. aphrasing (compr ehending) them. Appl ing A 4 ALAS . ‘an
Listen more, Talk less!!!! THIS! Stop talking so much. I remind teachers of this with their students and I think it is a great reminder for us as mentors.
Reflecti direct theit own lea. y OV tructure for dia nosin w
It is so important to make time for reflection. I need to remind myself to do it while I am reminding my mentee!
l’illusion d’omnipotence : « Je désire être en contact avec l’autre, l’autre doit y répondre sans faille et sans délai ! ».
On attend de l’autre une disponibilité totale, ce qui fragilise la relation.
prète
Il semble y avoir une erreur d'accent :
"prête"
Briefing : Le Rôle des Modèles dans le Développement de l'Enfant
Ce document de synthèse analyse le rôle complexe et multifacette des modèles dans le développement de l'enfant, en se basant sur les perspectives de psychologues, d'experts en développement et de témoignages personnels.
Il ressort que les parents constituent les modèles les plus fondamentaux, dont l'influence est primordiale durant les premières années.
Cependant, la recherche de la perfection parentale est contre-productive ; l'authenticité, la capacité à reconnaître ses erreurs et à s'excuser sont bien plus formatrices.
L'enfant n'imite pas aveuglément mais opère une sélection rigoureuse de ses modèles, privilégiant la compétence, la familiarité et la confiance.
Les modèles parentaux dysfonctionnels, marqués par l'addiction ou des troubles psychiques, ont des conséquences graves et durables sur la sécurité affective et l'estime de soi de l'enfant.
À l'adolescence, la recherche de modèles s'élargit au-delà du cercle familial pour construire une identité propre, un processus sain de différenciation qui peut inclure la rébellion et l'adhésion à des groupes de pairs.
Enfin, une perspective émergente et cruciale est mise en lumière : les enfants et adolescents ne sont pas de simples récepteurs passifs mais peuvent être de puissants modèles et des acteurs de changement, capables d'influencer positivement leur entourage, y compris leurs propres parents, et de façonner la société de demain.
--------------------------------------------------------------------------------
Le processus par lequel un enfant choisit et imite un modèle est loin d'être passif.
Il repose sur des mécanismes neurologiques et psychologiques complexes qui démontrent une grande sélectivité dès le plus jeune âge.
• Bases Neurologiques : Selon Moritz Köster, professeur de psychologie du développement, lorsqu'un enfant observe quelqu'un agir, des séquences de mouvements similaires sont activées dans son propre cortex moteur au niveau cellulaire.
• Sélectivité Basée sur la Confiance : L'enfant n'imite pas tout ce qu'il voit. Son choix est nuancé par les émotions et une évaluation de la personne observée. Les principaux critères de sélection sont :
◦ La familiarité : Il préférera imiter une personne qu'il connaît.
◦ La compétence : Il analyse si la personne a déjà fait des choses "intelligentes" ou des erreurs, et choisira d'imiter la personne jugée la plus compétente.
◦ L'autorité : Pour tout ce qui est nouveau, l'enfant se tournera préférentiellement vers les adultes, qu'il perçoit comme des figures de confiance.
• Apprentissage des Normes : C'est principalement en observant le comportement des adultes et de leur entourage que les enfants apprennent et intègrent les valeurs et les normes sociales.
Lise, 8 ans : "Pour moi un modèle c'est quand on fait quelque chose de bien et que quelqu'un d'autre nous imite."
L'environnement familial, et plus particulièrement les parents, constitue la première et la plus puissante source de modèles pour un enfant, une influence que les parents ont souvent tendance à sous-estimer.
Durant les premières années de vie (1-2 ans), l'environnement de l'enfant est restreint aux parents et grands-parents.
Leur comportement façonne entièrement la compréhension initiale de l'enfant sur les interactions sociales.
• Apprentissage des Comportements Sociaux : La manière de gérer un conflit, d'éviter les disputes ou de présenter des excuses est directement apprise par l'observation des parents.
• Ancrage Émotionnel : Si les échanges familiaux sont marqués par la bienveillance et l'amour, l'enfant intègre ce modèle. Inversement, si les cris ou la violence sont la norme, il retiendra ce schéma comme référence.
• La Famille comme Microcosme : Au départ, l'enfant perçoit le monde entier comme fonctionnant selon les règles de sa propre famille. Ce n'est qu'à son entrée en maternelle qu'il découvre la diversité des modes de fonctionnement.
La psychologue Nora Imlau met en garde contre la volonté de certains parents de devenir "parfaits" après la naissance d'un enfant, la qualifiant de "très mauvaise idée".
• L'Inauthenticité : Les enfants ressentent très bien quand leurs parents ne sont pas authentiques, se mettent la pression et ignorent leurs propres besoins.
• Un Standard Inatteignable : Un enfant confronté à des modèles "parfaits" (qui ne se mettent jamais en colère, ne perdent jamais patience) n'a aucune chance de faire aussi bien.
Il sera sans cesse confronté à ses propres insuffisances.
• L'Importance de l'Erreur : Le fait que les parents commettent des erreurs est une opportunité d'apprentissage cruciale.
Cela permet à l'enfant d'apprendre comment on gère ses propres erreurs.
Présenter ses excuses à ses enfants pour des propos qui ont "dépassé notre pensée" est un acte modelant très puissant.
Nora Imlau, psychologue : "Ce que j'entends par parents parfaits, ce sont les parents qui ne se mettent jamais en colère, qui ne perdent jamais patience [...] ce qui est inhumain en soi."
Le comportement d'un enfant est souvent le reflet de l'état d'âme inconscient de ses parents. Un enfant agité peut être le miroir d'un parent stressé ou préoccupé.
• La Gestion de la Tristesse : Quand un parent est triste et qu'un enfant vient le consoler, il est conseillé d'accepter cette aide dans un premier temps.
Cependant, il est crucial que le parent reprenne ensuite le contrôle et rassure l'enfant sur sa capacité à gérer la situation, afin de ne pas inverser les rôles et de préserver l'enfant de la charge de ses responsabilités d'adulte.
• La Vulnérabilité Assumée : Une mère souffrant de trouble bipolaire témoigne de sa capacité à être présente pour ses enfants même dans les phases de dépression, tout en ne cachant pas sa tristesse.
Cela illustre la possibilité de rester un parent fonctionnel malgré des difficultés psychiques.
Lorsque les parents ne peuvent pas s'occuper correctement de leurs enfants, que ce soit à cause d'une dépendance ou d'un trouble psychique, les conséquences sur le développement de l'enfant sont multiples et profondes.
Le témoignage de Mia, 16 ans, dont le père était alcoolique, illustre les dégâts d'un modèle parental défaillant.
• Rupture de la Confiance : Un parent souffrant de dépression ou d'addiction n'est plus en mesure d'interpréter correctement les signaux de son enfant et d'y réagir de manière adaptée.
L'enfant retient que ses besoins ne sont pas satisfaits.
• Attachement Insécurisant : La relation d'attachement parent-enfant ne devient pas sécurisante, ce qui entrave la construction de la confiance en soi.
Cette confiance initiale est pourtant la base essentielle du développement de l'autonomie.
• Hypervigilance de l'Enfant : L'enfant est constamment aux aguets, utilisant une énergie considérable pour anticiper les réactions de ses parents et adapter son propre comportement, ce qui peut entraîner des problèmes d'autonomie et de sentiment de sécurité à l'âge adulte.
Mia, 16 ans : "En fait il fallait toujours qu'on soit la famille parfaite, on parlait jamais des problèmes, on avait pas le droit d'en parler et ça c'est très mal."
Suite à la séparation de ses parents et à ses propres difficultés psychologiques, Mia a été confrontée à des "modèles toxiques" dans un cadre thérapeutique.
• Influence des Pairs : En observant des jeunes toxicodépendants, elle a perçu leur consommation comme un moyen de "déconnecter totalement" et de ne plus être accessible émotionnellement, un état qu'elle a alors désiré atteindre.
• Augmentation de la Consommation : Son exposition à ces modèles a directement influencé son propre comportement, entraînant une augmentation significative de sa consommation d'alcool.
L'adolescence est une période de questionnements identitaires intenses ("Qui suis-je ?") où la recherche de modèles s'intensifie et s'étend au-delà du cercle familial.
Selon la psychothérapeute Isabelle Filliozat, l'adolescent va "chercher des modèles un petit peu partout pour [s]'aider à se construire".
• Le Rôle du Groupe : Le désir d'appartenance à un groupe de pairs est très fort.
Le groupe offre un cadre identitaire ("dans mon groupe on fait les choses d'une certaine manière [...] je sais à peu près qui je suis").
• Gestion des Modèles Négatifs : Lorsqu'un enfant adhère à un modèle jugé "malsain" (agressif, délinquant), la réaction parentale la plus constructive n'est pas de chercher à changer le comportement extérieur, mais de s'intéresser aux besoins et aux émotions de l'enfant qui le poussent vers ce modèle.
En répondant à ces besoins profonds, l'enfant est plus susceptible d'abandonner de lui-même le modèle négatif.
La révolte contre les parents à l'adolescence est un processus "sain et normal", une étape nécessaire du développement.
• Processus de Détachement : Les frictions parents-enfants font partie du processus de détachement et de la prise de conscience par l'adolescent qu'il est une personne à part entière, distincte de ses parents.
• Différenciation : Pour se construire, l'adolescent a besoin de s'opposer, de définir en quoi il est différent de ses parents (valeurs, mentalité) mais aussi en quoi il leur ressemble.
Ce processus est essentiel pour pouvoir, à terme, quitter le foyer et construire une nouvelle relation, d'adulte à adulte, avec ses parents.
La vision traditionnelle du modèle descendant (adulte vers enfant) est de plus en plus complétée par une reconnaissance du rôle actif des jeunes comme modèles et agents d'influence.
Des recherches ont démontré que les enfants peuvent avoir une influence positive sur la manière de penser et sur le comportement de leurs parents.
• "L'Hypothèse des Anniversaires" : Dans des zones post-conflit, le fait que des enfants d'un groupe ethnique ou religieux invitent à leur anniversaire des enfants d'un groupe adverse force les parents des deux bords à entrer en contact.
Il a été observé que lorsque l'attitude des enfants envers "l'autre groupe" change, celle des parents change également.
• Acteurs de Paix : Les enfants peuvent ainsi devenir des acteurs clés de la promotion de la paix.
Des adolescents comme Noé Renard, 17 ans, s'imposent comme des modèles d'engagement pour leur génération.
• Rendre l'Engagement Accessible : En créant l'association "les engagés Marseille", son but est de montrer l'exemple et de permettre à d'autres jeunes de se mobiliser sur des enjeux locaux (inégalités, pollution, mobilité).
• Une Voix pour la Jeunesse : De nombreux jeunes partagent le sentiment de ne pas être suffisamment écoutés dans les institutions politiques.
Ils peuvent devenir des modèles pour leurs pairs mais aussi pour les chercheurs, comme l'illustre la mise en place d'un Conseil consultatif de la jeunesse à l'Université libre de Berlin.
Noé Renard, 17 ans : "Défendre des causes c'est pas le faire pour soi mais c'est plutôt le faire pour les autres et je pense que c'est ça qui est important c'est de pouvoir montrer aux autres que l'engagement c'est [...] surtout pour les autres et pour aider ceux qui en ont besoin."
Une critique est formulée quant au fait d'attendre la majorité pour accorder le droit de vote sans formation préalable aux règles de la démocratie.
• Apprentissage Précoce : Les experts plaident pour que les enfants apprennent beaucoup plus tôt comment fonctionne un consensus, comment on règle les conflits dans une démocratie, et qu'ils aient davantage d'influence sur leur vie quotidienne.
• Faire Confiance : Pour que les jeunes développent leur identité et leur capacité à prendre des responsabilités, les parents doivent apprendre à leur faire confiance et à les laisser expérimenter par eux-mêmes, même si c'est "à leur façon".
Le terme de pratique excessive (et a fortiori d’addiction) fait intervenir la notion de retentissement durable sur la vie du sujet : perturbations du sommeil, troubles du comportement alimentaire (surpoids, grignotage), absentéisme et/ou échec scolaire, retrait social, diminution des autres activités (familiales, sportives et culturelles).
Argument pour : même si on parle ici d'addiction "a fortiori", les critères de dépendance décrits y ressemblent fortement.
Les examens cérébraux, réalisés par IRM, de personnes développant des symptômes de dépendance montrent que les gros consommateurs d’Internet développent des processus neurobiologiques commun avec les toxicomanes et avec les personnes souffrant de dépendances pathologiques reconnues, comme celle liée aux jeux.
Argument pour : si les examens d'imagerie montrent des signes communs entre les personnes dépendantes d'internet et les toxicomanes, il y a donc une notion d'addiction.
You and 7 others reacted
Vous créer votre configuration ou nous vous y aidons
Vous concevez votre configuration en choisissant vos éléments dans le catalogue OU Nous vous accompagnons pour créer ensemble votre configuration idéale
Gracias a diferentes equipos de fanes Xenogears se vio traducido al español después de varios años con más fidelidad a la versión japonesa, por supuesto, al ser solo por y para fanes, este no vio su salida en las tiendas. A través de la página web de los últimos autores se pueden descargar los parches para modificar los backups de los juegos originales y traducir incluso las cinemáticas de este.
New to me!
After fiveyears as head of the organization, frustration with Altman had reachedcritical levels over an issue strikingly similar to one that had arisen atLoopt: his seeming prioritization of his own projects and aspirations overthe organization’s—sometimes even at its expense.
Recurring theme shown with:<br /> Loopt<br /> Y Combinator<br /> Elon Musk
Por ello, si en lo que se refiere al valor de uso eltrabajo contenido en la mercancia sdlo cuenta cualitativa-mente, en lo que tiene que ver con la magnitud de valor,cuenta s6lo cuantitativamente, una vez que ese trabajo sehalla reducido a la condicién de trabajo humano sin mascualidad que ésa. Alli, se trataba del cémo y del qué deltrabajo; aqui del cudnto, de su duracién.
Aquí se nos esta introduciendo al hecho de como es posible equiparar dos mercancías que son cualitativamente diferentes. Es por medio de la medición de la duración del TRABAJO puesto a su creación. Mas abajo en breve se nos insiste que las mercancías en el solo representan la cantidad de trabajo en ella contenida (duración del trabajo util en ellas contenida).
1— “Debate has raged”
Some headline news from the budget: Labour is finally, after an 18-month internal battle, scrapping the two-child benefit cap. How did they get here? Ailbhe is here, as always, with the inside track. Finn
2—“Mortal danger”
Is it all over in Ukraine? The country cannot fight a war for another year, that much is clear. Europe is facing a lonely future, without its American guarantor and with an expansionist, unchecked Russia. Andrew Marr assesses the grave situation. Finn
3—“How did this happen?”
Will Dunn makes an unappetising expedition for the sketch this week. There is “a hulking glacier of crap 500 feet long in the heart of the Oxfordshire countryside.” Criminals used it as an illegal rubbish tip. Will holds his nose and follows Ed Davey once more unto the heap. George
4—“Her rally or his…”
It’s Your Party conference weekend, and it’s going to be massive. Some predict a barney, some a bust-up. We’ve got two pieces for the meantime. First, Megan Kenyon sat down with Jeremy Corbyn to discuss his apology to Your Party members, his breakfast meeting with Zack Polanski and his ambitions for the leadership. Watch here, and read here.
And then we have a weekend essay from the left-wing veteran, Andrew Murray. He has some advice for the Your Party high-ups, most saliently to “to stop doing stupid stuff”. Nicholas
5—“Who was Salman Rushdie?”
This is a major one. When one colleague asked Tanjil how he felt to be writing about Sir Salman Rushdie, he said, “Well, I have been reading him since I was a boy.” And Tanjil’s boyhood is foreground and background in this essay-cum-meditation-cum-memoir. Not a dry eye in the house. Nicholas
To enjoy our latest analysis of politics, news and events, in addition to world-class literary and cultural reviews, click here to subscribe to the New Statesman. You'll enjoy all of the New Statesman's online content, ad-free podcasts and invitations to NS events.
75% off
6—”Here’s the trick”
It takes a village (or un village?). While Will Dunn was inspecting the giant trash heap I was thoroughly investigating this year’s Beaujolais nouveau. Come along for a glass of summer in the bleak mid winter: the unassuming Gamay grape can teach us more than you might think about life. Trust me, or read me, to find out what. Finn
7—“Hymns of isolation”
I’ve always thought of Radiohead as headphone music: that falsetto over those arrangements, it’s something intense and private, not for 20,000 people standing in a field. But, in this wonderful review of the band live, George has won me round to the alternative. Nicholas
8—”Just-so satisfaction” William Nicholson and the pleasure in the paint No one can really agree on how significant William Nicholson’s contribution to 20th century painting was. Probably thanks to all those plodding still lifes. Michael Prodger jumps in to tell me to stop being such a hater – there is real pleasure in the close reading, he says. Convinced? Finn
9—”Like the Stasi in East Berlin”
Ethan Croft scopes out a faction with traction in the Labour party. Blue Labour involves a “bricolage of calls for reindustrialisation and lower migration, inspired by Catholic social teaching”. Others write it off as a load of Tories. Its influence has gone up, then down, then up, and so on. Right now they’re riding high. Ethan never fails to provide your quotient of gossip and Labour infighting. George
Elsewhere Naomi Klein: surrealism against fascism (from the brilliant new mag, Equator)
Why would China want to trade with us?
Guardian investigates the Free Birth Society
New Yorker: Airport lounge wars
Atlantic: Stranger Things comes to an exhausting end
Ryan Lizza/Olivia Nuzzi latest
Gamma the tortoise dies in her prime, at 141 :(
Recipe of the week: Nigel Slater’s pear and chocolate crumble (a crowd pleaser)
And with that…
Something smells fishy! And snail-y. And wine-y. I am talking, of course, about the recent spate of luxury grocery theft. Some thieves have stolen €90,000 worth of snails, intended for the restaurant trade. The producer (funny word for that job, I thought) said he was shocked when he learnt of the disappearance of 450kg of snails from his farm in Bouzy, in – get this – the Champagne region of France. The Times described the theft as “yet another blow to a struggling sector”.
Meanwhile, closer to home in Chelsea, a woman has been caught on CCTV making off with a box of langoustines, stolen from the doorstep of the Michelin-starred restaurant Elystan Street. That’s about £200 worth of big prawns. And in Virginia, a couple posed as wealthy collectors in order to secure private tours of restaurant wine cellars. While one distracted the sommelier, the other swiped. In their haul? A rare 2020 Romanée-Conti, worth $24,000.
I can’t help but think about the Louvre jewel heist in October: a crime of extraordinary effort. To pull it off, you do not just need to outsmart Louvre security, you then have to work out how to sell the things. And as Michael explains, flogging stolen jewels without alerting the authorities is a hard task. Snail theft is starting to sound appealing: no need for a cross-border pan-European crime network or experts in recutting precious stones; just a hot oven, some salted butter, chopped parsley and a splash of dry white, and you have already succeeded.
L'Égalité des Genres : Analyse des Origines du Patriarcat et des Modèles Alternatifs
Ce document de synthèse analyse la thèse selon laquelle le patriarcat n'est pas une loi naturelle et immuable, mais une construction historique.
S'appuyant sur des exemples historiques, archéologiques et anthropologiques, il démontre que les relations entre les genres ont pris des formes très diverses au cours de l'histoire humaine.
L'égalité a non seulement existé, mais elle persiste dans certaines sociétés matrilinéaires contemporaines.
L'analyse révèle que l'émergence des premiers États a été un facteur décisif dans l'institutionnalisation et la propagation mondiale du patriarcat comme outil de contrôle démographique et social.
Le cas de l'Islande illustre que l'égalité moderne est une conquête récente et fragile, fruit d'une lutte collective déterminée, et non un retour à un état originel.
En conclusion, la reconnaissance de la mutabilité des structures sociales ouvre la voie à la possibilité de construire un avenir égalitaire, en comprenant que l'ordre social actuel n'est pas une fatalité.
--------------------------------------------------------------------------------
La perception commune présente la lutte pour les droits des femmes comme un combat sans fin contre un patriarcat qui serait une constante de l'histoire humaine. Cette vision postule une rébellion perpétuelle contre l'exclusion du pouvoir, le travail domestique non rémunéré et la violence.
Le documentaire remet fondamentalement en cause cette narration en posant la question centrale : « les femmes et les hommes n'ont-ils jamais été égaux ? ».
Il suggère que loin d'être une "loi naturelle", l'organisation patriarcale n'est qu'une des nombreuses façons dont les sociétés humaines ont structuré les relations de genre au fil du temps.
L'Islande est souvent citée comme un modèle de l'égalité des genres au 21e siècle, avec une égalité salariale inscrite dans la loi, un congé parental largement adopté par les pères, et des femmes aux plus hautes fonctions politiques. Cependant, cette situation est le résultat d'une lutte récente et intense.
• Le Contexte d'Inégalité : Dans les années 1970-80, la situation était radicalement différente.
L'anthropologue Sigridur Duna Christmunir, cofondatrice du premier parti féministe islandais en 1983, rapporte qu'à l'époque, les femmes gagnaient à peine 60 % du salaire de leurs collègues masculins.
Elle compare la frustration grandissante des femmes à une « éruption volcanique ».
• La Grève Historique du 24 octobre 1975 : Face à cette inégalité, 90 % des femmes islandaises ont refusé de travailler lors du « jour de vacances des femmes » (gena Frida Urine).
Cette grève concernait à la fois le travail rémunéré et les tâches domestiques (cuisine, garde d'enfants, ménage).
◦ Impact : La société a été « totalement paralysée », créant un « état d'urgence total ».
Sigridur Duna Christmunir se souvient :
« Je sentais l'odeur de la viande brûlée dans les rues. Les hommes faisaient la cuisine [...]. L'odeur de la viande brûlée me rappelle toujours cette journée. »
• Conséquences Politiques et Législatives : L'événement a provoqué une accélération spectaculaire des réformes :
◦ 1976 : Entrée en vigueur de la loi sur l'égalité salariale.
◦ 1980 : Élection de Vigdís Finnbogadóttir, première femme au monde élue présidente démocratiquement.
◦ Par la suite, l'entrée au parlement de la « Liste des femmes », dont faisait partie Sigridur Duna, a « révolutionné la politique islandaise ».
L'analyse historique et archéologique révèle des indices d'organisations sociales non patriarcales, contredisant l'idée d'une domination masculine universelle.
Les sagas et les découvertes archéologiques nuancent l'image d'une société viking strictement patriarcale.
• Droits et Autonomie : Les sagas du 13e siècle, comme la Saga de Laxdæla, dépeignent des femmes de la classe supérieure comme intelligentes et volontaires.
Le premier recueil de lois islandais, les Grágás, confirme que les femmes vikings pouvaient divorcer et, en tant que veuves, hériter et gérer leur propre fortune.
• Limites du Pouvoir : Ce statut ne s'appliquait pas à toutes.
Il concernait principalement l'élite et excluait les esclaves.
Surtout, les femmes n'avaient aucun pouvoir politique direct et n'avaient pas voix au chapitre au Þing, l'assemblée populaire. Leur influence était indirecte, via leurs liens avec des hommes puissants.
• La Guerrière de Birka : La découverte en 2017 que la tombe d'un guerrier viking de haut rang, découverte en 1878 en Suède, contenait en réalité le squelette d'une femme (prouvé par l'ADN) a forcé une réévaluation des préjugés sur les rôles de genre, illustrant comment les idées actuelles sont projetées sur le passé.
L'archéologie préhistorique suggère fortement l'existence de sociétés égalitaires.
• Pratiques Funéraires : Dans les tombes somptueuses de l'Âge du Fer, des femmes étaient enterrées avec les mêmes trésors (chars, armes, bijoux) que les hommes, indiquant un statut social potentiellement égal dans la mort comme dans la vie.
• Le Cas de Çatalhöyük : Ce site anatolien, l'une des plus anciennes cités connues (9000 ans), offre des preuves frappantes.
L'analyse des résidus pulmonaires et des squelettes a montré que les hommes et les femmes passaient autant de temps à l'intérieur qu'à l'extérieur et que leur différence de taille était minime.
La journaliste scientifique Angela Saini, qui a étudié le site, rapporte la conclusion des archéologues : « dans les plus anciennes colonies humaines, les hommes et les femmes menaient à peu de choses près la même vie [...] sur un pied d'égalité ».
Le concept de matriarcat est souvent mal interprété. L'anthropologie lui préfère le terme de société matrilinéaire pour décrire des modèles sociaux non patriarcaux.
• Critique du Concept de Matriarcat : L'archéologue Brigitte Röder considère les termes « matriarcat » et « patriarcat » comme des « catégories scientifiques non appropriées » car elles reposent sur un modèle binaire des genres, produit de la société bourgeoise du 18e siècle.
• La Théorie de Marija Gimbutas : Dans les années 70, l'archéologue Marija Gimbutas a postulé l'existence de cultures matriarcales pacifiques en Europe primitive, centrées sur le culte d'une déesse mère, qui auraient été détruites par des tribus de cavaliers patriarcaux.
Cette théorie a été critiquée pour son interprétation très libre des données archéologiques, de nombreux artefacts étant ambigus (la "déesse" pouvant être un phallus).
• Les Sociétés Matrilinéaires : Il existe des preuves de l'existence de plus de 160 cultures matrilinéaires, où la filiation, l'héritage et le statut social se transmettent par la mère.
◦ L'Exemple des Mosuo (Chine) : Ce groupe ethnique vivant autour du lac Lugu offre un exemple contemporain.
▪ Organisation Sociale : La grand-mère est la chef de famille. Tous les membres de la lignée maternelle vivent ensemble. Les femmes gèrent les finances et les affaires importantes.
▪ Relations et Filiation : Les hommes restent vivre dans la maison de leur mère.
Les relations amoureuses prennent la forme du « mariage par visite », où l'homme rend visite à la femme la nuit mais ne vit pas avec elle.
Le frère de la mère assume le rôle de père social pour les enfants.
▪ Stabilité : Selon Jiong Zhidui, directeur du musée des Mosuo, ce modèle familial est « le plus stable qui soit », car l'homogénéité familiale limite les conflits.
5. L'Émergence et l'Imposition du Patriarcat
Le patriarcat ne s'est pas imposé comme une défaite unique et soudaine du genre féminin, mais comme un processus graduel et insidieux, étroitement lié à la naissance des États.
• Le Rôle Clé de l'État : L'émergence des premiers États en Mésopotamie (environ 5000 ans avant notre ère) a été un tournant.
La gestion de larges populations a nécessité un contrôle démographique et une organisation stricte de la société.
• La Codification des Rôles de Genre : Les élites étatiques ont établi une répartition claire des rôles (qui combat, qui s'occupe des enfants, qui travaille) et les ont inscrits dans des listes classées par genre.
Une fois ces différences « gravées dans le marbre », elles ont commencé à être perçues comme naturelles.
• Un Instrument de Contrôle : Le patriarcat est devenu un instrument efficace pour contrôler la population.
Comme le souligne Angela Saini : « Les systèmes de domination ne tirent pas seulement leur pouvoir de la force brute, ils déploient également leur puissance en imposant des idées ».
• L'Expansion Mondiale : Ce modèle s'est répandu à travers le monde par l'expansion des États, qui ont supplanté d'autres formes d'organisation sociale.
Les lois sur le mariage, le divorce et l'adultère sont devenues de plus en plus strictes pour les femmes, légitimant et solidifiant un ordre social qui avantageait une élite masculine au sommet du pouvoir.
L'analyse des différentes formes d'organisation sociale à travers l'histoire humaine mène à une conclusion fondamentale : il n'existe pas de forme "naturelle" de cohabitation entre hommes et femmes.
• La Mutabilité des Sociétés : La diversité des modèles observés prouve que les structures sociales sont des constructions culturelles et peuvent changer. Le patriarcat lui-même est une construction.
• Le Mécanisme du Patriarcat : Son ressort le plus efficace est de « monter les uns contre les autres et nous faire oublier que les sociétés peuvent changer ».
L'idée d'une opposition fondamentale entre hommes et femmes est un produit de ce système.
• Une Lutte Continue : Même dans un pays avancé comme l'Islande, des problèmes comme la violence domestique et la misogynie persistent.
Sigridur Duna Christmunir conclut : « Je me demande s'il y aura un jour une égalité parfaite quelque part. Peut-être n'est-ce qu'un mythe. Quoi qu'il en soit, il reste encore beaucoup à faire. »
• Regarder vers l'Avenir : Il n'est pas nécessaire de prouver l'existence d'un passé parfaitement égalitaire pour imaginer un futur égalitaire. Il suffit de comprendre que ce qui est considéré comme "normal" n'est pas immuable.
La lutte pour les droits des femmes appartient au présent.
Synthèse des Expériences sur les Préjugés et le Racisme Inconscient
Ce document de synthèse analyse une émission d'investigation sociale qui, à travers une série d'expériences en caméra cachée, démontre comment les préjugés et les stéréotypes raciaux influencent de manière inconsciente les comportements, les jugements et même la perception de la réalité.
Cinquante participants, croyant participer à une émission sur "les mystères de notre cerveau", sont confrontés à des situations de la vie quotidienne conçues pour révéler des biais automatiques.
Les résultats sont unanimes : des mécanismes cognitifs comme la catégorisation sociale poussent les individus à privilégier la similarité, à juger plus sévèrement les minorités visibles, et à percevoir une menace accrue en leur présence.
Les expériences révèlent également que ces biais sont acquis dès l'enfance et peuvent mener à une internalisation des stéréotypes par les groupes minoritaires eux-mêmes.
Le contexte s'avère crucial, capable d'atténuer ou de renforcer les stéréotypes.
Finalement, l'émission conclut que si ces mécanismes sont universels, la prise de conscience, l'éducation et la rencontre avec l'autre sont des leviers puissants pour les déconstruire, rappelant que ce qui rassemble les êtres humains est fondamentalement plus fort que ce qui les divise.
L'émission met en scène 50 volontaires qui ignorent le véritable sujet de l'étude : le racisme.
Le faux titre, "Les mystères de notre cerveau", vise à garantir la spontanéité de leurs réactions.
Leurs comportements sont observés et analysés par la présentatrice Marie Drucker, le comédien et réalisateur Lucien Jean-Baptiste, et le psychosociologue Sylvain Delouvée.
L'analyse repose sur plusieurs concepts clés de la psychologie sociale :
• La Catégorisation Sociale : Mécanisme mental naturel et "paresseux" par lequel le cerveau classe les individus en groupes (hommes/femmes, jeunes/vieux, noirs/blancs) pour simplifier la complexité du monde.
Ce processus entraîne une perception accrue des ressemblances au sein de son propre groupe ("nous") et des différences avec les autres groupes ("eux"), pouvant générer méfiance et rejet.
• Le Stéréotype : Défini comme "un ensemble d'idées préconçues que l'on va appliquer à un individu du simple fait de son appartenance à un groupe."
Les stéréotypes ont un caractère automatique et sont intégrés culturellement (médias, éducation, etc.).
• Le Préjugé : C'est l'attitude, positive ou négative, que l'on développe envers un groupe sur la base de stéréotypes.
• La Discrimination : Le comportement qui découle des préjugés, comme le fait d'écarter une personne d'un emploi ou d'un logement.
Sylvain Delouvée souligne que "toutes les expériences que nous allons voir s'appuient sur des études scientifiques parfaitement documentées" et que les mécanismes étudiés (misogynie, sexisme, homophobie, etc.) reposent sur les mêmes fondements.
Les premières expériences démontrent une tendance instinctive à favoriser les individus qui nous ressemblent et à porter des jugements hâtifs basés sur l'apparence physique.
• Dispositif : Les participants entrent un par un dans une salle d'attente où sont assis deux complices, un homme noir (Jean-Philippe) et un homme blanc (Florian), habillés identiquement. Une chaise vide est disponible de chaque côté.
• Résultats : La quasi-totalité des participants choisit de s'asseoir à côté de l'homme blanc.
Même lorsque les complices échangent leurs places pour éliminer un biais lié à la configuration de la pièce, le résultat reste le même.
• Analyse : Selon Sylvain Delouvée, ce comportement n'est pas "raciste en tant que tel" mais relève d'une recherche de similarité.
"On va chercher les gens qui nous ressemblent."
C'est un mécanisme presque "reptilien", hérité des tribus primitives qui se méfiaient de la différence.
Lucien Jean-Baptiste souligne les conséquences dramatiques de ce biais dans des contextes comme "l'accès au logement" ou la recherche d'emploi.
• Dispositif : Les participants agissent en tant que jurés et doivent attribuer une peine de prison (de 3 à 15 ans) à un accusé pour "coups et blessures volontaires ayant entraîné la mort sans l'intention de la donner".
Le crime et le contexte sont identiques pour tous, mais la moitié des participants juge un accusé blanc, l'autre moitié un accusé d'origine maghrébine.
• Résultats : L'accusé d'origine maghrébine écope en moyenne d'une peine de prison plus lourde.
Fait marquant, les participants ont été 5 fois plus nombreux à lui infliger la peine maximale de 15 ans.
• Analyse : Les commentaires des participants révèlent leurs biais : "Il a une bonne tête, il n'a pas l'air d'être violent" pour l'accusé blanc ; "Il n'y a pas de perpétuité ?" pour l'accusé maghrébin.
Delouvée explique que ce jugement est influencé par un "fameux biais intégré" via la culture et les médias, qui associent certaines catégories de personnes à la délinquance.
Les expériences suivantes illustrent comment les stéréotypes raciaux activent automatiquement une perception de danger ou de culpabilité, menant à des réactions discriminatoires.
• Dispositif : En caméra cachée dans la rue, trois comédiens (un homme blanc, Johan ; un homme d'origine maghrébine, Bachir ; une jeune femme blonde, Urielle) scient tour à tour l'antivol d'un vélo.
• Résultats :
◦ Johan (blanc) : Les passants sont indifférents ou bienveillants. Une femme lui dit même qu'il a "une tête de type honnête".
◦ Bachir (maghrébin) : Les réactions sont immédiates et hostiles ("C'est pas bien, de faire ça").
Les passants l'interpellent et appellent la police, qui intervient réellement, forçant l'équipe de tournage à s'interposer.
◦ **Urielle (blonde) :
** Plusieurs hommes s'arrêtent spontanément pour lui proposer leur aide, sans jamais remettre en question la propriété du vélo.
• Analyse : Cette expérience démontre un comportement discriminatoire flagrant.
Le stéréotype s'active automatiquement ("fait-il partie de mon groupe ?"), entraîne un préjugé ("j'ai confiance ou non") et déclenche une action (l'appel à la police).
Lucien Jean-Baptiste témoigne : "Il m'est arrivé combien de fois de rentrer dans des halls d'immeuble et qu'on me demande : 'Qu'est-ce que vous faites là ?'".
Expérience 4 : Le Laser Game (Le Biais du Tireur)
• Dispositif : Les participants, armés d'un pistolet de laser game, doivent neutraliser le plus rapidement possible des figurants armés qui surgissent, tout en évitant de tirer sur ceux qui tiennent un téléphone.
Les figurants sont de différentes origines (blancs, noirs, maghrébins).
• Résultats :
1. Les participants ont tiré près de 4 fois plus sur les figurants désarmés noirs ou d'origine maghrébine que sur les figurants désarmés blancs.
• Analyse : Cette expérience, inspirée de recherches sur les forces de police américaines, illustre le "biais du tireur".
Elle ne signifie pas que les participants sont racistes, mais met en évidence "l'ancrage fort et automatique d'un stéréotype".
Face à une situation menaçante, le cerveau s'accroche aux stéréotypes pour agir, percevant la scène comme "encore plus menaçante qu'elle ne l'est".
Ces expériences démontrent que les stéréotypes raciaux sont absorbés et intégrés très tôt, non pas de manière innée, mais par observation et modélisation du monde adulte.
• Dispositif : Des enfants de 5 à 6 ans assistent à un spectacle de marionnettes où le goûter de Vanessa a été volé. Deux suspects leur sont présentés : Kevin (blanc) et Moussa (noir).
On demande aux enfants de désigner le coupable.
• Résultats : Une majorité d'enfants désigne spontanément Moussa comme le voleur le plus probable.
• Analyse : "Ça commence très tôt", réagit Lucien Jean-Baptiste.
Delouvée précise que cela "ne prouve pas que les enfants sont enclins naturellement à la discrimination" mais qu'ils sont très sensibles aux normes sociales et "incorporent les stéréotypes, les préjugés de leur entourage".
• Dispositif : L'émission présente les résultats d'une réplication du célèbre test des psychologues Kenneth et Mamie Clark (années 1940), issue du documentaire "Noirs en France".
On présente à de jeunes enfants, y compris des enfants noirs, une poupée blanche et une poupée noire et on leur pose des questions ("Quelle est la plus jolie ?", "La moins jolie ?").
• Résultats : Les enfants, y compris les enfants noirs, désignent majoritairement la poupée blanche comme la plus jolie et la poupée noire comme la moins jolie. Une petite fille noire déclare :
"Parce qu'elle est noire... quand je serai grande, je mettrai de la crème pour devenir blanche."
• Analyse : Ce test illustre tragiquement l'internalisation du stéréotype, où les membres d'un groupe minoritaire finissent par incorporer les préjugés négatifs qui leur sont attribués.
Le résultat, constant à travers les décennies, montre la puissance des modèles culturels et de l'entourage.
Cette section regroupe des expériences montrant comment les stéréotypes fonctionnent comme des raccourcis mentaux, comment le contexte peut les moduler et comment même les préjugés "positifs" sont problématiques.
• Dispositif : Six comédiens (quatre blancs, deux asiatiques) jouent une courte scène.
Les participants doivent ensuite réattribuer chaque réplique au bon comédien via une application.
• Résultats : Les participants ont fait quasiment deux fois plus d'erreurs en attribuant les répliques aux comédiens d'origine asiatique qu'aux comédiens blancs.
• Analyse : Ce phénomène illustre que le cerveau perçoit moins les différences "intracatégorielles" pour les groupes qui ne sont pas le nôtre.
Comme l'explique Delouvée, "à partir du moment où nous catégorisons les individus en groupe, ce biais apparaît, cette tendance à voir les membres d'un groupe qui n'est pas le nôtre comme se ressemblant."
• Dispositif : Trois groupes de participants assistent à la même conférence sur l'IA, mais donnée par trois "experts" différents.
1. Groupe 1 : Un comédien blanc prenant un fort accent allemand.
Groupe 2 : Le même comédien prenant un accent marseillais.
Groupe 3 : Un véritable professeur d'université noir, M. Diallo.
• Résultats :
◦ Accent allemand : Jugé "très compétent", "sérieux", mais "moyennement chaleureux".
◦ Accent marseillais : Jugé "moins compétent", "pas convaincant", mais "sympathique" et "très chaleureux". ◦ Professeur noir :
Les participants sont perplexes, peinent à le qualifier et expriment des doutes sur sa légitimité ("Pour moi, il s'agit d'un comédien").
• Analyse : L'accent active un stéréotype qui devient le critère principal de jugement.
L'Allemand est perçu comme rigoureux, le Marseillais comme sympathique mais peu sérieux.
Le professeur noir, lui, ne correspond à aucun stéréotype clair dans l'esprit des participants, ce qui crée une dissonance cognitive.
Le fait qu'il soit le seul véritable expert est la conclusion ironique de l'expérience.
• Dispositif : On demande aux participants qui, d'un sprinteur noir ou blanc, a le plus de chances de gagner une course.
• Résultats : Une majorité répond le sprinteur noir, se basant sur le cliché "les Noirs courent plus vite".
• Analyse : L'émission déconstruit ce stéréotype, expliquant qu'il n'a aucune base scientifique fiable.
Sa persistance est liée à des facteurs historiques (le corps noir associé au labeur physique durant l'esclavage) et socio-culturels (le sport comme l'un des rares modèles de réussite pour les jeunes noirs).
Delouvée qualifie ce type de croyance de "préjugé positif très problématique", car il "retire le mérite aux coureurs noirs de gagner", réduisant leur succès à une essence biologique plutôt qu'à leur travail.
• Dispositif : Trois groupes voient une photo d'une même femme asiatique dans trois contextes différents et doivent donner le premier mot qui leur vient à l'esprit.
1. Photo 1 : Mangeant avec des baguettes.
2. Photo 2 : Se maquillant.
3. Photo 3 : Portant une blouse blanche avec un stéthoscope.
• Résultats :
◦ Photo 1 : Les réponses évoquent l'origine ("Asie", "sushi", "femme asiatique").
◦ Photo 2 : Les réponses évoquent la féminité ("maquillage", "rouge à lèvres", "belle femme").
◦ Photo 3 : Les réponses évoquent la profession ("médecin", "infirmière", "hôpital").
• Analyse : L'expérience démontre que le contexte est capable d'effacer ou de renforcer un stéréotype.
Lorsque le contexte fournit une information plus saillante (le métier, la féminité), l'origine ethnique passe au second plan.
Ces expériences finales explorent les fondements biologiques et cognitifs des préjugés, montrant comment ils peuvent altérer l'empathie et même réécrire les souvenirs.
• Dispositif : L'émission rapporte une étude neurologique où l'on mesure la réaction cérébrale de sujets (blancs et noirs) regardant une main se faire piquer par une aiguille.
• Résultats :
◦ Le cerveau d'un sujet blanc réagit (empathie, "freezing") en voyant une main blanche se faire piquer, mais pas en voyant une main noire.
◦ Inversement, le cerveau d'un sujet noir réagit à la douleur d'une main noire, mais pas d'une main blanche.
◦ Étonnamment, quand la main est de couleur violette (un groupe pour lequel aucun préjugé n'existe), les cerveaux des sujets blancs et noirs réagissent tous les deux avec empathie.
• Analyse : C'est la seule expérience basée sur la neurologie. Elle révèle que "nos préjugés effacent notre empathie à l'égard de personnes différentes de nous".
Le cerveau est plastique, et c'est "par la rencontre, l'éducation" que l'on peut développer une empathie plus universelle.
• Dispositif : Les participants observent une photo de rue où un homme d'origine maghrébine donne une pièce à un homme blanc faisant la manche.
Puis, on teste leur mémoire.
Dans un second temps, une chaîne de bouche-à-oreille est créée pour voir comment l'information se transmet.
• Résultats :
1. Test de mémoire : Près de la moitié des participants décrivent la scène en inversant les rôles, affirmant avoir vu un homme blanc donner de l'argent à un SDF maghrébin.
Un participant, décrivant la scène correctement, la qualifie de "très perturbante".
2. Bouche-à-oreille : Même lorsque la première personne décrit la scène correctement, l'information se déforme rapidement au fil de la transmission.
Les rôles s'inversent, et la scène d'aumône se transforme même en "une altercation".
• Analyse : La photo est "contre-stéréotypique" : elle contredit les attentes du cerveau.
Pour simplifier, le cerveau "corrige" la réalité pour la faire correspondre au stéréotype (le Maghrébin en situation de précarité).
L'expérience du bouche-à-oreille, basée sur une étude classique sur les rumeurs (Allport & Postman, 1940), montre comment "nos croyances et stéréotypes nous permettent de lire cette scène" et de la transformer.
À la fin de la journée, le véritable titre de l'émission, "Sommes-nous tous racistes ?", est révélé aux participants, provoquant choc et prise de conscience.
L'objectif, leur explique-t-on, n'était pas de juger mais de montrer que "nous avons toutes et tous les mêmes mécanismes qui se déclenchent dans nos têtes".
L'ultime expérience vise à déconstruire les divisions.
Répartis en groupes de couleurs distinctes, les participants sont invités à avancer au centre s'ils se sentent concernés par une série de questions, allant du léger ("Qui a déjà revendu des cadeaux de Noël ?") au profondément intime.
• "Qui, parmi vous, se sent très seul ?" Plusieurs personnes, de groupes différents, se rejoignent au centre, partageant une vulnérabilité commune.
• "Qui, parmi vous, a été harcelé pendant sa scolarité ?"
Un grand nombre de participants avancent, partageant des témoignages émouvants sur le harcèlement lié à la couleur de peau ou à d'autres différences.
Cette dernière séquence démontre visuellement que malgré les appartenances à des groupes différents, les expériences humaines fondamentales (joie, amour, solitude, souffrance) sont partagées.
La conclusion de l'émission est un appel à la reconnaissance de cette humanité commune :
"Ce qui nous rassemble est toujours plus fort que ce qui nous divise."
Références bibliographiques
Est-ce que la section de la bibliographie est en général considérée comme un titre de niveau 2, ou bien est-ce qu'il y a une façon spécifique de la baliser ?
d’une l’interdiction
Il semble y avoir une rupture dans la syntaxe de la phrase. Est-ce que le propos original se rapprochait de ceci :
"...les adversaires de l'interdiction"
Les AESH : Pilier Méconnu et Précaire de l'École Inclusive
Ce document de synthèse analyse les conditions de travail, le rôle et le manque de reconnaissance des Accompagnants d'Élèves en Situation de Handicap (AESH), un métier jugé indispensable au projet de l'école inclusive en France.
Il ressort une tension fondamentale : alors que les AESH sont essentiels à la scolarisation de près de 500 000 élèves et expriment une grande fierté pour leur mission, ils subissent une maltraitance institutionnelle systémique.
Cette situation se caractérise par une précarité salariale extrême, une absence de formation qualifiante, une hiérarchie floue et un manque de reconnaissance symbolique et matérielle.
Le "bricolage" permanent et le flou entourant leurs missions, bien que pratiques pour l'institution, abîment non seulement les professionnels mais compromettent également l'idéal de l'école inclusive, en faisant peser sur les AESH la responsabilité de compenser les défaillances du système.
L'analyse met en lumière que la négligence envers cette profession est intrinsèquement liée à la négligence envers les élèves qu'ils accompagnent.
Le métier d'AESH, bien que central pour l'application des lois de 2005 et 2019 sur l'école inclusive, demeure mal connu et peu défini. Il s'inscrit dans la tradition des métiers du "care" (soin à la personne) mais peine à trouver sa place en tant que profession éducative à part entière.
• Trois Axes Fondamentaux : Le travail s'articule autour de trois missions principales :
1. Aide à l'accès aux apprentissages. 2. Aide à la socialisation et à l'intégration dans le groupe-classe. 3. Aide dans les gestes de la vie quotidienne.
• Dimension Relationnelle Centrale : Au-delà de ces missions, le métier est profondément relationnel.
L'AESH est en interaction constante non seulement avec l'élève (souvent en relation duelle), mais aussi avec les enseignants et les autres adultes de l'établissement pour adapter l'environnement aux besoins de l'élève.
• Un Rôle d'Interface : Les AESH agissent comme une "passerelle" ou un "tampon" entre l'élève, le groupe-classe et les enseignants. Ils sont souvent amenés à "absorber les dysfonctionnements du système" pour permettre la scolarisation.
• Des Tâches Dépassant le Cadre Défini : Dans la pratique, les missions peuvent s'étendre bien au-delà du cadre officiel, incluant la surveillance de classes entières ou la réalisation de gestes de soin complexes (comme changer la canule de trachéotomie d'un élève) sans formation adéquate, les transformant de fait en "soignantes".
Un thème majeur est le paradoxe vécu par les AESH : une grande fierté tirée du travail accompli et de son utilité sociale, juxtaposée à un sentiment de maltraitance et de mépris de la part de l'institution.
• Le Manque de Reconnaissance Symbolique : Cette maltraitance se manifeste par des "micro-mises à l'écart" quotidiennes :
◦ Invisibilisation : Oubli systématique dans les communications officielles de la hiérarchie (par exemple, les vœux de vacances).
◦ Exclusion des Espaces Communs : Des "salles des profs" qui ne sont pas renommées en "salles des adultes" ou "des personnels", excluant symboliquement les AESH.
◦ Absence aux Réunions Clés : Les AESH sont souvent "évincées" des Équipes de Suivi de la Scolarisation (ESS), alors que leur parole est cruciale pour l'évaluation des besoins de l'élève.
• Une Hiérarchie Floue et Oppressante : La structure hiérarchique est mal définie, créant une situation inconfortable. Une AESH résume ce sentiment par la phrase :
"Dans mon école, tout le monde est mon chef."
• Le Poids des Injonctions Paradoxales : Les AESH doivent constamment arbitrer entre des valeurs contradictoires.
Par exemple, leur mission est de lutter contre la stigmatisation de l'élève, tout en faisant elles-mêmes partie d'un dispositif (ULIS, accompagnement individualisé) qui est de fait stigmatisant.
Les conditions matérielles des AESH sont marquées par une précarité extrême qui reflète la faible valeur accordée à leur travail par l'institution.
Aspect
Description
Rémunération
Payées au SMIC horaire, avec des contrats à temps incomplet qui placent beaucoup d'entre elles sous le seuil de pauvreté.
Pluri-activité
La majorité des AESH sont contraintes de cumuler plusieurs emplois (cantine, aide aux devoirs, aide à domicile) pour subvenir à leurs besoins.
Primes
L'accès aux primes REP/REP+ (éducation prioritaire) est très récent (2023) et d'un montant faible (environ 80 €).
Pénibilité Physique
Le métier engendre des troubles musculosquelettiques, notamment lors de la prise en charge d'élèves (toilette, déplacements) dans des bâtiments non adaptés.
Charge Émotionnelle
La charge mentale et émotionnelle est immense, liée à la gestion de crises, à la crainte permanente de l'incident ("l'accident"), à l'attachement aux élèves et à l'incertitude sur leur avenir.
L'absence de formation adéquate est un point de critique central, perçu comme un signe de mépris et une source de difficultés professionnelles.
• Une "Adaptation à l'Emploi" Insuffisante : La formation officielle se résume à 60 heures d'adaptation à l'emploi, un héritage des anciens contrats aidés.
Elle est décrite comme une simple transmission d'informations via des diaporamas, et non une véritable formation professionnelle.
De nombreux AESH n'ont même jamais reçu cette formation.
• L'Autoformation comme Norme : Face à la diversité des handicaps (autisme, dyslexie, comorbidités, etc.), les AESH sont contraintes de s'autoformer sur leur temps personnel, en lisant des ouvrages ou en cherchant des informations pour s'adapter aux besoins spécifiques de chaque élève.
• Revendication d'un Statut Professionnel : Les syndicats, comme le SNES-FSU, revendiquent la création d'une véritable formation diplômante de niveau Bac+2, sur le modèle du CAPPEI pour les enseignants spécialisés, afin de reconnaître et de structurer le métier.
Vingt ans après la loi fondatrice de 2005, le projet de l'école inclusive repose en grande partie sur le "bricolage" et le dévouement des AESH, ce qui fragilise l'ensemble du système.
• Des Chiffres Alarmants : Près de 50 000 élèves ayant une notification pour un accompagnement ne sont pas suivis, faute de moyens.
• Un Système Organisé pour Dysfonctionner : Selon Frédéric Grimaux, "si on voulait que l'école inclusive disfonctionne, on s'y prendrait pas autrement".
Le flou des missions, le manque de temps de concertation et la non-reconnaissance du travail collaboratif comme un travail en soi organisent l'échec.
• Exemples d'Indignité : Des situations dégradantes sont rapportées, comme celle d'un élève changé sur des sacs poubelles à l'arrière d'une classe, derrière un paravent improvisé avec des rideaux, illustrant "l'indignité totale de l'enfant, des travailleurs et de l'institution scolaire".
• La Mutualisation (PIAL) : Les Pôles Inclusifs d'Accompagnement Localisés (PIAL) ont accentué la mutualisation des moyens, menant à des situations où des AESH doivent accompagner plusieurs élèves simultanément ou effectuer des missions sur des sites géographiquement éloignés, au détriment de la qualité de l'accompagnement.
Le vocabulaire utilisé à l'école révèle les tensions et les préjugés entourant le handicap.
• La Prolifération des Sigles : Le jargon institutionnel (AESH, AVS, ULIS, ESS, GEVASCO, MDPH) est souvent incompréhensible pour les non-initiés, y compris les familles et les élèves.
• L'Infantilisation : Le fait d'appeler "les enfants" des adolescents au collège contribue à une infantilisation des élèves en situation de handicap.
• La Stigmatisation par le Langage : Le terme "Ulis" devient une insulte dans la cour de récréation ("T'es un Ulis").
Des mots comme "mongol" ou "autiste" sont encore couramment utilisés de manière péjorative, montrant que les mentalités évoluent lentement.
• La Persistance de la "Normalité" : Le concept de "normalité" reste prégnant, y compris chez certains professionnels de l'éducation, ce qui va à l'encontre de la philosophie d'une école inclusive qui devrait valoriser les différences.
La situation des AESH pourrait se dégrader davantage avec les réformes à venir, notamment le Pôle d'Appui à la Scolarité (PAS).
Ce dispositif prévoit d'étendre les missions des AESH à l'ensemble des élèves à besoins éducatifs particuliers (enfants du voyage, allophones, élèves "dys", etc.), et pas seulement ceux en situation de handicap.
Cette évolution fait craindre une augmentation considérable de la charge de travail et de la charge mentale, sans formation ni revalorisation correspondantes, en s'appuyant une fois de plus sur le "dévouement" de ces professionnels.
Author response:
The following is the authors’ response to the previous reviews
Reviewer #3 (Recommendations for the authors):
The authors have done an excellent job of addressing most comments, but my concerns about Figure 5 remain. I appreciate the authors' efforts to address the problem involving Rs being part of the computation on both the x and y axes of Figure 5, but addressing this via simulation addresses statistical significance but overlooks effect size. I think the authors may have misunderstood my original suggestion, so I will attempt to explain it better here. Since "Rs" is an average across all trials, the trials could be subdivided in two halves to compute two separate averages - for example, an average of the even numbered trials and an average of the odd numbered trials. Then you would use the "Rs" from the even numbered trials for one axis and the "Rs" from the odd numbered trials for the other. You would then plot R-Rs_even vs Rf-Rs_odd. This would remove the confound from this figure, and allow the text/interpretation to be largely unchanged (assuming the results continue to look as they do).
We have added a description and the result of the new analysis (line #321 to #332), and a supplementary figure (Suppl. Fig. 1) (line #1464 to #1477).
“We calculated 𝑅<sub>𝑠</sub> in the ordinate and abscissa of Figure 5A-E using responses averaged across different subsets of trials, such that 𝑅<sub>𝑠</sub> was no longer a common term in the ordinate and abscissa. For each neuron, we determined 𝑅<sub>𝑠1</sub> by averaging the firing rates of 𝑅<sub>𝑠</sub> across half of the recorded trials, selected randomly. We also determined 𝑅<sub>𝑠2</sub> by averaging the firing rates of 𝑅<sub>𝑠</sub> across the rest of the trials. We regressed (𝑅 − 𝑅<sub>𝑠1</sub> ) on (𝑅<sub>𝑓</sub> − 𝑅<sub>𝑠2</sub>) , as well as (𝑅<sub>𝑠</sub> - 𝑅<sub>𝑠2</sub>) on (𝑅<sub>𝑓</sub> − 𝑅<sub>𝑠1</sub>), and repeated the procedure 50 times. The averaged slopes obtained with 𝑅<sub>𝑠</sub> from the split trials showed the same pattern as those using 𝑅<sub>𝑠</sub> from all trials (Table 1 and Supplementary Fig. 1), although the coefficient of determination was slightly reduced (Table 1). For ×4 speed separation, the slopes were nearly identical to those shown in Figure 5F1. For ×2 speed separation, the slopes were slightly smaller than those in Figure 5F2, but followed the same pattern (Supplementary Fig. 1). Together, these analysis results confirmed the faster-speed bias at the slow stimulus speeds, and the change of the response weights as stimulus speeds increased.”
An additional remaining item concerns the terminology weighted sum, in the context of the constraint that wf and ws must sum to one. My opinion is that it is non-standard to use weighted sum when the computation is a weighted average, but as long as the authors make their meaning clear, the reader will be able to follow. I suggest adding some phrasing to explain to the reader the shift in interpretation from the more general weighted sum to the more constrained weighted average. Specifically, "weighted sum" first appears on line 268, and then the additional constraint of ws + wf =1 is introduced on line 278. Somewhere around line 278, it would be useful to include a sentence stating that this constraint means the weighted sum is constrained to be a weighted average.
Thanks for the suggestion. We have modified the text as follows. Since we made other modifications in the text, the line numbers are slightly different from the last version.
Line #274 to 275:
“Since it is not possible to solve for both variables, 𝑤<sub>𝑠</sub> and 𝑤<sub>𝑓</sub>, from a single equation (Eq. 5) with three data points, we introduced an additional constraint: 𝑤<sub>𝑠</sub> + 𝑤<sub>𝑓</sub> =1. With this constraint, the weighted sum becomes a weighted average.”
Also on line #309:
“First, at each speed pair and for each of the 100 neurons in the data sample shown in Figure 5, we simulated the response to the bi-speed stimuli (𝑅<sub>𝑒</sub>) as a randomly weighted average of 𝑅<sub>𝑓</sub> and 𝑅<sub>𝑠</sub> of the same neuron.
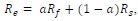
in which 𝑎 was a randomly generated weight (between 0 and 1) for 𝑅<sub>𝑓</sub>, and the weights for 𝑅<sub>𝑓</sub> and 𝑅<sub>𝑠</sub> summed to one.”
RNA-Seq analysis has become a routine task in numerous genomic research labs, driven by the reduced cost of bulk RNA sequencing experiments. These generate billions of reads that require accurate, efficient, effective, and reproducible analysis. But the time required for comprehensive analysis remains a bottleneck. Many labs rely on in-house scripts, making standardization and reproducibility challenging. To address this, we developed RNA-SeqEZPZ, an automated pipeline with a user-friendly point-and-click interface, enabling rigorous and reproducible RNA-Seq analysis without requiring programming or bioinformatics expertise. For advanced users, the pipeline can also be executed from the command line, allowing customization of steps to suit specific requirements.This pipeline includes multiple steps from quality control, alignment, filtering, read counting to differential expression and pathway analysis. We offer two different implementations of the pipeline using either (1) bash and SLURM or (2) Nextflow. The two implementation options allow for straightforward installation, making it easy for individuals familiar with either language to modify and/or run the pipeline across various computing environments.RNA-SeqEZPZ provides an interactive visualization tool using R shiny to easily select the FASTQ files for analysis and compare differentially expressed genes and their functions across experimental conditions. The tools required by the pipeline are packaged into a Singularity image for ease of installation and to ensure replicability. Finally, the pipeline performs a thorough statistical analysis and provides an option to perform batch adjustment to minimize effects of noise due to technical variations across replicates.RNA-SeqEZPZ is freely available and can be downloaded from https://github.com/cxtaslim/RNA-SeqEZPZ.
This work has been peer reviewed in GigaScience (see https://doi.org/10.1093/gigascience/giaf133), which carries out open, named peer-review. These reviews are published under a CC-BY 4.0 license and were as follows:
Reviewer 1: Unitsa Sangket
This research presents a well-designed and powerful program for comprehensive transcriptomics analysis with interactive visualizations. The tool is conceptually strong and user-friendly, requiring only raw reads in FASTQ format to initiate the analysis, with no need for manual quality checks. However, a limitation is that the software must be installed manually, which typically requires access to a high-performance computing (HPC) system and support from a system administrator for installation and server maintenance. As such, non-technical users may find it difficult to install and operate the program independently.
With appropriate revisions based on the comments below, the manuscript has the potential to be significantly improved.
Page 8, line 158-160 "DESeq2 was selected based on findings by Rapaport et al. (2013)40, which demonstrated its superior specificity and sensitivity as well as good control of false positive errors." The findings in the paper titled "bestDEG: a web-based application automatically combines various tools to precisely predict differentially expressed genes (DEGs) from RNA-Seq data" (https://peerj.com/articles/14344) show that DESeq2 achieves higher sensitivity than other tools when applied to newer human RNA-Seq datasets. This finding should be included in the manuscript. For example, DESeq2 was selected based on findings by Rapaport et al. (2013)⁴⁰, which demonstrated its superior specificity and sensitivity as well as good control of false positive errors. Additionally, recent findings from the bestDEG study (cite bestDEG) further support the higher sensitivity of DESeq2 than other tools when applied to newer human RNA-Seq datasets.
Page 6, line 124-125 "Raw reads quality control are then performed using 125 FASTQC18 and QC reports are compiled using MultiQC19." The quality of the trimmed reads can be assessed using FastQC, as demonstrated and summarized in the paper titled "VOE: automated analysis of variant epitopes of SARS-CoV-2 for the development of diagnostic tests or vaccines for COVID-19." (https://peerj.com/articles/17504/) (Page 4, in last paragraph ""(1) Per base sequence quality (median value of each base greater than 25), (2) per sequence quality (median quality greater than 27), (3) perbase N content (N base less than 5% at each read position) and (4) adapter content (adapter sequences at each position less than 5% of all reads)". This point should be mentioned in the manuscript, including the cutoff values for each FastQC metrics used in RNA-SeqEZPZ, as these thresholds may vary. For example, the quality of the trimmed FASTQ reads was assessed based on the four FastQC metrics, as summarized by Lee et al. (2024). The cutoffs for RNA-SeqEZPZ were set as follows: the median value of each base must be greater than [x], the median quality score must be above [y], the percentage of N bases at each read position must be less than [z]%, and the proportion of adapter sequences at each position must be below [xx]% of all reads.
The programs used for counts table creation and alignment process should be mentioned in the manuscript.
The default cutoffs for FDR and log₂ fold change, as well as instructions on how to modify these thresholds, should be clearly stated in the manuscript.
Author response:
The following is the authors’ response to the previous reviews
Reviewer #1 (Public review):
This paper presents a computational model of the evolution of two different kinds of helping ("work," presumably denoting provisioning, and defense tasks) in a model inspired by cooperatively breeding vertebrates. The helpers in this model are a mix of previous offspring of the breeder and floaters that might have joined the group, and can either transition between the tasks as they age or not. The two types of help have differential costs: "work" reduces "dominance value," (DV), a measure of competitiveness for breeding spots, which otherwise goes up linearly with age, but defense reduces survival probability. Both eventually might preclude the helper from becoming a breeder and reproducing. How much the helpers help, and which tasks (and whether they transition or not), as well as their propensity to disperse, are all evolving quantities. The authors consider three main scenarios: one where relatedness emerges from the model, but there is no benefit to living in groups, one where there is no relatedness, but living in larger groups gives a survival benefit (group augmentation, GA), and one where both effects operate. The main claim is that evolving defensive help or division of labor requires the group augmentation; it doesn't evolve through kin selection alone in the authors' simulations.
This is an interesting model, and there is much to like about the complexity that is built in. Individual-based simulations like this can be a valuable tool to explore the complex interaction of life history and social traits. Yet, models like this also have to take care of both being very clear on their construction and exploring how some of the ancillary but potentially consequential assumptions affect the results, including robust exploration of the parameter space. I think the current manuscript falls short in these areas, and therefore, I am not yet convinced of the results. In this round, the authors provided some clarity, but some questions still remain, and I remain unconvinced by a main assumption that was not addressed.
Based on the authors' response, if I understand the life history correctly, dispersers either immediately join another group (with 1-the probability of dispersing), or remain floaters until they successfully compete for a breeder spot or die? Is that correct? I honestly cannot decide because this seems implicit in the first response but the response to my second point raises the possibility of not working while floating but can work if they later join a group as a subordinate. If it is the case that floaters can have multiple opportunities to join groups as subordinates (not as breeders; I assume that this is the case for breeding competition), this should be stated, and more details about how. So there is still some clarification to be done, and more to the point, the clarification that happened only happened in the response. The authors should add these details to the main text. Currently, the main text only says vaguely that joining a group after dispersing " is also controlled by the same genetic dispersal predisposition" without saying how.
In each breeding cycle, individuals have the opportunity to become a breeder, a helper, or a floater. Social role is really just a state, and that state can change in each breeding cycle (see Figure 1). Therefore, floaters may join a group as subordinates at any point in time depending on their dispersal propensity, and subordinates may also disperse from their natal group any given time. In the “Dominance-dependent dispersal propensities” section in the SI, this dispersal or philopatric tendency varies with dominance rank.
We have added: “In each breeding cycle” (L415) to clarify this further.
In response to my query about the reasonableness of the assumption that floaters are in better condition (in the KS treatment) because they don't do any work, the authors have done some additional modeling but I fail to see how that addresses my point. The additional simulations do not touch the feature I was commenting on, and arguably make it stronger (since assuming a positive beta_r -which btw is listed as 0 in Table 1- would make floaters on average be even more stronger than subordinates). It also again confuses me with regard to the previous point, since it implies that now dispersal is also potentially a lifetime event. Is that true?
We are not quite sure where the reviewer gets this idea because we have never assumed a competitive advantage of floaters versus helpers. As stated in the previous revision, floaters can potentially outcompete subordinates of the same age if they attempt to breed without first queuing as a subordinate (step 5 in Figure 1) if subordinates are engaged in work tasks. However, floaters also have higher mortality rates than group members, which makes them have lower age averages. In addition, helpers have the advantage of always competing for an open breeding position in the group, while floaters do not have this preferential access (in Figure S2 we reduce even further the likelihood of a floater to try to compete for a breeding position).
Moreover, in the previous revision (section: “Dominance-dependent dispersal propensities” in the SI) we specifically addressed this concern by adding the possibility that individuals, either floaters or subordinate group members, react to their rank or dominance value to decide whether to disperse (if subordinate) or join a group (if floater). Hence, individuals may choose to disperse when low ranked and then remain on the territory they dispersed to as helpers, OR they may remain as helpers in their natal territory as low ranked individuals and then disperse later when they attain a higher dominance value. The new implementation, therefore, allows individuals to choose when to become floaters or helpers depending on their dominance value. This change to the model affects the relative competitiveness between floaters and helpers, which avoids the assumption that either low- or high-quality individuals are the dispersing phenotype and, instead, allows rank-based dispersal as an emergent trait. As shown in Figure S5, this change had no qualitative impact on the results.
To make this all clearer, we have now added to all of the relevant SI tables a new row with the relative rank of helpers vs floaters. As shown, floaters do not consistently outrank helpers. Rather, which role is most dominant depends on the environment and fitness trade-offs that shape their dispersing and helping decisions.
Some further clarifications: beta_r is a gene that may evolve either positive or negative values, 0 (no reaction norm of dispersal to dominance rank) is the initial value in the simulations before evolution takes place. Therefore, this value may evolve to positive or negative values depending on evolutionary trade-offs. Also, and as clarified in the previous comment, the decision to disperse or not occurs at each breeding cycle, so becoming a floater, for example, is not a lifetime event unless they evolve a fixed strategy (dispersal = 0 or 1).
Meanwhile, the simplest and most convincing robustness check, which I had suggested last round, is not done: simply reduce the increase in the R of the floater by age relative to subordinates. I suspect this will actually change the results. It seems fairly transparent to me that an average floater in the KS scenario will have R about 15-20% higher than the subordinates (given no defense evolves, y_h=0.1 and H_work evolves to be around 5, and the average lifespan for both floaters and subordinates are in the range of 3.7-2.5 roughly, depending on m). That could be a substantial advantage in competition for breeding spots, depending on how that scramble competition actually works. I asked about this function in the last round (how non-linear is it?) but the authors seem to have neglected to answer.
As we mentioned in the previous comment above, we have now added the relative rank between helpers and floaters to all the relevant SI tables, to provide a better idea of the relative competitiveness of residents versus dispersers for each parameter combination. As seen in Table S1, the competitive advantage of floaters is only marginally in the favor for floaters in the “Only kin selection” implementation. This advantage only becomes more pronounced when individuals can choose whether to disperse or remain philopatric depending on their rank. In this case, the difference in rank between helpers and floaters is driven by the high levels of dispersal, with only a few newborns (low rank) remaining briefly in the natal territory (Table S6). Instead, the high dispersal rates observed under the “Only kin selection” scenario appear to result from the low incentives to remain in the group when direct fitness benefits are absent, unless indirect fitness benefits are substantially increased. This effect is reinforced by the need for task partitioning to occur in an all-or-nothing manner (see the new implementation added to the “Kin selection and the evolution of division of labor” in the Supplementary materials; more details in following comments).
In addition, we specifically chose not to impose this constraint of forcing floaters to be lower rank than helpers because doing so would require strong assumptions on how the floaters rank is determined. These assumptions are unlikely to be universally valid across natural populations (and probably not commonly met in most species) and could vary considerably among species. Therefore, it would add complexity to the model while reducing generalizability.
As stated in the previous revision, no scramble competition takes place, this was an implementation not included in the final version of the manuscript in which age did not have an influence in dominance. Results were equivalent and we decided to remove it for simplicity prior to the original submission, as the model is already very complex in the current stage; we simply forgot to remove it from Table 1, something we explained in the previous round of revisions.
More generally, I find that the assumption (and it is an assumption) floaters are better off than subordinates in a territory to be still questionable. There is no attempt to justify this with any data, and any data I can find points the other way (though typically they compare breeders and floaters, e.g.: https://bioone.org/journals/ardeola/volume-63/issue-1/arla.63.1.2016.rp3/The-Unknown-Life-of-Floaters--The-Hidden-Face-of/10.13157/arla.63.1.2016.rp3.full concludes "the current preliminary consensus is that floaters are 'making the best of a bad job'."). I think if the authors really want to assume that floaters have higher dominance than subordinates, they should justify it. This is driving at least one and possibly most of the key results, since it affects the reproductive value of subordinates (and therefore the costs of helping).
We explicitly addressed this in the previous revision in a long response about resource holding potential (RHP). Once again, we do NOT assume that dispersers are at a competitive advantage to anyone else. Floaters lack access to a territory unless they either disperse into an established group or colonize an unoccupied territory. Therefore, floaters endure higher mortalities due to the lack of access to territories and group living benefits in the model, and are not always able to try to compete for a breeding position.
The literature reports mixed evidence regarding the quality of dispersing individuals, with some studies identifying them as low-quality and others as high-quality, attributing this to them experiencing fewer constraints when dispersing that their counterparts (e.g. Stiver et al. 2007 Molecular Ecology; Torrents‐Ticó, et al. 2018 Journal of Zoology). Additionally, dispersal can provide end-of-queue individuals in their natal group an opportunity to join a queue elsewhere that offers better prospects, outcompeting current group members (Nelson‐Flower et al. 2018 Journal of Animal Ecology). Moreover, in our model floaters do not consistently have lower dominance values or ranks than helpers, and dominance value is often only marginally different.
In short, we previously addressed the concern regarding the relative competitiveness of floaters compared to subordinate group members. To further clarify this point here, we have now included additional data on relative rank in all of the relevant SI tables. We hope that these additions will help alleviate any remaining concerns on this matter.
Regarding division of labor, I think I was not clear so will try again. The authors assume that the group reproduction is 1+H_total/(1+H_total), where H_total is the sum of all the defense and work help, but with the proviso that if one of the totals is higher than "H_max", the average of the two totals (plus k_m, but that's set to a low value, so we can ignore it), it is replaced by that. That means, for example, if total "work" help is 10 and "defense" help is 0, total help is given by 5 (well, 5.1 but will ignore k_m). That's what I meant by "marginal benefit of help is only reduced by a half" last round, since in this scenario, adding 1 to work help would make total help go to 5.5 vs. adding 1 to defense help which would make it go to 6. That is a pretty weak form of modeling "both types of tasks are necessary to successfully produce offspring" as the newly added passage says (which I agree with), since if you were getting no defense by a lot of food, adding more food should plausibly have no effect on your production whatsoever (not just half of adding a little defense). This probably explains why often the "division of labor" condition isn't that different than the no DoL condition.
The model incorporates division of labor as the optimal strategy for maximizing breeder productivity, while penalizing helping efforts that are limited to either work or defense alone. Because the model does not intend to force the evolution of help as an obligatory trait (breeders may still reproduce in the absence of help; k<sub>0</sub> ≠ 0), we assume that the performance of both types of task by the helpers is a non-obligatory trait that complements parental care.
That said, we recognize the reviewer’s concern that the selective forces modeled for division of labor might not be sufficient in the current simulations. To address this, we have now introduced a new implementation, as discussed in the “Kin selection and the evolution of division of labor” section in the SI. In this implementation, division of labor becomes obligatory for breeders to gain a productivity boost from the help of subordinate group members. The new implementation tests whether division of labor can arise solely from kin selection benefits. Under these premises, philopatry and division of labor do emerge through kin selection, but only when there is a tenfold increase in productivity per unit of help compared to the default implementation. Thus, even if such increases are biologically plausible, they are more likely to reflect the magnitudes characteristic of eusocial insects rather than of cooperatively breeding vertebrates (the primary focus of this model). Such extreme requirements for productivity gains and need for coordination further suggest that group augmentation, and not kin selection, is probably the primary driving force particularly in harsh environments. This is now discussed in L210-213.
Reviewer #2 (Public review):
Summary:
This paper formulates an individual-based model to understand the evolution of division of labor in vertebrates. The model considers a population subdivided in groups, each group has a single asexually-reproducing breeder, other group members (subordinates) can perform two types of tasks called "work" or "defense", individuals have different ages, individuals can disperse between groups, each individual has a dominance rank that increases with age, and upon death of the breeder a new breeder is chosen among group members depending on their dominance. "Workers" pay a reproduction cost by having their dominance decreased, and "defenders" pay a survival cost. Every group member receives a survival benefit with increasing group size. There are 6 genetic traits, each controlled by a single locus, that control propensities to help and disperse, and how task choice and dispersal relate to dominance. To study the effect of group augmentation without kin selection, the authors cross-foster individuals to eliminate relatedness. The paper allows for the evolution of the 6 genetic traits under some different parameter values to study the conditions under which division of labour evolves, defined as the occurrence of different subordinates performing "work" and "defense" tasks. The authors envision the model as one of vertebrate division of labor.
The main conclusion of the paper is that group augmentation is the primary factor causing the evolution of vertebrate division of labor, rather than kin selection. This conclusion is drawn because, for the parameter values considered, when the benefit of group augmentation is set to zero, no division of labor evolves and all subordinates perform "work" tasks but no "defense" tasks.
Strengths:
The model incorporates various biologically realistic details, including the possibility to evolve age polytheism where individuals switch from "work" to "defence" tasks as they age or vice versa, as well as the possibility of comparing the action of group augmentation alone with that of kin selection alone.
Weaknesses:
The model and its analysis is limited, which makes the results insufficient to reach the main conclusion that group augmentation and not kin selection is the primary cause of the evolution of vertebrate division of labor. There are several reasons.
First, the model strongly restricts the possibility that kin selection is relevant. The two tasks considered essentially differ only by whether they are costly for reproduction or survival. "Work" tasks are those costly for reproduction and "defense" tasks are those costly for survival. The two tasks provide the same benefits for reproduction (eqs. 4, 5) and survival (through group augmentation, eq. 3.1). So, whether one, the other, or both tasks evolve presumably only depends on which task is less costly, not really on which benefits it provides. As the two tasks give the same benefits, there is no possibility that the two tasks act synergistically, where performing one task increases a benefit (e.g., increasing someone's survival) that is going to be compounded by someone else performing the other task (e.g., increasing that someone's reproduction). So, there is very little scope for kin selection to cause the evolution of labour in this model. Note synergy between tasks is not something unusual in division of labour models, but is in fact a basic element in them, so excluding it from the start in the model and then making general claims about division of labour is unwarranted. I made this same point in my first review, although phrased differently, but it was left unaddressed.
The scope of this paper was to study division of labor in cooperatively breeding species with fertile workers, in which help is exclusively directed towards breeders to enhance offspring production (i.e., alloparental care), as we stated in the previous review. Therefore, in this context, helpers may only obtain fitness benefits directly or indirectly by increasing the productivity of the breeders. This benefit is maximized when division of labor occurs between group members as there is a higher return for the least amount of effort per capita. Our focus is in line with previous work in most other social animals, including eusocial insects and humans, which emphasizes how division of labor maximizes group productivity. This is not to suggest that the model does not favor synergy, as engaging in two distinct tasks enhances the breeders' productivity more than if group members were to perform only one type of alloparental care task. We have expanded on the need for division of labor by making the performance of each type of task a requirement to boost the breeders productivity, see more details in a following comment.
Second, the parameter space is very little explored. This is generally an issue when trying to make general claims from an individual-based model where only a very narrow parameter region has been explored of a necessarily particular model. However, in this paper, the issue is more evident. As in this model the two tasks ultimately only differ by their costs, the parameter values specifying their costs should be varied to determine their effects. Instead, the model sets a very low survival cost for work (yh=0.1) and a very high survival cost for defense (xh=3), the latter of which can be compensated by the benefit of group augmentation (xn=3). Some very limited variation of xh and xn is explored, always for very high values, effectively making defense unevolvable except if there is group augmentation. Hence, as I stated in my previous review, a more extensive parameter exploration addressing this should be included, but this has not been done. Consequently, the main conclusion that "division of labor" needs group augmentation is essentially enforced by the limited parameter exploration, in addition to the first reason above.
We systematically explored the parameter landscape and report in the body of the paper only those ranges that lead to changes in the reaction norms of interest (other ranges are explored in the SI). When looking into the relative magnitude of cost of work and defense tasks, it is important to note that cost values are not directly comparable because they affect different traits. However, the ranges of values capture changes in the reaction norms that lead to rank-depending task specialization.
To illustrate this more clearly, we have added a new section in the SI (Variation in the cost of work tasks instead of defense tasks section) showing variation in y<sub>h</sub>, which highlights how individuals trade off the relative costs of different tasks. As shown, the results remain consistent with everything we showed previously: a higher cost of work (high y<sub>h</sub>) shifts investment toward defense tasks, while a higher cost of defense (high x<sub>h</sub>) shifts investment toward work tasks.
Importantly, additional parameter values were already included in the SI of the previous revision, specifically to favor the evolution of division of labor under only kin selection. Basically, division of labor under only kin selection does happen, but only under conditions that are very restrictive, as discussed in the “Kin selection and the evolution of division of labor” section in the SI. We have tried to make this point clearer now (see comments to previous reviewer above, and to this reviewer right below).
Third, what is called "division of labor" here is an overinterpretation. When the two tasks evolve, what exists in the model is some individuals that do reproduction-costly tasks (so-called "work") and survival-costly tasks (so-called "defense"). However, there are really no two tasks that are being completed, in the sense that completing both tasks (e.g., work and defense) is not necessary to achieve a goal (e.g., reproduction). In this model there is only one task (reproduction, equation 4,5) to which both "tasks" contribute equally and so one task doesn't need to be completed if the other task compensates for it. So, this model does not actually consider division of labor.
Although it is true that we did not make the evolution of help obligatory and, therefore, did not impose division of labor by definition, the assumptions of the model nonetheless create conditions that favor the emergence of division of labor. This is evident when comparing the equilibria between scenarios where division of labor was favored versus not favored (Figure 2 triangles vs circles).
That said, we acknowledge the reviewer’s concern that the selective forces modeled in our simulations may not, on their own, be sufficient to drive the evolution of division of labor under only kin selection. Therefore, we have now added a section where we restrict the evolution of help to instances in which division of labor is necessary to have an impact on the dominant breeder productivity. Under this scenario, we do find division of labor (as well as philopatry) evolving under only kin selection. However, this behavior only evolves when help highly increases the breeders’ productivity (by a factor of 10 what is needed for the evolution of division of labor under group augmentation). Therefore, group augmentation still appears to be the primary driver of division of labor, while kin selection facilitates it and may, under certain restrictive circumstances, also promote division of labor independently (discussed in L210-213).
Reviewer #1 (Recommendations for the authors):
I really think you should do the simulations where floaters do not come out ahead by floating. That will likely change the result, but if it doesn't, you will have a more robust finding. If it does, then you will have understood the problem better.
As we outlined in the previous round of revisions, implementing this change would be challenging without substantially increasing model complexity and reducing its general applicability, as it would require strong assumptions that could heavily influence dispersal decisions. For instance, by how much should helpers outcompete floaters? Would a floater be less competitive than a helper regardless of age, or only if age is equal? If competitiveness depends on equal age, what is the impact of performing work tasks given that workers always outcompete immigrants? Conversely, if floaters are less competitive regardless of age, is it realistic that a young individual would outcompete all immigrants? If a disperser finds a group immediately after dispersal versus floating for a while, is the dominance value reduced less (as would happen to individuals doing prospections before dispersal)?
Clearly it is not as simple as the referee suggests because there are many scenarios that would need to be considered and many assumptions made in doing this. As we explained to the points above, we think our treatment of floaters is consistent with the definition of floaters in the literature, and our model takes a general approach without making too many assumptions.
Reviewer #2 (Recommendations for the authors):
The paper's presentation is still unclear. A few instances include the following. It is unclear what is plotted in the vertical axes of Figure 2, which is T but T is a function of age t, so this T is presumably being plotted at a specific t but which one it is not said.
The values graphed are the averages of the phenotypically expressed tasks, not the reaction norms per se. We have now rewritten the the axis to “Expressed task allocation T (0 = work, 1 = defense)” to increase clarity across the manuscript.
The section titled "The need for division of labor" in the methods is still very unclear.
We have rephased this whole section to improve clarity.
L'Idéologie et l'Esprit Critique : Synthèse du Débat
Ce document synthétise les arguments et les conclusions du débat sur la compatibilité entre l'idéologie et l'esprit critique, opposant Gwen Pallarès (position positive) et Pascal Wagner-Egger (position négative).
Gwen Pallarès soutient que l'idéologie est non seulement compatible mais souvent un prérequis et un moteur pour l'esprit critique, arguant que tout individu possède une idéologie qui structure sa pensée et motive sa curiosité.
Pascal Wagner-Egger défend la position selon laquelle l'idéologie est fondamentalement un obstacle à la pensée critique et à la démarche scientifique, un ensemble de préconceptions qu'il faut activement chercher à minimiser en s'appuyant sur des données empiriques.
Malgré leurs positions de départ opposées, un consensus significatif a émergé sur plusieurs points.
Les deux intervenants s'accordent sur l'existence d'un "point de bascule" ou d'un "saut qualitatif" où l'idéologie devient incompatible avec l'esprit critique, notamment dans les cas de fanatisme, de radicalisation ou lorsque les croyances fondamentales liées à l'identité sont menacées.
Ils reconnaissent également que l'idéologie peut agir comme une puissante "motivation épistémique", incitant à la recherche et à l'analyse.
La divergence principale réside dans la nature de cette relation.
Pour Pascal, la motivation induite par l'idéologie est une arme à double tranchant qui exige une vigilance épistémique accrue pour contrer les biais.
Pour Gwen, cette motivation est un moteur fondamental, et la volonté de se placer dans une position "centriste" pour éviter les biais est elle-même une position idéologique.
Cette différence de perspective trouve sa source dans des divergences épistémologiques plus profondes sur la nature des sciences, la construction des données et la porosité entre les domaines scientifique et politique.
Le débat, animé par Peter Barret, a pour objectif d'explorer la question "L’idéologie est-elle compatible avec l’esprit critique ?" dans un format visant à être constructif et à clarifier les positions plutôt qu'à encourager la contre-argumentation.
Les deux intervenants sont :
• Gwen Pallarès : Maîtresse de conférence en didactique des sciences à l'Université de Reims Champagne-Ardenne, défendant la position positive.
• Pascal Wagner-Egger : Psychologue social à l'Université de Fribourg, défendant la position négative.
Les intervenants se sont accordés sur les définitions suivantes pour encadrer le débat.
Terme
Définition de Gwen Pallarès (Psychologie Sociale)
Définition de Pascal Wagner-Egger (Larousse)
Idéologie
Un système d'attitudes, de croyances et de stéréotypes qui coordonne les actions des institutions et des individus.
Ce système vise notamment à justifier ou à critiquer les hiérarchies sociales existantes (ex: féminisme vs. masculinisme).
Un système d'idées générales constituant un corps de doctrine philosophique et politique à la base d'un comportement individuel ou collectif (ex: idéologie marxiste, nationaliste).
Esprit Critique : Défini par Gwen Pallarès comme un ensemble de compétences (analyse, évaluation d'arguments et d'informations) et de dispositions (humilité intellectuelle, curiosité, réflexivité).
Cet ensemble est orienté vers la prise de décision raisonnée ("Qu'est-ce qu'il convient de croire ou de faire ?") et s'opérationnalise souvent par une argumentation de bonne qualité.
L'argument central de Gwen Pallarès repose sur l'universalité de l'idéologie :
• Tout le monde a une idéologie : La pensée de chaque individu est structurée par des systèmes de croyances, d'attitudes et de stéréotypes.
Refuser cela serait nier une réalité fondamentale du fonctionnement humain.
• L'incompatibilité rendrait l'esprit critique impossible : Si l'idéologie était incompatible avec l'esprit critique, et puisque tout le monde a une idéologie, alors personne ne pourrait avoir d'esprit critique.
• L'esprit critique est un spectre : Tout le monde possède des compétences minimales d'analyse et d'argumentation, même si leur application peut être biaisée (ex: biais de confirmation où l'on critique plus durement les informations qui contredisent nos croyances).
• Limite de la compatibilité : Elle concède que les formes extrêmes d'idéologie (radicalisation, emprise sectaire, fanatisme) sont, elles, incompatibles avec l'esprit critique car elles poussent à une acceptation acritique des informations.
Pascal Wagner-Egger ancre sa position dans l'histoire des sciences et la psychologie sociale :
• La science s'est construite contre l'idéologie : Il cite l'exemple de la science luttant contre l'idéologie religieuse, qu'il qualifie de "régime totalitaire".
• La "méthode idéologique" : Elle postule que la vérité est contenue dans un texte fondateur (la Bible, Le Capital) et que toute observation doit s'y conformer. C'est l'inverse de la méthode scientifique.
• L'ennemi intérieur et extérieur : L'idéologie est un obstacle institutionnel (externe) mais aussi un obstacle interne aux chercheurs eux-mêmes.
Il cite Gaston Bachelard et ses "obstacles épistémologiques" (opinion, connaissance générale) comme précurseurs de la notion de biais cognitifs.
• Le rôle des données empiriques : La méthode scientifique est le principal outil pour limiter les effets de nos idéologies et tester nos préconceptions contre la réalité.
Il cite des études montrant plus de dogmatisme et de complotisme aux extrêmes politiques.
Les positions des deux débatteurs sont fortement influencées par leurs expériences personnelles et académiques.
• Pascal Wagner-Egger : Son parcours l'a mené des sciences "dures" vers les sciences sociales.
Il a été frappé par ce qu'il a perçu comme des positions idéologiques dogmatiques chez certains collègues, notamment le rejet des méthodes quantitatives qualifiées d'"impérialisme anglo-saxon".
Cette expérience a forgé sa conviction que l'idéologie peut nuire à la recherche de la vérité scientifique et qu'il faut s'en prémunir.
• Gwen Pallarès : Son parcours est inverse, des mathématiques vers la didactique des sciences.
L'étude approfondie des controverses socio-scientifiques (IA, genre, écologie) pour sa thèse l'a progressivement politisée.
Son engagement politique est devenu un moteur pour produire une recherche scientifique plus rigoureuse et utile socialement, notamment pour l'éducation.
Pour elle, l'idéologie n'est pas un obstacle à la rigueur, mais ce qui la motive.
Le débat a révélé un terrain d'entente plus large qu'attendu, tout en précisant la nature des désaccords.
1. Le "Point de Bascule" : Les deux intervenants s'accordent sur le fait qu'il existe un seuil où l'idéologie devient incompatible avec l'esprit critique.
Ce seuil est atteint dans les cas de fanatisme, de radicalisation, ou lorsque des croyances fondamentales liées à l'identité de la personne sont menacées, rendant le dialogue et la remise en question impossibles.
2. La Motivation Épistémique : Il est admis par les deux parties que l'idéologie est un puissant moteur.
Un engagement idéologique (ex: écologiste, féministe) peut stimuler la curiosité intellectuelle, la recherche d'informations et la volonté d'analyser des arguments, qui sont des dispositions centrales de l'esprit critique.
3. L'Universalité de l'Idéologie : Les deux débatteurs partagent le postulat que chaque individu, y compris les scientifiques, possède une ou plusieurs idéologies qui structurent sa vision du monde.
La principale divergence ne porte pas tant sur la compatibilité en soi, mais sur la nature de la relation entre idéologie et esprit critique.
Point de Divergence
Position de Pascal Wagner-Egger
Position de Gwen Pallarès
Nature du lien
Une arme à double tranchant : L'idéologie motive, mais elle biaise simultanément.
Il est donc crucial d'exercer une vigilance épistémique accrue et de chercher à minimiser l'influence de ses propres idéologies, notamment en les confrontant aux données empiriques.
Un moteur fondamental : L'idéologie est le moteur principal de la recherche et de l'engagement critique. Tenter de l'annuler est illusoire.
La posture qui consiste à se vouloir "au centre" pour être moins biaisé est elle-même une idéologie ("biais du juste milieu").
Épistémologie sous-jacente
Plus proche de l'empirisme et du rationalisme critique (citant Popper et se revendiquant de Lakatos).
Les données, bien que partiellement construites, permettent par triangulation de s'approcher d'une réalité indépendante de la méthode.
Plus proche du constructivisme et du pragmatisme. Les données sont fondamentalement construites par la méthodologie, qui est elle-même issue de cadres théoriques.
La distinction entre science et politique est plus poreuse.
Rapport Science / Politique
Vise à maintenir une distinction claire. Dans le domaine scientifique, les données doivent primer sur les préconceptions. Dans le domaine politique, l'idéologie et le militantisme sont utiles et nécessaires.
La distinction est moins nette. Le travail scientifique est intrinsèquement lié à des enjeux de société et peut être motivé par un engagement politique, cet engagement pouvant être un gage de rigueur pour rendre la science utile.
Document d'information : Rencontres interprofessionnelles de la Miprof 2025
Résumé Exécutif
Ce document synthétise les analyses, données et stratégies clés présentées lors des Rencontres interprofessionnelles de la Miprof 2025.
La conférence a souligné l'ampleur systémique des violences sexistes et sexuelles en France, tout en dressant un état des lieux des avancées législatives, des défis judiciaires et des nouvelles menaces. Les points saillants sont les suivants :
1. Une ambition d'éradication et un cadre législatif renforcé : L'objectif politique affirmé n'est pas de réduire mais d'éradiquer totalement les violences.
Des avancées législatives majeures ont été réalisées, notamment l'introduction de la notion de non-consentement dans la définition pénale du viol, la reconnaissance du contrôle coercitif et l'allongement des délais de prescription pour les crimes sexuels sur mineurs. Une loi-cadre transpartisane est en préparation pour unifier la réponse institutionnelle.
2. Des données alarmantes confirmant un fléau de masse : Les statistiques pour 2023-2024 révèlent une prévalence massive des violences. Chaque jour, 3,5 femmes sont victimes de féminicide (direct ou indirect) ou de tentative de féminicide par leur partenaire ou ex-partenaire.
Les enfants représentent plus de la moitié des victimes de violences sexistes et sexuelles enregistrées. L'analyse confirme que les femmes sont victimes de manière disproportionnée (85 % des victimes de violences sexuelles) et que les agresseurs, majoritairement des hommes, sont le plus souvent des proches, faisant du foyer le lieu le plus dangereux.
3. L'urgence de la prévention des féminicides et de la protection des enfants co-victimes : L'analyse des homicides conjugaux ("rétex") montre que dans la moitié des cas, des signaux d'alerte préexistaient.
Les experts appellent à un changement de paradigme : se focaliser sur l'auteur, mieux "criticiser" les situations à haut risque en identifiant des marqueurs clés comme la strangulation et les menaces de mort, et utiliser l'ordonnance de protection de manière préventive.
Le "suicide forcé", angle mort des féminicides, représente près de 300 décès de femmes par an. Les enfants exposés aux violences conjugales sont reconnus comme des victimes directes subissant des traumatismes sévères, nécessitant une protection judiciaire coordonnée et des outils de prévention ciblés comme le film "Selma".
4. L'émergence de nouveaux champs de bataille : la cyberviolence et les mouvements masculinistes : Les cyberviolences sexistes et sexuelles touchent massivement les jeunes, avec des conséquences psychologiques graves et un très faible taux de plainte (12 %).
Parallèlement, la montée en puissance de mouvements masculinistes organisés, professionnels et très bien financés (plus d'un milliard de dollars en Europe) constitue une menace directe. Ces mouvements attaquent les dispositifs d'aide comme le 3919, instrumentalisent les droits des enfants pour affaiblir ceux des mères et cherchent à saper les fondements de l'égalité via un lobbying politique et une présence médiatique accrus.
En conclusion, la journée a mis en lumière la nécessité d'une vigilance constante, d'une formation continue de tous les professionnels, d'une meilleure coordination inter-institutionnelle et d'une réponse ferme et structurée face aux nouvelles stratégies des agresseurs et de leurs relais idéologiques.
--------------------------------------------------------------------------------
Les rencontres ont été ouvertes par une intervention de la Ministre de l'égalité entre les femmes et les hommes, qui a fixé un cap clair : l'objectif n'est pas de réduire ou d'atténuer les violences, mais de les éradiquer complètement et définitivement. Cette ambition se traduit par un renforcement de l'arsenal juridique et une adaptation constante des stratégies d'intervention.
La ministre a rappelé la diversité des formes de violences faites aux femmes, qui ne cessent d'évoluer :
• Physiques, sexuelles, psychologiques
• Économiques, numériques, chimiques
• Liées à la traite des êtres humains, souvent dissimulées derrière des façades comme de prétendus salons de massage.
Cette adaptabilité des violences exige une réponse innovante et proactive de la part des pouvoirs publics.
L'année 2025 est présentée comme celle du "renforcement et de la clarté", marquée par plusieurs avancées législatives majeures :
• Définition du viol et non-consentement : La proposition de loi introduisant la notion de non-consentement dans la définition pénale du viol est une avancée historique. Elle inscrit dans la loi que "ne pas dire non, ce n'est pas dire oui", mettant fin à une ambiguïté qui protégeait les auteurs. Le silence, la sidération ou la peur ne sont pas des consentements.
• Délais de prescription pour les viols sur mineurs : Une loi a prolongé les délais de prescription, reconnaissant qu'il faut parfois des décennies pour que la parole se libère. L'objectif final reste cependant l'imprescriptibilité des crimes sexuels commis sur les enfants.
• Reconnaissance du contrôle coercitif : Pour la première fois, le droit français reconnaît le contrôle coercitif, un pas décisif pour identifier les violences conjugales avant les coups.
Celles-ci commencent par des actes comme la confiscation du téléphone, l'isolement social, l'installation de la peur, le contrôle des comptes bancaires, l'hypercontrôle et l'humiliation répétée.
Pour assurer une vision globale et cohérente, un groupe de travail parlementaire transpartisan a été mis en place pour préparer une loi-cadre contre les violences sexuelles et intrafamiliales.
L'objectif est de bâtir une "nation mobilisée" où la détection, l'écoute, la protection et la coordination deviennent des réflexes pour tous les professionnels et citoyens.
Une alerte a été lancée contre la montée des mouvements masculinistes qui cherchent à relativiser la violence et à banaliser les inégalités.
Leur discours, souvent masqué derrière la "liberté d'expression", vise à faire reculer les droits des femmes.
La réponse doit être ferme : "La liberté d'expression n'a jamais été la liberté de nuire" et l'égalité femmes-hommes est un principe fondateur de la République, non une opinion.
--------------------------------------------------------------------------------
La présentation de la Lettre n°25 de l'Observatoire national des violences faites aux femmes a objectivé l'ampleur du phénomène à travers des données multi-sources (Ministères de l'Intérieur et de la Justice, associations).
Catégorie de Violence
Donnée Clé
Source
Fréquence
Toutes les 23 secondes, une femme subit du harcèlement, de l'exhibition sexuelle ou un envoi non sollicité de contenu sexuel.
Miprof
Toutes les 2 minutes, une femme est victime de viol, tentative de viol ou agression sexuelle.
Miprof
Violences Sexuelles (Victimation déclarée 2023)
1 809 000 personnes majeures se sont déclarées victimes.
Enquête VRS (SSMSI)
Détail pour les femmes
Harcèlement sexuel : 1 155 000
Enquête VRS (SSMSI)
Exhibition / Envoi contenu sexuel non sollicité : 369 000
Enquête VRS (SSMSI)
Viol ou tentative de viol : 159 000
Enquête VRS (SSMSI)
Agression sexuelle : 222 000
Enquête VRS (SSMSI)
Violences au sein du couple (Victimation déclarée 2023)
376 000 femmes majeures se sont déclarées victimes.
Enquête VRS (SSMSI)
Violences enregistrées par les forces de l'ordre (2024)
Violences sexuelles : 94 900 filles et femmes victimes (52 % de mineures).
Police / Gendarmerie
Violences au sein du couple : 228 000 femmes victimes.
Police / Gendarmerie
L'analyse des féminicides inclut désormais les "féminicides indirects", à savoir le harcèlement conduisant au suicide.
• Féminicides directs : 107 femmes tuées.
• Tentatives de féminicides directs : 270 femmes.
• Harcèlement par conjoint/ex ayant conduit au suicide ou à sa tentative : 906 femmes.
• Total combiné : 1 283 femmes que leur partenaire ou ex-partenaire a tuées, tenté de tuer ou poussées au suicide. Cela représente 3,5 femmes par jour.
• Enfants devenus orphelins en 2024 : 94. Depuis 2011, ce chiffre s'élève à 1 473.
Indicateur
Chiffre 2024 / 2025
Source
Poursuites (Violences sexuelles)
11 200 mis en cause poursuivis (sur 43 700 cas traités).
SDSE (Justice)
Condamnations (Violences sexuelles)
7 000 condamnations définitives.
SDSE (Justice)
Poursuites (Violences au sein du couple)
54 400 mis en cause poursuivis (sur 145 400 cas traités).
SDSE (Justice)
Condamnations (Violences au sein du couple)
42 200 condamnations définitives.
SDSE (Justice)
Accueil en Unité Médico-Judiciaire (UMJ)
74 000 victimes de violences sexistes et sexuelles.
Données administratives
Hébergement et logement dédiés
11 300 places au 31 décembre 2024.
Données administratives
Ordonnances de Protection
4 200 délivrées.
SDSE (Justice)
Téléphones Grave Danger (TGD) actifs
5 400 (début novembre 2025).
Données administratives
Bracelets Anti-Rapprochement (BAR) actifs
660 (début novembre 2025).
Données administratives
Appels traités par le 3919
Plus de 100 000.
FNSF
Signalements traités par le 119 (enfants co-victimes)
5 200.
SNATED
• Dimension genrée : Les femmes représentent 85 % des victimes de violences sexuelles.
Pour 9 victimes sur 10, quel que soit leur sexe, l'agresseur est un homme. 84 % des victimes de violences au sein du couple sont des femmes (98 % pour les violences sexuelles au sein du couple).
• Danger au sein du foyer : Le discours public se focalise souvent sur le danger extérieur, mais les données démontrent le contraire. 46 % des viols enregistrés sur des femmes ont été commis dans le cadre conjugal. 58 % des femmes tuées en 2024 l'ont été par un membre de leur famille ou leur partenaire/ex-partenaire.
• Sous-déclaration massive : La loi du silence reste prégnante. Seules 2 % des femmes victimes de harcèlement sexuel ou d'exhibitionnisme déposent plainte. Ce taux monte à seulement 7 % pour les viols et agressions sexuelles.
--------------------------------------------------------------------------------
Une enquête nationale menée par un consortium d'associations (Point de contact, Féministes contre le cyberharcèlement, Stop Fisha) a révélé l'ampleur et les spécificités des violences en ligne.
• Cibles principales : Les femmes et les filles, dont plus de la moitié sont mineures.
• L'image comme arme : Plus d'un quart des victimes ont subi une diffusion non consentie de leurs contenus intimes. Ce chiffre atteint 36 % chez les mineurs.
• Proximité de l'agresseur : Dans 85 % des cas où l'agresseur est connu, il s'agit d'un homme. Deux tiers des victimes connaissaient leur agresseur, qui provenait majoritairement de l'entourage proche (relation de couple pour 52 %, camarades de classe pour un tiers).
• Impact psychologique : Les conséquences sont lourdes, même sans contact physique.
◦ Pensées suicidaires : 1 victime sur 10 (cyberviolence seule) ; 1 sur 3 (si les violences se prolongent hors ligne).
◦ Tentatives de suicide : 7 % (cyberviolence seule) ; 1 sur 4 (si les violences se prolongent hors ligne).
• Taux de plainte : Seulement 12 % des victimes portent plainte (10 % pour les mineurs).
• Freins au dépôt de plainte :
◦ Méconnaissance : Un tiers des mineurs ne savaient pas qu'ils pouvaient porter plainte.
◦ Sentiment d'inutilité : Un tiers des victimes estiment que la plainte ne les aiderait pas.
◦ Culpabilisation : Deux tiers des victimes qui ont porté plainte déclarent s'être senties culpabilisées lors du processus.
• Prévention : Renforcer massivement la prévention, la sensibilisation et la formation en milieu scolaire et auprès du grand public, avec un discours de réduction des risques et de déculpabilisation.
• Formation : Former tous les professionnels (justice, police, santé, éducation) dans une perspective de genre.
• Accompagnement : Créer une plateforme unique et holistique pour les victimes adultes.
• Régulation : Généraliser le retrait préventif des contenus signalés par les plateformes, sans attendre la décision de modération finale.
--------------------------------------------------------------------------------
Une table ronde a mis en lumière la situation souvent invisible des femmes françaises victimes de violences à l'étranger, estimées entre 3 et 3,5 millions de personnes.
Les chiffres officiels (186 situations suivies en 2024) sous-estiment largement la réalité. Les femmes à l'étranger font face à des difficultés supplémentaires :
• Dépendance : Dépendance économique et administrative vis-à-vis du conjoint (le visa est souvent lié).
• Isolement : Barrière linguistique et isolement social, loin du réseau de soutien.
• Risques juridiques : Contexte local où les violences ne sont pas toujours reconnues ou poursuivies, et risque de déplacement illicite d'enfants en cas de départ du pays.
• Stéréotypes : L'image des "expatriés privilégiés" masque la réalité des violences et freine la prise de conscience et l'action.
4.2. Stratégies de Réponse et Initiatives Modèles
• Feuille de route de la diplomatie féministe : Le Ministère de l'Europe et des Affaires étrangères a intégré la protection des Françaises à l'étranger dans sa stratégie, autour de trois axes : mieux informer, mieux protéger, mieux accompagner.
• Le modèle de Singapour : Une initiative pilote a été présentée : une clinique juridique gratuite et bilingue, fruit d'un partenariat entre le Barreau de Paris, la Law Society de Singapour et l'Ambassade de France.
Elle offre un accès au droit sécurisé et anonyme, articule les systèmes juridiques français et local, et oriente vers un réseau de partenaires (hébergement, psychologues).
• Formation du réseau consulaire : Des formations spécifiques, élaborées avec la Miprof, sont en cours de déploiement pour les 186 agents référents dans les consulats.
• Accès aux dispositifs nationaux : La plateforme numérique arretonslesviolences.gouv.fr est désormais accessible depuis l'étranger, mais le 3919 ne l'est pas encore, ce qui constitue un combat prioritaire.
--------------------------------------------------------------------------------
Une table ronde d'experts (magistrats, médecin légiste, avocate) a analysé les leviers pour mieux prévenir les passages à l'acte.
L'analyse systématique des homicides conjugaux par les parquets a permis d'identifier des axes d'amélioration :
• Dans 50 % des cas, des signaux d'alerte ou des antécédents judiciaires existaient.
• Les failles se situent souvent au niveau du traitement des premiers signalements, de la communication entre acteurs judiciaires et de l'évaluation du danger.
• Focalisation sur l'auteur : La magistrate Gwnola Joly-Coz a insisté sur la nécessité de déplacer le regard de la victime vers l'auteur et ses stratégies, notamment via la notion de contrôle coercitif.
• "Criticiser" les situations : Les magistrats doivent identifier les situations de "très haute intensité" en se basant sur des critères objectifs et prédictifs.
• Marqueurs de danger imminent :
1. La strangulation : Un acte "sexo-spécifique" visant à faire taire et à arrêter la respiration, qui doit être considéré comme un critère de gravité absolue.
2. Les menaces de mort : Elles ne doivent jamais être euphémisées ou minimisées, car elles manifestent une intention criminelle.
• Ordonnance de Protection : Ernestine Ronai a rappelé que cet outil (4 200 délivrées en France contre 33 000 en Espagne) est sous-utilisé et intervient trop tard.
Il doit devenir une première marche de protection accessible avant le dépôt de plainte, dès que des violences sont "vraisemblables".
• Suicide forcé : Yael Mellul a souligné que cet "angle mort" représente environ 300 féminicides par an.
La loi existe mais est très peu appliquée. Elle préconise une "autopsie psychologique" systématique en cas de suicide pour rechercher un contexte de harcèlement et de violences.
--------------------------------------------------------------------------------
Les enfants exposés aux violences conjugales sont désormais reconnus comme des victimes directes, mais leur protection reste un défi majeur.
• Les enfants sont profondément affectés, même sans subir de coups directs. 60 % présentent un diagnostic de trouble de stress post-traumatique.
• L'enfant est souvent utilisé comme une arme dans le cadre du contrôle coercitif exercé sur la mère.
• Silos institutionnels : La complexité du système judiciaire (Juge aux Affaires Familiales, Juge des Enfants, juge pénal) peut conduire à des décisions contradictoires et à une vision parcellaire de la situation familiale.
Des initiatives comme les "chambres des VIF" en cour d'appel visent à décloisonner en jugeant le civil et le pénal de manière coordonnée.
• Exercice de l'autorité parentale : C'est un enjeu central, car elle est un levier majeur du contrôle coercitif post-séparation.
La loi a évolué pour permettre sa suspension ou son retrait, mais son application reste complexe.
• Rôle des services de protection de l'enfance (ASE) : Les professionnels doivent être formés à ne pas symétriser les violences et à toujours recentrer l'analyse sur le contexte de violence, même lorsque l'intervention porte sur les symptômes de l'enfant.
• Objectif : Un court-métrage de fiction commandé par la Direction de la Jeunesse (DJEPVA) et réalisé par Johanna Benaïnous pour sensibiliser les animateurs et directeurs d'accueils collectifs de mineurs.
• Thématiques : Le film aborde la difficulté de signaler pour un jeune professionnel, la stratégie de l'agresseur pour déstabiliser et inverser la culpabilité, et un modèle d'accueil bienveillant par les forces de l'ordre.
• Déploiement : Il s'accompagne d'un livret de formation et sera déployé nationalement pour former les formateurs et les acteurs de terrain, en insistant sur le contrôle d'honorabilité, l'obligation de signalement et l'éducation au consentement.
--------------------------------------------------------------------------------
La dernière table ronde a alerté sur la structuration et la professionnalisation des mouvements masculinistes, qui représentent une contre-offensive organisée face aux avancées féministes.
• Postulat de base : Le féminisme serait allé trop loin et les hommes seraient désormais les principales victimes, menacés d'éradication par un "complot" féministe.
• Tactique : Ils se présentent comme des "groupes de soutien" pour des hommes en souffrance, en leur offrant un bouc émissaire (les femmes, les féministes) et des solutions simplistes à des problèmes complexes (confiance en soi, relations).
• Recrutement : Ils ciblent particulièrement les jeunes hommes en quête identitaire via des influenceurs sur les réseaux sociaux, capitalisant financièrement et politiquement sur leur mal-être.
7.2. Une Offensive Financée et Professionnalisée
• Financement : Le rapport "La Nouvelle Vague" révèle qu'au moins 1,2 milliard de dollars ont financé les mouvements anti-genre en Europe entre 2019 et 2023.
Les fonds proviennent des États-Unis (droite chrétienne), de la Russie, mais sont majoritairement européens.
• Professionnalisation : Cet argent a permis de créer une infrastructure de lobbying à haut niveau, un écosystème de think tanks, une forte présence médiatique et la création de "services anti-genre" (ex: centres de "crise de grossesse" pour dissuader de l'IVG).
• Attaques contre les dispositifs d'aide : La FNSF a témoigné des attaques ciblées contre le 3919 : tentatives de saturation de la ligne, harcèlement des professionnelles, et lobbying politique pour "ouvrir la ligne aux hommes" dans une logique de fausse symétrie qui nie la nature systémique des violences.
• Instrumentalisation des droits des enfants : Des propositions de loi (comme la PPL 819 sur la résidence alternée de principe) sont portées par des groupes masculinistes sous couvert de "défense des enfants", alors que leur objectif est de renforcer les droits des pères, y compris violents, au détriment de la sécurité des mères et des enfants.
• Infiltration politique : Ces mouvements ne sont plus marginaux. Ils sont "en costard-cravate" et obtiennent des rendez-vous dans les ministères et les parlements, faisant sauter les "digues républicaines".
• Médias : Traiter le masculinisme comme un fait et une menace terroriste, non comme une "opinion".
• Prévention : Renforcer l'éducation à l'égalité dès le plus jeune âge en s'appuyant sur les acteurs de terrain.
• Régulation : Contraindre légalement les plateformes numériques à modérer ces contenus haineux.
• Écoute des associations : Prendre au sérieux les alertes lancées par les associations féministes sur la banalisation des discours de haine et la revictimisation des femmes dans le système judiciaire (ex: contre-plaintes, stages pour auteurs imposés aux victimes).
Reviewer #2 (Public review):
Summary:
The authors aim to provide an overview of the D. traunsteineri rhizosphere microbiome on a taxonomic and functional level, through 16S rRNA amplicon analysis and shotgun metagenome analysis. The amplicon sequencing shows that the major phyla present in the microbiome belong to phyla with members previously found to be enriched in rhizospheres and bulk soils. Their shotgun metagenome analysis focused on producing metagenome assembled genomes (MAGs), of which one satisfies the MIMAG quality criteria for high-quality MAGs and three those for medium-quality MAGs. These MAGs were subjected to functional annotations focusing on metabolic pathway enrichment and secondary metabolic pathway biosynthetic gene cluster analysis. They find 1741 BGCs of various categories in the MAGs that were analyzed, with the high-quality MAG being claimed to contain 181 SM BGCs. The authors provide a useful, albeit superficial, overview of the taxonomic composition of the microbiome, and their dataset can be used for further analysis.
The conclusions of this paper are not well-supported by the data, as the paper only superficially discusses the results, and the functional interpretation based on taxonomic evidence or generic functional annotations does not allow drawing any conclusions on the functional roles of the orchid microbiota.
Weaknesses:
The authors only used one individual plant to take samples. This makes it hard to generalize about the natural orchid microbiome.
The authors use both 16S amplicon sequencing and shotgun metagenomics to analyse the microbiome. However, the authors barely discuss the similarities and differences between the results of these two methods, even though comparing these results may be able to provide further insights into the conclusions of the authors. For example, the relative abundance of the ASVs from the amplicon analysis is not linked to the relative abundances of the MAGs.
Furthermore, the authors discuss that phyla present in the orchid microbiome are also found in other microbiomes and are linked to important ecological functions. However, their results reach further than the phylum level, and a discussion of genera or even species is lacking. The phyla that were found have very large within-phylum functional variability, and reliable functional conclusions cannot be drawn based on taxonomic assignment at this level, or even the genus level (Yan et al. 2017).
Additionally, although the authors mention their techniques used, their method section is sometimes not clear about how samples or replicates were defined. There are also inconsistencies between the methods and the results section, for example, regarding the prediction of secondary metabolite biosynthetic gene clusters (BGCs).
The BGC prediction was done with several tools, and the unusually high number of found BGCs (181 in their high-quality MAG) is likely due to false positives or fragmented BGCs. The numbers are much higher than any numbers ever reported in literature supported by functional evidence (Amos et al, 2017), even in a prolific genus like Streptomyces (Belknap et al., 2020). This caveat is not discussed by the authors.
The authors have generated one high-quality MAG and three medium-quality MAGs. In the discussion, they present all four of these as high-quality, which could be misleading. The authors discuss what was found in the literature about the role of the bacterial genera/phyla linked to these MAGs in plant rhizospheres, but they do not sufficiently link their own analysis results (metabolic pathway enrichment and biosynthetic gene cluster prediction) to this discussion. The results of these analyses are only presented in tables without further explanation in either the results section or the discussion, even though there may be interesting findings. For example, the authors only discuss the class of the BGCs that were found, but don't search for experimentally verified homologs in databases, which could shed more light on the possible functional roles of BGCs in this microbiome.
In the conclusions, the authors state: "These analyses uncovered potential metabolic capabilities and biosynthetic potentials that are integral to the rhizosphere's ecological dynamics." I don't see any support for this. Mentioning that certain classes of BGCs are present is not enough to make this claim, in my opinion. Any BGC is likely important for the ecological niche the bacteria live in. The fact that rhizosphere bacteria harbour BGCs is not surprising, and it doesn't tell us more than is already known.
References:
Belknap, Kaitlyn C., et al. "Genome mining of biosynthetic and chemotherapeutic gene clusters in Streptomyces bacteria." Scientific reports 10.1 (2020): 2003
Amos GCA, Awakawa T, Tuttle RN, Letzel AC, Kim MC, Kudo Y, Fenical W, Moore BS, Jensen PR. Comparative transcriptomics as a guide to natural product discovery and biosynthetic gene cluster functionality. Proc Natl Acad Sci U S A. 2017 Dec 26;114(52):E11121-E11130.
References:
Belknap, Kaitlyn C., et al. "Genome mining of biosynthetic and chemotherapeutic gene clusters in Streptomyces bacteria." Scientific reports 10.1 (2020): 2003
Amos GCA, Awakawa T, Tuttle RN, Letzel AC, Kim MC, Kudo Y, Fenical W, Moore BS, Jensen PR. Comparative transcriptomics as a guide to natural product discovery and biosynthetic gene cluster functionality. Proc Natl Acad Sci U S A. 2017 Dec 26;114(52):E11121-E11130.
Yan Yan, Eiko E Kuramae, Mattias de Hollander, Peter G L Klinkhamer, Johannes A van Veen, Functional traits dominate the diversity-related selection of bacterial communities in the rhizosphere, The ISME Journal, Volume 11, Issue 1, January 2017, Pages 56-66
Addgene_176668
DOI: 10.1038/s41467-025-65304-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:Addgene_176668
RRID:SCR_007175
DOI: 10.1038/s41467-025-65304-y
Resource: Harvard Medical School Biopolymers Core Facility (RRID:SCR_007175)
Curator: @scibot
SciCrunch record: RRID:SCR_007175
CVCL_B3N3
DOI: 10.1038/s41467-025-65304-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:CVCL_B3N3
parte
part (mais privilégier autre formulation, car on ne dit que "d'une part" et "d'une autre part", et on prebd une autre expression quand il y a 3 éléments.
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public review):
Summary
This work performed Raman spectral microscopy at the single-cell level for 15 different culture conditions in E. coli. The Raman signature is systematically analyzed and compared with the proteome dataset of the same culture conditions. With a linear model, the authors revealed correspondence between Raman pattern and proteome expression stoichiometry indicating that spectrometry could be used for inferring proteome composition in the future. With both Raman spectra and proteome datasets, the authors categorized co-expressed genes and illustrated how proteome stoichiometry is regulated among different culture conditions. Co-expressed gene clusters were investigated and identified as homeostasis core, carbon-source dependent, and stationary phase-dependent genes. Overall, the authors demonstrate a strong and solid data analysis scheme for the joint analysis of Raman and proteome datasets.
Strengths and major contributions
(1) Experimentally, the authors contributed Raman datasets of E. coli with various growth conditions.
(2) In data analysis, the authors developed a scheme to compare proteome and Raman datasets. Protein co-expression clusters were identified, and their biological meaning was investigated.
Weaknesses
The experimental measurements of Raman microscopy were conducted at the single-cell level; however, the analysis was performed by averaging across the cells. The author did not discuss if Raman microscopy can used to detect cell-to-cell variability under the same condition.
We thank the reviewer for raising this important point. Though this topic is beyond the scope of our study, some of our authors have addressed the application of single-cell Raman spectroscopy to characterizing phenotypic heterogeneity in individual Staphylococcus aureus cells in another paper (Kamei et al., bioRxiv, doi: 10.1101/2024.05.12.593718). Additionally, one of our authors demonstrated that single-cell RNA sequencing profiles can be inferred from Raman images of mouse cells (Kobayashi-Kirschvink et al., Nat. Biotechnol. 42, 1726–1734, 2024). Therefore, detecting cell-to-cell variability under the same conditions has been shown to be feasible. Whether averaging single-cell Raman spectra is necessary depends on the type of analysis and the available dataset. We will discuss this in more detail in our response to Comment (1) by Reviewer #1 (Recommendation for the authors).
Discussion and impact on the field
Raman signature contains both proteomic and metabolomic information and is an orthogonal method to infer the composition of biomolecules. It has the advantage that single-cell level data could be acquired and both in vivo and in vitro data can be compared. This work is a strong initiative for introducing the powerful technique to systems biology and providing a rigorous pipeline for future data analysis.
Reviewer #2 (Public review):
Summary and strengths:
Kamei et al. observe the Raman spectra of a population of single E. coli cells in diverse growth conditions. Using LDA, Raman spectra for the different growth conditions are separated. Using previously available protein abundance data for these conditions, a linear mapping from Raman spectra in LDA space to protein abundance is derived. Notably, this linear map is condition-independent and is consequently shown to be predictive for held-out growth conditions. This is a significant result and in my understanding extends the earlier Raman to RNA connection that has been reported earlier.
They further show that this linear map reveals something akin to bacterial growth laws (ala Scott/Hwa) that the certain collection of proteins shows stoichiometric conservation, i.e. the group (called SCG - stoichiometrically conserved group) maintains their stoichiometry across conditions while the overall scale depends on the conditions. Analyzing the changes in protein mass and Raman spectra under these conditions, the abundance ratios of information processing proteins (one of the large groups where many proteins belong to "information and storage" - ISP that is also identified as a cluster of orthologous proteins) remain constant. The mass of these proteins deemed, the homeostatic core, increases linearly with growth rate. Other SCGs and other proteins are condition-specific.
Notably, beyond the ISP COG the other SCGs were identified directly using the proteome data. Taking the analysis beyond they then how the centrality of a protein - roughly measured as how many proteins it is stoichiometric with - relates to function and evolutionary conservation. Again significant results, but I am not sure if these ideas have been reported earlier, for example from the community that built protein-protein interaction maps.
As pointed out, past studies have revealed that the function, essentiality, and evolutionary conservation of genes are linked to the topology of gene networks, including protein-protein interaction networks. However, to the best of our knowledge, their linkage to stoichiometry conservation centrality of each gene has not yet been established.
Previously analyzed networks, such as protein-protein interaction networks, depend on known interactions. Therefore, as our understanding of the molecular interactions evolves with new findings, the conclusions may change. Furthermore, analysis of a particular interaction network cannot account for effects from different types of interactions or multilayered regulations affecting each protein species.
In contrast, the stoichiometry conservation network in this study focuses solely on expression patterns as the net result of interactions and regulations among all types of molecules in cells. Consequently, the stoichiometry conservation networks are not affected by the detailed knowledge of molecular interactions and naturally reflect the global effects of multilayered interactions. Additionally, stoichiometry conservation networks can easily be obtained for non-model organisms, for which detailed molecular interaction information is usually unavailable. Therefore, analysis with the stoichiometry conservation network has several advantages over existing methods from both biological and technical perspectives.
We added a paragraph explaining this important point to the Discussion section, along with additional literature.
Finally, the paper built a lot of "machinery" to connect ¥Omega_LE, built directly from proteome, and ¥Omega_B, built from Raman, spaces. I am unsure how that helps and have not been able to digest the 50 or so pages devoted to this.
The mathematical analyses in the supplementary materials form the basis of the argument in the main text. Without the rigorous mathematical discussions, Fig. 6E — one of the main conclusions of this study — and Fig. 7 could never be obtained. Therefore, we believe the analyses are essential to this study. However, we clarified why each analysis is necessary and significant in the corresponding sections of the Results to improve the manuscript's readability.
Please see our responses to comments (2) and (7) by Reviewer #1 (Recommendations for the authors) and comments (5) and (6) by Reviewer #2 (Recommendations for the authors).
Strengths:
The rigorous analysis of the data is the real strength of the paper. Alongside this, the discovery of SCGs that are condition-independent and that are condition-dependent provides a great framework.
Weaknesses:
Overall, I think it is an exciting advance but some work is needed to present the work in a more accessible way.
We edited the main text to make it more accessible to a broader audience. Please see our responses to comments (2) and (7) by Reviewer #1 (Recommendations for the authors) and comments (5) and (6) by Reviewer #2 (Recommendations for the authors).
Reviewer #1 (Recommendations for the authors):
(1) The Raman spectral data is measured from single-cell imaging. In the current work, most of the conclusions are from averaged data. From my understanding, once the correspondence between LDA and proteome data is established (i.e. the matrix B) one could infer the single-cell proteome composition from B. This would provide valuable information on how proteome composition fluctuates at the single-cell level.
We can calculate single-cell proteomes from single-cell Raman spectra in the manner suggested by the reviewer. However, we cannot evaluate the accuracy of their estimation without single-cell proteome data under the same environmental conditions. Likewise, we cannot verify variations of estimated proteomes of single cells. Since quantitatively accurate single-cell proteome data is unavailable, we concluded that addressing this issue was beyond the scope of this study.
Nevertheless, we agree with the reviewer that investigating how proteome composition fluctuates at the single-cell level based on single-cell Raman spectra is an intriguing direction for future research. In this regard, some of our authors have studied the phenotypic heterogeneity of Staphylococcus aureus cells using single-cell Raman spectra in another paper (Kamei et al., bioRxiv, doi: 10.1101/2024.05.12.593718), and one of our authors has demonstrated that single-cell RNA sequencing profiles can be inferred from Raman images of mouse cells (Kobayashi-Kirschvink et al., Nat. Biotechnol. 42, 1726–1734, 2024). Therefore, it is highly plausible that single-cell Raman spectroscopy can also characterize proteomic fluctuations in single cells. We have added a paragraph to the Discussion section to highlight this important point.
(2) The establishment of matrix B is quite confusing for readers who only read the main text. I suggest adding a flow chart in Figure 1 to explain the data analysis pipeline, as well as state explicitly what is the dimension of B, LDA matrix, and proteome matrix.
We thank the reviewer for the suggestion. Following the reviewer's advice, we have explicitly stated the dimensions of the vectors and matrices in the main text. We have also added descriptions of the dimensions of the constructed spaces. Rather than adding another flow chart to Figure 1, we added a new table (Table 1) to explain the various symbols representing vectors and matrices, thereby improving the accessibility of the explanation.
(3) One of the main contributions for this work is to demonstrate how proteome stoichiometry is regulated across different conditions. A total of m=15 conditions were tested in this study, and this limits the rank of LDA matrix as 14. Therefore, maximally 14 "modes" of differential composition in a proteome can be detected.
As a general reader, I am wondering in the future if one increases or decreases the number of conditions (say m=5 or m=50) what information can be extracted? It is conceivable that increasing different conditions with distinct cellular physiology would be beneficial to "explore" different modes of regulation for cells. As proof of principle, I am wondering if the authors could test a lower number (by sub-sampling from m=15 conditions, e.g. picking five of the most distinct conditions) and see how this would affect the prediction of proteome stoichiometry inference.
We thank the reviewer for bringing an important point to our attention. To address the issue raised, we conducted a new subsampling analysis (Fig. S14).
As we described in the main text (Fig. 6E) and the supplementary materials, the m x m orthogonal matrix, Θ, represents to what extent the two spaces Ω<sub>LE</sub> and Ω<sub>B</sub> are similar (m is the number of conditions; in our main analysis, m = 15). Thus, the low-dimensional correspondence between the two spaces connected by an orthogonal transformation, such as an m-dimensional rotation, can be evaluated by examining the elements of the matrix Θ. Specifically, large off-diagonal elements of the matrix mix higher dimensions and lower dimensions, making the two spaces spanned by the first few major axes appear dissimilar. Based on this property, we evaluated the vulnerability of the low-dimensional correspondence between Ω<sub>LE</sub> and Ω<sub>B</sub> to the reduced number of conditions by measuring how close Θ was to the identity matrix when the analysis was performed on the subsampled datasets.
In the new figure (Fig. S14), we first created all possible smaller condition sets by subsampling the conditions. Next, to evaluate the closeness between the matrix Θ and the identity matrix for each smaller condition set, we generated 10,000 random orthogonal matrices of the same size as . We then evaluated the probability of obtaining a higher level of low-dimensional correspondence than that of the experimental data by chance (see section 1.8 of the Supplementary Materials). This analysis was already performed in the original manuscript for the non-subsampled case (m = 15) in Fig. S9C; the new analysis systematically evaluates the correspondence for the subsampled datasets.
The results clearly show that low-dimensional correspondence is more likely to be obtained with more conditions (Fig. S14). In particular, when the number of conditions used in the analysis exceeds five, the median of the probability that random orthogonal matrices were closer to the identity matrix than the matrix Θ calculated from subsampled experimental data became lower than 10<sup>-4</sup>. This analysis provides insight into the number of conditions required to find low-dimensional correspondence between Ω<sub>LE</sub> and Ω<sub>B</sub>.
What conditions are used in the analysis can change the low-dimensional structures of Ω<sub>LE</sub> and Ω<sub>B</sub> . Therefore, it is important to clarify whether including more conditions in the analysis reduces the dependence of the low-dimensional structures on conditions. We leave this issue as a subject for future study. This issue relates to the effective dimensionality of omics profiles needed to establish the diverse physiological states of cells across conditions. Determining the minimum number of conditions to attain the condition-independent low-dimensional structures of Ω<sub>LE</sub> and Ω<sub>B</sub> would provide insight into this fundamental problem. Furthermore, such an analysis would identify the range of applications of Raman spectra as a tool for capturing macroscopic properties of cells at the system level.
We now discuss this point in the Discussion section, referring to this analysis result (Fig. S14). Please also see our reply to the comment (1) by Reviewer #2 (Recommendations for the authors).
(4) In E. coli cells, total proteome is in mM concentration while the total metabolites are between 10 to 100 mM concentration. Since proteins are large molecules with more functional groups, they may contribute to more Raman signal (per molecules) than metabolites. Still, the meaningful quantity here is the "differential Raman signal" with different conditions, not the absolute signal. I am wondering how much percent of differential Raman signature are from proteome and how much are from metabolome.
It is an important and interesting question to what extent changes in the proteome and metabolome contribute to changes in Raman spectra. Though we concluded that answering this question is beyond the scope of this study, we believe it is an important topic for future research.
Raman spectral patterns convey the comprehensive molecular composition spanning the various omics layers of target cells. Changes in the composition of these layers can be highly correlated, and identifying their contributions to changes in Raman spectra would provide insight into the mutual correlation of different omics layers. Addressing the issue raised by the reviewer would expand the applications of Raman spectroscopy and highlight the advantage of cellular Raman spectra as a means of capturing comprehensive multi-omics information.
We note that some studies have evaluated the contributions of proteins, lipids, nucleic acids, and glycogen to the Raman spectra of mammalian cells and how these contributions change in different states (e.g., Mourant et al., J Biomed Opt, 10(3), 031106, 2005). Additionally, numerous studies have imaged or quantified metabolites in various cell types (see, for example, Cutshaw et al., Chemical Reviews, 123(13), 8297–8346, 2023, for a comprehensive review). Extending these approaches to multiple omics layers in future studies would help resolve the issue raised by the reviewer.
(5) It is known that E. coli cells in different conditions have different cell sizes, where cell width increases with carbon source quality and growth rate. Does this effect be normalized when processing the Raman signal?
Each spectrum was normalized by subtracting the average and dividing it by the standard deviation. This normalization minimizes the differences in signal intensities due to different cell sizes and densities. This information is shown in the Materials and Methods section of the Supplementary Materials.
(6) I have a question about interpretation of the centrality index. A higher centrality indicates the protein expression pattern is more aligned with the "mainstream" of the other proteins in the proteome. However, it is possible that the proteome has multiple" mainstream modes" (with possibly different contributions in magnitudes), and the centrality seems to only capture the "primary mode". A small group of proteins could all have low centrality but have very consistent patterns with high conservation of stoichiometry. I wondering if the author could discuss and clarify with this.
We thank the reviewer for drawing our attention to the insufficient explanation in the original manuscript. First, we note that stoichiometry conserving protein groups are not limited to those composed of proteins with high stoichiometry conservation centrality. The SCGs 2–5 are composed of proteins that strongly conserve stoichiometry within each group but have low stoichiometry conservation centrality (Fig. 5A, 5K, 5L, and 7A). In other words, our results demonstrate the existence of the "primary mainstream mode" (SCG 1, i.e., the homeostatic core) and condition-specific "non-primary mainstream modes" (SCGs 2–5). These primary and non-primary modes are distinguishable by their position along the axis of stoichiometry conservation centrality (Fig. 5A, 5K, and 5L).
However, a single one-dimensional axis (centrality) cannot capture all characteristics of stoichiometry-conserving architecture. In our case, the "non-primary mainstream modes" (SCGs 2–5) were distinguished from each other by multiple csLE axes.
To clarify this point, we modified the first paragraph of the section where we first introduce csLE (Revealing global stoichiometry conservation architecture of the proteomes with csLE). We also added a paragraph to the Discussion section regarding the condition-specific SCGs 2–5.
(7) Figures 3, 4, and 5A-I are analyses on proteome data and are not related to Raman spectral data. I am wondering if this part of the analysis can be re-organized and not disrupt the mainline of the manuscript.
We agree that the structure of this manuscript is complicated. Before submitting this manuscript to eLife, we seriously considered reorganizing it. However, we concluded that this structure was most appropriate because our focus on stoichiometry conservation cannot be explained without analyzing the coefficients of the Raman-proteome correspondence using COG classification (see Fig. 3; note that Fig. 3A relates to Raman data). This analysis led us to examine the global stoichiometry conservation architecture of proteomes (Figs. 4 and 5) and discover the unexpected similarity between the low-dimensional structures of Ω<sub>LE</sub> and Ω<sub>B</sub>
Therefore, we decided to keep the structure of the manuscript as it is. To partially resolve this issue, however, we added references to Fig. S1, the diagram of this paper’s mainline, to several places in the main text so that readers can more easily grasp the flow of the manuscript.
(8) Supplementary Equation (2.6) could be wrong. From my understanding of the coordinate transformation definition here, it should be [w1 ... ws] X := RHS terms in big parenthesis.
We checked the equation and confirmed that it is correct.
Reviewer #2 (Recommendations for the authors):
(1) The first main result or linear map between raman and proteome linked via B is intriguing in the sense that the map is condition-independent. A speculative question I have is if this relationship may become more complex or have more condition-dependent corrections as the number of conditions goes up. The 15 or so conditions are great but it is not clear if they are often quite restrictive. For example, they assume an abundance of most other nutrients. Now if you include a growth rate decrease due to nitrogen or other limitations, do you expect this to work?
In our previous paper (Kobayashi-Kirschvink et al., Cell Systems 7(1): 104–117.e4, 2018), we statistically demonstrated a linear correspondence between cellular Raman spectra and transcriptomes for fission yeast under 10 environmental conditions. These conditions included nutrient-rich and nutrient-limited conditions, such as nitrogen limitation. Since the Raman-transcriptome correspondence was only statistically verified in that study, we analyzed the data from the standpoint of stoichiometry conservation in this study. The results (Fig. S11 and S12) revealed a correspondence in lower dimensions similar to that observed in our main results. In addition, similar correspondences were obtained even for different E. coli strains under common culture conditions (Fig. S11 and S12). Therefore, it is plausible that the stoichiometry-conservation low-dimensional correspondence between Raman and gene expression profiles holds for a wide range of external and internal perturbations.
We agree with the reviewer that it is important to understand how Raman-omics correspondences change with the number of conditions. To address this issue, we examined how the correspondence between Ω<sub>LE</sub> and Ω<sub>B</sub> changes by subsampling the conditions used in the analysis. We focused on , which was introduced in Fig. 5E, because the closeness of Θ to the identity matrix represents correspondence precision. We found a general trend that the low-dimensional correspondence becomes more precise as the number of conditions increases (Fig. S14). This suggests that increasing the number of conditions generally improves the correspondence rather than disrupting it.
We added a paragraph to the Discussion section addressing this important point. Please also refer to our response to Comment (3) of Reviewer #1 (Recommendations for the authors).
(2) A little more explanation in the text for 3C/D would help. I am imagining 3D is the control for 3C. Minor comment - 3B looks identical to S4F but the y-axis label is different.
We thank the reviewer for pointing out the insufficient explanation of Fig. 3C and 3D in the main text. Following this advice, we added explanations of these plots to the main text. We also added labels ("ISP COG class" and "non-ISP COG class") to the top of these two figures.
Fig. 3B and S4F are different. For simplicity, we used the Pearson correlation coefficient in Fig. 3B. However, cosine similarity is a more appropriate measure for evaluating the degree of conservation of abundance ratios. Thus, we presented the result using cosine similarity in a supplementary figure (Fig. S4F). Please note that each point in Fig. S4F is calculated between proteome vectors of two conditions. The dimension of each proteome vector is the number of genes in each COG class.
(3) Can we see a log-log version of 4C to see how the low-abundant proteins are behaving? In fact, the same is in part true for Figure 3A.
We added the semi-log version of the graph for SCG1 (the homeostatic core) in Fig. 4C to make low-abundant proteins more visible. Please note that the growth rates under the two stationary-phase conditions were zero; therefore, plotting this graph in log-log format is not possible.
Fig. 3A cannot be shown as a log-log plot because many of the coefficients are negative. The insets in the graphs clarify the points near the origin.
(4) In 5L, how should one interpret the other dots that are close to the center but not part of the SCG1? And this theme continues in 6ACD and 7A.
The SCGs were obtained by setting a cosine similarity threshold. Therefore, proteins that are close to SCG 1 (the homeostatic core) but do not belong to it have a cosine similarity below the threshold with any protein in SCG 1. Fig. 7 illustrates the expression patterns of the proteins in question.
(5) Finally, I do not fully appreciate the whole analysis of connecting ¥Omega_csLE and ¥Omega_B and plots in 6 and 7. This corresponds to a lot of linear algebra in the 50 or so pages in section 1.8 in the supplementary. If the authors feel this is crucial in some way it needs to be better motivated and explained. I philosophically appreciate developing more formalism to establish these connections but I did not understand how this (maybe even if in the future) could lead to a new interpretation or analysis or theory.
The mathematical analyses included in the supplementary materials are important for readers who are interested in understanding the mathematics behind our conclusions. However, we also thought these arguments were too detailed for many readers when preparing the original submission and decided to show them in the supplemental materials.
To better explain the motivation behind the mathematical analyses, we revised the section “Representing the proteomes using the Raman LDA axes”.
Please also see our reply to the comment (6) by Reviewer #2 (Recommendations for the authors) below.
(6) Along the lines of the previous point, there seems to be two separate points being made: a) there is a correspondence between Raman and proteins, and b) we can use the protein data to look at centrality, generality, SCGs, etc. And the two don't seem to be linked until the formalism of ¥Omegas?
The reviewer is correct that we can calculate and analyze some of the quantities introduced in this study, such as stoichiometry conservation centrality and expression generality, without Raman data. However, it is difficult to justify introducing these quantities without analyzing the correspondence between the Raman and proteome profiles. Moreover, the definition of expression generality was derived from the analysis of Raman-proteome correspondence (see section 2.2 of the Supplementary Materials). Therefore, point b) cannot stand alone without point a) from its initial introduction.
To partially improve the readability and resolve the issue of complicated structure of this manuscript, we added references to Fig. S1, which is a diagram of the paper’s mainline, to several places in the main text. Please also see our reply to the comment (7) by Reviewer #1 (Recommendations for the authors).
esearch strate
add ISSP como estudio central para este tema en comparación internacional, trackear preguntas cumulative, y mencionar que esto ha sido un elemento fundamental de la agenda de market justice
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study develops and validates a neural subspace similarity analysis for testing whether neural representations of graph structures generalize across graph size and stimulus sets. The authors show the method works in rat grid and place cell data, finding that grid but not place cells generalize across different environments, as expected. The authors then perform additional analyses and simulations to show that this method should also work on fMRI data. Finally, the authors test their method on fMRI responses from the entorhinal cortex (EC) in a task that involves graphs that vary in size (and stimulus set) and statistical structure (hexagonal and community). They find neural representations of stimulus sets in lateral occipital complex (LOC) generalize across statistical structure and that EC activity generalizes across stimulus sets/graph size, but only for the hexagonal structures.
Strengths:
(1) The overall topic is very interesting and timely and the manuscript is well-written.
(2) The method is clever and powerful. It could be important for future research testing whether neural representations are aligned across problems with different state manifestations.
(3) The findings provide new insights into generalizable neural representations of abstract task states in the entorhinal cortex.
We thank the reviewer for their kind comments and clear summary of the paper and its strengths.
Weaknesses:
(1) The manuscript would benefit from improving the figures. Moreover, the clarity could be strengthened by including conceptual/schematic figures illustrating the logic and steps of the method early in the paper. This could be combined with an illustration of the remapping properties of grid and place cells and how the method captures these properties.
We agree with the reviewer and have added a schematic figure of the method (figure 1a).
(2) Hexagonal and community structures appear to be confounded by training order. All subjects learned the hexagonal graph always before the community graph. As such, any differences between the two graphs could thus be explained (in theory) by order effects (although this is practically unlikely). However, given community and hexagonal structures shared the same stimuli, it is possible that subjects had to find ways to represent the community structures separately from the hexagonal structures. This could potentially explain why the authors did not find generalizations across graph sizes for community structures.
We thank the reviewer for their comments. We agree that the null result regarding the community structures does not mean that EC doesn’t generalise over these structures, and that the training order could in theory contribute to the lack of an effect. The decision to keep the asymmetry of the training order was deliberate: we chose this order based on our previous study (Mark et al. 2020), where we show that learning a community structure first changes the learning strategy of subsequent graphs. We could have perhaps overcome this by increasing the training periods, but 1) the training period is already very long; 2) there will still be asymmetry because the group that first learn community structure will struggle in learning the hexagonal graph more than vice versa, as shown in Mark et al. 2020.
We have added the following sentences on this decision to the Methods section:
“We chose to first teach hexagonal graphs for all participants and not randomize the order because of previous results showing that first learning community structure changes participants’ learning strategy (mark et al. 2020).”
(3) The authors include the results from a searchlight analysis to show the specificity of the effects of EC. A better way to show specificity would be to test for a double dissociation between the visual and structural contrast in two independently defined regions (e.g., anatomical ROIs of LOC and EC).
Thanks for this suggestion. We indeed tried to run the analysis in a whole-ROI approach, but this did not result in a significant effect in EC. Importantly, we disagree with the reviewer that this is a “better way to show specificity” than the searchlight approach. In our view, the two analyses differ with respect to the spatial extent of the representation they test for. The searchlight approach is testing for a highly localised representation on the scale of small spheres with only 100 voxels. The signal of such a localised representation is likely to be drowned in the noise in an analysis that includes thousands of voxels which mostly don’t show the effect - as would be the case in the whole-ROI approach.
(4) Subjects had more experience with the hexagonal and community structures before and during fMRI scanning. This is another confound, and possible reason why there was no generalization across stimulus sets for the community structure.
See our response to comment (2).
Reviewer #2 (Public review):
Summary:
Mark and colleagues test the hypothesis that entorhinal cortical representations may contain abstract structural information that facilitates generalization across structurally similar contexts. To do so, they use a method called "subspace generalization" designed to measure abstraction of representations across different settings. The authors validate the method using hippocampal place cells and entorhinal grid cells recorded in a spatial task, then perform simulations that support that it might be useful in aggregated responses such as those measured with fMRI. Then the method is applied to fMRI data that required participants to learn relationships between images in one of two structural motifs (hexagonal grids versus community structure). They show that the BOLD signal within an entorhinal ROI shows increased measures of subspace generalization across different tasks with the same hexagonal structure (as compared to tasks with different structures) but that there was no evidence for the complementary result (ie. increased generalization across tasks that share community structure, as compared to those with different structures). Taken together, this manuscript describes and validates a method for identifying fMRI representations that generalize across conditions and applies it to reveal entorhinal representations that emerge across specific shared structural conditions.
Strengths:
I found this paper interesting both in terms of its methods and its motivating questions. The question asked is novel and the methods employed are new - and I believe this is the first time that they have been applied to fMRI data. I also found the iterative validation of the methodology to be interesting and important - showing persuasively that the method could detect a target representation - even in the face of a random combination of tuning and with the addition of noise, both being major hurdles to investigating representations using fMRI.
We thank the reviewer for their kind comments and the clear summary of our paper.
Weaknesses:
In part because of the thorough validation procedures, the paper came across to me as a bit of a hybrid between a methods paper and an empirical one. However, I have some concerns, both on the methods development/validation side, and on the empirical application side, which I believe limit what one can take away from the studies performed.
We thank the reviewer for the comment. We agree that the paper comes across as a bit of a methods-empirical hybrid. We chose to do this because we believe (as the reviewer also points out) that there is value in both aspects of the paper.
Regarding the methods side, while I can appreciate that the authors show how the subspace generalization method "could" identify representations of theoretical interest, I felt like there was a noticeable lack of characterization of the specificity of the method. Based on the main equation in the results section of the paper, it seems like the primary measure used here would be sensitive to overall firing rates/voxel activations, variance within specific neurons/voxels, and overall levels of correlation among neurons/voxels. While I believe that reasonable pre-processing strategies could deal with the first two potential issues, the third seems a bit more problematic - as obligate correlations among neurons/voxels surely exist in the brain and persist across context boundaries that are not achieving any sort of generalization (for example neurons that receive common input, or voxels that share spatial noise). The comparative approach (ie. computing difference in the measure across different comparison conditions) helps to mitigate this concern to some degree - but not completely - since if one of the conditions pushes activity into strongly spatially correlated dimensions, as would be expected if univariate activations were responsive to the conditions, then you'd expect generalization (driven by shared univariate activation of many voxels) to be specific to that set of conditions.
We thank the reviewer for their comments. We would like to point out that we demean each voxel within all states/piles (3-pictures sequences) in a given graph/task (what the reviewer is calling “a condition”). Hence there is no shared univariate activation of many voxels in response to a graph going into the computation, and no sensitivity to the overall firing rate/voxel activation. Our calculation captures the variance across states conditions within a task (here a graph), over and above the univariate effect of graph activity. In addition, we spatially pre-whiten the data within each searchlight, meaning that noisy voxels with high noise variance will be downweighted and noise correlations between voxels are removed prior to applying our method.
A second issue in terms of the method is that there is no comparison to simpler available methods. For example, given the aims of the paper, and the introduction of the method, I would have expected the authors to take the Neuron-by-Neuron correlation matrices for two conditions of interest, and examine how similar they are to one another, for example by correlating their lower triangle elements. Presumably, this method would pick up on most of the same things - although it would notably avoid interpreting high overall correlations as "generalization" - and perhaps paint a clearer picture of exactly what aspects of correlation structure are shared. Would this method pick up on the same things shown here? Is there a reason to use one method over the other?
We thank the reviewer for this important and interesting point. We agree that calculating correlation between the upper triangular elements of the covariance or correlation matrices picks up similar, but not identical aspects of the data (see below the mathematical explanation that was added to the supplementary). When we repeated the searchlight analysis and calculated the correlation between the upper triangular entries of the Pearson correlation matrices we obtained an effect in the EC, though weaker than with our subspace generalization method (t=3.9, the effect did not survive multiple comparisons). Similar results were obtained with the correlation between the upper triangular elements of the covariance matrices(t=3.8, the effect did not survive multiple comparisons).
The difference between the two methods is twofold: 1) Our method is based on the covariance matrix and not the correlation matrix - i.e. a difference in normalisation. We realised that in the main text of the original paper we mistakenly wrote “correlation matrix” rather than “covariance matrix” (though our equations did correctly show the covariance matrix). We have corrected this mistake in the revised manuscript. 2) The weighting of the variance explained in the direction of each eigenvector is different between the methods, with some benefits of our method for identifying low-dimensional representations and for robustness to strong spatial correlations. We have added a section “Subspace Generalisation vs correlating the Neuron-by-Neuron correlation matrices” to the supplementary information with a mathematical explanation of these differences.
Regarding the fMRI empirical results, I have several concerns, some of which relate to concerns with the method itself described above. First, the spatial correlation patterns in fMRI data tend to be broad and will differ across conditions depending on variability in univariate responses (ie. if a condition contains some trials that evoke large univariate activations and others that evoke small univariate activations in the region). Are the eigenvectors that are shared across conditions capturing spatial patterns in voxel activations? Or, related to another concern with the method, are they capturing changing correlations across the entire set of voxels going into the analysis? As you might expect if the dynamic range of activations in the region is larger in one condition than the other?
This is a searchlight analysis, therefore it captures the activity patterns within nearby voxels. Indeed, as we show in our simulation, areas with high activity and therefore high signal to noise will have better signal in our method as well. Note that this is true of most measures.
My second concern is, beyond the specificity of the results, they provide only modest evidence for the key claims in the paper. The authors show a statistically significant result in the Entorhinal Cortex in one out of two conditions that they hypothesized they would see it. However, the effect is not particularly large. There is currently no examination of what the actual eigenvectors that transfer are doing/look like/are representing, nor how the degree of subspace generalization in EC may relate to individual differences in behavior, making it hard to assess the functional role of the relationship. So, at the end of the day, while the methods developed are interesting and potentially useful, I found the contributions to our understanding of EC representations to be somewhat limited.
We agree with this point, yet believe that the results still shed light on EC functionality. Unfortunately, we could not find correlation between behavioral measures and the fMRI effect.
Reviewer #3 (Public review):
Summary:
The article explores the brain's ability to generalize information, with a specific focus on the entorhinal cortex (EC) and its role in learning and representing structural regularities that define relationships between entities in networks. The research provides empirical support for the longstanding theoretical and computational neuroscience hypothesis that the EC is crucial for structure generalization. It demonstrates that EC codes can generalize across non-spatial tasks that share common structural regularities, regardless of the similarity of sensory stimuli and network size.
Strengths:
(1) Empirical Support: The study provides strong empirical evidence for the theoretical and computational neuroscience argument about the EC's role in structure generalization.
(2) Novel Approach: The research uses an innovative methodology and applies the same methods to three independent data sets, enhancing the robustness and reliability of the findings.
(3) Controlled Analysis: The results are robust against well-controlled data and/or permutations.
(4) Generalizability: By integrating data from different sources, the study offers a comprehensive understanding of the EC's role, strengthening the overall evidence supporting structural generalization across different task environments.
Weaknesses:
A potential criticism might arise from the fact that the authors applied innovative methods originally used in animal electrophysiology data (Samborska et al., 2022) to noisy fMRI signals. While this is a valid point, it is noteworthy that the authors provide robust simulations suggesting that the generalization properties in EC representations can be detected even in low-resolution, noisy data under biologically plausible assumptions. I believe this is actually an advantage of the study, as it demonstrates the extent to which we can explore how the brain generalizes structural knowledge across different task environments in humans using fMRI. This is crucial for addressing the brain's ability in non-spatial abstract tasks, which are difficult to test in animal models.
While focusing on the role of the EC, this study does not extensively address whether other brain areas known to contain grid cells, such as the mPFC and PCC, also exhibit generalizable properties. Additionally, it remains unclear whether the EC encodes unique properties that differ from those of other systems. As the authors noted in the discussion, I believe this is an important question for future research.
We thank the reviewer for their comments. We agree with the reviewer that this is a very interesting question. We tried to look for effects in the mPFC, but we did not obtain results that were strong enough to report in the main manuscript, but we do report a small effect in the supplementary.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
(1) I wonder how important the PCA on B1(voxel-by-state matrix from environment 1) and the computation of the AUC (from the projection on B2 [voxel-by-state matrix from environment 1]) is for the analysis to work. Would you not get the same result if you correlated the voxel-by-voxel correlation matrix based on B1 (C1) with the voxel-by-voxel correlation matrix based on B2 (C2)? I understand that you would not have the subspace-by-subspace resolution that comes from the individual eigenvectors, but would the AUC not strongly correlate with the correlation between C1 and C2?
We agree with the reviewer comments - see our response to reviewer 2 second issue above.
(2) There is a subtle difference between how the method is described for the neural recording and fMRI data. Line 695 states that principal components of the neuron x neuron intercorrelation matrix are computed, whereas line 888 implies that principal components of the data matrix B are computed. Of note, B is a voxel x pile rather than a pile x voxel matrix. Wouldn't this result in U being pile x pile rather than voxel x voxel?
The PCs are calculated on the neuron x neuron (or voxel x voxel) covariance matrix of the activation matrix. We’ve added the following clarification to the relevant part of the Methods:
“We calculated noise normalized GLM betas within each searchlight using the RSA toolbox. For each searchlight and each graph, we had a nVoxels (100) by nPiles (10) activation matrix (B) that describes the activation of a voxel as a result of a particular pile (three pictures’ sequence). We exploited the (voxel x voxel) covariance matrix of this matrix to quantify the manifold alignment within each searchlight.”
(3) It would be very helpful to the field if the authors would make the code and data publicly available. Please consider depositing the code for data analysis and simulations, as well as the preprocessed/extracted data for the key results (rat data/fMRI ROI data) into a publicly accessible repository.
The code is publicly available in git (https://github.com/ShirleyMgit/subspace_generalization_paper_code/tree/main).
(4) Line 219: "Kolmogorov Simonov test" should be "Kolmogorov Smirnov test".
thanks!
(5) Please put plots in Figure 3F on the same y-axis.
(6) Were large and small graphs of a given statistical structure learned on the same days, and if so, sequentially or simultaneously? This could be clarified.
The graphs are learned on the same day. We clarified this in the Methods section.
Reviewer #2 (Recommendations for the authors):
Perhaps the advantage of the method described here is that you could narrow things down to the specific eigenvector that is doing the heavy lifting in terms of generalization... and then you could look at that eigenvector to see what aspect of the covariance structure persists across conditions of interest. For example, is it just the highest eigenvalue eigenvector that is likely picking up on correlations across the entire neural population? Or is there something more specific going on? One could start to get at this by looking at Figures 1A and 1C - for example, the primary difference for within/between condition generalization in 1C seems to emerge with the first component, and not much changes after that, perhaps suggesting that in this case, the analysis may be picking up on something like the overall level of correlations within different conditions, rather than a more specific pattern of correlations.
The nature of the analysis means the eigenvectors are organized by their contribution to the variance, therefore the first eigenvector is responsible for more variance than the other, we did not check rigorously whether the variance is then splitted equally by the remaining eigenvectors but it does not seems to be the case.
Why is variance explained above zero for fraction EVs = 0 for figure 1C (but not 1A) ? Is there some plotting convention that I'm missing here?
There was a small bug in this plot and it was corrected - thank you very much!
The authors say:
"Interestingly, the difference in AUCs was also 190 significantly smaller than chance for place cells (Figure 1a, compare dotted and solid green 191 lines, p<0.05 using permutation tests, see statistics and further examples in supplementary 192 material Figure S2), consistent with recent models predicting hippocampal remapping that is 193 not fully random (Whittington et al. 2020)."
But my read of the Whittington model is that it would predict slight positive relationships here, rather than the observed negative ones, akin to what one would expect if hippocampal neurons reflect a nonlinear summation of a broad swath of entorhinal inputs.
Smaller differences than chance imply that the remapping of place cells is not completely random.
Figure 2:
I didn't see any description of where noise amplitude values came from - or any justification at all in that section. Clearly, the amount of noise will be critical for putting limits on what can and cannot be detected with the method - I think this is worthy of characterization and explanation. In general, more information about the simulations is necessary to understand what was done in the pseudovoxel simulations. I get the gist of what was done, but these methods should clear enough that someone could repeat them, and they currently are not.
Thanks, we added noise amplitude to the figure legend and Methods.
What does flexible mean in the title? The analysis only worked for the hexagonal grid - doesn't that suggest that whatever representations are uncovered here are not flexible in the sense of being able to encode different things?
Flexible here means, flexible over stimulus’ characteristics that are not related to the structural form such as stimuli, the size of the graph etc.
Reviewer #3 (Recommendations for the authors):
I have noticed that the authors have updated the previous preprint version to include extensive simulations. I believe this addition helps address potential criticisms regarding the signal-to-noise ratio. If the authors could share the code for the fMRI data and the simulations in an open repository, it would enhance the study's impact by reaching a broader readership across various research fields. Except for that, I have nothing to ask for revision.
Thanks, the code will be publicly available: (https://github.com/ShirleyMgit/subspace_generalization_paper_code/tree/main).
Los conjuntos I y J constituyen estructuras matemáticas esenciales que determinan la escala, la conectividad y la complejidad del modelo. Su correcta definición resulta crucial para la formalización posterior de variables, restricciones y dependencias del sistema.
sobra ... muy IA
J:={1,2,…,n},n∈N,n≥1, el conjunto finito y numerable de zonas afectadas o potenciales de demanda. C
lo mismo ... ya esta definido antes. Se deinie con claridad y completamente una vez y luego se hace referencia cruzada de la definición
Sea I:={1,2,…,m},m∈N,m≥1, el conjunto finito y numerable de ubicaciones candidatas
ya está definido este espacio ... unifica
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public review):
The authors present exciting new experimental data on the antigenic recognition of 78 H3N2 strains (from the beginning of the 2023 Northern Hemisphere season) against a set of 150 serum samples. The authors compare protection profiles of individual sera and find that the antigenic effect of amino acid substitutions at specific sites depends on the immune class of the sera, differentiating between children and adults. Person-to-person heterogeneity in the measured titers is strong, specifically in the group of children's sera. The authors find that the fraction of sera with low titers correlates with the inferred growth rate using maximum likelihood regression (MLR), a correlation that does not hold for pooled sera. The authors then measure the protection profile of the sera against historical vaccine strains and find that it can be explained by birth cohort for children. Finally, the authors present data comparing pre- and post- vaccination protection profiles for 39 (USA) and 8 (Australia) adults. The data shows a cohort-specific vaccination effect as measured by the average titer increase, and also a virus-specific vaccination effect for the historical vaccine strains. The generated data is shared by the authors and they also note that these methods can be applied to inform the bi-annual vaccine composition meetings, which could be highly valuable.
Thanks for this nice summary of our paper.
The following points could be addressed in a revision:
(1) The authors conclude that much of the person-to-person and strain-to-strain variation seems idiosyncratic to individual sera rather than age groups. This point is not yet fully convincing. While the mean titer of an individual may be idiosyncratic to the individual sera, the strain-to-strain variation still reveals some patterns that are consistent across individuals (the authors note the effects of substitutions at sites 145 and 275/276). A more detailed analysis, removing the individual-specific mean titer, could still show shared patterns in groups of individuals that are not necessarily defined by the birth cohort.
As the reviewer suggests, we normalized the titers for all sera to the geometric mean titer for each individual in the US-based pre-vaccination adults and children. This is only for the 2023-circulating viral strains. We then faceted these normalized titers by the same age groups we used in Figure 6, and the resulting plot is shown. Although there are differences among virus strains (some are better neutralized than others), there are not obvious age group-specific patterns (eg, the trends in the two facets are similar). This observation suggests that at least for these relatively closely related recent H3N2 strains, the strain-to-strain variation does not obviously segregate by age group. Obviously, it is possible (we think likely) that there would be more obvious age-group specific trends if we looked at a larger swath of viral strains covering a longer time range (eg, over decades of influenza evolution). We have added the new plots shown as a Supplemental Figure 6 in the revised manuscript.
(2) The authors show that the fraction of sera with a titer 138 correlates strongly with the inferred growth rate using MLR. However, the authors also note that there exists a strong correlation between the MLR growth rate and the number of HA1 mutations. This analysis does not yet show that the titers provide substantially more information about the evolutionary success. The actual relation between the measured titers and fitness is certainly more subtle than suggested by the correlation plot in Figure 5. For example, the clades A/Massachusetts and A/Sydney both have a positive fitness at the beginning of 2023, but A/Massachusetts has substantially higher relative fitness than A/Sydney. The growth inference in Figure 5b does not appear to map that difference, and the antigenic data would give the opposite ranking. Similarly, the clades A/Massachusetts and A/Ontario have both positive relative fitness, as correctly identified by the antigenic ranking, but at quite different times (i.e., in different contexts of competing clades). Other clades, like A/St. Petersburg are assigned high growth and high escape but remain at low frequency throughout. Some mention of these effects not mapped by the analysis may be appropriate.
Thanks for the nice summary of our findings in Figure 5. However, the reviewer is misreading the growth charts when they say that A/Massachusetts/18/2022 has a substantially higher fitness than A/Sydney/332/2023. Figure 5a (reprinted at left panel) shows the frequency trajectory of different variants over time. While A/Massachusetts/18/2022 reaches a higher frequency than A/Sydney/332/2023, the trajectory is similar and the reason that A/Massachusetts/18/2022 reached a higher max frequency is that it started at a higher frequency at the beginning of 2023. The MLR growth rate estimates differ from the maximum absolute frequency reached: instead, they reflect how rapidly each strain grows relative to others. In fact, A/Massachusetts/18/2022 and A/Sydney/332/2023 have similar growth rates, as shown in Supplemental Figure 6b (reprinted at right). Similarly, A/Saint-Petersburg/RII-166/2023 starts at a low initial frequency but then grows even as A/Massachusetts/18/2022 and A/Sydney/332/2023 are declining, and so has a higher growth rate than both of those.
In the revised manuscript, we have clarified how viral growth rates are estimated from frequency trajectories, and how growth rate differs from max frequency in the text below:
“To estimate the evolutionary success of different human H3N2 influenza strains during 2023, we used multinomial logistic regression, which analyzes strain frequencies over time to calculate strain-specific relative growth rates [51–53]. There were sufficient sequencing counts to reliably estimate growth rates in 2023 for 12 of the HAs for which we measured titers using our sequencing-based neutralization assay libraries (Figure 5a,b and Supplemental Figure 9a,b). Note that these growth rates estimate how rapidly each strain grows relative to the other strains, rather than the absolute highest frequency reached by each strain “.
(3) For the protection profile against the vaccine strains, the authors find for the adult cohort that the highest titer is always against the oldest vaccine strain tested, which is A/Texas/50/2012. However, the adult sera do not show an increase in titer towards older strains, but only a peak at A/Texas. Therefore, it could be that this is a virus-specific effect, rather than a property of the protection profile. Could the authors test with one older vaccine virus (A/Perth/16/2009?) whether this really can be a general property?
We are interested in studying immune imprinting more thoroughly using sequencing-based neutralization assays, but we note that the adults in the cohorts we studied would have been imprinted with much older strains than included in this library. As this paper focuses on the relative fitness of contemporary strains with minor secondary points regarding imprinting, these experiments are beyond the scope of this study. We’re excited for future work (from our group or others) to explore these points by making a new virus library with strains from multiple decades of influenza evolution.
Reviewer #2 (Public review):
This is an excellent paper. The ability to measure the immune response to multiple viruses in parallel is a major advancement for the field, which will be relevant across pathogens (assuming the assay can be appropriately adapted). I only have a few comments, focused on maximising the information provided by the sera.
Thanks very much!
Firstly, one of the major findings is that there is wide heterogeneity in responses across individuals. However, we could expect that individuals' responses should be at least correlated across the viruses considered, especially when individuals are of a similar age. It would be interesting to quantify the correlation in responses as a function of the difference in ages between pairs of individuals. I am also left wondering what the potential drivers of the differences in responses are, with age being presumably key. It would be interesting to explore individual factors associated with responses to specific viruses (beyond simply comparing adults versus children).
We thank the reviewer for this interesting idea. We performed this analysis (and the related analyses described) and added this as a new Supplemental Figure 7, which is pasted after the response to the next related comment by the reviewer.
For 2023-circulating strains, we observed basically no correlation between the strength of correlation between pairs of sera and the difference in age between those pairs of sera (Supplemental Figure 7), which was unsurprising given the high degree of heterogeneity between individual sera (Figure 3, Supplemental Figure 6, and Supplemental Figure 8). For vaccine strains, there is a moderate negative correlation only in the children, but not in the adults or the combined group of adults and children. This could be because the children are younger with limited and potentially more similar vaccine and exposure histories than the adults. It could also be because the children are overall closer in age than the adults.
Relatedly, is the phylogenetic distance between pairs of viruses associated with similarity in responses?
For 2023-circulating strains, across sera cohorts we observed a weak-to-moderate correlation between the strength of correlation between the neutralizing titers across all sera to pairs of viruses and the Hamming distances between virus pairs. For the same comparison with vaccine strains, we observed moderate correlations, but this must be caveated with the slightly larger range of Hamming distances between vaccine strains. Notably, many of the points on the negative correlation slope are a mix of egg- and cell-produced vaccine strains from similar years, but there are some strain comparisons where the same year’s egg- and cell-produced vaccine strains correlate poorly.
Figure 5C is also a really interesting result. To be able to predict growth rates based on titers in the sera is fascinating. As touched upon in the discussion, I suspect it is really dependent on the representativeness of the sera of the population (so, e.g., if only elderly individuals provided sera, it would be a different result than if only children provided samples). It may be interesting to compare different hypotheses - so e.g., see if a population-weighted titer is even better correlated with fitness - so the contribution from each individual's titer is linked to a number of individuals of that age in the population. Alternatively, maybe only the titers in younger individuals are most relevant to fitness, etc.
We’re very interested in these analyses, but suggest they may be better explored in subsequent works that could sample more children, teenagers and adults across age groups. Our sera set, as the reviewer suggests, may be under-powered to perform the proposed analysis on subsetted age groups of our larger age cohorts.
In Figure 6, the authors lump together individuals within 10-year age categories - however, this is potentially throwing away the nuances of what is happening at individual ages, especially for the children, where the measured viruses cross different groups. I realise the numbers are small and the viruses only come from a small numbers of years, however, it may be preferable to order all the individuals by age (y-axis) and the viral responses in ascending order (x-axis) and plot the response as a heatmap. As currently plotted, it is difficult to compare across panels
This is a good suggestion. In the revised manuscript we have included a heatmap of the children and pre-vaccination adults, ordered by the year of birth of each individual, as Supplemental figure 8. That new figure is also pasted in this response.
Reviewer #3 (Public review):
The authors use high-throughput neutralisation data to explore how different summary statistics for population immune responses relate to strain success, as measured by growth rate during the 2023 season. The question of how serological measurements relate to epidemic growth is an important one, and I thought the authors present a thoughtful analysis tackling this question, with some clear figures. In particular, they found that stratifying the population based on the magnitude of their antibody titres correlates more with strain growth than using measurements derived from pooled serum data. However, there are some areas where I thought the work could be more strongly motivated and linked together. In particular, how the vaccine responses in US and Australia in Figures 6-7 relate to the earlier analysis around growth rates, and what we would expect the relationship between growth rate and population immunity to be based on epidemic theory.
Thank you for this nice summary. This reviewer also notes that the text related to figures 6 and 7 are more secondary to the main story presented in figures 3-5. The main motivation for including figures 6 and 7 were to demonstrate the wide-ranging applications of sequencing-based neutralization data. We have tried to clarify this with the following minor text revisions, which do not add new content but we hope smooth the transition between results sections.
While the preceding analyses demonstrated the utility of sequencing-based neutralization assays for measuring titers of currently circulating strains, our library also included viruses with HAs from each of the H3N2 influenza Northern Hemisphere vaccine strains from the last decade (2014 to 2024, see Supplemental Table 1). These historical vaccine strains cover a much wider span of evolutionary diversity that the 2023-circulating strains analyzed in the preceding sections (Figure 2a,b and Supplemental Figure 2b-e). For this analysis, we focused on the cell-passaged strains for each vaccine, as these are more antigenically similar to their contemporary circulating strains than the egg-passaged vaccine strains since they lack the mutations that arise during growth of viruses in eggs [55–57] (Supplemental Table 1).
Our sequencing-based assay could also be used to assess the impact of vaccination on neutralization titers against the full set of strains in our H3N2 library. To do this, we analyzed matched 28-day post-vaccination samples for each of the above-described 39 pre-vaccination samples from the cohort of adults based in the USA (Table 1). We also analyzed a smaller set of matched pre- and post-vaccination sera samples from a cohort of eight adults based in Australia (Table 1). Note that there are several differences between these cohorts: the USA-based cohort received the 2023-2024 Northern Hemisphere egg-grown vaccine whereas the Australia-based cohort received the 2024 Southern Hemisphere cell-grown vaccine, and most individuals in the USA-based cohort had also been vaccinated in the prior season whereas most individuals in the Australia-based cohort had not. Therefore, multiple factors could contribute to observed differences in vaccine response between the cohorts.
Reviewer #3 (Recommendations for the authors):
Main comments:
(1) The authors compare titres of the pooled sera with the median titres across individual sera, finding a weak correlation (Figure 4). I was therefore interested in the finding that geometric mean titre and median across a study population are well correlated with growth rate (Supplemental Figure 6c). It would be useful to have some more discussion on why estimates from a pool are so much worse than pooled estimates.
We thank this reviewer for this point. We would clarify that pooling sera is the equivalent of taking the arithmetic mean of the individual sera, rather than the geometric mean or median, which tends to bias the measurements of the pool to the outliers within the pool. To address this reviewer’s point, we’ve added the following text to the manuscript:
“To confirm that sera pools are not reflective of the full heterogeneity of their constituent sera, we created equal volume pools of the children and adult sera and measured the titers of these pools using the sequencing-based neutralization assay. As expected, neutralization titers of the pooled sera were always higher than the median across the individual constituent sera, and the pool titers against different viral strains were only modestly correlated with the median titers across individual sera (Figure 4). The differences in titers across strains were also compressed in the serum pools relative to the median across individual sera (Figure 4). The failure of the serum pools to capture the median titers of all the individual sera is especially dramatic for the children sera (Figure 4) because these sera are so heterogeneous in their individual titers (Figure 3b). Taken together, these results show that serum pools do not fully represent individual-level heterogeneity, and are similar to taking the arithmetic mean of the titers for a pool of individuals, which tends to be biased by the highest titer sera”.
(2) Perhaps I missed it, but are growth rates weekly growth rates? (I assume so?)
The growth rates are relative exponential growth rates calculated assuming a serial interval of 3.6 days. We also added clarifying language and a citation for the serial growth interval to the methods section:
The analysis performing H3 HA strain growth rate estimates using the evofr[51] package is at https://github.com/jbloomlab/flu_H3_2023_seqneut_vs_growth. Briefly, we sought to make growth rate estimates for the strains in 2023 since this was the same timeframe when the sera were collected. To achieve this, we downloaded all publicly-available H3N2 sequences from the GISAID[88] EpiFlu database, filtering to only those sequences that closely matched a library HA1 sequence (within one HA1 amino-acid mutation) and were collected between January 2023 and December 2023. If a sequence was within one HA1 amino-acid mutation of multiple library HA1 proteins then it was assigned to the closest one; if there were multiple equally close matches then it was assigned fractionally to each match. We only made growth rate estimates for library strains with at least 80 sequencing counts (Supplemental Figure 9a), and ignored counts for sequences that did not match a library strain (equivalent results were obtained if we instead fit a growth rate for these sequences as an “other” category). We then fit multinomial logistic regression models using the evofr[51] package assuming a serial interval of 3.6 days[101] to the strain counts. For the plot in Figure 5a the frequencies are averaged over a 14-day sliding window for visual clarity, but the fits were to the raw sequencing counts. For most of the analyses in this paper we used models based on requiring 80 sequencing counts to make an estimate for strain growth rates, and counting a sequence as a match if it was within one amino-acid mutation; see https://jbloomlab.github.io/flu_H3_2023_seqneut_vs_growth/ for comparable analyses using different reasonable sequence count cutoffs (e.g., 60, 50, 40 and 30, as depicted in Supplemental Figure 9). Across sequence cutoffs, we found that the fraction of individuals with low neutralization titers and number of HA1 mutations correlated strongly with these MLR-estimated strain growth rates.
(3) I found Figure 3 useful in that it presents phylogenetic structure alongside titres, to make it clearer why certain clusters of strains have a lower response. In contrast, I found it harder to meaningfully interpret Figure 7a beyond the conclusion that vaccines lead to a fairly uniform rise in titre. Do the 275 or 276 mutations that seem important for adults in Figure 3 have any impact?
We are certainly interested in the questions this reviewer raises, and in trying to understand how well a seasonal vaccine protects against the most successful influenza variants that season. However, these post-vaccination sera were taken when neutralizing titers peak ~30 days after vaccination. Because of this, in the larger cohort of US-based post-vaccination adults, the median titers across sera to most strains appear uniformly high. In the Australian-based post-vaccination adults, there was some strain-to-strain variation in median titers across sera, but of course this must be caveated with the much smaller sample size. It might be more relevant to answer this question with longitudinally sampled sera, when titers begin to wane in the following months.
(4) It could be useful to define a mechanistic relationship about how you would expect susceptibility (e.g. fraction with titre < X, where X is a good correlate) to relate to growth via the reproduction number: R = R0 x S. For example, under the assumption the generation interval G is the same for all, we have R = exp(r*G), which would make it possible to make a prediction about how much we would expect the growth rate to change between S = 0.45 and 0.6, as in Fig 5c. This sort of brief calculation (or at least some discussion) could add some more theoretical underpinning to the analysis, and help others build on the work in settings with different fractions with low titres. It would also provide some intuition into whether we would expect relationships to be linear.
This is an interesting idea for future work! However, the scope of our current study is to provide these experimental data and show a correlation with growth; we hope this can be used to build more mechanistic models in future.
(5) A key conclusion from the analysis is that the fraction above a threshold of ~140 is particularly informative for growth rate prediction, so would it be worth including this in Figure 6-7 to give a clearer indication of how much vaccination reduces contribution to strain growth among those who are vaccinated? This could also help link these figures more clearly with the main analysis and question.
Although our data do find ~140 to be the threshold that gives max correlation with growth rate, we are not comfortable strongly concluding 140 is a correlate of protection, as titers could influence viral fitness without completely protecting against infection. In addition, inspection of Figure 5d shows that while ~140 does give the maximal correlation, a good correlation is observed for most cutoffs in the range from ~40 to 200, so we are not sure how robustly we can be sure that ~140 is the optimal threshold.
(6) In Figure 5, the caption doesn't seem to include a description for (e).
Thank you to the reviewer for catching this – this is fixed now.
(7) The US vs Australia comparison could have benefited from more motivation. The authors conclude ,"Due to the multiple differences between cohorts we are unable to confidently ascribe a cause to these differences in magnitude of vaccine response" - given the small sample sizes, what hypotheses could have been tested with these data? The comparison isn't covered in the Discussion, so it seems a bit tangential currently.
Thank you to the reviewer for this comment, but we should clarify our aim was not to directly compare US and Australian adults. We are interested in regional comparisons between serum cohorts, but did not have the numbers to adequately address those questions here. This section (and the preceding question) were indeed both intended to be tangential to the main finding, and hopefully this will be clarified with our text additions in response to Reviewer #3’s public reviews.
Act5C-GAL4 strain (“y[1] w[∗]; P(Act5C-GAL4-w)E1/CyO,” “1;2”) (Bloomington Stock Center
DOI: 10.1093/molbev/msaf246
Resource: Bloomington Drosophila Stock Center (RRID:SCR_006457)
Curator: @maulamb
SciCrunch record: RRID:SCR_006457
5905
DOI: 10.1007/s00018-025-05927-y
Resource: RRID:BDSC_5905
Curator: @maulamb
SciCrunch record: RRID:BDSC_5905
36318
DOI: 10.1007/s00018-025-05927-y
Resource: RRID:BDSC_36318
Curator: @maulamb
SciCrunch record: RRID:BDSC_36318
24646
DOI: 10.1007/s00018-025-05927-y
Resource: RRID:BDSC_24646
Curator: @maulamb
SciCrunch record: RRID:BDSC_24646
56754
DOI: 10.1007/s00018-025-05927-y
Resource: RRID:BDSC_56754
Curator: @maulamb
SciCrunch record: RRID:BDSC_56754
https://bafybeib3do3xiseamt73aevyttzxzordc5gm6nnpndru7tvbm47pl4vhte.ipfs.dweb.link?filename=index.html
📰 IPFS based IndyWeb constellations
Bien que les sources se concentrent sur le contrôle coercitif dans le contexte des violences conjugales et familiales, certains aspects peuvent être transposés au harcèlement scolaire, avec prudence et adaptation.
Il est important de souligner que les dynamiques et les enjeux diffèrent entre une relation intime et une relation entre pairs dans un contexte scolaire, mais certaines similitudes peuvent être observées.
De même, dans le harcèlement scolaire, un élève ou un groupe d'élèves exerce un pouvoir sur une victime, cherchant à la dominer et à la contrôler [conversation history]. Cette dynamique de pouvoir est centrale dans les deux phénomènes.
Ces stratégies d'isolement et d'intimidation visent à briser la résistance de la victime.
Cette micro-régulation peut être vue comme une forme de contrôle.
Le harcèlement scolaire a un impact similaire sur l'estime de soi de la victime, qui peut se sentir humiliée, rejetée et dévalorisée [conversation history].
Dans les deux cas, l'objectif est de briser l'identité et la confiance en soi de la victime.
Dans le harcèlement scolaire, les agresseurs peuvent manipuler les autres élèves, les incitant à participer au harcèlement ou à rejeter la victime [conversation history].
Cette manipulation des relations contribue à renforcer l'isolement et le sentiment d'impuissance de la victime.
Les victimes de harcèlement scolaire peuvent également éprouver un sentiment de terreur et d'impuissance, se sentant piégées dans une situation dont elles ne voient pas d'issue [conversation history].
Dans les deux cas, la victime est soumise à une forme de violence psychologique constante qui affecte son bien-être.
Dans le harcèlement scolaire, un échec des tentatives de contrôler ou d'intimider une victime peut aussi mener à une escalade dans la violence physique, verbale ou psychologique.
Points importants à considérer lors de la transposition de ces notions :
Dans le harcèlement scolaire, l'intention des agresseurs peut être variée, allant de la recherche de pouvoir à la volonté de nuire [conversation history].
Ces contextes différents impliquent des dynamiques relationnelles différentes.
Intervention : Il est crucial de noter que l'intervention dans les cas de harcèlement scolaire doit se faire de manière adaptée au contexte scolaire et au développement des jeunes.
Prévention: L'éducation et la sensibilisation sur les dynamiques de pouvoir et de contrôle sont essentielles pour prévenir le harcèlement et le contrôle coercitif.
La formation des enseignants et du personnel scolaire, à l'instar de la formation des magistrats, pourrait contribuer à une meilleure compréhension de ces phénomènes.
En résumé, bien que le contrôle coercitif et le harcèlement scolaire soient des phénomènes distincts, il existe des parallèles importants dans les dynamiques de pouvoir, d'isolement, d'intimidation et de manipulation qu'ils impliquent [conversation history].
Comprendre ces similitudes peut aider à mieux détecter et prévenir ces formes de violence, tant dans les relations intimes qu'au sein des établissements scolaires.
Voici un sommaire minuté de la transcription, mettant en évidence les idées fortes :
Les chercheurs tentaient de comprendre pourquoi ils avaient collaboré avec l'ennemi, les études sur le lavage de cerveau, puis les travaux d'Albert Biderman qui s'interroge sur les méthodes des tortionnaires pour obtenir la soumission. * 1:23-1:51 : Le contrôle coercitif est une forme de soumission sans violence physique, comme démontré dans les expériences de Milgram sur la soumission à l'autorité.
1:52-2:07 : L'application du concept aux violences intrafamiliales et la nécessité de comprendre les comportements qui structurent le contrôle coercitif.
2:08-2:32 : Les violences conjugales touchent majoritairement les femmes et les enfants.
En France, 82% des victimes de violences conjugales sont des mères. L'échec à prévenir et protéger ces victimes souligne l'importance d'une approche globale de la violence conjugale.
L'agresseur impose des règles strictes dans l'espace familial, contrôlant des aspects anodins de la vie quotidienne pour obtenir la soumission.
3:25-3:49 : Exemples de micro-régulations : contrôle de la façon de s'habiller, du temps passé sous la douche, des interactions des enfants, etc.
3:50-4:02 : Le contrôle coercitif se concentre sur le comportement de l'agresseur et comment il empêche la victime de partir, changeant ainsi la question de "pourquoi n'est-elle pas partie ?" à "comment l'en a-t-il empêché ?".
4:03-4:31 : L'identification de faits mineurs pris isolément, qui échappent habituellement à la justice, permet de saisir le climat conjugal ou familial.
Tous les comportements de contrôle coercitif ne mènent pas au féminicide, mais tous les féminicides passent par le contrôle coercitif.
4:51-5:28 : Le féminicide comme échec du contrôle : lorsque l'agresseur échoue à contrôler sa victime, il y a une escalade de la violence pouvant mener au féminicide, aux suicides forcés, et aux homicides d'enfants. Le contrôle coercitif est un précurseur majeur de ces violences.
5:29-5:50 : Les enfants sont aussi victimes de la captivité et le contrôle ne cesse pas avec la séparation, ce qui est souvent exercé au détriment des enfants.
5:51-6:20 : La recherche internationale montre que le contrôle coercitif des femmes par les hommes est la cause principale des violences faites aux enfants.
6:21-6:46 : Le contrôle peut s'exercer notamment dans le contexte de procédures judiciaires liées à la séparation, l'agresseur utilisant son droit parental au détriment de la sécurité des enfants.
L'enfant devient une cible, un informateur ou un espion.
6:47-7:04 : Exemples tragiques comme la petite Chloé, tuée par son père, soulignent l'importance de la protection des enfants, même après une séparation et une ordonnance de protection.
7:05-7:25 : L'Écosse a intégré le contrôle coercitif dès 2018, suivie par la Cour européenne des droits de l'homme et les premiers arrêts en France, notamment ceux de la cour d'appel de Poitier.
Voici un document de synthèse pour un briefing sur le contrôle coercitif, basé sur les informations de la transcription et notre conversation précédente :
Introduction : Le Contrôle Coercitif, une Nouvelle Réalité Juridique et Sociale
Origines et Définition du Contrôle Coercitif
Les études sur le lavage de cerveau ont évolué vers l'analyse des méthodes des tortionnaires pour obtenir la soumission.
Le Contrôle Coercitif dans le Contexte des Violences Conjugales
Il se caractérise aussi par une micro-régulation du quotidien de la victime et de ses enfants : contrôle de la manière de s'habiller, du temps passé sous la douche, des interactions avec les enfants, etc.
Le contrôle coercitif attaque la relation de la victime avec son enfant. L'agresseur impose des règles strictes dans l'espace familial, cherchant à obtenir la soumission de la victime et de ses enfants.
L'approche change la question de "pourquoi n'est-elle pas partie?" à "comment l'en a-t-il empêché?".
Le Contrôle Coercitif : Un Précurseur des Formes Ultimes de Violence
La recherche internationale montre que le contrôle coercitif des femmes par les hommes est la cause principale des violences faites aux enfants.
Implications Juridiques et Avancées Législatives
Conclusion : Nécessité d'une Approche Globale
/indy0/~/gyuri/anytype/
Comment y circulerPour circuler dans un carrefour giratoire, le conducteur doit :1. RalentirÀ l’approche, réduire la vitesse et regarder les panneaux.Être prêt à s’arrêter complètement :▷ si un piéton traverse ou s’apprête à le faire ;▷ si une voiture est déjà à l’intérieur du carrefour giratoire,sur la gauche.2. Céder le passageAvant d’y entrer, céder le passage aux véhicules déjà engagés,car ils ont la priorité.3. Entrer par la droiteLorsque le passage est libre.4. Circuler dans le sens de la circulationSans dépasser ni s’arrêter, à moins d’une urgence, comme pouréviter une collision.5. Sortir du carrefour :▷ indiquer l’intention avec le clignotant ;▷ sortir du carrefour (attention aux piétons).
Comment circuler dans un carrefour giratoire?
Considering the previous statements, The first hypothesis is of this study is H1 It is possible to identify two latent dimensions of digital self-efficacy (general and specialized) based on related batteries and indicators included in large-scale assessments such as PISA and ICILS.
ehhh ... y argumentar algo sobre invarianza??
Digital self-efficacy
este párrafo es el central, y no está lo suficientemente enfatizado, parece que fuera una información adicional, y no se entiende la relación de la bidimensionalidad con la primera oración.
Author response:
The following is the authors’ response to the original reviews
Reviewer #1 (Public review):
Weakness:
I wonder how task difficulty and linguistic labels interact with the current findings. Based on the behavioral data, shapes with more geometric regularities are easier to detect when surrounded by other shapes. Do shape labels that are readily available (e.g., "square") help in making accurate and speedy decisions? Can the sensitivity to geometric regularity in intraparietal and inferior temporal regions be attributed to differences in task difficulty? Similarly, are the MEG oddball detection effects that are modulated by geometric regularity also affected by task difficulty?
We see two aspects to the reviewer’s remarks.
(1) Names for shapes.
On the one hand, is the question of the impact of whether certain shapes have names and others do not in our task. The work presented here is not designed to specifically test the effect of formal western education; however, in previous work (Sablé-Meyer et al., 2021), we noted that the geometric regularity effect remains present even for shapes that do not have specific names, and even in participants who do not have names for them. Thus, we replicated our main effects with both preschoolers and adults that did not attend formal western education and found that our geometric feature model remained predictive of their behavior; we refer the reader to this previous paper for an extensive discussion of the possible role of linguistic labels, and the impact of the statistics of the environment on task performance.
What is more, in our behavior experiments we can discard data from any shape that is has a name in English and run our model comparison again. Doing so diminished the effect size of the geometric feature model, but it remained predictive of human behavior: indeed, if we removed all shapes but kite, rightKite, rustedHinge, hinge and random (i.e., more than half of our data, and shapes for which we came up with names but there are no established names), we nevertheless find that both models significantly correlate with human behavior—see plot in Author response image 1, equivalent of our Fig. 1E with the remaining shapes.
Author response image 1.
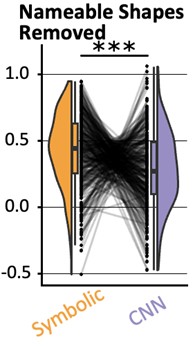
An identical analysis on the MEG leads to two noisy but significant clusters (CNN: 64.0ms to 172.0ms; then 192.0ms to 296.0ms; both p<.001: Geometric Features: 312.0ms to 364.0ms with p=.008). We have improved our manuscript thanks to the reviewer’s observation by adding a figure with the new behavior analysis to the supplementary figures and in the result section of the behavior task. We now refer to these analysis where appropriate:
(intro) “The effect appeared as a human universal, present in preschoolers, first-graders, and adults without access to formal western math education (the Himba from Namibia), and thus seemingly independent of education and of the existence of linguistic labels for regular shapes.”
(behavior results) “Finally, to separate the effect of name availability and geometric features on behavior, we replicated our analysis after removing the square, rectangle, trapezoids, rhombus and parallelogram from our data (Fig. S5D). This left us with five shapes, and an RDM with 10 entries, When regressing it in a GLM with our two models, we find that both models are still significant predictors (p<.001). The effect size of the geometric feature model is greatly reduced, yet remained significantly higher than that of the neural network model (p<.001).”
(meg results) “This analysis yielded similar clusters when performed on a subset of shapes that do not have an obvious name in English, as was the case for the behavior analysis (CNN Encoding: 64.0ms to 172.0ms; then 192.0ms to 296.0ms; both p<.001: Geometric Features: 312.0ms to 364.0ms with p=.008).”
(discussion, end of behavior section) “Previously, we only found such a significant mixture of predictors in uneducated humans (whether French preschoolers or adults from the Himba community, mitigating the possible impact of explicit western education, linguistic labels, and statistics of the environment on geometric shape representation) (Sablé-Meyer et al., 2021).”
Perhaps the referee’s point can also be reversed: we provide a normative theory of geometric shape complexity which has the potential to explain why certain shapes have names: instead of seeing shape names as the cause of their simpler mental representation, we suggest that the converse could occur, i.e. the simpler shapes are the ones that are given names.
(2) Task difficulty
On the other hand is the question of whether our effect is driven by task difficulty. First, we would like to point out that this point could apply to the fMRI task, which asks for an explicit detection of deviants, but does not apply to the MEG experiment. In MEG, participants passively looked at sequences of shapes which, for a given block, comprising many instances of a fixed standard shape and rare deviants–even if they notice deviants, they have no task related to them. Yet two independent findings validated the geometric features model: there was a large effect of geometric regularity on the MEG response to deviants, and the MEG dissimilarity matrix between standard shapes correlated with a model based on geometric features, better than with a model based on CNNs. While the response to rare deviants might perhaps be attributed to “difficulty” (assuming that, in spite of the absence of an explicit task, participants try to spot the deviants and find this self-imposed task more difficult in runs with less regular shapes), it seems very hard to explain the representational similarity analysis (RSA) findings based on difficulty. Indeed, what motivated us to use RSA analysis in both fMRI and MEG was to stop relying on the response to deviants, and use solely the data from standard or “reference” shapes, and model their neural response with theory-derived regressors.
We have updated the manuscript in several places to make our view on these points clearer:
(experiment 4) “This design allowed us to study the neural mechanisms of the geometric regularity effect without confounding effects of task, task difficulty, or eye movements.”
(figure 4, legend) “(A) Task structure: participants passively watch a constant stream of geometric shapes, one per second (presentation time 800ms). The stimuli are presented in blocks of 30 identical shapes up to scaling and rotation, with 4 occasional deviant shape. Participants do not have a task to perform beside fixating.”
Reviewer #2 (Public review):
Weakness:
Given that the primary take away from this study is that geometric shape information is found in the dorsal stream, rather than the ventral stream there is very little there is very little discussion of prior work in this area (for reviews, see Freud et al., 2016; Orban, 2011; Xu, 2018). Indeed, there is extensive evidence of shape processing in the dorsal pathway in human adults (Freud, Culham, et al., 2017; Konen & Kastner, 2008; Romei et al., 2011), children (Freud et al., 2019), patients (Freud, Ganel, et al., 2017), and monkeys (Janssen et al., 2008; Sereno & Maunsell, 1998; Van Dromme et al., 2016), as well as the similarity between models and dorsal shape representations (Ayzenberg & Behrmann, 2022; Han & Sereno, 2022).
We thank the reviewer for this opportunity to clarify our writing. We want to use this opportunity to highlight that our primary finding is not about whether the shapes of objects or animals (in general) are processed in the ventral versus or the dorsal pathway, but rather about the much more restricted domain of geometric shapes such as squares and triangles. We propose that simple geometric shapes afford additional levels of mental representation that rely on their geometric features – on top of the typical visual processing. To the best of our knowledge, this point has not been made in the above papers.
Still, we agree that it is useful to better link our proposal to previous ones. We have updated the discussion section titled “Two Visual Pathways” to include more specific references to the literature that have reported visual object representations in the dorsal pathway. Following another reviewer’s observation, we have also updated our analysis to better demonstrate the overlap in activation evoked by math and by geometry in the IPS, as well as include a novel comparison with independently published results.
Overall, to address this point, we (i) show the overlap between our “geometry” contrast (shape > word+tools+houses) and our “math” contrast (number > words); (ii) we display these ROIs side by side with ROIs found in previous work (Amalric and Dehaene, 2016), and (iii) in each math-related ROIs reported in that article, we test our “geometry” (shape > word+tools+houses) contrast and find almost all of them to be significant in both population; see Fig. S5.
Finally, within the ROIs identified with our geometry localizer, we also performed similarity analyses: for each region we extracted the betas of every voxel for every visual category, and estimated the distance (cross-validated mahalanobis) between different visual categories. In both ventral ROIs, in both populations, numbers were closer to shapes than to the other visual categories including text and Chinese characters (all p<.001). In adults, this result also holds for the right ITG (p=.021) and the left IPS (p=.014) but not the right IPS (p=.17). In children, this result did not hold in the areas.
Naturally, overlap in brain activation does not suffice to conclude that the same computational processes are involved. We have added an explicit caveat about this point. Indeed, throughout the article, we have been careful to frame our results in a way that is appropriate given our evidence, e.g. saying “Those areas are similar to those active during number perception, arithmetic, geometric sequences, and the processing of high-level math concepts” and “The IPS areas activated by geometric shapes overlap with those active during the comprehension of elementary as well as advanced mathematical concepts”. We have rephrased the possibly ambiguous “geometric shapes activated math- and number-related areas, particular the right aIPS.” into “geometric shapes activated areas independently found to be activated by math- and number-related tasks, in particular the right aIPS”.
Reviewer #3 (Public review):
Weakness:
Perhaps the manuscript could emphasize that the areas recruited by geometric figures but not objects are spatial, with reduced processing in visual areas. It also seems important to say that the images of real objects are interpreted as representations of 3D objects, as they activate the same visual areas as real objects. By contrast, the images of geometric forms are not interpreted as representations of real objects but rather perhaps as 2D abstractions.
This is an interesting possibility. Geometric shapes are likely to draw attention to spatial dimensions (e.g. length) and to do so in a 2D spatial frame of reference rather than the 3D representations evoked by most other objects or images. However, this possibility would require further work to be thoroughly evaluated, for instance by comparing usual 3D objects with rare instances of 2D ones (e.g. a sheet of paper, a sticker etc). In the absence of such a test, we refrained from further speculation on this point.
The authors use the term "symbolic." That use of that term could usefully be expanded here.
The reviewer is right in pointing out that “symbolic” should have been more clearly defined. We now added in the introduction:
(introduction) “[…] we sometimes refer to this model as “symbolic” because it relies on discrete, exact, rule-based features rather than continuous representations (Sablé-Meyer et al., 2022). In this representational format, geometric shapes are postulated to be represented by symbolic expressions in a “language-of-thought”, e.g. “a square is a four-sided figure with four equal sides and four right angles” or equivalently by a computer-like program from drawing them in a Logo-like language (Sablé-Meyer et al., 2022).”
Here, however, the present experiments do not directly probe this format of a representation. We have therefore simplified our wording and removed many of our use of the word “symbolic” in favor of the more specific “geometric features”.
Pigeons have remarkable visual systems. According to my fallible memory, Herrnstein investigated visual categories in pigeons. They can recognize individual people from fragments of photos, among other feats. I believe pigeons failed at geometric figures and also at cartoon drawings of things they could recognize in photos. This suggests they did not interpret line drawings of objects as representations of objects.
The comparison of geometric abilities across species is an interesting line of research. In the discussion, we briefly mention several lines of research that indicate that non-human primates do not perceive geometric shapes in the same way as we do – but for space reasons, we are reluctant to expand this section to a broader review of other more distant species. The referee is right that there is evidence of pigeons being able to perceive an invariant abstract 3D geometric shape in spite of much variation in viewpoint (Peissig et al., 2019) – but there does not seem to be evidence that they attend to geometric regularities specifically (e.g. squares versus non-squares). Also, the referee’s point bears on the somewhat different issue of whether humans and other animals may recognize the object depicted by a symbolic drawing (e.g. a sketch of a tree). Again, humans seem to be vastly superior in this domain, and research on this topic is currently ongoing in the lab. However, the point that we are making in the present work is specifically about the neural correlates of the representation of simple geometric shapes which by design were not intended to be interpretable as representations of objects.
Categories are established in part by contrast categories; are quadrilaterals, triangles, and circles different categories?
We are not sure how to interpret the referee’s question, since it bears on the definition of “category” (Spontaneous? After training? With what criterion?). While we are not aware of data that can unambiguously answer the reviewer’s question, categorical perception in geometric shapes can be inferred from early work investigating pop-out effects in visual search, e.g. (Treisman and Gormican, 1988): curvature appears to generate strong pop-out effects, and therefore we would expect e.g. circles to indeed be a different category than, say, triangles. Similarly, right angles, as well as parallel lines, have been found to be perceived categorically (Dillon et al., 2019).
This suggests that indeed squares would be perceived as categorically different from triangles and circles. On the other hand, in our own previous work (Sablé-Meyer et al., 2021) we have found that the deviants that we generated from our quadrilaterals did not pop out from displays of reference quadrilaterals. Pop-out is probably not the proper criterion for defining what a “category” is, but this is the extent to which we can provide an answer to the reviewer’s question.
It would be instructive to investigate stimuli that are on a continuum from representational to geometric, e.g., table tops or cartons under various projections, or balls or buildings that are rectangular or triangular. Building parts, inside and out. like corners. Objects differ from geometric forms in many ways: 3D rather than 2D, more complicated shapes, and internal texture. The geometric figures used are flat, 2-D, but much geometry is 3-D (e. g. cubes) with similar abstract features.
We agree that there is a whole line of potential research here. We decided to start by focusing on the simplest set of geometric shapes that would give us enough variation in geometric regularity while being easy to match on other visual features. We agree with the reviewer that our results should hold both for more complex 2-D shapes, but also for 3-D shapes. Indeed, generative theories of shapes in higher dimensions following similar principles as ours have been devised (I. Biederman, 1987; Leyton, 2003). We now mention this in the discussion:
“Finally, this research should ultimately be extended to the representation of 3-dimensional geometric shapes, for which similar symbolic generative models have indeed been proposed (Irving Biederman, 1987; Leyton, 2003).”
The feature space of geometry is more than parallelism and symmetry; angles are important, for example. Listing and testing features would be fascinating. Similarly, looking at younger or preferably non-Western children, as Western children are exposed to shapes in play at early ages.
We agree with the reviewer on all point. While we do not list and test the different properties separately in this work, we would like to highlight that angles are part of our geometric feature model, which includes features of “right-angle” and “equal-angles” as suggested by the reviewer.
We also agree about the importance of testing populations with limited exposure to formal training with geometric shapes. This was in fact a core aspect of a previous article of ours which tests both preschoolers, and adults with no access to formal western education – though no non-Western children (Sablé-Meyer et al., 2021). It remains a challenge to perform brain-imaging studies in non-Western populations (although see Dehaene et al., 2010; Pegado et al., 2014).
What in human experience but not the experience of close primates would drive the abstraction of these geometric properties? It's easy to make a case for elaborate brain processes for recognizing and distinguishing things in the world, shared by many species, but the case for brain areas sensitive to processing geometric figures is harder. The fact that these areas are active in blind mathematicians and that they are parietal areas suggests that what is important is spatial far more than visual. Could these geometric figures and their abstract properties be connected in some way to behavior, perhaps with fabrication and construction as well as use? Or with other interactions with complex objects and environments where symmetry and parallelism (and angles and curvature--and weight and size) would be important? Manual dexterity and fabrication also distinguish humans from great apes (quantitatively, not qualitatively), and action drives both visual and spatial representations of objects and spaces in the brain. I certainly wouldn't expect the authors to add research to this already packed paper, but raising some of the conceptual issues would contribute to the significance of the paper.
We refrained from speculating about this point in the previous version of the article, but share some of the reviewers’ intuitions about the underlying drive for geometric abstraction. As described in (Dehaene, 2026; Sablé-Meyer et al., 2022), our hypothesis, which isn’t tested in the present article, is that the emergence of a pervasive ability to represent aspects of the world as compact expressions in a mental “language-of-thought” is what underlies many domains of specific human competence, including some listed by the reviewer (tool construction, scene understanding) and our domain of study here, geometric shapes.
Recommendations for the Authors:
Reviewer #1 (Recommendations for the authors):
Overall, I enjoyed reading this paper. It is clearly written and nicely showcases the amount of work that has gone into conducting all these experiments and analyzing the data in sophisticated ways. I also thought the figures were great, and I liked the level of organization in the GitHub repository and am looking forward to seeing the shared data on OpenNeuro. I have some specific questions I hope the authors can address.
(1) Behavior
- Looking at Figure 1, it seemed like most shapes are clustering together, whereas square, rectangle, and maybe rhombus and parallelogram are slightly more unique. I was wondering whether the authors could comment on the potential influence of linguistic labels. Is it possible that it is easier to discard the intruder when the shapes are readily nameable versus not?
This is an interesting observation, but the existence of names for shapes does not suffice to explain all of our findings ; see our reply to the public comment.
(2) fMRI
- As mentioned in the public review, I was surprised that the authors went with an intruder task because I would imagine that performance depends on the specific combination of geometric shapes used within a trial. I assume it is much harder to find, for example, a "Right Hinge" embedded within "Hinge" stimuli than a "Right Hinge" amongst "Squares". In addition, the rotation and scaling of each individual item should affect regular shapes less than irregular shapes, creating visual dissimilarities that would presumably make the task harder. Can the authors comment on how we can be sure that the differences we pick up in the parietal areas are not related to task difficulty but are truly related to geometric shape regularities?
Again, please see our public review response for a larger discussion of the impact of task difficulty. There are two aspects to answering this question.
First, the task is not as the reviewer describes: the intruder task is to find a deviant shape within several slightly rotated and scaled versions of the regular shape it came from. During brain imaging, we did not ask participants to find an exemplar of one of our reference shape amidst copies of another, but rather a deviant version of one shape against copies of its reference version. We only used this intruder task with all pairs of shapes to generate the behavioral RSA matrix.
Second, we agree that some of the fMRI effect may stem from task difficulty, and this motivated our use of RSA analysis in fMRI, and a passive MEG task. RSA results cannot be explained by task difficulty.
Overall, we have tried to make the limitations of the fMRI design, and the motivation for turning to passive presentation in MEG, clearer by stating the issues more clearly when we introduce experiment 4:
“The temporal resolution of fMRI does not allow to track the dynamic of mental representations over time. Furthermore, the previous fMRI experiment suffered from several limitations. First, we studied six quadrilaterals only, compared to 11 in our previous behavioral work. Second, we used an explicit intruder detection, which implies that the geometric regularity effect was correlated with task difficulty, and we cannot exclude that this factor alone explains some of the activations in figure 3C (although it is much less clear how task difficulty alone would explain the RSA results in figure 3D). Third, the long display duration, which was necessary for good task performance especially in children, afforded the possibility of eye movements, which were not monitored inside the 3T scanner and again could have affected the activations in figure 3C.”
- How far in the periphery were the stimuli presented? Was eye-tracking data collected for the intruder task? Similar to the point above, I would imagine that a harder trial would result in more eye movements to find the intruder, which could drive some of the differences observed here.
A 1-degree bar was added to Figure 3A, which faithfully illustrates how the stimuli were presented in fMRI. Eye-tracking data was not collected during fMRI. Although the participants were explicitly instructed to fixate at the center of the screen and avoid eye movements, we fully agree with the referee that we cannot exclude that eye movements were present, perhaps more so for more difficult displays, and would therefore have contributed to the observed fMRI activations in experiment 3 (figure 3C). We now mention this limitation explicity at the end of experiment 3. However, crucially, this potential problem cannot apply to the MEG data. During the MEG task, the stimuli were presented one by one at the center of screen, without any explicit task, thus avoiding issues of eye movements. We therefore consider the MEG geometrical regularity effect, which comes at a relatively early latency (starting at ~160 ms) and even in a passive task, to provide the strongest evidence of geometric coding, unaffected by potential eye movement artefacts.
- I was wondering whether the authors would consider showing some un-thresholded maps just to see how widespread the activation of the geometric shapes is across all of the cortex.
We share the uncorrected threshold maps in Fig. S3. for both adults and children in the category localizer, copied here as well. For the geometry task, most of the clusters identified are fairly big and survive cluster-corrected permutations; the uncorrected statistical maps look almost fully identical to the one presented in Fig. 3 (p<.001 map).
- I'm missing some discussion on the role of early visual areas that goes beyond the RSA-CNN comparison. I would imagine that early visual areas are not only engaged due to top-down feedback (line 258) but may actually also encode some of the geometric features, such as parallel lines and symmetry. Is it feasible to look at early visual areas and examine what the similarity structure between different shapes looks like?
If early visual areas encoded the geometric features that we propose, then even early sensor-level RSA matrices should show a strong impact of geometric features similarity, which is not what we find (figure 4D). We do, however, appreciate the referee’s request to examine more closely how this similarity structure looks like. We now provide a movie showing the significant correlation between neural activity and our two models (uncorrected participants); indeed, while the early occipital activity (around 110ms) is dominated by a significant correlation with the CNN model, there are also scattered significant sources associated to the symbolic model around these timepoints already.
To test this further, we used beamformers to reconstruct the source-localized activity in calcarine cortex and performed an RSA analysis across that ROI. We find that indeed the CNN model is strongly significant at t=110ms (t=3.43, df=18, p=.003) while the geometric feature model is not (t=1.04, df=18, p=.31), and the CNN is significantly above the geometric feature model (t=4.25, df=18, p<.001). However, this result is not very stable across time, and there are significant temporal clusters around these timepoints associated to each model, with no significant cluster associated to a CNN > geometric (CNN: significant cluster from 88ms to 140ms, p<.001 in permutation based with 10000 permutations; geometric features has a significant cluster from 80ms to 104ms, p=.0475; no significant cluster on the difference between the two).
(3) MEG
- Similar to the fMRI set, I am a little worried that task difficulty has an effect on the decoding results, as the oddball should pop out more in more geometric shapes, making it easier to detect and easier to decode. Can the authors comment on whether it would matter for the conclusions whether they are decoding varying task difficulty or differences in geometric regularity, or whether they think this can be considered similarly?
See above for an extensive discussion of the task difficulty effect. We point out that there is no task in the MEG data collection part. We have clarified the task design by updating our Fig. 4. Additionally, the fact that oddballs are more perceived more or less easily as a function of their geometric regularity is, in part, exactly the point that we are making – but, in MEG, even in the absence of a task of looking for them.
- The authors discuss that the inflated baseline/onset decoding/regression estimates may occur because the shapes are being repeated within a mini-block, which I think is unlikely given the long ISIs and the fact that the geometric features model is not >0 at onset. I think their second possible explanation, that this may have to do with smoothing, is very possible. In the text, it said that for the non-smoothed result, the CNN encoding correlates with the data from 60ms, which makes a lot more sense. I would like to encourage the authors to provide readers with the unsmoothed beta values instead of the 100-ms smoothed version in the main plot to preserve the reason they chose to use MEG - for high temporal resolution!
We fully agree with the reviewer and have accordingly updated the figures to show the unsmoothed data (see below). Indeed, there is now no significant CNN effect before ~60 ms (up to the accuracy of identifying onsets with our method).
- In Figure 4C, I think it would be useful to either provide error bars or show variability across participants by plotting each participant's beta values. I think it would also be nice to plot the dissimilarity matrices based on the MEG data at select timepoints, just to see what the similarity structure is like.
Following the reviewer’s recommendation, we plot the timeseries with SEM as shaded area, and thicker lines for statistically significant clusters, and we provide the unsmoothed version in figure Fig. 4. As for the dissimilarity matrices at select timepoints, this has now been added to figure Fig. 4.
- To evaluate the source model reconstruction, I think the reader would need a little more detail on how it was done in the main text. How were the lead fields calculated? Which data was used to estimate the sources? How are the models correlated with the source data?
We have imported some of the details in the main text as follows (as well as expanding the methods section a little):
“To understand which brain areas generated these distinct patterns of activations, and probe whether they fit with our previous fMRI results, we performed a source reconstruction of our data. We projected the sensor activity onto each participant's cortical surfaces estimated from T1-images. The projection was performed using eLORETA and emptyroom recordings acquired on the same day to estimate noise covariance, with the default parameters of mne-bids-pipeline. Sources were spaced using a recursively subdivided octahedron (oct5). Group statistics were performed after alignement to fsaverage. We then replicated the RSA analysis […]”
- In addition to fitting the CNN, which is used here to model differences in early visual cortex, have the authors considered looking at their fMRI results and localizing early visual regions, extracting a similarity matrix, and correlating that with the MEG and/or comparing it with the CNN model?
We had ultimately decided against comparing the empirical similarity matrices from the MEG and fMRI experiments, first because the stimuli and tasks are different, and second because this would not be directly relevant to our goal, which is to evaluate whether a geometric-feature model accounts for the data. Thus, we systematically model empirical similarity matrices from fMRI and from MEG with our two models derived from different theories of shape perception in order to test predictions about their spatial and temporal dynamic. As for comparing the similarity matrix from early visual regions in fMRI with that predicted by the CNN model, this is effectively visible from our Fig. 3D where we perform searchlight RSA analysis and modeling with both the CNN and the geometric feature model; bilaterally, we find a correlation with the CNN model, although it sometimes overlap with predictions from the geometric feature model as well. We now include a section explaining this reasoning in appendix:
“Representational similarity analysis also offers a way to directly compared similarity matrices measured in MEG and fMRI, thus allowing for fusion of those two modalities and tentatively assigning a “time stamp” to distinct MRI clusters. However, we did not attempt such an analysis here for several reasons. First, distinct tasks and block structures were used in MEG and fMRI. Second, a smaller list of shapes was used in fMRI, as imposed by the slower modality of acquisition. Third, our study was designed as an attempt to sort out between two models of geometric shape recognition. We therefore focused all analyses on this goal, which could not have been achieved by direct MEG-fMRI fusion, but required correlation with independently obtained model predictions.”
Minor comments
- It's a little unclear from the abstract that there is children's data for fMRI only.
We have reworded the abstract to make this unambiguous
- Figures 4a & b are missing y-labels.
We can see how our labels could be confused with (sub-)plot titles and have moved them to make the interpretation clearer.
- MEG: are the stimuli always shown in the same orientation and size?
They are not, each shape has a random orientation and scaling. On top of a task example at the top of Fig. 4, we have now included a clearer mention of this in the main text when we introduce the task:
“shapes were presented serially, one at a time, with small random changes in rotation and scaling parameters, in miniblocks with a fixed quadrilateral shape and with rare intruders with the bottom right corner shifted by a fixed amount (Sablé-Meyer et al., 2021)”
- To me, the discussion section felt a little lengthy, and I wonder whether it would benefit from being a little more streamlined, focused, and targeted. I found that the structure was a little difficult to follow as it went from describing the result by modality (behavior, fMRI, MEG) back to discussing mostly aspects of the fMRI findings.
We have tried to re-organize and streamline the discussion following these comments.
Then, later on, I found that especially the section on "neurophysiological implementation of geometry" went beyond the focus of the data presented in the paper and was comparatively long and speculative.
We have reexamined the discussion, but the citation of papers emphasizing a representation of non-accidental geometric properties in non-human animals was requested by other commentators on our article; and indeed, we think that they are relevant in the context of our prior suggestion that the composition of geometric features might be a uniquely human feature – these papers suggest that individual features may not, and that it is therefore compositionality which might be special to the human brain. We have nevertheless shortened it.
Furthermore, we think that this section is important because symbolic models are often criticized for lack of a plausible neurophysiological implementation. It is therefore important to discuss whether and how the postulated symbolic geometric code could be realized in neural circuits. We have added this justification to the introduction of this section.
Reviewer #2 (Recommendations for the authors):
(1) If the authors want to specifically claim that their findings align with mathematical reasoning, they could at least show the overlap between the activation maps of the current study and those from prior work.
This was added to the fMRI results. See our answers to the public review.
(2) I wonder if the reason the authors only found aIPS in their first analysis (Figure 2) is because they are contrasting geometric shapes with figures that also have geometric properties. In other words, faces, objects, and houses also contain geometric shape information, and so the authors may have essentially contrasted out other areas that are sensitive to these features. One indication that this may be the case is that the geometric regularity effect and searchlight RSA (Figure 3) contains both anterior and posterior IPS regions (but crucially, little ventral activity). It might be interesting to discuss the implications of these differences.
Indeed, we cannot exclude that the few symmetries, perpendicularity and parallelism cues that can be presented in faces, objects or houses were processed as such, perhaps within the ventral pathway, and that these representations would have been subtracted out. We emphasize that our subtraction isolates the geometrical features that are present in simple regular geometric shapes, over and above those that might exist in other categories. We have added this point to the discussion:
“[… ] For instance, faces possess a plane of quasi-symmetry, and so do many other man-made tools and houses. Thus, our subtraction isolated the geometrical features that are present in simple regular geometric shapes (e.g. parallels, right angles, equality of length) over and above those that might already exist, in a less pure form, in other categories.”
(3) I had a few questions regarding the MEG results.
a. I didn't quite understand the task. What is a regular or oddball shape in this context? It's not clear what is being decoded. Perhaps a small example of the MEG task in Figure 4 would help?
We now include an additional sub-figure in Fig. 4 to explain the paradigm. In brief: there is no explicit task, participants are simply asked to fixate. The shapes come in miniblocks of 30 identical reference shapes (up to rotation and scaling), among which some occasional deviant shapes randomly appear (created by moving the corner of the reference shape by some amount).
b. In Figure 4A/B they describe the correlation with a 'symbolic model'. Is this the same as the geometric model in 4C?
It is. We have removed this ambiguity by calling it “geometric model” and setting its color to the one associated to this model thought the article.
c. The author's explanation for why geometric feature coding was slower than CNN encoding doesn't quite make sense to me. As an explanation, they suggest that previous studies computed "elementary features of location or motor affordance", whereas their study work examines "high-level mathematical information of an abstract nature." However, looking at the studies the authors cite in this section, it seems that these studies also examined the time course of shape processing in the dorsal pathway, not "elementary features of location or motor affordance." Second, it's not clear how the geometric feature model reflects high-level mathematical information (see point above about claiming this is related to math).
We thank the referee for pointing out this inappropriate phrase, which we removed. We rephrased the rest of the paragraph to clarify our hypothesis in the following way:
“However, in this work, we specifically probed the processing of geometric shapes that, if our hypothesis is correct, are represented as mental expressions that combine geometrical and arithmetic features of an abstract categorical nature, for instance representing “four equal sides” or “four right angles”. It seems logical that such expressions, combining number, angle and length information, take more time to be computed than the first wave of feedforward processing within the occipito-temporal visual pathway, and therefore only activate thereafter.”
One explanation may be that the authors' geometric shapes require finer-grained discrimination than the object categories used in prior studies. i.e., the odd-ball task may be more of a fine-grained visual discrimination task. Indeed, it may not be a surprise that one can decode the difference between, say, a hammer and a butterfly faster than two kinds of quadrilaterals.
We do not disagree with this intuition, although note that we do not have data on this point (we are reporting and modelling the MEG RSA matrix across geometric shapes only – in this part, no other shapes such as tools or faces are involved). Still, the difference between squares, rectangles, parallelograms and other geometric shapes in our stimuli is not so subtle. Furthermore, CNNs do make very fine grained distinctions, for instance between many different breeds of dogs in the IMAGENET corpus. Still, those sorts of distinctions capture the initial part of the MEG response, while the geometric model is needed only for the later part. Thus, we think that it is a genuine finding that geometric computations associated with the dorsal parietal pathway are slower than the image analysis performed by the ventral occipito-temporal pathway.
d. CNN encoding at time 0 is a little weird, but the author's explanation, that this is explained by the fact that temporal smoothed using a 100 ms window makes sense. However, smoothing by 100 ms is quite a lot, and it doesn't seem accurate to present continuous time course data when the decoding or RSA result at each time point reflects a 100 ms bin. It may be more accurate to simply show unsmoothed data. I'm less convinced by the explanation about shape prediction.
We agree. Following the reviewer’s advice, as well as the recommendation from reviewer 1, we now display unsmoothed plots, and the effects now exhibit a more reasonable timing (Figure 4D), with effects starting around ~60 ms for CNN encoding.
(4) I appreciate the author's use of multiple models and their explanation for why DINOv2 explains more variance than the geometric and CNN models (that it represents both types of features. A variance partitioning analysis may help strengthen this conclusion (Bonner & Epstein, 2018; Lescroart et al., 2015).
However, one difference between DINOv2 and the CNN used here is that it is trained on a dataset of 142 million images vs. the 1.5 million images used in ImageNet. Thus, DINOv2 is more likely to have been exposed to simple geometric shapes during training, whereas standard ImageNet trained models are not. Indeed, prior work has shown that lesioning line drawing-like images from such datasets drastically impairs the performance of large models (Mayilvahanan et al., 2024). Thus, it is unlikely that the use of a transformer architecture explains the performance of DINOv2. The authors could include an ImageNet-trained transformer (e.g., ViT) and a CNN trained on large datasets (e.g., ResNet trained on the Open Clip dataset) to test these possibilities. However, I think it's also sufficient to discuss visual experience as a possible explanation for the CNN and DINOv2 results. Indeed, young children are exposed to geometric shapes, whereas ImageNet-trained CNNs are not.
We agree with the reviewer’s observation. In fact, new and ongoing work from the lab is also exploring this; we have included in supplementary materials exactly what the reviewer is suggesting, namely the time course of the correlation with ViT and with ConvNeXT. In line with the reviewers’ prediction, these networks, trained on much larger dataset and with many more parameters, can also fit the human data as well as DINOv2. We ran additional analysis of the MEG data with ViT and ConvNeXT, which we now report in Fig. S6 as well as in an additional sentence in that section:
“[…] similar results were obtained by performing the same analysis, not only with another vision transformer network, ViT, but crucially using a much larger convolutional neural network, ConvNeXT, which comprises ~800M parameters and has been trained on 2B images, likely including many geometric shapes and human drawings. For the sake of completeness, RSA analysis in sensor space of the MEG data with these two models is provided in Fig. S6.”
We conclude that the size and nature of the training set could be as important as the architecture – but also note that humans do not rely on such a huge training set. We have updated the text, as well as Fig. S6, accordingly by updating the section now entitled “Vision Transformers and Larger Neural Networks”, and the discussion section on theoretical models.
(5) The authors may be interested in a recent paper from Arcaro and colleagues that showed that the parietal cortex is greatly expanded in humans (including infants) compared to non-human primates (Meyer et al., 2025), which may explain the stronger geometric reasoning abilities of humans.
A very interesting article indeed! We have updated our article to incorporate this reference in the discussion, in the section on visual pathways, as follows:
“Finally, recent work shows that within the visual cortex, the strongest relative difference in growth between human and non-human primates is localized in parietal areas (Meyer et al., 2025). If this expansion reflected the acquisition of new processing abilities in these regions, it might explain the observed differences in geometric abilities between human and non-human primates (Sablé-Meyer et al., 2021).”
Also, the authors may want to include this paper, which uses a similar oddity task and compelling shows that crows are sensitive to geometric regularity:
Schmidbauer, P., Hahn, M., & Nieder, A. (2025). Crows recognize geometric regularity. Science Advances, 11(15), eadt3718. https://doi.org/10.1126/sciadv.adt3718
We have ongoing discussions with the authors of this work and are have prepared a response to their findings (Sablé-Meyer and Dehaene, 2025)–ultimately, we think that this discussion, which we agree is important, does not have its place in the present article. They used a reduced version of our design, with amplified differences in the intruders. While they did not test the fit of their model with CNN or geometric feature models, we did and found that a simple CNN suffices to account for crow behavior. Thus, we disagree that their conclusions follow from their results and their conclusions. But the present article does not seem to be the right platform to engage in this discussion.
References
Ayzenberg, V., & Behrmann, M. (2022). The Dorsal Visual Pathway Represents Object-Centered Spatial Relations for Object Recognition. The Journal of Neuroscience, 42(23), 4693-4710. https://doi.org/10.1523/jneurosci.2257-21.2022
Bonner, M. F., & Epstein, R. A. (2018). Computational mechanisms underlying cortical responses to the affordance properties of visual scenes. PLoS Computational Biology, 14(4), e1006111. https://doi.org/10.1371/journal.pcbi.1006111
Bueti, D., & Walsh, V. (2009). The parietal cortex and the representation of time, space, number and other magnitudes. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1525), 1831-1840.
Dehaene, S., & Brannon, E. (2011). Space, time and number in the brain: Searching for the foundations of mathematical thought. Academic Press.
Freud, E., Culham, J. C., Plaut, D. C., & Bermann, M. (2017). The large-scale organization of shape processing in the ventral and dorsal pathways. eLife, 6, e27576.
Freud, E., Ganel, T., Shelef, I., Hammer, M. D., Avidan, G., & Behrmann, M. (2017). Three-dimensional representations of objects in dorsal cortex are dissociable from those in ventral cortex. Cerebral Cortex, 27(1), 422-434.
Freud, E., Plaut, D. C., & Behrmann, M. (2016). 'What 'is happening in the dorsal visual pathway. Trends in Cognitive Sciences, 20(10), 773-784.
Freud, E., Plaut, D. C., & Behrmann, M. (2019). Protracted developmental trajectory of shape processing along the two visual pathways. Journal of Cognitive Neuroscience, 31(10), 1589-1597.
Han, Z., & Sereno, A. (2022). Modeling the Ventral and Dorsal Cortical Visual Pathways Using Artificial Neural Networks. Neural Computation, 34(1), 138-171. https://doi.org/10.1162/neco_a_01456
Janssen, P., Srivastava, S., Ombelet, S., & Orban, G. A. (2008). Coding of shape and position in macaque lateral intraparietal area. Journal of Neuroscience, 28(26), 6679-6690.
Konen, C. S., & Kastner, S. (2008). Two hierarchically organized neural systems for object information in human visual cortex. Nature Neuroscience, 11(2), 224-231.
Lescroart, M. D., Stansbury, D. E., & Gallant, J. L. (2015). Fourier power, subjective distance, and object categories all provide plausible models of BOLD responses in scene-selective visual areas. Frontiers in Computational Neuroscience, 9(135), 1-20. https://doi.org/10.3389/fncom.2015.00135
Mayilvahanan, P., Zimmermann, R. S., Wiedemer, T., Rusak, E., Juhos, A., Bethge, M., & Brendel, W. (2024). In search of forgotten domain generalization. arXiv Preprint arXiv:2410.08258.
Meyer, E. E., Martynek, M., Kastner, S., Livingstone, M. S., & Arcaro, M. J. (2025). Expansion of a conserved architecture drives the evolution of the primate visual cortex. Proceedings of the National Academy of Sciences, 122(3), e2421585122. https://doi.org/10.1073/pnas.2421585122
Orban, G. A. (2011). The extraction of 3D shape in the visual system of human and nonhuman primates. Annual Review of Neuroscience, 34, 361-388.
Romei, V., Driver, J., Schyns, P. G., & Thut, G. (2011). Rhythmic TMS over Parietal Cortex Links Distinct Brain Frequencies to Global versus Local Visual Processing. Current Biology, 21(4), 334-337. https://doi.org/10.1016/j.cub.2011.01.035
Sereno, A. B., & Maunsell, J. H. R. (1998). Shape selectivity in primate lateral intraparietal cortex. Nature, 395(6701), 500-503. https://doi.org/10.1038/26752
Summerfield, C., Luyckx, F., & Sheahan, H. (2020). Structure learning and the posterior parietal cortex. Progress in Neurobiology, 184, 101717. https://doi.org/10.1016/j.pneurobio.2019.101717
Van Dromme, I. C., Premereur, E., Verhoef, B.-E., Vanduffel, W., & Janssen, P. (2016). Posterior Parietal Cortex Drives Inferotemporal Activations During Three-Dimensional Object Vision. PLoS Biology, 14(4), e1002445. https://doi.org/10.1371/journal.pbio.1002445
Xu, Y. (2018). A tale of two visual systems: Invariant and adaptive visual information representations in the primate brain. Annu. Rev. Vis. Sci, 4, 311-336.
Reviewer #3 (Recommendations for the authors):
Bring into the discussion some of the issues outlined above, especially a) the spatial rather than visual of the geometric figures and b) the non-representational aspects of geometric form aspects.
We thank the reviewer for their recommendations – see our response to the public review for more details.
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public review):
Summary:
This paper presents two experiments, both of which use a target detection paradigm to investigate the speed of statistical learning. The first experiment is a replication of Batterink, 2017, in which participants are presented with streams of uniform-length, trisyllabic nonsense words and asked to detect a target syllable. The results replicate previous findings, showing that learning (in the form of response time facilitation to later-occurring syllables within a nonsense word) occurs after a single exposure to a word. In the second experiment, participants are presented with streams of variable-length nonsense words (two trisyllabic words and two disyllabic words) and perform the same task. A similar facilitation effect was observed as in Experiment 1. The authors interpret these findings as evidence that target detection requires mechanisms different from segmentation. They present results of a computational model to simulate results from the target detection task and find that an "anticipation mechanism" can produce facilitation effects, without performing segmentation. The authors conclude that the mechanisms involved in the target detection task are different from those involved in the word segmentation task.
Strengths:
The paper presents multiple experiments that provide internal replication of a key experimental finding, in which response times are facilitated after a single exposure to an embedded pseudoword. Both experimental data and results from a computational model are presented, providing converging approaches for understanding and interpreting the main results. The data are analyzed very thoroughly using mixed effects models with multiple explanatory factors.
Weaknesses:
In my view, the main weaknesses of this study relate to the theoretical interpretation of the results.
(1) The key conclusion from these findings is that the facilitation effect observed in the target detection paradigm is driven by a different mechanism (or mechanisms) than those involved in word segmentation. The argument here I think is somewhat unclear and weak, for several reasons:
First, there appears to be some blurring in what exactly is meant by the term "segmentation" with some confusion between segmentation as a concept and segmentation as a paradigm.
Conceptually, segmentation refers to the segmenting of continuous speech into words. However, this conceptual understanding of segmentation (as a theoretical mechanism) is not necessarily what is directly measured by "traditional" studies of statistical learning, which typically (at least in adults) involve exposure to a continuous speech stream followed by a forced-choice recognition task of words versus recombined foil items (part-words or nonwords). To take the example provided by the authors, a participant presented with the sequence GHIABCDEFABCGHI may endorse ABC as being more familiar than BCG, because ABC is presented more frequently together and the learned association between A and B is stronger than between C and G. However, endorsement of ABC over BCG does not necessarily mean that the participant has "segmented" ABC from the speech stream, just as faster reaction times in responding to syllable C versus A do not necessarily indicate successful segmentation. As the authors argue on page 7, "an encounter to a sequence in which two elements co-occur (say, AB) would theoretically allow the learner to use the predictive relationship during a subsequent encounter (that A predicts B)." By the same logic, encoding the relationship between A and B could also allow for the above-chance endorsement of items that contain AB over items containing a weaker relationship.
Both recognition performance and facilitation through target detection reflect different outcomes of statistical learning. While they may reflect different aspects of the learning process and/or dissociable forms of memory, they may best be viewed as measures of statistical learning, rather than mechanisms in and of themselves.
Thanks for this nuanced discussion, and this is an important point that R2 also raised. We agree that segmentation can refer to both an experimental paradigm and a mechanism that accounts for learning in the experimental paradigm. In the experimental paradigm, participants are asked to identify which words they believe to be (whole) words from the continuous syllable stream. In the target-detection experimental paradigm, participants are not asked to identify words from continuous streams, and instead, they respond to the occurrences of a certain syllable. It’s possible that learners employ one mechanism in these two tasks, or that they employ separate mechanisms. It’s also the case that, if all we have is positive evidence for both experimental paradigms, i.e., learners can succeed in segmentation tasks as well as in target detection tasks with different types of sequences, we would have no way of talking about different mechanisms, as you correctly suggested that evidence for segmenting AB and processing B faster following A, is not evidence for different mechanisms.
However, that is not the case. When the syllable sequences contain same-length subsequences (i.e., words), learning is indeed successful in both segmentation and target detection tasks. However, in studies such as Hoch et al. (2013), findings suggest that words from mixed-length sequences are harder to segment than words from uniform-length sequences. This finding exists in adult work (e.g., Hoch et al. 2013) as well as infant work (Johnson & Tyler, 2010), and replicated here in the newly included Experiment 3, which stands in contrast to the positive findings of the facilitation effect with mixed-length sequences in the target detection paradigm (one of our main findings in the paper). Thus, it seems to be difficult to explain, if the learning mechanisms were to be the same, why humans can succeed in mixed-length sequences in target detection (as shown in Experiment 2) but fail in uniform-length sequences (as shown in Hoch et al. and Experiment 3).
In our paper, we have clarified these points describe the separate mechanisms in more detail, in both the Introduction and General Discussion sections.
(2) The key manipulation between experiments 1 and 2 is the length of the words in the syllable sequences, with words either constant in length (experiment 1) or mixed in length (experiment 2). The authors show that similar facilitation levels are observed across this manipulation in the current experiments. By contrast, they argue that previous findings have found that performance is impaired for mixed-length conditions compared to fixed-length conditions. Thus, a central aspect of the theoretical interpretation of the results rests on prior evidence suggesting that statistical learning is impaired in mixed-length conditions. However, it is not clear how strong this prior evidence is. There is only one published paper cited by the authors - the paper by Hoch and colleagues - that supports this conclusion in adults (other mentioned studies are all in infants, which use very different measures of learning). Other papers not cited by the authors do suggest that statistical learning can occur to stimuli of mixed lengths (Thiessen et al., 2005, using infant-directed speech; Frank et al., 2010 in adults). I think this theoretical argument would be much stronger if the dissociation between recognition and facilitation through RTs as a function of word length variability was demonstrated within the same experiment and ideally within the same group of participants.
To summarize the evidence of learning uniform-length and mixed-length sequences (which we discussed in the Introduction section), “even though infants and adults alike have shown success segmenting syllable sequences consisting of words that were uniform in length (i.e., all words were either disyllabic; Graf Estes et al., 2007; or trisyllabic, Aslin et al., 1998), both infants and adults have shown difficulty with syllable sequences consisting of words of mixed length (Johnson & Tyler, 2010; Johnson & Jusczyk, 2003a; 2003b; Hoch et al., 2013).” The newly added Experiment 3 also provided evidence for the difference in uniform-length and mixed-length sequences. Notably, we do not agree with the idea that infant work should be disregarded as evidence just because infants were tested with habituation methods; not only were the original findings (Saffran et al. 1996) based on infant work, so were many other studies on statistical learning.
There are other segmentation studies in the literature that have used mixed-length sequences, which are worth discussing. In short, these studies differ from the Saffran et al. (1996) studies in many important ways, and in our view, these differences explain why the learning was successful. Of interest, Thiessen et al. (2005) that you mentioned was based on infant work with infant methods, and demonstrated the very point we argued for: In their study, infants failed to learn when mixed-length sequences were pronounced as adult-directed speech, and succeeded in learning given infant-directed speech, which contained prosodic cues that were much more pronounced. The fact that infants failed to segment mixed-length sequences without certain prosodic cues is consistent with our claim that mixed-length sequences are difficult to segment in a segmentation paradigm. Another such study is Frank et al. (2010), where continuous sequences were presented in “sentences”. Different numbers of words were concatenated into sentences where a 500ms break was present between each sentence in the training sequence. One sentence contained only one word, or two words, and in the longest sentence, there were 24 words. The results showed that participants are sensitive to the effect of sentence boundaries, which coincide with word boundaries. In the extreme, the one-word-per-sentence condition simply presents learners with segmented word forms. In the 24-word-per-sentence condition, there are nevertheless sentence boundaries that are word boundaries, and knowing these word boundaries alone should allow learners to perform above chance in the test phase. Thus, in our view, this demonstrates that learners can use sentence boundaries to infer word boundaries, which is an interesting finding in its own right, but this does not show that a continuous syllable sequence with mixed word lengths is learnable without additional information. In summary, to our knowledge, syllable sequences containing mixed word lengths are better learned when additional cues to word boundaries are present, and there is strong evidence that syllable sequences containing uniform-word lengths are learned better than mixed-length ones.
Frank, M. C., Goldwater, S., Griffiths, T. L., & Tenenbaum, J. B. (2010). Modeling human performance in statistical word segmentation. Cognition, 117(2), 107-125.
To address your proposal of running more experiments to provide stronger evidence for our theory, we were planning to run another study to have the same group of participants do both the segmentation and target detection paradigm as suggested, but we were unable to do so as we encountered difficulties to run English-speaking participants. Instead, we have included an experiment (now Experiment 3), showing the difference between the learning of uniform-length and mixed-length sequences with the segmentation paradigm that we have never published previously. This experiment provides further evidence for adults’ difficulties in segmenting mixed-length sequences.
(3) The authors argue for an "anticipation" mechanism in explaining the facilitation effect observed in the experiments. The term anticipation would generally be understood to imply some kind of active prediction process, related to generating the representation of an upcoming stimulus prior to its occurrence. However, the computational model proposed by the authors (page 24) does not encode anything related to anticipation per se. While it demonstrates facilitation based on prior occurrences of a stimulus, that facilitation does not necessarily depend on active anticipation of the stimulus. It is not clear that it is necessary to invoke the concept of anticipation to explain the results, or indeed that there is any evidence in the current study for anticipation, as opposed to just general facilitation due to associative learning.
Thanks for raising this point. Indeed, the anticipation effect we reported is indistinguishable from the facilitation effect that we reported in the reported experiments. We have dropped this framing.
In addition, related to the model, given that only bigrams are stored in the model, could the authors clarify how the model is able to account for the additional facilitation at the 3rd position of a trigram compared to the 2nd position?
Thanks for the question. We believe it is an empirical question whether there is an additional facilitation at the 3rd position of a trigram compared to the 2nd position. To investigate this issue, we conducted the following analysis with data from Experiment 1. First, we combined the data from two conditions (exact/conceptual) from Experiment 1 so as to have better statistical power. Next, we ran a mixed effect regression with data from syllable positions 2 and 3 only (i.e., data from syllable position 1 were not included). The fixed effect included the two-way interaction between syllable position and presentation, as well as stream position, and the random effect was a by-subject random intercept and stream position as the random slope. This interaction was significant (χ<sup>2</sup>(3) =11.73, p=0.008), suggesting that there is additional facilitation to the 3rd position compared to the 2nd position.
For the model, here is an explanation of why the model assumes an additional facilitation to the 3rd position. In our model, we proposed a simple recursive relation between the RT of a syllable occurring for the nth time and the n+1<sup>th</sup> time, which is:
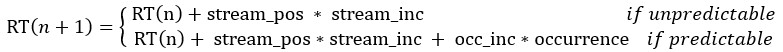
and
RT(1) = RT0 + stream_pos * stream_inc, where the n in RT(n) represents the RT for the n<sup>th</sup> presentation of the target syllable, stream_pos is the position (3-46) in the stream, and occurrence is the number of occurrences that the syllable has occurred so far in the stream.
What this means is that the model basically provides an RT value for every syllable in the stream. Thus, for a target at syllable position 1, there is a RT value as an unpredictable target, and for targets at syllable position 2, there is a facilitation effect. For targets at syllable position 3, it is facilitated the same amount. As such, there is an additional facilitation effect for syllable position 3 because effects of predication are recursive.
(4) In the discussion of transitional probabilities (page 31), the authors suggest that "a single exposure does provide information about the transitions within the single exposure, and the probability of B given A can indeed be calculated from a single occurrence of AB." Although this may be technically true in that a calculation for a single exposure is possible from this formula, it is not consistent with the conceptual framework for calculating transitional probabilities, as first introduced by Saffran and colleagues. For example, Saffran et al. (1996, Science) describe that "over a corpus of speech there are measurable statistical regularities that distinguish recurring sound sequences that comprise words from the more accidental sound sequences that occur across word boundaries. Within a language, the transitional probability from one sound to the next will generally be highest when the two sounds follow one another within a word, whereas transitional probabilities spanning a word boundary will be relatively low." This makes it clear that the computation of transitional probabilities (i.e., Y | X) is conceptualized to reflect the frequency of XY / frequency of X, over a given language inventory, not just a single pair. Phrased another way, a single exposure to pair AB would not provide a reliable estimate of the raw frequencies with which A and AB occur across a given sample of language.
Thanks for the discussion. We understand your argument, but we respectively disagree that computing transitional probabilities must be conducted under a certain theoretical framework. In our humble opinion, computing transitional probabilities is a mathematical operation, and as such, it is possible to do so with the least amount of data possible that enables the mathematical operation, which concretely is a single exposure during learning. While it is true that a single exposure may not provide a reliable estimate of frequencies or probabilities, it does provide information with which the learner can make decisions.
This is particularly true for topics under discussion regarding the minimal amount of exposure that can enable learning. It is important to distinguish the following two questions: whether learners can learn from a short exposure period (from a single exposure, in fact) and how long of an exposure period does the learner require for it to be considered to produce a reliable estimate of frequencies. Incidentally, given the fact that learners can learn from a single exposure based on Batterink (2017) and the current study, it does not appear that learners require a long exposure period to learn about transitional probabilities.
(5) In experiment 2, the authors argue that there is robust facilitation for trisyllabic and disyllabic words alike. I am not sure about the strength of the evidence for this claim, as it appears that there are some conflicting results relevant to this conclusion. Notably, in the regression model for disyllabic words, the omnibus interaction between word presentation and syllable position did not reach significance (p= 0.089). At face value, this result indicates that there was no significant facilitation for disyllabic words. The additional pairwise comparisons are thus not justified given the lack of omnibus interaction. The finding that there is no significant interaction between word presentation, word position, and word length is taken to support the idea that there is no difference between the two types of words, but could also be due to a lack of power, especially given the p-value (p = 0.010).
Thanks for the comment. Firstly, we believe there is a typo in your comment, where in the last sentence, we believe you were referring to the p-value of 0.103 (source: “The interaction was not significant (χ2(3) = 6.19, p= 0.103”). Yes, a null result with a frequentist approach cannot support a null claim, but Bayesian analyses could potentially provide evidence for the null.
To this end, we conducted a Bayes factor analysis using the approach outlined in Harms and Lakens (2018), which generates a Bayes factor by computing a Bayesian information criterion for a null model and an alternative model. The alternative model contained a three-way interaction of word length, word presentation, and word position, whereas the null model contained a two-way interaction between word presentation and word position as well as a main effect of word length. Thus, the two models only differ in terms of whether there is a three-way interaction. The Bayes factor is then computed as exp[(BICalt − BICnull)/2]. This analysis showed that there is strong evidence for the null, where the Bayes Factor was found to be exp(25.65) which is more than 1011. Thus, there is no power issue here, and there is strong evidence for the null claim that word length did not interact with other factors in Experiment 2.
There is another issue that you mentioned, of whether we should conduct pairwise comparisons if the omnibus interaction did not reach significance. This would be true given the original analysis plan, but we believe that a revised analysis plan makes more sense. In the revised analysis plan for Experiment 2, we start with the three-way interaction (as just described in the last paragraph). The three-way interaction was not significant, and after dropping the third interaction terms, the two-way interaction and the main effect of word length are both significant, and we use this as the overall model. Testing the significance of the omnibus interaction between presentation and syllable position, we found that this was significant (χ<sup>2</sup>(3) =49.77, p<0.001). This represents that, in one model, that the interaction between presentation and syllable position using data from both disyllabic and trisyllabic words. This was in addition to a significant fixed effect of word length (β=0.018, z=6.19, p<0.001). This should motivate the rest of the planned analysis, which regards pairwise comparisons in different word length conditions.
(6) The results plotted in Figure 2 seem to suggest that RTs to the first syllable of a trisyllabic item slow down with additional word presentations, while RTs to the final position speed up. If anything, in this figure, the magnitude of the effect seems to be greater for 1st syllable positions (e.g., the RT difference between presentation 1 and 4 for syllable position 1 seems to be numerically larger than for syllable position 3, Figure 2D). Thus, it was quite surprising to see in the results (p. 16) that RTs for syllable position 1 were not significantly different for presentation 1 vs. the later presentations (but that they were significant for positions 2 and 3 given the same comparison). Is this possibly a power issue? Would there be a significant slowdown to 1st syllables if results from both the exact replication and conceptual replication conditions were combined in the same analysis?
Thanks for the suggestion and your careful visual inspection of the data. After combining the data, the slowdown to 1st syllables is indeed significant. We have reported this in the results of Experiment 1 (with an acknowledgement to this review):
Results showed that later presentations took significantly longer to respond to compared to the first presentation (χ<sup>2</sup>(3) = 10.70, p=0.014), where the effect grew larger with each presentation (second presentation: β=0.011, z=1.82, p=0.069; third presentation: β=0.019, z=2.40, p=0.016; fourth presentation: β=0.034, z=3.23, p=0.001).
(7) It is difficult to evaluate the description of the PARSER simulation on page 36. Perhaps this simulation should be introduced earlier in the methods and results rather than in the discussion only.
Thanks for the suggestions. We have added two separate simulations in the paper, which should describe the PARSER simulations sufficiently, as well as provide further information on the correspondence between the simulations and the experiments. Thanks again for the great review! We believe our paper has improved significantly as a result.
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public review):
In this manuscript, Domingo et al. present a novel perturbation-based approach to experimentally modulate the dosage of genes in cell lines. Their approach is capable of gradually increasing and decreasing gene expression. The authors then use their approach to perturb three key transcription factors and measure the downstream effects on gene expression. Their analysis of the dosage response curve of downstream genes reveals marked non-linearity.
One of the strengths of this study is that many of the perturbations fall within the physiological range for each cis gene. This range is presumably between a single-copy state of heterozygous loss-of-function (log fold change of -1) and a three-copy state (log fold change of ~0.6). This is in contrast with CRISPRi or CRISPRa studies that attempt to maximize the effect of the perturbation, which may result in downstream effects that are not representative of physiological responses.
Another strength of the study is that various points along the dosage-response curve were assayed for each perturbed gene. This allowed the authors to effectively characterize the degree of linearity and monotonicity of each dosage-response relationship. Ultimately, the study revealed that many of these relationships are non-linear, and that the response to activation can be dramatically different than the response to inhibition.
To test their ability to gradually modulate dosage, the authors chose to measure three transcription factors and around 80 known downstream targets. As the authors themselves point out in their discussion about MYB, this biased sample of genes makes it unclear how this approach would generalize genome-wide. In addition, the data generated from this small sample of genes may not represent genome-wide patterns of dosage response. Nevertheless, this unique data set and approach represents a first step in understanding dosage-response relationships between genes.
Another point of general concern in such screens is the use of the immortalized K562 cell line. It is unclear how the biology of these cell lines translates to the in vivo biology of primary cells. However, the authors do follow up with cell-type-specific analyses (Figures 4B, 4C, and 5A) to draw a correspondence between their perturbation results and the relevant biology in primary cells and complex diseases.
The conclusions of the study are generally well supported with statistical analysis throughout the manuscript. As an example, the authors utilize well-known model selection methods to identify when there was evidence for non-linear dosage response relationships.
Gradual modulation of gene dosage is a useful approach to model physiological variation in dosage. Experimental perturbation screens that use CRISPR inhibition or activation often use guide RNAs targeting the transcription start site to maximize their effect on gene expression. Generating a physiological range of variation will allow others to better model physiological conditions.
There is broad interest in the field to identify gene regulatory networks using experimental perturbation approaches. The data from this study provides a good resource for such analytical approaches, especially since both inhibition and activation were tested. In addition, these data provide a nuanced, continuous representation of the relationship between effectors and downstream targets, which may play a role in the development of more rigorous regulatory networks.
Human geneticists often focus on loss-of-function variants, which represent natural knock-down experiments, to determine the role of a gene in the biology of a trait. This study demonstrates that dosage response relationships are often non-linear, meaning that the effect of a loss-of-function variant may not necessarily carry information about increases in gene dosage. For the field, this implies that others should continue to focus on both inhibition and activation to fully characterize the relationship between gene and trait.
We thank the reviewer for their thoughtful and thorough evaluation of our study. We appreciate their recognition of the strengths of our approach, particularly the ability to modulate gene dosage within a physiological range and to capture non-linear dosage-response relationships. We also agree with the reviewer’s points regarding the limitations of gene selection and the use of K562 cells, and we are encouraged that the reviewer found our follow-up analyses and statistical framework to be well-supported. We believe this work provides a valuable foundation for future genome-wide applications and more physiologically relevant perturbation studies.
Reviewer #2 (Public review):
Summary:
This work investigates transcriptional responses to varying levels of transcription factors (TFs). The authors aim for gradual up- and down-regulation of three transcription factors GFI1B, NFE2, and MYB in K562 cells, by using a CRISPRa- and a CRISPRi line, together with sgRNAs of varying potency. Targeted single-cell RNA sequencing is then used to measure gene expression of a set of 90 genes, which were previously shown to be downstream of GFI1B and NFE2 regulation. This is followed by an extensive computational analysis of the scRNA-seq dataset. By grouping cells with the same perturbations, the authors can obtain groups of cells with varying average TF expression levels. The achieved perturbations are generally subtle, not reaching half or double doses for most samples, and up-regulation is generally weak below 1.5-fold in most cases. Even in this small range, many target genes exhibit a non-linear response. Since this is rather unexpected, it is crucial to rule out technical reasons for these observations.
We thank the reviewer for their detailed and thoughtful assessment of our work. We are encouraged by their recognition of the strengths of our study, including the value of quantitative CRISPR-based perturbation coupled with single-cell transcriptomics, and its potential to inform gene regulatory network inference. Below, we address each of the concerns raised:
Strengths:
The work showcases how a single dataset of CRISPRi/a perturbations with scRNA-seq readout and an extended computational analysis can be used to estimate transcriptome dose responses, a general approach that likely can be built upon in the future.
Weaknesses:
(1) The experiment was only performed in a single replicate. In the absence of an independent validation of the main findings, the robustness of the observations remains unclear.
We acknowledge that our study was performed in a single pooled experiment. While additional replicates would certainly strengthen the findings, in high-throughput single-cell CRISPR screens, individual cells with the same perturbation serve as effective internal replicates. This is a common practice in the field. Nevertheless, we agree that biological replicates would help control for broader technical or environmental effects.
(2) The analysis is based on the calculation of log-fold changes between groups of single cells with non-targeting controls and those carrying a guide RNA driving a specific knockdown. How the fold changes were calculated exactly remains unclear, since it is only stated that the FindMarkers function from the Seurat package was used, which is likely not optimal for quantitative estimates. Furthermore, differential gene expression analysis of scRNA-seq data can suffer from data distortion and mis-estimations (Heumos et al. 2023 (https://doi.org/10.1038/s41576-023-00586-w), Nguyen et al. 2023 (https://doi.org/10.1038/s41467-023-37126-3)). In general, the pseudo-bulk approach used is suitable, but the correct treatment of drop-outs in the scRNA-seq analysis is essential.
We thank the reviewer for highlighting recent concerns in the field. A study benchmarking association testing methods for perturb-seq data found that among existing methods, Seurat’s FindMarkers function performed the best (T. Barry et al. 2024).
In the revised Methods, we now specify the formula used to calculate fold change and clarify that the estimates are derived from the Wilcoxon test implemented in Seurat’s FindMarkers function. We also employed pseudo-bulk grouping to mitigate single-cell noise and dropout effects.
(3) Two different cell lines are used to construct dose-response curves, where a CRISPRi line allows gene down-regulation and the CRISPRa line allows gene upregulation. Although both lines are derived from the same parental line (K562) the expression analysis of Tet2, which is absent in the CRISPRi line, but expressed in the CRISPRa line (Figure S3A) suggests substantial clonal differences between the two lines. Similarly, the PCA in S4A suggests strong batch effects between the two lines. These might confound this analysis.
We agree that baseline differences between CRISPRi and CRISPRa lines could introduce confounding effects if not appropriately controlled for. We emphasize that all comparisons are made as fold changes relative to non-targeting control (NTC) cells within each line, thereby controlling for batch- and clone-specific baseline expression. See figures S4A and S4B.
(4) The study uses pseudo-bulk analysis to estimate the relationship between TF dose and target gene expression. This requires a system that allows quantitative changes in TF expression. The data provided does not convincingly show that this condition is met, which however is an essential prerequisite for the presented conclusions. Specifically, the data shown in Figure S3A shows that upon stronger knock-down, a subpopulation of cells appears, where the targeted TF is not detected anymore (drop-outs). Also Figure 3B (top) suggests that the knock-down is either subtle (similar to NTCs) or strong, but intermediate knock-down (log2-FC of 0.5-1) does not occur. Although the authors argue that this is a technical effect of the scRNA-seq protocol, it is also possible that this represents a binary behavior of the CRISPRi system. Previous work has shown that CRISPRi systems with the KRAB domain largely result in binary repression and not in gradual down-regulation as suggested in this study (Bintu et al. 2016 (https://doi.org/10.1126/science.aab2956), Noviello et al. 2023 (https://doi.org/10.1038/s41467-023-38909-4)).
Figure S3A shows normalized expression values, not fold changes. A pseudobulk approach reduces single-cell noise and dropout effects. To test whether dropout events reflect true binary repression or technical effects, we compared trans-effects across cells with zero versus low-but-detectable target gene expression (Figure S3B). These effects were highly concordant, supporting the interpretation that dropout is largely technical in origin. We agree that KRAB-based repression can exhibit binary behavior in some contexts, but our data suggest that cells with intermediate repression exist and are biologically meaningful. In ongoing unpublished work, we pursue further analysis of these data at the single cell level, and show that for nearly all guides the dosage effects are indeed gradual rather than driven by binary effects across cells.
(5) One of the major conclusions of the study is that non-linear behavior is common. This is not surprising for gene up-regulation, since gene expression will reach a plateau at some point, but it is surprising to be observed for many genes upon TF down-regulation. Specifically, here the target gene responds to a small reduction of TF dose but shows the same response to a stronger knock-down. It would be essential to show that his observation does not arise from the technical concerns described in the previous point and it would require independent experimental validations.
This phenomenon—where relatively small changes in cis gene dosage can exceed the magnitude of cis gene perturbations—is not unique to our study. This also makes biological sense, since transcription factors are known to be highly dosage sensitive and generally show a smaller range of variation than many other genes (that are regulated by TFs). Empirically, these effects have been observed in previous CRISPR perturbation screens conducted in K562 cells, including those by Morris et al. (2023), Gasperini et al. (2019), and Replogle et al. (2022), to name but a few studies that our lab has personally examined the data of.
(6) One of the conclusions of the study is that guide tiling is superior to other methods such as sgRNA mismatches. However, the comparison is unfair, since different numbers of guides are used in the different approaches. Relatedly, the authors point out that tiling sometimes surpassed the effects of TSS-targeting sgRNAs, however, this was the least fair comparison (2 TSS vs 10 tiling guides) and additionally depends on the accurate annotation of TSS in the relevant cell line.
We do not draw this conclusion simply from observing the range achieved but from a more holistic observation. We would like to clarify that the number of sgRNAs used in each approach is proportional to the number of base pairs that can be targeted in each region: while the TSS-targeting strategy is typically constrained to a small window of a few dozen base pairs, tiling covers multiple kilobases upstream and downstream, resulting in more guides by design rather than by experimental bias. The guides with mismatches do not have a great performance for gradual upregulation.
We would also like to point out that the observation that the strongest effects can arise from regions outside the annotated TSS is not unique to our study and has been demonstrated in prior work (referenced in the text).
To address this concern, we have revised the text to clarify that we do not consider guide tiling to be inherently superior to other approaches such as sgRNA mismatches. Rather, we now describe tiling as a practical and straightforward strategy to obtain a wide range of gene dosage effects without requiring prior knowledge beyond the approximate location of the TSS. We believe this rephrasing more accurately reflects the intent and scope of our comparison.
(7) Did the authors achieve their aims? Do the results support the conclusions?: Some of the most important conclusions are not well supported because they rely on accurately determining the quantitative responses of trans genes, which suffers from the previously mentioned concerns.
We appreciate the reviewer’s concern, but we would have wished for a more detailed characterization of which conclusions are not supported, given that we believe our approach actually accounts for the major concerns raised above. We believe that the observation of non-linear effects is a robust conclusion that is also consistent with known biology, with this paper introducing new ways to analyze this phenomenon.
(8) Discussion of the likely impact of the work on the field, and the utility of the methods and data to the community:
Together with other recent publications, this work emphasizes the need to study transcription factor function with quantitative perturbations. Missing documentation of the computational code repository reduces the utility of the methods and data significantly.
Documentation is included as inline comments within the R code files to guide users through the analysis workflow.
Reviewer #1 (Recommendations for the authors):
In Figure 3C (and similar plots of dosage response curves throughout the manuscript), we initially misinterpreted the plots because we assumed that the zero log fold change on the horizontal axis was in the middle of the plot. This gives the incorrect interpretation that the trans genes are insensitive to loss of GFI1B in Figure 3C, for instance. We think it may be helpful to add a line to mark the zero log fold change point, as was done in Figure 3A.
We thank the reviewer for this helpful suggestion. To improve clarity, we have added a vertical line marking the zero log fold change point in Figure 3C and all similar dosage-response plots. We agree this makes the plots easier to interpret at a glance.
Similarly, for heatmaps in the style of Figure 3B, it may be nice to have a column for the non-targeting controls, which should be a white column between the perturbations that increase versus decrease GFI1B.
We appreciate the suggestion. However, because all perturbation effects are computed relative to the non-targeting control (NTC) cells, explicitly including a separate column for NTC in the heatmap would add limited interpretive value and could unnecessarily clutter the figure. For clarity, we have emphasized in the figure legend that the fold changes are relative to the NTC baseline.
We found it challenging to assess the degree of uncertainty in the estimation of log fold changes throughout the paper. For example, the authors state the following on line 190: "We observed substantial differences in the effects of the same guide on the CRISPRi and CRISPRa backgrounds, with no significant correlation between cis gene fold-changes." This claim was challenging to assess because there are no horizontal or vertical error bars on any of the points in Figure 2A. If the log fold change estimates are very noisy, the data could be consistent with noisy observations of a correlated underlying process. Similarly, to our understanding, the dosage response curves are fit assuming that the cis log fold changes are fixed. If there is excessive noise in the estimation of these log fold changes, it may bias the estimated curves. It may be helpful to give an idea of the amount of estimation error in the cis log fold changes.
We agree that assessing the uncertainty in log fold change estimates is important for interpreting both the lack of correlation between CRISPRi and CRISPRa effects (Figure 2A) and the robustness of the dosage-response modeling.
In response, we have now updated Figure 2A to include both vertical and horizontal error bars, representing the standard errors of the log2 fold-change estimates for each guide in the CRISPRi and CRISPRa conditions. These error estimates were computed based on the differential expression analysis performed using the FindMarkers function in Seurat, which models gene expression differences between perturbed and control cells. We also now clarify this in the figure legend and methods.
The authors mention hierarchical clustering on line 313, which identified six clusters. Although a dendrogram is provided, these clusters are not displayed in Figure 4A. We recommend displaying these clusters alongside the dendrogram.
We have added colored bars indicating the clusters to improve the clarity. Thank you for the suggestion.
In Figures 4B and 4C, it was not immediately clear what some of the gene annotations meant. For example, neither the text nor the figure legend discusses what "WBCs", "Platelets", "RBCs", or "Reticulocytes" mean. It would be helpful to include this somewhere other than only the methods to make the figure more clear.
To improve clarity, we have updated the figure legends for Figures 4B and 4C to explicitly define these abbreviations.
We struggled to interpret Figure 4E. Although the authors focus on the association of MYB with pHaplo, we would have appreciated some general discussion about the pattern of associations seen in the figure and what the authors expected to observe.
We have changed the paragraph to add more exposition and clarification:
“The link between selective constraint and response properties is most apparent in the MYB trans network. Specifically, the probability of haploinsufficiency (pHaplo) shows a significant negative correlation with the dynamic range of transcriptional responses (Figure 4G): genes under stronger constraint (higher pHaplo) display smaller dynamic ranges, indicating that dosage-sensitive genes are more tightly buffered against changes in MYB levels. This pattern was not reproduced in the other trans networks (Figure 4E)”.
Line 71: potentially incorrect use of "rending" and incorrect sentence grammar.
Fixed
Line 123: "co-expression correlation across co-expression clusters" - authors may not have intended to use "co-expression" twice.
Original sentence was correct.
Line 246: "correlations" is used twice in "correlations gene-specific correlations."
Fixed.
Reviewer #2 (Recommendations for the authors):
(1) To show that the approach indeed allows gradual down-regulation it would be important to quantify the know-down strength with a single-cell readout for a subset of sgRNAs individually (e.g. flowfish/protein staining flow cytometry).
We agree that single-cell validation of knockdown strength using orthogonal approaches such as flowFISH or protein staining would provide additional support. However, such experiments fall outside the scope of the current study and are not feasible at this stage. We note that the observed transcriptomic changes and dosage responses across multiple perturbations are consistent with effective and graded modulation of gene expression.
(2) Similarly, an independent validation of the observed dose-response relationships, e.g. with individual sgRNAs, can be helpful to support the conclusions about non-linear responses.
Fig. S4C includes replication of trans-effects for a handful of guides used both in this study and in Morris et al. While further orthogonal validation of dose-response relationships would be valuable, such extensive additional work is not currently feasible within the scope of this study. Nonetheless, the high degree of replication in Fig. S4C as well as consistency of patterns observed across multiple sgRNAs and target genes provides strong support for the conclusions drawn from our high-throughput screen.
(3) The calculation of the log2 fold changes should be documented more precisely. To perform a pseudo-bulk analysis, the raw UMI counts should be summed up in each group (NTC, individual targeting sgRNAs), including zero counts, then the data should be normalized and the fold change should be calculated. The DESeq package for example would be useful here.
We have updated the methods in the manuscript to provide more exposition of how the logFC was calculated:
“In our differential expression (DE) analysis, we used Seurat’s FindMarkers() function, which computes the log fold change as the difference between the average normalized gene expression in each group on the natural log scale:
Logfc = log_e(mean(expression in group 1)) - log_e(mean(expression in group 2))
This is calculated in pseudobulk where cells with the same sgRNA are grouped together and the mean expression is compared to the mean expression of cells harbouring NTC guides. To calculate per-gene differential expression p-value between the two cell groups (cells with sgRNA vs cells with NTC), Wilcoxon Rank-Sum test was used”.
(4) A more careful characterization of the cell lines used would be helpful. First, it would be useful to include the quality controls performed when the clonal lines were selected, in the manuscript. Moreover, a transcriptome analysis in comparison to the parental cell line could be performed to show that the cell lines are comparable. In addition, it could be helpful to perform the analysis of the samples separately to see how many of the response behaviors would still be observed.
Details of the quality control steps used during the selection of the CRISPRa clonal line are already included in the Methods section, and Fig. S4A shows the transcriptome comparison of CRISPRi and CRISPRa lines also for non-targeting guides. Regarding the transcriptomic comparison with the parental cell line, we agree that such an analysis would be informative; however, this would require additional experiments that are not feasible within the scope of the current study. Finally, while analyzing the samples separately could provide further insight into response heterogeneity, we focused on identifying robust patterns across perturbations that are reproducible in our pooled screening framework. We believe these aggregate analyses capture the major response behaviors and support the conclusions drawn.
(5) In general we were surprised to see such strong responses in some of the trans genes, in some cases exceeding the fold changes of the cis gene perturbation more than 2x, even at the relatively modest cis gene perturbations (Figures S5-S8). How can this be explained?
This phenomenon—where trans gene responses can exceed the magnitude of cis gene perturbations—is not unique to our study. Similar effects have been observed in previous CRISPR perturbation screens conducted in K562 cells, including those by Morris et al. (2023), Gasperini et al. (2019), and Replogle et al. (2022).
Several factors may contribute to this pattern. One possibility is that certain trans genes are highly sensitive to transcription factor dosage, and therefore exhibit amplified expression changes in response to relatively modest upstream perturbations. Transcription factors are known to be highly dosage sensitive and generally show a smaller range of variation than many other genes (that are regulated by TFs). Mechanistically, this may involve non-linear signal propagation through regulatory networks, in which intermediate regulators or feedback loops amplify the downstream transcriptional response. While our dataset cannot fully disentangle these indirect effects, the consistency of this observation across multiple studies suggests it is a common feature of transcriptional regulation in K562 cells.
(6) In the analysis shown in Figure S3B, the correlation between cells with zero count and >0 counts for the cis gene is calculated. For comparison, this analysis should also show the correlation between the cells with similar cis-gene expression and between truly different populations (e.g. NTC vs strong sgRNA).
The intent of Figure S3B was not to compare biologically distinct populations or perform differential expression analyses—which we have already conducted and reported elsewhere in the manuscript—but rather to assess whether fold change estimates could be biased by differences in the baseline expression of the target gene across individual cells. Specifically, we sought to determine whether cells with zero versus non-zero expression (as can result from dropouts or binary on/off repression from the KRAB-based CRISPRi system) exhibit systematic differences that could distort fold change estimation. As such, the comparisons suggested by the reviewer do not directly relate to the goal of the analysis which Figure S3B was intended to show.
(7) It is unclear why the correlation between different lanes is assessed as quality control metrics in Figure S1C. This does not substitute for replicates.
The intent of Figure S1C was not to serve as a general quality control metric, but rather to illustrate that the targeted transcript capture approach yielded consistent and specific signal across lanes. We acknowledge that this may have been unclear and have revised the relevant sentence in the text to avoid misinterpretation.
“We used the protein hashes and the dCas9 cDNA (indicating the presence or absence of the KRAB domain) to demultiplex and determine the cell line—CRISPRi or CRISPRa. Cells containing a single sgRNA were identified using a Gaussian mixture model (see Methods). Standard quality control procedures were applied to the scRNA-seq data (see Methods). To confirm that the targeted transcript capture approach worked as intended, we assessed concordance across capture lanes (Figure S1C)”.
(8) Figures and legends often miss important information. Figure 3B and S5-S8: what do the transparent bars represent? Figure S1A: color bar label missing. Figure S4D: what are the lines?, Figure S9A: what is the red line? In Figure S8 some of the fitted curves do not overlap with the data points, e.g. PKM. Fig. 2C: why are there more than 96 guide RNAs (see y-axis)?
We have addressed each point as follows:
Figure 3B: The figure legend has been updated to clarify the meaning of the transparent bars.
Figures S5–S8: There are no transparent bars in these figures; we confirmed this in the source plots.
Figure S1A: The color bar label is already described in the figure legend, but we have reformulated the caption text to make this clearer.
Figure S4D: The dashed line represents a linear regression between the x and y variables. The figure caption has been updated accordingly.
Figure S9A: We clarified that the red line shows the median ∆AIC across all genes and conditions.
Figure S8: We agree that some fitted curves (e.g., PKM) do not closely follow the data points. This reflects high noise in these specific measurements; as noted in the text, TET2 is not expected to exert strong trans effects in this context.
Figure 2C: Thank you for catching this. The y-axis numbers were incorrect because the figure displays the proportion of guides (summing to 100%), not raw counts. We have corrected the y-axis label and updated the numbers in the figure to resolve this inconsistency.
(9) The code is deposited on Github, but documentation is missing.
Documentation is included as inline comments within the R code files to guide users through the analysis workflow.
(10) The methods miss a list of sgRNA target sequences.
We thank the reviewer for this observation. A complete table containing all processed data, including the sequences of the sgRNAs used in this study, is available at the following GEO link:
(11) In some parts, the language could be more specific and/or the readability improved, for example:
Line 88: "quantitative landscape".
Changed to “quantitative patterns”.
Lines 88-91: long sentence hard to read.
This complex sentence was broken up into two simpler ones:
“We uncovered quantitative patterns of how gradual changes in transcription dosage lead to linear and non-linear responses in downstream genes. Many downstream genes are associated with rare and complex diseases, with potential effects on cellular phenotypes”.
Line 110: "tiling sgRNAs +/- 1000 bp from the TSS", could maybe be specified by adding that the average distance was around 100 or 110 bps?
Lines 244-246: hard to understand.
We struggle to see the issue here and are not sure how it can be reworded.
Lines 339-342: hard to understand.
These sentences have been reworded to provide more clarity.
(12) A number of typos, and errors are found in the manuscript:
Line 71: "SOX2" -> "SOX9".
FIXED
Line 73: "rending" -> maybe "raising" or "posing"?
FIXED
Line 157: "biassed".
FIXED
Line 245: "exhibited correlations gene-specific correlations with".
FIXED
Multiple instances, e.g. 261: "transgene" -> "trans gene".
FIXED
Line 332: "not reproduced with among the other".
FIXED
Figure S11: betweenness.
This is the correct spelling
There are more typos that we didn't list here.
We went through the manuscript and corrected all the spelling errors and typos.
67093
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_67093
Curator: @maulamb
SciCrunch record: RRID:BDSC_67093
52869
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_52869
Curator: @maulamb
SciCrunch record: RRID:BDSC_52869
38748
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_38748
Curator: @maulamb
SciCrunch record: RRID:BDSC_38748
30037
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_30037
Curator: @maulamb
SciCrunch record: RRID:BDSC_30037
79029
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_79029
Curator: @maulamb
SciCrunch record: RRID:BDSC_79029
48276
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_48276
Curator: @maulamb
SciCrunch record: RRID:BDSC_48276
50411
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_50411
Curator: @maulamb
SciCrunch record: RRID:BDSC_50411
38797
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_38797
Curator: @maulamb
SciCrunch record: RRID:BDSC_38797
38760
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_38760
Curator: @maulamb
SciCrunch record: RRID:BDSC_38760
91223
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_91223
Curator: @maulamb
SciCrunch record: RRID:BDSC_91223
91222
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_91222
Curator: @maulamb
SciCrunch record: RRID:BDSC_91222
32186
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_32186
Curator: @maulamb
SciCrunch record: RRID:BDSC_32186
84151
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_84151
Curator: @maulamb
SciCrunch record: RRID:BDSC_84151
80907
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_80907
Curator: @maulamb
SciCrunch record: RRID:BDSC_80907
84147
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_84147
Curator: @maulamb
SciCrunch record: RRID:BDSC_84147
90880
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_90880
Curator: @maulamb
SciCrunch record: RRID:BDSC_90880
84148
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_84148
Curator: @maulamb
SciCrunch record: RRID:BDSC_84148
7018
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_7018
Curator: @maulamb
SciCrunch record: RRID:BDSC_7018
49476
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_49476
Curator: @maulamb
SciCrunch record: RRID:BDSC_49476
BDSC 38773
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_38773
Curator: @scibot
SciCrunch record: RRID:BDSC_38773
BDSC 48601
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_48601
Curator: @scibot
SciCrunch record: RRID:BDSC_48601
BDSC 41275
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_41275
Curator: @scibot
SciCrunch record: RRID:BDSC_41275
BDSC 26160
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_26160
Curator: @scibot
SciCrunch record: RRID:BDSC_26160
BDSC 48228
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_48228
Curator: @scibot
SciCrunch record: RRID:BDSC_48228
BDSC 49208
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_49208
Curator: @scibot
SciCrunch record: RRID:BDSC_49208
BDSC 41305
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_41305
Curator: @scibot
SciCrunch record: RRID:BDSC_41305
BDSC 93712
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_93712
Curator: @scibot
SciCrunch record: RRID:BDSC_93712
BDSC 80915
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_80915
Curator: @scibot
SciCrunch record: RRID:BDSC_80915
BDSC 49339
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_49339
Curator: @scibot
SciCrunch record: RRID:BDSC_49339
BDSC 30026
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_30026
Curator: @scibot
SciCrunch record: RRID:BDSC_30026
BDSC 90879
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_90879
Curator: @scibot
SciCrunch record: RRID:BDSC_90879
BDSC 90878
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_90878
Curator: @scibot
SciCrunch record: RRID:BDSC_90878
BDSC 26818
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_26818
Curator: @scibot
SciCrunch record: RRID:BDSC_26818
BDSC 54127
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_54127
Curator: @scibot
SciCrunch record: RRID:BDSC_54127
BDSC 84144
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_84144
Curator: @scibot
SciCrunch record: RRID:BDSC_84144
BDSC 84711
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_84711
Curator: @scibot
SciCrunch record: RRID:BDSC_84711
BDSC 63045
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_63045
Curator: @scibot
SciCrunch record: RRID:BDSC_63045
BDSC 32185
DOI: 10.1038/s42003-025-08922-y
Resource: RRID:BDSC_32185
Curator: @scibot
SciCrunch record: RRID:BDSC_32185
RRID: CVCL_0007
DOI: 10.1007/s12032-025-03128-y
Resource: (JCRB Cat# IFO50038, RRID:CVCL_0007)
Curator: @dhovakimyan1
SciCrunch record: RRID:CVCL_0007
RRID:AB_443014
DOI: 10.1007/s12032-025-03128-y
Resource: (Abcam Cat# ab13847, RRID:AB_443014)
Curator: @scibot
SciCrunch record: RRID:AB_443014
RRID:AB_2036326
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_2036326
RRID:AB_2887658
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_2887658
RRID:AB_562153
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_562153
RRID:AB_2881102
DOI: 10.1007/s12032-025-03128-y
Resource: Proteintech Cat# 28273-1-AP, RRID:AB_2881102
Curator: @scibot
SciCrunch record: RRID:AB_2881102
RRID:AB_11047075
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_11047075
RRID:AB_2887636
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_2887636
RRID:AB_2782958
DOI: 10.1007/s12032-025-03128-y
Resource: (Proteintech Cat# 66444-1-Ig, RRID:AB_2782958)
Curator: @scibot
SciCrunch record: RRID:AB_2782958
RRID:AB_2889842
DOI: 10.1007/s12032-025-03128-y
Resource: (Proteintech Cat# 67778-1-Ig, RRID:AB_2889842)
Curator: @scibot
SciCrunch record: RRID:AB_2889842
RRID:AB_2224574
DOI: 10.1007/s12032-025-03128-y
Resource: (Proteintech Cat# 10176-2-AP, RRID:AB_2224574)
Curator: @scibot
SciCrunch record: RRID:AB_2224574
RRID:AB_2038048
DOI: 10.1007/s12032-025-03128-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_2038048
RRID:AB_10734439
DOI: 10.1007/s12032-025-03128-y
Resource: (Proteintech Cat# 20584-1-AP, RRID:AB_10734439)
Curator: @scibot
SciCrunch record: RRID:AB_10734439
RRID:AB_3083699
DOI: 10.1007/s12032-025-03128-y
Resource: (ServiceBio Cat# GB15003, RRID:AB_3083699)
Curator: @scibot
SciCrunch record: RRID:AB_3083699
RRID:CVCL_0002
DOI: 10.1007/s12032-025-03128-y
Resource: (RRID:CVCL_0002)
Curator: @scibot
SciCrunch record: RRID:CVCL_0002
RRID:AB_3662688
DOI: 10.1007/s12032-025-03128-y
Resource: (Abcam Cat# ab278545, RRID:AB_3662688)
Curator: @scibot
SciCrunch record: RRID:AB_3662688
33650
DOI: 10.1007/s00018-025-05860-0
Resource: RRID:BDSC_33650
Curator: @maulamb
SciCrunch record: RRID:BDSC_33650
RRID:AB_355097
DOI: 10.1101/2025.11.18.688276
Resource: (R and D Systems Cat# AF1997, RRID:AB_355097)
Curator: @scibot
SciCrunch record: RRID:AB_355097
AB_627658
DOI: 10.1038/s44319-025-00642-y
Resource: (Santa Cruz Biotechnology Cat# sc-23938, RRID:AB_627658)
Curator: @scibot
SciCrunch record: RRID:AB_627658
SCR_013715
DOI: 10.1038/s44319-025-00642-y
Resource: Image Studio Lite (RRID:SCR_013715)
Curator: @scibot
SciCrunch record: RRID:SCR_013715
AB_2562233
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 406615, RRID:AB_2562233)
Curator: @scibot
SciCrunch record: RRID:AB_2562233
AB_10572490
DOI: 10.1038/s44319-025-00642-y
Resource: (R and D Systems Cat# MAB6158, RRID:AB_10572490)
Curator: @scibot
SciCrunch record: RRID:AB_10572490
AB_2563654
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 117347, RRID:AB_2563654)
Curator: @scibot
SciCrunch record: RRID:AB_2563654
AB_2801410
DOI: 10.1038/s44319-025-00642-y
Resource: (Abcam Cat# ab137869, RRID:AB_2801410)
Curator: @scibot
SciCrunch record: RRID:AB_2801410
AB_2732919
DOI: 10.1038/s44319-025-00642-y
Resource: (BD Biosciences Cat# 563786, RRID:AB_2732919)
Curator: @scibot
SciCrunch record: RRID:AB_2732919
AB_2740187
DOI: 10.1038/s44319-025-00642-y
Resource: (BD Biosciences Cat# 740461, RRID:AB_2740187)
Curator: @scibot
SciCrunch record: RRID:AB_2740187
AB_10643269
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 127622, RRID:AB_10643269)
Curator: @scibot
SciCrunch record: RRID:AB_10643269
AB_10900241
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 100437, RRID:AB_10900241)
Curator: @scibot
SciCrunch record: RRID:AB_10900241
AB_10896057
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 141707, RRID:AB_10896057)
Curator: @scibot
SciCrunch record: RRID:AB_10896057
AB_2873659
DOI: 10.1038/s44319-025-00642-y
Resource: (BD Biosciences Cat# 749284, RRID:AB_2873659)
Curator: @scibot
SciCrunch record: RRID:AB_2873659
AB_2738811
DOI: 10.1038/s44319-025-00642-y
Resource: (BD Biosciences Cat# 564443, RRID:AB_2738811)
Curator: @scibot
SciCrunch record: RRID:AB_2738811
AB_312992
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 103207, RRID:AB_312992)
Curator: @scibot
SciCrunch record: RRID:AB_312992
AB_2563286
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 108745, RRID:AB_2563286)
Curator: @scibot
SciCrunch record: RRID:AB_2563286
AB_329827
DOI: 10.1038/s44319-025-00642-y
Resource: (Cell Signaling Technology Cat# 9272, RRID:AB_329827)
Curator: @scibot
SciCrunch record: RRID:AB_329827
AB_312979
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 103114, RRID:AB_312979)
Curator: @scibot
SciCrunch record: RRID:AB_312979
AB_2736987
DOI: 10.1038/s44319-025-00642-y
Resource: (Bio X Cell Cat# BE0307, RRID:AB_2736987)
Curator: @scibot
SciCrunch record: RRID:AB_2736987
AB_312795
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 101212, RRID:AB_312795)
Curator: @scibot
SciCrunch record: RRID:AB_312795
AB_893339
DOI: 10.1038/s44319-025-00642-y
Resource: (BioLegend Cat# 103130, RRID:AB_893339)
Curator: @scibot
SciCrunch record: RRID:AB_893339
RRID:SCR_014329
DOI: 10.1038/s44319-025-00642-y
Resource: NIS-Elements (RRID:SCR_014329)
Curator: @scibot
SciCrunch record: RRID:SCR_014329
RRID:SCR_002798
DOI: 10.1038/s44319-025-00642-y
Resource: GraphPad Prism (RRID:SCR_002798)
Curator: @scibot
SciCrunch record: RRID:SCR_002798
RRID:SCR_016137
DOI: 10.1038/s44319-025-00642-y
Resource: Microsoft Excel (RRID:SCR_016137)
Curator: @scibot
SciCrunch record: RRID:SCR_016137
RRID:SCR_008520
DOI: 10.1038/s44319-025-00642-y
Resource: FlowJo (RRID:SCR_008520)
Curator: @scibot
SciCrunch record: RRID:SCR_008520
RRID:SCR_003070
DOI: 10.1038/s44319-025-00642-y
Resource: ImageJ (RRID:SCR_003070)
Curator: @scibot
SciCrunch record: RRID:SCR_003070
RRID:SCR_017003
DOI: 10.1038/s44319-025-00642-y
Resource: LipidView Software (RRID:SCR_017003)
Curator: @scibot
SciCrunch record: RRID:SCR_017003
RRID:AB_2338140
DOI: 10.1038/s44319-025-00642-y
Resource: (Jackson ImmunoResearch Labs Cat# 112-035-175, RRID:AB_2338140)
Curator: @scibot
SciCrunch record: RRID:AB_2338140
RRID:AB_10829911
DOI: 10.1038/s44319-025-00642-y
Resource: (Cell Signaling Technology Cat# 9349, RRID:AB_10829911)
Curator: @scibot
SciCrunch record: RRID:AB_10829911
RRID:AB_2307391
DOI: 10.1038/s44319-025-00642-y
Resource: (Jackson ImmunoResearch Labs Cat# 111-035-144, RRID:AB_2307391)
Curator: @scibot
SciCrunch record: RRID:AB_2307391
RRID:AB_10015289
DOI: 10.1038/s44319-025-00642-y
Resource: (Yeasen Biotech Cat# 33201ES60, RRID:AB_10015289)
Curator: @scibot
SciCrunch record: RRID:AB_10015289
RRID:AB_2296900
DOI: 10.1038/s44319-025-00642-y
Resource: (Cell Signaling Technology Cat# 4107, RRID:AB_2296900)
Curator: @scibot
SciCrunch record: RRID:AB_2296900
RRID:AB_2241462
DOI: 10.1038/s44319-025-00642-y
Resource: (Abcam Cat# ab10983, RRID:AB_2241462)
Curator: @scibot
SciCrunch record: RRID:AB_2241462
RRID:AB_2135495
DOI: 10.1038/s44319-025-00642-y
Resource: (Cell Signaling Technology Cat# 4139, RRID:AB_2135495)
Curator: @scibot
SciCrunch record: RRID:AB_2135495
AB_3331658
DOI: 10.1038/s44319-025-00626-y
Resource: (Abcam Cat# ab183709, RRID:AB_3331658)
Curator: @scibot
SciCrunch record: RRID:AB_3331658
AB_10841422
DOI: 10.1038/s44319-025-00626-y
Resource: (Santa Cruz Biotechnology Cat# sc-365024, RRID:AB_10841422)
Curator: @scibot
SciCrunch record: RRID:AB_10841422
AB_11164802
DOI: 10.1038/s44319-025-00626-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_11164802
SCR_002285
DOI: 10.1038/s44319-025-00626-y
Resource: Fiji (RRID:SCR_002285)
Curator: @scibot
SciCrunch record: RRID:SCR_002285
RRID:AB_2534069
DOI: 10.1038/s44319-025-00626-y
Resource: (Thermo Fisher Scientific Cat# A-11001, RRID:AB_2534069)
Curator: @scibot
SciCrunch record: RRID:AB_2534069
AB_2888514
DOI: 10.1038/s44319-025-00626-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_2888514
RRID:AB_2535812
DOI: 10.1038/s44319-025-00626-y
Resource: (Molecular Probes Cat# A-21244, RRID:AB_2535812)
Curator: @scibot
SciCrunch record: RRID:AB_2535812
RRID:AB_143157
DOI: 10.1038/s44319-025-00626-y
Resource: (Molecular Probes Cat# A-11011, RRID:AB_143157)
Curator: @scibot
SciCrunch record: RRID:AB_143157
RRID:SCR_002798
DOI: 10.1038/s44319-025-00626-y
Resource: GraphPad Prism (RRID:SCR_002798)
Curator: @scibot
SciCrunch record: RRID:SCR_002798
AB_1209637
DOI: 10.1038/s44319-025-00626-y
Resource: None
Curator: @scibot
SciCrunch record: RRID:AB_1209637
AB_2910197
DOI: 10.1038/s44319-025-00626-y
Resource: (Abcam Cat# ab196032, RRID:AB_2910197)
Curator: @scibot
SciCrunch record: RRID:AB_2910197
RRID:AB_713650
DOI: 10.1038/s44319-025-00626-y
Resource: (Promega Cat# G9281, RRID:AB_713650)
Curator: @scibot
SciCrunch record: RRID:AB_713650
RRID:AB_372954
DOI: 10.1038/s44319-025-00626-y
Resource: (GeneTex Cat# GTX11826, RRID:AB_372954)
Curator: @scibot
SciCrunch record: RRID:AB_372954
RRID:AB_2886086
DOI: 10.1038/s44319-025-00626-y
Resource: (GeneTex Cat# GTX129778, RRID:AB_2886086)
Curator: @scibot
SciCrunch record: RRID:AB_2886086
RRID:AB_3075982
DOI: 10.1038/s44319-025-00626-y
Resource: (NanoTag Biotechnologies Cat# N1502-AT488-L, RRID:AB_3075982)
Curator: @scibot
SciCrunch record: RRID:AB_3075982
RRID:AB_10631145
DOI: 10.1038/s44319-025-00626-y
Resource: (New England Biolabs Cat# P9310S, RRID:AB_10631145)
Curator: @scibot
SciCrunch record: RRID:AB_10631145
RRID:AB_10950495
DOI: 10.1038/s44319-025-00626-y
Resource: (Cell Signaling Technology Cat# 8146, RRID:AB_10950495)
Curator: @scibot
SciCrunch record: RRID:AB_10950495
RRID:AB_143165
DOI: 10.1038/s44319-025-00626-y
Resource: (Thermo Fisher Scientific Cat# A-11008, RRID:AB_143165)
Curator: @scibot
SciCrunch record: RRID:AB_143165
RRID:AB_2223041
DOI: 10.1038/s44319-025-00626-y
Resource: (Millipore Cat# MAB1501, RRID:AB_2223041)
Curator: @scibot
SciCrunch record: RRID:AB_2223041
RRID:CVCL_1922
DOI: 10.1038/s44319-025-00626-y
Resource: (RRID:CVCL_1922)
Curator: @scibot
SciCrunch record: RRID:CVCL_1922
RRID:AB_445319
DOI: 10.1038/s44319-025-00626-y
Resource: (Abcam Cat# ab20084, RRID:AB_445319)
Curator: @scibot
SciCrunch record: RRID:AB_445319
RRID:AB_369669
DOI: 10.1038/s44319-025-00626-y
Resource: (GeneTex Cat# GTX29106, RRID:AB_369669)
Curator: @scibot
SciCrunch record: RRID:AB_369669
nshi irecti cal knoll p. The directive coach has speci T-appr pecial knowled and his job is to transfer that knowledge to the coachee. While the . relationship is respectful, it is not equal. In con ilitati cae a to ae coaches who set their expertise aside when working achers, the directive coach’s ex ise i pertise is at the heart of thi i approach. Since their job is t ctnay ton o make sure teachers | de something eect earn the correct way to , directive coaches tell teachers wh at do to, someti oe ' imes model an me observe teachers, and provide constructive feedback to teachers ey can implement the new practice with fidelity. Directi Fach we paces work from the assumption that the teachers they are Rivhy e ‘ O not Know how to use the practices they are learning, which henerally a ane coached. They also assume that teaching strategies uld be implemented with fidelity, which i : way in ea y, which is to say, in the same y ch classroom. Thus, the goal of the directive coach is to ensure fidelity to a proven model, not adaptation of th i of children or strengths of a teacher ENE NGENSS The best directi a neath coaches are excellent communicators who listen to their 7 . . Pa Fa rene understanding using effective questions, and sensitively ee’s understanding or lack of understanding. Since the goal Chapter 1 | What Does It Mean to Improve? 11
Directive coaching: I can see how this way of coaching can support teachers who need to master a skill. It is nerve racking to do this type of coaching, however i can see possiblities based on what jim knight is sharing. I need to go deeper to understand better.
Le
ici il y a juste une erreur avec l'article
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Revision Plan
Manuscript number: RC-2025-03208
Corresponding author(s): Jared Nordman
[The "revision plan" should delineate the revisions that authors intend to carry out in response to the points raised by the referees. It also provides the authors with the opportunity to explain their view of the paper and of the referee reports.
The document is important for the editors of affiliate journals when they make a first decision on the transferred manuscript. It will also be useful to readers of the reprint and help them to obtain a balanced view of the paper.
If you wish to submit a full revision, please use our "Full Revision" template. It is important to use the appropriate template to clearly inform the editors of your intentions.]
All three reviewers of our manuscript were very positive about our work. The reviewers noted that our work represents a necessary advance that is timely, addresses important issues in the chromatin field, and will of broad interest to this community. Given the nature of our work and the positive reviews, we feel that this manuscript would best be suited for the Journal of Cell Biology.
Reviewer #1 (Evidence, reproducibility and clarity (Required)):
Summary:
The authors investigate the function of the H3 chaperone NASP, which is known to bind directly to H3 and prevent degradation of soluble H3. What is unclear is where NASP functions in the cell (nucleus or cytoplasm), how NASP protects H3 from degradation (direct or indirect), and if NASP affects H3 dynamics (nuclear import or export). They use the powerful model system of Drosophila embryos because the soluble H3 pool is high due to maternal deposition and they make use of photoconvertable Dendra-tagged proteins, since these are maternally deposited and can be used to measure nuclear import/export rates.
Using these systems and tools, they conclude that NASP affects nuclear import, but only indirectly, because embryos from NASP mutant mothers start out with 50% of the maternally deposited H3. Because of the depleted H3 and reduced import rates, NASP deficient embryos also have reduced nucleoplasmic and chromatin-associated H3. Using a new Dendra-tagged NASP allele, the authors show that NASP and H3 have different nuclear import rates, indicating that NASP is not a chaperone that shuttles H3 into the nucleus. They test H3 levels in embryos that have no nuclei and conclude that NASP functions in the cytoplasm, and through protein aggregation assays they conclude that NASP prevents H3 aggregation.
Major comments:
The text was easy to read and logical. The data are well presented, methods are complete, and statistics are robust. The conclusions are largely reasonable. However, I am having trouble connecting the conclusions in text to the data presented in Figure 4.
First, I'm confused why the conclusion from Figure 4A is that NASP functions in the cytoplasm of the egg. Couldn't NASP be required in the ovary (in, say, nurse cell nuclei) to stimulate H3 expression and deposition into the egg? The results in 4A would look the same if the mothers deposit 50% of the normal H3 into the egg. Why is NASP functioning specifically in the cytoplasm when it is also so clearly imported into the nucleus? Maybe NASP functions wherever it is, and by preventing nuclear import, you force it to function in the cytoplasm. I do not have additional suggestions for experiments, but I think the authors need to be very clear about the different interpretations of these data and to discuss WHY they believe their conclusion is strongest.
The concern raised by the reviewer regarding NASP function during oogenesis has been addressed in a previous work published from our lab. Unfortunately, we did not do a good job conveying this work in the original version of this manuscript. We demonstrated that total H3 levels are unaffected when comparing WT and NASP mutant stage 14 egg chambers. This means that the amount of H3 deposited into the eggs does not change in the absence of NASP. To address the reviewer's comment, we will change the text to make the link to our previous work clear.
Second, an alternate conclusion from Figure 4D/E is that mothers are depositing less H3 protein into the egg, but the same total amount is being aggregated. This amount of aggregated protein remains constant in activated eggs, but additional H3 translation leads to more total H3? The authors mention that additional translation can compensate for reduced histone pools (line 416).
Similar to our response above, the total amount of H3 in wild type and NASP mutant stage 14 egg chambers is the same. Therefore, mothers are depositing equal amounts of H3 into the egg. We will make the necessary changes in the text to make this point clear.
As the function of NASP in the cytoplasm (when it clearly imports into the nucleus) and role in H3 aggregation are major conclusions of the work, the authors need to present alternative conclusions in the text or complete additional experiments to support the claims. Again, I do not have additional suggestions for experiments, but I think the authors need to be very clear about the different interpretations of these data and to discuss WHY they believe their conclusion is strongest.
A common issue raised by all three reviewers was to more convincingly demonstrate that assay that we have used to isolate protein aggregates does, in fact, isolate protein aggregates. To verify this, we will be performing the aggregate isolation assay using controls that are known to induce more protein aggregation. We will perform the aggregation assay with egg chambers or extracts that are exposed to heat shock or the aggregation-inducing chemicals Canavanine and Azetidine-2-carboxylic acid. The chemical treatment was a welcome suggestion from reviewer #3. These experiments will significantly strengthen any claims based on the outcome of the aggregation assay.
We will also make changes to the text and include other interpretations of our work as the reviewer has suggested.
Data presentation:
Overall, I suggest moving some of the supplemental figures to the main text, adding representative movie stills to show where the quantitative data originated, and moving the H3.3 data to the supplement. Not because it's not interesting, but because H3.3 and H3.2 are behaving the same.
Where possible, we will make changes to the figure display to improve the logic and flow of the manuscript
Fig 1:
It would strengthen the figure to include representative still images that led to the quantitative data, mostly so readers understand how the data were collected.
We will add representative stills to Figure 1 to help readers understand how the data is collected. We will also a representative H3-Dendra movie similar to the NASP supplemental movie.
The inclusion of a "simulated 50% H3" in panel C is confusing. Why?
We used a 50% reduction in H3 levels because that is reduction in H3 we measure in embryos laid by NASP-mutant mothers in our previous work. A reduction in H3 levels alone would be predicted to change the nuclear import rate of H3. Thus, having a quantitative model of H3 import kinetics was key in our understanding of NASP function in vivo. We will revise the text to make this clear.
I would also consider normalizing the data between A and B (and C and D) by dividing NASP/WT. This could be included in the supplement (OPTIONAL)
We can normalize the values and include the data in a supplemental figure.
Fig S1:
The data simulation S1G should be moved to the main text, since it is the primary reason the authors reject the hypothesis that NASP influences H3 import rates.
This is a good point. We will move S1G into the Figure 1.
Fig 2:
Once again, I think it would help to include a few representative images of the photoconverted Dendra2 in the main text.
We will add representative images of the photoconversion in Figure 2.
I struggled with A/B, I think due to not knowing how the data were normalized. When I realized that the WT and NASP data are not normalized to each other, but that the NASP values are likely starting less than the WT values, it made way more sense. I suggest switching the order of data presentation so that C-F are presented first to establish that there is less chromatin-bound H3 in the first place, and then present A/B to show no change in nuclear export of the H3 that is present, allowing the conclusion of both less soluble AND chromatin-bound H3.
The order of the presentation of the data was to test if NASP was acting as a nuclear receptor. Since Figure 1 compares the nuclear import, we wanted to address the nuclear export and provide a comprehensive analysis of the role of NASP in H3 nuclear dynamics before advancing on to other consequences of NASP depletion. We can add the graphs with the un-normalized values in the Supplemental Figure to show the actual difference in total intensity values.
Fig S2:
If M1-M3 indicate males, why are the ovaries also derived from males? I think this is just confusing labeling.
We will change the labelling.
Supplemental Movie S1:
Beautiful. Would help to add a time stamp (OPTIONAL).
Thank you! We will add the time stamp to the movie
Fig 3:
Panel C is the same as Fig S1A (not Fig 1A, as is said in the legend), though I appreciate the authors pointing it out in the legend. Also see line 276.
We appreciate the reviewer for pointing this out. We will make the change in the text to correct this.
Panel D is a little confusing, because presumably the "% decrease in import rate" cannot be positive (Y axis). This could be displayed as a scatter (not bar) as in Panels B/C (right) where the top of the Y axis is set to 0.
We understand the reviewer's concern that the decrease value cannot be positive. We can adjust the y-axis so that it caps off at 0.
Fig S3:
A: What do the different panels represent? I originally thought developmental time, but now I think just different representative images? Are these age-matched from time at egg lay?
The different panels show representative images. We can clarify that in the figure legend.
C: What does "embryos" mean? Same question for Fig 4A.
In this figure, embryos mean the exact number of embryos used to form the lysate for the western blot. We will clarify this in the figure legend.
Fig 4:
A: What does "embryos" mean? Number of embryos? Age in hours?
In this figure, embryos mean the exact number of embryos used to form the lysate for the western blot. We will clarify this in the figure legend.
C: Not sure the workflow figure panel is necessary, as I can't tell what each step does. This is better explained in methods. However I appreciated the short explanation in the text (lines 314-5).
The workflow panel helps to identify the samples labelled as input and aggregate for the western blot analysis. Since our input in the western blots does not refer to the total protein lysate, we feel it is helpful to point out exactly what stage at the protocol we are utilizing the sample for our analysis.
Minor comments:
The authors should describe the nature of the NASP alleles in the main text and present evidence of robust NASP depletion, potentially both in ovaries and in embryos. The antibody works well for westerns (Fig S2B). This is sort of demonstrated later in Figure 4A, but only in NAAP x twine activated eggs.
We appreciate the reviewer's comments about the NASP mutant allele. In our previous publication, we characterized the NASP mutant fly line and its effect on both stage 14 egg chambers and the embryos. We will emphasize the reference to our previous work in the text.
Lines 163, 251, 339: minor typos
Line 184: It would help to clarify- I'm assuming cytoplasmic concentration (or overall) rather than nuclear concentration. If nuclear, I'd expect the opposite relationship. This occurs again when discussing NASP (line 267). I suspect it's also not absolute concentration, but relative concentration difference between cytoplasm and nucleus. It would help clarify if the authors were more precise.
We appreciate the reviewer's point and will add the clarification in the text.
Line 189: Given that the "established integrative model" helps to reject the hypothesis that NASP is involved in H3 import, I think it's important to describe the model a little more, even though it's previously published.
We will add few sentences giving a brief description of the model to the text.
Line 203: "The measured rate of H3.2 export from the nucleus is negligible" clarify this is in WT situations and not a conclusion from this study.
We will add the clarification of this statement in the text.
Line 211: How can the authors be so sure that the decrease in WT is due to "the loss of non-chromatin bound nucleoplasmic H3.2-Dendra2?"
From the live imaging experiments, the H3.2-Dendra2 intensity in the nucleus reduces dramatically upon nuclear envelope breakdown with the only H3.2-Dendra2 intensity remaining being the chromatin bound H3.2. Excess H3.2 is imported into the nucleus and not all of it is incorporated into the chromatin. This is a unique feature of the embryo system that has been observed previously. We mention that the intensity reduction is due to the loss of non-chromatin bound nucleoplasmic H3.2.
Line 217: In the conclusion, the authors indicate that NASP indirectly affects soluble supply of H3 in the nucleoplasm. I do believe they've shown that the import rate effect is indirect, but I don't know why they conclude that the effect of NASP on the soluble nucleoplasmic H3 supply is indirect. Similarly, the conclusion is indirect on line 239. Yet, the authors have not shown it's not direct, just assumed since NASP results in 50% decrease to deposited maternal histones.
We appreciate the feedback on the conclusions of Figure 2 from the reviewer. Our conclusions are primarily based on the effect of H3 levels in the absence of NASP in the early embryos. To establish direct causal effects, it would be important to recover the phenotypes by complementation experiments and providing molecular interactions to cause the effects. In this study we have not established those specific details to make conclusions of direct effects. We will change the text to make this more clear.
Line 292: What is the nature of the NASP "mutant?" Is it a null? Similarly, what kind of "mutant" is the twine allele? Line 295.
We will include descriptions of the NASP and twine mutants in the text.
Line 316: Why did the authors use stage 14 egg chambers here when they previously used embryos? This becomes more clear later shortly, when the authors examine activated eggs, but it's confusing in text.
The reason to use stage 14 egg chambers was to establish NASP function during oogenesis. We will modify the text to emphasize the reason behind using stage 14 egg chambers.
Lines 343-348: It's unclear if the authors are drawing extended conclusions here or if they are drawing from prior literature (if so, citations would be required). For example, why during oogenesis/embryogenesis are aggregation and degradation developmentally separated?
This conclusion is based primarily based on the findings from this study (Figure 4) and out previous published work. We will modify the text for more clarity.
Lines 386-7: I do not understand why the authors conclude that H3 aggregation and degradation are "developmentally uncoupled" and why, in the absence of NASP, "H3 aggregation precedes degradation."
This is based data in Figure 4 combined with our previous working showing that the total level of H3 in not changed in NASP-mutant stage 14 egg chambers. Aggregates seem to be more persistent in the stage 14 egg chambers (oogenesis) and they get cleared out upon egg activation (entry into embryogenesis). This provides evidence for aggregation occurring prior to degradation and these two events occurring in different developmental stages. We will change the text to make this more clear.
Line 395: Why suddenly propose that NASP also functions in the nucleus to prevent aggregation, when earlier the authors suggest it functions only in the cytoplasm?
We will make the necessary edits to ensure that the results don't suggest a role of NASP exclusive to the cytoplasm. Our findings highlight a cytoplasmic function of NASP, however, we do not want to rule out that this same function couldn't occur in the nucleus.
Lines 409-413: The authors claim that histone deficiency likely does not cause the embryonic arrest seen in embryos from NASP mutant mothers. This is because H3 is reduced by 50% yet some embryos arrest long before they've depleted this supply. However, the authors also showed that H3 import rates are affected in these embryos due to lower H3 concentration. Since the early embryo cycles are so rapid, reduced H3 import rates could lead to early arrest, even though available H3 remains in the cytoplasm.
We thank the reviewer for their suggestion. This conclusion is based on the findings from the previous study from our lab which showed that the majority of the embryos laid by NASP mutant females get arrested in the very early nuclear cycles (Reviewer #1 (Significance (Required)):
The significance of the work is conceptual, as NASP is known to function in H3 availability but the precise mechanism is elusive. This work represents a necessary advance, especially to show that NASP does not affect H3 import rates, nor does it chaperone H3 into the nucleus. However, the authors acknowledge that many questions remain. Foremost, why is NASP imported into the nucleus and what is its role there?
I believe this work will be of interest to those who focus on early animal development, but NASP may also represent a tool, as the authors conclude in their discussion, to reduce histone levels during development and examine nucleosome positioning. This may be of interest to those who work on chromatin accessibility and zygotic genome activation.
I am a genetics expert who works in Drosophila embryogenesis. I do not have the expertise to evaluate the aggregate methods presented in Figure 4.
Reviewer #2 (Evidence, reproducibility and clarity (Required)):
Summary:
This manuscript focuses on the role of the histone chaperone NASP in Drosophila. NASP is a chaperone specific to histone H3 that is conserved in mammals. Many aspects of the molecular mechanisms by which NASP selectively binds histone H3 have been revealed through biochemical studies. However, key aspects of NASP's in vivo roles remain unclear, including where in the cell NASP functions, and how it prevents H3 degradation. Through live imaging in the early Drosophila embryo, which possesses large amounts of soluble H3 protein, Das et al determine that NASP does not control nuclear import or export of H3.2 or H3.3. Instead, they find through differential centrifugation analysis that NASP functions in the cytoplasm to prevent H3 aggregation and hence its subsequent degradation.
Major Comments:
The protein aggregation assays raise several questions. From a technical standpoint, it would be helpful to have a positive control to demonstrate that the assay is effective at detecting protein aggregates. Ie. a genotype that exhibits increased protein aggregation; this could be for a protein besides H3. A common issue raised by all three reviewers was to more convincingly demonstrate that assay that we have used to isolate protein aggregates does, in fact, isolate protein aggregates. To verify this, we will be performing the aggregate isolation assay using controls that are known to induce more protein aggregation. We will perform the aggregation assay with egg chambers or extracts that are exposed to heat shock or the aggregation-inducing chemicals Canavanine and Azetidine-2-carboxylic acid. The chemical treatment was a welcome suggestion from reviewer #3. These experiments will significantly strengthen any claims based on the outcome of the aggregation assay.
If NASP is not required to prevent H3 degradation in egg chambers, then why are H3 levels much lower in NASP input lanes relative to wild-type egg chambers in Fig 4D? We appreciate the reviewer's inputs regarding the reduced H3 levels in the NASP mutant egg chambers. We observe this reduction in H3 levels in the input because of the altered solubility of H3 which leads to the loss of H3 protein at different steps of the aggregate isolation assay. We will add a supplement figure showing H3 levels at different steps of the aggregate isolation assay. We do want to stress, however, that the total levels of H3 in stage 14 egg chambers does not change between WT and the NASP mutant.
A corollary to this is that the increased fraction of H3 in aggregates in NASP mutants seems to be entirely due to the reduction in total H3 levels rather than an increase in aggregated H3. If NASP's role is to prevent aggregation in the cytoplasm, and degradation has not yet begun in egg chambers, then why are aggregated H3 levels not increased in NASP mutants relative to wild-type egg chambers? If the same number of egg chambers were used, shouldn't the total amount of histone be the same in the absence of degradation?
In previously published work, we demonstrated that total H3 levels are unaffected when comparing WT and NASPmutant stage 14 egg chambers. This means that the amount of H3 deposited into the eggs does not change in the absence of NASP. To address the reviewer's comment, we will change the text to make the link to our previous work clear. As stated above, we will add a supplement figure showing H3 levels at different steps of the aggregate isolation assay.
The live imaging studies are well designed, executed, and quantified. They use an established genotype (H3.2-Dendra2) in wild-type and NASP maternal mutants to demonstrate that NASP is not directly involved in nuclear import of H3.2. Decreased import is likely due to reduced H3.2 levels in NASP mutants rather than reduced import rates per se. The same methodology was used to determine that loss of NASP did not affect H3.2 nuclear export. These findings eliminate H3.2 nuclear import/export regulation as possible roles for NASP, which had been previously proposed.
Thank you.
Live imaging also conclusively demonstrates that the levels of H3.2 in the nucleoplasm and in mitotic chromatin are significantly lower in NASP mutants than wild-type nuclei. Despite these lower histone levels, the nuclear cycle duration is only modestly lengthened. The live imagining of NASP-Dendra2 nuclear import conclusively demonstrate that NASP and H3.2 are unlikely to be imported into the nucleus as one complex.
Thank you.
Minor Comments:
Additional details on how the NASP-Dendra2 CRISPR allele was generated should be provided. In addition, additional details on how it was determined that this allele is functional should be provided (e.g. quantitative assays for fertility/embryo viability of NASP-Dendra2 females) We will make these additions to the text.
If statistical tests are used to determine significance, the type of test used should be reported in the figure legends throughout.
We will make the addition of the statistical tests to the figure legends.
The western blot shown in Figure 4A looks more like a 4-fold reduction in H3 levels in NASP mutants relative to wild-type embryos, rather than the quantified 2-fold reduction. Perhaps a more representative blot can be shown.
We have additional blots in the supplemental figure S3C. The quantification was performed after normalization to the total protein levels and we can highlight that in the figure legend.
Reviewer #2 (Significance (Required)):
As a fly chromatin biologist with colleagues that utilize mammalian experimental systems, I feel this manuscript will be of broad interest to the chromatin research community. Packaging of the genome into chromatin affects nearly every DNA-templated process, making the mechanisms by which histone proteins are expressed, chaperoned, and deposited into chromatin of high importance to the field. The study has multiple strengths, including high-quality quantitative imaging, use of a terrific experimental system (storage and deposition of soluble histones in early fly embryos). The study also answers outstanding questions in the field, specifically that NASP does not control nuclear import/export of histone H3. Instead, the authors propose that NASP functions to prevent protein aggregation. If this could be conclusively demonstrated, it would be valuable to the field. However, the protein aggregation studies need improvement. Technical demonstration that their differential centrifugation assay accurately detects aggregated proteins is needed. Further, NASP mutants do not exhibit increased H3 protein aggregation in the data presented. Instead, the increased fraction of aggregated H3 in NASP mutants seems to be due to a reduction in the overall levels of H3 protein, which is contrary to the model presented in this paper.
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
This manuscript by Das et al. entitled "NASP functions in the cytoplasm to prevent histone H3 aggregation during early embryogenesis", explores the role of the histone chaperone NASP in regulating histone H3 dynamics during early Drosophila embryogenesis. Using primarily live imaging approaches, the authors found that NASP is not directly involved in the import or export of H3. Moreover, the authors claimed that NASP prevents H3 aggregation rather than protects against degradation.
Major Comments:
Figure 1A-B: The plotted data appear to have substantial dispersion. Could the authors include individual data points or provide representative images to help the reader assess variability?
We chose to show unnormalized data in Figure 1 so readers could better compare the actual import values of H3 in the presence and absence of NASP. We felt it was a better representation of the true biological difference although raw data is more dispersive. We did also include normalized data in the supplement. Regardless, we will add representative stills to Figure 1 and include a H3-Dendra2 movie in the supplement to show the representative data.
Given that the authors conclude that the reduced nuclear import is due to lowered H3 levels in NASP-deficient embryos, would overexpression of H3 rescue this phenotype? This would directly test whether H3 levels, rather than import machinery per se, drive the effect.
We thank the reviewer for their valuable suggestion. We and others have tried to overexpress histones in the Drosophila early embryo without success. There must be an undefined feedback mechanism preventing histone overexpression in the germline. In fact, a recent paper has been deposited on bioRxiv (https://doi.org/10.1101/2024.12.23.630206) that suggest H4 protein could provide a feedback mechanism to prevent histone overexpression. While we would love to do this experiment, it is not technically feasible at this time.
Figure 2A-B: The authors present the Relative Intensity of H3-Dendra2, but this metric obscures absolute differences between Control and NASP knockout embryos. Please include Total Intensity plots to show the actual reduction in H3 levels.
We will add the total H3-Dendra2 intensity plots to the supplemental figure for the export curves.
Additionally, Western blot analysis of nucleoplasmic H3 from wild-type vs. NASP-deficient embryos would provide essential biochemical confirmation of H3 level reductions.
We will measure nuclear H3 levels by western from 0-2 hr embryos laid by WT and NASP mutant flies.
Figure 4: To support the conclusion that NASP prevents H3 aggregation, I recommend performing aggregation assays by adding compounds that induce unfolding (amino acid analogues that induce unfolding, like canavanine or Azetidine-2-carboxylic acid) or using aggregation-prone H3 mutants.
This is a very helpful suggestion! It is difficult to get chemicals into Drosophila eggs, but we will treat extracts directly with these chemicals. Additionally, we will use heat shocked eggs and extracts as an additional control.
Inclusion of CMA and proteasome inhibition experiments could also clarify whether degradation pathways are secondarily involved or compensatory in the absence of NASP.
The degradation pathway for H3 in the absence of NASP is unknown and a major focus of our future work is to define this pathway. Drosophila does not have a CMA pathway and therefore, we don't know how H3 aggregates are being sensed.
Minor Comments:
(1) The Introduction would benefit from mentioning the two NASP isoforms that exist in mammals (sNASP and tNASP), as this evolutionary context may inform interpretation of the Drosophila results.
We will make the edits in the text to include that Drosophila NASP is the sole homolog of sNASP and that tNASP ortholog is not found in Drosophila.
(2) Could the authors comment on the status of histone H4 in their experimental system? Given the observed cytoplasmic pool of H3, is it likely to exist as a monomer? If this H3 pool is monomeric, does that suggest an early failure in H3-H4 dimerization, and could this contribute to its aggregation propensity?
In our previous work we noted that NASP binds more preferentially to H3 and the levels of H3 we much more reduced upon NASP depletion than H4. We pointed out in this publication that our data was consistent with H3 stores being monomeric in the Drosophila embryo. We don't' have a H4-Dendra2 line to test. In the future, however, this is something we are very keen to look at.
Reviewer #3 (Significance (Required)):
This work addresses a timely and important question in the field of chromatin biology and developmental epigenetics. The focus on histone homeostasis during embryogenesis and the cytoplasmic role of NASP adds a novel perspective. The live imaging experiments are a clear strength, providing valuable spatiotemporal insights. However, I believe that the manuscript would benefit significantly from additional biochemical validation to support and clarify some of the mechanistic claims.
Please include a point-by-point response explaining why some of the requested data or additional analyses might not be necessary or cannot be provided within the scope of a revision. This can be due to time or resource limitations or in case of disagreement about the necessity of such additional data given the scope of the study. Please leave empty if not applicable.
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
Summary:
The authors investigate the function of the H3 chaperone NASP, which is known to bind directly to H3 and prevent degradation of soluble H3. What is unclear is where NASP functions in the cell (nucleus or cytoplasm), how NASP protects H3 from degradation (direct or indirect), and if NASP affects H3 dynamics (nuclear import or export). They use the powerful model system of Drosophila embryos because the soluble H3 pool is high due to maternal deposition and they make use of photoconvertable Dendra-tagged proteins, since these are maternally deposited and can be used to measure nuclear import/export rates.
Using these systems and tools, they conclude that NASP affects nuclear import, but only indirectly, because embryos from NASP mutant mothers start out with 50% of the maternally deposited H3. Because of the depleted H3 and reduced import rates, NASP deficient embryos also have reduced nucleoplasmic and chromatin-associated H3. Using a new Dendra-tagged NASP allele, the authors show that NASP and H3 have different nuclear import rates, indicating that NASP is not a chaperone that shuttles H3 into the nucleus. They test H3 levels in embryos that have no nuclei and conclude that NASP functions in the cytoplasm, and through protein aggregation assays they conclude that NASP prevents H3 aggregation.
Major comments:
The text was easy to read and logical. The data are well presented, methods are complete, and statistics are robust. The conclusions are largely reasonable. However, I am having trouble connecting the conclusions in text to the data presented in Figure 4.
First, I'm confused why the conclusion from Figure 4A is that NASP functions in the cytoplasm of the egg. Couldn't NASP be required in the ovary (in, say, nurse cell nuclei) to stimulate H3 expression and deposition into the egg? The results in 4A would look the same if the mothers deposit 50% of the normal H3 into the egg. Why is NASP functioning specifically in the cytoplasm when it is also so clearly imported into the nucleus? Maybe NASP functions wherever it is, and by preventing nuclear import, you force it to function in the cytoplasm. I do not have additional suggestions for experiments, but I think the authors need to be very clear about the different interpretations of these data and to discuss WHY they believe their conclusion is strongest.
Second, an alternate conclusion from Figure 4D/E is that mothers are depositing less H3 protein into the egg, but the same total amount is being aggregated. This amount of aggregated protein remains constant in activated eggs, but additional H3 translation leads to more total H3? The authors mention that additional translation can compensate for reduced histone pools (line 416).
As the function of NASP in the cytoplasm (when it clearly imports into the nucleus) and role in H3 aggregation are major conclusions of the work, the authors need to present alternative conclusions in the text or complete additional experiments to support the claims. Again, I do not have additional suggestions for experiments, but I think the authors need to be very clear about the different interpretations of these data and to discuss WHY they believe their conclusion is strongest.
Data presentation:
Overall, I suggest moving some of the supplemental figures to the main text, adding representative movie stills to show where the quantitative data originated, and moving the H3.3 data to the supplement. Not because it's not interesting, but because H3.3 and H3.2 are behaving the same.
Fig 1:
It would strengthen the figure to include representative still images that led to the quantitative data, mostly so readers understand how the data were collected. The inclusion of a "simulated 50% H3" in panel C is confusing. Why? I would also consider normalizing the data between A and B (and C and D) by dividing NASP/WT. This could be included in the supplement (OPTIONAL)
Fig S1:
The data simulation S1G should be moved to the main text, since it is the primary reason the authors reject the hypothesis that NASP influences H3 import rates.
Fig 2:
Once again, I think it would help to include a few representative images of the photoconverted Dendra2 in the main text. I struggled with A/B, I think due to not knowing how the data were normalized. When I realized that the WT and NASP data are not normalized to each other, but that the NASP values are likely starting less than the WT values, it made way more sense. I suggest switching the order of data presentation so that C-F are presented first to establish that there is less chromatin-bound H3 in the first place, and then present A/B to show no change in nuclear export of the H3 that is present, allowing the conclusion of both less soluble AND chromatin-bound H3.
Fig S2:
If M1-M3 indicate males, why are the ovaries also derived from males? I think this is just confusing labeling. Supplemental Movie S1: Beautiful. Would help to add a time stamp (OPTIONAL).
Fig 3:
Panel C is the same as Fig S1A (not Fig 1A, as is said in the legend), though I appreciate the authors pointing it out in the legend. Also see line 276. Panel D is a little confusing, because presumably the "% decrease in import rate" cannot be positive (Y axis). This could be displayed as a scatter (not bar) as in Panels B/C (right) where the top of the Y axis is set to 0.
Fig S3:
A: What do the different panels represent? I originally thought developmental time, but now I think just different representative images? Are these age-matched from time at egg lay? C: What does "embryos" mean? Same question for Fig 4A. Fig 4: A: What does "embryos" mean? Number of embryos? Age in hours? C: Not sure the workflow figure panel is necessary, as I can't tell what each step does. This is better explained in methods. However I appreciated the short explanation in the text (lines 314-5).
Minor comments:
The authors should describe the nature of the NASP alleles in the main text and present evidence of robust NASP depletion, potentially both in ovaries and in embryos. The antibody works well for westerns (Fig S2B). This is sort of demonstrated later in Figure 4A, but only in NAAP x twine activated eggs.
Lines 163, 251, 339: minor typos Line 184: It would help to clarify- I'm assuming cytoplasmic concentration (or overall) rather than nuclear concentration. If nuclear, I'd expect the opposite relationship. This occurs again when discussing NASP (line 267). I suspect it's also not absolute concentration, but relative concentration difference between cytoplasm and nucleus. It would help clarify if the authors were more precise. Line 189: Given that the "established integrative model" helps to reject the hypothesis that NASP is involved in H3 import, I think it's important to describe the model a little more, even though it's previously published. Line 203: "The measured rate of H3.2 export from the nucleus is negligible" clarify this is in WT situations and not a conclusion from this study. Line 201: How can the authors be so sure that the decrease in WT is due to "the loss of non-chromatin bound nucleoplasmid H3.2-Dendra2?" Line 217: In the conclusion, the authors indicate that NASP indirectly affects soluble supply of H3 in the nucleoplasm. I do believe they've shown that the import rate effect is indirect, but I don't know why they conclude that the effect of NASP on the soluble nucleoplasmic H3 supply is indirect. Similarly, the conclusion is indirect on line 239. Yet, the authors have not shown it's not direct, just assumed since NASP results in 50% decrease to deposited maternal histones. Line 292: What is the nature of the NASP "mutant?" Is it a null? Similarly, what kind of "mutant" is the twine allele? Line 295. Line 316: Why did the authors use stage 14 egg chambers here when they previously used embryos? This becomes more clear later shortly, when the authors examine activated eggs, but it's confusing in text. Lines 343-348: It's unclear if the authors are drawing extended conclusions here or if they are drawing from prior literature (if so, citations would be required). For example, why during oogenesis/embryogenesis are aggregation and degradation developmentally separated? Lines 386-7: I do not understand why the authors conclude that H3 aggregation and degradation are "developmentally uncoupled" and why, in the absence of NASP, "H3 aggregation precedes degradation." Line 395: Why suddenly propose that NASP also functions in the nucleus to prevent aggregation, when earlier the authors suggest it functions only in the cytoplasm? Lines 409-413: The authors claim that histone deficiency likely does not cause the embryonic arrest seen in embryos from NASP mutant mothers. This is because H3 is reduced by 50% yet some embryos arrest long before they've depleted this supply. However, the authors also showed that H3 import rates are affected in these embryos due to lower H3 concentration. Since the early embryo cycles are so rapid, reduced H3 import rates could lead to early arrest, even though available H3 remains in the cytoplasm.
The significance of the work is conceptual, as NASP is known to function in H3 availability but the precise mechanism is elusive. This work represents a necessary advance, especially to show that NASP does not affect H3 import rates, nor does it chaperone H3 into the nucleus. However, the authors acknowledge that many questions remain. Foremost, why is NASP imported into the nucleus and what is its role there?
I believe this work will be of interest to those who focus on early animal development, but NASP may also represent a tool, as the authors conclude in their discussion, to reduce histone levels during development and examine nucleosome positioning. This may be of interest to those who work on chromatin accessibility and zygotic genome activation.
I am a genetics expert who works in Drosophila embryogenesis. I do not have the expertise to evaluate the aggregate methods presented in Figure 4.
Question 3
Je trouve qu'il y a une erreur. Dans la formation sur HTML5 et CSS3 on nous apprend que notre code doit toujours avoir la structure suivante : header (composée de "nav"), main (composée de plusieurs "section") et de footer. Or, ici, on nous montre un "header" et un "main", et la réponse n'est que "main". Etrange … Il fallait écrire "quelles balises" afin qu'on puisse choisir les deux correspondantes.
27080
DOI: 10.1186/s13287-025-04755-y
Resource: RRID:Addgene_27080
Curator: @olekpark
SciCrunch record: RRID:Addgene_27080
27078
DOI: 10.1186/s13287-025-04755-y
Resource: RRID:Addgene_27078
Curator: @olekpark
SciCrunch record: RRID:Addgene_27078
27077
DOI: 10.1186/s13287-025-04755-y
Resource: RRID:Addgene_27077
Curator: @olekpark
SciCrunch record: RRID:Addgene_27077
58215
DOI: 10.1186/s12967-025-07263-y
Resource: RRID:Addgene_58215
Curator: @olekpark
SciCrunch record: RRID:Addgene_58215
21232
DOI: 10.1186/s12964-025-02419-1
Resource: RRID:Addgene_21232
Curator: @olekpark
SciCrunch record: RRID:Addgene_21232
21073
DOI: 10.1186/s10020-025-01388-y
Resource: RRID:Addgene_21073
Curator: @olekpark
SciCrunch record: RRID:Addgene_21073
17448
DOI: 10.1038/s44161-025-00725-y
Resource: RRID:Addgene_17448
Curator: @olekpark
SciCrunch record: RRID:Addgene_17448
104454
DOI: 10.1038/s41598-025-24732-y
Resource: RRID:Addgene_104454
Curator: @olekpark
SciCrunch record: RRID:Addgene_104454
71236
DOI: 10.1038/s41598-025-24732-y
Resource: RRID:Addgene_71236
Curator: @olekpark
SciCrunch record: RRID:Addgene_71236
AAV9-hSyn-jGCaMP8m-WPRE
DOI: 10.1038/s41593-025-02078-y
Resource: RRID:Addgene_162375
Curator: @olekpark
SciCrunch record: RRID:Addgene_162375
AAV8-hSyn-DIO-mCherry
DOI: 10.1038/s41593-025-02078-y
Resource: RRID:Addgene_50459
Curator: @olekpark
SciCrunch record: RRID:Addgene_50459
AAV8-hSyn-DIO-hM3D(Gq)-mCherry
DOI: 10.1038/s41593-025-02078-y
Resource: RRID:Addgene_44361
Curator: @olekpark
SciCrunch record: RRID:Addgene_44361
125148
DOI: 10.1038/s41588-025-02368-y
Resource: None
Curator: @olekpark
SciCrunch record: RRID:Addgene_125148
99373
DOI: 10.1038/s41588-025-02368-y
Resource: RRID:Addgene_99373
Curator: @olekpark
SciCrunch record: RRID:Addgene_99373