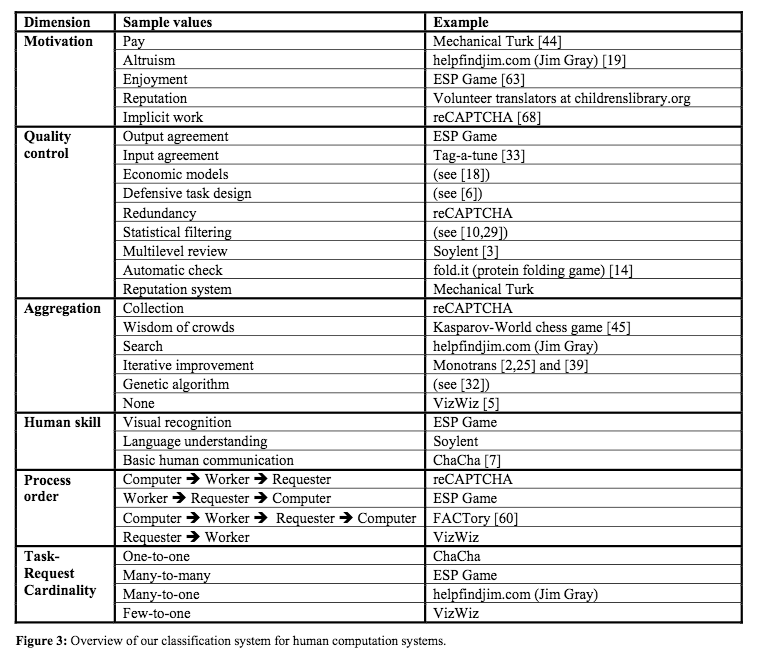
We develop reliable a posteriori error estimators for fully discrete Runge–Kutta discontinuous Galerkin approximations of nonlinear convection–diffusion systems endowed with a convex entropy in multip
令人惊讶的是,本文的核心挑战不是「计算精度」,而是「知道自己有多不精确」。a posteriori 误差估计器的作用是:在不知道真实解的情况下,对数值解的误差给出可靠的上界。这类似于在没有标准答案的考试中,能自动评估自己答错了多少——这在数值计算中是极高层次的自知能力,也是自适应网格细化的理论基础。