8,037 Matching Annotations
- Aug 2022
-
-
-
javascript.info javascript.info
-
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
www.nextinpact.com www.nextinpact.com
-
```bash $ nslookup -type=txt default._bimi.dropbox.com
text = "v=BIMI1; l=https://cfl.dropboxstatic.com/static/images/logo_catalog/dropbox_logo_glyph_m1_bimi.svg;" ```
-
-
bugzilla.mozilla.org bugzilla.mozilla.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
hypothes.is hypothes.is
-
-
stackoverflow.com stackoverflow.com
-
js function transclude(elementId) { var clone = document.getElementById(elementId).cloneNode(true), placeholder; clone.id = null; document.write('<br id="__placeholder__">'); placeholder = document.getElementById('__placeholder__'); placeholder.parentNode.insertBefore(clone, placeholder); placeholder.parentNode.removeChild(placeholder); return transclude; }```html
This is paragraph 1.
This is paragraph 2.
This is paragraph 3. It should contain paragraphs 1 and 2. <script>transclude("p1")("p2")</script>
```
-
-
datatracker.ietf.org datatracker.ietf.org
-
www.debuggex.com www.debuggex.com
-
-
example.com example.com
-
-
github.com github.com
-
```js / Adapted from: https://github.com/openannotation/annotator/blob/v1.2.x/src/plugin/document.coffee Annotator v1.2.10 https://github.com/openannotation/annotator Copyright 2015, the Annotator project contributors. Dual licensed under the MIT and GPLv3 licenses. https://github.com/openannotation/annotator/blob/master/LICENSE /
/* * nb. The
DocumentMetadatatype is renamed to avoid a conflict with the *DocumentMetadataclass below. * * @typedef {import('../../types/annotator').DocumentMetadata} Metadata /import { normalizeURI } from '../util/url';
/* * @typedef Link * @prop {string} link.href * @prop {string} [link.rel] * @prop {string} [link.type] /
/* * Extension of the
Metadatatype with non-optional fields fordc,eprintsetc. * * @typedef HTMLDocumentMetadata * @prop {string} title * @prop {Link[]} link * @prop {Record<string, string[]>} dc * @prop {Record<string, string[]>} eprints * @prop {Record<string, string[]>} facebook * @prop {Record<string, string[]>} highwire * @prop {Record<string, string[]>} prism * @prop {Record<string, string[]>} twitter * @prop {string} [favicon] * @prop {string} [documentFingerprint] // * HTMLMetadata reads metadata/links from the current HTML document. */ export class HTMLMetadata { / * @param {object} [options] * @param {Document} [options.document] */ constructor(options = {}) { this.document = options.document || document; }
/* * Returns the primary URI for the document being annotated * * @return {string} / uri() { let uri = decodeURIComponent(this._getDocumentHref());
// Use the `link[rel=canonical]` element's href as the URL if present. const links = this._getLinks(); for (let link of links) { if (link.rel === 'canonical') { uri = link.href; } } return uri;}
/ * Return metadata for the current page. * * @return {HTMLDocumentMetadata} */ getDocumentMetadata() { / @type {HTMLDocumentMetadata} */ const metadata = { title: document.title, link: [],
dc: this._getMetaTags('name', 'dc.'), eprints: this._getMetaTags('name', 'eprints.'), facebook: this._getMetaTags('property', 'og:'), highwire: this._getMetaTags('name', 'citation_'), prism: this._getMetaTags('name', 'prism.'), twitter: this._getMetaTags('name', 'twitter:'), }; const favicon = this._getFavicon(); if (favicon) { metadata.favicon = favicon; } metadata.title = this._getTitle(metadata); metadata.link = this._getLinks(metadata); const dcLink = metadata.link.find(link => link.href.startsWith('urn:x-dc')); if (dcLink) { metadata.documentFingerprint = dcLink.href; } return metadata;}
/ * Return an array of all the
contentvalues of<meta>tags on the page * where the value of the attribute begins with<prefix>. * * @param {string} attribute * @param {string} prefix - it is interpreted as a regex * @return {Record<string,string[]>} */ _getMetaTags(attribute, prefix) { / @type {Record<string,string[]>} */ const tags = {}; for (let meta of Array.from(this.document.querySelectorAll('meta'))) { const name = meta.getAttribute(attribute); const { content } = meta; if (name && content) { const match = name.match(RegExp(^${prefix}(.+)$, 'i')); if (match) { const key = match[1].toLowerCase(); if (tags[key]) { tags[key].push(content); } else { tags[key] = [content]; } } } } return tags; }/* @param {HTMLDocumentMetadata} metadata / _getTitle(metadata) { if (metadata.highwire.title) { return metadata.highwire.title[0]; } else if (metadata.eprints.title) { return metadata.eprints.title[0]; } else if (metadata.prism.title) { return metadata.prism.title[0]; } else if (metadata.facebook.title) { return metadata.facebook.title[0]; } else if (metadata.twitter.title) { return metadata.twitter.title[0]; } else if (metadata.dc.title) { return metadata.dc.title[0]; } else { return this.document.title; } }
/ * Get document URIs from
<link>and<meta>elements on the page. * * @param {Pick<HTMLDocumentMetadata, 'highwire'|'dc'>} [metadata] - * Dublin Core and Highwire metadata parsed from<meta>tags. * @return {Link[]} */ _getLinks(metadata = { dc: {}, highwire: {} }) { / @type {Link[]} */ const links = [{ href: this._getDocumentHref() }];// Extract links from `<link>` tags with certain `rel` values. const linkElements = Array.from(this.document.querySelectorAll('link')); for (let link of linkElements) { if ( !['alternate', 'canonical', 'bookmark', 'shortlink'].includes(link.rel) ) { continue; } if (link.rel === 'alternate') { // Ignore RSS feed links. if (link.type && link.type.match(/^application\/(rss|atom)\+xml/)) { continue; } // Ignore alternate languages. if (link.hreflang) { continue; } } try { const href = this._absoluteUrl(link.href); links.push({ href, rel: link.rel, type: link.type }); } catch (e) { // Ignore URIs which cannot be parsed. } } // Look for links in scholar metadata for (let name of Object.keys(metadata.highwire)) { const values = metadata.highwire[name]; if (name === 'pdf_url') { for (let url of values) { try { links.push({ href: this._absoluteUrl(url), type: 'application/pdf', }); } catch (e) { // Ignore URIs which cannot be parsed. } } } // Kind of a hack to express DOI identifiers as links but it's a // convenient place to look them up later, and somewhat sane since // they don't have a type. if (name === 'doi') { for (let doi of values) { if (doi.slice(0, 4) !== 'doi:') { doi = `doi:${doi}`; } links.push({ href: doi }); } } } // Look for links in Dublin Core data for (let name of Object.keys(metadata.dc)) { const values = metadata.dc[name]; if (name === 'identifier') { for (let id of values) { if (id.slice(0, 4) === 'doi:') { links.push({ href: id }); } } } } // Look for a link to identify the resource in Dublin Core metadata const dcRelationValues = metadata.dc['relation.ispartof']; const dcIdentifierValues = metadata.dc.identifier; if (dcRelationValues && dcIdentifierValues) { const dcUrnRelationComponent = dcRelationValues[dcRelationValues.length - 1]; const dcUrnIdentifierComponent = dcIdentifierValues[dcIdentifierValues.length - 1]; const dcUrn = 'urn:x-dc:' + encodeURIComponent(dcUrnRelationComponent) + '/' + encodeURIComponent(dcUrnIdentifierComponent); links.push({ href: dcUrn }); } return links;}
_getFavicon() { let favicon = null; for (let link of Array.from(this.document.querySelectorAll('link'))) { if (['shortcut icon', 'icon'].includes(link.rel)) { try { favicon = this._absoluteUrl(link.href); } catch (e) { // Ignore URIs which cannot be parsed. } } } return favicon; }
/* * Convert a possibly relative URI to an absolute one. This will throw an * exception if the URL cannot be parsed. * * @param {string} url / _absoluteUrl(url) { return normalizeURI(url, this.document.baseURI); }
// Get the true URI record when it's masked via a different protocol. // This happens when an href is set with a uri using the 'blob:' protocol // but the document can set a different uri through a <base> tag. _getDocumentHref() { const { href } = this.document.location; const allowedSchemes = ['http:', 'https:', 'file:'];
// Use the current document location if it has a recognized scheme. const scheme = new URL(href).protocol; if (allowedSchemes.includes(scheme)) { return href; } // Otherwise, try using the location specified by the <base> element. if ( this.document.baseURI && allowedSchemes.includes(new URL(this.document.baseURI).protocol) ) { return this.document.baseURI; } // Fall back to returning the document URI, even though the scheme is not // in the allowed list. return href;} } ```
-
-
github.com github.com
-
yaml definitions: Annotation: type: object required: - user - uri properties: id: type: string description: Unique ID for this Annotation. uri: type: string description: URI which is the target of this Annotation. target: type: array items: - type: object properties: scope: type: array items: - type: string selector: type: array items: - type: object properties: type: description: Type of Selector--see Web Annotation Data Model. type: string source: type: string user: type: string description: User URI in the form of an `acct` prefixed URI. document: type: object description: Target document metadata schema: $ref: '#/definitions/DocumentMetadata' permissions: type: object description: Permissions for this Annotation. created: type: string format: date-time updated: type: string format: date-time AnnotationList: type: object properties: total: type: number rows: type: array items: $ref: '#/definitions/Annotation' DocumentMetadata: type: object properties: eprints: type: object title: type: string twitter: type: object properties: image:src: type: array items: type: string title: type: array items: type: string description: type: array items: type: string card: type: array items: type: string site: type: array items: type: string dc: type: object favicon: type: string prism: type: object highwire: type: object link: type: array items: type: object properties: href: type: string facebook: type: object properties: site_name: type: array items: type: string description: type: array items: type: string title: type: array items: type: string url: type: array items: type: string image: type: array items: type: string type: type: array items: type: string
-
-
worldwideweb.cern.ch worldwideweb.cern.ch
-
www.youtube.com www.youtube.com
Tags
Annotators
URL
-
-
digital-archaeology.org digital-archaeology.org
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
-
lider-project.eu lider-project.eu
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
-
Tags
Annotators
URL
-
-
www.programmableweb.com www.programmableweb.com
-
www.ischool.berkeley.edu www.ischool.berkeley.edu
-
stackoverflow.com stackoverflow.com
-
These are the key parameters.
prop=revisions&rvprop=content&rvsection=0rvsection = 0specifies to only return the lead section.
-
-
podcasts.apple.com podcasts.apple.com
-
hypothes.is hypothes.is
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
signed-exchange-testing.dev signed-exchange-testing.dev
-
-
developer.chrome.com developer.chrome.com
-
For creating SXGs for testing purposes, you can create a self-signed certificate and enable chrome://flags/#allow-sxg-certs-without-extension to have your Chrome process the SXGs created with the certificate without the special extension.
```html
<link rel="prefetch" href="https://your-site.com/sample.sxg" />
Sample ```
Tags
Annotators
URL
-
-
web.dev web.dev
-
-
wicg.github.io wicg.github.io
-
www.fun-mooc.fr www.fun-mooc.fr
-
-
schema.org schema.org
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
-
The clientHeight property returns the inner height of an element in pixels. The property includes padding but excludes borders, margins and horizontal scrollbars.Alternatively, you can use the offsetHeight property, which returns the height of the element in pixels, including vertical padding and borders.
```js useEffect(() => { setDivHeight(ref.current.offsetHeight); console.log('height: ', ref.current.offsetHeight);
console.log('width: ', ref.current.offsetWidth); }, []); ```
Tags
Annotators
URL
-
-
-
www.youtube.com www.youtube.comYouTube1
-
-
hypothes.is hypothes.is
-
-
www.youtube.com www.youtube.com
-
-
hypothes.is hypothes.is
-
-
github-did.com github-did.com
-
-
www.nasa.gov www.nasa.gov
Tags
Annotators
URL
-
-
pudding.cool pudding.cool
-
hypothes.is hypothes.is
-
-
musicbrainz.org musicbrainz.org
-
bash curl -H 'Accept: application/ld+json' https://musicbrainz.org/artist/20ff3303-4fe2-4a47-a1b6-291e26aa3438
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
soundcloud.com soundcloud.com
-
goldhiphop.pro goldhiphop.pro
-
-
hackernews.api-docs.io hackernews.api-docs.io
Tags
Annotators
URL
-
-
www.programmableweb.com www.programmableweb.com
Tags
Annotators
URL
-
-
www.programmableweb.com www.programmableweb.comReddit1
Tags
Annotators
URL
-
-
www.biostars.org www.biostars.org
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
felixgerschau.com felixgerschau.com
Tags
Annotators
URL
-
-
lavillette.com lavillette.com
-
jazzalavillette.com jazzalavillette.com
Tags
Annotators
URL
-
-
agrovoc.fao.org agrovoc.fao.org
Tags
Annotators
URL
-
-
www.fao.org www.fao.org
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
www.meteck.org www.meteck.org
Tags
Annotators
URL
-
-
people.cs.uct.ac.za people.cs.uct.ac.za
-
hypothes.is hypothes.is
-
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
-
www.france.tv www.france.tv
-
indieweb.org indieweb.org
Tags
Annotators
URL
-
-
ostatus.github.io ostatus.github.io
-
www.salmon-protocol.org www.salmon-protocol.org
-
aaronparecki.com aaronparecki.com
-
codeontime.com codeontime.com
-
-
-
stackoverflow.com stackoverflow.com
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
developer.twitter.com developer.twitter.com
-
If your site is using multiple widgets you can set up Twitter widgets in your pages once, which will make your site faster, and widgets such as embedded Tweets will be more reliable for authors when using content management systems.
```html
<script>window.twttr = (function(d, s, id) { var js, fjs = d.getElementsByTagName(s)[0], t = window.twttr || {}; if (d.getElementById(id)) return t; js = d.createElement(s); js.id = id; js.src = "https://platform.twitter.com/widgets.js"; fjs.parentNode.insertBefore(js, fjs); t._e = []; t.ready = function(f) { t._e.push(f); }; return t; }(document, "script", "twitter-wjs"));</script>```
-
-
stackoverflow.com stackoverflow.com
-
```js export function Tweet({ tweetID, }) { const tweetRef = useRef(null); const [isLoading, setIsLoading] = useState(true);
useEffect(() => { const tweetEl = tweetRef?.current if (window.twttr && tweetEl) (async() => { await window.twttr.ready(); await window.twttr.widgets.createTweet( tweetID, tweetEl, { align: 'center', conversation: 'none', dnt: true, } ); setIsLoading(false); console.log('Tweet loaded') })(); return () => { tweetEl?.remove(); } }, [tweetID, tweetRef]);
return ( <div ref={tweetRef} className="w-full bg-gray-100 h-fit animate-fadeIn" id={tweetID}> {isLoading &&
🐦
} </div> ); }; ```
-
-
Tags
Annotators
URL
-
-
rahuulmiishra.medium.com rahuulmiishra.medium.com
-
medium.com medium.com
-
soundcloud.com soundcloud.com
- Jul 2022
-
soundcloud.com soundcloud.comMorning1
-
soundcloud.com soundcloud.com
-
isamatov.com isamatov.com
Tags
Annotators
URL
-
-
kentcdodds.com kentcdodds.com
Tags
Annotators
URL
-
-
mathewlowry.medium.com mathewlowry.medium.com
-
A Solid Social Knowledge GraphBy networked these second brains together via the Fediverse, the MyHub.ai toolkit creates a distributed Social Knowledge Graph for each Hub Editor.
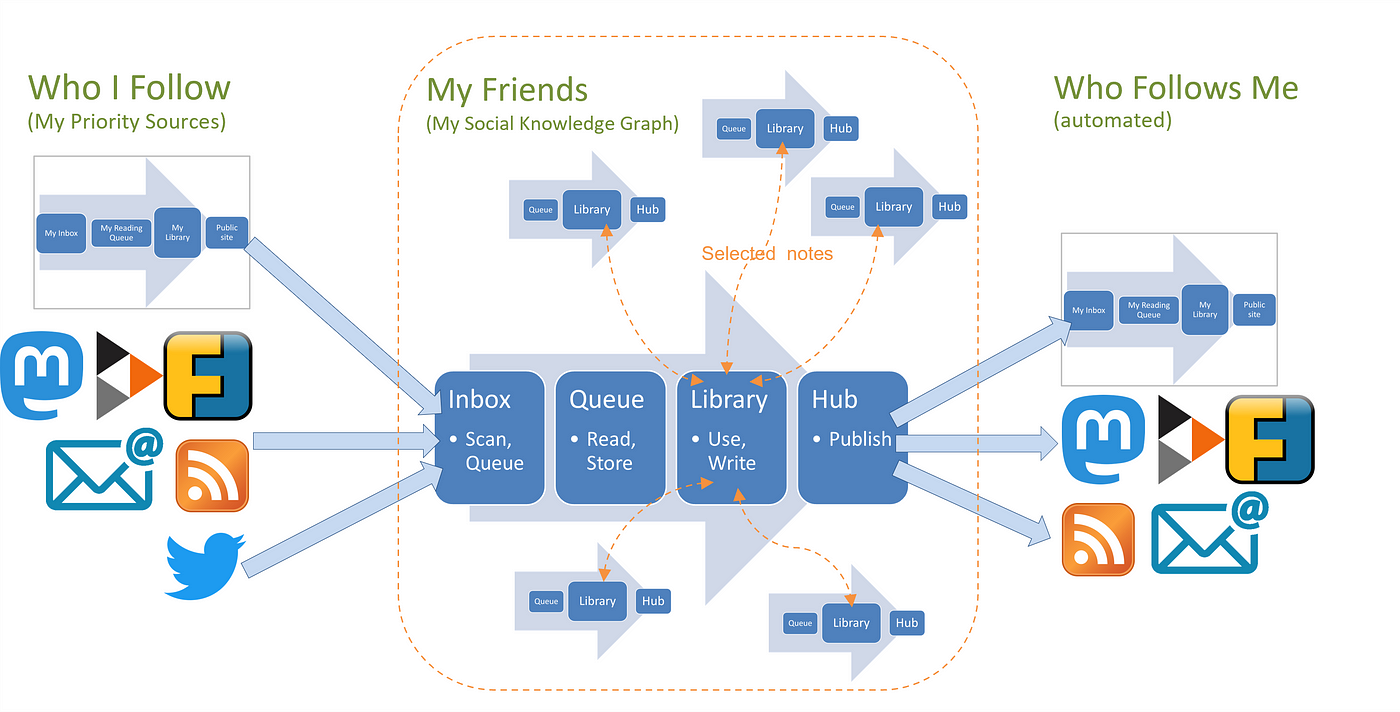
-
Your Hub’s CMS: a Thinking Management System for writersEach Hub’s content management system (CMS) is actually a “Thinking Management System”: a thinking tool based on a Personal Knowledge Graph (PKG) which is custom-designed to support thinking and writing.
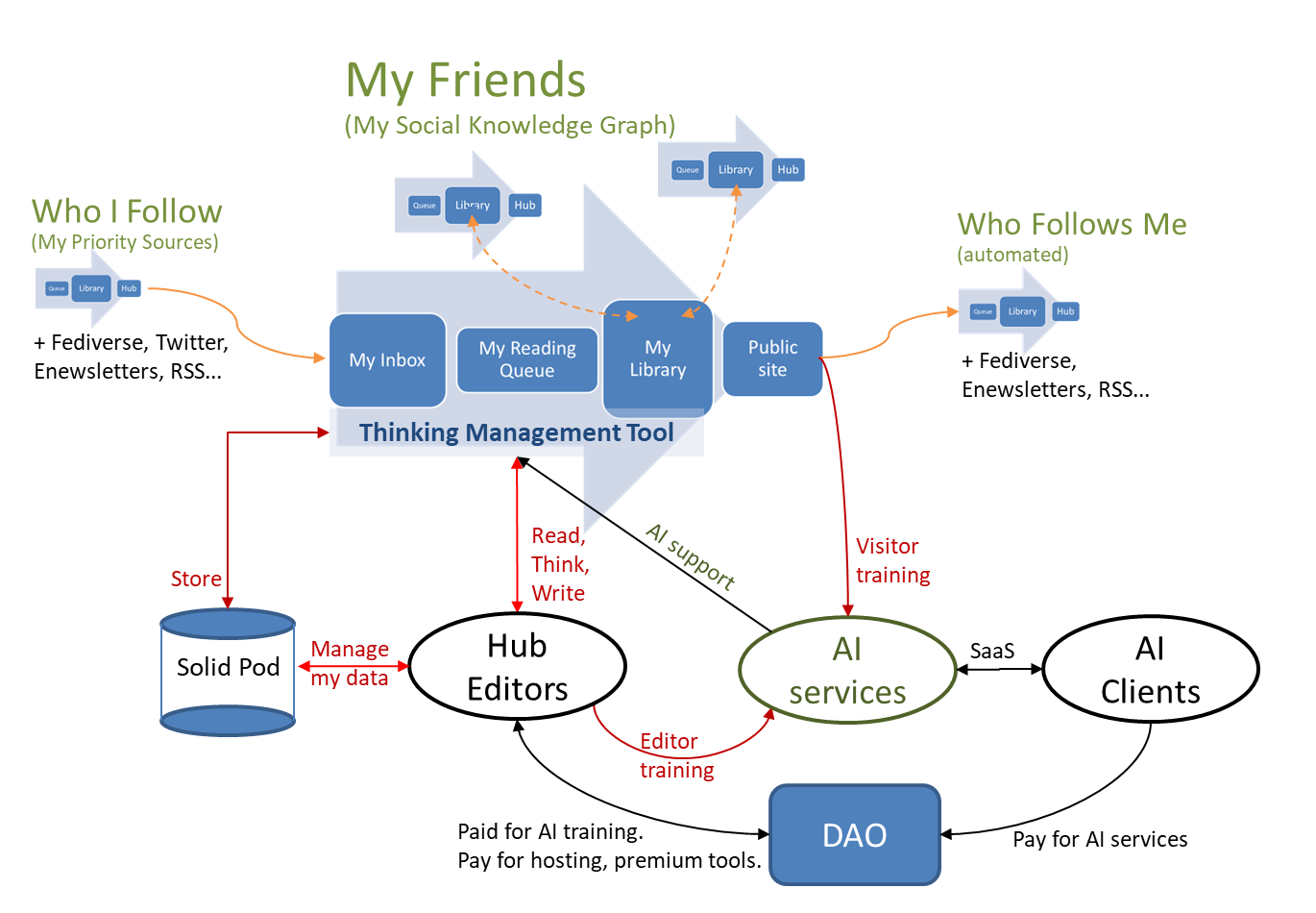
-
-
stackoverflow.com stackoverflow.com
-
```js const versions = [ { version: 1, data: 1}, { version: 3, data: 3}, { version: 17, data: 17}, { version: 95, data: 95} ];
function getNextVersion(v) { return versions.slice(0).reduceRight((a , b, i , arr) => b.version <= v ? (arr.length = 0, b) : b) } ```
-
-
soundcloud.com soundcloud.com
-
ricardometring.com ricardometring.com
-
Here's a complete function that removes accents, replaces special characters with hyphens, also removing additional hyphens:
```js const replaceSpecialChars = (str) => { return str.normalize('NFD').replace(/[\u0300-\u036f]/g, '') // Remove accents .replace(/([^\w]+|\s+)/g, '-') // Replace space and other characters by hyphen .replace(/--+/g, '-') // Replaces multiple hyphens by one hyphen .replace(/(^-+|-+$)/g, ''); // Remove extra hyphens from beginning or end of the string }
console.log(replaceSpecialChars('This is a sentence!!!')); ```
-
-
stackoverflow.com stackoverflow.com
-
```js function replaceDiacritics(s) { var s;
var diacritics =[ /[\300-\306]/g, /[\340-\346]/g, // A, a /[\310-\313]/g, /[\350-\353]/g, // E, e /[\314-\317]/g, /[\354-\357]/g, // I, i /[\322-\330]/g, /[\362-\370]/g, // O, o /[\331-\334]/g, /[\371-\374]/g, // U, u /[\321]/g, /[\361]/g, // N, n /[\307]/g, /[\347]/g, // C, c ];
var chars = ['A','a','E','e','I','i','O','o','U','u','N','n','C','c'];
for (var i = 0; i < diacritics.length; i++) { s = s.replace(diacritics[i],chars[i]); }
document.write(s); } ```
-
-
developer.mozilla.org developer.mozilla.org
-
hypothes.is hypothes.is
-
-
hypothes.is hypothes.is
-
-
hypothes.is hypothes.is
-
-
podcast.ausha.co podcast.ausha.co
-
notify.coar-repositories.org notify.coar-repositories.org
Tags
Annotators
URL
-
-
developers.cloudflare.com developers.cloudflare.com
-
perso.liris.cnrs.fr perso.liris.cnrs.fr
Tags
Annotators
URL
-
-
www.webtips.dev www.webtips.dev
Tags
Annotators
URL
-
-
www.yomo.run www.yomo.runYoMo1
-
-
web.dev web.dev
Tags
Annotators
URL
-
-
www.w3.org www.w3.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
-
datatracker.ietf.org datatracker.ietf.org
-
www.allocine.fr www.allocine.fr
-
www.youtube.com www.youtube.com
-
soundcloud.com soundcloud.com
-
www.w3.org www.w3.org
-
-
hearthis.at hearthis.at
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
dexie.org dexie.org
-
wellformedweb.org wellformedweb.org
-
```bash POST /news/comments/5 HTTP/1.1 Content-Type: text/xml
<item> <title>Foo Bar</title> <author>joe@bitworking.org</author> <link>http://www.bar.com/</link> <description>My Excerpt</description> </item> ```
-
-
stackoverflow.com stackoverflow.com
-
```js const dbName = 'CustomPeople';
const exists = await Dexie.exists(dbName);
if (exists) { var db = new Dexie(dbName); const dynamicDB = await db.open(); const existingVersionNumber = dynamicDB.verno; const columns = await ExternalDBService.getColumns(); db.close(); db = new Dexie(dbName); db.version(existingVersionNumber).stores({ People: columns }); return db.open(); } else { db = new Dexie(dbName); db.version(1).stores({ People: [] }); db.open(); } ```
-
-
tanstack.com tanstack.com
-
stackoverflow.com stackoverflow.com
-
```js function formatBytes(bytes, decimals = 2) { if (bytes === 0) return '0 Bytes';
const k = 1024; const dm = decimals < 0 ? 0 : decimals; const sizes = ['Bytes', 'KB', 'MB', 'GB', 'TB', 'PB', 'EB', 'ZB', 'YB']; const i = Math.floor(Math.log(bytes) / Math.log(k)); return parseFloat((bytes / Math.pow(k, i)).toFixed(dm)) + ' ' + sizes[i]; } ```
-
-
dexie.org dexie.org
-
-
developer.mozilla.org developer.mozilla.orgIDBIndex1
Tags
Annotators
URL
-
-
chowdera.com chowdera.com
Tags
Annotators
URL
-
-
www.bortzmeyer.org www.bortzmeyer.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
-
-
-
www.righto.com www.righto.com
-
hypothes.is hypothes.is
-
-
bbcmic.ro bbcmic.ro
-
-
-
-
archive.org archive.org
-
www.bbc.co.uk www.bbc.co.uk
-
fabricofparis.com fabricofparis.com
-
Tags
Annotators
URL
-
-
www.smashingmagazine.com www.smashingmagazine.com
-
developers.cloudflare.com developers.cloudflare.com
-
- Go to Settings > Network & internet.
- Select Advanced > Private DNS.
- Select the Private DNS provider hostname option.
- Enter
one.one.one.oneor1dot1dot1dot1.cloudflare-dns.comand press Save.
Tags
Annotators
URL
-
-
www.mesinspirationsculinaires.com www.mesinspirationsculinaires.com
-
cuisinezavecdjouza.fr cuisinezavecdjouza.fr
-
www.bmkparis.com www.bmkparis.com
Tags
Annotators
URL
-
-
developer.twitter.com developer.twitter.com
-
prim.iledefrance-mobilites.fr prim.iledefrance-mobilites.fr
Tags
Annotators
URL
-
-
developer.mozilla.org developer.mozilla.org
-
hypothes.is hypothes.is
-
-
fnp.huma-num.fr fnp.huma-num.fr
-
datatracker.ietf.org datatracker.ietf.org
-
-
```python doi_regexp = re.compile( r"(doi:\s|(?:https?://)?(?:dx.)?doi.org/)?(10.\d+(.\d+)/.+)$", flags=re.I ) """See http://en.wikipedia.org/wiki/Digital_object_identifier."""
handle_regexp = re.compile( r"(hdl:\s|(?:https?://)?hdl.handle.net/)?" r"([^/.]+(.[^/.]+)/.)$", flags=re.I ) """See http://handle.net/rfc/rfc3651.html. <Handle> = <NamingAuthority> "/" <LocalName> <NamingAuthority> = (<NamingAuthority> ".") <NAsegment> <NAsegment> = Any UTF8 char except "/" and "." <LocalName> = Any UTF8 char """
arxiv_post_2007_regexp = re.compile(r"(arxiv:)?(\d{4}).(\d{4,5})(v\d+)?$", flags=re.I) """See http://arxiv.org/help/arxiv_identifier and http://arxiv.org/help/arxiv_identifier_for_services."""
arxiv_pre_2007_regexp = re.compile( r"(arxiv:)?([a-z-]+)(.[a-z]{2})?(/\d{4})(\d+)(v\d+)?$", flags=re.I ) """See http://arxiv.org/help/arxiv_identifier and http://arxiv.org/help/arxiv_identifier_for_services."""
arxiv_post_2007_with_class_regexp = re.compile( r"(arxiv:)?(?:[a-z-]+)(?:.[a-z]{2})?/(\d{4}).(\d{4,5})(v\d+)?$", flags=re.I ) """Matches new style arXiv ID, with an old-style class specification; technically malformed, however appears in real data."""
hal_regexp = re.compile(r"(hal:|HAL:)?([a-z]{3}[a-z]*-|(sic|mem|ijn)_)\d{8}(v\d+)?$") """Matches HAL identifiers (sic mem and ijn are old identifiers form)."""
ads_regexp = re.compile(r"(ads:|ADS:)?(\d{4}[A-Za-z]\S{13}[A-Za-z.:])$") """See http://adsabs.harvard.edu/abs_doc/help_pages/data.html"""
pmcid_regexp = re.compile(r"PMC\d+$", flags=re.I) """PubMed Central ID regular expression."""
pmid_regexp = re.compile( r"(pmid:|https?://pubmed.ncbi.nlm.nih.gov/)?(\d+)/?$", flags=re.I ) """PubMed ID regular expression."""
ark_suffix_regexp = re.compile(r"ark:/[0-9bcdfghjkmnpqrstvwxz]+/.+$") """See http://en.wikipedia.org/wiki/Archival_Resource_Key and https://confluence.ucop.edu/display/Curation/ARK."""
lsid_regexp = re.compile(r"urn:lsid:[^:]+(:[^:]+){2,3}$", flags=re.I) """See http://en.wikipedia.org/wiki/LSID."""
orcid_urls = ["http://orcid.org/", "https://orcid.org/"]
gnd_regexp = re.compile( r"(gnd:|GND:)?(" r"(1|10)\d{7}[0-9X]|" r"[47]\d{6}-\d|" r"[1-9]\d{0,7}-[0-9X]|" r"3\d{7}[0-9X]" r")" ) """See https://www.wikidata.org/wiki/Property:P227."""
gnd_resolver_url = "http://d-nb.info/gnd/"
sra_regexp = re.compile(r"[SED]R[APRSXZ]\d+$") """Sequence Read Archive regular expression. See https://www.ncbi.nlm.nih.gov/books/NBK56913/#search.what_do_the_different_sra_accessi """
bioproject_regexp = re.compile(r"PRJ(NA|EA|EB|DB)\d+$") """BioProject regular expression. See https://www.ddbj.nig.ac.jp/bioproject/faq-e.html#project-accession https://www.ebi.ac.uk/ena/submit/project-format https://www.ncbi.nlm.nih.gov/bioproject/docs/faq/#under-what-circumstances-is-it-n """
biosample_regexp = re.compile(r"SAM(N|EA|D)\d+$") """BioSample regular expression. See https://www.ddbj.nig.ac.jp/biosample/faq-e.html https://ena-docs.readthedocs.io/en/latest/submit/samples/programmatic.html#accession-numbers-in-the-receipt-xml https://www.ncbi.nlm.nih.gov/biosample/docs/submission/faq/ """
ensembl_regexp = re.compile( r"({prefixes})(E|FM|G|GT|P|R|T)\d{{11}}$".format( prefixes="|".join(ENSEMBL_PREFIXES) ) ) """Ensembl regular expression. See https://asia.ensembl.org/info/genome/stable_ids/prefixes.html """
uniprot_regexp = re.compile( r"([A-NR-Z]0-9{1,2})|" r"([OPQ][0-9][A-Z0-9]{3}[0-9])(.\d+)?$" ) """UniProt regular expression. See https://www.uniprot.org/help/accession_numbers """
refseq_regexp = re.compile( r"((AC|NC|NG|NT|NW|NM|NR|XM|XR|AP|NP|YP|XP|WP)|" r"NZ[A-Z]{4})\d+(.\d+)?$" ) """RefSeq regular expression. See https://academic.oup.com/nar/article/44/D1/D733/2502674 (Table 1) """
genome_regexp = re.compile(r"GC[AF]_\d+.\d+$") """GenBank or RefSeq genome assembly accession. See https://www.ebi.ac.uk/ena/browse/genome-assembly-database """
geo_regexp = re.compile(r"G(PL|SM|SE|DS)\d+$") """Gene Expression Omnibus (GEO) accession. See https://www.ncbi.nlm.nih.gov/geo/info/overview.html#org """
arrayexpress_array_regexp = re.compile( r"A-({codes})-\d+$".format(codes="|".join(ARRAYEXPRESS_CODES)) ) """ArrayExpress array accession. See https://www.ebi.ac.uk/arrayexpress/help/accession_codes.html """
arrayexpress_experiment_regexp = re.compile( r"E-({codes})-\d+$".format(codes="|".join(ARRAYEXPRESS_CODES)) ) """ArrayExpress array accession. See https://www.ebi.ac.uk/arrayexpress/help/accession_codes.html """
ascl_regexp = re.compile(r"^ascl:[0-9]{4}.[0-9]{3,4}$", flags=re.I) """ASCL regular expression."""
swh_regexp = re.compile( r"swh:1:(cnt|dir|rel|rev|snp):[0-9a-f]{40}" r"(;(origin|visit|anchor|path|lines)=\S+)*$" ) """Matches Software Heritage identifiers."""
ror_regexp = re.compile(r"(?:https?://)?(?:ror.org/)?(0\w{6}\d{2})$", flags=re.I) """See https://ror.org/facts/#core-components.""" ```
-
-
www.youtube.com www.youtube.com
-
developer.chrome.com developer.chrome.com
-
wicg.github.io wicg.github.io
Tags
Annotators
URL
-
-
stackoverflow.com stackoverflow.com
