class constructor parameters should be documented within the __init__ class method docstring
init
class constructor parameters should be documented within the __init__ class method docstring
init
Scripts are considered to be single file executables run from the console. Docstrings for scripts are placed at the top of the file and should be documented well enough for users to be able to have a sufficient understanding of how to use the script.
Docstrings in scripts
Documenting your code, especially large projects, can be daunting. Thankfully there are some tools out and references to get you started
You can always facilitate documentation with tools.
(check the table below)
Commenting your code serves multiple purposes
Multiple purposes of commenting:
BUG, FIXME, TODOIn general, commenting is describing your code to/for developers. The intended main audience is the maintainers and developers of the Python code. In conjunction with well-written code, comments help to guide the reader to better understand your code and its purpose and design
Commenting code:
Along with these tools, there are some additional tutorials, videos, and articles that can be useful when you are documenting your project
Recommended videos to start documenting
(check the list below)
If you use argparse, then you can omit parameter-specific documentation, assuming it’s correctly been documented within the help parameter of the argparser.parser.add_argument function. It is recommended to use the __doc__ for the description parameter within argparse.ArgumentParser’s constructor.
argparse
There are specific docstrings formats that can be used to help docstring parsers and users have a familiar and known format.
Different docstring formats:
Daniele Procida gave a wonderful PyCon 2017 talk and subsequent blog post about documenting Python projects. He mentions that all projects should have the following four major sections to help you focus your work:
Public and Open Source Python projects should have the docs folder, and inside of it:
(check the table below for a summary)
Since everything in Python is an object, you can examine the directory of the object using the dir() command
dir() function examines directory of Python objects. For example dir(str).
Inside dir(str) you can find interesting property __doc__
Documenting your Python code is all centered on docstrings. These are built-in strings that, when configured correctly, can help your users and yourself with your project’s documentation.
Docstrings - built-in strings that help with documentation
Along with docstrings, Python also has the built-in function help() that prints out the objects docstring to the console.
help() function.
After typing help(str) it will return all the info about str object
The general layout of the project and its documentation should be as follows:
project_root/
│
├── project/ # Project source code
├── docs/
├── README
├── HOW_TO_CONTRIBUTE
├── CODE_OF_CONDUCT
├── examples.py
(private, shared or open sourced)
In all cases, the docstrings should use the triple-double quote (""") string format.
Think only about """ when using docstrings
With someone else’s platform, you often end up needing to construct elaborate work-arounds for missing functionality, or indeed cannot implement a required feature at all.
You can quickly implement 80% of the solution in Salesforce using a mix of visual programming (basic rule setting and configuration), but later it's not so straightforward to add the missing 20%
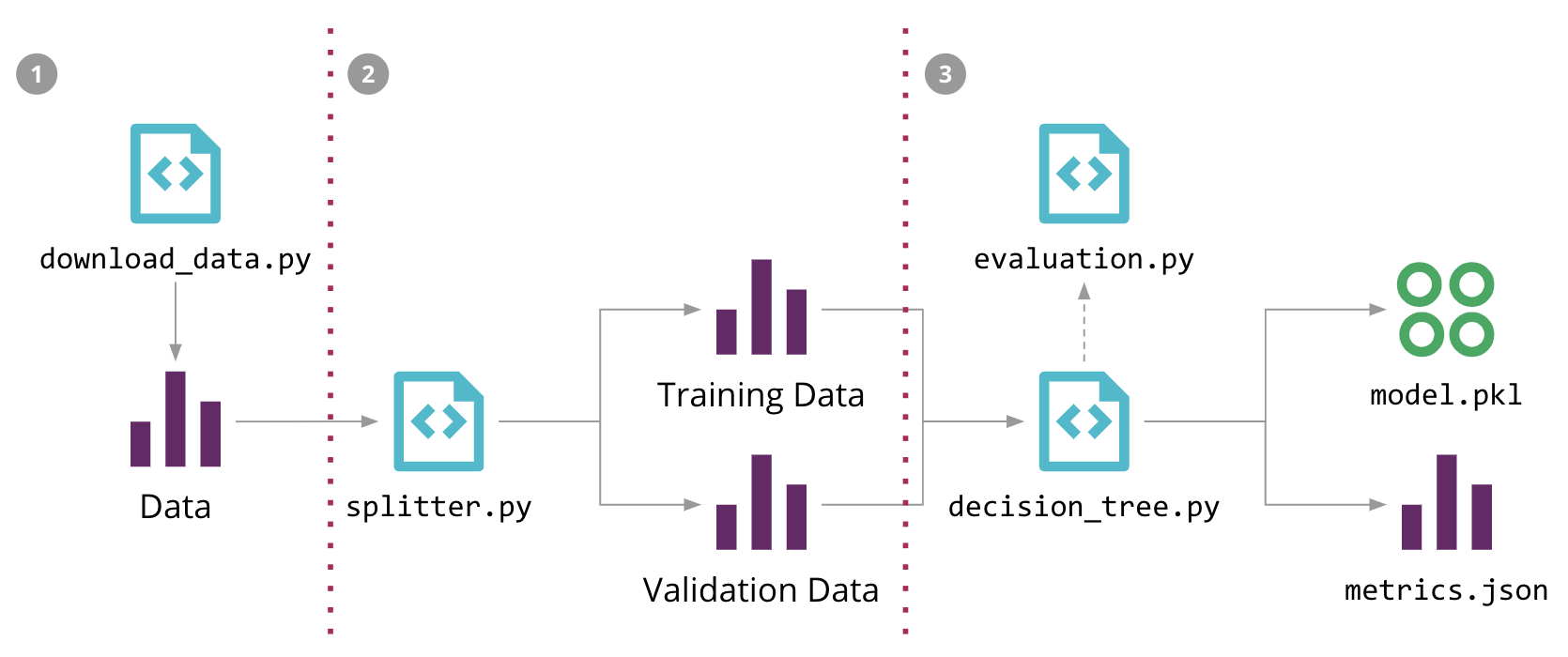
Machine Learning pipeline for our Sales Forecasting problem, and the 3 steps to automate it with DVC
Sales Forecasting process
Continuous Delivery for Machine Learning end-to-end process
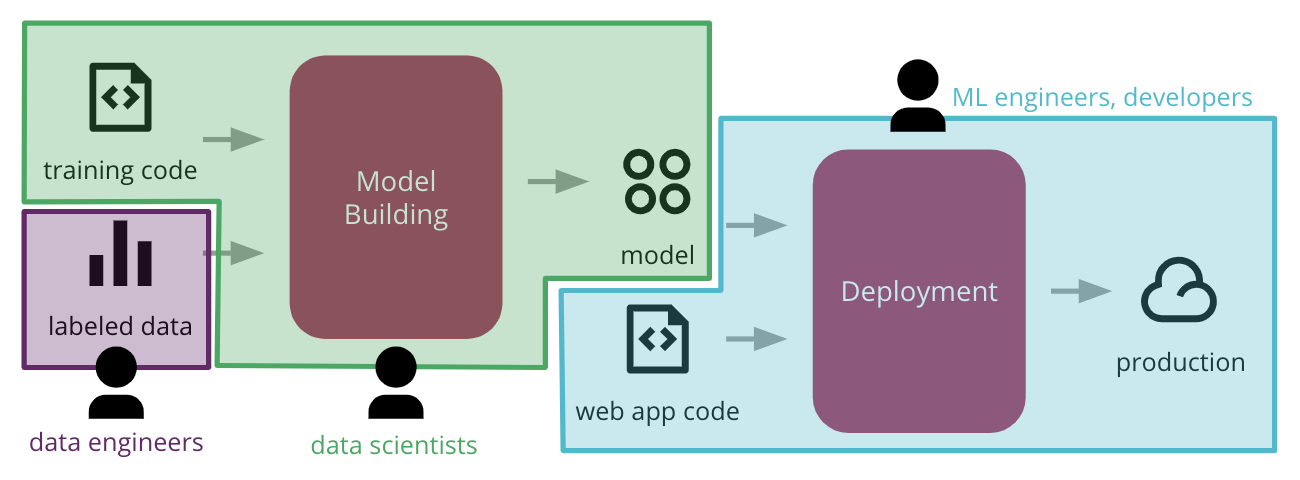
common functional silos in large organizations can create barriers, stifling the ability to automate the end-to-end process of deploying ML applications to production
Common ML process (leading to delays and frictions)
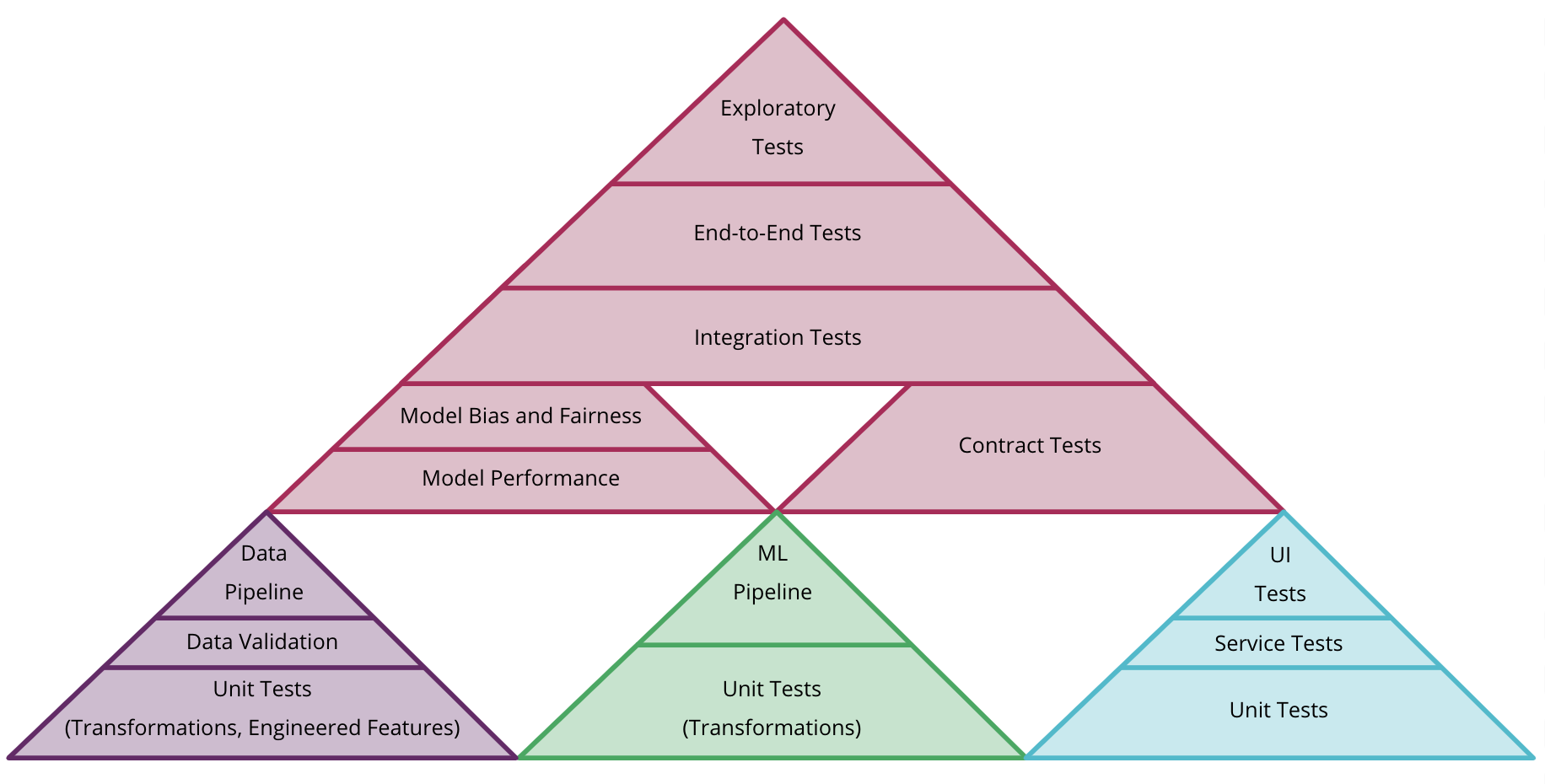
There are different types of testing that can be introduced in the ML workflow.
Automated tests for ML system:
example of how to combine different test pyramids for data, model, and code in CD4ML
Combining tests for data (purple), model (green) and code (blue)
A deployment pipeline automates the process for getting software from version control into production, including all the stages, approvals, testing, and deployment to different environments
Deployment pipeline
We chose to use GoCD as our Continuous Delivery tool, as it was built with the concept of pipelines as a first-class concern
GoCD - open source Continuous Delivery tool
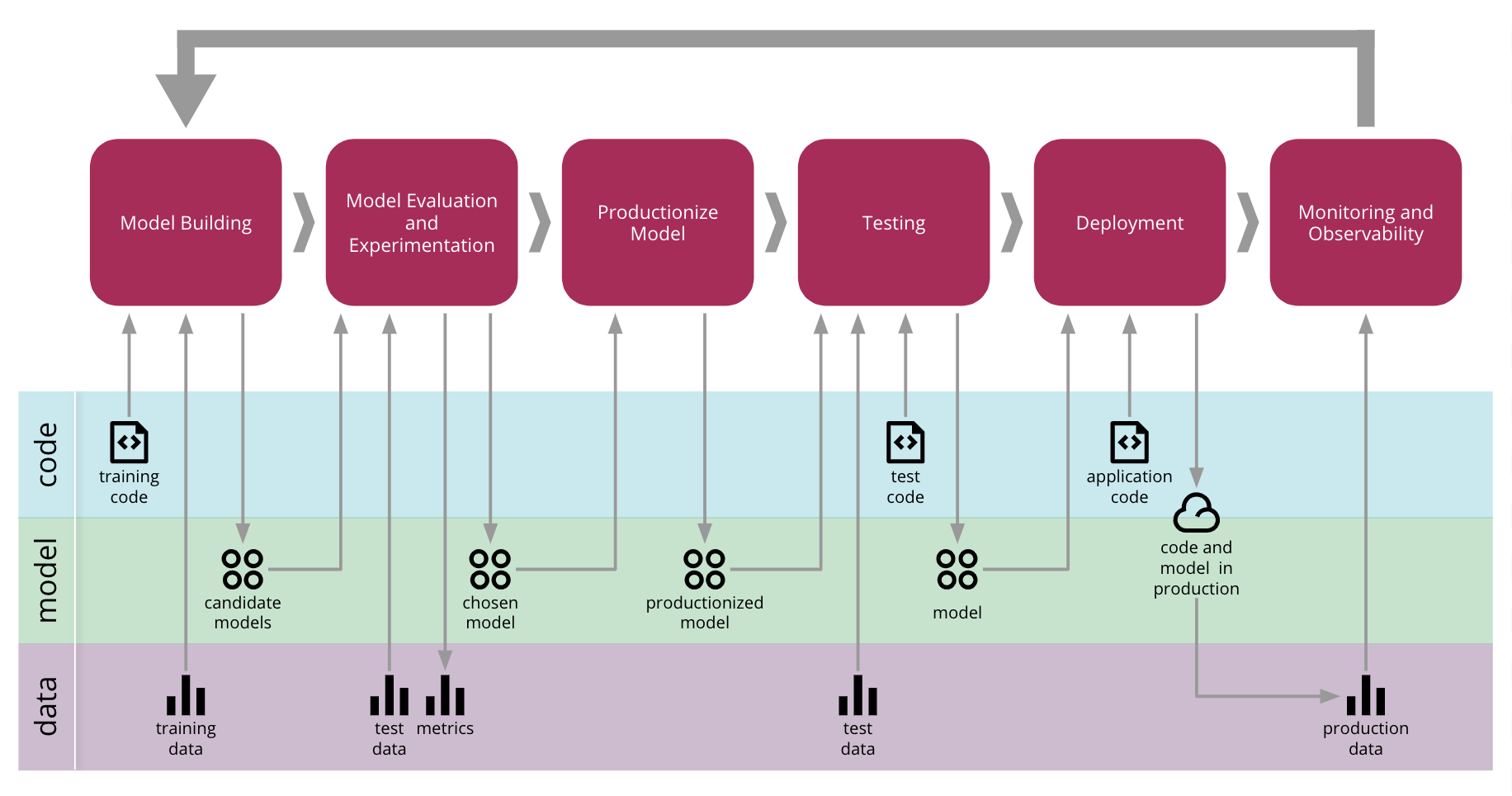
Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications.
Continuous Delivery for Machine Learning (CD4ML)
Development Pros Cons
Table comparing pros and cons of:
This kind of “exploring” is easiest when you develop on the prompt (or REPL), or using a notebook-oriented development system like Jupyter Notebooks
It's easier to explore the code:
but, it's not efficient to develop in them
notebook contains an actual running Python interpreter instance that you’re fully in control of. So Jupyter can provide auto-completions, parameter lists, and context-sensitive documentation based on the actual state of your code
Notebook makes it easier to handle dynamic Python features
They switch to get features like good doc lookup, good syntax highlighting, integration with unit tests, and (critically!) the ability to produce final, distributable source code files, as opposed to notebooks or REPL histories
Things missed in Jupyter Notebooks:
Exploratory programming is based on the observation that most of us spend most of our time as coders exploring and experimenting
In exploratory programming, we:
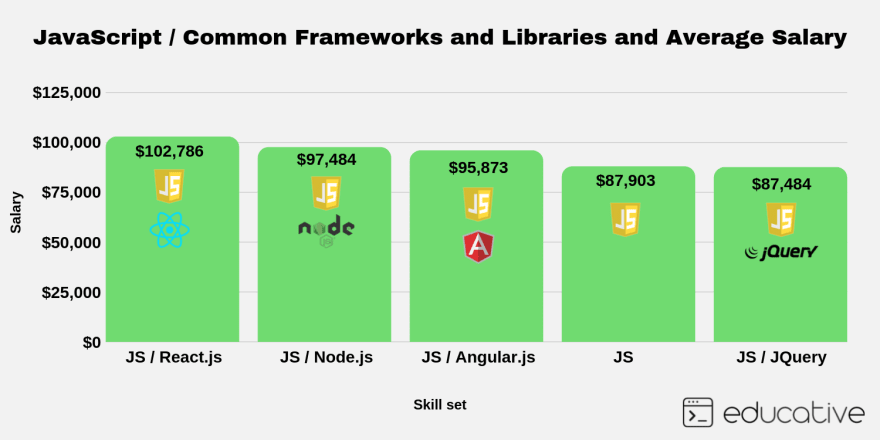
Frontend Devs: What should I learn after JavaScript? Explore these frameworks and libraries
Most paid JS frameworks and libraries:
The best way to explain the difference between launch and attach is to think of a launch configuration as a recipe for how to start your app in debug mode before VS Code attaches to it, while an attach configuration is a recipe for how to connect VS Code's debugger to an app or process that's already running.
Simple difference between two core debugging modes: Launch and Attach available in VS Code.
Depending on the request (attach or launch), different attributes are required, and VS Code's launch.json validation and suggestions should help with that.
Logpoint is a variant of a breakpoint that does not "break" into the debugger but instead logs a message to the console. Logpoints are especially useful for injecting logging while debugging production servers that cannot be paused or stopped. A Logpoint is represented by a "diamond" shaped icon. Log messages are plain text but can include expressions to be evaluated within curly braces ('{}').
Logpoints - log messages to the console when breakpoint is hit.
Can include expressions to be evaluated with {}, e.g.:
fib({num}): {result}
Here are some optional attributes available to all launch configurations
Optional arguments for launch.json:
presentation ("order", "group" or "hidden")preLaunchTaskpostDebugTaskinternalConsoleOptionsdebugServerserverReadyActionThe following attributes are mandatory for every launch configuration
In the launch.json file you've to define at least those 3 variables:
type (e.g. "node", "php", "go")request ("launch" or "attach")name (name to appear in the Debug launch configuration drop-down)Many debuggers support some of the following attributes
Some of the possibly supported attributes in launch.json:
programargsenvcwdportstopOnEntryconsole (e.g. "internalConsole", "integratedTerminal", "externalTerminal")Version control is at the heart of any modern engineering org. The ability for multiple engineers to asynchronously contribute to a codebase is crucial—and with notebooks, it’s very hard.
Version control in notebooks?
The priorities in building a production machine learning pipeline—the series of steps that take you from raw data to product—are not fundamentally different from those of general software engineering.
Reproducibility is an issue with notebooks. Because of the hidden state and the potential for arbitrary execution order, generating a result in a notebook isn’t always as simple as clicking “Run All.”
Problem of reproducibility in notebooks
A notebook, at a very basic level, is just a bunch of JSON that references blocks of code and the order in which they should be executed.But notebooks prioritize presentation and interactivity at the expense of reproducibility. YAML is the other side of that coin, ignoring presentation in favor of simplicity and reproducibility—making it much better for production.
Summary of the article:
Notebook = presentation + interactivity
YAML = simplicity + reproducibility
Notebook files, however, are essentially giant JSON documents that contain the base-64 encoding of images and binary data. For a complex notebook, it would be extremely hard for anyone to read through a plaintext diff and draw meaningful conclusions—a lot of it would just be rearranged JSON and unintelligible blocks of base-64.
Git traces plaintext differences and with notebooks it's a problem
There is no hidden state or arbitrary execution order in a YAML file, and any changes you make to it can easily be tracked by Git
In comparison to notebooks, YAML is more compatible for Git and in the end might be a better solution for ML
Python unit testing libraries, like unittest, can be used within a notebook, but standard CI/CD tooling has trouble dealing with notebooks for the same reasons that notebook diffs are hard to read.
unittest Python library doesn't work well in a notebook
CRDTs are designed for decentralized systems where there is no single central authority to decide what the final state should be. There is some unavoidable performance and memory overhead with doing this. Since Figma is centralized (our server is the central authority), we can simplify our system by removing this extra overhead and benefit from a faster and leaner implementation
CRDTs are designed for decentralized systems
Use camelCase when naming objects, functions, and instances.
camelCase for objects, functions and instances
const thisIsMyFuction() {}
Use PascalCase only when naming constructors or classes.
PascalCase for constructors and classes
// good
class User {
constructor(options) {
this.name = options.name;
}
}
const good = new User({
name: 'yup',
});
Use uppercase only in constants.
Uppercase for constants
export const API_KEY = 'SOMEKEY';
Let's replicate our inefficientSquare example, but this time we'll use our memoizer to cache results.
Replication of a function with the use of memoizer (check the code below this annotation)
The biggest problem with JSON.stringify is that it doesn't serialize certain inputs, like functions and Symbols (and anything you wouldn't find in JSON).
Problem with JSON.stringify.
This is why the previous code shouldn't be used in production
Memoization is an optimization technique used in many programming languages to reduce the number of redundant, expensive function calls. This is done by caching the return value of a function based on its inputs.
Memoization (simple definition)
If you'd just like to see refactorings without Quick Fixes, you can use the Refactor command (Ctrl+Shift+R).
To easily see all the refactoring options, use the "Refactor" command
Stary, dobry Uncle Bob mówi, że poza etatem trzeba na programowanie poświęcić 20h tygodniowo.Gdy podzielimy to na 7 dni w tygodniu, to wychodzi prawie 3 godziny dziennie.Dla jednych mało, dla innych dużo.
Uncle Bob's advice: ~ 3h/day for programming
University of Amsterdam scientists launch website that seeks ideal COVID-19 exit strategy. (2020 April 21) Science|Business. https://sciencebusiness.net/network-updates/university-amsterdam-scientists-launch-website-seeks-ideal-covid-19-exit-strategy
Guido Salvaneschi on Twitter referencing thread by Neil Ferguson
This type relation is sometimes written S <: T
subtyping allows a function to be written to take an object of a certain type T, but also work correctly, if passed an object that belongs to a type S that is a subtype of T (according to the Liskov substitution principle)
chose the term ad hoc polymorphism to refer to polymorphic functions that can be applied to arguments of different types, but that behave differently depending on the type of the argument to which they are applied (also known as function overloading or operator overloading)
I strongly suggest to anyone who wants to become a developer that they do it as well. I mean, it's really easy to see all the work that's out there, and all the things that are left to learn, and think that it's just way beyond you. But when you write it down, you have a place that you can go back to, and not only have I been able to help other people with my blog posts, but I help myself. I'm constantly Googling something and getting my own website in response, and like, oh yeah, I remember I did that before.
it pollutes the MultiDelegator class with every new delegate. If you use MultiDelegator several times, it will keep adding methods to the class, which is undesirable
The handler can be a method or a Proc object passed to the :with option. You can also use a block directly instead of an explicit Proc object.
Example of: letting you either pass a proc (as a keyword arg in this case) or as a block.
Our Cookie Solution plugins for WordPress, Magento, Joomla! and PrestaShop allow you to automate the blocking of scripts drastically reducing the necessity for direct interventions in the site’s code.
A NackClass is the same as NilClass except for any method it does not recognize, it return the instance of itself. nack.nack.nack.nack #=> nack Note I used to call this NullClass, but "nack" seems a little more fitting a term.
To be just a bit polemic, your first instinct was not to do that. And you probably wouldn't think of that in your unit tests either (the holy grail of dynamic langs). So someday it would blow up at runtime, and THEN you'd add that safeguard.
You can just leave your website at that address (it'll give you some serious street cred in the developer world), but if you have a custom domain you would like to use, it is very simple to make GitHub redirect your page. Log in to your domain registrar and find where to change your host records. If you don't know, you can usually Google "(domain registrar) change host records", and your registrar will have an explainer telling you how to do it. Change your domain's A Record to 204.232.175.78. This is GitHub's IP address, which allows GitHub to resolve your URL and serve the correct files. In your website's directory folder on your computer, create a file called "CNAME". On the first line, type your domain name. Save the file. In your GitHub application, you should see the file in the left column. Make sure it is checked and enter your commit message. Have it say something like "Adding CNAME file." Click "Sync branches." It can take as long as 48 hours for your domain to resolve to your GitHub page. However, it is usually pretty quick, so check back in an hour or so.
very useful.
Underneath that awkward Java-esque patina, JavaScript has always had a gorgeous heart.
aww
Nix is a purely functional package manager. This means that it treats packages like values in purely functional programming languages such as Haskell — they are built by functions that don’t have side-effects, and they never change after they have been built.
Optimize imports
Optimize imports on the fly in Webstorm with TypeScript
Larry Wall famously said he was driven to create Perl by how difficult it was to solve a problem while coding, as well as by an abundance of 'laziness, impatience and hubris'
the impetus may have been more the challenge of creating a language of his own.
To an outsider, creating your own programming language might seem akin to saying 'I'll build my own airplane
I've often wished for some standard variable to use for blocks and such. Like some people here, I had considered it. Usually I use _ but I know that means "unused" to many/most programmers. I like the % option that Clojure has.
Environment variables are 'exported by default', making it easy to do silly things like sending database passwords to Airbrake.
airbrake -- monitoring service
This naming convention helps developers understand the component’s contract
Reason is not a new language; it's a new syntax and toolchain powered by the battle-tested language, OCaml.
We might have some dirty mutable objects for performance - but our high-level API should be purely functional. You should be able to follow the React model of modelling your UI as a pure function of application state -> UI.
the abstraction I wished to have was a sort of a pure functional Vim, completely decoupled from terminal UI - where 'vim' is a function of (editor state, input) => (new editor state)
enquo() uses some dark magic to look at the argument, see what the user typed, and return that value as a quosure
If you love Ruby, you'll enjoy CoffeeScript as it makes the JavaScript more like the Ruby.
In 2017, I rewrote it again as a ClojureScript application, and it was only 500 lines of code! Holy cow!!!
going from 3k obj-c to 1,5k js to 0.5k in cljs!
For example the following pattern: (let [x true y true z true] (match [x y z] [_ false true] 1 [false true _ ] 2 [_ _ false] 3 [_ _ true] 4)) ;=> 4 expands into something similar to the following: (cond (= y false) (cond (= z false) (let [] 3) (= z true) (let [] 1) :else (throw (java.lang.Exception. "No match found."))) (= y true) (cond (= x false) (let [] 2) :else (cond (= z false) 3 (= z true) 4 :else (throw (java.lang.Exception. "No match found.")))) :else (cond (= z false) (let [] 3) (= z true) (let [] 4) :else (throw (java.lang.Exception. "No match found.")))) Note that y gets tested first. Lazy pattern matching consistently gives compact decision trees. This means faster pattern matching. You can find out more in the top paper cited below.
http://pauillac.inria.fr/~maranget/papers/ml05e-maranget.pdf
reactions bridge reactive and imperative programming
The problem with the annotation notion is that it's the first time that we consider a piece of data which is not merely a projection of data already present in the message store: it is out-of-band data that needs to be stored somewhere.
could be same, schemaless datastore?
many of the searches we want to do could be accomplished with a database that was nothing but a glorified set of hash tables
Hello sql and cloure.set ns! ;P
There are objects, sets of objects, and presentation tools. There is a presentation tool for each kind of object; and one for each kind of object set.
very clojure-y mood, makes me think of clojure REBL (browser) which in turn is inspired by the smalltalk browser and was taken out of datomic (which is inspired by RDF, mentioned above!)
That said, most Clojure programs begin life as text files, and it is the task of the reader to parse the text and produce the data structure the compiler will see
clojure compiler sees (real) clojure i.e. programs as clojure data structures (we) humans see clojure in their (semi-incidental) representation in text readers bridges the gap
Now, why semi- incidental? It's not necessary for clojure to be text but it is necesserry for it to be represented as some kind of symbolic representations for humans. It's pretty much always text
Good general theory does not search for the maximum generality, but for the right generality.
Especially true in practical programming
I was so fed up of the mega amounts of boilerplate with Redux and the recommendation of keeping your data loading at view level. It seems to me that things like this, with components being responsible for their own data, is the way to go in the future.
Null Coalescing Operator
Entities are the applications, services, and files in the ARGON worldview
smalltalk objects
In 1947, a high-flying moth bumped into Harvard’s Mark II Aiken Relay Calculator, was removed by computer operator William Burke, and then taped to the computer log - popularizing the existing term “debugging.”Figure 4: debugging
Go Programming Language publicly in 2009 they were also looking to solve certain challenges of the existing Computer languages. Of the many features that it demonstrated (we will get to those soon enough) it was also helpful in addressing the strange dilemma of hardware and software that was emerging.
Golang is a modern computing language, designed especially for modern computing needs.
we process millions of transactions per day here and we really need someone with more relevant experience who can handle these things without ramping up
I want to stop putting comments in my code. I want it to be first-class for my code to be in the left pane and my comments to be in the right pane, always binded together with anchors but always separate so my comments don't have to adhere to the limitations of the code's text area.
emacs--annotate.el
Interesting data science / development / technology blog from an Indian Start up
(if (instance? Throwable ret)
catching both Throwables: Errors and Exceptions
:ok
nice, return value: keyword!
(fn [system] (throw (ex-info "initializer not set, did you call `set-init`?" {}))))
interesting pattern, default function throws kind of like abstract base classes methods in python
The Women Who Contributed to Science but Were Buried in Footnotes
for example, comments and identifiers
Some better illustrated examples can be found in UBCx: SoftConst2x - Software Construction: Object Oriented Design's course lecture on Coupling.
If one object is part of another object, then we use a diamond at the start of the arrow (next to the containing object), and a normal arrow at the end.
Another way of thinking of this is, if the original owner (source) object and the owned (target) object share the same life cycle -- that is, the owned exists only when the owner does -- we say that the owner aggregates owned object(s). They share a whole-part relationship.
What I did like very much about the video, was when the instructor pointed out that there's a small fallacy: aggregation, in OOD, does not really imply that owned object(s) must be a list.
Grid devices can be nested or layered along with other devices and your plug-ins,
Thanks to training for Cycling ’74 Max, had a kind of micro-epiphany about encapsulation, a year or so ago. Nesting devices in one another sounds like a convenience but there’s a rather deep effect on workflow when you start arranging things in this way: you don’t have to worry about the internals of a box/patcher/module/device if you really know what you can expect out of it. Though some may take this for granted (after all, other modular systems have had it for quite a while), there’s something profound about getting modules that can include other modules. Especially when some of these are third-party plugins.
after the terminal operation of the stream pipeline commences.
Above is because of the nature of Streams in general: they are lazily executed (or put another way, execution is delayed until the latest convenient method call).
Full disclosure: I’m a co-maintainer of clj-time and I’m pretty vocal about encouraging people not to use clj-time when starting a new project: use Java Time instead. Conversion from an existing, clj-time-heavy project is another matter tho’, unfortunately.
sean cornfield co-mainainter of clj-time use Java.Time
Meditation can not only provide a welcome counterweight to this work with abstractions, it also cultives 10 qualities of character (Pali: paramis) that are useful during the practice of programming.
Generosity Morality Renunciation Understanding Effort Patience/tolerance Truthfulness Loving-kindness Equanimity
One thing Component taught me was to think of the entire system like an Object. Specifically, there is state that needs to be managed. So I suggest you think about -main as initializing your system state. Your system needs an http client, so initialize it before you do anything else
software design state on the outside, before anything else lessions from Component
For the sweet spot you're looking for, I suggest being clear about if you're designing or developing. If you're designing and at the REPL, force yourself to step away with pen and paper after you've gotten some fast feedback.
designing vs developing!
Re-open libraries for exploration I use in-ns to jump into library namespaces and re-define their vars. I insert bits of println statements to help understand how data flows through a library. These monkey-patches only exist in the running REPL. I usually put them inside a comment form. On a REPL restart, the library is back at its pristine state. In this example below, I re-open clj-http.headers to add tracing before the header transformation logic: [source] ;; set us up for re-opening libraries (require 'clj-http.headers) (in-ns 'clj-http.headers) (defn- header-map-request [req] (let [req-headers (:headers req)] (if req-headers (do (println "HEADERS: " req-headers) ;; <-- this is my added print (-> req (assoc :headers (into (header-map) req-headers) :use-header-maps-in-response? true))) req))) ;; Go back to to the user namespace to test the change (in-ns 'user) (require '[clj-http.client :as http]) (http/get "http://www.example.com") ;; This is printed in the REPL: ;; HEADERS: {accept-encoding gzip, deflate} An astute observer will notice this workflow is no different from the regular clojure workflow. Clojure gets out of your way and allows you to shape & experiment in the code in the REPL. You can use this technique to explore clojure.core too!
explore library code in the repl in-ns and the redefinition
Unmap namespaces during experimentation I use ns-unmap and ns-unalias to remove definitions from my namespace. These are the complementary functions of require and def. While exploring, you namespace will accrue failed experiments, especially around naming. Instead of using a giant hammer [tools.namespace], you can opt for finer-grained tools like these. Example: (require '[clojure.string :as thing]) (ns-unalias *ns* 'thing) ; *ns* refers to the current namespace
cleaning up the namespace fro repl experimentation
That is using a specific tool for a specific use case. You don’t actually have a table view of your data. Once it’s in a table, man, you’re good. That is the modeling. A sequel database table, you have this amazing high-level language for doing all sorts of cool operations with it.To turn this into some class hierarchy, it’s almost criminal. There, I said it. It’s like you’re throwing away the power that you have.
about a situation when you sometime want an is-a relationship but in most cases just have it as loosely structured (table-like) data format
A lot of this would be a non issue if we had end user programming. The problem today is that 'configurability' is itself something the programmer needs to implement
acme example rob pike apparently had an elaborate answer as to why he wouldn't allow to change the colorschme
Configuration knowledge is anti-knowledge -- learning how to conform to the inessential quirks of a system somebody else made up
good take on configuration
1 reply 1 retweet 5 likes Reply 1 Retweet 1 Retweeted 1 Like 5 Liked 5 Direct message Omar Rizwan @rsnous Feb 16 More Copy link to Tweet Embed Tweet Mute @rsnous Unmute @rsnous Block @rsnous Unblock @rsnous Report Tweet Add to other Moment Add to new Moment Replying to @rsnous @disquiet07 files are a weak lowest-common-denominator interface between programs in different languages (C, Python, Ruby, Swift, VB, bash, etc) in ecosystems with one language (iOS, JS, Lisp, Smalltalk), you often don't see files: you just persist the rich native structures of the language 4 replies 2 retweets 16 likes Reply 4 Retweet 2 Retweeted 2 Like 16 Liked 16 Direct message Gordon Brander @gordonbrander 3h3 hours ago More Copy link to Tweet Embed Tweet Mute @gordonbrander Unmute @gordonbrander Block @gordonbrander Unblock @gordonbrander Report Tweet Add to other Moment Add to new Moment Replying to @rsnous @disquiet07 OTOH — lowest common denominator interfaces allow for emergent behavior. They focus all the constraints in one place, leaving the rest of the system definition open-ended. Like defining the LEGO dot, but not what shape pieces may take. 1 reply 0 retweets 3 likes Reply 1 Retweet Retweeted Like 3 Liked 3 Direct message Omar Rizwan @rsnous 2h2 hours ago More Copy link to Tweet Embed Tweet Mute @rsnous Unmute @rsnous Block @rsnous Unblock @rsnous Report Tweet Add to other Moment Add to new Moment Replying to @gordonbrander @disquiet07 With files, imo the lack of structure 1. forces duplication of functions at the app level (de/serialization, cross-links, …) and 2. prevents coordination for higher-level behavior #1 here seems different from LEGO, but I can't quite articulate it in terms of your analogy 1 reply 0 retweets 2 likes Reply 1 Retweet Retweeted Like 2 Liked 2 Direct message Gordon Brander @gordonbrander 2h2 hours ago Follow Follow @gordonbrander Following Following @gordonbrander Unfollow Unfollow @gordonbrander Blocked Blocked @gordonbrander Unblock Unblock @gordonbrander Pending Pending follow request from @gordonbrander Cancel Cancel your follow request to @gordonbrander More Copy link to Tweet Embed Tweet Mute @gordonbrander Unmute @gordonbrander Mute this conversation Unmute this conversation Block @gordonbrander Unblock @gordonbrander Report Tweet Add to other Moment Add to new Moment Replying to @rsnous @disquiet07 I agree. Low-level interop has a high floor, high ceiling. Higher-level interop (like Smalltalk) has lower floors, because deeper system integration. However, that deeper integration often means you end up more entangled with the system’s strengths and weaknesses.
Rob Pike has described Plan 9 as "an argument" for simplicity and clarity, while others have described it as "UNIX, only moreso."
idea of a system as an argument pointed out by: https://twitter.com/rsnous/status/1054631468142493696
In computer science and logic, a dependent type is a type whose definition depends on a value. A "pair of integers" is a type. A "pair of integers where the second is greater than the first" is a dependent type because of the dependence on the value.
this is not the most impressive defitnition but it does the job ;) it's more like "relational types" where type definitions include relations between potential values
On the flip side, it can go further than mere types, including emulating dependent types and programming-by-contract.
spec though it's used at runtime (not compile time)
Perhaps part of the confusion - and you say this in a different way in your little memo - is that the C/C++ folks see OO as a liberation from a world that has nothing resembling a first-class functions, while Lisp folks see OO as a prison since it limits their use of functions/objects to the style of (9.). In that case, the only way OO can be defended is in the same manner as any other game or discipline -- by arguing that by giving something up (e.g. the freedom to throw eggs at your neighbor's house) you gain something that you want (assurance that your neighbor won't put you in jail).
[9] "Sum-of-product-of-function pattern - objects are (in effect) restricted to be functions that take as first argument a distinguished method key argument that is drawn from a finite set of simple names."
Sum-of-product-of-function pattern - objects are (in effect) restricted to be functions that take as first argument a distinguished method key argument that is drawn from a finite set of simple names.
fwiu: the "finte set of simple names" are all the objects defined in the codebase e.g. in java there are no functions as such just methods attached to classes i.e. "their key argument"
All you can do is send a message (AYCDISAM) = Actors model - there is no direct manipulation of objects, only communication with (or invocation of) them. The presence of fields in Java violates this.
from what I understand in Java... there are some variables on classes (class instances) that are only acessible through methods and for those the "only send message" paradigm holds but there are also fields which are like attributes in python which you can change directly
Parametric polymorphism - functions and data structures that parameterize over arbitrary values (e.g. list of anything). ML and Lisp both have this. Java doesn't quite because of its non-Object types.
generics so you've got a "template" collection e.g. Collectoin<animal> and you parametrise it with the Animal type in this example how is that broken by "non-Object types" in java</animal>
Ad hoc polymorphism - functions and data structures with parameters that can take on values of many different types.
does he mean that list in python is polymorphic because it can be list of integers or string or ... ?
Encapsulation - the ability to syntactically hide the implementation of a type. E.g. in C or Pascal you always know whether something is a struct or an array, but in CLU and Java you can hide the difference.
is this because:
Following Christopher Strachey,[2] parametric polymorphism may be contrasted with ad hoc polymorphism, in which a single polymorphic function can have a number of distinct and potentially heterogeneous implementations depending on the type of argument(s) to which it is applied. Thus, ad hoc polymorphism can generally only support a limited number of such distinct types, since a separate implementation has to be provided for each type.
kind of like clojure multimethods but those can dispatch on arbitary function hence arbitrary "property"
In programming languages and type theory, parametric polymorphism is a way to make a language more expressive, while still maintaining full static type-safety. Using parametric polymorphism, a function or a data type can be written generically so that it can handle values identically without depending on their type.[1] Such functions and data types are called generic functions and generic datatypes respectively and form the basis of generic programming.
so essentially this is just a way to escape the contrains of types--overspecifying the type of argument for e.g. append function
I guess the behaviour implement cannot really implement on the type of value
One is the linked list of lines you mention. I believe this is intended to solve a display problem that TECO (the original language in which Emacs was implemented) had solved differently using the "gap" data structure. The fundamental issue was that if you have a buffer represented as a single block of contiguous text, then insertion on a character-by-character basis can be O(n2), each time you insert a character, you have to copy the entire subsequent buffer over one space.
implementation, performence of text entry
Lisp macros were also useful for the definition of new control structures, as well as new data structures. In ZWEI, we created a new iterative control structure called charmap, which iterates over characters in an interval. Intervals are stored as doubly-linked lists of arrays, and the starting point might be in the middle of one array and the ending point might be in the middle of another array. The code to perform this iteration was not trivial, and someone reading it might easily not understand the function it was performing, even though that function was the conceptually simple one of iterating over characters. So we created a macro called charmap that expands into the double-loop code to iterate over the characters. It is simple and obvious, and is used in many places, greatly reducing the size of the code and making the functionality obvious at a glance.
use of macros implementing data structures making things more readable!
It became policy to avoid abbreviations in most cases. In ZWEI, we made a list of several words that were used extremely often, and established 'official' abbreviations for them, and always used only those abbreviations. ... Words not on this list were always spelled out in full.
abbreviations whitelist - good programming practice!
Some paragraphs are devoted to what must have been a novel concept at the time for such a system: that the Lisp Machine was a personal system, not time-shared, and this gave rise to features not viable on time-sharing systems, due to the fact that the user was not contending with other users for resources.
personal computers as novel concept (vs time sharing) and what it enables
Wehler et al38 reported that homeless and low-income mothers who experienced sexual assault in childhood were over 4 times more likely to have household level food insecurity than women who had not been abused
Esto es un ejemplo de "Programming" por eventos en la niñez que pueden tener implicaciones en el curso de la vida. Es como un tipo de predisposición, ya que una mujer que ha sido abusada sexualmente está cuatro veces más propensa a tener un hogar con inseguridad alimentaria. 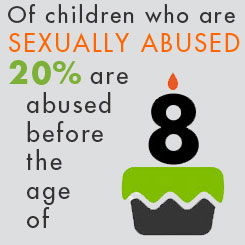

Use React for ephemeral state that doesn't matter to the app globally and doesn't mutate in complex ways. For example, a toggle in some UI element, a form input state. Use Redux for state that matters globally or is mutated in complex ways. For example, cached users, or a post draft. Sometimes you'll want to move from Redux state to React state (when storing something in Redux gets awkward) or the other way around (when more components need to have access to some state that used to be local).
Alternativas en Haskell a las listas como contenedores.
Raccomandazione 3.6g - Definire un modello di governance del dato e progettare automatismi organizzativi e tecnologici
ogni applicativo gestionale in uso nelle Pubbliche Amministrazioni centrali e locali DEVE(!) fare uso di [API (Application Programming Interface)] (https://pianotriennale-ict.readthedocs.io/it/latest/search.html?check_keywords=yes&area=default&q=api) al fine di pubblicare, in modalità automatica, dati tematici aggiornati in tempo reale.

Oggi (2018) l'uso delle API pubbliche nei software delle PA non va raccomandato, va imposto! Diversamente si continua a giocherellare come si fa per ora. Ma niente dati di qualità e su cui fare riferimento senza API pubbliche nei software della PA!
onDragStart
Pass in onDragStart and you should be good to go!
This behavior also argues for following the convention of placing an opening curly brace at the end of a line in JavaScript, rather than on the beginning of a new line. As shown here, this becomes more than just a stylistic preference in JavaScript.
I was on the righteous side all those years! Yey!
hi there please check on the Recent Updated SAS Training and Tutorial Course which can explain about the SAS and its integration with the R as well so please go through the Link:-
(== 10)
This confused me. I'm relatively new to Haskell and did not know about sectioning. After learning that detail, this makes sense as a (right) partial application of the (==) function.
Lucius Gregory Meredith, Mike Stay, and Sophia Drossopoulou. Policy as types. CoRR, 2013. URL: http://arxiv.org/abs/1307.7766.
I think I have my head around this one now.
C-H for pi calculus
type-safe enum pattern
a.k.a. Strongly typed enum pattern
a mutator method is a method used to control changes to a variable. They are also widely known as setter methods
For example, a method definition in Java would be:
class MyClassDef {
public void setProperty(String propertyVal) { .. }
}
For above, setProperty(..) method is the mutator
CS 252r: Advanced Topics in Programming Languages by Stephen Chong
In a let expression, the initial values are computed before any of the variables become bound.
let binding 先在当前环境中计算所有 init 表达式的值, 再 bind varible, 最后在扩展的环境中计算 expression
let* 按顺序依次计算 init 并进行 binding
letrec 则先 binding 后再计算 init 允许递归定义
Scheme pairs is the “dotted” notation (c1 . c2)
Scheme 中 pair 的记号
statically scoped language
scheme 是静态作用域编程语言
Oz
There is only one codebase per app, but there will be many deploys of the app
Typically Terraform violates the spirit of this principle. Though each deploy may be defined (typically as an environment) in the same repo, the codebase is different. We work around this making heavy use of modules to limit divergence between deploys.
Dynamic dispatch
a.k.a. Dynamic Method Dispatch
picking one and sticking to it is far better than the chaos that ensues when everybody does their own thing
Most of the recent advances in AI depend on deep learning, which is the use of backpropagation to train neural nets with multiple layers ("deep" neural nets).
Neural nets consist of layers of nodes, with edges from each node to the nodes in the next layer. The first and last layers are input and output. The output layer might only have two nodes, representing true or false. Each node holds a value representing how excited it is. Each edge has a value representing strength of connection, which determines how much of the excitement passes through.
The edges in an untrained neural net start with random values. The training data consists of a series of samples that are already labeled. If the output is wrong, the edges are adjusted according to how much they contributed to the error. It's called backpropagation because it starts with the output nodes and works toward the input nodes.
Deep neural nets can be effective, but only for single specific tasks. And they need huge sets of training data. They can also be tricked rather easily. Worse, someone who has access to the net can discover ways of adding noise to images that will make the net "see" things that obviously aren't there.
A mental map (or cognitive map) is our mental representation of a place. It includes features we consider important, and is likely to exclude features we consider unimportant.
(Urban planner Kevin Lynch, early 1960s)<br> Elements of mental maps
Modern maps could use augmented and virtual reality to help clarify those elements, making a place easier to navigate and use. But they can also add useless noise that makes the place seem more confusing than it actually is.
officially-approvedprogramminglanguagesatGoogle:C++,Java,Python,Go,orJavaScript.Minimizingthenumberofdifferentprogramminglanguagesusedreducesobstaclestocodereuse and programmer collaboration.
Googleの承認済みプログラム言語
Data analysis can be a very useful tool in software development.
Why is all the focus on teaching lay people how to code, and not teaching computer scientists and people who work in tech companies to center empathy and humanity in their work?
. . .
I think there should be an element of infusing discussions of ethics, humanity and social consequences into computer science curricula, and I believe that even human-centered design does not go far enough; I suggest that designers of tech consider more “empathetic and participatory design” where there is some degree of involving people who are not in the tech company as autonomous persons in product design decisions, and not just using them as research/testing subjects.
but the true technology of Java is not in the language, but the virtual machine itself. The JVM as it stands today, is a fast, abstract machine that you can plug any languages into, and is able to operate at speeds comparable to natively compiled binaries.
This is something really neat to ponder at... Thank you for your insight!
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823 sudo apt-get update sudo apt-get install sbt
hm. lots of moving parts. Doesn't give the minimal / orthogonal feel of kernel monte + safeScope. No Near / Far refs?
(describe any?) goes to stdout - ambient!
spotter: NG
Since Clojure uses the Java calling conventions, it cannot, and does not, make the same tail call optimization guarantees. Instead, it provides the recur special operator, which does constant-space recursive looping by rebinding and jumping to the nearest enclosing loop or function frame. While not as general as tail-call-optimization, it allows most of the same elegant constructs, and offers the advantage of checking that calls to recur can only happen in a tail position.
Clojure's answer to the JVM's lack to tail call optimization