588 Matching Annotations
- Jun 2026
-
culturedcode.com culturedcode.com
-
Vision Pro
-
- May 2026
-
www.facebook.com www.facebook.com
- Apr 2026
-
www.pollinateourplanet.com www.pollinateourplanet.com
-
“When pollinators decline, the first visible impact is reduced plant reproduction. Flowers may bloom, but without pollinators, they fail to produce fruits and seeds”
-
- Mar 2026
-
www.are.na www.are.na
-
-
- Tourist is an ugly human being* - It immediately establishes a critical tone.
- How alone you feel in this crowd- tourist fell slightly alienated but locals experience deeper issues like poverty and exploitation
- Heaps of Death and ruin- Tourists can leave anytime, while locals are stuck
-
- People who inhabit the place in which you just passed cannot stand you*- Tourists can leave anytime while locals are stuck with consequences of tourism
- And every tourist is a native somewhere- Travel freedom is privilege that many people in the world do not have due to money, or is it that they lack freedom of the mind?
-
-
- Dec 2025
-
www.youtube.com www.youtube.com
-
Very few people are willing to go for status through the use of violence, force, intimidation, and bullying.
for - stats - very few people willing to do violence for status
-
- Nov 2025
-
www.iflscience.com www.iflscience.com
-
we can’t recapture the same processes we used to learn to speak for the very first time
for - unlearning language - key insight - language - cannot recapture same process we used as child - cannot recapture the same processes we used to learn to speak language for the very first time - basically, we lose access to that original vocal learning circuit as an adult - question - language learning - what is this vocal learning circuit of an infant? - why do we lost access to the vocal learning circuit we had as a child? - observation - clue - language - accidental world recall and substitution - a clue to how we remember words - I wrote the above sentence "why do we lost access to the vocal learning circuit we had as a child?" when I meant to write: - "why do we LOSE access to the vocal learning circuit we had as a child?' - This very observation also has the same mistake: - "observation - clue - language - accidental world" instead of: - observation - clue - language - accidental WORD"! - I've noticed this accidental word substitution when we are in the midst of automatically composing sentences quite often and have also wondered about it often. - I think it offers an important clue about how we remember words, and that is critical for recall for using language itself. - We must store words in clusters that are indicated by the accidental recall
Tags
- unlearning language
- question - why do we lose access to the vocal learning circuit we had as a child?
- key insight - language - cannot recapture same process we used as child
- question - language learning - what is this vocal learning circuit of an infant?
- observation - clue - language - accidental word recall and substitution - a clue to how we remember words
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
out of the hundreds of people that I served in that industry, I only know two that got clean and sober
for - drug addiction - almost impossible to do it alone
-
- Aug 2025
-
Local file Local file
-
Note
Q
Second control group muss ich mir nochmal ansehen
-
Vorschlag
Q
Ja aber das muss dann bei effect size angepasst werden (zB Dummies müssen dann bei Effektgröße auf 0/1 gleich sein (zB employed/not employed), etc., wichtig für Vergleichbarkeit.
-
Vorschlag
Q
Ja aber das muss dann bei effect size angepasst werden (zB Dummies müssen dann bei Effektgröße auf 0/1 gleich sein (zB employed/not employed), etc., wichtig für Vergleichbarkeit.
-
Vorschlag
Q
Hier in private/public teilen (weiß nicht wie sinnvoll, weil manche not specified, bereden).
-
Vorschlag
Q
Ja hier eventuell DiD/RDD/ähnliche zusammenfasen. Hir müssen wir aber diskutieren ob wir hier auf Kausalität, Endogenität, etc abzielen – analog diskutieren wie zu WL-PL Paper.
Ganz wichtig: DiD in spirit vs. DiD richtig (würde in spirit nicht zu DiD tun)
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Hier zB manufacturing (1) vs. Rest (0) oder andere Einteilung.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Diskutieren was hier sinnvoll wäre.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. In dem Fall eventuell Information zu blue collar/white collar/Arbeiter/Angestellte falls vorhanden kodieren in 0, 1, etc.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Vermutlich rauslassen.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Vermutlich rauslassen.
-
Vorschlag Nummer 2
Q
Hier macht denk ich ausschließlich explizit low skilled/medium skilled/high skilled vs. other Sinn.
-
Vorschlag
Q
Hier macht denk ich ausschließlich explizit low skilled/medium skilled/high skilled vs. other Sinn.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Diskutieren (z.B. nur low income workers von einer Studie)
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Diskutieren
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde.
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Variable eventuell aus Regression draußen lassen (und argumentieren, dass die meisten eh working age oder sowas sind).
-
Vorschlag
Q
Nein, das macht nicht wirklich Sinn, hier geht es nur um die Zusammensetzung im Sample, nicht darum für was kontrolliert wurde. Das muss sowas sein wie: 1 wenn nur männlich/weiblich, 0 alles andere oder 0: alles andere, 1: nur männlich, 2: weiblich, etc.
-
Important
Q
Ja versteh ich, Vorschlag klingt gut. Weiß nicht inwiefern wir diese Variable eigentlich verwenden
-
Sollen wir die wage compensation rausschmeissen? Ist ja schon im vorherigen Dummy drin.
Q
Ja wage compensation muss in Wage compensation variable (muss geändert werden in Excel)
-
Vorschlag
Q
Anmerkung: Hier müssen wir im Text dann genau erklären, dass wir mit „State“ dann jene meinen wo der Staat letztendlich die Entscheidung gesetzt hat, auch wenn dies zuvor in Absprache mit Organisationen stattfand -> hier ist aber auch eine Robustness-Analyse möglich wo wir das nochmal verferinern in Mitsprache/Nicht-Mitsprache (wobei das eventuell tricky ist, weil nicht immer ganz klar ob es Mitsprache gab oder nicht, aber müsste man sich anschauen im Fall).
-
-
www.youtube.com www.youtube.com
-
the really interesting question is like how come a bunch of dump cells give rise to something very smart which is the brain
for - question - how do dumb cells give rise to a smart brain?
-
- Jul 2025
-
Local file Local file
-
He supplemented the commercial arithmetic with instruction in goodpractice in letter-writing, record-keeping, filing – and even that staple of theworkplace notebook, the things-to-do list
-
-
remnil.github.io remnil.github.io
-
indicating
Needs methods for effect size quantification? Shift focus from significance testing to robust description and uncertainty quantification.
-
- Jun 2025
-
github.com github.com
-
Be explicit in the demo's intend. Eg. if you're building a demo for argTypes, don't create a Button.svelte component and Button.stories.svelte stories and come up with examples for how to write argTypes for buttons. Instead, build an ArgTypes.svelte component and stories that clearly and only demonstrates argTypes.
-
-
www.biorxiv.org www.biorxiv.org
-
or methodological differences in screening algorithms.
This could have been elaborated a bit more. It is too generic and rather obvious
TODO: try bringing this up to Todd on Slack..
Tags
Annotators
URL
-
- Apr 2025
-
university.pressbooks.pub university.pressbooks.pub
-
Set the Language for a Chapter or a Text Passage
this should be added to the accessibility chapter
-
-
www.binpress.com www.binpress.com
-
A lot of it feels like someone who doesn’t like the old code and wants to do it “right.” I can agree that the old code is ugly. But it will take an awful lot of effort to make a new implementation. It’s a lot like what happened to Elvis: A rewrite was going to make it much better, but it took so long, during which Vim added more features, that eventually there are not so many Elvis users. And the rewritten Elvis may have nice code, but users don’t notice that.
-
- Mar 2025
-
github.com github.com
-
The goal of Lucia v3 was to be the easiest and cleanest way to implement database-backed sessions in your projects. It didn't have to be a library. I just assumed that a library will be the answer. But I ultimately came to conclusion that my assumption was wrong. I don't see this change as me abandoning the project. In fact, I think it's a step forward. If implementing sessions wasn't easy, I wouldn't be deprecating the package. But why wouldn't a library be the answer? It seems like a such an obvious answer. One word - database. I talked about how database adapters were a significant complexity tax to the library. I think a lot of people interpreted that as maintenance burden on myself. That's not wrong, but the bigger issue is how the adapters limit the API. Adapters always felt like a black box to me as both an end user and a maintainer. It's very hard to design something clean around it and makes everything clunky and fragile, especially when you need to deal with TypeScript shenanigans.
Tags
- too easy/simple/trivial for end-developers to write from scratch to expect (don't need library to do it for them; don't need to provide feature)
- creating/using library vs. copying code
- when not to create a library: too hard to support/maintain the many ways it would need to be flexible
- when not to create a library
Annotators
URL
-
-
library.scholarcy.com library.scholarcy.com
-
The figure of the grieving mother is a collectivity, with women characterized as part of a population of mothers with a collective experience of loss. Their dissent is practiced through invocations of a dead or imperiled soldier child, who signifies the claim to associative military masculinity. In contrast, the perspective of the returning veteran is grounded in individual experience. The film depicts women as caregivers, with their dissenting subjecthood derived from their relationships with men.
-
this narrative of personal growth and triumph is complicated by the fact that Tomas's newfound power and authority are rooted in traditional masculine ideals. The film ultimately suggests that the military peace movement is shaped by masculinized privilege, which can be both productive and limiting.
-
- Feb 2025
-
synaptica.nl synaptica.nl
-
Overview
Field to add: - allele frequencies from gnomad and 1000genomes - Transcript - Between gene and protein
-
Gene
Fields to add: - Exon number - get from VEP
-
Functional
Implement the search among our variants, which would be classified as "functional"
-
Affected Domain
Generate this image.
-
(PubMed:19903818, PubMed:8845167)
Write a small script that turns these into little link icons (similar to the one in the related variants panel) and populates it with the pubmed link.
-
Ensembl Gene
Add the ensembl transcript version as well.
-
dbSNP
Try to get this out of VEP output.
-
genome
This should be Reference sequence, rather than "genome"
-
Structure
Update the gene_list.csv file such that it chooses the right PDB name from the uniprot annotations - sometimes there are more than one, so the script must look for the most complete structure, if that exists.
-
-
eragriculture.github.io eragriculture.github.io
-
#> 1 OpenAlex Only 12427
damn the wrapper I made only finds around 1685 hits, I wonder if it is to do with the type of search?
api_endpoint <- oa_query( entity = "works", title_and_abstract.search = search_string, from_publication_date = from_date, to_publication_date = to_date )
-
-
synaptica.nl synaptica.nl
-
Substitution
Make sure this pre-selects possible mutations from the list file.
-
-
university.pressbooks.pub university.pressbooks.pub
-
Activate the H5P plugin
once H5P chapter is reviewed, add link to the (not yet existing) section "Active the H5P plugin"
-
- Jan 2025
-
www.mdpi.com www.mdpi.com
-
The success factors of startups can vary depending on the development stage of the company. As the organization moves into the startup phase, the strategy, core team expertise and diversified knowledge become crucial. Various models have been proposed to understand the factors that contribute to the success of startups at different stages of their development. These models provide insights into the seed startup process, organization creation and exchange with the market [18,60]. It is important to note that the success factors in one phase may not necessarily guarantee success in other phases [67]. Additionally, the choice of financing sources for startups varies depending on their lifecycle stage and financial requirements [50]
Success factors for startups evolve through their lifecycle, requiring adaptability and strategic shifts at each stage. It would be quite interesting to see this study [50] that looks into different financing sources based on the startup lifecycle page.
-
-
university.pressbooks.pub university.pressbooks.pub
-
View and Restore Previous Revisions Pressbooks saves the last 10 revisions of any changes you’ve made for each of the three separate stylesheets. You can access these revisions on the Custom Styles page below the save button. To view or restore a previous version of one of your stylesheets: Click the date stamp for the revision you’d like to view to open the Compare Revisions interface for a particular stylesheet Find the revision you’d like to restore from and click the ‘Restore This Revision‘ button
This could be a separate chapter (or included in the Editor chapter)
-
- Dec 2024
-
wiki.p2pfoundation.net wiki.p2pfoundation.net
-
wokism as a return to group collectivism that suppresses individual differentiation
for - definition - wokism - a return to group collectivism that suppresses individual differentiation - from - P2P Foundation Wiki - Somewheres, Nowheres and Everywheres - Michel Bauwens, 2022
interrogate - Do more research on this definition of Wokism - from - P2P Foundation Wiki - Somewheres, Nowheres and Everywheres - Michel Bauwens, 2022
Tags
- interrogate - Do more research on this definition of Wokism - from - P2P Foundation Wiki - Somewheres, Nowheres and Everywheres - Michel Bauwens, 2022
- definition - wokism - a return to group collectivism that suppresses individual differentiation - from - P2P Foundation Wiki - Somewheres, Nowheres and Everywheres - Michel Bauwens, 2022
Annotators
URL
-
-
university.pressbooks.pub university.pressbooks.pub
-
description
We should mention that the description can't serve as the accessible description for an image. That has to be linked to separately.
-
-
library.scholarcy.com library.scholarcy.com
-
he analysis reveals that media coverage is dominated by five themes: military justice, institutional structure, culture, gender/gender integration, and change. Gender is a relatively minor focus throughout media coverage, with attention to court cases dominating the majority of the coverage.
-
Institutional gaslighting includes political strategies to resist critiques of the institution or discredit evidence that undermines the authority or carefully crafted image of the institution.
-
Military exceptionalism is shaped by ideals of "good militaries" and "good soldiers," which are constructed as necessarily white, masculine, exclusive, and reproduced through the regulation of sex and the exclusion of women and racialized groups.
-
- Nov 2024
-
www.columbia.edu www.columbia.edu
-
GCM-dominated approach allows censorship of alternative perspectives,when the models have a common, or at least widespread, problem: lack of realistic sensitivityto injection of freshwater into the upper layers of the ocean.
for - climate crisis - Global Climate Models (GCM) limitation - do not allow alternative perspectives - unrealistic sensitivity to injection of fresh water into upper layers of the ocean - Jim Hansen
Tags
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
why do our journalists feel they' got to fly to other parts of the world with the camera crew to film some disaster that's elsewhere that's occurred elsewhere why can't those people be training to use the cameras and Report you we we've embedded this sort of colonial view of the world and this Elite view of the world and we like to think of ourselves as good people in this and there's something deeply problematic in all of this and we have to start to unpick this if we're going to be serious about climate change
for - climate crisis - hypocrisy - example - colonialism - journalists in Global North fly to Global South with full film crew - alternative - hire journalists in Global South to do the film work - Kevin Anderson
-
why is it when colleagues do field work they feel they have to fly backwards and forwards to do their field work often say in the southern hemisphere
for - climate crisis - hypocrisy - example - colonialism - scientists in Global North fly to Global South - alternative - hire scientists in Global South to do the field work - Kevin Anderson
Tags
- climate crisis - hypocrisy - example - colonialism - scientists in Global North fly to Global South - alternative - hire scientists in Global South to do the field work - Kevin Anderson
- climate crisis - hypocrisy - example - colonialism - journalists in Global North fly to Global South with full film crew - alternative - hire journalists in Global South to do the film work - Kevin Anderson
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
DNA simply does not replicate like a crystal you have to have a living organism to enable it to do so
for - quote - DNA simply does not replicate like a crystal. You have to have a living organism to enable it to do so. - Denis Noble
-
-
library.scholarcy.com library.scholarcy.com
-
and its management in state-buildin
-
worshiped Pan Hu, a legendary figure, as part of their New Year's celebrations.
more detailed, specific on beliefs
-
he treatment is anecdotal
-
"Miao albums" that were compiled by officials responsible for governing frontier areas during the late Yongzheng or early Qianlong periods. These albums contained illustrations and texts describing the customs and practices of different ethnic minority groups in southwest China.
-
Qing Imperial Illustrations of Tributary Peoples was based on direct observation,
-
China saw a rise in ethnographic representation of different peoples, including the development of a systematic ethnography of ethnic minority groups.
-
-
library.scholarcy.com library.scholarcy.com
-
The chapter also explores the development of anthropology and ethnography as academic disciplines, which began to take shape in the 19th century.
-
-
radanskoric.com radanskoric.com
-
If I decide to add it, which solution should I pick, battle tested Sorbet or core team endorsed RBS?
-
-
www.youtube.com www.youtube.com
-
build the internal infrastructure
We do not have to BUILD the internal infrastructure, we ARE the structure
-
- Oct 2024
-
university.pressbooks.pub university.pressbooks.pub
-
Video: I would replace it with a video that focuses on table accessibility. The current video shows how to create a table and then add content and then shows how to designate a row as the header row; this is not sufficient for accessibility. For accessibility reasons it is also necessary to go to Table cell properties and choose Cell type: Header cell and **Scope: Column" (or row).
-
Add or Delete Tables Using the Visual Editor
separate the two tasks. ("using the visual editor" is not necessary in the title)
structure: 1. Add a table 2. Change Table Appearance * Apply preset styles * Adjust Table Width and height * Change Border Weight * Add Table Caption 3. Make Your Table More Accessible 4. Add or remove table rows or columns 5. Delete a table 6. Create Interactive Tables with TablePress
-
All tables default to the Standard class.
replace screenshot below with actual tables (accessibility)
-
-
university.pressbooks.pub university.pressbooks.pub
-
Status & Visibility
could add a link here to the section in "Create and Manage Chapters" that refers to the "Status & Visibility" panel
-
-
answers.microsoft.com answers.microsoft.com
-
I am just surprised that there is no clear official name for such a popular and well known convention. Internet searching seems to indicate that the common term used is "Red Squiggly Line", but it seems like a term quickly made-up just to describe something for which we know no name. There's a technical name for the dot on an "i" for goodness sake (tittle).
-
-
library.scholarcy.com library.scholarcy.com
-
Benjamin's travelogue is a product of his imagination, influenced by biblical authority and rumors, rather than actual geographical knowledge.
-
rather a way to link places along a real but somewhat abstracted route.
-
medieval understanding of travel writing.
-
-
www.reddit.com www.reddit.com
-
Todoist for quick notes and todo lists. I'm also using my own TodoistToTxt (available on github) script running every minute to generate a todo.txt file out of Todoist inbox, which is rendered on PC with Rainmeter.
-
-
www.youtube.com www.youtube.com
-
18:17 A government who creates a currency does not need to tax its citizens to get dollars. 18:25 Currency issuers spend first before they tax - they do not use tax to spend
-
- Sep 2024
-
blog.nodejitsu.com blog.nodejitsu.com
-
Developers want to improve their project. If you find an issue, bring it up. If it's a valid concern, the author will probably want to have it fixed. In many cases, the author will consider it a valid issue, but simply not have the personal time or need to address it immediately. This is where open-source is great. Just fork the project and fix it
-
-
www.mikeperham.com www.mikeperham.com
-
Let your operating system handle daemons, respawning and logging while you focus on your application features and users.
-
This makes developing a modern daemon much easier. The init config file is what you use to configure logging, run as a user, and many other things you previous did in code. You tweak a few init config settings; your code focuses less on housekeeping and more on functionality.
-
Less system administration, easier debugging, simpler code, all because you leveraged the init system to do the work for you!
-
-
www.thelancet.com www.thelancet.com
-
Both biosphere boundaries
for - question - earth system boundaries - biodiversity - how do we reconcile these boundaries with climate departure?
question - earth system boundaries - biodiversity - how do we reconcile these boundaries with climate departure? - Does the term "functional integrity" imply autonomy from climate feedbacks? Obviously, climate feedback plays a huge role in determining biodiversity health - In 2013, Mora et al. found that climate departure, the year in which a climate variable moves out of the historical bounds will occur everywhere on the planet, regardless of an aggressive RCP pathway being taken. In this study, climate departure was found to take place (relative to 2013) - 37.5 years in the future under RCP45, or - 22.5 years in the future under RCP85 - It would seem that the biodiversity boundaries should take into consideration climate departure as species extinction and ecological system disruption is projected to occur, regardless of whether RCP45 or RCP85 is adopted. - Currently, we are still on a Business-As-Usual trajectory, but since 2013, scientific research has moved the danger threshold even lower so climate departure dates are likely even sooner than those calculated in the 2013 Mora paper
to - Mora, C., Frazier, A., Longman, R. et al. (2013). The projected timing of climate departure from recent variability. Nature 502, 183–187. https://doi.org/10.1038/nature12540 - https://hyp.is/3wZrokX9Ee-XrSvMGWEN2g/www.nature.com/articles/nature12540 - Researchgate copy - https://hyp.is/go?url=https%3A%2F%2Fwww.researchgate.net%2Fpublication%2F257598710_The_projected_timing_of_climate_departure_from_recent_variability&group=world
Tags
- to - Mora, C., Frazier, A., Longman, R. et al. (2013). The projected timing of climate departure from recent variability. Nature 502, 183–187. https://doi.org/10.1038/nature12540
- question - earth system boundaries - biodiversity - how do we reconcile these boundaries with climate departure?
Annotators
URL
-
-
www.youtube.com www.youtube.com
-
you've mentioned the word theory a lot of times. How can we test this?
for - question - how do you test the theory that consciousness is the foundation of reality? ( to Federico Faggin)
-
- Aug 2024
-
-
how do you know if, if, and when you are part of a larger cognitive system, right?
for - question - how do you know when you are part of a larger cognitive system? - answer - adjacency - synchronicity - lower level example - two neurons talking to each other - Michael Levin - Mark Solms foundation theory of affect
question - how do you know when you are part of a larger cognitive system? - answer - adjacency - synchronicity - lower level example - two neurons talking to each other - Michael Levin - Mark Solms foundation theory of affect
adjacency - between - answer - synchronicity - lower level example - two neurons talking to each other - Michael Levin - Mark Solms foundational theory of affect - adjacency relationship - This is a very interesting question and Michael Levin provides a very interesting answer - First, it is very interesting that Mark Solms points out that affect is foundational to cognition - This is evident once we begin to think of the fundamental goals of any individual of any species is to optimize survival - The positive or negative affects that we feel are a feedback signal that measures how successful we are in our efforts to survive - Hence, it is more accurate to ask: - How do you know if and when you are part of a larger affective-cognitive system? - Levin illustrates the multi-level nature of simultaneous consciousness by looking at two neurons "in dialogue" with each other, and potentially speculating about a "higher level of consciousness", which is in fact, the level you and I operate at and take for granted - This speculative question is very important for it also can be generalized to the next layer up, - Do collectives of humans, each one experiencing itself a unified, cohesive inner perspective, constitute a higher level "collective consciousness"? - If we humans experience feelings and thinking whilst we have a well defined physical body, then - what does a society feel and think whilst not having such a well defined physical body?
-
I have no idea. But what I do know is that it's not a, um, this is not a philosophical, uh, thing that we can decide arguing in an armchair. Yes, it is. No, it isn't. No, you have to do experiments and then you find out.
for - question - does the world have agency? <br /> - answer - don't know - but it's not philosophical - it's scientific - do experiments to determine answer - Michael Levin
Tags
- question - does the world have agency? - answer - don't know - but it's not philosophical - it's scientific - do experiments to determine answer - Michael Levin
- question - how do you know when you are part of a larger cognitive system? - answer - adjacency - synchronicity - lower level example - two neurons talking to each other - Michael Levin - Mark Solms foundation theory of affect
Annotators
URL
-
-
www.truthdig.com www.truthdig.com
-
for - building new sustainable cities
summary - Building new "sustainable cities from nothing often does not consider the embodied energy required to do so. When that is considered, it is usually not viable - A context where it is viable is where there is extreme poverty and inequality
to - Why do old places matter? - sustainability - https://hyp.is/vlBLGlQFEe-EpqflmmlqnQ/savingplaces.org/stories/why-do-old-places-matter-sustainability
-
- Jul 2024
-
www.youtube.com www.youtube.com
-
26:30 Brings up progress traps of this new technology
26:48
question How do we shift our (human being's) relationship with the rest of nature
27:00
metaphor - interspecies communications - AI can be compared to a new scientific instrument that extends our ability to see - We may discover that humanity is not the center of the universe
32:54
Question - Dr Doolittle question - Will we be able to talk to the animals? - Wittgenstein said no - Human Umwelt is different from others - but it may very well happen
34:54
species have culture - Marine mammals enact behavior similar to humans
- Unknown unknowns will likely move to known unknowns and to some known knowns
36:29
citizen science bioacoustic projects - audio moth - sound invisible to humans - ultrasonic sound - intrasonic sound - example - Amazonian river turtles have been found to have hundreds of unique vocalizations to call their baby turtles to safety out in the ocean
41:56
ocean habitat for whales - they can communicate across the entire ocean of the earth - They tell of a story of a whale in Bermuda can communicate with a whale in Ireland
43:00
progress trap - AI for interspecies communications - examples - examples - poachers or eco tourism can misuse
44:08
progress trap - AI for interspecies communications - policy
45:16
whale protection technology - Kim Davies - University of New Brunswick - aquatic drones - drones triangulate whales - ships must not get near 1,000 km of whales to avoid collision - Canadian government fines are up to 250,000 dollars for violating
50:35
environmental regulation - overhaul for the next century - instead of - treatment, we now have the data tools for - prevention
56:40 - ecological relationship - pollinators and plants have co-evolved
1:00:26
AI for interspecies communication - example - human cultural evolution controlling evolution of life on earth
Tags
- AI for interspecies communication - example - human cultural evolution controlling evolution of life on earth
- whale protection - bioacoustic and drones
- interspecies communication - umwelt
- citizen science bioacoustics
- progress trap - AI for interspecies communications - examples - poachers - ecotourism
- environmental overhaul - treatment to prevention
- progress trap - AI for interspecies communications - policy
- progress trap - AI applied to interspecies communications
- ecological relationships - pollinators and plants co-evolved
- question - How do we shift our relationship with the rest of nature? - ESP research objective
- metaphor - interspecies communication - AI is like a new scientific instrument
- - whale communication - span the entire ocean
Annotators
URL
-
- Jun 2024
-
-
how do we sort of cultivate an 00:40:56 intuition for complex systems right for those second third nth order effects
for - question - Entangled Worlds podcast - How do we cultivate intuition for complex systems - to access those higher order effects? - answer - Nora Bateson - practice everywhere
-
-
github.com github.com
-
we strive to heed upstream's recommendations on how they intend for their software to be consumed.
-
- May 2024
-
suu.instructure.com suu.instructure.com
-
Failure to assemble an appropriate IEP team:
Tags
Annotators
URL
-
- Mar 2024
-
quarto.org quarto.org
-
quarto publish gh-pages document.qmd
Explore
tokensto minimize the number of ssh passphrase asked by this command!
Tags
Annotators
URL
-
-
privacybot.io privacybot.io
Tags
Annotators
URL
-
- Feb 2024
-
dandavison.github.io dandavison.github.io
Tags
Annotators
URL
-
-
npproduction.wpenginepowered.com npproduction.wpenginepowered.com
- Jan 2024
-
docdrop.org docdrop.org
-
one of the greatest martial arts artists ever was bruce lee who i actually read a lot of his writings
for - William Li influences - Bruce Lee - know yourself - key question to ask people - what do they really enjoy?
-
-
-
What they say is this is due to is new EU policies about messenger apps. I'm not in the EU. I reckon it's really because there's a new Messenger desktop client for Windows 10, which does have these features. Downloading the app gives FB access to more data from your machine to sell to companies for personalized advertising purposes.
-
- Dec 2023
-
developers.google.com developers.google.com
-
Given the security implications of getting the implementation correct, we strongly encourage you to use OAuth 2.0 libraries when interacting with Google's OAuth 2.0 endpoints. It is a best practice to use well-debugged code provided by others, and it will help you protect yourself and your users. For more information, see Client libraries.
-
- Nov 2023
-
github.com github.com
-
Capybara.string(response.body)
const $html = Cypress.$(body)
-
-
github.com github.com
-
One more example of a simple approach to this that might help a lot too is add a PORO generator. It could be incredibly basic - rails g poro MyClass yields class MyClass end But by doing that and landing the file in the app/models directory, it would make it clear that was the intended location instead of lib.
-
So then they put it into lib only to find that they have to manually require it. Then later realize that this also means they now have to reboot their server any time they change the file (after a painfully long debugging time of "why what aren't my changes working?", because their lib folder classes are now second-class citizens). Then they go down the rabbit hole of adding lib to the autoload paths, which burns them because rake tasks then all get eager loaded in production. Then they inevitably realize anything inside app is autoloaded and make an app/lib per Xavier's advice.
-
I think the symmetry of the naming between lib and app/lib will lead a fresh Rails developer to seek out the answer to “Why are there two lib directories?", and they will become illuminated. And it will prevent them from seeking the answer to “How do I autoload lib?” which will start them on a rough path that leads to me advising them to undo it.
-
-
-
In API design, exceptional use cases may justify exceptional support. You design for the common case, and let the edge case be edge. In this case, I believe lib deserves ad-hoc API that allows users to do exactly that in one shot:
-
- Oct 2023
-
www.youtube.com www.youtube.com
-
https://www.youtube.com/watch?v=k_6BjUzwJX8
via https://everbookforever.com/
Leather sheet folded into four sections onto itself like a book cover. It holds six folders of pieces of paper (most of them folded in half making mini-booklet pages): - blank paper for future note taking use - templates (project pack, weekly schedule/to do template, project list, project templates) - logbook, journal like, dated, - contains notes, outlines, brain storms, and scratch pad - next actions/workstation (to do lists for email, home, work, calls ) - Project Pack (9 projects for the quarter, each has their own page or mini folder with details) - Work Week or the Weekly Review Folder (areas of focus/project list, yearly calendar on a page for planning, whatever folder, wild ideas,
When done, all the pages of folders are packed up and wrapped with an elastic band for easy carrying. It's like a paper (looks like A5) notebook deconstructed and filed into paper folders and wrapped in a pretty leather cover.
As sections are finished/done they can be archived into small booklets and presumably filed.
This looks shockingly like my own index-card productivity system based on a variety of Memindex/Bullet Journal/GTD.
-
- Sep 2023
-
-
this is AVS the very first Foundation model for animal communication
-
-
lacountylibrary.libnet.info lacountylibrary.libnet.info
-
https://lacountylibrary.libnet.info/event/9097350
https://www.youtube.com/watch?v=xMF37TXAV5w
Presenter Lawrence Mak broke down types of notes into the following three categories:<br /> - general notes (projects, ideas, journals, recipes, budgeting, homework, etc.)<br /> - lists (groceries, reading, gifts, to dos, assignments) - reminders (birthdays, bills, maintenance, health)
-
-
www.additudemag.com www.additudemag.com
-
Your Evening Routine Is Broken Your day’s fate is sealed long before the alarm sounds. To ensure a productive, positive tomorrow, get started tonight by following these 10 nighttime schedule rules. By Kathleen Nadeau, Ph.D. Verified Updated on January 25, 2021
An very brief article from [[ADDitude Magazine]] with some helpful bulleted lists of things covering the following
- Devise a Smart Bedtime Routine
- Morning Routine at Home
- Morning Routine at Work
- How to Build a Routine
Some of these tips deserve to be made into [[Anki]] cards later.
-
-
www.sciencedirect.com www.sciencedirect.com
-
Bacteriophages are virus that can infect bacteria host. Phages were used to treat infectious disease
-
-
cuis-smalltalk.github.io cuis-smalltalk.github.io
-
J. Piaget, J. Brunner, O. K. Moore, and S. Papert.
Unless there is a need to save space, write full names and maybe inlcude hyperlinks.
-
Sketchpad (1963), the RAND tablet (1964), and Doug Engelbart’s NLS ("oN-Line System") (1968). Later developments include Ted Nelson’s Xanadu
Why not include hyperlinks?
-
https://en.wikipedia.org/wiki/As_We_May_Think
Ask. This doesn't need to be a footnote in HTML; maybe it is this way because of a texinfo limitation regarding conditional compiling, I. e. HTML (which doesn't need this as a footnote) vs PDF (which needs it but only when a producing a document to be printed).
-
- Jul 2023
-
www.ncbi.nlm.nih.gov www.ncbi.nlm.nih.gov
-
In addition, methods such as structural equation modeling (Gonçalves and Hall 2003) and Granger causality (Goebel et al. 2003) may shed light on the direction of causality as well as whether the observed correlations are direct or indirect.
- [ ] look into [[structural equation modeling]] and [[Granger causality]]
Tags
Annotators
URL
-
-
bonnittaroy.substack.com bonnittaroy.substack.com
-
energetic signature
- [ ] Check if formal term
- [ ] If so, check if Roy is using it differently
-
finance capitalism
- [ ] Check if [[finance capitalism]] is a formal term
- [ ] If so, check if [[Bonnitta Roy]] is using it differently
-
collective agency is an emergent outcome of the self-organized actions of many individuals
Seems like [[collective agency]] (for Roy) is a kind of [[agency]] as an [[epiphenomena]]. This seems inconsistent with the notion that [[agency]] is the capacity for the agent (at whatever scale) is the most causally relevant factor in determining it's behavior (think this is Vervaeke's view).
- [ ] Need to look up how [[Michael Levin]] and [[John Vervaeke]] use it
-
-
github.com github.com
-
- May 2023
-
www.nicksantalucia.com www.nicksantalucia.com
-
“Why do we need to learn [this]?” where [this] is whatever I happened to be struggling with at the time. Unfortunately for everyone, this question – which should always elicit a homerun response from the teacher
The eternal student question, "Why do we need to learn this?" should always have a fantastic answer from their teachers.
-
-
patrickrhone.com patrickrhone.com
-
https://patrickrhone.com/dashplus/
referenced via Simon Woods at micro.camp https://hypothes.is/a/_GvLrPczEe2T-tfEqnLNhw
-
-
teuxdeux.com teuxdeux.comTeuxDeux1
-
kimberlyhirsh.com kimberlyhirsh.com
-
https://kimberlyhirsh.com/uploads/2023/5976538a38.jpg
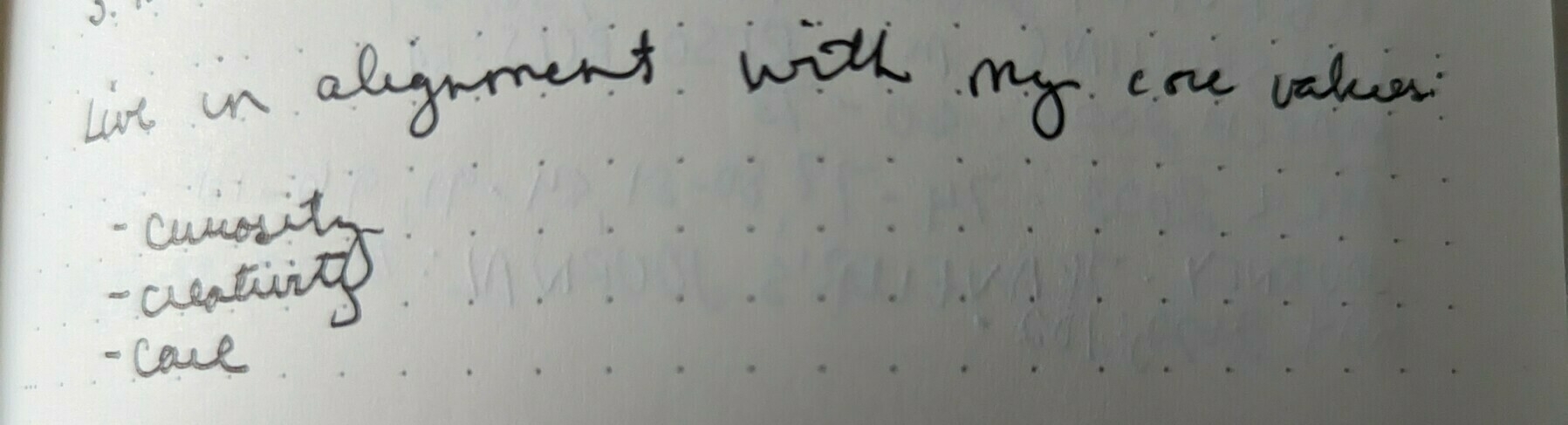
Putting a list of one's core values in the front of their notebook can be a useful reminder within their journaling or bullet journal practice.
-
-
jasonchatfield.medium.com jasonchatfield.medium.com
-
I would recommend ruling a line under the 6th point and having the rest as ‘if you get time’ tasks. Nothing else is allowed to get done until those first 6 tasks are complete: This is known as the Ivy Lee method.
The "Ivy Lee method" for productivity involves making a to do list with a line underneath the first six most important tasks and doing nothing else until the top six items are finished.
Jason Chatfield credits http://katiefarnan.com/blogs/the-form/lauren-layne for the idea.
-
Use David Allen’s GTD method and put your MIT (Most Important Task) at the top, and don’t attempt anything below it until that one task is done.
sometimes known as eating the frog first...
-
-
-
The someday card is described as being not only for individual to do items, but "big picture" goals.
-
-
ugmonk.com ugmonk.comAnalog2
-
Throughout the day, mark each task as completed, in-progress, or delegated. Feel free to create your own symbols.
Similar to the sorts of to do list task key in many bullet journals, the Analog system has "task signals" : - black filled circle means "complete task" - half filled circle means task is in progress - a right arrow in the circle means the task was delegated - a cross in the circle means that the task is an appointment, potentially with the appointment time added to the to do item
The system suggests that you can "create your own" task signals, though in true minimalist fashion, it doesn't give other suggestions. Presumably one could do other pattern fills of the circle or symbols within it to mean other things (example: bullet journal key symbols).
Interestingly, the to do circles start out not blank, but with a single thin line splitting the circle in half vertically. This is apparently a design choice, perhaps to make it easier to fill in half of the circle?

-
The Analog system utilizes a simplified version of an Eisenhower matrix which we'll call "today / next / someday" as a means of prioritizing to do list items on a temporal basis.
-
-
baronfig.com baronfig.com
- Mar 2023
-
-
We now take an opinionated stance on which second factor you should set up first – you'll no longer be asked to choose between SMS or setting up an authenticator app (known as TOTP), and instead see the TOTP setup screen immediately when first setting up 2FA.
-
-
www.ebay.com www.ebay.com
-
Vintage Memindex Wilson Wood Box 1937-38 Diary Planner Date Keeper Ephemera
Includes particularly good image of the individual day cards:

Notice that the tabs are done as 1/6th as most of these systems were manufactured/sold with out including Sunday.
-
-
stackoverflow.com stackoverflow.com
-
As an aside, I think I now prefer this technique to Python for at least one reason: passing arguments to the decorator method does not make the technique any more complex. Contrast this with Python: <artima.com/weblogs/viewpost.jsp?thread=240845>
-
def document(f): def wrap(x): print "I am going to square", x f(x) return wrap @document def square(x): print math.pow(x, 2) square(5)
-
-
homebrew-file.readthedocs.io homebrew-file.readthedocs.io
-
Use GitHub (or any git repository) for Brewfile management
-
-
www.levenger.com www.levenger.com
-
https://www.levenger.com/products/nantucket-bamboo-compact-bleacher?variant=42489708773525
This sort of reminds me about the way Rick Nicita kept his to do list on index cards spread out all over his desk.
Perhaps he might have benefitted from an index card bleacher?
-
-
-
Request this from the library.
-
- Feb 2023
-
www.seattletimes.com www.seattletimes.com
-
Read the Consumer Reports piece upon which this article was based.
-
-
www.rosslakeresort.com www.rosslakeresort.com
-
- Jan 2023
-
www.wikihow.com www.wikihow.com
-
Fix the men's room door at Press.
-
-
www.reddit.com www.reddit.com
-
There is an add on called "Spaced Repetition" that you may find useful. It can do both flashcards and full notes.
Look into plugin "Spaced Repetition" for Obsidian
-
-
connecti.cloud connecti.cloud
-
- Dec 2022
-
win-vector.com win-vector.com
-
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>John Mount</span> in Good Stationery as a Tool of Thought | MZLabs (<time class='dt-published'>11/30/2022 13:11:31</time>)</cite></small>
Read 2022-12-31
-
-
borretti.me borretti.me
-
https://borretti.me/article/unbundling-tools-for-thought
He covers much of what I observe in the zettelkasten overreach article.
Missing is any discussion of exactly what problem he's trying to solve other than perhaps, I want to solve them all and have a personal log of everything I've ever done.
Perhaps worth reviewing again to pull out specifics, but I just don't have the bandwidth today.
-
-
devcontainers.github.io devcontainers.github.ioFeatures1
Tags
Annotators
URL
-
-
github.com github.com
Tags
Annotators
URL
-
-
www.joshwcomeau.com www.joshwcomeau.com
Tags
Annotators
URL
-
-
inlandnwland.org inlandnwland.org
-
-
help.activecampaign.com help.activecampaign.com
-
If a contact ever reaches out and is no longer receiving messages because they accidentally marked one of your campaigns as spam, you can reach out to Product Support. We can remove them from the suppression list for you.
why not allow user to do it directly instead of force to contact support? If they'll remove it for you because you said the user asked you to... why not just let you remove the suppression yourself? Mailgun lets you directly delete suppressions via their API.
-
-
-
Let’s say the recipient is considering unsubscribing. He or she may be too busy to search through the email to find the unsubscribe link, so he or she just clicks “Report as SPAM” to stop the emails from coming. This is the last thing any marketer wants to see happen. It negatively impacts sender reputation, requiring extra work to improve email deliverability. With the list-unsubscribe header, you will avoid getting into this kind of trouble in the first place.
-
- Nov 2022
-
documentation.mailgun.com documentation.mailgun.com
-
You can access Events through a few interfaces: Webhooks (we POST data to your URL). The Events API (you GET data through the API). The Logs tab of the Control Panel (GUI).
-
-
www.cs.ucr.edu www.cs.ucr.edu
-
Dr. Miho Ohsaki re-examined workshe and her group had previously published and confirmed that the results are indeed meaningless in the sensedescribed in this work (Ohsaki et al., 2002). She has subsequently been able to redefine the clustering subroutine inher work to allow more meaningful pattern discovery (Ohsaki et al., 2003)
Look into what Dr. Miho Ohsaki changed about the clustering subroutine in her work and how it allowed for "more meaningful pattern discovery"
-
-
www.health.harvard.edu www.health.harvard.edu
-
A quick and dirty guide to choosing "slow carbs" (low GLI) and "fast carbs" (high GLI). Purportedly, insulin spikes (from high GLI foods) and prevent amino acids from entering the blood brain barrier. Need to fact-check this
-
-
cccrg.cochrane.org cccrg.cochrane.org
-
Statistical heterogeneity is the term given to differences in the effects of interventions and comesabout because of clinical and/or methodological differences between studies (ie it is a consequenceof clinical and/or methodological heterogeneity). Although some variation in the effects ofinterventions between studies will always exist, whether this variation is greater than what isexpected by chance alone needs to be determined.
If the statistical heterogeneity is larger that what's expected by chance alone, then what does that imply? That there's either clinical or methodological heterogeneity within the pooled studies.
What's the impact of the presence of clinical heterogeneity? The statistical heterogeneity (variation of effects/results of interventions) becomes greater than what's expected by chance alone
What's happens if methodological heterogeneity is present? The statistical heterogeneity (variation of effects/results of interventions) becomes greater than what's expected by chance alone
-
-
www.cisco.com www.cisco.com
-
Multimodal Learning Through Media:What the Research Says
A white paper written by Metiri Group commissioned by Cisco in 2008. I came here to fact check some claims on this YT video about a "Feynman Technique 2.0".
The claims were that
-
direct hands-on experience in unimodal learning is (on average) inferior to multi-modal learning that wasn't hand-on. viz., for "basic concepts", a more abstract learning model is better
-
"Once you get into higher-order concepts then hand-on experience is better"
Page 13 was displayed while making these claims.
These claims still need to be verified.
-
-
-
stackoverflow.com stackoverflow.com
-
I came to this page looking for a way to add Xournal++ to the official winget repository. The accepted answer seems like it might do this: https://stackoverflow.com/a/64367435/6457597
Need to open issue on GH repo about creating manifest file for Xournal++
-
-
www.honeybadger.io www.honeybadger.io
-
Until now, we had a lot of code. Although we were using a plugin to help with boilerplate code, ready endpoints, and webpages for sign in/sign up management, a lot of adaptations were necessary. This is when Doorkeeper comes to the rescue. It is not only an OAuth 2 provider for Rails but also a full OAuth 2 suite for Ruby and related frameworks (Sinatra, Devise, MongoDB, support for JWT, and more).
-
-
xournalpp.github.io xournalpp.github.io
-
Currently Xournal++ does not have shortcuts/keybindings configurable in the preferences. However you can write your custom plugin to achieve exactly that.
Must learn (and install) Lua (version >=5.3) to make custom shortcuts for Xournal++ via personally made plugins.
-
-
en.wikipedia.org en.wikipedia.org
-
Computers can only deal with well-structured problems
ie, "well-defined problems" in John Vervaeke's language. Cultivation of wisdom, per Vervaeke, is developing the capacity to navigate a ill-defined problem space, and realize (ie, recognize, and make real) what is relevant to resolving the situation.
Examples of ill-defined problems: - how to take good notes? - how to tell a funny joke? - how to go on a successful 1st date? - how to be a good friend?
May relate to Shapiro's "role theory". Needs further research
-
-
blog.chain.link blog.chain.link
-
What Is a Blockchain Oracle? A blockchain oracle is a secure piece of middleware that facilitates communication between blockchains and any off-chain system, including data providers, web APIs, enterprise backends, cloud providers, IoT devices, e-signatures, payment systems, other blockchains, and more. Oracles take on several key functions: Listen – monitor the blockchain network to check for any incoming user or smart contract requests for off-chain data. Extract – fetch data from one or multiple external systems such as off-chain APIs hosted on third-party web servers. Format – format data retrieved from external APIs into a blockchain readable format (input) and/or making blockchain data compatible with an external API (output). Validate – generate a cryptographic proof attesting to the performance of an oracle service using any combination of data signing, blockchain transaction signing, TLS signatures, Trusted Execution Environment (TEE) attestations, or zero-knowledge proofs. Compute – perform some type of secure off-chain computation for the smart contract, such as calculating a median from multiple oracle submissions or generating a verifiable random number for a gaming application. Broadcast – sign and broadcast a transaction on the blockchain in order to send data and any corresponding proof on-chain for consumption by the smart contract. Output (optional) – send data to an external system upon the execution of a smart contract, such as relaying payment instructions to a traditional payment network or triggering actions from a cyber-physical system.
Seems related to the paradox of information systems. Add to Anki deck
-
-
security.stackexchange.com security.stackexchange.com
-
From the Introduction to Ed25519, there are some speed benefits, and some security benefits. One of the more interesting security benefits is that it is immune to several side channel attacks: No secret array indices. The software never reads or writes data from secret addresses in RAM; the pattern of addresses is completely predictable. The software is therefore immune to cache-timing attacks, hyperthreading attacks, and other side-channel attacks that rely on leakage of addresses through the CPU cache. No secret branch conditions. The software never performs conditional branches based on secret data; the pattern of jumps is completely predictable. The software is therefore immune to side-channel attacks that rely on leakage of information through the branch-prediction unit. For comparison, there have been several real-world cache-timing attacks demonstrated on various algorithms. http://en.wikipedia.org/wiki/Timing_attack
Further arguments that Ed25519 is less vulnerable to - cache-timing attacks - hyperthreading attacks - other side-channel attacks that rely on leakage of addresses through CPU cache Also boasts - no secret branch conditions (no conditional branches based on secret data since pattern of jumps is predictable)
Predicable because underlying process that generated it isn't a black box?
Could ML (esp. NN, and CNN) be a parallel? Powerful in applications but huge risk given uncertainty of underlying mechanism?
Need to read papers on this
-
-
discourse.devontechnologies.com discourse.devontechnologies.com
-
I work primarily on Windows, but I support my kids who primarily use Mac for their college education. I have used DT on Mac, IPOS, IOS for about a year. On Windows, I have been using Kinook’s UltraRecall (UR) for the past 15 years. It is both a knowledge outliner and document manager. Built on top of a sql lite database. You can use just life DT and way way more. Of course, there is no mobile companion for UR. The MS Windows echo system in this regard is at least 12 years behind.
Reference for UltraRecall (UR) being the most DEVONthink like Windows alternative. No mobile companion for UR. Look into this being paired with Obsidian
-
-
gitlab.com gitlab.com
-
Good commit hygiene is considered a best practice. GitLab should encourage and enable these kinds of best practices. This feature currently creates a problem and requires workarounds that remove information, or significant manual work.
-
-
forum.obsidian.md forum.obsidian.md
-
https://forum.obsidian.md/t/alternative-checkboxes-icon-bullets-copy-and-paste/35962
A list of alternative checkboxes or icon bullets for Obsidian (and potentially other platforms). Potentially useful for search and filtering as well.
- [ ] to-do
- [/] incomplete
- [x] done
- [-] canceled
- [>] forwarded
- [<] scheduling
- [?] question
- [!] important
- [*] star
- ["] quote
- [l] location
- [b] bookmark
- [i] information
- [S] savings
- [I] idea
- [p] pros
- [c] cons
- [f] fire
- [k] key
- [w] win
- [u] up
- [d] down
-
-
www.obsidianroundup.org www.obsidianroundup.org
-
My highlights are littered with notes to self and action items - it's not all pure knowledge.
this is a good example of the personal side of note taking that isn't always outwardly seen
each person's notes will be personal to them
-
-
github.com github.com
-
Post.in_order_of(:type, %w[Draft Published Archived]).order(:created_at).pluck(:name) which generates SELECT posts.name FROM posts ORDER BY CASE posts.type WHEN 'Draft' THEN 1 WHEN 'Published' THEN 2 WHEN 'Archived' THEN 3 ELSE 4 END ASC, posts.created_at ASC
-
-
www.dropbox.com www.dropbox.com
-
-
github.com github.com
-
highly recommended that the resulting image be just one concern per container; predominantly this means just one process per container, so there is no need for a full init system
container images: whether to use full init process: implied here: don't need to if only using for single process (which doesn't fork, etc.)
-
- Oct 2022
-
stackoverflow.com stackoverflow.com
-
This breaks the TIMTOWTDI rule
-
-
bugs.python.org bugs.python.org
-
I'm afraid you missed the joke ;-) While you believe spaces are required on both sides of an em dash, there is no consensus on this point. For example, most (but not all) American authorities say /no/ spaces should be used. That's the joke. In writing a line about "only one way to do it", I used a device (em dash) for which at least two ways to do it (with spaces, without spaces) are commonly used, neither of which is obvious -- and deliberately picked a third way just to rub it in. This will never change ;-)
-
-
en.wikipedia.org en.wikipedia.org
-
The language was designed with this idea in mind, in that it “doesn't try to tell the programmer how to program.”
-
This motto has been very much discussed in the Perl community, and eventually extended to There’s more than one way to do it, but sometimes consistency is not a bad thing either (TIMTOWTDIBSCINABTE, pronounced Tim Toady Bicarbonate).[1] In contrast, part of the Zen of Python is, "There should be one— and preferably only one —obvious way to do it."
-
-
github.com github.com
-
Start using this. See if they've got a Visual Studio Code extension.
Tags
Annotators
URL
-
-
en.wikipedia.org en.wikipedia.org
-
Several templates and tools are available to assist in formatting, such as Reflinks (documentation), reFill (documentation) and Citation bot (documentation)
I clicked the link for reFill and thought it looked interesting. Would like to look into this further.
-
-
gamefound.com gamefound.com
-
After the first week of the campaign, we realized what are the main problematic pillars and fixed them right away. Nevertheless, even with these improvements and strong support from the Gamefound team, we’re not even close to achieving the backer numbers with which we could safely promise to create a game of the quality we think it deserves.
-
First and foremost, we need to acknowledge that even though the funding goal has been met–it does not meet the realistic costs of the project. Bluntly speaking, we did not have the confidence to showcase the real goal of ~1.5 million euros (which would be around 10k backers) in a crowdfunding world where “Funded in XY minutes!” is a regular highlight.
new tag: pressure to understate the real cost/estimate
-
-
www.flickr.com www.flickr.com
-
GTD Card Icon : Square (check box)Tag : 4th block. Squared as open-loop first, and filled later as accomplished. The GTD is advanced To-Do system proposed by David Allen. Next action of your project is described and processed through a certain flow. The GTD cards are classified into this class. 4th block is squared as open-loop first, and filled later as accomplished. The percentage of GTD Cards in my dock is less than 5 %.
-
-
web.archive.org web.archive.org
-
Several months back I'd thought about adapting the 43 folders system to a zettelkasten sort of system. I'm obviously not the first to have done so.
-
-
unix.stackexchange.com unix.stackexchange.com
-
The bash manual contains the statement For almost every purpose, aliases are superseded by shell functions.
-
-
ghuntley.com ghuntley.com
-
spamming open-source as a growth strategy is a super bad idea
Tags
Annotators
URL
-
- Sep 2022
-
metalblueberry.github.io metalblueberry.github.io
-
Some people eventually realize that the code quality is important, but they lack of the time to do it. This is the typical situation when you work under pressure or time constrains. It is hard to explain to you boss that you need another week to prepare your code when it is “already working”. So you ship the code anyway because you can not afford to spent one week more.
-
-
docs.google.com docs.google.com
-
I took along my son, who had never had any fresh water up his nose and who had seen lily pads only from train windows. On the journey over to the lake I began to wonder what it would be like. I wondered how time would have marred this unique, this holy spot--the coves and streams, the hills that the sun set behind, the camps and the paths behind the camps. I was sure that the tarred road would have found it out and I wondered in what other ways it would be desolated. It is strange how much you can remember about places like that once you allow your mind to return into the grooves which lead back. You remember one thing, and that suddenly reminds you of another thing. I guess I remembered clearest of all the early mornings, when the lake was cool and motionless, remembered how the bedroom smelled of the lumber it was made of and of the wet woods whose scent entered through the screen. The partitions in the camp were thin and did not extend clear to the top of the rooms, and as I was always the first up I would dress softly so as not to wake the others, and sneak out into the sweet outdoors and start out in the canoe, keeping close along the shore in the long shadows of the pines. I remembered being very careful never to rub my paddle against the gunwale for fear of disturbing the stillness of the cathedral.
-
-
stackoverflow.com stackoverflow.com
-
an equivalent of R's signif function in Ruby.
-
- Aug 2022
-
www.lowtechmagazine.com www.lowtechmagazine.com
-
graceful.dev graceful.dev
-
free course
observability = monitoring?
-
-
lifehacker.com lifehacker.com
-
I use the same 4x6 index cards I use for my commonplace book to write down my daily tasks
Ryan Holiday's note taking practice extends to using the same 4x6 inch index cards for his to do lists.
-
-
www.law.berkeley.edu www.law.berkeley.edu
-
Look into some of his lectures.
-
- Jul 2022
-
www.philips.com.au www.philips.com.au
-
www.youtube.com www.youtube.com
-
-
deleteme-z4xq4hvfe.s3.us-east-1.amazonaws.com deleteme-z4xq4hvfe.s3.us-east-1.amazonaws.com
-
you can't do a proj-ect, you can only do the action steps it requires.
link to: - https://hypothes.is/a/mVBBYgvIEe22ej8FOn5Cqg
-
-
www.hardscrabble.net www.hardscrabble.net
-
This option wasn’t offered by the library, but that doesn’t have to stop us. Isn’t that fun?
-
-
gist.github.com gist.github.com
-
5.5 Logic, reason, and common sense are your best tools for synthesizing reality and understanding what to do about it.
5.5 Logic, reason, and common sense are your best tools for synthesizing reality and understanding what to do about it.
-
-
www.legrand.us www.legrand.us
-
(For Squirrel.)
-
