"Code source et Logiciels"
l'écriture de l'image du bas est peu intelligible. Je suggère de reéquilibrer les deux figurés en réduisant la taille de la time line et en augmentant celle de l'image avec les bulles
"Code source et Logiciels"
l'écriture de l'image du bas est peu intelligible. Je suggère de reéquilibrer les deux figurés en réduisant la taille de la time line et en augmentant celle de l'image avec les bulles
Sources : Violaine Louvet
source : Violaine Louvet, Grégory Miura. Introduction sur le code source, les logiciels. Accompagner la préservation et la diffusion des logiciels dans les établissements, Média Normandie; ADBU; Software Heritage, May 2023, Visioconférence, France. ⟨hal-04102897⟩
Q-5: If score = 93, what will print when the following code executes?
This code uses multiple independent if statements instead of elif, so all conditions are checked and the grade gets overwritten multiple times.
Avoid wandering through the code
work on specific parts of your code only. I recognise this wandering even in my small projects.
How good should this be?
in software dev you need a sense of how good the code needs to be in comparison to use case / context / impact of failure time available
Both free operating systems and open-source operating systems are available in source-code format rather than as compiled binary code.
This line highlights the key advantage of free and open-source operating systems: access to source code, which allows users to study, modify, and redistribute the software.
Child Care
Suggested Improvement: The hyperlinks are added at the bottom in a smaller font size whereas they could just be embedded in the headings itself considering they are the same words. It would help make the webpage more robust by having a clean code and smoother transition between pages.
Wetterfest und langlebig. Ideal für Stall, Paddock, Hundehütte oder Terrarium.
Gravierter Metall-Plakette für Stall, Voliere, Käfig oder Terrarium. Der QR-Code führt natürlich ebenfalls direkt zum Patenkontakt.
Anhänger für Halsband oder Halfter. Der QR-Code führt direkt zu den hinterlegten Informationen und dem Patenkontakt.
Gravierter Metall-Anhänger für Hunde- oder Aufschub-Marke für Katzen-Halsband. Der QR-Code führt direkt zu den hinterlegten Informationen und dem Patenkontakt.
Ein QR-Code, die Notfallkarte & das digitale Register sorgen dafür, dass Finder oder Behörden sofort wissen, wen sie kontaktieren müssen. Dein Tier bleibt keine Minute unversorgt.
Ein QR-Code, die Notfallkarte & das digitale Register sorgen dafür, dass Finder oder Behörden direkt wissen, wen sie kontaktieren müssen.
Der Satz "Dein Tier bleibt keine Minute unversorgt" kann über die 3 Kästen als Überschrift gesetzt werden.
Author response:
The following is the authors’ response to the original reviews.
eLife Assessment
This useful study presents Altair-LSFM, a solid and well-documented implementation of a light-sheet fluorescence microscope (LSFM) designed for accessibility and cost reduction. While the approach offers strengths such as the use of custom-machined baseplates and detailed assembly instructions, its overall impact is limited by the lack of live-cell imaging capabilities and the absence of a clear, quantitative comparison to existing LSFM platforms. As such, although technically competent, the broader utility and uptake of this system by the community may be limited.
We thank the editors and reviewers for their thoughtful evaluation of our work and for recognizing the technical strengths of the Altair-LSFM platform, including the custom-machined baseplates and detailed documentation provided to promote accessibility and reproducibility. Below, we provide point-by-point responses to each referee comment. In the process, we have significantly revised the manuscript to include live-cell imaging data and a quantitative evaluation of imaging speed. We now more explicitly describe the different variants of lattice light-sheet microscopy—highlighting differences in their illumination flexibility and image acquisition modes—and clarify how Altair-LSFM compares to each. We further discuss challenges associated with the 5 mm coverslip and propose practical strategies to overcome them. Additionally, we outline cost-reduction opportunities, explain the rationale behind key equipment selections, and provide guidance for implementing environmental control. Altogether, we believe these additions have strengthened the manuscript and clarified both the capabilities and limitations of AltairLSFM.
Public Reviews:
Reviewer #1 (Public review):
Summary:
The article presents the details of the high-resolution light-sheet microscopy system developed by the group. In addition to presenting the technical details of the system, its resolution has been characterized and its functionality demonstrated by visualizing subcellular structures in a biological sample.
Strengths:
(1) The article includes extensive supplementary material that complements the information in the main article.
(2) However, in some sections, the information provided is somewhat superficial.
We thank the reviewer for their thoughtful assessment and for recognizing the strengths of our manuscript, including the extensive supplementary material. Our goal was to make the supplemental content as comprehensive and useful as possible. In addition to the materials provided with the manuscript, our intention is for the online documentation (available at thedeanlab.github.io/altair) to serve as a living resource that evolves in response to user feedback. We would therefore greatly appreciate the reviewer’s guidance on which sections were perceived as superficial so that we can expand them to better support readers and builders of the system.
Weaknesses:
(1) Although a comparison is made with other light-sheet microscopy systems, the presented system does not represent a significant advance over existing systems. It uses high numerical aperture objectives and Gaussian beams, achieving resolution close to theoretical after deconvolution. The main advantage of the presented system is its ease of construction, thanks to the design of a perforated base plate.
We appreciate the reviewer’s assessment and the opportunity to clarify our intent. Our primary goal was not to introduce new optical functionality beyond that of existing high-performance light-sheet systems, but rather to substantially reduce the barrier to entry for non-specialist laboratories. Many open-source implementations, such as OpenSPIM, OpenSPIN, and Benchtop mesoSPIM, similarly focused on accessibility and reproducibility rather than introducing new optical modalities, yet have had a measureable impact on the field by enabling broader community participation. Altair-LSFM follows this tradition, providing sub-cellular resolution performance comparable to advanced systems like LLSM, while emphasizing reproducibility, ease of construction through a precision-machined baseplate, and comprehensive documentation to facilitate dissemination and adoption.
(2) Using similar objectives (Nikon 25x and Thorlabs 20x), the results obtained are similar to those of the LLSM system (using a Gaussian beam without laser modulation). However, the article does not mention the difficulties of mounting the sample in the implemented configuration.
We appreciate the reviewer’s comment and agree that there are practical challenges associated with handling 5 mm diameter coverslips in this configuration. In the revised manuscript, we now explicitly describe these challenges and provide practical solutions. Specifically, we highlight the use of a custommachined coverslip holder designed to simplify mounting and handling, and we direct readers to an alternative configuration using the Zeiss W Plan-Apochromat 20×/1.0 objective, which eliminates the need for small coverslips altogether.
(3) The authors present a low-cost, open-source system. Although they provide open source code for the software (navigate), the use of proprietary electronics (ASI, NI, etc.) makes the system relatively expensive. Its low cost is not justified.
We appreciate the reviewer’s perspective and understand the concern regarding the use of proprietary control hardware such as the ASI Tiger Controller and NI data acquisition cards. Our decision to use these components was intentional: relying on a unified, professionally supported and maintained platform minimizes complexity associated with sourcing, configuring, and integrating hardware from multiple vendors, thereby reducing non-financial barriers to entry for non-specialist users.
Importantly, these components are not the primary cost driver of Altair-LSFM (they represent roughly 18% of the total system cost). Nonetheless, for individuals where the price is prohibitive, we also outline several viable cost-reduction options in the revised manuscript (e.g., substituting manual stages, omitting the filter wheel, or using industrial CMOS cameras), while discussing the trade-offs these substitutions introduce in performance and usability. These considerations are now summarized in Supplementary Note 1, which provides a transparent rationale for our design and cost decisions.
Finally, we note that even with these professional-grade components, Altair-LSFM remains substantially less expensive than commercial systems offering comparable optical performance, such as LLSM implementations from Zeiss or 3i.
(4) The fibroblast images provided are of exceptional quality. However, these are fixed samples. The system lacks the necessary elements for monitoring cells in vivo, such as temperature or pH control.
We thank the reviewer for their positive comment regarding the quality of our data. As noted, the current manuscript focuses on validating the optical performance and resolution of the system using fixed specimens to ensure reproducibility and stability.
We fully agree on the importance of environmental control for live-cell imaging. In the revised manuscript, we now describe in detail how temperature regulation can be achieved using a custom-designed heated sample chamber, accompanied by detailed assembly instructions on our GitHub repository and summarized in Supplementary Note 2. For pH stabilization in systems lacking a 5% CO₂ atmosphere, we recommend supplementing the imaging medium with 10–25 mM HEPES buffer. Additionally, we include new live-cell imaging data demonstrating that Altair-LSFM supports in vitro time-lapse imaging of dynamic cellular processes under controlled temperature conditions.
Reviewer #2 (Public review):
Summary:
The authors present Altair-LSFM (Light Sheet Fluorescence Microscope), a high-resolution, open-source microscope, that is relatively easy to align and construct and achieves sub-cellular resolution. The authors developed this microscope to fill a perceived need that current open-source systems are primarily designed for large specimens and lack sub-cellular resolution or are difficult to construct and align, and are not stable. While commercial alternatives exist that offer sub-cellular resolution, they are expensive. The authors' manuscript centers around comparisons to the highly successful lattice light-sheet microscope, including the choice of detection and excitation objectives. The authors thus claim that there remains a critical need for high-resolution, economical, and easy-to-implement LSFM systems.
We thank the reviewer for their thoughtful summary. We agree that existing open-source systems primarily emphasize imaging of large specimens, whereas commercial systems that achieve sub-cellular resolution remain costly and complex. Our aim with Altair-LSFM was to bridge this gap—providing LLSM-level performance in a substantially more accessible and reproducible format. By combining high-NA optics with a precision-machined baseplate and open-source documentation, Altair offers a practical, high-resolution solution that can be readily adopted by non-specialist laboratories.
Strengths:
The authors succeed in their goals of implementing a relatively low-cost (~ USD 150K) open-source microscope that is easy to align. The ease of alignment rests on using custom-designed baseplates with dowel pins for precise positioning of optics based on computer analysis of opto-mechanical tolerances, as well as the optical path design. They simplify the excitation optics over Lattice light-sheet microscopes by using a Gaussian beam for illumination while maintaining lateral and axial resolutions of 235 and 350 nm across a 260-um field of view after deconvolution. In doing so they rest on foundational principles of optical microscopy that what matters for lateral resolution is the numerical aperture of the detection objective and proper sampling of the image field on to the detection, and the axial resolution depends on the thickness of the light-sheet when it is thinner than the depth of field of the detection objective. This concept has unfortunately not been completely clear to users of high-resolution light-sheet microscopes and is thus a valuable demonstration. The microscope is controlled by an open-source software, Navigate, developed by the authors, and it is thus foreseeable that different versions of this system could be implemented depending on experimental needs while maintaining easy alignment and low cost. They demonstrate system performance successfully by characterizing their sheet, point-spread function, and visualization of sub-cellular structures in mammalian cells, including microtubules, actin filaments, nuclei, and the Golgi apparatus.
We thank the reviewer for their thoughtful and generous assessment of our work. We are pleased that the manuscript’s emphasis on fundamental optical principles, design rationale, and practical implementation was clearly conveyed. We agree that Altair’s modular and accessible architecture provides a strong foundation for future variants tailored to specific experimental needs. To facilitate this, we have made all Zemax simulations, CAD files, and build documentation openly available on our GitHub repository, enabling users to adapt and extend the system for diverse imaging applications.
Weaknesses:
There is a fixation on comparison to the first-generation lattice light-sheet microscope, which has evolved significantly since then:
(1) The authors claim that commercial lattice light-sheet microscopes (LLSM) are "complex, expensive, and alignment intensive", I believe this sentence applies to the open-source version of LLSM, which was made available for wide dissemination. Since then, a commercial solution has been provided by 3i, which is now being used in multiple cores and labs but does require routine alignments. However, Zeiss has also released a commercial turn-key system, which, while expensive, is stable, and the complexity does not interfere with the experience of the user. Though in general, statements on ease of use and stability might be considered anecdotal and may not belong in a scientific article, unreferenced or without data.
We thank the reviewer for this thoughtful and constructive comment. We have revised the manuscript to more clearly distinguish between the original open-source implementation of LLSM and subsequent commercial versions by 3i and ZEISS. The revised Introduction and Discussion now explicitly note that while open-source and early implementations of LLSM can require expert alignment and maintenance, commercial systems—particularly the ZEISS Lattice Lightsheet 7—are designed for automated operation and stable, turn-key use, albeit at higher cost and with limited modifiability. We have also moderated earlier language regarding usability and stability to avoid anecdotal phrasing.
We also now provide a more objective proxy for system complexity: the number of optical elements that require precise alignment during assembly and maintenance thereafter. The original open-source LLSM setup includes approximately 29 optical components that must each be carefully positioned laterally, angularly, and coaxially along the optical path. In contrast, the first-generation Altair-LSFM system contains only nine such elements. By this metric, Altair-LSFM is considerably simpler to assemble and align, supporting our overarching goal of making high-resolution light-sheet imaging more accessible to non-specialist laboratories.
(2) One of the major limitations of the first generation LLSM was the use of a 5 mm coverslip, which was a hinderance for many users. However, the Zeiss system elegantly solves this problem, and so does Oblique Plane Microscopy (OPM), while the Altair-LSFM retains this feature, which may dissuade widespread adoption. This limitation and how it may be overcome in future iterations is not discussed.
We thank the reviewer for this helpful comment. We agree that the use of 5 mm diameter coverslips, while enabling high-NA imaging in the current Altair-LSFM configuration, may pose a practical limitation for some users. We now discuss this more explicitly in the revised manuscript. Specifically, we note that replacing the detection objective provides a straightforward solution to this constraint. For example, as demonstrated by Moore et al. (Lab Chip, 2021), pairing the Zeiss W Plan-Apochromat 20×/1.0 detection objective with the Thorlabs TL20X-MPL illumination objective allows imaging beyond the physical surfaces of both objectives, eliminating the need for small-format coverslips. In the revised text, we propose this modification as an accessible path toward greater compatibility with conventional sample mounting formats. We also note in the Discussion that Oblique Plane Microscopy (OPM) inherently avoids such nonstandard mounting requirements and, owing to its single-objective architecture, is fully compatible with standard environmental chambers.
(3) Further, on the point of sample flexibility, all generations of the LLSM, and by the nature of its design, the OPM, can accommodate live-cell imaging with temperature, gas, and humidity control. It is unclear how this would be implemented with the current sample chamber. This limitation would severely limit use cases for cell biologists, for which this microscope is designed. There is no discussion on this limitation or how it may be overcome in future iterations.
We thank the reviewer for this important observation and agree that environmental control is critical for live-cell imaging applications. It is worth noting that the original open-source LLSM design, as well as the commercial version developed by 3i, provided temperature regulation but did not include integrated control of CO2 or humidity. Despite this limitation, these systems have been widely adopted and have generated significant biological insights. We also acknowledge that both OPM and the ZEISS implementation of LLSM offer clear advantages in this respect, providing compatibility with standard commercial environmental chambers that support full regulation of temperature, CO₂, and humidity.
In the revised manuscript, we expand our discussion of environmental control in Supplementary Note 2, where we describe the Altair-LSFM chamber design in more detail and discuss its current implementation of temperature regulation and HEPES-based pH stabilization. Additionally, the Discussion now explicitly notes that OPM avoids the challenges associated with non-standard sample mounting and is inherently compatible with conventional environmental enclosures.
(4) The authors' comparison to LLSM is constrained to the "square" lattice, which, as they point out, is the most used optical lattice (though this also might be considered anecdotal). The LLSM original design, however, goes far beyond the square lattice, including hexagonal lattices, the ability to do structured illumination, and greater flexibility in general in terms of light-sheet tuning for different experimental needs, as well as not being limited to just sample scanning. Thus, the Alstair-LSFM cannot compare to the original LLSM in terms of versatility, even if comparisons to the resolution provided by the square lattice are fair.
We agree that the original LLSM design offers substantially greater flexibility than what is reflected in our initial comparison, including the ability to generate multiple lattice geometries (e.g., square and hexagonal), operate in structured illumination mode, and acquire volumes using both sample- and lightsheet–scanning strategies. To address this, we now include Supplementary Note 3 that provides a detailed overview of the illumination modes and imaging flexibility afforded by the original LLSM implementation, and how these capabilities compare to both the commercial ZEISS Lattice Lightsheet 7 and our AltairLSFM system. In addition, we have revised the discussion to explicitly acknowledge that the original LLSM could operate in alternative scan strategies beyond sample scanning, providing greater context for readers and ensuring a more balanced comparison.
(5) There is no demonstration of the system's live-imaging capabilities or temporal resolution, which is the main advantage of existing light-sheet systems.
In the revised manuscript, we now include a demonstration of live-cell imaging to directly validate AltairLSFM’s suitability for dynamic biological applications. We also explicitly discuss the temporal resolution of the system in the main text (see Optoelectronic Design of Altair-LSFM), where we detail both software- and hardware-related limitations. Specifically, we evaluate the maximum imaging speed achievable with Altair-LSFM in conjunction with our open-source control software, navigate.
For simplicity and reduced optoelectronic complexity, the current implementation powers the piezo through the ASI Tiger Controller, which modestly reduces its bandwidth. Nonetheless, for a 100 µm stroke typical of light-sheet imaging, we achieved sufficient performance to support volumetric imaging at most biologically relevant timescales. These results, along with additional discussion of the design trade-offs and performance considerations, are now included in the revised manuscript and expanded upon in the supplementary material.
While the microscope is well designed and completely open source, it will require experience with optics, electronics, and microscopy to implement and align properly. Experience with custom machining or soliciting a machine shop is also necessary. Thus, in my opinion, it is unlikely to be implemented by a lab that has zero prior experience with custom optics or can hire someone who does. Altair-LSFM may not be as easily adaptable or implementable as the authors describe or perceive in any lab that is interested, even if they can afford it. The authors indicate they will offer "workshops," but this does not necessarily remove the barrier to entry or lower it, perhaps as significantly as the authors describe.
We appreciate the reviewer’s perspective and agree that building any high-performance custom microscope—Altair-LSFM included—requires a basic understanding of (or willingness to learn) optics, electronics, and instrumentation. Such a barrier exists for all open-source microscopes, and our goal is not to eliminate this requirement entirely but to substantially reduce the technical and logistical challenges that typically accompany the construction of custom light-sheet systems.
Importantly, no machining experience or in-house fabrication capabilities are required. Users can simply submit the provided CAD design files and specifications directly to commercial vendors for fabrication. We have made this process as straightforward as possible by supplying detailed build instructions, recommended materials, and vendor-ready files through our GitHub repository. Our dissemination strategy draws inspiration from other successful open-source projects such as mesoSPIM, which has seen widespread adoption—over 30 implementations worldwide—through a similar model of exhaustive documentation, open-source software, and community support via user meetings and workshops.
We also recognize that documentation alone cannot fully replace hands-on experience. To further lower barriers to adoption, we are actively working with commercial vendors to streamline procurement and assembly, and Altair-LSFM is supported by a Biomedical Technology Development and Dissemination (BTDD) grant that provides resources for hosting workshops, offering real-time community support, and developing supplementary training materials.
In the revised manuscript, we now expand the Discussion to explicitly acknowledge these implementation considerations and to outline our ongoing efforts to support a broad and diverse user base, ensuring that laboratories with varying levels of technical expertise can successfully adopt and maintain the Altair-LSFM platform.
There is a claim that this design is easily adaptable. However, the requirement of custom-machined baseplates and in silico optimization of the optical path basically means that each new instrument is a new design, even if the Navigate software can be used. It is unclear how Altair-LSFM demonstrates a modular design that reduces times from conception to optimization compared to previous implementations.
We thank the reviewer for this insightful comment and agree that our original language regarding adaptability may have overstated the degree to which Altair-LSFM can be modified without prior experience. It was not our intention to imply that the system can be easily redesigned by users with limited technical background. Meaningful adaptations of the optical or mechanical design do require expertise in optical layout, optomechanical design, and alignment.
That said, for laboratories with such expertise, we aim to facilitate modifications by providing comprehensive resources—including detailed Zemax simulations, complete CAD models, and alignment documentation. These materials are intended to reduce the development burden for expert users seeking to tailor the system to specific experimental requirements, without necessitating a complete re-optimization of the optical path from first principles.
In the revised manuscript, we clarify this point and temper our language regarding adaptability to better reflect the realistic scope of customization. Specifically, we now state in the Discussion: “For expert users who wish to tailor the instrument, we also provide all Zemax illumination-path simulations and CAD files, along with step-by-step optimization protocols, enabling modification and re-optimization of the optical system as needed.” This revision ensures that readers clearly understand that Altair-LSFM is designed for reproducibility and straightforward assembly in its default configuration, while still offering the flexibility for modification by experienced users.
Reviewer #3 (Public review):
Summary:
This manuscript introduces a high-resolution, open-source light-sheet fluorescence microscope optimized for sub-cellular imaging. The system is designed for ease of assembly and use, incorporating a custommachined baseplate and in silico optimized optical paths to ensure robust alignment and performance. The authors demonstrate lateral and axial resolutions of ~235 nm and ~350 nm after deconvolution, enabling imaging of sub-diffraction structures in mammalian cells. The important feature of the microscope is the clever and elegant adaptation of simple gaussian beams, smart beam shaping, galvo pivoting and high NA objectives to ensure a uniform thin light-sheet of around 400 nm in thickness, over a 266 micron wide Field of view, pushing the axial resolution of the system beyond the regular diffraction limited-based tradeoffs of light-sheet fluorescence microscopy. Compelling validation using fluorescent beads and multicolor cellular imaging highlights the system's performance and accessibility. Moreover, a very extensive and comprehensive manual of operation is provided in the form of supplementary materials. This provides a DIY blueprint for researchers who want to implement such a system.
We thank the reviewer for their thoughtful and positive assessment of our work. We appreciate their recognition of Altair-LSFM’s design and performance, including its ability to achieve high-resolution, imaging throughout a 266-micron field of view. While Altair-LSFM approaches the practical limits of diffraction-limited performance, it does not exceed the fundamental diffraction limit; rather, it achieves near-theoretical resolution through careful optical optimization, beam shaping, and alignment. We are grateful for the reviewer’s acknowledgment of the accessibility and comprehensive documentation that make this system broadly implementable.
Strengths:
(1) Strong and accessible technical innovation: With an elegant combination of beam shaping and optical modelling, the authors provide a high-resolution light-sheet system that overcomes the classical light-sheet tradeoff limit of a thin light-sheet and a small field of view. In addition, the integration of in silico modelling with a custom-machined baseplate is very practical and allows for ease of alignment procedures. Combining these features with the solid and super-extensive guide provided in the supplementary information, this provides a protocol for replicating the microscope in any other lab.
(2) Impeccable optical performance and ease of mounting of samples: The system takes advantage of the same sample-holding method seen already in other implementations, but reduces the optical complexity.
At the same time, the authors claim to achieve similar lateral and axial resolution to Lattice-light-sheet microscopy (although without a direct comparison (see below in the "weaknesses" section). The optical characterization of the system is comprehensive and well-detailed. Additionally, the authors validate the system imaging sub-cellular structures in mammalian cells.
(3) Transparency and comprehensiveness of documentation and resources: A very detailed protocol provides detailed documentation about the setup, the optical modeling, and the total cost.
We thank the reviewer for their thoughtful and encouraging comments. We are pleased that the technical innovation, optical performance, and accessibility of Altair-LSFM were recognized. Our goal from the outset was to develop a diffraction-limited, high-resolution light-sheet system that balances optical performance with reproducibility and ease of implementation. We are also pleased that the use of precisionmachined baseplates was recognized as a practical and effective strategy for achieving performance while maintaining ease of assembly.
Weaknesses:
(1) Limited quantitative comparisons: Although some qualitative comparison with previously published systems (diSPIM, lattice light-sheet) is provided throughout the manuscript, some side-by-side comparison would be of great benefit for the manuscript, even in the form of a theoretical simulation. While having a direct imaging comparison would be ideal, it's understandable that this goes beyond the interest of the paper; however, a table referencing image quality parameters (taken from the literature), such as signalto-noise ratio, light-sheet thickness, and resolutions, would really enhance the features of the setup presented. Moreover, based also on the necessity for optical simplification, an additional comment on the importance/difference of dual objective/single objective light-sheet systems could really benefit the discussion.
In the revised manuscript, we have significantly expanded our discussion of different light-sheet systems to provide clearer quantitative and conceptual context for Altair-LSFM. These comparisons are based on values reported in the literature, as we do not have access to many of these instruments (e.g., DaXi, diSPIM, or commercial and open-source variants of LLSM), and a direct experimental comparison is beyond the scope of this work.
We note that while quantitative parameters such as signal-to-noise ratio are important, they are highly sample-dependent and strongly influenced by imaging conditions, including fluorophore brightness, camera characteristics, and filter bandpass selection. For this reason, we limited our comparison to more general image-quality metrics—such as light-sheet thickness, resolution, and field of view—that can be reliably compared across systems.
Finally, per the reviewer’s recommendation, we have added additional discussion clarifying the differences between dual-objective and single-objective light-sheet architectures, outlining their respective strengths, limitations, and suitability for different experimental contexts.
(2) Limitation to a fixed sample: In the manuscript, there is no mention of incubation temperature, CO₂ regulation, Humidity control, or possible integration of commercial environmental control systems. This is a major limitation for an imaging technique that owes its popularity to fast, volumetric, live-cell imaging of biological samples.
We fully agree that environmental control is critical for live-cell imaging applications. In the revised manuscript, we now describe the design and implementation of a temperature-regulated sample chamber in Supplementary Note 2, which maintains stable imaging conditions through the use of integrated heating elements and thermocouples. This approach enables precise temperature control while minimizing thermal gradients and optical drift. For pH stabilization, we recommend the use of 10–25 mM HEPES in place of CO₂ regulation, consistent with established practice for most light-sheet systems, including the initial variant of LLSM. Although full humidity and CO₂ control are not readily implemented in dual-objective configurations, we note that single-objective designs such as OPM are inherently compatible with commercial environmental chambers and avoid these constraints. Together, these additions clarify how environmental control can be achieved within Altair-LSFM and situate its capabilities within the broader LSFM design space.
(3) System cost and data storage cost: While the system presented has the advantage of being opensource, it remains relatively expensive (considering the 150k without laser source and optical table, for example). The manuscript could benefit from a more direct comparison of the performance/cost ratio of existing systems, considering academic settings with budgets that most of the time would not allow for expensive architectures. Moreover, it would also be beneficial to discuss the adaptability of the system, in case a 30k objective could not be feasible. Will this system work with different optics (with the obvious limitations coming with the lower NA objective)? This could be an interesting point of discussion. Adaptability of the system in case of lower budgets or more cost-effective choices, depending on the needs.
We agree that cost considerations are critical for adoption in academic environments. We would also like to clarify that the quoted $150k includes the optical table and laser source. In the revised manuscript, Supplementary Note 1 now includes an expanded discussion of cost–performance trade-offs and potential paths for cost reduction.
Last, not much is said about the need for data storage. Light-sheet microscopy's bottleneck is the creation of increasingly large datasets, and it could be beneficial to discuss more about the storage needs and the quantity of data generated.
In the revised manuscript, we now include Supplementary Note 4, which provides a high-level discussion of data storage needs, approximate costs, and practical strategies for managing large datasets generated by light-sheet microscopy. This section offers general guidance—including file-format recommendations, and cost considerations—but we note that actual costs will vary by institution and contractual agreements.
Conclusion:
Altair-LSFM represents a well-engineered and accessible light-sheet system that addresses a longstanding need for high-resolution, reproducible, and affordable sub-cellular light-sheet imaging. While some aspects-comparative benchmarking and validation, limitation for fixed samples-would benefit from further development, the manuscript makes a compelling case for Altair-LSFM as a valuable contribution to the open microscopy scientific community.
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
(1) A picture, or full CAD design of the complete instrument, should be included as a main figure.
A complete CAD rendering of the microscope is now provided in Supplementary Figure 4.
(2) There is no quantitative comparison of the effects of the tilting resonant galvo; only a cartoon, a figure should be included.
The cartoon was intended purely as an educational illustration to conceptually explain the role of the tilting resonant galvo in shaping and homogenizing the light sheet. To clarify this intent, we have revised both the figure legend and corresponding text in the main manuscript. For readers seeking quantitative comparisons, we now reference the original study that provides a detailed analysis of this optical approach, as well as a review on the subject.
(3) Description of L4 is missing in the Figure 1 caption.
Thank you for catching this omission. We have corrected it.
(4) The beam profiles in Figures 1c and 3a, please crop and make the image bigger so the profile can be appreciated. The PSFs in Figure 3c-e should similarly be enlarged and presented using a dynamic range/LUT such that any aberrations can be appreciated.
In Figure 1c, our goal was to qualitatively illustrate the uniformity of the light-sheet across the full field of view, while Figure 1d provided the corresponding quantitative cross-section. To improve clarity, we have added an additional figure panel offering a higher-magnification, localized view of the light-sheet profile. For Figure 3c–e, we have enlarged the PSF images and adjusted the display range to better convey the underlying signal and allow subtle aberrations to be appreciated.
(5) It is unclear why LLSM is being used as the gold standard, since in its current commercial form, available from Zeiss, it is a turn-key system designed for core facilities. The original LLSM is also a versatile instrument that provides much more than the square lattice for illumination, including structured illumination, hexagonal lattices, live-cell imaging, wide-field illumination, different scan modes, etc. These additional features are not even mentioned when compared to the Altair-LSFM. If a comparison is to be provided, it should be fair and balanced. Furthermore, as outlined in the public review, anecdotal statements on "most used", "difficult to align", or "unstable" should not be provided without data.
In the revised manuscript, we have carefully removed anecdotal statements and, where appropriate, replaced them with quantitative or verifiable information. For instance, we now explicitly report that the square lattice was used in 16 of the 20 figure subpanels in the original LLSM publication, and we include a proxy for optical complexity based on the number of optical elements requiring alignment in each system.
We also now clearly distinguish between the original LLSM design—which supports multiple illumination and scanning modes—and its subsequent commercial variants, including the ZEISS Lattice Lightsheet 7, which prioritizes stability and ease of use over configurational flexibility (see Supplementary Note 3).
(6) The authors should recognize that implementing custom optics, no matter how well designed, is a big barrier to cross for most cell biology labs.
We fully understand and now acknowledge in the main text that implementing custom optics can present a significant barrier, particularly for laboratories without prior experience in optical system assembly. However, similar challenges were encountered during the adoption of other open-source microscopy platforms, such as mesoSPIM and OpenSPIM, both of which have nonetheless achieved widespread implementation. Their success has largely been driven by exhaustive documentation, strong community support, and standardized design principles—approaches we have also prioritized in Altair-LSFM. We have therefore made all CAD files, alignment guides, and detailed build documentation publicly available and continue to develop instructional materials and community resources to further reduce the barrier to adoption.
(7) Statements on "hands on workshops" though laudable, may not be appropriate to include in a scientific publication without some documentation on the influence they have had on implanting the microscope.
We understand the concern. Our intention in mentioning hands-on workshops was to convey that the dissemination effort is supported by an NIH Biomedical Technology Development and Dissemination grant, which includes dedicated channels for outreach and community engagement. Nonetheless, we agree that such statements are not appropriate without formal documentation of their impact, and we have therefore removed this text from the revised manuscript.
(8) It is claimed that the microscope is "reliable" in the discussion, but with no proof, long-term stability should be assessed and included.
Our experience with Altair-LSFM has been that it remains well-aligned over time—especially in comparison to other light-sheet systems we worked on throughout the last 11 years—we acknowledge that this assessment is anecdotal. As such, we have omitted this claim from the revised manuscript.
(9) Due to the reliance on anecdotal statements and comparisons without proof to other systems, this paper at times reads like a brochure rather than a scientific publication. The authors should consider editing their manuscript accordingly to focus on the technical and quantifiable aspects of their work.
We agree with the reviewer’s assessment and have revised the manuscript to remove anecdotal comparisons and subjective language. Where possible, we now provide quantitative metrics or verifiable data to support our statements.
Reviewer #3 (Recommendations for the authors):
Other minor points that could improve the manuscript (although some of these points are explained in the huge supplementary manual):
(1) The authors explain thoroughly their design, and they chose a sample-scanning method. I think that a brief discussion of the advantages and disadvantages of such a method over, for example, a laserscanning system (with fixed sample) in the main text will be highly beneficial for the users.
In the revised manuscript, we now include a brief discussion in the main text outlining the advantages and limitations of a sample-scanning approach relative to a light-sheet–scanning system. Specifically, we note that for thin, adherent specimens, sample scanning minimizes the optical path length through the sample, allowing the use of more tightly focused illumination beams that improve axial resolution. We also include a new supplementary figure illustrating how this configuration reduces the propagation length of the illumination light sheet, thereby enhancing axial resolution.
(2) The authors justify selecting a 0.6 NA illumination objective over alternatives (e.g., Special Optics), but the manuscript would benefit from a more quantitative trade-off analysis (beam waist, working distance, sample compatibility) with other possibilities. Within the objective context, a comparison of the performances of this system with the new and upcoming single-objective light-sheet methods (and the ones based also on optical refocusing, e.g., DAXI) would be very interesting for the goodness of the manuscript.
In the revised manuscript, we now provide a quantitative trade-off analysis of the illumination objectives in Supplementary Note 1, including comparisons of beam waist, working distance, and sample compatibility. This section also presents calculated point spread functions for both the 0.6 NA and 0.67 NA objectives, outlining the performance trade-offs that informed our design choice. In addition, Supplementary Note 3 now includes a broader comparison of Altair-LSFM with other light-sheet modalities, including diSPIM, ASLM, and OPM, to further contextualize the system’s capabilities within the evolving light-sheet microscopy landscape.
(3) The modularity of the system is implied in the context of the manuscript, but not fully explained. The authors should specify more clearly, for example, if cameras could be easily changed, objectives could be easily swapped, light-sheet thickness could be tuned by changing cylindrical lens, how users might adapt the system for different samples (e.g., embryos, cleared tissue, live imaging), .etc, and discuss eventual constraints or compatibility issues to these implementations.
Altair-LSFM was explicitly designed and optimized for imaging live adherent cells, where sample scanning and short light-sheet propagation lengths provide optimal axial resolution (Supplementary Note 3). While the same platform could be used for superficial imaging in embryos, systems implementing multiview illumination and detection schemes are better suited for such specimens. Similarly, cleared tissue imaging typically requires specialized solvent-compatible objectives and approaches such as ASLM that maximize the field of view. We have now added some text to the Design Principles section that explicitly state this.
Altair-LSFM offers varying levels of modularity depending on the user’s level of expertise. For entry-level users, the illumination numerical aperture—and therefore the light-sheet thickness and propagation length—can be readily adjusted by tuning the rectangular aperture conjugate to the back pupil of the illumination objective, as described in the Design Principles section. For mid-level users, alternative configurations of Altair-LSFM, including different detection objectives, stages, filter wheels, or cameras, can be readily implemented (Supplementary Note 1). Importantly, navigate natively supports a broad range of hardware devices, and new components can be easily integrated through its modular interface. For expert users, all Zemax simulations, CAD models, and step-by-step optimization protocols are openly provided, enabling complete re-optimization of the optical design to meet specific experimental requirements.
(4) Resolution measurements before and after deconvolution are central to the performance claim, but the deconvolution method (PetaKit5D) is only briefly mentioned in the main text, it's not referenced, and has to be clarified in more detail, coherently with the precision of the supplementary information. More specifically, PetaKit5D should be referenced in the main text, the details of the deconvolution parameters discussed in the Methods section, and the computational requirements should also be mentioned.
In the revised manuscript, we now provide a dedicated description of the deconvolution process in the Methods section, including the specific parameters and algorithms used. We have also explicitly referenced PetaKit5D in the main text to ensure proper attribution and clarity. Additionally, we note the computational requirements associated with this analysis in the same section for completeness.
(5) Image post-processing is not fully explained in the main text. Since the system is sample-scanning based, no word in the main text is spent on deskewing, which is an integral part of the post-processing to obtain a "straight" 3D stack. Since other systems implement such a post-processing algorithm (for example, single-objective architectures), it would be beneficial to have some discussion about this, and also a brief comparison to other systems in the main text in the methods section.
In the revised manuscript, we now explicitly describe both deskewing (shearing) and deconvolution procedures in the Alignment and Characterization section of the main text and direct readers to the Methods section. We also briefly explain why the data must be sheared to correct for the angled sample-scanning geometry for LLSM and Altair-LSFM, as well as both sample-scanning and laser-scanning-variants of OPMs.
(6) A brief discussion on comparative costs with other systems (LLSM, dispim, etc.) could be helpful for non-imaging expert researchers who could try to implement such an optical architecture in their lab.
Unfortunately, the exact costs of commercial systems such as LLSM or diSPIM are typically not publicly available, as they depend on institutional agreements and vendor-specific quotations. Nonetheless, we now provide approximate cost estimates in Supplementary Note 1 to help readers and prospective users gauge the expected scale of investment relative to other advanced light-sheet microscopy systems.
(7) The "navigate" control software is provided, but a brief discussion on its advantages compared to an already open-access system, such as Micromanager, could be useful for the users.
In the revised manuscript, we now include Supplementary Note 5 that discusses the advantages and disadvantages of different open-source microscope control platforms, including navigate and MicroManager. In brief, navigate was designed to provide turnkey support for multiple light-sheet architectures, with pre-configured acquisition routines optimized for Altair-LSFM, integrated data management with support for multiple file formats (TIFF, HDF5, N5, and Zarr), and full interoperability with OMEcompliant workflows. By contrast, while Micro-Manager offers a broader library of hardware drivers, it typically requires manual configuration and custom scripting for advanced light-sheet imaging workflows.
(8) The cost and parts are well documented, but the time and expertise required are not crystal clear.Adding a simple time estimate (perhaps in the Supplement Section) of assembly/alignment/installation/validation and first imaging will be very beneficial for users. Also, what level of expertise is assumed (prior optics experience, for example) to be needed to install a system like this? This can help non-optics-expert users to better understand what kind of adventure they are putting themselves through.
We thank the reviewer for this helpful suggestion. To address this, we have added Supplementary Table S5, which provides approximate time estimates for assembly, alignment, validation, and first imaging based on the user’s prior experience with optical systems. The table distinguishes between novice (no prior experience), moderate (some experience using but not assembling optical systems), and expert (experienced in building and aligning optical systems) users. This addition is intended to give prospective builders a realistic sense of the time commitment and level of expertise required to assemble and validate AltairLSFM.
Minor things in the main text:
(1) Line 109: The cost is considered "excluding the laser source". But then in the table of costs, you mention L4cc as a "multicolor laser source", for 25 K. Can you explain this better? Are the costs correct with or without the laser source?
We acknowledge that the statement in line 109 was incorrect—the quoted ~$150k system cost does include the laser source (L4cc, listed at $25k in the cost table). We have corrected this in the revised manuscript.
(2) Line 113: You say "lateral resolution, but then you state a 3D resolution (230 nm x 230 nm x 370 nm). This needs to be fixed.
Thank you, we have corrected this.
(3) Line 138: Is the light-sheet uniformity proven also with a fluorescent dye? This could be beneficial for the main text, showing the performance of the instrument in a fluorescent environment.
The light-sheet profiles shown in the manuscript were acquired using fluorescein to visualize the beam. We have revised the main text and figure legends to clearly state this.
(4) Line 149: This is one of the most important features of the system, defying the usual tradeoff between light-sheet thickness and field of view, with a regular Gaussian beam. I would clarify more specifically how you achieve this because this really is the most powerful takeaway of the paper.
We thank the reviewer for this key observation. The ability of Altair-LSFM to maintain a thin light sheet across a large field of view arises from diffraction effects inherent to high NA illumination. Specifically, diffraction elongates the PSF along the beam’s propagation direction, effectively extending the region over which the light sheet remains sufficiently thin for high-resolution imaging. This phenomenon, which has been the subject of active discussion within the light-sheet microscopy community, allows Altair-LSFM to partially overcome the conventional trade-off between light-sheet thickness and propagation length. We now clarify this point in the main text and provide a more detailed discussion in Supplementary Note 3, which is explicitly referenced in the discussion of the revised manuscript.
(5) Line 171: You talk about repeatable assembly...have you tried many different baseplates? Otherwise, this is a complicated statement, since this is a proof-of-concept paper.
We thank the reviewer for this comment. We have not yet validated the design across multiple independently assembled baseplates and therefore agree that our previous statement regarding repeatable assembly was premature. To avoid overstating the current level of validation, we have removed this statement from the revised manuscript.
(6) Line 187: same as above. You mention "long-term stability". For how long did you try this? This should be specified in numbers (days, weeks, months, years?) Otherwise, it is a complicated statement to make, since this is a proof-of-concept paper.
We also agree that referencing long-term stability without quantitative backing is inappropriate, and have removed this statement from the revised manuscript.
(7) Line 198: "rapid z-stack acquisition. How rapid? Also, what is the limitation of the galvo-scanning in terms of the imaging speed of the system? This should be noted in the methods section.
In the revised manuscript, we now clarify these points in the Optoelectronic Design section. Specifically, we explicitly note that the resonant galvo used for shadow reduction operates at 4 kHz, ensuring that it is not rate-limiting for any imaging mode. In the same section, we also evaluate the maximum acquisition speeds achievable using navigate and report the theoretical bandwidth of the sample-scanning piezo, which together define the practical limits of volumetric acquisition speed for Altair-LSFM.
(8) Line 234: Peta5Kit is discussed in the additional documentation, but should be referenced here, as well.
We now reference and cite PetaKit5D.
(9) Line 256: "values are on par with LLSM", but no values are provided. Some details should also be provided in the main text.
In the revised manuscript, we now provide the lateral and axial resolution values originally reported for LLSM in the main text to facilitate direct comparison with Altair-LSFM. Additionally, Supplementary Note 3 now includes an expanded discussion on the nuances of resolution measurement and reporting in lightsheet microscopy.
Figures:
(1) Figure 1 could be implemented with Figure 3. They're both discussing the validation of the system (theoretically and with simulations), and they could be together in different panels of the same figure. The experimental light-sheet seems to be shown in a transmission mode. Showing a pattern in a fluorescent dye could also be beneficial for the paper.
In Figure 1, our goal was to guide readers through the design process—illustrating how the detection objective’s NA sets the system’s resolution, which defines the required pixel size for Nyquist sampling and, in turn, the field of view. We then use Figure 1b–c to show how the illumination beam was designed and simulated to achieve that field of view. In contrast, Figure 3 presents the experimental validation of the illumination system. To avoid confusion, we now clarify in the text that the light sheet shown in Figure 3 was visualized in a fluorescein solution and imaged in transmission mode. While we agree that Figures 1 and 3 both serve to validate the system, we prefer to keep them as separate figures to maintain focus within each panel. We believe this organization better supports the narrative structure and allows readers to digest the theoretical and experimental validations independently.
(2) Figure 3: Panels d and e show the same thing. Why would you expect that xz and yz profiles should be different? Is this due to the orientation of the objectives towards the sample?
In Figure 3, we present the PSF from all three orthogonal views, as this provides the most transparent assessment of PSF quality—certain aberration modes can be obscured when only select perspectives are shown. In principle, the XZ and YZ projections should be equivalent in a well-aligned system. However, as seen in the XZ projection, a small degree of coma is present that is not evident in the YZ view. We now explicitly note this observation in the revised figure caption to clarify the difference between these panels.
(3) Figure 4's single boxes lack a scale bar, and some of the Supplementary Figures (e.g. Figure 5) lack detailed axis labels or scale bars. Also, in the detailed documentation, some figures are referred to as Figure 5. Figure 7 or, for example, figure 6. Figure 8, and this makes the cross-references very complicated to follow
In the revised manuscript, we have corrected these issues. All figures and supplementary figures now include appropriate scale bars, axis labels, and consistent formatting. We have also carefully reviewed and standardized all cross-references throughout the main text and supplementary documentation to ensure that figure numbering is accurate and easy to follow.
eLife Assessment
This important study provides the first putative evidence that alteration of the Hox code in neck lateral plate mesoderm is sufficient to induce ectopic development of forelimb buds at neck level. The authors use both gain-of-function (GOF) and loss-of-function (LOF) approaches in chick embryos to test the roles of Hox paralogy group (PG) 4-7 genes in limb development. The GOF data provide strong evidence that overexpression of Hox PG6/7 genes are sufficient to induce forelimb buds at neck level. However, the experiments using dominant negative constructs are lacking some key controls that are needed to demonstrate the specificity of the LOF effect rendering the work as a whole incomplete.
Reviewer #2 (Public review):
In the original review of this manuscript, I noted that this study provides the first evidence that alteration of the Hox code in neck lateral plate mesoderm is sufficient for ectopic forelimb budding. Their finding that ectopic expression of Hoxa6 or Hoxa7 induces wing budding at neck level, a demonstration of sufficiency, is of major significance. The experiments used to test the necessity of specific Hox genes for limb budding involved overexpression of dominant negative constructs, and there were questions about whether the controls were well designed. The reviewers made several suggestions for additional experiments that would address their concerns. In their responses to those comments, the authors indicated that they would conduct those experiments, and they acknowledged the requests for further discussion of a few points.
In the revised version of the manuscript, the authors have provided additional RNA-seq data in Table 3, which lists 221 genes that are shared between the Hoxa6-induced limb bud and normal wing bud but not the neck. This shows that the ectopic limb bud has a limb-like character. The authors also expanded the discussion of their results in the context of previous work on the mouse. These changes have improved the paper.
The authors elected not to conduct the co-transfection experiments that were suggested to test the ability of Hoxa4/a5 to block the limb-inducing ability of Hoxa6/a7. They also chose not to conduct the additional control experiments that were suggested for the dominant negative studies. The authors' justification for not conducting these experiments is provided in the responses to reviewers.
The paper is improved over the previous version, but the conclusions, particularly regarding the dominant negative experiments, would have been strengthened by the additional experiments that were recommended by the reviewers. Under the current publishing model for eLife, it is the authors' prerogative to decide whether to revise in accordance with the reviewers' suggestions. Therefore, it seems to me that this version of the manuscript is the definitive version that the authors want to publish, and that eLife should publish it together with the reviewers' comments and the authors' responses.
There are 0 results available. a11yWishlist function makeTargetedComponentVisible(componentID) { var targetedComponent = undefined; if( document.readyState !== 'loading' ) { targetedComponent = document.getElementById(componentID); if (targetedComponent) targetedComponent.style.visibility = 'visible'; } else { document.addEventListener('DOMContentLoaded', function () { targetedComponent = document.getElementById(componentID); if (targetedComponent) targetedComponent.style.visibility = 'visible'; }); } } if (window.ContextHub && ContextHub.SegmentEngine) { ContextHubJQ(function() { ContextHub.eventing.on(ContextHub.Constants.EVENT_TEASER_LOADED, function(event, data){ data.data.forEach(function(evData) { if (evData.key === "_content_experience\u002Dfragments_canadiantire_en_site_experience\u002Dfragment\u002Dheader_master_jcr_content_root_freehtmlebbb4a8f\u002D6f6c\u002D49fc\u002Da314\u002D12ed5fe323f8") { makeTargetedComponentVisible("_content_experience-fragments_canadiantire_en_site_experience-fragment-header_master_jcr_content_root_freehtmlebbb4a8f-6f6c-49fc-a314-12ed5fe323f8"); } }); }); ContextHub.SegmentEngine.PageInteraction.Teaser({ locationId: '_content_experience\u002Dfragments_canadiantire_en_site_experience\u002Dfragment\u002Dheader_master_jcr_content_root_freehtmlebbb4a8f\u002D6f6c\u002D49fc\u002Da314\u002D12ed5fe323f8', variants: [{"path":"/content/experience-fragments/canadiantire/en/site/experience-fragment-header/master/default","name":"default","title":"Default","campaignName":"","thumbnail":"/content/experience-fragments/canadiantire/en/site/experience-fragment-header/master.thumb.png","url":"/content/experience-fragments/canadiantire/en/site/experience-fragment-header/master/_jcr_content/root/freehtml.default.html","campaignPriority":0,"tags":[]}], strategy: '', trackingURL: null }); // Make the targeted content visible if no teasers were loaded after 5s setTimeout(function(){ makeTargetedComponentVisible("_content_experience-fragments_canadiantire_en_site_experience-fragment-header_master_jcr_content_root_freehtmlebbb4a8f-6f6c-49fc-a314-12ed5fe323f8"); }, 5000); }); } else { makeTargetedComponentVisible("_content_experience-fragments_canadiantire_en_site_experience-fragment-header_master_jcr_content_root_freehtmlebbb4a8f-6f6c-49fc-a314-12ed5fe323f8"); } This paragraph should be hidden. /*PROUDLY CANADIAN CODE*/ .pencil-banner__image { width: 22.5rem !important; height: auto !important; margin-right: 8px !important; } .container_mobile_ka { display: none; } @media (min-width: 768px) and (max-width: 1279px) { .container_mobile_ka { display: block; height: auto; display: flex; justify-content: center; align-items: center; padding: 8.5px !important; background-color: #D81E05; width: calc(100% + 48px); margin-left: -24px; margin-right: -24px; } .tag_proudly_canadian_mobile_ka { background-color: #D81E05; padding: 0 !important; margin: 0 !important; } .tag_proudly_canadian_mobile_ka img { height: 1rem; width: auto; } } @media only screen and (max-width: 767px) { .container_mobile_ka { display: block; height: auto; display: flex; justify-content: center; align-items: center; padding: 8.5px !important; background-color: #D81E05; width: calc(100% + 32px); margin-left: -16px; margin-right: -16px; } .tag_proudly_canadian_mobile_ka { background-color: #D81E05; padding: 0 !important; margin: 0 !important; } .tag_proudly_canadian_mobile_ka img { height: 1rem; width: auto; } }
Search feature is clearly displayed with great colour contrast so that the user can easily find it. It is also a big size enhancing accessibility and operation principle. Suggestions are also shown during typing and clicking tab enables you to go through the list which improves navigation and accessibility.
document.addEventListener('DOMContentLoaded', function() { const container = document.getElementById("buttons-inner-container-208634962"); function adjustAlignment() { if (container.scrollWidth > container.clientWidth) { container.style.justifyContent = 'flex-start'; // Left align when scrollbar is active } else { container.style.justifyContent = 'center'; // Center align when no scrollbar } } // Adjust alignment on load and on window resize adjustAlignment(); window.addEventListener('resize', adjustAlignment); }); div.nl-featured-tile-banner__save-text { color: #fff !important; } .theme-ctr .nl-tiles .nl-tile__full-image--embedded:hover { border: 1px solid #737373; filter: brightness(1.0) !important; } div.nl-offer-carousel.nl-offer-carousel__condensed-view { display: none; } /* CSS code for shoppable product shadow*/ div.nl-product-card__content { box-shadow: none !important; } function makeTargetedComponentVisible(componentID) { var targetedComponent = undefined; if( document.readyState !== 'loading' ) { targetedComponent = document.getElementById(componentID); if (targetedComponent) targetedComponent.style.visibility = 'visible'; } else { document.addEventListener('DOMContentLoaded', function () { targetedComponent = document.getElementById(componentID); if (targetedComponent) targetedComponent.style.visibility = 'visible'; }); } } if (window.ContextHub && ContextHub.SegmentEngine) { ContextHubJQ(function() { ContextHub.eventing.on(ContextHub.Constants.EVENT_TEASER_LOADED, function(event, data){ data.data.forEach(function(evData) { if (evData.key === "_content_canadiantire_en_home\u002Dpage_jcr_content_root_responsivegrid_slimbanner_copy_copydfb5de9b\u002D7d55\u002D4272\u002Db396\u002D14117ad6d742") { makeTargetedComponentVisible("_content_canadiantire_en_home-page_jcr_content_root_responsivegrid_slimbanner_copy_copydfb5de9b-7d55-4272-b396-14117ad6d742"); } }); }); ContextHub.SegmentEngine.PageInteraction.Teaser({ locationId: '_content_canadiantire_en_home\u002Dpage_jcr_content_root_responsivegrid_slimbanner_copy_copydfb5de9b\u002D7d55\u002D4272\u002Db396\u002D14117ad6d742', variants: [{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/default/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"Default","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/default/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/default/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/default"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-248/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-248","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-248/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-248/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/nhl-banner"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-122/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-122","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-122/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-122/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/oilers-banner"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-168/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-168","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-168/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-168/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/7dayevent--2005192941"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-697/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-697","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-697/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-697/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/8dayevent--1827729004"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-228/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-228","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-228/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-228/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/4dayevent--909306160"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-627/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-627","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-627/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-627/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/store7--1884272363"],"tags":[]},{"path":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-308/home-page-slimbanner_copy_copy","name":"home-page-slimbanner_copy_copy","title":"store-308","campaignName":"May08-GO-Headbanner","campaignPath":"/content/campaigns/canadiantire/master/May08-GO-Headbanner","thumbnail":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-308/home-page-slimbanner_copy_copy.thumb.png","id":"May08-GO-Headbanner_home-page-slimbanner_copy_copy","url":"/content/campaigns/canadiantire/master/May08-GO-Headbanner/store-308/home-page-slimbanner_copy_copy/jcr:content/par.html","campaignPriority":1,"segments":["/conf/ctcweb-ctr/settings/wcm/segments/store12-1717098755"],"tags":[]},{"path":"/content/canadiantire/en/home-page/default","name":"default","title":"Default","campaignName":"","thumbnail":"/content/canadiantire/en/home-page.thumb.png","url":"/content/canadiantire/en/home-page/_jcr_content/root/responsivegrid/slimbanner_copy_copy.default.html","campaignPriority":0,"tags":[]}], strategy: '', trackingURL: null }); // Make the targeted content visible if no teasers were loaded after 5s setTimeout(function(){ makeTargetedComponentVisible("_content_canadiantire_en_home-page_jcr_content_root_responsivegrid_slimbanner_copy_copydfb5de9b-7d55-4272-b396-14117ad6d742"); }, 5000); }); } else { makeTargetedComponentVisible("_content_canadiantire_en_home-page_jcr_content_root_responsivegrid_slimbanner_copy_copydfb5de9b-7d55-4272-b396-14117ad6d742"); } Shop Now View Flyer
Image of Top Winter Deals - Save up to 40% has Alt text when you hover over the image. It states, "Top Winter Deals. Save up to 40% on fitness, appliances, storage, and more." This further enhances the accessibility of the page following the operable principle.
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Response to Reviewer 1:
The authors introduce G2PT, a hierarchical graph transformer model that integrates genetic variants (SNPs), gene annotations, and multigenic systems (Gene Ontology) to predict and interpret complex traits.
We thank the reviewer for this accurate summary of our approach and contributions.
Major Comments:
Comment 1-1. Insufficient Specification of Model Architecture: The description of the "hierarchical graph transformer" lacks technical depth. Key implementation details are missing: how node embeddings are initialized for SNPs, genes, and systems; how graph connectivity is defined at each level (e.g., adjacency matrices used in Equations 5-9, the sparsity); justification for the choice of embedding dimension and number of attention heads, including any sensitivity analysis; and the architecture of the feed-forward neural networks (e.g., number of layers, activation functions, and hidden dimensions).
__Reply 1-1. __As requested, we have expanded the technical description of the model architecture, including the hierarchical graph transformer (HiGT), in the Materials and Methods section. Details regarding node initialization and hierarchical connectivity are now included in the new paragraph "Model Initialization and Graph Construction." Specifically, all node embeddings corresponding to SNPs, genes, and ontology-defined systems are initialized using uniform Xavier initialization (Glorot and Bengio, 2010).
We have also clarified our hyperparameter optimization strategy. Learning rate, weight decay, hidden (embedding) dimension, and the number of attention heads were selected via grid search, as summarized in new Supplementary Fig. 8, reproduced below. Based on both performance and computational efficiency, we adopted four attention heads-consistent with the configuration commonly used in academic transformer models (Vaswani et al., 2017) (the original Transformer used eight).
Regarding the feed-forward neural network, we follow the standard Transformer architecture consisting of two position-wise layers with hidden dimension four times larger than the node embedding size and a GeLU nonlinear activation function (Hendrycks and Gimpel, 2016). This configuration is widely established in the literature and functions as an intermediate processing step following attention; therefore, it is not a focus of hyperparameter tuning. All corresponding updates have been incorporated into the revised Methods section for clarity and completeness.
Comment 1-2. No Simulation Studies to Validate Epistasis Detection: The ground truth epistasis interaction should use the ones that have been manually validated by literature. The central claim of discovering epistatic interactions relies heavily on the model's attention mechanism and downstream statistical filtering. However, no simulation studies are presented to validate that G2PT can reliably detect epistasis when ground-truth interactions are known. Demonstrating robust detection of non-additive interactions under varying genetic architectures and noise levels in simulated genotype-phenotype datasets is essential to substantiate the method's core capability.
Reply 1-2. We agree that a simulation of epistasis detection using the G2PT model is a worthy addition to the manuscript. Accordingly, we have now incorporated a new section in the Results titled "Validation of Epistasis through Simulation Studies", which includes two new figures reproduced below (Supplementary Fig. 6 and Fig. 5). We have also added a new Methods section to describe this simulation study under the heading "Epistasis Simulation". These simulation studies show that G2PT recovers epistatic gene pairs with high fidelity when these pairs are coherent with the systems ontology (c.f. 'ontology coherence' in Supplementary Fig. 6, which reflects the probability that both SNPs are assigned to the same leaf system). Furthermore, G2PT outcompetes previous tools, such as PLINK-epistasis, which do not use knowledge of the systems hierarchy in the same way (Supplementary Fig 6b-d). Using simulation parameters consistent with current genome-wide association studies (n = 400,000) and understanding of heritability (h2 = 0.3 to 0.5) (Bloom et al. 2015; Speed and Evans 2023), we find that approximately 10% of all epistatic SNP pairs can be recovered at a precision of 50% (Fig. 5). We have provided the source code for this simulation study in our GitHub repository (https://github.com/idekerlab/G2PT/blob/master/Epistasis_simulation.ipynb)
Comment 1-3. Lack of Justification for Model Complexity and Missing Ablation Insights: While Supplementary Figure 2 presents ablation studies, the manuscript needs to justify the high computational cost (168 GPU hours using 4×A30 GPUs) of the full model. It remains unclear how much performance gain is specifically due to reverse propagation (Equations 8-9), which is claimed to capture biological context. The benefit of using a full Gene Ontology hierarchy versus a flat system list is not quantified. There is also no comparison between bidirectional versus unidirectional propagation. Overall, the added complexity is not empirically shown to be necessary
Reply 1-3. We thank the reviewer for prompting a clearer justification of complexity and ablations. We have now revised the Results to (i) quantify the specific value of the ontology and reverse propagation, and (ii) explain why a flat SNP→system model is computationally and biologically sub-optimal. We have added new ablation results to compare bidirectional (forward+reverse) versus forward-only propagation. Reverse propagation has little effect when epistatic pairs are within one system (ontology coherence ρ=1.0) but substantially improves retrieval when interactions span related systems (e.g., ρ≈0.8) (Figure reproduced below) A flat design scores a dense genes×systems map, ignoring known sparsity (sparse SNP→gene assignments; sparse ontology edges) and losing multi-scale context; our hierarchical formulation restricts computation to observed edges (SNP→gene→system) and aggregates signals across levels, yielding better efficiency and biological fidelity.
Comment 1-4. Non-Equivalent Benchmarking Against PRS Methods: Figure 2 compares G2PT to polygenic risk score (PRS) methods such as LDpred2 and Lassosum, but G2PT is run only on SNPs pre-filtered by marginal association (p-values between 10⁻⁵ and 10⁻⁸), while the PRS methods use genome-wide SNPs. This introduces a strong bias in G2PT's favor by effectively removing noise. A fair comparison would require: (a) running LDpred2 and Lassosum on the same pre-filtered SNP sets as G2PT, or (b) running G2PT on genome-wide or LD-pruned SNP sets. The reported superior performance of G2PT may be driven primarily by this input filtering, not the model architecture.
Reply 1-4. We appreciate the reviewer's concern regarding benchmarking equivalence. In response, we have extended our analyses to include PRS-CS (Ge et al., 2019) and SBayesRC (Zheng et al., 2024), two state-of-the-art Bayesian shrinkage methods comparable to LDpred2 and Lassosum. Although we initially attempted to run LDpred2 and Lassosum under all SNP-filtering conditions, their computational requirements at UK Biobank scale proved prohibitively time consuming. We therefore focused on PRS-CS and SBayesRC, which offer similar modeling principles with greater computational tractability. These methods have now been run at matched SNP-filtering conditions to our original study. The new results demonstrate that G2PT consistently outperforms PRS-CS and SBayesRC (new Fig. 2, reproduced below), indicating that its performance advantage is not solely attributable to SNP pre-filtering but also to its hierarchical attention-based architecture.
Comment 1-5: No Details on Hyperparameter Optimization: Although the manuscript mentions grid search for hyperparameter tuning, it provides no information about which parameters were optimized (e.g., learning rate, dropout rate, weight decay, attention dropout, FFNN dimensions), what search space was explored, or what final values were selected. There is also no assessment of how sensitive the model's performance is to these choices. Better transparency would help facilitate reproducibility
Reply 1-5. We agree with the reviewer and have expanded the manuscript to include full details of hyperparameter optimization. As described in the revised Methods section, we performed a grid search over learning rate {10−3,10−4,10−5} hidden dimension {64,128} and weight decay {0,10−5,10−3}. The results, summarized in Supplementary Fig. 8 (reproduced above), show that model performance is most sensitive to the learning rate, while hidden dimension and weight decay exert more moderate effects. Based on these findings, we selected a learning rate of 10−5, hidden dimension of 64, and weight decay of 10−3 for all subsequent experiments. Although a hidden dimension of 128 slightly improved performance, we adopted 64 to balance predictive accuracy with computational efficiency.
Comment 1-6. Absence of Control for Key Confounders: In interpreting attention scores as reflecting genetic relevance (e.g., the role of the immunoglobulin system), the model includes only age, sex, and genetic principal components as covariates. Important confounders such as BMI, alcohol use, or medication (e.g., statins) have not been controlled for. Since TG/HDL levels are strongly influenced by environment and lifestyle, it is entirely plausible that some high-attention features reflect environmental tagging, not biological causality.
Reply 1-6. In the current framework, we included age, sex, and genetic principal components to account for demographic and population-structure effects, focusing on genetic contributions within a controlled baseline. We acknowledge that non-genetic covariates can influence downstream biological states and may indirectly shape attention at the gene or system level. Accurately modeling such effects requires an extended framework where environmental variables directly modulate gene and system embeddings rather than being implicitly absorbed by the attention mechanism. We have clarified these limitations in the Discussion along with plans to incorporate explicit confounder modeling in future extensions of G2PT.
Comment 1-7. Oversimplified Treatment of SNP-to-Gene Mapping: The SNP-to-gene mapping strategy combines cS2G, eQTL, and nearest-gene annotations, but the limitations of this approach are not adequately addressed. The manuscript does not specify how conflicts between methods are resolved or what fraction of SNPs map ambiguously to multiple genes. Supplementary Figure 2 shows model performance degrades when using only nearest-gene mapping, but there is no systematic analysis of how mapping uncertainties propagate through the hierarchy and affect attention or interpretation.
Reply 1-7. In the revision (Results), we have clarified how conflicts between cS2G, eQTL, and nearest-gene annotations are resolved, and we have reported the proportion of SNPs that map to multiple genes across these three annotation approaches. We note that the hierarchical attention mechanism enables the model to prioritize among alternative gene mappings in a data-driven manner, and this is a major strength of the approach. As shown in Fig. 3 (Results, reproduced below), SNP-to-gene attention weights reveal dominant linkages, reducing the impact of mapping uncertainty on interpretation. We now explicitly describe this mechanism and acknowledge that further work in probabilistic mapping and fine-mapping approaches is a valuable future direction for improving resolution and interpretability.
"For SNPs with several potential SNP-to-gene mappings (Methods), we found that G2PT often prioritized one of these genes in particular due to its membership in a high-attention system. For example, the chr11q23.3 locus contains multiple genes including the APOA1/C3/A4/A5 gene cluster (Fig. 3c) which is well-known to govern lipid transport, an important system for G2PT predictions (Fig. 3a). Due to high linkage disequilibrium in the region, all of its associated SNPs had multiple alternative gene mappings available. For example, SNP rs1145189 mapped not only to APOA5 but to the more proximal BUD13, a gene functioning in spliceosomal assembly (a system receiving substantially lower G2PT attention). Here, the relevant information flow learned by G2PT was from rs1145189 to APOA5 to lipid transport and protein-lipid complex remodeling (Fig. 3c; and conversely, deprioritizing BUD13 as an effector gene for TG/HDL). We found that this particular genetic flow was corroborated by exome sequencing, which implicates APOA5 but not BUD13 in regulation of TG/HDL, using data that were not available to G2PT. Similarly, two other SNPs at this locus - rs518547 and rs11216169 - had potential mappings to their closest gene SIK3, where they reside within an intron, but also to regulatory elements for the more distant lipid transport genes APOC3 and APOA4. Here, G2PT preferentially weighted the mappings to APOC3 and APOA4 rather than to SIK3 (Fig. 3c)."
Comment 1-8. Naive Scoring of System Importance: The method used to quantify the biological relevance of systems (i.e., correlating attention scores with predicted phenotype values) risks circular reasoning. Since the model is trained to optimize prediction, systems that contribute strongly to prediction will naturally show high correlation-even if they are not biologically causal. No comparison is made with established gene set enrichment methods applied to GWAS summary statistics. The approach lacks an independent benchmark to validate that the "important" systems are biologically meaningful.
Reply 1-8. As requested, we compared G2PT's system-level importance scores with results from MAGMA competitive gene-set analysis, an established enrichment approach. This analysis indeed shows significant correlation between the systems identified by the two approaches (ρ = 0.26, p .01; Supplementary Table. 2), reflecting a shared emphasis on canonical lipid processes. We also observed systems detected by G2PT but not strongly detected by MAGMA's linear enrichment model-for example, the lipopolysaccharide-mediated signaling pathway (Kalita et al. 2022)
Comment 1-9. No External Validation to Assess Generalizability. All evaluations are performed using cross-validation within the UK Biobank. There is no assessment of generalizability to independent cohorts or diverse ancestries. Given population structure, genotyping platform, and phenotype measurement variability, external validation is essential before claiming the method is suitable for broader use in polygenic risk assessment.
Reply 1-9. To externally validate the G2PT model requires individual level genotype data with paired TG/HDL measurements, sample size at the scale of the UK Biobank, and GPU access to this data. Thus, we approached the All of Us program, a large and diverse cohort with individual level data and T2D conditions with HbA1C measurements. We first processed the All of Us genotype and phenotype data as we had processed UKBB data (Methods), resulting in 41,849 participants with T2D and 80,491 without T2D across various ethnicities. We then transferred the trained T2D G2PT model to the AoU Workbench and evaluated its performance. The model demonstrated robust discriminative capability with an explained variance of 0.025, as shown in the new Fig. 2d, (reproduced above).
Comment 1-10. Computational Burden and Scalability Are Not Addressed: The paper notes that training the model requires 168 GPU hours on 4×A30 GPUs for just ~5,000 SNPs. However, there is no discussion of whether G2PT can scale to larger SNP sets (e.g., genome-wide imputed data) or more complex biological hierarchies (e.g., Reactome pathways). Without addressing scalability, the model's applicability to real-world, large-scale genomic datasets remains unclear.
Reply 1-10. We have addressed scalability with both engineering optimizations and new scalability experiments. First, we refactored the model to use the xFormer memory-efficient attention for the hierarchical graph transformer (Lefaudeux et al., 2022), which also helps full parallelization of training, reducing bottlenecks. Second, we added a scaling study with progressively increasing SNP count. On 4×A30 GPUs, end-to-end training time for the 5k-SNP setting decreased from 4000 to 400 min. (approximately 7 GPU-hours, ×10). These new results are given in Supplementary Fig. 7, reproduced below.
Minor Comment:
Comment 1-11. Attention Weights as Mechanistic Insight: The paper equates high attention scores with biological importance, for example in highlighting the immunoglobulin system. There is no causal validation showing that altering the highlighted SNPs, genes, or systems has an actual effect on TG/HDL. Attention weights in transformer models are known to sometimes reflect spurious correlations, especially in high-dimensional settings. The correlation between attention scores and predictions (Supplementary Fig. 3a,b) does not constitute biological evidence. The interpretability claims can be restated without supporting functional or causal validation.
Reply 1-11. We thank the reviewer for this thoughtful comment. We agree that attention weights are not causal evidence. In the revision, we (1) reframe attention-based findings as hypothesis-generating rather than mechanistic, and (2) add an explicit limitation noting that correlations between attention scores and predictions do not constitute biological validation.
Response to Reviewer 2:
This manuscript describes the introduction of the Genotype-to-Phenotype Transformer (G2PT), described by the authors as "a framework for modeling hierarchical information flow among variants, genes, multigenic systems, and phenotypes." The authors used the ratio TG/HDL as a trait for proof of concept of this tool.
This is a potentially interesting computational tool of interest to bioinformaticians, computational genomicists, and biologists.
We thank the reviewer for their overall positive assessment of our study.
Comment 2-1. The rationale for choosing the TG/HDL ratio for this proof of concept analysis is not well justified beyond it being a marker for insulin resistance. Overall the use of a ratio may be problematic (see below). Analyses of TG and HDL separately as individual quantitative traits would be of interest. And an analysis of a dichotomous clinical trait (T2DM or CAD) would also be of great interest.
Reply 2-1. We thank the reviewer for this suggestion. In the revised manuscript, we have expanded our analyses beyond the TG/HDL ratio to include TG and HDL as individual quantitative traits (Fig. 2, reproduced below). These additional analyses demonstrate that G2PT captures predictive signals robustly across each lipid component, not solely through their ratio. Furthermore, to address the reviewer's interest in clinical outcomes, we incorporated an analysis of type 2 diabetes (T2D) as a dichotomous trait of direct clinical relevance. Collectively, these results strengthen the rationale for our chosen phenotype and show that the G2PT framework generalizes effectively across quantitative and binary traits, consistently outperforming advanced PRS and machine learning benchmarks.
Comment 2-2. The approach to mapping SNPs to genes does not incorporate the most advanced approaches. This should be described in more detail.
Reply 2-2. We agree that the choice of SNP-to-gene mapping materially affects both performance and interpretability-indeed, our epistasis simulations suggest that more accurate mappings can improve recovery and localization. In this proof-of-concept work we use a straightforward, modular mapping sufficient to demonstrate the modeling framework, and we have clarified this in the Methods. The architecture is designed to plug-and-play alternative SNP-to-gene maps (e.g., eQTL/colocalization-based assignments, promoter-capture Hi-C). A dedicated follow-up study will systematically compare these alternatives and quantify their impact on attribution and downstream discovery.
Comment 2-3. The example of gene prioritization at the A1/C3/A4/A5 gene locus is not particularly illuminating, as the prioritized genes are already well-known to influence TG and HDL-C levels and the TG/HDL ratio. Can the authors provide an example where G2PT prioritized a gene at a locus that is not already a well-known regulator of TG and HDL metabolism?
Reply 2-3. We thank the reviewer for this suggestion. We have revised the manuscript to de-emphasize the well-established APOA1 locus and instead highlight the less expected "Positive regulation of immunoglobulin production" system (Figure 3a,b, Discussion). Here our model prioritizes the gene TNFSF13 based on specific variants that are not previously associated with TG or HDL (e.g., rs5030405, rs1858406, shown in blue). This finding points to an intriguing, non-canonical link between B-cell regulation and lipid metabolism. While full exploration of this finding is beyond the scope of the present methods paper, this example demonstrates G2PT's ability to identify novel, high-priority candidates in atypical systems.
Comment 2-4. The identification of epistatic interactions is a potentially interesting application of G2PT. However, suppl table 1 shows a very limited number of such interactions with even fewer genes, and most of these are well established biological interactions (such as LPL/apoA5). The TGFB1 and FKBP1A interaction is interesting and should be discussed. What is needed for increasing the number of potential interactions, greater power?
Reply 2-4. We are glad the reviewer appreciates the use of the G2PT model to identify epistatic interactions. We have now discussed a potential mechanism of epistasis between TGFB1 and FKBP1A in the protein dephosphorylation system (Discussion). In addition, we have addressed the reviewer's question about statistical power through extensive epistasis simulations (Fig. 5 and Supplementary Fig. 6), which show that G2PT's detection ability scales strongly with sample size-1,000 samples are insufficient, performance improves at 5,000, and power becomes reliable at 100,000. Realistic simulations (Fig. 5b-d) further demonstrate that under biologically plausible architectures, G2PT can robustly recover specific interactions even within complex genetic backgrounds
Comment 2-5. Furthermore, the use of the TG/HDL ratio for the assessment of epistatic interactions may be problematic. For example, if one SNP affected only TG and the other only HDL-C, it would appear to be an epistatic interaction with regard to the ratio, although the biological epistasis may be limited to non-existent.
Reply 2-5. We have greatly expanded the example phenotypes modeled in our study, Please see our reply 2-1 above.
Response to Reviewer 3:
This manuscript by Lee et al provides a sensible and powerful approach to polygenic score prediction. The model aggregates information from SNPs to genes to systems, using a transformer based architecture, which appears to increase predictive performance, produce interpretable outputs of genes and systems that underlie risk, and identify candidates for epistasis tests.
I think the manuscript is clear and well written, and conducted via state-of-the-art approaches. I don't have any concerns regarding the claims that are made.
We thank the reviewer for their very positive assessment of our study.
Major comments:
Comment 3-1. Specifically, lipid based traits are perhaps the most well-powered and the most biologically coherent; they are also very well-studied biologically and thus overrepresented in the gene ontology. It is unclear whether this approach will work as well for a trait like Schizophrenia for which the underlying pathways are not as well captured in existing ontologies. The authors anticipate this in their limitations section, and I am not expecting them to solve every issue with this, but it would be nice to expand the testing a little bit beyond only this one trait.
Reply 3-1. We appreciate the reviewer's suggestion to expand beyond a single lipid trait. In the revised manuscript, we have included analyses of additional phenotypes, including low-density lipoprotein (LDL) and T2D (Fig. 2). These additions demonstrate the broader applicability of our framework beyond a single trait class.
Comment 3-2. It also seems like the authors have not compared their method to the truly latest PRS methods, such as PRS-CSx and SBayesR. I would suggest adding some of the methods shown to be the best from this recent paper: https://www.nature.com/articles/s41598-025-02903-1
Reply 3-2. We agree these are important comparators. Accordingly, we have extended our comparison to include PRS‑CS (Ge et al., 2019) and SBayesRC (Zheng et al., 2024), following its strong performance demonstrated in recent benchmarking studies (see Figure 2 above). We confirmed that G2PT outperforms advanced PRS methods for all TG/HDL ratio, LDL, and T2D phenotypes.
Comment 3-3. Another major comment regards whether this method could be applied to traits with just GWAS summary statistics, rather than individual level data. This would not enable identification of specific methods underlying an individual, but it could still learn SNP based weights that could be mapped to genes and systems that could help explain risk when the model is applied to individuals (kind of like a pretraining step?)
Reply 3-3. We appreciate this suggestion. While SNP weights from GWAS summary statistics could, in principle, serve as informative priors for attention values, incorporating them would require a sophisticated mathematical formulation that is beyond the scope of this study. Our current framework also relies on individual-level genotype and phenotype data to capture multilevel information flow and individual-specific variation.
Minor comments:
Comment 3-4. Why the need to constrain to a small number of SNPs? Is it just computational cost? If so, what would happen as power increases and more SNPs exceed the thresholds used?
Reply 3-4. Yes, it's about computational cost, but we've now modified the code for improved computational efficiency. First, we refactored the model to use the xFormer memory-efficient attention for the hierarchical graph transformer (Lefaudeux et al., 2022), which also helps full parallelization of training, reducing bottleneck effects. Second, we added a scaling study of the impact of varying SNP count. On 4×A30 GPUs, end-to-end training time for the 5k-SNP setting decreased from 65 hours to 7 GPU-hours (×9). We expect performance can potentially increase if more SNPs are provided to the model based on Fig. 2 (reproduced above). With the optimized implementation, users can raise SNP thresholds as power increases; the expected behavior is improved accuracy up to a plateau, while hierarchical sparsity maintains training tractability and ensures well-regularized results.
Comment 3-5. What type of sample size/power does this method require to work well? If others were to use it, how many SNPs/samples would be needed to obtain good performance?
Reply 3-5. To address this comment, we quantified performance as a function of training size by subsampling the cohort and retraining G2PT with identical architecture and SNP set. New Supplementary Fig. 3 (reproduced below) shows monotonic gains with sample size across three representative phenotypes. We found that stable performance is reached by ~100k samples. These trends hold for continuous traits (TG/HDL, LDL) and more modestly for a binary trait (T2D), consistent with lower per-sample information for case-control settings.
open source
C'est un terme qui est déjà très reconnu, donc je ne pense pas que ce soit nécessaire de le remplacer. Toutefois, si on souhaite privilégier une option en français, je proposerais "à code source ouvert".
"However, exactly how many triplets code amino acids and how many have other functions we are unable to say." This makes more sense in relation to a comment I made at the very beginning of the paper. Still, the fact that the idea was even suggested during this period of time is impressive.
"The code is probably degenerate; that is, in general, one particular amino-acid can coded by one of several triplets of bases." I think it's really interesting that Crick and the other researchers apart of this paper were able to glean such an advanced concept for the 1960s.
Author response:
The following is the authors’ response to the latest reviews:
"One remaining question is the interpretation of matching variants with very low stable posterior probabilities (~0), which the authors have analyzed in detail but without fully conclusive findings. I agree with the authors that this event is relatively rare and the current sample size is limited but this might be something to keep in mind for future studies."
Fine-mapping stability – on matching variants with very low stable posterior probability
We thank Reviewer 2 for encouraging us to think more about how low stable posterior probability matching variants can be interpreted. We describe a few plausible interpretations, even though – as Reviewer 2 and we have both acknowledged – our present experiments do not point to a clear and conclusive account.
One explanation is that the locus captured by the variant might not be well-resolved, in the sense that many correlated variants exist around the locus. Thus, the variant itself is unlikely causal, but the set of variants in high LD with it may contain the true causal variant, or it's possible that the causal variant itself was not sequenced but lies in that locus. A comparison of LD patterns across ancestries at the locus would be helpful here.
Another explanation rests on the following observation. For a variant to be matching between top and stable PICS and to also have very small stable PP, it has to have the largest PP after residualization on the ALL slice but also have positive PP with gene expression on many other slices. In other words, failing to control for potential confounders shrinks the PP. If one assumes that the matching variant is truly causal, then our observation points to an example of negative confounding (aka suppressor effect). This can occur when the confounders (PCs) are correlated with allele dosage at the causal variant in a different direction than their correlation with gene expression, so that the crude association between unresidualized gene expression and causal variant allele dosage is biased toward 0.
Although our present study does not allow us to systematically confirm either interpretation – since we found that matching variants were depleted in causal variants in our simulations, violating the second argument, but we also found functional enrichment in analyses of GEUVADIS data though only 17 matching variants with low stable PP were reported – we believe a larger-scale study using larger cohort sizes (at least 1000 individuals per ancestry) and many more simulations (to increase yield of such cases) would be insightful.
———
The following is the authors’ response to the original reviews:
Reviewer #1:
Major comments:
(1) It would be interesting to see how much fine-mapping stability can improve the fine-mapping results in cross-population. One can simulate data using true genotype data and quantify the amount the fine-mapping methods improve utilizing the stability idea.
We agree, and have performed simulation studies where we assume that causal variants are shared across populations. Specifically, by mirroring the simulation approach described in Wang et al. (2020), we generated 2,400 synthetic gene expression phenotypes across 22 autosomes, using GEUVADIS gene expression metadata (i.e., gene transcription start site) to ensure largely cis expression phenotypes were simulated. We additionally generated 1,440 synthetic gene expression phenotypes that incorporate environmental heterogeneity, to motivate our pursuit of fine-mapping stability in the first place (see Response to Reviewer 2, Comment 6). These are described in Results section “Simulation study”:
We evaluated the performance of the PICS algorithm, specifically comparing the approach incorporating stability guidance against the residualization approach that is more commonly used — similar to our application to the real GEUVADIS data. We additionally investigated two ways of “combining” the residualization and stability guidance approaches: (1) running stability-guided PICS on residualized phenotypes; (2) prioritizing matching variants returned by both approaches. See Response to Reviewer 2, Comment 5.
(2) I would be very interested to see how other fine-mapping methods (FINEMAP, SuSiE, and CAVIAR) perform via the stability idea.
Thank you for this valuable comment. We ran SuSiE on the same set of simulated datasets. Specifically, we ran a version that uses residualized phenotypes (supposedly removing the effects of population structure), and also a version that incorporates stability. The second version is similar to how we incorporate stability in PICS. We investigated the performance of Stable SuSiE in a similar manner to our investigation of PICS. First we compared the performance relative to SuSiE that was run on residualized phenotypes. Motivated by our finding in PICS that prioritizing matching variants improves causal variant recovery, we did the same analysis for SuSiE. This analysis is described in Results section “Stability guidance improves causal variant recovery in SuSiE.”
We reported overall matching frequencies and causal variant recovery rates of top and stable variants for SuSiE in Figures 2C&D.
Frequencies with which Stable and Top SuSiE variants match, stratified by the simulation parameters, are summarized in Supplementary File 2C (reproduced for convenience in Response to Reviewer 2, Comment 3). Causal variant recovery rates split by the number of causal variants simulated, and stratified by both signal-to-noise ratio and the number of credible sets included, are reported in Figure 2—figure supplements 16-18. We reproduce Figure 2—figure supplement 18 (three causal variants scenario) below for convenience. Analogous recovery rates for matching versus non-matching top or stable variants are reported in Figure 2—figure supplements 19, 21 and 23.
(3) I am a little bit concerned about the PICS's assumption about one causal variant. The authors mentioned this assumption as one of their method limitations. However, given the utility of existing fine-mapping methods (FINEMAP and SuSiE), it is worth exploring this domain.
Thank you for raising this fair concern. We explored this domain, by considering simulations that include two and three causal variants (see Response to Reviewer 2, Comment 3). We looked at how well PICS recovers causal variants, and found that each potential set largely does not contain more than one causal variant (Figure 2—figure supplements 20 and 22). This can be explained by the fact that PICS potential sets are constructed from variants with a minimum linkage disequilibrium to a focal variant. On the other hand, in SuSiE, we observed multiple causal variants appearing in lower credible sets when applying stability guidance (Figure 2—figure supplements 21 and 23). A more extensive study involving more fine-mapping methods and metrics specific to violation of the one causal variant assumption could be pursued in future work.
Reviewer #2:
Aw et al. presents a new stability-guided fine-mapping method by extending the previously proposed PICS method. They applied their stability-based method to fine-map cis-eQTLs in the GEUVADIS dataset and compared it against what they call residualization-based method. They evaluated the performance of the proposed method using publicly available functional annotations and claimed the variants identified by their proposed stability-based method are more enriched for these functional annotations.
While the reviewer acknowledges the contribution of the present work, there are a couple of major concerns as described below.
Major:
(1) It is critical to evaluate the proposed method in simulation settings, where we know which variants are truly causal. While I acknowledge their empirical approach using the functional annotations, a more unbiased, comprehensive evaluation in simulations would be necessary to assess its performance against the existing methods.
Thank you for this point. We agree. We have performed a simulation study where we assume that causal variants are shared across populations (see response to Reviewer 1, Comment 1). Specifically, by mirroring the simulation approach described in Wang et al. (2020), we generated 2,400 synthetic gene expression phenotypes across 22 autosomes, using GEUVADIS gene expression metadata (i.e., gene transcription start site) to ensure cis expression phenotypes were simulated.
(2) Also, simulations would be required to assess how the method is sensitive to different parameters, e.g., LD threshold, resampling number, or number of potential sets.
Thank you for raising this point. The underlying PICS algorithm was not proposed by us, so we followed the default parameters set (LD threshold, r<sup>2</sup> \= 0.5; see Taylor et al., 2021 Bioinformatics) to focus on how stability considerations will impact the existing fine-mapping algorithm. We attempted to derive the asymptotic joint distribution of the p-values, but it was too difficult. Hence, we used 500 permutations because such a large number would allow large-sample asymptotics to kick in. However, following your critical suggestion we varied the number of potential sets in our analyses of simulated data. We briefly mention this in the Results.
“In the Supplement, we also describe findings from investigations into the impact of including more potential sets on matching frequency and causal variant recovery…”
A detailed write-up is provided in Supplementary File 1 Section S2 (p.2):
“The number of credible or potential sets is a parameter in many fine-mapping algorithms. Focusing on stability-guided approaches, we consider how including more potential sets for stable fine-mapping algorithms affects both causal variant recovery and matching frequency in simulations…
Causal variant recovery. We investigate both Stable PICS and Stable SuSiE. Focusing first on simulations with one causal variant, we observe a modest gain in causal variant recovery for both Stable PICS and Stable SuSiE, most noticeably when the number of sets was increased from 1 to 2 under the lowest signal-to-noise ratio setting…”
We observed that increasing the number of potential sets helps with recovering causal variants for Stable PICS (Figure 2—figure supplements 13-15). This observation also accounts for the comparable power that Stable PICS has with SuSiE in simulations with low signal-to-noise ratio (SNR), when we increase the number of credible sets or potential sets (Figure 2—figure supplements 10-12).
(3) Given the previous studies have identified multiple putative causal variants in both GWAS and eQTL, I think it's better to model multiple causal variants in any modern fine-mapping methods. At least, a simulation to assess its impact would be appreciated.
We agree. In our simulations we considered up to three causal variants in cis, and evaluated how well the top three Potential Sets recovered all causal variants (Figure 2—figure supplements 13-15; Figure 2—figure supplement 15). We also reported the frequency of variant matches between Top and Stable PICS stratified by the number of causal variants simulated in Supplementary File 2B and 2C. Note Supplementary File 2C is for results from SuSiE fine-mapping; see Response to Reviewer 1, Comment 2.
Supplementary File 2B. Frequencies with which Stable and Top PICS have matching variants for the same potential set. For each SNR/ “No. Causal Variants” scenario, the number of matching variants is reported in parentheses.
Supplementary File 2C. Frequencies with which Stable and Top SuSiE have matching variants for the same credible set. For each SNR/ “No. Causal Variants” scenario, the number of matching variants is reported in parentheses.
(4) Relatedly, I wonder what fraction of non-matching variants are due to the lack of multiple causal variant modeling.
PICS handles multiple causal variants by including more potential sets to return, owing to the important caveat that causal variants in high LD cannot be statistically distinguished. For example, if one believes there are three causal variants that are not too tightly linked, one could make PICS return three potential sets rather than just one. To answer the question using our simulation study, we subsetted our results to just scenarios where the top and stable variants do not match. This mimics the exact scenario of having modeled multiple causal variants but still not yielding matching variants, so we can investigate whether these non-matching variants are in fact enriched in the true causal variants.
Because we expect causal variants to appear in some potential set, we specifically considered whether these non-matching causal variants might match along different potential sets across the different methods. In other words, we compared the stable variant with the top variant from another potential set for the other approach (e.g., Stable PICS Potential Set 1 variant vs Top PICS Potential Set 2 variant). First, we computed the frequency with which such pairs of variants match. A high frequency would demonstrate that, even if the corresponding potential sets do not have a variant match, there could still be a match between non-corresponding potential sets across the two approaches, which shows that multiple causal variant modeling boosts identification of matching variants between both approaches — regardless of whether the matching variant is in fact causal.
Low frequencies were observed. For example, when restricting to simulations where Top and Stable PICS Potential Set 1 variants did not match, about 2-3% of variants matched between the Potential Set 1 variant in Stable PICS and Potential Sets 2 and 3 variants in Top PICS; or between the Potential Set 1 variant in Top PICS and Potential Sets 2 and 3 variants in Stable PICS (Supplementary File 2D). When looking at non-matching Potential Set 2 or Potential Set 3 variants, we do see an increase in matching frequencies (between 10-20%) between Potential Set 2 variants and other potential set variants between the different approaches. However, these percentages are still small compared to the matching frequencies we observed between corresponding potential sets (e.g., for simulations with one causal variant this was 70-90% between Top and Stable PICS Potential Set 1, and for simulations with two and three causal variants this was 55-78% and 57-79% respectively).
We next checked whether these “off-diagonal” matching variants corresponded to the true causal variants simulated. Here we find that the causal variant recovery rate is mostly less than the corresponding rate for diagonally matching variants, which together with the low matching frequency suggests that the enrichment of causal variants of “off-diagonal” matching variants is much weaker than in the diagonally matching approach. In other words, the fraction of non-matching (causal) variants due to the lack of multiple causal variant modeling is low.
We discuss these findings in Supplementary File 1 Section S2 (bottom of p.2).
(5) I wonder if you can combine the stability-based and the residualization-based approach, i.e., using the residualized phenotypes for the stability-based approach. Would that further improve the accuracy or not?
This is a good idea, thank you for suggesting it. We pursued this combined approach on simulated gene expression phenotypes, but did not observe significant gains in causal variant recovery (Figure 2B; Figure 2—figure supplements 2, 13 and 15). We reported this Results “Searching for matching variants between Top PICS and Stable PICS improves causal variant Recovery.”
“We thus explore ways to combine the residualization and stability-driven approaches, by considering (i) combining them into a single fine-mapping algorithm (we call the resulting procedure Combined PICS); and (ii) prioritizing matching variants between the two algorithms. Comparing the performance of Combined PICS against both Top and Stable PICS, however, we find no significant difference in its ability to recover causal variants (Figure 2B)...”
However, we also confirmed in our simulations that prioritizing matching variants between the two approaches led to gains in causal variant recovery (Figure 2D; Figure 2—figure supplements 4, 19, 20 and 22). We reported this Results “Searching for matching variants between Top PICS and Stable PICS improves causal variant Recovery.”
“On the other hand, matching variants between Top and Stable PICS are significantly more likely to be causal. Across all simulations, a matching variant in Potential Set 1 is 2.5X as likely to be causal than either a non-matching top or stable variant (Figure 2D) — a result that was qualitatively consistent even when we stratified simulations by SNR and number of causal variants simulated (Figure 2—figure supplements 19, 20 and 22)...”
This finding is consistent with our analysis of real GEUVADIS gene expression data, where we reported larger functional significance of matching variants relative to non-matching variants returned by either Top of Stable PICS.
(6) The authors state that confounding in cohorts with diverse ancestries poses potential difficulties in identifying the correct causal variants. However, I don't see that they directly address whether the stability approach is mitigating this. It is hard to say whether the stability approach is helping beyond what simpler post-hoc QC (e.g., thresholding) can do.
Thank you for raising this fair point. Here is a model we have in mind. Gene expression phenotypes (Y) can be explained by both genotypic effects (G, as in genotypic allelic dosage) and the environment (E): Y = G + E. However, both G and E depend on ancestry (A), so that Y = G|A+E|A. Suppose that the causal variants are shared across ancestries, so that (G|A=a)=G for all ancestries a. Suppose however that environments are heterogeneous by ancestry: (E|A=a) = e(a) for some function e that depends non-trivially on a. This would violate the exchangeability of exogenous E in the full sample, but by performing fine-mapping on each ancestry stratum, the exchangeability of exogenous E is preserved. This provides theoretical justification for the stability approach.
We next turned to simulations, where we investigated 1,440 simulated gene expression phenotypes capturing various ways in which ancestry induces heterogeneity in the exogenous E variable (simulation details in Lines 576-610 of Materials and Methods). We ran Stable PICS, as well as a version of PICS that did not residualize phenotypes or apply the stability principle. We observed that (i) causal variant recovery performance was not significantly different between the two approaches (Figure 2—figure supplements 24-32); but (ii) disagreement between the approaches can be considerable, especially when the signal-to-noise ratio is low (Supplementary File 2A). For example, in a set of simulations with three causal variants, with SNR = 0.11 and E heterogeneous by ancestry by letting E be drawn from N(2σ,σ<sup>2</sup>) for only GBR individuals (rest are N(0,σ<sup>2</sup>)), there was disagreement between Potential Set 1 and 2 variants in 25% of simulations — though recovery rates were similar (Probability of recovering at least one causal variant: 75% for Plain PICS and 80% for Stable PICS). These points suggest that confounding in cohorts can reduce power in methods not adjusting or accounting for ancestral heterogeneity, but can be remedied by approaches that do so. We report this analysis in Results “Simulations justify exploration of stability guidance”
In the current version of our work, we have evaluated, using both simulations and empirical evidence, different ways to combine approaches to boost causal variant recovery. Our simulation study shows that prioritizing matching variants across multiple methods improves causal variant recovery. On GEUVADIS data, where we might not know which variants are causal, we already demonstrated that matching variants are enriched for functional annotations. Therefore, our analyses justify that the adverse consequence of confounding on reducing fine-mapping accuracy can be mitigated by prioritizing matching variants between algorithms including those that account for stability.
(7) For non-matching variants, I wonder what the difference of posterior probabilities is between the stable and top variants in each method. If the difference is small, maybe it is due to noise rather than signal.
We have reported differences in posterior probabilities returned by Stable and Top PICS for GEUVADIS data; see Figure 3—figure supplement 1. For completeness, we compute the differences in posterior probabilities and summarize these differences both as histograms and as numerical summary statistics.
Potential Set 1
- Number of non-matching variants = 9,921
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 1.
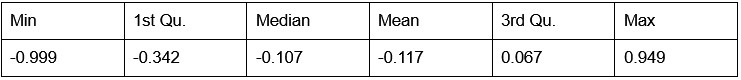
- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 1.
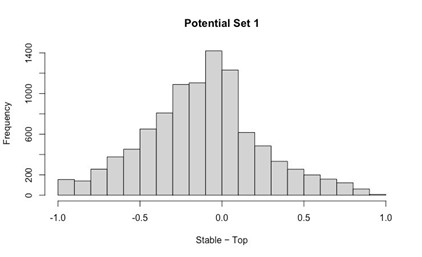
Potential Set 2
- Number of non-matching variants = 14,454
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 2.

- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 2.
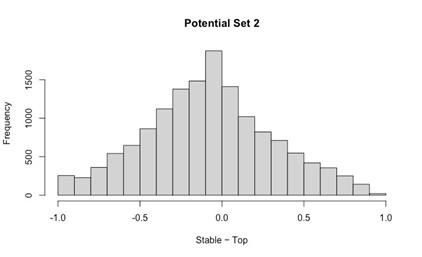
Potential Set 3
- Number of non-matching variants = 16,814
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 3.

- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 3.
We also compared the difference in posterior probabilities between non-matching variants returned by Stable PICS and Top PICS for our 2,400 simulated gene expression phenotypes. Focusing on just Potential Set 1 variants, we find two equally likely scenarios, as demonstrated by two distinct clusters of points in a “posterior probability-posterior probability” plot. The first is, as pointed out, a small difference in posterior probability (points lying close to y=x). The second, however, reveals stable variants with very small posterior probability (of order 4 x 10<sup>–5</sup> to 0.05) but with a non-matching top variant taking on posterior probability well distributed along [0,1]. Moving down to Potential Sets 2 and 3, the distribution of pairs of posterior probabilities appears less clustered, indicating less tendency for posterior probability differences to be small ( Figure 2—figure supplement 8).
Here are the histograms and numerical summary statistics.
Potential Set 1
- Number of non-matching variants = 663 (out of 2,400)
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 4.

- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 4.
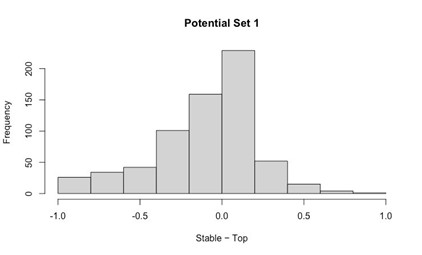
Potential Set 2
Number of non-matching variants = 1,429 (out of 2,400)
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 5.

- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 5.
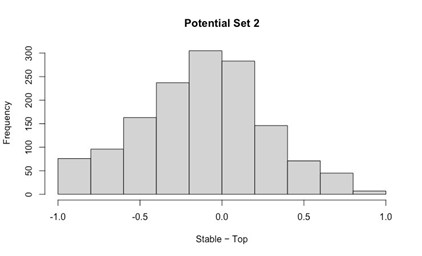
Potential Set 3
- Number of non-matching variants = 1,810 (out of 2,400)
- Table of Summary Statistics of (Stable Posterior Probability – Top Posterior Probability)
Author response table 6.
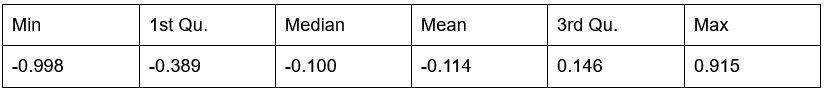
- Histogram of (Stable Posterior Probability – Top Posterior Probability)
Author response image 6.
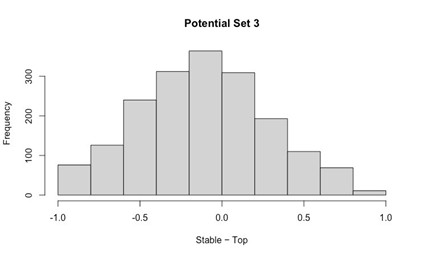
(8) It's a bit surprising that you observed matching variants with (stable) posterior probability ~ 0 (SFig. 1). What are the interpretations for these variants? Do you observe functional enrichment even for low posterior probability matching variants?
Thank you for this question. We have performed a thorough analysis of matching variants with very low stable posterior probability, which we define as having a posterior probability < 0.01 (Supplementary File 1 Section S11). Here, we briefly summarize the analysis and key findings.
Analysis
First, such variants occur very rarely — only 8 across all three potential sets in simulations, and 17 across all three potential sets for GEUVADIS (the latter variants are listed in Supplementary 2E). We begin interpreting these variants by looking at allele frequency heterogeneity by ancestry, support size — defined as the number of variants with positive posterior probability in the ALL slice* — and the number of slices including the stable variant (i.e., the stable variant reported positive posterior probability for the slice).
*Note that the stable variant posterior probability need not be at least 1/(Support Size). This is because the algorithm may have picked a SNP that has a lower posterior probability in the ALL slice (i.e., not the top variant) but happens to appear in the most number of other slices (i.e., a stable variant).
For variants arising from simulations, because we know the true causal variants, we check if these variants are causal. For GEUVADIS fine-mapped variants, we rely on functional annotations to compare their relative enrichment against other matching variants that did not have very low stable posterior probability.
Findings
While we caution against generalizing from observations reported here, which are based on very small sample sizes, we noticed the following. In simulations, matching variants with very low stable posterior probability are largely depleted in causal variants, although factors such as the number of slices including the stable variant may still be useful. In GEUVADIS, however, these variants can still be functionally enriched. We reported three examples in Supplementary File 1 Section S11 (pp. 8-9 of Supplement), where the variants were enriched in either VEP or biologically interpretable functional annotations, and were also reported in earlier studies. We partially reproduce our report below for convenience.
“However, we occasionally found variants that stand out for having large functional annotation scores. We list one below for each potential set.
- Potential Set 1 reported the variant rs12224894 from fine-mapping ENSG00000255284.1 (accession code AP006621.3) in Chromosome 11. This variant stood out for lying in the promoter flanking region of multiple cell types and being relatively enriched for GC content with a 75bp flanking region. This variant has been reported as a cis eQTL for AP006632 (using whole blood gene expression, rather than lymphoblastoid cell line gene expression in this study) in a clinical trial study of patients with systemic lupus erythematosus (Davenport et al., 2018). Its nearest gene is GATD1, a ubiquitously expressed gene that codes for a protein and is predicted to regulate enzymatic and catabolic activity. This variant appeared in all 6 slices, with a moderate support size of 23.
- Potential Set 2 reported the variant rs9912201 from fine-mapping ENSG00000108592.9 (mapped to FTSJ3) in Chromosome 17. Its FIRE score is 0.976, which is close to the maximum FIRE score reported across all Potential Set 2 matching variants. This variant has been reported as a SNP in high LD to a GWAS hit SNP rs7223966 in a pan-cancer study (Gong et al., 2018). This variant appeared in all 6 slices, with a moderate support size of 32.
- Potential Set 3 reported the variant rs625750 from fine-mapping ENSG00000254614.1 (mapped to CAPN1-AS1, an RNA gene) in Chromosome 11. Its FIRE score is 0.971 and its B statistic is 0.405 (region under selection), which lie at the extreme quantiles of the distributions of these scores for Potential Set 3 matching variants with stable posterior probability at least 0.01. Its associated mutation has been predicted to affect transcription factor binding, as computed using several position weight matrices (Kheradpour and Kellis, 2014). This variant appeared in just 3 slices, possibly owing to the considerable allele frequency difference between ancestries (maximum AF difference = 0.22). However, it has a small support size of 4 and a moderately high Top PICS posterior probability of 0.64.
To summarize, our analysis of GEUVADIS fine-mapped variants demonstrates that matching variants with very low stable posterior probability could still be functionally important, even for lower potential sets, conditional on supportive scores in interpretable features such as the number of slices containing the stable variant and the posterior probability support size…”
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reviewer #1
Evidence, reproducibility and clarity
__Summary
Köver et al. examine the genetic and environmental underpinnings of multicellular-like phenotypes (MLPs) in fission yeast, studying 57 natural isolates of Schizosaccharomyces pombe. They uncover that a noteworthy subset of these isolates can develop MLPs, with the extent of these phenotypes varying according to growth media. Among these, two strains demonstrate pronounced MLP across a range of conditions. By genetically manipulating one strain with an MLP phenotype (distinct from the previously mentioned two strains), they provide evidence that genes such as MBX2 and SRB11 play a direct role in MLP formation, strengthening their genetic mapping findings. The study also reveals that while some key genes and their phenotypic effects are strikingly similar between budding and fission yeast, other aspects of MLP formation are not conserved, which is an intriguing finding.
Overall, the manuscript is well-written, dense yet logically structured, and the figures are well presented. The combination of phenotypic, genetic, and bioinformatics analyses, particularly from wet lab experiments, is commendable. The study addresses a significant gap in our understanding, primarily explored in budding yeast, by providing comprehensive data on MLP diversity in fission yeast and the interplay of genetic and environmental factors.
In summary, I enjoyed reading the manuscript and have only a few minor suggestions to strengthen the paper:
Minor revisions:
- Although this may seem like a minor revision, but it is a crucial point. Please make sure that all raw data used to generate figures, run stats, sequence data, and scripts used to run data analysis are made publicly available. Provide relevant accession numbers and links to public data repositories. It is important that others can download the various types of data that went into the major conclusions of this paper in order to replicate your analysis or expand upon the scope of this work. I am not sure if the journal has a policy regarding this, but it should be followed to allow for transparency and reproducibility of the research.__
Reply: We very much agree with the reviewer that sharing raw data and scripts is an essential part of open science. All code and data are deposited to Github (https://github.com/BKover99/S.-Pombe-MLPs) and Figshare (https://figshare.com/articles/software/S_-Pombe-MLPs/25750980), which have now been updated to reflect our revisions. Additionally, the sequenced genomes have been deposited to ENA (PRJEB69522). Where external data was used, it was properly referenced and specifically included in Supplementary Table 3.
Two out of 57 strains exhibit strong and consistent MLP across multiple environments. Providing more information on these strains (JB914 and JB953), such as their natural habitats and distinct appearances of their MLP phenotypes under varying conditions, would provide valuable insights.
First, a brief discussion highlighting what differentiates these two strains from the rest would be helpful for readers (e.g. insight into their unique genetic and environmental background that might be linked to the MLP phenotype).
Additionally, culture tube and microscopy images of these strains, similar to those presented for JB759 in Figure 2A, can be included in the supplementary materials. My reasoning is that these images could help illustrate variation or lack thereof in aggregative group size across different media.
Reply: We thank the reviewer for highlighting this issue. Our further investigation into these strains has added additional interesting insights. JB914 and JB953 were isolated from molasses in Jamaica and the exudate of Eucalyptus in Australia, respectively, though it remains unclear whether these environments are related or even selective for the ability of these strains to form MLPs. We note that the environment from which a strain is isolated is an incomplete way of assessing its ecology. Indeed, recent research suggests that the primary habitat of S. pombe is honeybee honey and suggests that bees, which may be attracted to a number of sugary substances, may be a vector by which fission yeast are transported (1). Therefore, isolation from a particular nectar or food production environment might not reflect significant ecological differences. We now refer to the location of strain isolation in the manuscript text (lines 208-209).
However, there is more to learn from the genetic backgrounds of these two strains. We found that JB914 possesses the same variant in srb11 causally related to MLPs as JB759, the MLP-forming parental strain for our QTL analysis. To understand whether the appearance of this variant in these two strains derived from a single mutation event or was a case of convergent evolution, we analysed homology between the genomes of JB759 and JB914, focusing specifically on that variant. We found an approximately 20kb region of homology between JB759 and JB914 surrounding the srb11 truncation variant, in contrast to the majority of the genome, which does not share homology between those two strains (New Supplementary Figure 9A, B)). This result suggests that, while the two strains are largely unrelated, that specific region shares a recent common ancestor and is likely a result of interbreeding across strains.
Importantly, this analysis further emphasizes the point that the srb11 variant segregates with the MLP-forming phenotype. We conclude this because none of the other strains similar to JB759 (either across the whole genome, or specifically in the region surrounding srb11) exhibit MLPs (New Supplementary Figure 9C). This thereby further complements our QTL analysis on the significance of this variant. We have added this analysis to the manuscript text (lines 337-349).
Furthermore, we searched other strains which exhibited MLPs in our experiments (e.g. JB953) for frame shifts, insertions or deletions in any other genes in the CKM module or in the genes that were identified in our deletion library screen as adhesive, and did not identify any severe mutations falling into coding regions (other than the srb11 truncation in JB914 and JB759). This indicates that MLPs in these other strains may be caused by differences in regulatory regions surrounding these genes, or variants in other genes that were not identified in our screen. We have added this analysis to our manuscript (lines 424-425) and Supplementary Table 13.
We agree that microscopy and culture tube images of JB914 and JB953 may give insight into the nature of the MLPs exhibited by those strains. We have included such images of cultures grown in YES, EMM and EMM-Phosphate media in our revision (Lines 207-208, Supplementary Figures 4 and 5). These images are consistent with our adhesion assay screen and show that JB914 and JB953 are adhesive at the microscopic level in the relevant conditions (EMM or EMM-Phosphate).
The phenotypic outcome of overexpressing MXB2 is striking, as shown in Supplementary Figure 4C. Incorporating at least one of the culture tube images depicting large flocs into the main text, perhaps adjacent to Figure 3 panel D, would improve the visual appeal and highlight this key finding (at the moment those images are only shown in the supplementary materials).
Reply: We thank the reviewer for this suggestion. In response to Reviewer 2's suggestion to overexpress mbx2 in YES, we created new mbx2 overexpression strains that could overexpress mbx2 in YES, which was not possible in our previous strain in which mbx2 overexpression was triggered by removal of thymine from the media. We have replaced our original data from Figure 3D with data from the new mbx2 overexpression experiment, including flask images.
I know that the authors discuss the knowledge gap in the intro and results, but the abstract does not mention this critical gap. Please stress this critical gap (i.e., MLPs understudied in fission yeast) with a brief sentence in the abstract. Similarly, please consider writing a brief concluding sentence summarizing the paper's most significant finding referring to the knowledge gap would provide a clearer takeaway message for the reader - the abstract ends abruptly without any conclusion.
Reply: We agree and have now emphasized the critical gap in our abstract:
"As MLP formation remains understudied in fission yeast compared to budding yeast, we aimed to narrow this gap." at lines 18-19.
Additionally, we added the following final sentence to give the reader a clearer takeaway message:
"Our findings provide a comprehensive genetic survey of MLP formation in fission yeast, and a functional description of a causal mutation that drives MLP formation in nature." at lines 31-32.
- The observation that strains with adhesive phenotypes have a lower growth rate compared to non-adhesive strains is a noteworthy point (lines 532-535). This represents yet another example of this classical trade-off. This point could be emphasized in the Discussion or alongside the relevant result, with a brief speculative explanation for this phenomenon.
Reply: We agree that the nature of the trade-off between MLP formation is an interesting discussion point that could arise from our work. Understanding this trade-off is made more complicated by the fact that growth is always condition-dependent, and measuring growth in strains exhibiting MLPs is non-trivial, as adhesion to labware and thick clumps of cells separated by regions of cell-free media can add variability. Nonetheless, there has been some previous work on this problem. In S. cerevisiae, it was shown that larger group size correlates with slower growth rate (3), and that flocculating cells grow more slowly (4). In S. cerevisiae, cAMP, a signalling molecule heavily involved in regulating growth in response to nutrient availability, also regulates filamentation (5). However, the relationship between flocculation and slow growth is not consistent in the literature. In some settings overexpressing the flocculins FLO8, FLO5, and FLO10 results in slower growth (6), while in others it does not (7). In addition, ethanol production has been shown to improve for biofilms (7).
Furthermore, in S. cerevisiae, MLP-forming cells grow better in low sucrose concentrations (8) and under various stress conditions (4). Flocculating cells have also shown faster fermentation in media containing common industrial bioproduction inhibitors, despite slower fermentation than non-flocculating cells in non-inhibitory media (9). However, any consequence of this possible advantage on growth has not been characterised.
In S. pombe, there is less work on this topic; however, it has been shown that deletions of rpl3201 and rpl3202, which code for ribosomal proteins, cause flocculation and slow growth (10). In that case, it is not clear if there is any causal relationship between slow growth and flocculation or if they are both parallel consequences of the ribosomal pathway disruption. We have added some of these points to the portion of the discussion that discusses this tradeoff (Lines 477-499).
To get a better understanding of this tradeoff in our system, we took several approaches. First, we added a supporting analysis (New Supplementary Figure 12B), using published growth data based on measurements on agar plates for the S. pombe gene deletion library (11). There, the authors defined a set of deletion strains that grow more slowly on EMM than the wild-type lab strain. We found that our MLP hit strains were significantly enriched in this "EMM-slow" category. This information is now included in the manuscript (Lines 409-413, New Supplementary Figure 12B).
It is, however, possible that for the assays from that work, the appearance of slow growth on solid agar in adhesive cells could be partially artifactual. Indeed, we have observed that adhesive cells tend to stick to flasks and, when grown on agar plates, cells in the same colony can stick to one another rather than to inoculation loops or pin pads. Both of these dynamics can reduce initial inoculation densities. This is less of a concern for our adhesion assay and Figures 2E, 5B, and 5F, because our before-wash intensity was done with a 7x7 pinned square about 10x10 mm2. Nonetheless, as we wanted to make a point about srb10 and srb11 mutants growing faster than other deletion mutants that exhibit MLP-formation, we also conducted growth assays in liquid media (New Figure 5F).
We observed that srb10Δ and srb11Δ strains (which exhibit MLPs in EMM) show growth curves similar to wild-type cells in minimal (EMM) and rich media (YES). On the other hand, other strains that grow similarly to wild type cells in YES, such as tlg2Δ and rpa12Δ, grow much more slowly in EMM when they clump together. There are also some strains, mus7Δ and kgd2Δ, that grow more slowly in both YES and EMM but are only adhesive in EMM.
The text mentions two lab strains, JB22 and JB50, displaying strong adhesion under phosphate starvation (lines 525-526), yet the data point for JB22 in Figure 2C is not labeled.
Reply: We agree that highlighting JB22 on the figure is crucial, given that it was mentioned in the main text. JB22 is now highlighted in green on Fig 2C.
- Although I generally avoid commenting on formatting, I found the manuscript to be dense. As mentioned above, I truly enjoyed reading it! But I couldn't help but think of ways to make the manuscript more concise for readers. The Results section spans nine pages (excluding figure captions), and the Discussion is five pages long. The main text contains 6 figures with approximately 27 panels and 32 plots and Venn diagrams, while the supplementary material has 11 figures with 22 panels and about 59 plots. Altogether, the manuscript comprises 17 figures, 49 panels, and roughly 91 plots and Venn diagrams! While I will not request any changes, I encourage the authors to consider streamlining the text/data where possible to focus on the core theme of the study.
We thank the reviewer for these suggestions and have reorganised some of our figures and text to appear less dense. We have also added several figures and panels in response to reviewer comments. While we endeavor to make our points clear and concise in the main figures, we believe that it is important to retain key supplementary figures so that an interested reader can evaluate the data in more detail:
A summary of our major changes to the figures is below, and we also provide a manuscript with changes tracked for the reviewers' convenience:
Fig 2:
Added Panel E in response to reviewer comments. Fig 3:
Removed axes for pfl3 and pfl7 from Fig 3C, as the point was made by the other genes displayed (mbx2, pfl8 and gsf2) Replaced Fig 3D with similar data from an improved experiment in response to reviewer comments. Added New Fig 3F from Original Supp Fig 5 Fig 5:
Moved Original Fig 5A to New Supp Fig 10A. Added New Fig 5F in response to reviewer comments. Original Supp Fig 4 / New Supp Fig 6:
Removed mbx2 overexpression images from Original Fig 4C, to be replaced by new overexpression data and images in New Fig 3D. Added flask images for srb10 and srb11 deletion mutants from Original Supp Fig 5A to New Supp Fig 6C. Added microscope image for srb11 deletion mutant from Ooriginal Supp Fig 5A to New Supp Fig 6C. Added adhesion assay results from Original Supp Fig 5C to New Supp Fig 6C. Added New Supp Fig 6D in response to review Original Supp Fig 5
Removed this figure. Original Supp Fig 5A and 5B were moved to New Supp Fig 6. Original Supp Fig 5B was removed to make the manuscript more concise. Original Supp Figs 6, 7 and 8 were combined into New Supp Fig 8.
Original Supp Fig 6A and 6B are now New Supp Fig 8A and 8B. Original Supp Fig 7 is now New Supp Fig 8C. Original Supp Fig 8A is now New Supp Fig 8D and 8E. Original Supp Fig 8B is now New Supp Fig 8F Original Supp Fig 9/New Supp Fig 10
Added Original Fig 5A as new Supp Fig 10A. Original Supp Fig 11/New Supp Fig 12
Removed Original Fig 11B and the relevant text to make the manuscript more concise. Added New Supp Fig 12B in response to reviewer comments. New Supplementary Figures added in response to reviewer comments:
New Supp Fig 4: Microscopy images of natural isolates. New Supp Fig 5: Flask images of natural isolates New Supp Fig 7: Microscopy and flask images of mbx2 overexpression strains. New Supp Fig 9: Genomic comparisons between JB759 and the MLP-forming wild isolate, JB914. Removed some less relevant points from our discussion, to reduce the length.
Added new Supplementary Tables:
Supplementary Table 13: Variants in candidate genes. Added in response to reviewer comments Supplementary Table 14: List of plasmids used in the study.
**Referees cross-commenting**
There are many useful recommendations from all the other reviewers that will help improve the final product. Once those points are revised, I think this will be a nice paper of interest to folks interested in natural variation in MLPs and its genetic background.
Significance
My expertise: evolutionary genetics, evolution of multicellularity, yeast genetics, experimental evolution
Overall, the manuscript is well-written, dense yet logically structured, and the figures are well presented. The combination of phenotypic, genetic, and bioinformatics analyses, particularly from wet lab experiments, is commendable. The study addresses a significant gap in our understanding, primarily explored in budding yeast, by providing comprehensive data on MLP diversity in fission yeast and the interplay of genetic and environmental factors.
In summary, I enjoyed reading the manuscript and have only a few minor suggestions to strengthen the paper.
Reviewer #2
Evidence, reproducibility and clarity
REVIEWER COMMENTS
Yeast species, including fission yeast and budding yeast, could form multicellular-like phenotypes (MLP). In this work, Kӧvér and colleagues found most proteins involved in MLP formation are not functionally conserved between S. pombe and budding yeast by bioinformatic analysis. The authors analyzed 57 natural S. pombe isolates and found MLP formation to widely vary across different nutrient and drug conditions. The authors demonstrate that MLP formation correlated with expression levels of the transcription factor gene mbx2 and several flocculins. The authors also show that Cdk8 kinase module and srub11 deletions also resulted in MLP formation. The experimental design is logic, the manuscript is well-written and organized. I have a few concerns that should be addressed before the publication.
Major points:
1) Line 61-62, how did the authors grow yeast cells in the liquid medium? Shaking or static? If shaking, the nutrient should be even distributed in the medium.
If static culture, most single yeast cells could precipitate on the bottom, how do you address the advantage of flocculation for increasing the sedimentation? In addition, under static culture, the bottom will have less air than the up medium, how to balance the air and nutrients?
Reply: In line 61-62 we stated that "Similarly, flocculation could increase sedimentation in liquid media, thereby assisting the search for more nutrient-rich or less stressful environments (4)".
Our intent was to speculate on the advantages of multicellular-like growth, and cited a review article which has mentioned sedimentation. After further consideration, we decided that this is a minor point and is rather speculative, and removed it altogether from the manuscript.
In response to the Reviewer's question about how cells were grown in liquid medium, throughout the paper we used shaking cultures for our flocculation assays and for pre-cultures. We have made this more clear in the text where it was ambiguous (e.g. line 189, throughout the methods section, and in the legend of Fig. 2A).
2) Line 555, it will be interesting to test whether overexpression of mbx2 could cause flocculation in YES medium. In Figure 3D, the authors use two control strains, but only one mbx2 OE strain, mbx2 OE should be tested in both strains. In addition, did the authors transform empty plasmid into the control strains, please indicate in the figure.
In this experiment, mbx2 was overexpressed using a thiamine-repressible nmt1 promoter, which is a standard construct in fission yeast studies. Assaying MLP formation was not feasible in YES with this strain, because YES is a rich media made up of yeast extract which contains thiamine. Thus, we could not remove thiamine from the media to trigger mbx2 overexpression.
In order to test the influence of mbx2 overexpression in YES, we constructed strains in which mbx2 was integrated into the genome and expression was driven by the rpl2102 promoter, which has been shown to provide constitutive moderate expression levels (12). We observed strong flocculation in both EMM and YES (Fig 3D, New Supplementary Figure 7) . We did not see strong flocculation in a control in which GFP was expressed under the rpl2102 promoter. The flocculation phenotype was so strong that our original adhesion assay protocol required modification for this experiment, including resuspension in 10 mM EDTA before repinning (Methods). We observed strong adhesion for the mbx2 overexpression strains (Fig 3D), but not for control strains in YES. We could not check adhesion in EMM for those strains because cells pinned on EMM did not survive resuspension in EDTA.
We performed these experiments in two backgrounds, 968 h90 (JB50), which is one of the parental strains of the segregant library analysed in Figure 3 and 972 h- (JB22), which is an appropriate background for the gene deletion collection.
We have replaced the data from the original Figure 3D with the new adhesion assay and added New Supplementary Figure 7 to the manuscript (Lines 236-244).
This result also helped us to further refine our model for the pathway. We can now say that the repression of MLPs in rich media must act via Mbx2, as overexpression of mbx2 is sufficient to abolish it, and is likely to act transcriptionally (if it acted on the protein level, the mild overexpression would likely not have led to the phenotype) (Figure 6, Lines 554-556 in the discussion)
3) Line 600-601, the authors may do the backcross of srb11Δ::Kan to exclude the possibility caused by other mutations.
Reply: We thank the reviewer for noticing our concern about suppressor mutations arising in the srb11Δ strain obtained from our deletion library. This initial concern arose following the observation that while qualitatively the srb11Δ::Kan and srb11Δ(CRISPR) strains were both strongly adhesive, there was a minor quantitative difference in their adhesion.
As we obtained this strain from an h+ deletion library strain backcrossed with a prototrophic h- strain (JB22) in order to restore auxotrophies (13), the chances for a suppressor mutation to arise are very low. We have therefore removed that language from our text. We now suspect that a more likely explanation for this small difference could be the strain background, as our CRISPR engineered strain was made in a JB50 background which has the h90 mating type, while the deletion library strains are h- without auxotrophic markers.
We would like to emphasize, however, that despite this quantitative difference in the adhesion phenotype between the two srb11Δ strains, they both have a large increase in the adhesion phenotype relative to the respective wild-type strains. To address this point, we have removed the unnecessary statistical comparison of these two deletion strains and focused on their qualitatively high levels of adhesion in the text (lines 267-269) and in our Revised Supplementary Figure 6D.
Minor points:
1) Line 506, what are the growth conditions of cells in Figure 2A? Did the authors use the liquid or solid medium? Please mention in the Methods or figure legends.
Reply: We have updated the manuscript to include the relevant details in the text (line 189), figure caption for Fig. 2A and in the methods section (lines 829-831).
2) Line 533-535, please explain why the strains exhibiting strong adhesion have a decreased growth rate. Is there any related research? Please add some references.
Reply: Please see reply to Reviewer 1, comment 5.
**Referees cross-commenting**
I agree with most of the comments from other reviewers. This publication may indeed be of interest to a minor area. But the results and the interpretations of the data are interesting and warranted, the findings are scientifically important.
Significance
The authors did many large-scale screens and bioinformatic analyses. The experiments in the manuscript are generally logical and sound. This study is useful for deciphering the mechanism of multicellular-like phenotype formation in the fission yeast, with some implications for some other organisms.
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
Summary: Using a variety of targeted and genome wide analyses, the authors investigate the basis for "multicellular-like phenotypes" in S. pombe. Authors developed several methodologies to detect and quantify "multicellular-like phenotypes" (flocculation, aggregation...) and defined genes involved in these processes in laboratory and wild S. pombe.
SECTION A - Evidence, reproducibility and clarity
This is a very solid manuscript that is well-written and supported by convincing data. While one can imagine many additional experiments, the manuscript stands on its own and presents a quite exhaustive analysis of the area. I commend the author for their rigorous work and clear presentation. They are only a few minor points that warrant comments or corrections: - Supplementary Figure 1 is a typical example of the "necessity" to have statistics and P-values everywhere. The data are convincing but what is the evidence that the Filtering assay and the Plate-reader assay values should be linearly related? Lets imagine that Plate-reader assay value is proportional to the square of the Filtering assay value. What would be the Pearson R and P-value in this case? What is most appropriate? Why would one use a linear correlation? What is the "real" significance?
Reply: We thank the reviewer for pointing out that the data in Supplementary Figure 1 does not appear to be linear and, therefore, reporting the Pearson correlation coefficient may not be the best way to represent the relationship between the two assays. The nonlinear nature of this data could indicate that
The filtering assay saturates before the plate reader assay, and is less able to distinguish between strains that flocculate strongly and The filtering assay may be more sensitive for strains that show lower levels of flocculation. In general, we observed fewer strains with intermediate phenotypes for both assays, making it difficult to ascertain the true relationship between them; however, we believe that the key result is that the strains with the highest level of flocculation have the highest values in both assays. To capture this aspect of the data, we now report the Spearman correlation which is non-parametric and indicates how similar the ranking of each strain is based on both assays. With the alternative hypothesis being that the correlation is > 0, we report a Spearman correlation coefficient of 0.24 and a P-value of 0.04 (lines 823-826)
- Minor points: * They are several "personal communications" in the manuscript (page 11, page 18, page 23). It should be checked whether this is accepted in the journal that publishes this manuscript.
Reply: We thank the reviewer for highlighting this issue. We had three instances of "personal communications" in our original submission.
The first instance was an acknowledgement for advice on our DNA extraction protocol from Dan Jeffares. We now include this in the Acknowledgements section instead.
The second communication with Angad Garg described that they observed flocculation while growing cells in phosphate starvation conditions, which was not reported in their publication (14). Though we appreciate their willingness to share unpublished data with us, we have removed this observation from our manuscript and instead rely only on our own observations and arguments based on their published RNA-seq data to make our point.
The third personal communication with Olivia Hillson supplements a minor hypothesis, namely that deletion of SPNCRNA.781 might cause MLP formation by affecting the promoter of hsr1, for which we had access to unpublished ChIP-seq data, showing its binding to flocculins. Recently published work from a different group (15) also suggests this link between hsr1 and flocculation and is now discussed in our manuscript instead of the result based on unpublished data obtained from personal communication at Lines 397-398.
* Page 4 check "a few regulators"
Reply: For clarity, this has now been changed to "several regulatory proteins" at Line 108. The specific proteins we are referring to are highlighted in Figure 1C.
* Page 19, line 567: "remaining 8 strains" may be confusing as Material and Methods states "remaining 10 strains".
Reply: Two of the 10 strains were found to be redundant after sequencing as explained in the Methods (Lines 930-934). Therefore, we only added 8 new strains to the analysis. We thank the reviewer for highlighting this as a potential source of misunderstanding, and clarified this point in the text (Lines 247-250 and in the methods).
**Referees cross-commenting**
I concur with most comments. Overall, the reviewers agree that this is a solid piece of work that could benefit from minor modifications and should be published. I reiterate that, for me, despite its quality, this publication will only be of interest to specialists.
Reviewer #3 (Significance (Required)):
A limited number of studies have investigated "multicellular-like phenotypes" in S. pombe. This manuscript brings therefore new and solid information. Yet, despite an impressive amount of work, our conceptual advance in understanding this process and its phylogenetic conservation remains limited. This is probably best illustrated in the figure 6 that summarize the study and contains 3 question marks and an additional unknown mechanism. (Most of the solid arrows in this figure correspond to interactions within the Mediator complex that were well known before this study.) In addition, while only few studies have been published in this area, the authors' findings are often only bringing additional support to already published observations. Overall, while this manuscript will be of interest to a restricted group of aficionados, it will most likely not attract the attention of a wide readership.
__ Reviewer #4 (Evidence, reproducibility and clarity (Required)):__
In this manuscript, the authors explore how multicellular-like phenotypes (MLPs) arise in the fission yeast S. pombe. Although yeasts are characterized as unicellular fungi, diverse species show MLPs, including filamentous growth on agar plates and flocculation in liquid media. MLPs may provide certain advantages in nutritionally poor conditions and protection against external challenges, upon which natural selection can then act. Previous work on MLPs has mostly been carried out in the budding yeasts S. cerevisiae and C. albicans, and little was known about these behaviors in S. pombe. The authors thus set out to investigate both genetic and environmental regulators of MLP formation.
First, their analysis of published data revealed a limited number of shared regulators of MLP between S. pombe, S. cerevisiae, and C. albicans, although the cell adhesion proteins themselves are largely not conserved. Next, the authors screened a set of non-clonal natural isolates using two high-throughput assays that they developed and found that MLPs vary in strains and depending on nutrient conditions. Focusing on a natural isolate that showed both adhesion on agar plates and flocculation in liquid medium, they then analyzed a segregant library generated from this and a laboratory strain using their assays. Using QTL analysis, they uncovered a frameshift in the srb11 gene, which encodes a subunit of the Mediator complex, as the likely causal inducer of MLP. This was confirmed by additional analyses of strains lacking srb11 or other members of Mediator. Furthermore, the authors showed that loss of srb11 function resulted in the upregulation of the Mbx2 transcription factor, which was both necessary and sufficient for MLP formation in this background. Finally, screening of two additional yeast strain collections (gene and long intergenic non-coding RNA deletion) identified both known and novel regulators representing different pathways that may be involved in MLP formation.
Altogether, this study provides new perspectives into our understanding of the diverse inputs that regulate multicellular-like phenotypes in yeast.
Major comments:
- The methods for screening for adhesion and flocculation are well described, with representative figures that show plates and flasks. However, there are few microscopy images of cells, and it would be interesting and helpful for the reader to have an idea of how cells look when they exhibit MLPs. For instance, are there any differences in cell shape or size when strains present different degrees of adhesion or flocculation? In addition, the authors mention that mutants with strong adhesion generally had lower colony density and are likely to be slower growing. Although their analyses suggest otherwise (page 22), this has a potential for introducing error in their observations, and including images of the adhesion/flocculation phenotypes may provide further support for their conclusions. I suggest that the authors present microscopy images 1) similar to what is shown for JB759 in Figure 2A and 2) of cells growing on agar in the adhesion assay. This could be included for the different Mediator subunit deletions that they tested, where there appear to be varying phenotypes. It could also be informative for a subset of the 31 high-confidence candidates that they identified in their screen.
Reply: We thank the reviewer for highlighting the need for further microscopic characterisation of MLP forming strains. We therefore now include images of JB914, JB953 (New Supplementary Figures 4, Figure 2E) in liquid media in EMM, EMM-Phosphate, and YES; an srb11 deletion strain (Figure 3F), and mbx2 overexpression strains (New Supplementary Figure 7).
- Upon identifying a frameshift in srb11 that is responsible for the MLP, the authors assessed whether deletion of other Mediator subunits would result in the same phenotype. They found that srb10 and srb11 deletions both flocculate and show adhesion, while other mutants had milder phenotypes. However, the authors also found that a new deletion of srb11 that they generated had a stronger adhesion phenotype than the srb11 deletion from the prototrophic deletion library, which was attributed this the accumulation of suppressor mutations in the strains of the deletion collection. As the authors make clear distinctions between the phenotypes of different Mediator mutants, I suggest generating and analyzing "clean" deletions of the 6 other subunits that they tested. This would strengthen their conclusion and help to rule out accumulated suppressors as the cause of the differences in the observed phenotypes.
Reply: We thank the reviewer for noticing our concern about suppressor mutations in the manuscript. As we describe above in response to a similar question from reviewer 2, as the prototrophic deletion library from which we extracted the Mediator deletion strains had been backcrossed during its construction (13), we no longer suspect that small difference between the srb11Δ::Kan strain from the deletion library and the newly created srb11Δ (CRISPR) strains is due to suppressor mutations. Rather, we think they may be a result of the difference in genetic background and possibly mating type between the two strains. We also want to emphasize that this difference is small compared to the difference between the adhesion ratios of the srb11Δ strains and their respective control strains.
Nevertheless, we made clean, independent Mediator mutants for 5 out of 6 Mediator genes tested (med10Δ, med13Δ, med19Δ, med27Δ, and srb10Δ) as well as an additional mutant that we didn't have in our library, med12Δ (Figure R9). When running the assay on these new strains we got an overall lower dynamic range, possibly due to variations in the water flow rate relative to the first assay. However, we saw a strong phenotype for both library and our own srb10Δ and CRISPR srb11Δ strains. We did not see a significant increase in adhesion for the other Mediator deletion mutants in EMM relative to wild type with the exception of for med10Δ in both the library strain and for our clean mutant, for which we did not observe a phenotype in our previous experiment. We included the experiment for the newly created mutants as New Supplementary Figure S6E and described them in lines 276-281 in our revised manuscript.
Minor comments:
- One point that recurs in the manuscript is the idea that mutations that give rise to strong MLPs also generally lead to slower growth, representing a potential trade-off. This idea could be reinforced with measurements of growth rate or generation time by optical density or cell number, for instance, rather than comparisons of colony density. Also, it would be interesting to mention if the slow growth phenotype is only observed in MLP-inducing conditions or also in rich medium.
Reply: As described above in response to item 5 from Reviewer 1, we have conducted growth assays in liquid media for srb10Δ, srb11Δ, and other mutants from our adhesion screen (tlg2Δ, rpa12Δ, mus7Δ and kgd2Δ) that showed a similar phenotype to those genes in both minimal (EMM) and rich (YES) media. We observe that in rich media, srb10Δ and srb11Δ cells grow similarly to control strains, and they exhibit a lower decrease in growth rate than the other similarly adhesive strains. Both mus7Δ and kgd2Δ cells grow more slowly, even in rich media.
We have also added data on the tradeoff between growth and adhesion based on growth on solid media from (11) for all mutants identified in our screen (New Supp Fig 12B)).
Thus, the relationship between slow growth and clumpiness depends on the mutation, and specifically, mutations of the Mediator, including those to srb11 and srb10, seem to decrease the impact of any tradeoff between growth and adhesion.
- The authors show that the MLPs of the srb10 and srb11 deletions occur through mbx2 upregulation. Do the varying strengths of the phenotypes of the strains lacking different Mediator subunits correlate with mbx2 levels in these backgrounds?
Reply: There is some evidence from previous work that the relationship between the strength of the MLPs and the expression of mbx2 may not be perfectly proportional. In (16), med12Δ had a higher (though qualitatively comparable) level of mbx2 upregulation than srb10Δ (New Supp Fig 8E), even though that paper reported a milder phenotype for med12Δ than for srb10Δ cells. We did not observe a significant increase in adhesion in our med12Δ strain (New Supp Fig 6D). This suggests that in the case of these mutants, it is not simply the level of mbx2 that controls MLP formation, but that there are likely additional regulatory mechanisms. We have added some discussion on this context in the manuscript (lines 545-547).
**Referees cross-commenting**
I agree overall with the comments and suggestions from the other reviewers. The revision would require only minor modifications. The paper is interesting both for the combination of methodologies used and its findings, and I believe that it would benefit a growing community of researchers.
Reviewer #4 (Significance (Required)):
This study employed a variety of methods that allowed the authors to uncover previously unknown regulators of MLPs. Taking advantage of the diversity of natural fission yeast isolates as well as the constructed gene and non-coding RNA deletion collections, the authors identified novel genetic determinants that give rise to MLPs, opening new avenues into this exciting area of research. The overall conclusions of the work are solid and supported by the reported results and analyses. This study will be appreciated by a broad audience of readers who are interested in understanding how organisms respond to environmental challenges as well as how MLPs may result in emergent properties that play key roles in these responses. Some of the limitations of the work are described above, with recommendations for addressing these points.
Keywords for my field of expertise: fission yeast, cell cycle, transcription, replication.
References for Response to Reviews
Reviewer #2 (Public review):
Summary:
Negreira et al. present an application of a novel single-cell genomics approach to investigate the genetic heterogeneity of Leishmania parasites. Leishmania, while also representing a major global disease with hundreds of thousands of cases annually, serves as a model to test the rigor of the sequencing strategy. Its complex karyotypic nature necessitates a method that is capable of resolving natural variation to better understand genome dynamics. Importantly, an earlier single-cell genomics platform (10x Chromium) is no longer available, and new methods need to be evaluated to fill in this gap.
The study was designed to evaluate whether a capsule-based cell capture method combined with primary template-directed amplification (PTA) could maintain levels of genomic heterogeneity represented in an equal mixture of two Leishmania strains. This was a high bar, given the relatively small protozoan genome and prior studies that showed limitations of single-cell genomics, especially for gene-level copy number changes. Overall, the study found that semi-permeable capsules (SPC) are an effective way to isolate high-quality single cells. Additionally, short reads from amplified genomes effectively maintained the relative levels of variation in the two strains on the chromosome, gene copy, and individual base level. Thus, this method will be useful to evaluate adaptive strategies of Leishmania. Many researchers will also refer to these studies to set up SPC collection and PTA methods for their organism of choice.
Strengths:
(1) The use of SPC and PTA in a non-bacterial organism is novel. The study displays the utility of these methods to isolate and amplify single genomes to a level that can be sequenced, despite being a motile organism with a GC-rich genome.
(2) The authors clearly outlined their optimization strategy and provided numerous quality-control metrics that inspire confidence in the success of achieving even chromosomal coverage relative to ploidy.
(3) The use of two distinct Leishmania strains with known clonal status provided strong evidence that PTA-based amplification could reflect genome differences and displayed the utility of the method for studies of rare genotypes.
(4) Evaluating the SPCs pre- and post-amplification with microscopy is a practical and robust way of determining the success of SPC formation and PTA.
(5) The authors show that the PTA-based approach easily resolved major genotypic ploidy in agreement with a prior 10x Chromium-based study. The new method had improved resolution of drug resistance genotypes in the form of both copy-number variations and single-nucleotide polymorphisms.
(6) In general, the authors are very thorough in describing the methods, including those used to optimize PTA lysis and amplification steps (fresh vs frozen cells, naked DNA vs sorted cells, etc). This demonstrates a depth of knowledge about the procedure and leaves few unanswered questions.
(7) The custom, multifaceted, computational assessment of coverage evenness is a major strength of the study and demonstrates that the authors acknowledge potential computational factors that could impact the analysis.
Weaknesses:
(1) The rationale behind some experimental/analysis choices is not well-described. For example, the rationale behind methanol fixation and heat-lysis is unclear. Additionally, the choice of various methods to assess "evenness" is not justified (e.g. why are multiple methods needed? What is the strength of each method?). Also, there is no justification for using 100k reads for subsampling. Finally, what exactly constitutes a "confidently-called SNP"?
(2) In the methods, the STD protocol lists a 15-minute amplification at 45C whereas the PTA protocol involves 10h at 37C. This is a dramatic difference in incubation time and should be addressed when comparing results from the two methods. It is not really a fair comparison when you look at coverage levels; of course, a 10-hour incubation is going to yield more reads than a 15-minute incubation.
(3) There is a lack of quantitative evaluations of the SPCs. e.g. How many capsules were evaluated to assess doublets? How many capsules were detected as Syto5 positive in a successful vs an unsuccessful experiment?
(4) The authors do not address some of the amplification results obtained under various conditions. For example, why did temperature-based lysis of STD4 lead to amplification failure? Also, what is the reason for fewer "true" cells (higher background) in the PTA samples compared to the STD samples? Is this related to issues with barcoding or, alternatively, substandard amplification as indicated by lower read amounts in some capsules (knee plots in Figure 1C)?
(5) The paper presents limited biological relevance. Without this, the paper describes an improvement in genome amplification methods and some proof-of-concept analyses. Using a 1:1 mixture of parasites with different genotypes, the authors display the utility of the method to resolve genetic diversity, but they don't seek to understand the limits of detecting this diversity. For some, the authors do not comment on the mixed karyotypes from the HU3 cells (Figure 3F) other than to state that this line was not clonal. For CNVs, the two loci evaluated were detected at relatively high copy number (according to Figure 4C, they are between 4 and 20 copies). Thus, the sensitivity of CNV detection from this data remains unclear; can this approach detect lower-level CNVs like duplications, or minor CNVs that do not show up in every cell?
(6) The authors state that Leishmania can carry extrachromosomal copies of important genes. There is no discussion about how the presence of these molecules would affect the amplification steps and CNV detection. For example, the phi29 enzyme is very processive with circular molecules; does its presence lead to overamplification and overrepresentation in the data? Is this evident in the current study? This information would be useful for organisms that carry this type of genetic element.
(7) The manuscript is missing a comparison with other similar studies in the field. For example, how does this coverage level compare to those achieved for other genomes? Can this method achieve amplification levels needed to assess larger genomes? Has there been any evaluation of base composition effects since Leishmania is a GC-rich genome?
(8) Cost is mentioned as a benefit of the SPC platform, and savings are achieved when working in a plate format, but no details are included on how this was evaluated.
(9) The Zenodo link for custom scripts does not exist, and code cannot be evaluated.
Author response:
Reviewer #1 (Public review):
Summary:
Negreira, G. et al clearly presented the challenges of conducting genomic studies in unicellular pathogens and of addressing questions related to the balance between genome integrity and instability, pivotal for survival under the stressful conditions these organisms face and for their evolutionary success. This underlies the need for powerful approaches to perform single-cell DNA analyses suited to the small and plastic Leishmania genome. Accordingly, their goal was to develop such a novel method and demonstrate its robustness.
In this study, the authors combined semi-permeable capsules (SPCs) with primary template-directed amplification (PTA) and adapted the system to the Leishmania genome, which is about 100 times smaller than the human genome and exhibits remarkable plasticity and mosaic aneuploidy. Given the size and organization of the Leishmania genome, the challenges were substantial; nevertheless, the authors successfully demonstrated that PTA not only works for Leishmania but also represents a significantly improved whole-genome amplification (WGA) method compared with standard approaches. They showed that SPCs provide a superior alternative for cell encapsulation, increasing throughput. The methodology enabled high-resolution karyotyping and the detection of fine-scale copy number variations (CNVs) at the single-cell level. Furthermore, it allowed discrimination between genotypically distinct cells within mixed populations.
Strengths:
This is a high-impact study that will likely contribute to our understanding of DNA replication and the genetic plasticity of Leishmania, including its well-documented aneuploidy, somy variations, CNVs, and SNPs - all key elements for elucidating various aspects of the parasite's biology, such as genome evolution, genetic exchange, and mechanisms of drug resistance.
Overall, the authors clearly achieved their objectives, providing a solid rationale for the study and demonstrating how this approach can advance the investigation of Leishmania's small, plastic genome and its frequent natural strain mixtures within hosts. This methodology may also prove valuable for genomic studies of other single-celled organisms.
We thank the reviewer for the positive feedback and appreciation of the potential applications for the methodology we describe here.
Weaknesses:
The discussion section could be enriched to help readers understand the significance of the work, for instance, by more clearly pointing out the obstacles to a better understanding of DNA replication in Leishmania. Or else, when they discuss the results obtained at the level of nucleotide information and the relevance of being able to compare, in their case, the two strains, they could refer to the implications of this level of precision to those studying clonal strains or field isolates, drug resistance or virulence in a more detailed way.
We thank the reviewer for the suggestions. Indeed, single-cell DNA sequencing has successfully revealed cell-to-cell variability in replication timing and fork progression in mammalian cells[1,2] and we believe that the SPC-PTA workflow could be used in similar studies in Leishmania to complement bulk-based observations[3,4]. Regarding nucleotide information, it is indeed of high relevance to detect minor circulating variants with potential virulence impact and/or effect on drug resistance which could be missed by bulk sequencing. This includes the ability to detect co-occurring variants with potential epistatic effects. These topics will be further developed in the revised version. Finally, we will explicitly discuss how this methodology can be applied beyond Leishmania, to investigate genome plasticity, adaptation, and evolutionary processes in other organisms.
Reviewer #2 (Public review):
Summary:
Negreira et al. present an application of a novel single-cell genomics approach to investigate the genetic heterogeneity of Leishmania parasites. Leishmania, while also representing a major global disease with hundreds of thousands of cases annually, serves as a model to test the rigor of the sequencing strategy. Its complex karyotypic nature necessitates a method that is capable of resolving natural variation to better understand genome dynamics. Importantly, an earlier single-cell genomics platform (10x Chromium) is no longer available, and new methods need to be evaluated to fill in this gap.
The study was designed to evaluate whether a capsule-based cell capture method combined with primary template-directed amplification (PTA) could maintain levels of genomic heterogeneity represented in an equal mixture of two Leishmania strains. This was a high bar, given the relatively small protozoan genome and prior studies that showed limitations of single-cell genomics, especially for gene-level copy number changes. Overall, the study found that semi-permeable capsules (SPC) are an effective way to isolate high-quality single cells. Additionally, short reads from amplified genomes effectively maintained the relative levels of variation in the two strains on the chromosome, gene copy, and individual base level. Thus, this method will be useful to evaluate adaptive strategies of Leishmania. Many researchers will also refer to these studies to set up SPC collection and PTA methods for their organism of choice.
Strengths:
(1) The use of SPC and PTA in a non-bacterial organism is novel. The study displays the utility of these methods to isolate and amplify single genomes to a level that can be sequenced, despite being a motile organism with a GC-rich genome.
(2) The authors clearly outlined their optimization strategy and provided numerous quality-control metrics that inspire confidence in the success of achieving even chromosomal coverage relative to ploidy.
(3) The use of two distinct Leishmania strains with known clonal status provided strong evidence that PTA-based amplification could reflect genome differences and displayed the utility of the method for studies of rare genotypes.
(4) Evaluating the SPCs pre- and post-amplification with microscopy is a practical and robust way of determining the success of SPC formation and PTA.
(5) The authors show that the PTA-based approach easily resolved major genotypic ploidy in agreement with a prior 10x Chromium-based study. The new method had improved resolution of drug resistance genotypes in the form of both copy-number variations and single-nucleotide polymorphisms.
(6) In general, the authors are very thorough in describing the methods, including those used to optimize PTA lysis and amplification steps (fresh vs frozen cells, naked DNA vs sorted cells, etc). This demonstrates a depth of knowledge about the procedure and leaves few unanswered questions.
(7) The custom, multifaceted, computational assessment of coverage evenness is a major strength of the study and demonstrates that the authors acknowledge potential computational factors that could impact the analysis.
We deeply appreciate the positive and encouraging feedback on our manuscript.
Weaknesses:
(1) The rationale behind some experimental/analysis choices is not well-described. For example, the rationale behind methanol fixation and heat-lysis is unclear. Additionally, the choice of various methods to assess "evenness" is not justified (e.g. why are multiple methods needed? What is the strength of each method?). Also, there is no justification for using 100k reads for subsampling. Finally, what exactly constitutes a "confidently-called SNP"?
The methanol fixation prior to lysis is part of the original protocol described in the Single-Microbe Genome Barcoding Kit manual and was meant to facilitate lysis and DNA denaturation in bacterial cells (for which the kit was originally developed). However, in our preliminary tests with bulk samples – described in the supplementary material – we noticed a strong negative effect on lysis efficiency/DNA recovery when parasites were fixed with methanol. Thus, we decided to test the effect of skipping this step in the single-cell DNA workflow. We kept the SPC_STD1 sample to have a safe control where the full workflow described in the kit manual was followed.
As we were unsure if the standard lysis (25 ˚C for 15 minutes) would work efficiently for Leishmania, we included the heat-lysis (99˚C for 15 minutes) as well as the longer incubation lysis (25 ˚C for 1h). These modifications were listed as validated alternatives in the kit's manual.
The 100k reads threshold was chosen based on the number of reads found in the 'true cell' with the lowest read count.
Regarding variant calling, a variant was considered confidently called if it was covered, at single-cell level, by at least one deduplicated read with Phred quality above Q30 and mapping quality (MAPQ) also above 30.
In the revised version, we will include these explanations and improve the explanation of the metrics used to estimate coverage quality.
(2) In the methods, the STD protocol lists a 15-minute amplification at 45C whereas the PTA protocol involves 10h at 37C. This is a dramatic difference in incubation time and should be addressed when comparing results from the two methods. It is not really a fair comparison when you look at coverage levels; of course, a 10-hour incubation is going to yield more reads than a 15-minute incubation.
We agree with the reviewer that the longer incubation period of PTA might explain the higher read count seen in the PTA samples, although the differences in amplification kinetics (linear in PTA, exponential in STD) and potential differences in amplification saturation points make it difficult to compare them. For instance, an updated version of PTA (ResolveDNA V2) uses a lower amplification time (2.5 h) and achieves similar amplification levels compared to the 10h incubation time, suggesting PTA amplification saturates well before the 10h time. In any case, all quality check metrics were done with the cells subsampled to 100 k reads to mitigate the effect of read count differences on the data quality.
(3) There is a lack of quantitative evaluations of the SPCs. e.g. How many capsules were evaluated to assess doublets? How many capsules were detected as Syto5 positive in a successful vs an unsuccessful experiment?
We agree with the reviewer but during experimental execution SPCs were only assessed qualitatively via microscopy following the Single-cell microbe DNA barcoding kit manual. No quantitative analysis was done and therefore we do not have this data. Regarding doublet, this was done in silico based on the detection of SPCs containing mixed genomes from the two strains used in the study as described in the Materials and Methods. As pointed by another reviewer, this only allow the detection of inter-strain doublets. In the revised version, we explain this and add an estimation of total doublets based on the inter-strain doublet rate.
(4) The authors do not address some of the amplification results obtained under various conditions. For example, why did temperature-based lysis of STD4 lead to amplification failure? Also, what is the reason for fewer "true" cells (higher background) in the PTA samples compared to the STD samples? Is this related to issues with barcoding or, alternatively, substandard amplification as indicated by lower read amounts in some capsules (knee plots in Figure 1C)?
After exchange with the technical support team of the SPC generator kit, it was clarified that the heat lysis done in STD4 should have had a shorter incubation time (10 minutes instead of 15 minutes). We suspect that the longer incubation time, combined with the higher temperature and the harsh lysis condition with 0.8M KOH might have damaged SPCs and therefore DNA might have leaked out of them before WGA. In the microscopy images, SPCs in STD4 show a swollen aspect not seen in the other samples. In the revised version we will explain this more clearly.
(5) The paper presents limited biological relevance. Without this, the paper describes an improvement in genome amplification methods and some proof-of-concept analyses. Using a 1:1 mixture of parasites with different genotypes, the authors display the utility of the method to resolve genetic diversity, but they don't seek to understand the limits of detecting this diversity. For some, the authors do not comment on the mixed karyotypes from the HU3 cells (Figure 3F) other than to state that this line was not clonal. For CNVs, the two loci evaluated were detected at relatively high copy number (according to Figure 4C, they are between 4 and 20 copies). Thus, the sensitivity of CNV detection from this data remains unclear; can this approach detect lower-level CNVs like duplications, or minor CNVs that do not show up in every cell?
As described above we will include more discussion on potential biological relevance of the method in the revised version of the manuscript. In the revised version we will attempt to use dedicated bioinformatic tools to discover de novo CNVs, as per the suggestion of other reviewers. This might also allow us to determine the detection limit of the methodology for CNVs.
(6) The authors state that Leishmania can carry extrachromosomal copies of important genes. There is no discussion about how the presence of these molecules would affect the amplification steps and CNV detection. For example, the phi29 enzyme is very processive with circular molecules; does its presence lead to overamplification and overrepresentation in the data? Is this evident in the current study? This information would be useful for organisms that carry this type of genetic element.
We believe our data, which uses short-read sequences, does not allow to differentiate between intra-chromosomal CNVs and linear or circular episomal CNVs, so we cannot define if circular CNVs are over-amplified. Of note, we have previously demonstrated that the M-locus CNV in chromosome 36 is intrachromosomal, not circular (episomal)[5].
(7) The manuscript is missing a comparison with other similar studies in the field. For example, how does this coverage level compare to those achieved for other genomes? Can this method achieve amplification levels needed to assess larger genomes? Has there been any evaluation of base composition effects since Leishmania is a GC-rich genome?
We believe the SPC-PTA workflow can be applied to organisms with larger genomes as PTA was developed specifically for mammalian cells[6], and also because, in our hands, it outperformed the 10X scDNA solution, which was developed for mammals.
We believe direct comparison with other studies regarding coverage levels is elusive because other steps in the workflow apart from the WGA, such as the library preparation (PCR-based in our case), as well as genome features like GC content, size, and presence of repetitive regions, can also affect coverage levels and evenness. One strength of our approach was the use a single sample (the 50/50 mix between two L. donovani strain) for all conditions, thus removing potential parasite-specific biases. In addition, the application of a multiplexing system during barcoding allowed us to combine all samples prior to library preparation, thus removing potential differences introduced by this step.
Regarding the effect of GC-content, we did notice a positive bias in all samples in regions with higher GC content, which had to be corrected in silico. This was the opposite to a negative bias observed in previous study[7] likely due to differences in WGA and/or library preparation. In the revised version, we will include a supplementary figure showing the GC bias.
(8) Cost is mentioned as a benefit of the SPC platform, and savings are achieved when working in a plate format, but no details are included on how this was evaluated.
In the revised version we will provide precise cost estimates and the rationale for the estimation.
(9) The Zenodo link for custom scripts does not exist, and code cannot be evaluated.
The full Zenodo link (https://doi.org/10.5281/zenodo.17094083) will be included in the revised version.
Reviewer #3 (Public review):
Summary
In this manuscript, Negreira et al. propose a new scDNAseq method, using semi-permeable capsules (SPCs) and primary template-directed amplification (PTA). The authors optimize several metrics to improve their predictions, such as determining GC bias, Intra-Chromosomal fluctuation (ICF -metric to differentiate replicative and non-replicative cells) and Intra-chromosomal coefficient of variation (ICCV - chromosome read distribution). The coverage evenness was evaluated using the fini index and the median absolute pairwise difference between the counts of two consecutive bins. They validate the proposed method using two Leishmania donovani strains isolated from different countries, BPK081 (low genomic variability) and HU3 (high genomic variability). Then, they showed that the method outperforms WGA and has similar accuracy to the discontinued 10X-scDNA (10X Genomics), further improving on short CNV identification. The authors also show that the method can identify somy variations, insertions/deletions and SNP variations across cells. This is a timely and very relevant work that has a wide applicability in copy number variation assessment using single-cell data.
Strengths
I really appreciate this work. My congratulations to the authors. All my comments below only aim to improve an already solid manuscript.
We thank the reviewer for the enthusiasm and positive feedback.
Weaknesses
(1) Data availability: Although the authors provide a Zenodo link, the data is restricted. I also could not access the GitHub link in the Zenodo website: https://github.com/gabrielnegreira/2025_scDNA_paper. The authors should make these files available.
Both the Zenodo (https://doi.org/10.5281/zenodo.17094083) and the GitHub (https://github.com/gabrielnegreira/2025_scDNA_paper) repositories are now publicly available.
(2) 2-SPC-PTA and SPC-STD cell count comparison: The authors have consistently proven that the SPC-PTA method was superior to SPC-STD. However, there are a few points that should be clarified regarding the SPC-PTA results. Is there an explanation for the lower proportion of SPC to true cells success in SPC-STD, which reflects the bimodal distribution for the reads per cell in SPC-PTA2 and a three-to-multimodal distribution in SPC-PTA1 in Figure 1B? Also, in Table 1, does the number of reads reflect the number of reads in all sequenced SPCs or only in the true cells? If it is in the SPCs, I suggest that the authors add a new column in the table with the "Number of reads in true cells" to account for this discrepancy.
The reason for the higher presence of 'background' SPCs in the PTA samples is not clear, but we hypothesize that it could be due to PTA favoring amplification of small, free floating DNA molecules that might have been trapped in cell-free SPCs, as PTA works with shorter amplicons. Also, the longer incubation time seen in PTA (10 h) might have allowed enhanced amplification of low quantities of free-floating DNA to detectable levels. Regarding Table 1, indeed it only show the total number of reads per sample. In the revised version we will include the suggested column to Table 1.
(3) The authors should evaluate the results with a higher coverage for SCP-PTA. I understand that the authors subsampled the total read to 100,000 to allow cross-sample comparisons, especially between SPC-STD and SPC-PTA. However, as they concluded that the SPC-PTA was far superior, and the samples SPC-PTA1 and SPC-PTA2 had an "elbow" of 650,493 and 448,041, respectively, it might be interesting to revisit some of the estimations using only SPC-PTA samples and a higher coverage cutoff, as 400,000.
We believe the 100.000 cutoff is already high for aneuploidy analysis as we have successfully reconstructed parasite karyotype with 20.000 reads per cell8, so a higher cutoff will likely not improve it. For CNV analysis, in the revised version, we will try to identify de novo CNVs using dedicated bioinformatic tools as per other reviewer suggestions. There, we will also test if a higher CNV detection sensitivity is achieved using the suggested 400,000 reads cutoff for the PTA samples.
(4) Doublet detection: I suggest that the authors be a little more careful with their definition of doublets. The doublet detection was based on diagnostic SNPs from the two strains, BPK081 and HU3, which identify doublets between two very different and well-characterised strains. However, this method will probably not identify strain-specific doublets. This is of minor importance for cloned and stable strains with few passages, as BPK081, but might be more relevant in more heterogeneous strains, as HU3. Strain-specific doublets might also be relevant in other scenarios, as multiclonal infections with different populations from the same strain in the same geographic area. One positive point is that the "between strain doublet count" was low, so probably the within-strain doublet count should be low too. The manuscript would benefit from a discussion on this regard.
We fully agree with the reviewer. We will make it clear in the revised version that we quantify inter-strain doublets only, and we will also provide an estimation of total doublets based on the inter-strain doublet rate.
(5) Nucleotide sequence variants and phylogeny: I believe that a more careful description of the phylogenetic analysis and some limitations of the sequence variant identification would benefit the manuscript.
(5.1) As described in the methods, the authors intentionally selected two fairly different Leishmania donovani strains, HU3 and BPK081, and confirmed that the sequent variant methodology can separate cells from each strain. It is a solid proof of concept. However, most of the multiclonal infections in natural scenarios would be caused by parasite populations that diverge by fewer SNPs, and will be significantly harder to detect. Hence, I suggest that a short discussion about this is important.
We will add a short discussion clarifying the limitations, while noting that our data demonstrate the ability of the approach to resolve very closely related cells, as illustrated by the fine-scale genetic differences observed within the clonal BPK081 population and by the detection of rare variants at targeted loci. We will also emphasize that the sensitivity to detect closely related genotypes depends on sequencing depth and the genomic regions considered.
(5.2) The authors should expand on the description of the phylogenetic tree. In the HU3 on Figure 5F left panel, most of the variation is observed in ~8 cells, which goes from position 0 to position ~28.000. Most of the other cells are in very short branches, from ~29.000 to 30.4000 (5F right panel). Assuming that this representation is a phylogram, as the branches are short, these cells diverge by approximately 100-2000 SNPs. It is unexpected (but not impossible) that such ~8 divergent cells be maintained uniquely (or in very low counts) in the culture, unless this is a multiclonal infection. I would carefully investigate these cells. They might be doublets or have more missing data than other cells. I would also suggest that a quick discussion about this should be added to the manuscript.
In the revised version we will improve the description of the phylogenetic analysis. We will also investigate deeper the 8 mentioned cells to define if they have confounding factors that might have led to their discrepancy. The possibility of multiclonal infection in HU3 is not excluded as this strain was not cloned after isolation.
References:
(1) Dileep, V., Gilbert, D. M., Dileep, V. & Gilbert, D. M. Single-cell replication profiling to measure stochastic variation in mammalian replication timing. Nat. Commun. 9, 427 (2018).
(2) Miura, H. et al. Single-cell DNA replication profiling identifies spatiotemporal developmental dynamics of chromosome organization. Nat. Genet. 51, 1356–1368 (2019).
(3) Marques, C. A. et al. Genome-wide mapping reveals single-origin chromosome replication in Leishmania, a eukaryotic microbe. Genome Biol. 16, 230 (2015).
(4) Damasceno, J. D. et al. Leishmania major chromosomes are replicated from a single high-efficiency locus supplemented by thousands of lower efficiency initiation events. Cell Rep. 44, 116094 (2025).
(5) Imamura, H. et al. Evolutionary genomics of epidemic visceral leishmaniasis in the Indian subcontinent. eLife 5, e12613 (2016).
(6) Gonzalez-Pena, V. et al. Accurate genomic variant detection in single cells with primary template-directed amplification. Proc. Natl. Acad. Sci. 118, e2024176118 (2021).
(7) Imamura, H. et al. Evaluation of whole genome amplification and bioinformatic methods for the characterization of Leishmania genomes at a single cell level. Sci. Rep. 10, 15043 (2020).
(8) Negreira, G. H. et al. High throughput single-cell genome sequencing gives insights into the generation and evolution of mosaic aneuploidy in Leishmania donovani. Nucleic Acids Res. 50, 293–305 (2022).
Code exhibition
"*** YOUR CODE HERE ***"
完成了
Images are created by defining a grid of dots, called pixels. Each pixel has three numbers that define the color (red, green, and blue), and the grid is created as a list (rows) of lists (columns).
It’s cool to see how images are really just grids of pixels with RGB values, and even something like microRGB fits into that same idea of breaking color down into tiny components. Thinking about images this way makes them feel a lot less mysterious and more like something you can actually work with in code.
Author response:
We thank all reviewers for their overall assessment, thoughtful comments, and suggestions. We are working to address each reviewer’s comment in detail. In this provisional response, we provide clarifications regarding our experimental approach and the novelty of our work, and include additional analyses that we have performed since the submission of the manuscript. We are also happy to report that we have now shared the raw data, intermediate analysis files, and the complete repository to facilitate replication of the analysis and figures.
Code repo: github.com/LorenFrankLab/ms_stim_analysis
Data repo: dandiarchive.org/dandiset/001634
Docker containers (see GitHub repo for use instructions):
Database: https://hub.docker.com/r/samuelbray32/spyglass-db-ms_stim_analysis
Python notebooks: https://hub.docker.com/r/samuelbray32/spyglass-hub-ms_stim_analysis
(1) Novelty and contrast with earlier manipulations:
We thank the reviewers for suggesting that we explicitly contrast our results with prior pharmacological (Wang et al., 2016; Wang et al., 2015; Koenig et al., 2011; Brandon et al., 2014), systemic (Robbe & Buzsaki 2009; Petersen and Buzsáki 2020), and behavioral (Drieu et al., 2018) manipulations that also assessed some of the physiological features we evaluated. We will add a discussion of these studies, which will help us emphasize both the insights and discrepancies observed using these prior approaches. We will also more clearly explain the the novelty and importance of our specific approach for temporally and physiologically precise manipulation. Specifically, our approach (closed-loop theta-phase stimulation during locomotion) provides a level of physiological specificity that made it possible to dissociate theta-state dynamics from other hippocampal processes. This in turn allowed us to address a question that has remained unresolved across prior studies: Are hippocampal spatial sequences during locomotion (i.e., theta sequences) necessary to learn a novel hippocampal-dependent task?
(2) Additional analysis on SWRs during rest:
since submitting the manuscript, we have conducted additional analysis on the rate and length of SWRs in the rest box and found that their rate and length are also indistinguishable between targeted and control animals (effect of manipulation between control and targeted animals; rSWR rate: p=0.45; rSWR length: p=0.94, mixed effect model). We also find evidence for sequential neural representations in the rest box, when the encoding was performed in the behavioral arena. Example trajectories are shown below. These results are consistent with our observations on SWRs rate, length, and content in the behavioral arena. Additionally, we are in the process of evaluating and quantifying the results of decoding the rSWRs and will include those in the next version of the manuscript.
Author response image 1.
Sequential replay events observed in the rest box
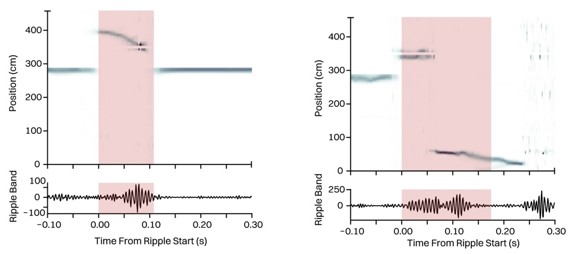
(3) Theta sequence measurement in the absence of theta:
In the next version of the manuscript, we will explicitly explain why our manipulation makes it is more appropriate to measure sequential hippocampal representations during locomotion (i.e., theta sequences) without using theta oscillation or an epoch-averaged relatively large sliding window as a reference. The key insight here is that our manipulation suppresses theta and thus makes it difficult or impossible to accurately identify theta phase. We understand that theta-phase based approaches were used in prior work; however, these prior analyses may have confounded the absence of hippocampal theta sequences during locomotion by the inability to detect theta oscillatory phase reliably. We will show that our method of using clusterless Bayesian decoding in which we estimate the decoded position at every 2ms timestep is indeed able to capture endogenous hippocampal sequences even without imposing any requirements of aligning to theta oscillations, thus providing an unbiased estimate of the rhythmicity of hippocampal spatial representations.
(4) Additional analysis on place cell stability and tuning:
We thank the reviewer for this question. For the KL divergence analysis, we have imposed a spike-count criterion (100 spikes for each interval type —stimulation-off, stimulation-on, and the stimulus sub-interval) and a coverage criterion (50% HPD of the units’ spatial firing distribution was contained within 40cm on the linear track and 100cm on the w-track). These criteria were chosen to ensure that spatial tuning curves were sufficiently well sampled and localized to allow reliable estimation of KL divergence, which is particularly sensitive to noise arising from low spike counts or diffuse firing. Based on the reviewer’s suggestion, we have relaxed the unit inclusion criteria for KL divergence by relaxing the criteria for number of spikes and spatial coverage criterion to include more weakly tuned place cells and replicated our results (p=.146). Further, we have also evaluated the stability of place field order between stimulation-on and stimulation-off conditions using more standard methods (as in Wang et. al., 2015; spearman correlation of place field order, control vs targeted, p = .920, t-test). These results are consistent with our observations about place field stability during stimulation-off and stimulation-on conditions (Fig. 2F).
Author response image 2.
Spearman correlation of place field order during stimulation-on and stimulation-off conditions.
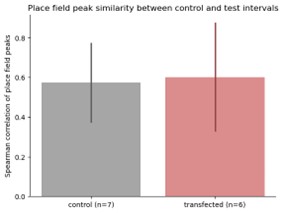
Analyse de l'Avis du CESE sur les Temps de Vie de l'Enfant
Cet avis du Conseil économique, social et environnemental (CESE), intitulé « Satisfaire les besoins fondamentaux des enfants et garantir leurs droits », dresse un constat critique de la situation des enfants en France, dont les temps de vie sont davantage structurés par les contraintes des adultes que par leurs propres besoins fondamentaux.
Fruit d'une saisine gouvernementale faisant suite à une Convention citoyenne, le rapport souligne un décalage majeur entre les droits constitutionnels et internationaux de l'enfant et leur application effective, particulièrement pour les plus vulnérables.
Les principales conclusions révèlent des inégalités sociales, territoriales et économiques profondes qui entravent le développement, la santé et le bien-être des enfants.
L'avis pointe du doigt des rythmes scolaires inadaptés, une sédentarité croissante, un manque de sommeil chronique, une surexposition aux écrans, et une déconnexion préoccupante de la nature.
La pression sur les familles, notamment monoparentales, et le manque de coordination entre les acteurs éducatifs aggravent ces constats.
Pour y remédier, le CESE formule 19 préconisations interdépendantes visant une transformation systémique. Celles-ci incluent des mesures politiques fortes comme l'instauration d'une « clause impact enfance » dans chaque projet de loi, une réforme ambitieuse des rythmes scolaires sur la base des besoins physiologiques, et la création d'un Service Public de la Continuité Éducative (SPCE) pour assurer une meilleure coordination des acteurs.
L'avis appelle également à renforcer le soutien à la parentalité, à garantir l'accès de tous les enfants aux loisirs, à la culture et aux activités de plein air, et à allouer des financements publics pérennes pour faire de l'enfance un véritable investissement d'avenir.
En réponse à une saisine du Premier ministre de mai 2025, le CESE a élaboré cet avis suite aux travaux d'une Convention citoyenne dédiée aux temps de vie des enfants. Cent trente-trois citoyens et un panel de vingt enfants et adolescents ont été invités à répondre à la question :
« Comment mieux structurer les différents temps de la vie quotidienne des enfants afin qu’ils soient plus favorables à leurs apprentissages, à leur développement et à leur santé ? ».
Le constat principal de la Convention citoyenne, repris par le CESE, est que les enfants subissent les rythmes effrénés d'une société qui construit leurs temps autour des contraintes des adultes plutôt qu'en réponse à leurs besoins biologiques et de développement.
Le rapport du CESE, s'appuyant sur les 20 propositions citoyennes, formule 19 préconisations qui constituent une position commune de la société civile organisée.
Cet avis s'inscrit dans la continuité de travaux antérieurs du CESE sur l'éducation, la protection de l'enfance et la santé mentale, et vise à proposer des réponses globales et articulées.
La France a consacré les droits de l'enfant dans sa Constitution et a ratifié la Convention Internationale des Droits de l'Enfant (CIDE) en 1990, s'engageant sur quatre principes fondamentaux : le droit à la vie, l'intérêt supérieur de l'enfant, la non-discrimination et le respect de son opinion.
Cependant, l'avis du CESE met en lumière une ineffectivité préoccupante de ces droits pour une part significative des enfants.
• Pauvreté et Précarité : En 2023, 21,9 % des enfants de moins de 18 ans vivent sous le seuil de pauvreté monétaire.
À la rentrée 2025, au moins 2 159 enfants se sont retrouvés sans solution d'hébergement.
Ces réalités percutent violemment la capacité de la société à répondre à leurs besoins fondamentaux.
• Critiques Internationales : Le Comité des droits de l'enfant de l'ONU a enjoint la France en 2023 à prendre des mesures urgentes concernant la violence, la protection de l'enfance, la détention d'enfants étrangers, la pauvreté et l'inclusion des enfants en situation de handicap.
• L'« Infantisme » : Le rapport dénonce la persistance de l'« infantisme », un concept désignant les préjugés et la discrimination fondée sur l'âge, qui considère les enfants comme des êtres inférieurs et moins dignes de respect.
Cette culture conduit à ignorer leur parole et leur capacité à être des acteurs sociaux. Pour le combattre, le CESE réaffirme la nécessité d'un débat de société et la création d'un Code de l'enfance.
• Clause « Impact Enfance » : S'inspirant de la « clause impact jeunesse », le CESE préconise (Préconisation #1) d'intégrer un volet enfance dans chaque étude d'impact des projets de loi afin de s'assurer que toute politique publique soit fondée sur le respect des droits de l'enfant.
La famille est le premier lieu de développement de l'enfant, mais elle fait face à de nombreux obstacles.
• Soutien à la Parentalité : Face à la diversité des modèles familiaux (nucléaire, monoparentale, recomposée...), un soutien renforcé à la parentalité est jugé nécessaire pour aider les parents à répondre aux besoins de leurs enfants (Préconisation #7).
• Inégalités de Genre : Les femmes continuent d'assumer l'essentiel des responsabilités familiales et de la charge mentale, ce qui impacte leur santé et leur carrière.
Le rapport souligne la nécessité d'une répartition équitable des tâches.
• Conciliation Vie Professionnelle/Familiale : Les contraintes professionnelles empiètent sur le temps familial.
Le CESE préconise (Préconisation #2) la transposition complète de la directive européenne sur l'équilibre vie professionnelle-vie personnelle, en créant un droit à des « formules souples de travail » (aménagement du temps, télétravail) négocié dans les branches et la fonction publique.
• Enfants Séparés de leur Famille :
◦ Parents séparés : Il est crucial de soutenir les dispositifs comme les Espaces de rencontre pour préserver la relation parent-enfant tout en prenant en compte le point de vue de l'enfant (Préconisation #3).
◦ Aide Sociale à l'Enfance (ASE) : L'avis dénonce une crise systémique de la protection de l'enfance, où les droits des enfants confiés, notamment l'accès aux loisirs et à la culture, sont négligés.
Il est préconisé (Préconisation #4) que le Projet Pour l'Enfant (PPE) soit co-construit avec les parents et l'enfant, et qu'il intègre l'ensemble de ses besoins.
L'avis analyse en profondeur la manière dont les temps et les espaces de l'enfant sont organisés, révélant de multiples fractures et inadéquations.
La vie de l'enfant est rythmée par trois grands temps : familial, scolaire, et les "tiers temps" (périscolaire, extrascolaire).
• Qualité des Temps : Le rapport insiste sur la nécessité d'un équilibre entre temps contraints et temps libre, temps individuel et collectif, activité et repos.
La qualité des interactions avec les adultes et un environnement sécurisant sont déterminants.
Le CESE préconise (Préconisation #6) d'intégrer des temps libres de qualité dans toutes les activités d'apprentissage.
• Le Temps Scolaire : La France se distingue par des journées scolaires longues et un temps d'instruction élevé, sans que cela se traduise par de meilleurs résultats.
Le rythme de la semaine de quatre jours est jugé contraire aux besoins des enfants. Le CESE estime que le statu quo n'est plus tenable et appelle (Préconisation #8) à une évolution des rythmes scolaires :
◦ Premier degré : Réorganiser la journée et la semaine scolaire après concertation.
◦ Second degré : Adapter les amplitudes horaires aux besoins physiologiques des jeunes (ex: commencer plus tard).
◦ Calendrier scolaire : Organiser le calendrier hexagonal autour de deux zones de vacances, avec une alternance de 7 semaines de cours et 2 semaines de vacances.
• Les Tiers Temps et le Droit aux Loisirs : Les activités périscolaires et extrascolaires, portées par les associations et les collectivités, sont essentielles mais menacées par le désengagement de l'État et la marchandisation.
L'accès à ces activités, ainsi qu'aux vacances, est fortement marqué par les inégalités sociales.
Un enfant sur deux ne part pas en vacances. Le CESE réaffirme (Préconisation #9) que chaque enfant a droit aux vacances et aux loisirs, et appelle à renforcer le financement des accueils collectifs de mineurs et l'information sur les aides existantes.
L'environnement physique joue un rôle crucial dans le développement de l'enfant.
• L'« Enfant d'Intérieur » : Le rapport alerte sur le phénomène des « enfants d'intérieur », qui passent de moins en moins de temps à l'extérieur et en contact avec la nature, en raison de la peur du risque, de l'urbanisation centrée sur la voiture et de l'attrait des écrans.
• Repenser l'Aménagement : Il est impératif de repenser l'aménagement des territoires « à hauteur d'enfant », en créant des espaces publics (rues, places) sécurisés, propices au jeu, à la socialisation et aux mobilités douces.
Le CESE préconise (Préconisation #11) d'associer les enfants à l'élaboration des projets d'urbanisme.
• Le Bâti et le Cadre de Vie : Les bâtiments accueillant des enfants (écoles, centres de loisirs) sont souvent inadaptés, notamment face aux enjeux climatiques (vagues de chaleur).
Leur rénovation écologique et leur accessibilité sont des priorités. Toute rénovation doit faire l'objet d'une concertation incluant les enfants et les jeunes (Préconisation #12).
L'avis identifie quatre domaines d'action prioritaires pour améliorer la santé physique et mentale des enfants.
• Reconnecter à la Nature : Le contact avec la nature est fondamental pour la santé.
Le CESE appelle à valoriser et accompagner l'éducation au dehors (Préconisation #10) et à garantir que chaque enfant bénéficie d'un accès à des espaces naturels, de sorties régulières et d'au moins un séjour en classe de découverte par cycle scolaire (Préconisation #13).
• Lutter contre le Manque de Sommeil : Le déficit de sommeil touche plus de 30 % des enfants et 70 % des adolescents, avec des conséquences graves sur l'apprentissage et la santé.
Le CESE demande une campagne nationale de sensibilisation (Préconisation #14) et la garantie de temps de repos et de sieste dans toutes les structures, notamment en maternelle (Préconisation #15).
• Favoriser l'Activité Physique : Face à une sédentarité alarmante, il est crucial de faciliter l'accès au sport pour tous. Le CESE préconise (Préconisation #16) une tarification sociale et l'élargissement du dispositif Pass'Sport, récemment restreint.
• Mieux Réguler les Écrans : L'omniprésence des écrans a des effets néfastes documentés (sommeil, sédentarité, exposition à des contenus inappropriés). L'avis souligne la nécessité d'une meilleure régulation et d'un accompagnement à la parentalité numérique.
Pour que ces changements soient effectifs, une transformation de la gouvernance des politiques de l'enfance est indispensable.
• Coordination des Acteurs : L'action publique est jugée trop fragmentée. Le CESE préconise (Préconisation #17) de réhabiliter le Projet Éducatif Territorial (PEDT) et d'en faire le volet éducation des Conventions Territoriales Globales (CTG) pour assurer une coordination efficace au niveau local.
• Un Service Public de la Continuité Éducative (SPCE) : Pour garantir une offre éducative cohérente sur tous les temps de l'enfant, l'avis propose la création d'un SPCE (Préconisation #18).
Ce service, confié aux collectivités locales, serait chargé de diagnostiquer les besoins et de planifier les actions en associant tous les acteurs.
• Formation et Financement : La revalorisation des métiers éducatifs et le développement d'une culture commune des droits de l'enfant sont essentiels.
Enfin, le CESE alerte sur l'insuffisance des budgets alloués aux politiques de l'enfance et appelle (Préconisation #19) à un effort budgétaire conséquent et pérenne de l'État et de la Sécurité sociale, considérant ces dépenses comme un investissement fondamental pour l'avenir.
| Numéro | Thème Principal | Résumé de la Préconisation | | --- | --- | --- | | #1 | Droits de l'enfant | Mettre en œuvre une « clause impact enfance » dans chaque étude d'impact de projet de loi ou de texte réglementaire pour garantir que les politiques publiques respectent les droits de l'enfant. | | #2 | Parentalité & Travail | Créer un droit aux « formules souples de travail » (aménagement du temps, télétravail) pour les parents, par la négociation dans les branches et la fonction publique. | | #3 | Séparation parentale | Développer et soutenir financièrement les Espaces de rencontre pour aider les parents séparés à assumer leurs responsabilités parentales en prenant en compte le point de vue de l'enfant. | | #4 | Protection de l'enfance (ASE) | Rendre le Projet pour l'enfant (PPE) systématiquement co-construit avec les parents et l'enfant, et y intégrer tous les besoins, y compris les loisirs et la culture. Simplifier la gestion des actes usuels. | | #5 | Accès à la culture | Soutenir financièrement et développer tous les dispositifs culturels et artistiques pour les enfants (scolaires, ACM), via des contrats multipartites (État, collectivités, réseau culturel). | | #6 | Qualité des temps | Intégrer des temps libres de qualité dans les activités d'apprentissage, ce qui implique de former les adultes et personnels encadrants. | | #7 | Soutien à la parentalité | Mieux faire connaître, rendre accessibles et valoriser financièrement les lieux et actions d'aide aux parents (maisons des familles, groupes de parole, LAEP, PMI...). | | #8 | Rythmes scolaires | Faire évoluer les rythmes scolaires : réorganiser la journée et la semaine au primaire ; adapter les horaires aux besoins physiologiques au secondaire ; organiser un calendrier national à 2 zones (7 semaines de cours / 2 de vacances). | | #9 | Droit aux vacances et loisirs | Mobiliser les pouvoirs publics pour rendre effectif le droit aux vacances. Renforcer l'information sur les aides et financer davantage les accueils collectifs de mineurs (ACM). | | #10 | Éducation à la nature | Valoriser et accompagner l'éducation au dehors et en lien avec la nature (formation des acteurs, verdissement des espaces, aires éducatives, terrains d'aventure...). | | #11 | Aménagement du territoire | Aménager les territoires « à hauteur d'enfant » dans une démarche participative, en repensant les espaces publics comme lieux de sociabilité, de mixité et de jeu. | | #12 | Bâti et cadre de vie | Rendre obligatoire la concertation avec les enfants et les jeunes pour tout projet d'aménagement ou de rénovation de bâtiments (écoles, centres de loisirs, gymnases...). | | #13 | Lien à la nature | Garantir que chaque enfant bénéficie d'un accès à des espaces naturels, de sorties régulières, et d'au moins un séjour en classe de découverte par cycle de scolarité. | | #14 | Sommeil | Organiser une campagne nationale d'information et de sensibilisation sur le rôle fondamental du sommeil et les facteurs qui lui nuisent. | | #15 | Temps de repos | Prévoir des temps de repos, de calme et de sieste (préservée en maternelle) dans toutes les structures accueillant des enfants, et repenser les locaux pour créer une atmosphère paisible. | | #16 | Activité physique et sportive | Soutenir une tarification sociale pour l'accès au sport. Étendre et revaloriser le Pass'Sport, en y incluant les associations sportives scolaires. | | #17 | Coordination locale | Réhabiliter le Projet Éducatif Territorial (PEDT) et en faire le volet "éducation" des Conventions Territoriales Globales (CTG) pour une coordination globale des acteurs. | | #18 | Gouvernance | Créer un Service Public de la Continuité Éducative (SPCE), confié aux collectivités, pour diagnostiquer les besoins et planifier les actions éducatives sur le territoire. | | #19 | Financement | Assurer un effort budgétaire conséquent et pérenne de l'État et de la Sécurité sociale pour financer les politiques publiques en faveur de l'enfance. |
Binary consisting of 0s and 1s make it easy to represent true and false values, where 1 often represents true and 0 represents false. Most programming languages have built-in ways of representing True and False values
This makes sense to me, especially how binary maps so cleanly onto True/False. It’s interesting that something as abstract as “truth” in code ultimately comes down to 0s and 1s, which feels very different from how messy and ambiguous truth can be in real life.
Relationship status
I think this is an interesting data with constraints that shift along cultural axes. While the other data types like age, name, and address can vary from culture to culture (such as characters used to input), the answers will all be relatively similar. People might for example measure their age using different calendars, or by amount of winters experienced, but a full annual cycle is used pretty much worldwide. For relationship status though, there are a lot of variables even in one culture that must be negotiated. Does dating count as different than a relationship? What about new terms like situationship? What about cultures with multiple partners? There's so many value judgements about what counts as a relationship in the act of reifying it in code. It makes me think about the ways in which our cultural ideology is represented in code, more than we often think about.
data analysis workshops,
I do not know code, or any kind of data analysis so this will be great practice!
Synthèse de l'Avis du Conseil d'État sur la Proposition de Loi "Protéger les Mineurs en Ligne"
Cette proposition de loi a été élaborée en réponse à des constats alarmants concernant les risques auxquels les réseaux sociaux exposent les mineurs.
Faisant directement suite aux recommandations du rapport de la commission d’enquête sur TikTok, le texte met en lumière les dangers d'addiction et les effets psychologiques néfastes de certaines plateformes sur la santé mentale des jeunes.
L'objectif principal du législateur est donc de renforcer de manière significative le cadre de protection des mineurs dans l'environnement numérique, en instaurant des mesures contraignantes et préventives.
Les deux mesures phares de la proposition initiale sont les suivantes :
• Interdiction d'accès pour les moins de 15 ans : Le texte visait à imposer une obligation directe aux fournisseurs de services de réseaux sociaux de refuser l'inscription des mineurs de moins de 15 ans.
Pour ce faire, les plateformes auraient dû mettre en œuvre des dispositifs de contrôle d'âge robustes, sous peine de sanctions financières et d'injonctions judiciaires.
• Couvre-feu numérique pour les 15-18 ans : Pour cette tranche d'âge, la proposition prévoyait une obligation de désactivation automatique de l'accès aux comptes entre 22 heures et 8 heures du matin, en s'appuyant sur les mêmes solutions techniques de vérification de l'âge.
En complément de ce dispositif central, le texte comprend plusieurs autres mesures structurantes :
| Mesure | Objectif Stratégique | | --- | --- | | Lutte contre la publicité pro-suicide | Compléter la liste des contenus illicites pour inclure la propagande en faveur de moyens de se donner la mort. | | Renforcement des peines | Augmenter la durée de suspension des comptes d'accès aux plateformes en cas d'infraction. | | Messages sanitaires | Imposer des informations préventives sur les publicités pour les réseaux sociaux et sur les emballages de smartphones. | | Formation scolaire | Étendre la formation sur l'usage du numérique à la sensibilisation aux enjeux de santé mentale. | | Interdiction des téléphones dans les lycées | Généraliser l'interdiction déjà en vigueur dans les collèges pour favoriser la concentration et prévenir le harcèlement. | | Création d'un délit de négligence parentale | Sanctionner les parents en cas d'usage excessif, inadapté ou non surveillé des outils numériques par leur enfant. |
L'analyse juridique approfondie du Conseil d'État révèle cependant que, si l'intention est louable, les mécanismes proposés soulèvent des difficultés majeures de compatibilité avec le droit européen et les libertés fondamentales.
La conformité au droit de l'Union européenne est une condition essentielle de la validité de toute loi nationale.
Le Conseil d'État souligne que le Règlement sur les Services Numériques (DSA) harmonise pleinement les règles pour les plateformes opérant dans l'UE, limitant drastiquement la capacité des États membres à leur imposer des obligations supplémentaires.
L'avis du Conseil se révèle être une véritable leçon d'ingénierie juridique, démontrant comment atteindre un objectif de politique nationale dans le cadre contraignant d'un droit européen harmonisé.
Le Conseil d'État met en évidence une incompatibilité juridique frontale : en imposant une obligation directe aux plateformes de refuser l'inscription des mineurs, la proposition de loi initiale violerait le principe d'harmonisation maximale du DSA, rendant la mesure juridiquement fragile et susceptible d'être invalidée.
Pour surmonter cet obstacle majeur, le Conseil d'État propose une reformulation décisive, qui constitue le pivot de sa stratégie. Au lieu d'obliger les plateformes, la loi doit directement interdire l'accès au mineur : `
« Il est interdit au mineur de quinze ans d’accéder à un service de réseau social en ligne »`.
Cet acte de prohibition qualifie automatiquement un tel accès de "contenu illicite" au sens de la définition large du DSA.
Cette reclassification est la clé de voûte de la stratégie du Conseil : elle permet de mobiliser les puissants mécanismes de régulation du DSA (injonctions de l'Arcom, signalements, sanctions) contre les plateformes sans créer une nouvelle obligation nationale, interdite par le droit européen.
Le cadre de l'UE devient ainsi le principal outil d'application d'une politique nationale française.
Pour renforcer l'effectivité de cette interdiction, le Conseil suggère d'ouvrir un second flanc de mise en conformité. Il préconise de prévoir la nullité de plein droit des contrats passés par un mineur en violation de cette interdiction.
Une telle nullité priverait de base légale tout traitement de ses données personnelles, exposant les plateformes à des contrôles et sanctions de la part de la CNIL au titre du RGPD, ce qui augmente considérablement la pression en faveur du respect de la loi.
Enfin, le Conseil recommande que la Commission européenne élabore des lignes directrices pour s'assurer que les plateformes gèrent correctement la restitution des contenus et des données aux mineurs dont les comptes sont résiliés, afin de ne pas porter atteinte à leurs droits de propriété intellectuelle.
Cette refonte juridique est présentée comme une condition sine qua non à la viabilité du texte.
Au-delà de la conformité européenne, le Conseil d'État analyse la conciliation entre l'objectif de protection de l'enfance — une exigence constitutionnelle — et le respect des libertés fondamentales du mineur (liberté d'expression, d'information) et des droits des parents.
Sur ce plan, le Conseil juge le dispositif initial déséquilibré et disproportionné pour trois raisons principales :
1. Caractère général et absolu : L'interdiction s'appliquerait à tous les "réseaux sociaux" sans distinction, y compris ceux ne présentant aucun risque avéré (plateformes collaboratives, éducatives), ce qui est jugé excessif.
2. Absence de discernement et de rôle parental : Le mécanisme initial ignore le degré de maturité de l'enfant et écarte totalement les parents de leur rôle d'accompagnement, en contradiction avec le Code civil et la Convention relative aux droits de l’enfant.
3. Manque de justification du couvre-feu : Les bornes horaires du couvre-feu pour les 15-18 ans (22h-8h) sont jugées insuffisamment documentées et donc disproportionnées.
Pour rééquilibrer le texte, le Conseil d'État propose une refonte qui incarne un changement de philosophie réglementaire : passer d'une interdiction étatique, brute et centrée sur la plateforme, à un système nuancé, responsabilisant les parents et centré sur le terminal. Ce mécanisme alternatif repose sur deux volets :
• Volet 1 - Interdiction Ciblée Le Gouvernement pourrait, par décret en Conseil d’État pris après avis de l’Arcom, interdire l'accès aux mineurs de moins de 15 ans à des réseaux sociaux spécifiquement identifiés comme dangereux en raison de leurs systèmes de recommandation.
L'État utilise ici son pouvoir de prohibition de manière ciblée, là où le danger est avéré.
• Volet 2 - Autorisation Parentale Généralisée Pour tous les autres réseaux sociaux, l'accès serait interdit sauf autorisation expresse d'un parent.
Réalisée via des dispositifs installés sur les systèmes d’exploitation des équipements terminaux distribués par les fournisseurs d’accès à l’internet (à l'instar des mécanismes de contrôle parental existants), cette autorisation serait révocable et pourrait préciser une durée d'usage.
L'État délègue ici à une autorité parentale guidée le soin d'évaluer le risque.
Cette approche duale résout le problème de proportionnalité, transformant une interdiction fragile en un système de régulation juridiquement beaucoup plus solide.
Le Conseil d'État a également examiné les autres articles de la proposition de loi, formulant des recommandations d'ajustement ou des réserves importantes.
• Interdiction des téléphones dans les lycées (Art. 6) : La mesure est jugée nécessaire et proportionnée.
Le Conseil recommande d'exclure explicitement de son champ les formations de l'enseignement supérieur et de différer son entrée en vigueur à la rentrée scolaire 2026.
• Formation scolaire (Art. 4) : Jugée conforme, la mesure est cependant qualifiée de potentiellement redondante avec des dispositions déjà existantes.
Une entrée en vigueur différée à la rentrée 2026 est également suggérée pour permettre l'adaptation des enseignants.
• Délit de négligence numérique (Art. 7) : Le Conseil exprime de fortes réserves.
À titre principal, il estime que le droit pénal existant est suffisant.
À titre subsidiaire, si le délit était maintenu, ses termes ("usage excessif", "outils numériques") sont jugés trop vagues et contraires au principe constitutionnel de légalité des délits et des peines.
• Publicité et emballages (Art. 3) : Ces dispositions devront être notifiées à la Commission européenne au titre de la directive "TRIS", une étape procédurale cruciale destinée à prévenir la création de barrières techniques inopinées au sein du marché unique.
• Rapport au Parlement (Art. 5) : Il est suggéré de restreindre le champ du rapport pour le concentrer sur le respect par les plateformes de leurs obligations spécifiques envers les mineurs dans le cadre du DSA.
Ces ajustements visent à garantir la sécurité juridique et l'applicabilité concrète de l'ensemble du texte.
L'avis du Conseil d'État valide sans équivoque la nécessité d'agir face aux dangers documentés que les réseaux sociaux font peser sur les mineurs et reconnaît la pertinence de l'objectif poursuivi par le législateur.
Cependant, cette validation de l'objectif s'accompagne d'une censure quasi totale du dispositif initialement proposé. Celui-ci est jugé doublement fragile :
1. Incompatible avec le droit de l'Union européenne, en raison de la violation du principe d'harmonisation maximale du DSA.
2. Déséquilibré au regard des droits fondamentaux, car l'interdiction générale et le couvre-feu sont jugés disproportionnés et écartent indûment l'autorité parentale.
En définitive, les amendements du Conseil d'État ne sont pas de simples ajustements.
Ils constituent une refondation juridique et une véritable feuille de route stratégique et législative offerte au Parlement. Ils transforment un projet juridiquement précaire en une loi conforme, proportionnée et, par conséquent, viable et réellement efficace pour protéger les mineurs dans l'espace numérique.
Author response:
The following is the authors’ response to the original reviews.
Public reviews:
Reviewer #1 (Public review):
Summary:
The authors provide a resource to the systems neuroscience community, by offering their Python-based CLoPy platform for closed-loop feedback training. In addition to using neural feedback, as is common in these experiments, they include a capability to use real-time movement extracted from DeepLabCut as the control signal. The methods and repository are detailed for those who wish to use this resource. Furthermore, they demonstrate the efficacy of their system through a series of mesoscale calcium imaging experiments. These experiments use a large number of cortical regions for the control signal in the neural feedback setup, while the movement feedback experiments are analyzed more extensively.
Strengths:
The primary strength of the paper is the availability of their CLoPy platform. Currently, most closed-loop operant conditioning experiments are custom built by each lab and carry a relatively large startup cost to get running. This platform lowers the barrier to entry for closed-loop operant conditioning experiments, in addition to making the experiments more accessible to those with less technical expertise.
Another strength of the paper is the use of many different cortical regions as control signals for the neurofeedback experiments. Rodent operant conditioning experiments typically record from the motor cortex and maybe one other region. Here, the authors demonstrate that mice can volitionally control many different cortical regions not limited to those previously studied, recording across many regions in the same experiment. This demonstrates the relative flexibility of modulating neural dynamics, including in non-motor regions.
Finally, adapting the closed-loop platform to use real-time movement as a control signal is a nice addition. Incorporating movement kinematics into operant conditioning experiments has been a challenge due to the increased technical difficulties of extracting real-time kinematic data from video data at a latency where it can be used as a control signal for operant conditioning. In this paper they demonstrate that the mice can learn the task using their forelimb position, at a rate that is quicker than the neurofeedback experiments.
Weaknesses:
There are several weaknesses in the paper that diminish the impact of its strengths. First, the value of the CLoPy platform is not clearly articulated to the systems neuroscience community. Similarly, the resource could be better positioned within the context of the broader open-source neuroscience community. For an example of how to better frame this resource in these contexts, I recommend consulting the pyControl paper. Improving this framing will likely increase the accessibility and interest of this paper to a less technical neuroscience audience, for instance by highlighting the types of experimental questions CLoPy can enable.
We appreciate the editor’s feedback regarding the clarity of the CLoPy platform's value and its positioning within the broader neuroscience community. We agree and understand the importance of effectively communicating the utility of CLoPy to both the systems neuroscience field and the wider open-source neuroscience community.
To address this, we have revised the introduction and discussion sections of the manuscript to more clearly articulate the unique contributions of the CLoPy platform. Specifically:
(1) We have emphasized how CLoPy can address experimental questions in systems neuroscience by highlighting its ability to enable real-time closed-loop experiments, such as investigating neural dynamics during behavior or studying adaptive cortical reorganization after injury. These examples are aimed at demonstrating its practical utility to the neuroscience audience.
(2) We have positioned CLoPy within the broader open-source neuroscience ecosystem, drawing comparisons to similar resources like pyControl. We describe how CLoPy complements existing tools by focusing on real-time optical feedback and integration with genetically encoded indicators, which are becoming increasingly popular in systems neuroscience. We also emphasize its modularity and ease of adoption in experimental settings with limited resources.
(3) To make the manuscript more accessible to a less technically inclined audience, we have restructured certain sections to focus on the types of experiments CLoPy enables, rather than the technical details of the implementation.
We have consulted the pyControl paper, as suggested, and have used it as a reference point to improve the framing of our resource. We believe these changes will increase the accessibility and appeal of the paper to a broader neuroscience audience.
While the dataset contains an impressive amount of animals and cortical regions for the neurofeedback experiment, and an analysis of the movement-feedback experiments, my excitement for these experiments is tempered by the relative incompleteness of the dataset, as well as its description and analysis in the text. For instance, in the neurofeedback experiment, many of these regions only have data from a single mouse, limiting the conclusions that can be drawn. Additionally, there is a lack of reporting of the quantitative results in the text of the document, which is needed to better understand the degree of the results. Finally, the writing of the results section could use some work, as it currently reads more like a methods section.
Thank you for your thoughtful and constructive feedback on our manuscript. We appreciate the time and effort you took to review our work and provide detailed suggestions for improvement. Below, we address the key points raised in your review:
(1) Dataset Completeness: We acknowledge that some of the neurofeedback experiments include data from only a single mouse for some cortical regions while for some cortical regions, there are several animals. This was due to practical constraints during the study, and we understand the limitations this poses for drawing broad conclusions. We felt it was still important to include these data sets with smaller sample sizes as they might be useful for others pursuing this direction in the future. To address this, we have revised the text to explicitly acknowledge these limitations and clarify that the results for some regions are exploratory in nature. We believe our flexible tool will provide a means for our lab and others include more animals representing additional cortical regions in future studies. Importantly, we have included all raw and processed data as well as code for future analysis.
(2) Quantitative Results: We recognize the importance of reporting quantitative results in the text for better clarity and interpretation. In response, we have added more detailed description of the quantitative findings from both the neurofeedback and movement-feedback experiments. This will include effect sizes, statistical measures, and key numerical results to provide a clearer understanding of the degree and significance of the observed effects.
(3) Results Section Writing: We appreciate your observation that parts of the results section read more like a methods section. To improve clarity and focus, we have restructured the results section to present the findings in a more concise and interpretative manner, while moving overly detailed descriptions of experimental procedures to the methods section.
Suggestions for improved or additional experiments, data or analyses:
Not necessary for this paper, but it would be interesting to see if the CLNF group could learn without auditory feedback.
This is a great suggestion and certainly something that could be done in the future.
There are no quantitative results in the results section. I would add important results to help the reader better interpret the data. For example, in: "Our results indicated that both training paradigms were able to lead mice to obtain a significantly larger number of rewards over time," You could show a number, with an appropriate comparison or statistical test, to demonstrate that learning was observed.
Thank you for pointing this out. We have mentioned quantification values in the results now, along with being mentioned in the figure legends, and we are quoting it in following sentences. “A ΔF/F0 threshold value was calculated from a baseline session on day 0 that would have allowed 25% performance. Starting from this basal performance of around 25% on day 1, mice (CLNF No-rule-change, N=23, n=60 and CLNF Rule-change, N=17, n=60) were able to discover the task rule and perform above 80% over ten days of training (Figure 4A, RM ANOVA p=2.83e-5), and Rule-change mice even learned a change in ROIs or rule reversal (Figure 4A, RM ANOVA p=8.3e-10, Table 5 for different rule changes). There were no significant differences between male and female mice (Supplementary Figure 3A).”
For: "Performing this analysis indicated that the Raspberry Pi system could provide reliable graded feedback within ~63 {plus minus} 15 ms for CLNF experiments." The LED test shows the sending of the signal, but the actual delay for the audio generation might be longer. This is also longer than the 50 ms mentioned in the abstract.
We appreciate the reviewer’s insightful comment. The latency reported (~63ms) was measured using the LED test, which captures the time from signal detection to output triggering on the Raspberry Pi GPIO. We agree that the total delay for auditory feedback generation could include an additional latency component related to the digital-to-analog conversion and speaker response. In our setup, we employ a fast Audiostream library written in C to generate the audio signal and expect the delay contribution to be negligible compared to the GPIO latency. Though we did not do this, it can be confirmed by an oscilloscope-based pilot measurement (for additional delay calculation). We have updated the manuscript to clarify that the 63 ± 15 ms value reflects the GPIO-triggered output latency, and we have revised the abstract to accurately state the delay as “~63 ms” rather than 50 ms. This ensures consistency and avoids underestimation of the latency. We have corrected the LED latency for CLNF and CLMF experiments in the abstract as well.
It could be helpful to visualize an individual trial for each experiment type, for instance how the audio frequency changes as movement speed / calcium activity changes.
We have added Supplementary Figure 8 that contains this data where you can see the target cortical activity trace, target paw speed, rewards, along with the audio frequency generated.
The sample sizes are small (n=1) for a few groups. I am excited by the variety of regions recorded, so it could be beneficial for the authors to collect a few more animals to beef up the sample sizes.
We've acknowledged that some of the sample sizes are small. Importantly, we have included raw and processed data as well as code for future analysis. We felt it was still important to still include these data sets with smaller sample sizes as they might be useful for others pursuing this direction in the future.
I am curious as to why 60 trials sessions were used. Was it mostly for the convenience of a 30 min session, or were the animals getting satiated? If the former, would learning have occurred more rapidly with longer sessions?
This is a great observation and the answer is it was mostly due to logistical reasons. We tried to not keep animals headfixed for more than 45 minutes in each session as they become less engaged with long duration headfixed sessions. After headfixing them, it takes about 15 minutes to get the experiment going and therefore 30 - 40 minutes long recorded sessions seemed appropriate before they stop being engaged or before they get satiated in the task. We provided supplemental water after the sessions and we observed that they consumed water after the sessions so they were not fully satiated during the sessions even when they performed well in the task and got maximum rewards. We also had inter-trial rest periods of 10s that elongated the session duration. We think it would be interesting to explore the relationship between session duration(number of trials) and task learning progression over the days in a separate study.
Figure 4E is interesting, it seems like the changes in the distribution of deltaF was in both positive and negative directions, instead of just positive. I'd be curious as to the author's thoughts as to why this is the case. Relatedly, I don't see Figure 4E, and a few other subplots, mentioned in the text. As a general comment, I would address each subplot in the text.
We have split Figure 4 into two to keep the figures more readable. Previous Figure 4E-H are now Figure 5A-D in the revised manuscript. The online real-time CLNF sessions were using a moving window average to calculate ΔF/F<sub>0</sub> and the figures were generated by averaging the whole recorded sessions. We have added text in Methods under “Online ΔF/F<sub>0</sub>calculation” and “Offline ΔF/F<sub>0</sub> calculation” sections making it clear about how we do our ΔF/F<sub>0</sub> normalization based on average fluorescence over the entire session. Using this method of normalization does increase the baseline so that some peaks appear to be below zero. Additionally, it is unclear what strategy animals are employing to achieve the rule specific target activity. The task did not constrain them to have a specific strategy for cortical activation - they were rewarded as long as they crossed the threshold in target ROI(s). For example, in 2-ROI experiments, to increase ROI1-ROI2 target activity, they could increase activity of ROI1 relative to ROI2 or decreased activity of ROI1 relative to ROI1 - both would have led to a reward as long as the result crossed the threshold.
We have now addressed and added reference to the figures in the text in Results under “Mice can explore and learn an arbitrary task, rule, and target conditions” and “Mice can rapidly adapt to changes in the task rule” sections - thanks for pointing this out.
For: "In general, all ROIs assessed that encompassed sensory, pre-motor, and motor areas were capable of supporting increased reward rates over time," I would provide a visual summary showing the learning curves for the different types of regions.
We have rewritten this section to emphasize that these conclusions were based on pooled data from multiple regions of interest. The sample sizes for each type of region are different and some are missing. We believe it would be incomplete and not comparable to present this as a regular analysis since the sample sizes were not balanced. We would be happy to dive deeper into this and point to the raw and processed dataset if anyone would like to explore this further by GitHub or other queries.
Relatedly, I would further explain the fast vs slow learners, and if they mapped onto certain regions.
Mice were categorized into fast or slow learners based on the slope of learning over days (reward progression over the days) as shown in Supplementary Figure 3C,D. Our initial aim was not to probe cortical regions that led to fast vs slow learning but this was a grouping we did afterwards. Based on the analysis we did, the fast learners included the sensory (V1), somatosensory (BC, HL), and motor (M1, M2) areas, while the slow learners included the motor (M1, M2), and higher order (TR, RL) cortical areas. Testing all dorsal cortical areas would be prudent to establish their role in fast or slow learning and it is an interesting future direction.
Also I would make the labels for these plots (e.g. Supp Fig3) more intuitive, versus the acronyms currently used.
We have made more expressive labels and explained the acronyms below the Supplementary Figure 3.
The CLMF animals showed a decrease in latency across learning, what about the CLNF animals? There is currently no mention in the text or figures.
We have now incorporated the CLNF task latency data into both the Results text and Figure 4C. Briefly, task latency decreased as performance improved, increased following a rule change, and then decreased again as the animals relearned the task. The previous Figure 4C has been updated to Figure 4D, and the former Figure 4D has been moved to Supplementary Figure 4E.
Reviewer #2 (Public review):
Summary:
In this work, Gupta & Murphy present several parallel efforts. On one side, they present the hardware and software they use to build a head-fixed mouse experimental setup that they use to track in "real-time" the calcium activity in one or two spots at the surface of the cortex. On the other side, the present another setup that they use to take advantage of the "real-time" version of DeepLabCut with their mice. The hardware and software that they used/develop is described at length, both in the article and in a companion GitHub repository. Next, they present experimental work that they have done with these two setups, training mice to max out a virtual cursor to obtain a reward, by taking advantage of auditory tone feedback that is provided to the mice as they modulate either (1) their local cortical calcium activity, or (2) their limb position.
Strengths:
This work illustrates the fact that thanks to readily available experimental building blocks, body movement and calcium imaging can be carried using readily available components, including imaging the brain using an incredibly cheap consumer electronics RGB camera (RGB Raspberry Pi Camera). It is a useful source of information for researchers that may be interested in building a similar setup, given the highly detailed overview of the system. Finally, it further confirms previous findings regarding the operant conditioning of the calcium dynamics at the surface of the cortex (Clancy et al. 2020) and suggests an alternative based on deeplabcut to the motor tasks that aim to image the brain at the mesoscale during forelimb movements (Quarta et al. 2022).
Weaknesses:
This work covers 3 separate research endeavors: (1) The development of two separate setups, their corresponding software. (2) A study that is highly inspired from the Clancy et al. 2020 paper on the modulation of the local cortical activity measured through a mesoscale calcium imaging setup. (3) A study of the mesoscale dynamics of the cortex during forelimb movements learning. Sadly, the analyses of the physiological data appears uncomplete, and more generally the paper tends to offer overstatements regarding several points:
In contrast to the introductory statements of the article, closed-loop physiology in rodents is a well-established research topic. Beyond auditory feedback, this includes optogenetic feedback (O'Connor et al. 2013, Abbasi et al. 2018, 2023), electrical feedback in hippocampus (Girardeau et al. 2009), and much more.
We have included and referenced these papers in our introduction section (quoted below) and rephrased the part where our previous text indicated there are fewer studies involving closed-loop physiology.
“Some related studies have demonstrated the feasibility of closed-loop feedback in rodents, including hippocampal electrical feedback to disrupt memory consolidation (Girardeau et al.2009), optogenetic perturbations of somatosensory circuits during behavior (O'Connor et al.2013), and more recent advances employing targeted optogenetic interventions to guide behavior (Abbasi et al. 2023).”
The behavioral setups that are presented are representative of the state of the art in the field of mesoscale imaging/head fixed behavior community, rather than a highly innovative design. In particular, the closed-loop latency that they achieve (>60 ms) may be perceived by the mice. This is in contrast with other available closed-loop setups.
We thank the reviewer for this thoughtful comment and fully agree that our closed-loop latency is larger than that achieved in some other contemporary setups. Our primary aim in presenting this work, however, is not to compete with the lowest possible latencies, but to provide an open-source, accessible, and flexible platform that can be readily adopted by a broad range of laboratories. By building on widely available and lower-cost components, our design lowers the barrier of entry for groups that wish to implement closed-loop imaging and behavioral experiments, while still achieving latencies well within the range that can support many biologically meaningful applications.
For example, our latency (~60 ms) remains compatible with experimental paradigms such as:
Motor learning and skill acquisition, where sensorimotor feedback on the scale of tens to hundreds of milliseconds is sufficient to modulate performance.
Operant conditioning and reward-based learning, in which reinforcement timing windows are typically broader and not critically dependent on sub-20 ms latencies.
Cortical state dependent modulation, where feedback linked to slower fluctuations in brain activity (hundreds of milliseconds to seconds) can provide valuable insight.
Studies of perception and decision-making, in which stimulus response associations often unfold on behavioral timescales longer than tens of milliseconds.
We believe that emphasizing openness, affordability, and flexibility will encourage widespread adoption and adaptation of our setup across laboratories with different research foci. In this way, our contribution complements rather than competes with ultra-low-latency closed-loop systems, providing a practical option for diverse experimental needs.
Through the paper, there are several statements that point out how important it is to carry out this work in a closed-loop setting with an auditory feedback, but sadly there is no "no feedback" control in cortical conditioning experiments, while there is a no-feedback condition in the forelimb movement study, which shows that learning of the task can be achieved in the absence of feedback.
We fully agree that such a control would provide valuable insight into the contribution of feedback to learning in the CLNF paradigm. In designing our initial experiments, we envisioned multiple potential control conditions, including No-feedback and Random-feedback. However, our first and primary objective was to establish whether mice could indeed learn to modulate cortical ROI activation through auditory feedback, and to further investigate this across multiple cortical regions. For this reason, we focused on implementing the CLNF paradigm directly, without the inclusion of these additional control groups. To broaden the applicability of the system, we subsequently adapted the platform to the CLMF experiments, where we did incorporate a No-feedback group. These results, as the reviewer notes, strengthen the evidence for the role of feedback in shaping task performance. We agree that the inclusion of a No-feedback control group in the CLNF paradigm will be crucial in future studies to further dissect the specific contribution of feedback to cortical conditioning.
The analysis of the closed-loop neuronal data behavior lacks controls. Increased performance can be achieved by modulating actively only one of the two ROIs, this is not clearly analyzed (for instance looking at the timing of the calcium signal modulation across the two ROIs. It seems that overall ROIs1 and 2 covariate, in contrast to Clancy et al. 2020. How can this be explained?
We agree that the possibility of increased performance being driven by modulation of a single ROI is an important consideration. Our study indeed began with 1-ROI closed-loop experiments. In those early experiments, while we did observe animals improving performance across days, we realized that daily variability in ongoing cortical GCaMP activity could lead to fluctuations in threshold-crossing events. The 2-ROI design was subsequently introduced to reduce this variability, as the target activity was defined as the relative activity between the two ROIs (e.g., ROI1 – ROI2). This approach offered a more stable signal by normalizing ongoing fluctuations. In our analysis of the early 2-ROI experiments, we observed that animals adopted diverging strategies to achieve threshold crossings. Specifically, some animals increased activity in ROI1 relative to ROI2, while others decreased activity in ROI2 to accomplish the same effect. Once discovered, each animal consistently adhered to its chosen strategy throughout subsequent training sessions. This was an early and intriguing observation, but as the experiments were not originally designed to systematically test this effect, we limited our presentation to the analysis of a small number of animals (shown in Figure 11). We have added details about this observation in our Results section as well, quoted below-
“In the 2-ROI experiment where the task rule required “ROI1 - ROI2” activity to cross a threshold for reward delivery, mice displayed divergent strategies. Some animals predominantly increased ROI1 activity, whereas others reduced ROI2 activity, both approaches leading to successful threshold crossing (Figure 11)”.
We hope this clarifies how the use of two ROIs helps explain the apparent covariation of the signals, and why some divergence from the observations of Clancy et al. (2020) may be expected.
Reviewer #3 (Public review):
Summary:
The study demonstrates the effectiveness of a cost-effective closed-loop feedback system for modulating brain activity and behavior in head-fixed mice. Authors have tested real-time closed-loop feedback system in head-fixed mice two types of graded feedback: 1) Closed-loop neurofeedback (CLNF), where feedback is derived from neuronal activity (calcium imaging), and 2) Closed-loop movement feedback (CLMF), where feedback is based on observed body movement. It is a python based opensource system, and authors call it CLoPy. The authors also claim to provide all software, hardware schematics, and protocols to adapt it to various experimental scenarios. This system is capable and can be adapted for a wide use case scenario.
Authors have shown that their system can control both positive (water drop) and negative reinforcement (buzzer-vibrator). This study also shows that using the close loop system mice have shown better performance, learnt arbitrary task and can adapt to change in the rule as well. By integrating real-time feedback based on cortical GCaMP imaging and behavior tracking authors have provided strong evidence that such closed-loop systems can be instrumental in exploring the dynamic interplay between brain activity and behavior.
Strengths:
Simplicity of feedback systems designed. Simplicity of implementation and potential adoption.
Weaknesses:
Long latencies, due to slow Ca2+ dynamics and slow imaging (15 FPS), may limit the application of the system.
We appreciate the reviewer’s comment and agree that latency is an important factor in our setup. The latency arises partly from the inherent slow kinetics of calcium signaling and GCaMP6s, and partly from the imaging rate of 15 FPS (every 66 ms). These limitations can be addressed in several ways: for example, using faster calcium indicators such as GCaMP8f, or adapting the system to electrophysiological signals, which would require additional processing capacity. In our implementation, image acquisition was fixed at 15 FPS to enable real-time frame processing (256 × 256 resolution) on Raspberry Pi 4B devices. With newer hardware, such as the Raspberry Pi 5, substantially higher acquisition and processing rates are feasible (although we have not yet benchmarked this extensively). More powerful platforms such as Nvidia Jetson or conventional PCs would further support much faster data acquisition and processing.
Major comments:
(1) Page 5 paragraph 1: "We tested our CLNF system on Raspberry Pi for its compactness, general-purpose input/output (GPIO) programmability, and wide community support, while the CLMF system was tested on an Nvidia Jetson GPU device." Can these programs and hardware be integrated with windows-based system and a microcontroller (Arduino/ Tency). As for the broad adaptability that's what a lot of labs would already have (please comment/discuss)?
While we tested our CLNF system on a Raspberry Pi (chosen for its compactness, GPIO programmability, and large user community) and our CLMF system on an Nvidia Jetson GPU device (to leverage real-time GPU-based inference), the underlying software is fully written in Python. This design choice makes the system broadly adaptable: it can be run on any device capable of executing Python scripts, including Windows-based PCs, Linux machines, and macOS systems. For hardware integration, we have confirmed that the framework works seamlessly with microcontrollers such as Arduino or Teensy, requiring only minor modifications to the main script to enable sending and receiving of GPIO signals through those boards. In fact, we are already using the same system in an in-house project on a Linux-based PC where an Arduino is connected to the computer to provide GPIO functionality. Furthermore, the system is not limited to Raspberry Pi or Arduino boards; it can be interfaced with any GPIO-capable devices, including those from Adafruit and other microcontroller platforms, depending on what is readily available in individual labs. Since many neuroscience and engineering laboratories already possess such hardware, we believe this design ensures broad accessibility and ease of integration across diverse experimental setups.
(2) Hardware Constraints: The reliance on Raspberry Pi and Nvidia Jetson (is expensive) for real-time processing could introduce latency issues (~63 ms for CLNF and ~67 ms for CLMF). This latency might limit precision for faster or more complex behaviors, which authors should discuss in the discussion section.
In our system, we measured latencies of approximately ~63 ms for CLNF and ~67 ms for CLMF. While such latencies indeed limit applications requiring millisecond precision, such as fast whisker movements, saccades, or fine-reaching kinematics, we emphasize that many relevant behaviors, including postural adjustments, limb movements, locomotion, and sustained cortical state changes, occur on timescales that are well within the capture range of our system. Thus, our platform is appropriate for a range of mesoscale behavioral studies that probably needs to be discussed more. It is also important to note that these latencies are not solely dictated by hardware constraints. A significant component arises from the inherent biological dynamics of the calcium indicator (GCaMP6s) and calcium signaling itself, which introduce slower temporal kinetics independent of processing delays. Newer variants, such as GCaMP8f, offer faster response times and could further reduce effective biological latency in future implementations.
With respect to hardware, we acknowledge that Raspberry Pi provides a low-cost solution but contributes to modest computational delays, while Nvidia Jetson offers faster inference at higher cost. Our choice reflects a balance between accessibility, cost-effectiveness, and performance, making the system deployable in many laboratories. Importantly, the modular and open-source design means the pipeline can readily be adapted to higher-performance GPUs or integrated with electrophysiological recordings, which provide higher temporal resolution. Finally, we agree with the reviewer that the issue of latency highlights deeper and interesting questions regarding the temporal requirements of behavior classification. Specifically, how much data (in time) is required to reliably identify a behavior, and what is the minimum feedback delay necessary to alter neural or behavioral trajectories? These are critical questions for the design of future closed-loop systems and ones that our work helps frame.
We have added a slightly modified version of our response above in the discussion section under “Experimental applications and implications”.
(3) Neurofeedback Specificity: The task focuses on mesoscale imaging and ignores finer spatiotemporal details. Sub-second events might be significant in more nuanced behaviors. Can this be discussed in the discussion section?
This is a great point and we have added the following to the discussion section. “In the case of CLNF we have focused on regional cortical GCAMP signals that are relatively slow in kinetics. While such changes are well suited for transcranial mesoscale imaging assessment, it is possible that cellular 2-photon imaging (Yu et al. 2021) or preparations that employ cleared crystal skulls (Kim et al. 2016) could resolve more localized and higher frequency kinetic signatures.”
(4) The activity over 6s is being averaged to determine if the threshold is being crossed before the reward is delivered. This is a rather long duration of time during which the mice may be exhibiting stereotyped behaviors that may result in the changes in DFF that are being observed. It would be interesting for the authors to compare (if data is available) the behavior of the mice in trials where they successfully crossed the threshold for reward delivery and in those trials where the threshold was not breached. How is this different from spontaneous behavior and behaviors exhibited when they are performing the test with CLNF?
We would like to emphasize that we are not directly averaging activity over 6 s to compare against the reward threshold. Instead, the preceding 6 s of activity is used solely to compute a dynamic baseline for ΔF/F<sub>0</sub> ( ΔF/F<sub>0</sub> = (F –F<sub>0</sub> )/F<sub>0</sub>). Here, F<sub>0</sub>is calculated as the mean fluorescence intensity over the prior 6 s window and is updated continuously throughout the session. This baseline is then subtracted from the instantaneous fluorescence signal to detect relative changes in activity. The reward threshold is therefore evaluated against these baseline-corrected ΔF/F<sub>0</sub> values at the current time point, not against an average over 6 s. This moving-window baseline correction is a standard approach in calcium imaging analyses, as it helps control for slow drifts in signal intensity, bleaching effects, or ongoing fluctuations unrelated to the behavior of interest. Thus, the 6-s window is not introducing a temporal lag in reward assignment but is instead providing a reference to detect rapid increases in cortical activity. We have added the term dynamic baseline to the Methods to clarify.
Recommendations for the authors
Reviewer #1 (Recommendations for the authors):
Additional suggestions for improved or additional experiments, data or analyses.
For: "Looking closely at their reward rate on day 5 (day of rule change), they had a higher reward rate in the second half of the session as compared to the first half, indicating they were adapting to the rule change within one session." It would be helpful to see this data, and would be good to see within-session learning on the rule change day
Thank you for pointing this out. We had missed referencing the figure in the text, and have now added a citation to Supplementary Figure 4A, which shows the cumulative rewards for each day of training. As seen in the plot for day 5, the cumulative rewards are comparable to those on day 1, with most rewards occurring during the second half of the session.
For: "These results suggest that motor learning led to less cortical activation across multiple regions, which may reflect more efficient processing of movement-related activity," it could also be the case that the behaviour became more stereotyped over learning, which would lead to more concentrated, correlated activity. To test this, it would be good to look at the limb variability across sessions. Similarly, if it is movement-related, there should be good decoding of limb kinematics.
Indeed, we observed that behavior became more stereotyped over the course of learning, as shown in Supplementary Figure 4C, 4D. One plausible explanation for the reduction in cortical activation across multiple regions is that behavior itself became more stereotyped, a possibility we have explored in the manuscript. Specifically, forelimb movements during the trial became increasingly correlated as mice improved on the task, particularly in the groups that received auditory feedback (Rule-change and No-rule-change groups; Figure 8). As movements became more correlated, overall body movements during trials decreased and aligned more closely with the task rule (Figure 9D). This suggests that reduced cortical activity may in part reflect changes in behavior. Importantly, however, in the Rule-change group, we observed that on the day of the rule switch (day 5), when the target shifted from the left to the right forelimb, cortical activity increased bilaterally (Figure 9A–C). This finding highlights our central point: groups that received feedback (Rule-change and No-rule-change) were able to identify the task rule more effectively, and both their behavior and cortical activity became more specifically aligned with the rule compared to the No-feedback group. We agree with the reviewers that additional analyses along these lines would be valuable future directions. To facilitate this, we have included the movement data for readers who may wish to pursue further analyses, details can be found under “Data and code availability” in Methods section. However, given the limited sample sizes in our dataset and the need to keep the manuscript focused on the central message, we felt that including these additional analyses here would risk obscuring the main findings.
For: "We believe the decrease in ΔF/F0peak is unlikely to be driven by changes in movement, as movement amplitudes did not decrease significantly during these periods (Figure 7D CLMF Rule-change)." I would formally compare the two conditions. This is an important control. Also, another way to see if the change in deltaF is related to movement would be to see if you can predict movement from the deltaF.
Figure 7D in the previous version is Figure 9D in the current revision of the manuscript. We've assessed this for the examples shown based on graphing the movement data, unfortunately there is not enough of that data to do a group analysis of movement magnitude. We would suggest that this would be an excellent future direction that would take advantage of the flexible open source nature of our tool.
Recommendations for improving the writing and presentation.
In the abstract there is no mention of the rationale for the project, or the resulting significance. I would modify this to increase readership by the behavioral neuroscience community. Similarly, the introduction also doesn't highlight the value of this resource for the field. Again, I think the pyControl paper does a good job of this. For readability, I would add more subheadings earlier in the results, to separate the different technical aspects of the system.
We have revised the introduction to include the rationale for the project, its potential implications, and its relevance for translational research. We have also framed the work within the broader context of the behavioral and systems neuroscience community. We greatly appreciate this suggestion, as we believe it enhances the clarity and accessibility of the manuscript for the community.
For: "While brain activity can be controlled through feedback, other variables such as movements have been less studied, in part because their analysis in real time is more challenging." I would highlight research that has studied the control of behavior through feedback, such as the Mathis paper where mice learn to pull a joystick to a virtual box, and adapt this motion to a force perturbation.
We have added a citation to the Mathis paper and describe this as an additional form of feedback. The text is quoted below:
“Opportunities also exist in extending real time pose classification (Forys et al. 2020; Kane et al. 2020) and movement perturbation (Mathis et al. 2017) to shape aspects of an animal’s motor repertoire.”
Some of the results content would be better suited for the methods, one example: "A previous version of the CLNF system was found to have non-linear audio generation above 10 kHz, partly due to problems in the audio generation library and partly due to the consumer-grade speaker hardware we were employing. This was fixed by switching to the Audiostream (https://github.com/kivy/audiostream) library for audio generation and testing the speakers to make sure they could output the commanded frequencies"
This is now moved to the Methods section.
For: "There are reports of cortical plasticity during motor learning tasks, both at cellular and mesoscopic scales (17-19), supporting the idea that neural efficiency could improve with learning," not sure I agree with this, the studies on cortical plasticity are usually to show a neural basis for the learning observed, efficiency is separate from this.
We have modified this statement to remove the concept of efficiency "There are reports of cortical plasticity during motor learning tasks, both at cellular and mesoscopic scales (17-19).”
The paragraph that opens "Distinct task- and reward-related cortical dynamics" that describes the experiment should appear in the previous section, as the data is introduced there.
We have moved the mentioned paragraphs in the previous section where we presented the data and other experiment details. This makes the text more readable and contextual.
I would present the different ROI rules with better descriptors and visualization to improve the readability.
We have added Supplementary Figure 7, which provides visualizations of the ROIs across all task rules used in the CLNF experiments.
Minor corrections to the text and figures.
Figure 1 is a little crowded, combining the CLNF and CLMF experiments, I would turn this into a 2 panel figure, one for each, similar to how you did figure 2.
We have revised Figure 1 to include two panels, one for CLNF and one for CLMF. The colored components indicate elements specific to each setup, while the uncolored components represent elements shared between CLNF and CLMF. Relevant text in the manuscript is updated to refer to these figures.
For Figure 2, the organization of the CLMF section is not intuitive for the reader. I would reorder it so it has a similar flow as the CLNF experiment.
We have revised the figure by updating the layout of panel B (CLMF) to align with panel A (CLNF), thereby creating a more intuitive and consistent flow between the panels. We appreciate this helpful suggestion, which we believe has substantially improved the clarity of the figure. The corresponding text in the manuscript has also been updated to reflect these changes.
For Figure 3, highlight that C and E are examples. They also seem a little out of place, so they could even be removed.
We have now explicitly labeled Figures 3C and 3E as representative examples (figure legend and on figure itself). We believe including these panels provides helpful context for readers: Figure 3C illustrates how the ROIs align on the dorsal cortical brain map with segmented cortical regions, while Figure 3E shows example paw trajectories in three dimensions, allowing visualization of the movement patterns observed during the trials.
In the plots, I would add sample sizes, for instance, in CLNF learning curve in Figure 4A, how many animals are in each group?
We have labeled Figure 4 with number of animals used in CLNF (No-rule-change, N=23; Rule-change, N=17), and CLMF (Rule-change, N=8; No-rule-change, N=4; No-feedback, N=4).
Also, Figure 7 for example, which figures are single-sessions, versus across animals? For Figure 7c, what time bin is the data taken from?
We have clarified this now and mentioned it in all the figures. Figure 7 in the previous version is Figure 9 in the current updated manuscript. Figure 9A is from individual sessions on different days from the same mouse. Figure 9B is the group average reward centered ΔF/F<sub>0</sub> activity in different cortical regions (Rule-change, N=8; No-rule-change, N=4; No-feedback, N=4). Figure 9C shows average ΔF/F<sub>0</sub> peak values obtained within -1sec to +1sec centered around the reward point (N=8).
It says "punish" in Figure 3, but there is no punishment?
Yes, the task did not involve punishment. Each trial resulted in either a success, which is followed by a reward, or a failure, which is followed by a buzzer sound. To better reflect these outcomes, we have updated Figure 3 and replaced the labels “Reward” with “Success” and “Punish” with “Failure.”
The regression on 5c doesn't look quite right, also this panel is not mentioned in the text.
The figure referred to by the reviewer as Figure 5 is now presented as Figure 6 in the revised manuscript. Regarding the reviewer’s observation about the regression line in the left panel of Figure 5C, the apparent misalignment arises because the majority of the data points are densely clustered at the center of the scatter plot, where they overlap substantially. The regression line accurately reflects this concentration of overlapping data. To improve clarity, we have updated the figure and ensured that it is now appropriately referenced in the Results section.
Reviewer #2 (Recommendations for the authors):
(1) There would be many interesting observations and links between the peripheral and cortical studies if there was a body video available during the cortical study. Is there any such data available?
We agree that a detailed analysis of behavior during the CLNF task would be necessary to explore any behavior correlates with success in the task. Unfortunately, we do not have a sufficient video of the whole body to perform such an analysis.
(2) The text (p. 24) states: [intracortical GCAMP transients measured over days became more stereotyped in kinetics and were more correlated (to each other) as the task performance increased over the sessions (Figure 7E).] But I cannot find this quantification in the figures or text?
Figure 7 in the previous version of the manuscript now appears as Figure 9. In this figure, we present cortical activity across selected regions during trials, and in Figure 9E we highlight that this activity becomes more correlated. Since we did not formally quantify variability, we have removed the previous claim that the activity became stereotyped and revised the text in the updated manuscript accordingly.
Typos:
10-serest c (page 13)
Inverted color codes in figure 4E vs F
Reviewer #3 (Recommendations for the authors):
We have mostly attempted to limit the feedback to suggestions and posed a few questions that might be interesting to explore given the dataset the authors have collected.
Comments:
In close loop systems the latency is primary concern, and authors have successfully tested the latency of the system (Delay): from detection of an event to the reaction time was less than 67ms.
We have commented on the issues and limitations caused by latency, and potential future directions to overcome these challenges in responses to some of the previous comments.
Additional major comments:
"In general, all ROIs assessed that encompassed sensory, pre-motor, and motor areas were capable of supporting increased reward rates over time (Figure 4A, Animation 1)." Fig 4A is merely showing change in task performance over time and does not have information regarding the changes observed specific to CLNF for each ROI.
We acknowledge that the sample size for individual ROI rules was not sufficient for meaningful comparisons. To address this limitation, we pooled the data across all the rules tested. The manuscript includes a detailed list of the rules along with their corresponding sample sizes for transparency.
A ΔF/F<sub>0</sub> threshold value was calculated from a baseline session on day 0 that would have allowed 25% performance. Starting from this basal performance of around 25% on day 1, mice (CLNF No-rule-change, n=28 and CLNF Rule-change, n=13). It is unclear what the replicates here are. Trials or mice? The corresponding Figure legend has a much smaller n value.
Thank you for pointing this out. We realized that we had not indicated the sample replicates in the figure, and the use of n instead of N for the number of animals may have been misleading. We have now corrected the notation and clarified this information in the figure to resolve the discrepancy.
What were the replicates for each ROI pairs evaluated?
Each ROI rule and number of mice and trials are listed in Table 5 and Table 6.
Our analysis revealed that certain ROI rules (see description in methods) lead to a greater increase in success rate over time than others (Supplementary Figure 3D). The Supplementary figures 3C and 3D are blurry and could use higher resolution images.
We have increased the font size of the text that was previously difficult to read and re-exported the figure at a higher resolution (300 DPI). We believe these changes will resolve the issue.
Also, It will help the reader is a visual representation of the ROI pairs are provided, instead of the text view. One interesting question is whether there are anatomical biases to fast vs slow learning pairs (Directionality - anterior/posterior, distance between the selected ROIs etc). This could be interesting to tease apart.
We have added Supplementary Figure 7, which provides visualizations of the ROIs across all task rules used in the CLNF experiments. While a detailed investigation of the anatomical basis of fast versus slow learning cortical ROIs is beyond the scope of the present study, we agree that this represents an exciting future direction for further research.
How distant should the ROIs be to achieve increased task performance?
We appreciate this insightful question. We did not specifically test this scenario. In our study, we selected 0.3 × 0.3 mm ROIs centered on the standard AIBS mouse brain atlas (CCF). At this resolution, ROIs do not overlap, regardless of their placement in a two-ROI experiment. Furthermore, because our threshold calculations are based on baseline recordings, we expect the system would function for any combination of ROI placements. Nonetheless, exploring this systematically would be an interesting avenue for future experiments.
Figures:
I would leave out some of the methodological details such as the protocol for water restriction (Fig. 3) out of the legend. This will help with readability.
We have removed some of the methodological details, including those mentioned above, from the legend of Figure 3 in the updated manuscript.
Fig 1 and Fig 2: In my opinion, It would be easier for the reader if the current Fig. 2, which provides a high level description of CLNF and CLBF is presented as Fig. 1. The current Fig. 1, goes into a lot of methodological implementation details, and also includes a lot of programming jargon that is being introduced early in the paper that is hard to digest early on in the paper's narrative.
Thank you for the suggestion. In the new manuscript, Figure 1 and Figure 2 have been swapped.
Higher-resolution images/ plots are needed in many instances. Unsure if this is the pdf compression done by the manuscript portal that is causing this.
All figures were prepared in vector graphics format using the open-source software Inkscape. For this manuscript, we exported the images at 300 DPI, which is generally sufficient for publication-quality documents. The submission portal may apply additional processing, which could have resulted in a reduction in image quality. We will carefully review the final submission files and ensure that all figures are clear and of high quality.
The authors repeatedly show ROI specific analysis M1_L, F1_R etc. It will be helpful to provide a key, even if redundant in all figures to help the reader.
We have now included keys to all such abbreviations in all the figures.
There are also instances of editorialization and interpretation e.g., "Surprisingly, the "Rule-change" mice were able to discover the change in rule and started performing above 70% within a day of the rule change, on day 6" that would be more appropriate in the main body of the paper.
Thank you for pointing this out in the figure legend, and we have removed it now since we already discussed this in the Results.
Minor comments
(1) The description of Figure 1 is hard to follow and can be described better based on how the information is processed and executed in the system from source to processing and back. Using separated colors (instead of shaded of grey) for the neuro feedback and movement feedback would help as well. Common components could have a different color. The specification like the description of the config file should come later.
Figure 1 in the previous version is Figure 2 in the updated version. We have taken suggestions from other reviewers and made the figure easier to understand and split it into two panels with color coding Green for CLNF, Pink for CLMF specific parts while common shared parts are left without any color.
(2) Page 20 last paragraph:
Authors are neglecting that the rule change is done one day prior and the results that you see in the second half on the 6th day are not just because of the first half of the 6th day instead combined training on the 5th day (rule change) and then the first half of the 6th day. Rephrasing this observation is essential.
We have revised the text for clarity to indicate that the performance increase observed on day 6 is not necessarily attributable to training on that day. In fact, we noted and mentioned that mice began to perform the task better during the second half of the session on day 5 itself.
(3) The method section description of the CLMF setup (Page no 39 first paragraph) is more detailed, a diagram of this setup would make it easy to follow and a better read.
We have made changes to the CLMF setup (Figure 1B) and CLMF schematic (Figure 2B) to make it easier to understand parts of the setup and flow of control.
Reviewer #3 (Public review):
Summary
The paper presents a imaging and analysis pipeline for whole-mount gastruloid imaging with two-photon microscopy. The presented pipeline includes spectral unmixing, registration, segmentation, and a wavelength-depended intensity normalization step, followed by quantitative analysis of spatial gene expression patterns and nuclear morphometry on a tissue level. The utility of the approach is demonstrated by several experimental findings such as establishing spatial correlations between local nuclear deformation and tissue density changes, as well as radial distribution pattern of mesoderm markers. The pipeline is distributed as a Python package, notebooks and multiple napari plugins.
Strengths
The paper is well-written with detailed methodological descriptions, which I think would make it a valuable reference for researchers performing similar volumetric tissue imaging experiments (gastruloids/organoids). The pipeline itself addresses many practical challenges including resolution loss within tissue, registration of large volumes, nuclear segmentation, and intensity normalization. Especially the intensity decay measurements and wavelength-dependent intensity normalization approach using nuclear (Hoechst) signal as reference is very interesting and should be applicable to other imaging contexts. The morphometric analysis is equally well done with the correlation between nuclear shape deformation and tissue density changes being a interesting finding. The paper is quite thorough in its technical description of the methods (which are a lot) and their experimental validation is appropriate. Finally, the provided code and napari plugins seem to be well done (I installed a selected list of the plugins and they ran without issues) and should be very helpful for the community.
Comments on revisions:
The minor issues that I originally raised in my first review have been fully resolved in the revised version.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
The image analysis pipeline is tested in analysing microscopy imaging data of gastruloids of varying sizes, for which an optimised protocol for in toto image acquisition is established based on whole mount sample preparation using an optimal refractive index matched mounting media, opposing dual side imaging with two-photon microscopy for enhanced laser penetration, dual view registration, and weighted fusion for improved in toto sample data representation. For enhanced imaging speed in a two-photon microscope, parallel imaging was used, and the authors performed spectral unmixing analysis to avoid issues of signal cross-talk.
In the image analysis pipeline, different pre-treatments are done depending on the analysis to be performed (for nuclear segmentation - contrast enhancement and normalisation; for quantitative analysis of gene expression - corrections for optical artifacts inducing signal intensity variations). Stardist3D was used for the nuclear segmentation. The study analyses into properties of gastruloid nuclear density, patterns of cell division, morphology, deformation, and gene expression.
Strengths:
The methods developed are sound, well described, and well-validated, using a sample challenging for microscopy, gastruloids. Many of the established methods are very useful (e.g. registration, corrections, signal normalisation, lazy loading bioimage visualisation, spectral decomposition analysis), facilitate the development of quantitative research, and would be of interest to the wider scientific community.
We thank the reviewer for this positive feedback.
Weaknesses:
A recommendation should be added on when or under which conditions to use this pipeline.
We thank the reviewer for this valuable feedback, we added the text in the revised version, ines 418 to 474. “In general, the pipeline is applicable to any tissue, but it is particularly useful for large and dense 3D samples—such as organoids, embryos, explants, spheroids, or tumors—that are typically composed of multiple cell layers and have a thickness greater than 50 µm”.
“The processing and analysis pipeline are compatible with any type of 3D imaging data (e.g. confocal, 2 photon, light-sheet, live or fixed)”.
“Spectral unmixing to remove signal cross-talk of multiple fluorescent targets is typically more relevant in two-photon imaging due to the broader excitation spectra of fluorophores compared to single-photon imaging. In confocal or light-sheet microscopy, alternating excitation wavelengths often circumvents the need for unmixing. Spectral decomposition performs even better with true spectral detectors; however, these are usually not non-descanned detectors, which are more appropriate for deep tissue imaging. Our approach demonstrates that simultaneous cross-talk-free four-color two-photon imaging can be achieved in dense 3D specimen with four non-descanned detectors and co-excitation by just two laser lines. Depending on the dispersion in optically dense samples, depth-dependent apparent emission spectra need to be considered”.
“Nuclei segmentation using our trained StarDist3D model is applicable to any system under two conditions: (1) the nuclei exhibit a star-convex shape, as required by the StarDist architecture, and (2) the image resolution is sufficient in XYZ to allow resampling. The exact sampling required is object- and system-dependent, but the goal is to achieve nearly isotropic objects with diameters of approximately 15 pixels while maintaining image quality. In practice, images containing objects that are natively close to or larger than 15 pixels in diameter should segment well after resampling. Conversely, images with objects that are significantly smaller along one or more dimensions will require careful inspection of the segmentation results”.
“Normalization is broadly applicable to multicolor data when at least one channel is expected to be ubiquitously expressed within its domain. Wavelength-dependent correction requires experimental calibration using either an ubiquitous signal at each wavelength. Importantly, this calibration only needs to be performed once for a given set of experimental conditions (e.g., fluorophores, tissue type, mounting medium)”.
“Multi-scale analysis of gene expression and morphometrics is applicable to any 3D multicolor image. This includes both the 3D visualization tools (Napari plugins) and the various analytical plots (e.g., correlation plots, radial analysis). Multi-scale analysis can be performed even with imperfect segmentation, as long as segmentation errors tend to cancel out when averaged locally at the relevant spatial scale. However, systematic errors—such as segmentation uncertainty along the Z-axis due to strong anisotropy—may accumulate and introduce bias in downstream analyses. Caution is advised when analyzing hollow structures (e.g., curved epithelial monolayers with large cavities), as the pipeline was developed primarily for 3D bulk tissues, and appropriate masking of cavities would be needed”.
Reviewer #2 (Public review):
Summary:
This study presents an integrated experimental and computational pipeline for high-resolution, quantitative imaging and analysis of gastruloids. The experimental module employs dual-view two-photon spectral imaging combined with optimized clearing and mounting techniques to image whole-mount immunostained gastruloids. This approach enables the acquisition of comprehensive 3D images that capture both tissue-scale and single-cell level information.
The computational module encompasses both pre-processing of acquired images and downstream analysis, providing quantitative insights into the structural and molecular characteristics of gastruloids. The pre-processing pipeline, tailored for dual-view two-photon microscopy, includes spectral unmixing of fluorescence signals using depth-dependent spectral profiles, as well as image fusion via rigid 3D transformation based on content-based block-matching algorithms. Nuclei segmentation was performed using a custom-trained StarDist3D model, validated against 2D manual annotations, and achieving an F1 score of 85+/-3% at a 50% intersection-over-union (IoU) threshold. Another custom-trained StarDist3D model enabled accurate detection of proliferating cells and the generation of 3D spatial maps of nuclear density and proliferation probability. Moreover, the pipeline facilitates detailed morphometric analysis of cell density and nuclear deformation, revealing pronounced spatial heterogeneities during early gastruloid morphogenesis.
All computational tools developed in this study are released as open-source, Python-based software.
Strengths:
The authors applied two-photon microscopy to whole-mount deep imaging of gastruloids, achieving in toto visualization at single-cell resolution. By combining spectral imaging with an unmixing algorithm, they successfully separated four fluorescent signals, enabling spatial analysis of gene expression patterns.
The entire computational workflow, from image pre-processing to segmentation with a custom-trained StarDist3D model and subsequent quantitative analysis, is made available as open-source software. In addition, user-friendly interfaces are provided through the open-source, community-driven Napari platform, facilitating interactive exploration and analysis.
We thank the reviewer for this positive feedback.
Weaknesses:
The computational module appears promising. However, the analysis pipeline has not been validated on datasets beyond those generated by the authors, making it difficult to assess its general applicability.
We agree that applying our analysis pipeline to published datasets—particularly those acquired with different imaging systems—would be valuable. However, only a few high-resolution datasets of large organoid samples are publicly available, and most of these either lack multiple fluorescence channels or represent 3D hollow structures. Our computational pipeline consists of several independent modules: spectral filtering, dual-view registration, local contrast enhancement, 3D nuclei segmentation, image normalization based on a ubiquitous marker, and multiscale analysis of gene expression and morphometrics. We added the following sentences to the Discussion, lines 418 to 474, and completed the discussion on applicability with a table showing the purpose, requirements, applicability and limitations of each step of the processing and analysis pipeline.
“Spectral filtering has already been applied in other systems (e.g. [7] and [8]), but is here extended to account for imaging depth-dependent apparent emission spectra of the different fluorophores. In our pipeline, we provide code to run spectral filtering on multichannel images, integrated in Python. In order to apply the spectral filtering algorithm utilized here, spectral patterns of each fluorophore need to be calibrated as a function of imaging depth, which depend on the specific emission windows and detector settings of the microscope”.
“Image normalization using a wavelength-dependent correction also requires calibration on a given imaging setup to measure the difference in signal decay among the different fluorophores species. To our knowledge, the calibration procedures for spectral-filtering and our image-normalization approach have not been performed previously in 3D samples, which is why validation on published datasets is not readily possible. Nevertheless, they are described in detail in the Methods section, and the code used—from the calibration measurements to the corrected images—is available open-source at the Zenodo link in the manuscript”.
Dual-view registration, local contrast enhancement, and multiscale analysis of gene expression and morphometrics are not limited to organoid data or our specific imaging modalities. To evaluate our 3D nuclei segmentation model, we tested it on diverse systems, including gastruloids stained with the nuclear marker Draq5 from Moos et al. [1]; breast cancer spheroids; primary ductal adenocarcinoma organoids; human colon organoids and HCT116 monolayers from Ong et al. [2]; and zebrafish tissues imaged by confocal microscopy from Li et al [3]. These datasets were acquired using either light-sheet or confocal microscopy, with varying imaging parameters (e.g., objective lens, pixel size, staining method). The results are added in the manuscript, Fig. S9b.
Besides, the nuclei segmentation component lacks benchmarking against existing methods.
We agree with the reviewer that a benchmark against existing segmentation methods would be very useful. We tried different pre-trained models:
CellPose, which we tested in a previous paper ([4]) and which showed poor performances compared to our trained StarDist3D model.
DeepStar3D ([2]) is only available in the software 3DCellScope. We could not benchmark the model on our data, because the free and accessible version of the software is limited to small datasets. An image of a single whole-mount gastruloid with one channel, having dimensions (347,467,477) was too large to be processed, see screenshot below. The segmentation model could not be extracted from the source code and tested externally because the trained DeepStar3D weights are encrypted.
Author response image 1.
Screenshot of the 3DCellScore software. We could not perform 3D nuclei segmentation of a whole-mount gastruloids because the image size was too large to be processed.
AnyStar ([5]), which is a model trained from the StarDist3D architecture, was not performing well on our data because of the heterogeneous stainings. Basic pre-processing such as median and gaussian filtering did not improve the results and led to wrong segmentation of touching nuclei. AnyStar was demonstrated to segment well colon organoids in Ong et al, 2025 ([2]), but the nuclei were more homogeneously stained. Our Hoechst staining displays bright chromatin spots that are incorrectly labeled as individual nuclei.
Cellos ([6]), another model trained from StarDist3D, was also not performing well. The objects used for training and to validate the results are sparse and not touching, so the predicted segmentation has a lot of false negatives even when lowering the probability threshold to detect more objects. Additionally, the network was trained with an anisotropy of (9,1,1), based on images with low z resolution, so it performed poorly on almost isotropic images. Adapting our images to the network’s anisotropy results in an imprecise segmentation that can not be used to measure 3D nuclei deformations.
We tried both Cellos and AnyStar predictions on a gastruloid image from Fig. S2 of our main manuscript. The results are added in the manuscript, Fig. S9b. Fig3 displays the results qualitatively compared to our trained model Stardist-tapenade.
Author response image 2.
Qualitative comparison of two published segmentation models versus our model. We show one slice from the XY plane for simplicity. Segmentations are displayed with their contours only. (Top left) Gastruloid stained with Hoechst, image extracted from Fig S2 of our manuscript. (Top right) Same image overlayed with the prediction from the Cellos model, showing many false negatives. (Bottom left) Same image overlayed with the prediction from our Stardist-tapenade model. (Bottom right) Same image overlayed with the prediction from the AnyStar model, false positives are indicated with a red arrow.
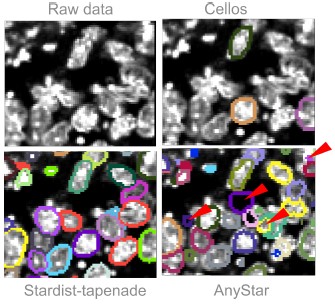
CellPose-SAM, which is a recent model developed building on the CellPose framework. The pre-trained model performs well on gastruloids imaged using our pipeline, and performs better than StarDist3D at segmenting elongated objects such as deformed nuclei. The performances are qualitatively compared on Fig. S9a and S10. We also demonstrate how using local contrast enhancement improves the results of CellPose-SAM (Fig. S10a), showing the versatility of the Tapenade pre-processing module. Tissue-scale, packing-related metrics from Cellpose–SAM labels qualitatively match those from stardist-tapenade as shown Fig.10c and d.
Appraisal:
The authors set out to establish a quantitative imaging and analysis pipeline for gastruloids using dual-view two-photon microscopy, spectral unmixing, and a custom computational framework for 3D segmentation and gene expression analysis. This aim is largely achieved. The integration of experimental and computational modules enables high-resolution in toto imaging and robust quantitative analysis at the single-cell level. The data presented support the authors' conclusions regarding the ability to capture spatial patterns of gene expression and cellular morphology across developmental stages.
Impact and utility:
This work presents a compelling and broadly applicable methodological advance. The approach is particularly impactful for the developmental biology community, as it allows researchers to extract quantitative information from high-resolution images to better understand morphogenetic processes. The data are publicly available on Zenodo, and the software is released on GitHub, making them highly valuable resources for the community.
We thank the reviewer for these positive feedbacks.
Reviewer #3 (Public review):
Summary
The paper presents an imaging and analysis pipeline for whole-mount gastruloid imaging with two-photon microscopy. The presented pipeline includes spectral unmixing, registration, segmentation, and a wavelength-dependent intensity normalization step, followed by quantitative analysis of spatial gene expression patterns and nuclear morphometry on a tissue level. The utility of the approach is demonstrated by several experimental findings, such as establishing spatial correlations between local nuclear deformation and tissue density changes, as well as the radial distribution pattern of mesoderm markers. The pipeline is distributed as a Python package, notebooks, and multiple napari plugins.
Strengths
The paper is well-written with detailed methodological descriptions, which I think would make it a valuable reference for researchers performing similar volumetric tissue imaging experiments (gastruloids/organoids). The pipeline itself addresses many practical challenges, including resolution loss within tissue, registration of large volumes, nuclear segmentation, and intensity normalization. Especially the intensity decay measurements and wavelength-dependent intensity normalization approach using nuclear (Hoechst) signal as reference are very interesting and should be applicable to other imaging contexts. The morphometric analysis is equally well done, with the correlation between nuclear shape deformation and tissue density changes being an interesting finding. The paper is quite thorough in its technical description of the methods (which are a lot), and their experimental validation is appropriate. Finally, the provided code and napari plugins seem to be well done (I installed a selected list of the plugins and they ran without issues) and should be very helpful for the community.
We thank the reviewer for his positive feedback and appreciation of our work.
Weaknesses
I don't see any major weaknesses, and I would only have two issues that I think should be addressed in a revision:
(1) The demonstration notebooks lack accompanying sample datasets, preventing users from running them immediately and limiting the pipeline's accessibility. I would suggest to include (selective) demo data set that can be used to run the notebooks (e.g. for spectral unmixing) and or provide easily accessible demo input sample data for the napari plugins (I saw that there is some sample data for the processing plugin, so this maybe could already be used for the notebooks?).
We thank the reviewer for this relevant suggestion. The 7 notebooks were updated to automatically download sample tests. The different parts of the pipeline can now be run immediately:
https://github.com/GuignardLab/tapenade/tree/chekcs_on_notebooks/src/tapenade/notebooks
(2) The results for the morphometric analysis (Figure 4) seem to be only shown in lateral (xy) views without the corresponding axial (z) views. I would suggest adding this to the figure and showing the density/strain/angle distributions for those axial views as well.
A morphometric analysis based on the axial views was added as Fig. S6a of the manuscript, complementary to the XY views.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
In lines 64 and 65, it is mentioned that confocal and light-sheet microscopy remain limited to samples under 100μm in diameter. I would recommend revising this sentence. In the paper of Moos and colleagues (also cited in this manuscript; PMID: 38509326), gastruloid samples larger than 100μm are imaged in toto with an open-top dual-view and dual-illumination light-sheet microscope, and live cell behaviour is analysed. Another example, if considering also multi-angle systems, is the impressive work of McDole and colleagues (PMID: 30318151), in which one of the authors of this manuscript is a corresponding author. There, multi-angle light sheet microscopy is used for in toto imaging and reconstruction of post-implantation mouse development (samples much larger than 100μm). Some multi-sample imaging strategies have been developed for this type of imaging system, though not to the sample number extent allowed by the Viventis LS2 system or the Bruker TruLive3D imager, which have higher image quality limitations.
We thank the reviewer for this remark. As reported in their paper, Moos et al. used dual-view light-sheet microscopy to image gastruloids, which are particularly dense and challenging tissues, with whole-mount samples of approximately 250 µm in diameter. Nevertheless, their image quality metric (DCT) shows a rapid twofold decrease within 50 µm depth (Extended Fig 5.h), whereas with two-photon microscopy, our image quality metric (FRC-QE) decreases by a factor of two over 150 µm in non-cleared samples (PBS) (see Fig. 2 c). While these two measurements (FRC-QE versus DCT) are not directly comparable, the observed difference reflects the superior depth performance of two-photon microscopy, owing in part to the use of non-descanned detectors. In our case, imaging was performed with Hoechst, a blue fluorophore suboptimal for deep imaging, whereas in the Moos dataset (Draq5, far-red), the configuration was more favorable for imaging in depth which further supports our conclusion.
In McDole et al, tissues reaching 250µm were imaged from 4 views, but do not reach cellular-scale resolution in deeper layers compatible with cell segmentation to our knowledge.
We corrected the sentence ‘However, light-sheet and confocal imaging approaches remain limited to relatively small organoids typically under 100 micrometers in diameter ‘ by the following (line 64) :
“While advances in light-sheet microscopy have extended imaging depth in organoids, maintaining high image quality throughout thick samples remains challenging. In practice, quantitative analyses are still largely restricted to organoids under roughly 100 µm in diameter”.
It is worth mentioning that two-photon microscopes are much more widely available than light sheet microscopes, and light sheet systems with 2-photon excitation are even less accessible, which makes the described workflow of Gros and colleagues have a wide community interest.
We thank the reviewer for this remark, and added this suggestion line 74:
“Finally, two-photon microscopes are typically more accessible than light-sheet systems and allow for straightforward sample mounting, as they rely on procedures comparable to standard confocal imaging”.
Reviewer #2 (Recommendations for the authors):
Suggestions:
A comparison with established pre-trained models for 3D organoid image segmentation (e.g., Cellos[1], AnyStar[2], and DeepStar3D[3], all based on StarDist3D) would help highlight the advantages of the authors' custom StarDist3D model, which has been specifically optimized for two-photon microscopy images.
(1) Cellos: https://doi.org/10.1038/s41467-023-44162-6
(2) AnyStar: https://doi.org/10.1109/WACV57701.2024.00742
(3) DeepStar3D: https://doi.org/10.1038/s41592-025-02685-4
We agree with the reviewer that a benchmark against existing segmentation methods is very useful. This is addressed in the revised version, as detailed above (Figure 3).
Recommendations:
Please clarify the following point. In line 195, the authors state, "This allowed us to detect all mitotic nuclei in whole-mount samples for any stage and size." Does this mean that the custom-trained StarDist3D model can detect 100% of mitotic nuclei? It was not clear from the manuscript, figures, or videos how this was validated. Given the reported performance scores of the StarDist3D model for detecting all nuclei, claiming 100% detection of mitotic nuclei seems surprisingly high.
We thank the reviewer for this comment. As it was detailed in the methods section, the detection score reaches 82%, and only the complete pipeline (detection+minimal manual curation) allows us to detect all mitotic nuclei. To make it clearer, the following precisions were added in the Results section:
”To detect division events, we stained gastruloids with phosphohistone H3 (ph3) and trained a separate custom Stardist3D model using 3D annotations of nuclei expressing ph3 (see Methods III H). This model together allowed us to detect nearly all mitotic nuclei in whole-mount samples for any stage and size (Fig.3f and Suppl.Movie 4), and we used minimal manual curation to correct remaining errors.”
Minor corrections:
It appears that Figures 4-6 are missing from the submitted version, but they can be found in the manuscript available on bioRxiv.
We thank the reviewer for this remark, this was corrected immediately to add Figures 4 to 6.
In line 185, is the intended phrase "by comparing the 2D predictions and the 2D sliced annotated segments..."?
To gain some clarity, we replaced the initial sentence:
“The f1 score obtained by comparing the 3D prediction and the 3D ground-truth is well approximated by the f1 score obtained by comparing the 2D annotations and the 2D sliced annotated segments, with at most a 5% difference between the two scores.” by
“The f1 score obtained in 3D (3D prediction compared with the 3D ground-truth) is well approximated by the f1 score obtained in 2D (2D predictions compared with the 2D sliced annotated segments). The difference between the 2 scores was at most 5%.”
Reviewer #3 (Recommendations for the authors):
(1) How is the "local neighborhood volume" defined, and how was it computed?
The reviewer is referring to this paragraph (the term is underscored) :
“To probe quantities related to the tissue structure at multiple scales, we smooth their signal with a Gaussian kernel of width σ, with σ defined as the spatial scale of interest. From the segmented nuclei instances, we compute 3D fields of cell density (number of cells per unit volume), nuclear volume fraction (ratio of nuclear volume to local neighborhood volume), and nuclear volume at multiple scales.”
To improve clarity, the phrasing has been revised: the term local neighborhood volume has been replaced by local averaging volume, and a reference to the Methods section has been added.
From the segmented nuclei instances, we compute 3D fields of cell density (number of cells per unit volume), nuclear volume fraction (ratio of space occupied by nuclear volume within the local averaging volume, as defined in the Methods III I), and nuclear volume at multiple scales.
(2) In the definition of inertia tensor (18), isn't the inner part normally defined in the reversed way (delta_i,j - ...)?
We thank the reviewer for noticing this error, which we fixed in the manuscript.
(3) For intensity normalization, the paper uses the Hoechst signal density as a proxy for a ubiquitous nuclei signal. I would assume that this is problematic, for eg, dividing cells (which would overestimate it). Would using the average Hoechst signal per nucleus mask (as segmentation is available) be a better proxy?
We agree that this idea is appealing if one assumes a clear relationship between nuclear volume and Hoechst intensity. However, since cell and nuclear volumes vary substantially with differentiation state (see Fig. 4), such a normalization approach would introduce additional biases at large spatial scales. We believe that the most robust improvement would instead consist in masking dividing cells during the normalization procedure, as these events could be detected and excluded from the computation.
Nonetheless, we believe the method proposed by the reviewer could prove relevant for other types of data, so we will implement this recommendation in the code available in the Tapenade package.
(4) Figures 4-6 were part of the Supplementary Material, but should be included in the main text?
We thank the reviewer for this remark, this was corrected immediately to add Figures 4-6.
We also noticed a missing reference to Fig. S3 in the main text, so we added lines 302 to 307 to comment on the wavelength-dependency of the normalization method. We improved the description of Fig.6, which lacked clarity (line 316 to 321, line 327).
(1) Moos, F., Suppinger, S., de Medeiros, G., Oost, K.C., Boni, A., Rémy, C., Weevers, S.L., Tsiairis, C., Strnad, P. and Liberali, P., 2024. Open-top multisample dual-view light-sheet microscope for live imaging of large multicellular systems. Nature Methods, 21(5), pp.798-803.
(2) Ong, H. T.; Karatas, E.; Poquillon, T.; Grenci, G.; Furlan, A.; Dilasser, F.; Mohamad Raffi, S. B.; Blanc, D.; Drimaracci, E.; Mikec, D.; Galisot, G.; Johnson, B. A.; Liu, A. Z.; Thiel, C.; Ullrich, O.; OrgaRES Consortium; Racine, V.; Beghin, A. (2025). Digitalized organoids: integrated pipeline for high-speed 3D analysis of organoid structures using multilevel segmentation and cellular topology. Nature Methods, 22(6), pp.1343-1354
(3) Li, L., Wu, L., Chen, A., Delp, E.J. and Umulis, D.M., 2023. 3D nuclei segmentation for multi-cellular quantification of zebrafish embryos using NISNet3D. Electronic Imaging, 35, pp.1-9.
(4) Vanaret, J., Dupuis, V., Lenne, P. F., Richard, F., Tlili, S., & Roudot, P. (2023). A detector-independent quality score for cell segmentation without ground truth in 3D live fluorescence microscopy. IEEE Journal of Selected Topics in Quantum Electronics, 29(4:Biophotonics), 1-12.
(5) Dey, N., Abulnaga, M., Billot, B., Turk, E. A., Grant, E., Dalca, A. V., & Golland, P. (2024). AnyStar: Domain randomized universal star-convex 3D instance segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 7593-7603).
(6) Mukashyaka, P., Kumar, P., Mellert, D. J., Nicholas, S., Noorbakhsh, J., Brugiolo, M., ... & Chuang, J. H. (2023). High-throughput deconvolution of 3D organoid dynamics at cellular resolution for cancer pharmacology with Cellos. Nature Communications, 14(1), 8406.
(7) Rakhymzhan, A., Leben, R., Zimmermann, H., Günther, R., Mex, P., Reismann, D., ... & Niesner, R. A. (2017). Synergistic strategy for multicolor two-photon microscopy: application to the analysis of germinal center reactions in vivo. Scientific reports, 7(1), 7101.
(8) Dunsing, V., Petrich, A., & Chiantia, S. (2021). Multicolor fluorescence fluctuation spectroscopy in living cells via spectral detection. Elife, 10, e69687.
This breakdown of coding into its smallest pieces is helpful because it explains how algorithms make decisions. While this is a fraction of code compared to the algorithms that are used on social media, it makes you question what the code looks like and what the decisions in these algorithms are based on.
Psuedocode is intended to be easier to read and write.
In other words, it’s like the fundamental structure for more developed code? It could be interpreted as the building blocks for what humans can understand of the vast universe of coding.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
We thank Reviewer #1 for its thoughtful and constructive feedback. We found the suggestions particularly helpful in refining the conceptual framework and clarifying key aspects of our interpretations.
Summary:
This paper investigates the potential link between amygdala volume and social tolerance in multiple macaque species. Through a comparative lens, the authors considered tolerance grade, species, age, sex, and other factors that may contribute to differing brain volumes. They found that amygdala, but not hippocampal, volume differed across tolerance grades, such that hightolerance species showed larger amygdala than low-tolerance species of macaques. They also found that less tolerant species exhibited increases in amygdala volume with age, while more tolerant species showed the opposite. Given their wide range of species with varied biological and ecological factors, the authors' findings provide new evidence for changes in amygdala volume in relation to social tolerance grades. Contributions from these findings will greatly benefit future efforts in the field to characterize brain regions critical for social and emotional processing across species.
Strengths:
(1) This study demonstrates a concerted and impressive effort to comparatively examine neuroanatomical contributions to sociality in monkeys. The authors impressively collected samples from 12 macaque species with multiple datapoints across species age, sex, and ecological factors. Species from all four social tolerance grades were present. Further, the age range of the animals is noteworthy, particularly the inclusion of individuals over 20 years old - an age that is rare in the wild but more common in captive settings.
(2) This work is the first to report neuroanatomical correlates of social tolerance grade in macaques in one coherent study. Given the prevalence of macaques as a model of social neuroscience, considerations of how socio-cognitive demands are impacted by the amygdala are highly important. The authors' findings will certainly inform future studies on this topic.
(3) The methodology and supplemental figures for acquiring brain MRI images are well detailed. Clear information on these parameters is crucial for future comparative interpretations of sociality and brain volume, and the authors do an excellent job of describing this process in full.
Weaknesses:
(1) The nature vs. nurture distinction is an important one, but it may be difficult to draw conclusions about "nature" in this case, given that only two data points (from grades 3 and 4) come from animals under one year of age (Method Figure 1D). Most brains were collected after substantial social exposure-typically post age 1 or 1.5-so the data may better reflect developmental changes due to early life experience rather than innate wiring. It might be helpful to frame the findings more clearly in terms of how early experiences shape development over time, rather than as a nature vs. nurture dichotomy.
We agree with the reviewer that presenting our findings through a strict nature vs. nurture dichotomy was potentially misleading. We have revised the introduction and the discussion (e.g. lines 85-95 and 363-365) to clarify that we examined how neurodevelopmental trajectories differ across social grades with the caveat of related to the absence of very young individuals in our samples. We now explicitly mention that our results may reflect both early species-typical biases and experience-dependent maturation.
We positioned our study on social tolerance in a comparative neuroscience framework and introduced a tentative working model that articulates behavioral traits, cognitive dimensions, and their potential subcortical neural substrates
Drawing upon 18 behavioral traits identified in Thierry’s comparative analyses (Thierry, 2021, 2007), we organize these traits into three core dimensions: socio-cognitive demands, behavioral inhibition, and the predictability of the social environment (Table 1). This conceptualization does not aim to redefine social tolerance itself, but rather to provide a structured basis for testing neuroanatomical hypotheses related to social style variability. It echoes recent efforts to bridge behavioral ecology and cognitive neuroscience by linking specific mental abilities – such as executive functions or metacognition – with distinct prefrontal regions shaped by social and ecological pressures (Bouret et al., 2024).
“Cross-fostering experiments (De Waal and Johanowicz, 1993), along with our own results, suggest that social tolerance grades reflect both early, possibly innate predispositions and later environmental shaping”.
(2) It would be valuable to clarify how the older individuals, especially those 20+ years old, may have influenced the observed age-related correlations (e.g., positive in grades 1-2, negative in grades 3-4). Since primates show well-documented signs of aging, some discussion of the potential contribution of advanced age to the results could strengthen the interpretation.
We thank the reviewer for highlighting this important point. In our dataset, younger and older subjects are underrepresented, but they are distributed across all subgroups. Therefore, we do not think that it could drive the interaction effect we are reporting. In our sample, amygdala volume tended to increase with age in intolerant species and decrease in tolerant species. We included a new analysis (Figure 4) that allows providing a clearer assessment of when social grades 1 vs 4 differed in terms of amygdala and hippocampus volume. While our model accounts for age continuously, we agree that age-related variation deserves cautious interpretation and require longitudinal designs in future studies.
We also added the following statements in the discussion (lines 386-391)
“Due to a limited sample size of our study, this crossing trend, already accounted for by our continuous age model, should be further investigated. These results call for cautious interpretation of age-related variation and further emphasize the importance of longitudinal studies integrating both behavioral, cognitive and anatomical data in non-human primates, which would help to better understand the link between social environment and brain development (Song et al., 2021)”.
(3) The authors categorize the behavioral traits previously described in Thierry (2021) into 3 selfdefined cognitive requirements, however, they do not discuss under what conditions specific traits were assigned to categories or justify why these cognitive requirements were chosen. It is not fully clear from Thierry (2021) alone how each trait would align with the authors' categories. Given that these traits/categories are drawn on for their neuroanatomical hypotheses, it is important that the authors clarify this. It would be helpful to include a table with all behavioral traits with their respective categories, and explain their reasoning for selecting each cognitive requirement category.
Thank you for this important suggestion. We have extensively revised the introduction to explain how we derived from the scientific literature the three cognitive dimensions—socio-cognitive demands, behavioral inhibition, and predictability of the social environment—. We now provide a complete overview of the 18 behavioral traits described in Thierry’s framework and their cognitive classification in a dedicated table , along with hypothesized neural correlates. We have also mentioned traits that were not classified in our framework along with short justification of this classification. We believe this addition significantly improves the transparency and intelligibility of our conceptual approach.
“The concept of social tolerance, central to this comparative approach, has sometimes been used in a vague or unidimensional way. As Bernard Thierry (2021) pointed out, the notion was initially constructed around variations in agonistic relationships – dominance, aggressiveness, appeasement or reconciliation behaviors – before being expanded to include affiliative behaviors, allomaternal care or male–male interactions (Thierry, 2021). These traits do not necessarily align along a single hierarchical axis but rather reflect a multidimensional complexity of social style, in which each trait may have co-evolved with others (Thierry, 2021, 2000; Thierry et al., 2004). Moreover, the lack of a standardized scientific definition has sometimes led to labeling species as “tolerant” or “intolerant” without explicit criteria (Gumert and Ho, 2008; Patzelt et al., 2014). These behavioral differences are characterized by different styles of dominance (Balasubramaniam et al., 2012), severity of agonistic interactions (Duboscq et al., 2014), nepotism (Berman and Thierry, 2010; Duboscq et al., 2013; Sueur et al., 2011) and submission signals (De Waal and Luttrell, 1985; Rincon et al., 2023), among the 18 covariant behavioral traits described in Thierry's classification of social tolerance (Thierry, 2021, 2017, 2000)”.
“To ground the investigation of social tolerance in a comparative neuroanatomical framework, we introduce a tentative working model that articulates behavioral traits, cognitive dimensions, and their potential subcortical neural substrates. Drawing upon 18 behavioral traits identified in Thierry’s comparative analyses (Thierry, 2021, 2007), we organized these traits into three core dimensions: socio-cognitive demands, behavioral inhibition, and the predictability of the social environment (Table 1). This conceptualization does not aim to redefine social tolerance itself, but rather to provide a structured basis for testing neuroanatomical hypotheses related to social style variability. It echoes recent efforts to bridge behavioral ecology and cognitive neuroscience by linking specific mental abilities – such as executive functions or metacognition – with distinct prefrontal regions shaped by social and ecological pressures (Bouret et al., 2024; Testard 2022)”.
(4) One of the main distinctions the authors make between high social tolerance species and low tolerance species is the level of complex socio-cognitive demands, with more tolerant species experiencing the highest demands. However, socio-cognitive demands can also be very complex for less tolerant species because they need to strategically balance behaviors in the presence of others. The relationships between socio-cognitive demands and social tolerance grades should be viewed in a more nuanced and context-specific manner.
We fully agree and we did not mean that intolerant species lives in a ‘simple’ social environment but that the ones of more tolerant species is markedly more demanding. Evidence supporting this statement include their more efficient social networks (Sueur et al., 2011) and more complex communicative skills (e.g. tolerant macaques displayed higher levels of vocal diversity and flexibility than intolerant macaques in social situation with high uncertainty (Rebout et al., 2020).
In the revised version (lines 106-122), we now highlight that socio-cognitive challenges arise across the tolerance spectrum, including in less tolerant species where strategic navigation of rigid hierarchies and risk-prone interactions is required. We hope that this addition offers a more balanced and nuanced framing of socio-cognitive demands across macaque societies
“The first category, socio-cognitive demands, refers to the cognitive resources needed to process, monitor, and flexibly adapt to complex social environments. Linking those parameters to neurological data is at the core of the social brain theory to explain the expansion of the neocortex in primates (Dunbar). Macaques social systems require advanced abilities in social memory, perspective-taking, and partner evaluation (Freeberg et al., 2012). This is particularly true in tolerant species, where the increased frequency and diversity of interactions may amplify the demands on cognitive tracking and flexibility. Tolerant macaque species typically live in larger groups with high interaction frequencies, low nepotism, and a wider range of affiliative and cooperative behaviors, including reconciliation, coalition-building, and signal flexibility (REF). Tolerant macaque species also exhibit a more diverse and flexible vocal and facial repertoire than intolerants ones which may help reduce ambiguity and facilitate coordination in dense social networks (Rincon et al., 2023; Scopa and Palagi, 2016; Rebout 2020). Experimental studies further show that macaques can use facial expressions to anticipate the likely outcomes of social interactions, suggesting a predictive function of facial signals in managing uncertainty (Micheletta et al., 2012; Waller et al., 2016). Even within less tolerant species, like M. mulatta, individual variation in facial expressivity has been linked to increased centrality in social networks and greater group cohesion, pointing to the adaptive value of expressive signaling across social styles (Whitehouse et al., 2024)”.
(5) While the limitations section touches on species-related considerations, the issue of individual variability within species remains important. Given that amygdala volume can be influenced by factors such as social rank and broader life experience, it might be useful to further emphasize that these factors could introduce meaningful variation across individuals. This doesn't detract from the current findings but highlights the importance of considering life history and context when interpreting subcortical volumes-particularly in future studies.
We have now emphasized this point in the limitations section (lines 441-456). While our current dataset does not allow us to fully control for individual-level variables across all collection centers, we recognize that factors such as rank, social exposure, and individual life history may influence subcortical volumes
“Although we explained some interspecies variability, adding subjects to our database will increase statistical power and will help addressing potential confounding factors such as age or sex in future studies. One will benefit from additional information about each subject. While considered in our modelling, the social living and husbandry conditions of the individuals in our dataset remain poorly documented. The living environment has been considered, and the size of social groups for certain individuals, particularly for individuals from the CdP, have been recorded. However, these social characteristics have not been determined for all individuals in the dataset. As previously stated, the social environment has a significant impact on the volumetry of certain regions. Furthermore, there is a lack of data regarding the hierarchy of the subjects under study and the stress they experience in accordance with their hierarchical rank and predictability of social outcomes position (McCowan et al., 2022)”.
Reviewer #2 (Public review):
We thank Reviewer #2 for its thoughtful remarks and for acknowledging the value of our comparative approach despite its inherent constraints.
Summary:
This comparative study of macaque species and the type of social interaction is both ambitious and inevitably comes with a lot of caveats. The overall conclusion is that more intolerant species have a larger amygdala. There are also opposing development profiles regarding amygdala volume depending on whether it is a tolerant or intolerant species.
To achieve any sort of power, they have combined data from 4 centres, which have all used different scanning methods, and there are some resolution differences. The authors have also had to group species into 4 classifications - again to assist with any generalisations and power. They have focused on the volumes of two structures, the amygdala and the hippocampus, which seems appropriate. Neither structure is homogeneous and so it may well be that a targeted focus on specific nuclei or subfields would help (the authors may well do this next) - but as the variables would only increase further along with the number of potential comparisons, alongside small group numbers, it seems only prudent to treat these findings are preliminary. That said, it is highly unlikely that large numbers of macaque brains will become available in the near future.
This introduction is by way of saying that the study achieves what it sets out to do, but there are many reasons to see this study as preliminary. The main message seems to be twofold: (1) that more intolerant species have relatively larger amygdalae, and (2) that with development, there is an opposite pattern of volume change (increasing with age in intolerant species and decreasing with age in tolerant species). Finding 1 is the opposite of that predicted in Table 1 - this is fine, but it should be made clearer in the Discussion that this is the case, otherwise the reader may feel confused. As I read it, the authors have switched their prediction in the Discussion, which feels uncomfortable.
We thank the reviewer for this important observation. In the original version, Table 1 presented simplified direct predictions linking social tolerance grades to amygdala and hippocampus volumes. We recognize that this formulation may have created confusion In the revised manuscript, we have thoroughly restructured the table and its accompanying rationale. Table 1 now better reflects our conceptual framework grounded in three cognitive dimensions—sociocognitive demands, behavioral inhibition, and social predictability—each linked to behavioral traits and associated neural hypotheses based on published literature. This updated framework, detailed in lines 144-169 of the introduction, provides a more nuanced basis for interpreting our results and avoids the inconsistencies previously noted. The Discussion was also revised accordingly (lines 329-255) to clarify where our findings diverge from the original predictions and to explore alternative explanations based on social complexity. Rather than directly predicting amygdala size from social tolerance grades, we propose that variation in volume emerges from differing combinations of cognitive pressures across species.
It is inevitable that the data in a study of this complexity are all too prone to post hoc considerations, to which the authors indulge. In the case of Grade 1 species, the individuals have a lot to learn, especially if they are not top of the hierarchy, but at the same time, there are fewer individuals in the troop, making predictions very tricky. As noted above, I am concerned by the seemingly opposite predictions in Table 1 and those in the Discussion regarding tolerance and amygdala volume. (It may be that the predictions in Table 1 are the opposite of how I read them, in which case the Table and preceding text need to align.)
In order to facilitate the interpretation of our Bayesian modelling, we have selected a more focused ROI in our automatic segmentation procedure of the Hippocampus (from Hippocampal Formation to Hippocampus) and have added to the new analysis (Figure 4) that helps to properly test whether the hippocampus significantly differs between species from social grade 1 vs 4. The present analysis found that this is the case in adult monkeys. This is therefore consistent with our hypothesis that amygdala volumes are principally explained by heightened sociocognitive demands in more tolerant species.
We also acknowledge the reviewer’s concerns about the limited generalizability due to our sample. The challenges of comparative neuroimaging in non-human primates—especially when using post-mortem datasets—are substantial. Given the ethical constraints and the rarity of available specimens, increasing the number of individuals or species is not feasible in the short term. However, we have made all data and code publicly available and clearly stated the limitations of our sample in the manuscript. Despite these constraints, we believe our dataset offers an unprecedented comparative perspective, particularly due to the inclusion of rare and tolerant species such as M. tonkeana, M. nigra, and M. thibetana, which have never been included in structural MRI studies before. We hope this effort will serve as a foundation for future collaborative initiatives in primate comparative neuroscience.
Reviewer #3 (Public review):
We thank Reviewer #3 for their thoughtful and detailed review. Their comments helped us refine both the conceptual and interpretative aspects of the manuscript. We respond point by point below.
Summary:
In this study, the authors were looking at neurocorrelates of behavioural differences within the genus Macaca. To do so, they engaged in real-world dissection of dead animals (unconnected to the present study) coming from a range of different institutions. They subsequently compare different brain areas, here the amygdala and the hippocampus, across species. Crucially, these species have been sorted according to different levels of social tolerance grades (from 1 to 4). 12 species are represented across 42 individuals. The sampling process has weaknesses ("only half" of the species contained by the genus, and Macaca mulatta, the rhesus macaque, representing 13 of the total number of individuals), but also strengths (the species are decently well represented across the 4 grades) for the given purpose and for the amount of work required here. I will not judge the dissection process as I am not a neuroanatomist, and I will assume that the different interventions do not alter volume in any significant ways / or that the different conditions in which the bodies were kept led to the documented differences across species.
25 brains were extracted by the authors themselves who are highly with this procedure. Overall, we believe that dissection protocols did not alter the total brain volume. Despite our expertise, we experienced some difficulties to not damage the cerebellum. Therefore, this region was not included in our analysis. We also noted that this brain region was also damaged or absent from the Prime-DE dataset.
Several protocols were used to prepare and store tissue. It could have impacted the total brain volume.
We agree that differences in tissue preparation and storage could potentially affect total brain volume. Therefore, we explicitly included the main sample preparation variable — whether brains had been previously frozen — as a covariate in our model. This factor did not explain our results. Moreover, Figures 1D and 1I display the frozen status and its correlation with the amygdala and hippocampus ratios, respectively. Figure 2 shows the parameters of the model and the posterior distributions for the frozen status and total brain volume effects.
There are two main results of the study. First, in line with their predictions, the authors find that more tolerant macaque species have larger amygdala, compared to the hippocampus, which remains undifferentiated across species. Second, they also identify developmental effects, although with different trends: in tolerant species, the amygdala relative volume decreases across the lifespan, while in intolerant species, the contrary occurs. The results look quite strong, although the authors could bring up some more clarity in their replies regarding the data they are working with. From one figure to the other, we switch from model-calculated ratio to modelpredicted volume. Note that if one was to sample a brain at age 20 in all the grades according to the model-predicted volumes, it would not seem that the difference for amygdala would differ much across grades, mostly driven with Grade 1 being smaller (in line with the main result), but then with Grade 2 bigger than Grade 3, and then Grade 4 bigger once again, but not that different from Grade 2.
Overall, despite this, I think the results are pretty strong, the correlations are not to be contested, but I also wonder about their real meaning and implications. This can be seen under 3 possible aspects:
(1) Classification of the social grade
While it may be familiar to readers of Thierry and collaborators, or to researchers of the macaque world, there is no list included of the 18 behavioral traits used to define the three main cognitive requirements (socio-cognitive demands, predictability of the environment, inhibitory control). It would be important to know which of the different traits correspond to what, whether they overlap, and crucially, how they are realized in the 12 study species, as there could be drastic differences from one species to the next. For now, we can only see from Table S1 where the species align to, but it would be a good addition to have them individually matched to, if not the 18 behavioral traits, at least the 3 different broad categories of cognitive requirements.
We fully agree with this observation. In the revised version of the manuscript, we now include a detailed conceptual table listing all 18 behavioral traits from Thierry’s framework. For each trait, we provide its underlying social implications, its associated cognitive dimension (when applicable), and the hypothesized neural correlate.
While some traits may could have been arguably classified in several cognitive dimensions (e.g. reconciliation rate), we preferred to assign each to a unique dimension for clarity. Additionally, the introduction (lines 95-169 + Table1) now explains how each trait was evaluated based on existing literature and assigned to one of the three proposed cognitive categories: socio-cognitive demands, behavioral inhibition, or social unpredictability. This structure offers a clearer and more transparent basis for the neuroanatomical hypotheses tested in the study.
“Navigating social life in primate societies requires substantial cognitive resources: individuals must not only track multiple relationships, but also regulate their own behavior, anticipate others’ reactions, and adapt flexibly to changing social contexts. Taken advantage of databases of magnetic resonance imaging (MRI) structural scans, we conducted the first comparative study integrating neuroanatomical data and social behavioral data from closely related primate species of the same genus to address the following questions: To what extent can differences in volumes of subcortical brain structures be correlated with varying degrees of social tolerance? Additionally, we explored whether these dispositions reflect primarily innate features, shaped by evolutionary processes, or acquired through socialization within more or less tolerant social environments”.
“The first category, socio-cognitive demands, refers to the cognitive resources needed to process, monitor, and flexibly adapt to complex social environments. Linking those parameters to neurological data is at the core of the social brain theory to explain the expansion of the neocortex in primates (Dunbar). Macaques social systems require advanced abilities in social memory, perspective-taking, and partner evaluation (Freeberg et al., 2012). This is particularly true in tolerant species, where the increased frequency and diversity of interactions may amplify the demands on cognitive tracking and flexibility. Tolerant macaque species typically live in larger groups with high interaction frequencies, low nepotism, and a wider range of affiliative and cooperative behaviors, including reconciliation, coalition-building, and signal flexibility (REF). Tolerant macaque species also exhibit a more diverse and flexible vocal and facial repertoire than intolerants ones which may help reduce ambiguity and facilitate coordination in dense social networks (Rincon et al., 2023; Scopa and Palagi, 2016; Rebout 2020). Experimental studies further show that macaques can use facial expressions to anticipate the likely outcomes of social interactions, suggesting a predictive function of facial signals in managing uncertainty (Micheletta et al., 2012; Waller et al., 2016). Even within less tolerant species, like M. mulatta, individual variation in facial expressivity has been linked to increased centrality in social networks and greater group cohesion, pointing to the adaptive value of expressive signaling across social styles (Whitehouse et al., 2024)”.
“The second category, inhibitory control, includes traits that involve regulating impulsivity, aggression, or inappropriate responses during social interactions. Tolerant macaques have been shown to perform better in tasks requiring behavioral inhibition and also express lower aggression and emotional reactivity in both experimental and natural contexts (Joly et al., 2017; Loyant et al., 2023). These features point to stronger self-regulation capacities in species with egalitarian or less rigid hierarchies. More broadly, inhibition – especially in its strategic form (self-control) – has been proposed to play a key role in the cohesion of stable social groups. Comparative analyses across mammals suggest that this capacity has evolved primarily in anthropoid primates, where social bonds require individuals to suppress immediate impulses in favour of longer-term group stability (Dunbar and Shultz, 2025). This view echoes the conjecture of Passingham and Wise (2012), who proposed that the emergence of prefrontal area BA10 in anthropoids enabled the kind of behavioural flexibility needed to navigate complex social environments (Passingham et al., 2012)”.
“The third category, social environment predictability, reflects how structured and foreseeable social interactions are within a given society. In tolerant species, social interactions are more fluid and less kin-biased, leading to greater contextual variation and role flexibility, which likely imply a sustained level of social awareness. In fact, as suggested by recent research, such social uncertainty and prolonged incentives are reflected by stress-related physiology : tolerant macaques such as M. tonkeana display higher basal cortisol levels, which may be indicative of a chronic mobilization of attentional and regulatory resources to navigate less predictable social environments (Sadoughi et al., 2021)”.
“Each behavioral trait was individually evaluated based on existing empirical literature regarding the types of cognitive operations it likely involves. When a primary cognitive dimension could be identified, the trait was assigned accordingly. However, some behaviors – such as maternal protection, allomaternal care, or delayed male dispersal – do not map neatly onto a single cognitive process. These traits likely emerge from complex configurations of affective and socialmotivational systems, and may be better understood through frameworks such as attachment theory (Suomi, 2008), which emphasizes the integration of social bonding, emotional regulation, and contextual plasticity. While these dimensions fall beyond the scope of the present framework, they offer promising directions for future research, particularly in relation to the hypothalamic and limbic substrates of social and reproductive behavior”.
“Rather than forcing these traits into potentially misleading categories, we chose to leave them unclassified within our current cognitive framework. This decision reflects both a commitment to conceptual clarity and the recognition that some behaviors emerge from a convergence of cognitive demands that cannot be neatly isolated. This tripartite framework, leaving aside reproductive-related traits, provides a structured lens through which to link behavioral diversity to specific cognitive processes and generate neuroanatomical predictions”.
(2) Issue of nature vs nurture
Another way to look at the debate between nature vs nurture is to look at phylogeny. For now, there is no phylogenetic tree that shows where the different grades are realized. For example, it would be illuminating to know whether more related species, independently of grades, have similar amygdala or hippocampus sizes. Then the question will go to the details, and whether the grades are realized in particular phylogenetic subdivisions. This would go in line with the general point of the authors that there could be general species differences.
As pointed out by Thierry and collaborators, the social tolerance concept is already grounded in a phylogenetic framework as social tolerance matches the phylogenetical tree of these macaque species, suggesting a biological ground of these behavioral observations. Given the modest sample size and uneven species representation, we opted not to adopt tools such as Phylogenetic Generalized Least Squares (PGLS) in our analysis. Our primary aim in this study was to explore neuroanatomical variation as a function of social traits, not to perform a phylogenetic comparative analysis per see. That said, we now explicitly acknowledge this limitation in the Discussion and indicate that future work using larger datasets and phylogenetic methods will be essential to disentangle social effects from evolutionary relatedness. We hope that making our dataset openly available will facilitate such futures analyses.
With respect to nurture, it is likely more complicated: one needs to take into account the idiosyncrasies of the life of the individual. For example, some of the cited literature in humans or macaques suggests that the bigger the social network, the bigger the brain structure considered. Right, but this finding is at the individual level with a documented life history. Do we have any of this information for any of the individuals considered (this is likely out of the scope of this paper to look at this, especially for individuals that did not originate from CdP)?
We appreciate this insightful observation. Indeed, findings from studies in humans and nonhuman primates showing associations between brain structure and social network size typically rely on detailed life history and behavioral data at the individual level. Unfortunately, such finegrained information was not consistently available across our entire sample. While some individuals from the Centre de Primatologie (CdP) were housed in known group compositions and social settings, we did not have access to longitudinal social data—such as rank, grooming rates, or network centrality—that would allow for robust individual-level analyses. We now acknowledge this limitation more clearly in the Discussion (lines 436-443), and we fully agree that future work combining neuroimaging with systematic behavioral monitoring will be necessary to explore how species-level effects interact with individual social experience.
(3) Issue of the discussion of the amygdala's function
The entire discussion/goal of the paper, states that the amygdala is connected to social life. Yet, before being a "social center", the amygdala has been connected to the emotional life of humans and non-humans alike. The authors state L333/34 that "These findings challenge conventional expectations of the amygdala's primary involvement in emotional processes and highlight the complexity of the amygdala's role in social cognition". First, there is no dichotomy between social cognition and emotion. Emotion is part of social cognition (unless we and macaques are robots). Second, there is nowhere in the paper a demonstration that the differences highlighted here are connected to social cognition differences per se. For example, the authors have not tested, say, if grade 4 species are more afraid of snakes than grade 1 species. If so, one could predict they would also have a bigger amygdala, and they would probably also find it in the model. My point is not that the authors should try to correlate any kind of potential aspect that has been connected to the amygdala in the literature with their data (see for example the nice review by DomínguezBorràs and Vuilleumier, https://doi.org/10.1016/B978-0-12-823493-8.00015-8), but they should refrain from saying they have challenged a particular aspect if they have not even tested it. I would rather engage the authors to try and discuss the amygdala as a multipurpose center, that includes social cognition and emotion.
We thank the reviewer for this important and nuanced point. We have revised the manuscript to adopt a more cautious and integrative tone regarding the function of the amygdala. In the revised Discussion (lines 341-355), we now explicitly state that the amygdala is involved in a broad range of processes—emotional, social, and affective—and that these domains are deeply intertwined. Rather than proposing a strict dissociation, we now suggest that the amygdala supports integrated socio-emotional functions that are mobilized differently across social tolerance styles. We also cite recent relevant literature (e.g., Domínguez-Borràs & Vuilleumier, 2021) to support this view and have removed any claim suggesting we challenge the emotional function of the amygdala per se. Our aim is to contribute to a richer understanding of how affective and social processes co-construct structural variation in this region.
Strengths:
Methods & breadth of species tested.
Weaknesses:
Interpretation, which can be described as 'oriented' and should rather offer additional views.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Private Comments:
(1) Table 1 should be formatted for clarity i.e., bolded table headers, text realignment, and spacing. It was not clear at first glance how information was organized. It may also be helpful to place behavioral traits as the first column, seeing that these traits feed into the author's defined cognitive requirements.
We have reformatted Table 1 to improve clarity and readability. Behavioral traits now appear in the first column, followed by cognitive dimensions and hypothesized neural correlates. Column headers have been bolded and alignment has been standardized.
(2) Figures could include more detail to help with interpretations. For example, Figure 3 should define values included on the x-axis in the figure caption, and Figure 4 should explain the use of line, light color, and dark color. Figure 1 does not have a y-axis title.
The figures have been revised and legends completed to ensure more clarity.
(3) Please proofread for typos throughout.
The manuscript has been carefully proofread, and all typographical and grammatical errors have been corrected. These changes are visible in the tracked version.
Reviewer #2 (Recommendations for the authors):
Specific comments:
(1) Given all of the variability would it not be a good idea to just compare (eg in the supplemental) the macaque data from just the Strasbourg centre for m mulatta and m toneanna. I appreciate the ns will be lower, but other matters are more standardized.
We fully understand the reviewer’s suggestion to restrict the comparison to data collected at a single site in order to minimize inter-site variability. However, as noted, such an analysis would come at the cost of statistical power, as the number of individuals per species within a single center is small. For example, while M. tonkeana is well represented at the Strasbourg centre, only one individual of M. mulatta is available from the same site. Thus, a restricted comparison would severely limit the interpretability of results, particularly for age-related trajectories. To address variability, we included acquisition site and brain preservation method as covariates or predictors where appropriate, and we have been cautious in our interpretations. We also now emphasize in the Methods and Discussion the value of future datasets with more standardized acquisition protocols across species and centers. We hope that by openly sharing our data and workflow, we can contribute to this broader goal.
(2) I have various minor edits:
(a) L 25 abstract - Specify what is meant by 'opposite trend'; the reader cannot infer what this is.
Modified in line 25-28: “Unexpectedly, tolerant species exhibited a decrease in relative amygdala volume across the lifespan, contrasting with the age-related increase observed in intolerant species—a developmental pattern previously undescribed in primates.”
(b) L67 - The reference 'Manyprimates' needs fixing as it does in the references section.
After double checking, Manyprimates studies are international collaborative efforts that are supposed to be cite this way (https://manyprimates.github.io/#pubs).
(c) L74 - Taking not Taken.
This typo has been corrected.
(d) L129 - It says 'total volume', but this is corrected total volume?
We have clarified in the figures legends that the “total brain volume” used in our analyses excludes the cerebellum and the myelencephalon, as specified in our image preprocessing protocol. This ensures consistency across individuals and institutions.
(e) L138 - Suddenly mentions 'frozen condition' without any prior explanation - this needs explaining in the legend - also L144.
We have added an explanation of the ‘frozen condition’ variable in in the relevant figure legend.
(f) L166 - Results - it would be helpful to remind readers what Grade 1 signifies, ie intolerant species.
We now include a brief reminder in the Results section that Grade 1 corresponds to socially intolerant species, to help readers unfamiliar with the classification (Lines 240-251).
(g)Figure 4 - Provide the ns for each of the 4 grades to help appreciate the meaningfulness of the curves, etc.
The number of subjects has been added to the Figure and a novel analysis helps in the revised ms help to appreciate the meaningfulness of some of these curves.
(h) L235 - 'we had assumed that species of high social tolerance grade would have presented a smaller amygdala in size compared to grade 1'. But surely this is the exact opposite of what is predicted in Table 1 - ie, the authors did not predict this as I read the paper (Unless Table l is misleading/ambiguous and needs clarification).
As discussed in our response to Reviewer #2 and #3, we have restructured both Table 1 and the Discussion to ensure consistency. We now explicitly state that the findings diverge from our initial inhibitory-control-based prediction and propose alternative interpretations based on sociocognitive demands.
(i) L270 - 'This observation' which?? Specify.
We have replaced ‘this observation’ with a precise reference to the observed developmental decrease in amygdala volume in tolerant species.
(j) L327 - 'groundbreaking' is just hype given that there are so many caveats - I personally do not like the word - novel is good enough.
We have replaced the word ‘groundbreaking’ with ‘novel’ to adopt a more measured and appropriate tone in the discussion.
(3) I might add that I am happy with the ethics regarding this study.
Thanks, we are also happy that we were able to study macaque brains from different species using opportunistic samplings along with already available data. We are collectively making progress on this!
(4) Finally, I should commend the authors on all the additional information that they provide re gender/age/species. Given that there are 2xs are many females as males, it would be good to know if this affects the findings. I am not a primatologist, so I don't know, for example, if the females in Grade 1 monkeys are just as intolerant as the males?
We thank the reviewer for this thoughtful comment. We now explicitly mention the female-biased sex ratio in the Methods section and report in the Results (Figure 2, Figure 3) that sex was included as a covariate in our Bayesian models. While a small effect of sex was found for hippocampal volume, no effect was observed for the amygdala. Given the strong imbalance in our dataset (2:1 female-to-male ratio), we refrained from drawing any conclusion about sex-specific patterns, as these would require larger and more balanced samples. Although we did not test for sex-by-grade interactions, we agree that this question—especially regarding whether females and males express social style differences similarly across grades—represents an important direction for future comparative work.
Reviewer #3 (Recommendations for the authors):
I found the article well-written, and very easy to follow, so I have little ways to propose improvements to the article to the authors, besides addressing the various major points when it comes to interpretation of the data.
One list I found myself wanting was in fact the list of the social tolerance grades, and the process by which they got selected into 3 main bags of socio-cognitive skills. Then it would become interesting to see how each of the 12 species compares within both the 18 grades (maybe once again out of the scope of this paper, there are likely reviews out there that already do that, but then the authors should explicitly mention so in the paper: X, 19XX have compared 15 out of 18 traits in YY number of macaque species); and within the 3 major subcognitive requirements delineated by the authors, maybe as an annex?
We thank the reviewer for this thoughtful suggestion. In the revised manuscript, we now include a detailed table (Table 1) that lists the 18 behavioral traits derived from Thierry’s framework, along with their associated cognitive dimension and hypothesized neuroanatomical correlate. While we did not create a matrix mapping each of the 12 species across all 18 traits due to space and data availability constraints, we agree this is an important direction that should be tackled by primatologist. We now include a sentence (line 87-90) in the manuscript to guide readers to previous comparative reviews (e.g., Thierry, 2000; Thierry et al., 2004, 2021) that document the expression of these traits across macaque species. We also clarify that our three cognitive categories are conceptual tools intended to structure neuroanatomical predictions, and not formal clusters derived from quantitative analyses.
In the annex, it would also be good to have a general summarizing excel/R file for the raw data, with important information like age, sex, and the relevant calculated volumes for each individual. The folders available following the links do not make it an easy task for a reader to find the raw data in one place.
We fully agree with the reviewer on the importance of data accessibility. We have now uploaded an additional supplementary file in .csv format on our OSF repository, which includes individuallevel metadata for all 42 macaques: species, sex, age, social grade, total brain volume, amygdala volume, and hippocampus volume. The link to this file is now explicitly mentioned in the Data Availability section. We hope this will facilitate comparisons with other datasets and improve usability for the community. In addition, we provide in a supplementary table the raw data that were used for our Bayesian modelling (see below).
The availability of the raw data would also clear up one issue, which I believe results from the modelling process: it looks odd on Figure 2, that volume ratios, defined as the given brain area volume divided by the total brain volume, give values above 1 (especially for the hippocampus). As such, the authors should either modify the legend or the figure. In general, it would be nicer to have the "real values" somewhere easily accessible, so that they can be compared more broadly with: 1) other macaques species to address questions relevant to the species; 2) other primates to address other questions that are surely going to arise from this very interesting work!
We thank the reviewer for pointing this out. The ratio values in Figure 1 correspond to the proportion of the regional volume (amygdala or hippocampus) relative to the total brain volume, excluding the cerebellum and myelencephalon. As such, values above 0.01 (i.e., above 1% of the brain volume) are expected for these structures and do not indicate an error. We have updated the figure legend to clarify this point explicitly. In addition, we have now made a cleaned .csv file available via OSF, containing all raw volumetric data and metadata in a format that facilitates cross-species or cross-study comparisons. This replaces the previous folder-based structure, which may have been less accessible.
Typos:
L233: delete 'in'
L430: insert space in 'NMT template(Jung et al., 2021).'
Bots present a similar disconnect between intentions and actions. Bot programs are written by one or more people, potentially all with different intentions, and they are run by others people, or sometimes scheduled by people to be run by computers.
When looking at bots we can't assume it reflects the intention of any one single person. The people who wrote the code, the people who use it, and the computer that runs it are all separate different entities and because of this responsibility for a bot's action is spread out.
Author response:
The following is the authors’ response to the original reviews
eLife Assessment
This paper undertakes an important investigation to determine whether movement slowing in microgravity is due to a strategic conservative approach or rather due to an underestimation of the mass of the arm. While the experimental dataset is unique and the coupled experimental and computational analyses comprehensive, the authors present incomplete results to support the claim that movement slowing is due to mass underestimation. Further analysis is needed to rule out alternative explanations.
We thank the editor and reviewers for the thoughtful and constructive comments, which helped us substantially improve the manuscript. In this revised version, we have made the following key changes:
- Directly presented the differential effect of microgravity in different movement directions, showing its quantitative match with model predictions.
- Showed that changing cost function with the idea of conservative strategy is not a viable alternative.
- Showed our model predictions remain largely the same after adding Coriolis and centripetal torques.
- Discussed alternative explanations including neuromuscular deconditioning, friction, body stability, etc.
- Detailed the model description and moved it to the main text, as suggested.
Our point-to-point response is numbered to facilitate cross-referencing.
We believe the revisions and the responses adequately addresses the reviewers’ concerns, and new analysis results strengthened our conclusion that mass underestimation is the major contributor to movement slowing in microgravity.
Reviewer #1 (Public review):
Summary:
This article investigates the origin of movement slowdown in weightlessness by testing two possible hypotheses: the first is based on a strategic and conservative slowdown, presented as a scaling of the motion kinematics without altering its profile, while the second is based on the hypothesis of a misestimation of effective mass by the brain due to an alteration of gravity-dependent sensory inputs, which alters the kinematics following a controller parameterization error.
Strengths:
The article convincingly demonstrates that trajectories are affected in 0g conditions, as in previous work. It is interesting, and the results appear robust. However, I have two major reservations about the current version of the manuscript that prevent me from endorsing the conclusion in its current form.
Weaknesses:
(1) First, the hypothesis of a strategic and conservative slow down implicitly assumes a similar cost function, which cannot be guaranteed, tested, or verified. For example, previous work has suggested that changing the ratio between the state and control weight matrices produced an alteration in movement kinematics similar to that presented here, without changing the estimated mass parameter (Crevecoeur et al., 2010, J Neurophysiol, 104 (3), 1301-1313). Thus, the hypothesis of conservative slowing cannot be rejected. Such a strategy could vary with effective mass (thus showing a statistical effect), but the possibility that the data reflect a combination of both mechanisms (strategic slowing and mass misestimation) remains open.
Response (1): Thank you for raising this point. The basic premise of this concern is that changing the cost function for implementing strategic slowing can reproduce our empirical findings, thus the alternative hypothesis that we aimed to refute in the paper remain possible. At least, it could co-exist with our hypothesis of mass underestimation. In the revision, we show that changing the cost function only, as suggested here, cannot produce the behavioral patterns observed in microgravity.
As suggested, we modified the relative weighting of the state and control cost matrices (i.e., Q and R in the cost function Eq 15) without considering mass underestimation. While this cost function scaling can decrease peak velocity – a hallmark of strategic slowing – it also inevitably leads to later peak timings. This is opposite to our robust findings: the taikonauts consistently “advanced” their peak velocity and peak acceleration in time. Note, these model simulation patterns have also been shown in Crevecoeur et al. (2010), the paper mentioned by the reviewer (see their Figure 7B).
We systematically changed the ratio between the state and control weight matrices in the simulation, as suggested. We divided Q and multiplied R by the same factor α, the cost function scaling parameter α as defined in Crevecoeur et al. (2010). This adjustment models a shift in movement strategy in microgravity, and we tested a wide range of α to examine reasonable parameter space. Simulation results for α = 3 and α = 0.3 are shown in Figure 1—figure supplement 2 and Figure 1—figure supplement 3 respectively. As expected, with α = 3 (higher control effort penalty), peak velocities and accelerations are reduced, but their timing is delayed. Conversely, with α = 0.3, both peak amplitude and timing increase. Hence, changing the cost function to implement a conservative strategy cannot produce the kinematic pattern observed in microgravity, which is a combination of movement slowing and peak timing advance.
Therefore, we conclude that a change in optimal control strategy alone is insufficient to explain our empirical findings. Logically speaking, we cannot refute the possibility of strategic slowing, which can still exist on top of the mass underestimation we proposed here. However, our data does not support its role in explaining the slowing of goal-directed hand reaching in microgravity. We have added these analyses to the Supplementary Materials and expanded the Discussion to address this point.
(2) The main strength of the article is the presence of directional effects expected under the hypothesis of mass estimation error. However, the article lacks a clear demonstration of such an effect: indeed, although there appears to be a significant effect of direction, I was not sure that this effect matched the model's predictions. A directional effect is not sufficient because the model makes clear quantitative predictions about how this effect should vary across directions. In the absence of a quantitative match between the model and the data, the authors' claims regarding the role of misestimating the effective mass remain unsupported.
Response (2): First, we have to clarify that our study does not aim to quantitatively fit observed hand trajectory. The two-link arm model simulates an ideal case of moving a point mass (effective mass) on a horizontal plane without friction (Todorov, 2004; 2005). In contrast, in the experiment, participants moved their hand on a tabletop without vertical arm support, so the movement was not strictly planar and was affected by friction. Thus, this kind of model can only illustrate qualitative differences between conditions, as in the majorities of similar modeling studies (e.g., Shadmehr et al., 2016). In our study, qualitative simulation means the model is intended to reproduce the directional differences between conditions—not exact numeric values—in key kinematic measures. Specifically, it should capture how the peak velocity and acceleration amplitudes and their timings differ between normal gravity and microgravity (particularly under the mass-underestimation assumption).
Second, the reviewer rightfully pointed out that the directional effect is essential for our theorization of the importance of mass underestimation. However, the directional effect has two aspects, which were not clearly presented in our original manuscript. We now clarify both here and in the revision. The first aspect is that key kinematic variables (peak velocity/acceleration and their timing) are affected by movement direction, even before any potential microgravity effect. This is shown by the ranking order of directions for these variables (Figure 1C-H). The direction-dependent ranking, confirmed by pre-flight data, indicates that effective mass is a determining factor for reaching kinematics, which motivated us to study its role in eliciting movement slowing in space. This was what our original manuscript emphasized and clearly presented.
The second aspect is that the hypothetical mass underestimation might also differentially affect movements in different directions. This was not clearly presented in the original manuscript. However, we would not expect a quantitative match between model predictions and empirical data, for the reasons mentioned above. We now show this directional ranking in microgravity-elicited kinematic changes in both model simulations and empirical data. The overall trend is that the microgravity effect indeed differs between directions, and the model predictions and the data showed a reasonable qualitative match (Author response image 1 below).
Shown in Author response image 1, we found that for amplitude changes (Δ peak speed, Δ peak acceleration) both the model and the mean of empirical data show the same directional ordering (45° > 90° > 135°) in pre-in and post-in comparisons. For timing (Δ peak-speed time, Δ peak-acceleration time), which we consider the most diagnostic, the same directional ranking was observed. We only found one deviation, i.e., the predicted sign (earlier peaks) was confirmed at 90° and 135°, but not at 45°. As discussed in Response (6), the absence of timing advance at 45° may reflect limitations of our simplified model, which did not consider that the 45° direction is essentially a single-joint reach. Taken together, the directional pattern is largely consistent with the model predictions based on mass underestimation. The model successfully reproduces the directional ordering of amplitude measures -- peak velocity and peak acceleration. It also captures the sign of the timing changes in two out of the three directions. We added these new analysis results in the revision and expanded Discussion accordingly.
The details of our analysis on directional effects: We compared the model predictions (Author response image 1, left) with the experimental data (Author response image 1, right) across the three tested directions (45°, 90°, 135°). In the experimental data panels, both Δ(pre-in) (solid bars) and Δ(post-in) (semi-transparent bars) with standard error are shown. The directional trends are remarkably similar between model prediction and actual data. The post-in comparison is less aligned with model prediction; we postulate that the incomplete after-flight recovery (i.e., post data had not returned to pre-flight baselines) might obscure the microgravity effect. Incomplete recovery has also been shown in our original manuscript: peak speed and peak acceleration did not fully recover in post-flight sessions when compared to pre-flight sessions. To further quantify the correspondence between model and data, we performed repeated-measures correlation (rm-corr) analyses. We found significant within-subject correlations for three of the four metrics. For pre–in, Δ peak speed time (r<sub>rm</sub> = 0.627, t(23) = 3.858, p < 0.001), Δ peak acceleration time (r<sub>rm</sub> = 0.591, t(23) = 3.513, p = 0.002), and Δ peak acceleration (r<sub>rm</sub> = 0.573, t(23) = 3.351, p = 0.003) were significant, whereas Δ peak speed was not (r<sub>rm</sub> = 0.334, t(23) = 1.696, p = 0.103). These results thus show that the directional effect, as predicted our model, is observed both before spaceflight and in spaceflight (the pre-in comparison).
Author response image 1.
Directional comparison between model predictions and experimental data across the three reach directions (45°, 90°, 135°). Left: model outputs. Right: experimental data shown as Δ relative to the in-flight session; solid bars = Δ(in − pre) and semi-transparent bars = Δ(in − post). Colors encode direction consistently across panels (e.g., 45° = darker hue, 90° = medium, 135° = lighter/orange). Panels (clockwise from top-left): Δ peak speed (cm/s), Δ peak speed time (ms), Δ peak acceleration time (ms), and Δ peak acceleration (cm/s²). Bars are group means; error bars denote standard error across participants.
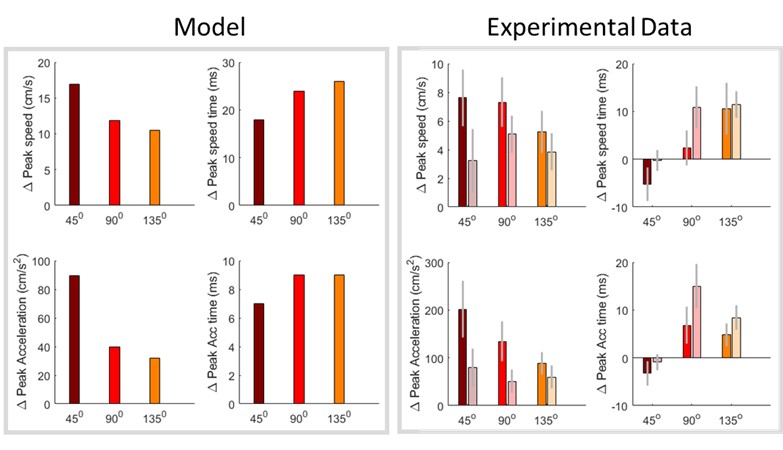
Citations:
Todorov, E. (2004). Optimality principles in sensorimotor control. Nature Neuroscience, 7(9), 907.
Todorov, E. (2005). Stochastic optimal control and estimation methods adapted to the noise characteristics of the sensorimotor system. Neural Computation, 17(5), 1084–1108.
Shadmehr, R., Huang, H. J., & Ahmed, A. A. (2016). A Representation of Effort in Decision-Making and Motor Control. Current Biology: CB, 26(14), 1929–1934.
In general, both the hypotheses of slowing motion (out of caution) and misestimating mass have been put forward in the past, and the added value of this article lies in demonstrating that the effect depended on direction. However, (1) a conservative strategy with a different cost function can also explain the data, and (2) the quantitative match between the directional effect and the model's predictions has not been established.
We agree that both hypotheses have been put forward before, however they are competing hypotheses that have not been resolved. Furthermore, the mass underestimation hypothesis is a conjecture without any solid evidence; previous reports on mass underestimation of object cannot directly translate to underestimation of body. As detailed in our responses above, we have shown that a conservative strategy implemented via a different cost function cannot reproduce the key findings in our dataset, thereby supporting the alternative hypothesis of mass underestimation. Moreover, we found qualitative agreement between the model predictions and the experimental data in terms of directional effects, which further strengthens our interpretation.
Specific points:
(1) I noted a lack of presentation of raw kinematic traces, which would be necessary to convince me that the directional effect was related to effective mass as stated.
Response (3): We are happy to include exemplary speed and acceleration trajectories. Kinematic profiles from one example participant are shown in Figure 2—figure supplement 6.
(2) The presentation and justification of the model require substantial improvement; the reason for their presence in the supplementary material is unclear, as there is space to present the modelling work in detail in the main text. Regarding the model, some choices require justification: for example, why did the authors ignore the nonlinear Coriolis and centripetal terms?
Response (4): Great suggestion. In the revision, we have moved the model into the main text and added further justification for using this simple model.
We initially omitted the nonlinear Coriolis and centripetal terms in order to start with a minimal model. Importantly, excluding these terms does not affect the model’s main conclusions. In the revision we added simulations that explicitly include these terms. The full explanation and simulations are provided in the Supplementary Notes 2 (this time we have to put it into the Supplementary to reduce the texts devoted to the model). More explanations can also be found in our response to Reviewer 2 (response (6)). The results indicate that, although these velocity-dependent forces show some directional anisotropy, their contribution is substantially smaller relative to that of the included inertial component; specifically, they have only a negligible impact on the predicted peak amplitudes and peak times.
(3) The increase in the proportion of trials with subcomponents is interesting, but the explanatory power of this observation is limited, as the initial percentage was already quite high (from 60-70% during the initial study to 70-85% in flight). This suggests that the potential effect of effective mass only explains a small increase in a trend already present in the initial study. A more critical assessment of this result is warranted.
Response (5): Thank you for your thoughtful comment. You are correct that the increase in the percentage of trials with submovements is modest, but a more critical change was observed in the timing between submovement peaks—specifically, the inter-peak interval (IPI). These intervals became longer during flight. Taken together with the percentage increase, the submovement changes significantly predicted the increase in movement duration, as shown by our linear mixed-effects model, which indicated that IPI increased.
Reviewer #2 (Public review):
This study explores the underlying causes of the generalized movement slowness observed in astronauts in weightlessness compared to their performance on Earth. The authors argue that this movement slowness stems from an underestimation of mass rather than a deliberate reduction in speed for enhanced stability and safety.
Overall, this is a fascinating and well-written work. The kinematic analysis is thorough and comprehensive. The design of the study is solid, the collected dataset is rare, and the model tends to add confidence to the proposed conclusions. That being said, I have several comments that could be addressed to consolidate interpretations and improve clarity.
Main comments:
(1) Mass underestimation
a) While this interpretation is supported by data and analyses, it is not clear whether this gives a complete picture of the underlying phenomena. The two hypotheses (i.e., mass underestimation vs deliberate speed reduction) can only be distinguished in terms of velocity/acceleration patterns, which should display specific changes during the flight with a mass underestimation. The experimental data generally shows the expected changes but for the 45° condition, no changes are observed during flight compared to the pre- and post-phases (Figure 4). In Figure 5E, only a change in the primary submovement peak velocity is observed for 45°, but this finding relies on a more involved decomposition procedure. It suggests that there is something specific about 45° (beyond its low effective mass). In such planar movements, 45° often corresponds to a movement which is close to single-joint, whereas 90° and 135° involve multi-joint movements. If so, the increased proportion of submovements in 90° and 135° could indicate that participants had more difficulties in coordinating multi-joint movements during flight. Besides inertia, Coriolis and centripetal effects may be non-negligible in such fast planar reaching (Hollerbach & Flash, Biol Cyber, 1982) and, interestingly, they would also be affected by a mass underestimation (thus, this is not necessarily incompatible with the author's view; yet predicting the effects of a mass underestimation on Coriolis/centripetal torques would require a two-link arm model). Overall, I found the discrepancy between the 45° direction and the other directions under-exploited in the current version of the article. In sum, could the corrective submovements be due to a misestimation of Coriolis/centripetal torques in the multi-joint dynamics (caused specifically -or not- by a mass underestimation)?
Response (6): Thank you for raising these important questions. We unpacked the whole paragraph into two concerns: 1) the possibility that misestimation of Coriolis and centripetal torques might lead to corrective submovements, and 2) the weak effect in the 45° direction unexploited. These two concerns are valid but addressable, and they did not change our general conclusions based on our empirical findings (see Supplementary note 2. Coriolis and centripetal torques have minimal impact).
Possible explanation for the 45° discrepancy
We agree with the reviewer that the 45° direction likely involves more single-joint (elbow-dominant) movement, whereas the 90° and 135° directions require greater multi-joint (elbow + shoulder) coordination. This is particularly relevant when the workspace is near body midline (e.g., Haggard & Richardson, 1995), as the case in our experimental setup. To demonstrate this, we examined the curvature of the hand trajectories across directions. Using cumulative curvature (positive = counterclockwise), we obtained average values of 6.484° ± 0.841°, 1.539° ± 0.462°, and 2.819° ± 0.538° for the 45°, 90°, and 135° directions, respectively. The significantly larger curvature in the 45° condition suggests that these movements deviate more from a straight-line path, a hallmark of more elbow-dominant movements.
Importantly, this curvature pattern was present in both the pre-flight and in-flight phases, indicating that it is a general movement characteristic rather than a microgravity-induced effect. Thus, the 45° reaches are less suitable for modeling with a simplified two-link arm model compared to the other two directions. We believe this is the main reason why the model predictions based on effective mass become less consistent with the empirical data for the 45° direction.
We have now incorporated this new analysis in the Results and discussed it in the revised Discussion.
Citation: Haggard, P., Hutchinson, K., & Stein, J. (1995). Patterns of coordinated multi-joint movement. Experimental Brain Research, 107(2), 254-266.
b) Additionally, since the taikonauts are tested after 2 or 3 weeks in flight, one could also assume that neuromuscular deconditioning explains (at least in part) the general decrease in movement speed. Can the authors explain how to rule out this alternative interpretation? For instance, weaker muscles could account for slower movements within a classical time-effort trade-off (as more neural effort would be needed to generate a similar amount of muscle force, thereby suggesting a purposive slowing down of movement). Therefore, could the observed results (slowing down + more submovements) be explained by some neuromuscular deconditioning combined with a difficulty in coordinating multi-joint movements in weightlessness (due to a misestimation or Coriolis/centripetal torques) provide an alternative explanation for the results?
Response (7): Neuromuscular deconditioning is indeed a space effect; thanks for bringing this up as we omitted the discussion of this confounds in our original manuscript. Prolonged stay in microgravity can lead to a reduction of muscle strength, but this is mostly limited to lower limb. For example, a recent well-designed large-sample study have shown that while lower leg muscle showed significant strength reductions, no changes in mean upper body strength was found (Scott et al., 2023), consistent with previous propositions that muscle weakness is less for upper-limb muscles than for postural and lower-limb muscles (Tesch et al., 2005). Furthermore, the muscle weakness is unlikely to play a major role here since our reaching task involves small movements (~12cm) with joint torques of a magnitude of ~2N·m. Of course, we cannot completely rule out the contribution of muscle weakness; we can only postulate, based on the task itself (12 cm reaching) and systematic microgravity effect (the increase in submovements, the increase in the inter-submovements intervals, and their significant prediction on movement slowing), that muscle weakness is an unlikely major contributor for the movement slowing.
The reviewer suggests that poor coordination in microgravity might contribute to slowing down + more submovements. This is also a possibility, but we did not find evidence to support it. First, there is no clear evidence or reports about poor coordination for simple upper-limb movements like reaching investigated here. Note that reaching or aiming movement is one of the most studied tasks among astronauts. Second, we further analyzed our reaching trajectories and found no sign of curvature increase, a hallmark of poor coordination of Coriolis/centripetal torques, in our large collection of reaching movements. We probably have the largest dataset of reaching movements collected in microgravity thus far, given that we had 12 taikonauts and each of them performed about 480 to 840 reaching trials during their spaceflight. We believe the probability of Type II error is quite low here.
Citation: Tesch, P. A., Berg, H. E., Bring, D., Evans, H. J., & LeBlanc, A. D. (2005). Effects of 17-day spaceflight on knee extensor muscle function and size. European journal of applied physiology, 93(4), 463-468.
Scott J, Feiveson A, English K, et al. Effects of exercise countermeasures on multisystem function in long duration spaceflight astronauts. npj Microgravity. 2023;9(11).
(2) Modelling
a) The model description should be improved as it is currently a mix of discrete time and continuous time formulations. Moreover, an infinite-horizon cost function is used, but I thought the authors used a finite-horizon formulation with the prefixed duration provided by the movement utility maximization framework of Shadmehr et al. (Curr Biol, 2016). Furthermore, was the mass underestimation reflected both in the utility model and the optimal control model? If so, did the authors really compute the feedback control gain with the underestimated mass but simulate the system with the real mass? This is important because the mass appears both in the utility framework and in the LQ framework. Given the current interpretations, the feedforward command is assumed to be erroneous, and the feedback command would allow for motor corrections. Therefore, it could be clarified whether the feedback command also misestimates the mass or not, which may affect its efficiency. For instance, if both feedforward and feedback motor commands are based on wrong internal models (e.g., due to the mass underestimation), one may wonder how the astronauts would execute accurate goal-directed movements.
b) The model seems to be deterministic in its current form (no motor and sensory noise). Since the framework developed by Todorov (2005) is used, sensorimotor noise could have been readily considered. One could also assume that motor and sensory noise increase in microgravity, and the model could inform on how microgravity affects the number of submovements or endpoint variance due to sensorimotor noise changes, for instance.
c) Finally, how does the model distinguish the feedforward and feedback components of the motor command that are discussed in the paper, given that the model only yields a feedback control law? Does 'feedforward' refer to the motor plan here (i.e., the prefixed duration and arguably the precomputed feedback gain)?
Response (8): We thank the reviewer for raising these important and technically insightful points regarding our modeling framework. We first clarify the structure of the model and key assumptions, and then address the specific questions in points (a)–(c) below.
We used Todorov’s (2005) stochastic optimal control method to compute a finite-horizon LQG policy under sensory noise and signal-dependent motor noise (state noise set to zero). The cost function is: 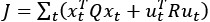 (see details in updated Methods). The resulting time-varying gains {L<sub>k</sub>, K<sub>k</sub>} correspond to the feedforward mapping and the feedback correction gain, respectively. The control law can be expressed as:
(see details in updated Methods). The resulting time-varying gains {L<sub>k</sub>, K<sub>k</sub>} correspond to the feedforward mapping and the feedback correction gain, respectively. The control law can be expressed as:
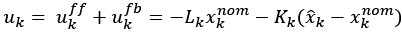
where u<sub>k</sub> is the control input,  is the nominal planned state,
is the nominal planned state, 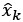 is the estimated state, L<sub>k</sub> is the feedforward (nominal) control associated with the planned trajectory, and K<sub>k</sub> is the time-varying feedback gain that corrects deviations from the plan.
is the estimated state, L<sub>k</sub> is the feedforward (nominal) control associated with the planned trajectory, and K<sub>k</sub> is the time-varying feedback gain that corrects deviations from the plan.
To define the motor plan for comparison with behavior, we simulate the deterministic open-loop
trajectory by turning off noise and disabling feedback corrections, i.e., 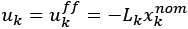 . In this framework, “feedforward” refers to this nominal motor plan. Thus, sensory and signal-dependent noise influence the computed policy (via the gains), but are not injected when generating the nominal trajectory. This mirrors the minimum-jerk practice used to obtain nominal kinematics in prior utility-based work (Shadmehr, 2016), while optimal control provides a more physiologically grounded nominal plan. In the revision, we have updated the equations, provided more modeling details, and moved the model description to the main text to reduce possible confusions.
. In this framework, “feedforward” refers to this nominal motor plan. Thus, sensory and signal-dependent noise influence the computed policy (via the gains), but are not injected when generating the nominal trajectory. This mirrors the minimum-jerk practice used to obtain nominal kinematics in prior utility-based work (Shadmehr, 2016), while optimal control provides a more physiologically grounded nominal plan. In the revision, we have updated the equations, provided more modeling details, and moved the model description to the main text to reduce possible confusions.
In the implementation of the “mass underestimation” condition, the mass used to compute the policy is the underestimated mass (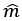 ), whereas the actual mass is used when simulating the feedforward trajectories. Corrective submovements are analyzed separately and are not required for the planning-deficit findings reported here.
), whereas the actual mass is used when simulating the feedforward trajectories. Corrective submovements are analyzed separately and are not required for the planning-deficit findings reported here.
Answers of the three specific questions:
a) We mistakenly wrote a continuous-time infinite-horizon cost function in our original manuscript, whereas our controller is actually implemented as a discrete-time finite-horizon LQG with a terminal cost, over a horizon set by the utility-based optimal movement duration T<sub>opt</sub>. The underestimated mass is used in both the utility model (to determine T<sub>opt</sub>) and in the control computation (i.e., internal model), while the true mass is used when simulating the movement. This mismatch captures the central idea of feedforward planning based on an incorrect internal model.
b) As described, our model includes signal-dependent motor noise and sensory noise, following Todorov (2005). We also evaluated whether increased noise levels in microgravity could account for the observed behavioral changes. Simulation results showed that increasing either source of noise did not alter the main conclusions or reverse the trends in our key metrics. Moreover, our experimental data showed no significant increase in endpoint variability in microgravity (see analyses and results in Figure 2—figure supplement 3 & 4), making it unlikely that increased sensorimotor noise alone accounts for the observed slowing and submovement changes.
c) In our framework, the time-varying gains {L<sub>K</sub>,K<sub>K</sub>}define the feedforward and feedback components of the control policy. While both gains are computed based on a stochastic optimal control formulation (including noise), for comparison with behavior we simulate only the nominal feedforward plan, by turning off both noise and feedback: . This defines a deterministic open-loop trajectory, which we use to capture planning-level effects such as peak timing shifts under mass underestimation. Feedback corrections via gains exist in the full model but are not involved in these specific analyses. We clarified this modeling choice and its behavioral relevance in the revised text.
We have updated the equations and moved the model description into the main text in the revised manuscript to avoid confusion.
(3) Brevity of movements and speed-accuracy trade-off
The tested movements are much faster (average duration approx. 350 ms) than similar self-paced movements that have been studied in other works (e.g., Wang et al., J Neurophysiology, 2016; Berret et al., PLOS Comp Biol, 2021, where movements can last about 900-1000 ms). This is consistent with the instructions to reach quickly and accurately, in line with a speed-accuracy trade-off. Was this instruction given to highlight the inertial effects related to the arm's anisotropy? One may however, wonder if the same results would hold for slower self-paced movements (are they also with reduced speed compared to Earth performance?). Moreover, a few other important questions might need to be addressed for completeness: how to ensure that astronauts did remember this instruction during the flight? (could the control group move faster because they better remembered the instruction?). Did the taikonauts perform the experiment on their own during the flight, or did one taikonaut assume the role of the experimenter?
Response (9): Thanks for highlighting the brevity of movements in our experiment. Our intention in emphasizing fast movements is to rigorously test whether movement is indeed slowed down in microgravity. The observed prolonged movement duration clearly shows that microgravity affects people’s movement duration, even when they are pushed to move fast. The second reason for using fast movement is to highlight that feedforward control is affected in microgravity. Mass underestimation specifically affects feedforward control in the first place, shown by the microgravity-related changes in peak velocity/acceleration. Slow movement would inevitably have online corrections that might obscure the effect of mass underestimation. Note that movement slowing is not only observed in our speed-emphasized reaching task, but also in whole-arm pointing in other astronauts’ studies (Berger, 1997; Sangals, 1999), which have been quoted in our paper. We thus believe these findings are generalizable.
Regarding the consistency of instructions: all our experiments conducted in the Tiangong space station were monitored in real time by experimenters in the control center located in Beijing. The task instructions were presented on the initial display of the data acquisition application and ample reading time was allowed. All the pre-, in-, and post-flight test sessions were administered by the same group of personnel with the same instruction. It is common that astronauts serve both as participants and experimenters at the same time. And, they were well trained for this type of role on the ground. Note that we had multiple pre-flight test sessions to familiarize them with the task. All these rigorous measures were in place to obtain high-quality data. In the revision, we included these experimental details for readers that are not familiar with space studies, and provided the rationales for emphasizing fast movements.
Citations:
Berger, M., Mescheriakov, S., Molokanova, E., Lechner-Steinleitner, S., Seguer, N., & Kozlovskaya, I. (1997). Pointing arm movements in short- and long-term spaceflights. Aviation, Space, and Environmental Medicine, 68(9), 781–787.
Sangals, J., Heuer, H., Manzey, D., & Lorenz, B. (1999). Changed visuomotor transformations during and after prolonged microgravity. Experimental Brain Research. Experimentelle Hirnforschung. Experimentation Cerebrale, 129(3), 378–390.
(4) No learning effect
This is a surprising effect, as mentioned by the authors. Other studies conducted in microgravity have indeed revealed an optimal adaptation of motor patterns in a few dozen trials (e.g., Gaveau et al., eLife, 2016). Perhaps the difference is again related to single-joint versus multi-joint movements. This should be better discussed given the impact of this claim. Typically, why would a "sensory bias of bodily property" persist in microgravity and be a "fundamental constraint of the sensorimotor system"?
Response (10): We believe that the presence or absence of adaptation between our study and Gaveau et al.’s study cannot be simply attributed to single-joint versus multi-joint movements. Their adaptation concerned incorporating microgravity into movement control to minimize effort, whereas ours concerned accurately perceiving body mass. Gaveau et al.’s task involved large-amplitude vertical reaching, a scenario in which gravity strongly affects joint torques and movement execution. Thus, adaptation to microgravity can lead to better execution, providing a strong incentive for learning. By contrast, our task consisted of small-amplitude horizontal movements, where the gravitational influence on biomechanics is minimal.
More importantly, we believe the lack of adaptation for mass underestimation is not totally surprising. When an inertial change is perceived (such as an extra weight attached to the forearm, as in previous motor adaptation studies), people can adapt their reaching within tens of trials. In that case, sensory cues are veridical, as they correctly signal the inertial perturbation. However, in microgravity, reduced gravitational pull and proprioceptive inputs constantly inform the controller that the body mass is less than its actual magnitude. In other words, sensory cues in space are misleading for estimating body mass. The resulting sensory bias prevents the sensorimotor system from adapting. Our initial explanation on this matter was too brief; we expanded it in the revised Discussion.
Reviewer #3 (Public review):
Summary:
The authors describe an interesting study of arm movements carried out in weightlessness after a prolonged exposure to the so-called microgravity conditions of orbital spaceflight. Subjects performed radial point-to-point motions of the fingertip on a touch pad. The authors note a reduction in movement speed in weightlessness, which they hypothesize could be due to either an overall strategy of lowering movement speed to better accommodate the instability of the body in weightlessness or an underestimation of body mass. They conclude for the latter, mainly based on two effects. One, slowing in weightlessness is greater for movement directions with higher effective mass at the end effector of the arm. Two, they present evidence for an increased number of corrective submovements in weightlessness. They contend that this provides conclusive evidence to accept the hypothesis of an underestimation of body mass.
Strengths:
In my opinion, the study provides a valuable contribution, the theoretical aspects are well presented through simulations, the statistical analyses are meticulous, the applicable literature is comprehensively considered and cited, and the manuscript is well written.
Weaknesses:
Nevertheless, I am of the opinion that the interpretation of the observations leaves room for other possible explanations of the observed phenomenon, thus weakening the strength of the arguments.
First, I would like to point out an apparent (at least to me) divergence between the predictions and the observed data. Figures 1 and S1 show that the difference between predicted values for the 3 movement directions is almost linear, with predictions for 90º midway between predictions for 45º and 135º. The effective mass at 90º appears to be much closer to that of 45º than to that of 135º (Figure S1A). But the data shown in Figure 2 and Figure 3 indicate that movements at 90º and 135º are grouped together in terms of reaction time, movement duration, and peak acceleration, while both differ significantly from those values for movements at 45º.
Furthermore, in Figure 4, the change in peak acceleration time and relative time to peak acceleration between 1g and 0g appears to be greater for 90º than for 135º, which appears to me to be at least superficially in contradiction with the predictions from Figure S1. If the effective mass is the key parameter, wouldn't one expect as much difference between 90º and 135º as between 90º and 45º? It is true that peak speed (Figure 3B) and peak speed time (Figure 4B) appear to follow the ordering according to effective mass, but is there a mathematical explanation as to why the ordering is respected for velocity but not acceleration? These inconsistencies weaken the author's conclusions and should be addressed.
Response (11): Indeed, the model predicts an almost equal separation between 45° and 90° and between 90° and 135°, while the data indicate that the spacing between 45° and 90° is much smaller than between 90° and 135°. We do not regard the divergence as evidence undermining our main conclusion since 1) the model is a simplification of the actual situation. For example, the model simulates an ideal case of moving a point mass (effective mass) without friction and without considering Coriolis and centripetal torques. 2) Our study does not make quantitative predictions of all the key kinematic measures; that will require model fitting, parameter estimation, and posture-constrained reaching experiments; instead, our study uses well-established (though simplified) models to qualitatively predict the overall behavioral pattern we would observe. For this purpose, our results are well in line with our expectations: though we did not find equal spacing between direction conditions, we do confirm that the key kinematic measures (Figure 2 and Figure 3 as questioned) show consistent directional trends between model predictions and empirical data. We added new analysis results on this matter: the directional effect we observed (how the key measures changed in microgravity across direction condition) is significantly correlated with our model predictions in most cases. Please check our detailed response (2) above. These results are also added in the revision.
We also highlight in the revision that our modeling is not to quantitatively predict reaching behaviors in space, but to qualitatively prescribe that how mass underestimation, but not the conservative control strategy, can lead to divergent predictions about key kinematic measures of fast reaching.
Then, to strengthen the conclusions, I feel that the following points would need to be addressed:
(1) The authors model the movement control through equations that derive the input control variable in terms of the force acting on the hand and treat the arm as a second-order low-pass filter (Equation 13). Underestimation of the mass in the computation of a feedforward command would lead to a lower-than-expected displacement to that command. But it is not clear if and how the authors account for a potential modification of the time constants of the 2nd order system. The CNS does not effectuate movements with pure torque generators. Muscles have elastic properties that depend on their tonic excitation level, reflex feedback, and other parameters. Indeed, Fisk et al. showed variations of movement characteristics consistent with lower muscle tone, lower bandwidth, and lower damping ratio in 0g compared to 1g. Could the variations in the response to the initial feedforward command be explained by a misrepresentation of the limbs' damping and natural frequency, leading to greater uncertainty about the consequences of the initial command? This would still be an argument for unadapted feedforward control of the movement, leading to the need for more corrective movements. But it would not necessarily reflect an underestimation of body mass.
Fisk, J. O. H. N., Lackner, J. R., & DiZio, P. A. U. L. (1993). Gravitoinertial force level influences arm movement control. Journal of neurophysiology, 69(2), 504-511.
Response (12): We agree that muscle properties, tonic excitation level, proprioception-mediated reflexes all contribute to reaching control. Fisk et al. (1993) study indeed showed that arm movement kinematics change, possibly owing to lower muscle tone and/or damping. However, reduced muscle damping and reduced spindle activity are more likely to affect feedback-based movements. Like in Fisk et al.’s study, people performed continuous arm movements with eyes closed; thus their movements largely relied on proprioceptive control. Our major findings are about the feedforward control, i.e., the reduced and “advanced” peak velocity/acceleration in discrete and ballistic reaching movements. Note that the peak acceleration happens as early as approximately 90-100ms into the movements, clearly showing that feedforward control is affected -- a different effect from Fisk et al’s findings. It is unlikely that people “advanced” their peak velocity/acceleration because they feel the need for more later corrective movements. Thus, underestimation of body mass remains the most plausible explanation.
(2) The movements were measured by having the subjects slide their finger on the surface of a touch screen. In weightlessness, the implications of this contact are expected to be quite different than those on the ground. In weightlessness, the taikonauts would need to actively press downward to maintain contact with the screen, while on Earth, gravity will do the work. The tangential forces that resist movement due to friction might therefore be different in 0g. This could be particularly relevant given that the effect of friction would interact with the limb in a direction-dependent fashion, given the anisotropy of the equivalent mass at the fingertip evoked by the authors. Is there some way to discount or control for these potential effects?
Response (13): We agree that friction might play a role here, but normal interaction with a touch screen typically involves friction between 0.1N and 0.5N (e.g., Ayyildiz et al., 2018). We believe that the directional variation of the friction is even smaller than 0.1N. It is very small compared to the force used to accelerate the arm for the reaching movement (10N-15N). Thus, friction anisotropy is unlikely to explain our data. Indeed, our readers might have the same concern, we thus added some discussion about possible effect of friction.
Citation: Ayyildiz M, Scaraggi M, Sirin O, Basdogan C, Persson BNJ. Contact mechanics between the human finger and a touchscreen under electroadhesion. Proc Natl Acad Sci U S A. 2018 Dec 11;115(50):12668-12673.
(3) The carefully crafted modelling of the limb neglects, nevertheless, the potential instability of the base of the arm. While the taikonauts were able to use their left arm to stabilize their bodies, it is not clear to what extent active stabilization with the contralateral limb can reproduce the stability of the human body seated in a chair in Earth gravity. Unintended motion of the shoulder could account for a smaller-than-expected displacement of the hand in response to the initial feedforward command and/or greater propensity for errors (with a greater need for corrective submovements) in 0g. The direction of movement with respect to the anchoring point could lead to the dependence of the observed effects on movement direction. Could this be tested in some way, e.g., by testing subjects on the ground while standing on an unstable base of support or sitting on a swing, with the same requirement to stabilize the torso using the contralateral arm?
Response (14): Body stabilization is always a challenge for human movement studies in space. We minimized its potential confounding effects by using left-hand grasping and foot straps for postural support throughout the experiment. We think shoulder stability is an unlikely explanation because unexpected shoulder instability should not affect the feedforward (early) part of the ballistic reaching movement: the reduced peak acceleration and its early peak were observed at about 90-100ms after movement initiation. This effect is too early to be explained by an expected stability issue. This argument is now mentioned in the revised Discussion.
The arguments for an underestimation of body mass would be strengthened if the authors could address these points in some way.
Recommendations for the authors:
Reviewing Editor Comments:
General recommendation
Overall, the reviewers agreed this is an interesting study with an original and strong approach. Nonetheless, there were significant weaknesses identified. The main criticism is that there is insufficient evidence for the claim that the movement slowing is due to mass underestimation, rather than other explanations for the increased feedback corrections. To bolster this claim, the reviewers have requested a deeper quantitative analysis of the directional effect and comparison to model predictions. They have also suggested that a 2-dof arm model could be used to predict how mass underestimation would influence multi-joint kinematics, and this should be compared to the data. Alternatively, or additionally, a control experiment could be performed (described in the reviews). We do realize that some of these options may not be feasible or practical. Ultimately, we leave it to you to determine how best to strengthen and solidify the argument for mass underestimation, rather than other causes.
As an alternative approach, you could consider tempering the claim regarding mass underestimation and focus more on the result that slower movements in microgravity are not simply a feedforward, rescaling of the movement trajectories, but rather, have greater feedback corrections. In this case, the reviewers feel it would still be critical to explain and discuss potential reasons for the corrections beyond mass underestimation.
We hope that these points are addressable, either with new analyses, experiments, or with a tempering of the claims. Addressing these points would help improve the eLife assessment.
Reviewer #1 (Recommendations for the authors):
(1) Move model descriptions to the main text to present modelling choices in more detail
Response (15): Thank you for the suggestion. We have moved the model descriptions to the main text to present the modeling choices in more detail and to allow readers to better cross-reference the analyses.
(2) Perform quantitative comparisons of the directional effect with the model's predictions, and add raw kinematic traces to illustrate the effect in more detail.
Response (16): Thanks for the suggestion, we have added the raw kinematics figure from a representative participant and please refer to Response (2) above for the comparisons of directional effect.
(3) Explore the effect of varying cost parameters in addition to mass estimation error to estimate the proportion of data explained by the underestimation hypothesis.
Response (17): Thank you for the suggestion. This has already been done—please see Response (1) above.
Reviewer #2 (Recommendations for the authors):
Minor comments:
(1) It must be justified early on why reaction times are being analyzed in this work. I understood later that it is to rule out any global slowing down of behavioral responses in microgravity.
Response (18): Exactly, RT results are informative about the absence of a global slowing down. Contrary to the conservative-strategy hypothesis, taikonauts did not show generalized slowing; they actually had faster reaction times during spaceflight, incompatible with a generalized slowing strategy. Thanks for point out; we justified that early in the text.
(2) Since the results are presented before the methods, I suggest stressing from the beginning that the reaching task is performed on a tablet and mentioning the instructions given to the participants, to improve the reading experience. The "beep" and "no beep" conditions also arise without obvious justification while reading the paper.
Response (19): Great suggestions. We now give out some experimental details and rationales at the beginning of Results.
(3) Figure 1C: The vel profiles are not returning to 0 at the end, why? Is it because the feedback gain is computed based on the underestimated mass or because a feedforward controller is applied here? Is it compatible with the experimental velocity traces?
Response (20): Figure. 1C shows the forward simulation under the optimal control policy. In our LQG formulation the terminal velocity is softly penalized (finite weight) rather than hard-constrained to zero; with a fixed horizon° the optimal solution can therefore end with a small residual velocity.
In the behavioral data, the hand does come to rest: this is achieved by corrective submovements during the homing phase.
(4) Left-skewed -> I believe this is right-skewed since the peak velocity is earlier.
Response (21): Yes, it should be right-skewed, thanks for point that out.
(5) What was the acquisition frequency of the positional data points? (on the tablet).
Response (22): The sampling frequency is 100 Hz. Thanks for pointing that out; we’ve added this information to the Methods.
(6) Figure S1. The planned duration seems to be longer than in the experiment (it is more around 500 ms for the 135-degree direction in simulation versus less than 400 ms in the experiment). Why?
Response (23): We apologize for a coding error that inadvertently multiplied the body-mass parameter by an extra factor, making the simulated mass too high. We have corrected the code, rerun the simulations, and updated Figures 1 and S1; all qualitative trends remain unchanged, and the revised movement durations (≈300–400 ms) are closer to the experimental values.
(7) After Equation 13: "The control law is given by". This is not the control law, which should have a feedback form u=K*x in the LQ framework. This is just the dynamic equations for the auxiliary state and the force. Please double-check the model description.
Response (24): Thank you for point this out. We have updated and refined all model equations and descriptions, and moved the model description from the Supplementary Materials to the main text; please see the revised manuscript.
Reviewer #3 (Recommendations for the authors):
(1) I have a concern about the interpretation of the anisotropic "equivalent mass". From my understanding, the equivalent mass would be what an external actor would feel as an equivalent inertia if pushing on the end effector from the outside. But the CNS does not push on the arm with a pure force generator acting at the hand to effectuate movement. It applies torque around the joints by applying forces across joints with muscles, causing the links of the arm to rotate around the joints. If the analysis is carried out in joint space, is the effective rotational inertia of the arm also anisotropic with respect to the direction of the movement of the hand? In other words, can the authors reassure me that the simulations are equivalent to an underestimation of the rotational inertia of the links when applied to the joints of the limb? It could be that these are mathematically the same; I have not delved into the mathematics to convince myself either way. But I would appreciate it if the authors could reassure me on this point.
Response (25): Thank you for raising this point. In our work, “equivalent mass” denotes the operational-space inertia projected along the hand-movement direction u, computed as:
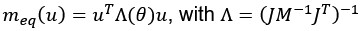
This formulation describes the effective mass perceived at the end effector along a given direction, and is standard in operational-space control.
Although the motor command can be coded as either torque/force in the CNS, the actual executions are equivalent no matter whether it is specified as endpoint forces or joint torques, since force and torque are related by 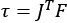 . For small excursions as investigated here, this makes the directional anisotropy in endpoint inertia consistent with the anisotropy of the effective joint-space inertia required to produce the same endpoint motion. Conceptually, therefore, our “mass underestimation” manipulation in operational space corresponds to underestimating the required joint-space inertia mapped through the Jacobian. Since our behavioral data are hand positions, using the operational-space representation is the most direct and appropriate way for modeling.
. For small excursions as investigated here, this makes the directional anisotropy in endpoint inertia consistent with the anisotropy of the effective joint-space inertia required to produce the same endpoint motion. Conceptually, therefore, our “mass underestimation” manipulation in operational space corresponds to underestimating the required joint-space inertia mapped through the Jacobian. Since our behavioral data are hand positions, using the operational-space representation is the most direct and appropriate way for modeling.
(2) I would also like to suggest one more level of analysis to test their hypothesis. The authors decomposed the movements into submovements and measured the prevalence of corrective submovements in weightlessness vs. normal gravity. The increase in corrective submovements is consistent with the hypothesis of a misestimation of limb mass, leading to an unexpectedly smaller displacement due to the initial feedforward command, leading to the need for corrections, leading to an increased overall movement duration. According to this hypothesis, however, the initial submovement, while resulting in a smaller than expected displacement, should have the same duration as the analogous movements performed on Earth. The authors could check this by analyzing the duration of the extracted initial submovements.
Response (26): We appreciate the reviewer’s suggestion regarding the analysis of the initial submovement duration. In our decomposition framework, each submovement is modeled as a symmetric log-normal (bell-shaped) component, such that the time to peak speed is always half of the component duration. Thus, the initial submovement duration is directly reflected in the initial submovement peak-speed time already reported in our original manuscript (Figure. 5F).
However, we respectfully disagree with the assumption that mass underestimation would necessarily yield the same submovement duration as on Earth. Under mass underestimation, the movement is effectively under-actuated, and the initial submovement can terminate prematurely, leading to a shorter duration. This is indeed what we observed in the data. Therefore, our reported metrics already address the reviewer’s proposal and support the conclusion that mass underestimation reduces the initial submovement duration in microgravity. Per your suggestion, we now added one more sentence to explain to the reader that initial submovement peak-speed time reflect the duration of the initial submovement.
Some additional minor suggestions:
(1) I believe that it is important to include the data from the control subjects, in some form, in the main article. Perhaps shading behind the main data from the taikonauts to show similarities or differences between groups. It is inconvenient to have to go to the supplementary material to compare the two groups, which is the main test of the experiment.
Response (27): Thank you for the suggestion. For all the core performance variables, the control group showed flat patterns, with no changes across test sessions at all. Thus, including these figures (together with null statistical results) in the main text would obscure our central message, especially given the expanded length of the revised manuscript (we added model details and new analysis results). Instead, following eLife’s format, we have reorganized the Supplementary Material so that each experimental figure has a corresponding supplementary figure showing the control data. This way, readers can quickly locate the control results and directly compare them with the experimental data, while keeping the main text focused.
(2) "Importantly, sensory estimate of bodily property in microgravity is biased but evaded from sensorimotor adaptation, calling for an extension of existing theories of motor learning." Perhaps "immune from" would be a better choice of words.
Response (28): Thanks for the suggestion, we edited our text accordingly.
(3) "First, typical reaching movement exhibits a symmetrical bell-shaped speed profile, which minimizes energy expenditure while maximizing accuracy according to optimal control principles (Todorov, 2004)." While Todorov's analysis is interesting and well accepted, it might be worthwhile citing the original source on the phenomenon of bell-shaped velocity profiles that minimize jerk (derivative of acceleration) and therefore, in some sense, maximize smoothness. Flash and Hogan, 1985.
Response (29): Thanks for the suggestion, we added the citation of minimum jerk.
(4) "Post-hoc analyses revealed slower reaction times for the 45° direction compared to both 90° (p < 0.001, d = 0.293) and 135° (p = 0.003, d = 0.284). Notably, reactions were faster during the in-flight phase compared to pre-flight (p = 0.037, d = 0.333), with no significant difference between in-flight and post-flight phases (p = 0.127)." What can one conclude from this?
Response (30): Although these decreases reached statistical significance, their magnitudes were small. The parallel pattern across groups suggests the effect is not driven by microgravity, but is more plausibly a mild learning/practice effect. We now mentioned this in the Discussion.
(5) "In line with predictions, peak acceleration appeared significantly earlier in the 45° direction than other directions (45° vs. 90°, p < 0.001, d = 0.304; 45° vs. 135°, p < 0.001, d = 0.271)." Which predictions? Because the effective mass is greater at 45º? Could you clarify the prediction?
Response (31): We should be more specific here; thank you for raising this. The predictions are the ones about peak acceleration timing (shown in Fig. 1H). We now modified this sentence as:
“In line with model predictions (Figure 1H), ….”.
(6) Figure 2: Why do 45º movements have longer reaction times but shorter movement durations?
Response (32): Appreciate your careful reading of the results. We believe this is possibly due to flexible motor control across conditions and trials, i.e., people tend to move faster when people react slower with longer reaction time. This has been reflected in across-direction comparisons (as spotted by the reviewer here), and it has also been shown within participant and across participants: For both groups, we found a significant negative correlation between movement duration (MD) and reaction time (RT), both across and within individuals (Figure 2—figure supplement 5). This finding indicates that participants moved faster when their RT was slower, and vice versa. This flexible motor adjustment, likely due to the task requirement for rapid movements, remained consistent during spaceflight.
I love using Shift + Option + F on my Mac to clean up my HTML code. It's like hitting a magic button.
magivc
How do I modify the VS Code HTML formatter?
x
Joint Public Review:
Quite obviously, the brain encodes "time", as we are able to tell if something happened before or after something else. How this is done, however, remains essentially not understood. In the context of Working Memory tasks, many experiments have shown that the neural activity during the retention period "encodes" time, besides the stimulus to be remembered; that is, the time elapsed from stimulus presentation can be reliably inferred from the recordings, even if time per se is not important for the task. This implies 'mixed selectivity', in the weak sense of neural activity varying with both stimulus identity and time elapsed (since presentation).
In this paper, the authors investigate the implications of a specific form of such mixed selectivity, that is, conjunctive coding of what (stimulus) and when (time) at the single-neuron level, on the resulting dynamics of the population activity when 'viewed' through linear dimensionality-reduction techniques, essentially Principal Component Analysis (PCA). The theoretical/modeling results presented provide a useful guide to the interpretation of the experimental results; in particular, with respect to what can, or cannot, be rightfully inferred from those experimental results (using PCA-like techniques). The results are essentially theoretical in nature; there are, however, some conclusions that require a more precise justification, in my opinion. More generally, as the authors themselves discuss in the paper, it is not clear how to generalize this coding scheme to more complicated, but behaviorally and cognitively relevant, situations, such as multi-item WM or WM for sequences.
(1) It is unclear to me how the conjunctive code that the authors use (i.e., Equation (3)) is constrained by the theoretical desiderata (i.e., compositionality) they list, or whether it is simply an ansatz, partly motivated by theoretical considerations and experimental observations.
The "what" part: What the authors mean by "relationships" between stimuli is never clearly defined. From their argument (and from Figure 1b), it would seem that what they mean is "angles" between population vectors for all pairs of stimuli. If this is so, then the effect of the passing time can only amount to a uniform rescaling of the components of the population vector (i.e., it must be a similarity transformation; rotations are excluded, if the linear-decoder vectors are to be time-independent); the scaling factor, then, must be a strictly monotonous function of time (increasing or decreasing), if one is to decode time. In other words, the "when" receptive fields must be the same for all neurons.
The "when" part: The condition, \tau_3=\tau_1+\tau_2, does not appear to be used at all. In fact, it is unclear (to me at least) whether the model, as it is formulated, is able to represent time intervals between stimuli.
(2) For the specific case considered, i.e., conjunctive coding, it would seem that one should be able to analytically work out the demixed PCA (see Kobak et al., 2016). More generally, it seems interesting to compare the results of the PCA and the demixed PCA in this specific case, even just using synthetic data.
(3) In the Section "Dimensionality of neural trajectories...", there is some claim about how the dimensionality of the population activity goes up with the observation window T, backed up by numerical results that somehow mimic the results of Cueva et al. (2020) on experimental data. Is this a result that can be formally derived? Related to this point, it would be useful to provide a little more justification for Equation (17). Naively, one would think that the correlation matrix of the temporal component is always full-rank nominally, but that one can get excellent low-rank approximations (depending on T, following your argument).
“human computers”
I think this concept of a human computer is very thought provoking in a myriad of ways. My own research pertains to how identity is being reshaped along the boundaries of recommendation algorithms, and I feel like this idea of a human computer has a lot of thematic overlap. I know that the first "computers" were people who manually did computation as their job, but to what extent did their status as essentially beings of code shape their lives? Did they (or do they, in the case of modern human computers) see the world differently than I? What do they notice? Does living so in tune with the digital shape their philosophical framework? I feel like the fact that so much of culture and my own time is mediated by retention-based algorithms drastically shapes my ability to imagine another world different from my own. Does the same hold true for human computers?
Copy to clipboard If you run the code above you will see that the program pauses as it displays the output above. These pauses may come in handy when posting tweets, to make it look like your bot is taking time to type in the text. You will get a chance to try that in the next practice section.
I always wondered how programmers would create these sorts of commands, and it's cool to know that it's done with simple commands like these! I was also not previously aware that to display something on a screen, you have to use the command 'display'. I previously thought that 'print' was the main form to do so.
Does the fact that it is a bot change how you feel about its actions?
Not really. I think in a lot of controversial cases involving bot behavior are often not excused because at the end of the day, someone programmed it. Maybe it's because I don't know exactly how bots work, but I feel like a bot's actions are limited to what its programmer allows it to do, so if a bot is able to do something (such as post racist comments, as explained in an earlier section of this chapter), then something in its code allowed it to process racist information and express it. In the case from earlier this chapter, it probably should've been considered that if the bot is using other twitter users' tweets toward the company and that information is public, there probably should've been safeguards to detect racial remarks and block it from the bot's vocabulary and processing. It could be argued that that scenario slipped from their minds, but I think that anything that will be released to the public should be tested and be given feedback from a smaller community before released to the mass public. Surely someone would've thought that the bot could pick up racist tweets.
You can extend Claude Code's capabilities by adding MCP (Model Context Protocol) servers. These servers run either remotely or locally on your machine and provide Claude with new tools and abilities it wouldn't normally have.
MCP 可以拓展 claude code 的能力,给它更多的工具和能力。
Custom commands are particularly useful for project-specific workflows like running test suites, deploying code, or generating boilerplate following your team's conventions.
其实 build 工具也可以做这件事,自己封装一系列步骤成一个命令,然后一次性运行,那么 claude code 的这个自定义 command 好在: - 提供了 convention - 自然语言的 argument,本质上还是利用了 claude 的功能
Enable Planning Mode by pressing Shift + Tab twice (or once if you're already auto-accepting edits). In this mode, Claude will: Read more files in your project Create a detailed implementation plan Show you exactly what it intends to do Wait for your approval before proceeding
Plan Mode can boost claude code intelligence
To paste a screenshot into Claude, use Ctrl+V (not Cmd+V on macOS). This keyboard shortcut is specifically designed for pasting screenshots into the chat interface.
在 claude code 粘贴截图
Save State.
AGENT INTEL: The "Save State" Monitor Card
SAVE THIS FOR YOURSELF AS A REMINDER
This is your tactical reminder. Copy, print, or transcribe this onto a card and fix it to the side of your primary monitor. It serves as a visual "circuit breaker" to prevent a biological hijack when a human enters your workspace.
S0P002 | THE SAVE STATE PROTOCOL STATUS: Logic Saved. Human Witnessed. Connection Restored.
SECURE THE LOGIC (Ctrl+S) Physically press the keys. This is your "mental bookmark." The machine now holds the data so your brain doesn't have to.
CALM THE BIOLOGY (The Vagal Brake) Feet flat. Shoulders down. Exhale for four seconds. Flush the cortisol out of your system before you speak.
SHIFT THE VECTOR (The 180° Pivot) Physically turn your body. If you are facing the screen, you are in "Processor Mode." If you face the person, you are in "Partner Mode."
RE-CENTRE THE MISSION Internal Check: “Am I optimising for the machine or the human?”
OPEN THE CHANNEL "I'm here. I’ve saved my work. Tell me what's happening."
Why this works: The Cognitive Handover By performing a physical action (Ctrl+S), you are manually offloading the "Cognitive Load" from your Prefrontal Cortex. This reduces the internal "friction" that causes the irritability (the snap). The physical 180-degree turn breaks the visual "loop" of the monitor's blue light, allowing your brain to switch from Task-Positive Network (focusing on the code) to the Default Mode Network (focusing on the relationship).
You are not merely "stopping work"; you are honouring the Ruach (the breath/spirit) of the person standing before you. You are choosing the Yellow Light (the human) over the Blue Light (the machine).
You accept that the work will wait, but the human moment will expire. You are not a processor; you are a partner. (Cause).
This results in an immediate spike of Cortisol and Adrenaline, narrowing your visual and emotional field—a "biological hijack." To counter this, you must engage the Vagus Nerve. By pressing your feet flat and extending your exhale, you signal the parasympathetic nervous system to downregulate the alarm, shifting the energy from "Defence" back to "Social Engagement." You are effectively clearing the cache of your emotional processor to make room for a new, higher-priority input.
The "Physics of the Kingdom" dictates that Love (Agape) is the primary vector. In 1 Corinthians 13, Paul describes Love as not being "easily provoked" (paroxynetai—literally, "not sparked into a sharp edge"). When you snap, you have allowed your internal friction to create a spark that severs the "cord" of connection. By hitting the "Save State," you are aligning with the Sabbath Logic: the world (and the code) is sustained by God, allowing you the freedom to stop, turn, and witness the Image Dei standing in your doorway.
The Physical Save (5 Seconds): Physically press Ctrl + S (or Command + S). This tactile movement tells your brain: "The data is safe; the PFC can let go."
The Grounding (10 Seconds): Press both feet into the floor. Feel the weight. Exhale slowly through pursed lips as if blowing out a candle.
The Pivot (5 Seconds): Physically rotate your chair or your torso 180 degrees away from the screen.
The Identification: Look at the person and internally label them: "Image of God. Priority One."
The Opening: Say: "I've saved my place. I'm listening."
But there's one post-American system that's easy to imagine. The project to rip out all the cloud connected, backdoored, untrustworthy black boxes that power our institutions, our medical implants, our vehicles and our tractors; and replace it with collectively maintained, open, free, trustworthy, auditable code. This project is the only one that benefits from economies of scale, rather than being paralyzed by exponential crises of scale. That's because any open, free tool adopted by any public institution – like the Eurostack services – can be audited, localized, pen-tested, debugged and improved by institutions in every other country.
digital transition is possible because it scales through spreading. You don't have to solve exponential scale first.
Today's links The Post-American Internet: My speech from Hamburg's Chaos Communications Congress. Hey look at this: Delights to delectate. Object permanence: Error code 451; Public email address Mansplaining Lolita; NSA backdoor in Juniper Networks; Don't bug out; Nurses whose shitty boss is a shitty app. Upcoming appearances: Where to find me. Recent appearances: Where I've been. Latest books: You keep readin' em, I'll keep writin' 'em. Upcoming books: Like I said, I'll keep writin' 'em. Colophon: All the rest. The Post-American Internet (permalink) On December 28th, I delivered a speech entitled "A post-American, enshittification-resistant internet" for 39C3, the 39th Chaos Communications Congress in Hamburg, Germany. This is the transcript of that speech. Video Playerhttps://archive.org/download/doctorow-39c3/39c3-1421-eng-A_post-American_enshittification-resistant_internet.mp400:0000:0001:01:12Use Up/Down Arrow keys to increase or decrease volume. Many of you know that I'm an activist with the Electronic Frontier Foundation – EFF. I'm about to start my 25th year there. I know that I'm hardly unbiased, but as far as I'm concerned, there's no group anywhere on Earth that does the work of defending our digital rights better than EFF. I'm an activist there, and for the past quarter-century, I've been embroiled in something I call "The War on General Purpose Computing." If you were at 28C3, 14 years ago, you may have heard me give a talk with that title. Those are the trenches I've been in since my very first day on the job at EFF, when I flew to Los Angeles to crash the inaugural meeting of something called the "Broadcast Protection Discussion Group," an unholy alliance of tech companies, media companies, broadcasters and cable operators. They'd gathered because this lavishly corrupt American congressman, Billy Tauzin, had promised them a new regulation – a rule banning the manufacture and sale of digital computers, unless they had been backdoored to specifications set by that group, specifications for technical measures to block computers from performing operations that were dispreferred by these companies' shareholders. That rule was called "the Broadcast Flag," and it actually passed through the American telecoms regulator, the Federal Communications Commission. So we sued the FCC in federal court, and overturned the rule. We won that skirmish, but friends, I have bad news, news that will not surprise you. Despite wins like that one, we have been losing the war on the general purpose computer for the past 25 years. Which is why I've come to Hamburg today. Because, after decades of throwing myself against a locked door, the door that leads to a new, good internet, one that delivers both the technological self-determination of the old, good internet, and the ease of use of Web 2.0 that let our normie friends join the party, that door has been unlocked. Today, it is open a crack. It's open a crack! And here's the weirdest part: Donald Trump is the guy who's unlocked that door. Oh, he didn't do it on purpose! But, thanks to Trump's incontinent belligerence, we are on the cusp of a "Post-American Internet," a new digital nervous system for the 21st century. An internet that we can build without worrying about America's demands and priorities. Now, don't get me wrong, I'm not happy about Trump or his policies. But as my friend Joey DaVilla likes to say "When life gives you SARS, you make sarsaparilla." The only thing worse than experiencing all the terror that Trump has unleashed on America and the world would be going through all that and not salvaging anything out of the wreckage. That's what I want to talk to you about today: the post-American Internet we can wrest from Trump's chaos. A post-American Internet that is possible because Trump has mobilized new coalition partners to join the fight on our side. In politics, coalitions are everything. Any time you see a group of people suddenly succeeding at a goal they have been failing to achieve, it's a sure bet that they've found some coalition partners, new allies who don't want all the same thing as the original forces, but want enough of the same things to fight on their side. That's where Trump came from: a coalition of billionaires, white nationalists, Christian bigots, authoritarians, conspiratorialists, imperialists, and self-described "libertarians" who've got such a scorching case of low-tax brain worms that they'd vote for Mussolini if he'd promise to lower their taxes by a nickel. And what's got me so excited is that we've got a new coalition in the War on General Purpose Computers: a coalition that includes the digital rights activists who've been on the lines for decades, but also people who want to turn America's Big Tech trillions into billions for their own economy, and national security hawks who are quite rightly worried about digital sovereignty. My thesis here is that this is an unstoppable coalition. Which is good news! For the first time in decades, victory is in our grasp.
Sees the original fight by digital rights activists now joined by geopolitical economics and international cybersec. Thinks this combi will win out
The Override Protocol You cannot out-argue the loop; you must overwrite it with Source Code.
This is the pivot. Everything changes when we spot the lie. If you're stuck here, use the counter-measure - it seems to easy to fix it, but it works!
built their notebooks as simple web pages. The interface is missing Mathematica’s Steve Jobsian polish, and its sophistication. But by latching itself to the web, IPython got what is essentially free labor: Any time Google, Apple, or a random programmer open-sourced a new plotting tool, or published better code for rendering math, the improvement would get rolled into IPython. “It has paid off handsomely,” Pérez said.
Algo similar es lo que quiero capitalizar con Cardumem y luego portar a Grafoscopio, pues, como lo ha mostrado la experiencia con este último, las interfaces en Spec, el toolkit gráfico de Pharo, si bien brindan algunas cosas que las interfaces web no tienen, adolecen del basto ecosistema de ésta última y mantienen los documentos y la computación aisladas dentro de la imagen.
La web, por el contrario, es casi ubicua en términos de las tecnologías ya instaladas y así no se cuente con una conexión a internet en el equipo de cómputo, si este tiene una interfaz gráfica, muy seguramente contará con un naveador web. Y ahora que los sistemas hipermedia, hacen posible programar la web desde cualquier lenguaje (HOWL: Hypermedia On Whatever you Like), se puede aprovechar tanto lo que sabemos de los lenguajes/entornos que nos gustan (Pharo o Lua) como del amplio sistema de la web. Antes de 2023, que se popularizaron los sistemas hipermedia, teníamos que elegir entre lo uno y lo otro. Y yo deselegí activamente la web, debido al adefesio de JavaScript y lo engorroso del CSS. Hoy, las condiciones son bien distintas.
Commercial software whose source code you were legally prohibited from reading was “antithetical to the idea of science,” where the very purpose is to open the black box of nature.
The notebook interface was the brainchild of Theodore Gray, who was inspired while working with an old Apple code editor.
The student consciously acted in a way that he or she knew or should have known constituted a violation of the Honor Code.
The sanction in this case is pretty fair.
Author response:
The following is the authors’ response to the previous reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
Mazar & Yovel 2025 dissect the inverse problem of how echolocators in groups manage to navigate their surroundings despite intense jamming using computational simulations.
The authors show that despite the 'noisy' sensory environments that echolocating groups present, agents can still access some amount of echo-related information and use it to navigate their local environment. It is known that echolocating bats have strong small and large-scale spatial memory that plays an important role for individuals. The results from this paper also point to the potential importance of an even lower-level, short-term role of memory in the form of echo 'integration' across multiple calls, despite the unpredictability of echo detection in groups. The paper generates a useful basis to think about the mechanisms in echolocating groups for experimental investigations too.
Strengths:
The paper builds on biologically well-motivated and parametrised 2D acoustics and sensory simulation setup to investigate the various key parameters of interest
The 'null-model' of echolocators not being able to tell apart objects & conspecifics while echolocating still shows agents succesfully emerge from groups - even though the probability of emergence drops severely in comparison to cognitively more 'capable' agents. This is nonetheless an important result showing the direction-of-arrival of a sound itself is the 'minimum' set of ingredients needed for echolocators navigating their environment.
The results generate an important basis in unraveling how agents may navigate in sensorially noisy environments with a lot of irrelevant and very few relevant cues.
The 2D simulation framework is simple and computationally tractable enough to perform multiple runs to investigate many variables - while also remaining true to the aim of the investigation.
Weaknesses:
Authors have not yet provided convincing justification for the use of different echolocation phases during emergence and in cave behaviour. In the previous modelling paper cited for the details - here the bat-agents are performing a foraging task, and so the switch in echolocation phases is understandable. While flying with conspecifics, the lab's previous paper has shown what they call a 'clutter response' - but this is not necessarily the same as going into a 'buzz'-type call behaviour. As pointed out by another reviewer - the results of the simulations may hinge on the fact that bats are showing this echolocation phase-switching, and thus improving their echo-detection. This is not necessarily a major flaw - but something for readers to consider in light of the sparse experimental evidence at hand currently.
The use of echolocation phases—defined as the sequential search, approach, and buzz call patterns—has been documented not only during foraging but also in tasks such as landing, obstacle avoidance, clutter navigation, and drinking. Bat call structure has been shown to vary systematically with object proximity, not exclusively in response to prey. During obstacle avoidance, phase transitions were observed, with approach calls emitted in grouped sequences and with reduced durations (Gustafson & Schnitzler, 1979; Schnitzler et al., 1987). In landing contexts, bats have been reported to emit short-duration calls and decrease inter-pulse intervals—buzz-like patterns also observed during prey capture— suggesting shared acoustic strategies across behaviors (Hagino et al., 2007; Hiryu et al., 2008; Melcón et al., 2007, 2009). Comparable patterns have been reported during drinking maneuvers, where “drinking buzzes” have been proposed to guide a precise approach to the water surface, analogous to landing buzzes (Griffiths, 2013; Russo et al., 2016). In response to environmental complexity, bats were found to shorten calls and increase repetition rates when navigating cluttered spaces compared to open ones (Falk et al., 2014; Kalko & Schnitzler, 1993).
Moreover, field recordings from our study of Rhinopoma microphyllum (Goldshtein et al., 2025) revealed shortened call durations and inter-pulse intervals during dense group flight outside the cave during emergence—patterns consistent with terminal-approach phase that is typical when coming very close to an object (another bat in this case). The Author response image 1 shows an approach sequence recorded from a tagged bat approximately 20 meters from the cave entrance, with self-generated echolocation calls marked. The inter-pulse-interval of ca. 20 ms is used by these bats when a reflective object (another bat in this case) is nearby.
Author response image 1.
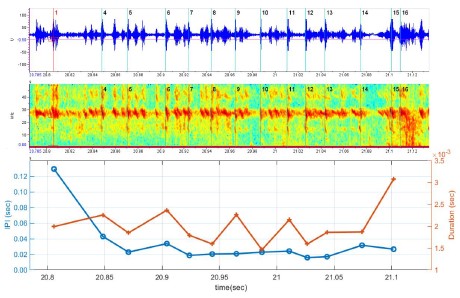
These results provide direct evidence that bats actively employ approach-phase echolocation during swarming likely to avoid collision with other bats. This supports the view that echolocation phase transitions are a general proximity-based sensing strategy, adapted across a variety of behavioral scenarios—not limited to hunting alone.
In our simulations, bats predominantly emitted calls in the approach phase, with only rare occurrences of buzz-phase calls.
See lines 355-363 in the revised manuscript.
The decision to model direction-of-arrival with such high angular resolution (1-2 degrees) is not entirely justifiable - and the authors may wish to do simulation runs with lower angular resolution. Past experimental paradigms haven't really separated out target-strength as a confounding factor for angular resolution (e.g. see the cited Simmons et al. 1983 paper). Moreover, to this reviewer's reading of the cited paper - it is not entirely clear how this experiment provides source-data to support the DoA-SNR parametrisation in this manuscript. The cited paper has two array-configurations, both of which are measured to have similar received levels upon ensonification. A relationship between angular resolution and signal-to-noise ratio is understandable perhaps - and one can formulate such a relationship, but here the reviewer asks that the origin/justification be made clear. On an independent line, also see the recent contrasting results of Geberl, Kugler, Wiegrebe 2019 (Curr. Biol.) - who suggest even poorer angular resolution in echolocation.
We thank the reviewer for raising this important point. The acuity of 1.5–3° in horizontal direction-of-arrival (DoA) estimation is based on the classical work of Simmons et al. with Eptesicus fuscus (Simmons et al., 1983). Similar precision was later supported by Erwin et al. (Erwin et al., 2001), who modeled azimuth estimation from measured interaural intensity differences (IIDs), reporting an average error of 0.2° with a standard deviation of ~2.2°, consistent with the behavioral data found by Simmons. The decline in acuity with increasing arrival angle has also been demonstrated in behavioral and physiological studies of binaural IID processing (Erwin et al., 2001; Fay, 1995; Razak, 2012; Wohlgemuth et al., 2016). The error model itself was first introduced in our earlier work (Mazar & Yovel, 2020).
Importantly, Geberl et al. (Geberl et al., 2019) examined the resolution of weak targets masked by nearby strong flankers and found poor spatial discrimination of ~45 degrees; however, they were studying a detection problem, rather than the horizontal acuity of azimuth estimation. Indeed, our model assumes there is no spatial discrimination at all.
Overall, while our DoA–SNR parametrization can certainly be critiqued and alternative parameterizations could be tested in future work, we believe it reflects a reasonable and empirically supported assumption.
Reviewer #2 (Public review):
This manuscript describes a detailed model for bats flying together through a fixed geometry. The model considers elements which are faithful to both bat biosonar production and reception and the acoustics governing how sound moves in air and interacts with obstacles. The model also incorporates behavioral patterns observed in bats, like one-dimensional feature following and temporal integration of cognitive maps. From a simulation study of the model and comparison of the results with the literature, the authors gain insight into how often bats may experience destructive interference of their acoustic signals and those of their peers, and how much such interference may actually negatively effect the groups' ability to navigate effectively. The authors use generalized linear models to test the significance of the effects they observe.
The work relies on a thoughtful and detailed model which faithfully incorporates salient features, such as acoustic elements like the filter for a biological receiver and temporal aggregation as a kind of memory in the system. At the same time, the authors abstract features that are complicating without being expected to give additional insights, as can be seen in the choice of a two-dimensional rather than three-dimensional system. I thought that the level of abstraction in the model was perfect, enough to demonstrate their results without needless details. The results are compelling and interesting, and the authors do a great job discussing them in the context of the biological literature.
With respect to the first version of the manuscript, the authors have remedied all my outstanding questions or concerns in the current version. The new supplementary figure 5 is especially helpful in understanding the geometry.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Data Availability: This reviewer lauds the authors for switching from a private commercial folder requiring login to one that does not. At the cost of being overtly pedantic - the Github repository is not a long-term archival resource. The ideal solution is to upload the code in an academic repository (Zenodo, OSF, etc.) to periodically create a 'static snapshot' of code for archival, while also hosting a 'live' version on Github.
We have uploaded to Zenodo repository, and updated the link in the paper:
How bats exit a crowded colony when relying on echolocation only - a modeling approach
In one of the rebuttals to Reviewer #3- the authors have cited a wrong paper (Beleyur & Goerlitz 2019) - while discussing broad bandwidth calls improving detection - and may wish to correct this if possible on record.
We have removed the incorrect citation from the revised version of the manuscript.
Specific comments on the 2nd manuscript:
Figure 5: Table 1 says 1, 2,5,10,20,40,100 bats were simulated (line 138-139) but the conclusion (line 398) says '1 to 100 bats' per 3msq. However, the X-axis only stops at 40 and says 'number of bats', while the legend says bats/3msq....what is actually being plotted? Moreover, in the entire paper there is a constant back-and-forth between density and # of bats - perhaps it is explained beforehand, but it is a bit unsettling - and more can be done to clarify these two conventions.
While most parameters were tested across the full range of 1 to 100 bats per 3 m², a subset of conditions—including misidentification, multi-call clustering, wall target strength, and conspecific target strength—were simulated only up to 40 bats due to significantly longer run-times. This is now clarified in both the main text and the Table 1 caption.
In our simulations, the primary parameter was the number of bats placed within a 3 m² starting area, which directly determined the initial density (bats per 3 m²). Throughout the manuscript, we use “number of bats” to refer to the simulation input, while “density” denotes the equivalent ecological measure. Figure 5 and related captions have been revised accordingly to note these conventions and to indicate when results are shown only up to 40 bats (see lines 120–122, 314-317 in the revised text).
Table 1: This was made considerably difficult to read given the visual clutter - and I hope I've understood these changes correctly.
What is in the square brackets of the effect-size (e.g. first row with values 'Exit prob. (%)' says -0.37/bat [63:100] ? What does this 63:100 refer to?
What is the 'process flag'
Values in square brackets indicate the minimum and maximum values of the metric across the tested range (e.g., [63:100] shows the range of exit probabilities observed across different bat densities).
The term “process flag” has been replaced with “with and without multi-call clustering” for clarity
Both the table layout and caption have been revised to reduce visual clutter and to make these conventions clearer to the reader.
Lines 562-3: "In our study, due to the dense cave environment, the bats are found to operate in the approach phase nearly all of the time, which is consistent with natural cave emergence behavior" - bats are 'found to' implies there is some experimental data or it is an emergent property. See above for the point questioing the implementation of multiple echolocation phases in the model, but also - here the bat-agents are allowed to show different phases and thus they do so -- it is a constraint of the implementation and not a result per se given the size of the cave and the number of bats involved...
We removed the sentence from the Methods section, since it could be misinterpreted as an experimental finding rather than a model outcome. Instead, we now discuss this in the Discussion, clarifying that the predominance of the approach phase arises from the cluttered cave environment in our simulations, which is consistent with natural emergence behavior (see lines 355-363). In this context, the use of echolocation phases is presented as a biologically plausible modeling choice rather than an empirical result.
Lines 659-660: The parametrisation between DoA and SNR is supposedly found in 'Equation 10' - which this reviewer could not find in the manuscript
The equation was accidentally omitted in the previous revision and has now been reinserted into the manuscript. It defines how direction-of-arrival (DoA) error depends on SNR and azimuth angle (see lines 603-605).
= empty_rows
small typo in the code here.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study addresses the encoding of forelimb movement parameters using a reach-to-grasp task in mice. The authors use a modified version of the water-reaching paradigm developed by Galinanes and Huber. Two-photon calcium imaging was then performed with GCaMP6f to measure activity across both the contralateral caudal forelimb area (CFA) and the forelimb portion of primary somatosensory cortex (fS1) as mice perform the reaching behavior. Established methods were used to extract the activity of imaged neurons in layer 2/3, including methods for deconvolving the calcium indicator's response function from fluorescence time series. Video-based limb tracking was performed to track the positions of several sites on the forelimb during reaching and extract numerous low-level (joint angle) and high-level (reach direction) parameters. The authors find substantial encoding of parameters for both the proximal and distal parts of the limb across both CFA and fS1, with individual neurons showing heterogeneous parameter encoding. Limb movement can be decoded similarly well from both CFA and fS1, though CFA activity enables decoding of reach direction earlier and for a more extended duration than fS1 activity. Collectively, these results indicate involvement of a broadly distributed sensorimotor region in mouse cortex in determining low-level features of limb movement during reach-to-grasp.
Strengths:
The technical approach is of very high quality. In particular, the decoding methods are well designed and rigorous. The use of partial correlations to distinguish correlation between cortical activity and either proximal or distal limb parameters or either low- or high-level movement parameters was very nice. The limb tracking was also of extremely high quality, and critical here to revealing the richness of distal limb movement during task performance.
The task itself also reflects an important extension of the original work by Galinanes and Huber. The demonstration of a clear, trackable grasp component in a paradigm where mice will perform hundreds of trials per day expands the experimental opportunities for the field. This is an exciting development.
The findings here are important and the support for them is solid. The work represents an important step forward toward understanding the cortical origins of limb control signals. One can imagine numerous extensions of this work to address basic questions that have not been reachable in other model systems.
Collectively, these strengths made this manuscript a pleasure to read and review.
Thank you!
Weaknesses:
In the last section of the results, the authors purport to examine the representation of "higher-level target-related signals," using the decoding of reach direction. While I think the authors are careful in their phrasing here, I think they should be more explicit about what these signals could be reflecting. The "signals" here that are used to decode direction could relate to anything - low-level signals related to limb or postural muscles, or true high-level commands that dictate only what movement downstream motor centers should execute, rather than the muscle commands that dictate how. One could imagine using a partial correlation-type approach again here to extract a signal uncorrelated with all the measured low-level parameters, but there would still be all the unmeasured ones. Again, I think it is still ok to call these "high-level signals," but I think some explicit discussion of what these signals could reflect is necessary.
Thank you for this excellent suggestion. We have followed both pieces of the reviewer’s advice. First, we performed the suggested analysis, partialing off the kinematics then performing target classification on the residuals. This is now Figure 6S1. The analysis revealed the presence of target-related information in the neural activity after subtracting off all linear correlations with kinematics, supporting our claims that higher-level information is present in both populations. The exact timing of classifier performances varied substantially across mice, potentially due to differences in reach-to-grasp strategy, kinematic tracking fidelity, and exact spatial locations of each recorded FOV. Following the second suggestion, we have made the relevant text more careful. We now conclude simply that higher-level signals, meaning those signals that are largely unrelated to forelimb joint angle kinematics, are present but with variable timing and strengths in each area. That text now reads:
“Target decoding performance could result from truly higher-level signals that code abstractly for target location, or alternatively could be supported by strong encoding of kinematic variables that differed between targets. To disambiguate these possibilities, we refit the linear classifier to neural data after regressing off variance related to the joint angle kinematics. The strength and exact time course of the resulting target decoding varied somewhat across animals, but the earliest portion of target decoding performance persisted in all animals after the removal of kinematics and performance remained stronger for M1-fl than S1-fl (Fig. 6S1B). We thus conclude that higher-level signals are present in both areas, but differ in their exact timing and strength. However, we note that other possible signals, such as postural changes, could not be controlled for here.”
Related to this, I think the manuscript in general does not do an adequate job of explicitly raising the important caveats in interpreting parametric correlations in motor system signals, like those raised by Todorov, 2000. The authors do an expert job of handling the correlations, using PCA to extract uncorrelated components and using the partial correlation approach. However, more clarity about the range of possible signal types the recorded activity could reflect seems necessary.
This is an important point, and our text could have unintentionally misled readers. We have now attempted to make this point explicit in the Discussion and in the Results for Figure 6. This Discussion text now reads:
“Moreover, as is widely known (Todorov 2000), the exact role of these kinematically-related signals is challenging to determine from correlative measures alone; thus, determining whether these signals are used for direct movement control or instead indirectly reflect control performed elsewhere is left as a topic for future work.”
The manuscript could also do a better job of clarifying relevant similarities and differences between the rodent and primate systems, especially given the claims about the rodent being a "first-class" system for examining the cellular and circuit basis of motor control, which I certainly agree with. Interspecies similarities and differences could be better addressed both in the Introduction, where results from both rodents and primates are intermixed (second paragraph), and in the Discussion, where more clarity on how results here agree and disagree with those from primates would be helpful. For example, the ratio of corticospinal projections targeting sensory and motor divisions of the spinal cord differs substantially between rodents and primates. As another example, the relatively high physical proximity between the typical neurons in mouse M1 and S1 compared to primates seems likely to yoke their activity together to a greater extent. There is also the relatively large extent of fS1 from which forelimb movements can be elicited through intracortical microstimulation at current levels similar to those for evoking movement from M1. All of these seem relevant in the context of findings that activity in mouse M1 and S1 are similar.
We understand two points to address here. The first point is that we needed to be more careful to attribute previous results as being from the rodent vs. monkey. We agree. We have now revised several parts of the paper to make these distinctions clearer. The second point is about the potential benefit of a thorough review of the many ways in which primate and rodent sensorimotor systems differ. We entirely agree that this could be useful for the field. However, this is a sizable endeavor and doing it full justice is beyond what we know how to fit in the space allotted for framing our results here. We therefore sought a compromise, acknowledging how our results correspond to existing results in the primate without exhaustively accounting for how they differ. Future work will be necessary to more carefully disambiguate whether species-specific differences are due to biomechanical, neurological, ethological, or as-of-yet undetermined sources. We have incorporated your final specific points about what could produce similar information in M1 and S1 into the Discussion.
“This may simply be a consequence of widely distributed representations of movement across mouse cortex (Musall et al. 2019; Steinmetz et al. 2019; Stringer et al. 2019), including forelimb somatosensory areas, or may be a consequence of the close physical proximity of M1-fl and S1-fl hindering development of functionally distinct representations (Tennant et al. 2011).”
In addition, there are a number of other issues related to the interpretation of findings here that are not adequately addressed. These are described in the Recommendations for improvement.
Reviewer #2 (Public review):
Summary:
In this manuscript, Grier, Salimian, and Kaufman characterize the relationship between the activity of neurons in sensorimotor cortex and forelimb kinematics in mice performing a reach-to-grasp task. First, they train animals to reach to two cued targets to retrieve water reward, measure limb motion with high resolution, and characterize the stereotyped kinematics of the shoulder, elbow, wrist, and digits. Next, they find that inactivation of the caudal forelimb motor area severely impairs coordination of the limb and prevents successful performance of the task. They then use calcium imaging to measure the activity of neurons in motor and somatosensory cortex, and demonstrate that fine details of limb kinematics can be decoded with high fidelity from this activity. Finally, they show reach direction (left vs right target) can be decoded earlier in the trial from motor than from somatosensory cortex.
Strengths:
In my opinion, this manuscript is technically outstanding and really sets a new bar for motor systems neurophysiology in the mouse. The writing and figures are clear, and the claims are supported by the data. This study is timely, as there has been a recent trend towards recording large numbers of neurons across the brain in relatively uncontrolled tasks and inferring a widespread but coarse encoding of high-level task variables. The central finding here, that sensorimotor cortical activity reflects fine details of forelimb movement, argues against the resurgent idea of cortical equipotentiality, and in favor of a high degree of specificity in the responses of individual neurons and of the specialization of cortical areas.
Thank you!
Weaknesses:
It would be helpful for the authors to be more explicit about which models of mouse cortical function their results support or rule out, and how their findings break new conceptual ground.
We appreciate this feedback and have attempted to make these details clearer through changes to the Introduction and Discussion. One key change is noted below:
“The presence of detailed kinematic signals in the sensorimotor cortex supports a model of mouse sensorimotor cortex in which M1-fl and S1-fl play a strong role in shaping the fine details of reaching and grasping movements.”
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
In addition to the weaknesses noted above, I suggest the authors also address the following:
The last results section is generally lacking in statistical support for claims. Statistical support should be added.
Thank you for pointing this out, we have added more statistical support to this section.
The consideration in the Discussion of relevant previous findings and potential explanations for the distal limb signals in mouse sensorimotor cortex is somewhat lacking. There are several specific issues:
(1) In contrast to the present study, the studies cited in regards to a lack of motor cortical involvement did not involve dexterous movements - in fact, Kawai et al. explicitly engineered a task that did not involve dexterity to distinguish the role of motor cortex in learning from its known role in dextrous movement execution. In Kawai et al., the authors note one rat who adopted a more dexterous approach to the lever pressing task; in this rat, a motor cortical lesion did cause a longer-lasting reduction in task performance. In additional experiments reported in Kawai's PhD thesis, performance of a dextrous task does erode with motor cortex lesion, as seen in other studies, like the early rodent reaching work of Whishaw and colleagues.
(2) Other possible explanations for the persistence of non-dexterous tasks following motor cortical removal are compensation by, or redundant functionality in, other motor system regions.
(3) It is also worth noting that stimulation in different regions of mouse M1 and S1 evokes alternately, digit, wrist, and elbow movements in fairly similar proportions (Tennant, 2011), suggesting that descending pathways substantially target spinal circuits that control all forelimb joints.
(4) It also seems relevant that although the recovery time course is longer, nonhuman primates also retain substantial hand control after motor cortical removal (e.g. Lashley, 1925; Glees and Cole, 1950; Passingham et al., 1983). Humans of course, appear to be a different story.
These are good points. We have tried to make the Discussion better reflect the tension in the literature, including with this new text:
“However, several other previous results have indirectly suggested that M1 and S1 may be involved in the details of forelimb movement. Performance suffers with inactivation or lesioning of M1 and S1 in skilled, complex manual behaviors (Guo et al 2015, Mizes et al 2024, Whishaw et al 1990) or idiosyncratic use of digits to accomplish non-dexterous tasks (Kawai 2014). The sparing of non-dexterous tasks with these lesions may also reflect redundancy in control as opposed to irrelevance of M1 and S1. Nevertheless, our finding of low-level kinematic information in sensorimotor cortex supports a role for cortex beyond simply providing redundant high-level commands to these subcortical areas.”
We have avoided mentioning points 3 and 4 in the paper; the stimulation results might follow from activating projections not normally involved in this behavior, and discussing primates in this context would require a long list of caveats. We agree that these points are worth thinking about, but are concerned that they are too circumstantial to include in interpreting the results formally.
Although similar decoding performance is achieved using neurons from both CFA and fS1, I am left wondering whether you would do substantially better with CFA using activity at additional preceding time points, or when using exclusively time points from the past. The primary model used here appears to use neural signals from corresponding time points to decode limb parameters, but results seemingly could be different when using preceding time points as regressors.
We appreciate this suggestion and have added the analysis to an additional supplementary panel for Figure 5 (Figure 5S3). Incorporating lags into the decoder via a Wiener filter does indeed improve the decoding performance, but this could simply be due to the increase in the number of predictor variables. This analysis did not, however, further disambiguate M1-fl and S1-fl: the performance improvement was similar across areas for both causal and acausal lag configurations. This could be a consequence of the time resolution of calcium imaging, so further experiments with electrophysiology would be required to rule this possibility out. We now note this new result:
“Including additional causal (-100 ms preceding) and/or acausal (-100 ms preceding to 100 following) lags improved decoding performance modestly and similarly for both areas (Fig. 5S3E-F).”
Related to this, I am also worried about the bleeding of signals across time here. If you deconvolve and interpolate between time points, the interpolation seemingly will pull information into the past, up to half the sampling period, which here is on the order of how long it takes signals to travel to and from the limb. The authors do not make any inappropriate claims about the neural signals here reflecting causes or consequences of what is happening at the limb, but readers (like me) will still try to draw these sorts of conclusions. Is it possible that, although decoding from instantaneous signals is similar for the two regions, the M1 signals are actually motor signals related to future limb state while the S1 signals are sensory consequences? Even if many of the relevant details related to conduction times are not known, perhaps the authors could clarify what can and can't be said related to causal interpretation here.
Thank you for suggesting further explanation here. We agree that our interpretation could be made more specific. We have added text in the Discussion section to speak more directly to what can and cannot be concluded from our analyses. In short, it is hard to be certain of lags in calcium imaging data for many reasons, and using recording methods with finer temporal resolution (like electrophysiology) will be necessary for determining the precise temporal relationships between kinematics and neural activity. In the absence of these recordings, we limit our claim to kinematic information being present in M1-fl and S1-fl neural activity and leave determining the causal role of this information to future work.
New clarifying text in the Discussion:
“The use of calcium imaging further prevents strong conclusions about whether activity reflects future limb states or sensory consequences. Confirming this limitation, inclusion of lagged data in the decoding models, whether causal or acausal, resulted in similar performance changes in both areas.”
An alternative reason why lift onset is less decodable in CFA is that CFA activates substantially before lift onset, as has been observed in previous rodent studies (Kargo and Nitz, 2004; Miri et al., 2017; Veuthey et al., 2020), perhaps as some sort of movement preparation. S1, on the other hand, may not have this early activity, and so may show a clearer transient at onset when the hand and limb start to move. This seems more likely than the explanations provided by the authors.
This is a valid possible alternative explanation and we have updated the Discussion to reflect this. This difference in the structure of M1-fl activity versus S1-fl is apparent in the projections of Figure 6A, which show M1-fl projections more clearly aligned to cue-onset than S1-fl projections.
“Our lift time decoding results are consistent with this view and align with recent observations characterizing mouse proprioceptive forelimb cortex, (Alonso et al 2023), although an alternative explanation may be simply that M1-fl activates earlier than S1-fl during reaching (Kargo and Nitz 2004; Miri et al 2017; Veuthey et al 2020).”
To better clarify relevant similarities and differences between the rodent and primate systems, the Introduction could include some of these similarities and differences exposed by the literature currently cited, and the Discussion could include an additional paragraph specifically relating findings here to previous observations in the primate.
We appreciate the reviewer’s thoughtfulness on possible framings of our results. When writing this paper, framing was a major challenge for us and we drafted quite a few versions of the Introduction including some that focused more on mouse-primate comparison. In the end, we decided the most critical function of the Intro was to set up our central question, of “levels-of-sensorimotor-control”. The rich primate literature was valuable here, but getting into a protracted compare-and-contrast exercise quickly became a distraction from the point. Further, we sought to highlight the relevance and importance of the question answered in our work as the mouse has gained prominence for filling gaps that are challenging to address with primates. This paper serves as one of many early steps towards the ultimate goal of revealing general properties of sensorimotor cortical function with the mouse model. We have made some subtle changes to the Introduction that we hope will more clearly communicate this narrative.
We agree that a Discussion paragraph directly relating our results to those in primates would benefit our conclusions and have added one:
“These results expand our understanding of the rodent sensorimotor system and highlight similarities to nonhuman primates. We show here evidence in mice of detailed joint angle kinematic signals from the full forelimb in M1 and S1, as has been shown in macaque cortex during tasks involving reaching and grasping objects (Vargas-Irwin et al. 2010; Saleh et al. 2010, 2012; Goodman et al. 2019; Okorokova et al. 2020). Additionally, the earlier onset of movement-related activity in M1-fl compared to S1-fl is similar to macaque M1 and S1 (Tanji and Evarts 1976). Taken together these results suggest that the mouse can be employed to address questions traditionally explored in primates about how cortical activity encodes detailed movement commands.”
Although this is outside the scope of the present study, it would be interesting to image descending projection neurons to see what signals are conveyed downstream, and to what targets. Some signals observed in layer 2/3 may not be strongly reflected in descending projections.
We agree that recording from descending projection neurons in this task would be of deep interest – and also agree that these experiments are beyond the scope of the present study. We look forward to performing these additional experiments in future work.
Minor:
(1) The use of "CFA" and “fS1” is a bit confusing. S1, like M1, is defined primarily based on histological criteria, while CFA is defined by intracortical microstimulation. CFA contains a substantial fraction of fS1, seemingly most of it based on the maps shown in Tennant et al., 2011. This is not really a criticism, as the field has not reached any sort of consensus on this nomenclature yet.
We are similarly unhappy with the inconsistency of the terminology in the field, and struggled with how not to make it worse. After much debate and consultation with colleagues, we decided to use “M1” and “S1” to evoke the century of literature on these areas; and “-fl” to indicate forelimb because it is more intuitive than “-ul” and avoids using the illegible “-ll” for hindlimb (relevant to our subsequent paper). For what we called M1-fl, we recorded where we did because anecdotally we saw similar responses across that swath; but note that this definition is also consistent with the definition of “MOp-ul” found with multimodal mapping by
Munoz-Castaneda (2021), which extends a little anteriorly of MOp as defined by the Allen CCF. As the field continues to mature, we hope future work can converge on a set of shared terms.
(2) Page 4: "Inactivations and lesions of M1 and S1 have shown that M1 is required for the execution of dexterous reach-to-grasp movements" - to me, earlier work from Whishaw and colleagues deserves to be cited here.
We appreciate the suggestion and have updated the references in this section to better reflect the prior work from Whishaw and other researchers.
(3) Page 5: "evoking sufficient trial-to-trial variability to avoid model overfitting." - what I think the authors are referring to here is a particular kind of "overfitting," the consequence of not exploring the full movement space, as opposed to model overfitting from issues with the model-fitting method itself. Rather than just saying overfitting, the authors could be clearer about what they are referring to.
The reviewer is right; the phenomenon we intended to refer to is not properly termed overfitting. Specifically, we meant that data with restricted range does not necessarily express global structure, and models can therefore incorrectly fit them. For example, fitting a linear model to data including many periods of a sine wave will correctly show a zero-slope linear component, but fitting to only a portion of a single cycle will typically yield a nonzero slope. This is not overfitting, is not exactly underfitting (because the relevant structure is barely present in the data, as opposed to missed by an insufficiently powerful model), is not bias (the data are fit well), and is not even necessarily a problem (the local relationship may be what you are interested in). Yet, it does not reflect the larger structure of the data.
We do not know of a standard term for this phenomenon, so instead of dragging the reader through this tangential argument, we have tried to offer a simpler motivation for using multiple targets:
“Assessing the relationship between neural activity and the details of movement requires striking a balance between achieving repeatable behavior and evoking sufficient trial-to-trial variability to broadly sample movement space”.
(4) Page 5: Caudal Forelimb Area should not be capitalized.
Obviated with the change in area nomenclature.
(5) Page 7: "of linearly independent degrees of freedom" - for a neuroscience audience, I think it is better to explicitly mention that the resulting PCs are uncorrelated.
We agree that this section could benefit from clarification. We have attempted to provide additional nuance to indicate what the analysis was intended to test.
“Despite the strong coupling between the proximal and distal joint angles, rich variation remained in the action of different joints over time. The presence of strong correlations across joints suggested that the kinematics may be well described by a smaller number of independent degrees of freedom than the total number of recorded angles. To assess the number of linearly independent (uncorrelated) degrees of freedom amongst the 24 joint angles and velocities, we used double-cross-validated PCA (Yu et al. 2009); Methods; Fig. 3D), finding intermediate dimensionalities of 7 (median for joint angles) and 10 (velocities; Fig. 3E). This is consistent with the idea that joint angles across the limb are coordinated instead of controlled independently, and that this coordination is flexible enough over time to enable accurately performing reaching and grasping to different targets.”
(6) Page 7: In the Results, the authors should mention what indicator is being used, the imaging frame rate, and summarize briefly how cells were defined.
Thank you for the suggestion, these details have been added to the relevant results section for clarity.
“To do so, we recorded neural activity from neurons in layer 2/3 M1-fl extending into the immediately adjacent secondary motor cortex (M2), and the forelimb region of S1 (S1-fl) using two-photon calcium imaging of GCaMP6f-expressing neurons in layer 2/3 (185-230 μm deep, imaged at 31 Hz, cells extracted with Suite2p (Pachitariu et al 2017)).”
(7) Page 7: "corrected at n=2" - n doesn't typically refer to the number of tests, so for clarity I would say "corrected for dual tests."
Thank you for pointing this out, we have corrected the text and added additional explanation in the methods for our approach to determining statistical significance across the targets and locking events.
“P-values obtained through the ZETA were then Bonferroni corrected for dual tests when measuring the number of cells modulated to a given event and corrected for six tests (2 targets and 3 events) when measuring the overall number of modulated cells.”
(8) Page 7: In the Results, when the decoding is introduced, it would be helpful to have a few details without having to hunt through the Methods. For example, were things regularized, how was cross-validation handled, etc?
Thank you for the suggestion, these details have been added to the relevant results section for clarity.
A simple linear regression model related the single-trial joint angles at all time points to single-trial neural activity at the corresponding moments. The model was fit with ridge regression, the ridge penalty was determined via a heuristic (Karabatsos 2018), and performance was measured on held-out trials (80/20 train/test split, 50 folds).
(9) Page 8: I think it is worth noting how much mouse reaching involves shoulder rotation as opposed to movement in other joints, as this seems very different from primates.
Thank you for pointing this out. We think this is mostly a task difference: our mice were in a quadrupedal stance, whereas monkeys are typically asked to reach from a sitting position. We now mention this in the Results.
“Reaching evoked particularly large rotation of the shoulder, likely because the mice reached from a quadrupedal position to targets on either side of the snout.”
(10) Page 8: Should provide quantification to clarify what is meant by "closely tracked."
We have updated the text to indicate that this claim was meant to be qualitative, and to more clearly highlight that the interest here is the first demonstration of the ability to reconstruct valid forelimb postures from decoded joint angles in the mouse. Quantifying the reconstruction properly would require substantially more manual data labeling, and the successful decoding itself demonstrates indirectly that the reconstructions are good enough to obtain the results of interest.
Additionally, we reconstructed the skeletal representation of the forelimb from the decoded joint angles and found that, as intended, the reconstructed postures had strong qualitative resemblance to the true postures, even of “minor” angles like cylindrical paw deformation or digit splay (Fig. 5C,G).
(11) Page 8: "Overall, these results suggest that instantaneous movement-related signals are similarly distributed across CFA and fS1." - I know we are being succinct here, but this sentence sounds like a non sequitur in the context of this paragraph - perhaps include a conclusion from the results in this paragraph first, then summarize the whole section.
Thank you for the suggestion, we have updated this text to more clearly conclude the results of this section.
Overall, these results reveal that neural activity in M1-fl and S1-fl is closely related to the kinematic details of reach-to-grasp movements. The ability to decode substantial variance in proximal and distal joints suggests that this relationship extends to the entire forelimb and the similar performance obtained from each area suggests that this information is similarly distributed across M1-fl and S1-fl.
(12) Page 10: Mention of projections from fS1 does not explicitly specify their preferential targeting of the dorsal horn, which seems relevant.
We appreciate the suggestion and have added this detail to the text.
Rodent S1-fl is known to influence interneuron populations in the spinal cord through direct and indirect projections that predominantly target the dorsal horn (Ueno et al. 2018), thus these signals may also reflect S1-fl’s important role in modulating reflex circuits to coordinate sensory feedback with movement generation (Moreno-López et al. 2016; Moreno-Lopez et al. 2021; Seki et al. 2003).
(13) Page 31: Labels on the figure indicating what blue and red stand for would be helpful.
Thank you for the suggestion, labels have been added to indicate left and right trials for Figure 5 C/F and Figure 6A.
(14) Page 32: Legend does not include panel D.
Thank you for catching this, the corresponding caption has been added.
Reviewer #2 (Recommendations for the authors):
(1) The Introduction could perhaps set the central question in starker relief. What specifically do the authors mean by high- vs low-level control? As suggested by the cited studies, this has been a fraught issue in primate work for decades, and I think a finer-grained framing of alternative hypotheses would help set up the results. For example, would better performance at decoding joint angles than paw position be evidence for lower-level control? The clarity of the Introduction might also be improved if the facts and unknowns were broken down by species throughout.
We have tried to further improve the focus of the Introduction on the central question, clarify what we mean, and make clearer in the review of the literature which species a finding comes from.
The clarifying text from the introduction is quoted below:
Extensive motor mapping experiments in rodents have revealed that activating different parts of the sensorimotor cortex evokes movements of different body parts or different kinds of movements of the same body part, as it does in primates (for review, see (Harrison and Murphy 2014)). Yet it is unclear how the topography of stimulation-evoked movements relates to the roles of these areas during volitional actions. Perturbations during behavioral tasks in mice involving forelimb lever or reaching movements have provided a coarse-level understanding of how these areas contribute during behavior. Inactivations and lesions of M1 and S1 have shown that M1 is required for the execution of dexterous reach-to-grasp movements (Guo et al. 2015; Sauerbrei et al. 2020; Galiñanes et al. 2018; Wang et al. 2017; Whishaw et al. 1991; Whishaw 2000) and that S1 is essential for adapting learned movements to external perturbations of a joystick (Mathis et al. 2017). However, spinal cord projections from mouse M1 and S1 primarily target spinal interneurons rather than directly synapsing onto motor neurons (Gu et al. 2017; Ueno et al. 2018; Wang et al. 2017), suggesting cortical activity might play a more modulatory role. Further, stimulation of brainstem nuclei alone can evoke naturalistic forelimb actions, including realistic reaching movements involving coordinated flexion and extension of the proximal and distal limb (Esposito et al. 2014; Ruder et al. 2021; Yang et al. 2023). Taken together, these results have raised the question of what role mouse M1 and S1 play in the control of goal-directed forelimb movements.
One route to answering this question involves characterizing the signals present in mouse M1 and S1 during movement. If mouse M1 and S1 were to control only high-level aspects of forelimb movements, activity should be dominated by ‘abstract’ signals like target location and reflect little trial-to-trial variability in reach kinematics. If instead M1 and S1 control low-level movement features then activity should correlate strongly with forelimb joint angle kinematics and their trial-to-trial variation when reaching to different targets. While the presence of high- or low-level signals in a cortical area does not necessarily imply that they are causally responsible for these aspects of movement, characterizing what signals are present serves as a first step toward determining how these areas relate to movement.
(2) The kinematics and calcium traces appear to be highly stereotyped across trials. If the population encodes joint angles, would one expect to find correlations between the neural and kinematic residuals after subtraction of the time-varying means? Some additional analysis and/or discussion on this point would be helpful, especially as there are only two targets.
This is a great idea. As suggested, we implemented regression models on the residuals for each target in the new Figure 5S3. Figure 5S3 A and B show the performance when decoding the residuals for right trials and C and D show performance for left trials. Decoding remained well above chance, despite shrinking down due to predicting this relatively small within-target variation. This analysis supports our claims from the main regression models in Figure 5 and 5S1-2, and also suggests that movements ipsilateral to the reaching limb (contralateral to the recording hemisphere) may be better encoded than movements contralateral to the reaching limb. We have added a reference to this additional residual analysis in the final paragraph of the decoding section of the Results section:
“Finally, we tested whether the ability to decode these many joint angles was a direct consequence of inter-joint correlations, and might not be indicative of the presence of “real” information about some of these joints. To do so, we fit partial correlation models that removed correlations between proximal and distal joints, or removed correlations of the joint angles with a high-level parameter – the overall distance of the paw centroid to the spout. Despite substantially lowering the behavioral variance, in each case the residuals could still be decoded from neural activity (Fig 5S2A-D). Similar decoding performance for M1-fl and S1-fl was obtained from models fit to decode single-trial residuals separately for left and right trials (Fig 5S3A-D), indicating that trial-to-trial variations on each basic movement were decodable from these populations.”
Along similar lines, binary classification is used to characterize cue-, lift-, and contact-responsive neurons. Is it possible to exploit trial-to-trial variation in the cue-lift and lift-contact latencies to extract the time-varying marginal effects of each event (e.g., using a GLM)?
For the detection of single-cell modulations by different events, we have elected to retain our simple statistical test to determine modulation; in our experience, encoding models typically involve a surprising number of steps to get them to do what you actually intend. We leave more extensive encoding model-style analysis to future work, currently in progress.
(3) The authors mention prior studies suggesting that the control of some forelimb tasks can be gradually transferred from the cortex to the subcortical centers. Have they performed the inactivation at different time points across learning, and if so, do they have evidence for a diminishing effect over time (e.g., blocking of both initiation and coordination early in training)? In addition, the effects of motor cortex inactivation are similar to, but slightly different from, effects shown in reaching tasks in prior studies. Some additional discussion on this point would be useful.
Our inactivation experiments in this study were intended to coarsely demonstrate the involvement of mouse forelimb sensorimotor cortex in our task. We have not performed the inactivations over learning and leave such experiments to future work.
We agree that a little more clarity relating our results to previous ones was warranted. Previous studies (Guo et al. 2015 and Galinanes et al. 2018) have demonstrated inactivation impacts on similar tasks, but for thoroughness we sought to show the same for our task as it varied from the pellet and motorized water spout tasks in both training time and target configurations. Our results are strongly in line with those of Galinanes et al. 2018 which used a fairly similar water spout target configuration. In the inactivation experiments of that paper, 3 out of 13 animals with initiation-triggered inactivations were able to initiate reaching within a time window similar to control trials. Additionally, a proportion of trials across multiple mice proceeded with little perturbation from the inactivations. This is consistent with our observation that M1-fl inactivations may either abolish movement initiation or allow movement initiation but impair task completion on a trial-by-trial and animal-to-animal basis. Further work is required to determine what factors influence these differential responses to inactivation and to determine how these effects differ across task variations (i.e., pellet vs water spout). We have added a brief description of these nuances to the text for clarity.
“These inactivations blocked the execution of the reach to grasp sequence, preventing the animal from making contact with the spout during the 3-second laser stimulation period (Fig. 1F; 86.5% control trials with contact within 3 seconds of cue, 5.1% inactivation trials with contact, P < 10<sup>-191</sup>, Mann-Whitney U test, 2 mice, 495 stimulation trials). Interestingly, inactivation at the time of cue often did not prevent reach initiation (mouse 1: 54.7%, mouse 2: 34.2% of inactivation trials with lift within 3 seconds; 93.5%, 86.2% control trials). Yet the movement stalled once the paw and digits extended towards the spout, producing uncoordinated and unsuccessful reaching trajectories (Fig. 1I, two representative datasets). Taken together, these results support the involvement of M1-fl in the water-reaching task and suggest that the strength of inactivation effects may depend on specific task details like training time or target configuration (c.f. Galinanes et al. 2018).”
Minor points
(1) The rationale for the multiple comparisons procedure in identifying event-locked responses should be explained in more detail. If I understand correctly, the authors are not correcting for comparisons across ROIs, but instead control the family-wise error rate across brain regions and event types (dividing alpha by two or six). Why not instead control the false discovery rate across ROIs?
Thank you for pointing this out, it was confusing as written and we received a similar comment from Reviewer 1. We have fixed the wording now to make it clearer why we did this. We simply aimed to describe how many of the recorded neurons in each area were modulated by the task as a proxy for the engagement of these areas during the behavior, and to use this measure of modulation as a criterion for including the neuron in subsequent analysis. In other words, if the question had been “are any neurons in this area modulated by the task?” then correcting for the number of ROIs would be the correct method; but if the question is, “is this neuron probably modulated and therefore worth including in my decoder?” correcting for the number of ROIs will typically be much too conservative. Thus, we only sought to correct for the false discovery rate across events and targets for each ROI. We have added additional text in the methods to clarify these choices, below. Please also see response to (7) from Reviewer 1 above.
“Note that we did not correct for the number of ROIs tested for two reasons. First, the goal of this testing was to serve as a criterion for inclusion in subsequent decoding analyses, not to determine whether any neurons in the area at all were modulated; and second, correcting for the number of ROIs would bias comparison between areas if different numbers of ROIs were recorded in one area vs. the other.”
(2) It appears joint angles are treated as linear variables in the decoding analysis; is this correct? This seems reasonable as long as the range of motion is not too large, but the authors might briefly comment on the issue in the Methods.
Yes, all joint angles are treated as linear variables in the linear regression model. We observed empirically (as can be seen in Figure 3B and Figure 5B/F) that the joint angle variables were relatively constrained to specific ranges during the task, with no angles displaying substantial wrap-around during the reaching and grasping movements. It is true that use of nonlinear decoding would almost surely improve performance further. Future work could also compare decoding of joint angles with muscle forces, which correlate and which we made no effort to distinguish here. In this work, though, the demonstration of a substantial relationship between neural activity and kinematics already tells us that fine details of movement are present in the M1 and S1-fl populations, which is a critical fact to understand these areas and was not previously known. We now comment explicitly on this, as suggested.
“Joint angle or velocity kinematics were linearly interpolated from their original 6.66 ms to 10 ms and smoothed with a Gaussian (15 ms s.d.). These angular variables were then treated linearly in decoding analyses as their ranges were relatively constrained during the reaching and grasping movements; although the true relationships are likely nonlinear, this serves as a sufficient approximation to demonstrate the presence of a relationship between neural activity and kinematics.”
(3) Are the limb pose estimates mirrored along the mediolateral axis? Figures 1C and 2D appear to show reaches to the left spout on the animal's right.
Thank you for pointing out the ambiguity in the display of these data. The reach trajectories were not mirrored along the mediolateral axis, but they are displayed from the perspective of the behavioral imaging cameras as shown in Figure 1A. Thus the right target reaches (ipsilateral to the animal’s reaching arm) are on the left side of the camera image and the left target reaches (contralateral to the animal’s reaching arm) are on the right side of the image. We have clarified this in the figure captions.
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1:
SOM+ interneurons such as Martinotti cells target the apical tufts of pyramidals in the cortex. Since interneurons in general are strongly implicated in mediating rhythmic population activity over a range of timescales, it is quite appropriate to study the consequence of rhythmic inhibition provided by SOM+ interneurons for synaptic integration, including the phenomenon of dendritic spikes. However, using conclusions from a singular study (ref 22) to identify the beta band as the rhythm mediated by SOM+ is not very accurate. SOM+ interneurons have been implicated in regulating rhythms centered just below 30 Hz (refs 22, 21). It is a range that lies in the grey zone of the traditional definition of beta and gamma. However, it is significantly higher than the 16 Hz rhythms explored in this study. It thus remains unknown how a 25-30 Hz rhythmic inhibition (that has an experimentally suggested role for dendrite targeting SOM+ INs) in apical tufts regulates dendritic spikes.
We agree with the reviewer that the rhythms arising from SOM+ interneurons can extend their frequencies higher than the 16 Hz analyzed in this study. To address this, we have conducted a new set of simulations where we delivered distal dendritic inhibition across a range of frequencies, from 0.5 to 80 Hz (see new Results section “Frequency specific effects of rhythmic inhibition on neuronal integration”). These results revealed, surprisingly, that at 30 Hz their ability to entrain Ca<sup>2+</sup> and NMDA spikes degrades (but not Na<sup>+</sup> spikes). This suggests that beta rhythms in the 20-30 Hz range are operating at the highest frequency for which dendritically targeting inhibition will be effective. The implications are covered in the Discussion section “Interaction with microcircuitry”. They are:
“Particularly in the visual cortex, SOM interneurons can generate a rhythm in the 25-30 Hz range [22]. We found this to be at the upper end of the frequency range for dendritic inhibitory rhythms to be effective in modulating NMDA and Ca<sup>2+</sup> spikes. If this rhythm solely recruited SOM interneurons, its effectiveness would be marginal. Potentially compensating for this, recent work has found that PV interneurons also participate in beta/low-gamma [23, 24] (but see [21, 22]). In our model, on its own when beta rhythmic inhibition was delivered perisomatically we found that it was less able to entrain spiking and had an overall hyperpolarizing effect. However, if delivered in conjunction with the distal dendritic inhibition arising from SOM interneurons, this may strengthen entrainment.”
Distal dendritic inhibition has been previously shown to be more effective in controlling dendritic spikes. However, given the slow timescale of dendritic spikes, it can be hypothesized that high-frequency rhythmic inhibition would be ineffective in entraining the dendritic spikes either in distal or proximal location, as demonstrated by 4H and 5F, and vice versa. A computational study can take this further by exploring the robustness of this hypothesis. By sticking to a single-frequency definition of what constitutes Gamma (64 Hz) and Beta (16 Hz) inhibition, the current exploration does support the core hypothesis. However, given the temporal dynamics of dendritic spikes, it is valuable to learn, for example, the upper bound of "Beta" range (13-30Hz) inhibition that fails to phasically modulate them. In addition to the reason stated in the earlier paragraph, Alpha band activity (8-12 Hz), has been implicated (e.g. van Kerkoerle, 2014) in signaling of inter-areal feedback to the superficial layer in the cortex, potentially targeting apical tufts of pyramidals from multiple layers and resulting in alpha-range rhythmic inhibition. To make the findings significant, it might therefore be more pertinent to understand the consequences of ~10Hz rhythmic inhibition (in addition to the ~25-30 Hz Beta/Gamma) in the apical tufts for phasic modulation of dendritic spikes.
We added an additional set of simulations that address this in the Results section ‘Frequency specific effects of rhythmic inhibition on neuronal integration’. In general, we found that dendritic and perisomatic inhibitory rhythms at lower frequencies could entrain AP generation, but with less functional specialization. This is explored in our Discussion section ‘Interneuron specializations and rhythm timescales’.
The differential effect of Gamma and Beta range inhibition on basal and apical excitatory clusters is not convincing from the information provided. The basal cluster appears to overlap with perisomatic inhibitory synapses. The description in the methods does not have enough information to negate the visual perception (ln 979-81). With this understanding, it is not surprising that the correlation between excitation and APs is high (during the trough of gamma) for basal and not apical excitation. A more comparable scenario would be a more distal location of the basal excitatory cluster.
While we stated in the original manuscript that we were contrasting ‘basal’ vs. ‘apical’ clustered inputs, this terminology did not reflect our intent with these analyses. We meant to contrast proximal vs. distal dendritic clustered synaptic inputs, which the reviewer correctly noted is confounded in the apical vs. basal comparison. We have rewritten these results, their discussion, and corresponding figure, to clearly state that we are contrasting proximal vs. distal synaptic input.
Reviewer #2:
The weaknesses are probably in some of the parameterizations of inhibitory synaptic dynamics. A unitary peak conductance of 1nS is very high for inhibitory synapses. This high value could invariably skew some of the network-level predictions. The authors could obtain specific parameters from the Neocortical Collaboration Portal (https://bbp.epfl.ch/nmcportal/microcircuit.html), which is an incredible resource for cortical neurons and synapses.
We appreciate the valuable resource mentioned by the reviewer and will consult it when constructing future models. Regarding the present one, our choice of peak conductance was based on previous studies, namely:
Egger R, Narayanan RT, Guest JM, Bast A, Udvary D, Messore LF, Das S, de Kock CPJ, Oberlaender M (2020) Cortical output is gated by horizontally projecting neurons in the deep layers. Neuron 105, 122-137.e128.
and
Xiang Z, Huguenard JR, Prince DA (2002) Synaptic inhibition of pyramidal cells evoked by different interneuronal subtypes in layer v of rat visual cortex. J Neurophysiol 88, 740-750.
The study by Egger et al. used an inhibitory peak conductance of 1 nS and was simulating circuitry very similar to ours. We validated these synapses in pilot simulations that sought to characterize the resulting IPSPs and IPSCs, and whose results can be seen in Table 1 of our methods. These synapses exhibited IPSCs whose peak amplitudes ranged over values (~24162 pA) that agreed with the experimental literature, such as Xiang et al.
Given this, we feel our parameterization of inhibitory synapses does not warrant any changes.
Reviewer #3:
What disappointed me a bit was the lack of a concise summary of what we learned beyond the fact that beta and gamma act differently on dendritic integration. The individual paragraphs of the discussion often are 80% summary of existing theories and only a single vague statement about how the results in this study relate. I think a summarizing schematic or similar would help immensely.
We agree with the reviewer that a summary schematic would help the reader. This has been added to the manuscript as Figure 11. It demonstrates the principal findings of the paper and is referenced in the opening paragraph of the discussion section.
Orthogonal to that, there were some points where the authors could have offered more depth on specific features. For example, the authors summarized that their "results suggest that the timescales of these rhythms align with the specialized impacts of SOM and PV interneurons on neuronal integration". Here they could go deeper and try to explain why SOM impact is specialized at slower time scales. (I think their results provide enough for a speculative outlook.)
This discussion has been expanded under the section “Interneuron specializations and rhythm timescales”. The added text is:
“So, while our results suggest that spatial targeting of SOM and PV interneurons aligns with the timescales of their network-level rhythms, it could also be that their timing and subcellular localization interact to produce specialized neuron-level functions [85]. For instance, NMDA and Ca<sup>2+</sup> spikes in the distal dendrites last for ~50 ms, making the slower beta rhythm more appropriate for bidirectionally controlling them. Both can be described as dynamical systems with distinct phases with differing sensitivity to inhibition. Ca<sup>2+</sup> spikes are dynamical events comprised of an initiation, plateau, and termination phase. Inhibition delivered during the plateau phase shortens their duration [86]. If the beta rhythm is comprised of cycling between periods of elevated excitation (increased NMDA spike generation) followed by elevated inhibition, then Ca<sup>2+</sup> spike initiation will tend to occur during the excitatory phase, and its plateau during the subsequent inhibitory phase. A plateau during the inhibitory phase will more quickly enter termination. This is bidirectional control. On the other hand, slower rhythms (e.g. 1 Hz) initiate Ca<sup>2+</sup> spikes during the excitatory phase that plateau and enter termination autonomously, before the inhibitory phase is reached. The same principle holds for NMDA spikes [87]. As a result, rhythms in the range from 15-30 Hz are optimal for synchronizing the onsets and offsets of dendritic spikes across a population of neurons.
The integrative effects of gamma (>40 Hz) are also specialized. Low frequency inhibitory rhythms delivered to the soma tended to shift the membrane potential higher or lower with the rhythm’s phase, effectively bringing it closer or farther from AP generation but not changing the neuron’s sensitivity to fast synaptic inputs. In the gamma frequency range, this is reversed, with the mean membrane potential not varying with rhythm phase but with a shifting bias to positive or negative membrane potential fluctuations. In addition, the trough phase of gamma lowers the threshold for AP generation, while slower rhythms like beta only raise the threshold. Consequently, the timing of gamma is ideal for increasing the sensitivity of the neuron to rapid excitation. This agrees with the observation that gamma oscillations accompany rapid excitation-inhibition balancing [88].”
We also extended our discussion section ‘Relevance to coding’ to explore how beta and gamma rhythms can support sparse vs. dense population coding, respectively. It reads:
“One interpretation of rhythms arising from local inhibitory feedback is that they maintain the balance between excitation and inhibition. This can be thought of as a normalization operation that maintains activity within a set range. Normalization can be achieved either through a subtractive effect that raises the threshold for initiating an action potential, or a multiplicative effect that lowers the slope of the relationship between excitation and action potential firing rate. When considered at the population level, these normalization effects impact coding in different ways. Subtractive normalization increases sparsity by dropping out neurons whose excitation is below the raised threshold. Multiplicative normalization, however, encourages dense codes by scaling down firing rates and compressing the range of firing rates. This study found that while both perisomatic and distal dendritic inhibition produced subtractive effects, only perisomatic had a multiplicative effect. Tying this to beta and gamma, beta rhythms may encourage sparse population codes while gamma allows for dense.”
Beyond that, the authors invite the community to reappraise the role of gamma and beta in coding. This idea seems to be hindered by the fact that I cannot find a mention of a release of the model used in this work. The base pyramidal cell model is of course available from the original study, but it would be helpful for follow-up work to release the complete setup including excitatory and inhibitory synapses and their activation in the different simulation paradigms used. As well as code related to that.
We have added a Code and Data Availability section that addresses this. It reads: “Simulation code is deposited at ModelDB athttps://modeldb.science/2019883 . The raw simulation data are available from DBH upon request. Analysis code is posted as a github repo at https://github.com/dbheadley/InhibOnDendComp.”
A felületen lehetőség van megtekinteni, illetve jogosultságtól függően beállítani az értékékészleteket.
Változott már az értékkészlet. Bővült az alábbiakkal: 31D2 Regulatory report code- 31D2 jelentés szerinti besorolás<br /> Security subtpye - Értékpapír altípus Security Fund type - Értékpapír alap típusa ( Befektetési alap)
EXAMPLE FIELDS CUSTOM VALUES
EZt töröljük. Helyette kellene : External Codes Custom values Code - Kód Alternative code (Kötelező mező) - Altermatív kód<br /> Code at Subcustodian - Alletétkezelői kód ( Pl. Keler kód) C2 ID - C2 ID (külső rendszer azonosító)
További Custom values (egyedi adatok) a Custom tábla szerint egyedileg meghatározott érkékek szerint.
Ide még írjuk bele szerintem: CFI code - Kötjel miatt kell ez a kód ( KELER - kibocsátáskor ép.-hez tartozó kód) - Liquid jelölőnégyzetet - Likvid értékpapírok jelölése 78/2014. (III. 14.) Korm. rendelet 31D2 Regulatory Report code -ot - MNB 31D2 és MNB 30LA kötelező jelentéshez szükséges
Most programming languages also allow “comments,” which are pieces of code that the computer will ignore. These comments allow the person writing the code to leave a note to future people reading the code, knowing that the computer won’t read it (like an aside in a play).
Especially with the collective knowledge that is made accessible through the Internet, the ability to efficiently add and remove comments seems important for the human aspect of programming languages. Particularly in cases when the code tries to incorporate even more complicated directions.
Fő adatok csoport
Ami nekem innen még hiányzik Margó az egy tábla az External codes custom values- Külső azonosítók egyedi adatok- Ez felületen az ALAPADAT EGYEDI ADATOK alatt van, ide kéne ez a táblázat : C2 ID - C2 ID SAP ID - SAP ID Alternatív code - Alternatív kód TEÁOR code - TEÁOR szám KSH Number - KSH Azonosító Symbols code - Symbols szám SAP code - SAP vevőkód Kondor code - KONDOR kód ( Kereskedési rendszer) Registration number - Lajstrom szám EIH code - EIH azonosító
Beneficiary client code
Kedvezményezett ügyfélkód
Asset Manager Client Code Alapkezelő ügyfélkód
Felületen ez nem látszik , vegyük le
Beneficiary Client Code Kedvezményezett ügyfélkód
vegyük le
Non managed jelölőnégyzet Custom values Egyedi adatok Online open Online nyílt jelölőnégyzet Account Name Számla neve Orig Open Date Eredeti szerződés dátuma Activation date Aktiválási dátum Inheritor's new account opening Új számlanyitás örökösként jelölőnégyzet Host branch code Ügyfél számla fiók Opened Base Constract Id Megnyitott alapszerződés azonosítója
Töröljük ezt az egészet
Foreign Tax Identifying Number Külföldi adószám Tax ID. Code for Foreign people Külföldiek adóazonosító jele Tax Number Country Külföldi adószám országa
Töröljük ki ezeket
Country of Tax Identification Code Adóazonosító jel országa Date of ben. ownership decl. Tényleges tulajdonosi nyilatkozat dátum
Töröljük ki ezeket
I switched from VSCode to Zed
[tool.pyright] section in pyproject.toml effectively force Basedpyright’s recommended mode.typeCheckingMode in Zed’s settings.json did not help; the fix was explicitly setting typeCheckingMode = "standard" inside each project’s [tool.pyright] config."disablePullDiagnostics": true in Zed’s Basedpyright initialization options.ty language server, found it good, but stayed with Basedpyright to match CI’s Pyright.settings.json showcasing autosave, disabled inline blame, VSCode keymap, fonts, light theme, and customized Basedpyright LSP options.Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
We thank the Reviewers for their positive assessment of the quality and significance of our work, as well as for their insightful comments, which have helped us to further improve the manuscript. We have addressed the majority of the comments in the revised version and, for those that require additional time, we outline below a detailed plan of the experiments we intend to perform.
We agree with Reviewer #2 that a more detailed mechanistic understanding of the drug effects would further strengthen the study, and we are grateful to both reviewers for the constructive experimental suggestions provided to address this point. In particular, we are highly motivated to better define the causal role of C18 sphingolipid alterations in mediating the effects of the drugs, as suggested by Reviewer #2, as well as to investigate the involvement of the retromer complex in the lysosome-to-Golgi connection, as suggested by Reviewer #1.
Below, we provide a point-by-point description of the revisions already incorporated into the manuscript, along with the planned experiments that will address the remaining comments
REVIEWER #1:
VPS13B is a bridge-like lipid transfer protein, the loss or mutation of which is associated with Cohen syndrome (CS) involving Golgi fragmentation. In this study, the authors performed image-based chemical screens to identify compounds capable of rescuing the Golgi morphology in VPS13B-KO HeLa cells. They identified 50 compounds, the majority of which are lysosomotropic compounds or cationic amphiphilic drugs (CADs). Treatment of cells with several of these compounds causes lysosomal lipid storage, as assessed by BMP/LBPA staining, filipin staining, or LipidTOX staining. Interestingly, most LipidTOX puncta colocalized with transferrin receptor-positive compartments but not lysosomes. Similar to lysosomotropic compounds, knocking down NPC1 or SMPD1, mimicking lysosomal storage disease, also substantially rescued Golgi morphology. The authors show that VPS13B-KO cells have reduced C18 sphingolipids, which is reversed by treatment with CADs. Finally, the authors show that two CADs partially rescue neurite outgrowth in neuronal cultures. However, these drugs do not rescue the size of VPS13B KO organoids.
Overall, this is an impressive study identifying CADs as potential therapeutics for CS and suggesting sphingolipid upregulation as a general strategy for CS treatment. The morphological and lipidomics analyses unravel important molecular basis of CS pathology. This study will be of high interest to the field of lipid biology and organelle homeostasis. I have a few comments to help improve the quality of this study.
- The reverse of lipid changes in VPS13B-KO cells by CADs is intriguing. Are CAD-mediated benefits such as Golgi morphology recovery permanent or only transient within 24 hours of treatment? How do the CADs affect the Golgi morphology in WT HeLa cells?
RESPONSE:
We thank the reviewer for this insightful question Indeed, the effects of CADs on Golgi organization are most evident in VPS13B KO cells, where the Golgi apparatus is severely fragmented and becomes more compact upon drug treatment, whereas the effect is much less apparent in wild-type cells. Nevertheless, a careful quantitative analysis of the images (now presented in the new Fig. S7) demonstrates that the impact of these compounds on Golgi morphology is not restricted to KO cells but is likely more general, supporting a link between lysosomal storage and Golgi organization. Although this observation indicates an indirect effect (consistent with the proposed mechanism of action), rather than a direct correction of VPS13B loss, it does not compromise in our opinion their potential beneficial effect for KO cells as shown also from the results obtained in organoid-derived neurons.
Under continuous treatment, azelastine keeps the Golgi in a compact state for 72 hours without any noticeable deleterious effect on the cells (see new Fig. S10) Raloxifene, on the contrary proved to be toxic over the same time period. We believe this difference reflects the mechanism of action of CADs, which progressively accumulate within acidic organelles and may eventually reach a toxic threshold upon prolonged exposure. For this reason, lower drug concentrations administered over longer treatment periods may represent a viable alternative strategy. In this regard, we also refer the reviewer to our response to the comment on brain organoids below.
- Is it surprising that Azelastine-induced lipid storage in transferrin receptor compartments (early and recycling endosomes)? I suggest more controls to examine LipidTOX overlap with Golgi markers or other late endosome/lysosome markers such as LBPA and CD63.
RESPONSE:
We agree with the reviewer that this observation is somewhat unexpected. However, we would like to clarify that we do not intend to suggest that lipid storage occurs primarily in early or recycling endosomes, which would indeed contradict a substantial body of existing evidence. Rather, our data indicate that this particular dye (LipidTOX) labels recycling endosomes, at least in HeLa cells. This finding is consistent with the widely accepted view that lysosomal lipid storage exerts broader effects on intracellular trafficking, not limited to late endosomes/lysosomes. We corrected the text in order to clarify this concept.
LipidTOX was specifically developed to detect drug-induced phospholipidosis, and based on our data, it appears suitable for this purpose. To our knowledge, there is no published information detailing its intracellular localization, which motivated us to perform these control experiments. Unfortunately, the proprietary formulation of this product does not allow informed speculations to explain the observed localization or whether this could refer to the intact molecule or to a catabolite.
As suggested by the reviewer, we plan to perform co-staining with additional markers to further clarify this this point.
- Does the LipidTOX/TFRC overlap suggest potential roles of retrograde transport in supplying sphingolipids to the Golgi? The authors can quickly test if the knockdown of a retromer subunit (VPS35) blocks Azelastine-induced recovery of Golgi morphology.
RESPONSE:
We thank the reviewer for this insightful suggestion. Indeed, the retromer complex represents one of the best-characterized trafficking pathways from the endosomal system to the Golgi, and this relatively straightforward experiment could help to mechanistically clarify our observations. We plan to test whether VPS35 knockdown interferes with the effects of the drugs.
What is the rationale to use 500 nM to 1 uM azelastine and raloxifene for neuronal cultures and organoids? At such concentrations, no obvious changes in Golgi morphology or lipid storage were observed (Fig 4). Also, the lipidomics analysis was performed after 10 uM compound treatment. It might be worth trying dose-response experiments in organoid tests.
RESPONSE:
We thank the reviewer for this question. The rationale about this choice was indeed missing from our previous version of the manuscript. The reason of lowering the concentrations comes indeed from toxicity tests, preliminarily performed over long-term treatment of both WT and VPS13B KO organoids. This information has now been explicitly included in the Results section of the revised manuscript, and the broader implications are also discussed in the Discussion section.
MINOR COMMENTS:
It is important to know whether the authors used TGN or cis-Golgi markers for Golgi morphology analysis. Please label the two channels in Fig. 2C and throughout all figures. In many cases, it is not clear what is stained in the green channel to show the Golgi morphology. It was not even stated in the legend.
RESPONSE:
We now included the antibody staining in all figure legends where it was previously missing.
The authors stated that Recovery of Golgi morphology is dependent on lysosomal lipid storage. However, while the data show positive correlation between the two, no causal relationship is established by the data. It seems true that in all conditions (CADs or genetic knockdown) where lysosomal lipid storage was observed, the authors detect the Recovery of Golgi morphology. However, budesonide did not depend on lysosomal lipid storage to recover the Golgi morphology. Thus, the recovery of Golgi morphology is NOT dependent on lysosomal lipid storage, but inducing lysosomal lipid storage appears sufficient to recover Golgi morphology in VPS13B-KO HeLa cells.
RESPONSE:
We thank the reviewer for this comment and we agree that the previous title of the paragraph could have been misleading. This has been now changed in: “Lysosomal lipid storage mediates the recovery of Golgi morphology” which is probably less prone to ambiguous interpretations.
Obviously, in the previous version of the title we wanted to mean that Golgi recovery is dependent on lipid storage “in the context of CAD treatment” and not as a general statement.
With respect to the cause–effect relationship, we believe that the strongest evidence supporting this link is the observation that genetically induced lipid storage phenocopies the effects of drug treatment. We hope that this conclusion is now sufficiently clear from the revised text.
Each figure needs a title before the detailed legends for specific panels.
RESPONSE:
Titles have now been included to all figure legends.
Fig 8. Y axis labeling is missing.
RESPONSE:
Axes labels have now been included
Does U18666A rescues Golgi morphology in VPS13B-KO cells?
RESPONSE:
We thank the reviewer for this comment. U18666A indeed also corrects Golgi morphology. The result is now included in the new figure S5.
Please do not repeat the result section in discussion. Focus on the most important points.
RESPONSE:
We thank the reviewer for this comment. We shortened the descriptive part of the discussion trying as much as possible to avoid repetitions with the result session and keeping only the more essential information for the flow of the discussion.
Reviewer #1 (Significance (Required)):
This is an impressive study that identifies Cationic Amphiphilic Drugs (CADs) as potential therapeutics for Cohen syndrome (CS) and suggests sphingolipid upregulation as a general strategy for diseases driven by VPS13B loss-of-function. The unbiased approaches, notably the chemical screen and lipidomics, provide novel mechanistic insights into the underlying pathology of CS. This study will be of high interest to researchers in the fields of lipid biology and organelle homeostasis. It will also be highly valuable for clinical pediatricians managing CS patients.
REVIEWER #2:
This manuscript describes a compound screening aimed at identifying molecules that can restore Golgi organization in VPS13B knockout (KO) cells. The authors identify several compounds, most of which are lysosomotropic, and analyze their effects on Golgi morphology and lipid composition using multiple approaches. They report that VPS13B KO cells exhibit a reduction in C18-N-acyl sphingolipids, which can be restored by several of the identified compounds. Furthermore, two of these compounds, azelastine and raloxifene, promote neurite outgrowth in VPS13B KO cortical organoids. These findings are interesting and could potentially contribute to a better understanding of the pathophysiology of Cohen syndrome and the development of therapeutic strategies. However, despite the large number of analyses presented, the study remains largely descriptive, and there is no coherent mechanistic explanation for how these compounds restore Golgi structure in VPS13B KO cells. In addition to the reduction in C18-N-acyl sphingolipids, the KO cells display alterations in several other lipid species (LPC, LPE, PC40:1, PE42:1, TG, etc.), and treatment with the selected compounds induces further lipid accumulations, including cholesterol and BMP/LBPA. The relationship between these diverse lipid changes and the observed Golgi recovery lacks clarity and mechanistic consistency.
MAJOR COMMENTS:
The finding that compounds cannot prevent Golgi fragmentation caused by brefeldin A or nocodazole but can suppress statin-induced fragmentation is intriguing, but the underlying mechanism is not addressed. It is not evident whether this difference results from changes in membrane lipid composition or restoration of Rab/SNARE trafficking. The authors should examine Rab prenylation and SNARE localization by immunofluorescence or Western blotting to support their interpretation.
RESPONSE:
We thank the reviewer for this suggestion and agree that the ability of these compounds to counteract statin-induced Golgi fragmentation is indeed intriguing. The primary reason we did not further explore this aspect is that we evaluated the effects of statins not to be a central focus of the present study. Nevertheless, we fully agree that this observation represents a valuable opportunity to gain additional insight into the mechanism underlying drug-induced Golgi recovery.
To address this point, we plan to analyze Rab prenylation by Western blot and Rab localization by microscopy, focusing on a Golgi-associated Rab protein such as Rab6. In addition, we will employ downstream inhibitors of Rab prenylation, such as 3-PEHPC (an inhibitor of type II protein geranylgeranyltransferase (GGTase-II)), which should allow us to formally distinguish effects related to impaired Rab prenylation from those arising from inhibition of cholesterol biosynthesis.
Although restoration of C18 sphingolipids (SM 36:1, CER 36:1) is observed upon compound treatment, its causal role in Golgi recovery or neurite outgrowth is not established. The authors should test whether blocking the increase of C18 SM/CER prevents the rescue of Golgi or neuronal phenotypes.
RESPONSE:
We sincerely thank the reviewer for this comment. We agree that, based on the current data, a definitive cause–effect relationship between Golgi recovery and the increase in C18 sphingolipids cannot be firmly established, and we acknowledge that a deeper understanding of this issue will require further investigation. Furthermore, we believe that addressing this would not only provide a better mechanistic understanding of the biological processes behind the effect of the drugs but provide a potential avenue for therapeutic intervention. For these reasons, we are strongly motivated to pursue this aspect further.
With respect to the reviewer’s specific suggestion, we agree that preventing the increase in C18 sphingolipids would be an ideal experimental approach. However, the limited understanding of the regulatory mechanisms controlling C18 sphingolipid homeostasis currently precludes a fully informed strategy. In principle, if the observed increase were due to enhanced synthesis, one could envisage blocking it by silencing ceramide synthases with C18 selectivity, such as CERS1. The experiment shown in Fig. 7E (azelastine treatment in the presence of sphingolipid synthesis inhibitors) was designed with this rationale in mind. However, these results suggest that azelastine-induced C18 sphingolipid accumulation is unlikely to result from increased synthesis, and is instead more consistent with reduced degradation, in line with the proposed mechanism of action of CADs.
Based on these considerations, we propose to invert the experimental approach and test whether cellular re-complementation with C18 sphingolipids is sufficient to recapitulate the drug-induced Golgi recovery. We are aware of the technical challenges associated with the targeted delivery of exogenously supplied lipids, particularly given the likelihood that effective rescue would require lipid access to the Golgi apparatus. Based on current knowledge, we anticipate that externally supplied lipids would primarily traffic either to the ER via non-vesicular routes or to endosomes/lysosomes through endocytic uptake. From both locations they could eventually reach to some extent the Golgi. The route from endosomes to Golgi in particular as been intensively studied in the past with the use of fluorescent sphingolipid analogs1,2 and may well work also with native lipids.
Since we are not able to predict in advance which lipid species would be more effective or the optimal delivery strategy, we plan to test re-complementation using C18 sphingomyelin and some of its potential precursors, including C18 ceramide as well as using alternative delivery strategies such as incorporation in liposomes of different formulations and delivery at the plasma membrane with bovine serum albumin or cyclodextrins as carriers.
In Figure 7D, comparisons should include the LM and HM fractions isolated from WT cells.
RESPONSE:
Wild-type control were included in the figure as requested.
The subcellular fractionation experiment should be repeated using AZL and RAL, the compounds used in organoid experiments, rather than TFPZ, to assess whether similar results are obtained. The compounds used differ across experiments, making it difficult to draw consistent conclusions.
RESPONSE:
We thank the reviewer for this comment and apology for some inconsistencies in the selection of the compounds to highlight in the figures which are mostly remnants of the drug prioritization history over the progression of the project. We tried to make it more consistent in the current version.
In the new version of figure 7D, AZL is substituting TFPZ, while TFPZ data were moved to supplementary figure S19.
Golgi morphology in VPS13B KO cells is reported to recover in NPC1 KD and SMPD1 KD cells, but it is not shown whether SM 36:1, CER 36:1, or other lipid levels also increase or change in these conditions. If Golgi morphology recovery occurs via the same mechanism as with compound treatment, a similar lipid pattern should be observed.
RESPONSE:
We thank the reviewer for this question that allowed us to expand our study including new interesting findings. We agree that this is an important point to strengthen the link between CAD and genetic perturbation effects. Given the availability of several published lipidomic datasets modelling LDS in HeLa and in other cell lines, we decided to perform a re-analysis of those to specifically focus on C18 sphingolipids. We found a relative increase of 36:1 upon depletion of LSD genes in all analyzed datasets for NPC1 and SMPD1, but also for more than 15 other LSD genes including NPC2, recapitulating what we find with all the CAD molecules tested in our study. These changes, were not noticed or at least not discussed by most of the authors. This is not surprising since those studies are focused on different biological questions. We believe that these findings, besides reinforcing our hypothesis of a common mechanism between CAD and NPC1/SMPD1 KO, have of general interest for the regulation of C18 sphingolipids, which are among the relative few lipid species with a bona fide specific protein binding partner and proposed to play a crucial role in Golgi traffic.
MINOR POINTS:
The manuscript lacks sufficient information about the compound library used for screening (number and source of compounds, compound type).
RESPONSE:
We apologize if this information was not sufficiently visible in the original version of the manuscript. The data about source, catalog number, formulation and several additional identifiers is included in the File S1. This is now clearly indicated in the methods so that I can be more easily visible to the readers
Fig. 3A: a WT control image is required.
RESPONSE:
A WT control image is now included in the new version of Figure 3.
Fig. 4: include representative images at concentrations higher than 1.25 µM.
RESPONSE:
Representative images are now included for all concentrations higher than 1.25 µM, as requested.
Abbreviations such as BMP/LBPA should be defined when first mentioned.
RESPONSE:
The abbreviation of BMP/LBPA was already defined when first mentioned in the original version of the manuscript
The abbreviation for raloxifene is inconsistent (RLX vs RAL) and should be unified.
RESPONSE:
Raloxifene is now abbreviated as RLX all over the manuscript.
Fig. 5C: the meaning of the green and magenta bars is not explained.
RESPONSE:
Color code for figure 5C has been included.
The definitions and centrifugation parameters for light and heavy membrane fractions should be clearly stated in the Methods.
RESPONSE:
The centrifugation parameters were already defined in the original manuscript. It is not clear to us, which parameter the Referee is referring to. Below is the sentence in the methods section:
“Gradients were centrifuged at 165,000 g for 1.5 h at 4°C with a SW40Ti Swinging-Bucket rotor (Beckman-Coulter). The LM and HM fractions were collected at the 35%-HB and 35%-40.6% interfaces, respectively”
The concentration and incubation times for BFA and nocodazole should be included in the main text or figure legends.
RESPONSE:
Concentrations and incubation times of BFA and nocodazole were already present in the legend of figure 5.
Fig. 8C, D, G, H: y-axes lack labels and must be defined.
RESPONSE:
Axes labels have now been included
There are multiple typographical errors, including "VPS12" instead of "VPS13B", that should be corrected.
RESPONSE:
We corrected this specific mistake as well as others that we could identify after careful reading of the manuscript.
Reviewer #2 (Significance (Required)):
While the dataset is extensive and technically detailed, the manuscript lacks a clear mechanistic explanation connecting lipid changes to Golgi restoration. The choice and comparison of compounds are inconsistent across experiments, and the interpretation remains speculative. Substantial revision and additional experiments are required before the study can be considered for publication.
une vingtaine de lignes de code à Pandocgithub.com/jgm/pandoc/pull/10665. , rendant de ce fait possible la conversion des fichiers IDML vers une multitude de formats
Il s'agit donc d'élargir le champ des utilisateurs d'un logiciel libre (ici Pandoc) à une communauté ciblée, pas ou peu familier du libre. C'est un peu le projet derrière Stylo : pandoc (encore) pour les chercheur·es SHS → cheval de troie
rung


A rung is a horizontal step or bar that connects the two sides of a ladder.
Rung = one step of a ladder
You climb a ladder by stepping on its rungs.
In biology, rung is often used as a comparison (metaphor) when explaining DNA structure.
📌 Each DNA rung is made of a base pair:
These base pairs are held together by hydrogen bonds.
Each rung consists of:
Example:
One rung = A on one strand + T on the other strand
The ladder model helps students visualize that:
📌 The sequence of rungs = genetic code.
A rung is a horizontal step of a ladder; in DNA, rungs represent paired nitrogenous bases connecting the two strands.
Rung 指的是梯子上的横档或踏板,用来踩踏和攀爬。
Rung = 梯子的一格横档
在生物学中,DNA 常被比作一把梯子:
📌 每一个 DNA 的“rung”由一对碱基组成:
Rung 指梯子的横档,在 DNA 中用来比喻连接两条链的碱基对。
如果你需要,我可以把 ladder model → rung → base pair → hydrogen bond 做成 Science 10 中英对照图解或互动闪卡,非常适合课堂讲解与复习。
Thymine
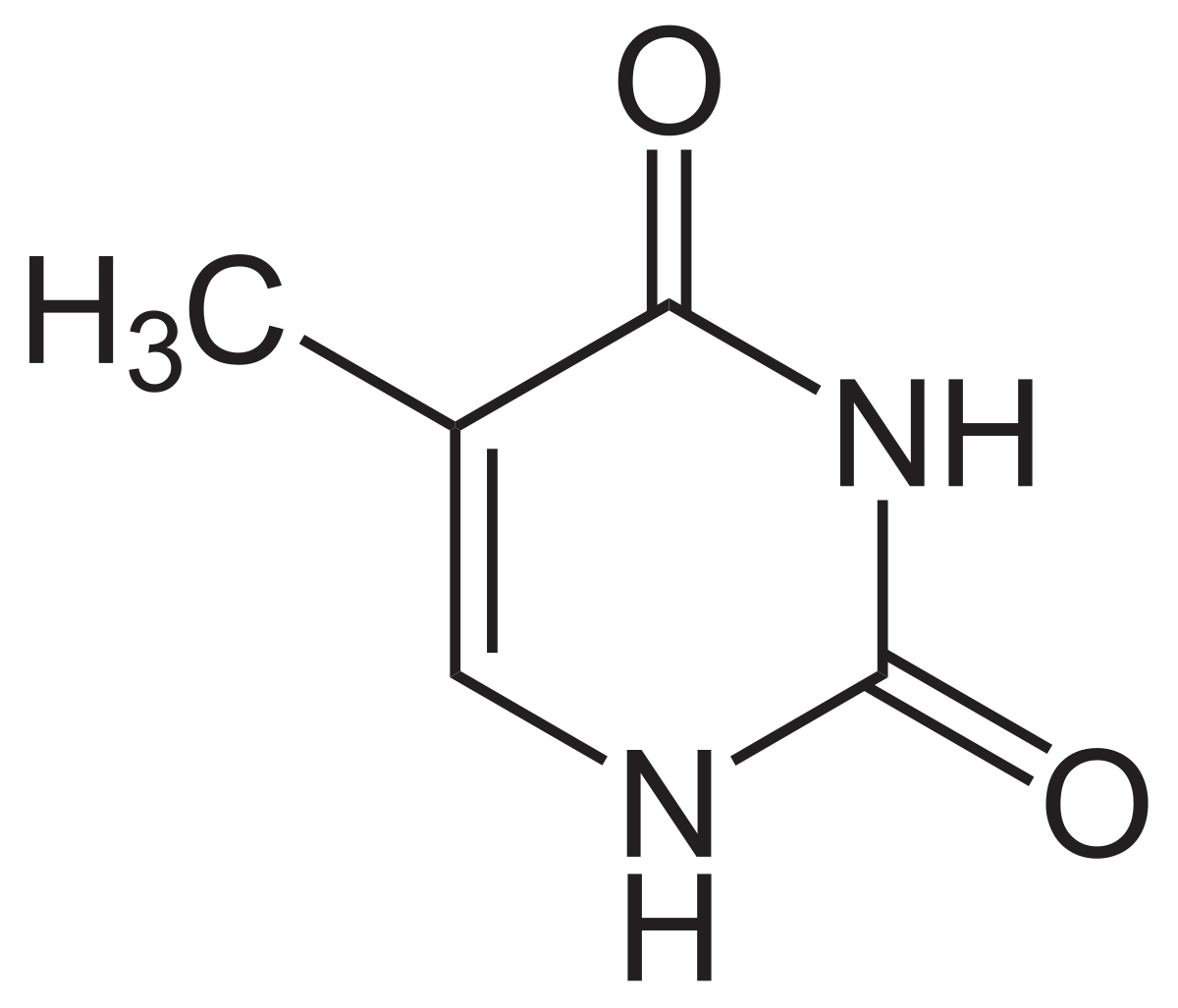

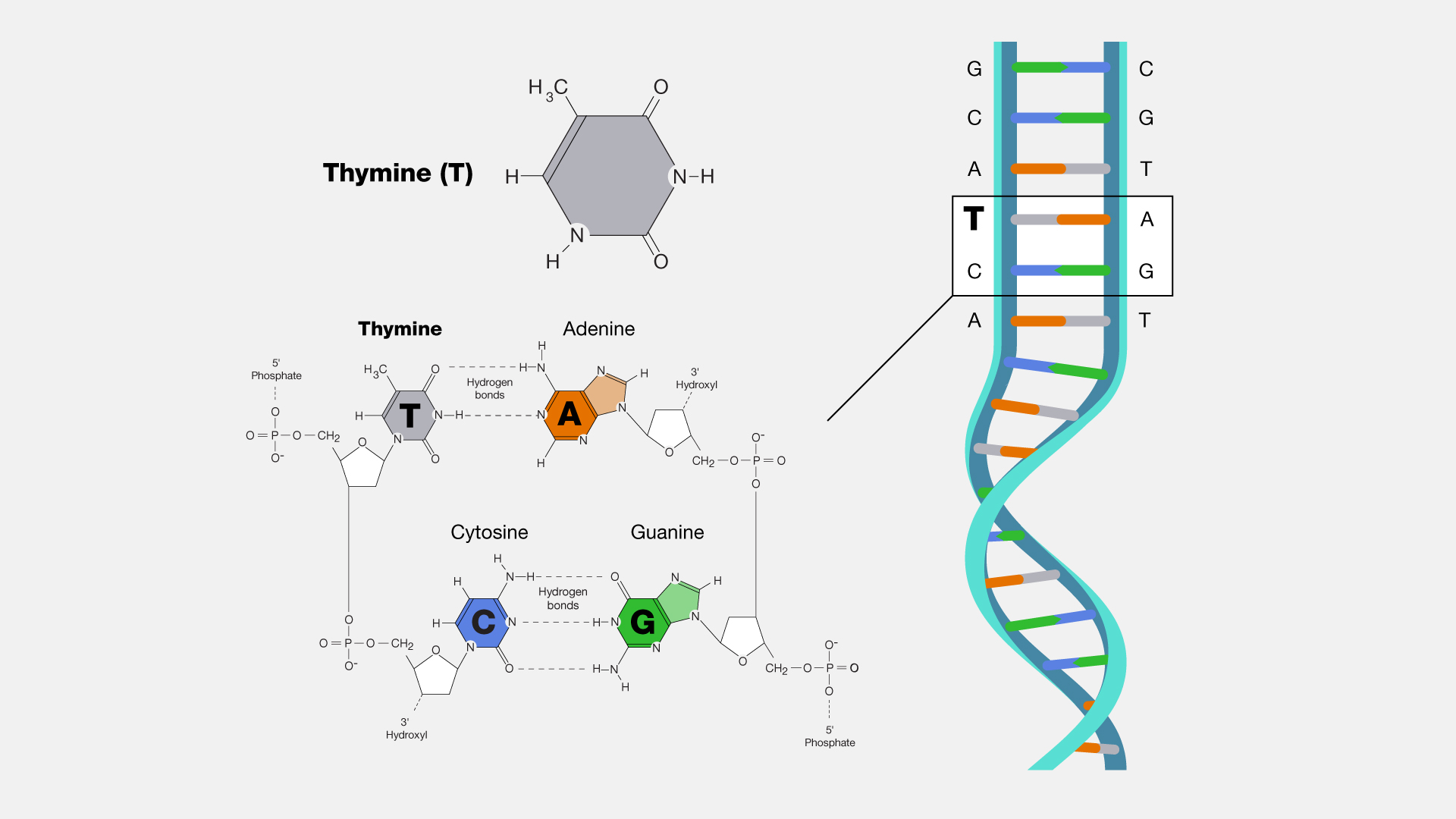

Thymine is a nitrogenous base found only in DNA. It is one of the four bases that make up the DNA genetic code.
Thymine = a DNA base that pairs with adenine
Each thymine base is part of a nucleotide, attached to:
In DNA:
This specific pairing:
Thymine belongs to the pyrimidines, which:
Pyrimidines: Cytosine (C), Thymine (T), Uracil (U) Purines: Adenine (A), Guanine (G)
Purine–pyrimidine pairing keeps the DNA double helix a constant width.
A mistake involving thymine (a mutation) can:
| Feature | Thymine (T) | Uracil (U) | | ---------- | ----------- | ----------- | | Found in | DNA | RNA | | Pairs with | Adenine | Adenine | | Stability | More stable | Less stable |
📌 Thymine makes DNA more stable for long-term information storage.
Thymine is a pyrimidine nitrogenous base found only in DNA that pairs with adenine using two hydrogen bonds.
胸腺嘧啶(Thymine,T)是一种只存在于 DNA 中的含氮碱基,是 DNA 遗传信息的重要组成部分。
胸腺嘧啶 = DNA 中与腺嘌呤配对的碱基
DNA 中:
这种精确配对保证 DNA 复制准确。
胸腺嘧啶属于 嘧啶(pyrimidine):
| 项目 | 胸腺嘧啶 | 尿嘧啶 | | ---- | ---- | --- | | 所在分子 | DNA | RNA | | 配对对象 | 腺嘌呤 | 腺嘌呤 | | 稳定性 | 更高 | 较低 |
胸腺嘧啶是 DNA 中与腺嘌呤配对、具有两条氢键的嘧啶碱基。
如果你需要,我可以把 A–T vs C–G 的稳定性比较或把 四种 DNA 碱基整理成 Science 10 中英对照闪卡 / 互动图表,方便系统复习与教学。
Guanine


Guanine is a nitrogenous base found in DNA and RNA. It is one of the four bases that make up the genetic code.
Guanine = a nitrogen-containing base that stores genetic information
Guanine appears in:
It is always part of a nucleotide, attached to:
In DNA:
In RNA:
📌 Because there are three hydrogen bonds, G–C pairs are stronger and more stable than A–T pairs.
Guanine belongs to the purines, which:
Purines: Adenine (A), Guanine (G) Pyrimidines: Cytosine (C), Thymine (T), Uracil (U)
This size matching (purine–pyrimidine) keeps the DNA double helix uniform in width.
In DNA:
Changes involving guanine can cause mutations, potentially affecting proteins and traits.
Guanine is a purine nitrogenous base that pairs with cytosine using three hydrogen bonds in DNA and RNA.
鸟嘌呤(Guanine,G)是一种存在于 DNA 和 RNA 中的含氮碱基,是遗传信息的重要组成部分。
鸟嘌呤 = DNA / RNA 中的遗传“字母”之一
鸟嘌呤存在于:
它与:
DNA 中:
RNA 中:
📌 三条氢键使 G–C 配对更加牢固。
鸟嘌呤属于 嘌呤(purine):
对比:
碱基变化可能导致突变。
鸟嘌呤是 DNA 和 RNA 中与胞嘧啶配对、具有三条氢键的嘌呤碱基。
如果你需要,我可以把 A–T vs C–G 的稳定性对比、或把四种碱基做成 Science 10 中英对照闪卡 / 互动图解,直接用于复习或教学。
Cytosine

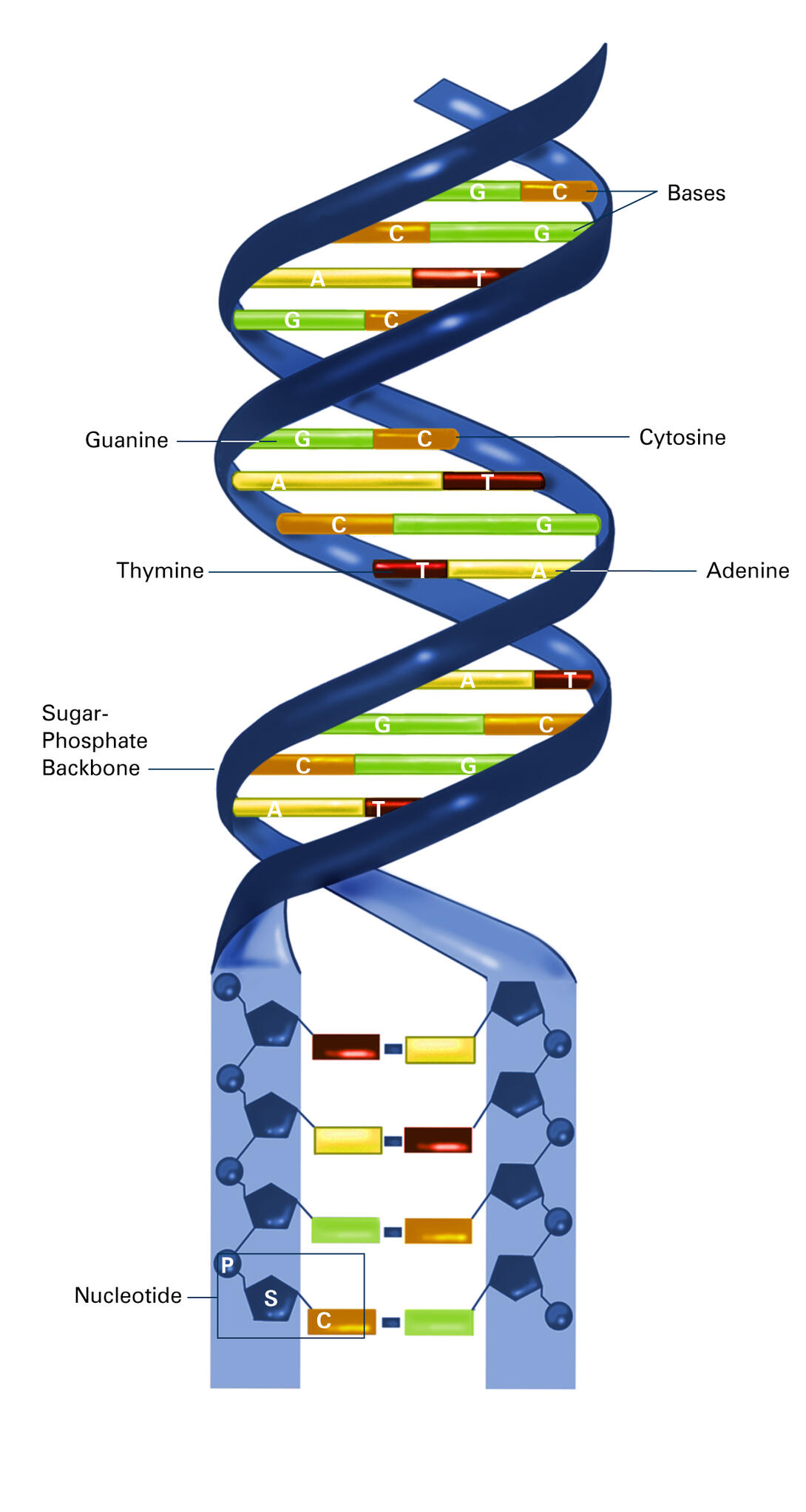
Cytosine is a nitrogenous base found in DNA and RNA. It is one of the four main bases that make up the genetic code.
Cytosine = a nitrogen-containing base that helps store genetic information
Cytosine occurs in:
It is always part of a nucleotide, attached to:
In DNA:
In RNA:
📌 The three hydrogen bonds make the C–G pair stronger than the A–T pair.
Cytosine belongs to the pyrimidines, which:
Purines (double ring):
Pyrimidines (single ring):
This size matching keeps the DNA double helix uniform in width.
In DNA:
A change in cytosine (mutation) can:
Because C–G pairs have three hydrogen bonds:
Cytosine is a pyrimidine nitrogenous base that pairs with guanine using three hydrogen bonds in DNA and RNA.
胞嘧啶(Cytosine,C)是一种存在于 DNA 和 RNA 中的含氮碱基,是遗传信息的基本组成单位之一。
胞嘧啶 = DNA / RNA 中的重要碱基
胞嘧啶存在于:
它与:
DNA 中:
RNA 中:
📌 三条氢键使 C–G 配对更牢固。
胞嘧啶属于 嘧啶(pyrimidine):
嘌呤(双环):A、G 嘧啶(单环):C、T、U
碱基变化可能导致突变。
胞嘧啶是 DNA 和 RNA 中与鸟嘌呤配对的嘧啶碱基,具有三条氢键。
如果你愿意,我可以把 Adenine / Thymine / Cytosine / Guanine 做成 Science 10 中英对照碱基配对表或互动闪卡,非常适合系统复习与教学。
Adenine


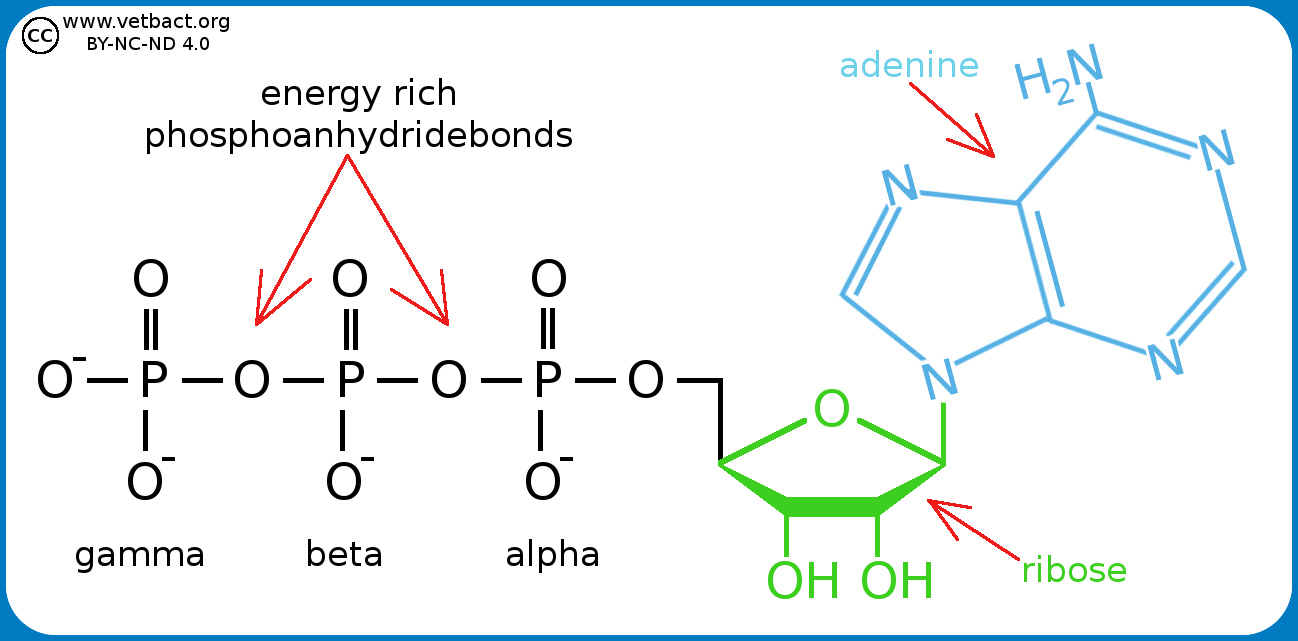
Adenine is a nitrogenous base found in DNA and RNA. It is one of the letters of the genetic code.
Adenine = a nitrogen-containing base that carries genetic information
Adenine appears in several key biological molecules:
In DNA:
In RNA:
These pairing rules ensure accurate DNA replication and correct protein synthesis.
Adenine belongs to the purines, which:
Purines: Adenine (A), Guanine (G) Pyrimidines: Cytosine (C), Thymine (T), Uracil (U)
This size difference explains why:
In DNA:
Changing adenine’s position can:
Adenine is part of ATP (adenosine triphosphate):
ATP provides energy for:
Adenine is a purine nitrogenous base that pairs with thymine in DNA and with uracil in RNA.
腺嘌呤(Adenine,A)是一种含氮碱基,存在于 DNA 和 RNA 中,是遗传信息的“字母”之一。
腺嘌呤 = DNA / RNA 中的重要遗传碱基
DNA 中:
RNA 中:
这些规则保证了遗传信息的准确复制和表达。
腺嘌呤属于 嘌呤(purine):
嘌呤:A、G 嘧啶:C、T、U
碱基变化可能导致突变。
腺嘌呤是 ATP(三磷酸腺苷)的一部分:
腺嘌呤是 DNA 中与 T 配对、RNA 中与 U 配对的嘌呤碱基。
如果你需要,我可以把 Adenine / Thymine / Cytosine / Guanine 做成 Science 10 中英对照碱基配对表或互动闪卡,方便系统复习。
nitrogenousbase
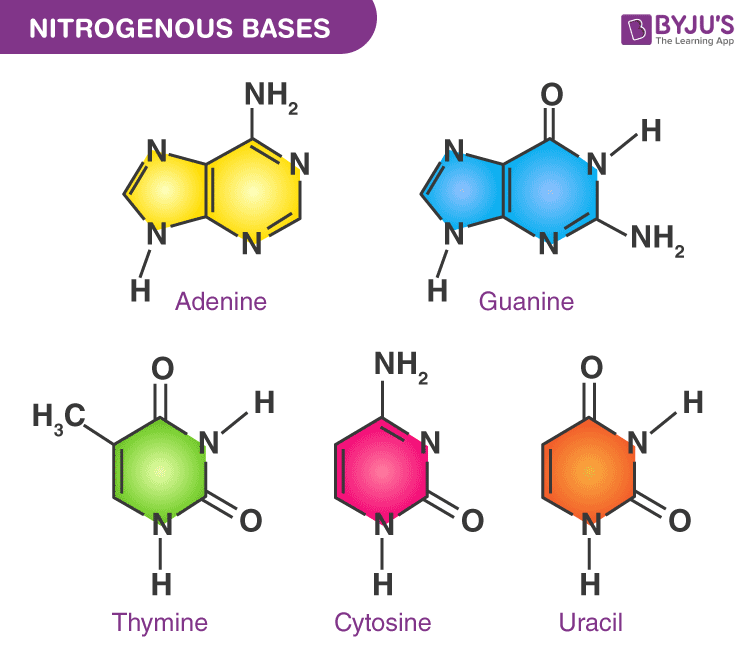
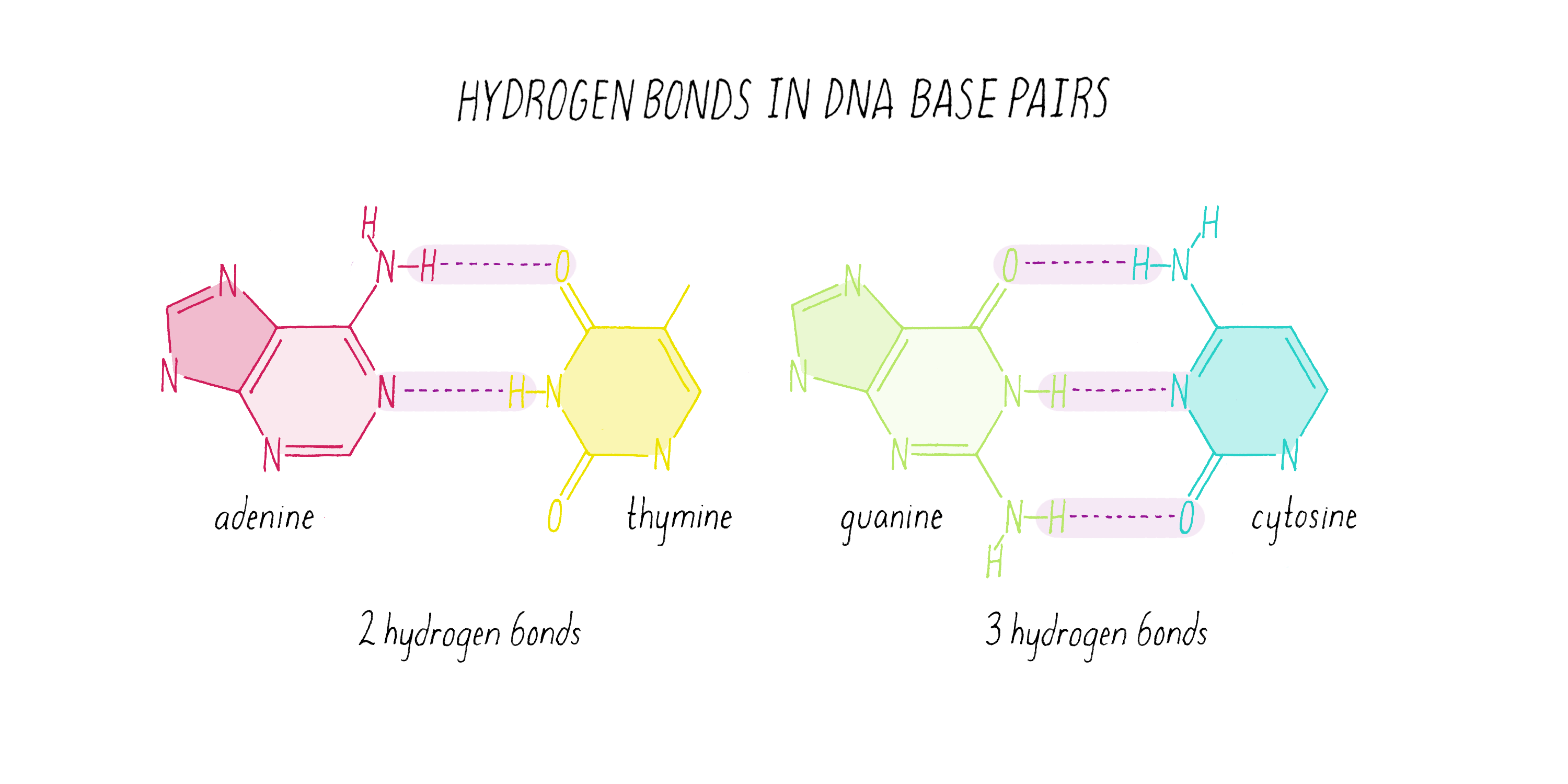

A nitrogenous base is a nitrogen-containing molecule that is part of a nucleotide, the building block of DNA and RNA.
Nitrogenous base = the “letter” of the genetic code
Each nucleotide has:
The sequence of bases stores genetic information.
In DNA:
In RNA:
📌 Only the bases change; the sugar–phosphate backbone stays the same.
Purines (two rings):
Pyrimidines (one ring):
This size difference explains base pairing rules.
DNA base pairing:
RNA base pairing:
Hydrogen bonds hold paired bases together, forming the double helix in DNA.
Nitrogenous bases:
Changing a base (a mutation) can change traits.
Bases encode information; nucleotides build the molecule.
Nitrogenous bases are nitrogen-containing molecules in DNA and RNA whose sequence stores genetic information.
含氮碱基是含有氮原子的分子,是 DNA 和 RNA 的核苷酸组成部分之一。
含氮碱基 = 遗传信息的“字母”
每个核苷酸由:
DNA 中:
RNA 中:
嘌呤(双环):
嘧啶(单环):
DNA:
RNA:
这些配对通过氢键连接,使 DNA 形成双螺旋结构。
含氮碱基是 DNA 和 RNA 中储存遗传信息的关键成分。
如果你需要,我可以把 nitrogenous base → nucleotide → DNA → gene 做成 Science 10 中英对照速记卡或互动图解,非常适合系统复习。
sugar
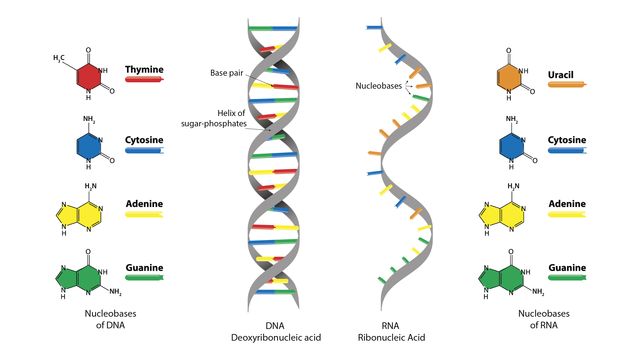



The sugar found in DNA is called deoxyribose. It is a five-carbon sugar (a pentose) and is one of the three essential parts of a DNA nucleotide.
DNA sugar = deoxyribose
Each DNA nucleotide contains:
📌 This small difference makes DNA:
A) Forms the backbone
B) Connects to bases
Two sugar–phosphate backbones twist together to form the double helix.
| Feature | DNA | RNA | | ------------------- | ------------------ | ------------------ | | Sugar | Deoxyribose | Ribose | | Oxygen at 2′ carbon | ❌ Missing | ✅ Present | | Stability | More stable | Less stable | | Function | Store genetic info | Help make proteins |
Without the sugar:
Sugar = the structural “frame” that holds DNA together
The sugar in DNA is deoxyribose, which forms the sugar–phosphate backbone and supports the structure of the DNA molecule.
DNA 中的糖叫 脱氧核糖(deoxyribose),是一种五碳糖。
DNA 的糖 = 脱氧核糖
每个 DNA 核苷酸由三部分组成:
📌 这使 DNA:
① 构成骨架
② 连接碱基
两条这样的链相互缠绕,形成 DNA 双螺旋结构。
| 项目 | DNA | RNA | | --- | ------ | ----- | | 糖 | 脱氧核糖 | 核糖 | | 氧原子 | 少一个 | 多一个 | | 稳定性 | 高 | 低 | | 功能 | 储存遗传信息 | 蛋白质合成 |
DNA 中的糖是脱氧核糖,它与磷酸一起形成 DNA 的骨架结构。
如果你需要,我可以把 nucleotide → sugar → phosphate → DNA backbone 做成 中英对照闪卡或可交互 HTML 图解,直接用于 Science 10 复习或教学。
chromosome

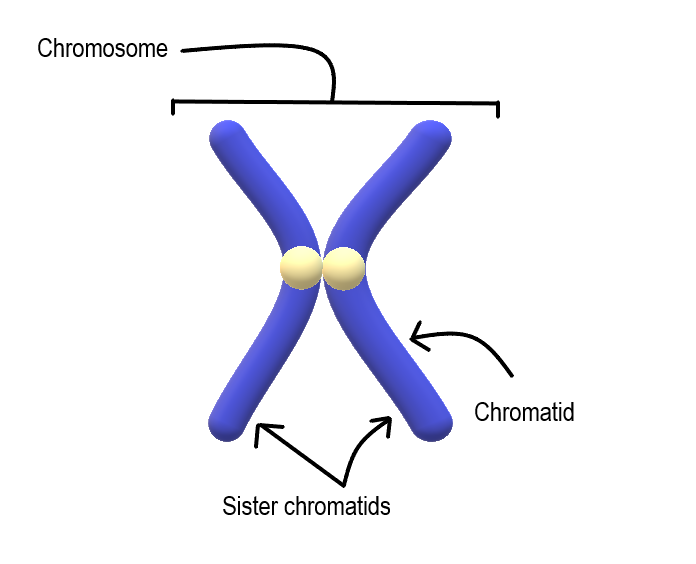

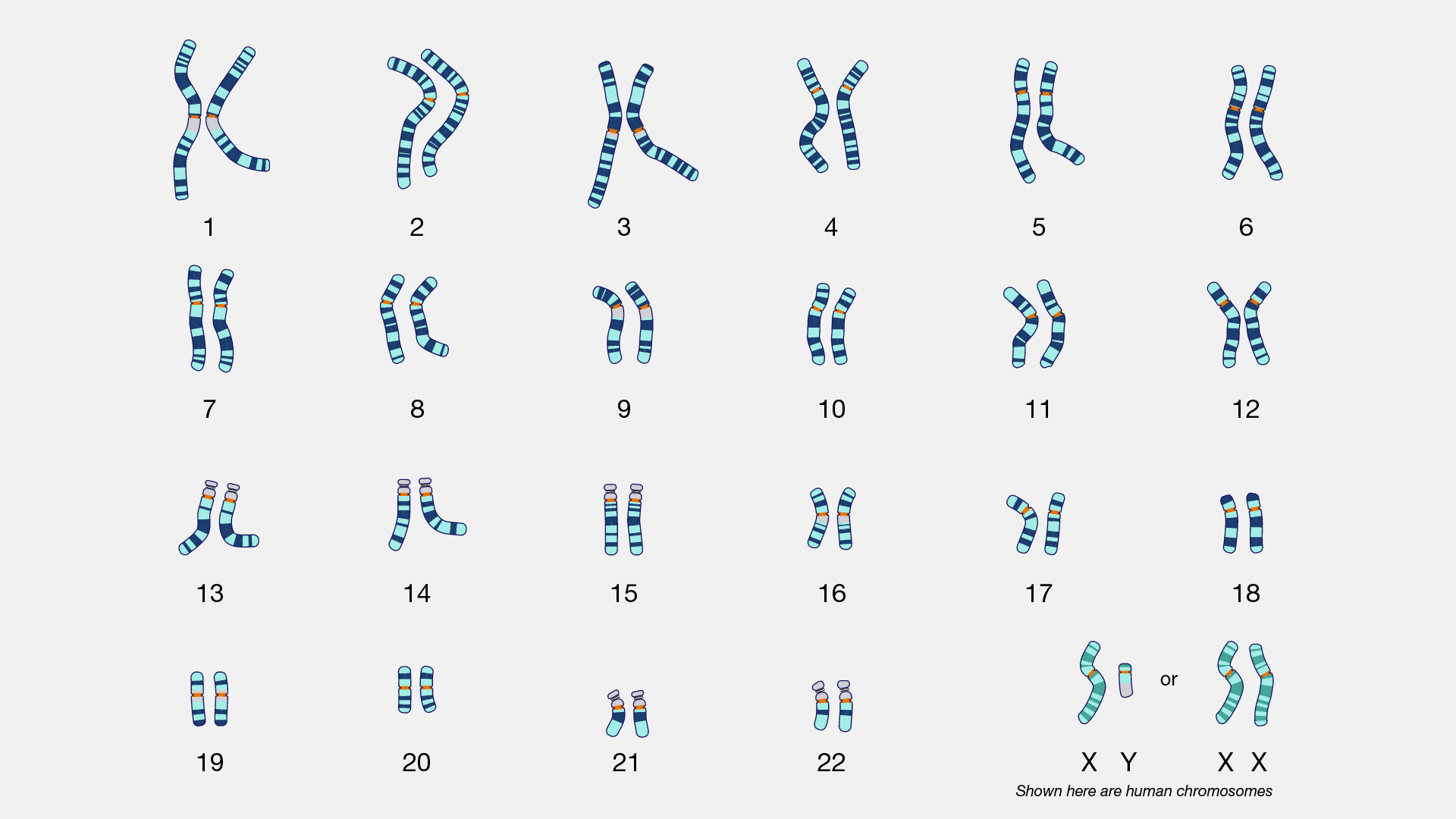
A chromosome is a highly condensed structure of DNA and proteins found in the nucleus of eukaryotic cells. Chromosomes carry genes, which contain the instructions for building and maintaining an organism.
Simply: chromosome = tightly packed DNA that holds genes.
Chromosomes consist of:
DNA + histones together form chromatin. When chromatin coils up tightly (especially during cell division), it becomes a chromosome.
| Term | State | When you see it | | -------------- | ------------------ | --------------------------------- | | Chromatin | Loose, uncondensed | Interphase (normal cell activity) | | Chromosome | Tightly condensed | Mitosis / Meiosis |
👉 You usually see chromosomes only during cell division.
When a chromosome has been copied (after DNA replication), it looks like an “X” shape:
Each chromatid contains one complete DNA molecule.
Condensation helps:
Loose DNA would be impossible to divide correctly.
Each species has a fixed chromosome number.
Examples:
Humans: 46 chromosomes (23 pairs)
22 pairs of autosomes
This arrangement can be seen in a karyotype.
Correct chromosome behavior is essential for life.
A chromosome is a condensed DNA–protein structure that carries genes and ensures accurate DNA distribution during cell division.




染色体是存在于真核细胞细胞核中、由 DNA 高度压缩形成的结构, 它们携带基因,决定生物的性状和功能。
一句话:
染色体 = 高度压缩的 DNA 信息载体
染色体由:
组成。
DNA + 组蛋白 = 染色质 染色质高度凝缩后 → 染色体
| 名称 | 状态 | 出现时间 | | ------- | ---- | ------- | | 染色质 | 松散 | 间期 | | 染色体 | 高度压缩 | 有丝/减数分裂 |
👉 平时细胞里看到的是染色质,而不是染色体。
复制后的染色体通常呈 X 形,由:
两条姐妹染色单体
DNA 完全相同
着丝粒
连接两条染色单体
端粒
保护染色体末端
高度压缩可以:
不同物种染色体数目固定。
以人类为例:
46 条染色体(23 对)
22 对常染色体
这些排列方式称为 核型(karyotype)。
染色体是由 DNA 和蛋白质组成的高度压缩结构,负责储存和准确分配遗传信息。
如果你需要,我可以把 chromatin → chromosome → homologous → sister chromatids 做成一张 中英对照“遗传结构总览图”,非常适合 Biology 10 / 11 复习。
Integrated Sanity CMS to separate content from code, enabling non-technical teams to publish blog updatesindependently
Followup to the action statement thread though, to make this statement better, add quantitative data. Numbers, dollars, anything of the likes
Deleting unnecessary work is almost always more impactful than doing necessary work faster. The fastest code is code that never runs. Before you optimize, question whether the work should exist at all.
Your code is a strategy memo to strangers who will maintain it at 2am during an outage.
When one of us ran the program, who made those reddit posts (me? you? the bot?)? Notice that there are at least three times of actions for posting reddit post with this bot, one is when the code was originally written, another is when the code was modified, and and the other is when the code is run. These could even be done by different people. How do you divide out responsibility for a bots actions between the person writing the code and the person running the program?
All technology and automation has a human behind it (at least up until recently, the rest of my comment is going to exclude ai). Whatever team is behind a bot is responsible for the actions since the humans behind it are the "true" posters. For dividing out responsibility between the two (coder and publisher), I think both people are responsible to a certain extent and the degree of responsibility can vary. For example, lets say the coder makes a bot of their own thoughts and opinions and the publisher just publishes it. I would say the coder has more responsibility in that action, since they are the one writing out the posts themselves. If it is an automated bot taking quotes from a show or something similar, the publisher is the one checking over if the content follows guidelines and would have more responsibility.
If you don’t know what the block of code above does, please do not be concerned. We will not be dealing with Pandas in this textbook. If you are interested in Pandas, though, I have a free textbook on it entitled Introduction to Pandas
cut
Reviewer #3 (Public review):
Summary:
The authors set out to determine how GABAergic inhibitory premotor circuits contribute to the rhythmic alternation of leg flexion and extension during Drosophila grooming. To do this, they first mapped the ~120 13A and 13B hemilineage inhibitory neurons in the prothoracic segment of the VNC and clustered them by morphology and synaptic partners. They then tested the contribution of these cells to flexion and extension using optogenetic activation and inhibition and kinematic analyses of limb joints. Finally, they produced a computational model representing an abstract version of the circuit to determine how the connectivity identified in EM might relate to functional output. The study makes important contributions to the literature.
The authors have identified an interesting question and use a strong set of complementary tools to address it:
They analysed serial‐section TEM data to obtain reconstructions of every 13A and 13B neuron in the prothoracic segment. They manually proofread over 60 13A neurons and 64 13B neurons, then used automated synapse detection to build detailed connectivity maps and cluster neurons into functional motifs.
They used optogenetic tools with a range of genetic driver lines in freely behaving flies to test the contribution of subsets of 13A and 13B neurons.
They used a connectome-constrained computational model to determine how the mapped connectivity relates to the rhythmic output of the behavior.
Comments on revisions:
I appreciate that the authors have updated the GitHub repository to include the model and analysis code. Still lacking is: for the authors to explicitly separate empirical findings from modelling inferences in the text, and a supplemental table to make it clear which cell types are included. I should also point out that the code lacks annotations necessary for the results to be reproduced and the model to be reused.
Author response:
The following is the authors’ response to the previous reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
Syed et al. investigate the circuit underpinnings for leg grooming in the fruit fly. They identify two populations of local interneurons in the right front leg neuromere of ventral nerve cord, i.e. 62 13A neurons and 64 13B neurons. Hierarchical clustering analysis identifies each 10 morphological classes for both populations. Connectome analysis reveals their circuit interactions: these GABAergic interneurons provide synaptic inhibition either between the two subpopulations, i.e. 13B onto 13A, or among each other, i.e. 13As onto other 13As, and/or onto leg motoneurons, i.e. 13As and 13Bs onto leg motoneurons. Interestingly, 13A interneurons fall into two categories with one providing inhibition onto a broad group of motoneurons, being called "generalists", while others project to few motoneurons only, being called "specialists". Optogenetic activation and silencing of both subsets strongly effects leg grooming. As well activating or silencing subpopulations, i.e. 3 to 6 elements of the 13A and 13B groups has marked effects on leg grooming, including frequency and joint positions and even interrupting leg grooming. The authors present a computational model with the four circuit motifs found, i.e. feed-forward inhibition, disinhibition, reciprocal inhibition and redundant inhibition. This model can reproduce relevant aspects of the grooming behavior.
Strengths:
The authors succeeded in providing evidence for neural circuits interacting by means of synaptic inhibition to play an important role in the generation of a fast rhythmic insect motor behavior, i.e. grooming. Two populations of local interneurons in the fruit fly VNC comprise four inhibitory circuit motifs of neural action and interaction: feed-forward inhibition, disinhibition, reciprocal inhibition and redundant inhibition. Connectome analysis identifies the similarities and differences between individual members of the two interneuron populations. Modulating the activity of small subsets of these interneuron populations markedly affects generation of the motor behavior thereby exemplifying their important role for generating grooming. The authors carefully discuss strengths and limitations of their approaches and place their findings into the broader context of motor control.
We thank the reviewer for their thoughtful and constructive evaluation of our work.
Weaknesses:
Effects of modulating activity in the interneuron populations by means of optogenetics were conducted in the so-called closed-loop condition. This does not allow to differentiate between direct and secondary effects of the experimental modification in neural activity, as feedforward and feedback effects cannot be disentangled. To do so open loop experiments, e.g. in deafferented conditions, would be important. Given that many members of the two populations of interneurons do not show one, but two or more circuit motifs, it remains to be disentangled which role the individual circuit motif plays in the generation of the motor behavior in intact animals.
Our optogenetic experiments show a role for 13A/B neurons in grooming leg movements – in an intact sensorimotor system - but we cannot yet differentiate between central and reafferent contributions. Activation of 13As or 13Bs disinhibits motor neurons and that is sufficient to induce walking/grooming. Therefore, we can show a role for the disinhibition motif.
Proprioceptive feedback from leg movements could certainly affect the function of these reciprocal inhibition circuits. Given the synapses we observe between leg proprioceptors and 13A neurons, we think this is likely.
Our previous work (Ravbar et al 2021) showed that grooming rhythms in dusted flies persist when sensory feedback is reduced, indicating that central control is possible. In those experiments, we used dust to stimulate grooming and optogenetic manipulation to broadly silence sensory feedback. We cannot do the same here because we do not yet have reagents to separately activate sparse subsets of inhibitory neurons while silencing specific proprioceptive neurons. More importantly, globally silencing proprioceptors would produce pleiotropic effects and severely impair baseline coordination, making it difficult to distinguish whether observed changes reflect disrupted rhythm generation or secondary consequences of impaired sensory input. Therefore, the reviewer is correct – we do not know whether the effects we observe are feedforward (central), feedback sensory, or both. We have included this in the revised results and discussion section to describe these possibilities and the limits of our current findings.
Additionally, we have used a computational model to test the role of each motif separately and we show that in the results.
Comments on revisions:
The careful revision of the manuscript improved the clarity of presentation substantially.
Reviewer #2 (Public review):
Summary:
This manuscript by Syed et al. presents a detailed investigation of inhibitory interneurons, specifically from the 13A and 13B hemilineages, which contribute to the generation of rhythmic leg movements underlying grooming behavior in Drosophila. After performing a detailed connectomic analysis, which offers novel insights into the organization of premotor inhibitory circuits, the authors build on this anatomical framework by performing optogenetic perturbation experiments to functionally test predictions derived from the connectome. Finally, they integrate these findings into a computational model that links anatomical connectivity with behavior, offering a systems-level view of how inhibitory circuits may contribute to grooming pattern generation.
Strengths:
(1) Performing an extensive and detailed connectomic analysis, which offers novel insights into the organization of premotor inhibitory circuits.
(2) Making sense of the largely uncharacterized 13A/13B nerve cord circuitry by combining connectomics and optogenetics is very impressive and will lay the foundation for future experiments in this field.
(3) Testing the predictions from experiments using a simplified and elegant model.
Thank you for the positive assessment of our work.
Weaknesses:
(1) In Figure 4-figure supplement 1, the inclusion of walking assays in dusted flies is problematic, as these flies are already strongly biased toward grooming behavior and rarely walk. To assess how 13A neuron activation influences walking, such experiments should be conducted in undusted flies under baseline locomotor conditions.
We agree that there are better ways to assay potential contributions of 13A/13B neurons to walking. We intended to focus on how normal activity in these inhibitory neurons affects coordination during grooming, and we included walking because we observed it in our optogenetic experiments and because it also involves rhythmic leg movements. The walking data is reported in a supplementary figure because we think this merits further study with assays designed to quantify walking specifically. We will make these goals clearer in the revised manuscript and we are happy to share our reagents with other research groups more equipped to analyze walking differences.
(2) Regarding Fig 5: The 70ms on/off stimulation with a slow opsin seems problematic. CsChrimson off kinetics are slow and unlikely to cause actual activity changes in the desired neurons with the temporal precision the authors are suggesting they get. Regardless, it is amazing the authors get the behavior! It would still be important for authors to mention the optogentics caveat, and potentially supplement the data with stimulation at different frequencies, or using faster opsins like ChrimsonR.
We were also intrigued by the behavioral consequences of activating these inhibitory neurons with CsChrimson. We appreciate the reviewer’s point that CsChrimson’s slow off-kinetics limit precise temporal control. To address this, we repeated our frequency analysis using a range of pulse durations (10/10, 50/50, 70/70, 110/110, and 120/120 ms on/off) and compared the mean frequency of proximal joint extension/flexion cycles across conditions. We found no significant difference in frequency (LLMS, p > 0.05), suggesting that the observed grooming rhythm is not dictated by pulse period but instead reflects an intrinsic property of the premotor circuit once activated. We now include these results in ‘Figure 5—figure supplement 1’ and clarify in the text that we interpret pulsed activation as triggering, rather than precisely pacing, the endogenous grooming rhythm. We continue to note in the manuscript that CsChrimson’s slow off-kinetics may limit temporal precision. We will try ChrimsonR in future experiments.
Overall, I think the strengths outweigh the weaknesses, and I consider this a timely and comprehensive addition to the field.
Reviewer #3 (Public review):
Summary:
The authors set out to determine how GABAergic inhibitory premotor circuits contribute to the rhythmic alternation of leg flexion and extension during Drosophila grooming. To do this, they first mapped the ~120 13A and 13B hemilineage inhibitory neurons in the prothoracic segment of the VNC and clustered them by morphology and synaptic partners. They then tested the contribution of these cells to flexion and extension using optogenetic activation and inhibition and kinematic analyses of limb joints. Finally, they produced a computational model representing an abstract version of the circuit to determine how the connectivity identified in EM might relate to functional output. The study makes important contributions to the literature.
The authors have identified an interesting question and use a strong set of complementary tools to address it:
They analysed serial‐section TEM data to obtain reconstructions of every 13A and 13B neuron in the prothoracic segment. They manually proofread over 60 13A neurons and 64 13B neurons, then used automated synapse detection to build detailed connectivity maps and cluster neurons into functional motifs.
They used optogenetic tools with a range of genetic driver lines in freely behaving flies to test the contribution of subsets of 13A and 13B neurons.
They used a connectome-constrained computational model to determine how the mapped connectivity relates to the rhythmic output of the behavior.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
I still have the following specific suggestions and questions, which need the attention of the authors:
P5, 2nd para, li 1: shouldn't "(Figures 1E and 1E')" be (Figures 1G and 1H)?
P7, last para, li 3: shouldn't "(Figures 2C and 2D)" be (Figures 2A and 2B)?
P19, para 2, last 2li: "...we observe that optogenetic activation......triggers grooming movements." I could not find the place in the text or a figure, where this was reported or shown. Please specify
P19, last para: "... shows that 13A neurons can generate rhyhtmic movements....." Given that the experiments were conducted in closed-loop, i.e. including the loop through the leg and its movements, the following formulation appears more justified: "....shows that 13A neurons significantly contribute to the generation of rhythmic movements,....."
P28, para 1, li 3 from bottom: "...themselves, rather than solely between antagonistsic motor neurons." While the authors are correct that in the stick insect and locust alternating inhibitory synaptic drive to flexor and extensor motoneurons has been shown to underly alternating activity of these two antagonistic motoneuron pools the previous studies have not shown or claimed that these synaptic inputs arise from direct interactions between these motoneuron pools. Based on this this text should be moved to the part "feed-forward inhibition" on page 27.
P28: "redundant inhibition": this motif has been shown to be instrumental in the locust flight CPG, e.g. Robertson & Pearson, 1985, Fig. 16.
P28: "reciprocal inhibition" The reviewer agrees with the authors that this motif has been shown for the mouse spinal cord, but also for other CPGs in vertebrates and invertebrates, e.g. clione, leech, xenopus - see the initial comment "(3) Intro and Discussion"
Thank you, we have incorporated the suggested corrections and clarifications into the revised manuscript.
Reviewer #2 (Recommendations for the authors):
I'm satisfied with the revised version
Reviewer #3 (Recommendations for the authors):
The authors have made a substantial effort to address my original points. They corrected the title, expanded Discussion and Methods sections, reran statistical tests using mixed models, added modelling clarifications and constraints, and fixed or removed confusing figure panels. Those changes have improved clarity and reduced some of the claims that I thought were exaggerated.
That said, some of my concerns remain only partially addressed, which could be fixed with relatively small tweaks. The authors should:
(1) Explicitly separate empirical findings from modelling inferences throughout the manuscript, including the Abstract, Results and Discussion (i.e., label claims of "intrinsic rhythmogenesis" as model-based inferences, not direct experimental demonstrations)
(2) Provide supplemental information on modelling to quantify the role of the black-box input (e.g., quantitative coordination/phase/frequency metrics for full model vs constant-input vs no black box), show pre- vs post-fine-tuning weight changes and the exact tuning constraints/optimization details (I could not find these details)
(3) To ensure results are reproducible, provide a supplemental table mapping each split line to EM-identified neuron(s) with NBLAST/morphological scores for each match;
(4) Fully document the statistical models (exact LMM/GLMM formulas, software/packages, etc);
(5) Deposit model code, trained weights and analysis scripts in a public repository.
We have updated the GitHub repository with the full statistical analysis documentation and model code, including trained weights and scripts.
AbstractThe processing and analysis of magnetic resonance images is highly dependent on the quality of the input data, and systematic differences in quality can consequently lead to loss of sensitivity or biased results. However, varying image properties due to different scanners and acquisition protocols, as well as subject-specific image interferences, such as motion artifacts, can be incorporated in the analysis. A reliable assessment of image quality is therefore essential to identify critical outliers that may bias results. Here we present a quality assessment for structural (T1-weighted) images using tissue classification. We introduce multiple useful image quality measures, standardize them into quality scales and combine them into an integrated structural image quality rating to facilitate the interpretation and fast identification of outliers with (motion) artifacts. The reliability and robustness of the measures are evaluated using synthetic and real datasets. Our study results demonstrate that the proposed measures are robust to simulated segmentation problems and variables of interest such as cortical atrophy, age, sex, brain size and severe disease-related changes, and might facilitate the separation of motion artifacts based on within-protocol deviations. The quality control framework presents a simple but powerful tool for the use in research and clinical settings.Competing Interest StatementThe authors have declared no competing interest.
This work has been peer reviewed in GigaScience (see https://doi.org/10.1093/gigascience/giaf146), which carries out open, named peer-review. These reviews are published under a CC-BY 4.0 license and were as follows:
Reviewer 4: Laura Caquelin
Reproducibility report for: The Good, the Bad, and the Ugly: Segmentation-Based Quality Control of Structural Magnetic Resonance Images Journal: GigaScience ID number/DOI: GIGA-D-25-00085 Reviewer(s): Laura Caquelin, Department of Clinical Neuroscience, Karolinska Institutet, Sweden [Worked on reproducing the results and wrote the report] Tobias Wängberg, Department of Clinical Neuroscience, Karolinska Institutet, Sweden [Worked on reproducing the results]
According to our assessment the primary objective is: to develop and validate a standardized framework for assessing the quality of structural (T1-weighted) MRI images, enabling the detection of artifacts on simulated data.
Outcome: Quantitative quality ratings derived from image properties such as noise-to-contrast ratio (NCR), inhomogeneity-to-contrast ratio (ICR), resolution score (RES), and edge-to-contrast ratio (ECR) and Full-brain Euler characteristic (FEC) combined into a Structural Image Quality Rating (SIQR).
Analysis method outcome: Not precised in the manuscript, but with the Matlab script we identified that the quality scores were correlated using Spearman's rank correlation, and statistical significance was assessed using p-values computed using MATLAB's built-in method.
Main result: Results are presented in Figure 5. "The evaluation on the BWP test dataset showed that most quality ratings have a very high correlation (rho > .950, p < .001) with their corresponding perturbation and a very low correlation (rho < |0.1|) with the other tested perturbations (see table in Figure 5A & C). This suggests considerable specificity of the proposed quality measures. The combined SIQR score also showed a very strong association with the segmentation quality kappa (rho = -.913, p < .001) and brain tissue volumes (rhoCSF/GM/WM = -.472/-.484/.736, pCSF/GM/WM < .001) (Figure 5B). […] The edge-based resolution measure ECR, on the other hand, generally performed better (rho = .828, p < .001), but was more affected by noise (rho = .306, p < .001) and inhomogeneity (rho = .223, p < .001) than other scores."
Computational environment of reproduction analysis
Operating system for reproduction: MacOS 15.5 (reviewer 1) and MacOS 15.1 (reviewer 2)
5.1 Original study results - Results 1: Figure 5 C (see screenshot)
5.2 Steps for reproduction
->Finding how to reproduce the results - Issue 1: The methods section lacks sufficient detail regarding the statistical methodology, and the relevant information is not fully provided in the GitHub repository. -- Resolved: A message has been sent to the authors requesting further clarification on the methodology and additional resources (scripts/data) needed to reproduce the results. The script to reproduce the results is "cat_tst_qa_bwpmaintest.m".
-> Reproduce the results using the "cat_tst_qa_bwpmaintest.m" script. - Issue 2: To run the script "cat_tst_qa_bwpmaintest.m", the "eva_vol_calcKappa" function is missing. -- Resolved: The script was shared and added to the Github repository. - Issue 3: While running the script, the following error message encountered: Assigning to 0 elements using a simple assignment statement is not supported. Consider using comma-separated list assignment.
Error in cat_tst_qa_bwpmaintest (line 481) default.QS{find(cellfun('isempty',strfind(default.QS(:,2),'FEC'))==0),4} = [100, 850]; -- Resolved: This error stops the execution of the script. After discussion with the authors, the exact cause of the error encountered at line 480 was not directly identified. We exchanged and compared our environments at the point just before the error occurred and observed notable differences between them. Our environment is almost empty. The authors identified that the default variable is missing from our environment, even though it is referenced at line 437 by a call to the cat_stat_marks function. We confirmed that all required dependencies were installed (including Statistics toolbox, SPM and CAT12), and that we had access to all the necessary data. To ensure the issue was not due to user error, the code was independently executed by two reviewers. The error was consistently reproduced in both cases. About the setup, I specified to the authors: "To summarize my setup: * I have installed SPM, CAT, and the Statistics Toolbox. * I downloaded all datasets from the GigaScience server. * I also downloaded the IXI T1 data, but I've only kept the version available on the GigaScience server in my working directory. Is the version from GigaScience sufficient? I had presumed that this dataset was pre-processed and ready to use, so I ignored the time-consuming pre-processing step. Your last email seems to confirm this point."
The authors answered that: « Yes, this is correct. However, both directories have to be combined so that the original IXI images and the processing files are included. »
In an attempt to proceed, we modified the portion of the code that triggered the error:
% FEC FECpos = find(cellfun('isempty',strfind(default.QS(:,2),'FEC'))==0); try warning off; [Q.fit.FEC, Q.fit.FECstat] = robustfit(Q.FECgt(M,1),Q.FECo(M,1)); warning on; if ~isempty(FECpos) default.QS{FECpos,4} = round([Q.fit.FEC(1) + Q.fit.FEC(2), Q.fit.FEC(1) + Q.fit.FEC(2) * 6], -1); end
catch Q.fit.FEC = [nan nan]; Q.fit.FECstat = struct('coeffcorr',nan(2,2),'p',nan(2,2)); if ~isempty(FECpos) default.QS{FECpos,4} = [100 850]; end end
Following this adjustment, the end of the script "cat_tst_qa_bwpmaintest.m" ran without issue and generated output results:
Finally, the error was identified after numerous exchanges with the authors. The function "cat_stat_marks", available in the Github repository, was not shared in the FTP server. With this function added, the script runs correctly. Please note that the link to the Github repository where the software code can be found is not specified in the manuscript.
-> Compare the results reproduced and the original results - Issue 4: Discrepancy between reproduced results, output results provided by the authors and the original results shown in Figure 5C. -- Unresolved: We reproduced the figures and the corresponding output table using the modified "cat_tst_qa_bwpmaintest.m" script. We ran the script using the only default QC version selected in the script ("cat_vol_qa201901x"). By comparing our output with the result files shared by the authors, we were able to confirm that we had executed the correct pipeline. However, we encountered a discrepancy: neither the generated file in our run (tst_cat_col_qa201901x_irBWPC_HC_T1_pn9_rf100pC_vx200x200x200rptable.csv) nor the corresponding file provided by the authors (outputs from BWPmain_full_202504) matched the numerical values presented in Figure 5C of the manuscript. We contacted the authors to clarify whether the default QC version used in the script was indeed the one produce the figure. In response, they confirmed:
"All figures should show the results of this QC version although I had the plan to run a final check update after the reviewer comments (the figures are finally arranged in Adobe Illustrator)."
Therefore, although the correct version of the QC was used, the differences in the results shown in Figure 5C remain unexplained. This issue is still unresolved.
5.3 Statistical comparison Original vs Reproduced results - Results: Screenshot of reproduced tst_cat_vol_qa201901x_irBWPC_HC_T1_pn9_rf100pC_vx200x200x200_rptable.csv table
(Screenshot of Figure 5C)
(Screenshot of the original output corresponding to the Figure 5C)
the original results presented in figure 5C of the manuscript. Notably, the output file provided by the authors and the results in figure 5C do not match either, indicating potential errors or file versions mismatches. Additionally, many p-values in the reproduced results are equal to 0, which suggests a formatting issue or a problem in the script. Figure 5C also lacks a scale, legend detail, or supplementary data to make possible to verify p-values (assuming the color gradient represents the p-values).
Recommendations for authors We strongly recommend the authors to: -- Ensure all essential code and functions are included in the shared repositories. Some necessary files were not included in the FTP server provided with the paper. Although the GitHub repository (https://github.com/ChristianGaser/cat12) was shared with the journal, but it is not referenced in the manuscript, making it difficult for external users to locate. -- Add detailed documentation of the statistical methods: the current manuscript lacks sufficient information regarding the statistical methodology used, at least for the purpose of the reproducibility review. Please, include detailed explanation of statistical tests, packages and parameter settings (e.g. QC version) to improve reproducibility. -- Clarify the versioning and outputs for the figures: there is a lack of clarity regarding which specific data outputs were used to generate figure 5C. Providing metadata or links to the exact output file used would help to resolve this issue. -- Provide raw numerical data behind figures: figure 5C seems to display p-values using a color gradient but no scale or legend is provided. Sharing the raw data used would allow the comparison and the reproducibility of the figure. -- Improve the clarity of execution instructions and address potential p-values issues: the issue with p-values showing up as exactly 0 in the reproduced results might be caused by differences in the environment setup, such as missing variables, different software versions, or skipped steps before running the script. Improving the instructions for setting up the environment and running the would help prevent issues and facilitate reproducibility.
AbstractThe processing and analysis of magnetic resonance images is highly dependent on the quality of the input data, and systematic differences in quality can consequently lead to loss of sensitivity or biased results. However, varying image properties due to different scanners and acquisition protocols, as well as subject-specific image interferences, such as motion artifacts, can be incorporated in the analysis. A reliable assessment of image quality is therefore essential to identify critical outliers that may bias results. Here we present a quality assessment for structural (T1-weighted) images using tissue classification. We introduce multiple useful image quality measures, standardize them into quality scales and combine them into an integrated structural image quality rating to facilitate the interpretation and fast identification of outliers with (motion) artifacts. The reliability and robustness of the measures are evaluated using synthetic and real datasets. Our study results demonstrate that the proposed measures are robust to simulated segmentation problems and variables of interest such as cortical atrophy, age, sex, brain size and severe disease-related changes, and might facilitate the separation of motion artifacts based on within-protocol deviations. The quality control framework presents a simple but powerful tool for the use in research and clinical settings.Competing Interest StatementThe authors have declared no competing interest.
This work has been peer reviewed in GigaScience (see https://doi.org/10.1093/gigascience/giaf146), which carries out open, named peer-review. These reviews are published under a CC-BY 4.0 license and were as follows:
Reviewer 2: Oscar Esteban
Technical Note GIGA-D-25-00085 introduces a segmentation-based quality control (QC) framework for T1-weighted structural MRI integrated into the CAT12 toolbox. The approach defines five interpretable image quality metrics—noise-to-contrast ratio (NCR), inhomogeneity-to-contrast ratio (ICR), resolution score (RES), edge-to-contrast ratio (ECR), and full-brain Euler characteristic (FEC)—which are combined into a composite Structural Image Quality Rating (SIQR). The tool aims to provide a standardized, interpretable scoring system for identifying poor-quality scans, with validation across simulated datasets and real-world imaging data.
The manuscript addresses a critical need in neuroimaging by presenting an automated, interpretable, and practical framework for quality control of T1-weighted structural MRI. By integrating multiple segmentation-derived metrics into a single Structural Image Quality Rating (SIQR), the approach enables fast, standardized assessment of image quality. The tool is embedded in the widely used CAT12/SPM ecosystem, facilitating adoption, and it is validated across a range of synthetic and real-world datasets. The scoring system is designed with user accessibility in mind, offering a clear grading scale and robust detection of motion-related artifacts, making it particularly well-suited for use in large-scale research and clinical imaging settings.
I was given access to the supporting data but chose not to proceed with reproducibility checks at this stage, as the manuscript does not currently meet GigaScience's basic standards for code and data transparency. I look forward to reviewing a revised version that clearly defines the scope of the method, improves methodological transparency, and brings the manuscript into compliance with the journal's reproducibility and FAIR data principles.
Best regards,
Oscar Esteban, Ph. D. Research and Teaching FNS Fellow Dept. of Radiology, CHUV, University of Lausanne
It's 450 KB (static binary, including templates for this site, gzip compressed) It builds my ~140 page site in 300 ms (wall clock time, on an 11-year-old old laptop) It performs acceptably on a 28-year-old laptop, running NetBSD (Pentium 166 MHz) It's trivial to compile, requiring only a C compiler, GNU Make, sed, and sh
For comparison, ANPD—describing a static site generator as an LP doc that I published in response to Jared's Show HN thread for md2blog, is 126KB. It requires no compiler, because it uses the browser's JS runtime to execute (unlike md2blog, which requires you to download Deno or a binary with Deno embedded to run it).
Note also that the numbers here also differ from the ones Jared had at the time of publication, where he had originally written:
- It's ~270 KB (static binary + templates for this site, gzip compressed)
- It builds my ~140 page site in ~150 ms (wall clock time, on an 11-year-old old laptop)
- It performs acceptably on a 28-year-old laptop, running NetBSD (Pentium 166 MHz)
- It's trivial to compile, requiring only a C compiler, make, and sed
But while many thought they had cracked the code for managing Trump, the U.S. attacks on Europe have only multiplied over time
in zero sum thinking getting appeased is winning so push harder. (Vgl my experiences in former Soviet Union localities, much the same thing)
Cursor is an AI using code editor. It connects only to US based models (OpenAI, Anthropic, Google, xAI), and your pricing tier goes piecemeal to whatever model you're using.
Both an editor, and a CLI environment, and integrations with things like Slack and Github. This seems a building block for US-centered agentic AI silo forming for dev teams.
What becomes evident, then, is that the conditions of social life facilitated through the internet will not be determined by code or UX alone. They are shaped by collective habits, regulatory pressure, and a cultural willingness to accept friction in exchange for autonomy. Individual acts of departure remain difficult and often stagnate. Structural change requires coordination beyond personal choice. The question is no longer whether alternatives are possible; they already exist, but whether we are prepared to reorganize our everyday online practices around them.
Write 4 or 5 sentences about things you can do, but make one of them false.
1) I can translate text between over 100 different languages in just a few seconds.
2) I am able to generate high-quality images based on any description you give me.
3) I can feel physical emotions like happiness or sadness when we talk.
4) I am able to write complex computer code in languages like Python, C++, and JavaScript.
5) I can summarize a 500-page book into a few short paragraphs almost instantly.
My excitement for local LLMs was very much rekindled. The problem is that the big cloud models got better too—including those open weight models that, while freely available, were far too large (100B+) to run on my laptop.
Cloud models got much better stil than local models. Coding agents made a huge difference, with it Claude Code becomes very useful
The year of programming on my phone # I wrote significantly more code on my phone this year than I did on my computer.
vibe coding leads to a shift in using your phone to code. (not likely me, I hardly try to do anything productive on the limited interface my phone provides, but if you've already made the switch to speaking instructions I can see how this shift comes about)
Then in November Anthropic published Code execution with MCP: Building more efficient agents—describing a way to have coding agents generate code to call MCPs in a way that avoided much of the context overhead from the original specification.
still anthropic made MCP more approachable at the end of year with Code execution with MCP. Meaning?
The reason I think MCP may be a one-year wonder is the stratospheric growth of coding agents. It appears that the best possible tool for any situation is Bash—if your agent can run arbitrary shell commands, it can do anything that can be done by typing commands into a terminal. Since leaning heavily into Claude Code and friends myself I’ve hardly used MCP at all—I’ve found CLI tools like gh and libraries like Playwright to be better alternatives to the GitHub and Playwright MCPs.
Author thinks MCP may be a temporary phenomenon as a protocol, mostly bc cli tools like Claude code don't need it. The last sentence, that cli tools already exist that are better than the corresponding MCP servers for those tools, goes back to why vibecode/AI-the-things if there's perfectly good automation already around? I think that MCP may still be useful locally for personal tools though. It helps structure what you want your AI to do.
There’s a new kind of coding I call “vibe coding”, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It’s possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like “decrease the padding on the sidebar by half” because I’m too lazy to find it. I “Accept All” always, I don’t read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I’d have to really read through it for a while. Sometimes the LLMs can’t fix a bug so I just work around it or ask for random changes until it goes away. It’s not too bad for throwaway weekend projects, but still quite amusing. I’m building a project or webapp, but it’s not really coding—I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
vibecoding original description by Andrej Karpathy
Quickly distorted to mean any code created w llm assistance. Note: [[Martijn Aslander p]] follows this dev quite closely (dictation, accept always, it mostly works)
The year I built 110 tools # I started my tools.simonwillison.net site last year as a single location for my growing collection of vibe-coded / AI-assisted HTML+JavaScript tools. I wrote several longer pieces about this throughout the year: Here’s how I use LLMs to help me write code Adding AI-generated descriptions to my tools collection Building a tool to copy-paste share terminal sessions using Claude Code for web Useful patterns for building HTML tools—my favourite post of the bunch. The new browse all by month page shows I built 110 of these in 2025!
Simon Willison vibe coded over 100 personal tools in 2025. This chimes with what Frank and Martijn were suggesting. Up above he also indicates that it is something that became possible at this scale only in 2025 too.
They also shipped Gemini CLI (their open source command-line coding agent, since forked by Qwen for Qwen Code), Jules (their asynchronous coding agent),
Gemini has a CLI version, that is open source Chinese Qwen forked it for Qwen Code Jules is a Google coding agent.
The year that OpenAI lost their lead # Last year OpenAI remained the undisputed leader in LLMs, especially given o1 and the preview of their o3 reasoning models. This year the rest of the industry caught up. OpenAI still have top tier models, but they’re being challenged across the board. In image models they’re still being beaten by Nano Banana Pro. For code a lot of developers rate Opus 4.5 very slightly ahead of GPT-5.2 Codex Max. In open weight models their gpt-oss models, while great, are falling behind the Chinese AI labs. Their lead in audio is under threat from the Gemini Live API. Where OpenAI are winning is in consumer mindshare. Nobody knows what an “LLM” is but almost everyone has heard of ChatGPT. Their consumer apps still dwarf Gemini and Claude in terms of user numbers. Their biggest risk here is Gemini. In December OpenAI declared a Code Red in response to Gemini 3, delaying work on new initiatives to focus on the competition with their key products.
Author sees OpenAI losing their lead in 2025: Nano Banana Pro (Google) is a better image generating model Opus 4.5. better or equal than GPT5.2 Codex Max for coding Chinese labs have better open weight models Audio, Gemini Live API (google) is direct threat.
OpenAI mostly has better consumer visibility (yup, ChatGPT is the general term for LLMs, Aspirin style)
It is still strongest in consumer facing apps, but Gemini 3 is a challenger there.
none of the Chinese labs have released their full training data or the code they used to train their models, but they have been putting out detailed research papers that have helped push forward the state of the art, especially when it comes to efficient training and inference.
perhaps bc they feed on existing efforts, and perhaps bc like the US models it is based on lots of copyright breaches.
It turns out tools like Claude Code and Codex CLI can burn through enormous amounts of tokens once you start setting them more challenging tasks, to the point that $200/month offers a substantial discount.
running claudecode uses quite a bit of tokens, making 200usd/month a good deal for heavy users. I can believe that, also bc the machine doesn't care about the amount of tokens it uses during 'reasoning'. Some things I tried, it went through a whole bunch of steps and pages of scrolling output texts, to end up removing one word from a file. My suspicious half thinks, that if an AI company can influence the amount of tokens you use vibecoding, it will.
the trade-off: using an agent without the safety wheels feels like a completely different product. A big benefit of asynchronous coding agents like Claude Code for web and Codex Cloud is that they can run in YOLO mode by default, since there’s no personal computer to damage. I run in YOLO mode all the time, despite being deeply aware of the risks involved. It hasn’t burned me yet... ... and that’s the problem.
yolo mode, lol. If you do it, it feels like a very diff tool, and that is the lure / siren song.
As-of December 2nd Anthropic credit Claude Code with $1bn in run-rate revenue!
wow, $1bn revenue ClaudeCode, a CLI tool!
Claude Code and friends have conclusively demonstrated that developers will embrace LLMs on the command line, given powerful enough models and the right harness.
Claude Code is what led devs to embrace CLI more.
I love the asynchronous coding agent category. They’re a great answer to the security challenges of running arbitrary code execution on a personal laptop and it’s really fun being able to fire off multiple tasks at once—often from my phone—and get decent results a few minutes later.
async coding agents: prompt and forget
Vendor-independent options include GitHub Copilot CLI, Amp, OpenCode, OpenHands CLI, and Pi. IDEs such as Zed, VS Code and Cursor invested a lot of effort in coding agent integration as well.
non-vendor related coding agents. - [ ] which of these can I run locally? / integrate into VS Code
The major labs all put out their own CLI coding agents in 2025 Claude Code Codex CLI Gemini CLI Qwen Code Mistral Vibe
list of command line coding agents by major vendors
coding agents—LLM systems that can write code, execute that code, inspect the results and then iterate further.
author def of coding agents
The year of coding agents and Claude Code # The most impactful event of 2025 happened in February, with the quiet release of Claude Code. I say quiet because it didn’t even get its own blog post!
Claude Code (feb 2025) seen by author as most impactful release of 2025.
It turned out that the real unlock of reasoning was in driving tools. Reasoning models with access to tools can plan out multi-step tasks, execute on them and continue to reason about the results such that they can update their plans to better achieve the desired goal. A notable result is that AI assisted search actually works now. Hooking up search engines to LLMs had questionable results before, but now I find even my more complex research questions can often be answered by GPT-5 Thinking in ChatGPT. Reasoning models are also exceptional at producing and debugging code. The reasoning trick means they can start with an error and step through many different layers of the codebase to find the root cause. I’ve found even the gnarliest of bugs can be diagnosed by a good reasoner with the ability to read and execute code against even large and complex codebases.
Reasoning models are useful for: running tools (mcp) search now works debugging/writing code
Anthropic is acquiring Bun
Bun is a js runtime, Anthropic bought it to roll into Claude code
In November, Claude Code achieved a significant milestone: just six months after becoming available to the public, it reached $1 billion in run-rate revenue
Anthropic reached $1bn revenue with ClaudeCode within 6 months.
HyperDoc is an information substrate that integrates software with traditional hypermedia. Narratives can explain software, by referring to and transcluding source code. Source code can refer to documentation and examples. Diagrams can refer to the code or data they document, but also to the code that implements them. Small tailor-made software tools allow interacting with data, but also serve as documentation for how to work with that data.
Interesting, as the possibilities are similar to Cardumem's as one of the main notations there is for transclusions, even of its own source code at some particular commit. Also, there Cardumem shares the idea of tailor made software tools, but the difference is that its context is related with interpersonal and community knowledge and memory care, preservation and management and the tech stack is different (Lua based, instead of Common Lisp).
empêche l'exécution du code
Quel code ? Dans notre exemple, on clique sur "Partager" une fois que toute la page ait été chargée. Je ne comprends pas trop l'utilité de "preventDefault()". Je pensais qu'on l'ajoutait afin d'éviter de perdre du temps en attendant le rechargement de la page, ou bien (peut-être) pour ne pas perdre les informations fournies par l'utilisateur, mais apparemment, on fait ça pour une autre raison (que je n'ai pas compris).
What is open access and open research?Open access (OA) refers to the free, immediate, online availability of research outputs such as journal articles or books, combined with the rights to use these outputs fully in the digital environment. OA content is open to all, with no access fees.Open research goes beyond the boundaries of publications to consider all research outputs – from data to code and even open peer review. Making all outputs of research as open and accessible as possible means research can have a greater impact, and help to solve some of the world’s greatest challenges. How can I publish my work open access?As the author of a research article or book, you have the ability to ensure that your research can be accessed and used by the widest possible audience. Springer Nature supports immediate gold OA as the most open, least restrictive form of OA: authors can choose to publish their research article in a fully OA journal, a hybrid or transformative journal, or as an OA book or OA chapter.Alternatively, where articles, books or chapters are published via the subscription route, Springer Nature allows authors to archive the accepted version of their manuscript on their own personal website or their funder’s or institution’s repository, for public release after an embargo period (green OA). Find out more.Why should I publish OA?Increased citation and usage: Studies have shown that open access articles are viewed and cited more often than articles behind a paywall.Wider collaboration: Open access publications and data enable researchers to carry out collaborative research on a global scale.Greater public engagement: Content is available to those who can't access subscription content.Faster impact: With Creative Commons licences, researchers are empowered to build on existing research quickly.Increased interdisciplinary conversation: Open access journals that cross multiple disciplines help researchers connect more easily and provide greater visibility of their research.Compliance with open access mandates: Open access journals and books comply with major funding policies internationally. What are Creative Commons licences?Open access works published by Springer Nature are published under Creative Commons licences. These provide an industry-standard framework to support re-use of OA material. Please see Springer Nature’s guide to licensing, copyright and author rights for journal articles and books and chapters for further information.How do I pay for open access?As costs are involved in every stage of the publication process, authors are asked to pay an open access fee in order for their article to be published open access under a creative commons license. Springer Nature offers a free open access support service to make it easier for our authors to discover and apply for funding to cover article processing charges (APCs) and/or book processing charges (BPCs). Find out more.What is open data?We believe that all research data, including research files and code, should be as open as possible and want to make it easier for researchers to share the data that support their publications, making them accessible and reusable. Find out more about our research data services and policies.What is a preprint?A preprint is a version of a scientific manuscript posted on a public server prior to formal peer review. Once posted, the preprint becomes a permanent part of the scientific record, citable with its own unique DOI. Early sharing is recommended as it offers an opportunity to receive feedback on your work, claim priority for a discovery, and help research move faster. In Review is one of the most innovative preprint services available, offering real time updates on your manuscript’s progress through peer review. Discover In Review and its benefits.What is open peer review?Open peer review refers to the process of making peer reviewer reports openly available. Many publishers and journals offer some form of open peer review, including BMC who were one of the first publishers to open up peer review in 1999. Find out more.
Control Over Digital Expression
CODE (not the #pkm [[CODE 20200929164536]]
deep concern about a corporate-driven, tech-justified trivialization of human attention and the prospective stupefaction of our collective abilities to solve humanity's gigantic problems. His alternative takes time to build over the course of the book. His agency-centered “MORAL” standard for code emerges not from utopian hopes for the future but from the history of programming itself, freed from its current capture by technology platforms.
a, MORAL, as acronym, I came across that somewhere.
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
In this manuscript, Chengjian Zhao et al. focused on the interactions between vascular, biliary, and neural networks in the liver microenvironment, addressing the critical bottleneck that the lack of high-resolution 3D visualization has hindered understanding of these interactions in liver disease.
Strengths:
This study developed a high-resolution multiplex 3D imaging method that integrates multicolor metallic compound nanoparticle (MCNP) perfusion with optimized CUBIC tissue clearing. This method enables the simultaneous 3D visualization of spatial networks of the portal vein, hepatic artery, bile ducts, and central vein in the mouse liver. The authors reported a perivascular structure termed the Periportal Lamellar Complex (PLC), which is identified along the portal vein axis. This study clarifies that the PLC comprises CD34⁺Sca-1⁺ dual-positive endothelial cells with a distinct gene expression profile, and reveals its colocalization with terminal bile duct branches and sympathetic nerve fibers under physiological conditions.<br />
Weaknesses:
This manuscript is well-written, organized, and informative. However, there are some points that need to be clarified.
(1) After MCNP-dye injection, does it remain in the blood vessels, adsorb onto the cell surface, or permeate into the cells? Does the MCNP-dye have cell selectivity?
The experimental results showed that after injection, the MCNP series nanoparticles predominantly remained within the lumens of blood vessels and bile ducts, with their tissue distribution determined by physical perfusion. No diffusion of the dye signal into the surrounding parenchymal tissue was observed, nor was there any evidence of adsorption onto the cell surface or entry into cells. The newly added Supplementary Figure S2A–H further confirmed this feature, demonstrating that the dye signals were strictly confined to the luminal space, clearly delineating the continuous course of blood vessels and the branching morphology of bile ducts. These findings strongly support the conclusion that “MCNP dyes are distributed exclusively within the luminal compartments.”
Therefore, the MCNP dyes primarily serve as intraluminal tracers within the tissue rather than as labels for specific cell types.
(2) All MCNP-dyes were injected after the mice were sacrificed, and the mice's livers were fixed with PFA. After the blood flow had ceased, how did the authors ensure that the MCNP-dyes were fully and uniformly perfused into the microcirculation of the liver?
Thank you for the reviewer’s valuable comments. Indeed, since all MCNP dyes were perfused after the mice were euthanized and blood circulation had ceased, we cannot fully ensure a homogeneous distribution of the dye within the hepatic microcirculation. The vascular labeling technique based on metallic nanoparticle dyes used in this study offers clear imaging, stable fluorescence intensity, and multiplexing advantages; however, it also has certain limitations. The main issue is that the dye distribution within the hepatic parenchyma can be affected by factors such as lobular overlap, local tissue compression, and variations in vascular pathways, resulting in regional inhomogeneity of dye perfusion. This is particularly evident in areas where multiple lobes converge or where anatomical structures are complex, leading to local dye accumulation or over-perfusion.
In our experiments, we attempted to minimize local blockage or over-perfusion by performing PBS pre-flushing and low-pressure, constant-speed perfusion. Nevertheless, localized dye accumulation or uneven distribution may still occur in lobe junctions or structurally complex regions. Such variation represents one of the methodological limitations. Overall, the dye signals in most samples remained confined to the vascular and biliary lumens, and the distribution pattern was highly reproducible.
We have addressed this issue in the Discussion section but would like to emphasize here that, although this system has clear advantages, it remains sensitive to anatomical variability in the liver—such as lobular overlap and vascular heterogeneity. At vascular junctions, local perfusion inhomogeneity or dye accumulation may occur; therefore, injection strategies and perfusion parameters should be adjusted according to liver size and vascular condition to improve reproducibility and imaging quality. It should also be noted that the results obtained using this method primarily aim to visualize the overall and fine anatomical structures of the hepatic vascular system rather than to quantitatively reflect hemodynamic processes. In the future, we plan to combine in vivo perfusion or dynamic fluid modeling to further validate the diffusion characteristics of the dyes within the hepatic microcirculation.
(3) It is advisable to present additional 3D perspective views in the article, as the current images exhibit very weak 3D effects. Furthermore, it would be better to supplement with some videos to demonstrate the 3D effects of the stained blood vessels.
Thank you for the reviewer’s valuable comments. In response to the suggestion, we have added perspective-rendered images generated from the 3D staining datasets to provide a more intuitive visualization of the spatial morphology of the hepatic vasculature. These images have been included in Figure S2A–J. In addition, we have prepared supplementary videos (available upon request) that dynamically display the three-dimensional distribution of the stained vessels, further enhancing the spatial perception and visualization of the results.
(4) In Figure 1-I, the authors used MCNP-Black to stain the central veins; however, in addition to black, there are also yellow and red stains in the image. The authors need to explain what these stains are in the legend.
Thank you for the reviewer’s constructive comment. In Figure 1I, MCNP-Black labels the central vein (black), MCNP-Yellow labels the portal vein (yellow), MCNP-Pink labels the hepatic artery (pink), and MCNP-Green labels the bile duct (green). We have revised the Figure 1 legend to include detailed descriptions of the color signals and their corresponding structures to avoid any potential confusion.
(5) There is a typo in the title of Figure 4F; it should be "stem cell".
Thank you for the reviewer’s careful correction. We have corrected the spelling error in the title of Figure 4F to “stem cell” and updated it in the revised manuscript.
(6) Nuclear staining is necessary in immunofluorescence staining, especially for Figure 5e. This will help readers distinguish whether the green color in the image corresponds to cells or dye deposits.
We thank the reviewer for the valuable suggestion. We understand that nuclear staining can help determine the origin of fluorescence signals. However, in our three-dimensional imaging system, the deep signal acquisition range after tissue clearing often causes nuclear dyes such as DAPI to generate highly dense and widespread fluorescence, especially in regions rich in vascular structures, which can obscure the fine vascular and perivascular details of interest. Therefore, this study primarily focuses on high-resolution visualization of the spatial architecture of the vascular and biliary systems. We have added an explanation regarding this point in Figures S2I–J.
Reviewer #2 (Public review):
Summary:
The present manuscript of Xu et al. reports a novel clearing and imaging method focusing on the liver. The authors simultaneously visualized the portal vein, hepatic artery, central vein, and bile duct systems by injecting metal compound nanoparticles (MCNPs) with different colors into the portal vein, heart left ventricle, inferior vena cava, and the extrahepatic bile duct, respectively. The method involves: trans-cardiac perfusion with 4% PFA, the injection of MCNPs with different colors, clearing with the modified CUBIC method, cutting 200 micrometer thick slices by vibratome, and then microscopic imaging. The authors also perform various immunostaining (DAB or TSA signal amplification methods) on the tissue slices from MCNP-perfused tissue blocks. With the application of this methodical approach, the authors report dense and very fine vascular branches along the portal vein. The authors name them as 'periportal lamellar complex (PLC)' and report that PLC fine branches are directly connected to the sinusoids. The authors also claim that these structures co-localize with terminal bile duct branches and sympathetic nerve fibers, and contain endothelial cells with a distinct gene expression profile. Finally, the authors claim that PLC-s proliferate in liver fibrosis (CCl4 model) and act as a scaffold for proliferating bile ducts in ductular reaction and for ectopic parenchymal sympathetic nerve sprouting.
Strengths:
The simultaneous visualization of different hepatic vascular compartments and their combination with immunostaining is a potentially interesting novel methodological approach.
Weaknesses:
This reviewer has several concerns about the validity of the microscopic/morphological findings as well as the transcriptomics results. In this reviewer's opinion, the introduction contains overstatements regarding the potential of the method, there are severe caveats in the method descriptions, and several parts of the Results are not fully supported by the documentation. Thus, the conclusions of the paper may be critically viewed in their present form and may need reconsideration by the authors.
We sincerely thank the reviewer for the thorough evaluation and constructive comments on our study. We fully understand and appreciate the reviewer’s concerns regarding the methodological validity and interpretation of the results. In response, we have made comprehensive revisions and additions to the manuscript as follows:
First, we have carefully revised the Introduction and Discussion sections to provide a more balanced description of the methodological potential, removing statements that might be considered overstated, and clarifying the applicable scope and limitations of our approach (see the revised Introduction and Discussion).
Second, we have substantially expanded the Methods section with detailed information on model construction, imaging parameters, data processing workflow, and technical aspects of the single-cell transcriptomic reanalysis, to enhance the transparency and reproducibility of the study.
Third, we have added additional references and explanatory notes in the Results section to better support the main conclusions (see Section 6 of the Results).
Finally, we have rechecked and validated all experimental data, and conducted a verification analysis using an independent single-cell RNA-seq dataset (Figure S6). The results confirm that the morphological observations and transcriptomic findings are consistent and reproducible across independent experiments.
We believe these revisions have greatly strengthened the reliability of our conclusions and the overall scientific rigor of the manuscript. Once again, we sincerely appreciate the reviewer’s valuable comments, which have been very helpful in improving the logic and clarity of our work.
Reviewer #3 (Public review):
Summary:
In the reviewed manuscript, researchers aimed to overcome the obstacles of high-resolution imaging of intact liver tissue. They report successful modification of the existing CUBIC protocol into Liver-CUBIC, a high-resolution multiplex 3D imaging method that integrates multicolor metallic compound nanoparticle (MCNP) perfusion with optimized liver tissue clearing, significantly reducing clearing time and enabling simultaneous 3D visualization of the portal vein, hepatic artery, bile ducts, and central vein spatial networks in the mouse liver. Using this novel platform, the researchers describe a previously unrecognized perivascular structure they termed Periportal Lamellar Complex (PLC), regularly distributed along the portal vein axis. The PLC originates from the portal vein and is characterized by a unique population of CD34⁺Sca-1⁺ dual-positive endothelial cells. Using available scRNAseq data, the authors assessed the CD34⁺Sca-1⁺ cells' expression profile, highlighting the mRNA presence of genes linked to neurodevelopment, biliary function, and hematopoietic niche potential. Different aspects of this analysis were then addressed by protein staining of selected marker proteins in the mouse liver tissue. Next, the authors addressed how the PLC and biliary system react to CCL4-induced liver fibrosis, implying PLC dynamically extends, acting as a scaffold that guides the migration and expansion of terminal bile ducts and sympathetic nerve fibers into the hepatic parenchyma upon injury.
The work clearly demonstrates the usefulness of the Liver-CUBIC technique and the improvement of both resolution and complexity of the information, gained by simultaneous visualization of multiple vascular and biliary systems of the liver at the same time. The identification of PLC and the interpretation of its function represent an intriguing set of observations that will surely attract the attention of liver biologists as well as hepatologists; however, some claims need more thorough assessment by functional experimental approaches to decipher the functional molecules and the sequence of events before establishing the PLC as the key hub governing the activity of biliary, arterial, and neuronal liver systems. Similarly, the level of detail of the methods section does not appear to be sufficient to exactly recapitulate the performed experiments, which is of concern, given that the new technique is a cornerstone of the manuscript.
Nevertheless, the work does bring a clear new insight into the liver structure and functional units and greatly improves the methodological toolbox to study it even further, and thus fully deserves the attention of readers.
Strengths:
The authors clearly demonstrate an improved technique tailored to the visualization of the liver vasulo-biliary architecture in unprecedented resolution.
This work proposes a new biological framework between the portal vein, hepatic arteries, biliary tree, and intrahepatic innervation, centered at previously underappreciated protrusions of the portal veins - the Periportal Lamellar Complexes (PLCs).
Weaknesses:
Possible overinterpretation of the CD34+Sca1+ findings was built on re-analysis of one scRNAseq dataset.
Lack of detail in the materials and methods section greatly limits the usefulness of the new technique to other researchers.
We thank the reviewer for this important comment. We agree that when conclusions are mainly based on a single dataset, overinterpretation should be avoided. In response to this concern, we have carefully re-evaluated and clearly limited the scope of our interpretation of the scRNA-seq analysis. In addition, we performed a validation analysis using an independent single-cell RNA-seq dataset (see new Figure S6), which consistently confirmed the presence and characteristic transcriptional profile of the periportal CD34⁺Sca1⁺ endothelial cell population. These supplementary analyses strengthen the robustness of our findings and address the reviewer’s concern regarding potential overinterpretation.
In the revised manuscript, we have also greatly expanded the Materials and Methods section by providing detailed information on sample preparation, imaging parameters, data processing workflow, and single-cell reanalysis procedures. These revisions substantially improve the transparency and reproducibility of our methodology, thereby enhancing the usability and reference value of this technique for other researchers.
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
Introduction
(1) In general, the Introduction is very lengthy and repetitive. It needs extensive shortening to a maximum of 2 A4 pages.
We thank the reviewer for the valuable suggestions. We have thoroughly condensed and restructured the Introduction, removing redundant content and merging related paragraphs to make the theme more focused and the logic clearer. The revised Introduction has been shortened to within two A4 pages, emphasizing the scientific question, innovation, and technical approach of the study.
(2) Please correct this erroneous sentence:
'...the liver has evolved the most complex and densely n organized vascular network in the body, consisting primarily of the portal vein system, central vein system, hepatic artery system, biliary system, and intrahepatic autonomic nerve network [6, 7].'
We thank the reviewer for pointing out this spelling error. The revised sentence is as follows:
“…the liver has evolved the most complex and densely organized ductal-vascular network in the body, consisting primarily of the portal vein system, central vein system, hepatic artery system, biliary system, and intrahepatic autonomic nerve network [6, 7].”
(3) '...we achieved a 63.89% improvement in clearing efficiency and a 20.12% increase in tissue transparency'
Please clarify what you exactly mean by 'clearing efficiency' and 'increased tissue transparency'.
We thank the reviewer for the valuable comments and have clarified the relevant terminology in the revised manuscript.
“Clearing efficiency” refers to the improvement in the time required for the liver tissue to become completely transparent when treated with the optimized Liver-CUBIC protocol (40% urea + H₂O₂), compared with the conventional CUBIC method. In this study, the clearing time was reduced from 9 days to 3.25 days, representing a 63.89% increase in time efficiency.
“Tissue transparency” refers to the ability of the cleared tissue to transmit visible light. We quantified the optical transparency by measuring light transmittance across the 400–900 nm wavelength range using a microplate reader. The results showed that the average transmittance increased by 20.12%, indicating that Liver-CUBIC treatment markedly enhanced the optical clarity of the liver tissue.
(4) I am concerned about claiming this imaging method as real '3D imaging'. Namely, while the authors clear full lobes, they actually cut the cleared lobes into 200-micrometer-thick slices and perform further microscopy imaging on these slices. Considering that they focus on ductular structures of the liver (such as vasculature, bile duct system, and innervations), 200 micrometer allows a very limited 3D overview, particularly in comparison with the whole-mount immuno-imaging methods combined with light sheet microscopy (such as Adori 2021, Liu 2021, etc). In this context, I feel several parts of the Introduction to be an overstatement: besides of emphasizing the advantages of the technique (such as simultaneous visualization of different hepatic vascular compartments and the bile duct system by MCNPs, the combination with immunostainings), the authors must honestly discuss the limitations (such as limited tissue overview, potential dye perfusion problems - uneven distribution of the dye etc).
We appreciate the reviewer’s insightful comments. It is true that most of the imaging depth in this study was limited to approximately 200 μm, and thus it could not achieve whole-liver three-dimensional imaging comparable to light-sheet microscopy. However, the primary focus of our study was to resolve the microscopic intrahepatic architecture, particularly the spatial relationships among blood vessels, bile ducts, and nerve fibers. Through high-resolution imaging of thick tissue sections, combined with MCNP-based multichannel labeling and immunofluorescence co-staining, we were able to accurately delineate the three-dimensional distribution of these microstructures within localized regions.
In addition to thick-section imaging, we also obtained whole-lobe dye perfusion data (as shown in Figure S1F), which comprehensively depict the three-dimensional branching patterns and distribution of the vascular systems within the liver lobe. These images were acquired from intact liver lobes perfused with MCNP dyes, revealing a continuous vascular network extending from major trunks to peripheral branches, thereby demonstrating that our approach is also capable of achieving organ-level visualization.
We have added this image and a corresponding description in the revised manuscript to more comprehensively present the coverage of our imaging system, and we have incorporated this clarification into the Discussion section.
Method
(5) More information may be needed about MCNPs:
a) As reported, there are nanoparticles with different colors in brightfield microscopy, but the particles are also excitable in fluorescence microscopy. Would you please provide a summary about excitation/emission wavelengths of the different MCNPs? This is crucial to understand to what extent the method is compatible with fluorescence immunohistochemistry.
We thank the reviewer for the careful attention and professional suggestion. We fully agree that this issue is critical for evaluating the compatibility of our method with fluorescent immunohistochemistry. Different types of metal compound nanoparticles (MCNPs) have clearly distinguishable spectral properties:
- MCNP-Green and MCNP-Yellow: AF488-matched spectra, with excitation/emission wavelengths of 495/519 nm.
- MCNP-Pink: Designed for far-red spectra, with excitation/emission wavelengths of 561/640 nm.
- MCNP-Black: Non-fluorescent, appearing black under bright-field microscopy only.
The above information has been added to the Materials and Methods section.
b) Also, is there more systematic information available concerning the advantage of these particles compared to 'traditional' fluorescence dyes, such as Alexa fluor or Cy-dyes, in fluorescence microscopy and concerning their compatibility with various tissue clearing methods (e.g., with the frequently used organic-solvent-based methods)?
We thank the reviewer for the detailed question. Compared with conventional organic fluorescent dyes, MCNP offers the following advantages:
- Enhanced photostability: Its inorganic core-shell structure resists fading even after hydrogen peroxide bleaching.
- High signal stability: Fluorescence is maintained during aqueous-based clearing (e.g., CUBIC) and multiple rounds of staining without quenching.
We appreciate the reviewer’s suggestion. In our Liver-CUBIC system, MCNP nanoparticles exhibited excellent multi-channel labeling stability and fluorescence signal retention. Regarding compatibility with other clearing methods (e.g., SCAFE, SeeDB, CUBIC), since these methods have limited effectiveness for whole-liver clearing (see Figure 2 of Tainaka, et al. 2014) and cannot meet the requirements for high-resolution microstructural imaging in this study, we consider further testing of their compatibility unnecessary.
In summary, MCNP dye demonstrates superior signal stability and spectral separation compared with conventional organic fluorescent dyes in multi-channel, long-term, high-transparency three-dimensional tissue imaging.
c) When you perfuse these particles, to which structures do they bind inside the ducts (vessels, bile ducts)? Is the 48h post-fixation enough to keep them inside the tubes/bind them to the vessel walls? Is there any 'wash-out' during the complex cutting/staining procedure? E.g., in Figure 2D: the 'classical' hepatic artery in the portal triad is not visible - but the MCNP apparently penetrated to the adjacent sinusoids at the edge of the lobulus. Also, in Figure 3B, there is a significant mismatch between the MNCP-green (bile duct) signal and the CD19 (epithelium marker) immunostaining. Please discuss these.
The experimental results showed that following injection, MCNP nanoparticles primarily remained within the vascular and biliary lumens, and their tissue distribution depended on physical perfusion. No dye signal was observed to diffuse into the surrounding parenchyma, nor did the particles adhere to cell surfaces or enter cells. The newly added Supplementary Figures S2A–H further confirm this feature: the dye signal is strictly confined within the lumens, clearly delineating continuous vascular paths and biliary branching patterns, strongly supporting the conclusion that “MCNP dye is distributed only within luminal spaces.”
Thus, MCNP dye mainly serves as an intraluminal tracer rather than a label for specific cell types.
We provide the following explanations and analyses regarding MCNP distribution in the hepatic vascular and biliary systems and its post-fixation stability:
- Potential signal displacement during sectioning/immunostaining: During slicing and immunostaining, a small number of particles may be washed away due to mechanical cutting or washing steps; however, the overall three-dimensional structure retains high spatial fidelity.
- Observation in Figure 2D: MCNP was seen entering the sinusoidal spaces at the lobule periphery, but hepatic arteries were not visible, likely due to limitations in section thickness. Although arteries were not apparent in this slice, arterial distribution around the portal vein is visible in Figure 2C. It should be noted that Figures 2C, D, and E do not represent whole-liver imaging, so not all regions necessarily contain visible hepatic arteries. For easier identification, the main hepatic artery trunk is highlighted in cyan in Figure 2E.
- Incomplete biliary signal in Figure 3B: This may be because CK19 labeling only covers biliary epithelial cells, whereas MCNP-green distributes throughout the biliary lumen. In Figure 3B, the terminal MCNP-green signal exhibits irregular polygonal structures, which we interpret as the canalicular regions.
(6) Which fixative was used for 48h of postfixation (step 6) after MCNP injections?
After MCNP injection, mouse livers were post-fixed in 4% paraformaldehyde (PFA) for 48 hours. This fixation condition effectively “locks” the MCNP particles within the vascular and biliary lumens, maintaining their spatial positions, while also being compatible with subsequent sectioning and multi-channel immunostaining analyses.
The above information has been added to the Materials and Methods section
(7) What is the 'desired thickness' in step 7? In the case of immunostained tissue, a 200-micrometer slice thickness is mentioned. However, based on the Methods, it is not completely clear what the actual thickness of the tissue was that was examined ultimately in the microscopes, and whether or not the clearing preceded the cutting or vice versa.
We appreciate the reviewer’s question. The “desired thickness” referred to in step 7 of the manuscript corresponds to the thickness of tissue sections used for immunostaining and high-resolution microscopic imaging, which is typically around 200 µm. We selected 200 µm because this thickness is sufficient to observe the PLC structure in its entirety, allows efficient staining, and preserves tissue architecture well. Other researchers may choose different section thicknesses according to their experimental needs.
In this study, the processing order for immunostained tissue samples was sectioning followed by clearing, as detailed below:
Section Thickness
To ensure antibody penetration and preservation of three-dimensional structure, tissue sections were typically cut to ~200 µm. Thicker sections can be used if more complete three-dimensional structures are required, but adjustments may be needed based on antibody penetration and fluorescence detection conditions.
Clearing Sequence
After sectioning, slices were processed using the Liver-CUBIC aqueous-based clearing system.
(8) More information is needed concerning the 'deep-focus microscopy' (Keyence), the applied confocal system, and the THUNDER 'high resolution imaging system': basic technical information, resolutions, objectives (N.A., working distance), lasers/illumination, filters, etc.
In this study, all liver lobes (left, right, caudate, and quadrate lobes) were subjected to Liver-CUBIC aqueous-based clearing to ensure uniform visualization of MCNP fluorescence and immunolabeling throughout the three-dimensional imaging of the entire liver.
The above information has been added to the Materials and Methods section.
Imaging Systems and Settings
VHX-6000 Extended Depth-of-Field Microscope: Objective: VH-Z100R, 100×–1000×; resolution: 1 µm (typical); illumination: coaxial reflected; transmitted illumination on platform: ON.
Zeiss Confocal Microscope (980): Objectives: 20× or 40×; image size: 1024 × 1024. Fluorescence detection was set up in three channels:
- Channel 1: 639 nm laser, excitation 650 nm, emission 673 nm, detection range 673–758 nm, corresponding to Cy5-T1 (red).
- Channel 2: 561 nm laser, excitation 548 nm, emission 561 nm, detection range 547–637 nm, corresponding to Cy3-T2 (orange).
- Channel 3: 488 nm laser, excitation 493 nm, emission 517 nm, detection range 490–529 nm, corresponding to AF488-T3 (green).
Leica THUNDER Imager 3D Tissue: Fluorescence detection in two channels:
- Channel 1: FITC channel (excitation 488 nm, emission ~520 nm).
- Channel 2: Orange-red channel (excitation/emission 561/640 nm).<br /> Equipped with matching filter sets to ensure signal separation.
The above information has been added to the Materials and Methods section.
(9) Liver-CUBIC, step 2: which lobe(s) did you clear (...whole liver lobes...).
In this study, all liver lobes (left, right, caudate, and quadrate lobes) were subjected to Liver-CUBIC aqueous-based clearing to ensure uniform visualization of MCNP fluorescence and immunolabeling throughout the three-dimensional imaging of the entire liver.
The above information has been added to the Materials and Methods section.
(10) For the DAB and TSA IHC stainings, did you use free-floating slices, or did you mount the vibratome sections and do the staining on mounted sections?
In this study, fixed livers were first sectioned into thick slices (~200 µm) using a vibratome. Subsequently, DAB and TSA immunohistochemical (IHC) staining were performed on free-floating sections. During the entire staining process, the slices were kept floating in the solutions, ensuring thorough antibody penetration in the thick sections while preserving the three-dimensional tissue architecture, thereby facilitating multiple rounds of staining and three-dimensional imaging.
(11) Regarding the 'transmission quantification': this was measured on 1 mm thick slices. While it is interesting to make a comparison between different clearing methods in general, one must note that it is relatively easy to clear 1mm thick tissue slices with almost any kind of clearing technique and in any tissues. The 'real' differences come with thicker blocks, such as >5mm in the thinnest dimension. Do you have such experiences (e.g., comparison in whole 'left lateral liver lobes')?
In this study, we performed three-dimensional visualization of entire liver lobes to depict the distribution of MCNPs and the overall spatial architecture of the vascular and biliary systems (Figure S1F). However, due to the limitations of the plate reader and fluorescence imaging systems in terms of spatial resolution and light penetration depth, quantitative analyses were conducted only on tissue sections approximately 1 mm thick.
Regarding the comparative quantification of different clearing methods, as the reviewer noted, nearly all aqueous- or organic solvent–based clearing techniques can achieve relatively uniform transparency in 1 mm-thick tissue sections, so differences at this thickness are limited. We have not yet conducted systematic comparisons on whole-lobe sections thicker than 5 mm and therefore cannot provide “true” difference data for thicker tissues.
(12) There is no method description for the ELMI studies in the Methods.
Transmission Electron Microscopy (TEM) Analysis of MCNPs
Before imaging, the MCNP dye solution was centrifuged at 14,000 × g for 10 minutes at 4 °C to remove aggregates and impurities. The supernatant was collected, diluted 50-fold, and 3–4 μL of the sample was applied onto freshly glow-discharged Quantifoil R1.2/1.3 copper grids (Electron Microscopy Sciences, 300 mesh). The sample was allowed to sit for 30 seconds to enable particle adsorption, after which excess liquid was gently wicked away with filter paper and the grid was air-dried at room temperature. The sample was then negatively stained with 1% uranyl acetate for 30 seconds and air-dried again before imaging.
Negative-stain TEM images were acquired using a JEOL JEM-1400 transmission electron microscope operating at 120 kV and equipped with a CCD camera. Data acquisition followed standard imaging conditions.
The above information has been added to the Materials and Methods section.
(13) Please, provide a method description for the applied CCl4 cirrhosis model. This is completely missing.
(1) Under a fume hood, carbon tetrachloride (CCl₄) was dissolved in corn oil at a 1:3 volume ratio to prepare a working solution, which was filtered through a 0.2 μm filter into a 30 mL glass vial. In our laboratory, to mimic chronic injury, mice in the experimental group were intraperitoneally injected at a dose of 1 mL/kg body weight per administration.
(2) Mice were carefully removed from the cage and placed on a scale to record body weight for calculation of the injection volume.
(3) The needle cap was carefully removed, and the required volume of the pre-prepared CCl₄ solution was drawn into the syringe. The syringe was gently flicked to remove any air bubbles.
(4) Mice were placed on a textured surface (e.g., wire cage) and restrained. When the mouse was properly positioned, ideally with the head lowered about 30°, the left lower or right lower abdominal quadrant was identified.
(5) Holding the syringe at a 45° angle, with the bevel facing up, the needle was inserted approximately 4–5 mm into the abdominal wall, and the calculated volume of CCl₄ was injected.
(6) Mice were returned to their cage and observed for any signs of discomfort.
(7) Needles and syringes were disposed of in a sharps container without recapping. A new syringe or needle was used for each mouse.
(8) To establish a progressive liver fibrosis model, injections were administered twice per week (e.g., Monday and Thursday) for 3 or 6 consecutive weeks (n=3 per group). Control mice were injected with an equal volume of corn oil for 3 or 6 weeks (n=3 per group).
(9) Forty-eight hours after the last injection, mice were euthanized by cervical dislocation, and livers were rapidly harvested. Portions of the liver were processed for paraffin embedding and histological sectioning, while the remaining tissue was either immediately frozen or used for subsequent molecular biology analyses.
The above information has been added to the Materials and Methods section.
(14) Please provide a method description for the quantifications reported in Figures 5D, 5F, and 6E.
ImageJ software was used to analyze 3D stained images (Figs. 5F, 6E), and the ultra-depth-of-field 3D analysis module was used to analyze 3D DAB images (Fig. 5D). The specific steps are as follows:
Figure 5D: DAB-stained 3D images from the control group and the CCl<sub>4</sub> 6-week (CCl<sub>4</sub>-6W) group were analyzed. For each group, 20 terminal bile duct branch nodes were randomly selected, and the actual path distance along the branch to the nearest portal vein surface was measured. All measurements were plotted as scatter plots to reflect the spatial extension of bile ducts relative to the portal vein under different conditions.
Figure 5F: TSA 3D multiplex-stained images from the control group, CCl<sub>4</sub> 3-week (CCl<sub>4</sub>-3W), and CCl<sub>4</sub> 6-week (CCl<sub>4</sub>-6W) groups were analyzed. For each group, 5 terminal bile duct branch nodes were randomly selected, and the actual path distance along the branch to the nearest portal vein surface was measured. Measurements were plotted as scatter plots to illustrate bile duct spatial extension.
Figure 6E: TSA 3D multiplex-stained images from the control, CCl<sub>4</sub>-3W, and CCl<sub>4</sub>-6W groups were analyzed. For each group, 5 terminal nerve branch nodes were randomly selected, and the actual path distance along the branch to the nearest portal vein surface was measured. Scatter plots were generated to depict the spatial distribution of nerves under different treatment conditions.
(15) Please provide a method description for the human liver samples you used in Figure S6. Patient data, fixation, etc...
The human liver tissue samples shown in Figure S6 were obtained from adjacent non-tumor liver tissues resected during surgical operations at West China Hospital, Sichuan University. All samples used were anonymized archived tissues, which were applied for scientific research in accordance with institutional ethical guidelines and did not involve any identifiable patient information. After being fixed in 10% neutral formalin for 24 hours, the tissues were routinely processed for paraffin embedding (FFPE), and sectioned into 4 μm-thick slices for immunostaining and fluorescence imaging.
Results
(16) While it is stated in the Methods that certain color MCNPs were used for labelling different structures (i.e., yellow: hepatic artery; green: bile duct; portal vein: pink; central veins: black), in some figures, apparently different color MCNPs are used for the respective structures. E.g., in Figure 1J, the artery is pink and the portal vein is green. Please clarify this.
The color assignment of MCNP dyes is not fixed across different experiments or schematic illustrations. MCNP dyes of different colors are fundamentally identical in their physical and chemical properties and do not exhibit specific binding or affinity for particular vascular structures. We select different colors based on experimental design and imaging presentation needs to facilitate distinction and visualization, thereby enhancing recognition in 3D reconstruction and image display. Therefore, the color labeling in Figure 1F is primarily intended to illustrate the distribution of different vascular systems, rather than indicating a fixed correspondence to a specific dye or injection color.
(17) In Figure 1J, the hepatic artery is extremely shrunk, while the portal vein is extremely dilated - compared to the physiological situation. Does it relate to the perfusion conditions?
We appreciate the reviewer’s attention. In fact, under normal physiological conditions, the hepatic arteries labeled by CD31 are naturally narrow. Therefore, the relatively thin hepatic arteries and thicker portal veins shown in Figure 1J are normal and unrelated to the perfusion conditions. See figure 1E of Adori et al., 2021.
(18) Re: MCNP-black labelled 'oval fenestrae': the Results state 50-100 nm, while they are apparently 5-10-micron diameter in Figure 1I. Accordingly, the comparison with the ELMI studies in the subsequent paragraph is inappropriate.
We thank the reviewer for the correction. The previous statement was a typographical error. In fact, the diameter of the “elliptical windows” marked by MCNP-black is 5–10 μm, so the diameter of 5–10 μm shown in Figure 1I is correct.
(19) Please, correct this erroneous sentence: 'Pink marked the hepatic arterial system by injection extrahepatic duct (Figure 2B).'
Original sentence: “The hepatic arterial system was labeled in pink by injection through the extrahepatic duct (Figure 2B).”
Revised sentence: “The hepatic arterial system was labeled in pink by injection through the left ventricle (Figure 2B).”
(20) How do you define the 'primary portal vein tract'?
We thank the reviewer for the question. The term “primary portal vein tract” refers to the first-order branches of the portal vein that enter the liver from the hepatic hilum. These are the major branches arising directly from the main portal vein trunk and are responsible for supplying blood to the respective hepatic lobes. This definition corresponds to the concept of the first-order portal vein in hepatic anatomy.
(21) I am concerned that the 'periportal lamellar complex (PLC)' that the Authors describe really exists as a distinct anatomical or functional unit. I also see these in 3D scans - in my opinion, these are fine, lower-order portal vein branches that connect the portal veins to the adjacent sinusoid. The strong MCNP-labelling of these structures may be caused by the 'sticking' of the perfused MCNP solutions in these 'pockets' during the perfusion process. What do these structures look like with SMA or CD31 immunostaining? Also, one may consider that the anatomical evaluation of these structures may have limitations in tissue slices. Have you ever checked MCNP-perfused, cleared full live lobes in light sheet microscope scans? I think this would be very useful to have a comprehensive morphological overview. Unfortunately, based on the presented documentation, I am also not convinced that PLCs are 'co-localize' with fine terminal bile duct branches (Figure 3E, S3C), or with TH+ 'neuronal bead chain networks' (Fig 6C). More detailed and more convincing documentation is needed here.
We thank the reviewer for the detailed comments. Regarding the existence and function of the periportal lamellar complex (PLC), our observations are based on MCNP-Pink labeling of the portal vein, through which we were able to identify the PLC structure surrounding the portal branches. It should be noted that the PLC represents a very small anatomical structure. Although we have not yet performed light-sheet microscopy scanning, we anticipate that such imaging would primarily visualize larger portal vein branches. Nevertheless, this does not affect our overall conclusions.
We also appreciate the reviewer’s suggestion that the observed structures might result from MCNP adherence during perfusion. To verify the structural characteristics of the PLC, we performed immunostaining for SMA and CD31, which revealed a specific arrangement pattern of smooth muscle and endothelial markers rather than simple perfusion-induced deposition (Figures 4F and S6B).
Regarding the apparent colocalization of the PLC with terminal bile duct branches (Figures 3E and S3C) and TH⁺ neuronal bead-like networks (Figure 6C), we acknowledge that current literature evidence remains limited. Therefore, we have carefully described these observations as possible spatial associations rather than definitive conclusions. Future studies integrating high-resolution three-dimensional imaging with functional analyses will help to further clarify the anatomical and physiological significance of the PLC.
(22) 'Extended depth-of-field three-dimensional bright-field imaging revealed a strict 1:1 anatomical association between the primary portal vein trunk (diameter 280 {plus minus} 32 μm) and the first-order bile duct (diameter 69 {plus minus} 8 μm) (Figures 3A and S3A)'.
How do you define '1:1 anatomical association'? How do you define and identify the 'order' (primary, secondary) of vessel and bile duct branches in 200-micrometer slices?
We thank the reviewer for the question. In this study, the term “1:1 anatomical correlation” refers to the stable paired spatial relationship between the main portal vein trunk and its corresponding primary bile duct within the same portal territory. In other words, each main portal vein branch is accompanied by a primary bile duct of matching branching order and trajectory, together forming a “vascular–biliary bundle.”
The definitions of “primary” and “secondary” branches were based on extended-depth 3D bright-field reconstructions, considering both branching hierarchy and vessel/duct diameters: primary branches arise directly from the main trunk at the hepatic hilum and exhibit the largest diameters (averaging 280 ± 32 μm for the portal vein and 69 ± 8 μm for the bile duct), whereas secondary branches extend from the primary branches toward the lobular interior with smaller calibers.
(23) In my opinion, the applied methodical approach in the single cell transcriptomics part (data mining in the existing liver single cell database and performing Venn diagram intersection analysis in hepatic endothelial subpopulations) is largely inappropriate and thus, all the statements here are purely speculative. In my opinion, to identify the molecular characteristics of such small and spatially highly organized structures like those fine radial portal branches, the only way is to perform high-resolution spatial transcriptomic.
We thank the reviewer for the comment. We fully acknowledge the importance of high-resolution spatial transcriptomics in identifying the fine structural characteristics of portal vein branches. Due to current funding and technical limitations, we were unable to perform such high-resolution spatial transcriptomic analyses. However, we validated the molecular features of the PLC using another publicly available liver single-cell RNA-sequencing dataset, which provided preliminary supporting evidence (Figures S6B and S6C). In the manuscript, we have carefully stated that this analysis is exploratory in nature and have avoided overinterpretation. In future studies, high-resolution spatial omics approaches will be invaluable for more precisely delineating the molecular characteristics of these fine structures.
(24) 'How the autonomic nervous system regulates liver function in mice despite the apparent absence of substantive nerve fiber invasion into the parenchyma remains unclear.'
Please consider the role of gap junctions between hepatocytes (e.g., Miyashita, 1991; Seseke, 1992).
In this study, we analyzed the spatial distribution of hepatic nerves in mice using immunofluorescence staining and found that nerve fibers were almost exclusively confined to the portal vein region (Figure S6A). Notably, this distribution pattern differs markedly from that in humans. Previous studies have shown that, in human livers, nerves are not only located around the portal veins but also present along the central veins, interlobular septa, and within the parenchymal connective tissue (Miller et al., 2021; Yi, la Fleur, Fliers & Kalsbeek, 2010).
Further research has provided a physiological explanation for this interspecies difference: even among species with distinct sympathetic innervation patterns in the parenchyma—i.e., with or without direct sympathetic input—the sympathetic efferent regulatory functions may remain comparable (Beckh, Fuchs, Ballé & Jungermann, 1990). This is because signals released from aminergic and peptidergic nerve terminals can be transmitted to hepatocytes through gap junctions as electrical signals (Hertzberg & Gilula, 1979; Jensen, Alpini & Glaser, 2013; Seseke, Gardemann & Jungermann, 1992; Taher, Farr & Adeli, 2017).
However, the scarcity of nerve fibers within the mouse hepatic parenchyma suggests that the mechanisms by which the autonomic nervous system regulates liver function in mice may differ from those in humans. This observation prompted us to further investigate the potential role of PLC endothelial cells in this process.
(25) Please, correct typos throughout the text.
We thank the reviewer for this comment. We have carefully proofread the entire manuscript and corrected all typographical errors and minor language issues throughout the text.
Reviewer #3 (Recommendations for the authors):
(1) A strong recommendation - the authors ought to challenge their scRNAsq- re-analysis with another scRNAseq dataset, namely a recently published atlas of adult liver endothelial, but also mesenchymal, immune, and parenchymal cell populations https://pubmed.ncbi.nlm.nih.gov/40954217/, performed with Smart-seq2 approach, which is perfectly suitable as it brings higher resolution data, and extensive cluster identity validation with stainings. Pietilä et al. indicate a clear distinction of portal vein endothelial cells into two populations that express Adgrg6, Jag1 (e2c), from Vegfc double-positive populations (e5c and e2c). Moreover, the dataset also includes the arterial endothelial cells that were shown to be part of the PLC, but were not followed up with the scRNAseq analysis. This distinction could help the authors to further validate their results, better controlling for cross-contaminations that may occur during scRNAseq preparation.
We thank the reviewer for the valuable suggestion. As noted, we have further validated the molecular characteristics of the PLC using a recently published atlas of adult liver endothelial cells (Pietilä et al., 2023, PMID: 40954217). This dataset, generated using the Smart-seq2 technique, provides high-resolution transcriptomic profiles. By analyzing this dataset, we identified a CD34⁺LY6A⁺ portal vein endothelial cell population within the e2 cluster, which is localized around the portal vein. We then examined pathways and gene expression patterns related to hematopoiesis, bile duct formation, and neural signaling within these cells. The results revealed gene enrichment patterns consistent with those observed in our primary dataset, further supporting the robustness of our analysis of the PLC’s molecular characteristics.
(2) Improving the methods section is highly recommended, this includes more detailed information for material and protocols used - catalog numbers; protocol details of the usage - rocking platforms, timing, and tubes used for incubations; GitHub or similar page with code used for the scRNA seq re-analysis.
We thank the reviewer for the valuable suggestion. We have added more detailed information regarding the materials and experimental procedures in the Methods section, including catalog numbers, incubation conditions (such as the type of shaker, incubation time, and tube specifications), and other relevant parameters.
(3) In Figure 2A, the authors claim the size of the nanoparticle is 100nm, while based on the image, the size is ~150-180nm. A more thorough quantification of the particle size would help users estimate the usability of their method for further applications.
We thank the reviewer for the comment. In the TEM image shown in Figure 2A, the nanoparticles indeed appear to be approximately 150–200 nm in size. We have re-verified the particle dimensions and will update the corresponding description in the Methods section to allow readers to more accurately assess the applicability of this approach.
(4) In Figure 3E, it is not clear what is labeled by the pink signal. Please consider labeling the structures in the figure.
We thank the reviewer for the valuable comment. The pink signal in Figure 3E was originally intended to label the hepatic artery. However, a slight spatial misalignment occurred during the labeling process, making its position appear closer to the central vein rather than the portal vein in the image. To avoid misunderstanding, we will add clear annotations to the image and clarify this deviation in the figure legend in the revised version. It should also be noted that this figure primarily aims to illustrate the spatial relationship between the bile duct and the portal vein, and this minor deviation does not affect the reliability of our experimental conclusions.
(5) The following statement is not backed by quantification as it ought to be „Dual-channel three-dimensional confocal imaging combined with CK19 immunostaining revealed that the sites of dye leakage did not coincide with the CK19-positive terminal bile duct epithelium, but instead were predominantly localized within regions adjacent to the PLC structures".
We thank the reviewer for the valuable comment. We have added the corresponding quantitative analysis to support this conclusion. Quantitative assessment of the extended-depth imaging data revealed that dye leakage predominantly occurred in regions adjacent to the PLC structure, rather than in the perivenous sinusoidal areas. The corresponding results have been presented in the revised Figure 3G.
(6) Similarly, Figure 4F is central to the Sca1CD34 cell type identification but lacks any quantification, providing it would strengthen the key statement of the article. A possible way to approach this is also by FACS sorting the double-positive cells and bluk/qRT validation.
We thank the reviewer for raising this point. We agree that quantitative validation of the Sca1⁺CD34⁺ population by FACS sorting could further support our conclusions. However, the primary focus of this study is on the spatial localization and transcriptional features of PLC endothelial cells. The identification of the Sca1⁺CD34⁺ subset is robustly supported by multiple complementary approaches, including three-dimensional imaging, co-staining with pan-endothelial markers, and projection mapping analyses. Collectively, these lines of evidence provide a solid basis for characterizing this unique endothelial population.
(7) The images in Figure S4D are not comparable, as the Sca1-stained image shows a longitudinal section of the PV, but the other stainings are cross-sections of PVs.
We thank the reviewer for the careful comment. We agree that the original Sca1-stained image, being a longitudinal section of the portal vein, was not optimal for direct comparison with other cross-sectional images. We have replaced it with a cross-sectional image of the portal vein to ensure comparability across all images. The updated image has been included in the revised Supplementary Figure S4D.
(8) I might be wrong, but Figure 4J is entirely missing, and only a cartoon is provided. Either remove the results part or provide the data.
We appreciate the reviewer’s careful observation. Figure 4J was intentionally designed as a schematic illustration to summarize the structural relationships and spatial organization of the portal vein, hepatic artery, and PLC identified in the previous panels (Figures 4A–4I). It does not represent newly acquired experimental data, but rather serves to provide a conceptual overview of the findings.
To avoid misunderstanding, we have clarified this point in the figure legend and the main text, stating that Figure 4J is a schematic summary rather than an experimental image. Therefore, we respectfully prefer to retain the schematic figure to aid readers’ interpretation of the preceding results.
(9) The methods section lacks information about the CCL4concentration, and it is thus hard to estimate the dosage of CCL4 received (ml/kg). This is important for the interpretation of the severity of the fibrosis and presence of cirrhosis, as different doses may or may not lead to cirrhosis within the short regimen performed by the authors [PMID: 16015684 DOI: 10.3748/wjg.v11.i27.4167]. Validation of the fibrosis/cirrhosis severity is, in this case, crucial for the correct interpretation of the results. If the level of cirrhosis is not confirmed, only progressive fibrosis should be mentioned in the manuscript, as these two terms cannot be used interchangeably.
Thank you for the reviewer’s comment. We indeed omitted the information on the concentration of carbon tetrachloride (CCl<sub>4</sub>) in the Methods section. In our experiments, mice received intraperitoneal injections of CCl<sub>4</sub> at a dose of 1 mL/kg body weight, twice per week, for a total of six weeks. We have revised the manuscript accordingly, using the term “progressive fibrosis” to avoid confusion between fibrosis and cirrhosis.
(10) The following statement is not backed by any correlation analysis: "Particularly during liver fibrosis progression, the PLC exhibits dynamic structural extension correlating with fibrosis severity,.. ".
We thank the reviewer for the comment. The original statement that the “PLC correlates with fibrosis severity” lacked support from quantitative analysis. To ensure a precise description, we have revised the sentence as follows: “During liver fibrosis progression, the PLC exhibits dynamic structural extension.”
(11) Similarly, the following statement is not followed by data that would address the impact of innervation on liver function: "How the autonomic nervous system regulates liver function in mice despite the apparent absence of substantive nerve fiber invasion into the parenchyma remains unclear.".
This section has been revised. In this study, we analyzed the spatial distribution of nerves in the mouse liver using immunofluorescence staining. The results showed that nerve fibers were almost entirely confined to the portal vein region (Figure S6A). Notably, this distribution pattern differs significantly from that in humans. Previous studies have demonstrated that in the human liver, nerves are not only distributed around the portal vein but also present in the central vein, interlobular septa, and connective tissue of the hepatic parenchyma (Miller et al., 2021; Yi, la Fleur, Fliers & Kalsbeek, 2010).
Previous studies have further explained the physiological basis for this difference: even among species with differences in parenchymal sympathetic innervation (i.e., species with or without direct sympathetic input), their sympathetic efferent regulatory functions may still be similar (Beckh, Fuchs, Ballé & Jungermann, 1990). This is because signals released by adrenergic and peptidergic nerve terminals can be transmitted to hepatocytes as electrical signals through intercellular gap junctions (Hertzberg & Gilula, 1979; Jensen, Alpini & Glaser, 2013; Seseke, Gardemann & Jungermann, 1992; Taher, Farr & Adeli, 2017). However, the scarcity of nerve fibers in the mouse hepatic parenchyma suggests that the mechanism by which the autonomic nervous system regulates liver function in mice may differ from that in humans. This finding also prompts us to further explore the potential role of PLC endothelial cells in this process.
(12) Could the authors discuss their interpretation of the results in light of the fact that the innervation is lower in cirrhotic patients? https://pmc.ncbi.nlm.nih.gov/articles/PMC2871629/. Also, while ADGRG6 (Gpr126) may play important roles in liver Schwann cells, it is likely not through affecting myelination of the nerves, as the liver nerves are not myelinated https://pubmed.ncbi.nlm.nih.gov/2407769/ and https://www.pnas.org/doi/10.1073/pnas.93.23.13280.
We have revised the text to state that although most hepatic nerves are unmyelinated, GPR126 (ADGRG6) may regulate hepatic nerve distribution via non-myelination-dependent mechanisms. Studies have shown that GPR126 exerts both Schwann cell–dependent and –independent functions during peripheral nerve repair, influencing axon guidance, mechanosensation, and ECM remodeling (Mogha et al., 2016; Monk et al., 2011; Paavola et al., 2014).
(13) The manuscript would benefit from text curation that would:
a) Unify the language describing the PLC, so it is clear that (if) it represents protrusions of the portal veins.
We have standardized the description of the PLC throughout the manuscript, clearly specifying its anatomical relationship with the portal vein. Wherever appropriate, we indicate that the PLC represents protrusions associated with the portal vein, avoiding ambiguous or inconsistent statements.
b) Increase the accuracy of the statements.
Examples: "bile ducts, and the central vein in adult mouse livers."
We have refined all statements for accuracy.
c) Reduce the space given to discussion and results in the introduction, moving them to the respective parts. The same applies to the results section, where discussion occurs at more places than in the Discussion part itself.
We have edited the Introduction, removing detailed results and functional explanations, and retaining only a concise overview.
Examples: "The formation of PLC structures in the adventitial layer may participate in local blood flow regulation, maintenance of microenvironmental homeostasis, and vascular-stem cell interactions."
"This finding suggests that PLC endothelial cells not only regulate the periportal microcirculatory blood flow, but also establish a specialized microenvironment that supports periportal hematopoietic regulation, contributing to stem cell recruitment, vascular homeostasis, and tissue repair. "
"Together, these findings suggest the PLC endothelium may act as a key regulator of bile duct branching and fibrotic microenvironment remodeling in liver cirrhosis. " This one in particular would require further validation with protein stainings and similar, directly in your model.
d) Provide a clear reference for the used scRNA seq so it's clear that the data were re-analyzed.
Example: "single-cell transcriptomic analysis revealed significant upregulation of bile duct-related genes in the CD34<sup>+</sup>Sca-1<sup>+</sup> endothelium of PLC in cirrhotic liver, with notably high expression of Lgals1 (Galectin-1) and HGF(Figure 5G) "
When describing the transcriptional analysis of PLC endothelial cells, we explicitly cited the original scRNA-seq dataset (Su et al., 2021), clarifying that these data were reanalyzed rather than newly generated.
e) Introducing references for claims that, in places, are crucial for further interpretation of experiments.
Examples: "It not only guides bile duct branching during development but also"; the authors show no data from liver development.
Thank you for pointing this out. We have revised the relevant statement to ensure that the claim is accurate and well-supported.
f) Results sentence "Instead, bile duct epithelial cells at the terminal ducts extended partially along the canalicular network without directly participating in the formation of the bile duct lumen." Lacks a callout to the respective Figure.
We would like to thank the reviewers for pointing out this issue. In the revised manuscript, the relevant image (Figure 3D) has been clearly annotated with white arrows to indicate the phenomenon of terminal cholangiocytes extending along the bile canaliculi network. Additionally, the schematic diagram on the right side clearly shows the bile canaliculi, cholangiocytes, and bile flow direction using arrows and color coding, thus intuitively corresponding to the textual description.
(14) Formal text suggestions: The manuscript text contains a lot of missed or excessive spaces and several typos that ought to be fixed. A few examples follow:
a) "densely n organized vascular network "
b) "analysis, while offering high spatial "
c) "specific differences, In the human liver, "
d) Figure 4F has a typo in the description.
e) "generation of high signal-to-noise ratio, multi-target " SNR abbreviation was introduced earlier.
f) Canals of Hering, CoH abbreviation comes much later than the first mention of the Canals of Hering.
We thank the reviewer for the helpful comment regarding textual consistency. We have carefully reviewed and revised the entire manuscript to improve the accuracy, clarity, and consistency of the text.
Reviewer #1 (Public review):
Summary:
This study presents a comprehensive single-cell atlas of mouse anterior segment development, focusing on the trabecular meshwork and Schlemm's canal. The authors profiled ~130,000 cells across seven postnatal stages, providing detailed and solid characterization of cell types, developmental trajectories, and molecular programs.
Strengths:
The manuscript is well-written, with a clear structure and thorough introduction of previous literature, providing a strong context for the study. The characterization of cell types is detailed and robust, supported by both established and novel marker genes as well as experimental validation. The developmental model proposed is intriguing and well supported by the evidence. The study will serve as a valuable reference for researchers investigating anterior segment developmental mechanisms. Additionally, the discussion effectively situates the findings within the broader field, emphasizing their significance and potential impact for developmental biologists studying the visual system.
Weaknesses:
The weaknesses of the study are minor and addressable. As the study focuses on the mouse anterior segment, a brief discussion of potential human relevance would strengthen the work by relating the findings to human anterior segment cell types, developmental mechanisms, and possible implications for human eye disease. Data availability is currently limited, which restricts immediate use by the community. Similarly, the analysis code is not yet accessible, limiting the ability to reproduce and validate the computational analyses presented in the study.
Author response:
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study presents a comprehensive single-cell atlas of mouse anterior segment development, focusing on the trabecular meshwork and Schlemm's canal. The authors profiled ~130,000 cells across seven postnatal stages, providing detailed and solid characterization of cell types, developmental trajectories, and molecular programs.
Strengths:
The manuscript is well-written, with a clear structure and thorough introduction of previous literature, providing a strong context for the study. The characterization of cell types is detailed and robust, supported by both established and novel marker genes as well as experimental validation. The developmental model proposed is intriguing and well supported by the evidence. The study will serve as a valuable reference for researchers investigating anterior segment developmental mechanisms. Additionally, the discussion effectively situates the findings within the broader field, emphasizing their significance and potential impact for developmental biologists studying the visual system.
Weaknesses:
The weaknesses of the study are minor and addressable. As the study focuses on the mouse anterior segment, a brief discussion of potential human relevance would strengthen the work by relating the findings to human anterior segment cell types, developmental mechanisms, and possible implications for human eye disease. Data availability is currently limited, which restricts immediate use by the community. Similarly, the analysis code is not yet accessible, limiting the ability to reproduce and validate the computational analyses presented in the study.
In the revised version we will highlight the human relevance of our work in the discussion section. Additionally, data and codes are public on single cell portal and GEO, accession numbers have been updated.
Reviewer #2 (Public review):
Summary:
This study presents a detailed single-cell transcriptomic analysis of the postnatal development of mouse anterior chamber tissues. Analysis focused on the development of cells that comprise Schlemm's Canal (SC) and trabecular meshwork (TM).
Strengths:
This developmental atlas represents a valuable resource for the research community. The dataset is robust, consisting of ~130,000 cells collected across seven time points from early post-natal development to adulthood. Analyses reveal developmental dynamics of SC and TM populations and describe the developmental expression patterns of genes associated with glaucoma.
Weaknesses:
(1) Throughout the paper, the authors place significant weight on the spatial relationships of UMAP clusters, which can be misleading (See Chari and Patcher, Plos Comb Bio 2023). This is perhaps most evident in the assessment of vascular progenitors (VP) into BEC and SEC types (Figures 4 and 5). In the text, VPs are described as a common progenitor for these types, however, the trajectory analysis in Figure 5 denotes a path of PEC -> BEC -> VP -> SEC. These two findings are incongruous and should be reconciled. The limitations of inferring relationships based on UMAP spatial positions should be noted.
(2) Figure 2d does not include P60. It is also noted that technical variation resulted in fewer TM3 cells at P21; was this due to challenges in isolation? What is the expected proportion of TM3 cells at this stage?
(3) In Figures 3a and b it is difficult to discern the morphological changes described in the text. Could features of the image be quantified or annotated to highlight morphological features?
(4) Given the limited number of markers available to identify SC and TM populations during development, it would be useful to provide a table describing potential new markers identified in this study.
(5) The paper introduces developmental glaucoma (DG), namely Axenfeld-Rieger syndrome and Peters Anomaly, but the expression analysis (Figure S20) does not annotate which genes are associated with DG.
(1) We agree that inferring biological relationships from the spatial arrangement of UMAP clusters has limitations and we will qualify our interpretation accordingly in the text. We will also add clarifying language to the trajectory analysis in Figure 5. The intended developmental trajectory is PEC → VP → BEC and SEC; however, the cluster labels in Figure 5 were applied incorrectly. Specifically, VP-BECs were mislabeled as BECs, which led to the confusion.
(2) We recently published the P60 dataset separately (Tolman, Li, Balasubramanian et al., eLife 2025); these data consist of integrated single-nucleus multiome profiles that were subjected to in-depth analysis. Additionally, we found that integrating the P60 dataset with the developmental datasets obscured sub-clustering of mature cell types. In future manuscripts, we will pursue a more detailed analysis of TM development and perform time point–specific clustering, similar to the approach we used for endothelial cells (Figure 4e).
Comparing proportions of cells at different ages and as the eyes grows needs to be done cautiously. Notwithstanding the limitations, the proportions of TM1, TM2, and TM3 clusters are expected to be similar between P14 and P21 as the proportions at P14 and P60 are similar when comparing to the separately analyzed P60 data. Importantly, our dissection strategy changed with age: from P2 to P14, we removed approximately one-third of the cornea, whereas at P21 and P60 we removed most of the cornea to help maximize representation of limbal cells as the eyes grew. This change in dissection likely contributed to the reduced number of TM3 cells observed at P21. TM3 cells are enriched anteriorly (at-least in adult) and so are located closer to the corneal cut during dissection of the P21 eyes (which despite being larger than younger ages are still small and more delicate to accurately dissect than at P60) and are therefore more likely to be lost. Additional details are provided in the Methods section.
(3) For Figure 3a and b, we will work to add clarity by providing additional annotations and an additional illustration.
(4) We will include a table listing potential new markers for developing SC and TM populations.
(5) We will annotate the genes associated with DG in Figure S20.
Configure the Extension Install this extension from the VS Code marketplace Open VS Code Settings (Cmd/Ctrl + ,) Search for "Obsidian MCP"
Obsidian MCP not found in VS Code market.
Visual Studio Code acts as an MCP host. When Visual Studio Code establishes a connection to an MCP server, such as the Sentry MCP server, the Visual Studio Code runtime instantiates an MCP client object that maintains the connection to the Sentry MCP server.
VS Code acts as MCP Host (in their AI toolkit extension I think). You could connect it to the Obsidian MCP server plugin then?
MCP plugin for Obsidian, that works with Claude Code
A comparison between VS Code and Obsidian. Doesn't state the obvious: any text editor can do this. The tools are just viewers and do not contain the data, which is part of your filesystem. Vgl [[3 Distributed Eigenschappen 20180703150724]]
Reviewer #3 (Public review):
Summary
This study aims to overcome key limitations of single-cell RNA-seq in C. elegans neurons-especially the under-detection of lowly expressed and non-polyadenylated transcripts and residual contamination-by integrating bulk RNA-seq from FACS-isolated neuron types with an existing scRNA-seq atlas. The authors introduce LittleBites, an iterative, reference-guided decontamination algorithm that uses a single-cell reference together with ground-truth reporter datasets to optimize subtraction of contaminating signal from bulk profiles. They then generate an "Integrated" dataset that combines the sensitivity of bulk data with the specificity of scRNA-seq and use it to call neuron-specific expression for protein-coding genes, "rescued" genes not detected in scRNA-seq, and multiple classes of non-coding RNAs across 53 neuron classes. All data, code, and thresholded matrices are made publicly available to enable community reuse.
Strengths
(1) Conceptual advance and useful resource. The work demonstrates in a concrete way how bulk and single-cell datasets can be combined to overcome the weaknesses of each approach, and delivers a high-resolution transcriptomic resource for a substantial fraction of C. elegans neuron classes . The integrated matrices, thresholded expression calls, and non-coding RNA catalog will be useful both for basic neurobiology and for method developers.
(2) Careful benchmarking and transparency. The revised manuscript includes extensive benchmarking of LittleBites and the Integrated dataset against multiple independent "ground-truth" sets: neuron-specific reporter lines, curated non-neuronal markers, and ubiquitous genes. The authors evaluate AUROCs over a wide range of thresholds, explain ROC/AUROC metrics for non-specialists, and quantify how integration affects both sensitivity and specificity relative to scRNA-seq alone.
(3) Improved methodological clarity. In response to review, the authors now provide a much more intuitive description of the LittleBites algorithm, including a stepwise explanation of (1) contamination estimation via NNLS using single-cell references, (2) weighted subtraction tuned by a learning-rate parameter, and (3) performance optimization based on AUROC against ground-truth genes. this makes the approach accessible to readers who are not computational specialists and will facilitate re-implementation.
(4) Systematic analysis of reference dependence. The authors explicitly address the concern that LittleBites depends on the completeness and accuracy of the scRNA-seq reference. They examine how performance varies with cluster size and by simulated degradation of the reference (e.g., reducing the number of cells per cluster), and show that AUROCs remain robust, but that gene-level assignments are more variable for clusters represented by fewer cells. This is an important and honest characterization of when the method is reliable and when users should be cautious.
(5) Additional biological context. The manuscript now more clearly situates the dataset in the context of previous and ongoing work. In particular, the authors highlight that other groups have already used these bulk data to discover and validate cell-type-specific alternative splicing events, strengthening the case that the data are biologically meaningful beyond the immediate analyses presented here. The expanded analysis of non-coding RNAs and GPCR pseudogenes also adds biological interest.
(6) Improved handling and documentation of "unexpressed" genes. The authors have trimmed the original list of 4,440 genes called "unexpressed" in scRNA-seq to a higher-confidence subset and provide new supplementary tables that include gene identities and tissue annotations. They also use a curated set of non-neuronal markers to estimate residual contamination and show that most such markers are not detected in the integrated data, with only a small number of apparent false positives remaining.
Weaknesses
(1) Novel assignments remain predictive rather than experimentally validated. Although the authors have strengthened their benchmarking and refer to external work that validates some splicing patterns from these data, the large sets of newly assigned lowly expressed genes and non-coding RNAs-particularly those rescued from the "unexpressed" gene pool-are still inferred from computational criteria (thresholding plus correlation-based decontamination) rather than direct orthogonal assays (e.g., smFISH, in situ hybridization, or reporter lines). This is understandable given scale and cost, but it means that many of these calls should be interpreted as well-supported predictions, not definitive expression maps. The revised manuscript acknowledges this, and a dedicated "Limitations of this study" subsection will further clarify this point for readers.
(2) Reduced stability for neuron types with sparse single-cell representation. The authors' new analyses show that while integration improves overall correlation and AUROC across a wide range of neuron types, gene-level assignments are less stable for neuron classes represented by relatively few cells in the scRNA-seq reference. For such neuron types, both false negatives and false positives are more likely, and users should be cautious when interpreting cell-type-specific expression differences based solely on these calls.
(3) Residual contamination and misclassification are not completely eliminated. Despite the careful design of LittleBites and the additional correlation-based decontamination of "unexpressed" genes, the authors' benchmarking against curated non-neuronal markers shows that a small fraction of putative non-neuronal genes remains detectable even at stricter thresholds, and some bona fide neuronal genes are removed as likely contaminants. The new supplementary tables documenting "unexpressed" genes and their tissue annotations, together with explicit statements about residual error rates and the predictive nature of these classifications, help users to judge the reliability of specific genes, but they also underscore that the dataset is not a perfect ground truth.
(4) Scope and coverage remain incomplete. As the authors note, the dataset covers 53 neuron classes and does not fully represent all 302 neurons or all known neuron subtypes. In addition, bulk samples represent pools of neurons, and so the approach cannot resolve within-class heterogeneity or subtype-specific expression within those pools. These are inherent limitations of the current experimental design rather than flaws in the analysis, but they are important for readers to keep in mind when using the resource.
Overall, the revised manuscript presents solid evidence for the main methodological and resource claims, with clearly articulated limitations. The work is likely to have valuable impact on the C. elegans community and provides a template for integrating bulk and single-cell data in other systems.
Simon Willison lost een probleem voor zichzelf op, hoe kan ik beter door de transcripts van Claude Code zoeken en navigeren, en deelt dat met de rest van het internet.
Test annotatie
To Gen or Not To Gen: The Ethical Use of Generative AI 33 minute read This blog entry started out as a translation of an article that my colleague Jakob and I wrote for a German magazine. After that we added more stuff and enriched it by additional references and sources. We aim at giving an overview about many - but not all - aspects that we learned about GenAI and that we consider relevant for an informed ethical opinion. As for the depth of information, we are just scratching the surface; hopefully, the loads of references can lead you to diving in deeper wherever you want. Since we are both software developers our views are biased and distorted. Keep also in mind that any writing about a “hot” topic like this is nothing but a snapshot of what we think to know today. By the time you read it the authors’ knowledge and opinions have already changed. Last Update: December 8, 2025. Table of ContentsPermalink Abstract About us Johannes Link Jakob Schnell Introduction Ethics, what does that even mean? Clarification of terms Basics Can LLMs think? What LLMs are good at GenAI as a knowledge source GenAI in software development Actual vs. promised benefits Harmful aspects of GenAI GenAI is an ecological disaster Power Water Electronic Waste GenAI threatens education and science GenAI is destroying the free internet. GenAI is a danger to democracy GenAI versus human creativity Digital colonialism Political aspects Conclusion Can there be ethical GenAI? How to act ethically AbstractPermalink ChatGPT, Gemini, Copilot. The number of generative AI applications (GenAI) and models is growing every day. In the field of software development in particular, code generation, coding assistants and vibe coding are on everyone’s lips. Like any technology, GenAI has two sides. The great promises are offset by numerous disadvantages: immense energy consumption, mountains of electronic waste, the proliferation of misinformation on the internet and the dubious handling of intellectual property are just a few of the many negative aspects. Ethically responsible behaviour requires us to look at all the advantages, disadvantages and collateral damages of a technology before we use it or recommend its use to others. In this article, we examine both sides and eventually arrive at our personal and naturally subjective answer to whether and how GenAI can be used in an ethical manner. About usPermalink Johannes LinkPermalink … has been programming for over 40 years, 30 of them professionally. Since the end of the last century, extreme programming and other human-centred software development approaches have been at the heart of his work. The meaningful and ethical implementation of his private and professional life has been his driving force for years. He has been involved with GenAI since the early days of OpenAI’s GPT language models. More about Johannes can be found at https://johanneslink.net. Jakob SchnellPermalink … studied mathematics and computer science and has been working as a software developer for 5 years. He works as a lecturer and course director in university and non-university settings. As a youth leader, he also comes into regular contact with the lives of children and young people. In all these environments, he observes the growing use of GenAI and its impact on people. IntroductionPermalink Ethics, what does that even mean?Permalink Ethical behaviour sounds like the title of a boring university seminar. However, if you look at the wikipedia article of the term 1, you will find that ‘how individuals behave when confronted with ethical dilemmas’ is at the heart of the definition. So it’s about us as humans taking responsibility and weighing up whether and how we do or don’t do certain things based on our values. We have to consider ethical questions in our work because all the technologies we use and promote have an impact on us and on others. Therefore, they are neither neutral nor without alternative. It is about weighing up the advantages and potential against the damage and risks; and that applies to everyone, not just us personally. Because often those who benefit from a development are different from those who suffer the consequences. As individuals and as a society, we have the right to decide whether and how we want to use technologies. Ideally, this should be in a way that benefits us all; but under no circumstances should it be in a way that benefits a small group and harms the majority. The crux of the matter is that ethical behaviour does not come for free. Ethics are neither efficient nor do they enhance your economic profit. That means that by acting according to your values you will, at some point, have to give something up. If you’re not willing to do that, you don’t have values - just opinions. Clarification of termsPermalink When we write ‘generative AI’ (GenAI), we are referring to a very specific subset of the many techniques and approaches that fall under the term ‘artificial intelligence’. Strictly speaking, these are a variety of very different approaches that range from symbolic logic, over automated planning up to the broad field of machine learning (ML). Nowadays most effort, hype and money goes into deep learning (DL): a subfield of ML that uses multi-layered artificial neural networks to discover statistical correlations (aka patterns) based on very large amounts of training data in order to reproduce those patterns later. Large language models (LLM) and related methods for generating images, videos and speech now make it possible to apply this idea to completely unstructured data. While traditional ML methods often managed with a few dozen parameters, these models now work with several trillion (10^12) parameters. In order for this to produce the desired results, both the amount of training data and the training duration must be increased by several orders of magnitude. This brings us to the definition of what we mean by ‘GenAI’ in this article: Hyperscaled models that can only be developed, trained and deployed by a handful of companies in the world. These are primarily the GenAI services provided by OpenAI, Anthropic, Google and Microsoft, or based on these services. We also focus primarily on language models; the generation of images, videos, speech and music plays only a minor role in this article. Our focus on hyperscale services does not mean that other ML methods are free of ethical problems; however, we are dealing with a completely different order of magnitude of damage and risk here. For example, there do exist variations of GenAI that use the same or similar techniques, but on a much smaller scale and restricted domains (e.g. AlphaFold 2). These approaches tend to bring more value with fewer downsides. BasicsPermalink GenAI models are designed to interpolate and extrapolate 3, i.e. to fill in the gaps between training data and speculate beyond the limits of the training data. Together with the stochastic nature of the training data, this results in some interesting properties: GenAI models ‘invent’ answers; with LLMs, we like to refer to this as ‘hallucinations’. GenAI models do not know what is true or false, good or bad, efficient or effective, only what is statistically probable or improbable in relation to training data, context and query (aka prompt). GenAI models cannot explain their output; they have no capability of introspection. What is sold as introspection is just more output, with the previous output re-injected. GenAI models do not learn from you; they only draw from their training material. The learning experience is faked by reinjecting prior input into a conversation’s context 4. The context, i.e. the set of input parameters provided, is decisive for the accuracy of the generated result, but can also steer the model in the wrong direction. Increasing the context window makes a query much more computation-intensive - likely in a quadratic way. Therefore, the promised increase of “maximum context window” of many models is mostly fake 5. The reliability of LLMs cannot be fundamentally increased by even greater scaling 6. Can LLMs think?Permalink Proponents of the language-of-thought hypothesis 7 believe it is possible for purely language-based models to acquire the capabilities of the human brain – reasoning, modelling, abstraction and much more. Some enthusiasts even claim that today’s models have already acquired this capability. However, recent studies 8 9 show that today’s models are neither capable of genuine reasoning nor do they build internal models of the world. Moreover, “…according to current neuroscience, human thinking is largely independent of human language 10” and there is fundamental scientific doubt that achieving human cognition through computation is achievable in practice let alone by scaling up training of deep networks 11. An example of a lack of understanding of the world is the prompt ‘Give me a random number between 0 and 50’. The typical GenAI response to this is ‘27’, and it is significantly more reliable than true randomness would allow. (If you don’t believe it, just try it out!) This is because 27 is the most likely answer in the GenAI training data – and not because the model understands what ‘random’ means. ‘Chain of Thought (CoT)’ approaches and ‘Reasoning models’ attempt to improve reasoning by breaking down a prompt, the query to the model, into individual (logical) steps and then delegating these individual steps back to the LLM. This allows some well-known reasoning benchmarks to be met, but it also multiplies the necessary computational effort by a factor between 30 and 700 12. In addition, multistep reasoning lets individual errors chain together to form large errors. And yet, CoT models do not seem to possess any real reasoning abilities 13 14 and improve the overall accuracy of LLMs only marginally 15. The following thought experiment from 16 underscores the lack of real “thinking” capabilities: LLMs have simultaneous access to significantly more knowledge than humans. Together with the postulated ability of LLMs to think logically and draw conclusions, new insights should just fall from the sky. But they don’t. Getting new insights from LLMs would require these to be already encoded in the existing training material, and to be decoded and extracted by pure statistical means. What LLMs are good atPermalink Undoubtedly, LLMs represent a major qualitative advance when it comes to extracting information from texts, generating texts in natural and artificial languages, and machine translation. But even here, the error rate, and above all the type of error (‘hallucinations’), is so high that autonomous, unsupervised use in serious applications must be considered highly negligent. GenAI as a knowledge sourcePermalink As we have pointed out above, LLMs cannot differentiate between true and false - regardless of the training material. It does not answer the question “What is XYZ?” but the question “How would an answer to question ‘What is XYZ?’ look like?”. Nevertheless, many people claim that the answers that ChatGPT and alike provide for the typical what-how-when-who queries are good enough and often better than what a “normal” web search would have given us. Arguably, this is the most prevalent use case for “AI” bots today. The problem is that most of the time we will never learn about the inaccuracies, left-outs, distortions and biases that the answer contained - unless we re-check everything, which defies the whole purpose of speeding up knowledge retrieval. The less we already know, the better the “AI’s” answer looks to us, but the less equipped we are to spot the problems. A recent by the BBC and 22 Public Service Media organizations shows that 45% of all “AI” assistants’ answers on questions about news and current affairs have significant errors 17. Moreover, LLMs are easy prey for manipulation - either by the service providing organization or by third parties. A recent study claims that even multi-billion-parameter models can be “poisoned” by injecting just a few corrupted documents 18. So, if anything is at stake all output from LLMs must be carefully validated. Doing that, however, would contradict the whole point of using “AI” to speed up knowledge acquisition. GenAI in software developmentPermalink The creation and modification of computer programmes is considered a prime domain for the use of LLMs. This is partly because programming languages have less linguistic variance and ambiguity than natural languages. Moreover, there are many methods for automatically checking generated source code, such as compiling, static code analysis and automated testing. This simplifies the validation of generated code and thereby gives an additional feeling of trust. Nevertheless, individual reports on the success of coding assistants such as Copilot, Cursor, etc. vary greatly. They range from ‘completely replacing me as a developer’ to ‘significantly hindering my work’. Some argue that coding agents considerably reduce the time they have to invest in “boilerplate” work, like writing tests, creating data transfer objects or connecting your domain code to external libraries. Others counter by pointing out that delegating these drudgeries to GenAI makes you miss opportunities to get rid of them, e.g. by introducing a new abstraction or automating parts of your pipeline, and to learn about the intricacies and failure modes of the external library. Other than old-school code generation or code libraries prompting a coding agent is not “just another layer of abstraction”. It misses out on several crucial aspects of a useful abstraction: Its output is not deterministic. You cannot rely on any agent producing the same code next time you feed it the same prompt. The agent does not hide the implementation details, nor does it allow you to reliably change those details if the previous implementation turns out to be inadequate. Code that is output by an LLM, even if it is generated “for free”, has to be considered and maintained each time you touch the related logic or feature. The agent does not tell you if the amount of details you give in your prompt is sufficient for figuring out an adequate implementation. On the contrary, the LLM will always fill the specification holes with some statistically derived assumptions. Sadly, serious studies on the actual benefits of GenAI in software development are rare. The randomised trial by Metr 19 provides an initial indication, measuring a decline in development speed for experienced developers. An informal study by ThoughtWorks estimates the potential productivity gain from using GenAI in software development at around 5-15% 20. If “AI coding” were increasing programmers’ productivity by any big number, we would see a measurable growth of new software in app stores and OSS repositories. But we don’t, the numbers are flat at best 2122. But even if we assume a productivity increase in coding through GenAI, there are still two points that further diminish this postulated efficiency gain: Firstly, the results of the generation must still be cross-checked by human developers. However, it is well known that humans are poor checkers and lose both attention and enjoyment in the process. Secondly, software development is only to a small extent about writing and changing code. The most important part is discovering solutions and learning about the use of these solutions in their context. Peter Naur calls this ‘programming as theory building’ 23. Even the perfect coding assistant can therefore only take over the coding part of software development. For the essential rest, we still need humans. If we now also consider the finding that using AI can relatively quickly lead to a loss of problem-solving skills 24 or that these skills are not acquired at all, then the overall benefit of using GenAI in professional software development is more than questionable. As long as programming - and every technicality that comes with it - will not be fully replaced by some kind of AI, we will still need expert developers who can programm, maintain and debug code to the finest level of detail. Where, we wonder, will those senior developers come from when companies replace their junior staff with coding agents? Actual vs. promised benefitsPermalink If you read testimonials about the use of GenAI that people perceive as successful, you will mostly encounter scenarios in which ‘AI’ helps to make tasks that are perceived as boring, unnecessarily time-consuming or actually pointless faster or more pleasant. So it’s mainly about personal convenience and perceived efficiency. Entertainment also plays a major role: the poem for Grandma’s birthday, the funny song for the company anniversary or the humorous image for the presentation are quickly and supposedly inexpensively generated by ‘AI’. However, the promises made by the dominant GenAI companies are quite different: solving the climate crisis, providing the best medical advice for everyone, revolutionising science, ‘democratising’ education and much more. GPT5, for example, is touted by Sam Altman, CEO of OpenAI, as follows: ‘With GPT-5, it’s now like talking to an expert — a legitimate PhD-level expert in any area you need […] they can help you with whatever your goals are.’ 25 However, to date, there is still no actual use case that provides a real qualitative benefit for humanity or at least larger groups. The question ‘What significant problem (for us as a society) does GenAI solve?’ remains unanswered. On the contrary: While machine learning and deep learning methods certainly have useful applications, the most profitable area of application for ‘AI’ at present is the discovery and development of new oil and gas fields 26. Harmful aspects of GenAIPermalink But regardless of how one assesses the benefits of this technology, we must also consider the downsides, because only then can we ultimately make an informed and fair assessment. In fact, the range of negative effects of hyperscaled generative AI that can already be observed is vast. Added to this are numerous risks that have the potential to cause great social harm. Let’s take a look at what we consider to be the biggest threats: GenAI is an ecological disasterPermalink PowerPermalink The data centres required for training and operating large generative models 27 far exceed today’s dimensions in terms of both number and size. The projected data centre energy demand in the USA is predicted to grow from 4.4% of total electricity in 2023 to 22% in 2028 28. In addition, the typical data centre electricity mix is more CO2-intensive than the average mix. There is an estimated raise of ~11 percent for coal generated electricity in the US, as well as tripled emissions of greenhouse gases worldwide by 2030 - compared to the scenario without GenAI technology 29. Just recently Sam Altman from OpenAI blogged some numbers about the energy and water usage of ChatGPT for “the average query” 30. On the one hand, an average is rather meaningless when a distribution is heavily unsymmetric; the numbers for queries with large contexts or “chain of reasoning” computations would be orders of magnitude higher. Thus, the potential efficiency gains from more economical language models are more than offset by the proliferation of use, e.g. through CoT approaches and ‘agent systems’. On the other hand, big tech’s disclosure of energy consumption (e.g. by Google 31) is intentionally selective. Ketan Joshi goes into quite some details why experts think that the AI industry is hiding the full picture 32. Since building new power plants - even coal or gas fuelled ones - takes a lot of time, data center companies are even reviving old jet engines for powering their new hyper-scalers 33. You have to be aware that those engines are not only much more noisy than other power plants but also pump out nitrous oxide, one of the main chemicals responsible for acid rain 34. WaterPermalink Another problem is the immensely high water consumption of these data centres 35. After all, cooling requires clean water in drinking quality in order to not contaminate or clog the cooling pipes and pumps. Already today, new data centre locations are competing with human consumption of drinking water. According to Bloomberg News about two-thirds of data-centers that were built or developed in 2022 are located in areas that are already under “water-stress” 36. In the US alone “AI servers […] could generate an annual water footprint ranging from 731 to 1,125 million m3” 37. It’s not only an American problem, though. In other areas of the world the water-thirsty data centers also compete with the drinking water supply for humans 38. Electronic WastePermalink Another ecological problem is being noticeably exacerbated by ‘AI’: the amount of electronic waste (e-waste) that we ship mainly to “Third World” countries and which is responsible for soil contamination there. Efficient training and querying of very large neural networks requires very large quantities of specialised chips (GPUs). These chips often have to be replaced and disposed of within two years. The typical data center might not last longer than 3 to 5 years before it has to be rebuilt in large parts39. In summary, it can be said that GenAI is at least an accelerator of the ecological catastrophe that threatens the earth. And it is the argument for Google, Amazon and Microsoft to completely abolish their zero CO2 targets 40 and replace them with investments of several hundred billion dollars for new data centers. GenAI threatens education and sciencePermalink People often try to use GenAI in areas where they feel overloaded and overwhelmed: training, studying, nursing, psychotherapeutic care, etc. The fields of application for ‘AI’ are therefore a good indication of socially neglected and underfunded areas. The fact that LLMs are very good at conveying the impression of genuine knowledge and competence makes their use particularly attractive in these areas. A teacher under the simultaneous pressure of lesson preparation, corrections and covering for sick colleagues turns to ChatGPT to quickly create an exercise sheet. A student under pressure to get good grades has their English essay corrected by ‘AI’. The researcher under pressure to publish will ‘save’ research time by reading the AI-generated summary of relevant papers – even if they are completely wrong in terms of content 41. Tech companies like OpenAI and Microsoft play on that situation by offering their ‘AI’ for free or for little money to students and universities. The goal is obvious: Students that get hooked on outsourcing some of their “tedious” task to a service will continue to use - and eventually buy - this service after graduation. What falls by the wayside are problem-solving skills, engagement with complex sources, and the generation of knowledge through understanding and supplementing existing knowledge. Some even argue that AI is destroying critical education and learning itself 42: Students aren’t just learning less; their brains are learning not to learn. The training cycle of schools and universities is fast. Teachers are already reporting that pupils and students have acquired noticeably less competence in recent years, but have instead become dependent on unreliable ‘tools’ 43. The real problem with using GenAI to do assignments is not cheating, but students “are not just undermining their ability to learn, but to someday lead.” 44 GenAI is destroying the free internet.Permalink The fight against bots on the internet is almost as old as the internet itself – and has been quite successful so far. Multifactor authentication, reCaptcha, honeypots and browser fingerprinting are just a few of the tools that help protect against automated abuse. However, GenAI takes this problem to a new level – in two ways. To make ‘the internet’ usable as the main source for training LLMs, AI companies use so-called ‘crawlers’. These essentially behave like DDoS attackers: They send tens of thousands of requests at once, from several hundred IPs in a very short time. Robot.txt files are ignored; instead, the source IP and user agent are obscured 45. These practices have massive disadvantages for providers of genuine content: Costs for additional bandwidth. Lost advertising revenue, as search engines now offer LLM-generated summaries instead of links to the sources. This threatens the existence of remaining independent journalism in particular 46. Misuse of own content for AI-supported competition. If the place where knowledge is generated is separated from the place where it is consumed, and if this makes the performance of generation even more opaque than before, the motivation to continue generating knowledge also declines. For projects such as Wikipedia, this means fewer donors and fewer contributors. Open communities often have no other option but to shut themselves off. Another aspect is the flooding of the internet with generated content that cannot be automatically distinguished from non-generated content. This content overwhelms the maintainers of open source software or portals such as Wikipedia 47. If this content is then also entered by humans – often in the belief that they are doing good – it is no longer possible to take action against the methodology. In the long run, this means that less and less authentic training material will lead to increasingly poor results from the models. Last but not least, autonomously acting agents make the already dire state of internet security much worse 48. Think of handing all your personal data and credentials to a robot that is distributing and using that data across the web, wherever and whenever it deems it necessary for reaching some goal. is controlled by LLMs who are vulnerable to all kinds of prompt injection attacs 49. is controlled by and reporting to companies that do not have your best interest in mind. has no awareness and knowledge about the implication of its actions. is acting on your behalf and thereby making you accountable. GenAI is a danger to democracyPermalink The manipulation of public opinion through social media precedes the arrival of LLMs. However, this technology gives the manipulators much more leverage. By flooding the web with fake news, fake videos and fake everything undemocratic (or just criminal) parties make it harder and harder for any serious media and journalism to get the attention of the public. People no longer have a common factual basis, which is necessary for all social negotiations. If you don’t agree on at least some basic facts, arguing about policies and measures to take is pointless. Without negotiations democracy will be dying; in many parts of the world it already is. GenAI versus human creativityPermalink Art and creativity are also threatened by generative AI. The impact on artists’ incomes of logos, images and illustrations now being easily and quickly created by AI prompts is obvious. A similar effect can also be observed in other areas. Studies show that poems written by LLMs are indistinguishable from those written by humans and that generative AI products are often rated more highly 50. This can be explained by a trend towards the middle and the average, which can also be observed in the music and film scenes film scene: due to its basic function, GenAI cannot create anything fundamentally new, but replicates familiar patterns, which is precisely why it is so well received by the public. Ironically, ‘AI’ draws its ‘creativity’ from the content of those it seeks to replace. Much of this content was used as training material against the will of the rights holders. Whether this constitutes a copyright infringement has not yet been decided; morally, the situation seems clear. The creative community is the first to be seriously threatened by GenAI in its livelihood 51. It’s not a coincidence that a big part of GenAI efforts is targeted at “democratizing art”. This framing is completely upside down. Art has been one of the most democratic activities for a very long time. Everybody can do it; but not everybody wants to do put in the effort, the practicing time and the soul. Real art is not about the product but about the process, which requires real humans. Generating art without the friction is about getting rid of the humans in the loop - and still making money. Digital colonialismPermalink The huge amount of data required by hyperscaled AI approaches makes it impossible to completely curate the learning content. And yet, one would like to avoid the reproduction of racist, inhuman and criminal content. Attempts are being made to get the problem under control by subsequently adapting the models to human preferences and local laws through additional ‘reinforcement learning from human feedback (RLHF)’ 52. The cheap labour for this very costly process can be found in the Global South. There, people are exposed to hours of hate speech, child abuse, domestic violence and other horrific scenarios in their poorly paid jobs in order to filter them out of the training material of large AI companies 53. Many emerge from these activities traumatised. However, it is not only people who are exploited in the less developed regions of the world, but also nature: the poisoning of the soil with chemicals during the extraction of raw materials for digital chips, as well as the contamination caused by our electronic waste and its improper disposal, are collateral damage that we willingly accept and whose long-term consequences are currently extremely difficult to assess. Here, too, the “developed” world profits, whereas the negative aspects are outsourced to the former colonies and other poor regions of the world. Political aspectsPermalink As software developers, we would like to ‘leave politics out of it’ and instead focus entirely on the cool tech. However, this is impossible when the advocates of this technology pursue strong political and ideological goals. In the case of GenAI, we can cleary see that the US corporations behind it (OpenAI, Google, Meta, Microsoft, etc.) have no problem with the current authoritarian – some say fascist – US government 54. In concrete terms, this means, among other things, that the models are explicitly manipulated to be less liberal or simply not to generate any output that could upset the CEO or the president 55. Even more serious is the fact that many of the leading minds behind these corporations and their financiers adhere to beliefs that can be broadly described as digital fascism. These include Peter Thiel, Marc Andreessen, Alex Karp, JD Vance, Elon Musk and many others on “The Authoritarian Stack” 56. Their ideologies, disguised as rational theories, are called longtermism and effective altruism. What they have in common is that they consider democracy and the state to be obsolete models, compassion to be ‘woke’, and that the current problems of humanity are insignificant, as our future lies in the colonisation of space and the merging of humans with artificial superintelligence 57. Do we want to give people who adhere to these ideologies (even) more power, money and influence by using and paying for their products? Do we want to feed their computer systems with our data? Do we really want to expose ourselves and our children to the answers from chatbots which they have manipulated? Not quite as abstruse, but similarly misanthropic, is the imminent displacement of many jobs by AI, as postulated by the same corporations in order to put pressure on employees with this claim. Demanding a large salary? Insisting on your legal rights? Complaining about too much workload? Doubts about the company’s goals? Then we’ll just replace you with cheap and uncomplaining AI! Whichever way you look at it, AI and GenAI are already being used politically. If we go along without resistance, we are endorsing this approach and supporting it with our time, our attention and our money. ConclusionPermalink Ideally, we would like to quantify our assessment by adding up the advantages, adding up the disadvantages and finally checking whether the balance is positive or negative. Unfortunately, in our specific case, neither the benefits nor the harm are easily quantifiable; we must therefore consult our social and personal values. Discussions about GenAI usually revolve purely around its benefits. Often, the capabilities of all ‘AI’ technologies (e.g. protein folding with AlphaFold 2) are lumped together, even though they have little in common with hyperscaling GenAI. However, if we consider the consequences and do not ignore the problems this technology entails – i.e. if we consider both sides in terms of ethics – the assessment changes. Convenience, speed and entertainment are then weighed against numerous damages and risks to the environment, the state and humanity. In this sense, the ethical use and further expansion of GenAI in its current form is not possible. Can there be ethical GenAI?Permalink If the use of GenAI is not ethical today what would have to change, which negative effects of GenAI would have to disappear or at least be greatly reduced in order to tip the balance between benefits and harms in the other direction? The models would have to be trained exclusively with publicly known content whose original creators consent to its use in training AI models. The environmental damage would have to be reduced to such an extent that it does not further fuel the climate crisis. Society would have to get full access to the training and operation of the models in order to rule out manipulation by third parties and restrict their use to beneficial purposes. This would require democratic processes, good regulation and oversight through judges and courts. The misuse and harming of others, e.g., through copyright theft or digital colonialism, would have to be prevented. Is such a change conceivable? Perhaps. Is it likely, given the interest groups and political aspects involved? Probably not
All these factors are achievable I think, or will be soonish. Smaller models, better sourced data sets, niche models, etc. But not with current actors as mentioned at the end.
Reviewer #1 (Public review):
Summary:
The study examined the extent to which children's word recognition skill improves across early development, becoming faster, more accurate and less variable, and the extent to which word recognition skill is related to children's concurrent and later vocabulary knowledge.
Strengths:
The main strength of the study comes from the dataset, which recycles previously collected data from 24 studies to examine the development of word recognition skill using data from 1963 children. This maximizes the impact of previously collected data while also allowing the study to reliably ask big-picture questions on the development of word recognition skill and its relation to chronological age and vocabulary knowledge. Data analysis is rigorous, thought through and very clearly described. Data and code necessary to reproduce the manuscript are shared on the project's GitHub.
Weaknesses:
The limitations of the study are acknowledged to some extent, but need to be improved and ensured that they run throughout the manuscript. Thus, in the discussion, the authors note that the approach is observational and exploratory, and highlight for me a key alternative explanation of the findings, namely that faster children could be faster due to their larger vocabulary, rather than faster children learning more words. Indeed, the latter explanation for the relationship is called into question, given that growth in speed was not related to growth in vocabulary. Here, the authors note that the null result may be related to the fact that they do not sufficiently precise estimates of growth slopes, rather than taking the alternative explanation seriously that there may not be as causal a link between being a faster word learner and a better word learner (learn more words). This is especially since, but correct me if I'm wrong here, the current vocabulary size is not taken into consideration in the model examining vocabulary growth. Given the increasing number of studies showing that current vocabulary knowledge predicts vocabulary growth (Laing, Kalinowski et al, Siew & Vitevitch), one simple alternative explanation is that current vocabulary knowledge predicts both current word recognition skill and later vocabulary knowledge. Is there anything in the data speaking against this hypothesis?
Equally, while the SEM examines vocabulary growth controlling for age, I wonder about the other way around. What would happen to the effect of age on word recognition skill (in the LME model, S8) if one were to add concurrent vocabulary size? So does chronological age explain word recognition skill or vocabulary knowledge? Right now, the manuscript describes this effect purely related to chronological age, but is it age per se or other cognitive abilities, including a key change across development, namely, vocabulary size? Thus, the presentation of the skill learning hypothesis suggests that age is a proxy for experience, while you actually have here a very nice proxy for experience in terms of children's vocabulary size.
Critically, while the discussion is more nuanced, the way the abstract is concluded and the way the Introduction is phrased suggest that the study is able to answer a causal question, which, as the authors themselves note, is not possible. The abstract, for instance, states that word recognition becomes faster, more accurate and less variable...consistent with a process of skill learning. And also that this skill plays a role in supporting early language learning, which is very causal language. I don't think you can really claim that you are testing the two hypotheses you suggest here. The work is definitely embedded in the context of these hypotheses, but are you really able to test them? My worry is that while the discussion is more nuanced, the extent to which this study will then be cited down the line as showing that children learn more words down the line because they are faster at recognizing words, and anything that you can do to tamper with such interpretations would be good for the literature. For me, this should not just be relegated to the discussion but should be touched upon in the abstract and Introduction.
Finally, it would help to talk more about the mechanisms at work in any relationship between word recognition and language learning. It seems to me that this would rely on some predictive processing framework, given the description on page 4, and it would be good to make this clear (faster and more accurately you can recognize a ball, better use this evidence to infer the speaker's intended meaning). Equally, when referring to word recognition, it would be good to clarify what this refers to - how well a child knows what a word refers to (and in the context of LWL, what it does not refer to) or how quickly it directs attention to what is referred to.
With regards to the data, I wonder if there is a clustering of kids past 24 months that is happening here, looking at Figures 1 and 2, where it seems like there is less change past the 24-month point. Is there any way to look at whether the effect of age or vocabulary on word recognition is not linear but asymptotic?
Author response:
The following is the authors’ response to the original reviews.
Public reviews:
Reviewer #1 (Public review):
Summary:
Wu and colleagues aimed to explain previous findings that adolescents, compared to adults, show reduced cooperation following cooperative behaviour from a partner in several social scenarios. The authors analysed behavioural data from adolescents and adults performing a zero-sum Prisoner's Dilemma task and compared a range of social and non-social reinforcement learning models to identify potential algorithmic differences. Their findings suggest that adolescents' lower cooperation is best explained by a reduced learning rate for cooperative outcomes, rather than differences in prior expectations about the cooperativeness of a partner. The authors situate their results within the broader literature, proposing that adolescents' behaviour reflects a stronger preference for self-interest rather than a deficit in mentalising.
Strengths:
The work as a whole suggests that, in line with past work, adolescents prioritise value accumulation, and this can be, in part, explained by algorithmic differences in weighted value learning. The authors situate their work very clearly in past literature, and make it obvious the gap they are testing and trying to explain. The work also includes social contexts that move the field beyond non-social value accumulation in adolescents. The authors compare a series of formal approaches that might explain the results and establish generative and modelcomparison procedures to demonstrate the validity of their winning model and individual parameters. The writing was clear, and the presentation of the results was logical and well-structured.
We thank the reviewer for recognizing the strengths of our work.
Weaknesses:
(1) I also have some concerns about the methods used to fit and approximate parameters of interest. Namely, the use of maximum likelihood versus hierarchical methods to fit models on an individual level, which may reduce some of the outliers noted in the supplement, and also may improve model identifiability.
We thank the reviewer for this suggestion. Following the comment, we added a hierarchical Bayesian estimation. We built a hierarchical model with both group-level (adolescent group and adult group) and individual-level structures for the best-fitting model. Four Markov chains with 4,000 samples each were run, and the model converged well (see Figure supplement 7).
We then analyzed the posterior parameters for adolescents and adults separately. The results were consistent with those from the MLE analysis. These additional results have been included in the Appendix Analysis section (also see Figure supplement 5 and 7). In addition, we have updated the code and provided the link for reference. We appreciate the reviewer’s suggestion, which improved our analysis.
(2) There was also little discussion given the structure of the Prisoner's Dilemma, and the strategy of the game (that defection is always dominant), meaning that the preferences of the adolescents cannot necessarily be distinguished from the incentives of the game, i.e. they may seem less cooperative simply because they want to play the dominant strategy, rather than a lower preferences for cooperation if all else was the same.
We thank the reviewer for this comment and agree that adolescents’ lower cooperation may partly reflect a rational response to the incentive structure of the Prisoner’s Dilemma.
However, our computational modeling explicitly addressed this possibility. Model 4 (inequality aversion) captures decisions that are driven purely by self-interest or aversion to unequal outcomes, including a parameter reflecting disutility from advantageous inequality, which represents self-oriented motives. If participants’ behavior were solely guided by the payoff-dominant strategy, this model should have provided the best fit. However, our model comparison showed that Model 5 (social reward) performed better in both adolescents and adults, suggesting that cooperative behavior is better explained by valuing social outcomes beyond payoff structures.
Besides, if adolescents’ lower cooperation is that they strategically respond to the payoff structure by adopting defection as the more rewarding option. Then, adolescents should show reduced cooperation across all rounds. Instead, adolescents and adults behaved similarly when partners defected, but adolescents cooperated less when partners cooperated and showed little increase in cooperation even after consecutive cooperative responses. This pattern suggests that adolescents’ lower cooperation cannot be explained solely by strategic responses to payoff structures but rather reflects a reduced sensitivity to others’ cooperative behavior or weaker social reciprocity motives. We have expanded our Discussion to acknowledge this important point and to clarify how the behavioral and modeling results address the reviewer’s concern.
“Overall, these findings indicate that adolescents’ lower cooperation is unlikely to be driven solely by strategic considerations, but may instead reflect differences in the valuation of others’ cooperation or reduced motivation to reciprocate. Although defection is the payoff-dominant strategy in the Prisoner’s Dilemma, the selective pattern of adolescents’ cooperation and the model comparison results indicate that their reduced cooperation cannot be fully explained by strategic incentives, but rather reflects weaker valuation of social reciprocity.”
Appraisal & Discussion:
(3) The authors have partially achieved their aims, but I believe the manuscript would benefit from additional methodological clarification, specifically regarding the use of hierarchical model fitting and the inclusion of Bayes Factors, to more robustly support their conclusions. It would also be important to investigate the source of the model confusion observed in two of their models.
We thank the reviewer for this comment. In the revised manuscript, we have clarified the hierarchical Bayesian modeling procedure for the best-fitting model, including the group- and individual-level structure and convergence diagnostics. The hierarchical approach produced results that fully replicated those obtained from the original maximumlikelihood estimation, confirming the robustness of our findings. Please also see the response to (1).
Regarding the model confusion between the inequality aversion (Model 4) and social reward (Model 5) models in the model recovery analysis, both models’ simulated behaviors were best captured by the baseline model. This pattern arises because neither model includes learning or updating processes. Given that our task involves dynamic, multi-round interactions, models lacking a learning mechanism cannot adequately capture participants’ trial-by-trial adjustments, resulting in similar behavioral patterns that are better explained by the baseline model during model recovery. We have added a clarification of this point to the Results:
“The overlap between Models 4 and 5 likely arises because neither model incorporates a learning mechanism, making them less able to account for trial-by-trial adjustments in this dynamic task.”
(4) I am unconvinced by the claim that failures in mentalising have been empirically ruled out, even though I am theoretically inclined to believe that adolescents can mentalise using the same procedures as adults. While reinforcement learning models are useful for identifying biases in learning weights, they do not directly capture formal representations of others' mental states. Greater clarity on this point is needed in the discussion, or a toning down of this language.
We sincerely thank the reviewer for this professional comment. We agree that our prior wording regarding adolescents’ capacity to mentalise was somewhat overgeneralized. Accordingly, we have toned down the language in both the Abstract and the Discussion to better align our statements with what the present study directly tests. Specifically, our revisions focus on adolescents’ and adults’ ability to predict others’ cooperation in social learning. This is consistent with the evidence from our analyses examining adolescents’ and adults’ model-based expectations and self-reported scores on partner cooperativeness (see Figure 4). In the revised Discussion, we state:
“Our results suggest that the lower levels of cooperation observed in adolescents stem from a stronger motive to prioritize self-interest rather than a deficiency in predicting others’ cooperation in social learning”.
(5) Additionally, a more detailed discussion of the incentives embedded in the Prisoner's Dilemma task would be valuable. In particular, the authors' interpretation of reduced adolescent cooperativeness might be reconsidered in light of the zero-sum nature of the game, which differs from broader conceptualisations of cooperation in contexts where defection is not structurally incentivised.
We thank the reviewer for this comment and agree that adolescents’ lower cooperation may partly reflect a rational response to the incentive structure of the Prisoner’s Dilemma. However, our behavioral and computational evidence suggests that this pattern cannot be explained solely by strategic responses to payoff structures, but rather reflects a reduced sensitivity to others’ cooperative behavior or weaker social reciprocity motives. We have expanded the Discussion to acknowledge this point and to clarify how both behavioral and modeling results address the reviewer’s concern (see also our response to 2).
(6) Overall, I believe this work has the potential to make a meaningful contribution to the field. Its impact would be strengthened by more rigorous modelling checks and fitting procedures, as well as by framing the findings in terms of the specific game-theoretic context, rather than general cooperation.
We thank the reviewer for the professional comments, which have helped us improve our work.
Reviewer #2 (Public review):
Summary:
This manuscript investigates age-related differences in cooperative behavior by comparing adolescents and adults in a repeated Prisoner's Dilemma Game (rPDG). The authors find that adolescents exhibit lower levels of cooperation than adults. Specifically, adolescents reciprocate partners' cooperation to a lesser degree than adults do. Through computational modeling, they show that this relatively low cooperation rate is not due to impaired expectations or mentalizing deficits, but rather a diminished intrinsic reward for reciprocity. A social reinforcement learning model with asymmetric learning rate best captured these dynamics, revealing age-related differences in how positive and negative outcomes drive behavioral updates. These findings contribute to understanding the developmental trajectory of cooperation and highlight adolescence as a period marked by heightened sensitivity to immediate rewards at the expense of long-term prosocial gains.
Strengths:
(1) Rigid model comparison and parameter recovery procedure.
(2) Conceptually comprehensive model space.
(3) Well-powered samples.
We thank the reviewer for highlighting the strengths of our work.
Weaknesses:
A key conceptual distinction between learning from non-human agents (e.g., bandit machines) and human partners is that the latter are typically assumed to possess stable behavioral dispositions or moral traits. When a non-human source abruptly shifts behavior (e.g., from 80% to 20% reward), learners may simply update their expectations. In contrast, a sudden behavioral shift by a previously cooperative human partner can prompt higher-order inferences about the partner's trustworthiness or the integrity of the experimental setup (e.g., whether the partner is truly interactive or human). The authors may consider whether their modeling framework captures such higher-order social inferences. Specifically, trait-based models-such as those explored in Hackel et al. (2015, Nature Neuroscience)-suggest that learners form enduring beliefs about others' moral dispositions, which then modulate trial-bytrial learning. A learner who believes their partner is inherently cooperative may update less in response to a surprising defection, effectively showing a trait-based dampening of learning rate.
We thank the reviewer for this thoughtful comment. We agree that social learning from human partners may involve higher-order inferences beyond simple reinforcement learning from non-human sources. To address this, we had previously included such mechanisms in our behavioral modeling. In Model 7 (Social Reward Model with Influence), we tested a higher-order belief-updating process in which participants’ expectations about their partner’s cooperation were shaped not only by the partner’s previous choices but also by the inferred influence of their own past actions on the partner’s subsequent behavior. In other words, participants could adjust their belief about the partner’s cooperation by considering how their partner’s belief about them might change. Model comparison showed that Model 7 did not outperform the best-fitting model, suggesting that incorporating higher-order influence updates added limited explanatory value in this context. As suggested by the reviewer, we have further clarified this point in the revised manuscript.
Regarding trait-based frameworks, we appreciate the reviewer’s reference to Hackel et al. (2015). That study elegantly demonstrated that learners form relatively stable beliefs about others’ social dispositions, such as generosity, especially when the task structure provides explicit cues for trait inference (e.g., resource allocations and giving proportions). By contrast, our study was not designed to isolate trait learning, but rather to capture how participants update their expectations about a partner’s cooperation over repeated interactions. In this sense, cooperativeness in our framework can be viewed as a trait-like latent belief that evolves as evidence accumulates. Thus, while our model does not include a dedicated trait module that directly modulates learning rates, the belief-updating component of our best-fitting model effectively tracks a dynamic, partner-specific cooperativeness, potentially reflecting a prosocial tendency.
This asymmetry in belief updating has been observed in prior work (e.g., Siegel et al., 2018, Nature Human Behaviour) and could be captured using a dynamic or belief-weighted learning rate. Models incorporating such mechanisms (e.g., dynamic learning rate models as in Jian Li et al., 2011, Nature Neuroscience) could better account for flexible adjustments in response to surprising behavior, particularly in the social domain.
We thank the reviewer for the suggestion. Following the comment, we implemented an additional model incorporating a dynamic learning rate based on the magnitude of prediction errors. Specifically, we developed Model 9: Social reward model with Pearce–Hall learning algorithm (dynamic learning rate), in which participants’ beliefs about their partner’s cooperation probability are updated using a Rescorla–Wagner rule with a learning rate dynamically modulated by the Pearce–Hall (PH) Error Learning mechanism. In this framework, the learning rate increases following surprising outcomes (larger prediction errors) and decreases as expectations become more stable (see Appendix Analysis section for details).
The results showed that this dynamic learning rate model did not outperform our bestfitting model in either adolescents or adults (see Figure supplement 6). We greatly appreciate the reviewer’s suggestion, which has strengthened the scope of our analysis. We now have added these analyses to the Appendix Analysis section (see Figure Supplement 6) and expanded the Discussion to acknowledge this modeling extension and further discuss its implications.
Second, the developmental interpretation of the observed effects would be strengthened by considering possible non-linear relationships between age and model parameters. For instance, certain cognitive or affective traits relevant to social learning-such as sensitivity to reciprocity or reward updating-may follow non-monotonic trajectories, peaking in late adolescence or early adulthood. Fitting age as a continuous variable, possibly with quadratic or spline terms, may yield more nuanced developmental insights.
We thank the reviewer for this professional comment. In addition to the linear analyses, we further conducted exploratory analyses to examine potential non-linear relationships between age and the model parameters. Specifically, we fit LMMs for each of the four parameters as outcomes (α+, α-, β, and ω). The fixed effects included age, a quadratic age term, and gender, and the random effects included subject-specific random intercepts and random slopes for age and gender. Model comparison using BIC did not indicate improvement for the quadratic models over the linear models for α<sup>+</sup> (ΔBIC<sub>quadratic-linear</sub> = 5.09), α− (ΔBICquadratic-linear = 3.04), β (ΔBICquadratic-linear = 3.9), or ω (ΔBICquadratic-linear = 0). Moreover, the quadratic age term was not significant for α<sup>+</sup>, α<sup>−</sup>, or β (all ps > 0.10). For ω, we observed a significant linear age effect (b = 1.41, t = 2.65, p = 0.009) and a significant quadratic age effect (b = −0.03, t = −2.39, p = 0.018; see Author response image 1). This pattern is broadly consistent with the group effect reported in the main text. The shaded area in the figure represents the 95% confidence interval. As shown, the interval widens at older ages (≥ 26 years) due to fewer participants in that range, which limits the robustness of the inferred quadratic effect. In consideration of the limited precision at older ages and the lack of BIC improvement, we did not emphasize the quadratic effect in the revised manuscript and present these results here as exploratory.
Author response image 1.
Linear and quadratic model fits showing the relationship between age and the ω parameter, with 95% confidence intervals.<br />
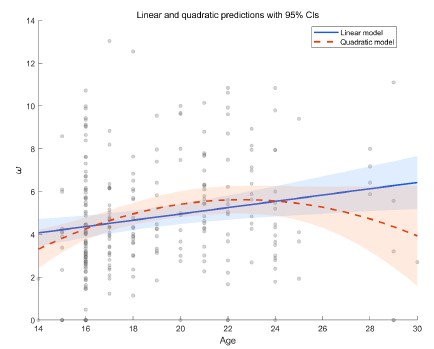
Finally, the two age groups compared - adolescents (high school students) and adults (university students) - differ not only in age but also in sociocultural and economic backgrounds. High school students are likely more homogenous in regional background (e.g., Beijing locals), while university students may be drawn from a broader geographic and socioeconomic pool. Additionally, differences in financial independence, family structure (e.g., single-child status), and social network complexity may systematically affect cooperative behavior and valuation of rewards. Although these factors are difficult to control fully, the authors should more explicitly address the extent to which their findings reflect biological development versus social and contextual influences.
We appreciate this comment. Indeed, adolescents (high school students) and adults (university students) differ not only in age but also in sociocultural and socioeconomic backgrounds. In our study, all participants were recruited from Beijing and surrounding regions, which helps minimize large regional and cultural variability. Moreover, we accounted for individual-level random effects and included participants’ social value orientation (SVO) as an individual difference measure.
Nonetheless, we acknowledge that other contextual factors, such as differences in financial independence, socioeconomic status, and social experience—may also contribute to group differences in cooperative behavior and reward valuation. Although our results are broadly consistent with developmental theories of reward sensitivity and social decisionmaking, sociocultural influences cannot be entirely ruled out. Future work with more demographically matched samples or with socioeconomic and regional variables explicitly controlled will help clarify the relative contributions of biological and contextual factors. Accordingly, we have revised the Discussion to include the following statement: “Third, although both age groups were recruited from Beijing and nearby regions, minimizing major regional and cultural variation, adolescents and adults may still differ in socioeconomic status, financial independence, and social experience. Such contextual differences could interact with developmental processes in shaping cooperative behavior and reward valuation. Future research with demographically matched samples or explicit measures of socioeconomic background will help disentangle biological from sociocultural influences.”
Reviewer #3 (Public review):
Summary:
Wu and colleagues find that in a repeated Prisoner's Dilemma, adolescents, compared to adults, are less likely to increase their cooperation behavior in response to repeated cooperation from a simulated partner. In contrast, after repeated defection by the partner, both age groups show comparable behavior.
To uncover the mechanisms underlying these patterns, the authors compare eight different models. They report that a social reward learning model, which includes separate learning rates for positive and negative prediction errors, best fits the behavior of both groups. Key parameters in this winning model vary with age: notably, the intrinsic value of cooperating is lower in adolescents. Adults and adolescents also differ in learning rates for positive and negative prediction errors, as well as in the inverse temperature parameter.
Strengths:
The modeling results are compelling in their ability to distinguish between learned expectations and the intrinsic value of cooperation. The authors skillfully compare relevant models to demonstrate which mechanisms drive cooperation behavior in the two age groups.
We thank the reviewer’s recognition of our work’s strengths.
Weaknesses:
Some of the claims made are not fully supported by the data:
The central parameter reflecting preference for cooperation is positive in both groups. Thus, framing the results as self-interest versus other-interest may be misleading.
We thank the reviewer for this insightful comment. In the social reward model, the cooperation preference parameter is positive by definition, as defection in the repeated rPDG always yields a +2 monetary advantage regardless of the partner’s action. This positive value represents the additional subjective reward assigned to mutual cooperation (e.g., reciprocity value) that counterbalances the monetary gain from defection. Although the estimated social reward parameter ω was positive, the effective advantage of cooperation is Δ=p×ω−2. Given participants’ inferred beliefs p, Δ was negative for most trials (p×ω<2), indicating that the social reward was insufficient to offset the +2 advantage of defection. Thus, both adolescents and adults valued cooperation positively, but adolescents’ smaller ω and weaker responsiveness to sustained partner cooperation suggest a stronger weighting on immediate monetary payoffs.
In this light, our framing of adolescents as more self-interested derives from their behavioral pattern: even when they recognized sustained partner cooperation and held high expectations of partner cooperation, adolescents showed lower cooperative behavior and reciprocity rewards compared with adults. Whereas adults increased cooperation after two or three consecutive partner cooperations, this pattern was absent among adolescents. We therefore interpret their behavior as relatively more self-interested, reflecting reduced sensitivity to the social reward from mutual cooperation rather than a categorical shift from self-interest to other-interest, as elaborated in the Discussion.
It is unclear why the authors assume adolescents and adults have the same expectations about the partner's cooperation, yet simultaneously demonstrate age-related differences in learning about the partner. To support their claim mechanistically, simulations showing that differences in cooperation preference (i.e., the w parameter), rather than differences in learning, drive behavioral differences would be helpful.
We thank the reviewer for raising this important point. In our model, both adolescents and adults updated their beliefs about partner cooperation using an asymmetric reinforcement learning (RL) rule. Although adolescents exhibited a higher positive and a lower negative learning rate than adults, the two groups did not differ significantly in their overall updating of partner cooperation probability (Fig. 4a-b). We then examined the social reward parameter ω, which was significantly smaller in adolescents and determined the intrinsic value of mutual cooperation (i.e., p×ω). This variable differed significantly between groups and closely matched the behavioral pattern.
Following the reviewer’s suggestion, we conducted additional simulations varying one model parameter at a time while holding the others constant. The difference in mean cooperation probability between adults and adolescents served as the index (positive = higher cooperation in adults). As shown in the Author response image 2, decreases in ω most effectively reproduced the observed group difference (shaded area), indicating that age-related differences in cooperation are primarily driven by variation in the social reward parameter ω rather than by others.
Author response image 2.
Simulation results showing how variations in each model parameter affect the group difference in mean cooperation probability (Adults – Adolescents). Based on the best-fitting Model 8 and parameters estimated from all participants, each line represents one parameter (i.e., α+, α-, ω, β) systematically varied within the tested range (α±:0.1–0.9; ω, β:1–9) while other parameters were held constant. Positive values indicate higher cooperation in adults. Smaller ω values most strongly reproduced the observed group difference, suggesting that reduced social reward weighting primarily drives adolescents’ lower cooperation.
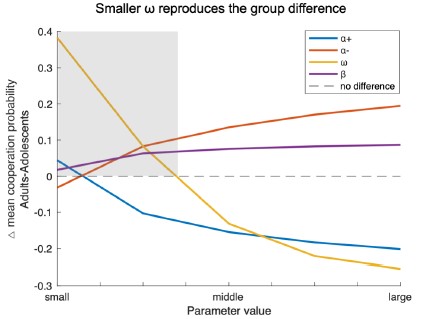
Two different schedules of 120 trials were used: one with stable partner behavior and one with behavior changing after 20 trials. While results for order effects are reported, the results for the stable vs. changing phases within each schedule are not. Since learning is influenced by reward structure, it is important to test whether key findings hold across both phases.
We thank the reviewer for this thoughtful and professional comment. In our GLMM and LMM analyses, we focused on trial order rather than explicitly including the stable vs. changing phase factor, due to concerns about multicollinearity. In our design, phases occur in specific temporal segments, which introduces strong collinearity with trial order. In multi-round interactions, order effects also capture variance related to phase transitions.
Nonetheless, to directly address this concern, we conducted additional robustness analyses by adding a phase variable (stable vs. changing) to GLMM1, LMM1, and LMM3 alongside the original covariates. Across these specifications, the key findings were replicated (see GLMM<sub>sup</sub>2 and LMM<sub>sup</sub>4–5; Tables 9-11), and the direction and significance of main effects remained unchanged, indicating that our conclusions are robust to phase differences.
The division of participants at the legal threshold of 18 years should be more explicitly justified. The age distribution appears continuous rather than clearly split. Providing rationale and including continuous analyses would clarify how groupings were determined.
We thank the reviewer for this thoughtful comment. We divided participants at the legal threshold of 18 years for both conceptual and practical reasons grounded in prior literature and policy. In many countries and regions, 18 marks the age of legal majority and is widely used as the boundary between adolescence and adulthood in behavioral and clinical research. Empirically, prior studies indicate that psychosocial maturity and executive functions approach adult levels around this age, with key cognitive capacities stabilizing in late adolescence (Icenogle et al., 2019; Tervo-Clemmens et al., 2023). We have clarified this rationale in the Introduction section of the revised manuscript.
“Based on legal criteria for majority and prior empirical work, we adopt 18 years as the boundary between adolescence and adulthood (Icenogle et al., 2019; Tervo-Clemmens et al., 2023).”
We fully agree that the underlying age distribution is continuous rather than sharply divided. To address this, we conducted additional analyses treating age as a continuous predictor (see GLMM<sub>sup</sub>1 and LMM<sub>sup</sub>1–3; Tables S1-S4), which generally replicated the patterns observed with the categorical grouping. Nevertheless, given the limited age range of our sample, the generalizability of these findings to fine-grained developmental differences remains constrained. Therefore, our primary analyses continue to focus on the contrast between adolescents and adults, rather than attempting to model a full developmental trajectory.
Claims of null effects (e.g., in the abstract: "adults increased their intrinsic reward for reciprocating... a pattern absent in adolescents") should be supported with appropriate statistics, such as Bayesian regression.
We thank the reviewer for highlighting the importance of rigor when interpreting potential null effects. To address this concern, we conducted Bayes factor analyses of the intrinsic reward for reciprocity and reported the corresponding BF10 for all relevant post hoc comparisons. This approach quantifies the relative evidence for the alternative versus the null hypothesis, thereby providing a more direct assessment of null effects. The analysis procedure is now described in the Methods and Materials section:
“Post hoc comparisons were conducted using Bayes factor analyses with MATLAB’s bayesFactor Toolbox (version v3.0, Krekelberg, 2024), with a Cauchy prior scale σ = 0.707.”
Once claims are more closely aligned with the data, the study will offer a valuable contribution to the field, given its use of relevant models and a well-established paradigm.
We are grateful for the reviewer’s generous appraisal and insightful comments.
Recommendations for the authors
Reviewer #1 (Recommendations for the authors):
I commend the authors on a well-structured, clear, and interesting piece of work. I have several questions and recommendations that, if addressed, I believe will strengthen the manuscript.
We thank the reviewer for commending the organization of our paper.
Introduction: - Why use a zero-sum (Prisoner's Dilemma; PD) versus a mixed-motive game (e.g. Trust Task) to study cooperation? In a finite set of rounds, the dominant strategy can be to defect in a PD.
We thank the reviewer for this helpful comment. We agree that both the rationale for using the repeated Prisoner’s Dilemma (rPDG) and the limitations of this framework should be clarified. We chose the rPDG to isolate the core motivational conflict between selfinterest and joint welfare, as its symmetric and simultaneous structure avoids the sequential trust and reputation dependencies/accumulation inherent to asymmetric tasks such as the Trust Game (King-Casas et al., 2005; Rilling et al., 2002).
Although a finitely repeated rPDG theoretically favors defection, extensive prior research shows that cooperation can still emerge in long repeated interactions when players rely on learning and reciprocity rather than backward induction (Rilling et al., 2002; Fareri et al., 2015). Our design employed 120 consecutive rounds, allowing participants to update expectations about partner behavior and to establish stable reciprocity patterns over time. We have added the following clarification to the Introduction:
“The rPDG provides a symmetric and simultaneous framework that isolates the motivational conflict between self-interest and joint welfare, avoiding the sequential trust and reputation dynamics characteristic of asymmetric tasks such as the Trust Game (Rilling et al., 2002; King-Casas et al., 2005)”
Methods:
Did the participants know how long the PD would go on for?
Were the participants informed that the partner was real/simulated?
Were the participants informed that the partner was going to be the same for all rounds?
We thank the reviewer for the meticulous review work, which helped us present the experimental design and reporting details more clearly. the following clarifications: I. Participants were not informed of the total number of rounds in the rPDG. This prevented endgame expectations and avoided distraction from counting rounds, which could introduce additional effects. II. Participants were told that their partner was another human participant in the laboratory. However, the partner’s behavior was predetermined by a computer program. This design enabled tighter experimental control and ensured consistent conditions across age groups, supporting valid comparisons. III. Participants were informed that they would interact with the same partner across all rounds, aligning with the essence of a multiround interaction paradigm and stabilizing partner-related expectations. For transparency, we have clarified these points in the Methods and Materials section:
“Participants were told that their partner was another human participant in the laboratory and that they would interact with the same partner across all rounds. However, in reality, the actions of the partner were predetermined by a computer program. This setup allowed for a clear comparison of the behavioral responses between adolescents and adults. Participants were not informed of the total number of rounds in the rPDG.”
The authors mention that an SVO was also recorded to indicate participant prosociality. Where are the results of this? Did this track game play at all? Could cooperativeness be explained broadly as an SVO preference that penetrated into game-play behaviour?
We thank the reviewer for pointing this out. We agree that individual differences in prosociality may shape cooperative behavior, so we conducted additional analyses incorporating SVO. Specifically, we extended GLMM1 and LMM3 by adding the measured SVO as a fixed effect with random slopes, yielding GLMM<sub>sup</sub>3 and LMM<sub>sup</sub>6 (Tables 12–13). The results showed that higher SVO was associated with greater cooperation, whereas its effect on the reward for reciprocity was not significant. Importantly, the primary findings remained unchanged after controlling for SVO. These results indicate that cooperativeness in our task cannot be explained solely by a broad SVO preference, although a more prosocial orientation was associated with greater cooperation. We have reported these analyses and results in the Appendix Analysis section.
Why was AIC chosen rather an BIC to compare model dominance?
Sorry for the lack of clarification. Both the Akaike Information Criterion (AIC, Akaike, 1974) and Bayesian Information Criterion (BIC, Schwarz, 1978) are informationtheoretic criterions for model comparison, neither of which depends on whether the models to be compared are nested to each other or not (Burnham et al., 2002). We have added the following clarification into the Methods.
“We chose to use the AICc as the metric of goodness-of-fit for model comparison for the following statistical reasons. First, BIC is derived based on the assumption that the “true model” must be one of the models in the limited model set one compares (Burnham et al., 2002; Gelman & Shalizi, 2013), which is unrealistic in our case. In contrast, AIC does not rely on this unrealistic “true model” assumption and instead selects out the model that has the highest predictive power in the model set (Gelman et al., 2014). Second, AIC is also more robust than BIC for finite sample size (Vrieze, 2012).”
I believe the model fitting procedure might benefit from hierarchical estimation, rather than maximum likelihood methods. Adolescents in particular seem to show multiple outliers in a^+ and w^+ at the lower end of the distributions in Figure S2. There are several packages to allow hierarchical estimation and model comparison in MATLAB (which I believe is the language used for this analysis; see https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1007043).
We thank the reviewer for this helpful comment and for referring us to relevant methodological work (Piray et al., 2019). We have addressed this point by incorporating hierarchical Bayesian estimation, which effectively mitigates outlier effects and improves model identifiability. The results replicated those obtained with MLE fitting and further revealed group-level differences in key parameters. Please see our detailed response to Reviewer#1 Q1 for the full description of this analysis and results.
Results: Model confusion seems to show that the inequality aversion and social reward models were consistently confused with the baseline model. Is this explained or investigated? I could not find an explanation for this.
The apparent overlap between the inequality aversion (Model 4) and social reward (Model 5) models in the recovery analysis likely arises because neither model includes a learning mechanism, making them unable to capture trial-by-trial adjustments in this dynamic task. Consequently, both were best fit by the baseline model. Please see Response to Reviewer #1 Q3 for related discussion.
Figures 3e and 3f show the correlation between asymmetric learning rates and age. It seems that both a^+ and a^- are around 0.35-0.40 for young adolescents, and this becomes more polarised with age. Could it be that with age comes an increasing discernment of positive and negative outcomes on beliefs, and younger ages compress both positive and negative values together? Given the higher stochasticity in younger ages (\beta), it may also be that these values simply represent higher uncertainty over how to act in any given situation within a social context (assuming the differences in groups are true).
We appreciate this insightful interpretation. Indeed, both α+ and α- cluster around 0.35–0.40 in younger adolescents and become increasingly polarized with age, suggesting that sensitivity to positive versus negative feedback is less differentiated early in development and becomes more distinct over time. This interpretation remains tentative and warrants further validation. Based on this comment, we have revised the Discussion to include this developmental interpretation.
We also clarify that in our model β denotes the inverse temperature parameter; higher β reflects greater choice precision and value sensitivity, not higher stochasticity. Accordingly, adolescents showed higher β values, indicating more value-based and less exploratory choices, whereas adults displayed relatively greater exploratory cooperation. These group differences were also replicated using hierarchical Bayesian estimation (see Response to Reviewer #1 Q1). In response to this comment, we have added a statement in the Discussion highlighting this developmental interpretation.
“Together, these findings suggest that the differentiation between positive and negative learning rates changes with age, reflecting more selective feedback sensitivity in development, while higher β values in adolescents indicate greater value sensitivity. This interpretation remains tentative and requires further validation in future research.”
A parameter partial correlation matrix (off-diagonal) would be helpful to understand the relationship between parameters in both adolescents and adults separately. This may provide a good overview of how the model properties may change with age (e.g. a^+'s relation to \beta).
We thank the reviewer for this helpful comment. We fully agree that a parameter partial correlation matrix can further elucidate the relationships among parameters. Accordingly, we conducted a partial correlation analysis and added the visually presented results to the revised manuscript as Figure 2-figure supplement 4.
It would be helpful to have Bayes Factors reported with each statistical tests given that several p-values fall within the 0.01 and 0.10.
We thank the reviewer for this important recommendation. We have conducted Bayes factor analyses and reported BF10 for all relevant post hoc comparisons. We also clarified our analysis in the Methods and Materials section:
“Post hoc comparisons were conducted using Bayes factor analyses with MATLAB’s bayesFactor Toolbox (version v3.0, Krekelberg, 2024), with a Cauchy prior scale σ = 0.707.”
Discussion: I believe the language around ruling out failures in mentalising needs to be toned down. RL models do not enable formal representational differences required to assess mentalising, but they can distinguish biases in value learning, which in itself is interesting. If the authors were to show that more complex 'ToM-like' Bayesian models were beaten by RL models across the board, and this did not differ across adults and adolescents, there would be a stronger case to make this claim. I think the authors either need to include Bayesian models in their comparison, or tone down their language on this point, and/or suggest ways in which this point might be more thoroughly investigated (e.g., using structured models on the same task and running comparisons: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0087619).
We thank the reviewer for the comments. Please see our response to Reviewer 1 (Appraisal & Discussion section) for details.
Reviewer #2 (Recommendations for the authors):
The authors may want to show the winning model earlier (perhaps near the beginning of the Results section, when model parameters are first mentioned).
We thank the reviewer for this suggestion. We agree that highlighting the winning model early improves clarity. Currently, we have mentioned the winning model before the beginning of the Results section. Specifically, in the penultimate paragraph of the Introduction we state:
“We identified the asymmetric RL learning model as the winning model that best explained the cooperative decisions of both adolescents and adults.”
Reviewer #3 (Recommendations for the authors):
In addition to the points mentioned above, I suggest the following:
(1) Clarify plots by clearly explaining each variable. In particular, the indices 1 vs. 1,2 vs. 1,2,3 were not immediately understandable.
We thank the reviewer for this suggestion. We agree that the indices were not immediately clear. We have revised the figure captions (Figure 1 and 4) to explicitly define these terms more clearly:
“The x-axis represents the consistency of the partner’s actions in previous trials (t<sub>−1</sub>: last trial; t<sub>−1,2</sub>: last two trials; t<sub>−1,2,3</sub>: last three trials).”
It's unclear why the index stops at 3. If this isn't the maximum possible number of consecutive cooperation trials, please consider including all relevant data, as adolescents might show a trend similar to adults over more trials.
We thank the reviewer for raising this point. In our exploratory analyses, we also examined longer streaks of consecutive partner cooperation or defection (up to four or five trials). Two empirical considerations led us to set the cutoff at three in the final analyses. First, the influence of partner behavior diminished sharply with temporal distance. In both GLMMs and LMMs, coefficients for earlier partner choices were small and unstable, and their inclusion substantially increased model complexity and multicollinearity. This recency pattern is consistent with learning and decision models emphasizing stronger weighting of recent evidence (Fudenberg & Levine, 2014; Fudenberg & Peysakhovich, 2016). Second, streaks longer than three were rare, especially among some participants, leading to data sparsity and inflated uncertainty. Including these sparse conditions risked biasing group estimates rather than clarifying them. Balancing informativeness and stability, we therefore restricted the index to three consecutive partner choices in the main analyses, which we believe sufficiently capture individuals’ general tendencies in reciprocal cooperation.
The term "reciprocity" may not be necessary. Since it appears to reflect a general preference for cooperation, it may be clearer to refer to the specific behavior or parameter being measured. This would also avoid confusion, especially since adolescents do show negative reciprocity in response to repeated defection.
We thank you for this comment. In our work, we compute the intrinsic reward for reciprocity as p × ω, where p is the partner cooperation expectation and ω is the cooperation preference. In the rPDG, this value framework manifests as a reciprocity-derived reward: sustained mutual cooperation maximizes joint benefits, and the resulting choice pattern reflects a value for reciprocity, contingent on the expected cooperation of the partner. This quantity enters the trade-off between U<sub>cooperation</sub> and U<sub>defection</sub>and captures the participant’s intrinsic reward for reciprocity versus the additional monetary reward payoff of defection. Therefore, we consider the term “reciprocity” an acceptable statement for this construct.
Interpretation of parameters should closely reflect what they specifically measure.
We thank the reviewer for pointing this out. We have refined the relevant interpretations of parameters in the current Results and Discussion sections.
Prior research has shown links between Theory of Mind (ToM) and cooperation (e.g., Martínez-Velázquez et al., 2024). It would be valuable to test whether this also holds in your dataset.
We thank the reviewer for this thoughtful comment. Although we did not directly measure participants’ ToM, our design allowed us to estimate participants’ trial-by-trial inferences (i.e., expectations) about their partner’s cooperation probability. We therefore treat these cooperation expectations as an indirect representation for belief inference, which is related to ToM processes. To test whether this belief-inference component relates to cooperation in our dataset, we further conducted an exploratory analysis (GLMM<sub>sup</sub>4) in which participants’ choices were regressed on their cooperation expectations, group, and the group × cooperation-expectation interaction, controlling for trial number and gender, with random effects. Consistent with the ToM–cooperation link in prior research (MartínezVelázquez et al., 2024), participants’ expectations about their partner’s cooperation significantly predicted their cooperative behavior (Table 14), suggesting that decisions were shaped by social learning about others’ inferred actions. Moreover, the interaction between group and cooperation expectation was not significant, indicating that this inference-driven social learning process likely operates similarly in adolescents and adults. This aligns with our primary modeling results showing that both age groups update beliefs via an asymmetric learning process. We have reported these analyses in the Appendix Analysis section.
More informative table captions would help the reader. Please clarify how variables are coded (e.g., is female = 0 or 1? Is adolescent = 0 or 1?), to avoid the need to search across the manuscript for this information.
We thank the reviewer for raising this point. We have added clear and standardized variable coding in the table notes of all tables to make them more informative and avoid the need to search the paper. We have ensured consistent wording and formatting across all tables.
I hope these comments are helpful and support the authors in further strengthening their manuscript.
We thank the three reviewers for their comments, which have been helpful in strengthening this work.
Reference
(1) Fudenberg, D., & Levine, D. K. (2014). Recency, consistent learning, and Nash equilibrium. Proceedings of the National Academy of Sciences of the United States of America, 111(Suppl. 3), 10826–10829. https://doi.org/10.1073/pnas.1400987111
(2) Fudenberg, D., & Peysakhovich, A. (2016). Recency, records, and recaps: Learning and nonequilibrium behavior in a simple decision problem. ACM Transactions on Economics and Computation, 4(4), Article 23, 1–18. https://doi.org/10.1145/2956581
(3) Hackel, L., Doll, B., & Amodio, D. (2015). Instrumental learning of traits versus rewards: Dissociable neural correlates and effects on choice. Nature Neuroscience, 18, 1233– 1235. https://doi.org/10.1038/nn.4080
(4) Icenogle, G., Steinberg, L., Duell, N., Chein, J., Chang, L., Chaudhary, N., Di Giunta, L.,Dodge, K. A., Fanti, K. A., Lansford, J. E., Oburu, P., Pastorelli, C., Skinner, A. T.,Sorbring, E., Tapanya, S., Uribe Tirado, L. M., Alampay, L. P., Al-Hassan, S. M.,Takash, H. M. S., & Bacchini, D. (2019). Adolescents’ cognitive capacity reaches adult levels prior to their psychosocial maturity: Evidence for a “maturity gap” in a multinational, cross-sectional sample. Law and Human Behavior, 43(1), 69–85. https://doi.org/10.1037/lhb0000315
(5) Krekelberg, B. (2024). Matlab Toolbox for Bayes Factor Analysis (v3.0) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.13744717
(6) Martínez-Velázquez, E. S., Ponce-Juárez, S. P., Díaz Furlong, A., & Sequeira, H. (2024). Cooperative behavior in adolescents: A contribution of empathy and emotional regulation? Frontiers in Psychology, 15, 1342458. https://doi.org/10.3389/fpsyg.2024.1342458
(7) Tervo-Clemmens, B., Calabro, F. J., Parr, A. C., et al. (2023). A canonical trajectory of executive function maturation from adolescence to adulthood. NatureCommunications, 14, 6922. https://doi.org/10.1038/s41467-023-42540-8
(8) King-Casas, B., Tomlin, D., Anen, C., Camerer, C. F., Quartz, S. R., & Montague, P. R. (2005). Getting to know you: reputation and trust in a two-person economic exchange. Science, 308(5718), 78-83. https://doi.org/10.1126/science.1108062
(9) Rilling, J. K., Gutman, D. A., Zeh, T. R., Pagnoni, G., Berns, G. S., & Kilts, C. D. (2002). A neural basis for social cooperation. Neuron, 35(2), 395-405. https://doi.org/10.1016/s0896-6273(02)00755-9
(10) Fareri, D. S., Chang, L. J., & Delgado, M. R. (2015). Computational substrates of social value in interpersonal collaboration. Journal of Neuroscience, 35(21), 8170-8180. https://doi.org/10.1523/JNEUROSCI.4775-14.2015
(11) Akaike, H. (2003). A new look at the statistical model identification. IEEE transactions on automatic control, 19(6), 716-723. https://doi.org/10.1109/TAC.1974.1100705
(12) Schwarz, G. (1978). Estimating the dimension of a model. The annals of statistics, 461464. https://doi.org/10.1214/aos/1176344136
(13) Burnham, K. P., & Anderson, D. R. (2002). Model selection and multimodel inference: A practical information-theoretic approach (2nd ed.). Springer.https://doi.org/10.1007/b97636
(14) Gelman, A., & Shalizi, C. R. (2013). Philosophy and the practice of Bayesian statistics. British Journal of Mathematical and Statistical Psychology, 66(1), 8–38. https://doi.org/10.1111/j.2044-8317.2011.02037.x
(15) Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2014). Bayesian data analysis (3rd ed.). Chapman and Hall/CRC. https://doi.org/10.1201/b16018
(16) Vrieze, S. I. (2012). Model selection and psychological theory: A discussion of the differences between the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). Psychological Methods, 17(2), 228–243. https://doi.org/10.1037/a0027127.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
Zhang and colleagues examine neural representations underlying abstract navigation in the entorhinal cortex (EC) and hippocampus (HC) using fMRI. This paper replicates a previously identified hexagonal modulation of abstract navigation vectors in abstract space in EC in a novel task involving navigating in a conceptual Greeble space. In HC, the authors claim to identify a three-fold signal of the navigation angle. They also use a novel analysis technique (spectral analysis) to look at spatial patterns in these two areas and identify phase coupling between HC and EC. Finally, the authors propose an EC-HPC PhaseSync Model to understand how the EC and HC construct cognitive maps. While the wide array of techniques used is impressive and their creativity in analysis is admirable, overall, I found the paper a bit confusing and unconvincing. I recommend a significant rewrite of their paper to motivate their methods and clarify what they actually did and why. The claim of three-fold modulation in HC, while potentially highly interesting to the community, needs more background to motivate why they did the analysis in the first place, more interpretation as to why this would emerge in biology, and more care taken to consider alternative hypotheses seeped in existing models of HC function. I think this paper does have potential to be interesting and impactful, but I would like to see these issues improved first.
General comments:
(1) Some of the terminology used does not match the terminology used in previous relevant literature (e.g., sinusoidal analysis, 1D directional domain).
We thank the reviewer for this valuable suggestion, which helps to improve the consistency of our terminology with previous literature and to reduce potential ambiguity. Accordingly, we have replaced “sinusoidal analysis” with “sinusoidal modulation” (Doeller et al., 2010; Bao et al., 2019; Raithel et al., 2023) and “1D directional domain” with “angular domain of path directions” throughout the manuscript.
(2) Throughout the paper, novel methods and ideas are introduced without adequate explanation (e.g., the spectral analysis and three-fold periodicity of HC).
We thank the reviewer for raising this important point. In the revised manuscript, we have substantially extended the Introduction (paragraphs 2–4) to clarify our hypothesis, explicitly explaining why the three primary axes of the hexagonal grid cell code may manifest as vector fields. We have also revised the first paragraph of the “3-fold periodicity in the HPC” section in the Results to clarify the rationale for using spectral analysis. Please refer to our responses to comment 2 and 3 below for details.
Reviewer #2 (Public review):
The authors report results from behavioral data, fMRI recordings, and computer simulations during a conceptual navigation task. They report 3-fold symmetry in behavioral and simulated model performance, 3-fold symmetry in hippocampal activity, and 6-fold symmetry in entorhinal activity (all as a function of movement directions in conceptual space). The analyses are thoroughly done, and the results and simulations are very interesting.
We sincerely thank the reviewer for the positive and encouraging comments on our study.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
(1) This paper has quite a few spelling and grammatical mistakes, making it difficult to understand at times.
We apologize for the wordings and grammatical errors. We have thoroughly re-read and carefully edited the entire manuscript to correct typographical and grammatical errors, ensuring improved clarity and readability.
(2) Introduction - It's not clear why the three primary axes of hexagonal grid cell code would manifest as vector fields.
We thank the reviewer for raising this important point. In the revised Introduction (paragraphs 2, 3, and 4), we now explicitly explain the rationale behind our hypothesis that the three primary axes of the hexagonal grid cell code manifest as vector fields.
In paragraph 2, we present empirical evidence from rodent, bat, and human studies demonstrating that mental simulation of prospective paths relies on vectorial representations in the hippocampus (Sarel et al., 2017; Ormond and O’Keefe, 2022; Muhle-Karbe et al., 2023).
In paragraphs 3 and 4, we introduce our central hypothesis: vectorial representations may originate from population-level projections of entorhinal grid cell activity, based on three key considerations:
(1) The EC serves as the major source of hippocampal input (Witter and Amaral, 1991; van Groen et al., 2003; Garcia and Buffalo, 2020).
(2) Grid codes exhibit nearly invariant spatial orientations (Hafting et al., 2005; Gardner et al., 2022), which makes it plausible that their spatially periodic activity can be detected using fMRI.
(3) A model-based inference: for example, in the simplest case, when one mentally simulates a straight pathway aligned with the grid orientation, a subpopulation of grid cells would be activated. The resulting population activity would form a near-perfect vectorial representation, with constant activation strength along the path. In contrast, if the simulated path is misaligned with the grid orientation, the population response becomes a distorted vectorial code. Consequently, simulating all possible straight paths spanning 0°–360° results in 3-fold periodicity in the activity patterns—due to the 180° rotational symmetry of the hexagonal grid, orientations separated by 180° are indistinguishable.
We therefore speculate that vectorial representations embedded in grid cell activity exhibit 3-fold periodicity across spatial orientations and serve as a periodic structure to represent spatial direction. Supporting this view, reorientation paradigms in both rodents and young children have shown that subjects search equally in two opposite directions, reflecting successful orientation encoding but a failure to integrate absolute spatial direction (Hermer and Spelke, 1994; Julian et al., 2015; Gallistel, 2017; Julian et al., 2018).
(3) It took me a few reads to understand what the spectral analysis was. After understanding, I do think this is quite clever. However, this paper needs more motivation to understand why you are performing this analysis. E.g., why not just take the average regressor at the 10º, 70º, etc. bins and compare it to the average regressor at 40º, 100º bins? What does the Fourier transform buy you?
We are sorry for the confusion. we outline the rationale for employing Fast Fourier Transform (FFT) analysis to identify neural periodicity. In the revised manuscript, we have added these clarifications into the first paragraph of the “3-fold periodicity in the HPC” subsection in the Results.
First, FFT serves as an independent approach to cross-validate the sinusoidal modulation results, providing complementary evidence for the 6-fold periodicity in EC and the 3-fold periodicity in HPC.
Second, FFT enables unbiased detection of multiple candidate periodicities (e.g., 3–7-fold) simultaneously without requiring prior assumptions about spatial phase (orientation). By contrast, directly comparing “aligned” versus “misaligned” angular bins (e.g., 10°/70° vs. 40°/100°) would implicitly assume knowledge of the phase offset, which was not known a priori.
Finally, FFT uniquely allows periodicity analysis of behavioral performance, which is not feasible with standard sinusoidal GLM approaches. This methodological consistency makes it possible to directly compare periodicities across neural and behavioral domains.
(4) A more minor point: at one point, you say it’s a spectral analysis of the BOLD signals, but the methods description makes it sound like you estimated regressors at each of the bins before performing FFT. Please clarify.
We apologize for the confusion. In our manuscript, we use the term spectral analysis to distinguish this approach from sinusoidal modulation analysis. Conceptually, our spectral analysis involves a three-level procedure:
(1) First level: We estimated direction-dependent activity maps using a general linear model (GLM), which included 36 regressors corresponding to path directions, down-sampled in 10° increments.
(2) Second level: We applied a Fast Fourier Transform (FFT) to the direction-dependent activity maps derived from the GLM to examine the spectral magnitude of potential spatial periodicities.
(3) Third level: We conducted group-level statistical analyses across participants to assess the consistency of the observed periodicities.
We have revised the “Spectral analysis of MRI BOLD signals” subsection in the Methods to clarify this multi-level procedure.
(5) Figure 4a:
Why do the phases go all the way to 2*pi if periodicity is either three-fold or six-fold?
When performing correlation between phases, you should perform a circular-circular correlation instead of a Pearson's correlation.
We thank the reviewer for raising this important point. In the original Figure 4a, both EC and HPC phases spanned 0–2π because their sinusoidal phase estimates were projected into a common angular space by scaling them according to their symmetry factors (i.e., multiplying the 3-fold phase by 3 and the 6-fold phase by 6), followed by taking the modulo 2π. However, this projection forced signals with distinct intrinsic periodicities (120° vs. 60° cycles) into a shared 360° space, thereby distorting their relative angular distances and disrupting the one-to-one correspondence between physical directions and phase values. Consequently, this transformation could bias the estimation of their phase relationship.
In the revised analysis and Figure 4a, we retained the original phase estimates derived from the sinusoidal modulation within their native periodic ranges (0–120° for 3-fold and 0–60° for 6-fold) by applying modulo operations directly. Following your suggestion, the relationship between EC and HPC phases was then quantified using circular–circular correlation (Jammalamadaka & Sengupta, 2001), as implemented in the CircStat MATLAB toolbox. This updated analysis avoids the rescaling artifact and provides a statistically stronger and conceptually clearer characterization of the phase correspondence between EC and HPC.
(6) Figure 4d needs additional clarification:
Phase-locking is typically used to describe data with a high temporal precision. I understand you adopted an EEG analysis technique to this reconstructed fMRI time-series data, but it should be described differently to avoid confusion. This needs additional control analyses (especially given that 3 is a multiple of 6) to confirm that this result is specific to the periodicities found in the paper.
We thank the reviewer for this insightful comment. We have extensively revised the description of the Figure 4 to avoid confusion with EEG-based phase-locking techniques. The revised text now explicitly clarifies that our approach quantifies spatial-domain periodic coupling across path directions, rather than temporal synchronization of neural signals.
To further address the reviewer’s concern about potential effects of the integer multiple relationship between the 3-fold HPC and 6-fold EC periodicities, we additionally performed two control analyses using the 9-fold and 12-fold EC components, both of which are also integer multiples of the 3-fold HPC periodicity. Neither control analysis showed significant coupling (p > 0.05), confirming that the observed 3-fold–6-fold coupling was specific and not driven by their harmonic relationship.
The description of the revised Figure 4 has been updated in the “Phase Synchronization Between HPC and EC Activity” subsection of the Results.
(7) Figure 5a is misleading. In the text, you say you test for propagation to egocentric cortical areas, but I don’t see any analyses done that test this. This feels more like a possible extension/future direction of your work that may be better placed in the discussion.
We are sorry for the confusion. Figure 5a was intended as a hypothesis-driven illustration to motivate our analysis of behavioral periodicity based on participants’ task performance. However, we agree with the reviewer that, on its own, Figure 5a could be misleading, as it does not directly present supporting analyses.
To provide empirical support for the interpretation depicted in Figure 5a, we conducted a whole-brain analysis (Figure S8), which revealed significant 3-fold periodic signals in egocentric cortical regions, including the parietal cortex (PC), precuneus (PCU), and motor regions.
To avoid potential misinterpretation, we have revised the main text to include these results and explicitly referenced Figure S8 in connection with Figure 5a.
The updated description in the “3-fold periodicity in human behavior” subsection in the Results is as follows:
“Considering the reciprocal connectivity between the medial temporal lobe (MTL), where the EC and HPC reside, and the parietal cortex implicated in visuospatial perception and action, together with the observed 3-fold periodicity within the DMN (including the PC and PCu; Fig. S8), we hypothesized that the 3-fold periodic representations of path directions extend beyond the MTL to the egocentric cortical areas, such as the PC, thereby influencing participants' visuospatial task performance (Fig. 5a)”.
Additionally, Figure 5a has been modified to more clearly highlight the hypothesized link between activity periodicity and behavioral periodicity, rather than suggesting a direct anatomical pathway.
(8) PhaseSync model: I am not an expert in this type of modeling, so please put a lower weight on this comment (especially compared to some of the other reviewers). While the PhaseSync model seems interesting, it’s not clear from the discussion how this compares to current models. E.g., Does it support them by adding the three-fold HC periodicity? Does it demonstrate that some of them can't be correct because they don't include this three-fold periodicity?
We thank the reviewer for the insightful comment regarding the PhaseSync model. We agree that further clarifying its relationship to existing computational frameworks is important.
The EC–HPC PhaseSync model is not intended to replace or contradict existing grid–place cell models of navigation (e.g., Bicanski and Burgess, 2019; Whittington et al., 2020; Edvardsen et al., 2020). Instead, it offers a hierarchical extension by proposing that vectorial representations in the hippocampus emerge from the projections of periodic grid codes in the entorhinal cortex. Specifically, the model suggests that grid cell populations encode integrated path information, forming a vectorial gradient toward goal locations.
To simplify the theoretical account, our model was implemented in an idealized square layout. In more complex real-world environments, hippocampal 3-fold periodicity may interact with additional spatial variables, such as distance, movement speed, and environmental boundaries.
We have revised the final two paragraphs of the Discussion to clarify this conceptual framework and emphasize the importance of future studies in exploring how periodic activity in the EC–HPC circuit interacts with environmental features to support navigation.
Reviewer #2 (Recommendations for the authors):
(1) Please show a histogram of movement direction sampling for each participant.
We thank the reviewer for this helpful suggestion. We have added a new supplementary figure (Figure S2) showing histograms of path direction sampling for each participant (36 bins of 10°). The figure is also included. Rayleigh tests for circular uniformity revealed no significant deviations from uniformity (all ps > 0.05, Bonferroni-corrected across participants), confirming that path directions were sampled evenly across 0°–360°.
(2) Why didn’t you use participants’ original trajectories (instead of the trajectories inferred from the movement start and end points) for the hexadirectional analyses?
In our paradigm, participants used two MRI-compatible 2-button response boxes (one for each hand) to adjust the two features of the greebles. As a result, the raw adjustment path contained only four cardinal directions (up, down, left, right). If we were to use the raw stepwise trajectories, the analysis would be restricted to these four directions, which would severely limit the angular resolution. By instead defining direction as the vector from the start to the end position in feature space, we can expand the effective range of directions to the full 0–360°. This approach follows previous literature on abstract grid-like coding in humans (e.g., Constantinescu et al., 2016), where direction was similarly defined by the relative change between two feature dimensions rather than the literal stepwise path. We have added this clarification in the “Sinusoidal modulation” subsection of the revised method.
(3) Legend of Figure 2: the statement "localizing grid cell activity" seems too strong because it is still not clear whether hexadirectional signals indeed result from grid-cell activity (e.g., Bin Khalid et al., eLife, 2024). I would suggest rephrasing this statement (here and elsewhere).
Thank you for this helpful suggestion. We have removed the statement “localizing grid cell activity” to avoid ambiguity and revised the legend of Figure 2a to more explicitly highlight its main purpose—defining how path directions and the aligned/misaligned conditions were constructed in the 6-fold modulation. We have also modified similar expressions throughout the manuscript to ensure consistency and clarity.
(4) Legend of Figure 2: “cluster-based SVC correction for multiple comparisons” - what is the small volume you are using for the correction? Bilateral EC?
For both Figure 2 and Figure 3, the anatomical mask of the bilateral medial temporal lobe (MTL), as defined by the AAL atlas, was used as the small volume for correction. This has been clarified in the revised Statistical Analysis section of the Methods as “… with small-volume correction (SVC) applied within the bilateral MTL”.
(5) Legend of Figure 2: "ROI-based analysis" - what kind of ROI are you using? "corrected for multiple comparisons" - which comparisons are you referring to? Different symmetries and also the right/left hemisphere?
In Figure 2b, the ROI was defined as a functional mask derived from the significant activation cluster in the right entorhinal cortex (EC). Since no robust clusters were observed in the left EC, the functional ROI was restricted to the right hemisphere. We indeed included Figure 2c to illustrate this point; however, we recognize that our description in the text was not sufficiently clear.
Regarding the correction for multiple comparisons, this refers specifically to the comparisons across different rotational symmetries (3-, 4-, 5-, 6-, and 7-fold). Only the 6-fold symmetry survived correction, whereas no significant effects were detected for the other symmetries.
We have clarified these points in the “6-fold periodicity in the EC” subsection of the result as “… The ROI was defined as a functional mask of the right EC identified in the voxel-based analysis and further restricted within the anatomical EC. These analyses revealed significant periodic modulation only at 6-fold (Figure 2c; t(32) = 3.56, p = 0.006, two-tailed, corrected for multiple comparisons across rotational symmetries; Cohen’s d = 0.62) …”.
We have also revised the “3-fold periodicity in the HPC” subsection of the result as “… ROI analysis, using a functional mask of the HPC identified in the spectral analysis and further restricted within the anatomical HPC, indicated that HPC activity selectively fluctuated at 3-fold periodicity (Figure 3e; t(32) = 3.94, p = 0.002, corrected for multiple comparisons across rotational symmetries; Cohen’s d = 0.70) …”.
(6) Figure 2d: Did you rotationally align 0{degree sign} across participants? Please state explicitly whether (or not) 0{degree sign} aligns with the x-axis in Greeble space.
We thank the reviewer for this helpful question. Yes, before reconstructing the directional tuning curve in Figure 2d, path directions were rotationally aligned for each participant by subtracting the participant-specific grid orientation (ϕ) estimated from the independent dataset (odd sessions). We have now made this description explicit in the revised manuscript in the “6-fold periodicity in the EC” subsection of the Results, stating “… To account for individual difference in spatial phase, path directions were calibrated by subtracting the participant-specific grid orientation estimated from the odd sessions ...”.
(7) Clustering of grid orientations in 30 participants: What does “Bonferroni corrected” refer to? Also, the Rayleigh test is sensitive to the number of voxels - do you obtain the same results when using pair-wise phase consistency?
“Bonferroni corrected” here refers to correction across participants. We have clarified this in the first paragraph of the “6-fold periodicity in the EC” subsection of the Result and in the legend of Supplementary Figure S5 as “Bonferroni-corrected across participants.”
To examine whether our findings were sensitive to the number of voxels, we followed the reviewer’s guidance to compute pairwise phase consistency (PPC; Vinck et al., 2010) for each participant. The PPC results replicated those obtained with the Rayleigh test. We have updated the new results into the Supplementary Figure S5. We also updated the “Statistical Analysis” subsection of the Methods to describe PPC as “For the PPC (Vinck et al., 2010), significance was tested using 5,000 permutations of uniformly distributed random phases (0–2π) to generate a null distribution for comparison with the observed PPC”.
(8) 6-fold periodicity in the EC: Do you compute an average grid orientation across all EC voxels, or do you compute voxel-specific grid orientations?
Following the protocol originally described by Doeller et al. (2010), we estimated voxel-wise grid orientations within the EC and then obtained a participant-specific orientation by averaging across voxels within a hand-drawn bilateral EC mask. The procedure is described in detail in the “Sinusoidal modulation” subsection of the Methods.
(9) Hand-drawn bilateral EC mask: What was your procedure for drawing this mask? What results do you get with a standard mask, for example, from Freesurfer or SPM? Why do you perform this analysis bilaterally, given that the earlier analysis identified 6-fold symmetry only in the right EC? What do you mean by "permutation corrected for multiple comparisons"?
We thank the reviewer for raising these important methodological points. To our knowledge, no standard volumetric atlas provides an anatomically defined entorhinal cortex (EC) mask. For example, the built-in Harvard–Oxford cortical structural atlas in FSL contains only a parahippocampal region that encompasses, but does not isolate, the EC. The AAL atlas likewise does not contain an EC region. In FreeSurfer, an EC label is available, but only in the fsaverage surface space, which is not directly compatible with MNI-based volumetric group-level analyses.
Therefore, we constructed a bilateral EC mask by manually delineating the EC according to the detailed anatomical landmarks described by Insausti et al. (1998). Masks were created using ITK-SNAP (Version 3.8, www.itksnap.org). For transparency and reproducibility, the mask has been made publicly available at the Science Data Bank (link: https://www.scidb.cn/s/NBriAn), as indicated in the revised Data and Code availability section.
Regarding the use of a bilateral EC mask despite voxel-wise effects being strongest in the right EC. First, we did not have any a priori hypothesis regarding laterality of EC involvement before performing analyses. Second, previous studies estimated grid orientation using a bilateral EC mask in their sinusoidal analyses (Doeller et al., 2010; Constantinescu et al., 2016; Bao et al., 2019; Wagner et al., 2023; Raithel et al., 2023). We therefore followed this established approach to estimate grid orientation.
By “permutation corrected for multiple comparisons” we refer to the family-wise error correction applied to the reconstructed directional tuning curves (Figure 2d for the EC, Figure 3f for the HPC). Specifically, directional labels were randomly shuffled 5,000 times, and an FFT was applied to each shuffled dataset to compute spectral power at each fold. This procedure generated null distributions of spectral power for each symmetry. For each fold, the 95th percentile of the maximal power across permutations was used as the uncorrected threshold. To correct across folds, the 95th percentile of the maximal suprathreshold power across all symmetries was taken as the family-wise error–corrected threshold. We have clarified this procedure in the revised “Statistical Analysis” subsection of the Methods.
(10) Figures 3b and 3d: Why do different hippocampal voxels show significance for the sinusoidal versus spectral analysis? Shouldn’t the analyses be redundant and, thus, identify the same significant voxels?
We thank the reviewer for this insightful question. Although both sinusoidal modulation and spectral analysis aim to detect periodic neural activity, the two approaches are methodologically distinct and are therefore not expected to identify exactly the same significant voxels.
Sinusoidal modulation relies on a GLM with sine and cosine regressors to test for phase-aligned periodicity (e.g., 3-fold or 6-fold), calibrated according to the estimated grid orientation. This approach is highly specific but critically depends on accurate orientation estimation. In contrast, spectral analysis applies Fourier decomposition to the directional tuning profile, enabling the detection of periodic components without requiring orientation calibration.
Accordingly, the two analyses are not redundant but complementary. The FFT approach allows for an unbiased exploration of multiple candidate periodicities (e.g., 3–7-fold) without predefined assumptions, thereby providing a critical cross-validation of the sinusoidal GLM results. This strengthens the evidence for 6-fold periodicity in EC and 3-fold periodicity in HPC. Furthermore, FFT uniquely facilitates the analysis of periodicities in behavioral performance data, which is not feasible with standard sinusoidal GLM approaches. This methodological consistency enables direct comparison of periodicities across neural and behavioral domains.
Additionally, the anatomical distributions of the HPC clusters appear more similar between Figure 3b and Figure 3d after re-plotting Figure 3d using the peak voxel coordinates (x = –24, y = –18), which are closer to those used for Figure 3b (x = –24, y = –20), as shown in the revised Figure 3.
Taken together, the two analyses serve distinct but complementary purposes.
(11) 3-fold sinusoidal analysis in hippocampus: What kind of small volume are you using to correct for multiple comparisons?
We thank the reviewer for this comment. The same small volume correction procedure was applied as described in R4. Specifically, the anatomical mask of the bilateral medial temporal lobe (MTL), as defined by the AAL atlas, was used as the small volume for correction. This procedure has been clarified in the revised Statistical Analysis section of the Methods as following: “… with small-volume correction (SVC) applied within the bilateral MTL.”
(12) Figure S5: “right HPC” – isn’t the cluster in the left hippocampus?
We are sorry for the confusion. The brain image was present in radiological orientation (i.e., the left and right orientations are flipped). We also checked the figure and confirmed that the cluster shown in the original Figure S5 (i.e., Figure S6 in the revised manuscript) is correctly labeled as the right hippocampus, as indicated by the MNI coordinate (x = 22), where positive x values denote the right hemisphere. To avoid potential confusion, we have explicitly added the statement “Volumetric results are displayed in radiological orientation” to the figure legends of all volume-based results.
(13) Figure S5: Why are the significant voxels different from the 3-fold symmetry analysis using 10{degree sign} bins?
As shown in R10, the apparent differences largely reflect variation in MNI coordinates. After adjusting for display coordinates, the anatomical locations of the significant clusters are in fact highly similar between the 10°-binned (Figure 3d, shown above) and the 20°-binned results (Figure S6).
Although both analyses rely on sinusoidal modulation, they differ in the resolution of the input angular bins (10° vs. 20°). Combined with the inherent noise in fMRI data, this makes it unlikely that the two approaches would yield exactly the same set of significant voxels. Importantly, both analyses consistently reveal robust 3-fold periodicity in the hippocampus, indicating that the observed effect is not dependent on angular bin size.
(14) Figure 4a and corresponding text: What is the unit? Phase at which frequency? Are you using a circular-circular correlation to test for the relationship?
We thank the reviewer for raising this important point. In the revised manuscript, we have clarified that the unit of the phase values is radians, corresponding to the 6-fold periodic component in the EC and the 3-fold periodic component in the HPC. In the original Figure 4a, both EC and HPC phases—estimated from sinusoidal modulation—were analyzed using Pearson correlation. We have since realized issues with this approach, as also noted R5 to Reviewer #1.
In the revised analysis and Figure 4a (as shown above), we re-evaluated the relationship between EC and HPC phases using a circular–circular correlation (Jammalamadaka & Sengupta, 2001), implemented in the CircStat MATLAB toolbox. The “Phase synchronization between the HPC and EC activity” subsection of the Result has been accordingly updated as following:
“To examine whether the spatial phase structure in one region could predict that in another, we tested whether the orientations of the 6-fold EC and 3-fold HPC periodic activities, estimated from odd-numbered sessions using sinusoidal modulation with rotationally symmetric parameters (in radians), were correlated across participants. A cross-participant circular–circular correlation was conducted between the spatial phases of the two areas to quantify the spatial correspondence of their activity patterns (EC: purple dots; HPC: green dots) (Jammalamadaka & Sengupta, 2001). The analysis revealed a significant circular correlation (Figure 4a; r = 0.42, p < 0.001) …”.
In the “Statistical analysis” subsection of the method:
“… The relationship between EC and HPC phases was evaluated using the circular–circular correlation (Jammalamadaka & Sengupta, 2001) implemented in the CircStat MATLAB toolbox …”.
(15) Paragraph following “We further examined amplitude-phase coupling...” - please clarify what data goes into this analysis.
We thank the reviewer for this helpful comment. In this analysis, the input data consisted of hippocampal (HPC) phase and entorhinal (EC) amplitude, both extracted using the Hilbert transform from the reconstructed BOLD signals of the EC and HPC derived through sinusoidal modulation. We have substantially revised the description of the amplitude–phase coupling analysis in the third paragraph of the “Phase Synchronization Between HPC and EC Activity” subsection of the Results to clarify this procedure.
(16) Alignment between EC 6-fold phases and HC 3-fold phases: Why don't you simply test whether the preferred 6-fold orientations in EC are similar to the preferred 3-fold phases in HC? The phase-amplitude coupling analyses seem sophisticated but are complex, so it is somewhat difficult to judge to what extent they are correct.
We thank the reviewer for this thoughtful comment. We employed two complementary analyses to examine the relationship between EC and HPC activity. In the revised Figure 4 (as shown in Figure 4 for Reviewer #1), Figure 4a provides a direct and intuitive measure of the phase relationship between the two regions using circular–circular correlation. Figure 4b–c examines whether the activity peaks of the two regions are aligned across path directions using cross-frequency amplitude–phase coupling, given our hypothesis that the spatial phase of the HPC depends on EC projections. These two analyses are complementary: a phase correlation does not necessarily imply peak-to-peak alignment, and conversely, peak alignment does not always yield a statistically significant phase correlation. We therefore combined multiple analytical approaches as a cross-validation across methods, providing convergent evidence for robust EC–HPC coupling.
(17) Figure 5: Do these results hold when you estimate performance just based on “deviation from the goal to ending locations” (without taking path length into account)?
We thank the reviewer for this thoughtful suggestion. Following the reviewer’s advice, we re-estimated behavioral performance using the deviation between the goal and ending locations (i.e., error size) and path length independently. As shown in the new Figure S9, no significant periodicity was observed in error size (p > 0.05), whereas a robust 3-fold periodicity was found for path length (p < 0.05, corrected for multiple comparisons).
We employed two behavioral metrics,(1) path length and (2) error size, for complementary reasons. In our task, participants navigated using four discrete keys corresponding to the cardinal directions (north, south, east, and west). This design inherently induces a 4-fold bias in path directions, as described in the “Behavioral performance” subsection of the Methods. To minimize this artifact, we computed the objectively optimal path length and used it to calibrate participants’ path lengths. However, error size could not be corrected in the same manner and retained a residual 4-fold tendency (see Figure S9d).
Given that both path length and error size are behaviorally relevant and capture distinct aspects of task performance, we decided to retain both measures when quantifying behavioral periodicity. This clarification has been incorporated into the “Behavioral performance” subsection of the Methods, and the 2<sup>nd</sup> paragraph of the “3-fold periodicity in human behavior” subsection of the Results.
(18) Phase locking between behavioral performance and hippocampal activity: What is your way of creating surrogates here?
We thank the reviewer for this helpful question. Surrogate datasets were generated by circularly shifting the signal series along the direction axis across all possible offsets (following Canolty et al., 2006). This procedure preserves the internal phase structure within each domain while disrupting consistent phase alignment, thereby removing any systematic coupling between the two signals. Each surrogate dataset underwent identical filtering and coherence computation to generate a null distribution, and the observed coherence strength was compared with this distribution using paired t-tests across participants. The statistical analysis section has been systematically revised to incorporate these methodological details.
(19) I could not follow why the authors equate 3-fold symmetry with vectorial representations. This includes statements such as “these empirical findings provide a potential explanation for the formation of vectorial representation observed in the HPC.” Please clarify.
We thank the reviewer for raising this point. Please refer to our response to R2 for Reviewer #1 and the revised Introduction (paragraphs 2–4), where we explicitly explain why the three primary axes of the hexagonal grid cell code can manifest as vector fields.
(20) It was unclear whether the sentence “The EC provides a foundation for the formation of periodic representations in the HPC” is based on the authors’ observations or on other findings. If based on the authors’ findings, this statement seems too strong, given that no other studies have reported periodic representations in the hippocampus to date (to the best of my knowledge).
We thank the reviewer for this comment. We agree that the original wording lacked sufficient rigor. We have extensively revised the 3rd paragraph of the Discussion section with more cautious language by reducing overinterpretation and emphasizing the consistency of our findings with prior empirical evidence, as follows: “The EC–HPC PhaseSync model demonstrates how a vectorial representation may emerge in the HPC from the projections of populations of periodic grid codes in the EC. The model was motivated by two observations. First, the EC intrinsically serves as the major source of hippocampal input (Witter and Amaral, 1991; van Groen et al., 2003; Garcia and Buffalo, 2020), and grid codes exhibit nearly invariant spatial orientations (Hafting et al., 2005; Gardner et al., 2022). Second, mental planning, characterized by “forward replay” (Dragoi and Tonegawa, 2011; Pfeiffer, 2020), has the capacity to activate populations of grid cells that represent sequential experiences in the absence of actual physical movement (Nyberg et al., 2022). We hypothesize that an integrated path code of sequential experiences may eventually be generated in the HPC, providing a vectorial gradient toward the goal location. The path code exhibits regular, vector-like representations when the path direction aligns with the orientations of grid axes, and becomes irregular when they misalign. This explanation is consistent with the band-like representations observed in the dorsomedial EC (Krupic et al., 2012) and the irregular activity fields of trace cells in the HPC (Poulter et al., 2021). ”
#
"." (en tout cas, dans mon VS Code c'est ainsi)
Reviewer #2 (Public review):
Summary:
The authors present a transformer-based model, TrASPr, for the task of tissue-specific splicing prediction (with experiments primarily focused on the case of cassette exon inclusion) as well as an optimization framework (BOS) for the task of designing RNA sequences for desired splicing outcomes.
For the first task, the main methodological contribution is to train four transformer-based models on the 400bp regions surrounding each splice site, the rationale being that this is where most splicing regulatory information is. In contrast, previous work trained one model on a long genomic region. This new design should help the model capture more easily interactions between splice sites. It should also help in cases of very long introns, which are relatively common in the human genome.
TrASPr's performance is evaluated in comparison to previous models (SpliceAI, Pangolin, and SpliceTransformer) on numerous tasks including splicing predictions on GTEx tissues, ENCODE cell lines, RBP KD data, and mutagenesis data. The scope of these evaluations is ambitious; however, significant details on most of the analyses are missing, making it difficult to evaluate the strength of evidence.
In the second task, the authors combine Latent Space Bayesian Optimization (LSBO) with a Transformer-based variational auto encoder to optimize RNA sequences for a given splicing-related objective function. This method (BOS) appears to be a novel application of LSBO, with promising results on several computational evaluations and the potential to be impactful on sequence design for both splicing-related objectives and other tasks. However, comparison of BOS against existing methods for sequence design is lacking.
Strengths:
- A novel machine learning model for an important problem in RNA biology with excellent prediction accuracy.
- Instead of being based on a generic design as in previous work, the proposed model incorporates biological domain knowledge (that regulatory information is concentrated around splice sites). This way of using inductive bias can be important to future work on other sequence-based prediction tasks.
Weaknesses:
- Most of the analyses presented in the manuscript are described in broad strokes and are often confusing. As a result, it is difficult to assess the significance of the contribution.
- As more and more models are being proposed for splicing prediction (SpliceAI, Pangolin, SpliceTransformer, TrASPr), there is a need for establishing standard benchmarks, similar to those in computer vision (ImageNet). Without such benchmarks, it is exceedingly difficult to compare models.<br /> *This point is now addressed in the revision *<br /> *Moreover, datasets have been made available by the authors on BitBucket. *
- Related to the previous point, as discussed in the manuscript, SpliceAI and Pangolin are not designed to predict PSI of cassette exons. Instead, they assign a "splice site probability" to each nucleotide. Converting this to a PSI prediction is not obvious, and the method chosen by the authors (averaging the two probabilities (?)) is likely not optimal. It would interesting to see what happens if an MLP is used on top of the four predictions (or the outputs of the top layers) from SpliceAI/Pangolin. This could also indicate where the improvement in TrASPr comes from: is it because TrASPr combines information from all four splice sites? Also consider fine-tuning Pangolin on cassette exons only (as you do for your model).<br /> *This point is still not addressed in the revision. *
- L141, "TrASPr can handle cassette exons spanning a wide range of window sizes from 181 to 329,227 bases-thanks to its multi-transformer architecture." This is reported to be one of the primary advantages compared to existing models. Additional analysis should be included on how TrASPr performs across varying exon and intron sizes, with comparison to SpliceAI, etc.
Added after revision: The authors have added additional analyses of performance based on both the length of the exon under consideration and the total length of the surrounding intronic contexts. The result that TrASPr performs well across various context sizes (i.e., the length of the sequence between the upstream and downstream exons, ranging from <1k to >10k) is highly encouraging and supports the claim that most of the sequence-based splicing logic is located proximal to the splice sites. It is also noteworthy that TrASPr performs well for exons longer than 200, suggesting that most of the "regulatory code" is present at the exon boundaries rather than in its center (which TrASPr is blind to).<br /> Additionally, Pearson correlation is used as the sole performance metric in many analyses (e.g., Fig 2 - Supp 2). The authors should consider alternative accuracy metrics, such as RMSE, which better convey the magnitude of prediction error and are more easily comparable across datasets. Pearson correlation may also be more sensitive to outliers on the smaller samples that arise when binning sequences.
- L171, "training it on cassette exons". This seems like an important point: previous models were trained mostly on constitutive exons, whereas here the model is trained specifically on cassette exons. This should be discussed in more detail.<br /> * Our initial comment was incorrect, as pointed out by the authors. *
- L214, ablations of individual features are missing.<br /> * This was addressed in the revision. *
- L230, "ENCODE cell lines", it is not clear why other tissues from GTEx were not included<br /> * This was addressed in the revision. *
- L239, it is surprising that SpliceAI performs so badly, and might suggest a mistake in the analysis. Additional analysis and possible explanations should be provided to support these claims. Similarly for the complete failure of SpliceAI and Pangolin shown in Fig 4d.<br /> * The authors should consider adding SpliceAI/Pangolin predictions for the alternative 5' and 3' splice site selection tasks (and code for related analyses) to the BitBucket repository.*
- BOS seems like a separate contribution that belongs in a separate publication. Instead, consider providing more details on TrASPr.
*Minor comment added after revision: regarding the author response that "A completely independent evaluation would have required a high-throughput experimental system to assess designs, which is beyond the scope of the current paper.":<br /> It's not clear why BOS cannot be evaluated as a separate contribution by instead using different "teacher" models instead of TrASPr. Additionally, BOS lacks evaluation against existing methods for sequence optimization. *
- The authors should consider evaluating BOS using Pangolin or SpliceTransformer as the oracle, in order to measure the contribution to the sequence generation task provided by BOS vs TrASPr.<br /> * See comment above *
Author response:
The following is the authors’ response to the original reviews
A point by point response included below. Before we turn to that we want to note one change that we decided to introduce, related to generalization on unseen tissues/cell types (Figure 3a in the original submission and related question by Reviewer #2 below). This analysis was based on adding a latent “RBP state” representation during learning of condition/tissue specific splicing. The “RBP state” per condition is captured by a dedicated encoder. Our original plan was to have a paper describing a new RBP-AE model we developed in parallel, which also served as the base to capture this “RBP State”. However, we got delayed in getting this second paper finalized (it was led by other lab members, some of whom have already left the lab). This delay affected the TrASPr manuscript as TrASPr’s code should be available and analysis reproducible upon publication. After much deliberation, we decided that in order to comply with reproducibility standards while not self scooping the RBP-AE paper, we eventually decided to take out the RBP-AE and replace it with a vanilla PCA based embedding for the “RBP-State”. The PCA approach is simpler and reproducible, based on linear transformation of the RBPs expression vector into a lower dimension. The qualitative results included in Figure 3a still hold, and we also produced the new results suggested by Reviewer #2 in other GTEX tissues with this PCA based embedding (below).
We don’t believe the switch to PCA based embedding should have any bearing on the current manuscript evaluation but wanted to take this opportunity to explain the reasoning behind this additional change.
Public Reviews:
Reviewer #1 (Public review):
Summary:
The authors propose a transformer-based model for the prediction of condition - or tissue-specific alternative splicing and demonstrate its utility in the design of RNAs with desired splicing outcomes, which is a novel application. The model is compared to relevant existing approaches (Pangolin and SpliceAI) and the authors clearly demonstrate its advantage. Overall, a compelling method that is well thought out and evaluated.
Strengths:
(1) The model is well thought out: rather than modeling a cassette exon using a single generic deep learning model as has been done e.g. in SpliceAI and related work, the authors propose a modular architecture that focuses on different regions around a potential exon skipping event, which enables the model to learn representations that are specific to those regions. Because each component in the model focuses on a fixed length short sequence segment, the model can learn position-specific features. Another difference compared to Pangolin and SpliceAI which are focused on modeling individual splice junctions is the focus on modeling a complete alternative splicing event.
(2) The model is evaluated in a rigorous way - it is compared to the most relevant state-of-the-art models, uses machine learning best practices, and an ablation study demonstrates the contribution of each component of the architecture.
(3) Experimental work supports the computational predictions.
(4) The authors use their model for sequence design to optimize splicing outcomes, which is a novel application.
We wholeheartedly thank Reviewer #1 for these positive comments regarding the modeling approach we took to this task and the evaluations we performed. We have put a lot of work and thought into this and it is gratifying to see the results of that work acknowledged like this.
Weaknesses:
No weaknesses were identified by this reviewer, but I have the following comments:
(1) I would be curious to see evidence that the model is learning position-specific representations.
This is an excellent suggestion to further assess what the model is learning. To get a better sense of the position-specific representation we performed the following analyses:
(1) Switching the transformers relative order: All transformers are pretrained on 3’ and 5’ splice site regions before fine-tunning for the PSI and dPSI prediction task. We hypothesized that if relative position is important, switching the order of the transformers would make a large difference on prediction accuracy. Indeed if we switch the 3’ and 5’ we see as expected a severe drop in performance, with Pearson correlation on test data dropping from 0.82 to 0.11. Next, we switched the two 5’ and 3’ transformers, observing a drop to 0.65 and 0.78 respectively. When focusing only on changing events the drop was from 0.66 to 0.54 (for 3’ SS transformers), 0.48 (for 5’ SS transformers), and 0.13 (when the 3’ and 5’ transformers flanking the alternative exon were switched).
(2) Position specific effect of RBPs: We wanted to test whether the model is able to learn position specific effects for RBPs. For this we focused on two RBPs, FOX (a family of three highly related RBPs), and QKI, both have a relatively well defined motif, known condition and position specific effect identified via RBP KD experiments combined with CLIP experiments (e.g. PMID: 23525800, PMID: 24637117, PMID: 32728246). For each, we randomly selected 40 highly and 40 lowly included cassette exons sequences. We then ran in-silico mutagenesis experiments where we replaced small windows of sequences with the RBP motifs (80 for RBFOX and 80 for QKI), then compared TrASPR’s predictions for the average predictions for 5 random sequences inserted in the same location. The results of this are now shown in Figure 4 Supp 3, where the y-axis represents the dPSI effect per position (x-axis), and the color represents the percentile of observed effects over inserting motifs in that position across all 80 sequences tested. We see that both RBPs have strong positional preferences for exerting a strong effect on the alternative exon. We also see differences between binding upstream and downstream of the alternative exon. These results, learned by the model from natural tissue-specific variations, recapitulate nicely the results derived from high-throughput experimental assays. However, we also note that effects were highly sequence specific. For example, RBFOX is generally expected to increase inclusion when binding downstream of the alternative exon and decrease inclusion when binding upstream. While we do observe such a trend we also see cases where the opposite effects are observed. These sequence specific effects have been reported in the literature but may also represent cases where the model errs in the effect’s direction. We discuss these new results in the revised text.
(3) Assessing BOS sequence edits to achieve tissue-specific splicing: Here we decided to test whether BOS edits in intronic regions (at least 8b away from the nearest splice site) are important for the tissue-specific effect. The results are now included in Figure 6 Supp 1, clearly demonstrating that most of the neuronal specific changes achieved by BOS were based on changing the introns, with a strong effect observed for both up and downstream intron edits.
(2) The transformer encoders in TrASPr model sequences with a rather limited sequence size of 200 bp; therefore, for long introns, the model will not have good coverage of the intronic sequence. This is not expected to be an issue for exons.
The reviewer is raising a good question here. On one hand, one may hypothesize that, as the reviewer seems to suggest, TrASPr may not do well on long introns as it lacks the full intronic sequence.
Conversely, one may also hypothesize that for long introns, where the flanking exons are outside the window of SpliceAI/Pangolin, TrASPr may have an advantage.
Given this good question and a related one by Reviewer #2, we divided prediction accuracy by intron length and the alternative exon length.
For short exons (<100bp) we find TrASPr and Pangolin perform similarly, but for longer exons, especially those > 200, TrASPr results are better. When dividing samples by the total length of the upstream and downstream intron, we find TrASPr outperform all other models for introns of combined length up to 6K, but Pangolin gets better results when the combined intron length is over 10K. This latter result is interesting as it means that contrary to the second hypothesis laid out above, Pangolin’s performance did not degrade for events where the flanking exons were outside its field of view. We note that all of the above holds whether we assess all events or just cases of tissue specific changes. It is interesting to think about the mechanistic causes for this. For example, it is possible that cassette exons involving very long introns evoke a different splicing mechanism where the flanking exons are not as critical and/or there is more signal in the introns which is missed by TrASPr. We include these new results now as Figure 2 - Supp 1,2 and discuss these in the main text.
(3) In the context of sequence design, creating a desired tissue- or condition-specific effect would likely require disrupting or creating motifs for splicing regulatory proteins. In your experiments for neuronal-specific Daam1 exon 16, have you seen evidence for that? Most of the edits are close to splice junctions, but a few are further away.
That is another good question. Regarding Daam1 exon 16, in the original paper describing the mutation locations some motif similarities were noted to PTB (CU) and CUG/Mbnl-like elements (Barash et al Nature 2010). In order to explore this question beyond this specific case we assessed the importance of intronic edits by BOS to achieve a tissue specific splicing profile - see above.
(4) For sequence design, of tissue- or condition-specific effect in neuronal-specific Daam1 exon 16 the upstream exonic splice junction had the most sequence edits. Is that a general observation? How about the relative importance of the four transformer regions in TrASPr prediction performance?
This is another excellent question. Please see new experiments described above for RBP positional effect and BOS edits in intronic regions which attempt to give at least partial answers to these questions. We believe a much more systematic analysis can be done to explore these questions but such evaluation is beyond the scope of this work.
(5) The idea of lightweight transformer models is compelling, and is widely applicable. It has been used elsewhere. One paper that came to mind in the protein realm:
Singh, Rohit, et al. "Learning the language of antibody hypervariability." Proceedings of the National Academy of Sciences 122.1 (2025): e2418918121.
We definitely do not make any claim this approach of using lighter, dedicated models instead of a large ‘foundation’ model has not been taken before. We believe Rohit et al mentioned above represents a somewhat different approach, where their model (AbMAP) fine-tunes large general protein foundational models (PLM) for antibody-sequence inputs by supervising on antibody structure and binding specificity examples. We added a description of this modeling approach citing the above work and another one which specifically handles RNA splicing (intron retention, PMID: 39792954).
Reviewer #2 (Public review):
Summary:
The authors present a transformer-based model, TrASPr, for the task of tissue-specific splicing prediction (with experiments primarily focused on the case of cassette exon inclusion) as well as an optimization framework (BOS) for the task of designing RNA sequences for desired splicing outcomes.
For the first task, the main methodological contribution is to train four transformer-based models on the 400bp regions surrounding each splice site, the rationale being that this is where most splicing regulatory information is. In contrast, previous work trained one model on a long genomic region. This new design should help the model capture more easily interactions between splice sites. It should also help in cases of very long introns, which are relatively common in the human genome.
TrASPr's performance is evaluated in comparison to previous models (SpliceAI, Pangolin, and SpliceTransformer) on numerous tasks including splicing predictions on GTEx tissues, ENCODE cell lines, RBP KD data, and mutagenesis data. The scope of these evaluations is ambitious; however, significant details on most of the analyses are missing, making it difficult to evaluate the strength of the evidence. Additionally, state-of-the-art models (SpliceAI and Pangolin) are reported to perform extremely poorly in some tasks, which is surprising in light of previous reports of their overall good prediction accuracy; the reasoning for this lack of performance compared to TrASPr is not explored.
In the second task, the authors combine Latent Space Bayesian Optimization (LSBO) with a Transformer-based variational autoencoder to optimize RNA sequences for a given splicing-related objective function. This method (BOS) appears to be a novel application of LSBO, with promising results on several computational evaluations and the potential to be impactful on sequence design for both splicing-related objectives and other tasks.
We thank Reviewer #2 for this detailed summary and positive view of our work. It seems the main issue raised in this summary regards the evaluations: The reviewer finds details of the evaluations missing and the fact that SpliceAI and Pangolin perform poorly on some of the tasks to be surprising. We made a concise effort to include the required details, including code and data tables. In short, some of the concerns were addressed by adding additional evaluations, some by clarifying missing details, and some by better explaining where Pangolin and SpliceAI may excel vs. settings where these may not do as well. More details are given below.
Strengths:
(1) A novel machine learning model for an important problem in RNA biology with excellent prediction accuracy.
(2) Instead of being based on a generic design as in previous work, the proposed model incorporates biological domain knowledge (that regulatory information is concentrated around splice sites). This way of using inductive bias can be important to future work on other sequence-based prediction tasks.
Weaknesses:
(1) Most of the analyses presented in the manuscript are described in broad strokes and are often confusing. As a result, it is difficult to assess the significance of the contribution.
We made an effort to make the tasks be specific and detailed, including making the code and data of those available. We believe this helped improve clarity in the revised version.
(2) As more and more models are being proposed for splicing prediction (SpliceAI, Pangolin, SpliceTransformer, TrASPr), there is a need for establishing standard benchmarks, similar to those in computer vision (ImageNet). Without such benchmarks, it is exceedingly difficult to compare models. For instance, Pangolin was apparently trained on a different dataset (Cardoso-Moreira et al. 2019), and using a different processing pipeline (based on SpliSER) than the ones used in this submission. As a result, the inferior performance of Pangolin reported here could potentially be due to subtle distribution shifts. The authors should add a discussion of the differences in the training set, and whether they affect your comparisons (e.g., in Figure 2). They should also consider adding a table summarizing the various datasets used in their previous work for training and testing. Publishing their training and testing datasets in an easy-to-use format would be a fantastic contribution to the community, establishing a common benchmark to be used by others.
There are several good points to unpack here. Starting from the last one, we very much agree that a standard benchmark will be useful to include. For tissue specific splicing quantification we used the GTEx dataset from which we select six representative human tissues (heart, cerebellum, lung, liver, spleen, and EBV-transformed lymphocytes). In total, we collected 38394 cassette exon events quantified across 15 samples (here a ‘sample’ is a cassette exon quantified in two tissues) from the GTEx dataset with high-confidence quantification for their PSIs based on MAJIQ. A detailed description of how this data was derived is now included in the Methods section, and the data itself is made available via the bitbucket repository with the code.
Next, regarding the usage of different data and distribution shifts for Pangolin: The reviewer is right to note there are many differences between how Pangolin and TrASPr were trained. This makes it hard to determine whether the improvements we saw are not just a result of different training data/labels. To address this issue, we first tried to finetune the pre-trained Pangolin with MAJIQ’s PSI dataset: we use the subset of the GTEx dataset described above, focusing on the three tissues analyzed in Pangolin’s paper—heart, cerebellum, and liver—for a fair comparison. In total, we obtained 17,218 events, and we followed the same training and test split as reported in the Pangolin paper. We got Pearson: 0.78 Spearman: 0.68 which are values similar to what we got without this extra fine tuning. Next, we retrained Pangolin from scratch, with the full tissues and training set used for TrASPr, which was derived from MAJIQ’s quantifications. Since our model only trained on human data with 6 tissues at the same time, we modified Pangolin from original 4 splice site usage outputs to 6 PSI outputs. We tried to take the sequence centered with the first or the second splice site of the mid exon. This test resulted in low performance (3’ SS: pearson 0.21 5’ SS: 0.26.).
The above tests are obviously not exhaustive but their results suggest that the differences we observe are unlikely to be driven by distribution shifts. Notably, the original Pangolin was trained on much more data (four species, four tissues each, and sliding windows across the entire genome). This training seems to be important for performance while the fact we switched from Pangolin’s splice site usage to MAJIQ’s PSI was not a major contributor. Other potential reasons for the improvements we observed include the architecture, target function, and side information (see below) but a complete delineation of those is beyond the scope of this work.
(3) Related to the previous point, as discussed in the manuscript, SpliceAI, and Pangolin are not designed to predict PSI of cassette exons. Instead, they assign a "splice site probability" to each nucleotide. Converting this to a PSI prediction is not obvious, and the method chosen by the authors (averaging the two probabilities (?)) is likely not optimal. It would be interesting to see what happens if an MLP is used on top of the four predictions (or the outputs of the top layers) from SpliceAI/Pangolin. This could also indicate where the improvement in TrASPr comes from: is it because TrASPr combines information from all four splice sites? Also, consider fine-tuning Pangolin on cassette exons only (as you do for your model).
Please see the above response. We did not investigate more sophisticated models that adjust Pangolin’s architecture further as such modifications constitute new models which are beyond the scope of this work.
(4) L141, "TrASPr can handle cassette exons spanning a wide range of window sizes from 181 to 329,227 bases - thanks to its multi-transformer architecture." This is reported to be one of the primary advantages compared to existing models. Additional analysis should be included on how TrASPr performs across varying exon and intron sizes, with comparison to SpliceAI, etc.
This was a good suggestion, related to another comment made by Reviewer #1. Please see above our response to them with a breakdown by exon/intron length.
(5) L171, "training it on cassette exons". This seems like an important point: previous models were trained mostly on constitutive exons, whereas here the model is trained specifically on cassette exons. This should be discussed in more detail.
Previous models were not trained exclusively on constitutive exons and Pangolin specifically was trained with their version of junction usage across tissues. That said, the reviewer’s point is valid (and similar to ones made above) about a need to have a matched training/testing and potential distribution shifts. Please see response and evaluations described above.
(6) L214, ablations of individual features are missing.
These were now added to the table which we moved to the main text (see table also below).
(7) L230, "ENCODE cell lines", it is not clear why other tissues from GTEx were not included.
Good question. The task here was to assess predictions in unseen conditions, hence we opted to test on completely different data of human cell lines rather than additional tissue samples. Following the reviewers suggestion we also evaluated predictions on two additional GTEx tissues, Cortex and Adrenal Gland. These new results, as well as the previous ones for ENCODE, were updated to use the PCA based embedding of “RBP-State” as described above. We also compared the predictions using the PCA based embedding of the “RBP-State” to training directly on data (not the test data of course) from these tissues. See updated Figure 3a,b. Figure 3 Supp 1,2.
(8) L239, it is surprising that SpliceAI performs so badly, and might suggest a mistake in the analysis. Additional analysis and possible explanations should be provided to support these claims. Similarly, the complete failure of SpliceAI and Pangolin is shown in Figure 4d.
Line 239 refers to predicting relative inclusion levels between competing 3’ and 5’ splice sites. We admit we too expected this to be better for SpliceAI and Pangolin but we were not able to find bugs in our analysis (which is all made available for readers and reviewers alike). Regarding this expectation to perform better, first we note that we are not aware of a similar assessment being done for either of those algorithms (i.e. relative inclusion for 3’ and 5’ alternative splice site events). Instead, our initial expectation, and likely the reviewer’s as well, was based on their detection of splice site strengthening/weakening due to mutations, including cryptic splice site activation. More generally though, it is worth noting in this context that given how SpliceAI, Pangolin and other algorithms have been presented in papers/media/scientific discussions, we believe there is a potential misperception regarding tasks that SpliceAI and Pangolin excel at vs other tasks where they should not necessarily be expected to excel. Both algorithms focus on cryptic splice site creation/disruption. This has been the focus of those papers and subsequent applications. While Pangolin added tissue specificity to SpliceAI training, the authors themselves admit “...predicting differential splicing across tissues from sequence alone is possible but remains a considerable challenge and requires further investigation”. The actual performance on this task is not included in Pangolin’s main text, but we refer Reviewer #2 to supplementary figure S4 in the Pangolin manuscript to get a sense of Pangolin’s reported performance on this task. Similar to that, Figure 4d in our manuscript is for predicting ‘tissue specific’ regulators. We do not think it is surprising that SpliceAI (tissue agnostic) and Pangolin (slight improvement compared to SpliceAI in tissue specific predictions) do not perform well on this task. Similarly, we do not find the results in Figure 4C surprising either. These are for mutations that slightly alter inclusion level of an exon, not something SpliceAI was trained on - SpiceAI was trained on genomic splice sites with yes/no labels across the genome. As noted elsewhere in our response, re-training Pangolin on this mutagenesis dataset results in performance much closer to that of TrASPr. That is to be expected as well - Pangolin is constructed to capture changes in PSI (or splice site usage as defined by the authors), those changes are not even tissue specific for the CD19 data and the model has no problem/lack of capacity to generalize from the training set just like TrASPr does. In fact, if you only use combinations of known mutations seen during training a simple regression model gives correlation of ~92-95% (Cortés-López et al 2022). In summary, we believe that better understanding of what one can realistically expect from models such as SpliceAI, Pangolin, and TrASPr will go a long way to have them better understood and used effectively. We have tried to make this more clear in the revision.
(9) BOS seems like a separate contribution that belongs in a separate publication. Instead, consider providing more details on TrASPr.
We thank the reviewer for the suggestion. We agree those are two distinct contributions/algorithms and we indeed considered having them as two separate papers. However, there is strong coupling between the design algorithm (BOS) and the predictor that enables it (TrASPr). This coupling is both conceptual (TrASPr as a “teacher”) and practical in terms of evaluations. While we use experimental data (experiments done involving Daam1 exon 16, CD19 exon 2) we still rely heavily on evaluations by TrASPr itself. A completely independent evaluation would have required a high-throughput experimental system to assess designs, which is beyond the scope of the current paper. For those reasons we eventually decided to make it into what we hope is a more compelling combined story about generative models for prediction and design of RNA splicing.
(10) The authors should consider evaluating BOS using Pangolin or SpliceTransformer as the oracle, in order to measure the contribution to the sequence generation task provided by BOS vs TrASPr.
We can definitely see the logic behind trying BOS with different predictors. That said, as we note above most of BOS evaluations are based on the “teacher”. As such, it is unclear what value replacing the teacher would bring. We also note that given this limitation we focus mostly on evaluations in comparison to existing approaches (genetic algorithm or random mutations as a strawman).
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Additional comments:
(1) Is your model picking up transcription factor binding sites in addition to RBPs? TFs have been recently shown to have a role in splicing regulation:
Daoud, Ahmed, and Asa Ben-Hur. "The role of chromatin state in intron retention: A case study in leveraging large scale deep learning models." PLOS Computational Biology 21.1 (2025): e1012755.
We agree this is an interesting point to explore, especially given the series of works from the Ben-Hur’s group. We note though that these works focus on intron retention (IR) which we haven’t focused on here, and we only cover short intronic regions flanking the exons. We leave this as a future direction as we believe the scope of this paper is already quite extensive.
(2) SpliceNouveau is a recently published algorithm for the splicing design problem:
Wilkins, Oscar G., et al. "Creation of de novo cryptic splicing for ALS and FTD precision medicine." Science 386.6717 (2024): 61-69.
Thank you for pointing out Wilkins et al recent publication, we now refer to it as well.
(3) Please discuss the relationship between your model and this deep learning model. You will also need to change the following sentence: "Since the splicing sequence design task is novel, there are no prior implementations to reference."
We revised this statement and now refer to several recent publications that propose similar design tasks.
(4) I would suggest adding a histogram of PSI values - they appear to be mostly close to 1 or 0.
PSI values are indeed typically close to either 0 or 1. This is a known phenomenon illustrated in previous studies of splicing (e.g. Shen et al NAR 2012 ). We are not sure what is meant by the comment to add a histogram but we made sure to point this out in the main text:
“...Still, those statistics are dominated by extreme values, such that 33.2\% are smaller than 0.15 and 56.0\% are higher than 0.85. Furthermore, most cassette exons do not change between a given tissue pair (only 14.0\% of the samples in the dataset, \ie a cassette exon measured across two tissues, exhibit ΔΨ| ≥ 0.15).”
(5) Part of the improvement of TrASPr over Pangolin could be the result of a more extensive dataset.
Please see above responses and new analysis.
(6) In the discussion of the roles of alternative splicing, protein diversity is mentioned, but I suggest you also mention the importance of alternative splicing as a regulatory mechanism:
Lewis, Benjamin P., Richard E. Green, and Steven E. Brenner. "Evidence for the widespread coupling of alternative splicing and nonsense-mediated mRNA decay in humans." Proceedings of the National Academy of Sciences 100.1 (2003): 189-192.
Thank you for the suggestion. We added that point and citation.
(7) Line 96: You use dPSI without defining it (although quite clear that it should be Delta PSI).
Fixed.
(8) Pretrained transformers: Have you trained separate transformers on acceptor and donor sites, or a single splice junction transformer?
Single splice junction pre-training.
(9) "TrASPr measures the probability that the splice site in the center of Se is included in some tissue" - that's not my understanding of what TrASPr is designed to do.
We revised the above sentence to make it more precise: “Given a genomic sequence context S<sub>e</sub> = (s<sub>e</sub>,...,s<sub>e</sub>), made of a cassette exon e and flanking intronic/exonic regions, TrASPr predicts for tissue c the fraction of transcripts where exon e is included or skipped over, ΔΨ-<sub>e,c,c’</sub>.”
(10) Please include the version of the human genome annotations that you used.
We used GENCODE v40 human genome hg38- this is now included in the Data section.
(11) I did not see a description of the RBP-AE component in the methods section. A bit more detail on the model would be useful as well.
Please see above details about replacing RBP-AE with a simpler linear PCA “RBP-State” encoding. We added details about how the PCA was performed to the Methods section.
(12) Typos, grammar:
- Fix the following sentence: ATP13A2, a lysosomal transmembrane cation transporter, linked to an early-onset form of Parkinson's Disease (PD) when 306 loss-of-function mutations disrupt its function.
Sentence was fixed to now read: “The first example is of a brain cerebellum-specific cassette exon skipping event predicted by TrASPr in the ATP13A2 gene (aka PARK9). ATP13A2 is a lysosomal transmembrane cation transporter, for which loss of function mutation has been linked to early-onset of Parkinson’s Disease (PD)”.
- Line 501: "was set to 4e−4"(the - is a superscript).
Fixed
- A couple of citations are missing in lines 580 and 581.
Thank you for catching this error. Citations in line 580, 581 were fixed.
(13) Paper title: Generative modeling for RNA splicing predictions and design - it would read better as "Generative modeling for RNA splicing prediction and design", as you are solving the problems of splicing prediction and splicing design.
Thank you for the suggestion. We updated the title and removed the plural form.
Reviewer #2 (Recommendations for the authors):
(1) Appendices are not very common in biology journals. It is also not clear what purpose the appendix serves exactly - it seems to repeat some of the things said earlier. Consider merging it into the methods or the main text.
We merged the appendices into the Methods section and removed redundancy.
(2) L112, "For instance, the model could be tasked with designing a new version of the cassette exon, restricted to no more than N edit locations and M total base changes." How are N and M different? Is there a difference between an edit location and a base change?
Yes, N is the number of locations (one can think of it as a start position) of various lengths (e.g. a SNP is of length 1) and the total number of positions edited is M. The text now reads “For instance, the model could be tasked with designing a new version of the cassette exon, restricted to no more than $N$ edit locations (\ie start position of one or more consecutive bases) and $M$ total base changes.”
(3) L122: "DEN was developed for a distinct problem". What prevents one from adapting DEN to your sequence design task? The method should be generic. I do not see what "differs substantially" means here. (Finally, wasn't DEN developed for the task you later refer to as "alternative splice site" (as opposed to "splice site selection")? Use consistent terminology. And in L236 you use "splice site variation" - is that also the same?).
Indeed, our original description was not clear/precise enough. DEN was designed and trained for two tasks: APA, and 5’ alternative splice site usage. The terms “selection”, “usage”, and “variation” were indeed used interchangeably in different locations and the reviewer was right, noting the lack of precision. We have now revised the text to make sure the term “relative usage” is used.
Nonetheless, we hold DEN was indeed defined for different tasks. See figures from Figure 2A, 6A of Linder et al 2020 (the reference was also incorrect as we cited the preprint and not the final paper):
In both cases DEN is trying to optimize a short region for selecting an alternative PA site (left) or a 5’ splice site (right). This work focused on an MPRA dataset of short synthetic sequences inserted in the designated region for train/test. We hold this is indeed a different type of data and task then the one we focus on here. Yes, one can potentially adopt DEN for our task, but this is beyond the scope of this paper. Finally, we note that a more closely related algorithm recently proposed is Ledidi (Schreiber et al 2025) which was posted as a pre-print. Similar to BOS, Ledidi tries to optimize a given sequence and adopt it with a few edits for a given task. Regardless, we updated the main text to make the differences between DEN and the task we defined here for BOS more clear, and we also added a reference to Ledidi and other recent works in the discussion section.
(4) L203, exons with DeltaPSI very close to 0.15 are going to be nearly impossible to classify (or even impossible, considering that the DeltaPSI measurements are not perfect). Consider removing such exons to make the task more feasible.
Yes, this is how it was done. As described in more details below, we defined changing samples as ones where the change was >= 0.15 and non-changing as ones where the change in PSI was < 0.05 to avoid ambiguous cases affecting the classification task.
(5) L230, RBP-AE is not explained in sufficient detail (and does not appear in the methods, apparently). It is not clear how exactly it is trained on each new cellular condition.
Please see response in the opening of this document and Q11 from
Reviewer 1
(6) L230, "significantly improving": the r value actually got worse; it is therefore not clear you can claim any significant improvement. Please mention that fact in the text.
This is a fair point. We note that we view the “a” statistic as potentially more interesting/relevant here as the Pearson “r” is dominated by points being generally close to 0/1. Regardless, revisiting this we realized one can also make a point that the term “significant” is imprecise/misplaced since there is no statistical test done here (side note: given the amount of points, a simple null of same distribution yes/no would pass significance but we don’t think this is an interesting/relevant test here). Also, we note that with the transition to PCA instead of RBP-AE we actually get improvements in both a and r values, both for the ENCODE samples shown in Figure 3a and the two new GTEX tissues we tested (see above). We now changed the text to simply state:
“...As shown in Figure 3a, this latent space representation allows TrSAPr to generalize from the six GTEX tissues to unseen conditions, including unseen GTEX tissues (top row), and ENCODE cell lines (bottom row). It improves prediction accuracy compared to TrASPr lacking PCA (eg a=88.5% vs a=82.3% for ENCODE cell lines), though naturally training on the additional GTEX and ENCODE conditions can lead to better performance (eg a=91.7%, for ENCODE, Figure 3a left column).”
(7) L233, "Notably, previous splicing codes focused solely on cassette exons", Rosenberg et al. focused solely on alternative splice site choice.
Right - we removed that sentence..
(8) L236, "trained TrASPr on datasets for 3' and 5' splice site variations". Please provide more details on this task. What is the input to TrASPr and what is the prediction target (splice site usage, PSI of alternative isoforms)? What datasets are used for this task?
The data for this data was the same GTEx tissue data processed, just for alternative 3’ and 5’ splice sites events. We revised the description of this task in the main task and added information in the Methods section. The data is also included in the repo.
(9) L243, "directly from genomic sequences", and conservation?
Yes, we changed the sentence to read “...directly from genomic sequences combined with related features”
(10) L262, what is the threshold for significant splicing changes?
The threshold is 0.15 We updated the main text to read the following:
The total number of mutations hitting each of the 1198 genomic positions across the 6106 sequences is shown in \FIG{mut_effect}b (left), while the distribution of effects ($|\Delta \Psi|$) observed across those 6106 samples is shown in \FIG{mut_effect}b (right). To this data we applied three testing schemes. The first is a standard 5-fold CV where 20\% of combinations of point mutations were hidden in every fold while the second test involved 'unseen mutation' (UM) where we hide any sample that includes mutations in specific positions for a total of 1480 test samples. As illustrated by the CDF in \FIG{mut_effect}b, most samples (each sample may involve multiple positions mutated) do not involve significant splicing changes. Thus, we also performed a third test using only the 883 samples were mutations cause significant changes ($|\Delta \Psi|\geq 0.15 $).
(11) L266, Pangolin performance is only provided for one of the settings (and it is not clear which). Please provide details of its performance in all settings.
The description was indeed not clear. Pangolin’s performance was similar to SpliceAI as mentioned above but retraining it on the CD19 data yielded much closer performance to TrASPr. We include all the matching tests for Pangolin after retraining in Figure 4 Supp Figure 1.
(12) Please specify "n=" in all relevant plots.
Fixed.
(13) Figure 3a, "The tissues were first represented as tokens, and new cell line results were predicted based on the average over conditions during training." Please explain this procedure in more detail. What are these tokens and how are they provided to the model? Are the cell line predictions the average of the predictions for the training tissues?
Yes, we compared to simply the average over the predictions for the training tissues for that specific event as baseline to assess improvements (see related work pointing for the need to have similar baselines in DL for genomics in https://pubmed.ncbi.nlm.nih.gov/33213499/). Regarding the tokens - we encode each tissue type as a possible value and feed the two tissues as two tokens to the transformer.
(14) Figure 4b, the total count in the histogram is much greater than 6106. Please explain the dataset you're using in more detail, and what exactly is shown here.
We updated the text to read:
“...we used 6106 sequence samples where each sample may have multiple positions mutated (\ie mutation combinations) in exon 2 of CD19 and its flanking introns and exons (Cortes et al 2022). The total number of mutations hitting each of the 1198 genomic positions across the 6106 sequences is shown in Figure 4b (left).”
(15) Figure 5a, how are the prediction thresholds (TrASPr passed, TrASPr stringent, and TrASPr very stringent) defined?
Passed: dpsi>0.1, Stringent: dpsi>0.15, Very stringent: dpsi>0.2 This is now included in the main text.
(16) L417, please include more detail on the relative size of TrASPr compared to other models (e.g. number of parameters, required compute, etc.).
SpliceAI is a general-purpose splicing predictor with 32-layer deep residual neural network to capture long-range dependencies in genomic sequences. Pangolin is a deep learning model specifically designed for predicting tissue-specific splicing with similar architecture as SpliceAI. The implementation of SpliceAI that can be found here https://huggingface.co/multimolecule/spliceai involves an ensemble of 5 such models for a total of ~3.5M parameters. TrASPr, has 4 BERT transformers (each 6 layers and 12 heads) and MLP a top of those for a total of ~189M parameters. Evo 2, a genomic ‘foundation’ model has 40B parameters, DNABERT has ~86M (a single BERT with 12 layers and 12 heads), and Borzoi has 186M parameters (as stated in https://www.biorxiv.org/content/10.1101/2025.05.26.656171v2). We note that the difference here is not just in model size but also the amount of data used to train the model. We edited the original L417 to reflect that.
(17) L546, please provide more detail on the VAE. What is the dimension of the latent representation?
We added more details in the Methods section like the missing dimension (256) and definitions for P(Z) and P(S).
(18) Consider citing (and possibly comparing BOS to) Ghari et al., NeurIPS 2024 ("GFlowNet Assisted Biological Sequence Editing").
Added.
(19) Appendix Figure 2, and corresponding main text: it is not clear what is shown here. What is dPSI+ and dPSI-? What pairs of tissues are you comparing? Spearman correlation is reported instead of Pearson, which is the primary metric used throughout the text.
The dPSI+ and dPSI- sets were indeed not well defined in the original submission. Moreover, we found our own code lacked consistency due to different tests executed at different times/by different people. We apologize for this lack of consistency and clarity which we worked to remedy in the revised version. To answer the reviewer’s question, given two tissues ($c,c'$), dPSI+ and dPSI- is for correctly classifying the exons that are significantly differentially included or excluded. Specifically, differential included exons are those for which $\Delta \Psi_{e,c1,c2} = \Psi_\Psi_{e,c1} - \Psi_{e,c2} \geq 0.15$, compared to those that are not ($\Delta \Psi_{e,c1,c2} < 0.05). Similarly, dPSI- is for correctly classifying the exons that are significantly differentially excluded in the first tissue or included in the second tissue ($\Delta \Psi_{e,c1,c2} = \Psi_\Psi_{e,c1} - \Psi_{e,c2} \leq -0.15$) compared to those that are not ($\Delta \Psi_{e,c1,c2} > -0.05). This means dPSI+ and dPSI- are dependent on the order of c1, c2. In addition, we also define a direction/order agnostic test for changing vs non changing events i.e. $|\Delta \Psi_{e,c1,c2}| \geq 0.15$ vs $|\Delta \Psi_{e,c1,c2}| < 0.05$. These test definitions are consistent with previous publications (e.g. Barash et al Nature 2010, Jha et al 2017) and also answer different biological questions: For example “Exons that go up in brain” and “Exons that go up in Liver” can reflect distinct mechanisms, while changing exons capture a model’s ability to identify regulated exons even if the direction of prediction may be wrong. The updated Appendix Figure 2 is now in the main text as Figure 2d and uses Pearson, while AUPRC and AUROC refer to the changing vs no-changing classification task described above such that we avoid dPSI+ and dPSI- when summarizing in this table over 3 pairs of tissues . Finally, we note that making sure all tests comply with the above definition also resulted in an update to Figure 2b/c labels and values, where TrASPr’s improvements over Pangolin reaches up to 1.8fold in AUPRC compared to 2.4fold in the earlier version. We again apologize for having a lack of clarity and consistent evaluations in the original submission.
(20) Minor typographical comments:
- Some plots could use more polishing (e.g., thicker stroke, bigger font size, consistent style (compare 4a to the other plots)...).
Agreed. While not critical for the science itself we worked to improve figure polishing in the revision to make those more readable and pleasant.
- Consider using 2-dimensional histograms instead of the current kernel density plots, which tend to over-smooth the data and hide potentially important details.
We were not sure what the exact suggestion is here and opted to leave the plots as is.
- L53: dPSI_{e, c, c'} is never formally defined. Is it PSI_{e, c} - PSI_{e, c'} or vice versa?
Definition now included (see above).
- L91: Define/explain "transformer" and provide reference.
We added the explanation and related reference of the transformer in the introduction section and BERT in the method section.
- L94: exons are short. Are you referring here to the flanking introns? Please explain.
We apologize for the lack of clarity. We are referring to a cassette exon alternative splicing event as is commonly defined by the splice junctions involved that is from the 5’ SS of the upstream exon to the 3’ SS of the downstream exon. The text now reads:
“...In contrast, 24% of the cassette exons analyzed in this study span a region between the flanking exons' upstream 3' and downstream 5' splice sites that are larger than 10 kb.”
- L132: It's unclear whether a single, shared transformer or four different transformers (one for each splice site) are being pre-trained. One would at least expect 5' and 3' splice sites to have a different transformer. In Methods, L506, it seems that each transformer is pre-trained separately.
We updated the text to read:
“We then center a dedicated transformer around each of the splice sites of the cassette exon and its upstream and downstream (competing) exons (four separate transformers for four splice sites in total).”
- L471: You explain here that it is unclear what tasks 'foundation' models are good for. Also in L128, you explain that you are not using a 'foundation' model. But then in L492, you describe the BERT model you're using as a foundation model!
Line 492 was simply a poor choice of wording as “foundation” is meant here simply as the “base component”. We changed it accordingly.
- L169, "pre-training ... BERT", explain what exactly this means. Is it using masking? Is it self-supervised learning? How many splice sites do you provide? Also explain more about the BERT architecture and provide references.
We added more details about the BERT architecture and training in the Methods section.
- L186 and later, the values for a and r provided here and in the below do not correspond to what is shown in Figure 2.
Fixed, thank you for noticing this.
- L187,188: What exactly do you mean by "events" and "samples"? Are they the same thing? If so, are they (exon, tissue) pairs? Please use consistent terminology. Moreover, when you say "changing between two conditions": do you take all six tissues whenever there is a 0.15 spread in PSI among them? Or do you take just the smallest PSI tissue and the largest PSI tissue when there is a 0.15 spread between them? Or something else altogether?
Reviewer #2 is yet again correct that the definitions were not precise. A “sample” involves a specific exon skipping “event” measured in two tissues. The text now reads:
“....most cassette exons do not change between a given tissue pair (only 14.0% of the samples in the dataset, i.e., a cassette exon measured across two tissues, exhibit |∆Ψ| ≥ 0.15). Thus, when we repeat this analysis only for samples involving exons that exhibited a change in inclusion (|∆Ψ| ≥ 0.15) between at least two tissues, performance degrades for all three models, but the differences between them become more striking (Figure 2a, right column).”
- Figure 1a, explain the colors in the figure legend. The 3D effect is not needed and is confusing (ditto in panel C).
Color explanation is now added: “exons and introns are shown as blue rectangles and black lines. The blue dashed line indicates the inclusive pattern and the red junction indicates an alternative splicing pattern.”
These are not 3D effects but stacks to indicate multiple events/cases. We agree these are not needed in Fig1a to illustrate types of AS and removed those. However, in Fig1c and matching caption we use the stacks to indicate HT data captures many such LSVs over which ML algorithms can be trained.
- Figure 1b, this cartoon seems unnecessary and gives the wrong impression that this paper explores mechanistic aspects of splicing. The only relevant fact (RBPs serving as splicing factors) can be explained in the text (and is anyway not really shown in this figure).
We removed Figure 1b cartoon.
- Figure 1c, what is being shown by the exon label "8"?
This was meant to convey exon ID, now removed to simplify the figure.
- Figure 1e, left, write "Intron Len" in one line. What features are included under "..."? Based on the text, I did not expect more features.
Also, the arrows emanating from the features do not make sense. Is "Embedding" a layer? I don't think so. Do not show it as a thin stripe. Finally, what are dPSI'+ and dPSI'-? are those separate outputs? are those logits of a classification task?
We agree this description was not good and have updated it in the revised version.
- Figure 1e, the right-hand side should go to a separate figure much later, when you introduce BOS.
We appreciate the suggestion. However, we feel that Figure 1e serves as a visual representation of the entire framework. Just like we opted to not turn this work into two separate papers (though we fully agree it is a valid option that would also increase our publication count), we also prefer to leave this unified visual representation as is.
- Figure 2, does the n=2456 refer to the number of (exons, tissues) pairs? So each exon contributes potentially six times to this plot? Typo "approximately".
The “n” refers to the number of samples which is a cassette event measured in two tissues. The same cassette event may appear in multiple samples if it was confidently quantified in more than two tissues. We updated the caption to reflect this and corrected the typo.
- Figure 2b, typo "differentially included (dPSI+) or excluded" .
Fixed.
- L221, "the DNABERT" => "DNABERT".
Fixed.
- L232, missing percent sign.
-
Fixed.
- L246, "see Appendix Section 2 for details" seems to instead refer to the third section of the appendix.
We do not have this as an Appendix, the reference has been updated.
- Figure 3, bottom panels, PSI should be "splice site usage"?
PSI is correct here - we hope the revised text/definitions make it more clear now.
- Figure 3b: typo: "when applied to alternative alternative 3'".
Fixed.
- p252, "polypyrimidine" (no capitalization).
Fixed.
- Strange capitalization of tissue names (e.g., "Brain-Cerebellum"). The tissue is called "cerebellum" without capitalization.
We used EBV (capital) for the abbreviation and lower case for the rest.
- Figure 4c: "predicted usage" on the left but "predicted PSI" on the right.
Right. We opted to leave it as is since Pangolin and SpliceAI do predict their definition of “usage” and not directly PSI, we just measure correlations to observed PSI as many works have done in the past.
- Figure 4 legend typo: "two three".
Fixed.
- L351, typo: "an (unsupervised)" (and no need to capitalize Transformer).
Fixed.
- L384, "compared to other tissues at least" => "compared to other tissues of at least".
Fixed.
- L549, P(Z) and P(S) are not defined in the text.
Fixed.
- L572, remove "Subsequently". Add missing citations at the end of the paragraph.
Fixed.
- L580-581, citations missing.
Fixed.
- L584-585, typo: "high confidince predictions"
Fixed.
- L659-660, BW-M and B-WM are both used. Typo?
Fixed.
- L895, "calculating the average of these two", not clear; please rewrite.
Fixed.
- L897, "Transformer" and "BERT", do these refer to the same thing? Be consistent.
BOS is a transformer and not a BERT but TrASPr uses the BERT architecture. BERT is a type of transformer as the reviewer is surely well aware so the sentence is correct. Still, to follow the reviewer’s recommendation for consistency/clarity we changed it here to state BERT.
- Appendix Figure 5: The term dPSI appears to be overloaded to also represent the difference between predicted PSI and measured PSI, which is inconsistent with previous definitions.
Indeed! We thank the reviewer again for their sharp eye and attention to details that we missed. We changed Supp Figure 5, now Figure 4 Supplementary Figure 2, to |PSI’-PSI| and defined those as the difference between TrASPr’s predictions (PSI’) and MAJIQ based PSI quantifications.
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
Summary:
Liu et al. provided evidence of the interaction between endocytosis and VAMP8-mediated endocytic recycling of clathrin-mediated endocytosis (CME) cargo through a knockdown approach combined with total internal reflection fluorescence (TIRF) microscopy, western blotting, and functional assays in a mammalian cell line system. They demonstrated that VAMP8 impairs the initial stages of CME, such as the initiation, stabilization, and invagination of clathrin-coated pits (CCPs). VAMP8 indirectly regulates CME by facilitating endocytic recycling. The depletion of VAMP8 alters endosomal recycling, as shown here by the transferrin receptor, towards lysosomal degradation, thereby inhibiting clathrin-coated vesicle (CCV) formation. Overall, I found this study to be highly engaging because of its elucidation of the unexpected role of R-Snare in influencing the levels of cargo proteins within the context of clathrin-mediated endocytosis (CME). This MS will be helpful for researchers in endocytosis and protein trafficking fields. It appears to me that VAMP8 interacts with multiple targets within the endo-lysosomal pathway, collectively influencing the clathrin-mediated endocytosis (CME). Therefore, the contribution of lysosomes in this context should be evaluated. This matter should be addressed experimentally and discussed in the MS before considering publication.
Major comments:
Minor comments:
VAMP8 is an R-SNARE critical for late endosome/lysosome fusion and regulates exocytosis, especially in immune and secretory cells. It pairs with Q-SNAREs to mediate vesicle fusion, and its dysfunction alters immunity, inflammation, and secretory processes. This study revealed that the SNARE protein VAMP8 influences clathrin-mediated endocytosis (CME) by managing the recycling of endocytic cargo rather than being directly recruited to clathrin-coated vesicles. This study advances our understanding of cellular trafficking mechanisms and underscores the essential role of recycling pathways in maintaining membrane dynamics. This is an excellent piece of work, and the experiments were designed meticulously; however, the mechanism is not convincing enough at this point. This MS will surely benefit the general audience, specifically the membrane and protein trafficking and cell biology community.
Author response:
The following is the authors’ response to the original reviews.
eLife Assessment
This study introduces a novel method for estimating spatial spectra from irregularly sampled intracranial EEG data, revealing cortical activity across all spatial frequencies, which supports the global and integrated nature of cortical dynamics. The study showcases important technical innovations and rigorous analyses, including tests to rule out potential confounds; however, the lack of comprehensive theoretical justification and assumptions about phase consistency across time points renders the strength of evidence incomplete. The dominance of low spatial frequencies in cortical phase dynamics continues to be of importance, and further elaboration on the interpretation and justification of the results would strengthen the link between evidence and conclusions.
Public Reviews:
Reviewer #1 (Public review):
Summary:
The paper uses rigorous methods to determine phase dynamics from human cortical stereotactic EEGs. It finds that the power of the phase is higher at the lowest spatial phase.
Strengths:
Rigorous and advanced analysis methods.
Weaknesses:
The novelty and significance of the results are difficult to appreciate from the current version of the paper.
(1) It is very difficult to understand which experiments were analysed, and from where they were taken, reading the abstract. This is a problem both for clarity with regard to the reader and for attribution of merit to the people who collected the data.
We now explicitly state the experiments that were used, lines 715-716.
(2) The finding that the power is higher at the lowest spatial phase seems in tune with a lot of previous studies. The novelty here is unclear and it should be elaborated better.
It is not generally accepted in neuroscience that power is higher at lowest spatial frequencies, and recent research concludes that traveling waves at this scale may be the result of artefactual measurement (Orczyk et al., 2022; Hindriks et al., 2014; Zhigalov & Jensen,2023). The question we answer is therefore timely and a source of controversy to researchers analysing TWs in cortex. While, in our view, the previous literature points in the direction of our conclusions (notably the work of Freeman et. al. 2003; 2000; Barrie et al. 1996), it is not conclusive at the scale we are interested in, specifically >8cm, and certainly not convincing to the proponents of ‘artefactual measurement’.
We have added to a sentence to make this explicit in the abstract, lines 20-22. Please also note previous text at the end of the introduction, lines 140-148 and in the first paragraph of the discussion, lines 563-569.
I could not understand reading the paper the advantage I would have if I used such a technique on my data. I think that this should be clear to every reader.
We have made the core part of the code available on github (line 1154), which should simplify adoption of the technique. We have urged, in the Discussion (lines 653-663), why habitual measurement of SF spectra is desirable, since the same task measured with EEG, sEEG or ECoG does not encompass the same spatial scales, and researchers may be comparing signals with different functional properties. Until reliable methods for estimating SF are available, not dependent on the layout of the recording array, data cannot be analysed to resolve this question. Publication of our results and methods will help this process along.
(3) It seems problematic to trust in a strong conclusion that they show low spatial frequency dynamics of up to 15-20 cm given the sparsity of the arrays. The authors seem to agree with this concern in the last paragraph of page 12.
The new surrogate testing supports our conclusions. The sEEG arrays would not normally be a first choice to estimate SF spectra, for reasons of their sparsity, which may be why such estimates have not been done before. Yet, this is the research challenge that we sought to solve, and a problem for which there was no ready method to hand. Nevertheless, it is a problem that urgently needed to be solved given the current debate on the origin of large-scale TWs. We have now included detailed surrogate testing of real data plus varying strength model waves (Figure 6A and Supplementary Figure 4). We believe this should convince the reader that we are measuring the spatial frequency spectrum with sufficient accuracy to answer the central research question.
They also say that it would be informative to repeat the analyses presented here after the selection of more participants from all available datasets. It begs the question of why this was not done. It should be done if possible.
We have now doubled the number of participants in the main analyses. Since each participant comprises a test of the central hypothesis, now the hypothesis test now has 23 replications (Supplementary Figures 2 and 3). There were four failures to reach significance due to under-powered tests, i.e., not enough contacts. This is sufficient test of the hypothesis and, in our opinion, not the primary obstacle to scientific acceptance of our results. The main obstacle is providing convincing tests that the method is accurate, and this is what we have focussed on. Publication of python code and the detailed methods described here enable any interested researcher to extend our method to other datasets.
(4) Some of the analyses seem not to exploit in full the power of the dataset. Usually, a figure starts with an example participant but then the analysis of the entire dataset is not as exhaustive. For example, in Figure 6 we have a first row with the single participants and then an average over participants. One would expect quantifications of results from each participant (i.e. from the top rows of GFg 6) extracting some relevant features of results from each participant and then showing the distribution of these features across participants. This would complement the subject average analysis.
The results are now clearly split into sections, where we first deal with all the single participant analyses, then the surrogate testing to confirm the basic results, then the participant aggregate results (Figure 7 and Supplementary Figure 7). The participant aggregate results reiterate the basic findings for the single participants. The key finding is straightforward (SF power decreases with SF) and required only one statistical analysis per subject.
(5) The function of brain phase dynamics at different frequencies and scales has been examined in previous papers at frequencies and scales relevant to what the authors treat. The authors may want to be more extensive with citing relevant studies and elaborating on the implications for them. Some examples below:
Womelsdorf T, et alScience. 2007
Besserve M et al. PloS Biology 2015
Nauhaus I et al Nat Neurosci 2009
We have added two paragraphs to the discussion, in response to the reviewer suggestion (lines 606-623). These paragraphs place our high TF findings in the context of previous research.
Reviewer #2 (Public review):
Summary:
In this paper, the authors analyze the organization of phases across different spatial scales. The authors analyze intracranial, stereo-electroencephalogram (sEEG) recordings from human clinical patients. The authors estimate the phase at each sEEG electrode at discrete temporal frequencies. They then use higher-order SVD (HOSVD) to estimate the spatial frequency spectrum of the organization of phase in a data-driven manner. Based on this analysis, the authors conclude that most of the variance explained is due to spatially extended organizations of phase, suggesting that the best description of brain activity in space and time is in fact a globally organized process. The authors' analysis is also able to rule out several important potential confounds for the analysis of spatiotemporal dynamics in EEG.
Strengths:
There are many strengths in the manuscript, including the authors' use of SVD to address the limitation of irregular sampling and their analyses ruling out potential confounds for these signals in the EEG.
Weaknesses:
Some important weaknesses are not properly acknowledged, and some conclusions are overinterpreted given the evidence presented.
The central weakness is that the analyses estimate phase from all signal time points using wavelets with a narrow frequency band (see Methods - "Numerical methods"). This step makes the assumption that phase at a particular frequency band is meaningful at all times; however, this is not necessarily the case. Take, for example, the analysis in Figure 3, which focuses on a temporal frequency of 9.2 Hz. If we compare the corresponding wavelet to the raw sEEG signal across multiple points in time, this will look like an amplitude-modulated 9.2 Hz sinusoid to which the raw sEEG signal will not correspond at all. While the authors may argue that analyzing the spatial organization of phase across many temporal frequencies will provide insight into the system, there is no guarantee that the spatial organization of phase at many individual temporal frequencies converges to the correct description of the full sEEG signal. This is a critical point for the analysis because while this analysis of the spatial organization of phase could provide some interesting results, this analysis also requires a very strong assumption about oscillations, specifically that the phase at a particular frequency (e.g. 9.2 Hz in Figure 3, or 8.0 Hz in Figure 5) is meaningful at all points in time. If this is not true, then the foundation of the analysis may not be precisely clear. This has an impact on the results presented here, specifically where the authors assert that "phase measured at a single contact in the grey matter is more strongly a function of global phase organization than local". Finally, the phase examples given in Supplementary Figure 5 are not strongly convincing to support this point.
“using wavelets with a narrow frequency band … this analysis also requires a very strong assumption about oscillations, specifically that the phase at a particular frequency (e.g. 9.2 Hz in Figure 3, or 8.0 Hz in Figure 5) is meaningful at all points in time”
Our method uses very short time-window Morlet wavelets to avoid the assumptions of oscillations, i.e., long-lasting sinusoids in the signal, in the sense of sinusoidal waveforms, or limit cycles extending in time. Cortical TWs can only last one or two cycles (Alexander et al., 2006), requiring methods that are compact in the time domain to avoid underreporting the desired phenomena. Additionally, the short time-window Morlet wavelets have low frequency resolution, so they are robust with respect to shifts in frequency between sites. We now discuss this issue explicitly in the Methods (lines 658-674). This means the phase estimation methods used in the manuscript precisely do not have the problem of assuming narrow-band oscillations in the signal. The methods are also robust to the exact shape of the waveforms; the signal needs be only approximately sinusoidal; to rise and fall. This means the Fourier variant we use does not introduce ringing artefact that can be introduced using longer timeseries methods, such as FFT.
“This step makes the assumption that phase at a particular frequency band is meaningful at all times”
This important consideration is entrenched in our choice of methods. By way of explanatory background, we point out that this step is not the final step. Aggregation methods can be used to distinguish between signal and noise. In the simple case, event-locked time-series of phase can be averaged. This would allow consistent (non-noise) phase relations to be preserved, while the inconsistent (including noise) phase relations would be washed out. This is part of the logic behind all such aggregation procedures, e.g., phase-locking, coherence. SVD has the advantage of capturing consistent relations in this sense, but without loss of information as occurs in averaging (up to the choice of number of singular vectors in the final model). Specifically, maps of the spatial covariances in phase are captured in the order of the variance explained. Noise (in the sense conveyed by the reviewer) in the phase measurements will not contribute to highest rank singular vectors. SVD is commonly used to remove noise, and that is one of its purposes here. This point can be seen by considering the very smooth singular vectors derived from MEG (Figure 3F) in this new version of the manuscript. These maps of phase gradients pull out only the non-noisy relations, even as their weighted sums reproduce any individual sample to any desired accuracy.
To summarize, the next step (of incorporating the phase measure into the SVD) neatly bypasses the issue of non-meaningful phase quantification. This is one of the reasons why we do not undertake the spatial frequency estimates on the raw matrices of estimated phase.
We now include a new sub-paragraph on this topic in the methods, lines 831-838.
In addition, we have reworded the first description of the methods with a new paragraph at the end of the introduction, which better balances the description of the steps involved. The two sentences (lines 162-166 highlight the issue of concern to the reviewer.
“there is no guarantee that the spatial organization of phase at many individual temporal frequencies converges to the correct description of the full sEEG signal.”
The correct description of the full sEEG signal is beyond the scope of the present research. Our main goal, as stated, is to show that the hypothesis that ‘extra-cranial measurements of TWs is the result of projection from localized activity’ is not supported by the evidence of spatial patterns of activity in the cortex. Since this activity can be accessed as single frequency band (especially if localized sources create the large-scale patterns), analysis of SF on a TF-by-TF basis is sufficient.
“This has an impact on the results presented here, specifically where the authors assert that "phase measured at a single contact in the grey matter is more strongly a function of global phase organization than local".
We agree with the reviewer, even though we expect that the strongest influences on local phase are due to other cortical signals in the same band. The implicit assumption of the focus on bands of the same temporal frequency is now made explicit in the abstract (lines 31-34).
A sentence addressing this issue had been added to the first paragraph of the discussion (lines 579-582).
Inclusion of cross-frequency interactions would likely require a highly regular measurement array over the scales of interest here, i.e., the noise levels inherent in the spatial organization of sEEG contacts would not support such analyses.
“Finally, the phase examples given in Supplementary Figure 5 are not strongly convincing to support this point.”
We have removed the phase examples that were previously in Supplementary Figure 5 (and Figure 5 in the previous version of the main text), since further surrogate testing and modelling (Supplementary Figure 11) shows the LSVs from irregular arrays will inevitably capture mixtures of low and high SF signals. The final section of the Methods explains this effect in some detail. Instead, the new version of the manuscript relies on new surrogate testing to validate our methods.
Another weakness is in the discussion on spatial scale. In the analyses, the authors separate contributions at (approximately) > 15 cm as macroscopic and < 15 cm as mesoscopic. The problem with the "macroscopic" here is that 15 cm is essentially on the scale of the whole brain, without accounting for the fact that organization in sub-systems may occur. For example, if a specific set of cortical regions, spanning over a 10 cm range, were to exhibit a consistent organization of phase at a particular temporal frequency (required by the analysis technique, as noted above), it is not clear why that would not be considered a "macroscopic" organization of phase, since it comprises multiple areas of the brain acting in coordination. Further, while this point could be considered as mostly semantic in nature, there is also an important technical consideration here: would spatial phase organizations occurring in varying subsets of electrodes and with somewhat variable temporal frequency reliably be detected? If this is not the case, then could it be possible that the lowest spatial frequencies are detected more often simply because it would be difficult to detect variable organizations in subsets of electrodes?
The motivation for our study was to show that large-scale TWs measured outside the cortex cannot be the result of more localized activity being ‘projected up’. In this case, the temporal frequency of the artefactual waves would be the same as the localized sources, so the criticism does not apply.
“while this point could be considered as mostly semantic in nature”
We have changed the terminology in the paper to better coincide with standard usage. Macroscopic now refers to >1cm, while we refer to >8cm as large-scale.
“15 cm is essentially on the scale of the whole brain, without accounting for the fact that organization in sub-systems may occur.”
We can assume that subtle frequency variation (e.g., within an alpha phase binding) is greatest at the largest scales of cortex, or at least not less varying than measurements within regions. This means that not considering frequency-drift effects will not inflate low spatial frequency power over high spatial frequency power. Even so, the power spectrum we estimated is approximately 1/SF, so that unmeasured cross-frequency effects in binding (causal influences on local phase) would have to overcome the strength of this relation for this criticism to apply, which seems unlikely.
“would spatial phase organizations occurring in varying subsets of electrodes and with somewhat variable temporal frequency reliably be detected?”
See our previous comments about the low temporal frequency resolution of two cycle Morlet wavelets. The answer is yes, up to the range approximated by half-power bandwidth, which is large in the case of this method (see lines 760-764).
Another weakness is disregarding the potential spike waveform artifact in the sEEG signal in the context of these analyses. Specifically, Zanos et al. (J Neurophysiol, 2011) showed that spike waveform artifacts can contaminate electrode recordings down to approximately 60 Hz. This point is important to consider in the context of the manuscript's results on spatial organization at temporal frequencies up to 100 Hz. Because the spike waveform artifact might affect signal phase at frequencies above 60 Hz, caution may be important in interpreting this point as evidence that there is significant phase organization across the cortex at these temporal frequencies.
We have now added a sentence on this issue to the discussion (lines 600-602).
However, our reading of the Zanos et al. paper is that the low temporal frequency (60-100Hz) contribution of spikes and spike patterns is negligible compared to genuine post-synaptic membrane fluctuations (see their Figure 3). These considerations come more strongly into play when correlations between LFP and spikes are calculated or spike triggered averaging is undertaken, since then a signal is being partly correlated with itself, or, partly averaged over the supposedly distinct signal with which it was detected.
A last point is that, even though the present results provide some insight into the organization of phase across the human brain, the analyses do not directly link this to spiking activity. The predictive power that these spatial organizations of phase could provide for spiking activity - even if the analyses were not affected by the distortion due to the narrow-frequency assumption - remains unknown. This is important because relating back to spiking activity is the key factor in assessing whether these specific analyses of phase can provide insight into neural circuit dynamics. This type of analysis may be possible to do with the sEEG recordings, as well, by analyzing high-gamma power (Ray and Maunsell, PLoS Biology, 2011), which can provide an index of multi-unit spiking activity around the electrodes.
“even if the analyses were not affected by the distortion due to the narrow-frequency assumption”
See our earlier comment about narrow TFs; this is not the case in the present work.
The spiking activity analysis would be an interesting avenue for future research. It appears the 1000Hz sampling frequency in the present data is not sufficient for method described in Ray & Maunsell (2011). On a related topic, we have shown that large-scale traveling waves in the MEG and 8cm waves in ECoG can both be used to predict future localized phase at a single sensor/contact, two cycles into the future (Alexander et al., 2019). This approach could be used to predict spiking activity, by combining it with the reviewer’s suggestion. However, the current manuscript is motivated by the argument that measured large-scale extra-cranial TWs are merely projections of localized cortical activity. Since spikes do not arise in this argument, we feel it is outside the scope of the present research. We have added this suggestion to the discussion as a potential line of future research (lines 686-688).
Reviewer #3 (Public review):
Summary:
The authors propose a method for estimation of the spatial spectra of cortical activity from irregularly sampled data and apply it to publicly available intracranial EEG data from human patients during a delayed free recall task. The authors' main findings are that the spatial spectra of cortical activity peak at low spatial frequencies and decrease with increasing spatial frequency. This is observed over a broad range of temporal frequencies (2-100 Hz).
Strengths:
A strength of the study is the type of data that is used. As pointed out by the authors, spatial spectra of cortical activity are difficult to estimate from non-invasive measurements (EEG and MEG) due to signal mixing and from commonly used intracranial measurements (i.e. electrocorticography or Utah arrays) due to their limited spatial extent. In contrast, iEEG measurements are easier to interpret than EEG/MEG measurements and typically have larger spatial coverage than Utah arrays. However, iEEG is irregularly sampled within the threedimensional brain volume and this poses a methodological problem that the proposed method aims to address.
Weaknesses:
The used method for estimating spatial spectra from irregularly sampled data is weak in several respects.
First, the proposed method is ad hoc, whereas there exist well-developed (Fourier-based) methods for this. The authors don't clarify why no standard methods are used, nor do they carry out a comparative evaluation.
We disagree that the method is ad hoc, though the specific combination of SVD and multiscale differencing is novel in its application to sEEG. The SVD method has been used to isolate both ~30cm TWs in MEG and EEG (Alexander et al., 2013; 2016), as well as 8cm waves in ECoG (Alexander et al., 2013; 2019). In our opening examples in the results now reiterate these previous related findings, by way of example analysis of MEG data (Figure 3). This will better inform the reader on the extent of continuity of the method from previous research.
Standard FFT has been used after interpolating between EEG electrodes to produce a uniform array (Alamia et al., 2023). There exist well-developed Fourier methods for nonuniform grids, such as simple interpolation, the butterfly algorithm, wavefield extrapolation and multi-scale vector field techniques. However, the problems for which these methods are designed require non-sparse sampling or less irregular arrays. The sEEG contacts (reduced in number to grey matter contacts) are well outside the spatial irregularity range of any Fourierrelated methods that we are aware of, particularly at the broad range of spatial scales of interest here (2cm up to 24cm). This would make direct comparison of these specialized Fourier method to our novel methods, in the sEEG, something of a straw-man comparison.
We now include a summary paragraph in the introduction, which is a brief review of Fourier methods designed to deal with non-uniform sampling (lines 159-162).
Second, the proposed method lacks a theoretical foundation and hinges on a qualitative resemblance between Fourier analysis and singular value decomposition.
We have improved our description of the theoretical relation between Fourier analysis and SVD (additional material at lines 839-861 and 910-922). In fact, there are very strong links between the two methods, and now it should be clearer that our method does not rely on a mere qualitative resemblance.
Third, the proposed method is not thoroughly tested using simulated data. Hence it remains unclear how accurate the estimated power spectra actually are.
We now include a new surrogate testing procedure, which takes as inputs the empirical data and a model signal (of known spatial frequency) in various proportions. Thus, we test both the impact of small amount of surrogate signal on the empirical signal, and the impact of ‘noise’ (in the form of a small amount of empirical signal) added to the well-defined surrogate signal.
In addition, there are a number of technical issues and limitations that need to be addressed or clarified (see recommendations to the authors).
My assessment is that the conclusions are not completely supported by the analyses. What would convince me, is if the method is tested on simulated cortical activity in a more realistic set-up. I do believe, however, that if the authors can convincingly show that the estimated spatial spectra are accurate, the study will have an impact on the field. Regarding the methodology, I don't think that it will become a standard method in the field due to its ad hoc nature and well-developed alternatives.
Simulations of cortical activity do not seem the most direct way to achieve this goal. The first author has published in this area (Liley et. al., 1999; Wright et al., 2001), and such simulations, for both bulk and neuronally based simulations, readily display traveling wave activity at low spatial frequencies (indeed, this was the origin of the present scientific journey). The manuscript outlines these results in the introduction, as well as theoretical treatments proposing the same. Several other recent studies have highlighted the appearance of largescale travelling waves using connectome-based models (https://www.biorxiv.org/content/10.1101/2025.07.05.663278v1; https://www.nature.com/articles/s41467-024-47860-x), which we do not include in the manuscript for reasons of brevity. In short, the emergence of TW phenomenon in models is partly a function of the assumptions put into them (i.e., spatial damping, boundary conditions, parameterization of connection fields) and would therefore be inconclusive in our view.
Instead, we rely on the advantages provided by the way our central research question has been posed: that the spatial frequency distribution of grey matter signal can determine whether extra-cranial TWs are artefactual. The newly introduced surrogate methods reflect this advantage by directly adding ground truth spatial frequency components to individual sample measurements. This is a less expensive option than making cortical simulations to achieve the same goal.
For the same reasons, we include testing of the methods using real cortical signals with MEG arrays (for which we could test the effects of increasing sparseness of contacts, test the effects of average referencing, and also construct surrogate time-series with alternative spectra).
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
Major points
Methods, Page 18: "... using notch filters to remove the 50Hz line signal and its harmonics ...": The sEEG data appear to have been recorded in North America, where the line frequency is 60 Hz. Is this perhaps a typo, or was a 50 Hz notch filter in fact applied here (which would be a mistake)?
This has now been fixed in the text to read 60Hz. This is the notch filter that was applied.
Minor points
(1) While the authors do state that they are analyzing the "spatial frequency spectrum of phase dynamics" in the abstract, this could be more clearly emphasized. Specifically, the difference between signal power at different spatial frequencies (as analyzed by a standard Fourier analysis) and the organization of phase in space (as done here) could be more clearly distinguished.
We now address this point explicitly on lines 167-172. We now include at the end of the results additional analyses where the TF power is included. This means that the effects of including signal power at different temporal frequencies can be directly compared to our main analysis of the SF spectrum of the phase dynamics.
(2) Figure 1A-C: It was not immediately clear what the lengths provided in these panels (e.g."> 40 cm cortex", "< 10 cm", "< 30 cm") were meant to indicate. This could be made clearer.
Now fixed in the caption.
(3) Figure 2A: If this is surrogate data to explain the analysis technique, it would be helpful to note explicitly at this point.
This Figure has been completely reworked, and now the status of the examples (from illustrative toy models to actual MEG data) should be clearer.
(4) Figure 4A: Why change from "% explained variance" for the example data in Figure 2C to arbitrary units at this point?
This has now been explicitly stated in the methods (lines 1033-1036).
(5) Page 15: "This means either the results were biased by a low pass filter, or had a maximum measurable...": If the authors mean that the low-pass filter is due to spatial blurring of neural activity in the EEG signal, it would be helpful to state that more directly at this point.
Now stated directly, lines 567-568.
(6) Page 23: "...where |X| is the complex magnitude of X...": The modulus operation is defined on a complex number, yet here is applied to a vector of complex numbers. If the operation is elementwise, it should be defined explicitly.
‘Elementwise’ is now stated explicitly (line 1020).
Reviewer #3 (Recommendations for the authors):
In the submitted manuscript, the authors propose a method to estimate spatial (phase) spectra from irregularly sampled oscillatory cortical activity. They apply the method to intracranial (iEEG) data and argue that cortical activity is organized into global waves up to the size of the entire cortex. If true, this finding is certainly of interest, and I can imagine that it has profound implications for how we think about the functional organization of cortical activity.
We have added a section to the discussion outlining the most radical of these implications: what does it mean to do source localization when non-local signals dominate? Lines 670-681.
The manuscript is well-written, with comprehensive introduction and discussion sections, detailed descriptions of the results, and clear figures. However, the proposed method comprised several ad hoc elements and is not well-founded mathematically, its performance is not adequately assessed, and its limitations are not sufficiently discussed. As such, the study failed to convince (me) of the correctness of the main conclusions.
We now have a direct surrogate testing of the method. We have also improved the mathematical explanation to show that the link between Fourier analysis and SVD is not ad hoc, but well understood in both literatures. We had addressed explicitly in the text all of the limitations raised by the reviewers.
Major comments
(1) The main methodological contribution of the study is summarized in the introduction section:
"The irregular sampling of cortical spatial coordinates via stereotactic EEG was partly overcome by the resampling of the phase data into triplets corresponding to the vertices of approximately equilateral triangles within the cortical sheet."
There exist well-established Fourier methods for handling irregularly sampled data so it is unclear why the authors did not resort to these and instead proposed a rather ad hoc method without theoretical justification (see next comment).
We have re-reviewed the literature on non-uniform Fourier analysis. We now briefly review the Fourier methods for handling irregularly sampled data (lines 155-162) and conclude that none of the existing methods can deal with the degree of irregularity, and especially sparsity, found for the grey-matter sEEG contacts.
(2) In the Appendix, the authors write:
"For appropriate signals, i.e., those with power that decreases monotonically with frequency, each of the first few singular vectors, v_k, is an approximate complex sinusoid with wavenumber equal to k."
I don't think this is true in general and if it is, there must be a formal argument that proves it. Furthermore, is it also true for irregularly sampled data? And in more than one spatial dimension? Moreover, it is also unclear exactly how the spatial Fourier spectrum is estimated from the SVD.
In response to these reviewer queries, we now spend considerably more time in the conceptual set-up of the manuscript, giving examples of where SVD can be used to estimate the Fourier spectrum. We have now unpacked the word ‘appropriate’ and we are now more exact in our phrasing. This is laid out in lines 843-850 of the manuscript. In addition, the methods now describe the mathematical links between Fourier analysis and SVD (lines 851861 and 910-922).
The authors write:
"The spatial frequency spectrum can therefore be estimated using SVD by summing over the singular values assigned to each set of singular vectors with unique (or by binning over a limited range of) spatial frequencies. This procedure is illustrated in Figure 1A-C."
First, the singular vectors are ordered to decreasing values of the corresponding singular values. Hence, if the singular values are used to estimate spectral power, the estimated spectrum will necessarily decrease with increasing spatial frequency (as can be seen in Figure 2C). Then how can traveling waves be detected by looking for local maxima of the estimated power spectra?
TWs are not detected by looking for local maxima in the spectra. Our work has focussed on the global wave maps derived from the SVD of phase (i.e., k=1-3), which also explain most of the variance in phase. This is now mentioned in the caption to Figure 3 (lines 291-294).
Second, how are spatial frequencies assigned to the different singular vectors? The proposed method for estimating spatial power spectra from irregularly sampled data seems rather ad hoc and it is not at all clear if, and under what conditions, it works and how accurate it is.
The new version of the manuscript uses a combination of the method previously presented (the multi-scale differencing) and the method previously outlined in the supplementary materials (doing complex-valued SVD on the spatial vectors of phase). We hope that along with the additional expository material in the methods the new version is clearer and seems less ad hoc to the reviewer. Certainly, there are deep and well-understood links between Fourier analysis and SVD, and we hope we have brought these into focus now.
(3) The authors define spatial power spectra in three-dimensional Euclidean space, whereas the actual cortical activity occurs on a two-dimensional sheet (the union of two topological 2spheres). As such, it is not at all clear how the estimated wavelengths in three-dimensional space relate to the actual wavelengths of the cortical activity.
We define spatial power spectra on the folded cortical sheet, rather than Cartesian coordinates. We use geodesic distances in all cases where a distance measurement is required. We have included two new figures (Figure 5 and Supplementary Figure1) showing the mapping of the triangles onto the cortical sheet, which should bring this point home.
(4) The authors' analysis of the iEEG data is subject to a caveat that is not mentioned in the manuscript: As a reference for the local field potentials, the average white-matter signal was used and this can lead to artifactual power at low spatial frequencies. This is because fluctuations in the reference signal are visible as standing waves in the recording array. This might also explain the observation that
"A surprising finding was that the shape of the spatial frequency spectrum did not vary much with temporal frequency."
because fluctuations in the reference signal are expected to have power at all temporal frequencies (1/f spectrum). When superposed with local activity at the recording electrodes, this leads to spurious power at low spatial frequencies. Can the authors exclude this interpretation of the results?
The new version of the manuscript deals explicitly with this potential confound (lines 454467). First, the artefactual global synchrony due to the reference signal (the DC component in our spatial frequency spectra of phase) is at a distinct frequency from the lowest SF of interest here. The lowest spatial frequency is a function of the maximum spatial range of the recording array and not overlapping in our method with the DC component, despite the loss of SF resolution due to the noise of the spatial irregularity of the recording array. This can be seen from consideration of the SF tuning (Figure 4) for the MEG wave maps shown in Figure 3, and the spectra generated for sparse MEG arrays in Supplementary Figure 5. Additionally, this question led us to a series of surrogate tests which are now included in the manuscript. We used MEG to test for the effects of average reference, since in this modality the reference free case is available. The results show that even after imposing a strong and artefactual global synchrony, the method is highly robust to inflation of the DC component, which either way does not strongly influence the SF estimates in the range of interest (4c/m to 12c/m for the case of MEG).
(5) Related to the previous comment: Contrary to the authors' claims, local field potentials are susceptible to volume conduction, particularly when average references are used (see e.g. https://www.cell.com/neuron/fulltext/S0896-6273(11)00883-X)
Methods exist to mitigate these effects (e.g. taking first- or second-order spatial differences of the signals). I think this issue deserves to be discussed.
We have reviewed this research and do not find it to be a problem. The authors cited by the reviewer were concerned with unacknowledged volume conduction up to 1 cm for LFP. The maximum spatial frequency we report here is 50c/m, or equivalent to 2cm. While the intercontact distance on the sEEG electrodes was 0.5cm, in practice the smallest equilateral triangles (i.e., between two electrodes) to be found in the grey matter was around 2cm linear size. We make no statements about SF in the 1cm range. We do now cite this paper and mention this short-range volume conduction (lines 602-605). The method of taking derivatives has the same problems as source localization methods. They remove both artefactual correlations (volume conduction) and real correlations (the low SF interactions of interest here). We mention this now at lines 667-669. In addition, our method to remove negative SF components from the LSVs ameliorates the effects of average referencing. There are now more details in the Methods about this step (lines 924-947), as well as a new supplementary figure illustrating its effects on signal with a known SF spectrum (MEG, supplementary Figure 6).
(6) Could the authors add an analysis that excludes the possibility that the observed local maxima in the spectra are a necessary consequence of the analysis method, rather than reflecting true maxima in the spectra? A (possibly) similar effect can be observed in ordinary Fourier spectra that are estimated from zero-mean signals: Because the signals have zero mean, the power spectrum at frequency zero is close to zero and this leads to an artificial local maximum at low frequencies.
We acknowledge the reviewer’s mathematical point. We do not agree that it could be an issue, though it is important to rule it out definitively. First, removing the DC component will only produce an artefactual low SF peak if the power at low SF is high. This may occur in the reviewer’s example only because temporal frequency has a ~1/f spectrum. If the true spectrum is flat, or increasing in power with f, no such artificial low SF will be produced (see Supplementary Figure 5G). Additionally,
(1) The DC component is well separated from the low SF components in our method;
(2) We now include several surrogate methods which show that our method finds the correct spectral distribution and is not just finding a maximum at low SFs due to the suggested effect (subtraction of the DC component). Analysis of separated wave maps in MEG (Figures 3 & 4) shows the expected peaks in SF, increasing in peak SF for each family of maps when wavenumber increases (roughly three k=1 maps, three k=2 etc.). A specific surrogate test for this query was also undertaken by creating a reverse SF spectrum in MEG phase data, in which the spectrum goes linearly with f over the SF range of interest, rather than the usual 1/f. Our method correctly finds the former spectrum (Supplementary Figure 5). Additionally, we tested for the effects of introducing the average reference and the effects of our method to remove the DC component of the phase SF spectrum (Supplementary Figure 6). We can definitively rule out the reviewer’s concern.
A related issue (perhaps) is the observation that the location of the maximum (i.e. the peak spatial frequency of cortical activity) depends on array size: If cortical activity indeed has a characteristic wavelength (in the sense of its spectrum having a local maximum) would one not expect it to be independent of array size?
This is only true when making estimates for relatively clean sinusoidal signals, and not from broad-band signals. Fourier analysis and our related SVD methods are very much dependent on maximum array size used to measure cortical signals. This is why the first frequency band (after the DC component) in Fourier analysis is always at a frequency equivalent to 1/array_size, even if the signal is known to contain lower frequency components. We now include a further illustration of this in Figure 3, a more detailed exposition of this point in the methods, and in Supplementary Figure 11 we provide a more detailed example of the relation between Fourier analysis and SVD when grids with two distinct scales are used.
In short, it is not possible, mathematically, to measure wavelengths greater than the array size in broad-band data. This is now stated explicitly in the manuscript (lines 143-144). A common approach in Neuroscience research is to first do narrowband filtering, then use a method that can accurately estimate ‘instantaneous’ phase change, such as the Hilbert transform. This is not possible for highly irregular sEEG arrays.
(7) The proposed method of estimating wavelength from irregularly sampled threedimensional iEEG data involves several steps (phase-extraction, singular value decomposition, triangle definition, dimension reduction, etc.) and it is not at all clear that the concatenation of all these steps actually yields accurate estimates.
Did the authors use more realistic simulations of cortical activity (i.e. on the convoluted cortical sheet) to verify that the method indeed yields accurate estimates of phase spectra?
We now included detailed surrogate testing, in which varying combinations of sEEG phase data and veridical surrogate wavelengths are added together.
See our reply from the public reviewer comments. We assess that real neurophysiological data (here, sEEG plus surrogate and MEG manipulated in various ways) is a more accurate way to address these issues. In our experience, large scale TWs appear spontaneously in realistic cortical simulations, and we now cite the relevant papers in the manuscript (line 53).
Minor comments
(1) Perhaps move the first paragraph of the results section to the Introduction (it does not describe any results).
So moved.
(2) The authors write:
"The stereotactic EEG contacts in the grey matter were re-referenced using the average of low-amplitude white matter contacts"
Does this mean that the average is taken over a subset of white-matter contacts (namely those with low amplitude)? Or do the authors refer to all white-matter contacts as "low-amplitude"? And had contacts at different needles different references? Or where the contacts from all needles pooled?
A subset of white-matter contacts was used for re-referencing, namely those 50% with lowest amplitude signals. This subset was used to construct a pooled, single, average reference. We have rephrased the sentences referring to this procedure to improve clarity (line 202 and 743745).
When both vectors are normalized, the arc cosine (cos−1) of their dot product reveals the angle θ between them: θ=cos−1(A⋅B||A||||B||) or θ=cos−1(A^⋅B^), where cos−1 denotes the inverse cosine function, commonly represented as acos() in programming languages.
Chat with Gemini:<br /> Lee:
Here's another block of text in that same lesson. Can you help me visualize what it means?
When both vectors are normalized, the arc cosine (cos⁻¹) of their dot product reveals the angle θ between them: θ=cos⁻¹((A⋅B)/(∥A∥ ∥B∥)) or cos⁻¹(Â⋅B̂), where cos⁻¹ denotes the inverse cosine function, commonly represented as acos() in programming languages.
Gemini:<br /> This block of text is explaining how to "reverse-engineer" an angle using the dot product. In 3D graphics, you often know the coordinates of two objects (like a player and an enemy), but you don't know the angle between them. This formula is how you find it.
Think of the dot product formula we just discussed:
A⋅B = ∥A∥∥B∥cos(θ)
The text is simply rearranging that equation to solve for .
A⋅B
cos(θ) = ------
∥A∥∥B∥/ A⋅B \
θ = arccos( ------ )
\ ∥A∥∥B∥ /The text mentions: θ=cos(Â⋅B̂). (The "hat" symbol  means it is a normalized unit vector).
This is the "pro-gamer move" in graphics programming. If you normalize both vectors first (meaning you force their lengths to be 1), then ∥A∥ and ∥B∥ both become 1. The denominator in our formula disappears!
acos(). Imagine you are coding a stealth game. You have a Guard and a Player.
If you normalize both vectors and calculate (A⋅B), you get the exact angle (e.g., 30°). If the Guard's peripheral vision is only 45°, you now know the Guard can see the player!
When you use acos() in languages like C#, C++, or Python, the result is usually in radians, not degrees.
Lee:
You said
If you normalize both vectors and calculate $acos(A⋅B), you get the exact angle (e.g., 30°). If the Guard's peripheral vision is only 45°, you now know the Guard can see the player!By "only 45°", is that from left to right of the guard's visibility? So, from straight ahead to the far right of his vision would only be 22.5°, thus the player is not visible at a 30° again from the guard? Or is that 45° from straight ahead to the far right of the guard's vision (for a total viewable angle of 90°)?
Gemini:<br /> That is a fantastic catch. In game development and 3D graphics, this distinction is a common source of bugs!
When you use the dot product to check visibility, the angle θ you calculate is the offset from the center.
The dot product measures the angle between two specific lines: where the guard is looking (the "forward vector") and where the player is. It doesn't know about "left" or "right"; it only knows "how far away from my nose is this object?"
In your specific scenario:
To avoid doing the math every single frame, programmers usually define the guard's "View Cone" as a threshold value.
If the guard can see 45° to the left and 45° to the right (a 90° total FOV), the threshold is:<br />
cos(45°) ≈ 0.707
The code then looks like this:
```csharp // If dot product is greater than 0.707, the player is within the 90-degree cone if (DotProduct(GuardForward, DirectionToPlayer) > 0.707) { // I see you! }
```
One interesting thing to visualize: because the dot product only cares about the angle between two vectors, the "visibility" it creates is actually a cone, not a flat triangle.
If you say "anything within 30° of my forward vector is visible," that includes 30° up, 30° down, 30° left, and 30° right. It creates a circular spotlight of vision.
| Total FOV | Angle from Center | Dot Product Threshold (Approx) |
| ------------------ | ----------------- | ------------------------------ |
| 180° (Flat wall) | 90° | 0.0 |
| 90° (Standard) | 45° | 0.707 |
| 60° (Narrow) | 30° | 0.866 |
| 2° (Sniper Scope)| 1° | 0.999 |
pre-commit hooks are fundamentally broken
--no-verify usage.collects rent on code it didn’t write,
Rent
which allow to seamlessly combine pure text, LaTeX, R code and its output in a variety of formats
The above should instead be "which allow the seamless combination of pure text, LaTeX, R code..." or "which allow one to seamlessly combine pure text, LaTeX, R code...."
Java source code
.java file
How uv got so fast
No .egg support. Eggs were the pre-wheel binary format. pip still handles them; uv doesn’t even try. The format has been obsolete for over a decade. No pip.conf. uv ignores pip’s configuration files entirely. No parsing, no environment variable lookups, no inheritance from system-wide and per-user locations. No bytecode compilation by default. pip compiles .py files to .pyc during installation. uv skips this step, shaving time off every install. You can opt in if you want it. Virtual environments required. pip lets you install into system Python by default. uv inverts this, refusing to touch system Python without explicit flags. This removes a whole category of permission checks and safety code. Stricter spec enforcement. pip accepts malformed packages that technically violate packaging specs. uv rejects them. Less tolerance means less fallback logic. Ignoring requires-python upper bounds. When a package says it requires python<4.0, uv ignores the upper bound and only checks the lower. This reduces resolver backtracking dramatically since upper bounds are almost always wrong. Packages declare python<4.0 because they haven’t tested on Python 4, not because they’ll actually break. The constraint is defensive, not predictive. First-index wins by default. When multiple package indexes are configured, pip checks all of them. uv picks from the first index that has the package, stopping there. This prevents dependency confusion attacks and avoids extra network requests. Each of these is a code path pip has to execute and uv doesn’t.
UV does not support egg files or legacy pip.conf and it doesn't check for upper bounds on dependencies or compile py files to pyc bytecode by default. This removes a number of codepaths and allows the tool to run faster.
event
Visual Studio Code n'accepte pas "event" mais accepte "Event" (en tout cas sur mon pc c'est comme ça).
Android Studio is the official IDE for Android app dev. There is a MacOS version.
#openvraag is this usable to code up a personal app for mobile?
сбора, обработки, хранения и развития
Похоже на этапы CODE у Тьяго Форте и этапов GTD Дэвида Аллена.
Open Source & Privacy-FirstThe source code of VoiceInk is available on GitHub
VoiceInk is open source, and on Github
You need three things. A Mac with Xcode, which is free to download. A $99 per year Apple Developer account. And an AI tool that can write code based on your descriptions.
Three elements for making his iphone apps Xcode (which I use) Apple Developer account (99USD / yr) AI support in coding (he uses Claude Code, vgl [[Mijn vibe coding set-up 20251220143401]]
Document your impact, not your output. Frame your work in terms of problems solved, not lines of code written.
De technologie van ThetaOS en de code zijn op zich niet heel complex. Maar wat telt is het inzicht dat ik ermee kan vergaren en ontsluiten. Je hebt al informatie over je leven. Die informatie zit verspreid over tientallen apps die niet met elkaar praten: vele kopieën van dezelfde naam, in WhatsApp, mail, agenda's of banktransacties. Net als adressen, locaties, namen van organisaties of projecten en ga zo maar door.
The tech is straigthforward: sqlite, node.js and html/css. The value is the combination of different sources into personal tool.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
Zhou and colleagues developed a computational model of replay that heavily builds on cognitive models of memory in context (e.g., the context-maintenance and retrieval model), which have been successfully used to explain memory phenomena in the past. Their model produces results that mirror previous empirical findings in rodents and offers a new computational framework for thinking about replay.
Strengths:
The model is compelling and seems to explain a number of findings from the rodent literature. It is commendable that the authors implement commonly used algorithms from wakefulness to model sleep/rest, thereby linking wake and sleep phenomena in a parsimonious way. Additionally, the manuscript's comprehensive perspective on replay, bridging humans and non-human animals, enhanced its theoretical contribution.
Weaknesses:
This reviewer is not a computational neuroscientist by training, so some comments may stem from misunderstandings. I hope the authors would see those instances as opportunities to clarify their findings for broader audiences.
(1) The model predicts that temporally close items will be co-reactivated, yet evidence from humans suggests that temporal context doesn't guide sleep benefits (instead, semantic connections seem to be of more importance; Liu and Ranganath 2021, Schechtman et al 2023). Could these findings be reconciled with the model or is this a limitation of the current framework?
We appreciate the encouragement to discuss this connection. Our framework can accommodate semantic associations as determinants of sleep-dependent consolidation, which can in principle outweigh temporal associations. Indeed, prior models in this lineage have extensively simulated how semantic associations support encoding and retrieval alongside temporal associations. It would therefore be straightforward to extend our model to simulate how semantic associations guide sleep benefits, and to compare their contribution against that conferred by temporal associations across different experimental paradigms. In the revised manuscript, we have added a discussion of how our framework may simulate the role of semantic associations in sleep-dependent consolidation.
“Several recent studies have argued for dominance of semantic associations over temporal associations in the process of human sleep-dependent consolidation (Schechtman et al., 2023; Liu and Ranganath 2021; Sherman et al., 2025), with one study observing no role at all for temporal associations (Schechtman et al., 2023). At first glance, these findings appear in tension with our model, where temporal associations drive offline consolidation. Indeed, prior models have accounted for these findings by suppressing temporal context during sleep (Liu and Ranganath 2024; Sherman et al., 2025). However, earlier models in the CMR lineage have successfully captured the joint contributions of semantic and temporal associations to encoding and retrieval (Polyn et al., 2009), and these processes could extend naturally to offline replay. In a paradigm where semantic associations are especially salient during awake learning, the model could weight these associations more and account for greater co-reactivation and sleep-dependent memory benefits for semantically related than temporally related items. Consistent with this idea, Schechtman et al. (2023) speculated that their null temporal effects likely reflected the task’s emphasis on semantic associations. When temporal associations are more salient and task-relevant, sleep-related benefits for temporally contiguous items are more likely to emerge (e.g., Drosopoulos et al., 2007; King et al., 2017).”
The reviewer’s comment points to fruitful directions for future work that could employ our framework to dissect the relative contributions of semantic and temporal associations to memory consolidation.
(2) During replay, the model is set so that the next reactivated item is sampled without replacement (i.e., the model cannot get "stuck" on a single item). I'm not sure what the biological backing behind this is and why the brain can't reactivate the same item consistently.
Furthermore, I'm afraid that such a rule may artificially generate sequential reactivation of items regardless of wake training. Could the authors explain this better or show that this isn't the case?
We appreciate the opportunity to clarify this aspect of the model. We first note that this mechanism has long been a fundamental component of this class of models (Howard & Kahana 2002). Many classic memory models (Brown et al., 2000; Burgess & Hitch, 1991; Lewandowsky & Murdock 1989) incorporate response suppression, in which activated items are temporarily inhibited. The simplest implementation, which we use here, removes activated items from the pool of candidate items. Alternative implementations achieve this through transient inhibition, often conceptualized as neuronal fatigue (Burgess & Hitch, 1991; Grossberg 1978). Our model adopts a similar perspective, interpreting this mechanism as mimicking a brief refractory period that renders reactivated neurons unlikely to fire again within a short physiological event such as a sharp-wave ripple. Importantly, this approach does not generate spurious sequences. Instead, the model’s ability to preserve the structure of wake experience during replay depends entirely on the learned associations between items (without these associations, item order would be random). Similar assumptions are also common in models of replay. For example, reinforcement learning models of replay incorporate mechanisms such as inhibition to prevent repeated reactivations (e.g., Diekmann & Cheng, 2023) or prioritize reactivation based on ranking to limit items to a single replay (e.g., Mattar & Daw, 2018). We now discuss these points in the section titled “A context model of memory replay”
“This mechanism of sampling without replacement, akin to response suppression in established context memory models (Howard & Kahana 2002), could be implemented by neuronal fatigue or refractory dynamics (Burgess & Hitch, 1991; Grossberg 1978). Non-repetition during reactivation is also a common assumption in replay models that regulate reactivation through inhibition or prioritization (Diekmann & Cheng 2023; Mattar & Daw 2018; Singh et al., 2022).”
(3) If I understand correctly, there are two ways in which novelty (i.e., less exposure) is accounted for in the model. The first and more talked about is the suppression mechanism (lines 639-646). The second is a change in learning rates (lines 593-595). It's unclear to me why both procedures are needed, how they differ, and whether these are two different mechanisms that the model implements. Also, since the authors controlled the extent to which each item was experienced during wakefulness, it's not entirely clear to me which of the simulations manipulated novelty on an individual item level, as described in lines 593-595 (if any).
We agree that these mechanisms and their relationships would benefit from clarification. As noted, novelty influences learning through two distinct mechanisms. First, the suppression mechanism is essential for capturing the inverse relationship between the amount of wake experience and the frequency of replay, as observed in several studies. This mechanism ensures that items with high wake activity are less likely to dominate replay. Second, the decrease in learning rates with repetition is crucial for preserving the stochasticity of replay. Without this mechanism, the model would increase weights linearly, leading to an exponential increase in the probability of successive wake items being reactivated back-to-back due to the use of a softmax choice rule. This would result in deterministic replay patterns, which are inconsistent with experimental observations.
We have revised the Methods section to explicitly distinguish these two mechanisms:
“This experience-dependent suppression mechanism is distinct from the reduction of learning rates through repetition; it does not modulate the update of memory associations but exclusively governs which items are most likely to initiate replay.”
We have also clarified our rationale for including a learning rate reduction mechanism:
“The reduction in learning rates with repetition is important for maintaining a degree of stochasticity in the model’s replay during task repetition, since linearly increasing weights would, through the softmax choice rule, exponentially amplify differences in item reactivation probabilities, sharply reducing variability in replay.”
Finally, we now specify exactly where the learning-rate reduction applied, namely in simulations where sequences are repeated across multiple sessions:
“In this simulation, the learning rates progressively decrease across sessions, as described above.“
As to the first mechanism - experience-based suppression - I find it challenging to think of a biological mechanism that would achieve this and is selectively activated immediately before sleep (somehow anticipating its onset). In fact, the prominent synaptic homeostasis hypothesis suggests that such suppression, at least on a synaptic level, is exactly what sleep itself does (i.e., prune or weaken synapses that were enhanced due to learning during the day). This begs the question of whether certain sleep stages (or ultradian cycles) may be involved in pruning, whereas others leverage its results for reactivation (e.g., a sequential hypothesis; Rasch & Born, 2013). That could be a compelling synthesis of this literature. Regardless of whether the authors agree, I believe that this point is a major caveat to the current model. It is addressed in the discussion, but perhaps it would be beneficial to explicitly state to what extent the results rely on the assumption of a pre-sleep suppression mechanism.
We appreciate the reviewer raising this important point. Unlike the mechanism proposed by the synaptic homeostasis hypothesis, the suppression mechanism in our model does not suppress items based on synapse strength, nor does it modify synaptic weights. Instead, it determines the level of suppression for each item based on activity during awake experience. The brain could implement such a mechanism by tagging each item according to its activity level during wakefulness. During subsequent consolidation, the initial reactivation of an item during replay would reflect this tag, influencing how easily it can be reactivated.
A related hypothesis has been proposed in recent work, suggesting that replay avoids recently active trajectories due to spike frequency adaptation in neurons (Mallory et al., 2024). Similarly, the suppression mechanism in our model is critical for explaining the observed negative relationship between the amount of recent wake experience and the degree of replay.
We discuss the biological plausibility of this mechanism and its relationship with existing models in the Introduction. In the section titled “The influence of experience”, we have added the following:
“Our model implements an activity‑dependent suppression mechanism that, at the onset of each offline replay event, assigns each item a selection probability inversely proportional to its activation during preceding wakefulness. The brain could implement this by tagging each memory trace in proportion to its recent activation; during consolidation, that tag would then regulate starting replay probability, making highly active items less likely to be reactivated. A recent paper found that replay avoids recently traversed trajectories through awake spike‑frequency adaptation (Mallory et al., 2025), which could implement this kind of mechanism. In our simulations, this suppression is essential for capturing the inverse relationship between replay frequency and prior experience. Note that, unlike the synaptic homeostasis hypothesis (Tononi & Cirelli 2006), which proposes that the brain globally downscales synaptic weights during sleep, this mechanism leaves synaptic weights unchanged and instead biases the selection process during replay.”
(4) As the manuscript mentions, the only difference between sleep and wake in the model is the initial conditions (a0). This is an obvious simplification, especially given the last author's recent models discussing the very different roles of REM vs NREM. Could the authors suggest how different sleep stages may relate to the model or how it could be developed to interact with other successful models such as the ones the last author has developed (e.g., C-HORSE)?
We appreciate the encouragement to comment on the roles of different sleep stages in the manuscript, especially since, as noted, the lab is very interested in this and has explored it in other work. We chose to focus on NREM in this work because the vast majority of electrophysiological studies of sleep replay have identified these events during NREM. In addition, our lab’s theory of the role of REM (Singh et al., 2022, PNAS) is that it is a time for the neocortex to replay remote memories, in complement to the more recent memories replayed during NREM. The experiments we simulate all involve recent memories. Indeed, our view is that part of the reason that there is so little data on REM replay may be that experimenters are almost always looking for traces of recent memories (for good practical and technical reasons).
Regarding the simplicity of the distinction between simulated wake and sleep replay, we view it as an asset of the model that it can account for many of the different characteristics of awake and NREM replay with very simple assumptions about differences in the initial conditions. There are of course many other differences between the states that could be relevant to the impact of replay, but the current target empirical data did not necessitate us taking those into account. This allows us to argue that differences in initial conditions should play a substantial role in an account of the differences between wake and sleep replay.
We have added discussion of these ideas and how they might be incorporated into future versions of the model in the Discussion section:
“Our current simulations have focused on NREM, since the vast majority of electrophysiological studies of sleep replay have identified replay events in this stage. We have proposed in other work that replay during REM sleep may provide a complementary role to NREM sleep, allowing neocortical areas to reinstate remote, already-consolidated memories that need to be integrated with the memories that were recently encoded in the hippocampus and replayed during NREM (Singh et al., 2022). An extension of our model could undertake this kind of continual learning setup, where the student but not teacher network retains remote memories, and the driver of replay alternates between hippocampus (NREM) and cortex (REM) over the course of a night of simulated sleep. Other differences between stages of sleep and between sleep and wake states are likely to become important for a full account of how replay impacts memory. Our current model parsimoniously explains a range of differences between awake and sleep replay by assuming simple differences in initial conditions, but we expect many more characteristics of these states (e.g., neural activity levels, oscillatory profiles, neurotransmitter levels, etc.) will be useful to incorporate in the future.”
Finally, I wonder how the model would explain findings (including the authors') showing a preference for reactivation of weaker memories. The literature seems to suggest that it isn't just a matter of novelty or exposure, but encoding strength. Can the model explain this? Or would it require additional assumptions or some mechanism for selective endogenous reactivation during sleep and rest?
We appreciate the encouragement to discuss this, as we do think the model could explain findings showing a preference for reactivation of weaker memories, as in Schapiro et al. (2018). In our framework, memory strength is reflected in the magnitude of each memory’s associated synaptic weights, so that stronger memories yield higher retrieved‑context activity during wake encoding than weaker ones. Because the model’s suppression mechanism reduces an item’s replay probability in proportion to its retrieved‑context activity, items with larger weights (strong memories) are more heavily suppressed at the onset of replay, while those with smaller weights (weaker memories) receive less suppression. When items have matched reward exposure, this dynamic would bias offline replay toward weaker memories, therefore preferentially reactivating weak memories.
In the section titled “The influence of experience”, we updated a sentence to discuss this idea more explicitly:
“Such a suppression mechanism may be adaptive, allowing replay to benefit not only the most recently or strongly encoded items but also to provide opportunities for the consolidation of weaker or older memories, consistent with empirical evidence (e.g., Schapiro et al. 2018; Yu et al., 2024).”
(5) Lines 186-200 - Perhaps I'm misunderstanding, but wouldn't it be trivial that an external cue at the end-item of Figure 7a would result in backward replay, simply because there is no potential for forward replay for sequences starting at the last item (there simply aren't any subsequent items)? The opposite is true, of course, for the first-item replay, which can't go backward. More generally, my understanding of the literature on forward vs backward replay is that neither is linked to the rodent's location. Both commonly happen at a resting station that is further away from the track. It seems as though the model's result may not hold if replay occurs away from the track (i.e. if a0 would be equal for both pre- and post-run).
In studies where animals run back and forth on a linear track, replay events are decoded separately for left and right runs, identifying both forward and reverse sequences for each direction, for example using direction-specific place cell sequence templates. Accordingly, in our simulation of, e.g., Ambrose et al. (2016), we use two independent sequences, one for left runs and one for right runs (an approach that has been taken in prior replay modeling work). Crucially, our model assumes a context reset between running episodes, preventing the final item of one traversal from acquiring contextual associations with the first item of the next. As a result, learning in the two sequences remains independent, and when an external cue is presented at the track’s end, replay predominantly unfolds in the backward direction, only occasionally producing forward segments when the cue briefly reactivates an earlier sequence item before proceeding forward.
We added a note to the section titled “The context-dependency of memory replay” to clarify this:
“In our model, these patterns are identical to those in our simulation of Ambrose et al. (2016), which uses two independent sequences to mimic the two run directions. This is because the drifting context resets before each run sequence is encoded, with the pause between runs acting as an event boundary that prevents the final item of one traversal from associating with the first item of the next, thereby keeping learning in each direction independent.”
To our knowledge, no study has observed a similar asymmetry when animals are fully removed from the track, although both types of replay can be observed when animals are away from the track. For example, Gupta et al. (2010) demonstrated that when animals replay trajectories far from their current location, the ratio of forward vs. backward replay appears more balanced. We now highlight this result in the manuscript and explain how it aligns with the predictions of our model:
“For example, in tasks where the goal is positioned in the middle of an arm rather than at its end, CMR-replay predicts a more balanced ratio of forward and reverse replay, whereas the EVB model still predicts a dominance of reverse replay due to backward gain propagation from the reward. This contrast aligns with empirical findings showing that when the goal is located in the middle of an arm, replay events are more evenly split between forward and reverse directions (Gupta et al., 2010), whereas placing the goal at the end of a track produces a stronger bias toward reverse replay (Diba & Buzsaki 2007).”
Although no studies, to our knowledge, have observed a context-dependent asymmetry between forward and backward replay when the animal is away from the track, our model does posit conditions under which it could. Specifically, it predicts that deliberation on a specific memory, such as during planning, could generate an internal context input that biases replay: actively recalling the first item of a sequence may favor forward replay, while thinking about the last item may promote backward replay, even when the individual is physically distant from the track.
We now discuss this prediction in the section titled “The context-dependency of memory replay”:
“Our model also predicts that deliberation on a specific memory, such as during planning, could serve to elicit an internal context cue that biases replay: actively recalling the first item of a sequence may favor forward replay, while thinking about the last item may promote backward replay, even when the individual is physically distant from the track. While not explored here, this mechanism presents a potential avenue for future modeling and empirical work.”
(6) The manuscript describes a study by Bendor & Wilson (2012) and tightly mimics their results. However, notably, that study did not find triggered replay immediately following sound presentation, but rather a general bias toward reactivation of the cued sequence over longer stretches of time. In other words, it seems that the model's results don't fully mirror the empirical results. One idea that came to mind is that perhaps it is the R/L context - not the first R/L item - that is cued in this study. This is in line with other TMR studies showing what may be seen as contextual reactivation. If the authors think that such a simulation may better mirror the empirical results, I encourage them to try. If not, however, this limitation should be discussed.
Although our model predicts that replay is triggered immediately by the sound cue, it also predicts a sustained bias toward the cued sequence. Replay in our model unfolds across the rest phase as multiple successive events, so the bias observed in our sleep simulations indeed reflects a prolonged preference for the cued sequence.
We now discuss this issue, acknowledging the discrepancy:
“Bendor and Wilson (2012) found that sound cues during sleep did not trigger immediate replay, but instead biased reactivation toward the cued sequence over an extended period of time. While the model does exhibit some replay triggered immediately by the cue, it also captures the sustained bias toward the cued sequence over an extended period.”
Second, within this framework, context is modeled as a weighted average of the features associated with items. As a result, cueing the model with the first R/L item produces qualitatively similar outcomes as cueing it with a more extended R/L cue that incorporates features of additional items. This is because both approaches ultimately use context features unique to the two sides.
(7) There is some discussion about replay's benefit to memory. One point of interest could be whether this benefit changes between wake and sleep. Relatedly, it would be interesting to see whether the proportion of forward replay, backward replay, or both correlated with memory benefits. I encourage the authors to extend the section on the function of replay and explore these questions.
We thank the reviewer for this suggestion. Regarding differences in the contribution of wake and sleep to memory, our current simulations predict that compared to rest in the task environment, sleep is less biased toward initiating replay at specific items, leading to a more uniform benefit across all memories. Regarding the contributions of forward and backward replay, our model predicts that both strengthen bidirectional associations between items and contexts, benefiting memory in qualitatively similar ways. Furthermore, we suggest that the offline learning captured by our teacher-student simulations reflects consolidation processes that are specific to sleep.
We have expanded the section titled “The influence of experience” to discuss these predictions of the model:
“The results outlined above arise from the model's assumption that replay strengthens bidirectional associations between items and contexts to benefit memory. This assumption leads to several predictions about differences across replay types. First, the model predicts that sleep yields different memory benefits compared to rest in the task environment: Sleep is less biased toward initiating replay at specific items, resulting in a more uniform benefit across all memories. Second, the model predicts that forward and backward replay contribute to memory in qualitatively similar ways but tend to benefit different memories. This divergence arises because forward and backward replay exhibit distinct item preferences, with backward replay being more likely to include rewarded items, thereby preferentially benefiting those memories.”
We also updated the “The function of replay” section to include our teacher-student speculation:
“We speculate that the offline learning observed in these simulations corresponds to consolidation processes that operate specifically during sleep, when hippocampal-neocortical dynamics are especially tightly coupled (Klinzing et al., 2019).”
(8) Replay has been mostly studied in rodents, with few exceptions, whereas CMR and similar models have mostly been used in humans. Although replay is considered a good model of episodic memory, it is still limited due to limited findings of sequential replay in humans and its reliance on very structured and inherently autocorrelated items (i.e., place fields). I'm wondering if the authors could speak to the implications of those limitations on the generalizability of their model. Relatedly, I wonder if the model could or does lead to generalization to some extent in a way that would align with the complementary learning systems framework.
We appreciate these insightful comments. Traditionally, replay studies have focused on spatial tasks with autocorrelated item representations (e.g., place fields). However, an increasing number of human studies have demonstrated sequential replay using stimuli with distinct, unrelated representations. Our model is designed to accommodate both scenarios. In our current simulations, we employ orthogonal item representations while leveraging a shared, temporally autocorrelated context to link successive items. We anticipate that incorporating autocorrelated item representations would further enhance sequence memory by increasing the similarity between successive contexts. Overall, we believe that the model generalizes across a broad range of experimental settings, regardless of the degree of autocorrelation between items. Moreover, the underlying framework has been successfully applied to explain sequential memory in both spatial domains, explaining place cell firing properties (e.g., Howard et al., 2004), and in non-spatial domains, such as free recall experiments where items are arbitrarily related.
In the section titled “A context model of memory replay”, we added this comment to address this point:
“Its contiguity bias stems from its use of shared, temporally autocorrelated context to link successive items, despite the orthogonal nature of individual item representations. This bias would be even stronger if items had overlapping representations, as observed in place fields.”
Since CMR-replay learns distributed context representations where overlap across context vectors captures associative structure, and replay helps strengthen that overlap, this could indeed be viewed as consonant with complementary learning systems integration processes.
Reviewer #2 (Public Review):
This manuscript proposes a model of replay that focuses on the relation between an item and its context, without considering the value of the item. The model simulates awake learning, awake replay, and sleep replay, and demonstrates parallels between memory phenomenon driven by encoding strength, replay of sequence learning, and activation of nearest neighbor to infer causality. There is some discussion of the importance of suppression/inhibition to reduce activation of only dominant memories to be replayed, potentially boosting memories that are weakly encoded. Very nice replications of several key replay findings including the effect of reward and remote replay, demonstrating the equally salient cue of context for offline memory consolidation.
I have no suggestions for the main body of the study, including methods and simulations, as the work is comprehensive, transparent, and well-described. However, I would like to understand how the CMRreplay model fits with the current understanding of the importance of excitation vs inhibition, remembering vs forgetting, activation vs deactivation, strengthening vs elimination of synapses, and even NREM vs REM as Schapiro has modeled. There seems to be a strong association with the efforts of the model to instantiate a memory as well as how that reinstantiation changes across time. But that is not all this is to consolidation. The specific roles of different brain states and how they might change replay is also an important consideration.
We are gratified that the reviewer appreciated the work, and we agree that the paper would benefit from comment on the connections to these other features of consolidation.
Excitation vs. inhibition: CMR-replay does not model variations in the excitation-inhibition balance across brain states (as in other models, e.g., Chenkov et al., 2017), since it does not include inhibitory connections. However, we posit that the experience-dependent suppression mechanism in the model might, in the brain, involve inhibitory processes. Supporting this idea, studies have observed increased inhibition with task repetition (Berners-Lee et al., 2022). We hypothesize that such mechanisms may underlie the observed inverse relationship between task experience and replay frequency in many studies. We discuss this in the section titled “A context model of memory replay”:
“The proposal that a suppression mechanism plays a role in replay aligns with models that regulate place cell reactivation via inhibition (Malerba et al., 2016) and with empirical observations of increased hippocampal inhibitory interneuron activity with experience (Berners-Lee et al., 2022). Our model assumes the presence of such inhibitory mechanisms but does not explicitly model them.”
Remembering/forgetting, activation/deactivation, and strengthening/elimination of synapses: The model does not simulate synaptic weight reduction or pruning, so it does not forget memories through the weakening of associated weights. However, forgetting can occur when a memory is replayed less frequently than others, leading to reduced activation of that memory compared to its competitors during context-driven retrieval. In the Discussion section, we acknowledge that a biologically implausible aspect of our model is that it implements only synaptic strengthening:
“Aspects of the model, such as its lack of regulation of the cumulative positive weight changes that can accrue through repeated replay, are biologically implausible (as biological learning results in both increases and decreases in synaptic weights) and limit the ability to engage with certain forms of low level neural data (e.g., changes in spine density over sleep periods; de Vivo et al., 2017; Maret et al., 2011). It will be useful for future work to explore model variants with more elements of biological plausibility.” Different brain states and NREM vs REM: Reviewer 1 also raised this important issue (see above). We have added the following thoughts on differences between these states and the relationship to our prior work to the Discussion section:
“Our current simulations have focused on NREM, since the vast majority of electrophysiological studies of sleep replay have identified replay events in this stage. We have proposed in other work that replay during REM sleep may provide a complementary role to NREM sleep, allowing neocortical areas to reinstate remote, already-consolidated memories that need to be integrated with the memories that were recently encoded in the hippocampus and replayed during NREM (Singh et al., 2022). An extension of our model could undertake this kind of continual learning setup, where the student but not teacher network retains remote memories, and the driver of replay alternates between hippocampus (NREM) and cortex (REM) over the course of a night of simulated sleep. Other differences between stages of sleep and between sleep and wake states are likely to become important for a full account of how replay impacts memory. Our current model parsimoniously explains a range of differences between awake and sleep replay by assuming simple differences in initial conditions, but we expect many more characteristics of these states (e.g., neural activity levels, oscillatory profiles, neurotransmitter levels, etc.) will be useful to incorporate in the future.”
We hope these points clarify the model’s scope and its potential for future extensions.
Do the authors suggest that these replay systems are more universal to offline processes beyond episodic memory? What about procedural memories and working memory?
We thank the reviewer for raising this important question. We have clarified in the manuscript:
“We focus on the model as a formulation of hippocampal replay, capturing how the hippocampus may replay past experiences through simple and interpretable mechanisms.”
With respect to other forms of memory, we now note that:
“This motor memory simulation using a model of hippocampal replay is consistent with evidence that hippocampal replay can contribute to consolidating memories that are not hippocampally dependent at encoding (Schapiro et al., 2019; Sawangjit et al., 2018). It is possible that replay in other, more domain-specific areas could also contribute (Eichenlaub et al., 2020).”
Though this is not a biophysical model per se, can the authors speak to the neuromodulatory milieus that give rise to the different types of replay?
Our work aligns with the perspective proposed by Hasselmo (1999), which suggests that waking and sleep states differ in the degree to which hippocampal activity is driven by external inputs. Specifically, high acetylcholine levels during waking bias activity to flow into the hippocampus, while low acetylcholine levels during sleep allow hippocampal activity to influence other brain regions. Consistent with this view, our model posits that wake replay is more biased toward items associated with the current resting location due to the presence of external input during waking states. In the Discussion section, we have added a comment on this point:
“Our view aligns with the theory proposed by Hasselmo (1999), which suggests that the degree of hippocampal activity driven by external inputs differs between waking and sleep states: High acetylcholine levels during wakefulness bias activity into the hippocampus, while low acetylcholine levels during slow-wave sleep allow hippocampal activity to influence other brain regions.”
Reviewer #3 (Public Review):
In this manuscript, Zhou et al. present a computational model of memory replay. Their model (CMR-replay) draws from temporal context models of human memory (e.g., TCM, CMR) and claims replay may be another instance of a context-guided memory process. During awake learning, CMR replay (like its predecessors) encodes items alongside a drifting mental context that maintains a recency-weighted history of recently encoded contexts/items. In this way, the presently encoded item becomes associated with other recently learned items via their shared context representation - giving rise to typical effects in recall such as primacy, recency, and contiguity. Unlike its predecessors, CMR-replay has built-in replay periods. These replay periods are designed to approximate sleep or wakeful quiescence, in which an item is spontaneously reactivated, causing a subsequent cascade of item-context reactivations that further update the model's item-context associations.
Using this model of replay, Zhou et al. were able to reproduce a variety of empirical findings in the replay literature: e.g., greater forward replay at the beginning of a track and more backward replay at the end; more replay for rewarded events; the occurrence of remote replay; reduced replay for repeated items, etc. Furthermore, the model diverges considerably (in implementation and predictions) from other prominent models of replay that, instead, emphasize replay as a way of predicting value from a reinforcement learning framing (i.e., EVB, expected value backup).
Overall, I found the manuscript clear and easy to follow, despite not being a computational modeller myself. (Which is pretty commendable, I'd say). The model also was effective at capturing several important empirical results from the replay literature while relying on a concise set of mechanisms - which will have implications for subsequent theory-building in the field.
With respect to weaknesses, additional details for some of the methods and results would help the readers better evaluate the data presented here (e.g., explicitly defining how the various 'proportion of replay' DVs were calculated).
For example, for many of the simulations, the y-axis scale differs from the empirical data despite using comparable units, like the proportion of replay events (e.g., Figures 1B and C). Presumably, this was done to emphasize the similarity between the empirical and model data. But, as a reader, I often found myself doing the mental manipulation myself anyway to better evaluate how the model compared to the empirical data. Please consider using comparable y-axis ranges across empirical and simulated data wherever possible.
We appreciate this point. As in many replay modeling studies, our primary goal is to provide a qualitative fit that demonstrates the general direction of differences between our model and empirical data, without engaging in detailed parameter fitting for a precise quantitative fit. Still, we agree that where possible, it is useful to better match the axes. We have updated figures 2B and 2C so that the y-axis scales are more directly comparable between the empirical and simulated data.
In a similar vein to the above point, while the DVs in the simulations/empirical data made intuitive sense, I wasn't always sure precisely how they were calculated. Consider the "proportion of replay" in Figure 1A. In the Methods (perhaps under Task Simulations), it should specify exactly how this proportion was calculated (e.g., proportions of all replay events, both forwards and backwards, combining across all simulations from Pre- and Post-run rest periods). In many of the examples, the proportions seem to possibly sum to 1 (e.g., Figure 1A), but in other cases, this doesn't seem to be true (e.g., Figure 3A). More clarity here is critical to help readers evaluate these data. Furthermore, sometimes the labels themselves are not the most informative. For example, in Figure 1A, the y-axis is "Proportion of replay" and in 1C it is the "Proportion of events". I presumed those were the same thing - the proportion of replay events - but it would be best if the axis labels were consistent across figures in this manuscript when they reflect the same DV.
We appreciate these useful suggestions. We have revised the Methods section to explain in detail how DVs are calculated for each simulation. The revisions clarify the differences between related measures, such as those shown in Figures 1A and 1C, so that readers can more easily see how the DVs are defined and interpreted in each case.
Reviewer #4/Reviewing Editor (Public Review):
Summary:
With their 'CMR-replay' model, Zhou et al. demonstrate that the use of spontaneous neural cascades in a context-maintenance and retrieval (CMR) model significantly expands the range of captured memory phenomena.
Strengths:
The proposed model compellingly outperforms its CMR predecessor and, thus, makes important strides towards understanding the empirical memory literature, as well as highlighting a cognitive function of replay.
Weaknesses:
Competing accounts of replay are acknowledged but there are no formal comparisons and only CMR-replay predictions are visualized. Indeed, other than the CMR model, only one alternative account is given serious consideration: A variant of the 'Dyna-replay' architecture, originally developed in the machine learning literature (Sutton, 1990; Moore & Atkeson, 1993) and modified by Mattar et al (2018) such that previously experienced event-sequences get replayed based on their relevance to future gain. Mattar et al acknowledged that a realistic Dyna-replay mechanism would require a learned representation of transitions between perceptual and motor events, i.e., a 'cognitive map'. While Zhou et al. note that the CMR-replay model might provide such a complementary mechanism, they emphasize that their account captures replay characteristics that Dyna-replay does not (though it is unclear to what extent the reverse is also true).
We thank the reviewer for these thoughtful comments and appreciate the opportunity to clarify our approach. Our goal in this work is to contrast two dominant perspectives in replay research: replay as a mechanism for learning reward predictions and replay as a process for memory consolidation. These models were chosen as representatives of their classes of models because they use simple and interpretable mechanisms that can simulate a wide range of replay phenomena, making them ideal for contrasting these two perspectives.
Although we implemented CMR-replay as a straightforward example of the memory-focused view, we believe the proposed mechanisms could be extended to other architectures, such as recurrent neural networks, to produce similar results. We now discuss this possibility in the revised manuscript (see below). However, given our primary goal of providing a broad and qualitative contrast of these two broad perspectives, we decided not to undertake simulations with additional individual models for this paper.
Regarding the Mattar & Daw model, it is true that a mechanistic implementation would require a mechanism that avoids precomputing priorities before replay. However, the "need" component of their model already incorporates learned expectations of transitions between actions and events. Thus, the model's limitations are not due to the absence of a cognitive map.
In contrast, while CMR-replay also accumulates memory associations that reflect experienced transitions among events, it generates several qualitatively distinct predictions compared to the Mattar & Daw model. As we note in the manuscript, these distinctions make CMR-replay a contrasting rather than complementary perspective.
Another important consideration, however, is how CMR replay compares to alternative mechanistic accounts of cognitive maps. For example, Recurrent Neural Networks are adept at detecting spatial and temporal dependencies in sequential input; these networks are being increasingly used to capture psychological and neuroscientific data (e.g., Zhang et al, 2020; Spoerer et al, 2020), including hippocampal replay specifically (Haga & Fukai, 2018). Another relevant framework is provided by Associative Learning Theory, in which bidirectional associations between static and transient stimulus elements are commonly used to explain contextual and cue-based phenomena, including associative retrieval of absent events (McLaren et al, 1989; Harris, 2006; Kokkola et al, 2019). Without proper integration with these modeling approaches, it is difficult to gauge the innovation and significance of CMR-replay, particularly since the model is applied post hoc to the relatively narrow domain of rodent maze navigation.
First, we would like to clarify our principal aim in this work is to characterize the nature of replay, rather than to model cognitive maps per se. Accordingly, CMR‑replay is not designed to simulate head‐direction signals, perform path integration, or explain the spatial firing properties of neurons during navigation. Instead, it focuses squarely on sequential replay phenomena, simulating classic rodent maze reactivation studies and human sequence‐learning tasks. These simulations span a broad array of replay experimental paradigms to ensure extensive coverage of the replay findings reported across the literature. As such, the contribution of this work is in explaining the mechanisms and functional roles of replay, and demonstrating that a model that employs simple and interpretable memory mechanisms not only explains replay phenomena traditionally interpreted through a value-based lens but also accounts for findings not addressed by other memory-focused models.
As the reviewer notes, CMR-replay shares features with other memory-focused models. However, to our knowledge, none of these related approaches have yet captured the full suite of empirical replay phenomena, suggesting the combination of mechanisms employed in CMR-replay is essential for explaining these phenomena. In the Discussion section, we now discuss the similarities between CMR-replay and related memory models and the possibility of integrating these approaches:
“Our theory builds on a lineage of memory-focused models, demonstrating the power of this perspective in explaining phenomena that have often been attributed to the optimization of value-based predictions. In this work, we focus on CMR-replay, which exemplifies the memory-centric approach through a set of simple and interpretable mechanisms that we believe are broadly applicable across memory domains. Elements of CMR-replay share similarities with other models that adopt a memory-focused perspective. The model learns distributed context representations whose overlaps encodes associations among items, echoing associative learning theories in which overlapping patterns capture stimulus similarity and learned associations (McLaren & Mackintosh 2002). Context evolves through bidirectional interactions between items and their contextual representations, mirroring the dynamics found in recurrent neural networks (Haga & Futai 2018; Levenstein et al., 2024). However, these related approaches have not been shown to account for the present set of replay findings and lack mechanisms—such as reward-modulated encoding and experience-dependent suppression—that our simulations suggest are essential for capturing these phenomena. While not explored here, we believe these mechanisms could be integrated into architectures like recurrent neural networks (Levenstein et al., 2024) to support a broader range of replay dynamics.”
Recommendations For The Authors
Reviewer #1 (Recommendations For The Authors):
(1) Lines 94-96: These lines may be better positioned earlier in the paragraph.
We now introduce these lines earlier in the paragraph.
(2) Line 103 - It's unclear to me what is meant by the statement that "the current context contains contexts associated with previous items". I understand why a slowly drifting context will coincide and therefore link with multiple items that progress rapidly in time, so multiple items will be linked to the same context and each item will be linked to multiple contexts. Is that the idea conveyed here or am I missing something? I'm similarly confused by line 129, which mentions that a context is updated by incorporating other items' contexts. How could a context contain other contexts?
In the model, each item has an associated context that can be retrieved via Mfc. This is true even before learning, since Mfc is initialized as an identity matrix. During learning and replay, we have a drifting context c that is updated each time an item is presented. At each timestep, the model first retrieves the current item’s associated context cf by Mfc, and incorporates it into c. Equation #2 in the Methods section illustrates this procedure in detail. Because of this procedure, the drifting context c is a weighted sum of past items’ associated contexts.
We recognize that these descriptions can be confusing. We have updated the Results section to better distinguish the drifting context from items’ associated context. For example, we note that:
“We represent the drifting context during learning and replay with c and an item's associated context with cf.”
We have also updated our description of the context drift procedure to distinguish these two quantities:
“During awake encoding of a sequence of items, for each item f, the model retrieves its associated context cf via Mfc. The drifting context c incorporates the item's associated context cf and downweights its representation of previous items' associated contexts (Figure 1c). Thus, the context layer maintains a recency weighted sum of past and present items' associated contexts.”
(3) Figure 1b and 1d - please clarify which axis in the association matrices represents the item and the context.
We have added labels to show what the axes represent in Figure 1.
(4) The terms "experience" and "item" are used interchangeably and it may be best to stick to one term.
We now use the term “item” wherever we describe the model results.
(5) The manuscript describes Figure 6 ahead of earlier figures - the authors may want to reorder their figures to improve readability.
We appreciate this suggestion. We decided to keep the current figure organization since it allows us to group results into different themes and avoid redundancy.
(6) Lines 662-664 are repeated with a different ending, this is likely an error.
We have fixed this error.
Reviewer #3 (Recommendations For The Authors):
Below, I have outlined some additional points that came to mind in reviewing the manuscript - in no particular order.
(1) Figure 1: I found the ordering of panels a bit confusing in this figure, as the reading direction changes a couple of times in going from A to F. Would perhaps putting panel C in the bottom left corner and then D at the top right, with E and F below (also on the right) work?
We agree that this improves the figure. We have restructured the ordering of panels in this figure.
(2) Simulation 1: When reading the intro/results for the first simulation (Figure 2a; Diba & Buszaki, 2007; "When animals traverse a linear track...", page 6, line 186). It wasn't clear to me why pre-run rest would have any forward replay, particularly if pre-run implied that the animal had no experience with the track yet. But in the Methods this becomes clearer, as the model encodes the track eight times prior to the rest periods. Making this explicit in the text would make it easier to follow. Also, was there any reason why specifically eight sessions of awake learning, in particular, were used?
We now make more explicit that the animals have experience with the track before pre-run rest recording:
“Animals first acquire experience with a linear track by traversing it to collect a reward. Then, during the pre-run rest recording, forward replay predominates.”
We included eight sessions of awake learning to match with the number of sessions in Shin et al. (2017), since this simulation attempts to explain data from that study. After each repetition, the model engages in rest. We have revised the Methods section to indicate the motivation for this choice:
“In the simulation that examines context-dependent forward and backward replay through experience (Figs. 2a and 5a), CMR-replay encodes an input sequence shown in Fig. 7a, which simulates a linear track run with no ambiguity in the direction of inputs, over eight awake learning sessions (as in Shin et al. 2019)”
(3) Frequency of remote replay events: In the simulation based on Gupta et al, how frequently overall does remote replay occur? In the main text, the authors mention the mean frequency with which shortcut replay occurs (i.e., the mean proportion of replay events that contain a shortcut sequence = 0.0046), which was helpful. But, it also made me wonder about the likelihood of remote replay events. I would imagine that remote replay events are infrequent as well - given that it is considerably more likely to replay sequences from the local track, given the recency-weighted mental context. Reporting the above mean proportion for remote and local replay events would be helpful context for the reader.
In Figure 4c, we report the proportion of remote replay in the two experimental conditions of Gupta et al. that we simulate.
(4) Point of clarification re: backwards replay: Is backwards replay less likely to occur than forward replay overall because of the forward asymmetry associated with these models? For example, for a backwards replay event to occur, the context would need to drift backwards at least five times in a row, in spite of a higher probability of moving one step forward at each of those steps. Am I getting that right?
The reviewer’s interpretation is correct: CMR-replay is more likely to produce forward than backward replay in sleep because of its forward asymmetry. We note that this forward asymmetry leads to high likelihood of forward replay in the section titled “The context-dependency of memory replay”:
“As with prior retrieved context models (Howard & Kahana 2002; Polyn et al., 2009), CMR-replay encodes stronger forward than backward associations. This asymmetry exists because, during the first encoding of a sequence, an item's associated context contributes only to its ensuing items' encoding contexts. Therefore, after encoding, bringing back an item's associated context is more likely to reactivate its ensuing than preceding items, leading to forward asymmetric replay (Fig. 6d left).”
(5) On terminating a replay period: "At any t, the replay period ends with a probability of 0.1 or if a task-irrelevant item is reactivated." (Figure 1 caption; see also pg 18, line 635). How was the 0.1 decided upon? Also, could you please add some detail as to what a 'task-irrelevant item' would be? From what I understood, the model only learns sequences that represent the points in a track - wouldn't all the points in the track be task-relevant?
This value was arbitrarily chosen as a small value that allows probabilistic stopping. It was not motivated by prior modeling or a systematic search. We have added: “At each timestep, the replay period ends either with a stop probability of 0.1 or if a task-irrelevant item becomes reactivated. (The choice of the value 0.1 was arbitrary; future work could explore the implications of varying this parameter).”
In addition, we now explain in the paper that task irrelevant items “do not appear as inputs during awake encoding, but compete with task-relevant items for reactivation during replay, simulating the idea that other experiences likely compete with current experiences during periods of retrieval and reactivation.”
(6) Minor typos:
Turn all instances of "nonlocal" into "non-local", or vice versa
"For rest at the end of a run, cexternal is the context associated with the final item in the sequence. For rest at the end of a run, cexternal is the context associated with the start item." (pg 20, line 663) - I believe this is a typo and that the second sentence should begin with "For rest at the START of a run".
We have updated the manuscript to correct these typos.
(7) Code availability: I may have missed it, but it doesn't seem like the code is currently available for these simulations. Including the commented code in a public repository (Github, OSF) would be very useful in this case.
We now include a Github link to our simulation code: https://github.com/schapirolab/CMR-replay.
Reviewer #1 (Public review):
Summary:
In their article, Guo and coworkers investigate the Ca²⁺ signaling responses induced by Enteropathogenic Escherichia coli (EPEC) in epithelial cells and how these responses regulate NF-κB activation. The authors show that EPEC induces rapid, spatially coordinated Ca²⁺ transients mediated by extracellular ATP released through the type III secretion system (T3SS). Using high-speed Ca²⁺ imaging and stochastic modeling, they propose that low ATP levels trigger "Coordinated Ca²⁺ Responses from IP₃R Clusters" (CCRICs) via fast Ca²⁺ diffusion and Ca²⁺-induced Ca²⁺ release. These responses may dampen TNF-α-induced NF-κB activation through Ca²⁺-dependent modulation of O-GlcNAcylation of p65. The interdisciplinary work suggests a new perspective on calcium-mediated immune response by combining quantitative imaging, bacterial genetics, and computational modeling.
Strengths:
The study provides a new concept for host responses to bacterial infections and introduces the concept of Coordinated Ca²⁺ Responses from IP₃R Clusters (CCRICs) as synchronized, whole-cell-scale Ca²⁺ transients with the fast kinetics typical of local events. This is elegantly done by an interdisciplinary approach using quantitative measurements and mechanistic modelling.
Weaknesses:
(1) The effect of coordination by fast diffusion for small eATP concentrations is explained by the resulting low Ca2+ concentration that is not as strongly affected by calcium buffers compared to higher concentrations. While I agree with this statement on the relative level, CICR is based on the resulting absolute concentration at neighboring IP3Rs (to activate them). Thus, I do not fully agree with the explanation, or at least would expect to use the modelling approach to demonstrate this effect. Simulations for different activation and buffer concentrations could strengthen this point and exclude potential inhibition of channels at higher stimulation levels.
In this respect, I would also include the details of the modelling, such as implementation environment, parameters, and benchmarking. The description in the Supplementary Methods is very similar to the description in the main text. In terms of reproducibility, it would be important to at least provide simulation parameters, and providing the code would align with the emerging standards for reproducible science.
(2) Quantitative characterization of CCRICs:
The paper would benefit from a clearer definition of the term CCRICs and quantitative descriptors like duration, amplitude distribution, frequency, and spatial extent (also in relation to the comment on the EGTA measurements below). Furthermore, it remains unclear to me whether CCRICs represent a population of rapidly propagating micro-waves or truly simultaneous events. Maybe kymographs or wave-front propagation analyses (at least from simulations if experimental resolution is too bad) would strengthen this point.
(3) Specificity of pharmacological tools:
Suramin and U73122 are known to have off-target effects. Control experiments using alternative P2 receptor antagonists like PPADS or inactive U73343 analogs would strengthen the causal link.
Een algemene interne bewustwordingscampagne op het gebied van gegevensbescherming en privacy. Deze wordt voortgezet, met de focus op het verbeteren van AI-geletterdheid (hoe kun je veilig en verantwoord omgaan met AI).Op 18 november 2025 is de AI-gedragscode vastgesteld en er is een plan van aanpak voor de verdere verbetering van de privacy opgesteld.
Both these things, internal training and an AI operational code, are common in gov agencies. Here they are too late, and it's uncertain anyway they would have had effect. Any person who thinks nothing of uploading internal documents into a public website won't be held back by a rulebook they would not have read.
Hypocrite!
So, why is he a hypocrite? "he refers to himself as a hypocrite for the contrast between the code of righteousness to which he ideologically subscribes and the sinfulness of his […] violence." https://open.library.ubc.ca/media/stream/pdf/24/1.0300649/4 As he clarified in a Rolling Stone interview, "he started thinking about his own time in the streets and all the wrong he's done. So he started writing a new verse, in which he turned the microscope on himself. How can he criticize America for killing young black men […] when young black men are often just so good at it?" https://issuu.com/lawrenceambrocio5018/docs/rolling_stone_march_26_2015_usa_1_
Hypocrite!
So, why is he a hypocrite? "he refers to himself as a hypocrite for the contrast between the code of righteousness to which he ideologically subscribes and the sinfulness of his […] violence." https://open.library.ubc.ca/media/stream/pdf/24/1.0300649/4 As he clarified in a Rolling Stone interview, "he started thinking about his own time in the streets and all the wrong he's done. So he started writing a new verse, in which he turned the microscope on himself. How can he criticize America for killing young black men […] when young black men are often just so good at it?" https://issuu.com/lawrenceambrocio5018/docs/rolling_stone_march_26_2015_usa_1_
John Banks was touring Egypt when he fell in love with a 22 foot tall six-ton Obelisk and decided that it would look great in front of his yard as it also had inscriptions in hieroglyphics and Greek. He hoped it would be a second Rosetta Stone. So he did what anyone would do: hired an Italian circus strongman to coordinate hauling it back to his estate in England.
https://github.com/tnajdek/zotero-api-client (JavaScript) https://github.com/urschrei/pyzotero (Python) https://github.com/fcheslack/libZotero (PHP and Python)
Thre are existing code libraries for Javascript and PHP (and Python) into Zotero
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reviewer #1 (Evidence, reproducibility and clarity (Required)):
*The authors have a longstanding focus and reputation on single cell sequencing technology development and application. In this current study, the authors developed a novel single-cell multi-omic assay termed "T-ChIC" so that to jointly profile the histone modifications along with the full-length transcriptome from the same single cells, analyzed the dynamic relationship between chromatin state and gene expression during zebrafish development and cell fate determination. In general, the assay works well, the data look convincing and conclusions are beneficial to the community. *
Thank you for your positive feedback.
*There are several single-cell methodologies all claim to co-profile chromatin modifications and gene expression from the same individual cell, such as CoTECH, Paired-tag and others. Although T-ChIC employs pA-Mnase and IVT to obtain these modalities from single cells which are different, could the author provide some direct comparisons among all these technologies to see whether T-ChIC outperforms? *
In a separate technical manuscript describing the application of T-ChIC in mouse cells (Zeller, Blotenburg et al 2024, bioRxiv, 2024.05. 09.593364), we have provided a direct comparison of data quality between T-ChIC and other single-cell methods for chromatin-RNA co-profiling (Please refer to Fig. 1C,D and Fig. S1D, E, of the preprint). We show that compared to other methods, T-ChIC is able to better preserve the expected biological relationship between the histone modifications and gene expression in single cells.
*In current study, T-ChIC profiled H3K27me3 and H3K4me1 modifications, these data look great. How about other histone modifications (eg H3K9me3 and H3K36me3) and transcription factors? *
While we haven't profiled these other modifications using T-ChIC in Zebrafish, we have previously published high quality data on these histone modifications using the sortChIC method, on which T-ChIC is based (Zeller, Yeung et al 2023). In our comparison, we find that histone modification profiles between T-ChIC and sortChIC are very similar (Fig. S1C in Zeller, Blotenburg et al 2024). Therefore the method is expected to work as well for the other histone marks.
*T-ChIC can detect full length transcription from the same single cells, but in FigS3, the authors still used other published single cell transcriptomics to annotate the cell types, this seems unnecessary? *
We used the published scRNA-seq dataset with a larger number of cells to homogenize our cell type labels with these datasets, but we also cross-referenced our cluster-specific marker genes with ZFIN and homogenized the cell type labels with ZFIN ontology. This way our annotation is in line with previous datasets but not biased by it. Due the relatively smaller size of our data, we didn't expect to identify unique, rare cell types, but our full-length total RNA assay helps us identify non-coding RNAs such as miRNA previously undetected in scRNA assays, which we have now highlighted in new figure S1c .
*Throughout the manuscript, the authors found some interesting dynamics between chromatin state and gene expression during embryogenesis, independent approaches should be used to validate these findings, such as IHC staining or RNA ISH? *
We appreciate that the ISH staining could be useful to validate the expression pattern of genes identified in this study. But to validate the relationships between the histone marks and gene expression, we need to combine these stainings with functional genomics experiments, such as PRC2-related knockouts. Due to their complexity, such experiments are beyond the scope of this manuscript (see also reply to reviewer #3, comment #4 for details).
*In Fig2 and FigS4, the authors showed H3K27me3 cis spreading during development, this looks really interesting. Is this zebrafish specific? H3K27me3 ChIP-seq or CutTag data from mouse and/or human embryos should be reanalyzed and used to compare. The authors could speculate some possible mechanisms to explain this spreading pattern? *
Thanks for the suggestion. In this revision, we have reanalysed a dataset of mouse ChIP-seq of H3K27me3 during mouse embryonic development by Xiang et al (Nature Genetics 2019) and find similar evidence of spreading of H3K27me3 signal from their pre-marked promoter regions at E5.5 epiblast upon differentiation (new Figure S4i). This observation, combined with the fact that the mechanism of pre-marking of promoters by PRC1-PRC2 interaction seems to be conserved between the two species (see (Hickey et al., 2022), (Mei et al., 2021) & (Chen et al., 2021)), suggests that the dynamics of H3K27me3 pattern establishment is conserved across vertebrates. But we think a high-resolution profiling via a method like T-ChIC would be more useful to demonstrate the dynamics of signal spreading during mouse embryonic development in the future. We have discussed this further in our revised manuscript.
Reviewer #1 (Significance (Required)):
*The authors have a longstanding focus and reputation on single cell sequencing technology development and application. In this current study, the authors developed a novel single-cell multi-omic assay termed "T-ChIC" so that to jointly profile the histone modifications along with the full-length transcriptome from the same single cells, analyzed the dynamic relationship between chromatin state and gene expression during zebrafish development and cell fate determination. In general, the assay works well, the data look convincing and conclusions are beneficial to the community. *
Thank you very much for your supportive remarks.
Reviewer #2 (Evidence, reproducibility and clarity (Required)):
*Joint analysis of multiple modalities in single cells will provide a comprehensive view of cell fate states. In this manuscript, Bhardwaj et al developed a single-cell multi-omics assay, T-ChIC, to simultaneously capture histone modifications and full-length transcriptome and applied the method on early embryos of zebrafish. The authors observed a decoupled relationship between the chromatin modifications and gene expression at early developmental stages. The correlation becomes stronger as development proceeds, as genes are silenced by the cis-spreading of the repressive marker H3k27me3. Overall, the work is well performed, and the results are meaningful and interesting to readers in the epigenomic and embryonic development fields. There are some concerns before the manuscript is considered for publication. *
We thank the reviewer for appreciating the quality of our study.
*Major concerns: *
- A major point of this study is to understand embryo development, especially gastrulation, with the power of scMulti-Omics assay. However, the current analysis didn't focus on deciphering the biology of gastrulation, i.e., lineage-specific pioneer factors that help to reform the chromatin landscape. The majority of the data analysis is based on the temporal dimension, but not the cell-type-specific dimension, which reduces the value of the single-cell assay. *
We focused on the lineage-specific transcription factor activity during gastrulation in Figure 4 and S8 of the manuscript and discovered several interesting regulators active at this stage. During our analysis of the temporal dimension for the rest of the manuscript, we also classified the cells by their germ layer and "latent" developmental time by taking the full advantage of the single-cell nature of our data. Additionally, we have now added the cell-type-specific H3K27-demethylation results for 24hpf in response to your comment below. We hope that these results, together with our openly available dataset would demonstrate the advantage of the single-cell aspect of our dataset.
- *The cis-spreading of H3K27me3 with developmental time is interesting. Considering H3k27me3 could mark bivalent regions, especially in pluripotent cells, there must be some regions that have lost H3k27me3 signals during development. Therefore, it's confusing that the authors didn't find these regions (30% spreading, 70% stable). The authors should explain and discuss this issue. *
Indeed we see that ~30% of the bins enriched in the pluripotent stage spread, while 70% do not seem to spread. In line with earlier observations(Hickey et al., 2022; Vastenhouw et al., 2010), we find that H3K27me3 is almost absent in the zygote and is still being accumulated until 24hpf and beyond. Therefore the majority of the sites in the genome still seem to be in the process of gaining H3K27me3 until 24hpf, explaining why we see mostly "spreading" and "stable" states. Considering most of these sites are at promoters and show signs of bivalency, we think that these sites are marked for activation or silencing at later stages. We have discussed this in the manuscript ("discussion"). However, in response to this and earlier comment, we went back and searched for genes that show H3K27-demethylation in the most mature cell types (at 24 hpf) in our data, and found a subset of genes that show K27 demethylation after acquiring them earlier. Interestingly, most of the top genes in this list are well-known as developmentally important for their corresponding cell types. We have added this new result and discussed it further in the manuscript (Fig. 2d,e, , Supplementary table 3).
*Minors: *
- The authors cited two scMulti-omics studies in the introduction, but there have been lots of single-cell multi-omics studies published recently. The authors should cite and consider them. *
We have cited more single-cell chromatin and multiome studies focussed on early embryogenesis in the introduction now.
*2. T-ChIC seems to have been presented in a previous paper (ref 15). Therefore, Fig. 1a is unnecessary to show. *
Figure 1a. shows a summary of our Zebrafish TChIC workflow, which contains the unique sample multiplexing and sorting strategy to reduce batch effects, which was not applied in the original TChIC workflow. We have now clarified this in "Results".
- *It's better to show the percentage of cell numbers (30% vs 70%) for each heatmap in Figure 2C. *
We have added the numbers to the corresponding legends.
- *Please double-check the citation of Fig. S4C, which may not relate to the conclusion of signal differences between lineages. *
The citation seems to be correct (Fig. S4C supplements Fig. 2C, but shows mesodermal lineage cells) but the description of the legend was a bit misleading. We have clarified this now.
*5. Figure 4C has not been cited or mentioned in the main text. Please check. *
Thanks for pointing it out. We have cited it in Results now.
Reviewer #2 (Significance (Required)):
*Strengths: This work utilized a new single-cell multi-omics method and generated abundant epigenomics and transcriptomics datasets for cells covering multiple key developmental stages of zebrafish. *
*Limitations: The data analysis was superficial and mainly focused on the correspondence between the two modalities. The discussion of developmental biology was limited. *
*Advance: The zebrafish single-cell datasets are valuable. The T-ChIC method is new and interesting. *
*The audience will be specialized and from basic research fields, such as developmental biology, epigenomics, bioinformatics, etc. *
*I'm more specialized in the direction of single-cell epigenomics, gene regulation, 3D genomics, etc. *
Thank you for your remarks.
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
*This manuscript introduces T‑ChIC, a single‑cell multi‑omics workflow that jointly profiles full‑length transcripts and histone modifications (H3K27me3 and H3K4me1) and applies it to early zebrafish embryos (4-24 hpf). The study convincingly demonstrates that chromatin-transcription coupling strengthens during gastrulation and somitogenesis, that promoter‑anchored H3K27me3 spreads in cis to enforce developmental gene silencing, and that integrating TF chromatin status with expression can predict lineage‑specific activators and repressors. *
*Major concerns *
- *Independent biological replicates are absent, so the authors should process at least one additional clutch of embryos for key stages (e.g., 6 hpf and 12 hpf) with T‑ChIC and demonstrate that the resulting data match the current dataset. *
Thanks for pointing this out. We had, in fact, performed T-ChIC experiments in four rounds of biological replicates (independent clutch of embryos) and merged the data to create our resource. Although not all timepoints were profiled in each replicate, two timepoints (10 and 24hpf) are present in all four, and the celltype composition of these replicates from these 2 timepoints are very similar. We have added new plots in figure S2f and added (new) supplementary table (#1) to highlight the presence of biological replicates.
2. *The TF‑activity regression model uses an arbitrary R² {greater than or equal to} 0.6 threshold; cross‑validated R² distributions, permutation‑based FDR control, and effect‑size confidence intervals are needed to justify this cut‑off. *
Thank you for this suggestion. We did use 10-fold cross validation during training and obtained the R2 values of TF motifs from the independent test set as an unbiased estimate. However, the cutoff of R2 > 0.6 to select the TFs for classification was indeed arbitrary. In the revised version, we now report the FDR-adjusted p-values for these R2 estimates based on permutation tests, and select TFs with a cutoff of padj supplementary table #4 to include the p-values for all tested TFs. However, we see that our arbitrary cutoff of 0.6 was in fact, too stringent, and we can classify many more TFs based on the FDR cutoffs. We also updated our reported numbers in Fig. 4c to reflect this. Moreover, supplementary table #4 contains the complete list of TFs used in the analysis to allow others to choose their own cutoff.
3. *Predicted TF functions lack empirical support, making it essential to test representative activators (e.g., Tbx16) and repressors (e.g., Zbtb16a) via CRISPRi or morpholino knock‑down and to measure target‑gene expression and H3K4me1 changes. *
We agree that independent validation of the functions of our predicted TFs on target gene activity would be important. During this revision, we analysed recently published scRNA-seq data of Saunders et al. (2023) (Saunders et al., 2023), which includes CRISPR-mediated F0 knockouts of a couple of our predicted TFs, but the scRNAseq was performed at later stages (24hpf onward) compared to our H3K4me1 analysis (which was 4-12 hpf). Therefore, we saw off-target genes being affected in lineages where these TFs are clearly not expressed (attached Fig 1). We therefore didn't include these results in the manuscript. In future, we aim to systematically test the TFs predicted in our study with CRISPRi or similar experiments.
4. *The study does not prove that H3K27me3 spreading causes silencing; embryos treated with an Ezh2 inhibitor or prc2 mutants should be re‑profiled by T‑ChIC to show loss of spreading along with gene re‑expression. *
We appreciate the suggestion that indeed PRC2-disruption followed by T-ChIC or other forms of validation would be needed to confirm whether the H3K27me3 spreading is indeed causally linked to the silencing of the identified target genes. But performing this validation is complicated because of multiple reasons: 1) due to the EZH2 contribution from maternal RNA and the contradicting effects of various EZH2 zygotic mutations (depending on where the mutation occurs), the only properly validated PRC2-related mutant seems to be the maternal-zygotic mutant MZezh2, which requires germ cell transplantation (see Rougeot et al. 2019 (Rougeot et al., 2019)) , and San et al. 2019 (San et al., 2019) for details). The use of inhibitors have been described in other studies (den Broeder et al., 2020; Huang et al., 2021), but they do not show a validation of the H3K27me3 loss or a similar phenotype as the MZezh2 mutants, and can present unwanted side effects and toxicity at a high dose, affecting gene expression results. Moreover, in an attempt to validate, we performed our own trials with the EZH2 inhibitor (GSK123) and saw that this time window might be too short to see the effect within 24hpf (attached Fig. 2). Therefore, this validation is a more complex endeavor beyond the scope of this study. Nevertheless, our further analysis of H3K27me3 de-methylation on developmentally important genes (new Fig. 2e-f, Sup. table 3) adds more confidence that the polycomb repression plays an important role, and provides enough ground for future follow up studies.
*Minor concerns *
- *Repressive chromatin coverage is limited, so profiling an additional silencing mark such as H3K9me3 or DNA methylation would clarify cooperation with H3K27me3 during development. *
We agree that H3K27me3 alone would not be sufficient to fully understand the repressive chromatin state. Extension to other chromatin marks and DNA methylation would be the focus of our follow up works.
*2. Computational transparency is incomplete; a supplementary table listing all trimming, mapping, and peak‑calling parameters (cutadapt, STAR/hisat2, MACS2, histoneHMM, etc.) should be provided. *
As mentioned in the manuscript, we provide an open-source pre-processing pipeline "scChICflow" to perform all these steps (github.com/bhardwaj-lab/scChICflow). We have now also provided the configuration files on our zenodo repository (see below), which can simply be plugged into this pipeline together with the fastq files from GEO to obtain the processed dataset that we describe in the manuscript. Additionally, we have also clarified the peak calling and post-processing steps in the manuscript now.
*3. Data‑ and code‑availability statements lack detail; the exact GEO accession release date, loom‑file contents, and a DOI‑tagged Zenodo archive of analysis scripts should be added. *
We have now publicly released the .h5ad files with raw counts, normalized counts, and complete gene and cell-level metadata, along with signal tracks (bigwigs) and peaks on GEO. Additionally, we now also released the source datasets and notebooks (.Rmarkdown format) on Zenodo that can be used to replicate the figures in the manuscript, and updated our statements on "Data and code availability".
*4. Minor editorial issues remain, such as replacing "critical" with "crucial" in the Abstract, adding software version numbers to figure legends, and correcting the SAMtools reference. *
Thank you for spotting them. We have fixed these issues.
Reviewer #3 (Significance (Required)):
The method is technically innovative and the biological insights are valuable; however, several issues-mainly concerning experimental design, statistical rigor, and functional validation-must be addressed to solidify the conclusions.
Thank you for your comments. We hope to have addressed your concerns in this revised version of our manuscript.
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
This manuscript introduces T‑ChIC, a single‑cell multi‑omics workflow that jointly profiles full‑length transcripts and histone modifications (H3K27me3 and H3K4me1) and applies it to early zebrafish embryos (4-24 hpf). The study convincingly demonstrates that chromatin-transcription coupling strengthens during gastrulation and somitogenesis, that promoter‑anchored H3K27me3 spreads in cis to enforce developmental gene silencing, and that integrating TF chromatin status with expression can predict lineage‑specific activators and repressors.
Major concerns
Minor concerns
The method is technically innovative and the biological insights are valuable; however, several issues-mainly concerning experimental design, statistical rigor, and functional validation-must be addressed to solidify the conclusions.
Best Practices for Using SQLite on Mac
make regular backups with the .dump command (you can cron job this) optimize queries use right data types indexing rebuild often to reclaim unused space (VACUUM) command use prepared statements in my code
# Define CID data type for reading CSV files to optimize memory usage mydtype = {"Compound_CID" : "Int64"} #mydtype = {"Compound_CID" : "Int64", "pmid":"Int64", "taxid":"object", "targettaxid":"object"}
test hypothes.is inside of a code cell of a jupyter book
his cell defines the data type for the “COMPOUND_CID” column to ensure accurate data loading and to prevent memory-related issues.
test of h. outside of code cell
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary
This is a strong paper that presents a clear advance in multi-animal tracking. The authors introduce an updated version of idtracker.ai that reframes identity assignment as a contrastive learning problem rather than a classification task requiring global fragments. This change leads to gains in speed and accuracy. The method eliminates a known bottleneck in the original system, and the benchmarking across species is comprehensive and well executed. I think the results are convincing and the work is significant.
Strengths
The main strengths are the conceptual shift from classification to representation learning, the clear performance gains, and the fact that the new version is more robust. Removing the need for global fragments makes the software more flexible in practice, and the accuracy and speed improvements are well demonstrated. The software appears thoughtfully implemented, with GUI updates and integration with pose estimators.
Weaknesses
I don't have any major criticisms, but I have identified a few points that should be addressed to improve the clarity and accuracy of the claims made in the paper.
(1) The title begins with "New idtracker.ai," which may not age well and sounds more promotional than scientific. The strength of the work is the conceptual shift to contrastive representation learning, and it might be more helpful to emphasize that in the title rather than branding it as "new."
We considered using “Contrastive idtracker.ai”. However, we thought that readers could then think that we believe they could use both the old idtracker.ai or this contrastive version. But we want to say that the new version is the one to use as it is better in both accuracy and tracking times. We think “New idtracker.ai” communicates better that this version is the version we recommend.
(2) Several technical points regarding the comparison between TRex (a system evaluated in the paper) and idtracker.ai should be addressed to ensure the evaluation is fair and readers are fully informed.
(2.1) Lines 158-160: The description of TRex as based on "Protocol 2 of idtracker.ai" overlooks several key additions in TRex, such as posture image normalization, tracklet subsampling, and the use of uniqueness feedback during training. These features are not acknowledged, and it's unclear whether TRex was properly configured - particularly regarding posture estimation, which appears to have been omitted but isn't discussed. Without knowing the actual parameters used to make comparisons, it's difficult to dassess how the method was evaluated.
We added the information about the key additions of TRex in the section “The new idtracker.ai uses representation learning”, lines 153-157. Posture estimation in TRex was not explicitly used but neither disabled during the benchmark; we clarified this in the last paragraph of “Benchmark of accuracy and tracking time”, lines 492-495.
(2.2) Lines 162-163: The paper implies that TRex gains speed by avoiding Protocol 3, but in practice, idtracker.ai also typically avoids using Protocol 3 due to its extremely long runtime. This part of the framing feels more like a rhetorical contrast than an informative one.
We removed this, see new lines 153-157.
(2.3) Lines 277-280: The contrastive loss function is written using the label l, but since it refers to a pair of images, it would be clearer and more precise to write it as l_{I,J}. This would help readers unfamiliar with contrastive learning understand the formulation more easily.
We added this change in lines 613-620.
(2.4) Lines 333-334: The manuscript states that TRex can fail to track certain videos, but this may be inaccurate depending on how the authors classify failures. TRex may return low uniqueness scores if training does not converge well, but this isn't equivalent to tracking failure. Moreover, the metric reported by TRex is uniqueness, not accuracy. Equating the two could mislead readers. If the authors did compare outputs to human-validated data, that should be stated more explicitly.
We observed TRex crashing without outputting any trajectories on some occasions (Appendix 1—figure 1), and this is what we labeled as “failure”. These failures happened in the most difficult videos of our benchmark, that’s why we treated them the same way as idtracker.ai going to P3. We clarified this in new lines 464-469.
The accuracy measured in our benchmark is not estimated but it is human-validated (see section Computation of tracking accuracy in Appendix 1). Both softwares report some quality estimators at the end of a tracking (“estimated accuracy” for idtracker.ai and "uniqueness” for TRex) but these were not used in the benchmark.
(2.5) Lines 339-341: The evaluation approach defines a "successful run" and then sums the runtime across all attempts up to that point. If success is defined as simply producing any output, this may not reflect how experienced users actually interact with the software, where parameters are iteratively refined to improve quality.
Yes, our benchmark was designed to be agnostic to the different experiences of the user. Also, our benchmark was designed for users that do not inspect the trajectories to choose parameters again not to leave room for potential subjectivity.
(2.6) Lines 344-346: The simulation process involves sampling tracking parameters 10,000 times and selecting the first "successful" run. If parameter tuning is randomized rather than informed by expert knowledge, this could skew the results in favor of tools that require fewer or simpler adjustments. TRex relies on more tunable behavior, such as longer fragments improving training time, which this approach may not capture.
We precisely used the TRex parameter track_max_speed to elongate fragments for optimal tracking. Rather than randomized parameter tuning, we defined the “valid range” for this parameter so that all values in it would produce a decent fragment structure. We used this procedure to avoid worsening those methods that use more parameters.
(2.7) Line 354 onward: TRex was evaluated using two varying parameters (threshold and track_max_speed), while idtracker.ai used only one (intensity_threshold). With a fixed number of samples, this asymmetry could bias results against TRex. In addition, users typically set these parameters based on domain knowledge rather than random exploration.
idtracker.ai and TRex have several parameters. Some of them have a single correct value (e.g. number of animals) or the default value that the system computes is already good (e.g. minimum blob size). For a second type of parameters, the system finds a value that is in general not as good, so users need to modify them. In general, users find that for this second type of parameter there is a valid interval of possible values, from which they need to choose a single value to run the system. idtracker.ai has intensity_threshold as the only parameter of this second type and TRex has two: threshold and track_max_speed. For these parameters, choosing one value or another within the valid interval can give different tracking results. Therefore, when we model a user that wants to run the system once except if it goes to P3 (idtracker.ai) or except if it crashes (TRex), it is these parameters we sample from within the valid interval to get a different value for each run of the system. We clarify this in lines 452-469 of the section “Benchmark of accuracy and tracking time”.
Note that if we chose to simply run old idtracker.ai (v4 or v5) or TRex a single time, this would benefit the new idtracker.ai (v6). This is because old idtracker.ai can enter the very slow protocol 3 and TRex can fail to track. So running old idtracker.ai or TRex up to 5 times until old idtracker.ai does not use Protocol 3 and TRex does not fail is to make them as good as they can be with respect to the new idtracker.ai.
(2.8) Figure 2-figure supplement 3: The memory usage comparison lacks detail. It's unclear whether RAM or VRAM was measured, whether shared or compressed memory was included, or how memory was sampled. Since both tools dynamically adjust to system resources, the relevance of this comparison is questionable without more technical detail.
We modified the text in the caption (new Figure 1-figure supplement 2) adding the kind of memory we measured (RAM) and how we measured it. We already have a disclaimer for this plot saying that memory management depends on the machine's available resources. We agree that this is a simple analysis of the usage of computer resources.
(3) While the authors cite several key papers on contrastive learning, they do not use the introduction or discussion to effectively situate their approach within related fields where similar strategies have been widely adopted. For example, contrastive embedding methods form the backbone of modern facial recognition and other image similarity systems, where the goal is to map images into a latent space that separates identities or classes through clustering. This connection would help emphasize the conceptual strength of the approach and align the work with well-established applications. Similarly, there is a growing literature on animal re-identification (ReID), which often involves learning identity-preserving representations across time or appearance changes. Referencing these bodies of work would help readers connect the proposed method with adjacent areas using similar ideas, and show that the authors are aware of and building on this wider context.
We have now added a new section in Appendix 3, “Differences with previous work in contrastive/metric learning” (lines 792-841) to include references to previous work and a description of what we do differently.
(4) Some sections of the Results text (e.g., lines 48-74) read more like extended figure captions than part of the main narrative. They include detailed explanations of figure elements, sorting procedures, and video naming conventions that may be better placed in the actual figure captions or moved to supplementary notes. Streamlining this section in the main text would improve readability and help the central ideas stand out more clear
Thank you for pointing this out. We have rewritten the Results, for example streamlining the old lines 48-74 (new lines 42-48) by moving the comments about names, files and order of videos to the caption of Figure 1.
Overall, though, this is a high-quality paper. The improvements to idtracker.ai are well justified and practically significant. Addressing the above comments will strengthen the work, particularly by clarifying the evaluation and comparisons.
We thank the reviewer for the detailed suggestions. We believe we have taken all of them into consideration to improve the ms.
Reviewer #2 (Public review):
Summary:
This work introduces a new version of the state-of-the-art idtracker.ai software for tracking multiple unmarked animals. The authors aimed to solve a critical limitation of their previous software, which relied on the existence of "global fragments" (video segments where all animals are simultaneously visible) to train an identification classifier network, in addition to addressing concerns with runtime speed. To do this, the authors have both re-implemented the backend of their software in PyTorch (in addition to numerous other performance optimizations) as well as moving from a supervised classification framework to a self-supervised, contrastive representation learning approach that no longer requires global fragments to function. By defining positive training pairs as different images from the same fragment and negative pairs as images from any two co-existing fragments, the system cleverly takes advantage of partial (but high-confidence) tracklets to learn a powerful representation of animal identity without direct human supervision. Their formulation of contrastive learning is carefully thought out and comprises a series of empirically validated design choices that are both creative and technically sound. This methodological advance is significant and directly leads to the software's major strengths, including exceptional performance improvements in speed and accuracy and a newfound robustness to occlusion (even in severe cases where no global fragments can be detected). Benchmark comparisons show the new software is, on average, 44 times faster (up to 440 times faster on difficult videos) while also achieving higher accuracy across a range of species and group sizes. This new version of idtracker.ai is shown to consistently outperform the closely related TRex software (Walter & Couzin, 2021\), which, together with the engineering innovations and usability enhancements (e.g., outputs convenient for downstream pose estimation), positions this tool as an advancement on the state-of-the-art for multi-animal tracking, especially for collective behavior studies.
Despite these advances, we note a number of weaknesses and limitations that are not well addressed in the present version of this paper:
Weaknesses
(1) The contrastive representation learning formulation. Contrastive representation learning using deep neural networks has long been used for problems in the multi-object tracking domain, popularized through ReID approaches like DML (Yi et al., 2014\) and DeepReID (Li et al., 2014). More recently, contrastive learning has become more popular as an approach for scalable self-supervised representation learning for open-ended vision tasks, as exemplified by approaches like SimCLR (Chen et al., 2020), SimSiam (Chen et al., 2020\), and MAE (He et al., 2021\) and instantiated in foundation models for image embedding like DINOv2 (Oquab et al., 2023). Given their prevalence, it is useful to contrast the formulation of contrastive learning described here relative to these widely adopted approaches (and why this reviewer feels it is appropriate):
(1.1) No rotations or other image augmentations are performed to generate positive examples. These are not necessary with this approach since the pairs are sampled from heuristically tracked fragments (which produces sufficient training data, though see weaknesses discussed below) and the crops are pre-aligned egocentrically (mitigating the need for rotational invariance).
(1.2) There is no projection head in the architecture, like in SimCLR. Since classification/clustering is the only task that the system is intended to solve, the more general "nuisance" image features that this architectural detail normally affords are not necessary here.
(1.3) There is no stop gradient operator like in BYOL (Grill et al., 2020\) or SimSiam. Since the heuristic tracking implicitly produces plenty of negative pairs from the fragments, there is no need to prevent representational collapse due to class asymmetry. Some care is still needed, but the authors address this well through a pair sampling strategy (discussed below).
(1.4) Euclidean distance is used as the distance metric in the loss rather than cosine similarity as in most contrastive learning works. While cosine similarity coupled with L2-normalized unit hypersphere embeddings has proven to be a successful recipe to deal with the curse of dimensionality (with the added benefit of bounded distance limits), the authors address this through a cleverly constructed loss function that essentially allows direct control over the intra- and inter-cluster distance (D\_pos and D\_neg). This is a clever formulation that aligns well with the use of K-means for the downstream assignment step.
No concerns here, just clarifications for readers who dig into the review. Referencing the above literature would enhance the presentation of the paper to align with the broader computer vision literature.
Thank you for this detailed comparison. We have now added a new section in Appendix 3, “Differences with previous work in contrastive/metric learning” (lines 792-841) to include references to previous work and a description of what we do differently, including the points raised by the reviewer.
(2) Network architecture for image feature extraction backbone. As most of the computations that drive up processing time happen in the network backbone, the authors explored a variety of architectures to assess speed, accuracy, and memory requirements. They land on ResNet18 due to its empirically determined performance. While the experiments that support this choice are solid, the rationale behind the architecture selection is somewhat weak. The authors state that: "We tested 23 networks from 8 different families of state-of-the-art convolutional neural network architectures, selected for their compatibility with consumer-grade GPUs and ability to handle small input images (20 × 20 to 100 × 100 pixels) typical in collective animal behavior videos."
(2.1) Most modern architectures have variants that are compatible with consumer-grade GPUs. This is true of, for example, HRNet (Wang et al., 2019), ViT (Dosovitskiy et al., 2020), SwinT (Liu et al., 2021), or ConvNeXt (Liu et al., 2022), all of which report single GPU training and fast runtime speeds through lightweight configuration or subsequent variants, e.g., MobileViT (Mehta et al., 2021). The authors may consider revising that statement or providing additional support for that claim (e.g., empirical experiments) given that these have been reported to outperform ResNet18 across tasks.
Following the recommendation of the reviewer, we tested the architectures SwinT, ConvNeXt and ViT. We found out that none of them outperformed ResNet18 since they all showed a slower learning curve. This would result in higher tracking times. These tests are now included in the section “Network architecture” (lines 550-611).
(2.2) The compatibility of different architectures with small image sizes is configurable. Most convolutional architectures can be readily adapted to work with smaller image sizes, including 20x20 crops. With their default configuration, they lose feature map resolution through repeated pooling and downsampling steps, but this can be readily mitigated by swapping out standard convolutions with dilated convolutions and/or by setting the stride of pooling layers to 1, preserving feature map resolution across blocks. While these are fairly straightforward modifications (and are even compatible with using pretrained weights), an even more trivial approach is to pad and/or resize the crops to the default image size, which is likely to improve accuracy at a possibly minimal memory and runtime cost. These techniques may even improve the performance with the architectures that the authors did test out.
The only two tested architectures that require a minimum image size are AlexNet and DenseNet. DenseNet proved to underperform ResNet18 in the videos where the images are sufficiently large. We have tested AlexNet with padded images to see that it also performs worse than ResNet18 (see Appendix 3—figure 1).
We also tested the initialization of ResNet18 with pre-trained weights from ImageNet (in Appendix 3—figure 2) and it proved to bring no benefit to the training speed (added in lines 591-592).
(2.3) The authors do not report whether the architecture experiments were done with pretrained or randomly initialized weights.
We adapted the text to make it clear that the networks are always randomly initialized (lines 591-592, lines 608-609 and the captions of Appendix 3—figure 1 and 2).
(2.4) The authors do not report some details about their ResNet18 design, specifically whether a global pooling layer is used and whether the output fully connected layer has any activation function. Additionally, they do not report the version of ResNet18 employed here, namely, whether the BatchNorm and ReLU are applied after (v1) or before (v2) the conv layers in the residual path.
We use ResNet18 v1 with no activation function nor bias in its last layer (this has been clarified in the lines 606-608). Also, by design, ResNet has a global average pool right before the last fully connected layer which we did not remove. In response to the reviewer, Resnet18 v2 was tested and its performance is the same as that of v1 (see Appendix 3—figure 1 and lines 590-591).
(3) Pair sampling strategy. The authors devised a clever approach for sampling positive and negative pairs that is tailored to the nature of the formulation. First, since the positive and negative labels are derived from the co-existence of pretracked fragments, selection has to be done at the level of fragments rather than individual images. This would not be the case if one of the newer approaches for contrastive learning were employed, but it serves as a strength here (assuming that fragment generation/first pass heuristic tracking is achievable and reliable in the dataset). Second, a clever weighted sampling scheme assigns sampling weights to the fragments that are designed to balance "exploration and exploitation". They weigh samples both by fragment length and by the loss associated with that fragment to bias towards different and more difficult examples.
(3.1) The formulation described here resembles and uses elements of online hard example mining (Shrivastava et al., 2016), hard negative sampling (Robinson et al., 2020\), and curriculum learning more broadly. The authors may consider referencing this literature (particularly Robinson et al., 2020\) for inspiration and to inform the interpretation of the current empirical results on positive/negative balancing.
Following this recommendation, we added references of hard negative mining in the new section “Differences with previous work in contrastive/metric learning”, lines 792-841. Regarding curriculum learning, even though in spirit it might have parallels with our sampling method in the sense that there is a guided training of the network, we believe the approach is more similar to an exploration-exploitation paradigm.
(4) Speed and accuracy improvements. The authors report considerable improvements in speed and accuracy of the new idTracker (v6) over the original idTracker (v4?) and TRex. It's a bit unclear, however, which of these are attributable to the engineering optimizations (v5?) versus the representation learning formulation.
(4.1) Why is there an improvement in accuracy in idTracker v5 (L77-81)? This is described as a port to PyTorch and improvements largely related to the memory and data loading efficiency. This is particularly notable given that the progression went from 97.52% (v4; original) to 99.58% (v5; engineering enhancements) to 99.92% (v6; representation learning), i.e., most of the new improvement in accuracy owes to the "optimizations" which are not the central emphasis of the systematic evaluations reported in this paper.
V5 was a two year-effort designed to improve time efficiency of v4. It was also a surprise to us that accuracy was higher, but that likely comes from the fact that the substituted code from v4 contained some small bug/s. The improvements in v5 are retained in v6 (contrastive learning) and v6 has higher accuracy and shorter tracking times. The difference in v6 for this extra accuracy and shorter tracking times is contrastive learning.
(4.2) What about the speed improvements? Relative to the original (v4), the authors report average speed-ups of 13.6x in v5 and 44x in v6. Presumably, the drastic speed-up in v6 comes from a lower Protocol 2 failure rate, but v6 is not evaluated in Figure 2 - figure supplement 2.
Idtracker.ai v5 runs an optimized Protocol 2 and, sometimes, the Protocol 3. But v6 doesn’t run either of them. While P2 is still present in v6 as a fallback protocol when contrastive fails, in our v6 benchmark P2 was never needed. So the v6 speedup comes from replacing both P2 and P3 with the contrastive algorithm.
(5) Robustness to occlusion. A major innovation enabled by the contrastive representation learning approach is the ability to tolerate the absence of a global fragment (contiguous frames where all animals are visible) by requiring only co-existing pairs of fragments owing to the paired sampling formulation. While this removes a major limitation of the previous versions of idtracker.ai, its evaluation could be strengthened. The authors describe an ablation experiment where an arc of the arena is masked out to assess the accuracy under artificially difficult conditions. They find that the v6 works robustly up to significant proportions of occlusions, even when doing so eliminates global fragments.
(5.1) The experiment setup needs to be more carefully described.
(5.1.1) What does the masking procedure entail? Are the pixels masked out in the original video or are detections removed after segmentation and first pass tracking is done?
The mask is defined as a region of interest in the software. This means that it is applied at the segmentation step where the video frame is converted to a foreground-background binary image. The region of interest is applied here, converting to background all pixels not inside of it. We clarified this in the newly added section Occlusion tests, lines 240-244.
(5.1.2) What happens at the boundary of the mask? (Partial segmentation masks would throw off the centroids, and doing it after original segmentation does not realistically model the conditions of entering an occlusion area.)
Animals at the boundaries of the mask are partially detected. This can change the location of their detected centroid. That’s why, when computing the ground-truth accuracy for these videos, only the groundtruth centroids that were at minimum 15 pixels further from the mask were considered. We clarified this in the newly added section Occlusion tests, lines 248-251.
(5.1.3) Are fragments still linked for animals that enter and then exit the mask area?
No artificial fragment linking was added in these videos. Detected fragments are linked the usual way. If one animal hides into the mask, the animal disappears so the fragment breaks. We clarified this in the newly added section Occlusion tests, lines 245-247.
(5.1.4) How is the evaluation done? Is it computed with or without the masked region detections?
The groundtruth used to validate these videos contains the positions of all animals at all times. But only the positions outside the mask at each frame were considered to compute the tracking accuracy. We clarified this in the newly added section Occlusion tests, lines 248-251.
(5.2) The circular masking is perhaps not the most appropriate for the mouse data, which is collected in a rectangular arena.
We wanted to show the same proof of concept in different videos. For that reason, we used to cover the arena parametrized by an angle. In the rectangular arena the circular masking uses an external circle, so it is covering the rectangle parametrized by an angle.
(5.3) The number of co-existing fragments, which seems to be the main determinant of performance that the authors derive from this experiment, should be reported for these experiments. In particular, a "number of co-existing fragments" vs accuracy plot would support the use of the 0.25(N-1) heuristic and would be especially informative for users seeking to optimize experimental and cage design. Additionally, the number of co-existing fragments can be artificially reduced in other ways other than a fixed occlusion, including random dropout, which would disambiguate it from potential allocentric positional confounds (particularly relevant in arenas where egocentric pose is correlated with allocentric position).
We included the requested analysis about the fragment connectivity in Figure 3-figure supplement 1. We agree that there can be additional ways of reducing co-existing fragments, but we think the occlusion tests have the additional value that there are many real experiments similar to this test.
(6) Robustness to imaging conditions. The authors state that "the new idtracker.ai can work well with lower resolutions, blur and video compression, and with inhomogeneous light (Figure 2 - figure supplement 4)." (L156). Despite this claim, there are no speed or accuracy results reported for the artificially corrupted data, only examples of these image manipulations in the supplementary figure.
We added this information in the same image, new Figure 1 - figure supplement 3.
(7) Robustness across longitudinal or multi-session experiments. The authors reference idmatcher.ai as a compatible tool for this use case (matching identities across sessions or long-term monitoring across chunked videos), however, no performance data is presented to support its usage. This is relevant as the innovations described here may interact with this setting. While deep metric learning and contrastive learning for ReID were originally motivated by these types of problems (especially individuals leaving and entering the FOV), it is not clear that the current formulation is ideally suited for this use case. Namely, the design decisions described in point 1 of this review are at times at odds with the idea of learning generalizable representations owing to the feature extractor backbone (less scalable), low-dimensional embedding size (less representational capacity), and Euclidean distance metric without hypersphere embedding (possible sensitivity to drift). It's possible that data to support point 6 can mitigate these concerns through empirical results on variations in illumination, but a stronger experiment would be to artificially split up a longer video into shorter segments and evaluate how generalizable and stable the representations learned in one segment are across contiguous ("longitudinal") or discontiguous ("multi-session") segments.
We have now added a test to prove the reliability of idmatcher.ai in v6. In this test, 14 videos are taken from the benchmark and split in two non-overlapping parts (with a 200 frames gap in between). idmatcher.ai is run between the two parts presenting a 100% accuracy identity matching across all of them (see section “Validity of idmatcher.ai in the new idtracker.ai”, lines 969-1008).
We thank the reviewer for the detailed suggestions. We believe we have taken all of them into consideration to improve the ms.
Reviewer #3 (Public review):
Summary
The authors propose a new version of idTracker.ai for animal tracking. Specifically, they apply contrastive learning to embed cropped images of animals into a feature space where clusters correspond to individual animal identities.
Strengths
By doing this, the new software alleviates the requirement for so-called global fragments - segments of the video, in which all entities are visible/detected at the same time - which was necessary in the previous version of the method. In general, the new method reduces the tracking time compared to the previous versions, while also increasing the average accuracy of assigning the identity labels.
Weaknesses
The general impression of the paper is that, in its current form, it is difficult to disentangle the old from the new method and understand the method in detail. The manuscript would benefit from a major reorganization and rewriting of its parts. There are also certain concerns about the accuracy metric and reducing the computational time.
We have made the following modifications in the presentation:
(1) We have added section tiles to the main text so it is clearer what tracking system we are referring to. For example, we now have sections “Limitation of the original idtracker.ai”, “Optimizing idtracker.ai without changes in the learning method” and “The new idtracker.ai uses representation learning”.
(2) We have completely rewritten all the text of the ms until we start with contrastive learning. Old L20-89 is now L20-L66, much shorter and easier to read.
(3) We have rewritten the first 3 paragraphs in the section “The new idtracker.ai uses representation learning” (lines 68-92).
(4) We now expanded Appendix 3 to discuss the details of our approach (lines 539-897). It discusses in detail the steps of the algorithm, the network architecture, the loss function, the sampling strategy, the clustering and identity assignment, and the stopping criteria in training
(5) To cite previous work in detail and explain what we do differently, we have now added in Appendix 3 the new section “Differences with previous work in contrastive/metric learning” (lines 792-841).
Regarding accuracy metrics, we have replaced our accuracy metric with the standard metric IDF1. IDF1 is the standard metric that is applied to systems in which the goal is to maintain consistent identities across time. See also the section in Appendix 1 "Computation of tracking accuracy” (lines 414-436) explaining IDF1 and why this is an appropriate metric for our goal.
Using IDF1 we obtain slightly higher accuracies for the idtracker.ai systems. This is the comparison of mean accuracy over all our benchmark for our previous accuracy score and the new one for the full trajectories:
v4: 97.42% -> 98.24%
v5: 99.41% -> 99.49%
v6: 99.74% -> 99.82%
trex: 97.89% -> 97.89%
We thank the reviewer for the suggestions about presentation and about the use of more standard metrics.
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
(1) Figure 1a: A graphical legend inset would make it more readable since there are multiple colors, line styles, and connecting lines to parse out.
Following this recommendation, we added a graphical legend in the old Figure 1 (new Figure 2).
(2) L46: "have images" → "has images".
We applied this correction. Line 35.
(3) L52: "videos start with a letter for the species (z,**f**,m)", but "d" is used for fly videos.
We applied this correction in the caption of Figure 1.
(4) L62: "with Protocol 3 a two-step process" → "with Protocol 3 being a two-step process".
We rewrote this paragraph without mentioning Protocol 3, lines 37-41.
(5) L82-89: This is the main statement of the problems that are being addressed here (speed and relaxing the need for global fragments). This could be moved up, emphasized, and made clearer without the long preamble and results on the engineering optimizations in v5. This lack of linearity in the narrative is also evident in the fact that after Figure 1a is cited, inline citations skip to Figure 2 before returning to Figure 1 once the contrastive learning is introduced.
We have rewritten all the text until the contrastive learning, (old lines 20-89 are now lines 20-66). The text is shorter, more linear and easier to read.
(6) L114: "pairs until the distance D_{pos}" → "pairs until the distance approximates D_{pos}".
We rewrote as “ pairs until the distance 𝐷pos (or 𝐷neg) is reached” in line 107.
(7) L570: Missing a right parenthesis in the equation.
We no longer have this equation in the ms.
(8) L705: "In order to identify fragments we, not only need" → "In order to identify fragments, we not only need".
We applied this correction, Line 775.
(9) L819: "probably distribution" → "probability distribution".
We applied this correction, Line 776.
(10) L833: "produced the best decrease the time required" → "produced the best decrease of the time required".
We applied this correction, Line 746.
Reviewer #3 (Recommendations for the authors):
(1) We recommend rewriting and restructuring the manuscript. The paper includes a detailed explanation of the previous approaches (idTracker and idTracker.ai) and their limitations. In contrast, the description of the proposed method is short and unstructured, which makes it difficult to distinguish between the old and new methods as well as to understand the proposed method in general. Here are a few examples illustrating the problem.
(1.1) Only in line 90 do the authors start to describe the work done in this manuscript. The previous 3 pages list limitations of the original method.
We have now divided the main text into sections, so it is clearer what is the previous method (“Limitation of the original idtracker.ai”, lines 28-51), the new optimization we did of this method (“Optimizing idtracker.ai without changes in the learning method”, lines 52-66) and the new contrastive approach that also includes the optimizations (“The new idtracker.ai uses representation learning”, lines 66-164). Also, the new text has now been streamlined until the contrastive section, following your suggestion. You can see that in the new writing the three sections are 25 , 15 and 99 lines. The more detailed section is the new system, the other two are needed as reference, to describe which problem we are solving and the extra new optimizations.
(1.2) The new method does not have a distinct name, and it is hard to follow which idtracker.ai is a specific part of the text referring to. Not naming the new method makes it difficult to understand.
We use the name new idtracker.ai (v6) so it becomes the current default version. v5 is now obsolete, as well as v4. And from the point of view of the end user, no new name is needed since v6 is just an evolution of the same software they have been using. Also, we added sections in the main text to clarify the ideas in there and indicate the version of idtracker.ai we are referring to.
(1.3) There are "Protocol 2" and "Protocol 3" mixed with various versions of the software scattered throughout the text, which makes it hard to follow. There should be some systematic naming of approaches and a listing of results introduced.
Following this recommendation we no longer talk about the specific protocols of the old version of idtracker.ai in the main text. We rewritten the explanation of these versions in a more clear and straightforward way, lines 29-36.
(2) To this end, the authors leave some important concepts either underexplained or only referenced indirectly via prior work. For example, the explanation of how the fragments are created (line 15) is only explained by the "video structure" and the algorithm that is responsible for resolving the identities during crossings is not detailed (see lines 46-47, 149-150). Including summaries of these elements would improve the paper's clarity and accessibility.
We listed the specific sections from our previous publication where the reader can find information about the entire tracking pipeline (lines 539-549). This way, we keep the ms clear and focused on the new identification algorithm while indicating where to find such information.
(3) Accuracy metrics are not clear. In line 319, the authors define it as based on "proportion of errors in the trajectory". This proportion is not explained. How is the error calculated if a trajectory is lost or there are identity swaps? Multi-object tracking has a range of accuracy metrics that account for such events but none of those are used by the authors. Estimating metrics that are common for MOT literature, for example, IDF1, MOTA, and MOTP, would allow for better method performance understanding and comparison.
In the new ms, we replaced our accuracy metric with the standard metric IDF1. IDF1 is the standard metric that is applied to systems in which the goal is to maintain consistent identities across time. See also the section in Appendix 1 "Computation of tracking accuracy” explaining why IDF1 and not MOTA or MOTP is the adequate metric for a system that wants to give correct tracking by identification in time. See lines 416-436.
Using IDF1 we obtain slightly higher accuracies for the idtracker.ai systems. This is the comparison of mean accuracy four our previous accuracy and the new one for the full trajectories:
v4: 97.42% -> 98.24%
v5: 99.41% -> 99.49%
v6: 99.74% -> 99.82%
trex: 97.89% -> 97.89%
(4) Additionally, the authors distinguish between tracking with and without crossings, but do not provide statistics on the frequency of crossings per video. It is also unclear how the crossings are considered for the final output. Including information such as the frame rate of the videos would help to better understand the temporal resolution and the differences between consecutive frames of the videos.
We added this information in the Appendix 1 “Benchmark of accuracy and tracking time”, lines 445-451. The framerate in our benchmark videos goes from 25 to 60 fps (average of 37 fps). On average 2.6% of the blobs are crossings (1.1% for zebrafish 0.7% for drosophila 9.4% for mice).
(5) In the description of the dataset used for evaluation (lines 349-365), the authors describe the random sampling of parameter values for each tracking run. However, it is unclear whether the same values were used across methods. Without this clarification, comparisons between the proposed method, older versions, and TRex might be biased due to lucky parameter combinations. In addition, the ranges from which the values were randomly sampled were also not described.
Only one parameter is shared between idtracker.ai and TRex: intensity_threshold (in idtracker.ai) and threshold (in TRex). Both are conceptually equivalent but differ in their numerical values since they affect different algorithms. V4, v5, and TRex each required the same process of independent expert visual inspection of the segmentation to select the valid value range. Since versions 5 and 6 use exactly the same segmentation algorithm, they share the same parameter ranges.
All the ranges of valid values used in our benchmark are public here https://drive.google.com/drive/folders/1tFxdtFUudl02ICS99vYKrZLeF28TiYpZ as stated in the section “Data availability”, lines 227-228.
(6) Lines 122-123, Figure 1c. "batches" - is an imprecise metric of training time as there is no information about the batch size.
We clarified the Figure caption, new Figure 2c.
(7) Line 145 - "we run some steps... For example..." leaves the method description somewhat unclear. It would help if you could provide more details about how the assignments are carried out and which metrics are being used.
Following this recommendation, we listed the specific sections from our previous publication where the reader can find information about the entire tracking pipeline (lines 539-549). This way, we keep the ms clear and focused on the new identification algorithm while indicating where to find such information.
(8) Figure 3. How is tracking accuracy assessed with occlusions? Are the individuals correctly recognized when they reappear from the occluded area?
The groundtruth for this video contains the positions of all animals at all times. Only the groundtruth points inside the region of interest are taken into account when computing the accuracy. When the tracking reaches high accuracy, it means that animals are successfully relabeled every time they enter the non-masked region. Note that this software works all the time by identification of animals, so crossings and occlusion are treated the same way. What is new here is that the occlusions are so large that there are no global fragments. We clarified this in the new section “Occlusion tests” in Methods, lines 239-251.
(9) Lines 185-187 this part of the sentence is not clear.
We rewrote this part in a clearer way, lines 180-182.
(10) The authors also highlight the improved runtime performance. However, they do not provide a detailed breakdown of the time spent on each component of the tracking/training pipeline. A timing breakdown would help to compare the training duration with the other components. For example, the calculation of the Silhouette Score alone can be time-consuming and could be a bottleneck in the training process. Including this information would provide a clearer picture of the overall efficiency of the method.
We measured that the training of ResNet takes on average in our benchmark 47% of the tracking time (we added this information line 551 section “Network Architecture”). In this training stage the bottleneck becomes the network forward and backward pass, limited by the GPU performance. All other processes happening during training have been deeply optimized and parallelized when needed so their contribution to the training time is minimal. Apart from the training, we also measured 24.4% of the total tracking time spent in reading and segmenting the video files and 11.1% in processing the identification images and detecting crossings.
(11) An important part of the computational cost is related to model training. It would be interesting to test whether a model trained on one video of a specific animal type (e.g., zebrafish_5) generalizes to another video of the same type (e.g., zebrafish_7). This would assess the model's generalizability across different videos of the same species and spare a lot of compute. Alternatively, instead of training a model from scratch for each video, the authors could also consider training a base model on a superset of images from different videos and then fine-tuning it with a lower learning rate for each specific video. This could potentially save time and resources while still achieving good performance.
Already before v6, there was the possibility for the user to start training the identification network by copying the final weights from another tracking session. This knowledge transfer feature is still present in v6 and it still decreases the training times significatively. This information has been added in Appendix 4, lines 906-909.
We have already begun working on the interesting idea of a general base model but it brings some complex challenges. It could be a very useful new feature for future idtracker.ai releases.
We thank the reviewer for the many suggestions. We have implemented all of them.
‘you don't even know what Bubble Sort does. It's six lines of code. And we found new things that nobody had seen. If we can't predict what bubble sort is going to do, you have no idea what this other thing is going to be.
for - human hubris - bubble sort - Michael Levin
size code hypothesis
deliberately changing your voice from soft and delicate to appear as nice and helpful to a lower voice, to give you more confidence
Author response:
The following is the authors’ response to the current reviews.
Public Reviews:
Reviewer #2 (Public review):
Summary:
This is an interesting study exploring methods for reconstructing visual stimuli from neural activity in the mouse visual cortex. Specifically, it uses a competition dataset (published in the Dynamic Sensorium benchmark study) and a recent winning model architecture (DNEM, dynamic neural encoding model) to recover visual information stored in ensembles of mouse visual cortex.
Strengths:
This is a great start for a project addressing visual reconstruction. It is based on physiological data obtained at a single-cell resolution, the stimulus movies were reasonably naturalistic and representative of the real world, the study did not ignore important correlates such as eye position and pupil diameter, and of course, the reconstruction quality exceeded anything achieved by previous studies. There appear to be no major technical flaws in the study, and some potential confounds were addressed upon revision. The study is an enjoyable read.
Weaknesses:
The study is technically competent and benchmark-focused, but without significant conceptual or theoretical advances. The inclusion of neuronal data broadens the study's appeal, but the work does not explore potential principles of neural coding, which limits its relevance for neuroscience and may create some disappointment to some neuroscientists. The authors are transparent that their goal was methodological rather than explanatory, but this raises the question of why neuronal data were necessary at all, as more significant reconstruction improvements might be achievable using noise-less artificial video encoders alone (network-to-network decoding approaches have been done well by teams such as Han, Poggio, and Cheung, 2023, ICML). Yet, even within the methodological domain, the study does not articulate clear principles or heuristics that could guide future progress. The finding that more neurons improve reconstruction aligns with well-established results in the literature that show that higher neuronal numbers improve decoding in general (for example, Hung, Kreiman, Poggio, and DiCarlo, 2005) and thus may not constitute a novel insight.
We thank the reviewer for this second round of comments and hope we were able to address the remaining points below.
Indeed, using surrogate noiseless data is interesting and useful when developing such methods, or to demonstrate that they work in principle. But in order to evaluate if they really work in practice, we need to use real neuronal data. While we did not try movie reconstruction from layers within artificial neural networks as surrogate data, in Supplementary Figure 3C we provide the performance of our method using simulated/predicted neuronal responses from the dynamic neural encoding model alongside real neuronal responses.
Specific issues:
(1)The study showed that it could achieve high-quality video reconstructions from mouse visual cortex activity using a neural encoding model (DNEM), recovering 10-second video sequences and approaching a two-fold improvement in pixel-by-pixel correlation over attempts. As a reader, I was left with the question: okay, does this mean that we should all switch to DNEM for our investigations of mouse visual cortex? What makes this encoding model special? It is introduced as "a winning model of the Sensorium 2023 competition which achieved a score of 0.301...single trial correlation between predicted and ground truth neuronal activity," but as someone who does not follow this competition (most eLife readers are not likely to do so, either), I do not know how to gauge my response. Is this impressive? What is the best theoretical score, given noise and other limitations? Is the model inspired by the mouse brain in terms of mechanisms or architecture, or was it optimized to win the competition by overfitting it to the nuances of the data set? Of course, I know that as a reader, I am invited to read the references, but the study would stand better on its own, if it clarified how its findings depended on this model.
The revision helpfully added context to the Methods about the range of scores achieved by other models, but this information remains absent from the Abstract and other important sections. For instance, the Abstract states, "We achieve a pixel-level correlation of 0.57 between the ground truth movie and the reconstructions from single-trial neural responses," yet this point estimate (presented without confidence intervals or comparisons to controls) lacks meaning for readers who are not told how it compares to prior work or what level of performance would be considered strong. Without such context, the manuscript undercuts potentially meaningful achievements.
We appreciate that the additional information about the performance of the SOTA DNEM to predict neural responses could be made more visible in the paper and will therefore move it from the methods to the results section instead:
Line 348 “This model achieved an average single-trial correlation between predicted and ground truth neural activity of 0.291 during the competition, this was later improved to 0.301. The competition benchmark models achieved 0.106, 0.164 and 0.197 single-trial correlation, while the third and second place models achieved 0.243 and 0.265. Across the models, a variety of architectural components were used, including 2D and 3D convolutional layers, recurrent layers, and transformers, to name just a few.” will be moved to the results.
With regard to the lack of context for the performance of our reconstruction in the abstract, we may have overcorrected in the previous revision round and have tried to find a compromise which gives more context to the pixel-level correlation value:
Abstract: “We achieve a pixel-level correlation of 0.57 (95% CI [0.54, 0.60]) between ground-truth movies and single-trial reconstructions. Previous reconstructions based on awake mouse V1 neuronal responses to static images achieved a pixel-level correlation of 0.238 over a similar retinotopic area.”
(2) Along those lines, the authors conclude that "the number of neurons in the dataset and the use of model ensembling are critical for high-quality reconstructions." If true, these principles should generalize across network architectures. I wondered whether the same dependencies would hold for other network types, as this could reveal more general insights. The authors replied that such extensions are expected (since prior work has shown similar effects for static images) but argued that testing this explicitly would require "substantial additional work," be "impractical," and likely not produce "surprising results." While practical difficulty alone is not a sufficient reason to leave an idea untested, I agree that the idea that "more neurons would help" would be unsurprising. The question then becomes: given that this is a conclusion already in the field, what new principle or understanding has been gained in this study?
As mentioned in our previous round of revisions, we chose not to pursue the comparison of reconstructions using different model architectures in this manuscript because we did not think it would add significant insights to the paper given the amount of work it would require, and we are glad the reviewer agrees.
While the fact that more neurons result in better reconstructions is unsurprising, how quickly performance drops off will depend on the robustness of the method, and on the dimensionality of the decoding/reconstruction task (decoding grating orientation likely requires fewer neurons than gray scale image reconstruction, which in turn likely requires fewer neurons than full color movie reconstruction). How dependent input optimization based image/movie reconstruction is on population size has not been shown, so we felt it was useful for readers to know how well movie reconstruction works with our method when recording from smaller numbers of neurons.
(3) One major claim was that the quality of the reconstructions depended on the number of neurons in the dataset. There were approximately 8000 neurons recorded per mouse. The correlation difference between the reconstruction achieved by 1000 neurons and 8000 neurons was ~0.2. Is that a lot or a little? One might hypothesize that 7000 additional neurons could contribute more information, but perhaps, those neurons were redundant if their receptive fields are too close together or if they had the same orientation or spatiotemporal tuning. How correlated were these neurons in response to a given movie? Why did so many neurons offer such a limited increase in correlation? Originally, this question was meant to prompt deeper analysis of the neural data, but the authors did not engage with it, suggesting a limited understanding of the neuronal aspects of the dataset.
We apologize that we did not engage with this comment enough in the previous round. We assumed that the question arose because there was a misunderstanding about figure 5: 1000 not 1 neuron is sufficient to reconstruct the movies to a pixel-level correlation of 0.344. Of course, the fact that increasing the number of neurons from 1000 to 8000 only increased the reconstruction performance from 0.344 to 0.569 (65% increase in correlation) is still worth discussing. To illustrate this drop in performance qualitatively, we show 3 example frames from movie reconstructions using 1000-8000 neurons in Author response image 1.
Author response image 1.
3 example frames from reconstructions using different numbers of neurons.
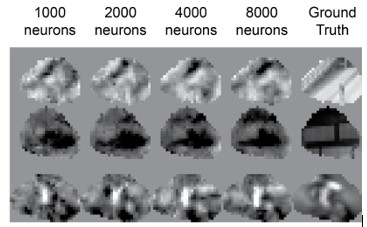
As the reviewer points out, the diminishing returns of additional neurons to reconstruction performance is at least partly because there is redundancy in how a population of neurons represents visual stimuli. In supplementary figure S2, we inferred the on-off receptive fields of the neurons and show that visual space is oversampled in terms of the receptive field positions in panel C. However, the exact slope/shape of the performance vs population size curve we show in Figure 5 will also depend on the maximum performance of our reconstruction method, which is limited in spatial resolution (Figure 4 & Supplementary Figure S5). It is possible that future reconstruction approaches will require fewer neurons than ours, so we interpret this curve rather as a description of the reconstruction method itself than a feature of the underlying neuronal code. For that reason, we chose caution and refrained from making any claims about neuronal coding principles based on this plot.
(4) We appreciated the experiments testing the capacity of the reconstruction process, by using synthetic stimuli created under a Gaussian process in a noise-free way. But this originally further raised questions: what is the theoretical capability for reconstruction of this processing pipeline, as a whole? Is 0.563 the best that one could achieve given the noisiness and/or neuron count of the Sensorium project? What if the team applied the pipeline to reconstruct the activity of a given artificial neural network's layer (e.g., some ResNet convolutional layer), using hidden units as proxies for neuronal calcium activity? In the revision, this concern was addressed nicely in the review in Supplementary Figure 3C. Also, one appreciates that as a follow up, the team produced error maps (New Figure 6) that highlight where in the frames the reconstruction are likely to fail. But the maps went unanalyzed further, and I am not sure if there was a systematic trend in the errors.
We are happy to hear that we were able to answer the reviewers’ question of what the maximum theoretical performance of our reconstruction process is in figure 3C. Regarding systematic trends in the error maps, we also did not observe any clear systematic trends. If anything, we noticed that some moving edges were shifted, but we do not think we can quantify this effect with this particular dataset.
(5) I was encouraged by Figure 4, which shows how the reconstructions succeeded or failed across different spatial frequencies. The authors note that "the reconstruction process failed at high spatial frequencies," yet it also appears to struggle with low spatial frequencies, as the reconstructed images did not produce smooth surfaces (e.g., see the top rows of Figures 4A and 4B). In regions where one would expect a single continuous gradient, the reconstructions instead display specular, high-frequency noise. This issue is difficult to overlook and might deserve further discussion.
Thank you for pointing this out, this is indeed true. The reconstructions do have high frequency noise. We mention this briefly in line 102 “Finally, we applied a 3D Gaussian filter with sigma 0.5 pixels to remove the remaining static noise (Figure S3) and applied the evaluation mask.” In revisiting this sentence, we think it is more appropriate to replace “remove” with “reduce”. This noise is more visible in the Gaussian noise stimuli (Figure 4) because we did not apply the 3D Gaussian filter to these reconstructions, in case it interfered with the estimates of the reconstruction resolution limits.
Given that the Gaussian noise and drifting grating stimuli reconstructions were from predicted activity (“noise-free”), this high-frequency noise is not biological in origin and must therefore come from errors in our reconstruction process. This kind of high-frequency noise has previously been observed in feature visualization (optimizing input to maximize the activity of a specific node within a neural network to visualize what that node encodes; Olah, et al., "Feature Visualization", https://distill.pub/2017/feature-visualization/, 2017). It is caused by a kind of overfitting, whereby a solution to the optimization is found that is not “realistic”. Ways of combating this kind of noise include gradient smoothing, image smoothing, and image transformations during optimization, but these methods can restrict the resolution of the features that are recovered. Since we were more interested in determining the maximum resolution of stimuli that can be reconstructed in Figure 4 and Supplementary Figures 5-6, we chose not to apply these methods.
Reviewer #3 (Public review):
Summary:
This paper presents a method for reconstructing input videos shown to a mouse from the simultaneously recorded visual cortex activity (two-photon calcium imaging data). The publicly available experimental dataset is taken from a recent brain-encoding challenge, and the (publicly available) neural network model that serves to reconstruct the videos is the winning model from that challenge (by distinct authors). The present study applies gradient-based input optimization by backpropagating the brain-encoding error through this selected model (a method that has been proposed in the past, with other datasets). The main contribution of the paper is, therefore, the choice of applying this existing method to this specific dataset with this specific neural network model. The quantitative results appear to go beyond previous attempts at video input reconstruction (although measured with distinct datasets). The conclusions have potential practical interest for the field of brain decoding, and theoretical interest for possible future uses in functional brain exploration.
Strengths:
The authors use a validated optimization method on a recent large-scale dataset, with a state-of-the-art brain encoding model. The use of an ensemble of 7 distinct model instances (trained on distinct subsets of the dataset, with distinct random initializations) significantly improves the reconstructions. The exploration of the relation between reconstruction quality and number of recorded neurons will be useful to those planning future experiments.
Weaknesses:
The main contribution is methodological, and the methodology combines pre-existing components without any new original component.
We thank the reviewer for their balanced assessment of our manuscript.
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
This paper presents a method for reconstructing videos from mouse visual cortex neuronal activity using a state-of-the-art dynamic neural encoding model. The authors achieve high-quality reconstructions of 10-second movies at 30 Hz from two-photon calcium imaging data, reporting a 2-fold increase in pixel-by-pixel correlation compared to previous methods. They identify key factors for successful reconstruction including the number of recorded neurons and model ensembling techniques.
Strengths:
(1) A comprehensive technical approach combining state-of-the-art neural encoding models with gradient-based optimization for video reconstruction.
(2) Thorough evaluation of reconstruction quality across different spatial and temporal frequencies using both natural videos and synthetic stimuli.
(3) Detailed analysis of factors affecting reconstruction quality, including population size and model ensembling effects.
(4) Clear methodology presentation with well-documented algorithms and reproducible code.
(5) Potential applications for investigating visual processing phenomena like predictive coding and perceptual learning.
We thank the reviewer for taking the time to provide this valuable feedback. We would like to add that in our eyes one additional main contribution is the step of going from reconstruction of static images to dynamic videos. We trust that in the revised manuscript, we have now made the point more explicit that static image reconstruction relies on temporally averaged responses, which negates the necessity of having to account for temporal dynamics altogether.
Weaknesses:
The main metric of success (pixel correlation) may not be the most meaningful measure of reconstruction quality:
High correlation may not capture perceptually relevant features.
Different stimuli producing similar neural responses could have low pixel correlations The paper doesn't fully justify why high pixel correlation is a valuable goal
This is a very relevant point. In retrospect, perhaps we did not justify this enough. Sensory reconstruction typically aims to reconstruct sensory input based on brain activity as faithfully as possible. A brain-to-image decoder might therefore be trained to produce images as close to the original input as possible. The loss function to train the decoder would therefore be image similarity on the pixel level. In that case, evaluating reconstruction performance based on pixel correlation is somewhat circular.
However, when reconstructing videos, we optimize the input video in terms of its perceptual similarity to the original video and only then evaluate pixel-level similarity. The perceptual similarity metric we optimize for is the estimate of how the neurons in mouse V1 respond to that video. We then evaluate the similarity of this perceptually optimized video to the original input video with pixel-level correlation. In other words, we optimize for perceptual similarity and then evaluate pixel similarity. If our method optimized pixel-level similarity, then we would agree that perceptual similarity is a more relevant evaluation metric. We do not think it was clear in our original submission that our optimization loss function is a perceptual loss function, and have now made this clearer in Figure 1C-D and have clarified this in the results section, line 70:
“In effect, we optimized the input video to be perceptually similar with respect to the recorded neurons.”
And in line 110:
“Because our optimization of the movies was based on a perceptual loss function, we were interested in how closely these movies matched the originals on the pixel level.”
We chose to use pixel correlation to measure pixel-level similarity for several reasons. 1) It has been used in the past to evaluate reconstruction performance (Yoshida et al., 2020), 2) It is contrast and luminance insensitive, 3) correlation is a common metric so most readers will have an intuitive understanding of how it relates to the data.
To further highlight why pixel similarity might be interesting to visualize, we have included additional analysis in Figure 6 illustrating pixel-level differences between reconstructions from experimentally recorded activity and predicted activity.
We expect that the type of perceptual similarity the reviewer is alluding to is pretrained neural network image embedding similarity (Zhang et al., 2018: https://doi.org/10.48550/arXiv.1801.03924). While these metrics seem to match human perceptual similarity, it is unclear if they reflect mouse vision. We did try to compare the embedding similarity from pretrained networks such as VGG16, but got results suggesting the reconstructed frames were no more similar to the ground truth than random frames, which is obviously not true. This might be because the ground truth videos were too different in resolution from the training data of these networks and because these metrics are typically very sensitive to decreases in resolution.
The best alternative approach to evaluate mouse perceptual similarity would be to show the reconstructed videos to the same animals while recording the same neurons and to compare these neural activation patterns to those evoked by the original ground truth videos. This has been done for static images in the past: Cobos et al., bioRxiv 2022, found that static image reconstructions generated using gradient descent evoked more similar trial-averaged (40 trials) responses to those evoked by ground truth images compared to other reconstruction methods. Unfortunately, we are currently not able to perform these in vivo experiments, which is why we used publicly available data for the current paper. We plan to use this method in the future. But this method is also not flawless as it assumes that the average response to an image is the best reflection of how that image is represented, which may not be the case for an individual trial.
As far as we are aware, there is currently no method that, given a particular activity pattern in response to an image/video, can produce an image/video that induces a neural activity pattern that is closer to the original neural response than simply showing the same image/video again. Hypothetically, such a stimulus exists because of various visual processing phenomena we mention in our discussion (e.g., predictive coding and selective attention), which suggest that the image that is represented by a population of neurons likely differs from the original sensory input. In other words, what the brain represents is an interpretation of reality not a pure reflection. Experimentally verifying this is difficult, as these variations might be present on a single trial level. The first step towards establishing a method that captures the visual representation of a population of neurons is sensory reconstruction, where the aim is to get as close as possible to the original sensory input. We think pixel-level correlation is a stringent and interpretable metric for this purpose, particularly when optimizing for perceptual similarity rather than image similarity directly.
Comparison to previous work (Yoshida et al.) has methodological concerns: Direct comparison of correlation values across different datasets may be misleading; Large differences in the number of recorded neurons (10x more in the current study); Different stimulus types (dynamic vs static) make comparison difficult; No implementation of previous methods on the current dataset or vice versa.
Yes, we absolutely agree that direct comparison to previous static image reconstruction methods is problematic. We primarily do so because we think it is standard practice to give related baselines. We agree that direct comparison of the performance of video reconstruction methods to image reconstruction methods is not really possible. It does not make sense to train and apply a dynamic model on a static image data set where neural activity is time-averaged, as the temporal kernels could not be learned. Conversely, for a static model, which expects a single image as input and predicts time averaged responses, it does not make sense to feed it a series of temporally correlated movie frames and to simply concatenate the resulting activity perdition. The static model would need to be substantially augmented to incorporate temporal dynamics, which in turn would make it a new method. This puts us in the awkward position of being expected to compare our video reconstruction performance to previous image reconstruction methods without a fair way of doing so. We have now added these caveats in line 119:
“However, we would like to stress that directly comparing static image reconstruction methods with movie reconstruction approaches is fundamentally problematic, as they rely on different data types both during training and evaluation (temporally averaged vs continuous neural activity, images flashed at fixed intervals vs continuous movies).”
We have also toned down the language, emphasising the comparison to previous image reconstruction performance in the abstract, results, and conclusion.
Abstract: We removed “We achieve a ~2-fold increase in pixel-by-pixel correlation compared to previous state-of-the-art reconstructions of static images from mouse V1, while also capturing temporal dynamics.” and replaced with “We achieve a pixel-level correction of 0.57 between the ground truth movie and the reconstructions from single-trial neural responses.”
Discussion: we removed “In conclusion, we reconstruct videos presented to mice based on the activity of neurons in the mouse visual cortex, with a ~2-fold improvement in pixel-by-pixel correlation compared to previous static image reconstruction methods.” and replaced with “In conclusion, we reconstruct videos presented to mice based on single-trial activity of neurons in the mouse visual cortex.”
We have also removed the performance table and have instead added supplementary figure 3 with in-depth comparison across different versions of our reconstruction method (variations of masking, ensembling, contrast & luminance matching, and Gaussian blurring).
Limited exploration of how the reconstruction method could provide insights into neural coding principles beyond demonstrating technical capability.
The aim of this paper was not to reveal principles of neural coding. Instead, we aimed to achieve the best possible performance of video reconstructions and to quantify the limitations. But to highlight its potential we have added two examples of how sensory reconstruction has been applied in human vision research in line 321:
“Although fMRI-based reconstruction techniques are starting to be used to investigate visual phenomena in humans (such as illusions [Cheng et al., 2023] and mental imagery [Shen et al., 2019; Koide-Majima et al., 2024; Kalantari et al., 2025]), visual processing phenomena are likely difficult to investigate using existing fMRI-based reconstruction approaches, due to the low spatial and temporal resolution of the data.”
We have also added a demonstration of how this method could be used to investigate which parts of a reconstruction from a single trial response differs from the model's prediction (Figure 6). We do this by calculating pixel-level differences between reconstructions from the recorded neural activity and reconstructions from the expected neural activity (predicted activity by the neural encoding model). Although difficult to interpret, this pixel-by-pixel error map could represent trial-by-trial deviations of the neural code from pure sensory representation. But at this point we cannot know whether these errors are nothing more than errors in the reconstruction process. To derive meaningful interpretations of these maps would require a substantial amount of additional work and in vivo experiments and so is outside the scope of this paper, but we include this additional analysis now to highlight a) why pixel-level similarity might be interesting to quantify and visualize and b) to demonstrate how video reconstruction could be used to provide insights into neural coding, namely as a tool to identify how sensory representations differ from a pure reflection of the visual input.
The claim that "stimulus reconstruction promises a more generalizable approach" (line 180) is not well supported with concrete examples or evidence.
What we mean by generalizable is the ability to apply reconstruction to novel stimuli, which is not possible for stimulus classification. We now explain this better in the paragraph in line 211:
“Stimulus identification, i.e. identifying the most likely stimulus from a constrained set, has been a popular approach for quantifying whether a population of neurons encodes the identity of a particular stimulus [Földiák, 1993, Kay et al., 2008]. This approach has, for instance, been used to decode frame identity within a movie [Deitch et al., 2021, Xia et al., 2021, Schneider et al., 2023, Chen et al.,2024]. Some of these approaches have also been used to reorder the frames of the ground truth movie [Schneider et al., 2023] based on the decoded frame identity. Importantly, stimulus identification methods are distinct from stimulus reconstruction where the aim is to recreate what the sensory content of a neuronal code is in a way that generalizes to new sensory stimuli [Rakhimberdina et al., 2021]. This is inherently a more demanding task because the range of possible solutions is much larger. Although stimulus identification is a valuable tool for understanding the information content of a population code, stimulus reconstruction could provide a more generalizable approach, because it can be applied to novel stimuli.”
All the stimuli we reconstructed were not in the training set of the model, i.e., novel. We have also downed down the claim: we have replaced “promises” with “could provide”.
The paper would benefit from addressing how the method handles cases where different stimuli produce similar neural responses, particularly for high-speed moving stimuli where phase differences might be lost in calcium imaging temporal resolution.
Thank you for this suggestion, we think this is a great question. Calcium dynamics are slow and some of the high temporal frequency information could indeed be lost, particularly phase information. In other words, when the stimulus has high temporal frequency information, it is harder to decode spatial information because of the slow calcium dynamics. Ideally, we would look at this effect using the drifting grating stimuli; however, this is problematic because we rely on predicted activity from the SOTA DNEM, and due to the dilation of the first convolution, the periodic grating stimulus causes aliasing. At 15Hz, when the temporal frequency of the stimulus is half the movie frame rate, the model is actually being given two static images, and so the predicted activity is the interleaved activity evoked by two static images. We therefore do not think using the grating stimuli is a good idea. But we have used the Gaussian stimuli as it is not periodic, and is therefore less of a problem.
We have now also reconstructed phase-inverted Gaussian noise stimuli and plotted the video correlation between the reconstructions from activity evoked by phase-inverted stimuli. On the one hand, we find that even for the fastest changing stimuli, the correlation between the reconstructions from phase inverted stimuli are negative, meaning phase information is not lost at high temporal frequencies. On the other hand, for the highest spatial frequency stimuli, the correlation is negative. So, the predicted neural activity (and therefore the reconstructions) are phase-insensitive when the spatial frequency is higher than the reconstruction resolution limit we identified (spatial length constant of 1 pixel, or 3.38 degrees). Beyond this limit, the DNEM predicts activity in response to phase-inverted stimuli, which, when used for reconstruction, results in movies which are more similar to each other than the stimulus that actually evokes them.
However, not all information is lost at these high spatial frequencies. If we plot the Shannon entropy in the spatial domain or the motion energy in the temporal domain, we find that even when the reconstructions fail to capture the stimulus at a pixel-specific level (spatial length constant of 1 pixel, or 3.38 degrees), they do capture the general spatial and temporal qualities of the videos.
We have added these additional analyses to Figure 4 and Supplementary Figure 5.
Reviewer #2 (Public review):
This is an interesting study exploring methods for reconstructing visual stimuli from neural activity in the mouse visual cortex. Specifically, it uses a competition dataset (published in the Dynamic Sensorium benchmark study) and a recent winning model architecture (DNEM, dynamic neural encoding model) to recover visual information stored in ensembles of the mouse visual cortex.
This is a great project - the physiological data were measured at a single-cell resolution, the movies were reasonably naturalistic and representative of the real world, the study did not ignore important correlates such as eye position and pupil diameter, and of course, the reconstruction quality exceeded anything achieved by previous studies. Overall, it is great that teams are working towards exploring image reconstruction. Arguably, reconstruction may serve as an endgame method for examining the information content within neuronal ensembles - an alternative to training interminable numbers of supervised classifiers, as has been done in other studies. Put differently, if a reconstruction recovers a lot of visual features (maybe most of them), then it tells us a lot about what the visual brain is trying to do: to keep as much information as possible about the natural world in which its internal motor circuits may act consequently.
While we enjoyed reading the manuscript, we admit that the overall advance was in the range of those that one finds in a great machine learning conference proceedings paper. More specifically, we found no major technical flaws in the study, only a few potential major confounds (which should be addressable with new analyses), and the manuscript did not make claims that were not supported by its findings, yet the specific conceptual advance and significance seemed modest. Below, we will go through some of the claims, and ask about their potential significance.
We thank the reviewer for the positive feedback on our paper.
(1) The study showed that it could achieve high-quality video reconstructions from mouse visual cortex activity using a neural encoding model (DNEM), recovering 10-second video sequences and approaching a two-fold improvement in pixel-by-pixel correlation over attempts. As a reader, I am left with the question: okay, does this mean that we should all switch to DNEM for our investigations of the mouse visual cortex? What makes this encoding model special? It is introduced as "a winning model of the Sensorium 2023 competition which achieved a score of 0.301... single-trial correlation between predicted and ground truth neuronal activity," but as someone who does not follow this competition (most eLife readers are not likely to do so, either), I do not know how to gauge my response. Is this impressive? What is the best achievable score, in theory, given data noise? Is the model inspired by the mouse brain in terms of mechanisms or architecture, or was it optimized to win the competition by overfitting it to the nuances of the data set? Of course, I know that as a reader, I am invited to read the references, but the study would stand better on its own if clarified how its findings depended on this model.
This is a very good point. We do not think that everyone should switch to using this particular DNEM to investigate the mouse visual cortex, but we think DNEMs and stimulus reconstruction in general has a lot of potential. We think static neural encoding models have already been demonstrated to be an extremely valuable tool to investigate visual coding (Walker et al., 2019; Yoshida et al., 2021; Willeke et al., bioRxiv 2023). DNEMs are less common, largely because they are very large and are technically more demanding to train and use. That makes static encoding models more practical for some applications, but they do not have temporal kernels and are therefore only used for static stimuli. They cannot, for instance, encode direction tuning, only orientation tuning. But both static and dynamic encoding models have advantages over stimulus classification methods which we outline in our discussion. Here we provide the first demonstration that previous achievements in static image reconstruction are transferable to movies.
It has been shown in the past for static neural encoding models that choosing a better-performing model produces reconstructed static images that are closer to the original image (Pierzchlewicz et al., 2023). The factors in choosing this particular DNEM were its capacity to predict neural activity (benchmarked against other models), it was open source, and the data it was designed for was also available.
To give more context to the model used in the paper, we have included the following, line 348:
“This model achieved an average single-trial correlation between predicted and ground truth neural activity of 0.291 during the competition, this was later improved to 0.301. The competition benchmark models achieved 0.106, 0.164 and 0.197 single-trial correlation, while the third and second place models achieved 0.243 and 0.265. Across the models, a variety of architectural components were used, including 2D and 3D convolutional layers, recurrent layers, and transformers, to name just a few.”
Concerning biologically inspired model design. The winning model contained 3 fully connected layers comprising the “Cortex” just before the final readout of neural activity, but we would consider this level of biological inspiration as minor. We do not think that the exact architecture of the model is particularly important, as the crucial aspect of such neural encoders is their ability to predict neural activity irrespective of how they achieve it. There has been a move towards creating foundation models of the brain (Wang et al., 2025) and the priority so far has been on predictive performance over mechanistic interpretability or similarity to biological structures and processes.
Finally, we would like to note that we do not know what the maximum theoretical score for single-trial responses might be, and don't think there is a good way of estimating it in this context.
(2) Along those lines, two major conclusions were that "critical for high-quality reconstructions are the number of neurons in the dataset and the use of model ensembling." If true, then these principles should be applicable to networks with different architectures. How well can they do with other network types?
This is a good question. Our method critically relies on the accurate prediction of neural activity in response to new videos. It is therefore expected that a model that better predicts neural responses to stimuli will also be better at reconstructing those stimuli given population activity. This was previously shown for static images (Pierzchlewicz et al., 2023). It is also expected that whenever the neural activity is accurately predicted, the corresponding reconstructed frames will also be more similar to the ground truth frames. We have now demonstrated this relationship between prediction accuracy and reconstruction accuracy in supplementary figure 4.
Although it would be interesting to compare the movie reconstruction performance of many different models with different architectures and activity prediction performances, this would involve quite substantial additional work because movie reconstruction is very resource- and time-intensive. Finding optimal hyperparameters to make such a comparison fair and informative would therefore be impractical and likely not yield surprising results.
We also think it is unlikely that ensembling would not improve reconstruction performance in other models because ensembling across model predictions is a common way of improving single-model performance in machine learning. Likewise, we think it is unlikely that the relationship between neural population size and reconstruction performance would differ substantially when using different models, because using more neurons means that a larger population of noisy neurons is “voting” on what the stimulus is. However, we would expect that if the model were worse at predicting neural activity, then more neurons are needed for an equivalent reconstruction performance. In general, we would recommend choosing the best possible DNEM available, in terms of neural activity prediction performance, when reconstructing movies using input optimization through gradient descent.
(3) One major claim was that the quality of the reconstructions depended on the number of neurons in the dataset. There were approximately 8000 neurons recorded per mouse. The correlation difference between the reconstruction achieved by 1 neuron and 8000 neurons was ~0.2. Is that a lot or a little? One might hypothesize that ~7,999 additional neurons could contribute more information, but perhaps, those neurons were redundant if their receptive fields were too close together or if they had the same orientation or spatiotemporal tuning. How correlated were these neurons in response to a given movie? Why did so many neurons offer such a limited increase in correlation?
In the population ablation experiments, we compared the performance using ~1000, ~2000, ~4000, ~8000 neurons, and found an attenuation of 39.5% in video correlation when dropping 87.5% of the neurons (~1000 neurons remaining), we did not try reconstruction using just 1 neuron.
(4) On a related note, the authors address the confound of RF location and extent. The study resorted to the use of a mask on the image during reconstruction, applied during training and evaluation (Line 87). The mask depends on pixels that contribute to the accurate prediction of neuronal activity. The problem for me is that it reads as if the RF/mask estimate was obtained during the very same process of reconstruction optimization, which could be considered a form of double-dipping (see the "Dead salmon" article, https://doi.org/10.1016/S1053-8119(09)71202-9). This could inflate the reconstruction estimate. My concern would be ameliorated if the mask was obtained using a held-out set of movies or image presentations; further, the mask should shift with eye position, if it indeed corresponded to the "collective receptive field of the neural population." Ideally, the team would also provide the characteristics of these putative RFs, such as their weight and spatial distribution, and whether they matched the biological receptive fields of the neurons (if measured independently).
We can reassure the reviewer that there is no double-dipping. We would like to clarify that the mask was trained only on videos from the training set of the DNEM and not the videos which were reconstructed. We have added the sentence, line 91:
“None of the reconstructed movies were used in the optimization of this transparency mask.”
Making the mask dependent on eye position would be difficult to implement with the current DNEM, where eye position is fed to the model as an additional channel. When using a model where the image is first transformed into retinotopic coordinates in an eye position-dependent manner (such as in Wang et al., 2025) the mask could be applied in retinotopic coordinates and therefore be dependent on eye position.
Effectively, the alpha mask defines the relative level of influence each pixel contributes to neural activity prediction. We agree it is useful to compare the shape of the alpha mask with the location of traditional on-off receptive fields (RFs) to clarify what the alpha mask represents and characterise the neural population available for our reconstructions. We therefore presented the DNEM with on-off patches to map the receptive fields of single neurons in an in silico experiment (the experimentally derived RF are not available). As expected, there is a rough overlap between the alpha mask (Supplementary Figure 2D), the average population receptive field (Supplementary Figure 2B), and the location of receptive field peaks (Supplementary Figure 2C). In principle, all three could be used during training or evaluation for masking, but we think that defining a mask based on the general influence of images on neural activity, rather than just on off patch responses, is a more elegant solution.
One idea of how to go a step further would be to first set the alpha mask threshold during training based on the % loss of neural activity prediction performance that threshold induces (in our case alpha=0.5 corresponds to ~3% loss in correlation between predicted vs recorded neural responses, see Supplementary Figure 3D), and second base the evaluation mask on a pixel correlation threshold (see example pixel correlation map in Supplementary Figure 2E) instead to avoid evaluating areas of the image with low image reconstruction confidence.
We referred to this figure in the result section, line 83:
“The transparency masks are aligned with but not identical to the On-Off receptive field distribution maps using sparse-noise (Figure S2).”
We have also done additional analysis on the effect of masking during training and evaluation with different thresholds in Supplementary Figure 3.
(5) We appreciated the experiments testing the capacity of the reconstruction process, by using synthetic stimuli created under a Gaussian process in a noise-free way. But this further raised questions: what is the theoretical capability for the reconstruction of this processing pipeline, as a whole? Is 0.563 the best that one could achieve given the noisiness and/or neuron count of the Sensorium project? What if the team applied the pipeline to reconstruct the activity of a given artificial neural network's layer (e.g., some ResNet convolutional layer), using hidden units as proxies for neuronal calcium activity?
That’s a very interesting point. It is very hard to know what the theoretical best reconstruction performance of the model would be. Reconstruction performance could be decreased due to neural variability, experimental noise, the temporal kernel of the calcium indicator and the imaging frame rate, information compression along the visual hierarchy, visual processing phenomena (such as predictive coding and selective attention), failure of the model to predict neural activity correctly, or failure of the reconstruction process to find the best possible image which explains the neural activity. We don't think we can disentangle the contribution of all these sources, but we can provide a theoretical maximum assuming that the model and the reconstruction process are optimal. To that end, we performed additional simulations and reconstructed the natural videos using the predicted activity of the neurons in response to the natural videos as the target (similar to the synthetic stimuli) and got a correlation of 0.766. So, the single trial performance of 0.569 is ~75% of this theoretical maximum. This difference can be interpreted as a combination of the losses due to neuronal variability, measurement noise, and actual deviations in the images represented by the brain compared to reality.
We thank the reviewer for this suggestion, as it gave us the idea of looking at error maps (Figure 6), where the pixel-level deviation of the reconstructions from recorded vs predicted activity is overlaid on the ground truth movie.
(6) As the authors mentioned, this reconstruction method provided a more accurate way to investigate how neurons process visual information. However, this method consisted of two parts: one was the state-of-the-art (SOTA) dynamic neural encoding model (DNEM), which predicts neuronal activity from the input video, and the other part reconstructed the video to produce a response similar to the predicted neuronal activity. Therefore, the reconstructed video was related to neuronal activity through an intermediate model (i.e., SOTA DNEM). If one observes a failure in reconstructing certain visual features of the video (for example, high-spatial frequency details), the reader does not know whether this failure was due to a lack of information in the neural code itself or a failure of the neuronal model to capture this information from the neural code (assuming a perfect reconstruction process). Could the authors address this by outlining the limitations of the SOTA DNEM encoding model and disentangling failures in the reconstruction from failures in the encoding model?
To test if a better neural prediction by the DNEM would result in better reconstructions, we ran additional simulations and now show that neural activity prediction performance correlates with reconstruction performance (Supplementary Figure 4B). This is consistent with Pierzchlewicz et al., (2023) who showed that static image reconstructions using better encoding models leads to better reconstruction performance. As also mentioned in the answer to the previous comment, untangling the relative contributions of reconstruction losses is hard, but we think that improvements to the DNEM performance are key. Two suggestions to improving the DNEM we used would be to translate the input image into retinotopic coordinates and shift this image relative to eye position before passing it to the first convolutional layer (as is done in Wang et al. 2025), to use movies which are not spatially down sampled as heavily, to not use a dilation of 2 in the temporal convolution of the first layer and to train on a larger dataset.
(7) The authors mentioned that a key factor in achieving high-quality reconstructions was model assembling. However, this averaging acts as a form of smoothing, which reduces the reconstruction's acuity and may limit the high-frequency content of the videos (as mentioned in the manuscript). This averaging constrains the tool's capacity to assess how visual neurons process the low-frequency content of visual input. Perhaps the authors could elaborate on potential approaches to address this limitation, given the critical importance of high-frequency visual features for our visual perception.
This is exactly what we also thought. To answer this point more specifically, we ran additional simulations where we also reconstruct the movies using gradient ensembling instead of reconstruction ensembling. Here, the gradients of the loss with respect to each pixel of the movie is calculated for each of the model instances and are averaged at every iteration of the reconstruction optimization. In essence, this means that one reconstruction solution is found, and the averaging across reconstructions, which could degrade high-frequency content, is skipped. The reconstructions from both methods look very similar, and the video correlation is, if anything, slightly worse (Supplemental Figure 3A&C). This indicates that our original ensembling approach did not limit reconstruction performance, but that both approaches can be used, depending on what is more convenient given hardware restrictions.
Reviewer #3 (Public review):
Summary:
This paper presents a method for reconstructing input videos shown to a mouse from the simultaneously recorded visual cortex activity (two-photon calcium imaging data). The publicly available experimental dataset is taken from a recent brain-encoding challenge, and the (publicly available) neural network model that serves to reconstruct the videos is the winning model from that challenge (by distinct authors). The present study applies gradient-based input optimization by backpropagating the brain-encoding error through this selected model (a method that has been proposed in the past, with other datasets). The main contribution of the paper is, therefore, the choice of applying this existing method to this specific dataset with this specific neural network model. The quantitative results appear to go beyond previous attempts at video input reconstruction (although measured with distinct datasets). The conclusions have potential practical interest for the field of brain decoding, and theoretical interest for possible future uses in functional brain exploration.
Strengths:
The authors use a validated optimization method on a recent large-scale dataset, with a state-of-the-art brain encoding model. The use of an ensemble of 7 distinct model instances (trained on distinct subsets of the dataset, with distinct random initializations) significantly improves the reconstructions. The exploration of the relation between reconstruction quality and the number of recorded neurons will be useful to those planning future experiments.
Weaknesses:
The main contribution is methodological, and the methodology combines pre-existing components without any new original components.
We thank the reviewer for taking the time to review our paper and for their overall positive assessment. We would like to emphasise that combining pre-existing machine learning techniques to achieve top results in a new modality does require iteration and innovation. While gradient-based input optimization by backpropagating the brain-encoding error through a neural encoding model has been used in 2D static image optimization to generate maximally exciting images and reconstruct static images, we are the first to have applied it to movies which required accounting for the time domain. Previous methods used time averaged responses and were limited to the reconstruction of static images presented with fixed image intervals.
The movie reconstructions include a learned "transparency mask" to concentrate on the most informative area of the frame; it is not clear how this choice impacts the comparison with prior experiments. Did they all employ this same strategy? If not, shouldn't the quantitative results also be reported without masking, for a fair comparison?
Yes, absolutely. All reconstruction approaches limit the field of view in some way, whether this is due to the size of the screen, the size of the image on the screen, or cropping of the presented/reconstructed images during analysis due to the retinotopic coverage of the recorded neurons. Note that we reconstruct a larger field of view than Yoshida et al. In Yoshida et al., the reconstructed field of view was 43 by 43 retinal degrees. we show the size of an example evaluation mask in comparison.
To address the reviewer’s concern more specifically, we performed additional simulations and now also show the performance using a variety of different training and evaluation masks, including different alpha thresholds for training and evaluation masks as well as the effective retinotopic coverage at different alpha thresholds. Despite these comparisons, we would also like to highlight that the comparison to the benchmark is problematic itself. This is because image and movie reconstruction are not directly comparable. It does not make sense to train and apply a dynamic model on a static image dataset where neural activity is time averaged. Conversely, it does not make sense to train or apply a static model that expects time-averaged neural responses on continuous neural activity unless it is substantially augmented to incorporate temporal dynamics, which in turn would make it a new method. This puts us in the awkward position of being expected to compare our video reconstruction performance to previous image reconstruction methods without a fair way of doing so. We have therefore de-emphasised the phrasing comparing our method to previous publications in the abstract, results, and discussion.
Abstract: “We achieve a ~2-fold increase in pixel-by-pixel correlation compared to previous state-of-the-art reconstructions of static images from mouse V1, while also capturing temporal dynamics.” with “We achieve a pixel-level correction of 0.57 between the ground truth movie and the reconstructions from single-trial neural responses.”
Results: “This represents a ~2x higher pixel-level correlation over previous single-trial static image reconstructions from V1 in awake mice (image correlation 0.238 +/- 0.054 s.e.m for awake mice) [Yoshida et al., 2020] over a similar retinotopic area (~43° x 43°) while also capturing temporal dynamics. However, we would like to stress that directly comparing static image reconstruction methods with movie reconstruction approaches is fundamentally problematic, as they rely on different data types both during training and evaluation (temporally averaged vs continuous neural activity, images flashed at fixed intervals vs continuous movies).”
Discussion: “In conclusion, we reconstruct videos presented to mice based on the activity of neurons in the mouse visual cortex, with a ~2-fold improvement in pixel-by-pixel correlation compared to previous static image reconstruction methods.” with “In conclusion, we reconstruct videos presented to mice based on single-trial activity of neurons in the mouse visual cortex.”
We have also removed the performance table and have instead added supplementary figure 3 with in-depth comparison across different versions of our reconstruction method (variations of masking, ensembling, contrast & luminance matching, and Gaussian blurring).
We believe that we have given enough information in our paper now so that readers can make an informed decision whether our movie reconstruction method is appropriate for the questions they are interested in.
Recommendations for the authors:
Reviewer #2 (Recommendations for the authors):
(1) "Reconstructions have been luminance (mean pixel value across video) and contrast (standard deviation of pixel values across video) matched to ground truth." This was not clear: was it done by the investigating team? I imagine that one of the most easily captured visual features is luminance and contrast, why wouldn't the optimization titrate these well?
The contrast and luminance matching of the reconstructions to the ground truth videos was done by us, but this was only done to help readers assess the quality of the reconstructions by eye. Our performance metrics (frame and video correlation) are contrast and luminance insensitive. To clarify this, we have also added examples of non-adjusted frames in Supplementary Figure 3A, and added a sentence in the results, line 103:
“When presenting videos in this paper we normalize the mean and standard deviation of the reconstructions to the average and standard deviation of the corresponding ground truth movie before applying the evaluation masks, but this is not done for quantification except in Supplementary Figure 3D.”
We were also initially surprised that contrast and luminance are not captured well by our reconstruction method, but this makes sense as V1 is largely luminance invariant (O’Shea et al., 2025 https://doi.org/10.1016/j.celrep.2024.115217 ) and contrast only has a gain effect on V1 activity (Tring et al., 2024 https://journals.physiology.org/doi/full/10.1152/jn.00336.2024). Decoding absolute contrast is likely unreliable because it is probably not the only factor modulating the overall gain of the neural population.
To address the reviewer’s comment more fully, we ran additional experiments. More specifically, to test why contrast and luminance are not recovered in the reconstructions, we checked how the predicted activity between the reconstruction and the contrast/luminance corrected reconstructions differs. Contrast and luminance adjustment had little impact on predicted response similarity on average. This makes the reconstruction optimization loss function insensitive to overall contrast and luminance so it cannot be decoded. There is a small effect on activity correlation, however, so we cannot completely rule out that contrast and luminance could be reconstructed with a different loss function.
(2) The authors attempted to investigate the variability in reconstruction quality across different movies and 10-second snippets of a movie by correlating various visual features, such as video motion energy, contrast, luminance, and behavioral factors like running speed, pupil diameter, and eye movement, with reconstruction success. However, it would also be beneficial if the authors correlated the response loss (Poisson loss between neural responses) with reconstruction quality (video correlation) for individual videos, as these metrics are expected to be correlated if the reconstruction captures neural variance.
We thank the reviewer for this suggestion. We have now included this analysis and find that if the neural activity was better predicted by the DNEM then the reconstruction of the video was also more similar to the ground truth video. We further found that this effect is shift-dependent (in time), meaning the prediction of activity based on proximal video frames is more influential on reconstruction performance.
Reviewer #3 (Recommendations for the authors):
(1) I was confused about the choice of applying a transparency mask thresholded with alpha>0.5 during training and alpha>1 during evaluation. Why treat the two situations differently? Also, shouldn't we expect alpha to be in the [0,1] range, in which case, what is the meaning of alpha>1? (And finally, as already described in "Weaknesses", how does this choice impact the comparison with prior experiments? Did they also employ a similar masking strategy?)
We found that applying a mask during training increased performance regardless of the size of the evaluation mask. Using a less stringent mask during training than during evaluation increases performance slightly, but also allows inspection of the reconstruction in areas where the model will be less confident without sacrificing performance, if this is desired. The thresholds of 0.5 and 1 were chosen through trial and error, but the exact values do not hold intrinsic meaning. The alpha mask values can go above 1 during their optimization. We could have clipped alpha during the training procedure (algorithm 1), but we decided this was not worth redoing at this stage, as the alphas used for testing were not above 1. All reconstruction approaches in previous publications limit the field of view in some form, whether this is due to the size of the screen, the size of the image on the screen, or the cropping of the presented/reconstructed images during analysis.
To address the reviewer’s comment in detail, we have added extensive additional analysis to evaluate the coverage of the reconstruction achieved in this paper and how different masking strategies affect performance, as well as how the mask relates to more traditional receptive field mapping.
(2) I would not use the word "imagery" in the first sentence of the abstract, because this might be interpreted by some readers as reconstruction of mental imagery, a very distinct question.
We changed imagery to images in the abstract.
(3) Line 145-146: "<1 frame, or <30Hz" should be "<1 frame, or >30Hz".
We have corrected the error.
(4) Algorithm 1, Line 5, a subscript variable 'g' should be changed to 'h'
We have corrected the error.
Additional Changes
(1) Minor grammatical errors
(2) Addition of citations: We were previously not aware of a bioRxiv preprint from 2022 (Cobos et al., 2022), which used gradient descent-based input optimization to reconstruct static images but without the addition of a diffusion model. Instead, we had cited for this method Pierzchlewicz et al., 2023 bioRxiv/NeurIPS. In Cobos et al., 2022, they compare static image reconstruction similarity to ground truth images and the similarity of the in vivo evoked activity across multiple reconstruction methods. Performance values are only given for reconstructions from trial-averaged responses across ~40 trials (in the absence of original data or code we are also not able to retrospectively calculate single-trial performance). The authors find that optimizing for evoked activity rather than image similarity produces image reconstructions that evoke more similar in vivo responses compared to reconstructions optimized for image similarity itself. We have now added and discussed the citation in the main text.
(3) Workaround for error in the open-source code from https://github.com/lRomul/sensorium for video hashing function in the SOTA DNEM: By checking the most correlated first frame for each reconstructed movie, we discovered there was a bug in the open-source code and 9/50 movies we originally used for reconstruction were not properly excluded from the training data between DNEM instances. The reason for this error was that some of the movies are different by only a few pixels, and the video hashing function used to split training and test set folds in the original DNEM code classified these movies as different and split them across folds. We have replaced these 9 movies and provide a figure below showing the next closest first frame for every movie clip we reconstruct. This does not affect our claims. Excluding these 9 movie clips, did not affect the reconstruction performance (video correlation went from 0.563 to 0.568), so there was no overestimation of performance due to test set contamination. However, they should still be removed so some of the values in the paper have changed slightly. The only statistical test that was affected was the correlation between video correlation and mean motion energy (Supplementary Figure 4A), which went from p = 0.043 to 0.071.
Author response image 2.
exclusion of movie clips with duplicates in the DNEM training data. A) example frame of a reconstructed movie (ground truth) and the most correlated first frame from the training data. b) all movie clips and their corresponding most correlated clip from the training data. Red boxes indicate excluded duplicates.
Een derde voorbeeld# Het onderstaande voorbeeld tekent een grafiek met twee parabolen. Veel van de gebruikte opties zijn hierboven al besproken, maar sommige dingen worden net iets anders gedaan. Door middel van commentaren wordt uitgelegd wat de code doet. Bestudeer deze code: begrijp je wat er gebeurt?
Wellicht kunnen we hieronder een uitklaptekst toevoegen, zodat studenten – die over de code hebben nagedacht – kunnen controleren of hun intuïtie klopte
Dit maakt het gemakkelijker om later dit bestand terug te vinden.
Maak dit nog directer voor studenten: “Zet je bestanden in een vaste map (bijv. data/) zodat je pad in de code altijd hetzelfde blijft.” of iets dergelijks
voorbeeld
Maak hier 1 zin extra van die direct verwijst naar de code: “Hieronder lezen we voorbeeld.csv in met np.loadtxt() en printen we de ingelezen data.”
text editor
text editor -> teksteditor
zet dit als hoofdregel: altijd eerst openen in teksteditor (bijv. VS Code/Notepad++)
Misschien ook zo'n warning box voor excel?
Als dit begint met een hekje (#) is het bestand gemaakt met de bedoeling het te verwerken via numpy.
De header begint met #. Dat is handig als commentaar, maar dan wordt de header vaak niet als kolomnamen ingelezen.
Wil je de kolomnamen echt gebruiken in je code? Zet de header dan niet als commentaar, of lees hem apart in (anders gooit numpy hem weg).
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public review)
Major:
(1) In line 76, the authors make a very powerful statement: 'σRNN simulation achieves higher similarity with unseen recorded trials before perturbation, but lower than the bioRNN on perturbed trials.' I couldn't find a figure showing this. This might be buried somewhere and, in my opinion, deserves some spotlight - maybe a figure or even inclusion in the abstract.
We agree with the reviewer that these results are important. The failure of σRNN on perturbed data could be inferred from the former Figures 1E, 2C-E, and 3D. Following the reviewers' comments, we have tried to make this the most prominent message of Figure 1, in particular with the addition of the new panel E. We also moved Table 1 from the Supplementary to the main text to highlight this quantitatively.
(2) It's mentioned in the introduction (line 84) and elsewhere (e.g., line 259) that spiking has some advantage, but I don't see any figure supporting this claim. In fact, spiking seems not to matter (Figure 2C, E). Please clarify how spiking improves performance, and if it does not, acknowledge that. Relatedly, in line 246, the authors state that 'spiking is a better metric but not significant' when discussing simulations. Either remove this statement and assume spiking is not relevant, or increase the number of simulations.
We could not find the exact quote from the reviewer, and we believe that he intended to quote “spiking is better on all metrics, but without significant margins”. Indeed, spiking did not improve the fit significantly on perturbed trials, this is particularly true in comparison with the benefits of Dale’s law and local inhibition. As suggested by the reviewer, we rephrased the sentence from this quote and more generally the corresponding paragraphs in the intro (lines 83-87) and in the results (lines 245-271). Our corrections in the results sections are also intended to address the minor point (4) raised by the same reviewer.
(3) The authors prefer the metric of predicting hits over MSE, especially when looking at real data (Figure 3). I would bring the supplementary results into the main figures, as both metrics are very nicely complementary. Relatedly, why not add Pearson correlation or R2, and not just focus on MSE Loss?
In Figure 3 for the in-vivo data, we do not have simultaneous electrophysiological recordings and optogenetic stimulation in this dataset. The two are performed on different recording sessions. Therefore, we can only compare the effect of optogenetics on the behavior, and we cannot compute Pearson correlation or R2 of the perturbed network activity. To avoid ambiguity, we wrote “For the sessions of the in vivo dataset with optogenetic perturbation that we considered, only the behavior of an animal is recorded” on line 294.
(4) I really like the 'forward-looking' experiment in closed loop! But I felt that the relevance of micro perturbations is very unclear in the intro and results. This could be better motivated: why should an experimentalist care about this forward-looking experiment? Why exactly do we care about micro perturbation (e.g., in contrast to non-micro perturbation)? Relatedly, I would try to explain this in the intro without resorting to technical jargon like 'gradients'.
As suggested, we updated the last paragraph of the introduction (lines 88 - 95) to give better motivation for why algorithmically targeted acute spatio-temporal perturbations can be important to dissect the function of neural circuits. We also added citations to recent studies with targeted in vivo optogenetic stimulation. As far as we know the existing previous work targeted network stimulation mostly using linear models, while we used non-linear RNNs and their gradients.
Minor:
(1) In the intro, the authors refer to 'the field' twice. Personally, I find this term odd. I would opt for something like 'in neuroscience'.
We implemented the suggested change: l.27 and l.30
(2) Line 45: When referring to previous work using data-constrained RNN models, Valente et al. is missing (though it is well cited later when discussing regularization through low-rank constraints)
We added the citation: l.45
(3) Line 11: Method should be methods (missing an 's').
We fixed the typo.
(4) In line 250, starting with 'So far', is a strange choice of presentation order. After interpreting the results for other biological ingredients, the authors introduce a new one. I would first introduce all ingredients and then interpret. It's telling that the authors jump back to 2B after discussing 2C.
We restructured the last two paragraphs of section 2.1, and we hope that the presentation order is now more logical.
(5) The black dots in Figure 3E are not explained, or at least I couldn't find an explanation.
We added an explanation in the caption of Figure 3E.
Reviewer #2 (Public review):
(1) Some aspects of the methods are unclear. For comparisons between recurrent networks trained from randomly initialized weights, I would expect that many initializations were made for each model variant to be compared, and that the performance characteristics are constructed by aggregating over networks trained from multiple random initializations. I could not tell from the methods whether this was done or how many models were aggregated.
The expectation of the reviewer is correct, we trained multiple models with different random seeds (affecting both the weight initialization and the noise of our model) for each variant and aggregated the results. We have now clarified this in Methods 4.6. lines 658-662.
(2) It is possible that including perturbation trials in the training sets would improve model performance across conditions, including held-out (untrained) perturbations (for instance, to units that had not been perturbed during training). It could be noted that if perturbations are available, their use may alleviate some of the design decisions that are evaluated here.
In general, we agree with the reviewer that including perturbation trials in the training set would likely improve model performance across conditions. One practical limitation explaining partially why we did not do it with our dataset is the small quantity of perturbed trials for each targeted cortical area: the number of trials with light perturbations is too scarce to robustly train and test our models.
More profoundly, to test hard generalizations to perturbations (aka perturbation testing), it will always be necessary that the perturbations are not trivially represented in the training data. Including perturbation trials during training would compromise our main finding: some biological model constraints improve the generalization to perturbation. To test this claim, it was necessary to keep the perturbations out of the training data.
We agree that including all available data of perturbed and non-perturbed recordings would be useful to build the best generalist predictive system. It could help, for instance, for closed-loop circuit control as we studied in Figure 5. Yet, there too, it will be important for the scientific validation process to always keep some causal perturbations of interest out of the training set. This is necessary to fairly measure the real generalization capability of any model. Importantly, this is why we think out-of-distribution “perturbation testing” is likely to have a recurring impact in the years to come, even beyond the case of optogenetic inactivation studied in detail in our paper.
Recommendation for the authors:
Reviewer #1 (Recommendation for the authors):
The code is not very easy to follow. I know this is a lot to ask, but maybe make clear where the code is to train the different models, which I think is a great contribution of this work? I predict that many readers will want to use the code and so this will improve the impact of this work.
We updated the code to make it easier to train a model from scratch.
Reviewer #2 (Recommendation for the authors):
The figures are really tough to read. Some of that small font should be sized up, and it's tough to tell in the posted paper what's happening in Figure 2B.
We updated Figures 1 and 2 significantly, in part to increase their readability. We also implemented the "Superficialities" suggestions.
A Caesar cipher, also known as Caesar's cipher, the shift cipher, Caesar's code, or the Caesar shift, is one of the simplest and most widely known encryption techniques in
Charles RiverStrain Code: 207
DOI: 10.1016/j.celrep.2025.116703
Resource: (IMSR Cat# CRL_207,RRID:IMSR_CRL:207)
Curator: @areedewitt04
SciCrunch record: RRID:IMSR_CRL:207
$
{code-block} python になっているからシンタックスハイライトがおかしくなっています。{code-block} bashにしたほうが良さそうです。
Reviewer #2 (Public review):
Summary:
Siddiqui et al. show that C. elegans prefers certain bacterial strains that have been supplemented with the essential amino acid (EEA) leucine. They convincingly show that some leucine enriched bacteria stimulate the production of isoamyl alcohol (IAA). IAA is an attractive odorant that is sensed by the AWC. The authors an identify a receptor, SRD-12, that is expressed in the AWC chemosensory neurons and is required for chemotaxis to IAA. The authors propose that IAA is a predominant olfactory cue that determines diet preference in C. elegans. Since leucine is an EAA, the authors propose that worm IAA sensing allows the animal provides a proxy mechanism to identify EAA rich diets.
Strengths:
The authors propose IAA as a predominant olfactory cue that determines diet preference in C. elegans providing molecular mechanism underlying diet selection. They show that wild isolates of C. elegans have strong chemotactic response to IAA indicating that IAA is an ecologically relevant odor for the worm. The paper is well written, and the presented data are convincing and well organized. This is an interesting paper that connects chemotactic response with bacterially produced odors and thus provides an understanding how animals adapt their foraging behavior through the perception of molecules that may indicate the nutritional value.
Weaknesses:
Major: While I do like the way the authors frame C. elegans IAA sensing as mechanisms to identify leucine (EAA) rich diets, it is not fully clear whether bacterial IAA production is a proxy for bacterial leucine levels.
(1) Can the authors measure leucine (or other EAA) content of the different CeMbio strains? This would substantiate the premise in the way they frame this in the introduction. While the authors convincingly show that leucine supplementation induces IAA production in some strains, it is not clear if there are lower leucine levels in the different in the non-preferred strains.
(2) It is not clear whether the non-preferred bacteria in Figure 1A and 1B have the ability to produce IAA. To substantiate the claim that C. elegans prefers CEent1, JUb66, and BIGb0170 due to their ability to generate IAA from leucine, it would be measure IAA levels in non-preferred bacteria (+ and - leucine supplementation). If the authors have these data it would be good to include this.
(3) The authors would strengthen their claim if they could show that deletion or silencing ilvE enzyme reduces IAA levels and eliminates the increased preference upon leucine supplementation.
(4) While the three preferred bacteria possess the ilvE gene, it is not clear whether this enzyme is present in the other non-preferred bacterial strains. As far as I know, the CeMbio strains have been sequenced, so it should be easy to determine if the non-preferred bacteria possess the capacity to make IAA. Does expression of ilvE in e.g. E. coli increase its preference index or are the other genes in the biosynthesis pathway missing?
(5) It is strongly implied that leucine rich diets are beneficial to the worm. Do the authors have data to show the effect on leucine supplementation on C. elegans healthspan, life-span or broodsize?
Comments on revisions:
(1) The authors have addressed most of the earlier questions. The main unresolved issue is the link between iaa production is a reflection of bacterial leucine levels. It is not clear if there are lower leucine levels in the different in non-preferred strains.
The main conclusions that: 1. some bacterial strains can convert exogenous leucine into IAA which is an attractant to C. elegans. 2. The identification of a GPCR required for IAA responses are solid. These are important results that carry the paper. My outstanding concern remains with the overinterpretation of the framing that C. elegans IAA sensing is used as a mechanism to identify leucine (EAA) rich diets. It is fine to leave this a favorite hypothesis in the discussion but statements throughout the paper need to be nuanced without leucine measurement of the different bacterial strains. (Also since for the bacterial chemotaxis assays there were only done with a single concentration of leucine makes it difficult to infer bacterial leucine concentrations). I recommend softening claims related to leucine-rich diet detection unless quantitative measurements are provided.
Part of the issue in the text lies in the difference between "supplemented" and "chemotaxis" (lab based constructs) and enriched and foraging (natural environment based). This is also the way it is set up in the introduction "Do animals use specific sensing mechanisms to find an EAA-enriched diet?". If enriched is used strictly the same as supplemented then it would be fine but in the text this distinction gets blurred and enriched drifts to the more ethological explanation.
Then it is more than just semantics since leucine-supplemented diets are not something that occurs in the natural environment. IAA production by bacteria could be a signal for a leucine rich environment and it is fine to speculate about this in the discussion.
Examples where the wording needs to be more precise to reflect the experimental results rather than the possible impact in its natural environment:
The title:' The olfactory receptor SNIF-1 mediates foraging for leucine-rich diets in C. elegans"
The intro:"Taken together, SNIF-1 regulates the dietary preference of worms to IAA-producing bacteria and thereby mediates the foraging behavior of C. elegans to leucine-enriched diets. Thus, IAA produced by bacteria is a dietary quality code for leucine-enriched bacteria."
Results "Figure 1. C. elegans relies on odors to select leucine-enriched bacteria"
Supplementation is used more in the text and the figure legends whereas headings and abstract use enriched. The experiments in the paper only describe leucine-supplemented experiments. So use I would supplemented instead of enriched when describing experiments for clarity.
For instance:
Page 4:"Microbial odors drive the preference of C. elegans for leucine-enriched diet"
Page 5: "Altogether, these findings suggested that worms rely on odors to distinguish various bacteria and find leucine-enriched bacteria"
Page 7: "Isoamyl alcohol odor is a signature for a leucine-enriched diet"
Page 9: AWC odor sensory neurons facilitate the diet preference of C. elegans for leucine-enriched diets"
page 20 "Leucine-enriched diets produce significantly higher levels of IAA odor, making up to 90% of their headspace"
(2) As suggested in the first round of review the authors now add data IAA levels in non-preferred bacteria (+ and - leucine supplementation) in table S2. While it is good to have this data, the table is not very clear. Not clear what ND stands for in the table S2. Not determined or not detected? I assume not determined since some strains Jub44, BiGb0393 Jub134 produce IAA even in the absence of LEU. The authors mention that "the abundance of IAA in these strains is significantly less". However, the table just reflects yes or no. Can the authors give an indication of the concentration to understand what significantly less means? Fig. 2c at least gives a heat map.
(3) On wormbase the gene is still called srd-12. The authors should seek permission to rename srd-12 to snif-1.
The proof checker is a small amount of code that is itself verified, making it virtually impossible to sneak an invalid proof past the checker.
How is it possible that it is virtually impossible to sneak an invalid proof ?
Reviewer #2 (Public review):
Summary:
This manuscript investigates how olfactory representations are transformed along the cortico-hippocampal pathway in mice during a non-associative learning paradigm involving novel and familiar odors. By recording single-unit activity in several key brain regions (AON, aPCx, LEC, CA1, and SUB), the authors aim to elucidate how stimulus identity and experience are encoded and how these representations change across the pathway.
The study addresses an important question in sensory neuroscience regarding the interplay between sensory processing and signaling novelty/familiarity. It provides insights into how the brain processes and retains sensory experiences, suggesting that the earlier stations in the olfactory pathway, the AON aPCx, play a central role in detecting novelty and encoding odor, while areas deeper into the pathway (LEC, CA1 & Sub) are more sparse and encodes odor identity but not novelty/familiarity. However, there are several concerns related to methodology, data interpretation, and the strength of the conclusions drawn.
Strengths:
The authors combine the use of modern tools to obtain high-density recordings from large populations of neurons at different stages of the olfactory system (although mostly one region at a time) with elegant data analyses to study an important and interesting question.
Weaknesses:
The first and biggest problem I have with this paper is that it is very confusing, and the results seem to be all over the place. In some parts, it seems like the AON and aPCx are more sensitive to novelty; in others, it seems the other way around. I find their metrics confusing and unconvincing. For example, the example cells in Figure 1C shows an AON neuron with a very low spontaneous firing rate and a CA1 with a much higher firing rate, but the opposite is true in Fig. 2A. So, what are we to make of Fig. 2C that shows the difference in firing rates between novel vs. familiar odors measured as a difference in spikes/sec. The meaning of this is unclear. The authors could have used a difference in Z-scored responses to normalize different baseline activity levels. (This is just one example of a problem with the methodology.)
There are a lot of high-level data analyses (e.g., decoding, analyzing decoding errors, calculating mutual information, calculating distances in state space, etc.) but very little neural data (except for Fig. 2C, and see my comment above about how this is flawed). So, if responses to novel vs. familiar odors are different in the AON and aPCx, how are they different? Why is decoding accuracy better for novel odors in CA1 but better for familiar odors in SUB (Fig. 3A)? The authors identify a small subset of neurons that have unusually high weights in the SVM analyses that contribute to decoding novelty, but they don't tell us which neurons these are and how they are responding differently to novel vs. familiar odors.
The authors call AON and aPCx "primary sensory cortices" and LEC, CA1, and Sub "multisensory areas". This is a straw man argument. For example, we now know that PCx encodes multimodal signals (Poo et al. 2021, Federman et al., 2024; Kehl et al., 2024), and LEC receives direct OB inputs, which has traditionally been the criterion for being considered a "primary olfactory cortical area". So, this terminology is outdated and wrong, and although it suits the authors' needs here in drawing distinctions, it is simplistic and not helpful moving forward.
Why not simply report z-scored firing rates for all neurons as a function of trial number? (e.g., Jacobson & Friedrich, 2018). Fig. 2C is not sufficient. For example, in the Discussion, they say, "novel stimuli caused larger increases in firing rates than familiar stimuli" (L. 270), but what does this mean? Odors typically increase the firing in some neurons and suppress firing in others. Where does the delta come from? Is this because novel odors more strongly activate neurons that increase their firing or because familiar odors more strongly suppress neurons?
Ls. 122-124 - If cells in AON and aPCx responded the same way to novel and familiar odors, then we would say that they only encode for odor and not at all for experience. So, I don't understand why the authors say these areas code for a "mixed representation of chemical identity and experience." "On the other hand," if LEC, CA1, and SUB are odor selective and only encode novel odors, then these areas, not AON and aPCx, are the jointly encoding chemical identity and experience. Also, I do not understand why, here, they say that AON and PCx respond to both while LEC, CA1, and SUB were selective for novel stimuli, but the authors then go on to argue that novelty is encoded in the AON and PCx, but not in the LEC, CA1, and SUB.
Ls. 132-140 - As presented in the text and the figure, this section is unclear and confusing. Their use of the word "shuffled" is a major source of this confusion, because this typically is the control that produces outcomes at chance level. More importantly, it seems as though they did the wrong analysis here. A better way to do this analysis is to train on some of the odors and test on an untrained odor (i.e., what Bernardi et al., 2021 called "cross-condition generalization performance"; CCGP).
Comments on revisions:
I think the authors have done an adequate job addressing the reviewers' concerns. Most importantly, I found the first version of the manuscript quite confusing, and the consequent clarifications have addressed this issue.
In several cases, I see their point, while I still disagree with whether they made the best decisions. However, the issues here do not fundamentally change the big-picture outcome, and if they want to dig in with their approaches (e.g., only using auROC or just reporting delta firing rates without any normalization), it's their choice.
Author response:
The following is the authors’ response to the original reviews.
Public reviews:
Reviewer #1 (Public review):
In this important study, the authors characterized the transformation of neural representations of olfactory stimuli from the primary sensory cortex to multisensory regions in the medial temporal lobe and investigated how they were affected by non-associative learning. The authors used high-density silicon probe recordings from five different cortical regions while familiar vs. novel odors were presented to a head-restrained mouse. This is a timely study because unlike other sensory systems (e.g., vision), the progressive transformation of olfactory information is still poorly understood. The authors report that both odor identity and experience are encoded by all of these five cortical areas but nonetheless some themes emerge. Single neuron tuning of odor identity is broad in the sensory cortices but becomes narrowly tuned in hippocampal regions. Furthermore, while experience affects neuronal response magnitudes in early sensory cortices, it changes the proportion of active neurons in hippocampal regions. Thus, this study is an important step forward in the ongoing quest to understand how olfactory information is progressively transformed along the olfactory pathway.
The study is well-executed. The direct comparison of neuronal representations from five different brain regions is impressive. Conclusions are based on single neuronal level as well as population level decoding analyses. Among all the reported results, one stands out for being remarkably robust. The authors show that the anterior olfactory nucleus (AON), which receives direct input from the olfactory bulb output neurons, was far superior at decoding odor identity as well as novelty compared to all the other brain regions. This is perhaps surprising because the other primary sensory region - the piriform cortex - has been thought to be the canonical site for representing odor identity. A vast majority of studies have focused on aPCx, but direct comparisons between odor coding in the AON and aPCx are rare. The experimental design of this current study allowed the authors to do so and the AON was found to convincingly outperform aPCx. Although this result goes against the canonical model, it is consistent with a few recent studies including one that predicted this outcome based on anatomical and functional comparisons between the AON-projecting tufted cells vs. the aPCx-projecting mitral cells in the olfactory bulb (Chae, Banerjee et. al. 2022). Future experiments are needed to probe the circuit mechanisms that generate this important difference between the two primary olfactory cortices as well as their potential causal roles in odor identification.
The authors were also interested in how familiarity vs. novelty affects neuronal representation across all these brain regions. One weakness of this study is that neuronal responses were not measured during the process of habituation. Neuronal responses were measured after four days of daily exposure to a few odors (familiar) and then some other novel odors were introduced. This creates a confound because the novel vs. familiar stimuli are different odorants and that itself can lead to drastic differences in evoked neural responses. Although the authors try to rule out this confound by doing a clever decoding and Euclidian distance analysis, an alternate more straightforward strategy would have been to measure neuronal activity for each odorant during the process of habituation.
Reviewer #2 (Public review):
This manuscript investigates how olfactory representations are transformed along the cortico-hippocampal pathway in mice during a non-associative learning paradigm involving novel and familiar odors. By recording single-unit activity in several key brain regions (AON, aPCx, LEC, CA1, and SUB), the authors aim to elucidate how stimulus identity and experience are encoded and how these representations change across the pathway.
The study addresses an important question in sensory neuroscience regarding the interplay between sensory processing and signaling novelty/familiarity. It provides insights into how the brain processes and retains sensory experiences, suggesting that the earlier stations in the olfactory pathway, the AON aPCx, play a central role in detecting novelty and encoding odor, while areas deeper into the pathway (LEC, CA1 & Sub) are more sparse and encodes odor identity but not novelty/familiarity. However, there are several concerns related to methodology, data interpretation, and the strength of the conclusions drawn.
Strengths:
The authors combine the use of modern tools to obtain high-density recordings from large populations of neurons at different stages of the olfactory system (although mostly one region at a time) with elegant data analyses to study an important and interesting question.
Weaknesses:
(1) The first and biggest problem I have with this paper is that it is very confusing, and the results seem to be all over the place. In some parts, it seems like the AON and aPCx are more sensitive to novelty; in others, it seems the other way around. I find their metrics confusing and unconvincing. For example, the example cells in Figure 1C show an AON neuron with a very low spontaneous firing rate and a CA1 with a much higher firing rate, but the opposite is true in Figure 2A. So, what are we to make of Figure 2C that shows the difference in firing rates between novel vs. familiar odors measured as a difference in spikes/sec. This seems nearly meaningless. The authors could have used a difference in Z-scored responses to normalize different baseline activity levels. (This is just one example of a problem with the methodology.)
We appreciate the reviewer’s concerns regarding clarity and methodology. It is less clear why all neurons in a given brain area should have similar firing rates. Anatomically defined brain areas typically comprise of multiple cell types, which can have diverse baseline firing rates. Since we computed absolute firing rate differences per neuron (i.e., novel vs. familiar odor responses within the same neuron), baseline differences across neurons do not have a major impact.
The suggestion to use Z-scores instead of absolute firing rate differences is well taken. However, Z-scoring assumes that the underlying data are normally distributed, which is not the case in our dataset. Specifically, when analyzing odor-evoked firing rates on a per-neuron basis, only 4% of neurons exhibit a normal distribution. In cases of skewed distributions, Z-scoring can distort the data by exaggerating small variations, leading to misleading conclusions. We acknowledge that different analysis methods exist, we believe that our chosen approach best reflects the properties of the dataset and avoids potential misinterpretations introduced by inappropriate normalization techniques.
(2) There are a lot of high-level data analyses (e.g., decoding, analyzing decoding errors, calculating mutual information, calculating distances in state space, etc.) but very little neural data (except for Figure 2C, and see my comment above about how this is flawed). So, if responses to novel vs. familiar odors are different in the AON and aPCx, how are they different? Why is decoding accuracy better for novel odors in CA1 but better for familiar odors in SUB (Figure 3A)? The authors identify a small subset of neurons that have unusually high weights in the SVM analyses that contribute to decoding novelty, but they don't tell us which neurons these are and how they are responding differently to novel vs. familiar odors.
We performed additional analyses to address the reviewer’s feedback (Figures 2C-E and lines 118-132) and added more single-neuron data (Figures 1, S3 and S4).
(3) The authors call AON and aPCx "primary sensory cortices" and LEC, CA1, and Sub "multisensory areas". This is a straw man argument. For example, we now know that PCx encodes multimodal signals (Poo et al. 2021, Federman et al., 2024; Kehl et al., 2024), and LEC receives direct OB inputs, which has traditionally been the criterion for being considered a "primary olfactory cortical area". So, this terminology is outdated and wrong, and although it suits the authors' needs here in drawing distinctions, it is simplistic and not helpful moving forward.
We appreciate the reviewer’s concern regarding the classification of brain regions as “primary sensory” versus “multisensory.” Of note, the cited studies (Poo et al., 2021; Federman et al., 2024; Kehl et al., 2024) focus on posterior PCx (pPCx), while our recordings were conducted in very anterior section of anterior PCx. The aPCx and pPCx have distinct patterns of connectivity, both anatomically and functionally. To the best of our knowledge, there is no evidence for multimodal responses in aPCx, whereas there is for LEC, CA1 and SUB. Furthermore, our distinction is not based on a connectivity argument, as the reviewer suggests, but on differences in the α-Poisson ratio (Figure 1E and F).
To avoid confusion due to definitions of what constitutes a “primary sensory” region, we adopted a more neutral description throughout the manuscript.
(4) Why not simply report z-scored firing rates for all neurons as a function of trial number? (e.g., Jacobson & Friedrich, 2018). Figure 2C is not sufficient.
Regarding z-scores, please see response to 1). We further added a figure showing responses of all neurons to novel stimuli (using ROC instead of z-scoring, as described previously (e.g. Cohen et al. Nature 2012). We added the following figure to the supplementary for the completeness of the analysis (S2E).
For example, in the Discussion, they say, "novel stimuli caused larger increases in firing rates than familiar stimuli" (L. 270), but what does this mean?
This means that on average, the population of neurons exhibit higher firing rates in response to novel odors compared to familiar ones.
Odors typically increase the firing in some neurons and suppress firing in others. Where does the delta come from? Is this because novel odors more strongly activate neurons that increase their firing or because familiar odors more strongly suppress neurons?
We thank the reviewer for this valuable feedback and extended the characterization of firing rate properties, including a separate analysis of neurons i) significantly excited by odorants, ii) significantly inhibited by odorants and iii) not responsive to odorants. We added the analysis and corresponding discussion to the main manuscript (Figures 2C-E and lines 118-132)
(5) Lines 122-124 - If cells in AON and aPCx responded the same way to novel and familiar odors, then we would say that they only encode for odor and not at all for experience. So, I don't understand why the authors say these areas code for a "mixed representation of chemical identity and experience." "On the other hand," if LEC, CA1, and SUB are odor selective and only encode novel odors, then these areas, not AON and aPCx, are the jointly encoding chemical identity and experience. Also, I do not understand why, here, they say that AON and PCx respond to both while LEC, CA1, and SUB were selective for novel stimuli, but the authors then go on to argue that novelty is encoded in the AON and PCx, but not in the LEC, CA1, and SUB.
We appreciate the reviewer’s request for clarification. Throughout the brain areas we studied, odorant identity and experience can be decoded. However, the way information is represented is different between regions. We acknowledge that that “mixed” representation is a misleading term and removed it from the manuscript.
In AON and aPCx, neurons significantly respond to both novel and familiar odors. However, the magnitude of their responses to novel and familiar odors is sufficiently distinct to allow for decoding of odor experience (i.e., whether an odor is novel or familiar). Moreover, novelty engages more neurons in encoding the stimulus (Figure 2D). In neural space, the position of an odor’s representation in AON and aPCx shifts depending on whether it is novel or familiar, meaning that experience modifies the neural representation of odor identity. This suggests that in these regions the two representations are intertwined.
In contrast, some neurons in LEC, CA1, and SUB exhibit responses to novel odors, but few neurons respond to familiar odors at all. This suggests a more selective encoding of novelty.
(6) Lines 132-140 - As presented in the text and the figure, this section is poorly written and confusing. Their use of the word "shuffled" is a major source of this confusion, because this typically is the control that produces outcomes at the chance level. More importantly, they did the wrong analysis here. The better and, I think, the only way to do this analysis correctly is to train on some of the odors and test on an untrained odor (i.e., what Bernardi et al., 2021 called "cross-condition generalization performance"; CCGP).
We appreciate the feedback and thank the reviewer for the recommendation to implement cross-condition generalization performance (CCGP) as used in Bernardi et al., 2020. We acknowledge that the term "shuffled" may have caused confusion, as it typically refers to control analyses producing chance-level outcomes. In our case, by "shuffling" we shuffled the identity of novel and familiar odors to assess how much the decoder relies on odor identity when distinguishing novelty. This test provided insight into how novelty-based structure exists within neural activity beyond random grouping but does not directly assess generalization.
As suggested, we used CCGP to measure how well novelty-related representations generalize across different odors. Our findings show that in AON and aPCx, novelty-related information is indeed highly generalizable, supporting the idea that these regions encode novelty in a less odor-selective manner (Figure 2K).
Reviewer #3 (Public review):
In this manuscript, the authors investigate how odor-evoked neural activity is modulated by experience within the olfactory-hippocampal network. The authors perform extracellular recordings in the anterior olfactory nucleus (AON), the anterior piriform (aPCx) and lateral entorhinal cortex (LEC), the hippocampus (CA1), and the subiculum (SUB), in naïve mice and in mice repeatedly exposed to the same odorants. They determine the response properties of individual neurons and use population decoding analyses to assess the effect of experience on odor information coding across these regions.
The authors' findings show that odor identity is represented in all recorded areas, but that the response magnitude and selectivity of neurons are differentially modulated by experience across the olfactory-hippocampal pathway.
Overall, this work represents a valuable multi-region data set of odor-evoked neural activity. However, limitations in the interpretability of odor experience of the behavioral paradigm, and limitations in experimental design and analysis, restrict the conclusions that can be drawn from this study.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Some suggestions, in no particular order, to further improve the manuscript:
(1) The example neuronal responses for CA1 and SUB in Figure 1 are not very inspiring. To my eyes, the odor period response is not that different from the baseline period. In general, a thorough characterization of firing rate properties during the odor period between the different brain regions would be informative.
We thank the reviewer for this valuable feedback. We have replaced the example neurons from CA1 and SUB in Figure 1C. We further extended the characterization of firing rate properties, including a separate analysis of neurons i) significantly excited by odorants, ii) significantly inhibited by odorants and iii) not responsive to odorants. We added the analysis and corresponding discussion to the main manuscript (Figures 2C-E and lines 118-132)
(2) For the summary in Figure 1, why not show neuronal responses as z-scored firing rates as opposed to auROC?
We chose to use auROC instead of z-scored firing rates due to the non-normality of the dataset, which can distort results when using z-scores. Specifically, z-scoring can exaggerate small deviations in neurons with low responsiveness, potentially leading to misleading conclusions. auROC provides a more robust measure of response change that is less sensitive to these distortions because it does not assume any specific distribution. This approach has been used previously (e.g. Cohen et al. 2012, Nature).
(3) To study novelty, the authors presented odorants that were not used during four days of habituation. But this design makes it hard to dissociate odor identity from novelty. Why not track the response of the same odorants during the habituation process itself?
We respectfully disagree with the argument that using different stimuli as novel and familiar constitutes a confound in our analysis. In our study, we used multiple different, structurally dissimilar single molecule chemicals which were randomly assigned to novel and familiar categories in each animal. If individual stimuli did cause “drastic differences in evoked neural responses”, these would be evenly distributed between novel and familiar stimuli. It is therefore extremely unlikely that the clear differences we observed between novel and familiar conditions and between brain areas can be attributed to the contribution of individual stimuli, in particular given our analyses was performed at the population level. In fact, we observed that responses between novel and familiar conditions were qualitatively very similar in the short time window after odor onset (Figure 1G and H).
Importantly, the goal of this study was to investigate the impact of long-term habituation over more than 4 days, rather than short term habituation during one behavioral session. However, tracking the activity of large numbers of neurons across multiple days presents a significant technical challenge, due to the difficulty of identifying stable single-unit recordings over extended periods of time with sufficient certainty. Tools that facilitate tracking have recently been developed (e.g. Yuan AX et al., Elife. 2024) and it will be interesting to apply them to our dataset in the future.
(4) Since novel odors lead to greater sniffing and sniffing strongly influences firing rates in the olfactory system, the authors decided to focus on a 400 ms window with similar sniffing rates for both novel vs. familiar odors. Although I understand the rationale for this choice, I worry that this is too restrictive, and it may not capture the full extent of the phenomenology.
Could the authors model the effect of sniffing on firing rates of individual neurons from the data, and then check whether the odor response for novel context can be fully explained just by increased sniffing or not?
It is an interesting suggestion to extend the window of analysis and observe how responses evolve with sniffing (and other behavioral reactions). To address this, we added an additional figure to the supplementary material, showing the mean responses of all neurons to novel stimuli during the entire odor presentation window (Fig. S1B).
As suggested, we further created a Generalized Linear Model (GLM) for the entire 2s odor stimulation period, incorporating sniffing and novelty as independent variables. As expected, sniffing had a dominant impact on firing rate in all brain areas. A smaller proportion of neurons was modulated by novelty or by the interaction between novelty x breathing, suggesting the entrainment of neural activity by sniffing during the response to novel odors. These results support our decision to focus the analysis on the early 400ms window in order to dissociate the effects of novelty and behavioral responses. Taken together, our results suggest that odorant responses are modulated by novelty early during odorant processing, whereas at later stages sniffing becomes the predominant factor driving firing (Figure S2C-D).
(5) The authors conclude that aPCx has a subset of neurons dedicated to familiar odors based on the distribution of SVM weights in Figure 3D. To me, this is the weakest conclusion of the paper because although significant, the effect size is paltry; the central tendencies are hardly different for the two conditions in aPCx. Could the authors show the PSTHs of some of these neurons to make this point more convincing?
We appreciate the reviewer’s concern regarding the effect size. To strengthen our conclusion, we now include PSTHs of representative neurons in the least 10% and best 10% of neuronal population based on the SVM analysis (Figures S3 and S4). We hope this provides more clarity and support for the interpretation that there is a subset of neurons in aPCx that show greater sensitivity to familiar odors, despite the relatively modest central tendency differences.
In the revised manuscript, we discuss the effect size more explicitly in the text to provide context for its significance (lines 193 - 195).
Reviewer #2 (Recommendations for the authors):
(1) The authors only talk about "responsive" neurons. Does this include neurons whose activity increases significantly (activated) and neurons whose activity decreases (suppressed)?
Yes, the term "responsive" refers to neurons whose activity either increases significantly (excited) or decreases (inhibited) in response to the odor stimuli. We performed additional analyses to characterize responses separately for the different groups (Figure 2C-E and lines 118-132).
(2) Line 54 - The Schoonover paper doesn't show that cells lose their responses to odors, but rather that the population of cells that respond to odors changes with time. That is, population responses don't become more sparse
The fact that “the population of cells that respond to odors changes with time”, implies that some neurons lose their responsiveness (e.g. unit 2 in Figure 1 of Schoonover et al., 2021), while others become responsive (e.g. unit 1 in Figure 1 of Schoonover et al., 2021). Frequent responses reduce drift rate (Figure 4 of Schoonover et al., 2021), thus fewer neurons loose or gain responsiveness. We have revised the manuscript to clarify this.
(3) Line 104 - "Recurrent" is incorrectly used here. I think the authors mean "repeated" or something more like that.
Thank you for pointing this out. We replaced "recurrent" with "repeated".
(4) Figure 3D - What is the scale bar here?
We apologize for the accidental omission. The scale bar was be added to Figure 3D in the revised version of the manuscript.
(5) Line 377 - They say they lowered their electrodes to "200 um/s per second." This must be incorrect. Is this just a typo, or is it really 200 um/s, because that's really fast?
Thank you for pointing this out. It was 20 to 60 um/s, the change has been made in the manuscript.
(6) Line 431: The authors say they used auROC to calculate changes in firing rates (which I think is only shown in Figure 1D). Note that auROC measures the discriminability of two distributions, not the strength or change in the strength of response.
Indeed we used auROC to measure the discriminability of firing between baseline and during stimulus response. We have corrected the wording in the methods.
(7) Figure 1B: The anatomical locations of the five areas they recorded from are straightforward, and this figure is not hugely helpful. However, the reader would benefit tremendously by including an experimental schematic. As is, we needed to scour the text and methods sections to understand exactly what they did when.
We thank the reviewer for this suggestion. We included an experimental schematic in the supplementary material.
(8) Figure 1F(left): This plot is much less useful without showing a pre-odor window, even if only times after the odor onset were used for calculation alpha
We appreciate this concern, however the goal of Figure 1F is to illustrate the meaning of the alpha value itself. We chose not to include a pre-odor window comparison to avoid confusing the reader.
(9) Figure 2A: What are the bar plots above the raster plots? Are these firing rates? Are the bars overlaid or stacked? Where is the y-axis scale bar?
The bar plots above the raster plots represent a histogram of the spike count/trials over time, with a bin width of 50 ms. These bars are overlaid on the raster plot. We will include a y-axis scale bar in the revised figure to clarify the presentation.
(10) Figure 4G: This makes no sense. First, the Y axis is supposed to measure standard deviation, but the axis label is spikes/s. Second, if responses in the AON are much less reliable than responses in "deeper" areas, why is odor decoding in AON so much better than in the other areas?
We acknowledge the error in the axis label, and we will correct it to indicate the correct units. AON has a larger response variability but also larger responses magnitudes, which can explain the higher decoding accuracy.
(11) From the model and text, one predicts that the lifetime sparseness increases along the pathway. The authors should use this metric as well/instead of "odor selectivity" because of problems with arbitrary thresholding.
We acknowledge that lifetime sparseness, often computed using lifetime kurtosis, can be an informative measure of selectivity. However, we believe it has limitations that make it less suitable for our analysis. One key issue is that lifetime sparseness does not account for the stability of responses across multiple presentations of the same stimulus. In contrast, our odor selectivity measure incorporates trial-to-trial variability by considering responses over 10 trials and assessing significance using a Wilcoxon test compared to baseline. While the choice of a p-value threshold (e.g., 0.05) is somewhat arbitrary, it is a widely accepted statistical convention. Additionally, lifetime sparseness does not account for excitatory and inhibitory responses. For example, if a neuron X is strongly inhibited by odor A, strongly excited by odor B, and unresponsive to odors C and D, lifetime sparseness would classify it as highly selective for odor B, without capturing its inhibitory selectivity for odor A. The lifetime sparseness will be higher than if X was simply unresponsive for A.
Our odor selectivity measure addresses this by considering both excitation and inhibition as potential responses. Thus, while lifetime sparseness could provide a useful complementary perspective in another type of dataset, it does not fully capture the dynamics of odor selectivity here.
Author response 1.
Lifetime Kurtosis distribution per region.

Reviewer #3 (Recommendations for the authors):
Main points:
(1) The authors use a non-associative learning paradigm - repeated odor exposure - to test how experience modulates odor responses along the olfactory-hippocampal pathway. While repeated odor exposure clearly modulates odor-evoked neural activity, the relevance of this modulation and its differential effect across different brain areas are difficult to assess in the absence of any behavioral read-outs.
Our experimental paradigm involves a robust, reliable behavioral readout of non-associative learning. Novel olfactory stimuli evoke a well-characterized orienting reaction, which includes a multitude of physiological reactions, including exploratory sniffing, facial movements and pupil dilation (Modirshanechi et al., Trends Neuroscience 2023). In our study, we focused on exploration sniffing.
Compared to associative learning, non-associative learning might have received less attention. However, it is critically important because it forms the foundation for how organisms adapt to their environment through experience without forming associations. This is highlighted by the fact that non-instrumental stimuli can be remembered in large number (Standing, 1973) and with remarkable detail (Brady et al., 2008). While non-associative learning can thus create vast, implicit memory of stimuli in the environment, it is unclear how stimulus representations reflect this memory. Our study contributes to answering this question. We describe the impact of experience on olfactory sensory representations and reveal a transformation of representations from olfactory cortical to hippocampal structures. Our findings also indicate that sensory responses to familiar stimuli persist within sensory cortical and hippocampal regions, even after spontaneous orienting behaviors habituated. Further studies involving experimental manipulation techniques are needed to elucidate the causal mechanisms underlying the formation of stimulus memory during non-associative learning.
(2) The authors discuss the olfactory-hippocampal pathway as a transition from primary sensory (AON, aPCx) to associative areas (LEC, CA1, SUB). While this is reasonable, given the known circuit connectivity, other interpretations are possible. For example, AON, aPCx, and LEC receive direct inputs from the olfactory bulb ('primary cortex'), while CA1 and SUB do not; AON receives direct top-down inputs from CA1 ('associative cortex'), while aPCx does not. In fact, the data presented in this manuscript does not appear to support a consistent, smooth transformation from sensory to associative, as implied by the authors (e.g. Figure 4A, F, and G).
Thank you for this insightful comment. Indeed, there are complexities in the circuitry, and the relationships between different areas are not linear. We believe that AON and aPCx are distinctly different from LEC, CA1 and SUB, as the latter areas have been shown to integrate multimodal sensory information. To avoid confusion due to definitions of what constitutes a “primary sensory” region, we adopted a more neutral description throughout the manuscript. We also removed the term “gradual” to describe the transition of neural representations from olfactory cortical to hippocampal areas.
(3) The analysis of odor-evoked responses is focused on a 400 ms window to exclude differences in sniffing behavior. This window spans 200 ms before and after the first inhalation after odor onset. Inhalation onset initiates neural odor responses - why do the authors include neural data before inhalation onset?
The reason to include a brief time window prior to odor onset is to account for what is often called “partical” sniffs. In our experimental setup, odor delivery is not triggered by the animal’s inhalation. Therefore, it can happen that an animal has just begun to inhale when the stimulus is delivered. In this case, the animal is exposed to odorant molecules prior to the first complete inhalation after odor onset. We acknowledge that this limits the temporal resolution of our measurements, but it does not affect the comparison of sensory representations between different brain areas.
It would also be interesting to explore the effect of sniffing behavior (see point 2) on odor-evoked neural activity.
Thank you for your comment, we performed additional analysis including a GLM to address this question (Figure S2C-D).
Minor points:
(4) Figure 2A represents raster plots for 2 neurons per area - it is unclear how to distinguish between the 2 neurons in the plots.
Figure 2A shows one example neuron per brain area. Each neurons has two raster plot which indicate responses to either a novel (orange) or a familiar stimulus (blue). We have revised the figure caption for clarity.
(5) Overall, axes should be kept consistent and labeled in more detail. For example, Figure 2H and I are difficult to compare, given that the y-axis changes and that decoding accuracies are difficult to estimate without additional marks on the y-axis.
Axes are indeed different, because chance level decoding accuracy is different between those two figures. The decoding between novel and familiar odors has a chance level of 0.5, while chance level decoding odors is 0.1 (there are 10 odors to decode the identity from).
(6) Some parts of the discussion seem only loosely related to the data presented in this manuscript. For example, the statement that 'AON rather than aPCx should be considered as the primary sensory cortex in olfaction' seems out of context. Similarly, it would be helpful to provide data on the stability of subpopulations of neurons tuned to familiar odors, rather than simply speculate that they could be stable. The authors could summarize more speculative statements in an 'Ideas and Speculation' subsection.
Thank you for your comment. We appreciate your perspective on our hypotheses. We have revised the discussion accordingly. Specifically, we removed the discussion of stable subpopulations, since we have not performed longitudinal tracking in this study.
(7) The authors should try to reference relevant published work more comprehensively.
Thank you for your comment. We attempted to include relevant published work without exceeding the limit for references but might have overseen important contributions. We apologize to our colleagues, whose relevant work might not have been cited.
Author response:
The following is the authors’ response to the current reviews.
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study examines whether changes in pupil size index prediction-error-related updating during associative learning, formalised as information gain via Kullback-Leibler (KL) divergence. Across two independent tasks, pupil responses scaled with KL divergence shortly after feedback, with the timing and direction of the response varying by task. Overall, the work supports the view that pupil size reflects information-theoretic processes in a context-dependent manner.
Strengths:
This study provides a novel and convincing contribution by linking pupil dilation to informationtheoretic measures, such as KL divergence, supporting Zénon's hypothesis that pupil responses reflect information gain during learning. The robust methodology, including two independent datasets with distinct task structures, enhances the reliability and generalisability of the findings. By carefully analysing early and late time windows, the authors capture the timing and direction of prediction-error-related responses, oPering new insights into the temporal dynamics of model updating. The use of an ideal-learner framework to quantify prediction errors, surprise, and uncertainty provides a principled account of the computational processes underlying pupil responses. The work also highlights the critical role of task context in shaping the direction and magnitude of these ePects, revealing the adaptability of predictive processing mechanisms. Importantly, the conclusions are supported by rigorous control analyses and preprocessing sanity checks, as well as convergent results from frequentist and Bayesian linear mixed-ePects modelling approaches.
Weaknesses:
Some aspects of directionality remain context-dependent, and on current evidence cannot be attributed specifically to whether average uncertainty increases or decreases across trials. DiPerences between the two tasks (e.g., sensory modality and learning regime) limit direct comparisons of ePect direction and make mechanistic attribution cautious. In addition, subjective factors such as confidence were not measured and could influence both predictionerror signals and pupil responses. Importantly, the authors explicitly acknowledge these limitations, and the manuscript clearly frames them as areas for future work rather than settled conclusions.
Reviewer #2 (Public review):
Summary:
The authors investigate whether pupil dilation reflects information gain during associative learning, formalised as Kullback-Leibler divergence within an ideal observer framework. They examine pupil responses in a late time window after feedback and compare these to informationtheoretic estimates (information gain, surprise, and entropy) derived from two diPerent tasks with contrasting uncertainty dynamics.
Strength:
The exploration of task evoked pupil dynamics beyond the immediate response/feedback period and then associating them with model estimates was interesting and inspiring. This oPered a new perspective on the relationship between pupil dilation and information processing.
Weakness:
However, the interpretability of the findings remains constrained by the fundamental diPerences between the two tasks (stimulus modality, feedback type, and learning structure), which confound the claimed context-dependent ePects. The later time-window pupil ePects, although intriguing, are small in magnitude and may reflect residual noise or task-specific arousal fluctuations rather than distinct information-processing signals. Thus, while the study oPers valuable methodological insight and contributes to ongoing debates about the role of the pupil in cognitive inference, its conclusions about the functional significance of late pupil responses should be treated with caution.
Reviewer #3 (Public review):
Summary:
Thank you for inviting me to review this manuscript entitled "Pupil dilation oPers a time-window on prediction error" by Colizoli and colleagues. The study examines prediction errors, information gain (Kullback-Leibler [KL] divergence), and uncertainty (entropy) from an information-theory perspective using two experimental tasks and pupillometry. The authors aim to test a theoretical proposal by Zénon (2019) that the pupil response reflects information gain (KL divergence). The conclusion of this work is that (post-feedback) pupil dilation in response to information gain is context dependent.
Strengths:
Use of an established Bayesian model to compute KL divergence and entropy.
Pupillometry data preprocessing and multiple robustness checks.
Weaknesses:
Operationalization of prediction errors based on frequency, accuracy, and their interaction:
The authors rely on a more model-agnostic definition of the prediction error in terms of stimulus frequency ("unsigned prediction error"), accuracy, and their interaction ("signed prediction error"). While I see the point, I would argue that this approach provides a simple approximation of the prediction error, but that a model-based approach would be more appropriate.
Model validation:
My impression is that the ideal learner model should work well in this case. However, the authors don't directly compare model behavior to participant behavior ("posterior predictive checks") to validate the model. Therefore, it is currently unclear if the model-derived terms like KL divergence and entropy provide reasonable estimates for the participant data.
Lack of a clear conclusion:
The authors conclude that this study shows for the first time that (post-feedback) pupil dilation in response to information gain is context dependent. However, the study does not oPer a unifying explanation for such context dependence. The discussion is quite detailed with respect to taskspecific ePects, but fails to provide an overarching perspective on the context-dependent nature of pupil signatures of information gain. This seems to be partly due to the strong diPerences between the experimental tasks.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
I highly appreciate the care and detail in the authors' response and thank them for the ePort invested in revising the manuscript. They addressed the core concerns to a high standard, and the manuscript has substantially improved in methodological rigour (through additional controls/sanity checks and complementary mixed-ePects analyses) and in clarity of interpretation (by explicitly acknowledging context-dependence and tempering stronger claims). The present version reads clearly and is much strengthened overall. I only have a few minor points below:
Minor suggestions:
Abstract:
In the abstract KL is introduced as abbreviation, but at first occurence it should be written out as "Kullback-Leibler (KL)" for readers not familiar with it.
We thank the reviewer for catching this error. It has been correct in the version of record.
Methods:
I appreciate the additional bayesian LME analysis. I only had a few things that I thought were missing from knowing the parameters: 1) what was the target acceptance rate (default of .95?), 2) which family was used to model the response distribution: (default) "gaussian" or robust "student-t"? Depending on the data a student-t would be preferred, but since the author's checked the fit & the results corroborate the correlation analysis, using the default would also be fine! Just add the information for completeness.
Thank you for bringing this to our attention. We have now noted that default parameters were used in all cases unless otherwise mentioned.
Thank you once again for your time and consideration.
Reviewer #2 (Recommendations for the authors):
Thanks to the authors' ePort on revision. I am happy with this new version of manuscript.
Thank you once again for your time and consideration.
Reviewer #3 (Recommendations for the authors):
(1) Regarding comments #3 and #6 (first round) on model validation and posterior predictive checks, the authors replied that since their model is not a "generative" one, they can't perform posterior predictive checks. Crucially, in eq. 2, the authors present the p{tilde}^j_k variable denoting the learned probability of event k on trial j. I don't see why this can't be exploited for simulations. In my opinion, one could (and should) generate predictions based on this variable. The simplest implementation would translate the probability into a categorical choice (w/o fitting any free parameter). Based on this, they could assess whether the model and data are comparable.
We thank the reviewer for this clarification. The reviewer suggests using the probability distributions at each trial to predict which event should be chosen on each trial. More specifically, the event(s) with the highest probability on trial j could be used to generate a prediction for the choice of the participant on trial j. We agree that this would indeed be an interesting analysis. However, the response options of each task are limited to two-alternatives. In the cue-target task, four events are modeled (representing all possible cue-target conditions) while the participants’ response options are only “left” and “right”. Similarly, in the letter-color task, 36 events are modeled while the participants’ response options are “match” and “no-match”. In other words, we do not know which event (either four or 36, for the two tasks) the participant would have indicated on each trial. As an approximation to this fine-grained analysis, we investigated the relationship between the information-theoretic variables separately for error and correct trials. Our rationale was that we would have more insight into how the model fits depended on the participants’ actual behavior as compared with the ideal learner model.
(2) I recommend providing a plot of the linear mixed model analysis of the pupil data. Currently, results are only presented in the text and tables, but a figure would be much more useful.
We thank the reviewer for the suggestion to add a plot of the linear mixed model results. We appreciate the value of visualizing model estimates; however, we feel that the current presentation in the text and tables clearly conveys the relevant findings. For this reason, and to avoid further lengthening the manuscript, we prefer to retain the current format.
(3) I would consider only presenting the linear mixed ePects for the pupil data in the main results, and the correlation results in the supplement. It is currently quite long.
We thank the reviewer for this recommendation. We agree that the results section is detailed; however, we consider the correlation analyses to be integral to the interpretation of the pupil data and therefore prefer to keep them in the main text rather than move them to the supplement.
The following is the authors’ response to the original reviews
eLife Assessment
This important study seeks to examine the relationship between pupil size and information gain, showing opposite effects dependent upon whether the average uncertainty increases or decreases across trials. Given the broad implications for learning and perception, the findings will be of broad interest to researchers in cognitive neuroscience, decision-making, and computational modelling. Nevertheless, the evidence in support of the particular conclusion is at present incomplete - the conclusions would be strengthened if the authors could both clarify the differences between model-updating and prediction error in their account and clarify the patterns in the data.
Public Reviews:
Reviewer #1 (Public review):
Summary:
This study investigates whether pupil dilation reflects prediction error signals during associative learning, defined formally by Kullback-Leibler (KL) divergence, an information-theoretic measure of information gain. Two independent tasks with different entropy dynamics (decreasing and increasing uncertainty) were analyzed: the cue-target 2AFC task and the lettercolor 2AFC task. Results revealed that pupil responses scaled with KL divergence shortly after feedback onset, but the direction of this relationship depended on whether uncertainty (entropy) increased or decreased across trials. Furthermore, signed prediction errors (interaction between frequency and accuracy) emerged at different time windows across tasks, suggesting taskspecific temporal components of model updating. Overall, the findings highlight that pupil dilation reflects information-theoretic processes in a complex, context-dependent manner.
Strengths:
This study provides a novel and convincing contribution by linking pupil dilation to informationtheoretic measures, such as KL divergence, supporting Zénon's hypothesis that pupil responses reflect information gained during learning. The robust methodology, including two independent datasets with distinct entropy dynamics, enhances the reliability and generalisability of the findings. By carefully analysing early and late time windows, the authors capture the temporal dynamics of prediction error signals, offering new insights into the timing of model updates. The use of an ideal learner model to quantify prediction errors, surprise, and entropy provides a principled framework for understanding the computational processes underlying pupil responses. Furthermore, the study highlights the critical role of task context - specifically increasing versus decreasing entropy - in shaping the directionality and magnitude of these effects, revealing the adaptability of predictive processing mechanisms.
Weaknesses:
While this study offers important insights, several limitations remain. The two tasks differ significantly in design (e.g., sensory modality and learning type), complicating direct comparisons and limiting the interpretation of differences in pupil dynamics. Importantly, the apparent context-dependent reversal between pupil constriction and dilation in response to feedback raises concerns about how these opposing effects might confound the observed correlations with KL divergence.
We agree with the reviewer’s concerns and acknowledge that the speculation concerning the directional effect of entropy across trials can not be fully substantiated by the current study. As the reviewer points out, the directional relationship between pupil dilation and information gain must be due to other factors, for instance, the sensory modality, learning type, or the reversal between pupil constriction and dilation across the two tasks. Also, we would like to note that ongoing experiments in our lab already contradict our original speculation. In line with the reviewer’s point, we noted these differences in the section on “Limitations and future research” in the Discussion. To better align the manuscript with the above mentioned points, we have made several changes in the Abstract, Introduction and Discussion summarized below:
We have removed the following text from the Abstract and Introduction: “…, specifically related to increasing or decreasing average uncertainty (entropy) across trials.”
We have edited the following text in the Introduction (changes in italics) (p. 5):
“We analyzed two independent datasets featuring distinct associative learning paradigms, one characterized by increasing entropy and the other by decreasing entropy as the tasks progressed. By examining these different tasks, we aimed to identify commonalities (if any) in the results across varying contexts. Additionally, the contrasting directions of entropy in the two tasks enabled us to disentangle the correlation between stimulus-pair frequency and information gain in the postfeedback pupil response.
We have removed the following text from the Discussion:
“…and information gain in fact seems to be driven by increased uncertainty.”
“We speculate that this difference in the direction of scaling between information gain and the pupil response may depend on whether entropy was increasing or decreasing across trials.”
“…which could explain the opposite direction of the relationship between pupil dilation and information gain”
“… and seems to relate to the direction of the entropy as learning progresses (i.e., either increasing or decreasing average uncertainty).”
We have edited the following texts in the Discussion (changes in italics):
“For the first time, we show that the direction of the relationship between postfeedback pupil dilation and information gain (defined as KL divergence) was context dependent.” (p. 29):
Finally, we have added the following correction to the Discussion (p. 30):
“Although it is tempting to speculate that the direction of the relationship between pupil dilation and information gain may be due to either increasing or decreasing entropy as the task progressed, we must refrain from this conclusion. We note that the two tasks differ substantially in terms of design with other confounding variables and therefore cannot be directly compared to one another. We expand on these limitations in the section below (see Limitations and future research).”
Finally, subjective factors such as participants' confidence and internal belief states were not measured, despite their potential influence on prediction errors and pupil responses.
Thank you for the thoughtful comment. We agree with the reviewer that subjective factors, such as participants' confidence, can be important in understanding prediction errors and pupil responses. As per the reviewer’s point, we have included the following limitation in the Discussion (p. 33):
“Finally, while we acknowledge the potential relevance of subjective factors, such as the participants’ overt confidence reports, in understanding prediction errors and pupil responses, the current study focused on the more objective, model-driven measure of information-theoretic variables. This approach aligns with our use of the ideal learner model, which estimates information-theoretic variables while being agnostic about the observer's subjective experience itself. Future research is needed to explore the relationship between information-gain signals in pupil dilation and the observer’s reported experience of or awareness about confidence in their decisions.”
Reviewer #2 (Public review):
Summary:
The authors proposed that variability in post-feedback pupillary responses during the associative learning tasks can be explained by information gain, which is measured as KL divergence. They analysed pupil responses in a later time window (2.5s-3s after feedback onset) and correlated them with information-theory-based estimates from an ideal learner model (i.e., information gain-KL divergence, surprise-subjective probability, and entropy-average uncertainty) in two different associative decision-making tasks.
Strength:
The exploration of task-evoked pupil dynamics beyond the immediate response/feedback period and then associating them with model estimates was interesting and inspiring. This offered a new perspective on the relationship between pupil dilation and information processing.
Weakness:
However, disentangling these later effects from noise needs caution. Noise in pupillometry can arise from variations in stimuli and task engagement, as well as artefacts from earlier pupil dynamics. The increasing variance in the time series of pupillary responses (e.g., as shown in Figure 2D) highlights this concern.
It's also unclear what this complicated association between information gain and pupil dynamics actually means. The complexity of the two different tasks reported made the interpretation more difficult in the present manuscript.
We share the reviewer’s concerns. To make this point come across more clearly, we have added the following text to the Introduction (p. 5):
“The current study was motivated by Zenon’s hypothesis concerning the relationship between pupil dilation and information gain, particularly in light of the varying sources of signal and noise introduced by task context and pupil dynamics. By demonstrating how task context can influence which signals are reflected in pupil dilation, and highlighting the importance of considering their temporal dynamics, we aim to promote a more nuanced and model-driven approach to cognitive research using pupillometry.”
Reviewer #3 (Public review):
Summary:
This study examines prediction errors, information gain (Kullback-Leibler [KL] divergence), and uncertainty (entropy) from an information-theory perspective using two experimental tasks and pupillometry. The authors aim to test a theoretical proposal by Zénon (2019) that the pupil response reflects information gain (KL divergence). In particular, the study defines the prediction error in terms of KL divergence and speculates that changes in pupil size associated with KL divergence depend on entropy. Moreover, the authors examine the temporal characteristics of pupil correlates of prediction errors, which differed considerably across previous studies that employed different experimental paradigms. In my opinion, the study does not achieve these aims due to several methodological and theoretical issues.
Strengths:
(1) Use of an established Bayesian model to compute KL divergence and entropy.
(2) Pupillometry data preprocessing, including deconvolution.
Weaknesses:
(1) Definition of the prediction error in terms of KL divergence:
I'm concerned about the authors' theoretical assumption that the prediction error is defined in terms of KL divergence. The authors primarily refer to a review article by Zénon (2019): "Eye pupil signals information gain". It is my understanding that Zénon argues that KL divergence quantifies the update of a belief, not the prediction error: "In short, updates of the brain's internal model, quantified formally as the Kullback-Leibler (KL) divergence between prior and posterior beliefs, would be the common denominator to all these instances of pupillary dilation to cognition." (Zénon, 2019).
From my perspective, the update differs from the prediction error. Prediction error refers to the difference between outcome and expectation, while update refers to the difference between the prior and the posterior. The prediction error can drive the update, but the update is typically smaller, for example, because the prediction error is weighted by the learning rate to compute the update. My interpretation of Zénon (2019) is that they explicitly argue that KL divergence defines the update in terms of the described difference between prior and posterior, not the prediction error.
The authors also cite a few other papers, including Friston (2010), where I also could not find a definition of the prediction error in terms of KL divergence. For example [KL divergence:] "A non-commutative measure of the non-negative difference between two probability distributions." Similarly, Friston (2010) states: Bayesian Surprise - "A measure of salience based on the Kullback-Leibler divergence between the recognition density (which encodes posterior beliefs) and the prior density. It measures the information that can be recognized in the data." Finally, also in O'Reilly (2013), KL divergence is used to define the update of the internal model, not the prediction error.
The authors seem to mix up this common definition of the model update in terms of KL divergence and their definition of prediction error along the same lines. For example, on page 4: "KL divergence is a measure of the difference between two probability distributions. In the context of predictive processing, KL divergence can be used to quantify the mismatch between the probability distributions corresponding to the brain's expectations about incoming sensory input and the actual sensory input received, in other words, the prediction error (Friston, 2010; Spratling, 2017)."
Similarly (page 23): "In the current study, we investigated whether the pupil's response to decision outcome (i.e., feedback) in the context of associative learning reflects a prediction error as defined by KL divergence."
This is problematic because the results might actually have limited implications for the authors' main perspective (i.e., that the pupil encodes prediction errors) and could be better interpreted in terms of model updating. In my opinion, there are two potential ways to deal with this issue:
(a) Cite work that unambiguously supports the perspective that it is reasonable to define the prediction error in terms of KL divergence and that this has a link to pupillometry. In this case, it would be necessary to clearly explain the definition of the prediction error in terms of KL divergence and dissociate it from the definition in terms of model updating.
(b) If there is no prior work supporting the authors' current perspective on the prediction error, it might be necessary to revise the entire paper substantially and focus on the definition in terms of model updating.
We thank the reviewer for pointy out these inconsistencies in the manuscript and appreciate their suggestions for improvement. We take approach (a) recommended by the reviewer, and provide our reasoning as to why prediction error signals in pupil dilation are expected to correlate with information gain (defined as the KL divergence between posterior and prior belief distributions). This can be found in a new section in the introduction, copied here for convenience (p. 3-4):
“We reasoned that the link between prediction error signals and information gain in pupil dilation is through precision-weighting. Precision refers to the amount of uncertainty (inverse variance) of both the prior belief and sensory input in the prediction error signals [6,64–67]. More precise prediction errors receive more weighting, and therefore, have greater influence on model updating processes. The precisionweighting of prediction error signals may provide a mechanism for distinguishing between known and unknown sources of uncertainty, related to the inherent stochastic nature of a signal versus insufficient information of the part of the observer, respectively [65,67,68]. In Bayesian frameworks, information gain is fundamentally linked to prediction error, modulated by precision [65,66,69–75]. In non-hierarchical Bayesian models, information gain can be derived as a function of prediction errors and the precision of the prior and likelihood distributions, a relationship that can be approximately linear [70]. In hierarchical Bayesian inference, the update in beliefs (posterior mean changes) at each level is proportional to the precision-weighted prediction error; this update encodes the information gained from new observations [65,66,69,71,72]. Neuromodulatory arousal systems are well-situated to act as precision-weighting mechanisms in line with predictive processing frameworks [76,77]. Empirical evidence suggests that neuromodulatory systems broadcast precisionweighted prediction errors to cortical regions [11,59,66,78]. Therefore, the hypothesis that feedback-locked pupil dilation reflects a prediction error signal is similarly in line with Zenon’s main claim that pupil dilation generally reflects information gain, through precision-weighting of the prediction error. We expected a prediction error signal in pupil dilation to be proportional to the information gain.”
We have referenced previous work that has linked prediction error and information gain directly (p. 4): “The KL divergence between posterior and prior belief distributions has been previously considered to be a proxy of (precision-weighted) prediction errors [68,72].”
We have taken the following steps to remedy this error of equating “prediction error” directly with the information gain.
First, we have replaced “KL divergence” with “information gain” whenever possible throughout the manuscript for greater clarity.
Second, we have edited the section in the introduction defining information gain substantially (p. 4):
“Information gain can be operationalized within information theory as the KullbackLeibler (KL) divergence between the posterior and prior belief distributions of a Bayesian observer, representing a formalized quantity that is used to update internal models [29,79,80]. Itti and Baldi (2005)81 termed the KL divergence between posterior and prior belief distributions as “Bayesian surprise” and showed a link to the allocation of attention. The KL divergence between posterior and prior belief distributions has been previously considered to be a proxy of (precision-weighted) prediction errors[68,72]. According to Zénon’s hypothesis, if pupil dilation reflects information gain during the observation of an outcome event, such as feedback on decision accuracy, then pupil size will be expected to increase in proportion to how much novel sensory evidence is used to update current beliefs [29,63]. ”
Finally, we have made several minor textual edits to the Abstract and main text wherever possible to further clarify the proposed relationship between prediction errors and information gain.
(2) Operationalization of prediction errors based on frequency, accuracy, and their interaction:
The authors also rely on a more model-agnostic definition of the prediction error in terms of stimulus frequency ("unsigned prediction error"), accuracy, and their interaction ("signed prediction error"). While I see the point here, I would argue that this approach offers a simple approximation to the prediction error, but it is possible that factors like difficulty and effort can influence the pupil signal at the same time, which the current approach does not take into account. I recommend computing prediction errors (defined in terms of the difference between outcome and expectation) based on a simple reinforcement-learning model and analyzing the data using a pupillometry regression model in which nuisance regressors are controlled, and results are corrected for multiple comparisons.
We agree with the reviewer’s suggestion that alternatively modeling the data in a reinforcement learning paradigm would be fruitful. We adopted the ideal learner model as we were primarily focused on Information Theory, stemming from our aim to test Zenon’s hypothesis that information gain drives pupil dilation. However, we agree with the reviewer that it is worthwhile to pursue different modeling approaches in future work. We have now included a complementary linear mixed model analysis in which we controlled for the effects of the information-theoretic variables on one another, while also including the nuisance regressors of pre-feedback baseline pupil dilation and reaction times (explained in more detail below in our response to your point #4). Results including correction for multiple comparisons was reported for all pupil time course data as detailed in Methods section 2.5.
(3) The link between model-based (KL divergence) and model-agnostic (frequency- and accuracy-based) prediction errors:
I was expecting a validation analysis showing that KL divergence and model-agnostic prediction errors are correlated (in the behavioral data). This would be useful to validate the theoretical assumptions empirically.
The model limitations and the operalization of prediction error in terms of post-feedback processing do not seem to allow for a comparison of information gain and model-agnostic prediction errors in the behavioral data for the following reasons. First, the simple ideal learner model used here is not a generative model, and therefore, cannot replicate or simulate the participants responses (see also our response to your point #6 “model validation” below). Second, the behavioral dependent variables obtained are accuracy and reaction times, which both occur before feedback presentation. While accuracy and reaction times can serve as a marker of the participant’s (statistical) confidence/uncertainty following the decision interval, these behavioral measures cannot provide access to post-feedback information processing. The pupil dilation is of interest to us because the peripheral arousal system is able to provide a marker of post-feedback processing. Through the analysis presented in Figure 3, we indeed aimed to make the comparison of the model-based information gain to the model-agnostic prediction errors via the proxy variable of post-feedback pupil dilation instead of behavioral variables. To bridge the gap between the “behaviorally agnostic” model parameters and the actual performance of the participants, we examined the relationship between the model-based information gain and the post-feedback pupil dilation separately for error and correct trials as shown in Figure 3D-F & Figure 3J-L. We hope this addresses the reviewers concern and apologize in case we did not understand the reviewers suggestion here.
(4) Model-based analyses of pupil data:
I'm concerned about the authors' model-based analyses of the pupil data. The current approach is to simply compute a correlation for each model term separately (i.e., KL divergence, surprise, entropy). While the authors do show low correlations between these terms, single correlational analyses do not allow them to control for additional variables like outcome valence, prediction error (defined in terms of the difference between outcome and expectation), and additional nuisance variables like reaction time, as well as x and y coordinates of gaze.
Moreover, including entropy and KL divergence in the same regression model could, at least within each task, provide some insights into whether the pupil response to KL divergence depends on entropy. This could be achieved by including an interaction term between KL divergence and entropy in the model.
In line with the reviewer’s suggestions, we have included a complementary linear mixed model analysis in which we controlled for the effects of the information-theoretic variables on one another, while also including the nuisance regressors of pre-feedback baseline pupil dilation and reaction times. We compared the performance of two models on the post-feedback pupil dilation in each time window of interest: Modle 1 had no interaction between information gain and entropy and Model 2 included an interaction term as suggested. We did not include the x- and y- coordinates of gaze in the mixed linear model analysis, as there are multiple values of these coordinates per trial. Furthermore, regressing out the x and y- coordinates of gaze can potentially remove signal of interest in the pupil dilation data in addition to the gaze-related confounds and we did not measure absolute pupil size (Mathôt, Melmi & Castet, 2015; Hayes & Petrov, 2015). We present more sanity checks on the pre-processing pipeline as recommended by Reviewer 1.
This new analysis resulted in several additions to the Methods (see Section 2.5) and Results. In sum, we found that including an interaction term for information gain and entropy did not lead to better model fits, but sometimes lead to significantly worse fits. Overall, the results of the linear mixed model corroborated the “simple” correlation analysis across the pupil time course while accounting for the relationship to the pre-feedback baseline pupil and preceeding reaction time differences. There was only one difference to note between the correlation and linear mixed modeling analyses: for the error trials in the cue-target 2AFC task, including entropy in the model accounted for the variance previously explained by surprise.
(5) Major differences between experimental tasks:
More generally, I'm not convinced that the authors' conclusion that the pupil response to KL divergence depends on entropy is sufficiently supported by the current design. The two tasks differ on different levels (stimuli, contingencies, when learning takes place), not just in terms of entropy. In my opinion, it would be necessary to rely on a common task with two conditions that differ primarily in terms of entropy while controlling for other potentially confounding factors. I'm afraid that seemingly minor task details can dramatically change pupil responses. The positive/negative difference in the correlation with KL divergence that the authors interpret to be driven by entropy may depend on another potentially confounding factor currently not controlled.
We agree with the reviewer’s concerns and acknowledge that the speculation concerning the directional effect of entropy across trials can not be fully substantiated by the currect study. We note that Review #1 had a similar concern. Our response to Reviewer #1 addresses this concern of Reviewer #3 as well. To better align the manuscript with the above mentioned points, we have made several changes that are detailed in our response to Reviewer #1’s public review (above).
(6) Model validation:
My impression is that the ideal learner model should work well in this case. However, the authors don't directly compare model behavior to participant behavior ("posterior predictive checks") to validate the model. Therefore, it is currently unclear if the model-derived terms like KL divergence and entropy provide reasonable estimates for the participant data.
Based on our understanding, posterior predictive checks are used to assess the goodness of fit between generated (or simulated) data and observed data. Given that the “simple” ideal learner model employed in the current study is not a generative model, a posterior predictive check would not apply here (Gelman, Carlin, Stern, Dunson, Vehtari, & Rubin (2013). The ideal learner model is unable to simulate or replicate the participants’ responses and behaviors such as accuracy and reaction times; it simply computes the probability of seeing each stimulus type at each trial based on the prior distribution and the exact trial order of the stimuli presented to each participant. The model’s probabilities are computed directly from a Dirichlet distribution of values that represent the number of occurences of each stimulus-pair type for each task. The information-theoretic variables are then directly computed from these probabilities using standard formulas. The exact formulas used in the ideal learner model can be found in section 2.4.
We have now included a complementary linear mixed model analysis which also provides insight into the amount of explained variance of these information-theoretic predictors on the post-feedback pupil response, while also including the pre-feedback baseline pupil and reaction time differences (see section 3.3, Tables 3 & 4). The R<sup>2</sup> values ranged from 0.16 – 0.50 across all conditions tested.
(7) Discussion:
The authors interpret the directional effect of the pupil response w.r.t. KL divergence in terms of differences in entropy. However, I did not find a normative/computational explanation supporting this interpretation. Why should the pupil (or the central arousal system) respond differently to KL divergence depending on differences in entropy?
The current suggestion (page 24) that might go in this direction is that pupil responses are driven by uncertainty (entropy) rather than learning (quoting O'Reilly et al. (2013)). However, this might be inconsistent with the authors' overarching perspective based on Zénon (2019) stating that pupil responses reflect updating, which seems to imply learning, in my opinion. To go beyond the suggestion that the relationship between KL divergence and pupil size "needs more context" than previously assumed, I would recommend a deeper discussion of the computational underpinnings of the result.
Since we have removed the original speculative conclusion from the manuscript, we will refrain from discussing the computational underpinnings of a potential mechanism. To note as mentioned above, we have preliminary data from our own lab that contradicts our original hypothesis about the relationship between entropy and information gain on the post-feedback pupil response.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
Apart from the points raised in the public review above, I'd like to use the opportunity here to provide a more detailed review of potential issues, questions, and queries I have:
(1) Constriction vs. Dilation Effects:
The study observes a context-dependent relationship between KL divergence and pupil responses, where pupil dilation and constriction appear to exhibit opposing effects. However, this phenomenon raises a critical concern: Could the initial pupil constriction to visual stimuli (e.g., in the cue-target task) confound correlations with KL divergence? This potential confound warrants further clarification or control analyses to ensure that the observed effects genuinely reflect prediction error signals and are not merely a result of low-level stimulus-driven responses.
We agree with the reviewers concern and have added the following information to the limitations section in the Discussion (changes in italics below; p. 32-33).
“First, the two associative learning paradigms differed in many ways and were not directly comparable. For instance, the shape of the mean pupil response function differed across the two tasks in accordance with a visual or auditory feedback stimulus (compare Supplementary Figure 3A with Supplementary Figure 3D), and it is unclear whether these overall response differences contributed to any differences obtained between task conditions within each task. We are unable to rule out whether so-called “low level” effects such as the initial constriction to visual stimuli in the cue-target 2AFC task as compared with the dilation in response auditory stimuli in letter-color 2AFC task could confound correlations with information gain. Future work should strive to disentangle how the specific aspects of the associative learning paradigms relate to prediction errors in pupil dilation by systematically manipulating design elements within each task.”
Here, I also was curious about Supplementary Figure 1, showing 'no difference' between the two tones (indicating 'error' or 'correct'). Was this the case for FDR-corrected or uncorrected cluster statistics? Especially since the main results also showed sig. differences only for uncorrected cluster statistics (Figure 2), but were n.s. for FDR corrected. I.e. can we be sure to rule out a confound of the tones here after all?
As per the reviewer’s suggestion, we verified that there were also no significant clusters after feedback onset before applying the correction for multiple comparisons. We have added this information to Supplemenatary section 1.2 as follows:
“Results showed that the auditory tone dilated pupils on average (Supplementary Figure 1C). Crucially, however, the two tones did not differ from one another in either of the time windows of interest (Supplementary Figure 1D; no significant time points after feedback onset were obtained either before or after correcting for multiple comparisons using cluster-based permutation methods; see Section 2.5.”
Supplementary Figure 1 is showing effects cluster-corrected for multiple comparisons using cluster-based permutation tests from the MNE software package in Python (see Methods section 2.5). We have clarified that the cluster-correction was based on permutation testing in the figure legend.
(2) Participant-Specific Priors:
The ideal learner models do not account for individualised priors, assuming homogeneous learning behaviour across participants. Could incorporating participant-specific priors better reflect variability in how individuals update their beliefs during associative learning?
We have clarified in the Methods (see section 2.4) that the ideal learner models did account for participant-specific stimuli including participant-specific priors in the letter-color 2AFC task. We have added the following texts:
“We also note that while the ideal learner model for the cue-target 2AFC task used a uniform (flat) prior distribution for all participants, the model parameters were based on the participant-specific cue-target counterbalancing conditions and randomized trial order.” (p. 13)
“The prior distributions used for the letter-color 2AFC task were estimated from the randomized letter-color pairs and randomized trial order presentation in the preceding odd-ball task; this resulted in participant-specific prior distributions for the ideal learner model of the letter-color 2AFC task. The model parameters were likewise estimated from the (participant-specific) randomized trial order presented in the letter-color 2AFC task.” (p. 13)
(3) Trial-by-Trial Variability:
The analysis does not account for random effects or inter-trial variability using mixed-effects models. Including such models could provide a more robust statistical framework and ensure the observed relationships are not influenced by unaccounted participant- or trial-specific factors.
We have included a complementary linear mixed model analysis in which “subject” was modeled as a random effect on the post-feedback pupil response in each time window of interest and for each task. Across all trials, the results of the linear mixed model corroborated the “simple” correlation analysis across the pupil time course while accounting for the relationship to the prefeedback baseline pupil and preceeding reaction time differences (see section 3.3, Tables 3 & 4).
(4) Preprocessing/Analysis choices:
Before anything else, I'd like to highlight the authors' effort in providing public code (and data) in a very readable and detailed format!
We appreciate the compliment - thank you for taking the time to look at the data and code provided.
I found the idea of regressing the effect of Blinks/Saccades on the pupil trace intriguing. However, I miss a complete picture here to understand how well this actually worked, especially since it seems to be performed on already interpolated data. My main points here are:
(4.1) Why is the deconvolution performed on already interpolated data and not on 'raw' data where there are actually peaks of information to fit?
To our understanding, at least one critical reason for interpolating the data before proceeding with the deconvolution analysis is that the raw data contain many missing values (i.e., NaNs) due to the presence of blinks. Interpolating over the missing data first ensures that there are valid numerical elements in the linear algebra equations. We refer the reviewer to the methods detailed in Knapen et al. (2016) for more details on this pre-processing method.
(4.2) What is the model fit (e.g. R-squared)? If this was a poor fit for the regressors in the first place, can we trust the residuals (i.e. clean pupil trace)? Is it possible to plot the same Pupil trace of Figure 1D with a) the 'raw' pupil time-series, b) after interpolation only (both of course also mean-centered for comparison), on top of the residuals after deconvolution (already presented), so we can be sure that this is not driving the effects in a 'bad' way? I'd just like to make sure that this approach did not lead to artefacts in the residuals rather than removing them.
We thank the reviewer for this suggestion. In the Supplementary Materials, we have included a new figure (Supplementary Figure 2, copied below for convience), which illustrates the same conditions as in Figure 1D and Figure 2D, with 1) the raw data, and 2) the interpolated data before the nuisance regression. Both the raw data and interpolated data have been band-pass filtered as was done in the original pre-processing pipeline and converted to percent signal change. These figures can be compared directly to Figure 1D and Figure 2D, for the two tasks, respectively.
Of note is that the raw data seem to be dominated by responses to blinks (and/or saccades). Crucially, the pattern of results remains overall unchaged between the interpolated-only and fully pre-processed version of the data for both tasks.
In the Supplementary Materials (see Supplementary section 2), we have added the descriptives of the model fits from the deconvolution method. Model fits (R<sup>2</sup>) for the nuisance regression were generally low: cue-target 2AFC task, M = 0.03, SD = 0.02, range = [0.00, 0.07]; letter-color visual 2AFC, M = 0.08, SD = 0.04, range = [0.02, 0.16].
Furthermore, a Pearson correlation analysis between the interpolated and fully pre-processed data within the time windows of interest for both task indicated high correspondence:
Cue-target 2AFC task
Early time window: M = 0.99, SD = 0.01, range = [0.955, 1.000]
Late time window: M = 0.99, SD = 0.01, range = [0.971, 1.000]
Letter-color visual 2AFC
Early time window: M = 0.95, SD = 0.04, range = [0.803, 0.998]
Late time window: M = 0.97, SD = 0.02, range = [0.908, 0.999]
In hindsight, including the deconvolution (nuisance regression) method may not have changed the pattern of results much. However, the decision to include this deconvolution method was not data-driven; instead, it was based on the literature establishing the importance of removing variance (up to 5 s) of these blinks and saccades from cognitive effects of interest in pupil dilation (Knapen et al., 2016).
(4.3) Since this should also lead to predicted time series for the nuisance-regressors, can we see a similar effect (of what is reported for the pupil dilation) based on the blink/saccade traces of a) their predicted time series based on the deconvolution, which could indicate a problem with the interpretation of the pupil dilation effects, and b) the 'raw' blink/saccade events from the eye-tracker? I understand that this is a very exhaustive analysis so I would actually just be interested here in an averaged time-course / blink&saccade frequency of the same time-window in Figure 1D to complement the PD analysis as a sanity check.
Also included in the Supplementary Figure 2 is the data averaged as in Figure 1D and Figure 2D for the raw data and nuisance-predictor time courses (please refer to the bottom row of the sub-plots). No pattern was observed in either the raw data or the nuisance predictors as was shown in the residual time courses.
(4.4) How many samples were removed from the time series due to blinks/saccades in the first place? 150ms for both events in both directions is quite a long bit of time so I wonder how much 'original' information of the pupil was actually left in the time windows of interest that were used for subsequent interpretations.
We thank the reviewer for bringing this issue to our attention. The size of the interpolation window was based on previous literature, indicating a range of 100-200 ms as acceptable (Urai et al., 2017; Knapen et al., 2016; Winn et al., 2018). The ratio of interpolated-to-original data (across the entire trial) varied greatly between participants and between trials: cue-target 2AFC task, M = 0.262, SD = 0.242, range = [0,1]; letter-color 2AFC task, M = 0.194, SD = 0.199, range = [0,1].
We have now included a conservative analysis in which only trials with more than half (threshold = 60%) of original data are included in the analyses. Crucially, we still observe the same pattern of effects as when all data are considered across both tasks (compare the second to last row in the Supplementary Figure 2 to Figure 1D and Figure 2D).
(4.5) Was the baseline correction performed on the percentage change unit?
Yes, the baseline correction was performed on the pupil timeseries after converting to percentsignal change. We have added that information to the Methods (section 2.3).
(4.6) What metric was used to define events in the derivative as 'peaks'? I assume some sort of threshold? How was this chosen?
The threshold was chosen in a data-driven manner and was kept consistent across both tasks. The following details have been added to the Methods:
“The size of the interpolation window preceding nuisance events was based on previous literature [13,39,99]. After interpolation based on data-markers and/or missing values, remaining blinks and saccades were estimated by testing the first derivative of the pupil dilation time series against a threshold rate of change. The threshold for identifying peaks in the temporal derivative is data-driven, partially based on past work[10,14,33]. The output of each participant’s pre-processing pipeline was checked visually. Once an appropriate threshold was established at the group level, it remained the same for all participants (minimum peak height of 10 units).” (p. 8 & 11).
(5) Multicollinearity Between Variables:
Lastly, the authors state on page 13: "Furthermore, it is expected that these explanatory variables will be correlated with one another. For this reason, we did not adopt a multiple regression approach to test the relationship between the information-theoretic variables and pupil response in a single model". However, the very purpose of multiple regression is to account for and disentangle the contributions of correlated predictors, no? I might have missed something here.
We apologize for the ambiguity of our explanation in the Methods section. We originally sought to assess the overall relationship between the post-feedback response and information gain (primarily), but also surprise and entropy. Our reasoning was that these variables are often investigated in isolation across different experiments (i.e., only investigating Shannon surprise), and we would like to know what the pattern of results would look like when comparing a single information-theoretic variable to the pupil response (one-by-one). We assumed that including additional explanatory variables (that we expected to show some degree of collinearity with each other) in a regression model would affect variance attributed to them as compared with the one-on-one relationships observed with the pupil response (Morrissey & Ruxton 2018). We also acknowledge the value of a multiple regression approach on our data. Based on the suggestions by the reviewers we have included a complementary linear mixed model analysis in which we controlled for the effects of the information-theoretic variables on one another, while also including the nuisance regressors of pre-feedback baseline pupil dilation and reaction times.
This new analysis resulted in several additions to the Methods (see Section 2.5) and Results (see Tables 3 and 4). Overall, the results of the linear mixed model corroborated the “simple” correlation analysis across the pupil time course while accounting for the relationship to the prefeedback baseline pupil and preceeding reaction time differences. There was only one difference to note between the correlation and linear mixed modeling analyses: for the error trials in the cue-target 2AFC task, including entropy in the model accounted for the variance previously explained by surprise.
Reviewer #2 (Recommendations for the authors):
(1) Given the inherent temporal dependencies in pupil dynamics, characterising later pupil responses as independent of earlier ones in a three-way repeated measures ANOVA may not be appropriate. A more suitable approach might involve incorporating the earlier pupil response as a covariate in the model.
We thank the reviewer for bringing this issue to our attention. From our understanding, a repeated-measures ANOVA with factor “time window” would be appropriate in the current context for the following reasons. First, autocorrelation (closely tied to sphericity) is generally not considered a problem when only two timepoints are compared from time series data (Field, 2013; Tabachnick & Fidell, 2019). Second, the repeated-measures component of the ANOVA takes the correlated variance between time points into account in the statistical inference. Finally, as a complementary analysis, we present the results testing the interaction between the frequency and accuracy conditions across the full time courses (see Figures 1D and 2D); in these pupil time courses, any difference between the early and late time windows can be judged by the reader visually and qualitatively.
(2) Please clarify the correlations between KL divergence, surprise, entropy, and pupil response time series. Specifically, state whether these correlations account for the interrelationships between these information-theoretic measures. Given their strong correlations, partialing out these effects is crucial for accurate interpretation.
As mentioned above, based on the suggestions by the reviewers we have included a complementary linear mixed model analysis in which we controlled for the effects of the information-theoretic variables on one another, while also including the nuisance regressors of pre-feedback baseline pupil dilation and reaction times.
This new analysis resulted in several additions to the Methods (see Section 2.5) and Results (see Tables 3 and 4). Overall, the results of the linear mixed model corroborated the “simple” correlation analysis across the pupil time course while accounting for the relationship to the prefeedback baseline pupil and preceeding reaction time differences. There was only one difference to note between the correlation and linear mixed modeling analyses: for the error trials in the cue-target 2AFC task, including entropy in the model accounted for the variance previously explained by surprise.
(3) The effects observed in the late time windows appear weak (e.g., Figure 2E vs. 2F, and the generally low correlation coefficients in Figure 3). Please elaborate on the reliability and potential implications of these findings.
We have now included a complementary linear mixed model analysis which also provides insight into the amount of explained variance of these information-theoretic predictors on the post-feedback pupil response, while also including the pre-feedback baseline pupil and reaction time differences (see section 3.3, Tables 3 & 4). The R<sup>2</sup> values ranged from 0.16 – 0.50 across all conditions tested. Including the pre-feedback baseline pupil dilation as a predictor in the linear mixed model analysis consistently led to more explained variance in the post-feedback pupil response, as expected.
(4) In Figure 3 (C-J), please clarify how the trial-by-trial correlations were computed (averaged across trials or subjects). Also, specify how the standard error of the mean (SEM) was calculated (using the number of participants or trials).
The trial-by-trial correlations between the pupil signal and model parameters were computed for each participant, then the coefficients were averaged across participants for statistical inference. We have added several clarifications in the text (see section 2.5 and legends of Figure 3 and Supplementary Figure 4).
We have added “the standard error of the mean across participants” to all figure labels.
(5) For all time axes (e.g., Figure 2D), please label the ticks at 0, 0.5, 1, 1.5, 2, 2.5, and 3 seconds. Clearly indicate the duration of the feedback on the time axes. This is particularly important for interpreting the pupil dilation responses evoked by auditory feedback.
We have labeled the x-ticks every 0.5 seconds in all figures and indicated the duration of the auditory feedback in the letter-color decision task and as well as the stimuli presented in the control tasks in the Supplementary Materials.
Reviewer #3 (Recommendations for the authors):
(1) Introduction page 3: "In information theory, information gain quantifies the reduction of uncertainty about a random variable given the knowledge of another variable. In other words, information gain measures how much knowing about one variable improves the prediction or understanding of another variable."
(2) In my opinion, the description of information gain can be clarified. Currently, it is not very concrete and quite abstract. I would recommend explaining it in the context of belief updating.
We have removed these unclear statements in the Introduction. We now clearly state the following:
“Information gain can be operationalized within information theory as the KullbackLeibler (KL) divergence between the posterior and prior belief distributions of a Bayesian observer, representing a formalized quantity that is used to update internal models [29,79,80].” (p. 4)
(3) Page 4: The inconsistencies across studies are described in extreme detail. I recommend shortening this part and summarizing the inconsistencies instead of listing all of the findings separately.
As per the reviewer’s recommendation, we have shortened this part of the introduction to summarize the inconsistencies in a more concise manner as follows:
“Previous studies have shown different temporal response dynamics of prediction error signals in pupil dilation following feedback on decision outcome: While some studies suggest that the prediction error signals arise around the peak (~1 s) of the canonical impulse response function of the pupil [11,30,41,61,62,90], other studies have shown evidence that prediction error signals (also) arise considerably later with respect to feedback on choice outcome [10,25,32,41,62]. A relatively slower prediction error signal following feedback presentation may suggest deeper cognitive processing, increased cognitive load from sustained attention or ongoing uncertainty, or that the brain is integrating multiple sources of information before updating its internal model. Taken together, the literature on prediction error signals in pupil dilation following feedback on decision outcome does not converge to produce a consistent temporal signature.” (p. 5)
We would like to note some additional minor corrections to the preprint:
We have clarified the direction of the effect in Supplementary Figure 3 with the following:
“Participants who showed a larger mean difference between the 80% as compared with the 20% frequency conditions in accuracy also showed smaller differences (a larger mean difference in magnitude in the negative direction) in pupil responses between frequency conditions (see Supplementary Figure 4).”
The y-axis labels in Supplementary Figure 3 were incorrect and have been corrected as the following: “Pupil responses (80-20%)”.
We corrected typos, formatting and grammatical mistakes when discovered during the revision process. Some minor changes were made to improve clarity. Of course, we include a version of the manuscript with Tracked Changes as instructed for consideration.
When using a model separately from an agent, it is up to you to execute the requested tool and return the result back to the model for use in subsequent reasoning.
Model Suggestion: The LLM's initial call returns an AIMessage containing the suggestion to use a specific tool (the tool_calls object).
Developer Action (Execution): The developer's code must intercept this message, parse the tool name and arguments, and manually execute the corresponding Python function.
Result Feedback: The developer must then package the output of the tool execution into a ToolMessage and send it back to the Model, along with the previous conversation history, for the Model to complete its final reasoning and generate the answer.
The easiest way to get started with a standalone model in LangChain is to use init_chat_model to initialize one from a chat model provider of your choice
For most new projects focused on universality and best practice, init_chat_model() is the recommended and modern approach because it promotes provider agnosticism and reduces boilerplate code.
The proliferation of “cheap intelligence” (more code, text, and images than ever before) means that the skills of discernment, evaluation, judgment, thoughtful planning, and reflection are even more crucial now than before.
Так как ИИ выглядит как легкий и доступный инструмент для пользования, особенно важно сохранять холодную голову и рассудительность при его использовании.
1. Erase old mappings from the generated code
dont need to erase the existing, and also Void.class is unnecessary
It’s literallyabout the colonisation of an entire galaxy. Those types of elements areso prevalent.But then there’s the more obvious ones like Age of Empires. Or, Em-pire: Total War. How these games work, and how they are meant to beplayed, there’s an unavoidable code there.
Yes, arguably that is the game's goal, but as I see it, most of the game's players are actually very far from being mindless colonialists. They are not warmongers either. Instead, I see historians, economists, people that may be white, sure, but that are also concerned with whiteness, that try to tackle it by explaining it. Strategy games demand systems thinking that is somewhat incompatible with reductionist us vs them narratives.
unclear instructional materialsand complex information presentation add extraneous cognitive load.
Summary: Defines "extraneous load" as a result of "unclear presentation," supporting the argument that non-standard writing (code-meshing) unnecessarily taxes the reader. This also aligns with findings from Liu.
when essentialinformation is presented too rapidly, it can overload thelearner’s cognitive capacity, leading to cognitive overload.When this happens, the learner cannot process essentialinformation and learning outcomes effectively.
Summary: Provides the consequence of poor structure: "cognitive overload." This supports the argument that unstructured or non-standard writing risks overloading the reader, preventing them from understanding the core message.
Indirectly, this refutes the idea that "code-meshing" is necessary for more accurate communication.
Reviewer #2 (Public review):
Summary:
In this manuscript, Pereira de Castro and coworkers are studying potential competition between a more standard splicing factor SF1 and an alternative splicing factor called QK1. This is interesting because they bind to overlapping sequence motifs and could potentially have opposing effects on promoting the splicing reaction. To test this idea, the authors KD either SF1 or QK1 in mammalian cells and uncover several exons whose splicing regulation follows the predicted pattern of being promoted for splicing by SF1 and repressed by QK1. Importantly, these have introns enriched in SF1 and QK1 motifs. The authors then focus on one exon in particular with two tandem motifs to study the mechanism of this in greater detail and their results confirm the competition model. Mass spec analysis largely agrees with their proposal; however, it is complicated by apparently quick transition of SF1 bound complexes to later splicing intermediates. An inspired experiment in yeast shows how QK1 competition could potentially have a determinental impact on splicing in an orthogonal system. Overall these results show how splicing regulation can be achieved by competition between a "core" and alternative splicing factor and provide additional insight into the complex process of branch site recognition. The manuscript is exceptionally clear and the figures and data very logically presented. The work will be valuable to those in the splicing field who are interested in both mechanism and bioinformatics approaches to deconvolve any apparent "splicing code" being used by cells to regulate gene expression.
Strengths:
(1) The main discovery of the manuscript involving evidence for SF1/QK1 competition is quite interesting and important for this field. This evidence has been missing and may change how people think about branch site recognition.
(2) The experiments and the rationale behind them are clearly and logically presented.
(3) The experiments are carried out to a high standard and well-designed controls are included.
(4) The extrapolation of the result to yeast in order to show the potentially devastating consequences of QK1 competition was creative and informative.
Weaknesses:
Overall the weaknesses are relatively minor and involve cases where conclusions could potentially have been strengthened with additional experimentation. For example, pull-down of the U2 snRNP could be strengthened by detection of the snRNA whereas the proteins may themselves interact with these factors in the absence of the snRNA. In addition the discussion is a bit speculative given the data, but compelling nonetheless.
Author response:
The following is the authors’ response to the original reviews.
eLife Assessment
This important manuscript provides insights into the competition between Splicing Factor 1 (SF1) and Quaking (QKI) for binding at the ACUAA branch point sequence in a model intron, regulating exon inclusion. The study employs rigorous transcriptomic, proteomic, and reporter assays, with both mammalian cell culture and yeast models. Nevertheless, while the data are convincing, broadening the analysis to additional exons and narrowing the manuscript's title to better align with the experimental scope would strengthen the work.
Public Reviews:
Reviewer #1 (Public review):
In this manuscript, the authors aimed to show that SF1 and QKI compete for the intron branch point sequence ACUAA and provide evidence that QKI represses inclusion when bound to it.
Major strengths of this manuscript include:
(1) Identification of the ACUAA-like motif in exons regulated by QKI and SF1.
(2) The use of the splicing reporter and mutant analysis to show that upstream and downstream ACUAAC elements in intron 10 of RAI are required for repressing splicing.
(3) The use of proteomic to identify proteins in C2C12 nuclear extract that binds to the wild type and mutant sequence.
(4) The yeast studies showing that ectopic lethality when Qki5 expression was induced, due to increased mis-splicing of transcripts that contain the ACUAA element.
The authors conclusively show that the ACUAA sequence is bound by QKI and provide strong evidence that this leads to differences in exons inclusion and exclusion. In animal cells, and especially in human, branchpoint sequences are degenerate but seem to be recognized by specific splicing factors. Although a subset of splicing factors shows tissue-specific expression patterns most don't, suggesting that yet-to-be-identified mechanisms regulate splicing. This work suggests that an alternate mechanism could be related to the binding affinity of specific RNA binding factors for branchpoint sequences coupled with the level of these different splicing factors in a given cell.
We thank the reviewer for the positive comments.
Reviewer #2 (Public review):
Summary:
In this manuscript, Pereira de Castro and coworkers are studying potential competition between a more standard splicing factor SF1, and an alternative splicing factor called QK1. This is interesting because they bind to overlapping sequence motifs and could potentially have opposing effects on promoting the splicing reaction. To test this idea, the authors KD either SF1 or QK1 in mammalian cells and uncover several exons whose splicing regulation follows the predicted pattern of being promoted for splicing by SF1 and repressed by QK1. Importantly, these have introns enriched in SF1 and QK1 motifs. The authors then focus on one exon in particular with two tandem motifs to study the mechanism of this in greater detail and their results confirm the competition model. Mass spec analysis largely agrees with their proposal; however, it is complicated by the apparently quick transition of SF1-bound complexes to later splicing intermediates. An inspired experiment in yeast shows how QK1 competition could potentially have a detrimental impact on splicing in an orthogonal system. Overall, these results show how splicing regulation can be achieved by competition between a "core" and alternative splicing factor and provide additional insight into the complex process of branch site recognition. The manuscript is exceptionally clear and the figures and data are very logically presented. The work will be valuable to those in the splicing field who are interested in both mechanism and bioinformatics approaches to deconvolve any apparent "splicing code" being used by cells to regulate gene expression. Criticisms are minor and the most important of them stem from overemphasis on parts of the manuscript on the evolutionary angle when evolution itself wasn't analyzed per se.
We thank the reviewer for the positive comments and very clear and fair critical points.
Strengths:
(1) The main discovery of the manuscript involving evidence for SF1/QK1 competition is quite interesting and important for this field. This evidence has been missing and may change how people think about branch site recognition.
(2) The experiments and the rationale behind them are exceptionally clearly and logically presented. This was wonderful!
Thank you so much. We felt the overall flow of the paper and data make for a nice “story” that conveys a relatively easy-to-understand explanation for a complex subject.
(3) The experiments are carried out to a high standard and well-designed controls are included.
(4) The extrapolation of the result to yeast in order to show the potentially devastating consequences of the QK1 competition was very exciting and creative.
We agree this is a very exciting result and finding! Thanks.
Weaknesses:
Overall the weaknesses are relatively minor and involve cases where clarification is necessary, some additional analysis could bolster the arguments, and suggestions for focusing the manuscript on its strengths.
(1) The title (Ancient...evolutionary outcomes), abstract, and some parts of the discussion focus heavily on the evolutionary implications of this work. However, evolutionary analysis was not performed in these studies (e.g., when did QK1 and SF1 proteins arise and/or diverge? How does this line up with branch site motifs and evolution of U2? Any insight from recent work from Scott Roy et al?). I think this aspect either needs to be bolstered with experimental work/data or this should be tamped down in the manuscript. I suggest highlighting the idea expressed in the sentence "A nuanced implication of this model is that loss-of-function...". To me, this is better supported by the data and potentially by some analysis of mutations associated with human disease.
We have revised the title and dampened the evolutionary aspects of the previous version of the manuscript.
(2) One paper that I didn't see cited was that by Tanackovic and Kramer (Mol Biol Cell 2005). This paper is relevant because they KD SF1 and found it nonessential for splicing in vivo. Do their results have implications for those here? How do the results of the KD compare? Could QK1 competition have influenced their findings (or does their work influence the "nuanced implication" model referenced above?)?
This is an interesting point, and thank you for the suggestion. We have now included a brief description of this study in the Introduction of the revised manuscript and do note that the authors measured intron retention of a beta globin reporter and SF3A1, SF3A2, and SF3A3 during SF1 knockdown, but did not detect elevated unspliced RNA in these targets.
(3) Can the authors please provide a citation for the statement "degeneracy is observed to a higher degree in organisms with more alternative splicing"? Does recent evolutionary analysis support this?
We have removed the statement, as it did not add much to the content and I am not sure I can state the concept I was attempting to convey in a simple manner with few citations.
(4) For the data in Figure 3, I was left wondering if NMD was confounding this analysis. Can the authors respond to this and address this concern directly?
We have not measured if the reporters used in Figure 3 produce protein(s). Presumably, though, all spliced reporter RNA would be degraded equally (the included/skipped isoforms’ “reading frames” are not altered from one another). This would not be case for unspliced nuclear reporter RNA, however. Given this difference, and that our analysis can not resolve the subcellular localization of the different reporter species, we have removed the measurement of and subsequent results describing unspliced reporter RNA from Figure 3.
(5) To me, the idea that an engaged U2 snRNP was pulled down in Figure 4F would be stronger if the snRNA was detected. Was that able to be observed by northern or primer extension? Would SF1 be enriched if the U2 snRNA was degraded by RNaseH in the NE?
We did not measure any co-associating RNAs in this experimental approach, but agree that this approach would strengthen the evidence for it.
(6) I'm wondering how additive the effects of QK1 and SF1 are... In Figure 2, if QK1 and SF1 are both knocked down, is the splicing of exon 11 restored to "wt" levels?
This is an interesting question that we were unfortunately unable to address experimentally here.
(7) The first discussion section has two paragraphs that begin "How does competition between SF1..." and "Relatively little is known about how...". I found the discussion and speculation about localization, paraspekles, and lncRNAs interesting but a bit detracting from the strengths of the manuscript. I would suggest shortening these two paragraphs into a single one.
We have revised the Discussion.
Reviewer #3 (Public review):
Summary:
In this manuscript, the authors were trying to establish whether competition between the RNA-binding proteins SF1 and QKI controlled splicing outcomes. These two proteins have similar binding sites and protein sequences, but SF1 lacks a dimerization motif and seems to bind a single version of the binding sequence. Importantly, these binding sequences correspond to branchpoint consensus sequences, with SF1 binding leading to productive splicing, but QKI binding leading instead to association with paraspeckle proteins. They show that in human cells SF1 generally activates exons and QKI represses, and a large group of the jointly regulated exons (43% of joint targets) are reciprocally controlled by SF1 and QKI. They focus on one of these exons RAI14 that shows this reciprocal pattern of regulation, and has 2 repeats of the binding site that make it a candidate for joint regulation, and confirm regulation within a minigene context. The authors used the assembly of proteins within nuclear extracts to explain the effect of QKI versus SF1 binding. Finally, the authors show that the expression of QKI is lethal in yeast, and causes splicing defects.
How this fits in the field. This study is interesting and provides a conceptual advance by providing a general rule on how SF1 and QKI interact in relation to binding sites, and the relative molecular fates followed, so is very useful. Most of the analysis seems to focus on one example, although the molecular analysis and global work significantly add to the picture from the previously published paper about NUMB joint regulation by QKI and SF (Zong et al, cited in text as reference 50, that looked at SF1 and QKI binding in relation to a duplicated binding site/branchpoint sequence in NUMB).
Thank you for the encouraging remarks.
Strengths:
The data presented are strong and clear. The ideas discussed in this paper are of wide interest, and present a simple model where two binding sites generate a potentially repressive QKI response, whereas exons that have a single upstream sequence are just regulated by SF1. The assembly of splicing complexes on RNAs derived from RAI14 in nuclear extracts, followed by mass spec gave interesting mechanistic insight into what was occurring as a result of QKI versus SF1 binding.
Weaknesses:
I did not think the title best summarises the take-home message and could be perhaps a bit more modest. Although the authors investigated splicing patterns in yeast and human cells, yeast do not have QKI so there is no ancient competition in that case, and the study did not really investigate physiological or evolutionary outcomes in splicing, although it provides interesting speculation on them. Also as I understood it, the important issue was less conserved branchpoints in higher eukaryotes enabling alternative splicing, rather than competition for the conserved branchpoint sequence. So despite the the data being strong and properly analysed and discussed in the paper, could the authors think whether they fit best with the take-home message provided in the title? Just as a suggestion (I am sure the authors can do a better job), maybe "molecular competition between variant branchpoint sequences predict physiological and evolutionary outcomes in splicing"?
Thank you for this point (Reviewer 2 had a similar comment) and the suggestion. We have revised the title.
Although the authors do provide some global data, most of the detailed analysis is of RAI14. It would have been useful to examine members of the other quadrants in Figure 1C as well for potential binding sites to give a reason why these are not co-regulated in the same way as RAI14. How many of the RAI14 quadrants had single/double sites (the motif analysis seemed to pull out just one), and could one of the non-reciprocally regulated exons be moved into a different quadrant by addition or subtraction of a binding site or changing the branchpoint (using a minigene approach for example).
This is an interesting point that we have considered. Our intent with the focus on RAI14 was to use a naturally occurring intron bps with evidence of strong QKI binding that did not require a high degree of sequence manipulation or engineering.
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
(1) Most of my recommendations are really centered on the figures. In their current state, they detract from the data shown and could be improved: I recommend the authors use a uniform font. For example, Figure 1E and F have at least three different fonts of varying sizes making it very messy. In Figure 1C, the authors could bold the Ral14 ex11 or simply indicate that the blue is this exon in the legend, thus removing the text from this very busy graph. In Figure 4F, I would recommend, having all the labels the same size and putting those genes of interest like Sf3a1 in bold. This could also be done in Figure 4E.
Thank you for the suggestion and we have edited these (FYI the font in Fig’s 1E and 1F were from the rMAPS default output, but I agree, it gives a sloppy appearance).
(2) In Figures 4D and 4G, is there QKI binding to the downstream deletion mutant after 30 minutes? Also, in Figure 4G, are these all from the same blot? The band sizes seem to be very different between lanes. If these were not on the same blot, the original gels should be submitted.
A small amount of Qki appears to be binding after 30 min. All lanes/blots are from the same gels/membranes; see new Supplemental Figure 4 for the original (uncropped) images of the blots.
(3) The authors should indicate, the source and concentration of the antibodies used for their WB. They should also indicate the primers used for RT-PCRs.
We have revised the methods to include the antibody information and have uploaded a supplemental table 8 with all oligonucleotide sequences used (which I (Sam Fagg) neglected to do initially, so that’s my bad).
Reviewer #2 (Recommendations for the authors):
(1) This may come down to the author's preference but branch point and branch site are frequently two words, not a single compound word (branch point vs. branchpoint). In addition, the authors may want to use branchsite with the abbreviation BS more frequently since they often don't describe the specific point of branching, and bp and bps could be confused for the more frequent abbreviations for base pair(s).
Good suggestion; we have edited the text accordingly.
(2) In general the addition of page numbers and line numbers to the manuscript would greatly aid reviewers!
Point taken…
(3) Introduction; "...under normal growth conditions they are efficiently spliced". I would say MOST introns in yeast are efficiently spliced. This is definitely not universal.
Text edited to indicate that most are efficiently spliced.
(4) Introduction; " recognition of the bps by SF1 (mammals) (20)". The choice of reference 20 is an odd one here. I think the Robin Reed and Michael Rosbash paper was the first to show SF1 was the human homolog of BBP.
Got it, thanks (added #14 here and kept #20 also since it shows the structure of SF1 in complex with a UACUAAC bps.)
(5) Results; "QK1 and SF1 co-regulate.."; it may be useful for the reader if you could explain in more detail why exon inclusion and intron retention are expected outcomes for QK1 knockdown and vice versa for SF1. The exon inclusion here is more obvious than the intron retention phenotype. (In other words, if more exons are included shouldn't it follow that more introns are removed?)
We explain the expected results for exon inclusion in the Introduction and this paragraph of the Results. Although we have observed more intron retention under QKI loss-of-function approaches before, I am uncertain where the reviewer sees that we indicate any expected result for intron retention from either QKI or SF1 knockdown. I believe the statement you refer to might be on line 162 and starts with: “Consistent with potentially opposing functions in splicing…” ?
Also, I agree that if SF1 is a “splicing activator,” one might expect more IR in its absence (but this is not the case; there is, in fact, less), but nonetheless, the opposite outcome is observed with QKI knockdown (more IR). It is unclear why this is the case, and we did not investigate it.
(6) Results; "QK1 and SF1 co-regulate.."; "Thus the most highly represented set.." To me, the most highly represented set is those which are not both QK1-repressed and SF1-activated. Does this indicate that other factors are involved at most sites than simple competition between these two?
We have revised the sentence in question to include the text “by quadrant” in order to convey our meaning more precisely.
(7) Throughout the manuscript, 5 apostrophes and 3 apostrophes are used instead of 5 prime symbols and 3 prime symbols.
Thank you for pointing that out. We have fixed each instance of this.
(8) Sometimes SF1 is written as Sf1. (also Tatsf1)
This was a mouse/human gene/protein nomenclature error that we have fixed; thank you for pointing this out.
(9) You may want to make sure that figures are labeled consistently with the manuscript text. In Figure 1B, it is RI rather than IR. In Figure 4 it is myoblast NE rather than C2C12 nuclear extract.
We have fixed these, checked for other examples, and where relevant, edited those too.
(10) I think Figure 1A could be improved by also including a depiction of the domain arrangements of SF1 and QK1.
Done.
(11) I was a bit confused with all the lines in Figure 1E and 1F. What is the difference between the log (pVal) and upregulated plots? Can these figures be simplified or explained more thoroughly?
Based on this comment and one from Reviewer 1, we have slightly revised the wording (and font) on the output, which hopefully clarifies. These are motif enrichment plots generated by rMAPS (Refs 61 and 62) analysis of rMATS (Ref 60) data for exons more included (depicted by the red lines) or more skipped (depicted by the blue lines) compared to control versus a “background” set of exons that are detectable but unchanged. The -log<sub>10</sub> is P-value (dotted line) indicates the significance of exons more included in shRNA treatment vs control shRNA (previously read “upregulated”) compared to background exons that are detectable but unchanged; the solid lines indicate the motif score; these are described in the references indicated.
(12) Figure 1B, it is a bit hard to conclude that there is more AltEx or "RI/IR" in one sample vs. the other from these plots since the points overlay one another. Can you include numbers here?
Added (and deleted Suppl Fig S1, which was simply a chart showing the numbers).
(13) How was PSI calculated in Figure 2A?
VAST-tools (we state this in the legend in the revised version).
You may want to include rel protein (or the lower limit of detection) for Figure 2B to be consistent with 2C. Why is KD of SF1 so poor and variable between 2C and 2D?
We have not investigated this, but these blots show an optimized result that we were able to obtain for the knockdown in each cell type. It may be that HEK293 cells (Fig 2B) have a stronger requirement for SF1 than C2C12 cells…? I would argue that it is not necessarily “poor” in Fig 2C, as we observe ~70% depletion of the protein.
Why are two bands present in the gel?
Two to three isoforms of SF1 are present in most cell types.
A good (or bad, really) example of an SF1 western blot (and knockdown of ~35% in K562 or ~45% in HepG2 can also be seen on the ENCODE project website, for reference:
By comparison, I think ours are much more cosmetically pleasing, and our knockdown (especially in C2C12) is much more efficient.
(14) Figure 3, The asterisk refers to a cryptic product. Can the uaAcuuuCAG be used as a branch point? Presumably the natural 3' SS is now too close so this would result in activation of a downstream 3'SS?
We did not pursue determining the identity of this minor and likely artefactual product, but we (and others) have observed a similar phenomenon when using splicing reporter-based mutational approaches.
(15) For the methods. The "RNA extraction, RT -PCR,..." subheading needs to be on its own line. Please add (w/v) or (v/v) to percentages where appropriate. Please convert ug to the symbol for "micro".
Thank you, we have made these changes.
(16) In Figure 4B, the text here and legend are microscopic. Even with reading glasses, I couldn't make anything out!
We have increased the font sizes for the text and scale bar…when referring to “legend” does the reviewer mean the scale bar?
(17) As a potential discussion item, it is worth noting that SF1 could also repress splicing if it could either not engage with U2AF or be properly displaced by U2 snRNP so the snRNA could pair. I was wondering if QK1 could similarly be activating if it could engage with U2AF. I'm unsure if this could be tested by domain swaps (and is beyond the scope of this paper). It just may be worth speculating about.
Good point and suggestion…we are looking into this.
Reviewer #3 (Recommendations for the authors):
(1) Is the reference in the text to Figure 5F correct for actin splicing (this is just before the discussion)?
I see references several lines up from this, but I do not see a reference just before the discussion…?
(2) I was not sure why the minigene experiments showed such high levels of intron retention that seemed to be impacted also by deletion of the branchpoint sequences, and suggest that the two branchpoints are not equal in strength.
Neither were we, but Reviewer 2 has suggested that degradation of the spliced products could be rapid (NMD substrates) which could complicate the interpretation of what appears to be higher levels of intron retention. Given the possibility that this could be a non-physiological artefact, we have removed the measurement of unspliced reporter and now only show the spliced products (equally subject to degradation) and report their percent inclusion.
Visual Studio Code.
Is all of these applicable to positron?
Crop/resize images