The Library Bookshelves plugin allows you to curate virtual bookshelves just like you would a shelf around a theme in your library. Bookshelves are displayed as customizable Slick carousels, using cover art from, and links to, your library catalog. The plugin creates a Bookshelves post type, shortcode, widget, and custom taxonomy.
8,037 Matching Annotations
- May 2022
-
sl.wordpress.org sl.wordpress.org
-
-
sl.wordpress.org sl.wordpress.org
-
www.wordpresspluginfinder.com www.wordpresspluginfinder.com
-
The plugin convert content of your blog posts and pages to most popular e-book formats for readers – pdf, ePub, mobi and fb2, using php-librasries: mPDF; PHPePub; MOBIClass; bgFB2. Plugin displays a icons form for download converted files before and/or after content on your blog pages. You can create OPDS catalogue on your site with this plugin, if you enable the option. OPDS catalog support the file-types: 'epub', 'fb2', 'pdf', 'mobi', 'zip', 'rtf', 'doc', 'docx', 'htm', 'html', 'txt', 'djvu', 'mp3', 'm4a', 'm4b'.
Q.: How can users access the OPDS catalogue?
A.: OPDS catalogue URL
http://yoursite.com/feed/opds.
-
-
blog.front-matter.io blog.front-matter.io
-
I’m looking forward to the first scholarly publisher that not only provides ePub files of his journal articles, but also makes them available via OPDS. Although OPDS is currently used mostly for electronic books, I think that this is a very interesting protocol for scholarly publishers.
-
-
specs.opds.io specs.opds.io
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.comYouTube1
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
cataloguebm.villeurbanne.fr cataloguebm.villeurbanne.fr
-
-
catalogue.bpi.fr catalogue.bpi.fr
-
bibliotheques-specialisees.paris.fr bibliotheques-specialisees.paris.fr
Tags
Annotators
URL
-
-
www.thoughtco.com www.thoughtco.com
-
thecodebarbarian.com thecodebarbarian.com
-
With some extra work, you can download the entire text version of Moby-Dick from Project Gutenberg using Axios.
```js const axios = require('axios'); const epub = require('epub-gen');
axios.get('http://www.gutenberg.org/files/2701/2701-0.txt'). then(res => res.data). then(text => { text = text.slice(text.indexOf('EXTRACTS.')); text = text.slice(text.indexOf('CHAPTER 1.'));
const lines = text.split('\r\n'); const content = []; for (let i = 0; i < lines.length; ++i) { const line = lines[i]; if (line.startsWith('CHAPTER ')) { if (content.length) { content[content.length - 1].data = content[content.length - 1].data.join('\n'); } content.push({ title: line, data: ['<h2>' + line + '</h2>'] }); } else if (line.trim() === '') { if (content[content.length - 1].data.length > 1) { content[content.length - 1].data.push('</p>'); } content[content.length - 1].data.push('<p>'); } else { content[content.length - 1].data.push(line); } } const options = { title: 'Moby-Dick', author: 'Herman Melville', output: './moby-dick.epub', content }; return new epub(options).promise;}). then(() => console.log('Done')); ```
-
-
www.edrlab.org www.edrlab.org
Tags
Annotators
URL
-
-
idpf.org idpf.org
-
-
www.w3.org www.w3.orgEPUB 3.21
Tags
Annotators
URL
-
-
idpf.org idpf.org
-
This specification, Open Annotation in EPUB, defines a profile of the W3C Open Annotation specification [OpenAnnotation] for the creation, distribution and rendering of annotations for EPUB® Publications.
This appendix is informative
All examples use the same hypothetical publication of Alice in Wonderland, and are given in the collection structure with a single annotation.
-
Commentary Annotation on Publication with URI
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@id": "http://www.example.org/ebooks/A1B0D67E-2E81-4DF5/v2.epub", "@type": "dctypes:Text" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Commentary Annotation on Publication without Identifying URI
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Collection Metadata
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "dc:title": "Alice in Wonderland Annotations", "dc:publisher": "Example Organization", "dc:creator": "Anne O'Tater", "dcterms:modified": "2014-03-17T12:30:00Z", "dc:description": "Anne's collection of annotations on Alice in Wonderland", "dc:rights": [ { "@value": "Quelques droits en Français", "@language": "fr" }, { "@value": "Some Rights in English", "@language": "en" } ], "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] } -
Annotation with Ancillary Resources in the Zip
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "hasTarget": { "@type": "oa:SpecificResource", "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" } }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love Alice in Wonderland! <img src='/imgs/heart.jpg'/></div>" }, "motivatedBy": "oa:commenting" } ] } -
Styling of Selection
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "@type": "oa:Annotation", "styledBy": { "@type": "oa:CssStyle", "format": "text/css", "chars": ".red { border: 1px solid red; }" }, "hasTarget": { "@type": "oa:SpecificResource", "hasSelector": { "@type": "oa:FragmentSelector", "value": "epubcfi(/6/4[chap01ref]!/4[body01]/10[para05]/3:10)" }, "hasSource": { "@type": "dctypes:Text", "uniqueIdentifier": "isbn:123456789x", "originURL": "http://www.example.com/publisher/book/", "dc:identifier": "urn:uuid:A1B0D67E-2E81-4DF5-9E67-A64CBE366809", "dcterms:modified": "2011-01-01T12:00:00Z" }, "styleClass": "red" }, "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<div xml:lang='en' xmlns='http://www.w3.org/1999/xhtml'>I love this part of the text</div>", "language": "en" }, "motivatedBy": "oa:commenting" } ] }- Replying to an Annotation
json-ld { "@context": "http://www.idpf.org/epub/oa/1.0/context.json", "@id": "http://example.org/epub/annotations.json", "@type": "epub:AnnotationCollection", "annotations": [ { "@id": "urn:uuid:B81AF8C4-B04A-4D3D-B1D3-23F7C02E56BB", "@type": "oa:Annotation", "motivatedBy": "oa:replying", "hasTarget": "urn:uuid:E7E3799F-3CD5-4F69-87C6-5478B22873D6", "hasBody": { "@type": "dctypes:Text", "format": "application/xhtml+xml", "chars": "<span xmlns='http://www.w3.org/1999/xhtml'>I agree!</span>" } } ] }
-
-
-
dev.to dev.to
-
Say hello to the sassy new Media Queries!
js const html = document.getElementsByTagName('html')[0]; const toggleTheme = (theme) => { html.dataset.theme = theme; }html <script> // If `prefers-color-scheme` is not supported, fall back to light mode. // In this case, light.css will be downloaded with `highest` priority. if (window.matchMedia('(prefers-color-scheme: dark)').media === 'not all') { document.documentElement.style.display = 'none'; document.head.insertAdjacentHTML( 'beforeend', '<link rel="stylesheet" href="/light.css" onload="document.documentElement.style.display = \'\'">' ); } </script> <!-- Conditionally either load the light or the dark stylesheet. The matching file will be downloaded with `highest`, the non-matching file with `lowest` priority. If the browser doesn't support `prefers-color-scheme`, the media query is unknown and the files are downloaded with `lowest` priority (but above I already force `highest` priority for my default light experience). --> <link rel="stylesheet" href="/dark.css" media="(prefers-color-scheme: dark)"> <link rel="stylesheet" href="/light.css" media="(prefers-color-scheme: light)"> <!-- The main stylesheet --> <link rel="stylesheet" href="/style.css">html <img src="./sun.svg" data-light-src="./sun.svg" data-dark-src="./moon.svg" alt="light theme" id="theme-selector" onclick="switchTheme(this)">
Tags
Annotators
URL
-
-
dev.to dev.to
-
The only catch with this method is, it will also invert all the images in your application. So we will add the same rule to all images to reverse the effect.
css html[theme='dark-mode'] img{ filter: invert(1) hue-rotate(180deg); }and we will also add a transition to the HTML element to make sure the transition does not become flashy!css html { transition: color 300ms, background-color 300ms; }
Tags
Annotators
URL
-
-
les-ateliers-du-web-semantique.gitpages.huma-num.fr les-ateliers-du-web-semantique.gitpages.huma-num.fr
-
www.pangaea.de www.pangaea.de
-
bash $ curl -I 'https://doi.pangaea.de/10.1594/PANGAEA.944307' HTTP/2 200 server: nginx/1.21.6 date: Tue, 17 May 2022 22:20:09 GMT content-type: text/html;charset=utf-8 content-length: 49033 Path=/; Domain=.pangaea.de; Secure; HttpOnly vary: Cookie, Authorization, Accept cache-control: public x-cid: 46ac5408249e9724e81cb2964e712475 link: <https://doi.pangaea.de/10.1594/PANGAEA.944307>;rel="cite-as", <https://doi.pangaea.de/10.1594/PANGAEA.944307?format=zip>;rel="item";type="application/zip", <https://orcid.org/0000-0001-6414-6293>;rel="author", <https://orcid.org/0000-0002-8923-0827>;rel="author", <https://orcid.org/0000-0001-9823-1373>;rel="author", <https://orcid.org/0000-0002-6512-0770>;rel="author"```bash $ curl -H 'Accept: application/ld+json' 'https://doi.pangaea.de/10.1594/PANGAEA.944307' | jq '.'{ "@context": "http://schema.org/", "@type": "Dataset", "url": "https://doi.pangaea.de/10.1594/PANGAEA.944307", "creator": [ { "@type": "Person", "name": "Sergio Trias-Navarro", "familyName": "Trias-Navarro", "givenName": "Sergio", "email": "sergio.trias@unipa.it" }, { "@type": "Person", "name": "Maria de la Fuente", "familyName": "de la Fuente", "givenName": "Maria", "email": "mdelafuente@ub.edu" }, { "@id": "https://orcid.org/0000-0001-6414-6293", "@type": "Person", "name": "Leopoldo D Pena", "familyName": "Pena", "givenName": "Leopoldo D", "identifier": "https://orcid.org/0000-0001-6414-6293", "email": "lpena@ub.edu" }, { "@id": "https://orcid.org/0000-0002-8923-0827", "@type": "Person", "name": "Jaime Frigola", "familyName": "Frigola", "givenName": "Jaime", "identifier": "https://orcid.org/0000-0002-8923-0827", "email": "jfrigola@ub.edu" }, { "@id": "https://orcid.org/0000-0001-9823-1373", "@type": "Person", "name": "Antonio Caruso", "familyName": "Caruso", "givenName": "Antonio", "identifier": "https://orcid.org/0000-0001-9823-1373", "email": "antonio.caruso@unipa.it" }, { "@id": "https://orcid.org/0000-0002-6512-0770", "@type": "Person", "name": "Isabel Cacho", "familyName": "Cacho", "givenName": "Isabel", "identifier": "https://orcid.org/0000-0002-6512-0770", "email": "icacho@ub.edu" }, { "@type": "Person", "name": "Fabrizio Lirer", "familyName": "Lirer", "givenName": "Fabrizio", "email": "fabrizio.lirer@uniroma1.it" } ], "name": "Surface hydrology characterization at western flank of Sicily Channel during the last 15 kyr BP, through planktic foraminifera ecology, stable oxygen isotopes and elemental geochemical measurements", "publisher": { "@type": "Organization", "name": "PANGAEA", "disambiguatingDescription": "Data Publisher for Earth & Environmental Science", "url": "https://www.pangaea.de/" }, "includedInDataCatalog": { "@type": "DataCatalog", "name": "PANGAEA", "disambiguatingDescription": "Data Publisher for Earth & Environmental Science", "url": "https://www.pangaea.de/" }, "datePublished": "2022-05-16", "description": "In this study, we present a new detailed characterization of past surface hydrography in the western edge of the Sicily channel in order to identify potential variations in the water exchange between the western and eastern Mediterranean sub-basins through the Sicily channel. For this purpose, we use a sediment core currently located in the main pathway of the Modified Atlantic Surface Water (MAW) towards the Strait of Sicily. Here we present a multi-proxy approach combining planktic foraminifera ecology with δ18O records of Globigerina bulloides as well as Globigerinoides ruber and with elemental geochemical measurements as Ti/Al, K/Al, Ba/Ti.", "abstract": "In this study, we present a new detailed characterization of past surface hydrography in the western edge of the Sicily channel in order to identify potential variations in the water exchange between the western and eastern Mediterranean sub-basins through the Sicily channel. For this purpose, we use a sediment core currently located in the main pathway of the Modified Atlantic Surface Water (MAW) towards the Strait of Sicily. Here we present a multi-proxy approach combining planktic foraminifera ecology with δ18O records of Globigerina bulloides as well as Globigerinoides ruber and with elemental geochemical measurements as Ti/Al, K/Al, Ba/Ti.", "citation": { "@id": "https://doi.org/10.1016/j.gloplacha.2021.103582", "@type": [ "CreativeWork", "PublicationIssue" ], "identifier": "https://doi.org/10.1016/j.gloplacha.2021.103582", "url": "https://doi.org/10.1016/j.gloplacha.2021.103582", "creator": [ { "@type": "Person", "name": "Sergio Trias-Navarro", "familyName": "Trias-Navarro", "givenName": "Sergio", "email": "sergio.trias@unipa.it" }, { "@id": "https://orcid.org/0000-0002-6512-0770", "@type": "Person", "name": "Isabel Cacho", "familyName": "Cacho", "givenName": "Isabel", "identifier": "https://orcid.org/0000-0002-6512-0770", "email": "icacho@ub.edu" }, { "@type": "Person", "name": "Maria de la Fuente", "familyName": "de la Fuente", "givenName": "Maria", "email": "mdelafuente@ub.edu" }, { "@id": "https://orcid.org/0000-0001-6414-6293", "@type": "Person", "name": "Leopoldo D Pena", "familyName": "Pena", "givenName": "Leopoldo D", "identifier": "https://orcid.org/0000-0001-6414-6293", "email": "lpena@ub.edu" }, { "@id": "https://orcid.org/0000-0002-8923-0827", "@type": "Person", "name": "Jaime Frigola", "familyName": "Frigola", "givenName": "Jaime", "identifier": "https://orcid.org/0000-0002-8923-0827", "email": "jfrigola@ub.edu" }, { "@type": "Person", "name": "Fabrizio Lirer", "familyName": "Lirer", "givenName": "Fabrizio", "email": "fabrizio.lirer@uniroma1.it" }, { "@id": "https://orcid.org/0000-0001-9823-1373", "@type": "Person", "name": "Antonio Caruso", "familyName": "Caruso", "givenName": "Antonio", "identifier": "https://orcid.org/0000-0001-9823-1373", "email": "antonio.caruso@unipa.it" } ], "name": "Surface hydrographic changes at the western flank of the Sicily Channel associated with the last sapropel", "datePublished": "2021", "issueNumber": "204", "pagination": "103582", "isPartOf": { "@type": "CreativeWorkSeries", "name": "Global and Planetary Change" } }, "spatialCoverage": { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 38.007388999999996, "longitude": 11.795789000000005 } }, "temporalCoverage": "2016-06-25T05:19:44", "inLanguage": "en", "conditionsOfAccess": "access rights needed", "isAccessibleForFree": false, "keywords": "elemental geochemistry; Mediterranean Sea; planktic foraminifera; Sicily Channel; stable oxygen isotopes", "size": { "@type": "QuantitativeValue", "value": 4, "unitText": "datasets" }, "distribution": { "@type": "DataDownload", "encodingFormat": "application/zip", "contentUrl": "https://doi.pangaea.de/10.1594/PANGAEA.944307?format=zip" } } ```
-
-
xkcd.com xkcd.com
-
-
mappings.dbpedia.org mappings.dbpedia.org
Tags
Annotators
URL
-
-
mappings.dbpedia.org mappings.dbpedia.orgOntology1
Tags
Annotators
URL
-
-
scigraph.springernature.com scigraph.springernature.com
-
bash $ curl -H 'Accept: application/ld+json' 'https://scigraph.springernature.com/pub.10.1007/978-0-387-89976-3_10' { "@context": "https://springernature.github.io/scigraph/jsonld/sgcontext.json", "about": [ { "id": "http://purl.org/au-research/vocabulary/anzsrc-for/2008/08", "inDefinedTermSet": "http://purl.org/au-research/vocabulary/anzsrc-for/2008/", "name": "Information and Computing Sciences", "type": "DefinedTerm" }, { "id": "http://purl.org/au-research/vocabulary/anzsrc-for/2008/0806", "inDefinedTermSet": "http://purl.org/au-research/vocabulary/anzsrc-for/2008/", "name": "Information Systems", "type": "DefinedTerm" } ], "author": [ { "affiliation": { "alternateName": "Counseling, Educational, Psychology, and Special Education Department, Michigan State University, 461 Erickson Hall, 48824-1034, East Lansing, MI, USA", "id": "http://www.grid.ac/institutes/grid.17088.36", "name": [ "Counseling, Educational, Psychology, and Special Education Department, Michigan State University, 461 Erickson Hall, 48824-1034, East Lansing, MI, USA" ], "type": "Organization" }, "familyName": "Reckase", "givenName": "Mark D.", "id": "sg:person.01166264366.27", "sameAs": [ "https://app.dimensions.ai/discover/publication?and_facet_researcher=ur.01166264366.27" ], "type": "Person" } ], "datePublished": "2009-05-22", "datePublishedReg": "2009-05-22", "description": "Computerized adaptive testing (CAT) is a methodology for constructing a test, administering it to an examinee, and scoring the test using interactive computer technology. This methodology has a history that is as long as that of interactive computing. An early summary of CAT methods is given in Weiss (1974). A detailed description of the development of an operational application for the Armed Services Vocational Aptitude Battery is given in (Sands 1997). There are also several books available that describe the basic components of CAT procedures (Wainer, Dorans, Flaugher, Green, Mislevy, Steinberg and Thissen 1990; Parshall, Spray and Davey 2002; van der Linden and Glas 2000) so the basic details of the methodology are not presented here. A review of that literature will show that most of the current CAT methodology is based on the assumption that a unidimensional IRT model accurately represents the interaction between persons and test items. In this chapter, the generalization of the CAT methodology to the multidimensional case is considered. To provide a framework for this material, a brief summary of the conceptual basis for CAT is provided.", "genre": "chapter", "id": "sg:pub.10.1007/978-0-387-89976-3_10", "inLanguage": "en", "isAccessibleForFree": false, "isPartOf": { "isbn": [ "978-0-387-89975-6", "978-0-387-89976-3" ], "name": "Multidimensional Item Response Theory", "type": "Book" }, "keywords": [ "interactive computing", "computer technology", "interactive computer technology", "computerized adaptive testing", "Armed Services Vocational Aptitude Battery", "adaptive testing", "operational applications", "basic components", "computing", "unidimensional IRT model", "CAT methodology", "methodology", "test items", "IRT models", "CAT procedure", "technology", "basic details", "framework", "detailed description", "applications", "conceptual basis", "multidimensional case", "generalization", "testing", "examinees", "model", "items", "method", "description", "brief summary", "detail", "persons", "MIRT", "batteries", "test", "CAT method", "components", "assumption", "development", "chapter", "summary", "basis", "literature", "book", "procedure", "interaction", "Weiss", "cases", "review", "history", "materials", "Earlier summaries" ], "name": "Computerized Adaptive Testing Using MIRT", "pagination": "311-339", "productId": [ { "name": "dimensions_id", "type": "PropertyValue", "value": [ "pub.1046349288" ] }, { "name": "doi", "type": "PropertyValue", "value": [ "10.1007/978-0-387-89976-3_10" ] } ], "publisher": { "name": "Springer Nature", "type": "Organisation" }, "sameAs": [ "https://doi.org/10.1007/978-0-387-89976-3_10", "https://app.dimensions.ai/details/publication/pub.1046349288" ], "sdDataset": "chapters", "sdDatePublished": "2022-05-10T10:51", "sdLicense": "https://scigraph.springernature.com/explorer/license/", "sdPublisher": { "name": "Springer Nature - SN SciGraph project", "type": "Organization" }, "sdSource": "s3://com-springernature-scigraph/baseset/20220509/entities/gbq_results/chapter/chapter_412.jsonl", "type": "Chapter", "url": "https://doi.org/10.1007/978-0-387-89976-3_10" }
Tags
Annotators
URL
-
-
scigraph.springernature.com scigraph.springernature.com
-
schema:ScholarlyArticle is used to describe journal articles; schema:Chapter is used to describe book chapters; schema:Book is used to describe books; schema:Periodical is used to describe journals; schema:Person is used to describe researchers (e.g. authors, editors, grant recipients) schema:MonetaryGrant is used to describe awarded research grants; schema:MedicalStudy is used to describe clinical trials; sgo:Patent is used to describe patents.

-
-
rdfdictionary.sourceforge.net rdfdictionary.sourceforge.net
Tags
Annotators
URL
-
-
www.legislation.gov.uk www.legislation.gov.uk
Tags
Annotators
URL
-
-
www.legislation.gov.uk www.legislation.gov.uk
-
If you are using RDFa within your pages, you can use the resource attribute to indicate that you are linking to a piece of legislation while including a link to another source of information. For example,
html The <a rel="cite" resource="http://www.legislation.gov.uk/id/ukpga/1999/17" href="http://en.wikipedia.org/wiki/Disability_Rights_Commission_Act_1999">Disability Rights Commission Act 1999</a> replaced the National Disability Council with the Disability Rights Commission (DRC).will generate the triple<> xhv:cite <http://www.legislation.gov.uk/id/ukpga/1999/17>
Tags
Annotators
URL
-
-
eur-lex.europa.eu eur-lex.europa.eu
-
eur-lex.europa.eu eur-lex.europa.eu
Tags
Annotators
URL
-
-
webgate.ec.europa.eu webgate.ec.europa.eu
Tags
Annotators
URL
-
-
www.metalex.eu www.metalex.eu
-
-
schema.org schema.org
Tags
Annotators
URL
-
-
about.workflowhub.eu about.workflowhub.eu
Tags
Annotators
URL
-
-
wttr.in wttr.in
-
biu-cujas.univ-paris1.fr biu-cujas.univ-paris1.fr
Tags
Annotators
URL
-
-
theodi.org theodi.org
-
The simplest way to publish a description of your dataset is to publish DCAT metadata using RDFa. RDFa allows machine-readable metadata to be embedded in a webpage. This means that publishing your dataset metadata can be easily achieved by updating the HTML for your dataset homepage.
```html
<html prefix="dct: http://purl.org/dc/terms/ rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# dcat: http://www.w3.org/ns/dcat# foaf: http://xmlns.com/foaf/0.1/"> <head> <title>DCAT in RDFa</title> </head> <br /> <body> <div typeof="dcat:Dataset" resource="http://gov.example.org/dataset/finances">
Example DCAT Dataset
25th October 2010
10th March 2013
This is the description.
<div property="dct:license" resource="http://reference.data.gov.uk/id/open-government-licence"> <span property="dct:title">UK Open Government Licence (OGL)</span> </div> <div property="dct:publisher" resource="http://example.org/publisher"> <span property="foaf:name">Example Publisher</span> </div> <div> <span property="dcat:keyword">Examples</span>, <span property="dcat:keyword">DCAT</span> </div> <div> Weekly </div> <div property='dcat:distribution' typeof='dcat:Distribution'> <span property="dct:title">CSV download</span>
- Format <span content='text/csv' property='dcat:mediaType'>CSV</span>
- Size <span content='240585277' datatype='xsd:decimal' property='dcat:byteSize'>1024MB</span>
- Issues <span property='dct:issued'>2012-01-01</span>
</html> ```
Tags
Annotators
URL
-
-
javascript.plainenglish.io javascript.plainenglish.io
-
resources.data.gov resources.data.gov
Tags
Annotators
URL
-
-
resources.data.gov resources.data.gov
Tags
Annotators
URL
-
-
www.slideshare.net www.slideshare.net
-
www.slideshare.net www.slideshare.net
-
www.slideshare.net www.slideshare.net
Tags
Annotators
URL
-
-
semiceu.github.io semiceu.github.io
-
Abstract GeoDCAT-AP is an extension of the DCAT application profile for data portals in Europe (DCAT-AP) for describing geospatial datasets, dataset series, and services. Its basic use case is to make spatial datasets, dataset series, and services searchable on general data portals, thereby making geospatial information better findable across borders and sectors. For this purpose, GeoDCAT-AP provides an RDF vocabulary and the corresponding RDF syntax binding for the union of metadata elements of the core profile of ISO 19115:2003 and those defined in the framework of the INSPIRE Directive of the European Union.
Tags
Annotators
URL
-
-
inspire.ec.europa.eu inspire.ec.europa.eu
Tags
Annotators
URL
-
-
data.bnf.fr data.bnf.fr
Tags
Annotators
URL
-
-
data.bnf.fr data.bnf.fr
Tags
Annotators
URL
-
-
www.bnf.fr www.bnf.fr
Tags
Annotators
URL
-
-
triplydb.com triplydb.com
-
-
triplydb.com triplydb.com
-
DCAT is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web. This document defines the schema and provides examples for its use. DCAT enables a publisher to describe datasets and data services in a catalog using a standard model and vocabulary that facilitates the consumption and aggregation of metadata from multiple catalogs. This can increase the discoverability of datasets and data services. It also makes it possible to have a decentralized approach to publishing data catalogs and makes federated search for datasets across catalogs in multiple sites possible using the same query mechanism and structure. Aggregated DCAT metadata can serve as a manifest file as part of the digital preservation process.
-
-
doc.data.gouv.fr doc.data.gouv.frDCAT1
Tags
Annotators
URL
-
-
data.culture.fr data.culture.fr
Tags
Annotators
URL
-
-
skos-play.sparna.fr skos-play.sparna.fr
Tags
Annotators
URL
-
-
skos.um.es skos.um.es
Tags
Annotators
URL
-
-
opds-validator.appspot.com opds-validator.appspot.com
Tags
Annotators
URL
-
-
lov.linkeddata.es lov.linkeddata.es
Tags
Annotators
URL
-
-
jmvanel.free.fr jmvanel.free.fr
-
2014-07-15 <jmvanel> Hi I wonder if there is a vocab' for bug reports and enhancement requests ( probably in relation with DOAP) <tobyink> jmvanel: http://ontologi.es/doap-bugs <jmvanel> Thanks tobyink ; added in http://prefix.cc/dbug Asked on ##linux Hi I'd like a tool to watch a directory and record the file sizes and timestamps , so that later I can draw a plot of my activity <vlt> jmvanel: inotify tools <jmvanel> thanks , vlt ; that's rather low level , but can be certainly used ... overbusy today with my Specifications for semantic hosting
Tags
Annotators
URL
-
-
github.com github.com
-
We use the Web Annotation Protocol to sync bookmarks and last reading position across devices. At a glance it covers all the use cases here, and it's a well-defined protocol with multiple independent implementations. In particular, WAP defines a relation for discovery. Here's how we link to the annotation endpoint for a specific book in an OPDS 1.2 feed. Note the distinctive link relation and media type:
xml <link href="https://circulation.librarysimplified.org/NYNYPL/annotations/Gutenberg%20ID/40278/" type="application/ld+json; profile="http://www.w3.org/ns/anno.jsonld"" rel="http://www.w3.org/ns/oa#annotationService"/>
-
-
hypothes.is hypothes.is
-
-
developer.twitter.com developer.twitter.com
-
www.bnf.fr www.bnf.fr
-
www.slideshare.net www.slideshare.net
-
signposting.org signposting.org
-
Signposting is an approach to make the scholarly web more friendly to machines. It uses Typed Links as a means to clarify patterns that occur repeatedly in scholarly portals. For resources of any media type, these typed links are provided in HTTP Link headers. For HTML resources, they may additionally be provided in HTML link elements. Throughout this site, examples use the former approach.
http HTTP/1.1 302 Found Server: Apache-Coyote/1.1 Vary: Accept Location: http://www.dlib.org/dlib/november15/vandesompel/11vandesompel.html Link: <http://orcid.org/0000-0002-0715-6126> ; rel="author", <http://orcid.org/0000-0003-3749-8116> ; rel="author" Expires: Tue, 31 May 2016 17:18:50 GMT Content-Type: text/html;charset=utf-8 Content-Length: 217 Date: Tue, 31 May 2016 16:38:15 GMT Connection: keep-alive
-
-
www.zotero.org www.zotero.org
-
-
gist.github.com gist.github.com
-
# Defines all Languages known to GitHub.
Tags
Annotators
URL
-
-
archivesetmanuscrits.bnf.fr archivesetmanuscrits.bnf.fr
-
www.youtube.com www.youtube.com
-
bibliotheques.paris.fr bibliotheques.paris.fr
-
obvil.sorbonne-universite.fr obvil.sorbonne-universite.fr
-
www.theses.fr www.theses.frThèses1
-
xml <link rel="related" type="application/atom+xml;profile=opds-catalog" title="theses.fr > Flux ATOM et OPDS des thèses accessibles en ligne" href="/?q=&sort=dateSoutenance+desc&access=oui&format=atom"/>
Tags
Annotators
URL
-
-
www.dcc.ac.uk www.dcc.ac.uk
Tags
Annotators
URL
-
-
www.citethisforme.com www.citethisforme.com
Tags
Annotators
URL
-
-
anansi-project.github.io anansi-project.github.io
Tags
Annotators
URL
-
-
vaemendis.net vaemendis.net
-
The OPDS Page Streaming Extension (OPDS-PSE) is an unofficial extension of the Open Distribution Publication System. Its goal is to enrich the OPDS feed with information allowing the client to request a specific page of a document without having to download it completely. This extension was designed primarily for comic books, to allow reading them on connected devices without having to wait for the book to be completely downloaded.
Example :
- Namespace declaration in the feed element (in our example, we use the prefix
« pse »):
xml <feed xmlns="http://www.w3.org/2005/Atom" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:pse="http://vaemendis.net/opds-pse/ns" xmlns:opds="http://opds-spec.org/2010/catalog" xml:lang="en" xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/" >- Additional link in an entry to allow page by page access to the document :
xml <link rel="http://vaemendis.net/opds-pse/stream" type="image/jpeg" href="/opds-comics/stream/1217?page={pageNumber}&width={maxWidth}" pse:count="35" /> - Namespace declaration in the feed element (in our example, we use the prefix
Tags
Annotators
URL
-
-
sudonull.com sudonull.com
-
twitter.com twitter.com
-
You can now tag citations in @CiteULike with #CITO! Add the tag "cito--(relationship)--permalink". Example:"cito--usesmethodin--423382".
-
-
jodischneider.com jodischneider.com
-
Machine Tags
cito--cites--1375511says “this article CiTO:cites article 137511”.
-
-
jbiomedsem.biomedcentral.com jbiomedsem.biomedcentral.com
-
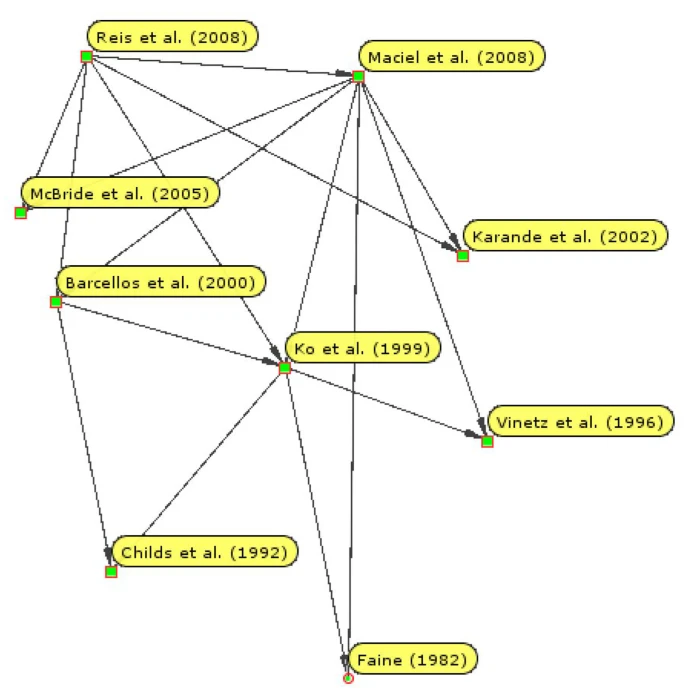
A CiTO citation network
-
-
opencitations.net opencitations.net
-
Exemplar output (in JSON)
json [ { "oci": "02001010806360107050663080702026306630509-0200101080636102703040309", "citing": "10.1186/1756-8722-6-59", "cited": "10.1186/ar3439", "creation": "2013", "timespan": "P2Y", "journal_sc": "no", "author_sc": "no" }, { "oci": "02001010806360107050663080702026306630509-0200101080636102704000806", "citing": "10.1186/1756-8722-6-59", "cited": "10.1186/ar4086", "creation": "2013", "timespan": "P1Y", "journal_sc": "no", "author_sc": "no" }, { "oci": "02001010806360107050663080702026306630509-020010200003619122437020001023704023707090006", "citing": "10.1186/1756-8722-6-59", "cited": "10.1200/jco.2012.42.7906", "creation": "2013", "timespan": "P0Y", "journal_sc": "no", "author_sc": "no" }, { "oci": "02001010806360107050663080702026306630509-02003010009360008080300010805370200010237060604070907", "citing": "10.1186/1756-8722-6-59", "cited": "10.3109/08830185.2012.664797", "creation": "2013", "timespan": "P0Y", "journal_sc": "no", "author_sc": "no" }
Tags
Annotators
URL
-
-
opencitations.net opencitations.net
-
COCI, the OpenCitations Index of Crossref open DOI-to-DOI citations
COCI, the OpenCitations Index of Crossref open DOI-to-DOI citations, is an RDF dataset containing details of all the citations that are specified by the open references to DOI-identified works present in Crossref, as of the latest COCI update*
[...]
Open Citation Identifiers
Each Open Citation Identifier [[OCI]] has a simple structure: the lower-case letters "oci" followed by a colon, followed by two numbers separated by a dash (e.g. https://w3id.org/oc/index/coci/ci/02001010806360107050663080702026306630509-02001010806360107050663080702026305630301), in which the first number identifies the citing work and the second number identifies the cited work.
Tags
Annotators
URL
-
-
opencitations.net opencitations.net
-
|Prefix|Supplier|Identifier type|Example| |--- |--- |--- |--- | |010|Wikidata|Wikidata Identifier (QID)|oci:01027931310-01022252312| |020|Crossref|Digital Object Identifier (DOI)|oci:02001010806360107050663080702026306630509-02001010806360107050663080702026305630301| |030|OpenCitations Corpus|OpenCitations Corpus Internal Identifier|oci:0301-03018| |040|Dryad|Digital Object Identifier (DOI)|oci:040050006013613273410133708070900-04003070302361019113701000000040801| |050|CROCI|Digital Object Identifier (DOI)|oci:05001000106361937321411281422370200010237000837000001-050010008073602000009020002|
Tags
Annotators
URL
-
-
figshare.com figshare.com
-
e.g.oci:01027931310-01022252312
-
-
opencitations.net opencitations.net
Tags
Annotators
URL
-
-
opencitations.net opencitations.net
Tags
Annotators
URL
-
-
semanticpublishing.wordpress.com semanticpublishing.wordpress.com
-
sparontologies.github.io sparontologies.github.io
-
http://purl.org/spar/cito/Citation
Tags
Annotators
URL
-
-
ec-jrc.github.io ec-jrc.github.io
-
Currently, DataCite is the de facto standard for data citation. Therefore, the ability to transform metadata records from and to the DataCite metadata schema would enable, respectively, the harvesting of DataCite records, and the publication of metadata records in the DataCite infrastructure (thus enabling their citation).
-
-
www.slideshare.net www.slideshare.net
-
oasislab.pubpub.org oasislab.pubpub.org
Tags
Annotators
URL
-
-
gallica.bnf.fr gallica.bnf.fr
-
www.openedition.org www.openedition.org
-
```html <link rel="alternate" type="application/opml+xml" title="Outline" href="https://www.openedition.org/?page=opml" />
<link rel="alternate" type="application/atom+xml;profile=opds-catalog" title="OpenEdition OPDS Catalogue" href="http://opds.openedition.org" /> ```
Tags
Annotators
URL
-
-
www.quietthyme.com www.quietthyme.com
-
-
www.goodreads.com www.goodreads.comAPI1
Tags
Annotators
URL
-
-
www.goodreads.com www.goodreads.com
-
-
www.liseuses.net www.liseuses.net
-
- Feedbooks : http://fr.feedbooks.com/catalog
- Atramenta : https://www.atramenta.net/opds/
- Gallica : https://gallica.bnf.fr/opds
- Ebooks Gratuits : https://www.ebooksgratuits.com/opds/
- Archive.org : http://bookserver.archive.org/catalog
- Projet Gutenberg : http://m.gutenberg.org/ebooks/?format=opds
- Framabookin : https://framabookin.org/
Tags
Annotators
URL
-
-
wiki.mobileread.com wiki.mobileread.com
Tags
Annotators
URL
-
-
www.digitalocean.com www.digitalocean.com
-
www.youtube.com www.youtube.com
-
How Beck used Gameboy sounds to remix his songs ~ @RoyceOnTheRadio
-
-
www.youtube.com www.youtube.com
-
idpf.org idpf.org
-
A Canonical Fragment Identifier (CFI) is a similar construct to these, but expresses a location within an EPUB Publication. For example:
book.epub#epubcfi(/6/4[chap01ref]!/4[body01]/10[para05]/3:10)
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
readium.org readium.org
Tags
Annotators
URL
-
-
drafts.opds.io drafts.opds.io
-
blog.ubiquitypress.com blog.ubiquitypress.com
-
example.com example.com
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
hypothes.is hypothes.is
-
-
niklasblog.com niklasblog.com
Tags
Annotators
URL
-
-
fullstackopen.com fullstackopen.com
-
-
-
html <link rel="search" type="application/opensearchdescription+xml" href="http://www.nature.com/opensearch/opensearch.xml" title="nature.com" /> <link rel="search" type="application/sru+xml" href="http://www.nature.com/opensearch/request" title="nature.com" />
-
-
www.flickr.com www.flickr.com
Tags
Annotators
URL
-
-
wiki.openstreetmap.org wiki.openstreetmap.org
Tags
Annotators
URL
-
-
wiki.openstreetmap.org wiki.openstreetmap.org
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
fr.slideshare.net fr.slideshare.net
-
hea-www.harvard.edu hea-www.harvard.edu
Tags
Annotators
URL
-
-
ontologiemoat.wordpress.com ontologiemoat.wordpress.com
Tags
Annotators
URL
-
-
www.slideshare.net www.slideshare.net
Tags
Annotators
URL
-
-
healis.eu healis.eu
-
-
-
-
-
-
-
-
www.w3.org www.w3.org
-
convert.erfideo.com convert.erfideo.com
-
-
datatracker.ietf.org datatracker.ietf.org
-
fr.blog.openfoodfacts.org fr.blog.openfoodfacts.org
-
sparql PREFIX food: <https://data.lirmm.fr/ontologies/food#> SELECT ?s ?code WHERE { ?s <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> food:FoodProduct . ?s food:containsIngredient ?i . ?i food:food <https://fr.openfoodfacts.org/ingredient/sucre> . ?i food:rank "1" OPTIONAL { ?s food:code ?code } . }
-
-
wiki.openfoodfacts.org wiki.openfoodfacts.org
Tags
Annotators
URL
-
-
www.programmableweb.com www.programmableweb.com
Tags
Annotators
URL
-
-
www.editionsladecouverte.fr www.editionsladecouverte.fr
-
addons.mozilla.org addons.mozilla.org
-
hypothes.is hypothes.is
-
-
hypothes.is hypothes.is
-
-
slideplayer.fr slideplayer.fr
Tags
Annotators
URL
-
-
www.gfii.fr www.gfii.frDataCite1
-
project-thor.readme.io project-thor.readme.io
Tags
Annotators
URL
-
-
citation.crosscite.org citation.crosscite.org
Tags
Annotators
URL
-
-
support.datacite.org support.datacite.org
Tags
Annotators
URL
-
-
support.datacite.org support.datacite.org
Tags
Annotators
URL
-
-
support.datacite.org support.datacite.org
-
Key to DataCite service is the concept of a long-term or persistent identifier. A persistent identifier is an association between a character string and a resource. Resources can be files, parts of files, persons, organisations, abstractions, etc. DataCite uses Digital Object Identifiers (DOIs)(2) at the present time and is considering the use of other identifier schemes in the future.
Tags
Annotators
URL
-
-
schema.datacite.org schema.datacite.org
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
geohash.org geohash.org
-
http://geohash.org/c216ne:Mt_Hood http://geohash.org/?q=45.37,-121.7&format=gpx http://geohash.org/?q=45.37,-121.7&format=url&redirect=0
- osm — open the location in OpenStreetMaps
- gmaps — open the location in Google Maps
- gc — go to the nearest geocaches in Geocaching.com
- gpx — go directly to GPX download page
- garmin — go directly to Garmin download page
- text — show coordinates as plain text
- url — show Geohash URL as plain text
- maxlen — maximum length of the Geohash
Tags
Annotators
URL
-
-
github.com github.com
-
hash://sha256/9f86d081884c7d659a2feaa0?type=text/plain#top \__/ \____/ \______________________/ \_____________/ \_/ | | | | | scheme algorithm hash query fragment
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
Tags
Annotators
URL
-
-
-
Creating a New Identifier
If you would like to add or update a permanent identifier of the form
https://w3id.org/..., the preferred procedure is to perform the following steps:-
- Fork the Repository for this system on Github.
-
- Add or update a new redirect entry and commit your changes.
-
- Submit a Pull Request for your changes.
The maintainers of this system will then act on that Pull Request and merge it into this system's content. You will then be able to see your changes in the repository and via resolution of the identifier you created or edited.
-
-
-
wals.info wals.info
-
-
Tags
Annotators
URL
-
-
www.ariadne.ac.uk www.ariadne.ac.uk
-
www.culturepub.fr www.culturepub.fr
Tags
Annotators
URL
-
-
scontent-cdt1-1.xx.fbcdn.net scontent-cdt1-1.xx.fbcdn.net
-
www.parismuseescollections.paris.fr www.parismuseescollections.paris.fr
-
www.programmableweb.com www.programmableweb.com
Tags
Annotators
URL
-
-
collections.louvre.fr collections.louvre.fr
-
api.finto.fi api.finto.fi
-
-
shacl-play.sparna.fr shacl-play.sparna.fr
-
-
blog.sparna.fr blog.sparna.fr
-
www.youtube.com www.youtube.com
-
www.eidr.org www.eidr.org
-
bugzilla.mozilla.org bugzilla.mozilla.org
Tags
Annotators
URL
-
-
www.google.com www.google.com
Tags
Annotators
URL
-
-
docs.gitlab.com docs.gitlab.com
Tags
Annotators
URL
-
-
yoyo-code.com yoyo-code.com
Tags
Annotators
URL
-
-
blog.cloudflare.com blog.cloudflare.com
-
To address this issue, and to make it easier for non-web browser environments to implement fetch in a consistent way, WinterCG is working on documenting a subset of the fetch standard that deals specifically with those different requirements and constraints.
Tags
Annotators
URL
-
-
www.slideshare.net www.slideshare.net
-
www.slideshare.net www.slideshare.net
Tags
Annotators
URL
-
-
hypothes.is hypothes.is
-
-
eur-lex.europa.eu eur-lex.europa.eu
Tags
Annotators
URL
-
-
-
-
anvaka.github.io anvaka.github.io
Tags
Annotators
URL
-
-
www.bbcbasic.co.uk www.bbcbasic.co.uk
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
Blu Cantrell's voice ! ❤️
-
-
www.youtube.com www.youtube.com